OpenNLP - Szybki przewodnik
NLP to zestaw narzędzi służących do uzyskiwania znaczących i przydatnych informacji ze źródeł w języku naturalnym, takich jak strony internetowe i dokumenty tekstowe.
Co to jest Open NLP?
Apache OpenNLPto biblioteka Java typu open source, która służy do przetwarzania tekstu w języku naturalnym. Korzystając z tej biblioteki, możesz zbudować wydajną usługę przetwarzania tekstu.
OpenNLP zapewnia usługi, takie jak tokenizacja, segmentacja zdań, tagowanie części mowy, wyodrębnianie nazwanych jednostek, fragmentowanie, analizowanie i rozwiązywanie współodniesień itp.
Funkcje OpenNLP
Poniżej przedstawiono godne uwagi funkcje OpenNLP -
Named Entity Recognition (NER) - Open NLP obsługuje NER, za pomocą którego możesz wyodrębnić nazwy lokalizacji, osób i rzeczy, nawet podczas przetwarzania zapytań.
Summarize - Korzystanie z summarize funkcja, możesz podsumować paragrafy, artykuły, dokumenty lub ich kolekcję w NLP.
Searching - W OpenNLP podany ciąg wyszukiwania lub jego synonimy można zidentyfikować w podanym tekście, nawet jeśli dane słowo jest zmienione lub błędnie zapisane.
Tagging (POS) - Oznaczanie w NLP służy do podzielenia tekstu na różne elementy gramatyczne do dalszej analizy.
Translation - W NLP tłumaczenie pomaga w tłumaczeniu jednego języka na inny.
Information grouping - Ta opcja w NLP grupuje informacje tekstowe w treści dokumentu, podobnie jak części mowy.
Natural Language Generation - Służy do generowania informacji z bazy danych i automatyzacji raportów informacyjnych, takich jak analiza pogody czy raporty medyczne.
Feedback Analysis - Jak sama nazwa wskazuje, NLP zbiera różnego rodzaju informacje zwrotne od ludzi na temat produktów, aby przeanalizować, jak skutecznie produkt zdobywa ich serca.
Speech recognition - Chociaż analiza ludzkiej mowy jest trudna, NLP ma kilka wbudowanych funkcji spełniających to wymaganie.
Otwórz interfejs API NLP
Biblioteka Apache OpenNLP zapewnia klasy i interfejsy do wykonywania różnych zadań przetwarzania języka naturalnego, takich jak wykrywanie zdań, tokenizacja, znajdowanie nazwy, tagowanie części mowy, dzielenie zdań, analizowanie, rozwiązywanie współodniesień i kategoryzowanie dokumentów.
Oprócz tych zadań możemy również szkolić i oceniać nasze własne modele dla każdego z tych zadań.
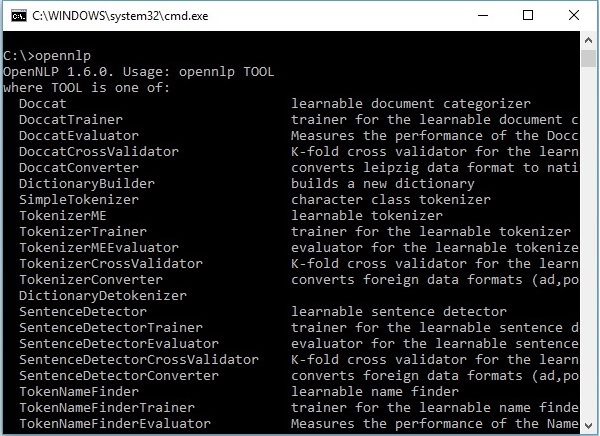
OpenNLP CLI
Oprócz biblioteki OpenNLP zapewnia również interfejs wiersza poleceń (CLI), w którym możemy trenować i oceniać modele. Omówimy ten temat szczegółowo w ostatnim rozdziale tego samouczka.
Otwarte modele NLP
Aby wykonywać różne zadania NLP, OpenNLP udostępnia zestaw predefiniowanych modeli. Ten zestaw zawiera modele dla różnych języków.
Pobieranie modeli
Możesz postępować zgodnie z instrukcjami podanymi poniżej, aby pobrać predefiniowane modele dostarczone przez OpenNLP.
Step 1 - Otwórz stronę indeksu modeli OpenNLP, klikając poniższy link - http://opennlp.sourceforge.net/models-1.5/.

Step 2- Odwiedzając podany link, zobaczysz listę komponentów różnych języków i linki do ich pobrania. Tutaj możesz uzyskać listę wszystkich predefiniowanych modeli dostarczonych przez OpenNLP.
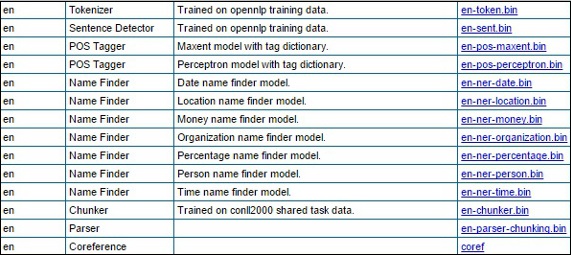
Pobierz wszystkie te modele do folderu C:/OpenNLP_models/>, klikając ich odnośniki. Wszystkie te modele są zależne od języka i podczas ich używania musisz upewnić się, że język modelu pasuje do języka tekstu wejściowego.
Historia OpenNLP
W 2010 roku OpenNLP wszedł do inkubacji Apache.
W 2011 roku wydano Apache OpenNLP 1.5.2 Incubating, który w tym samym roku ukończył jako projekt najwyższego poziomu Apache.
W 2015 roku OpenNLP został wydany w wersji 1.6.0.
W tym rozdziale omówimy, w jaki sposób możesz skonfigurować środowisko OpenNLP w swoim systemie. Zacznijmy od procesu instalacji.
Instalowanie OpenNLP
Poniżej przedstawiono kroki do pobrania Apache OpenNLP library w twoim systemie.
Step 1 - Otwórz stronę główną Apache OpenNLP klikając poniższy link - https://opennlp.apache.org/.
Step 2 - Teraz kliknij Downloadspołączyć. Po kliknięciu zostaniesz przekierowany na stronę, na której znajdziesz różne serwery lustrzane, które przekierują Cię do katalogu dystrybucji Apache Software Foundation.
Step 3- Na tej stronie można znaleźć łącza do pobierania różnych dystrybucji Apache. Przejrzyj je, znajdź dystrybucję OpenNLP i kliknij ją.
Step 4 - Po kliknięciu zostaniesz przekierowany do katalogu, w którym możesz zobaczyć indeks dystrybucji OpenNLP, jak pokazano poniżej.
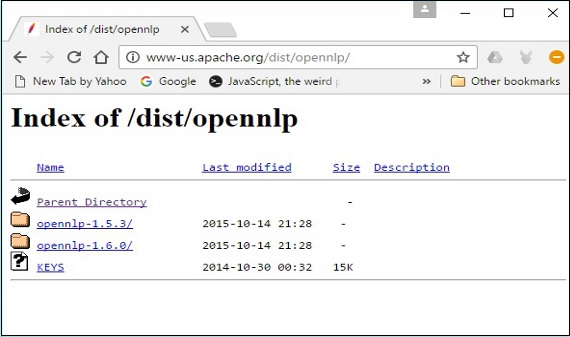
Kliknij najnowszą wersję z dostępnych dystrybucji.
