SAP HANA - Szybki przewodnik
SAP HANA to połączenie HANA Database, Data Modeling, HANA Administration i Data Provisioning w jednym pakiecie. W SAP HANA HANA to skrót od High-Performance Analytic Appliance.
Według byłego dyrektora SAP, dr Vishala Sikki, HANA oznacza nową architekturę Hasso. HANA wzbudziła zainteresowanie w połowie 2011 r., A różne firmy z listy Fortune 500 zaczęły rozważać tę opcję jako możliwość zaspokojenia potrzeb magazynu biznesowego.
Funkcje SAP HANA
Poniżej przedstawiono główne cechy SAP HANA -
SAP HANA to połączenie innowacji w zakresie oprogramowania i sprzętu do przetwarzania ogromnych ilości danych w czasie rzeczywistym.
Oparty na architekturze wielordzeniowej w środowisku systemów rozproszonych.
Na podstawie typu wiersza i kolumny przechowywania danych w bazie danych.
Używany szeroko w Memory Computing Engine (IMCE) do przetwarzania i analizowania ogromnych ilości danych w czasie rzeczywistym.
Obniża koszty posiadania, zwiększa wydajność aplikacji, umożliwia uruchamianie nowych aplikacji w środowisku czasu rzeczywistego, które wcześniej nie było możliwe.
Jest napisany w C ++, obsługuje i działa tylko na jednym systemie operacyjnym Suse Linux Enterprise Server 11 SP1 / 2.
Potrzeba SAP HANA
Obecnie firmy odnoszące największe sukcesy szybko reagują na zmiany rynkowe i nowe możliwości. Kluczem do tego jest efektywne i wydajne wykorzystanie danych i informacji przez analityków i menedżerów.
HANA pokonuje ograniczenia wymienione poniżej -
W związku ze wzrostem „Wolumenu danych” wyzwaniem dla firm jest zapewnienie dostępu do danych w czasie rzeczywistym w celu analizy i wykorzystania biznesowego.
Wiąże się to z wysokimi kosztami utrzymania dla firm IT w zakresie przechowywania i utrzymywania dużych ilości danych.
Ze względu na niedostępność danych w czasie rzeczywistym wyniki analizy i przetwarzania są opóźnione.
Dostawcy SAP HANA
SAP nawiązał współpracę z wiodącymi dostawcami sprzętu IT, takimi jak IBM, Dell, Cisco itp., I połączył ją z usługami i technologią licencjonowaną SAP w celu sprzedaży platformy SAP HANA.
W sumie jest 11 dostawców, którzy produkują urządzenia HANA i zapewniają wsparcie na miejscu w zakresie instalacji i konfiguracji systemu HANA.
Top few Vendors include -
- IBM
- Dell
- HP
- Cisco
- Fujitsu
- Lenovo (Chiny)
- NEC
- Huawei
Według statystyk dostarczonych przez SAP, IBM jest jednym z głównych dostawców sprzętu sprzętowego SAP HANA i ma udział w rynku na poziomie 50-52%, ale według innego badania rynkowego przeprowadzonego przez klientów HANA, IBM ma udział w rynku sięgający 70%.
Instalacja SAP HANA
Dostawcy sprzętu HANA zapewniają wstępnie skonfigurowane urządzenia dla sprzętu, systemu operacyjnego i oprogramowania SAP.
Dostawca finalizuje instalację, instalując i konfigurując komponenty platformy HANA na miejscu. Ta wizyta na miejscu obejmuje wdrożenie systemu HANA w centrum danych, łączność z siecią organizacji, dostosowanie identyfikatora systemu SAP, aktualizacje z rozwiązania Solution Manager, łączność z routerem SAP, włączenie SSL i inną konfigurację systemu.
Klient / Klient zaczyna się od połączenia systemu Data Source z klientami BI. Instalacja HANA Studio jest zakończona na systemie lokalnym i dodawany jest system HANA w celu modelowania danych i administrowania nimi.
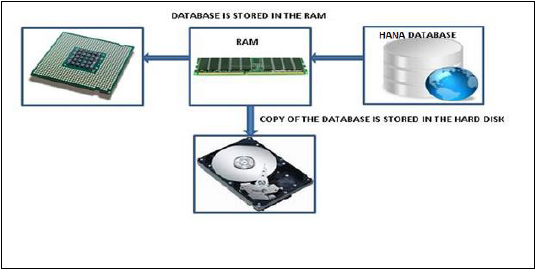
Baza danych w pamięci oznacza, że wszystkie dane z systemu źródłowego są przechowywane w pamięci RAM. W konwencjonalnym systemie baz danych wszystkie dane są przechowywane na dysku twardym. Baza danych SAP HANA w pamięci nie marnuje czasu na ładowanie danych z dysku twardego do pamięci RAM. Zapewnia szybszy dostęp do danych do procesorów wielordzeniowych w celu przetwarzania i analizy informacji.
Funkcje bazy danych w pamięci
Główne cechy bazy danych w pamięci SAP HANA to -
SAP HANA to hybrydowa baza danych w pamięci.
Łączy technologię bazową opartą na wierszach, kolumnach i obiektowo.
Wykorzystuje przetwarzanie równoległe z architekturą procesora wielordzeniowego.
Konwencjonalna baza danych odczytuje dane z pamięci w ciągu 5 milisekund. Baza danych SAP HANA w pamięci odczytuje dane w ciągu 5 nanosekund.
Oznacza to, że odczyty pamięci w bazie danych HANA są 1 milion razy szybsze niż odczyty z pamięci twardego dysku konwencjonalnej bazy danych.
Analitycy chcą widzieć aktualne dane od razu w czasie rzeczywistym i nie chcą czekać na dane, aż zostaną załadowane do systemu SAP BW. Przetwarzanie w pamięci SAP HANA umożliwia ładowanie danych w czasie rzeczywistym z wykorzystaniem różnych technik udostępniania danych.
Zalety bazy danych w pamięci
Baza danych HANA wykorzystuje przetwarzanie w pamięci, aby zapewnić najszybsze prędkości pobierania danych, co jest kuszące dla firm zmagających się z transakcjami online na dużą skalę lub z terminowym prognozowaniem i planowaniem.
Pamięć dyskowa jest nadal standardem dla przedsiębiorstw, a cena pamięci RAM stale spada, więc architektury intensywnie korzystające z pamięci ostatecznie zastąpią wolne, mechaniczne dyski obrotowe i obniżą koszt przechowywania danych.
Magazyn oparty na kolumnach w pamięci zapewnia nawet 11-krotną kompresję danych, zmniejszając w ten sposób przestrzeń do przechowywania ogromnych danych.
Ta przewaga szybkości oferowana przez system pamięci RAM jest dodatkowo zwiększona dzięki zastosowaniu wielordzeniowych procesorów, wielu procesorów na węzeł i wielu węzłów na serwer w środowisku rozproszonym.
Studio SAP HANA to narzędzie oparte na Eclipse. Studio SAP HANA jest zarówno centralnym środowiskiem programistycznym, jak i głównym narzędziem administracyjnym dla systemu HANA. Dodatkowe funkcje to -
Jest to narzędzie klienckie, za pomocą którego można uzyskać dostęp do lokalnego lub zdalnego systemu HANA.
Zapewnia środowisko do administracji HANA, modelowania informacji HANA i udostępniania danych w bazie danych HANA.
Z SAP HANA Studio można korzystać na następujących platformach -
Microsoft Windows 32 i 64-bitowe wersje: Windows XP, Windows Vista, Windows 7
SUSE Linux Enterprise Server SLES11: x86 64-bitowy
Mac OS, klient HANA Studio nie jest dostępny
W zależności od instalacji HANA Studio nie wszystkie funkcje mogą być dostępne. Podczas instalacji programu Studio określ funkcje, które chcesz zainstalować, zgodnie z rolą. Aby pracować nad najnowszą wersją studia HANA, można użyć Software Life Cycle Manager do aktualizacji klienta.
Perspektywy / funkcje SAP HANA Studio
SAP HANA Studio zapewnia perspektywy do pracy nad następującymi funkcjami HANA. Możesz wybrać perspektywę w HANA Studio z następującej opcji -
HANA Studio → Window → Open Perspective → Other
Administracja Sap Hana Studio
Zestaw narzędzi do różnych zadań administracyjnych, z wyłączeniem przenośnych obiektów repozytorium czasu projektowania. Dołączone są również ogólne narzędzia do rozwiązywania problemów, takie jak śledzenie, przeglądarka katalogu i konsola SQL.
Rozwój bazy danych SAP HANA Studio
Zapewnia zestaw narzędzi do tworzenia treści. Dotyczy to w szczególności scenariuszy DataMarts i ABAP on SAP HANA, które nie obejmują tworzenia natywnych aplikacji SAP HANA (XS).
Tworzenie aplikacji SAP HANA Studio
System SAP HANA zawiera niewielki serwer WWW, który może służyć do hostowania niewielkich aplikacji. Udostępnia zestaw narzędzi do tworzenia natywnych aplikacji SAP HANA, takich jak kod aplikacji napisany w języku Java i HTML.
Domyślnie wszystkie funkcje są instalowane.
Do wykonywania funkcji administracyjnych i monitorowania bazy danych HANA można użyć perspektywy konsoli administracyjnej SAP HANA.
Dostęp do Edytora administratora można uzyskać na kilka sposobów -
From System View Toolbar - Wybierz domyślny przycisk Otwórz administrację
In System View - Kliknij dwukrotnie System HANA lub Otwórz perspektywę
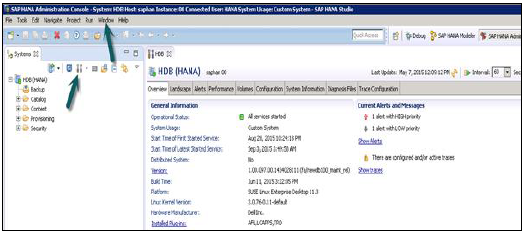
HANA Studio: Administrator Editor
W widoku administracyjnym: studio HANA udostępnia wiele zakładek do sprawdzania konfiguracji i kondycji systemu HANA. Karta Przegląd zawiera informacje ogólne, takie jak stan operacyjny, czas rozpoczęcia pierwszej i ostatnio uruchomionej usługi, wersję, datę i godzinę kompilacji, platformę, producenta sprzętu itp.
Dodawanie systemu HANA do Studio
Do studia HANA można dodać jeden lub wiele systemów w celu administrowania i modelowania informacji. Aby dodać nowy system HANA, wymagana jest nazwa hosta, numer instancji oraz nazwa użytkownika bazy danych i hasło.
- Port 3615 powinien być otwarty, aby połączyć się z bazą danych
- Port 31015 Instancja nr 10
- Port 30015 Instancja nr 00
- Należy również otworzyć port SSh
Dodawanie systemu do Hana Studio
Aby dodać system do studia HANA, postępuj zgodnie z podanymi krokami.
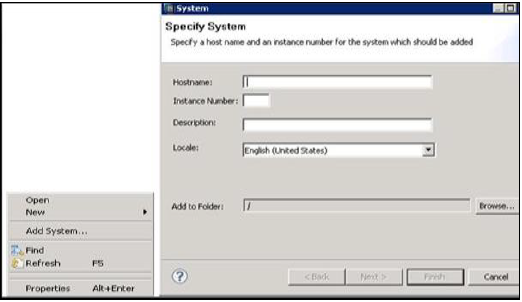
Kliknij prawym przyciskiem myszy w obszarze Nawigatora i kliknij Dodaj system. Wpisz dane systemu HANA, tj. Nazwę hosta i numer instancji i kliknij dalej.
Wprowadź nazwę użytkownika bazy danych i hasło, aby połączyć się z bazą danych SAP HANA. Kliknij Dalej, a następnie Zakończ.
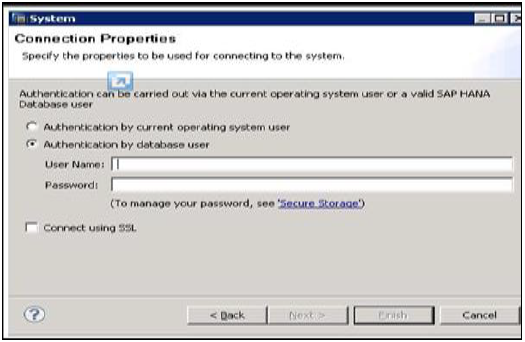
Po kliknięciu przycisku Zakończ system HANA zostanie dodany do widoku systemu w celu administrowania i modelowania. Każdy system HANA ma dwa główne węzły podrzędne, katalog i zawartość.
Katalog i zawartość
Katalog
Zawiera wszystkie dostępne schematy, tj. Wszystkie struktury danych, tabele i dane, widoki kolumn, procedury, których można użyć w zakładce Treść.
Zadowolony
Karta Zawartość zawiera repozytorium czasu projektowania, które zawiera wszystkie informacje o modelach danych utworzonych za pomocą HANA Modeler. Modele te są pogrupowane w paczkach. Węzeł treści zapewnia różne widoki tych samych danych fizycznych.
Monitor systemu w studiu HANA zapewnia przegląd całego systemu HANA na pierwszy rzut oka. Z Monitora systemu można przejść do szczegółów pojedynczego systemu w Edytorze administracyjnym. Informuje o dysku danych, dysku dziennika, dysku śledzenia, alertach o wykorzystaniu zasobów z priorytetem.
Następujące informacje są dostępne w Monitorze systemu -

SAP HANA Information Modeler; znany również jako HANA Data Modeler jest sercem HANA System. Umożliwia tworzenie widoków modelowania na górze tabel bazy danych i implementację logiki biznesowej w celu stworzenia sensownego raportu do analizy.
Funkcje narzędzia do modelowania informacji
Zapewnia wiele widoków danych transakcyjnych przechowywanych w fizycznych tabelach bazy danych HANA do celów analizy i logiki biznesowej.
Informacyjny modeler działa tylko w przypadku tabel magazynowania opartych na kolumnach.
Widoki modelowania informacji są używane przez aplikacje oparte na języku Java lub HTML lub narzędzia SAP, takie jak SAP Lumira lub Analysis Office, do celów raportowania.
Możliwe jest również użycie narzędzi innych firm, takich jak MS Excel, do połączenia z HANA i tworzenia raportów.
Widoki modelowania SAP HANA wykorzystują rzeczywistą moc SAP HANA.
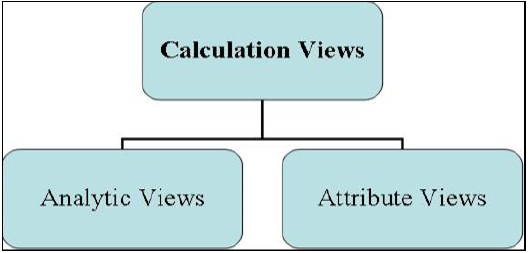
Istnieją trzy typy widoków informacji, zdefiniowane jako -
- Widok atrybutów
- Widok analityczny
- Widok obliczeń
Sklep z wierszami i kolumnami
Widoki SAP HANA Modeler można tworzyć tylko na górze tabel opartych na kolumnach. Przechowywanie danych w tabelach kolumnowych nie jest niczym nowym. Wcześniej zakładano, że przechowywanie danych w strukturze opartej na kolumnach zajmuje więcej pamięci i nie jest zoptymalizowane pod kątem wydajności.
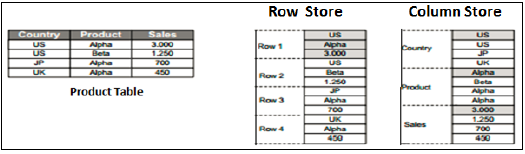
Wraz z ewolucją SAP HANA, HANA użyła kolumnowego przechowywania danych w widokach informacji i przedstawiła rzeczywiste korzyści tabel kolumnowych w porównaniu do tabel opartych na wierszach.
Sklep kolumnowy
W tabeli magazynu kolumn dane są przechowywane w pionie. Tak więc podobne typy danych łączą się, jak pokazano w powyższym przykładzie. Zapewnia szybsze operacje odczytu i zapisu pamięci za pomocą In-Memory Computing Engine.
W konwencjonalnej bazie danych dane są przechowywane w strukturze opartej na wierszach, tj. Poziomo. SAP HANA przechowuje dane w strukturze opartej na wierszach i kolumnach. Zapewnia to optymalizację wydajności, elastyczność i kompresję danych w bazie danych HANA.
Przechowywanie danych w tabeli opartej na kolumnach ma następujące zalety -
Kompresja danych
Szybszy dostęp do odczytu i zapisu do tabel w porównaniu z konwencjonalną pamięcią opartą na wierszach
Elastyczność i przetwarzanie równoległe
Wykonuj agregacje i obliczenia z większą prędkością
Istnieje wiele metod i algorytmów przechowywania danych w strukturze opartej na kolumnach - skompresowany słownik, skompresowany długości przebiegu i wiele innych.
W skompresowanym słowniku komórki są przechowywane w postaci liczb w tabelach, a komórki liczbowe są zawsze zoptymalizowane pod kątem wydajności w porównaniu ze znakami.
W skompresowanej długości przebiegu zapisuje mnożnik z wartością komórki w formacie liczbowym, a mnożnik pokazuje powtarzalną wartość w tabeli.

