Metodologie programowania - krótki przewodnik
Gdy programy są opracowywane w celu rozwiązywania rzeczywistych problemów, takich jak zarządzanie zapasami, przetwarzanie list płac, przyjmowanie studentów, przetwarzanie wyników egzaminów itp., Wydają się być ogromne i złożone. Podejście do analizy tak złożonych problemów, planowania rozwoju oprogramowania i kontrolowania procesu wytwarzania nazywa sięprogramming methodology.
Rodzaje metodologii programowania
Istnieje wiele rodzajów metodologii programowania rozpowszechnionych wśród twórców oprogramowania -
Programowanie proceduralne
Problem jest podzielony na procedury lub bloki kodu, z których każda wykonuje jedno zadanie. Wszystkie procedury razem tworzą cały program. Nadaje się tylko do małych programów o niskim poziomie złożoności.
Example- W przypadku kalkulatora, który wykonuje dodawanie, odejmowanie, mnożenie, dzielenie, pierwiastek kwadratowy i porównywanie, każda z tych operacji może być opracowana jako oddzielna procedura. W programie głównym każda procedura byłaby wywoływana na podstawie wyboru użytkownika.
Programowanie obiektowe
Tutaj rozwiązanie obraca się wokół bytów lub obiektów, które są częścią problemu. Rozwiązanie dotyczy tego, jak przechowywać dane związane z encjami, jak zachowują się one i jak współdziałają ze sobą, aby uzyskać spójne rozwiązanie.
Example - Jeśli będziemy musieli rozwijać system zarządzania płacami, będziemy mieli takie podmioty jak pracownicy, struktura wynagrodzeń, zasady urlopów itp., Wokół których trzeba będzie budować rozwiązanie.
Programowanie funkcjonalne
Tutaj problem lub pożądane rozwiązanie jest podzielone na jednostki funkcjonalne. Każda jednostka wykonuje swoje zadanie i jest samowystarczalna. Jednostki te są następnie zszywane razem, tworząc kompletne rozwiązanie.
Example - Przetwarzanie listy płac może mieć jednostki funkcjonalne, takie jak przechowywanie danych pracowników, obliczanie podstawowego wynagrodzenia, obliczanie wynagrodzenia brutto, przetwarzanie urlopów, przetwarzanie spłaty pożyczki itp.
Programowanie logiczne
Tutaj problem jest podzielony na jednostki logiczne, a nie jednostki funkcjonalne. Example:W systemie zarządzania szkołą użytkownicy mają bardzo zdefiniowane role, takie jak wychowawca klasy, nauczyciel przedmiotu, asystent laboratoryjny, koordynator, kierownik naukowy itp. Oprogramowanie można więc podzielić na jednostki w zależności od ról użytkownika. Każdy użytkownik może mieć inny interfejs, uprawnienia itp.
Twórcy oprogramowania mogą wybrać jedną lub kombinację więcej niż jednej z tych metod w celu opracowania oprogramowania. Należy zauważyć, że w każdej z omawianych metodologii problem należy podzielić na mniejsze jednostki. Aby to zrobić, programiści stosują dowolne z następujących dwóch podejść -
- Podejście odgórne
- Podejście oddolne
Podejście odgórne lub modułowe
Problem jest podzielony na mniejsze jednostki, które można dalej podzielić na jeszcze mniejsze jednostki. Każda jednostka nazywa się amodule. Każdy moduł jest samowystarczalną jednostką, która posiada wszystko co niezbędne do wykonania swojego zadania.
Poniższa ilustracja przedstawia przykład, w jaki sposób można zastosować podejście modułowe do tworzenia różnych modułów podczas opracowywania programu przetwarzania listy płac.
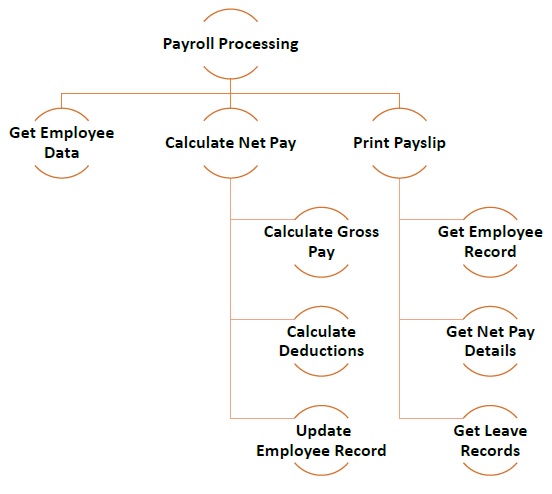
Podejście oddolne
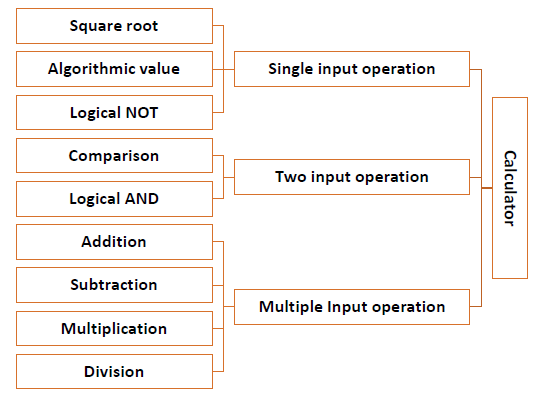
W podejściu oddolnym projektowanie systemu rozpoczyna się od najniższego poziomu komponentów, które następnie są ze sobą połączone w celu uzyskania komponentów wyższego poziomu. Ten proces trwa do momentu wygenerowania hierarchii wszystkich komponentów systemu. Jednak w prawdziwym scenariuszu bardzo trudno jest poznać na początku wszystkie komponenty najniższego poziomu. Tak więc podejście od dołu do góry jest stosowane tylko w przypadku bardzo prostych problemów.