Step 5- Każda dystrybucja zapewnia pliki źródłowe i binarne biblioteki OpenNLP w różnych formatach. Pobierz pliki źródłowe i binarne,apache-opennlp-1.6.0-bin.zip i apache-opennlp1.6.0-src.zip (dla Windowsa).

Ustawianie ścieżki klas
Po pobraniu biblioteki OpenNLP należy ustawić jej ścieżkę do pliku bininformator. Załóżmy, że pobrałeś bibliotekę OpenNLP na dysk E swojego systemu.
Teraz wykonaj kroki podane poniżej -
Step 1 - Kliknij prawym przyciskiem myszy „Mój komputer” i wybierz „Właściwości”.
Step 2 - Kliknij przycisk „Zmienne środowiskowe” na karcie „Zaawansowane”.
Step 3 - Wybierz plik path zmienną i kliknij Edit przycisk, jak pokazano na poniższym zrzucie ekranu.
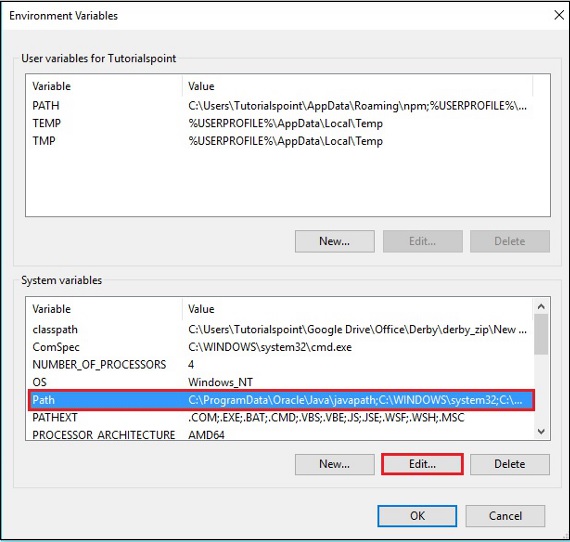
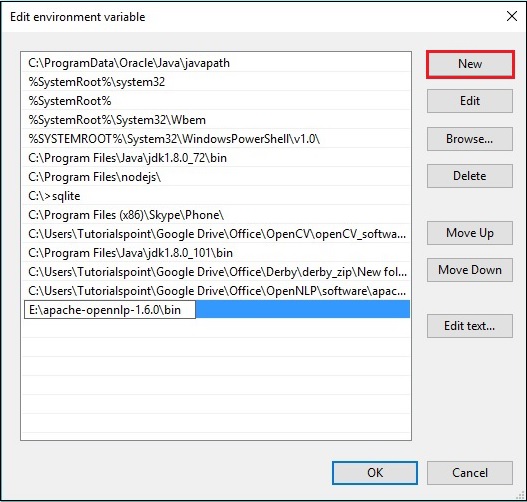
Step 4 - W oknie Edytuj zmienną środowiskową kliknij plik New i dodaj ścieżkę do katalogu OpenNLP E:\apache-opennlp-1.6.0\bin i kliknij OK przycisk, jak pokazano na poniższym zrzucie ekranu.
Instalacja Eclipse
Możesz ustawić środowisko Eclipse dla biblioteki OpenNLP, ustawiając plik Build path do plików JAR lub za pomocą pom.xml.
Ustawianie ścieżki budowania do plików JAR
Wykonaj poniższe kroki, aby zainstalować OpenNLP w Eclipse -
Step 1 - Upewnij się, że w systemie jest zainstalowane środowisko Eclipse.
Step 2- Otwórz Eclipse. Kliknij Plik → Nowy → Otwórz nowy projekt, jak pokazano poniżej.
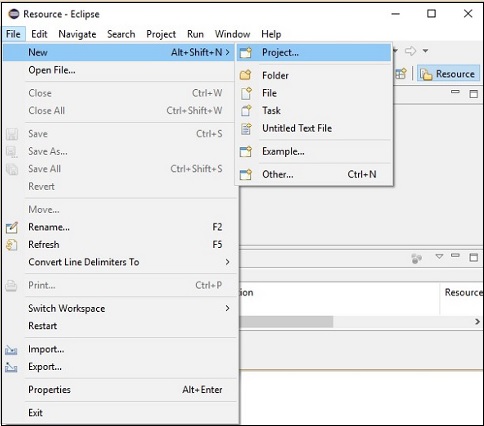
Step 3 - Dostaniesz New Projectczarodziej. W tym kreatorze wybierz projekt Java i kontynuuj, klikającNext przycisk.
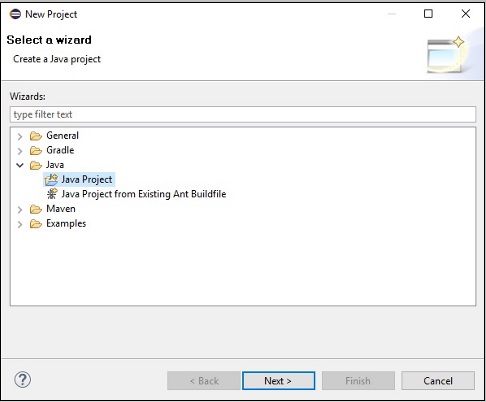
Step 4 - Następnie otrzymasz plik New Java Project wizard. Tutaj musisz utworzyć nowy projekt i kliknąćNext przycisk, jak pokazano poniżej.
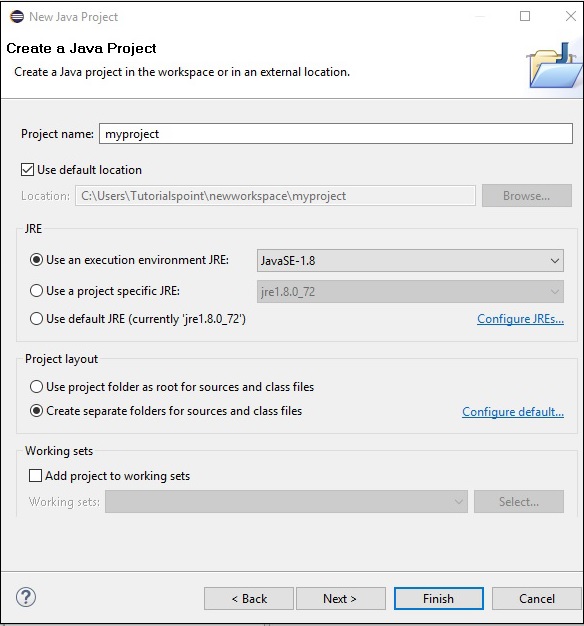
Step 5 - Po utworzeniu nowego projektu kliknij go prawym przyciskiem myszy, wybierz Build Path i kliknij Configure Build Path.
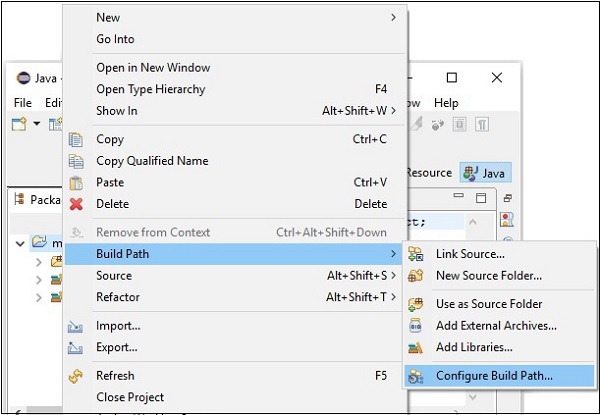
Step 6 - Następnie otrzymasz plik Java Build Pathczarodziej. Tutaj kliknijAdd External JARs przycisk, jak pokazano poniżej.