Różnica funkcjonalna - magazyn wierszy a kolumna
Zawsze zaleca się korzystanie z pamięci opartej na kolumnach, jeśli instrukcja SQL ma wykonywać funkcje agregujące i obliczenia. Tabele oparte na kolumnach zawsze działają lepiej podczas uruchamiania funkcji agregujących, takich jak Suma, Liczba, Maks., Min.
Przechowywanie oparte na wierszach jest preferowane, gdy dane wyjściowe muszą zwracać cały wiersz. Poniższy przykład ułatwia zrozumienie.

W powyższym przykładzie, podczas uruchamiania funkcji Aggregate (Sum) w kolumnie sprzedaży z klauzulą Where, podczas wykonywania zapytania SQL będzie używana tylko kolumna Date and Sales, więc jeśli jest to tabela magazynu oparta na kolumnach, zostanie zoptymalizowana pod kątem wydajności, szybciej niż dane jest wymagane tylko z dwóch kolumn.
Podczas uruchamiania prostego zapytania wybierającego, na wyjściu musi zostać wydrukowany pełny wiersz, dlatego zaleca się przechowywanie tabeli jako wiersza opartego na tym scenariuszu.
Widoki modelowania informacji
Widok atrybutów
Atrybuty są niemierzalnymi elementami w tabeli bazy danych. Reprezentują dane podstawowe i są podobne do cech BW. Widoki atrybutów są wymiarami w bazie danych lub są używane do łączenia wymiarów lub innych widoków atrybutów w modelowaniu.
Ważne cechy to -
- Widoki atrybutów są używane w widokach analitycznych i obliczeniowych.
- Widok atrybutów reprezentuje dane podstawowe.
- Służy do filtrowania rozmiaru tabel wymiarów w widoku analitycznym i obliczeniowym.
Widok analityczny
Widoki analityczne wykorzystują moc SAP HANA do wykonywania obliczeń i funkcji agregacji w tabelach w bazie danych. Ma co najmniej jedną tabelę faktów, która zawiera miary i klucze podstawowe tabel wymiarów i otoczona tabelami wymiarów zawiera dane podstawowe.
Ważne cechy to -
Widoki analityczne są przeznaczone do wykonywania zapytań o schemat gwiazdy.
Widoki analityczne zawierają co najmniej jedną tabelę faktów i tabele wielu wymiarów z danymi podstawowymi oraz umożliwiają wykonywanie obliczeń i agregacji
Są podobne do modułów informacyjnych i obiektów informacyjnych w SAP BW.
Widoki analityczne można tworzyć na podstawie widoków atrybutów i tabel faktów i wykonywać obliczenia, takie jak liczba sprzedanych jednostek, łączna cena itp.
Widoki obliczeniowe
Widoki obliczeń są używane na wierzchu widoków analitycznych i atrybutów w celu wykonywania złożonych obliczeń, które nie są możliwe w przypadku widoków analitycznych. Widok obliczeń jest połączeniem tabel bazowych kolumn, widoków atrybutów i widoków analitycznych w celu zapewnienia logiki biznesowej.
Ważne cechy to -
Widoki obliczeń są definiowane graficznie za pomocą funkcji modelowania HANA lub za pomocą skryptów w języku SQL.
Jest stworzony do wykonywania skomplikowanych obliczeń, które nie są możliwe w przypadku innych widoków - widoków atrybutów i analitycznych w modelarzu SAP HANA.
Jeden lub więcej widoków atrybutów i widoków analitycznych jest używanych za pomocą wbudowanych funkcji, takich jak projekty, suma, łączenie, ranga w widoku obliczeń.
SAP HANA został początkowo opracowany w językach Java i C ++ i zaprojektowany do uruchamiania wyłącznie systemu operacyjnego Suse Linux Enterprise Server 11. System SAP HANA składa się z wielu komponentów, które są odpowiedzialne za podkreślenie mocy obliczeniowej systemu HANA.
Najważniejszym elementem systemu SAP HANA jest Index Server, zawierający procesor SQL / MDX do obsługi zapytań do bazy danych.
System HANA zawiera serwer nazw, serwer preprocesorów, serwer statystyk i silnik XS, który służy do komunikacji i hostowania małych aplikacji internetowych i różnych innych komponentów.

Serwer indeksów
Index Server jest sercem systemu bazodanowego SAP HANA. Zawiera aktualne dane i silniki do przetwarzania tych danych. Gdy SQL lub MDX jest uruchamiany dla systemu SAP HANA, serwer indeksu obsługuje wszystkie te żądania i przetwarza je. Całe przetwarzanie HANA odbywa się na serwerze indeksu.
Index Server zawiera silniki danych do obsługi wszystkich instrukcji SQL / MDX, które trafiają do systemu bazy danych HANA. Posiada również warstwę trwałości, która odpowiada za trwałość systemu HANA i zapewnia przywrócenie systemu HANA do najnowszego stanu po ponownym uruchomieniu systemu po awarii.
Index Server posiada również Menedżera sesji i transakcji, który zarządza transakcjami i śledzi wszystkie uruchomione i zamknięte transakcje.

Serwer indeksu - architektura
Procesor SQL / MDX
Odpowiada za przetwarzanie transakcji SQL / MDX z silnikami danych odpowiedzialnymi za wykonywanie zapytań. Segmentuje wszystkie zapytania i kieruje je do odpowiedniego silnika w celu optymalizacji wydajności.
Zapewnia również autoryzację wszystkich żądań SQL / MDX, a także zapewnia obsługę błędów w celu wydajnego przetwarzania tych instrukcji. Zawiera kilka silników i procesorów do wykonywania zapytań -
MDX (Multi Dimension Expression) to język zapytań dla systemów OLAP, takich jak SQL jest używany w relacyjnej bazie danych. MDX Engine jest odpowiedzialny za obsługę zapytań i manipulowanie wielowymiarowymi danymi przechowywanymi w kostkach OLAP.
Silnik planowania jest odpowiedzialny za wykonywanie operacji planowania w bazie danych SAP HANA.
Calculation Engine konwertuje dane do modeli obliczeniowych w celu stworzenia logicznego planu wykonania wspierającego równoległe przetwarzanie wyciągów.
Procesor procedur składowanych wykonuje wywołania procedur w celu zoptymalizowania przetwarzania; konwertuje kostki OLAP na kostki zoptymalizowane pod kątem platformy HANA.
Zarządzanie transakcjami i sesjami
Jest odpowiedzialny za koordynację wszystkich transakcji bazy danych i śledzenie wszystkich uruchomionych i zamkniętych transakcji.
Gdy transakcja jest wykonywana lub nieudana, Menedżer transakcji powiadamia odpowiedni silnik danych o podjęciu niezbędnych działań.
Komponent do zarządzania sesjami jest odpowiedzialny za inicjowanie i zarządzanie sesjami i połączeniami dla systemu SAP HANA przy użyciu predefiniowanych parametrów sesji.
Warstwa trwałości
Odpowiada za trwałość i atomowość transakcji w systemie HANA. Warstwa trwałości zapewnia wbudowany system odzyskiwania po awarii dla bazy danych HANA.
Zapewnia przywrócenie bazy danych do najnowszego stanu i gwarantuje, że wszystkie transakcje zostaną zakończone lub cofnięte w przypadku awarii lub ponownego uruchomienia systemu.
Jest również odpowiedzialny za zarządzanie danymi i dziennikami transakcji, a także za tworzenie kopii zapasowych danych, tworzenie kopii zapasowych dzienników i konfigurację systemu HANA. Kopie zapasowe są przechowywane jako punkty zapisu w woluminach danych za pośrednictwem koordynatora punktu zapisu, który jest zwykle ustawiany na zapisywanie co 5–10 minut.
Serwer preprocesora
Serwer preprocesorów w systemie SAP HANA służy do analizy danych tekstowych.
Index Server używa serwera preprocesora do analizy danych tekstowych i wyodrębniania informacji z danych tekstowych, gdy używane są możliwości wyszukiwania tekstu.
Serwer nazw
Serwer NAME zawiera informacje o krajobrazie systemu systemu HANA. W środowisku rozproszonym istnieje wiele węzłów, a każdy węzeł ma wiele procesorów, serwer nazw ma topologię systemu HANA i zawiera informacje o wszystkich uruchomionych komponentach, a informacje są rozproszone na wszystkie komponenty.
Tutaj zapisana jest topologia systemu SAP HANA.
Skraca czas ponownego indeksowania, ponieważ utrzymuje, które dane znajdują się na którym serwerze w środowisku rozproszonym.
Serwer statystyczny
Ten serwer sprawdza i analizuje kondycję wszystkich komponentów w systemie HANA. Serwer statystyczny odpowiada za zbieranie danych związanych z zasobami systemowymi, ich alokację i zużycie zasobów oraz ogólną wydajność systemu HANA.
Dostarcza również danych historycznych związanych z wydajnością systemu do celów analiz, sprawdzania i naprawiania problemów związanych z wydajnością w systemie HANA.
Silnik XS
Silnik XS pomaga zewnętrznym aplikacjom opartym na języku Java i HTML uzyskać dostęp do systemu HANA za pomocą klienta XS. Ponieważ system SAP HANA zawiera serwer WWW, który może służyć do hostowania małych aplikacji opartych na języku JAVA / HTML.
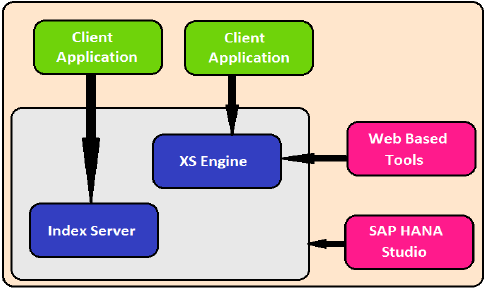
XS Engine przekształca model trwałości przechowywany w bazie danych w model zużycia dla klientów udostępnianych za pośrednictwem protokołu HTTP / HTTPS.
Agent hosta SAP
Agent hosta SAP powinien być zainstalowany na wszystkich komputerach, które są częścią krajobrazu systemu SAP HANA. Agent SAP Host jest używany przez Software Update Manager SUM do instalowania automatycznych aktualizacji wszystkich komponentów systemu HANA w środowisku rozproszonym.
Struktura LM
Struktura LM systemu SAP HANA zawiera informacje o aktualnych szczegółach instalacji. Te informacje są używane przez Menedżera aktualizacji oprogramowania do instalowania automatycznych aktualizacji składników systemu HANA.
Agent diagnostyczny SAP Solution Manager (SAP SOLMAN)
Ten agent diagnostyczny dostarcza wszystkie dane do SAP Solution Manager w celu monitorowania systemu SAP HANA. Ten agent zapewnia wszystkie informacje o bazie danych HANA, w tym aktualny stan bazy danych i informacje ogólne.
Udostępnia szczegóły konfiguracji systemu HANA, gdy SAP SOLMAN jest zintegrowany z systemem SAP HANA.
Repozytorium SAP HANA Studio
Repozytorium SAP HANA Studio pomaga programistom HANA aktualizować bieżącą wersję HANA Studio do najnowszych wersji. Studio Repository zawiera kod, który dokonuje tej aktualizacji.
Menedżer aktualizacji oprogramowania dla SAP HANA
SAP Market Place służy do instalowania aktualizacji systemów SAP. Software Update Manager dla systemu HANA pomaga w aktualizacji systemu HANA z SAP Market place.
Służy do pobierania oprogramowania, wiadomości od klientów, notatek SAP i żądania kluczy licencyjnych do systemu HANA. Służy również do dystrybucji studia HANA na systemy użytkowników końcowych.
Opcja SAP HANA Modeler służy do tworzenia widoków informacji na górze schematów → tabel w bazie danych HANA. Te widoki są używane przez aplikacje oparte na JAVA / HTML lub aplikacje SAP, takie jak SAP Lumira, Office Analysis lub oprogramowanie innych firm, takie jak MS Excel, do celów raportowania w celu spełnienia logiki biznesowej oraz wykonywania analiz i wyodrębniania informacji.
Modelowanie HANA odbywa się na górze tabel dostępnych na karcie Katalog w obszarze Schemat w studio HANA, a wszystkie widoki są zapisywane w tabeli zawartości w obszarze Pakiet.
Możesz utworzyć nowy pakiet na karcie Zawartość w studio HANA, klikając prawym przyciskiem myszy Zawartość i Nowy.
Wszystkie widoki modelowania utworzone w jednym pakiecie znajdują się w tym samym pakiecie w HANA Studio i są podzielone na kategorie według typu widoku.
Każdy widok ma inną strukturę tabel wymiarów i faktów. Tabele wymiarów są definiowane za pomocą danych podstawowych, a tabela faktów zawiera klucz podstawowy dla tabel wymiarów i miar, takich jak liczba sprzedanych jednostek, średni czas opóźnienia, cena całkowita itp.
Tabela faktów i wymiarów
Tabela faktów zawiera podstawowe klucze do tabeli wymiarów i miar. Są one połączone z tabelami wymiarów w widokach HANA w celu spełnienia logiki biznesowej.
Example of Measures - Liczba sprzedanych jednostek, cena całkowita, średni czas opóźnienia itp.
Tabela wymiarów zawiera dane podstawowe i jest połączona z co najmniej jedną tabelą faktów w celu utworzenia logiki biznesowej. Tabele wymiarów służą do tworzenia schematów z tabelami faktów i można je znormalizować.
Example of Dimension Table - Klient, produkt itp.
Załóżmy, że firma sprzedaje produkty klientom. Każda sprzedaż jest faktem, który ma miejsce w firmie, a tabela faktów służy do rejestrowania tych faktów.
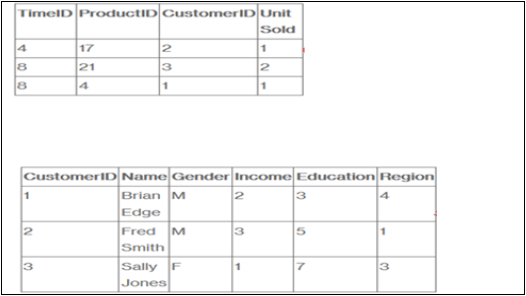
Na przykład wiersz 3 w tabeli faktów rejestruje fakt, że klient 1 (Brian) kupił jeden przedmiot w czwartym dniu. W pełnym przykładzie mielibyśmy również tabelę produktów i harmonogram, abyśmy wiedzieli, co kupiła. i kiedy dokładnie.
Tabela faktów zawiera listę zdarzeń, które mają miejsce w naszej firmie (lub przynajmniej zdarzenia, które chcemy przeanalizować - liczba sprzedanych jednostek, marża i przychody ze sprzedaży). W tabelach wymiarów wymieniono czynniki (klient, czas i produkt), według których chcemy analizować dane.
Schematy to logiczny opis tabel w hurtowni danych. Schematy są tworzone przez połączenie wielu tabel faktów i wymiarów w celu spełnienia pewnej logiki biznesowej.
Baza danych wykorzystuje model relacyjny do przechowywania danych. Jednak hurtownia danych używa schematów, które łączą wymiary i tabele faktów w celu spełnienia logiki biznesowej. Istnieją trzy typy schematów używanych w hurtowni danych -
- Schemat gwiazdy
- Schemat płatków śniegu
- Schemat galaktyki
Schemat gwiazdy
W schemacie gwiaździstym każdy wymiar jest łączony z jedną tabelą faktów. Każdy wymiar jest reprezentowany tylko przez jeden wymiar i nie podlega dalszej normalizacji.
Tabela wymiarów zawiera zestaw atrybutów używanych do analizy danych.
Example - W przykładzie podanym poniżej mamy tabelę faktów FactSales, która zawiera klucze podstawowe dla wszystkich tabel Dim i mierzy sprzedane jednostki i dolary w celu wykonania analizy.
Mamy cztery tabele wymiarów - DimTime, DimItem, DimBranch, DimLocation
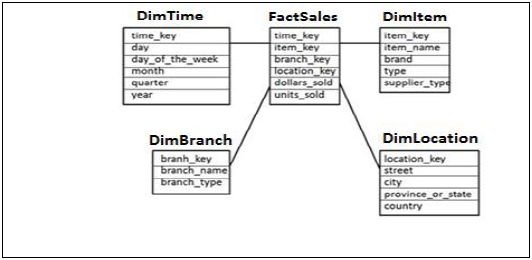
Każda tabela wymiarów jest połączona z tabelą faktów, ponieważ tabela faktów ma klucz podstawowy dla każdej tabeli wymiarów używanej do łączenia dwóch tabel.
Fakty / miary w tabeli faktów są używane do celów analitycznych wraz z atrybutem w tabelach wymiarów.
Schemat płatków śniegu
W schemacie Płatki śniegu niektóre tabele wymiarów są dalej, znormalizowane, a tabele wymiarów są połączone z jedną tabelą faktów. Normalizacja służy do organizowania atrybutów i tabel bazy danych, aby zminimalizować nadmiarowość danych.
Normalizacja polega na podzieleniu tabeli na mniej nadmiarowe mniejsze tabele bez utraty jakichkolwiek informacji, a mniejsze tabele są łączone z tabelą wymiarów.
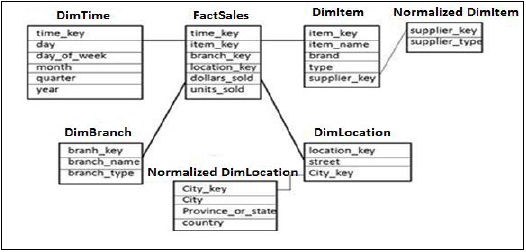
W powyższym przykładzie tabele wymiarów DimItem i DimLocation są znormalizowane bez utraty jakichkolwiek informacji. Nazywa się to schematem płatków śniegu, w którym tabele wymiarów są dalej znormalizowane do mniejszych tabel.
Schemat galaktyki
W schemacie Galaxy istnieje wiele tabel faktów i tabel wymiarów. Każda tabela faktów przechowuje klucze główne kilku tabel wymiarów i miar / faktów do przeprowadzenia analizy.
W powyższym przykładzie istnieją dwie tabele faktów FactSales, FactShipping i wiele tabel wymiarów połączonych z tabelami faktów. Każda tabela faktów zawiera klucz podstawowy do połączonych tabel Dim i miar / faktów do wykonania analizy.
Dostęp do tabel w bazie danych HANA można uzyskać z poziomu HANA Studio na karcie Katalog w obszarze Schematy. Nowe tabele można utworzyć za pomocą dwóch metod podanych poniżej -
- Korzystanie z edytora SQL
- Korzystanie z opcji GUI
Edytor SQL w HANA Studio
Konsolę SQL można otworzyć, wybierając nazwę schematu, w którym ma zostać utworzona nowa tabela za pomocą opcji Edytor SQL Widok systemu lub klikając prawym przyciskiem myszy na nazwę schematu, jak pokazano poniżej -