Przyjrzyjmy się składnikom programu kalkulatora.
Typowy proces tworzenia oprogramowania obejmuje następujące kroki -
- Gromadzenie wymagań
- Definicja problemu
- Projekt systemu
- Implementation
- Testing
- Documentation
- Szkolenie i wsparcie
- Maintenance
Pierwsze dwa kroki pomagają zespołowi w zrozumieniu problemu, co jest najważniejszym pierwszym krokiem w kierunku rozwiązania. Wzywa się osobę odpowiedzialną za zebranie wymagań, zdefiniowanie problemu i zaprojektowanie systemusystem analyst.
Gromadzenie wymagań
Zwykle klienci lub użytkownicy nie są w stanie jasno określić swoich problemów lub wymagań. Mają niejasne pojęcie o tym, czego chcą. Dlatego programiści systemów muszą zebrać wymagania klienta, aby zrozumieć problem, który należy rozwiązać lub co należy dostarczyć. Szczegółowe zrozumienie problemu jest możliwe tylko po uprzednim zrozumieniu obszaru biznesowego, dla którego opracowywane jest rozwiązanie. Niektóre kluczowe pytania, które pomagają w zrozumieniu biznesu, obejmują:
- Co zostało zrobione?
- Jak to się robi?
- Jaka jest częstotliwość zadania?
- Jaka jest liczba decyzji lub transakcji?
- Jakie napotykasz problemy?
Niektóre techniki pomagające w gromadzeniu tych informacji to:
- Interviews
- Questionnaires
- Badanie istniejących dokumentów systemowych
- Analiza danych biznesowych
Analitycy systemowi muszą stworzyć jasny i zwięzły, ale dokładny dokument wymagań, aby zidentyfikować wymagania SMART - specyficzne, mierzalne, uzgodnione, realistyczne i określone w czasie. Niezastosowanie się do tego skutkuje -
- Niekompletna definicja problemu
- Nieprawidłowe cele programu
- Ponownie pracuj, aby dostarczyć klientowi wymagany wynik
- Zwiększone koszty
- Opóźniona dostawa
Ze względu na głębokość wymaganych informacji gromadzenie wymagań jest również znane jako detailed investigation.
Definicja problemu
Po zebraniu wymagań i ich przeanalizowaniu należy jasno określić problem. Definicja problemu powinna jednoznacznie określać, jaki problem lub problemy wymagają rozwiązania. Jasne stwierdzenie problemu jest konieczne, aby -
- Zdefiniuj zakres projektu
- Skoncentruj się na zespole
- Utrzymuj projekt na dobrej drodze
- Potwierdź, że pożądany rezultat został osiągnięty pod koniec projektu
Często kodowanie jest najbardziej istotną częścią każdego procesu tworzenia oprogramowania. Jednak kodowanie jest tylko częścią procesu i może zająć minimalną ilość czasu, jeśli system jest zaprojektowany poprawnie. Zanim system będzie można zaprojektować, należy znaleźć rozwiązanie dla danego problemu.
Pierwszą rzeczą, na którą należy zwrócić uwagę podczas projektowania systemu, jest to, że początkowo analityk systemu może wymyślić więcej niż jedno rozwiązanie. Ale ostateczne rozwiązanie lub produkt może być tylko jeden. Dogłębna analiza danych zebranych podczas fazy zbierania wymagań może pomóc w znalezieniu unikalnego rozwiązania. Prawidłowe zdefiniowanie problemu jest również kluczowe dla znalezienia rozwiązania.
W obliczu problemu wielu rozwiązań analitycy sięgają po pomoce wizualne, takie jak schematy blokowe, diagramy przepływu danych, diagramy relacji encji itp., Aby dogłębnie zrozumieć każde rozwiązanie.
Schemat blokowy
Schemat blokowy to proces ilustrujący przepływy pracy i dane w systemie za pomocą symboli i diagramów. Jest to ważne narzędzie pomagające analitykowi systemowemu w znalezieniu rozwiązania problemu. Przedstawia wizualnie elementy systemu.
Oto zalety schematu blokowego -
Wizualna reprezentacja pomaga w zrozumieniu logiki programu
Działają jako plany rzeczywistego kodowania programu
Diagramy blokowe są ważne dla dokumentacji programu
Diagramy blokowe są ważną pomocą podczas obsługi programu
Oto wady schematu blokowego -
Złożonej logiki nie można przedstawić za pomocą schematów blokowych
W przypadku jakiejkolwiek zmiany w logice lub w przepływie danych / pracy schemat blokowy musi zostać całkowicie przerysowany
Schemat przepływu danych
Diagram przepływu danych lub DFD to graficzna reprezentacja przepływu danych przez system lub podsystem. Każdy proces ma swój własny przepływ danych i istnieją poziomy diagramów przepływu danych. Poziom 0 pokazuje dane wejściowe i wyjściowe dla całego systemu. Następnie system jest podzielony na moduły, a poziom 1 DFD pokazuje przepływ danych dla każdego modułu z osobna. W razie potrzeby moduły można dalej podzielić na podmoduły i narysować poziom 2 DFD.