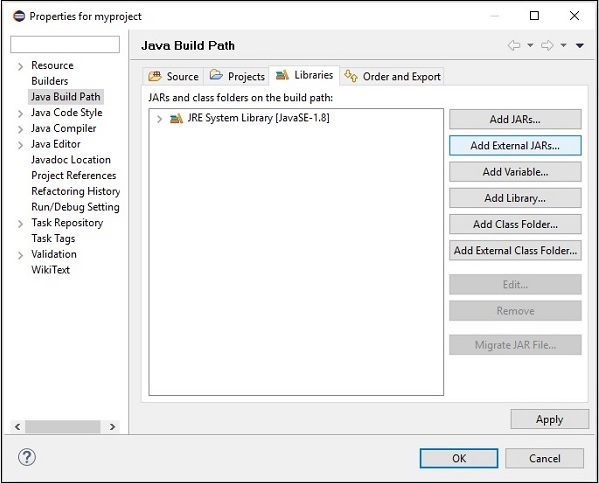
Step 7 - Wybierz pliki jar opennlp-tools-1.6.0.jar i opennlp-uima-1.6.0.jar zlokalizowany w lib folder z apache-opennlp-1.6.0 folder.
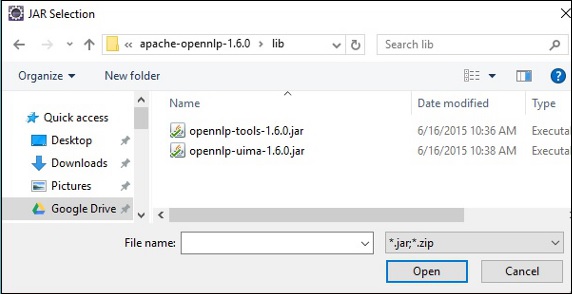
Po kliknięciu Open na powyższym ekranie wybrane pliki zostaną dodane do Twojej biblioteki.
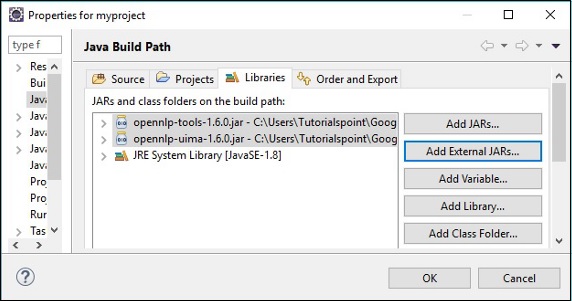
Po kliknięciu OK, pomyślnie dodasz wymagane pliki JAR do bieżącego projektu i możesz zweryfikować te dodane biblioteki, rozszerzając Biblioteki, do których istnieją odniesienia, jak pokazano poniżej.

Korzystanie z pom.xml
Przekonwertuj projekt na projekt Maven i Dodaj następujący kod do jego pom.xml.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>W tym rozdziale omówimy klasy i metody, których będziemy używać w kolejnych rozdziałach tego samouczka.
Wykrywanie zdań
SentenceModel, klasa
Ta klasa reprezentuje predefiniowany model, który jest używany do wykrywania zdań w danym surowym tekście. Ta klasa należy do pakietuopennlp.tools.sentdetect.
Konstruktor tej klasy akceptuje plik InputStream obiekt pliku modelu detektora zdań (en-sent.bin).
SentenceDetectorME, klasa
Ta klasa należy do pakietu opennlp.tools.sentdetecti zawiera metody dzielenia surowego tekstu na zdania. Ta klasa używa modelu maksymalnej entropii do oceny znaków końca zdania w ciągu w celu określenia, czy oznaczają one koniec zdania.
Poniżej przedstawiono ważne metody tej klasy.
| S.Nr | Metody i opis |
|---|---|
| 1 | sentDetect() Ta metoda służy do wykrywania zdań w przekazanym nieprzetworzonym tekście. Przyjmuje zmienną String jako parametr i zwraca tablicę String, która przechowuje zdania z podanego surowego tekstu. |
| 2 | sentPosDetect() Ta metoda służy do wykrywania pozycji zdań w danym tekście. Ta metoda przyjmuje zmienną łańcuchową reprezentującą zdanie i zwraca tablicę obiektów tego typuSpan. Klasa o nazwie Span z opennlp.tools.util pakiet służy do przechowywania początkowej i końcowej liczby całkowitej zestawów. |
| 3 | getSentenceProbabilities() Ta metoda zwraca prawdopodobieństwa skojarzone z ostatnimi wywołaniami funkcji sentDetect() metoda. |
Tokenizacja
Klasa TokenizerModel
Ta klasa reprezentuje predefiniowany model, który jest używany do tokenizacji danego zdania. Ta klasa należy do pakietuopennlp.tools.tokenizer.
Konstruktor tej klasy akceptuje plik InputStream obiekt pliku modelu tokenizera (entoken.bin).
Zajęcia
Aby przeprowadzić tokenizację, biblioteka OpenNLP udostępnia trzy główne klasy. Wszystkie trzy klasy implementują interfejs o nazwieTokenizer.
| S.Nr | Klasy i opis |
|---|---|
| 1 | SimpleTokenizer Ta klasa tokenizuje dany surowy tekst za pomocą klas znaków. |
| 2 | WhitespaceTokenizer Ta klasa używa białych znaków do tokenizacji podanego tekstu. |
| 3 | TokenizerME Ta klasa konwertuje surowy tekst na oddzielne tokeny. Używa maksymalnej entropii do podejmowania decyzji. |
Te klasy zawierają następujące metody.
| S.Nr | Metody i opis |
|---|---|
| 1 | tokenize() Ta metoda służy do tokenizacji surowego tekstu. Ta metoda akceptuje zmienną String jako parametr i zwraca tablicę Strings (tokenów). |
| 2 | sentPosDetect() Ta metoda służy do uzyskania pozycji lub rozpiętości tokenów. Przyjmuje zdanie (lub) surowy tekst w postaci łańcucha i zwraca tablicę obiektów tego typuSpan. |
Oprócz powyższych dwóch metod TokenizerME klasa ma getTokenProbabilities() metoda.
| S.Nr | Metody i opis |
|---|---|
| 1 | getTokenProbabilities() Ta metoda służy do pobierania prawdopodobieństw skojarzonych z ostatnimi wywołaniami metody tokenizePos() metoda. |
NameEntityRecognition
Klasa TokenNameFinderModel
Ta klasa reprezentuje predefiniowany model, który jest używany do wyszukiwania nazwanych jednostek w danym zdaniu. Ta klasa należy do pakietuopennlp.tools.namefind.
Konstruktor tej klasy akceptuje plik InputStream obiekt pliku modelu wyszukiwarki nazw (enner-person.bin).
NameFinderME klasa
Klasa należy do pakietu opennlp.tools.namefindi zawiera metody wykonywania zadań NER. Ta klasa używa modelu maksymalnej entropii, aby znaleźć nazwane jednostki w danym surowym tekście.
| S.Nr | Metody i opis |
|---|---|
| 1 | find() Ta metoda służy do wykrywania nazw w surowym tekście. Przyjmuje zmienną typu String reprezentującą surowy tekst jako parametr i zwraca tablicę obiektów typu Span. |
| 2 | probs() Ta metoda służy do uzyskania prawdopodobieństwa ostatniej dekodowanej sekwencji. |
Znajdowanie części mowy
Klasa POSModel
Ta klasa reprezentuje predefiniowany model, który jest używany do oznaczania części mowy danego zdania. Ta klasa należy do pakietuopennlp.tools.postag.