Po otwarciu edytora SQL nazwę schematu można potwierdzić na podstawie nazwy zapisanej w górnej części edytora SQL. Nową tabelę można utworzyć za pomocą instrukcji SQL Create Table -
Create column Table Test1 (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);W tej instrukcji SQL utworzyliśmy tabelę kolumn „Test1”, zdefiniowaliśmy typy danych tabeli i klucz podstawowy.
Po napisaniu zapytania SQL Utwórz tabelę kliknij opcję Wykonaj u góry edytora SQL po prawej stronie. Po wykonaniu instrukcji otrzymamy wiadomość potwierdzającą, jak pokazano na migawce podanej poniżej -
Instrukcja `` Utwórz kolumnę Table Test1 (ID INTEGER, NAME VARCHAR (10), PRIMARY KEY (ID)) ''
pomyślnie wykonane w 13 ms 761 μs (czas przetwarzania serwera: 12 ms 979 μs) - Dotyczy wierszy: 0

Instrukcja wykonania informuje również o czasie potrzebnym do wykonania instrukcji. Po pomyślnym wykonaniu instrukcji kliknij prawym przyciskiem myszy kartę Tabela pod nazwą schematu w widoku systemu i odśwież. Nowa tabela zostanie odzwierciedlona na liście tabel pod nazwą schematu.
Instrukcja Insert służy do wprowadzania danych do tabeli za pomocą edytora SQL.
Insert into TEST1 Values (1,'ABCD')
Insert into TEST1 Values (2,'EFGH');Kliknij Wykonaj.
Możesz kliknąć prawym przyciskiem myszy nazwę tabeli i użyć opcji Otwórz definicję danych, aby zobaczyć typ danych tabeli. Otwórz podgląd danych / Otwórz zawartość, aby zobaczyć zawartość tabeli.
Tworzenie tabeli przy użyciu opcji GUI
Innym sposobem tworzenia tabeli w bazie danych HANA jest użycie opcji GUI w HANA Studio.
Kliknij prawym przyciskiem myszy kartę Tabela w Schemacie → Wybierz opcję „Nowa tabela”, jak pokazano na migawce podanej poniżej.
Po kliknięciu na Nowa tabela → Otworzy się okno do wpisania nazwy tabeli, wybierz nazwę schematu z listy rozwijanej, Zdefiniuj typ tabeli z rozwijanej listy: Magazyn kolumn lub Magazyn wierszy.
Zdefiniuj typ danych, jak pokazano poniżej. Kolumny można dodawać, klikając znak +, klucz podstawowy można wybrać, klikając komórkę pod kluczem podstawowym przed nazwą kolumny, domyślnie aktywna będzie opcja Not Null.
Po dodaniu kolumn kliknij Wykonaj.
Po wykonaniu (F8) kliknij prawym przyciskiem myszy kartę Tabela → Odśwież. Nowa tabela zostanie odzwierciedlona na liście tabel pod wybranym schematem. Poniżej opcji wstawiania można wstawić dane do tabeli. Wybierz instrukcję, aby zobaczyć zawartość tabeli.

Wstawianie danych do tabeli za pomocą GUI w studio HANA
Możesz kliknąć prawym przyciskiem myszy nazwę tabeli i użyć opcji Otwórz definicję danych, aby zobaczyć typ danych tabeli. Otwórz podgląd danych / Otwórz zawartość, aby zobaczyć zawartość tabeli.
Aby używać tabel z jednego schematu do tworzenia widoków, należy zapewnić dostęp do schematu domyślnemu użytkownikowi, który uruchamia wszystkie widoki w HANA Modeling. Można to zrobić, przechodząc do edytora SQL i uruchamiając to zapytanie -
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
Pakiety SAP HANA są wyświetlane na karcie Zawartość w studiu HANA. Wszystkie modele HANA są zapisywane w pakietach.
Możesz utworzyć nowy pakiet, klikając prawym przyciskiem myszy kartę Zawartość → Nowy → Pakiet
Możesz również utworzyć pakiet podrzędny w ramach pakietu, klikając prawym przyciskiem myszy nazwę pakietu. Po kliknięciu pakietu prawym przyciskiem myszy otrzymujemy 7 opcji: możemy utworzyć widoki atrybutów HANA, widoki analityczne i widoki obliczeniowe w ramach pakietu.
Możesz także utworzyć tabelę decyzyjną, zdefiniować uprawnienie analityczne i utworzyć procedury w pakiecie.
Gdy klikniesz prawym przyciskiem myszy Pakiet i kliknij Nowy, możesz również utworzyć pakiety podrzędne w pakiecie. Musisz podać nazwę pakietu, opis podczas tworzenia pakietu.
Widoki atrybutów w SAP HANA Modeling są tworzone na górze tabel wymiarów. Służą do łączenia tabel wymiarów lub innych widoków atrybutów. Możesz również skopiować nowy widok atrybutów z już istniejących widoków atrybutów w innych pakietach, ale to nie pozwala na zmianę atrybutów widoku.
Charakterystyka widoku atrybutów
Widoki atrybutów w HANA służą do łączenia tabel wymiarów lub innych widoków atrybutów.
Widoki atrybutów są używane w widokach analitycznych i obliczeniowych do analizy w celu przekazania danych podstawowych.
Są podobne do Charakterystyki w BM i zawierają dane podstawowe.
Widoki atrybutów są używane do optymalizacji wydajności w tabelach wymiarów o dużych rozmiarach; można ograniczyć liczbę atrybutów w widoku atrybutów, które są następnie używane do celów raportowania i analizy.
Widoki atrybutów służą do modelowania danych podstawowych w celu nadania kontekstu.
Jak utworzyć widok atrybutów?
Wybierz nazwę pakietu, pod którą chcesz utworzyć widok atrybutów. Kliknij prawym przyciskiem myszy Pakiet → Idź do nowego → Widok atrybutów
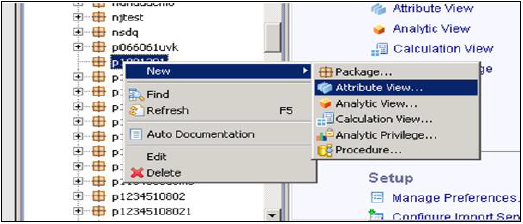
Po kliknięciu widoku atrybutów otworzy się nowe okno. Wprowadź nazwę i opis widoku atrybutów. Z rozwijanej listy wybierz Typ widoku i podtyp. W podtypach istnieją trzy typy widoków atrybutów - standardowy, czasowy i pochodny.
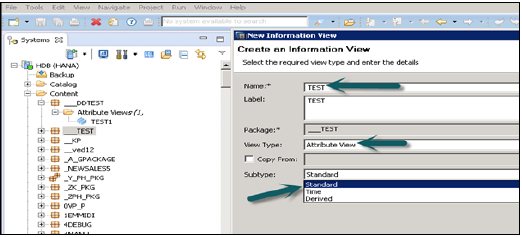
Widok atrybutów podtypu czasu to specjalny typ widoku atrybutów, który dodaje wymiar czasu do Data Foundation. Po wprowadzeniu nazwy atrybutu, typu i podtypu oraz kliknięciu przycisku Zakończ, otworzą się trzy okienka robocze -
Okienko scenariusza z bazą danych i warstwą semantyczną.
Okienko szczegółów pokazuje atrybut wszystkich tabel dodanych do Data Foundation i łączących się między nimi.
Okienko danych wyjściowych, w którym możemy dodać atrybuty z okienka szczegółów, aby przefiltrować raport.
Możesz dodać obiekty do Data Foundation, klikając znak „+” umieszczony obok Data Foundation. Możesz dodać wiele tabel wymiarów i widoków atrybutów w okienku scenariusza i połączyć je za pomocą klucza podstawowego.
Po kliknięciu Dodaj obiekt w Data Foundation, pojawi się pasek wyszukiwania, z którego możesz dodawać tabele wymiarów i widoki atrybutów do okienka scenariusza. Po dodaniu tabel lub widoków atrybutów do Data Foundation można je połączyć za pomocą klucza podstawowego w okienku szczegółów, jak pokazano poniżej.
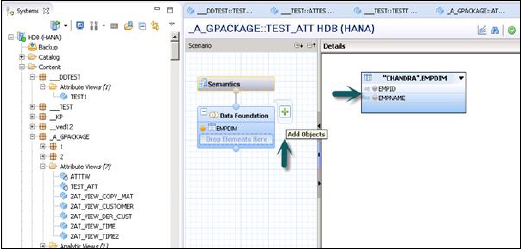
Po zakończeniu łączenia wybierz wiele atrybutów w panelu szczegółów, kliknij prawym przyciskiem myszy i Dodaj do wyjścia. Wszystkie kolumny zostaną dodane do okienka Wyjście. Teraz kliknij opcję Aktywuj, a otrzymasz komunikat potwierdzający w dzienniku zadań.
Teraz możesz kliknąć prawym przyciskiem myszy widok atrybutów i przejść do podglądu danych.
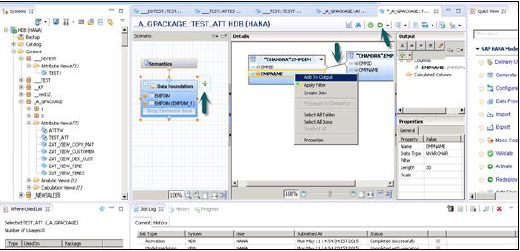
Note- Kiedy widok nie jest aktywowany, ma na sobie diament. Jednak po aktywacji ten diament znika, co potwierdza, że widok został pomyślnie aktywowany.
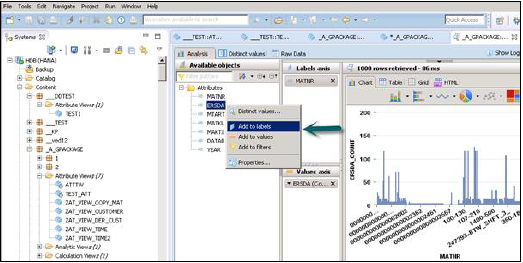
Po kliknięciu Podgląd danych pokaże wszystkie atrybuty, które zostały dodane do okienka Wyjście w obszarze Dostępne obiekty.
Te obiekty można dodać do etykiet i osi wartości, klikając prawym przyciskiem myszy i dodając lub przeciągając obiekty, jak pokazano poniżej -
Widok analityczny ma postać schematu Gwiazdy, w którym łączymy jedną tabelę faktów z wieloma tabelami wymiarów. Widoki analityczne wykorzystują rzeczywistą moc SAP HANA do wykonywania złożonych obliczeń i agregowania funkcji poprzez łączenie tabel w postaci schematu gwiaździstego i wykonywanie zapytań w schemacie gwiaździstym.
Charakterystyka widoku analitycznego
Poniżej przedstawiono właściwości widoku analitycznego SAP HANA -
Widoki analityczne służą do wykonywania złożonych obliczeń i funkcji agregujących, takich jak Suma, Liczba, Min, Max itd.
Widoki analityczne są przeznaczone do uruchamiania zapytań schematu uruchamiania.
Każdy widok analityczny ma jedną tabelę faktów otoczoną tabelami wielu wymiarów. Tabela faktów zawiera klucz podstawowy dla każdej tabeli Dim i miar.
Widoki analityczne są podobne do obiektów informacyjnych i zestawów informacji SAP BW.
Jak utworzyć widok analityczny?
Wybierz nazwę pakietu, pod którą chcesz utworzyć widok analityczny. Kliknij prawym przyciskiem myszy Pakiet → Idź do nowego → Widok analityczny. Po kliknięciu widoku analitycznego otworzy się nowe okno. Wprowadź nazwę widoku i opis iz rozwijanej listy wybierz Typ widoku i wykończenie.
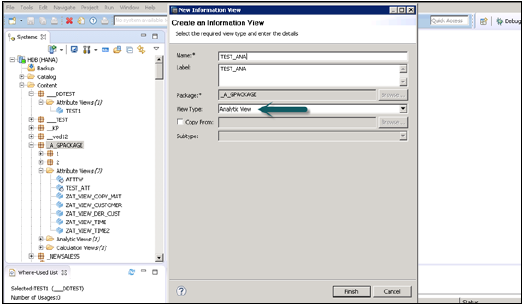
Po kliknięciu przycisku Zakończ można wyświetlić widok analityczny z opcjami Data Foundation i Star Join.
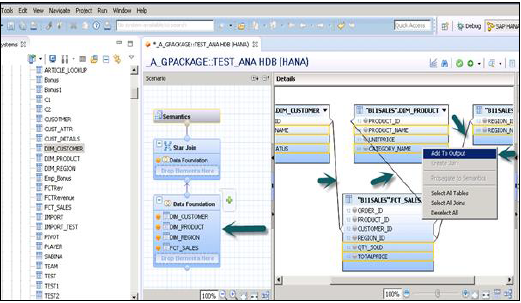
Kliknij Data Foundation, aby dodać tabele wymiarów i faktów. Kliknij Połącz gwiazdkę, aby dodać widoki atrybutów.
Dodaj tabele Dim i Fact do Data Foundation, używając znaku „+”. W poniższym przykładzie dodano 3 tabele dim: DIM_CUSTOMER, DIM_PRODUCT, DIM_REGION i 1 tabelę faktów FCT_SALES do okienka szczegółów. Łączenie tabeli wymiarów z tabelą faktów za pomocą kluczy podstawowych przechowywanych w tabeli faktów.
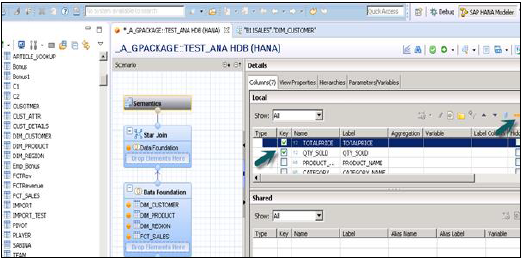
Wybierz Atrybuty z tabeli Dim and Fact, aby dodać je do okienka Output, jak pokazano na migawce pokazanej powyżej. Teraz zmień typ danych Fakty, z tabeli faktów na miary.
Kliknij warstwę semantyczną, wybierz fakty i kliknij znak miar, jak pokazano poniżej, aby zmienić typ danych na miary i aktywować widok.
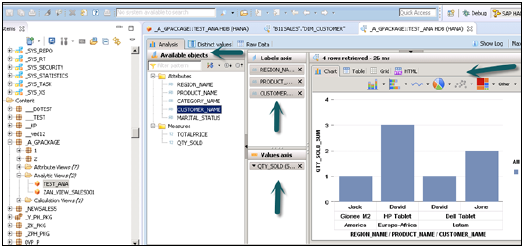
Po aktywowaniu widoku i kliknięciu Podgląd danych wszystkie atrybuty i miary zostaną dodane do listy Dostępne obiekty. Dodaj atrybuty do osi etykiet i zmierz do osi wartości na potrzeby analizy.
Istnieje możliwość wyboru różnych typów wykresów i wykresów.
Widoki obliczeń służą do korzystania z innych widoków analitycznych, atrybutów i innych widoków obliczeń oraz tabel kolumn bazowych. Służą one do wykonywania złożonych obliczeń, które nie są możliwe w przypadku innych typów widoków.
Charakterystyka widoku obliczeniowego
Poniżej podano kilka charakterystyk widoków obliczeniowych -
Widoki obliczeń służą do korzystania z widoków analitycznych, atrybutów i innych widoków obliczeń.
Służą do wykonywania złożonych obliczeń, które nie są możliwe w przypadku innych widoków.
Istnieją dwa sposoby tworzenia widoków obliczeń - edytor SQL lub edytor graficzny.
Wbudowane węzły Union, Join, Projection i Aggregation.
Jak stworzyć widok obliczeń?
Wybierz nazwę pakietu, pod którą chcesz utworzyć widok obliczeń. Kliknij prawym przyciskiem myszy Pakiet → Przejdź do nowego → Widok obliczeń. Po kliknięciu w Widok obliczeń otworzy się nowe okno.
Wprowadź nazwę widoku, opis i wybierz typ widoku jako widok obliczeń, podtyp standardowy lub czas (jest to specjalny rodzaj widoku, który dodaje wymiar czasu). Możesz użyć dwóch typów widoku obliczeń - graficznego i skryptu SQL.
Graficzne widoki obliczeń
Ma domyślne węzły, takie jak agregacja, projekcja, łączenie i łączenie. Służy do korzystania z innych widoków atrybutów, analitycznych i innych widoków obliczeń.
Widoki obliczeń oparte na skrypcie SQL
Jest napisany w skryptach SQL, które są zbudowane na poleceniach SQL lub funkcjach zdefiniowanych przez HANA.
Kategoria danych
Cube w tym domyślnym węźle to Aggregation. Możesz wybrać łączenie gwiazdowe z wymiarem kostki.
Wymiar, w tym domyślnym węźle jest Rzutowanie.
Widok obliczeń z łączeniem w gwiazdę
Nie zezwala na dodawanie tabel kolumn bazowych, widoków atrybutów ani widoków analitycznych do podstawy danych. Wszystkie tabele wymiarów muszą zostać zmienione na widoki Obliczenia wymiarów, aby można było używać ich w połączeniu gwiazdowym. Wszystkie tabele faktów można dodawać i używać domyślnych węzłów w widoku obliczeń.
Przykład
Poniższy przykład pokazuje, jak możemy użyć widoku obliczeń z łączeniem w gwiazdę -
Masz cztery tabele, dwie tabele Dim i dwie tabele faktów. Musisz znaleźć listę wszystkich pracowników z datą przystąpienia, imieniem EmpI, empId, wynagrodzeniem i bonusem.
Skopiuj i wklej poniższy skrypt w edytorze SQL i wykonaj.
Dim Tables − Empdim and Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');Fact Tables − Empfact1, Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);Teraz musimy zaimplementować widok obliczeń z łączeniem w gwiazdę. Najpierw zmień obie tabele wymiarów na Widok obliczeń wymiarów.
Utwórz widok obliczeń z łączeniem w gwiazdę. W panelu graficznym dodaj 2 projekcje dla 2 tabel faktów. Dodaj obie tabele faktów do obu projekcji i dodaj atrybuty tych prognoz do okienka danych wyjściowych.