Pseudo kod
Po zaprojektowaniu systemu jest on przekazywany kierownikowi projektu do wdrożenia, czyli kodowania. Rzeczywiste kodowanie programu odbywa się w języku programowania, który jest zrozumiały tylko dla programistów przeszkolonych w tym języku. Jednak zanim nastąpi faktyczne kodowanie, podstawowe zasady działania, przepływy pracy i przepływy danych programu są zapisywane przy użyciu notacji podobnej do używanego języka programowania. Taki zapis nazywa siępseudocode.
Oto przykład pseudokodu w C ++. Programista musi po prostu przetłumaczyć każdą instrukcję na składnię C ++, aby uzyskać kod programu.

Identyfikowanie operacji matematycznych
Wszystkie instrukcje dla komputera są ostatecznie wdrażane jako operacje arytmetyczne i logiczne na poziomie maszyny. Te operacje są ważne, ponieważ -
- Zajmują miejsce w pamięci
- Poświęć trochę czasu na wykonanie
- Określ wydajność oprogramowania
- Wpływa na ogólną wydajność oprogramowania
Analitycy systemowi próbują zidentyfikować wszystkie główne operacje matematyczne, jednocześnie identyfikując unikalne rozwiązanie danego problemu.
Prawdziwy problem jest złożony i duży. Jeśli zostanie opracowane rozwiązanie monolityczne, stwarza to następujące problemy -
Trudne do napisania, przetestowania i wdrożenia jednego dużego programu
Modyfikacje po dostarczeniu gotowego produktu są prawie niemożliwe
Utrzymanie programu bardzo trudne
Jeden błąd może spowodować zatrzymanie całego systemu
Aby przezwyciężyć te problemy, rozwiązanie należy podzielić na mniejsze części tzw modules. Technika dzielenia jednego dużego rozwiązania na mniejsze moduły w celu ułatwienia rozwoju, implementacji, modyfikacji i utrzymania to tzwmodular technique programowania lub tworzenia oprogramowania.
Zalety programowania modułowego
Programowanie modułowe oferuje te zalety -
Umożliwia szybszy rozwój, ponieważ każdy moduł może być rozwijany równolegle
Moduły można wykorzystać ponownie
Ponieważ każdy moduł ma być testowany niezależnie, testowanie jest szybsze i bardziej niezawodne
Łatwiejsze debugowanie i utrzymanie całego programu
Moduły są mniejsze i mają niższy poziom złożoności, dzięki czemu są łatwe do zrozumienia
Identyfikacja modułów
Identyfikacja modułów w oprogramowaniu jest trudnym zadaniem, ponieważ nie może być jednego poprawnego sposobu na zrobienie tego. Oto kilka wskazówek dotyczących identyfikowania modułów -
Jeśli dane są najważniejszym elementem systemu, stwórz moduły obsługujące powiązane dane.
Jeśli usługa świadczona przez system jest zróżnicowana, należy rozbić system na moduły funkcjonalne.
Jeśli wszystko inne zawiedzie, podziel system na moduły logiczne, zgodnie ze swoim zrozumieniem systemu podczas fazy zbierania wymagań.
W celu kodowania każdy moduł należy ponownie podzielić na mniejsze moduły w celu ułatwienia programowania. Można to zrobić ponownie, korzystając z trzech udostępnionych powyżej wskazówek w połączeniu z określonymi zasadami programowania. Na przykład w przypadku języka programowania zorientowanego obiektowo, takiego jak C ++ i Java, każda klasa ze swoimi danymi i metodami może tworzyć pojedynczy moduł.
Rozwiązanie krok po kroku
Aby zaimplementować moduły, przebieg procesu każdego modułu musi być opisany krok po kroku. Rozwiązanie krok po kroku można opracować za pomocąalgorithms lub pseudocodes. Dostarczanie rozwiązania krok po kroku zapewnia następujące korzyści -
Każdy, kto czyta rozwiązanie, może zrozumieć zarówno problem, jak i rozwiązanie.
Jest to równie zrozumiałe dla programistów i nieprogramistów.
Podczas kodowania każda instrukcja musi zostać po prostu przekonwertowana na instrukcję programu.
Może być częścią dokumentacji i pomagać w utrzymaniu programu.
Szczegóły na poziomie mikro, takie jak nazwy identyfikatorów, wymagane operacje itp., Są opracowywane automatycznie
Spójrzmy na przykład.

Struktury kontrolne
Jak widać w powyższym przykładzie, nie jest konieczne, aby działała logika programu sequentially. W języku programowaniacontrol structurespodejmować decyzje o przebiegu programu na podstawie zadanych parametrów. Są to bardzo ważne elementy każdego oprogramowania i należy je zidentyfikować przed rozpoczęciem kodowania.
Algorytmy i pseudocodes pomóc analitykom i programistom w określeniu, gdzie wymagane są struktury kontrolne.