Konstruktor tej klasy akceptuje plik InputStream obiekt pliku modelu pos-taggera (enpos-maxent.bin).
Klasa POSTaggerME
Ta klasa należy do pakietu opennlp.tools.postagi służy do przewidywania części mowy danego surowego tekstu. Do podejmowania decyzji używa maksymalnej entropii.
| S.Nr | Metody i opis |
|---|---|
| 1 | tag() Ta metoda służy do przypisywania zdania znaczników tokenów POS. Ta metoda przyjmuje tablicę tokenów (String) jako parametr i zwraca tagi (tablicę). |
| 2 | getSentenceProbabilities() Ta metoda jest używana do uzyskania prawdopodobieństw dla każdego znacznika ostatnio oznaczonego zdania. |
Analiza zdania
ParserModel, klasa
Ta klasa reprezentuje predefiniowany model, który jest używany do analizowania danego zdania. Ta klasa należy do pakietuopennlp.tools.parser.
Konstruktor tej klasy akceptuje plik InputStream obiekt pliku modelu parsera (en-parserchunking.bin).
Parser Factory, klasa
Ta klasa należy do pakietu opennlp.tools.parser i jest używany do tworzenia parserów.
| S.Nr | Metody i opis |
|---|---|
| 1 | create() Jest to metoda statyczna i służy do tworzenia obiektu analizatora składni. Ta metoda akceptuje obiekt Filestream pliku modelu parsera. |
ParserTool, klasa
Ta klasa należy do opennlp.tools.cmdline.parser pakiet i służy do analizowania zawartości.
| S.Nr | Metody i opis |
|---|---|
| 1 | parseLine() Ta metoda ParserToolklasa jest używana do analizowania surowego tekstu w OpenNLP. Ta metoda akceptuje -
|
Kruszenie
Klasa ChunkerModel
Ta klasa reprezentuje predefiniowany model, który służy do dzielenia zdania na mniejsze części. Ta klasa należy do pakietuopennlp.tools.chunker.
Konstruktor tej klasy akceptuje plik InputStream obiekt chunker plik modelu (enchunker.bin).
Klasa ChunkerME
Ta klasa należy do pakietu o nazwie opennlp.tools.chunker i służy do podzielenia danego zdania na mniejsze części.
| S.Nr | Metody i opis |
|---|---|
| 1 | chunk() Ta metoda służy do podzielenia danego zdania na mniejsze części. Akceptuje tokeny wyroku iPsztuka Ofa SPeech tagi jako parametry. |
| 2 | probs() Ta metoda zwraca prawdopodobieństwa ostatniej zdekodowanej sekwencji. |
Podczas przetwarzania języka naturalnego jednym z problemów do rozwiązania jest ustalenie początku i końca zdania. Ten proces jest znany jakoSwejście Boundary Dizambiguacja (SBD) lub po prostu łamanie zdań.
Techniki, których używamy do wykrywania zdań w danym tekście, zależą od języka tekstu.
Wykrywanie zdań za pomocą języka Java
Możemy wykryć zdania w podanym tekście w Javie za pomocą wyrażeń regularnych i zestawu prostych reguł.
Załóżmy na przykład, że na końcu zdania w danym tekście kończy się kropka, znak zapytania lub wykrzyknik, a następnie możemy podzielić zdanie za pomocą split() metoda Stringklasa. Tutaj musimy przekazać wyrażenie regularne w formacie String.
Poniżej znajduje się program, który określa zdania w danym tekście za pomocą wyrażeń regularnych Java (split method). Zapisz ten program w pliku o nazwieSentenceDetection_RE.java.
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}Skompiluj i uruchom zapisany plik java z wiersza poleceń, używając następujących poleceń.
javac SentenceDetection_RE.java
java SentenceDetection_REPodczas wykonywania powyższy program tworzy dokument PDF z następującym komunikatem.
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesWykrywanie zdań za pomocą OpenNLP
Aby wykryć zdania, OpenNLP używa predefiniowanego modelu, pliku o nazwie en-sent.bin. Ten predefiniowany model jest uczony do wykrywania zdań w danym surowym tekście.
Plik opennlp.tools.sentdetect pakiet zawiera klasy i interfejsy, które są używane do wykonywania zadania wykrywania zdań.
Aby wykryć zdanie za pomocą biblioteki OpenNLP, musisz -
Załaduj en-sent.bin model przy użyciu SentenceModel klasa
Utwórz wystąpienie SentenceDetectorME klasa.
Wykryj zdania za pomocą sentDetect() metoda tej klasy.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który wykrywa zdania z podanego surowego tekstu.
Krok 1: Ładowanie modelu
Model wykrywania zdań jest reprezentowany przez nazwaną klasę SentenceModel, który należy do pakietu opennlp.tools.sentdetect.
Aby załadować model wykrywania zdań -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie SentenceModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu -
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);Krok 2: tworzenie wystąpienia klasy SentenceDetectorME
Plik SentenceDetectorME klasa pakietu opennlp.tools.sentdetectzawiera metody dzielenia surowego tekstu na zdania. Ta klasa używa modelu Maximum Entropy do oceny znaków końca zdania w ciągu w celu określenia, czy oznaczają one koniec zdania.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku, jak pokazano poniżej.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Krok 3: Wykrywanie zdania
Plik sentDetect() metoda SentenceDetectorMEklasa służy do wykrywania zdań w przekazanym do niej nieprzetworzonym tekście. Ta metoda akceptuje zmienną typu String jako parametr.
Wywołaj tę metodę, przekazując format String zdania do tej metody.
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
Poniżej znajduje się program, który wykrywa zdania w danym surowym tekście. Zapisz ten program w pliku o nazwieSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SentenceDetectorME.java
java SentenceDetectorMEPodczas wykonywania powyższy program odczytuje podany ciąg znaków i wykrywa zawarte w nim zdania i wyświetla następujące dane wyjściowe.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesWykrywanie pozycji zdań
Możemy również wykryć pozycje zdań za pomocą metody sentPosDetect () metody SentenceDetectorME class.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program wykrywający pozycje zdań z podanego surowego tekstu.
Krok 1: Ładowanie modelu
Model wykrywania zdań jest reprezentowany przez nazwaną klasę SentenceModel, który należy do pakietu opennlp.tools.sentdetect.
Aby załadować model wykrywania zdań -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie SentenceModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu.
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);Krok 2: tworzenie wystąpienia klasy SentenceDetectorME
Plik SentenceDetectorME klasa pakietu opennlp.tools.sentdetectzawiera metody dzielenia surowego tekstu na zdania. Ta klasa używa modelu Maximum Entropy do oceny znaków końca zdania w ciągu w celu określenia, czy oznaczają one koniec zdania.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);Krok 3: Wykrywanie pozycji zdania
Plik sentPosDetect() metoda SentenceDetectorMEklasa służy do wykrywania pozycji zdań w przekazanym do niej nieprzetworzonym tekście. Ta metoda akceptuje zmienną typu String jako parametr.
Wywołaj tę metodę, przekazując format String zdania jako parametr do tej metody.