Dodaj sprzężenie z domyślnego węzła i połącz obie tabele faktów. Dodaj parametry Łączenia faktów do okienka wyjściowego.
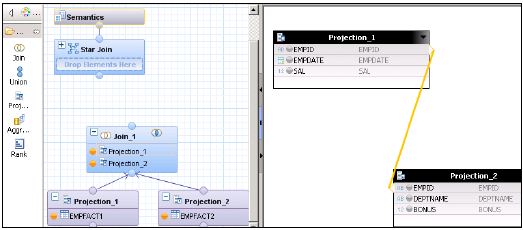
W Połącz w gwiazdę dodaj oba widoki Obliczenia wymiaru i dodaj Połączenie faktów do Połączenia w gwiazdę, jak pokazano poniżej. Wybierz parametry w panelu Wyjście i aktywuj Widok.
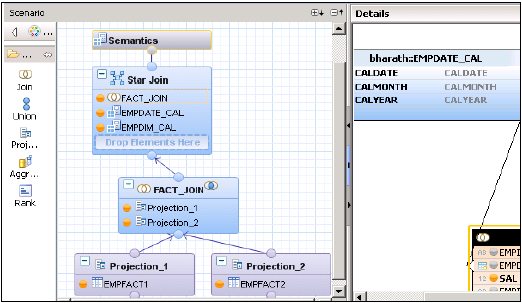
Widok obliczeń SAP HANA - łączenie w gwiazdę
Po pomyślnym aktywowaniu widoku kliknij prawym przyciskiem myszy nazwę widoku i kliknij Podgląd danych. Dodaj atrybuty i miary do osi wartości i etykiet i wykonaj analizę.
Korzyści z używania Star Join
Upraszcza proces projektowania. Nie ma potrzeby tworzenia widoków analitycznych i widoków atrybutów, a bezpośrednio tabele faktów mogą być używane jako projekcje.
3NF jest możliwe dzięki Star Join.
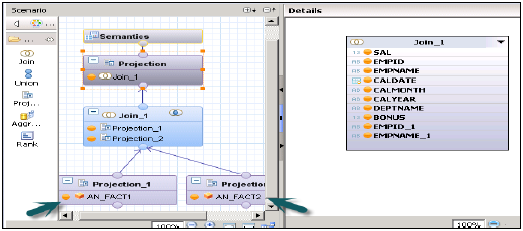
Widok obliczeń bez łączenia w gwiazdę
Utwórz 2 widoki atrybutów w 2 tabelach Dim-Dodaj wyjście i aktywuj oba widoki.
Utwórz 2 widoki analityczne w tabelach faktów → Dodaj zarówno widoki atrybutów, jak i Fakt1 / Fakt2 w Data Foundation w widoku analitycznym.
Teraz utwórz widok obliczeniowy → Wymiar (rzutowanie). Utwórz rzutowanie obu widoków analitycznych i połącz je. Dodaj atrybuty tego Dołącz do okienka wyjściowego. Teraz dołącz do projekcji i ponownie dodaj wyjście.
Aktywuj widok pomyślnie i przejdź do podglądu danych do analizy.
Uprawnienia analityczne służą do ograniczania dostępu do widoków informacji platformy HANA. Możesz przypisać różne typy praw różnym użytkownikom w różnych komponentach widoku w uprawnieniach analitycznych.
Czasami wymagane jest, aby dane w tym samym widoku nie były dostępne dla innych użytkowników, którzy nie mają żadnych odpowiednich wymagań dotyczących tych danych.
Przykład
Załóżmy, że masz widok analityczny EmpDetails, który zawiera szczegółowe informacje o pracownikach firmy - nazwa Emp, identyfikator Emp, Dział, wynagrodzenie, data dołączenia, logowanie do Emp dane logowania wszystkich pracowników, możesz to ukryć, korzystając z opcji uprawnień analitycznych.
Uprawnienia analityczne są stosowane tylko do atrybutów w widoku informacyjnym. Nie możemy dodawać środków ograniczających dostęp do uprawnień analitycznych.
Uprawnienia analityczne służą do kontrolowania dostępu do odczytu w widokach informacji SAP HANA.
Możemy więc ograniczyć dane według logowania Empname, EmpId, Emp lub według Emp Dept, a nie wartości liczbowych, takich jak wynagrodzenie, premia.
Tworzenie uprawnień analitycznych
Kliknij prawym przyciskiem myszy nazwę pakietu i przejdź do nowego uprawnienia analitycznego lub możesz otworzyć za pomocą szybkiego uruchamiania HANA Modeler.
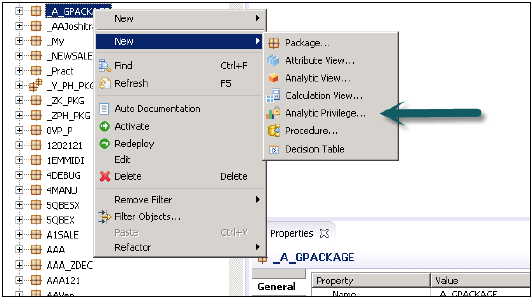
Wprowadź nazwę i opis uprawnienia analitycznego → Zakończ. Otworzy się nowe okno.
Możesz kliknąć przycisk Dalej i dodać widok modelowania w tym oknie, zanim klikniesz przycisk Zakończ. Istnieje również opcja skopiowania istniejącego pakietu Analytic Privilege.
Po kliknięciu przycisku Dodaj pokaże Ci wszystkie widoki na karcie Treść.
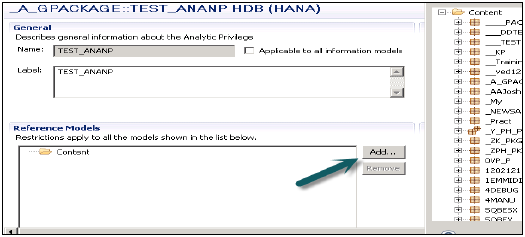
Wybierz Widok, który chcesz dodać do pakietu Analytic Privilege i kliknij OK. Wybrany widok zostanie dodany pod modelami referencyjnymi.
Teraz, aby dodać atrybuty z wybranego widoku pod uprawnieniem analitycznym, kliknij przycisk Dodaj z oknem Ograniczenia skojarzonych atrybutów.
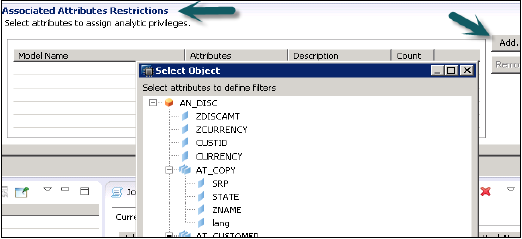
Dodaj obiekty, które chcesz dodać do uprawnień analitycznych z opcji wybierz obiekt i kliknij OK.
W opcji Przypisz ograniczenie umożliwia dodawanie wartości, które chcesz ukryć w widoku modelowania od określonego użytkownika. Możesz dodać wartość obiektu, która nie będzie odzwierciedlona w podglądzie danych w widoku modelowania.
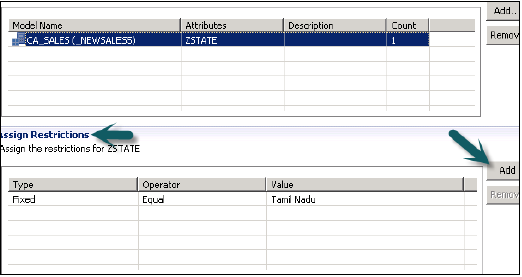
Musimy teraz aktywować przywilej analityczny, klikając zieloną okrągłą ikonę u góry. Komunikat o statusie - zakończony pomyślnie potwierdza pomyślną aktywację w dzienniku zadań i możemy teraz korzystać z tego widoku, dodając do roli.
Teraz, aby dodać tę rolę do użytkownika, przejdź do zakładki bezpieczeństwa → Użytkownik → Wybierz użytkownika, któremu chcesz zastosować te uprawnienia analityczne.
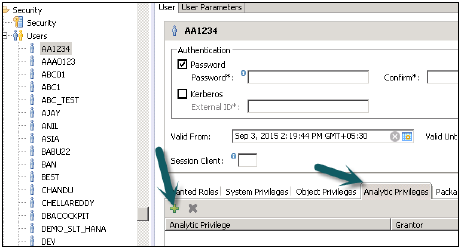
Wyszukaj uprawnienie analityczne, które chcesz zastosować, podając nazwę i kliknij OK. Ten widok zostanie dodany do roli użytkownika w obszarze Uprawnienia analityczne.
Aby usunąć uprawnienia analityczne określonego użytkownika, wybierz widok na karcie i użyj opcji Usuń czerwony. Użyj przycisku Wdrażanie (znak strzałki u góry lub F8, aby zastosować to do profilu użytkownika).
SAP HANA Information Composer to samoobsługowe środowisko modelowania dla użytkowników końcowych do analizowania zestawu danych. Umożliwia importowanie danych z formatu skoroszytu (.xls, .csv) do bazy danych HANA oraz tworzenie widoków modelowania do analizy.
Information Composer bardzo różni się od HANA Modeler i oba są przeznaczone dla oddzielnych grup użytkowników. Osoby sprawne technicznie, które mają duże doświadczenie w modelowaniu danych, używają HANA Modeler. Użytkownik biznesowy, który nie ma żadnej wiedzy technicznej, korzysta z narzędzia Information Composer. Zapewnia proste funkcje z łatwym w użyciu interfejsem.
Funkcje narzędzia Information Composer
Data extraction - Information Composer pomaga wyodrębnić dane, wyczyścić dane, wyświetlić podgląd danych oraz zautomatyzować proces tworzenia fizycznej tabeli w bazie danych HANA.
Manipulating data - Pomaga nam łączyć dwa obiekty (tabele fizyczne, widok analityczny, widok atrybutów i widoki obliczeń) i tworzyć widok informacji, który może być używany przez narzędzia SAP BO, takie jak SAP Business Objects Analysis, SAP Business Objects Explorer i inne narzędzia, takie jak MS Excel.
Zapewnia scentralizowaną usługę IT w postaci adresu URL, do którego można uzyskać dostęp z dowolnego miejsca.
Jak przesłać dane za pomocą Information Composer?
Pozwala na przesłanie dużej ilości danych (do 5 milionów komórek). Link do dostępu do Information Composer -
http://<server>:<port>/IC
Zaloguj się do SAP HANA Information Composer. Za pomocą tego narzędzia można ładować dane lub manipulować nimi.
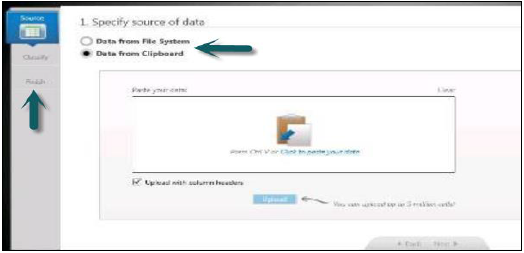
Aby przesłać dane, można to zrobić na dwa sposoby -
- Przesyłanie pliku .xls, .csv bezpośrednio do bazy danych HANA
- Innym sposobem jest skopiowanie danych do schowka i skopiowanie stamtąd do bazy danych HANA.
- Umożliwia ładowanie danych wraz z nagłówkiem.
Po lewej stronie w narzędziu Information Composer masz trzy opcje -
Wybierz Źródło danych → Klasyfikuj dane → Opublikuj
Po opublikowaniu danych w bazie danych HANA nie można zmienić nazwy tabeli. W takim przypadku musisz usunąć tabelę ze schematu w bazie danych HANA.
Schemat „SAP_IC”, w którym istnieją tabele, takie jak IC_MODELS, IC_SPREADSHEETS. Szczegóły tabel utworzonych za pomocą IC można znaleźć pod tymi tabelami.