Struktury kontrolne należą do tych trzech typów -
Struktury kontroli decyzji
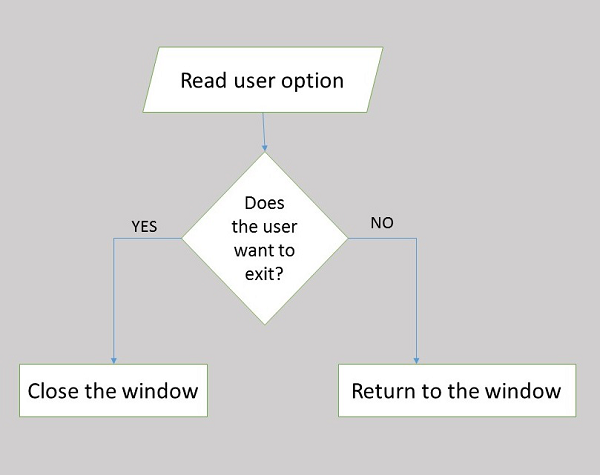
Struktury kontroli decyzji są używane, gdy następny krok do wykonania zależy od kryteriów. Kryterium to jest zwykle co najmniej jednym wyrażeniem logicznym, które należy ocenić. Wyrażenie logiczne zawsze przyjmuje wartość „prawda” lub „fałsz”. Jeden zestaw instrukcji jest wykonywany, jeśli kryterium ma wartość „prawda”, a inny zestaw jest wykonywany, jeśli wynikiem kryterium jest „fałsz”. Na przykład, jeśli instrukcja
Struktury kontroli wyboru
Struktury kontroli wyboru są używane, gdy sekwencja programu zależy od odpowiedzi na określone pytanie. Na przykład program ma wiele opcji dla użytkownika. Instrukcja do wykonania w następnej kolejności zależy od wybranej opcji. Na przykład,switch komunikat, case komunikat.
Struktury kontroli powtórzeń / pętli
Struktura kontroli powtarzania jest używana, gdy zestaw instrukcji ma być powtarzany wiele razy. Liczba powtórzeń może być znana przed jej rozpoczęciem lub może zależeć od wartości wyrażenia. Na przykład,for komunikat, while komunikat, do while oświadczenie itp.
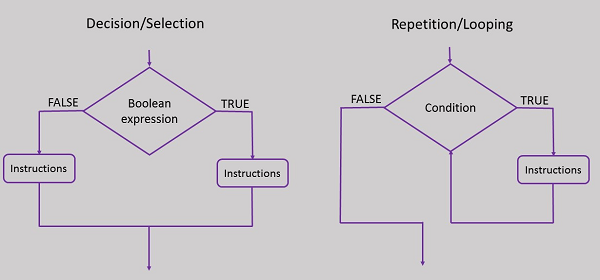
Jak widać na powyższym obrazku, zarówno struktury selekcji, jak i struktury decyzyjne są implementowane podobnie na schemacie blokowym. Kontrola wyboru to nic innego jak seria instrukcji decyzyjnych podejmowanych sekwencyjnie.
Oto kilka przykładów z programów, które pokazują, jak działają te stwierdzenia -

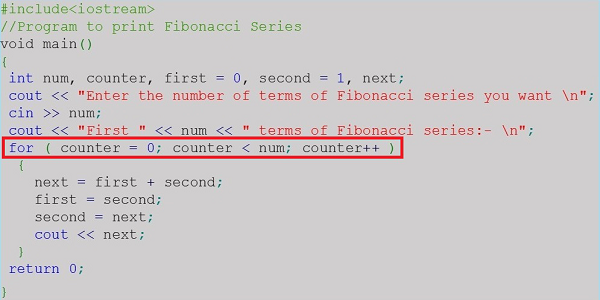
Skończony zestaw kroków, które należy wykonać, aby rozwiązać każdy problem, nazywa się algorithm. Algorytm jest zwykle opracowywany przed faktycznym kodowaniem. Jest napisany w języku angielskim, dzięki czemu jest zrozumiały nawet dla osób nie będących programistami.
Czasami algorytmy są pisane przy użyciu pseudocodes, tj. język podobny do używanego języka programowania. Algorytm pisania do rozwiązania problemu ma następujące zalety -
Promuje efektywną komunikację między członkami zespołu
Umożliwia analizę problemu
Działa jako plan kodowania
Pomaga w debugowaniu
Stanowi część dokumentacji oprogramowania do wykorzystania w przyszłości podczas fazy konserwacji
Oto cechy dobrego i poprawnego algorytmu -
Posiada zestaw wejść
Kroki są jednoznacznie zdefiniowane
Ma skończoną liczbę kroków
Daje pożądany efekt
Przykładowe algorytmy
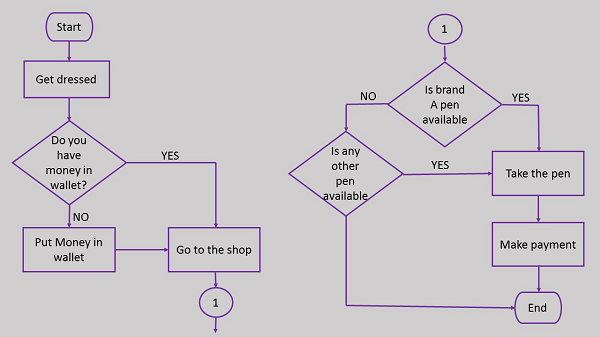
Najpierw weźmy przykład z rzeczywistej sytuacji tworzenia algorytmu. Oto algorytm wejścia na rynek w celu zakupu długopisu.

Krok 4 w tym algorytmie jest sam w sobie kompletnym zadaniem i można dla niego napisać oddzielny algorytm. Stwórzmy teraz algorytm sprawdzający, czy liczba jest dodatnia czy ujemna.

Flowchartto schematyczne przedstawienie sekwencji logicznych kroków programu. Schematy blokowe wykorzystują proste kształty geometryczne do przedstawiania procesów i strzałki pokazujące relacje i przepływ procesów / danych.
