PyBrain - sieć testowa
W tym rozdziale zobaczymy przykład, w którym zamierzamy uczyć dane i testować błędy w wyuczonych danych.
Będziemy korzystać z trenerów -
BackpropTrainer
BackpropTrainer to trener, który szkoli parametry modułu zgodnie z nadzorowanym lub zbiorem danych ClassificationDataSet (potencjalnie sekwencyjnym) poprzez wsteczną propagację błędów (w czasie).
TrainUntilConvergence
Służy do trenowania modułu w zbiorze danych, dopóki nie osiągnie zbieżności.
Kiedy tworzymy sieć neuronową, zostanie ona przeszkolona na podstawie przekazanych jej danych szkoleniowych. Teraz to, czy sieć jest odpowiednio przeszkolona, czy nie, będzie zależeć od przewidywania danych testowych testowanych w tej sieci.
Zobaczmy krok po kroku przykład roboczy, w którym zbudujemy sieć neuronową i przewidzimy błędy szkoleniowe, testowe i walidacyjne.
Testowanie naszej sieci
Oto kroki, które podejmiemy, aby przetestować naszą sieć -
- Importowanie wymaganego PyBrain i innych pakietów
- Utwórz ClassificationDataSet
- Dzielenie zbiorów danych 25% jako dane testowe i 75% jako dane wytrenowane
- Konwertowanie danych testowych i wytrenowanych danych z powrotem jako ClassificationDataSet
- Tworzenie sieci neuronowej
- Szkolenie sieci
- Wizualizacja błędu i danych walidacyjnych
- Procent dla danych testowych Błąd
Step 1
Importowanie wymaganego PyBrain i innych pakietów.
Pakiety, których potrzebujemy, są importowane, jak pokazano poniżej -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravelStep 2
Następnym krokiem jest utworzenie ClassificationDataSet.
W przypadku zestawów danych będziemy używać zestawów danych z zestawów danych sklearn, jak pokazano poniżej -
Zobacz zbiory danych load_digits ze sklearn w poniższym linku -
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
# we are having inputs are 64 dim array and since the digits are from 0-9 the
classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasetsStep 3
Dzielenie zbiorów danych 25% jako dane testowe i 75% jako dane przeszkolone -
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)Więc tutaj użyliśmy metody na zbiorze danych o nazwie splitWithProportion () o wartości 0,25, która podzieli zbiór danych na 25% jako dane testowe i 75% jako dane treningowe.
Step 4
Konwertowanie danych testowych i wytrenowanych danych z powrotem jako ClassificationDataSet.
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()Użycie metody splitWithProportion () na zbiorze danych konwertuje zbiór danych na nadzorowany zbiór danych, więc przekonwertujemy zbiór danych z powrotem do zbioru danych klasyfikacji, jak pokazano w powyższym kroku.
Step 5
Następnym krokiem jest stworzenie sieci neuronowej.
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)Tworzymy sieć, w której dane wejściowe i wyjściowe są używane z danych szkoleniowych.
Step 6
Szkolenie sieci
Teraz ważną częścią jest szkolenie sieci na zestawie danych, jak pokazano poniżej -
trainer = BackpropTrainer(net, dataset=training_data,
momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)Używamy metody BackpropTrainer () i używamy zbioru danych w utworzonej sieci.
Step 7
Następnym krokiem jest wizualizacja błędu i walidacja danych.
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()Użyjemy metody o nazwie trainUntilConvergence na danych uczących, które będą zbieżne dla okresów 10. Zwróci ona błąd uczenia i walidacji, które wykreśliliśmy, jak pokazano poniżej. Niebieska linia pokazuje błędy uczenia, a czerwona linia pokazuje błąd walidacji.
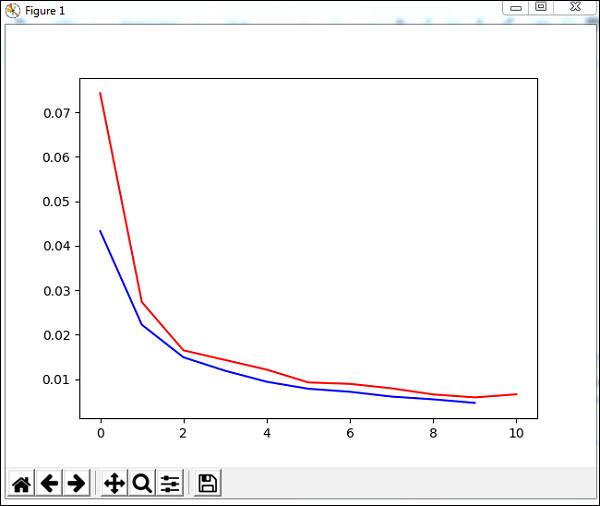
Całkowity błąd otrzymany podczas wykonywania powyższego kodu pokazano poniżej -
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')Błąd zaczyna się od 0,04, a później spada dla każdej epoki, co oznacza, że sieć jest szkolona i poprawia się z każdą epoką.
Step 8
Procent błędu danych testowych
Możemy sprawdzić procentowy błąd metodą percentError, jak pokazano poniżej -
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))Percent Error on testData - 3,34075723830735
Otrzymujemy procent błędu, czyli 3,34%, co oznacza, że sieć neuronowa jest dokładna w 97%.
Poniżej znajduje się pełny kod -
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))