Korzystanie ze schowka
Innym sposobem przesyłania danych w IC jest użycie schowka. Skopiuj dane do schowka i prześlij je za pomocą Information Composer. Information Composer umożliwia również podgląd danych, a nawet podsumowanie danych w tymczasowej pamięci. Posiada wbudowaną funkcję czyszczenia danych, która służy do usuwania wszelkich niespójności danych.
Po wyczyszczeniu danych należy sklasyfikować dane, czy są przypisane. IC ma wbudowaną funkcję sprawdzania typu przesyłanych danych.
Ostatnim krokiem jest opublikowanie danych do fizycznych tabel w bazie danych HANA. Podaj nazwę techniczną i opis tabeli, która zostanie załadowana do schematu IC_Tables.
Role użytkowników związane z korzystaniem z danych opublikowanych w programie Information Composer
Można zdefiniować dwa zestawy użytkowników do korzystania z danych opublikowanych z IC.
IC_MODELER służy do tworzenia fizycznych tabel, przesyłania danych i tworzenia widoków informacji.
IC_PUBLIC umożliwia użytkownikom przeglądanie widoków informacji utworzonych przez innych użytkowników. Ta rola nie pozwala użytkownikowi przesyłać ani tworzyć żadnych widoków informacji za pomocą IC.
Wymagania systemowe dla programu Information Composer
Server Requirements −
Wymagane jest co najmniej 2 GB dostępnej pamięci RAM.
Na serwerze musi być zainstalowana Java 6 (64-bitowa).
Serwer Information Composer musi znajdować się fizycznie obok serwera HANA.
Client Requirements −
- Internet Explorer z zainstalowanym programem Silverlight 4.
Opcja HANA Export and Import umożliwia przenoszenie tabel, modeli informacyjnych, krajobrazów do innego lub istniejącego systemu. Nie musisz odtwarzać wszystkich tabel i modeli informacyjnych, ponieważ możesz po prostu wyeksportować je do nowego systemu lub zaimportować do istniejącego systemu docelowego, aby zmniejszyć wysiłek.
Dostęp do tej opcji można uzyskać z menu Plik u góry lub klikając prawym przyciskiem myszy dowolną tabelę lub model informacji w studiu HANA.
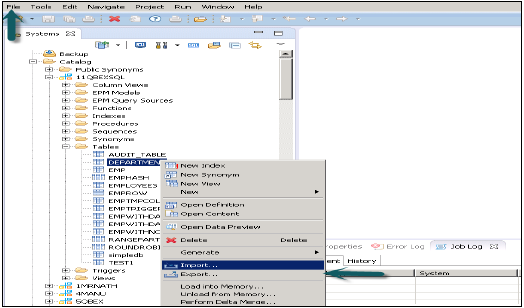
Eksportowanie modelu tabeli / informacji w HANA Studio
Przejdź do menu plików → Eksportuj → Zobaczysz opcje, jak pokazano poniżej -

Opcje eksportu w ramach zawartości SAP HANA
Jednostka dostawy
Jednostka dostawy to pojedyncza jednostka, którą można przypisać do wielu paczek i wyeksportować jako jedną jednostkę, dzięki czemu wszystkie paczki przypisane do jednostki dostawy mogą być traktowane jako jedna jednostka.
Użytkownicy mogą użyć tej opcji, aby wyeksportować wszystkie pakiety, które tworzą jednostkę dostawy, i odpowiednie obiekty w niej zawarte, na serwer HANA lub do lokalnej lokalizacji klienta.
Użytkownik powinien utworzyć jednostkę dostawy przed jej użyciem.
Można to zrobić za pomocą HANA Modeler → Delivery Unit → Select System i Next → Create → Wypełnij szczegóły, takie jak nazwa, wersja itp. → OK → Dodaj paczki do jednostki dostawy → Zakończ
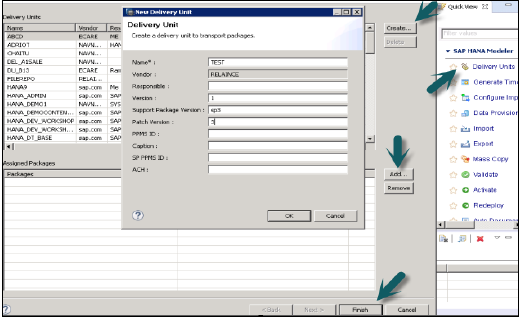
Po utworzeniu jednostki dostawy i przypisaniu do niej paczek, użytkownik może zobaczyć listę paczek za pomocą opcji Eksportuj -
Idź do Plik → Eksportuj → Jednostka dostawy → Wybierz jednostkę dostawy.
Możesz zobaczyć listę wszystkich paczek przypisanych do jednostki dostawy. Daje możliwość wyboru lokalizacji eksportu -
- Eksportuj na serwer
- Eksportuj do klienta
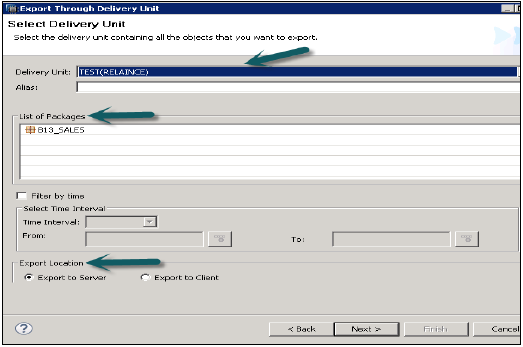
Jednostkę dostawy można wyeksportować do lokalizacji serwera HANA lub do lokalizacji klienta, jak pokazano.
Użytkownik może ograniczyć eksport za pomocą opcji „Filtruj według czasu”, co oznacza, że widoki informacyjne, które są aktualizowane w określonym przedziale czasu, będą eksportowane tylko.
Wybierz jednostkę dostawy i lokalizację eksportu, a następnie kliknij Dalej → Zakończ. Spowoduje to wyeksportowanie wybranej jednostki dostawy do określonej lokalizacji.
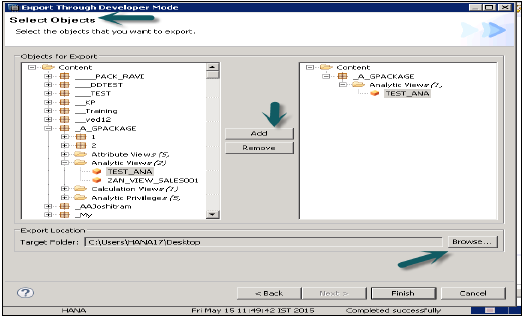
Tryb dewelopera
Ta opcja może służyć do eksportowania pojedynczych obiektów do lokalizacji w systemie lokalnym. Użytkownik może wybrać pojedynczy widok informacji lub grupę widoków i pakietów oraz wybrać lokalną lokalizację klienta do wyeksportowania i zakończenia.
Pokazuje to poniższa migawka.
Tryb wsparcia
Można to wykorzystać do wyeksportowania obiektów wraz z danymi do celów wsparcia SAP. Można tego użyć na żądanie.
Example- Użytkownik tworzy widok informacji, który zgłasza błąd, którego nie jest w stanie rozwiązać. W takim przypadku może skorzystać z tej opcji, aby wyeksportować widok wraz z danymi i udostępnić go SAP w celu debugowania.

Export Options under SAP HANA Studio -
Landscape - Aby wyeksportować krajobraz z jednego systemu do drugiego.
Tables - Ta opcja może służyć do eksportowania tabel wraz z ich zawartością.
Opcja importu w ramach zawartości SAP HANA
Idź do Plik → Importuj, zobaczysz wszystkie opcje, jak pokazano poniżej w obszarze Importuj.
Dane z pliku lokalnego
Służy do importowania danych z pliku płaskiego, takiego jak plik .xls lub .csv.
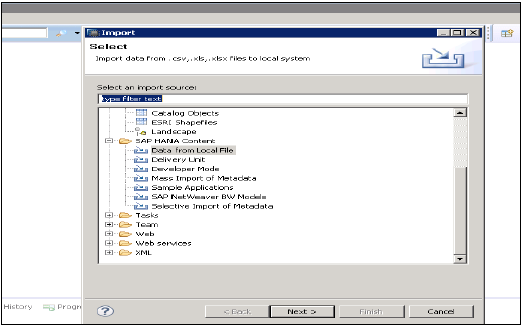
Kliknij Nex → Wybierz system docelowy → Zdefiniuj właściwości importu
Wybierz plik źródłowy, przeglądając system lokalny. Daje również opcję, jeśli chcesz zachować wiersz nagłówka. Daje również opcję utworzenia nowej tabeli w ramach istniejącego schematu lub jeśli chcesz zaimportować dane z pliku do istniejącej tabeli.
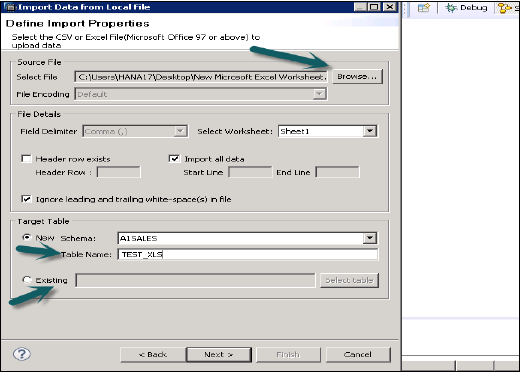
Po kliknięciu Dalej daje możliwość zdefiniowania klucza podstawowego, zmiany typu danych kolumn, zdefiniowania typu przechowywania tabeli, a także umożliwia zmianę proponowanej struktury tabeli.
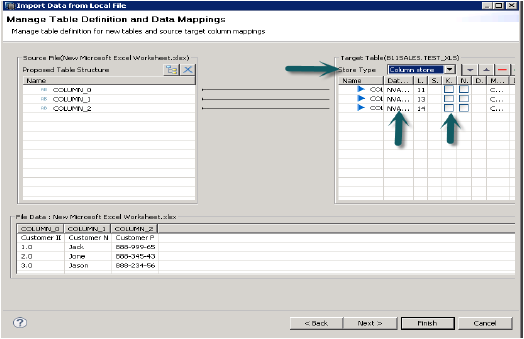
Po kliknięciu na koniec tabela ta zostanie wypełniona pod listą tabel we wspomnianym schemacie. Możesz zrobić podgląd danych i sprawdzić definicję danych w tabeli i będzie taka sama jak w pliku .xls.

Jednostka dostawy
Wybierz opcję Jednostka dostawy, przechodząc do Plik → Importuj → Jednostka dostawy. Możesz wybrać serwer lub klienta lokalnego.
Możesz wybrać „Zastąp nieaktywne wersje”, co pozwala na nadpisanie dowolnej nieaktywnej wersji istniejących obiektów. Jeżeli użytkownik wybierze opcję „Aktywuj obiekty”, to po imporcie wszystkie importowane obiekty zostaną domyślnie uaktywnione. Użytkownik nie musi ręcznie uruchamiać aktywacji importowanych widoków.

Kliknij Zakończ, a po pomyślnym zakończeniu zostanie wypełniony w systemie docelowym.
Tryb dewelopera
Przeglądaj w poszukiwaniu lokalizacji klienta lokalnego, do której widoki są eksportowane i wybierz widoki do zaimportowania, użytkownik może wybrać poszczególne widoki lub grupę widoków i pakietów i kliknąć przycisk Zakończ.
Masowy import metadanych
Przejdź do Plik → Importuj → Import masowy metadanych → Dalej i wybierz system źródłowy i docelowy.
Skonfiguruj system pod kątem importu masowego i kliknij przycisk Zakończ.
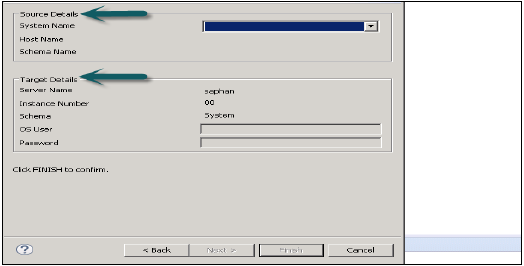
Selektywny import metadanych
Umożliwia wybór tabel i schematu docelowego do importowania metadanych z aplikacji SAP.
Idź do Plik → Importuj → Selektywny import metadanych → Dalej
Wybierz połączenie źródłowe typu „Aplikacje SAP”. Pamiętaj, że składnica danych powinna już zostać utworzona typu Aplikacje SAP → Kliknij Dalej
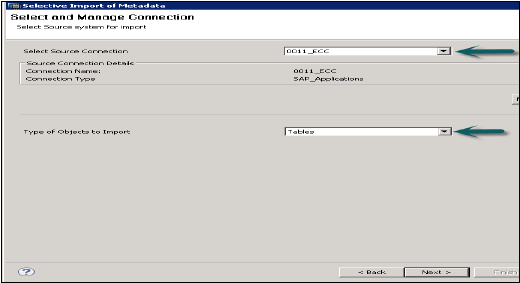
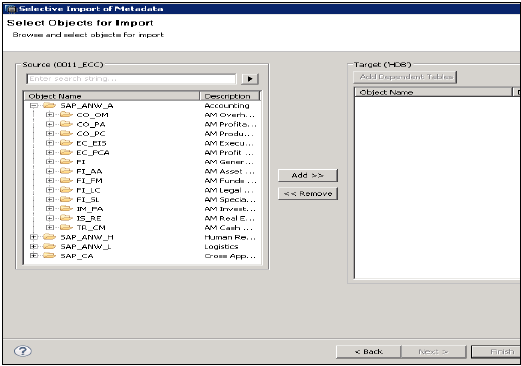
Wybierz tabele, które chcesz zaimportować, iw razie potrzeby zweryfikuj dane. Następnie kliknij Zakończ.
Wiemy, że korzystając z funkcji Information Modeling w SAP HANA możemy tworzyć różne widoki informacyjne Widoki atrybutów, Widoki analityczne, widoki obliczeniowe. Te widoki mogą być używane przez różne narzędzia raportowania, takie jak SAP Business Object, SAP Lumira, Design Studio, Office Analysis, a nawet narzędzia innych firm, takie jak MS Excel.
Te narzędzia raportowania umożliwiają kierownikom biznesowym, analitykom, kierownikom sprzedaży i wyższym pracownikom kierownictwa analizowanie informacji historycznych w celu tworzenia scenariuszy biznesowych i decydowania o strategii biznesowej firmy.
Powoduje to potrzebę korzystania z widoków HANA Modeling przez różne narzędzia raportowania oraz generowania raportów i pulpitów nawigacyjnych, które są łatwe do zrozumienia dla użytkowników końcowych.

W większości firm, w których wdrożono SAP, raportowanie na platformie HANA odbywa się za pomocą narzędzi platformy BI, które wykorzystują zapytania zarówno SQL, jak i MDX za pomocą połączeń Relational i OLAP. Dostępnych jest wiele narzędzi BI, takich jak - Web Intelligence, Crystal Reports, Dashboard, Explorer, Office Analysis i wiele innych.
Narzędzia do raportowania
Web Intelligence i Crystal Reports to najpopularniejsze narzędzia BI używane do raportowania. WebI wykorzystuje warstwę semantyczną zwaną Wszechświatem do łączenia się ze źródłem danych, a te Wszechświaty są używane do raportowania w narzędziu. Te Wszechświaty są projektowane przy pomocy narzędzia do projektowania Wszechświata UDT lub narzędzia do projektowania informacji IDT. IDT obsługuje źródła danych z obsługą wielu źródeł. Jednak UDT obsługuje tylko jedno źródło.
Główne narzędzia używane do projektowania interaktywnych dashboardów - Design Studio i Dashboard Designer. Design Studio to przyszłe narzędzie do projektowania dashboardów, które wykorzystują widoki HANA za pośrednictwem połączenia BICS Consumer Service BI. Projekt pulpitu nawigacyjnego (xcelsius) używa IDT do korzystania ze schematów w bazie danych HANA z połączeniem relacyjnym lub OLAP.
SAP Lumira ma wbudowaną funkcję bezpośredniego łączenia lub ładowania danych z bazy danych HANA. Widoki HANA można bezpośrednio wykorzystywać w Lumira do wizualizacji i tworzenia historii.
Usługa Office Analysis używa połączenia OLAP do łączenia się z widokami informacji HANA. To połączenie OLAP można utworzyć w CMC lub IDT.
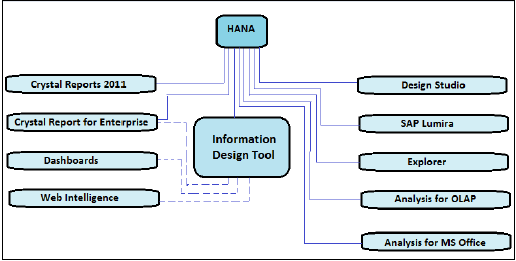
Na powyższym rysunku pokazano wszystkie narzędzia BI z liniami ciągłymi, które można bezpośrednio połączyć i zintegrować z SAP HANA za pomocą połączenia OLAP. Przedstawia również narzędzia, które wymagają połączenia relacyjnego przy użyciu IDT do połączenia z platformą HANA, są pokazane liniami przerywanymi.
Połączenie relacyjne a połączenie OLAP
Zasadniczo chodzi o to, że jeśli potrzebujesz dostępu do danych z tabeli lub konwencjonalnej bazy danych, twoje połączenie powinno być połączeniem relacyjnym, ale jeśli źródłem jest aplikacja, a dane są przechowywane w kostce (wielowymiarowej, takiej jak kostki informacyjne, modele informacyjne) użyj połączenia OLAP.
- Połączenie relacyjne można utworzyć tylko w IDT / UDT.
- OLAP można utworzyć zarówno w IDT, jak i CMC.
Inną rzeczą, na którą należy zwrócić uwagę, jest to, że połączenie relacyjne zawsze tworzy instrukcję SQL do uruchomienia z raportu, podczas gdy połączenie OLAP zwykle tworzy instrukcję MDX
Narzędzie do projektowania informacji
W narzędziu do projektowania informacji (IDT) można utworzyć relacyjne połączenie z widokiem lub tabelą SAP HANA przy użyciu sterowników JDBC lub ODBC i zbudować Wszechświat przy użyciu tego połączenia, aby zapewnić dostęp do narzędzi klienckich, takich jak pulpity nawigacyjne i analiza sieciowa, jak pokazano na powyższym rysunku.
Możesz utworzyć bezpośrednie połączenie z SAP HANA przy użyciu sterowników JDBC lub ODBC.
Crystal Reports for Enterprise
W Crystal Reports for Enterprise można uzyskać dostęp do danych SAP HANA za pomocą istniejącego połączenia relacyjnego utworzonego za pomocą narzędzia do projektowania informacji.
Możesz także połączyć się z SAP HANA za pomocą połączenia OLAP utworzonego za pomocą narzędzia do projektowania informacji lub CMC.
Studio projektowe
Design Studio może uzyskać dostęp do danych SAP HANA za pomocą istniejącego połączenia OLAP utworzonego w narzędziu do projektowania informacji lub CMC, tak samo jak Office Analysis.
Pulpity nawigacyjne
Pulpity nawigacyjne mogą łączyć się z SAP HANA tylko za pośrednictwem relacyjnego Wszechświata. Klienci korzystający z pulpitów nawigacyjnych na platformie SAP HANA powinni zdecydowanie rozważyć utworzenie nowych pulpitów nawigacyjnych za pomocą Design Studio.
Web Intelligence
Web Intelligence może łączyć się z SAP HANA tylko za pośrednictwem relacyjnego wszechświata.
SAP Lumira
Lumira może łączyć się bezpośrednio z widokami analitycznymi i obliczeniowymi SAP HANA. Może również łączyć się z SAP HANA za pośrednictwem SAP BI Platform przy użyciu relacyjnego Wszechświata.
Office Analysis, wydanie dla OLAP
W wersji Office Analysis dla OLAP można połączyć się z SAP HANA za pomocą połączenia OLAP zdefiniowanego w Centralnej Konsoli Zarządzania lub w narzędziu do projektowania informacji.
poszukiwacz
Przestrzeń informacyjną można utworzyć na podstawie widoku SAP HANA przy użyciu sterowników JDBC.
Tworzenie połączenia OLAP w CMC
Możemy stworzyć połączenie OLAP dla wszystkich narzędzi BI, których chcemy używać oprócz widoków HANA, takich jak OLAP do analizy, Crystal Report for enterprise, Design Studio. Połączenie relacyjne za pośrednictwem IDT służy do łączenia analizy sieciowej i pulpitów nawigacyjnych z bazą danych HANA.
Te połączenia można utworzyć za pomocą IDT oraz CMC i oba połączenia są zapisywane w BO Repository.
Zaloguj się do CMC za pomocą nazwy użytkownika i hasła.
Z rozwijanej listy połączeń wybierz połączenie OLAP. Pokaże również już utworzone połączenia w CMC. Aby utworzyć nowe połączenie, przejdź do zielonej ikony i kliknij na nią.
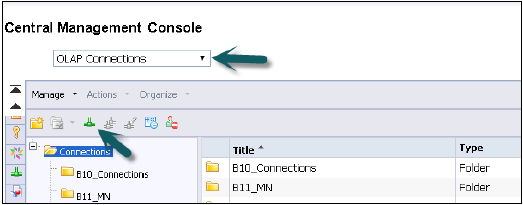
Wprowadź nazwę i opis połączenia OLAP. Wiele osób może łączyć się z widokami HANA w różnych narzędziach platformy BI.
Provider - SAP HANA
Server - Wprowadź nazwę serwera HANA
Instance - Numer instancji
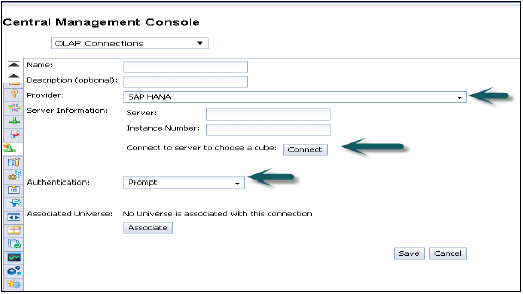
Daje również możliwość połączenia się z pojedynczą kostką (można też wybrać połączenie z pojedynczym widokiem analitycznym lub obliczeniowym) lub z pełnym systemem HANA.
Kliknij Połącz i wybierz widok modelowania, wprowadzając nazwę użytkownika i hasło.
Typy uwierzytelniania - podczas tworzenia połączenia OLAP w CMC możliwe są trzy typy uwierzytelniania.
Predefined - Nie będzie ponownie pytać o nazwę użytkownika i hasło podczas korzystania z tego połączenia.
Prompt - Za każdym razem zapyta o nazwę użytkownika i hasło
SSO - Specyficzne dla użytkownika
Enter user - nazwa użytkownika i hasło do systemu HANA oraz zapisz, a nowe połączenie zostanie dodane do istniejącej listy połączeń.
Teraz otwórz BI Launchpad, aby otworzyć wszystkie narzędzia platformy BI do raportowania, takie jak Office Analysis dla OLAP, i poprosi o wybranie połączenia. Domyślnie pokaże ci Widok informacyjny, jeśli określiłeś go podczas tworzenia tego połączenia, w przeciwnym razie kliknij Dalej i przejdź do folderów → Wybierz widoki (Widoki analityczne lub obliczeniowe).
SAP Lumira connectivity with HANA system
Otwórz SAP Lumira w programie Start, kliknij menu pliku → Nowy → Dodaj nowy zestaw danych → Połącz z SAP HANA → Dalej