Symbole schematów blokowych
Oto wykres przedstawiający niektóre typowe symbole używane przy rysowaniu schematów blokowych.
| Symbol | Nazwa symbolu | Cel, powód |
|---|---|---|

|
Zacząć zakończyć | Używany na początku i na końcu algorytmu do pokazania początku i końca programu. |

|
Proces | Wskazuje procesy, takie jak operacje matematyczne. |

|
Wejście wyjście | Używane do oznaczania wejść i wyjść programu. |

|
Decyzja | Oznacza stwierdzenia decyzyjne w programie, gdzie zwykle odpowiedź brzmi Tak lub Nie. |
|
|
Strzałka | Pokazuje relacje między różnymi kształtami. |

|
Łącznik na stronie | Łączy dwie lub więcej części schematu blokowego, które znajdują się na tej samej stronie. |

|
Złącze poza stroną | Łączy dwie części schematu blokowego, które są rozmieszczone na różnych stronach. |
Wytyczne dotyczące tworzenia schematów blokowych
Oto kilka punktów, o których należy pamiętać podczas opracowywania schematu blokowego -
Schemat blokowy może mieć tylko jeden symbol początku i jeden symbol zatrzymania
Odnośniki do łączników na stronie są określane za pomocą numerów
Odnośniki do łączników poza stroną są przy użyciu alfabetów
Ogólny przepływ procesów przebiega od góry do dołu lub od lewej do prawej
Strzały nie powinny się przecinać
Przykładowe schematy blokowe
Oto schemat blokowy wejścia na rynek w celu zakupu długopisu.
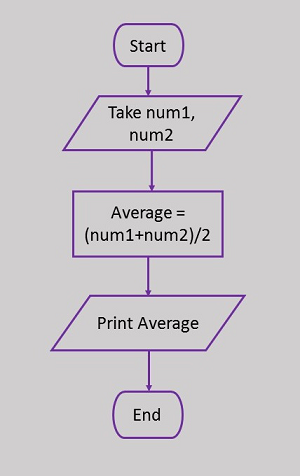
Oto schemat blokowy obliczania średniej z dwóch liczb.
Jak wiesz, komputer nie ma własnej inteligencji; po prostu następuje poinstructions podane przez użytkownika. Instructionssą elementami składowymi programu komputerowego, a zatem i oprogramowania. Udzielanie jasnych instrukcji ma kluczowe znaczenie dla stworzenia udanego programu. Jako programista lub programista powinieneś nabrać zwyczaju pisania jasnych instrukcji. Oto dwa sposoby, aby to zrobić.
Jasność wypowiedzi
Wyrażenie w programie to sekwencja operatorów i operandów służących do wykonywania obliczeń arytmetycznych lub logicznych. Oto kilka przykładów prawidłowych wyrażeń -
- Porównanie dwóch wartości
- Definiowanie zmiennej, obiektu lub klasy
- Obliczenia arytmetyczne przy użyciu jednej lub więcej zmiennych
- Pobieranie danych z bazy danych
- Aktualizacja wartości w bazie danych
Pisanie jednoznacznych wyrażeń to umiejętność, którą każdy programista musi rozwinąć. Oto kilka punktów, o których należy pamiętać podczas pisania takich wyrażeń -
Jednoznaczny wynik
Ocena wyrażenia musi dać jeden wyraźny wynik. Na przykład jednoargumentowe operatory powinny być używane ostrożnie.
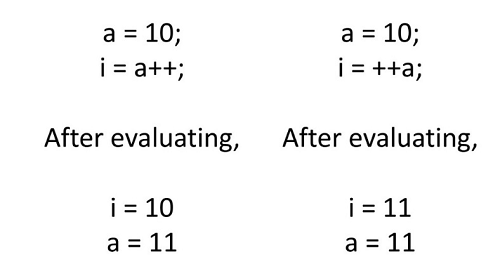
Unikaj złożonych wyrażeń
Nie próbuj osiągnąć wielu rzeczy w jednym wyrażeniu. Podziel się na dwa lub więcej wyrażeń w momencie, gdy sprawy zaczną się komplikować.
Prostota instrukcji
Nie tylko w przypadku komputerów musisz pisać jasne instrukcje. Każdy, kto później czyta program (nawet Ty sam !!), powinien być w stanie zrozumieć, co stara się osiągnąć instrukcja. Bardzo często programiści nie kończą swoich programów, gdy wracają do nich po jakimś czasie. Wskazuje to, że utrzymanie i modyfikacja takich programów byłoby dość trudne.
Pisanie prostych instrukcji pomaga uniknąć tego problemu. Oto kilka wskazówek, jak pisać proste instrukcje -
Avoid clever instructions - Sprytne instrukcje mogą później nie wyglądać tak mądrze, jeśli nikt nie będzie w stanie ich właściwie zrozumieć.
One instruction per task - Próba wykonania więcej niż jednej rzeczy naraz komplikuje instrukcje.
Use standards- Każdy język ma swoje standardy, przestrzegaj ich. Pamiętaj, że nie pracujesz sam nad projektem; przestrzegaj standardów projektu i wytycznych dotyczących kodowania.
W tym rozdziale omówimy, jak napisać dobry program. Ale zanim to zrobimy, zobaczmy, jakie są cechy dobrego programu -
Portable- Program lub oprogramowanie powinno działać na wszystkich komputerach tego samego typu. Przez ten sam typ rozumiemy, że oprogramowanie opracowane dla komputerów osobistych powinno działać na wszystkich komputerach. Lub oprogramowanie napisane na tablety powinno działać na wszystkich tabletach o odpowiednich specyfikacjach.
Efficient- Oprogramowanie, które szybko wykonuje powierzone zadania, jest wydajne. Optymalizacja kodu i optymalizacja pamięci to tylko niektóre ze sposobów na zwiększenie wydajności programu.