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);Krok 4: Drukowanie rozpiętości zdań
Plik sentPosDetect() metoda SentenceDetectorME class zwraca tablicę obiektów tego typu Span. Klasa o nazwie Span of theopennlp.tools.util pakiet służy do przechowywania początkowej i końcowej liczby całkowitej zestawów.
Możesz przechowywać rozpiętości zwrócone przez sentPosDetect() w tablicy Span i wydrukuj je, jak pokazano w poniższym bloku kodu.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
Poniżej znajduje się program, który wykrywa zdania w podanym surowym tekście. Zapisz ten program w pliku o nazwieSentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SentencePosDetection.java
java SentencePosDetectionPodczas wykonywania powyższy program odczytuje podany ciąg znaków i wykrywa zawarte w nim zdania i wyświetla następujące dane wyjściowe.
[0..16)
[17..43)
[44..93)Zdania wraz z ich pozycjami
Plik substring() metoda klasy String akceptuje metodę begin i end offsetsi zwraca odpowiedni ciąg. Możemy użyć tej metody do wydrukowania zdań i ich rozpiętości (pozycji) razem, jak pokazano w poniższym bloku kodu.
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);Poniżej znajduje się program do wykrywania zdań z podanego surowego tekstu i wyświetlania ich wraz z ich pozycjami. Zapisz ten program w pliku o nazwieSentencesAndPosDetection.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SentencesAndPosDetection.java
java SentencesAndPosDetectionPodczas wykonywania powyższy program odczytuje podany ciąg znaków i wykrywa zdania wraz z ich pozycjami i wyświetla następujące dane wyjściowe.
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)Wykrywanie prawdopodobieństwa zdania
Plik getSentenceProbabilities() metoda SentenceDetectorME class zwraca prawdopodobieństwa skojarzone z ostatnimi wywołaniami metody sentDetect ().
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();Poniżej znajduje się program wyświetlający prawdopodobieństwa związane z wywołaniami metody sentDetect (). Zapisz ten program w pliku o nazwieSentenceDetectionMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbsPodczas wykonywania powyższy program czyta podany String i wykrywa zdania i je drukuje. Ponadto zwraca również prawdopodobieństwa związane z ostatnimi wywołaniami metody sentDetect (), jak pokazano poniżej.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0Proces dzielenia danego zdania na mniejsze części (żetony) jest znany jako tokenization. Ogólnie rzecz biorąc, dany tekst surowy jest tokenizowany na podstawie zestawu ograniczników (głównie białych znaków).
Tokenizacja jest wykorzystywana w zadaniach takich jak sprawdzanie pisowni, przetwarzanie wyszukiwań, identyfikacja części mowy, wykrywanie zdań, klasyfikacja dokumentów dokumentów itp.
Tokenizacja za pomocą OpenNLP
Plik opennlp.tools.tokenize pakiet zawiera klasy i interfejsy, które są używane do wykonywania tokenizacji.
Aby tokenizować podane zdania na prostsze fragmenty, biblioteka OpenNLP udostępnia trzy różne klasy -
SimpleTokenizer - Ta klasa tokenizuje podany surowy tekst przy użyciu klas znaków.
WhitespaceTokenizer - Ta klasa używa białych znaków do tokenizacji podanego tekstu.
TokenizerME- Ta klasa konwertuje surowy tekst na oddzielne tokeny. Używa maksymalnej entropii do podejmowania decyzji.
SimpleTokenizer
Aby tokenizować zdanie za pomocą SimpleTokenizer klasa, musisz -
Utwórz obiekt odpowiedniej klasy.
Tokenizuj zdanie za pomocą tokenize() metoda.
Wydrukuj tokeny.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który tokenizuje podany surowy tekst.
Step 1 - Tworzenie instancji odpowiedniej klasy
W obu klasach nie ma dostępnych konstruktorów do ich tworzenia. Dlatego musimy tworzyć obiekty tych klas za pomocą zmiennej statycznejINSTANCE.
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 - Tokenizuj zdania
Obie te klasy zawierają metodę o nazwie tokenize(). Ta metoda akceptuje nieprzetworzony tekst w formacie String. Podczas wywoływania tokenizuje dany ciąg znaków i zwraca tablicę ciągów znaków (tokenów).
Tokenizuj zdanie za pomocą tokenizer() metoda, jak pokazano poniżej.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Wydrukuj tokeny
Po tokenizacji zdania możesz wydrukować tokeny za pomocą for loop, jak pokazano niżej.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Poniżej znajduje się program, który tokenizuje dane zdanie za pomocą klasy SimpleTokenizer. Zapisz ten program w pliku o nazwieSimpleTokenizerExample.java.
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SimpleTokenizerExample.java
java SimpleTokenizerExamplePodczas wykonywania powyższy program odczytuje podany ciąg (nieprzetworzony tekst), tokenizuje go i wyświetla następujące dane wyjściowe -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
Aby tokenizować zdanie za pomocą WhitespaceTokenizer klasa, musisz -
Utwórz obiekt odpowiedniej klasy.
Tokenizuj zdanie za pomocą tokenize() metoda.
Wydrukuj tokeny.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który tokenizuje podany surowy tekst.
Step 1 - Tworzenie instancji odpowiedniej klasy
W obu klasach nie ma dostępnych konstruktorów do ich tworzenia. Dlatego musimy tworzyć obiekty tych klas za pomocą zmiennej statycznejINSTANCE.
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 - Tokenizuj zdania
Obie te klasy zawierają metodę o nazwie tokenize(). Ta metoda akceptuje nieprzetworzony tekst w formacie String. Podczas wywoływania tokenizuje dany ciąg znaków i zwraca tablicę ciągów znaków (tokenów).
Tokenizuj zdanie za pomocą tokenizer() metoda, jak pokazano poniżej.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Wydrukuj tokeny
Po tokenizacji zdania możesz wydrukować tokeny za pomocą for loop, jak pokazano niżej.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Poniżej znajduje się program, który tokenizuje dane zdanie za pomocą WhitespaceTokenizerklasa. Zapisz ten program w pliku o nazwieWhitespaceTokenizerExample.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExamplePodczas wykonywania powyższy program odczytuje dany ciąg (nieprzetworzony tekst), tokenizuje go i wyświetla następujące dane wyjściowe.
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesKlasa TokenizerME
OpenNLP używa również predefiniowanego modelu, pliku o nazwie de-token.bin, do tokenizacji zdań. Jest wyszkolony do tokenizacji zdań w danym surowym tekście.
Plik TokenizerME klasa opennlp.tools.tokenizerpackage jest używany do ładowania tego modelu i tokenizacji podanego surowego tekstu za pomocą biblioteki OpenNLP. Aby to zrobić, musisz -
Załaduj en-token.bin model przy użyciu TokenizerModel klasa.
Utwórz wystąpienie TokenizerME klasa.
Tokenizuj zdania za pomocą tokenize() metoda tej klasy.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który tokenizuje zdania z danego surowego tekstu przy użyciu rozszerzenia TokenizerME klasa.
Step 1 - Ładowanie modelu
Model do tokenizacji jest reprezentowany przez nazwaną klasę TokenizerModel, który należy do pakietu opennlp.tools.tokenize.
Aby załadować model tokenizera -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie TokenizerModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu.
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 - Tworzenie wystąpienia klasy TokenizerME
Plik TokenizerME klasa pakietu opennlp.tools.tokenizezawiera metody cięcia surowego tekstu na mniejsze części (tokeny). Używa maksymalnej entropii do podejmowania decyzji.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku, jak pokazano poniżej.