Różnica między połączeniem się z SAP HANA a pobraniem z SAP HANA polega na tym, że będzie pobierać dane z systemu Hana do repozytorium BO, a odświeżanie danych nie nastąpi wraz ze zmianami w systemie HANA. Wprowadź nazwę serwera HANA i numer wystąpienia. Wprowadź nazwę użytkownika i hasło → kliknij Połącz.
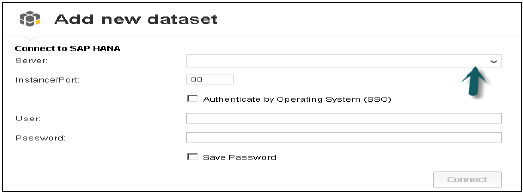
Pokaże wszystkie widoki. Możesz wyszukiwać według nazwy widoku → Wybierz Widok → Dalej. Pokaże wszystkie miary i wymiary. Jeśli chcesz, możesz wybrać spośród tych atrybutów → kliknij opcję tworzenia.
W SAP Lumira znajdują się cztery zakładki -
Prepare - Możesz zobaczyć dane i wykonać dowolne obliczenia niestandardowe.
Visualize- Możesz dodawać wykresy i wykresy. Kliknij oś X i oś Y + znak, aby dodać atrybuty.
Compose- Ta opcja może być użyta do stworzenia sekwencji Wizualizacji (opowieść) → kliknij Tablica, aby dodać numery tablic → utwórz → pokaże wszystkie wizualizacje po lewej stronie. Przeciągnij pierwszą wizualizację, a następnie dodaj stronę, a następnie dodaj drugą wizualizację.
Share- Jeśli jest zbudowany na SAP HANA, możemy publikować tylko na serwerze SAP Lumira. W przeciwnym razie możesz również opublikować artykuł z SAP Lumira w SAP Community Network SCN lub na platformie BI.
Zapisz plik, aby użyć go później → Idź do File-Save → wybierz Local → Save
Creating a Relational Connection in IDT to use with HANA views in WebI and Dashboard -
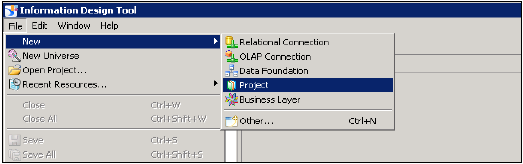
Otwórz narzędzie do projektowania informacji → przechodząc do narzędzi klienta platformy BI. Kliknij Nowy → Projekt Wprowadź nazwę projektu → Zakończ.
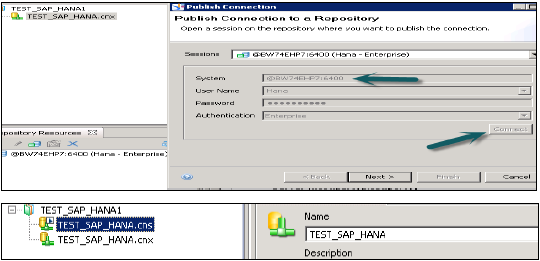
Kliknij prawym przyciskiem myszy nazwę projektu → Idź do nowego → Wybierz połączenie relacyjne → Wprowadź nazwę połączenia / zasobu → Dalej → wybierz SAP z listy, aby połączyć się z systemem HANA → SAP HANA → Wybierz sterowniki JDBC / ODBC → kliknij Dalej → Wprowadź szczegóły systemu HANA → Kliknij Dalej i Zakończ.

Możesz również przetestować to połączenie, klikając opcję Testuj połączenie.
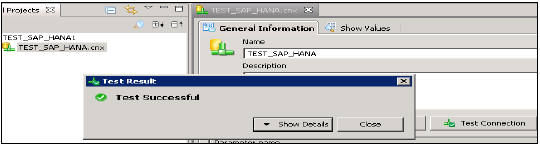
Testuj połączenie → Pomyślnie. Następnym krokiem jest opublikowanie tego połączenia w repozytorium, aby było dostępne do użytku.
Kliknij prawym przyciskiem myszy nazwę połączenia → kliknij Publikuj połączenie w repozytorium → Wprowadź nazwę i hasło repozytorium BO → Kliknij Połącz → Dalej → Zakończ → Tak.
Utworzy nowe połączenie relacyjne z rozszerzeniem .cns.
.cns - typ połączenia reprezentuje zabezpieczone połączenie repozytorium, które powinno zostać użyte do stworzenia bazy danych.
.cnx - reprezentuje niezabezpieczone połączenie lokalne. Jeśli użyjesz tego połączenia podczas tworzenia i publikowania Wszechświata, nie pozwoli ci to opublikować go w repozytorium.
Wybierz typ połączenia .cns → Kliknij prawym przyciskiem myszy → kliknij Nowa podstawa danych → Wprowadź nazwę bazy danych → Dalej → Jedno źródło / wiele źródeł → kliknij Dalej → Zakończ.

Wyświetli wszystkie tabele w bazie danych HANA z nazwą schematu w środkowym okienku.
Zaimportuj wszystkie tabele z bazy danych HANA do panelu głównego, aby utworzyć Universe. Połącz tabele Dim i Fact z kluczami podstawowymi w tabelach Dim, aby utworzyć schemat.
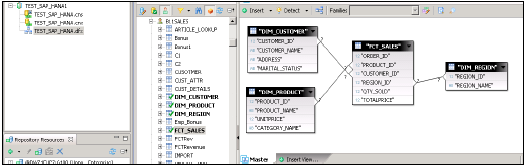
Kliknij dwukrotnie Łączenie i wykrywanie liczności → Wykryj → OK → Zapisz wszystko u góry. Teraz musimy stworzyć nową warstwę biznesową na bazie danych, która będzie używana przez narzędzia aplikacji BI.
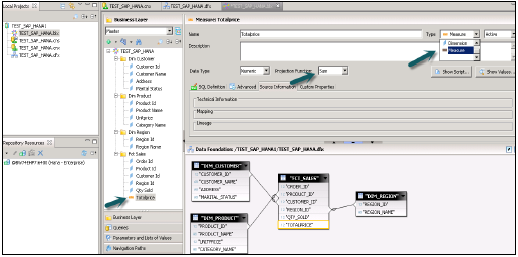
Kliknij prawym przyciskiem myszy .dfx i wybierz nową warstwę biznesową → Wprowadź nazwę → Zakończ →. Pokaże wszystkie obiekty automatycznie, w panelu głównym →. Zmień wymiar na miary (w razie potrzeby zmień rzutowanie typu miary) → Zapisz wszystko.
Kliknij prawym przyciskiem myszy plik .bfx → kliknij Opublikuj → Do repozytorium → kliknij Dalej → Zakończ → Wszechświat został pomyślnie opublikowany.
Teraz otwórz raport WebI z BI Launchpad lub bogatego klienta Webi z narzędzi klienta platformy BI → Nowy → wybierz Wszechświat → TEST_SAP_HANA → OK.
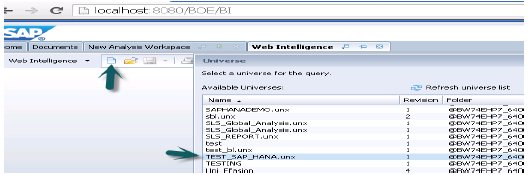
Wszystkie obiekty zostaną dodane do panelu zapytań. Możesz wybrać atrybuty i miary z lewego panelu i dodać je do obiektów wyników. PlikRun query uruchomi zapytanie SQL, a wynik zostanie wygenerowany w formie raportu w WebI, jak pokazano poniżej.
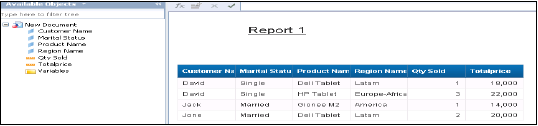
Microsoft Excel jest uważany przez wiele organizacji za najpopularniejsze narzędzie do raportowania i analizy BI. Menedżerowie biznesowi i analitycy mogą łączyć ją z bazą danych HANA, aby rysować tabele przestawne i wykresy do analizy.
Łączenie MS Excel z HANA
Otwórz Excel i przejdź do zakładki Dane → z innych źródeł → kliknij Kreator połączenia danych → Inne / Zaawansowane i kliknij Dalej → Otworzą się właściwości łącza danych.
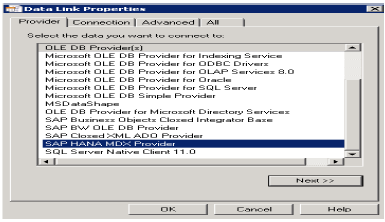
Wybierz dostawcę SAP HANA MDX z tej listy, aby połączyć się z dowolnym źródłem danych MDX → Wprowadź szczegóły systemu HANA (nazwa serwera, instancja, nazwa użytkownika i hasło) → kliknij Testuj połączenie → Połączenie powiodło się → OK.
Wyświetli listę wszystkich pakietów w rozwijanej liście, które są dostępne w systemie HANA. Możesz wybrać widok Informacje → kliknij Dalej → Wybierz tabelę przestawną / inne → OK.
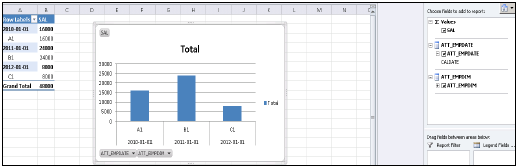
Wszystkie atrybuty z widoku informacji zostaną dodane do MS Excel. Możesz wybrać różne atrybuty i miary do raportowania, jak pokazano, a także możesz wybrać różne wykresy, takie jak wykresy kołowe i słupkowe, z opcji projektu u góry.
Bezpieczeństwo oznacza ochronę krytycznych danych firmy przed nieautoryzowanym dostępem i wykorzystaniem oraz zapewnienie zgodności i standardów zgodnie z polityką firmy. SAP HANA umożliwia klientowi wdrożenie różnych polityk i procedur bezpieczeństwa oraz spełnienie wymagań zgodności firmy.
SAP HANA obsługuje wiele baz danych w jednym systemie HANA i nazywa się to kontenerami baz danych dla wielu dzierżawców. System HANA może również zawierać więcej niż jeden kontener baz danych dla wielu dzierżawców. System z wieloma kontenerami zawsze ma dokładnie jedną bazę danych systemu i dowolną liczbę kontenerów bazy danych dla wielu dzierżawców. System SAP HANA zainstalowany w tym środowisku jest identyfikowany za pomocą pojedynczego identyfikatora systemu (SID). Kontenery baz danych w systemie HANA identyfikowane są poprzez identyfikator SID oraz nazwę bazy danych. Klient SAP HANA, znany jako studio HANA, łączy się z określonymi bazami danych.
SAP HANA zapewnia wszystkie funkcje związane z bezpieczeństwem, takie jak uwierzytelnianie, autoryzacja, szyfrowanie i inspekcja, a także niektóre funkcje dodatkowe, które nie są obsługiwane w innych bazach danych dla wielu dzierżawców.
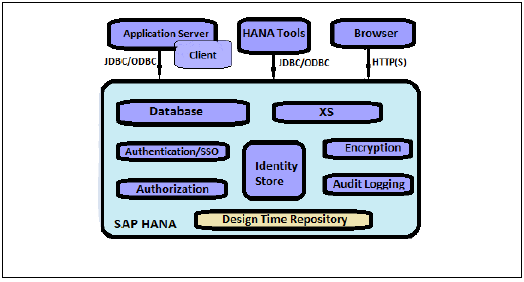
Poniżej znajduje się lista funkcji związanych z bezpieczeństwem, udostępnianych przez SAP HANA -
- Zarządzanie użytkownikami i rolami
- Uwierzytelnianie i logowanie jednokrotne
- Authorization
- Szyfrowanie komunikacji danych w sieci
- Szyfrowanie danych w warstwie trwałości
Dodatkowe funkcje w wielodostępnej bazie danych HANA -
Database Isolation - Polega na zapobieganiu atakom typu cross tenant poprzez mechanizm systemu operacyjnego
Configuration Change blacklist - Obejmuje zapobieganie zmianie niektórych właściwości systemu przez administratorów baz danych dzierżawców
Restricted Features - Obejmuje wyłączenie niektórych funkcji bazy danych, które zapewniają bezpośredni dostęp do systemu plików, sieci lub innych zasobów.
Zarządzanie użytkownikami i rolami SAP HANA
Konfiguracja zarządzania użytkownikami i rolami SAP HANA zależy od architektury systemu HANA.
Jeśli SAP HANA jest zintegrowany z narzędziami platformy BI i działa jako baza danych raportowania, to użytkownik końcowy i rola są zarządzane na serwerze aplikacji.
Jeśli użytkownik końcowy łączy się bezpośrednio z bazą danych SAP HANA, to użytkownik i rola w warstwie bazy danych systemu HANA są wymagane zarówno dla użytkowników końcowych, jak i administratorów.
Każdy użytkownik chcący pracować z bazą danych HANA musi mieć użytkownika bazy danych z niezbędnymi uprawnieniami. Użytkownik uzyskujący dostęp do systemu HANA może być użytkownikiem technicznym lub końcowym w zależności od wymagań dostępu. Po pomyślnym zalogowaniu się do systemu weryfikowana jest autoryzacja użytkownika do wykonania wymaganej operacji. Wykonanie tej operacji zależy od uprawnień nadanych użytkownikowi. Te uprawnienia można nadać przy użyciu ról w HANA Security. HANA Studio to jedno z potężnych narzędzi do zarządzania użytkownikami i rolami systemu bazodanowego HANA.
Typy użytkowników
Typy użytkowników różnią się w zależności od zasad bezpieczeństwa i różnych uprawnień przypisanych do profilu użytkownika. Typem użytkownika może być użytkownik technicznej bazy danych lub użytkownik końcowy potrzebuje dostępu do systemu HANA w celu raportowania lub manipulacji danymi.
Użytkownicy standardowi
Użytkownicy standardowi to użytkownicy, którzy mogą tworzyć obiekty we własnych schematach i mają dostęp do odczytu w modelach informacyjnych systemu. Dostęp do odczytu zapewnia rola PUBLIC, która jest przypisana do każdego standardowego użytkownika.
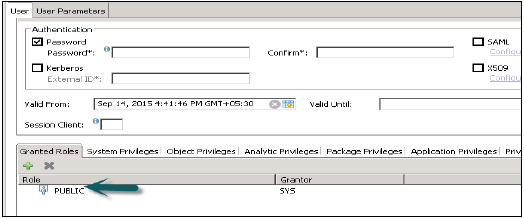
Użytkownicy z ograniczeniami
Użytkownicy z ograniczeniami to użytkownicy, którzy uzyskują dostęp do systemu HANA za pomocą niektórych aplikacji i nie mają uprawnień SQL w systemie HANA. Po utworzeniu tych użytkowników początkowo nie mają oni żadnego dostępu.
Jeśli porównamy użytkowników z ograniczeniami z użytkownikami standardowymi -
Użytkownicy z ograniczeniami nie mogą tworzyć obiektów w bazie danych HANA ani własnych schematów.
Nie mają dostępu do przeglądania żadnych danych w bazie danych, ponieważ nie mają dodanej do profilu ogólnej roli publicznej, takiej jak zwykli użytkownicy.
Mogą łączyć się z bazą danych HANA tylko przy użyciu protokołu HTTP / HTTPS.
Techniczni użytkownicy baz danych są wykorzystywani wyłącznie do celów administracyjnych, takich jak tworzenie nowych obiektów w bazie danych, nadawanie uprawnień innym użytkownikom, na pakietach, aplikacjach itp.
Działania związane z administrowaniem użytkownikami SAP HANA
W zależności od potrzeb biznesowych i konfiguracji systemu HANA, istnieją różne czynności użytkownika, które można wykonać za pomocą narzędzia administracyjnego, takiego jak studio HANA.
Do najczęściej wykonywanych czynności należą:
- Utwórz użytkowników
- Przyznaj role użytkownikom
- Zdefiniuj i utwórz role
- Usuwanie użytkowników
- Resetowanie haseł użytkowników
- Ponowna aktywacja użytkowników po zbyt wielu nieudanych próbach logowania
- Dezaktywowanie użytkowników, gdy jest to wymagane
Jak tworzyć użytkowników w HANA Studio?
Tylko użytkownicy bazy danych z uprawnieniami ROLA ADMINISTRATOR mogą tworzyć użytkowników i role w HANA Studio. Aby utworzyć użytkowników i role w HANA Studio, przejdź do konsoli administratora HANA. Zobaczysz zakładkę bezpieczeństwa w widoku systemu -
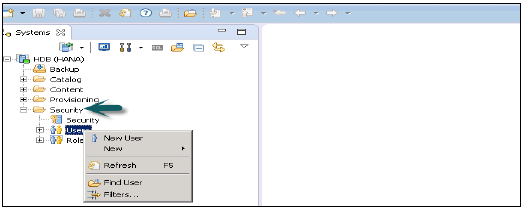
Po rozwinięciu zakładki bezpieczeństwa daje to opcję użytkownika i ról. Aby utworzyć nowego użytkownika, kliknij prawym przyciskiem myszy użytkownika i przejdź do nowego użytkownika. Otworzy się nowe okno, w którym można zdefiniować parametry użytkownika i użytkownika.
Wpisz nazwę użytkownika (mandat), aw polu Uwierzytelnianie wprowadź hasło. Hasło jest stosowane, podczas zapisywania hasła dla nowego użytkownika. Możesz także utworzyć użytkownika z ograniczonym dostępem.
Podana nazwa roli nie może być identyczna z nazwą istniejącego użytkownika lub roli. Zasady dotyczące haseł obejmują minimalną długość hasła oraz określenie, jakie typy znaków (dolna, górna, cyfra, znaki specjalne) muszą być częścią hasła.
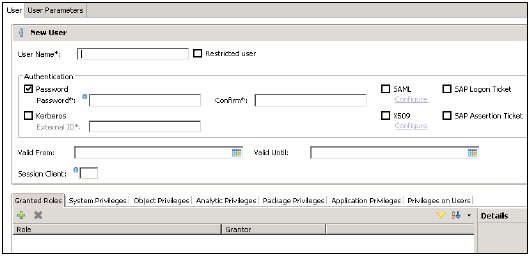
Można skonfigurować różne metody autoryzacji, takie jak SAML, certyfikaty X509, bilet logowania SAP itp. Użytkownicy w bazie danych mogą być uwierzytelniani za pomocą różnych mechanizmów -
Mechanizm uwierzytelniania wewnętrznego za pomocą hasła.
Mechanizmy zewnętrzne, takie jak Kerberos, SAML, SAP Logon Ticket, SAP Assertion Ticket czy X.509.
Użytkownik może być jednocześnie uwierzytelniany przez więcej niż jeden mechanizm. Jednak w danym momencie tylko jedno hasło i jedna nazwa główna protokołu Kerberos mogą być ważne. Należy określić jeden mechanizm uwierzytelniania, aby umożliwić użytkownikowi łączenie się i pracę z instancją bazy danych.
Daje również możliwość zdefiniowania ważności użytkownika, możesz wspomnieć o przedziale ważności, wybierając daty. Określenie ważności jest opcjonalnym parametrem użytkownika.
Niektórzy użytkownicy, którzy są domyślnie dostarczani z bazą danych SAP HANA to - SYS, SYSTEM, _SYS_REPO, _SYS_STATISTICS.
Gdy to zrobisz, następnym krokiem jest zdefiniowanie uprawnień dla profilu użytkownika. Istnieją różne typy uprawnień, które można dodać do profilu użytkownika.
Role przyznane użytkownikowi
Służy do dodawania wbudowanych ról SAP.HANA do profilu użytkownika lub do dodawania ról niestandardowych utworzonych na karcie Role. Role niestandardowe umożliwiają definiowanie ról zgodnie z wymaganiami dostępu i można je dodawać bezpośrednio do profilu użytkownika. Eliminuje to potrzebę zapamiętywania i dodawania obiektów do profilu użytkownika za każdym razem dla różnych typów dostępu.
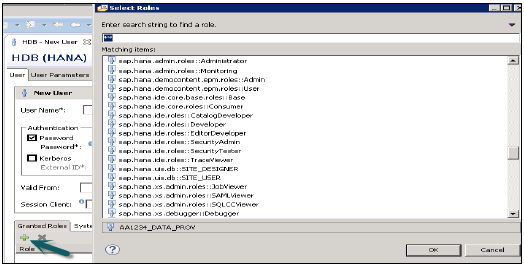
PUBLIC- To jest rola ogólna i jest domyślnie przypisywana wszystkim użytkownikom bazy danych. Ta rola obejmuje dostęp tylko do odczytu do widoków systemu i uprawnienia do wykonywania niektórych procedur. Tych ról nie można cofnąć.