Effective- Oprogramowanie powinno pomóc w rozwiązaniu problemu. Oprogramowanie, które to robi, jest uważane za skuteczne.
Reliable - Program powinien dawać to samo wyjście za każdym razem, gdy podawany jest ten sam zestaw wejść.
User friendly - Interfejs programu, klikalne linki i ikony itp. Powinny być przyjazne dla użytkownika.
Self-documenting - Każdy program lub oprogramowanie, którego nazwy identyfikacyjne, nazwy modułów itp. Mogą się opisywać ze względu na użycie nazw jawnych.
Oto kilka sposobów pisania dobrych programów.
Właściwe nazwy identyfikatorów
Nazwa, która identyfikuje dowolną zmienną, obiekt, funkcję, klasę lub metodę jest nazywana identifier. Podanie odpowiednich nazw identyfikatorów sprawia, że program sam się dokumentuje. Oznacza to, że nazwa obiektu powie, co robi lub jakie informacje przechowuje. Weźmy przykład tej instrukcji SQL:
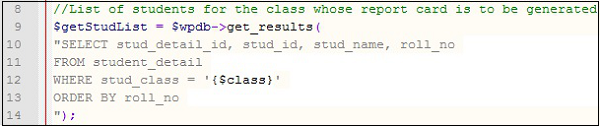
Spójrz na wiersz 10. Mówi każdemu, kto czyta program, że należy wybrać identyfikator studenta, nazwisko i numer listy. Nazwy zmiennych sprawiają, że jest to oczywiste. Oto kilka wskazówek dotyczących tworzenia prawidłowych nazw identyfikatorów -
Stosuj się do wskazówek językowych
Nie wahaj się podawać długich nazw, aby zachować przejrzystość
Używaj wielkich i małych liter
Nie nadawaj tej samej nazwy dwóm identyfikatorom, nawet jeśli język na to pozwala
Nie nadawaj tych samych nazw więcej niż jednemu identyfikatorowi, nawet jeśli mają one wzajemnie wykluczający się zakres
Komentarze
Na powyższym obrazku spójrz na wiersz 8. Informuje czytelnika, że kilka następnych wierszy kodu pobierze listę uczniów, których karta raportu ma zostać wygenerowana. Ta linia nie jest częścią kodu, ale podana tylko w celu uczynienia programu bardziej przyjaznym dla użytkownika.
Takie wyrażenie, które nie jest kompilowane, ale zapisywane jako notatka lub wyjaśnienie dla programisty, nazywa się a comment. Spójrz na komentarze w następnym segmencie programu. Komentarze zaczynają się od //.

Komentarze można wstawiać jako -
Wstęp do programu wyjaśniający jego cel
Na początku i / lub końcu bloków logicznych lub funkcjonalnych
Zwróć uwagę na specjalne scenariusze lub wyjątki
Należy unikać dodawania zbędnych komentarzy, ponieważ może to przynieść efekt przeciwny do zamierzonego, przerywając przepływ kodu podczas czytania. Kompilator może ignorować komentarze i wcięcia, ale czytelnik ma tendencję do czytania każdego z nich.
Wcięcie
Nazywa się odległość tekstu od lewego lub prawego marginesu indent. W programach do oddzielenia logicznie rozdzielonych bloków kodu używane są wcięcia. Oto przykład wciętego segmentu programu:
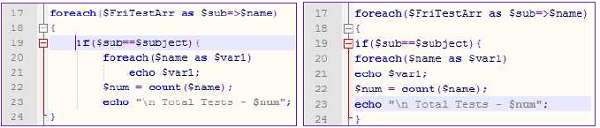
Jak widać, program z wcięciem jest bardziej zrozumiały. Przepływ sterowania zfor loop do if iz powrotem do forjest bardzo jasne. Wcięcia są szczególnie przydatne w przypadku struktur sterujących.
Wstawianie spacji lub linii jest również częścią wcięcia. Oto kilka sytuacji, w których możesz i powinieneś używać wcięć -
Puste linie między logicznymi lub funkcjonalnymi blokami kodu w programie
Puste przestrzenie wokół operatorów
Zakładki na początku nowych struktur sterowania
Nazywa się identyfikowanie i usuwanie błędów z programu lub oprogramowania debugging. Idealnie debugowanie jest częścią procesu testowania, ale w rzeczywistości odbywa się na każdym etapie programowania. Koderzy powinni debugować najmniejsze ze swoich modułów, zanim przejdą dalej. Zmniejsza to liczbę błędów zgłaszanych podczas fazy testowania i znacznie skraca czas testowania i nakład pracy. Przyjrzyjmy się typom błędów, które mogą pojawić się w programie.
Błędy składniowe
Syntax errorsto błędy gramatyczne w programie. Każdy język ma swój własny zestaw reguł, takich jak tworzenie identyfikatorów, pisanie wyrażeń itp. Do pisania programów. W przypadku naruszenia tych zasad wywoływane są błędysyntax errors. Wiele nowoczesnychintegrated development environmentsmoże zidentyfikować błędy składniowe podczas pisania programu. W przeciwnym razie zostanie wyświetlony podczas kompilacji programu. Weźmy przykład -
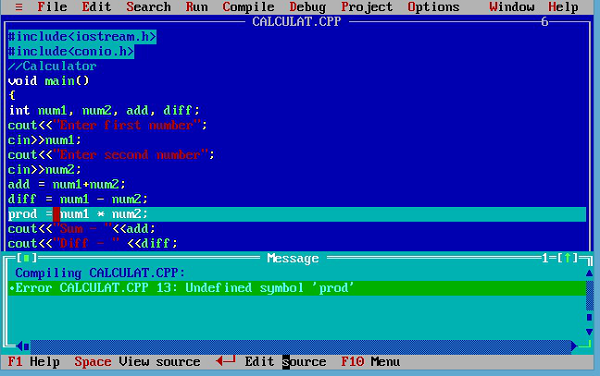
W tym programie nie została zadeklarowana zmienna prod, która jest generowana przez kompilator.