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 - Tokenizacja wyroku
Plik tokenize() metoda TokenizerMEklasa jest używana do tokenizacji przekazanego do niej surowego tekstu. Ta metoda przyjmuje zmienną String jako parametr i zwraca tablicę Strings (tokenów).
Wywołaj tę metodę, przekazując format String zdania do tej metody w następujący sposób.
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
Poniżej znajduje się program, który tokenizuje podany surowy tekst. Zapisz ten program w pliku o nazwieTokenizerMEExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac TokenizerMEExample.java
java TokenizerMEExamplePodczas wykonywania powyższy program odczytuje podany ciąg i wykrywa zawarte w nim zdania i wyświetla następujący wynik -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiePobieranie pozycji tokenów
Możemy również uzyskać pozycje lub spans tokenów przy użyciu rozszerzenia tokenizePos()metoda. To jest metoda interfejsu Tokenizera pakietuopennlp.tools.tokenize. Ponieważ wszystkie (trzy) klasy Tokenizera implementują ten interfejs, możesz znaleźć tę metodę we wszystkich z nich.
Ta metoda przyjmuje zdanie lub surowy tekst w postaci ciągu znaków i zwraca tablicę obiektów tego typu Span.
Możesz uzyskać pozycje żetonów za pomocą tokenizePos() metoda w następujący sposób -
//Retrieving the tokens
tokenizer.tokenizePos(sentence);Drukowanie pozycji (przęseł)
Klasa o nazwie Span z opennlp.tools.util pakiet służy do przechowywania początkowej i końcowej liczby całkowitej zestawów.
Możesz przechowywać rozpiętości zwrócone przez tokenizePos() w tablicy Span i wydrukuj je, jak pokazano w poniższym bloku kodu.
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);Wspólne drukowanie żetonów i ich pozycji
Plik substring() metoda klasy String akceptuje metodę begin i endprzesuwa i zwraca odpowiedni ciąg. Możemy użyć tej metody, aby wydrukować tokeny i ich rozpiętości (pozycje) razem, jak pokazano w poniższym bloku kodu.
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
Poniżej znajduje się program, który pobiera zakresy tokenów surowego tekstu przy użyciu rozszerzenia SimpleTokenizerklasa. Drukuje również żetony wraz z ich pozycjami. Zapisz ten program w pliku o nazwieSimpleTokenizerSpans.java.
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpansPodczas wykonywania powyższy program odczytuje podany ciąg (nieprzetworzony tekst), tokenizuje go i wyświetla następujące dane wyjściowe -
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
Poniżej znajduje się program, który pobiera zakresy tokenów surowego tekstu przy użyciu rozszerzenia WhitespaceTokenizerklasa. Drukuje również żetony wraz z ich pozycjami. Zapisz ten program w pliku o nazwieWhitespaceTokenizerSpans.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}Skompiluj i uruchom zapisany plik java z wiersza poleceń, używając następujących poleceń
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpansPodczas wykonywania powyższy program odczytuje dany ciąg (nieprzetworzony tekst), tokenizuje go i wyświetla następujące dane wyjściowe.
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
Poniżej znajduje się program, który pobiera zakresy tokenów surowego tekstu przy użyciu rozszerzenia TokenizerMEklasa. Drukuje również żetony wraz z ich pozycjami. Zapisz ten program w pliku o nazwieTokenizerMESpans.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac TokenizerMESpans.java
java TokenizerMESpansPodczas wykonywania powyższy program odczytuje podany ciąg (nieprzetworzony tekst), tokenizuje go i wyświetla następujące dane wyjściowe -
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) TutorialspointPrawdopodobieństwo tokenizera
Metoda getTokenProbabilities () klasy TokenizerME służy do uzyskiwania prawdopodobieństw związanych z ostatnimi wywołaniami metody tokenizePos ().
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Poniżej znajduje się program wyświetlający prawdopodobieństwa związane z wywołaniami metody tokenizePos (). Zapisz ten program w pliku o nazwieTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac TokenizerMEProbs.java
java TokenizerMEProbsPodczas wykonywania powyższy program odczytuje podany ciąg znaków, tokenizuje zdania i drukuje je. Ponadto zwraca również prawdopodobieństwa związane z ostatnimi wywołaniami metody tokenizerPos ().
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Proces znajdowania nazwisk, osób, miejsc i innych bytów z danego tekstu jest znany jako Named Entity Rpoznanie (NER). W tym rozdziale omówimy, jak przeprowadzić NER przez program Java z wykorzystaniem biblioteki OpenNLP.
Rozpoznawanie nazwanych jednostek przy użyciu otwartego NLP
Aby wykonać różne zadania NER, OpenNLP używa różnych predefiniowanych modeli, a mianowicie en-nerdate.bn, en-ner-location.bin, en-ner-organization.bin, en-ner-person.bin i en-ner-time. kosz. Wszystkie te pliki są predefiniowanymi modelami, które są uczone do wykrywania odpowiednich jednostek w danym surowym tekście.
Plik opennlp.tools.namefindpakiet zawiera klasy i interfejsy, które są używane do wykonywania zadania NER. Aby wykonać zadanie NER przy użyciu biblioteki OpenNLP, musisz -
Załaduj odpowiedni model za pomocą pliku TokenNameFinderModel klasa.
Utwórz wystąpienie NameFinder klasa.
Znajdź nazwiska i wydrukuj je.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który wykrywa encje nazwy z danego surowego tekstu.
Krok 1: Ładowanie modelu
Model wykrywania zdań jest reprezentowany przez nazwaną klasę TokenNameFinderModel, który należy do pakietu opennlp.tools.namefind.
Aby załadować model NER -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę odpowiedniego modelu NER w formacie String do jego konstruktora).
Utwórz wystąpienie TokenNameFinderModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu.
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);Krok 2: Utworzenie wystąpienia klasy NameFinderME
Plik NameFinderME klasa pakietu opennlp.tools.namefindzawiera metody wykonywania zadań NER. Ta klasa używa modelu Maximum Entropy, aby znaleźć nazwane jednostki w danym surowym tekście.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku, jak pokazano poniżej -
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);Krok 3: Znalezienie nazwisk w zdaniu
Plik find() metoda NameFinderMEklasa służy do wykrywania nazw w przekazanym do niej nieprzetworzonym tekście. Ta metoda akceptuje zmienną typu String jako parametr.
Wywołaj tę metodę, przekazując format String zdania do tej metody.
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);Krok 4: Drukowanie rozpiętości nazw w zdaniu
Plik find() metoda NameFinderMEclass zwraca tablicę obiektów typu Span. Klasa o nazwie Span of theopennlp.tools.util pakiet służy do przechowywania pliku start i end liczba całkowita zbiorów.
Możesz przechowywać rozpiętości zwrócone przez find() w tablicy Span i wydrukuj je, jak pokazano w poniższym bloku kodu.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
Poniżej znajduje się program, który odczytuje podane zdanie i rozpoznaje rozpiętości nazwisk znajdujących się w nim osób. Zapisz ten program w pliku o nazwieNameFinderME_Example.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac NameFinderME_Example.java
java NameFinderME_ExamplePodczas wykonywania powyższy program odczytuje podany String (nieprzetworzony tekst), wykrywa nazwiska osób w nim i wyświetla ich pozycje (przęsła), jak pokazano poniżej.
[0..1) person
[2..3) personNazwy wraz z ich pozycjami
Plik substring() metoda klasy String akceptuje metodę begin i end offsetsi zwraca odpowiedni ciąg. Możemy użyć tej metody do wydrukowania nazw i ich rozpiętości (pozycji) razem, jak pokazano w poniższym bloku kodu.