Modelowanie
Zawiera wszystkie uprawnienia wymagane do korzystania z narzędzia do modelowania informacji w studiu SAP HANA.
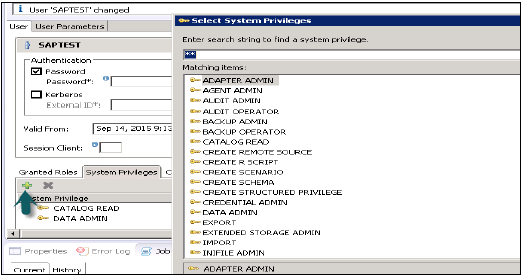
Uprawnienia systemowe
Istnieją różne typy uprawnień systemowych, które można dodać do profilu użytkownika. Aby dodać uprawnienia systemowe do profilu użytkownika, kliknij + podpisz.
Uprawnienia systemowe służą do tworzenia kopii zapasowych / przywracania, administrowania użytkownikami, uruchamiania i zatrzymywania instancji itp.
Administrator treści
Zawiera podobne uprawnienia jak w roli MODELOWANIE, ale z tym że rola ta może nadawać te uprawnienia innym użytkownikom. Zawiera również uprawnienia repozytorium do pracy z importowanymi obiektami.
Administrator danych
Jest to rodzaj przywileju wymagany do dodawania danych z obiektów do profilu użytkownika.
Poniżej podano typowe obsługiwane uprawnienia systemowe -
Dołącz debuger
Autoryzuje debugowanie wywołania procedury, wywoływanego przez innego użytkownika. Ponadto wymagane jest uprawnienie DEBUG do odpowiedniej procedury.
Administrator audytu
Steruje wykonywaniem następujących poleceń związanych z kontrolą - UTWÓRZ POLITYKĘ AUDYTU, UPUŚĆ POLITYKĘ AUDYTU i ZMIEŃ POLITYKĘ AUDYTU oraz zmiany konfiguracji kontroli. Umożliwia również dostęp do widoku systemu AUDIT_LOG.
Operator audytu
Autoryzuje wykonanie polecenia ALTER SYSTEM CLEAR AUDIT LOG. Umożliwia również dostęp do widoku systemu AUDIT_LOG.
Administrator kopii zapasowych
Autoryzuje polecenia BACKUP i RECOVERY do definiowania i inicjowania procedur tworzenia kopii zapasowych i odzyskiwania.
Operator kopii zapasowej
Upoważnia polecenie BACKUP do zainicjowania procesu tworzenia kopii zapasowej.
Czytaj katalog
Upoważnia użytkowników do niefiltrowanego dostępu tylko do odczytu do wszystkich widoków systemu. Zwykle zawartość tych widoków jest filtrowana na podstawie uprawnień użytkownika uzyskującego dostęp.
Utwórz schemat
Autoryzuje tworzenie schematów baz danych za pomocą polecenia CREATE SCHEMA. Domyślnie każdy użytkownik jest właścicielem jednego schematu, z tym uprawnieniem może on tworzyć dodatkowe schematy.
UTWÓRZ STRUKTURYZOWANY PRZYWILEJ
Upoważnia do tworzenia uprawnień strukturalnych (uprawnień analitycznych). Tylko właściciel uprawnienia analitycznego może dalej nadawać lub cofać to uprawnienie innym użytkownikom lub rolom.
Administrator poświadczeń
Autoryzuje polecenia poświadczeń - UTWÓRZ / ZMIEN / ODRZUĆ POTWIERDZENIE.
Administrator danych
Uprawnia do odczytu wszystkich danych w widokach systemowych. Umożliwia także wykonywanie dowolnych poleceń języka definicji danych (DDL) w bazie danych SAP HANA
Użytkownik mający to uprawnienie nie może wybierać ani zmieniać tabel przechowywanych z danymi, do których nie ma uprawnień dostępu, ale może usuwać tabele lub modyfikować definicje tabel.
Administrator bazy danych
Autoryzuje wszystkie polecenia związane z bazami danych w wielu bazach danych, takie jak CREATE, DROP, ALTER, RENAME, BACKUP, RECOVERY.
Eksport
Uprawnia do eksportu do bazy danych za pomocą polecenia EXPORT TABLE.
Należy zauważyć, że oprócz tego uprawnienia użytkownik wymaga uprawnienia SELECT do eksportowanych tabel źródłowych.
Import
Autoryzuje czynności importu w bazie danych za pomocą poleceń IMPORT.
Należy zauważyć, że oprócz tego uprawnienia użytkownik wymaga uprawnienia INSERT do importowanych tabel docelowych.
Inifile Admin
Uprawnia do zmiany ustawień systemowych.
Administrator licencji
Autoryzuje polecenie SET SYSTEM LICENSE do zainstalowania nowej licencji.
Log Admin
Autoryzuje komendy ALTER SYSTEM LOGGING [ON | OFF] do włączania lub wyłączania mechanizmu opróżniania dziennika.
Monitoruj administratora
Autoryzuje polecenia ALTER SYSTEM dla ZDARZEŃ.
Administrator Optymalizatora
Autoryzuje polecenia ALTER SYSTEM dotyczące poleceń SQL PLAN CACHE i ALTER SYSTEM UPDATE STATISTICS, które mają wpływ na zachowanie optymalizatora zapytań.
Administrator zasobów
To uprawnienie upoważnia polecenia dotyczące zasobów systemowych. Na przykład ALTER SYSTEM RECLAIM DATAVOLUME i ALTER SYSTEM RESET MONITORING VIEW. Autoryzuje również wiele poleceń dostępnych w konsoli zarządzania.
Administrator roli
To uprawnienie upoważnia do tworzenia i usuwania ról za pomocą poleceń CREATE ROLE i DROP ROLE. Uprawnia również do nadawania i odbierania ról za pomocą poleceń GRANT i REVOKE.
Role aktywowane, czyli role, których twórcą jest wstępnie zdefiniowany użytkownik _SYS_REPO, nie mogą być nadawane innym rolom lub użytkownikom ani bezpośrednio usuwane. Nawet użytkownicy mający uprawnienia ROLA ADMINISTRATORA nie mogą tego zrobić. Sprawdź dokumentację dotyczącą aktywowanych obiektów.
Savepoint Admin
Autoryzuje wykonanie procesu punktu zapisu za pomocą polecenia ALTER SYSTEM SAVEPOINT.
Komponenty bazy danych SAP HANA mogą tworzyć nowe uprawnienia systemowe. Te uprawnienia używają nazwy komponentu jako pierwszego identyfikatora uprawnienia systemowego i nazwy przywileju komponentu jako drugiego identyfikatora.
Uprawnienia do obiektów / SQL
Uprawnienia do obiektów są również znane jako uprawnienia SQL. Te uprawnienia są używane, aby umożliwić dostęp do obiektów, takich jak wybieranie, wstawianie, aktualizowanie i usuwanie tabel, widoków lub schematów.
Poniżej podano możliwe typy uprawnień do obiektów -
Uprawnienia do obiektów dotyczące obiektów bazy danych, które istnieją tylko w środowisku wykonawczym
Uprawnienia do obiektów na aktywowanych obiektach utworzonych w repozytorium, takich jak widoki obliczeniowe
Uprawnienie do obiektu na schemacie zawierającym aktywowane obiekty utworzone w repozytorium,
Uprawnienia do obiektów / SQL to zbiór wszystkich uprawnień DDL i DML dotyczących obiektów bazy danych.
Poniżej podano typowe obsługiwane uprawnienia do obiektów -
W bazie danych HANA znajduje się wiele obiektów bazy danych, więc nie wszystkie uprawnienia mają zastosowanie do wszystkich rodzajów obiektów bazy danych.
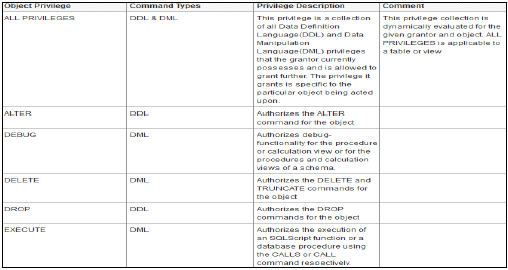
Uprawnienia do obiektów i ich zastosowanie do obiektów bazy danych -
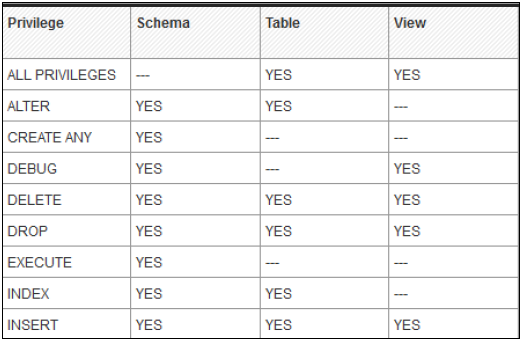
Uprawnienia analityczne
Czasami wymagane jest, aby dane w tym samym widoku nie były dostępne dla innych użytkowników, którzy nie mają żadnych odpowiednich wymagań dotyczących tych danych.
Uprawnienia analityczne służą do ograniczania dostępu do widoków informacji HANA na poziomie obiektu. W uprawnieniach analitycznych możemy zastosować zabezpieczenia na poziomie wierszy i kolumn.
Uprawnienia analityczne są używane do -
- Alokacja zabezpieczeń na poziomie wiersza i kolumny dla określonego zakresu wartości.
- Alokacja zabezpieczeń na poziomie wierszy i kolumn dla widoków modelowania.
Uprawnienia do pakietu
W repozytorium SAP HANA można ustawić autoryzacje pakietów dla określonego użytkownika lub dla roli. Uprawnienia do pakietu są używane w celu umożliwienia dostępu do modeli danych - widoków analitycznych lub obliczeniowych albo do obiektów repozytorium. Wszystkie uprawnienia przypisane do pakietu repozytorium są również przypisane do wszystkich pakietów podrzędnych. Możesz również wspomnieć, czy przypisane uprawnienia użytkowników mogą być przekazywane innym użytkownikom.
Kroki, aby dodać uprawnienia pakietu do profilu użytkownika -
Kliknij kartę Uprawnienia pakietu w studiu HANA w obszarze Tworzenie użytkownika → Wybierz +, aby dodać jeden lub więcej pakietów. Użyj klawisza Ctrl, aby wybrać wiele pakietów.
W oknie dialogowym Wybierz pakiet repozytorium użyj całej lub części nazwy pakietu, aby zlokalizować pakiet repozytorium, do którego chcesz zezwolić na dostęp.
Wybierz co najmniej jeden pakiet repozytorium, do którego chcesz zezwolić na dostęp, wybrane pakiety pojawią się na karcie Uprawnienia do pakietu.
Poniżej podano uprawnienia, które są używane w pakietach repozytorium, aby autoryzować użytkownika do modyfikowania obiektów -
REPO.READ - Dostęp do odczytu do wybranego pakietu i obiektów czasu projektowania (zarówno natywnych, jak i importowanych)
REPO.EDIT_NATIVE_OBJECTS - Uprawnienia do modyfikacji obiektów w pakietach.
Grantable to Others - Jeśli wybierzesz w tym celu opcję „Tak”, pozwoli to przypisanym uprawnieniom użytkownika przekazać innym użytkownikom.
Uprawnienia aplikacji
Uprawnienia aplikacji w profilu użytkownika służą do definiowania uprawnień dostępu do aplikacji HANA XS. Można to przypisać do pojedynczego użytkownika lub do grupy użytkowników. Uprawnienia aplikacji mogą być również wykorzystywane do zapewniania różnych poziomów dostępu do tej samej aplikacji, na przykład w celu zapewnienia zaawansowanych funkcji administratorom baz danych i dostępu w trybie tylko do odczytu zwykłym użytkownikom.
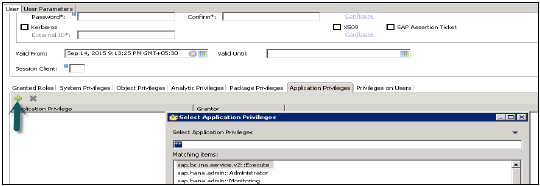
Aby zdefiniować uprawnienia specyficzne dla aplikacji w profilu użytkownika lub dodać grupę użytkowników, należy użyć poniższych uprawnień -
- Plik uprawnień aplikacji (.xsprivileges)
- Plik dostępu do aplikacji (.xsaccess)
- Plik definicji roli (<RoleName> .hdbrole)
Wszyscy użytkownicy SAP HANA, którzy mają dostęp do bazy danych HANA, są weryfikowani za pomocą innej metody uwierzytelniania. System SAP HANA obsługuje różne typy metod uwierzytelniania i wszystkie te metody logowania są konfigurowane w momencie tworzenia profilu.
Poniżej lista metod uwierzytelniania obsługiwanych przez SAP HANA -
- Nazwa użytkownika Hasło
- Kerberos
- SAML 2.0
- Bilety logowania SAP
- X.509
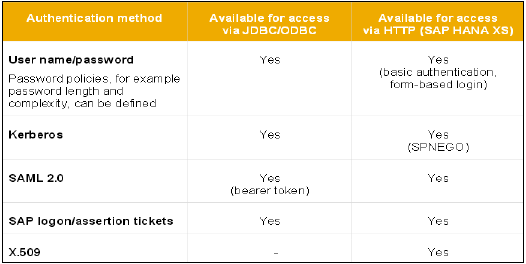
Nazwa użytkownika Hasło
Ta metoda wymaga, aby użytkownik HANA wprowadził nazwę użytkownika i hasło w celu zalogowania się do bazy danych. Ten profil użytkownika jest tworzony w sekcji Zarządzanie użytkownikami w HANA Studio → zakładka Bezpieczeństwo.
Hasło powinno być zgodne z polityką haseł, tj. Długość hasła, złożoność, małe i duże litery itp.
Możesz zmienić politykę haseł zgodnie ze standardami bezpieczeństwa organizacji. Należy pamiętać, że polityki dotyczącej haseł nie można dezaktywować.