Błędy semantyczne
Semantic errors są również nazywane logical errors. Instrukcja nie zawiera błędów składniowych, więc będzie się kompilować i działać poprawnie. Jednak nie da to pożądanego wyniku, ponieważ logika jest nieprawidłowa. Weźmy przykład.
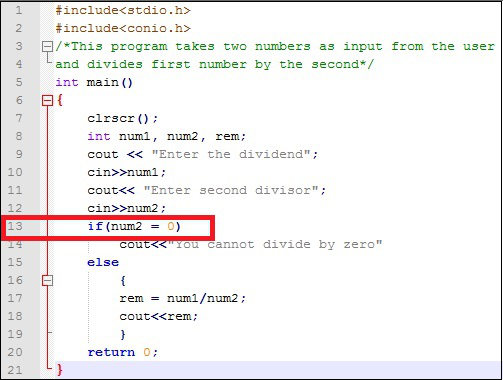
Spójrz na wiersz 13. Tutaj programista chce sprawdzić, czy dzielnik jest równy 0, aby uniknąć dzielenia przez 0. Jednak zamiast używać operatora porównania ==, został użyty operator przypisania =. Teraz za każdym razem, gdy wyrażenie „if” zwróci wartość „prawda”, a na wyjściu program wyświetli „Nie można podzielić przez 0”. Zdecydowanie nie to, co było zamierzone !!
Żaden program nie może wykryć błędów logicznych; muszą one zostać zidentyfikowane przez samego programistę, gdy pożądany wynik nie zostanie osiągnięty.
Błędy w czasie wykonywania
Błędy uruchomieniowe to błędy występujące podczas wykonywania programu. Oznacza to, że program nie zawiera błędów składniowych. Niektóre z najczęstszych błędów czasu wykonywania, które może napotkać Twój program, to:
- Nieskończona pętla
- Dzielenie przez „0”
- Błędna wartość wprowadzona przez użytkownika (powiedzmy ciąg znaków zamiast liczby całkowitej)
Optymalizacja kodu
Wywoływana jest każda metoda modyfikacji kodu w celu poprawy jego jakości i wydajności code optimization. Code qualityokreśla żywotność kodu. Jeśli kod może być używany i utrzymywany przez długi czas, przenoszony z produktu na produkt, jego jakość jest uważana za wysoką i ma dłuższą żywotność. Wręcz przeciwnie, jeśli fragment kodu może być używany i utrzymywany tylko przez krótkie okresy, powiedzmy do czasu, gdy wersja jest ważna, uważa się, że jest on niskiej jakości i ma krótki okres trwałości.
Decyduje o niezawodności i szybkości kodu code efficiency. Wydajność kodu jest ważnym czynnikiem zapewniającym wysoką wydajność oprogramowania.
Istnieją dwa podejścia do optymalizacji kodu -
Intuition based optimization (IBO)- Tutaj programista próbuje zoptymalizować program w oparciu o własne umiejętności i doświadczenie. Może to działać w przypadku małych programów, ale kończy się niepowodzeniem w miarę wzrostu złożoności programu.
Evidence based optimization (EBO)- W tym przypadku używane są zautomatyzowane narzędzia, aby znaleźć wąskie gardła wydajności, a następnie odpowiednie fragmenty zostały odpowiednio zoptymalizowane. Każdy język programowania ma własny zestaw narzędzi do optymalizacji kodu. Na przykład PMD, FindBug i Clover służą do optymalizacji kodu Java.
Kod jest zoptymalizowany pod kątem czasu wykonywania i zużycia pamięci, ponieważ czas jest ograniczony, a pamięć kosztowna. Musi istnieć równowaga między nimi. Gdybytime optimization zwiększa obciążenie pamięci lub memory optimization spowalnia kod, cel optymalizacji zostanie utracony.

Optymalizacja czasu wykonywania
Optymalizacja kodu pod kątem czasu wykonania jest niezbędna do zapewnienia szybkiej obsługi użytkownikom. Oto kilka wskazówek dotyczących optymalizacji czasu wykonywania -
Użyj poleceń, które mają wbudowaną optymalizację czasu wykonywania
Użyj przełącznika zamiast warunku if
Zminimalizuj wywołania funkcji w strukturach pętli
Zoptymalizuj struktury danych używane w programie
Optymalizacja pamięci
Jak wiesz, dane i instrukcje zajmują pamięć. Kiedy mówimy o danych, odnosi się to również do danych tymczasowych, które są wynikiem wyrażeń. Musimy również śledzić, ile instrukcji składa się na program lub moduł, który próbujemy zoptymalizować. Oto kilka wskazówek dotyczącychmemory optimization -
Użyj poleceń, które mają wbudowaną optymalizację pamięci
Zachowaj minimalne użycie zmiennych, które muszą być przechowywane w rejestrach
Unikaj deklarowania zmiennych globalnych wewnątrz pętli, które są wykonywane wielokrotnie
Unikaj używania funkcji intensywnie wykorzystujących procesor, takich jak sqrt ()
Nazywa się każdy tekst, ilustracje lub wideo, które opisują oprogramowanie lub program jego użytkownikom program or software document. Użytkownikiem może być każdy, od programisty, analityka systemu i administratora do użytkownika końcowego. Na różnych etapach rozwoju można stworzyć wiele dokumentów dla różnych użytkowników. W rzeczywistości,software documentation to krytyczny proces w całym procesie tworzenia oprogramowania.