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);Poniżej znajduje się program do wykrywania nazw z podanego surowego tekstu i wyświetlania ich wraz z ich pozycjami. Zapisz ten program w pliku o nazwieNameFinderSentences.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac NameFinderSentences.java
java NameFinderSentencesPodczas wykonywania powyższy program odczytuje podany String (nieprzetworzony tekst), wykrywa nazwiska osób w nim i wyświetla ich pozycje (rozpiętości), jak pokazano poniżej.
[0..1) person MikeZnajdowanie nazw lokalizacji
Ładując różne modele, możesz wykryć różne nazwane jednostki. Poniżej znajduje się program Java, który ładuje pliken-ner-location.binmodel i wykrywa nazwy lokalizacji w zadanym zdaniu. Zapisz ten program w pliku o nazwieLocationFinder.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac LocationFinder.java
java LocationFinderPodczas wykonywania powyższy program odczytuje podany String (nieprzetworzony tekst), wykrywa nazwiska osób w nim i wyświetla ich pozycje (przęsła), jak pokazano poniżej.
[4..5) location HyderabadPrawdopodobieństwo narzędzia NameFinder
Plik probs()metoda NameFinderME klasa służy do uzyskania prawdopodobieństwa ostatniej zdekodowanej sekwencji.
double[] probs = nameFinder.probs();Poniżej znajduje się program do drukowania prawdopodobieństw. Zapisz ten program w pliku o nazwieTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac TokenizerMEProbs.java
java TokenizerMEProbsPodczas wykonywania powyższy program odczytuje podany String, tokenizuje zdania i drukuje je. Ponadto zwraca również prawdopodobieństwa ostatniej zdekodowanej sekwencji, jak pokazano poniżej.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Korzystając z OpenNLP, możesz także wykryć części mowy danego zdania i je wydrukować. Zamiast pełnych nazw części mowy, OpenNLP używa krótkich form każdej części mowy. Poniższa tabela przedstawia różne części przemówień wykryte przez OpenNLP i ich znaczenie.
| Części mowy | Znaczenie części mowy |
|---|---|
| NN | Rzeczownik, liczba pojedyncza lub masa |
| DT | Determiner |
| VB | Czasownik, forma podstawowa |
| VBD | Czasownik, czas przeszły |
| VBZ | Czasownik, trzecia osoba liczby pojedynczej obecny |
| W | Przyimek lub koniunkcja podrzędna |
| NNP | Rzeczownik w liczbie pojedynczej |
| DO | do |
| JJ | Przymiotnik |
Oznaczanie części mowy
Aby oznaczyć części mowy w zdaniu, OpenNLP używa modelu, pliku o nazwie en-posmaxent.bin. Jest to predefiniowany model, który jest uczony do oznaczania części mowy danego surowego tekstu.
Plik POSTaggerME klasa opennlp.tools.postagpakiet służy do wczytywania tego modelu i oznaczania części mowy danego surowego tekstu za pomocą biblioteki OpenNLP. Aby to zrobić, musisz -
Załaduj en-pos-maxent.bin model przy użyciu POSModel klasa.
Utwórz wystąpienie POSTaggerME klasa.
Tokenizuj zdanie.
Wygeneruj tagi za pomocą tag() metoda.
Wydrukuj tokeny i tagi za pomocą POSSample klasa.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który oznacza części mowy w danym surowym tekście przy użyciu rozszerzenia POSTaggerME klasa.
Krok 1: Załaduj model
Model oznaczania punktów sprzedaży jest reprezentowany przez nazwaną klasę POSModel, który należy do pakietu opennlp.tools.postag.
Aby załadować model tokenizera -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie POSModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu -
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);Krok 2: Tworzenie wystąpienia klasy POSTaggerME
Plik POSTaggerME klasa pakietu opennlp.tools.postagsłuży do przewidywania części mowy danego surowego tekstu. Do podejmowania decyzji używa maksymalnej entropii.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku, jak pokazano poniżej -
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);Krok 3: Tokenizacja wyroku
Plik tokenize() metoda whitespaceTokenizerklasa jest używana do tokenizacji przekazanego do niej surowego tekstu. Ta metoda akceptuje zmienną String jako parametr i zwraca tablicę Strings (tokenów).
Utwórz wystąpienie whitespaceTokenizer class i wywołaj tę metodę, przekazując format String zdania do tej metody.
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Krok 4: Generowanie tagów
Plik tag() metoda whitespaceTokenizerclass przypisuje tagi POS do zdania tokenów. Ta metoda przyjmuje tablicę tokenów (String) jako parametr i zwraca tag (tablicę).
Wywołaj tag() poprzez przekazanie do niej tokenów wygenerowanych w poprzednim kroku.
//Generating tags
String[] tags = tagger.tag(tokens);Krok 5: Drukowanie tokenów i tagów
Plik POSSampleklasa reprezentuje zdanie oznaczone tagiem POS. Aby utworzyć instancję tej klasy, wymagalibyśmy tablicy tokenów (tekstu) i tablicy tagów.
Plik toString()metoda tej klasy zwraca otagowane zdanie. Utwórz wystąpienie tej klasy, przekazując token i tablice tagów utworzone w poprzednich krokach i wywołaj jegotoString() metoda, jak pokazano w poniższym bloku kodu.
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
Poniżej znajduje się program, który oznacza części mowy w danym surowym tekście. Zapisz ten program w pliku o nazwiePosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac PosTaggerExample.java
java PosTaggerExamplePodczas wykonywania powyższy program czyta podany tekst i wykrywa części mowy tych zdań i wyświetla je, jak pokazano poniżej.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBWydajność POS Taggera
Poniżej znajduje się program, który oznacza fragmenty mowy danego surowego tekstu. Monitoruje również wydajność i wyświetla wydajność taggera. Zapisz ten program w pliku o nazwiePosTagger_Performance.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac PosTaggerExample.java
java PosTaggerExamplePowyższy program podczas wykonywania odczytuje podany tekst i taguje części mowy tych zdań i wyświetla je. Ponadto monitoruje również wydajność taggera POS i wyświetla go.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sPrawdopodobieństwo Taggera POS
Plik probs() metoda POSTaggerME class służy do znajdowania prawdopodobieństw dla każdego znacznika ostatnio oznaczonego zdania.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Poniżej znajduje się program, który wyświetla prawdopodobieństwa dla każdego znacznika ostatniego oznaczonego zdania. Zapisz ten program w pliku o nazwiePosTaggerProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac TokenizerMEProbs.java
java TokenizerMEProbsPodczas wykonywania powyższy program odczytuje podany surowy tekst, oznacza części mowy każdego tokena w nim i wyświetla je. Ponadto wyświetla również prawdopodobieństwa dla każdej części mowy w danym zdaniu, jak pokazano poniżej.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072Korzystając z API OpenNLP, możesz przeanalizować podane zdania. W tym rozdziale omówimy, jak analizować surowy tekst przy użyciu interfejsu API OpenNLP.
Przetwarzanie surowego tekstu przy użyciu biblioteki OpenNLP
Aby wykryć zdania, OpenNLP używa predefiniowanego modelu, pliku o nazwie en-parserchunking.bin. Jest to wstępnie zdefiniowany model, który jest uczony do analizowania podanego surowego tekstu.