W programowaniu modułowym dokumentacja nabiera jeszcze większego znaczenia, ponieważ różne moduły oprogramowania są opracowywane przez różne zespoły. Jeśli ktoś inny niż zespół programistów chce lub musi zrozumieć moduł, dobra i szczegółowa dokumentacja ułatwi zadanie.
Oto kilka wskazówek dotyczących tworzenia dokumentów -
Dokumentacja powinna być z punktu widzenia czytelnika
Dokument powinien być jednoznaczny
Nie powinno być powtórzeń
Należy stosować standardy branżowe
Dokumenty należy zawsze aktualizować
Każdy nieaktualny dokument powinien zostać wycofany po należytym zarejestrowaniu wycofania
Zalety dokumentacji
Oto niektóre z zalet dostarczania dokumentacji programu -
Śledzi wszystkie części oprogramowania lub programu
Konserwacja jest łatwiejsza
Programiści inni niż deweloper mogą zrozumieć wszystkie aspekty oprogramowania
Poprawia ogólną jakość oprogramowania
Pomaga w szkoleniu użytkowników
Zapewnia decentralizację wiedzy, zmniejszając koszty i wysiłek, jeśli ludzie nagle opuszczą system
Przykładowe dokumenty
Z oprogramowaniem może być skojarzonych wiele typów dokumentów. Niektóre z ważnych to:
User manual - Opisuje instrukcje i procedury dla użytkowników końcowych dotyczące korzystania z różnych funkcji oprogramowania.
Operational manual - Wymienia i opisuje wszystkie wykonywane operacje oraz ich wzajemne zależności.
Design Document- Zawiera przegląd oprogramowania i szczegółowo opisuje elementy projektu. Dokumentuje szczegóły, takie jakdata flow diagrams, entity relationship diagramsitp.
Requirements Document- Zawiera listę wszystkich wymagań systemu, a także analizę wykonalności wymagań. Może mieć przypadki użytkowników, scenariusze rzeczywistego życia itp.
Technical Documentation - Jest to dokumentacja rzeczywistych komponentów programistycznych, takich jak algorytmy, schematy blokowe, kody programów, moduły funkcjonalne itp.
Testing Document - Zapisuje plan testów, przypadki testowe, plan walidacji, plan weryfikacji, wyniki testów, itp. Testowanie to jedna z faz tworzenia oprogramowania, która wymaga intensywnej dokumentacji.
List of Known Bugs- Każde oprogramowanie zawiera błędy lub błędy, których nie można usunąć, ponieważ zostały wykryte bardzo późno lub są nieszkodliwe lub ich naprawienie zajmie więcej wysiłku i czasu niż jest to konieczne. Te błędy są wymienione w dokumentacji programu, aby można je było usunąć w późniejszym terminie. Pomagają również użytkownikom, wdrażającym i konserwatorom, jeśli błąd zostanie aktywowany.
Program maintenance to proces modyfikowania oprogramowania lub programu po dostarczeniu w celu osiągnięcia któregokolwiek z tych wyników -
- Popraw błędy
- Poprawić wydajność
- Dodaj funkcjonalności
- Usuń przestarzałe części
Pomimo powszechnego przekonania, że konserwacja jest wymagana do naprawienia błędów pojawiających się po uruchomieniu oprogramowania, w rzeczywistości większość prac konserwacyjnych obejmuje dodawanie mniejszych lub większych możliwości do istniejących modułów. Na przykład niektóre nowe dane są dodawane do raportu, nowe pole dodawane do formularzy zgłoszeniowych, kod do modyfikacji w celu uwzględnienia zmienionych przepisów rządowych itp.
Rodzaje konserwacji
Czynności konserwacyjne można podzielić na cztery kategorie -
Corrective maintenance- Naprawiono błędy, które pojawiają się po wdrożeniu na miejscu. Błędy mogą zostać wskazane przez samych użytkowników.
Preventive maintenance - Modyfikacje wprowadzone w celu uniknięcia błędów w przyszłości nazywane są konserwacją prewencyjną.
Adaptive maintenance- Zmiany w środowisku pracy wymagają czasem modyfikacji oprogramowania. Nazywa się to konserwacją adaptacyjną. Na przykład, jeśli rządowa polityka edukacyjna ulegnie zmianie, odpowiednie zmiany muszą zostać wprowadzone w module przetwarzania wyników uczniów w oprogramowaniu do zarządzania szkołą.
Perfective maintenance- Zmiany dokonane w istniejącym oprogramowaniu w celu uwzględnienia nowych wymagań klienta nazywane są konserwacją perfekcyjną. Celem jest bycie zawsze na bieżąco z najnowszymi technologiami.
Narzędzia do konserwacji
Twórcy oprogramowania i programiści używają wielu narzędzi, aby pomóc im w utrzymaniu oprogramowania. Oto niektóre z najczęściej używanych -
Program slicer - wybiera część programu, na którą miałaby mieć wpływ zmiana
Data flow analyzer - śledzi wszystkie możliwe przepływy danych w oprogramowaniu
Dynamic analyzer - śledzi ścieżkę wykonywania programu
Static analyzer - umożliwia ogólne przeglądanie i podsumowanie programu
Dependency analyzer - pomaga w zrozumieniu i analizie współzależności różnych części programu