Plik Parser klasa opennlp.tools.Parser pakiet jest używany do przechowywania składników analizy i pliku ParserTool klasa opennlp.tools.cmdline.parser pakiet jest używany do analizowania zawartości.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program, który analizuje podany surowy tekst przy użyciu rozszerzenia ParserTool klasa.
Krok 1: Ładowanie modelu
Model analizy tekstu jest reprezentowany przez nazwaną klasę ParserModel, który należy do pakietu opennlp.tools.parser.
Aby załadować model tokenizera -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie ParserModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu.
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);Krok 2: Tworzenie obiektu klasy Parser
Plik Parser klasa pakietu opennlp.tools.parserreprezentuje strukturę danych do przechowywania składników analizy. Możesz utworzyć obiekt tej klasy za pomocą staticcreate() metoda ParserFactory klasa.
Wywołaj create() metoda ParserFactory przekazując obiekt modelu utworzony w poprzednim kroku, jak pokazano poniżej -
//Creating a parser Parser parser = ParserFactory.create(model);Krok 3: Analiza zdania
Plik parseLine() metoda ParserToolklasa jest używana do analizowania surowego tekstu w OpenNLP. Ta metoda akceptuje -
zmienna typu String reprezentująca tekst do przeanalizowania.
obiekt parsera.
liczba całkowita reprezentująca liczbę analiz do wykonania.
Wywołaj tę metodę, przekazując w zdaniu następujące parametry: obiekt analizy utworzony w poprzednich krokach oraz liczbę całkowitą reprezentującą wymaganą liczbę analiz do wykonania.
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
Poniżej znajduje się program, który analizuje podany surowy tekst. Zapisz ten program w pliku o nazwieParserExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac ParserExample.java
java ParserExamplePodczas wykonywania powyższy program odczytuje podany surowy tekst, analizuje go i wyświetla następujące dane wyjściowe -
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))Dzielenie zdań odnosi się do łamania / dzielenia zdania na części słów, takie jak grupy słów i grupy czasowników.
Dzielenie zdania za pomocą OpenNLP
Aby wykryć zdania, OpenNLP używa modelu, pliku o nazwie en-chunker.bin. Jest to predefiniowany model, który jest uczony do dzielenia zdań w podanym surowym tekście.
Plik opennlp.tools.chunker pakiet zawiera klasy i interfejsy używane do znajdowania nierekurencyjnych adnotacji składniowych, takich jak fragmenty fraz rzeczownikowych.
Możesz podzielić zdanie za pomocą metody chunk() z ChunkerMEklasa. Ta metoda przyjmuje tokeny zdania i tagi POS jako parametry. Dlatego przed rozpoczęciem procesu chunkingu należy przede wszystkim tokenizować zdanie i generować jego części tagi POS.
Aby podzielić zdanie za pomocą biblioteki OpenNLP, musisz -
Tokenizuj zdanie.
Wygeneruj dla niego tagi POS.
Załaduj en-chunker.bin model przy użyciu ChunkerModel klasa
Utwórz wystąpienie ChunkerME klasa.
Podziel zdania na kawałki, używając chunk() metoda tej klasy.
Poniżej przedstawiono kroki, które należy wykonać, aby napisać program dzielący zdania z podanego surowego tekstu.
Krok 1: Tokenizacja zdania
Tokenizuj zdania za pomocą tokenize() metoda whitespaceTokenizer class, jak pokazano w poniższym bloku kodu.
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Krok 2: Generowanie tagów POS
Wygeneruj tagi POS zdania za pomocą tag() metoda POSTaggerME class, jak pokazano w poniższym bloku kodu.
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);Krok 3: Ładowanie modelu
Model fragmentacji zdania jest reprezentowany przez nazwaną klasę ChunkerModel, który należy do pakietu opennlp.tools.chunker.
Aby załadować model wykrywania zdań -
Stworzyć InputStream obiekt modelu (Utwórz wystąpienie FileInputStream i przekaż ścieżkę modelu w formacie String do jego konstruktora).
Utwórz wystąpienie ChunkerModel klasę i zdaj InputStream (obiekt) modelu jako parametr jego konstruktora, jak pokazano w poniższym bloku kodu -
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);Krok 4: Tworzenie wystąpienia klasy chunkerME
Plik chunkerME klasa pakietu opennlp.tools.chunkerzawiera metody do dzielenia zdań. Jest to fragment oparty na maksymalnej entropii.
Utwórz wystąpienie tej klasy i przekaż obiekt modelu utworzony w poprzednim kroku.
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);Krok 5: Dzielenie zdania
Plik chunk() metoda ChunkerMEclass służy do dzielenia zdań w przekazanym do niej surowym tekście. Ta metoda akceptuje jako parametry dwie tablice String reprezentujące tokeny i tagi.
Wywołaj tę metodę, przekazując jako parametry tablicę tokenów i tablicę tagów utworzoną w poprzednich krokach.
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
Poniżej znajduje się program do dzielenia zdań w podanym surowym tekście. Zapisz ten program w pliku o nazwieChunkerExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następującego polecenia -
javac ChunkerExample.java
java ChunkerExamplePodczas wykonywania powyższy program odczytuje podany ciąg i dzieli zdania w nim na kawałki, a następnie wyświetla je, jak pokazano poniżej.
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPWykrywanie pozycji żetonów
Możemy również wykryć pozycje lub rozpiętości fragmentów za pomocą chunkAsSpans() metoda ChunkerMEklasa. Ta metoda zwraca tablicę obiektów typu Span. Klasa o nazwie Span of theopennlp.tools.util pakiet służy do przechowywania pliku start i end liczba całkowita zbiorów.
Możesz przechowywać rozpiętości zwrócone przez chunkAsSpans() w tablicy Span i wydrukuj je, jak pokazano w poniższym bloku kodu.
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
Poniżej znajduje się program, który wykrywa zdania w podanym surowym tekście. Zapisz ten program w pliku o nazwieChunkerSpansEample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac ChunkerSpansEample.java
java ChunkerSpansEamplePodczas wykonywania powyższy program odczytuje podany ciąg i rozpiętość fragmentów w nim, a następnie wyświetla następujące dane wyjściowe -
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPWykrywanie prawdopodobieństwa chunkera
Plik probs() metoda ChunkerME class zwraca prawdopodobieństwa ostatniej zdekodowanej sekwencji.
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();Poniżej znajduje się program do drukowania prawdopodobieństw ostatniej zdekodowanej sekwencji przez chunker. Zapisz ten program w pliku o nazwieChunkerProbsExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Skompiluj i uruchom zapisany plik Java z wiersza polecenia, używając następujących poleceń -
javac ChunkerProbsExample.java
java ChunkerProbsExamplePodczas wykonywania powyższy program czyta podany łańcuch, dzieli go na kawałki i wypisuje prawdopodobieństwa ostatniej zdekodowanej sekwencji.
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051OpenNLP zapewnia interfejs wiersza poleceń (CLI) do wykonywania różnych operacji za pośrednictwem wiersza poleceń. W tym rozdziale weźmiemy kilka przykładów, aby pokazać, jak możemy używać interfejsu wiersza poleceń OpenNLP.
Tokenizacja
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSkładnia
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..Komenda
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txtwynik
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologiesWykrywanie zdań
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSkładnia
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..Komenda
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txtWynik
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesRozpoznawanie nazwanych jednostek
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at TutorialspointSkładnia
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..Komenda
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txtWynik
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018sCzęści znakowania mowy
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSkładnia
> opennlp POSTagger path_for_models../en-token.bin <inputfile..Komenda
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txtWynik
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s