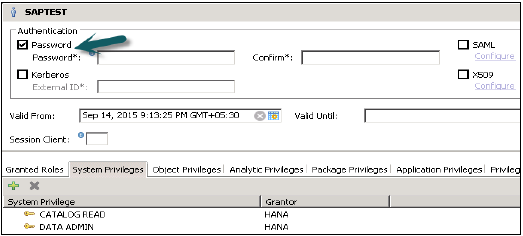
Kerberos
Wszyscy użytkownicy łączący się z systemem bazodanowym HANA przy użyciu zewnętrznej metody uwierzytelniania również powinni mieć użytkownika bazy danych. Wymagane jest mapowanie zewnętrznego logowania na użytkownika wewnętrznej bazy danych.
Ta metoda umożliwia użytkownikom uwierzytelnianie systemu HANA bezpośrednio przy użyciu sterowników JDBC / ODBC przez sieć lub za pomocą aplikacji front-end w SAP Business Objects.
Umożliwia również dostęp HTTP w rozszerzonej usłudze HANA przy użyciu silnika HANA XS. Wykorzystuje mechanizm SPENGO do uwierzytelniania Kerberos.
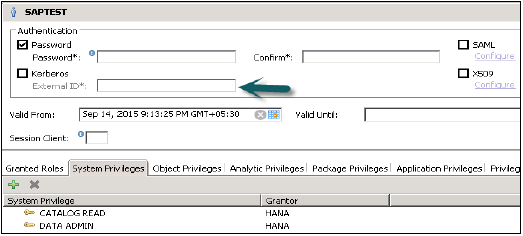
SAML
SAML oznacza Security Assertion Markup Language i może służyć do uwierzytelniania użytkowników uzyskujących dostęp do systemu HANA bezpośrednio z klientów ODBC / JDBC. Może również służyć do uwierzytelniania użytkowników w systemie HANA przechodzących przez HTTP za pośrednictwem silnika HANA XS.
SAML jest używany tylko do celów uwierzytelniania, a nie do autoryzacji.
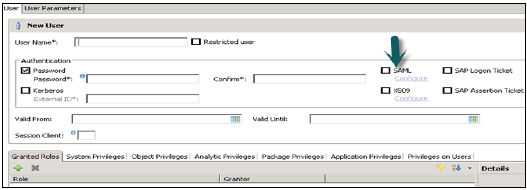
SAP Logon and Assertion Tickets
Bilety SAP Logon / assertion mogą służyć do uwierzytelniania użytkowników w systemie HANA. Bilety te są wydawane użytkownikom podczas logowania się do systemu SAP, który jest skonfigurowany do wystawiania takich biletów jak SAP Portal, itp. Użytkownik określony w biletach logowania SAP powinien zostać utworzony w systemie HANA, ponieważ nie zapewnia wsparcia dla mapowania użytkowników.
Certyfikaty klienta X.509
Certyfikatów X.509 można również używać do logowania się do systemu HANA za pośrednictwem żądania dostępu HTTP z silnika HANA XS. Użytkownicy są uwierzytelniani przez certyfikaty podpisane przez zaufany urząd certyfikacji, który jest przechowywany w systemie HANA XS.
Użytkownik w zaufanym certyfikacie powinien istnieć w systemie HANA, ponieważ nie ma obsługi mapowania użytkowników.
Logowanie jednokrotne w systemie HANA
Pojedyncze logowanie można skonfigurować w systemie HANA, który umożliwia logowanie się do systemu HANA z poziomu wstępnego uwierzytelnienia na kliencie. Logowanie użytkowników do aplikacji klienckich przy użyciu różnych metod uwierzytelniania i SSO umożliwia użytkownikowi bezpośredni dostęp do systemu HANA.
Logowanie jednokrotne można skonfigurować za pomocą poniższych metod konfiguracji -
- SAML
- Kerberos
- Certyfikaty klienta X.509 dla dostępu HTTP z aparatu HANA XS
- Bilety SAP Logon / Assertion
Autoryzacja jest sprawdzana, gdy użytkownik próbuje połączyć się z bazą danych HANA i wykonać pewne operacje na bazie danych. Gdy użytkownik łączy się z bazą danych HANA za pomocą narzędzi klienckich za pośrednictwem JDBC / ODBC lub przez HTTP w celu wykonania pewnych operacji na obiektach bazy danych, o odpowiedniej akcji decyduje dostęp, który jest przyznany użytkownikowi.
Uprawnienia nadane użytkownikowi są określane przez uprawnienia do obiektu przypisane do profilu użytkownika lub roli nadanej użytkownikowi. Autoryzacja to połączenie obu dostępów. Gdy użytkownik próbuje wykonać jakąś operację na bazie danych HANA, system przeprowadza kontrolę autoryzacji. Po znalezieniu wszystkich wymaganych uprawnień system zatrzymuje to sprawdzanie i przyznaje żądany dostęp.
Istnieją różne typy uprawnień, które są używane w SAP HANA, jak wspomniano w sekcji Rola użytkownika i zarządzanie -
Uprawnienia systemowe
Dotyczą one autoryzacji systemu i baz danych dla użytkowników oraz kontroli działań systemu. Są używane do zadań administracyjnych, takich jak tworzenie schematów, tworzenie kopii zapasowych danych, tworzenie użytkowników i ról itp. Uprawnienia systemowe są również używane do wykonywania operacji na repozytorium.
Uprawnienia do obiektów
Mają zastosowanie do operacji bazy danych i mają zastosowanie do obiektów bazy danych, takich jak tabele, schematy itp. Służą do zarządzania obiektami bazy danych, takimi jak tabele i widoki. Na podstawie obiektów bazy danych można zdefiniować różne akcje, takie jak Wybierz, Wykonaj, Zmień, Upuść, Usuń.
Służą również do sterowania zdalnymi obiektami danych, które są połączone poprzez dostęp danych SMART do SAP HANA.
Uprawnienia analityczne
Mają zastosowanie do danych we wszystkich pakietach, które są tworzone w repozytorium HANA. Służą do sterowania widokami modelowania tworzonymi w pakietach, takich jak widok atrybutów, widok analityczny i widok obliczeniowy. Stosują zabezpieczenia na poziomie wierszy i kolumn do atrybutów, które są zdefiniowane w widokach modelowania w pakietach HANA.
Uprawnienia do pakietu
Mają one zastosowanie, aby umożliwić dostęp i możliwość korzystania z pakietów utworzonych w repozytorium bazy danych HANA. Pakiet zawiera różne widoki modelowania, takie jak widoki atrybutów, analitycznych i obliczeniowych, a także uprawnienia analityczne zdefiniowane w bazie danych repozytorium HANA.
Uprawnienia aplikacji
Mają zastosowanie do aplikacji HANA XS, która uzyskuje dostęp do bazy danych HANA za pośrednictwem żądania HTTP. Służą do kontrolowania dostępu do aplikacji utworzonych za pomocą silnika HANA XS.
Uprawnienia aplikacji można nadawać użytkownikom / rolom bezpośrednio za pomocą HANA Studio, ale zaleca się, aby były one stosowane do ról utworzonych w repozytorium w czasie projektowania.
Autoryzacja repozytorium w bazie danych SAP HANA
_SYS_REPO to użytkownik jest właścicielem wszystkich obiektów w repozytorium HANA. Ten użytkownik powinien mieć zewnętrzną autoryzację dla obiektów, na których modelowane są obiekty repozytorium w systemie HANA. _SYS_REPO jest właścicielem wszystkich obiektów, więc można go używać tylko do udzielania dostępu do tych obiektów, żaden inny użytkownik nie może zalogować się jako użytkownik _SYS_REPO.
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
Zarządzanie licencjami SAP HANA i klucze są wymagane do korzystania z bazy danych HANA. Możesz zainstalować lub usunąć klucze licencyjne HANA za pomocą HANA Studio.
Rodzaje kluczy licencyjnych
System SAP HANA obsługuje dwa typy kluczy licencyjnych -
Temporary License Key- Klucze licencji tymczasowej są automatycznie instalowane podczas instalowania bazy danych HANA. Klucze te są ważne tylko przez 90 dni i należy poprosić o stałe klucze licencyjne w sklepie SAP przed upływem tego 90-dniowego okresu po instalacji.
Permanent License Key- Stałe klucze licencyjne są ważne tylko do wcześniej określonej daty wygaśnięcia. Klucze licencyjne określają ilość pamięci licencjonowanej dla docelowej instalacji HANA. Można je zainstalować z miejsca SAP Market w zakładce Klucze i żądania. Po wygaśnięciu stałego klucza licencyjnego wydawany jest tymczasowy klucz licencyjny, który jest ważny tylko przez 28 dni. W tym okresie musisz ponownie zainstalować stały klucz licencyjny.
Istnieją dwa typy stałych kluczy licencyjnych dla systemu HANA -
Unenforced - Jeśli zainstalowany jest niewymuszony klucz licencyjny, a zużycie systemu HANA przekracza ilość pamięci dostępnej w licencji, nie ma to wpływu na działanie SAP HANA.
Enforced- Jeśli jest zainstalowany wymuszony klucz licencyjny, a zużycie systemu HANA przekracza ilość pamięci dostępnej w licencji, system HANA zostaje zablokowany. W takim przypadku należy ponownie uruchomić system HANA lub zażądać i zainstalować nowy klucz licencyjny.
Istnieją różne scenariusze licencyjne, które można zastosować w systemie HANA w zależności od krajobrazu systemu (Standalone, HANA Cloud, BW on HANA itp.) I nie wszystkie te modele są oparte na pamięci instalacji systemu HANA.
Jak sprawdzić właściwości licencji HANA
Kliknij prawym przyciskiem myszy system HANA → Właściwości → Licencja
Zawiera informacje o typie licencji, dacie rozpoczęcia i dacie wygaśnięcia, alokacji pamięci oraz informacji (klucz sprzętowy, identyfikator systemu), które są wymagane do zażądania nowej licencji za pośrednictwem SAP Market Place.
Zainstaluj klucz licencyjny → Przeglądaj → Wprowadź ścieżkę, służy do instalowania nowego klucza licencyjnego, a opcja usuwania służy do usuwania starego klucza wygaśnięcia.
Karta Wszystkie licencje w obszarze Licencja zawiera informacje o nazwie produktu, opisie, kluczu sprzętowym, czasie pierwszej instalacji itp.
Zasady audytu SAP HANA określają czynności, które mają zostać poddane audytowi, a także warunek, w jakim musi zostać wykonane, aby było ono istotne dla audytu. Polityka audytu określa jakie czynności zostały wykonane w systemie HANA oraz kto w jakim czasie je wykonał.
Funkcja audytu bazy danych SAP HANA umożliwia monitorowanie akcji wykonywanych w systemie HANA. Aby można było z niej korzystać, polityka audytu SAP HANA musi być aktywowana w systemie HANA. Kiedy akcja jest wykonywana, zasady wyzwalają zdarzenie inspekcji w celu zapisania do ścieżki audytu. Możesz także usuwać wpisy audytu w ścieżce audytu.
W środowisku rozproszonym, w którym masz wiele baz danych, zasady inspekcji można włączyć w każdym systemie. W przypadku bazy danych systemu zasady inspekcji są zdefiniowane w pliku nameserver.ini, a dla bazy danych dzierżawców w pliku global.ini.
Aktywacja zasad audytu
Aby zdefiniować politykę audytu w systemie HANA, należy mieć uprawnienie systemowe - Administrator audytu.
Przejdź do opcji Bezpieczeństwo w systemie HANA → Inspekcja
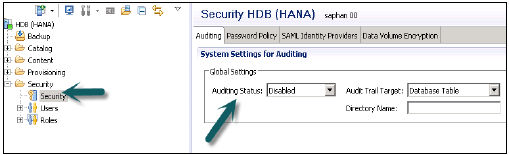
W obszarze Ustawienia globalne → ustaw stan inspekcji jako włączony.
Możesz także wybrać cele ścieżki audytu. Możliwe są następujące cele ścieżki audytu:
Syslog (domyślnie) - system rejestrowania systemu operacyjnego Linux.
Database Table - Wewnętrzna tabela bazy danych, użytkownik z uprawnieniami administratora audytu lub operatora audytu może wykonywać tylko wybrane operacje na tej tabeli.
CSV text - Ten typ ścieżki audytu jest używany tylko do celów testowych w środowisku nieprodukcyjnym.
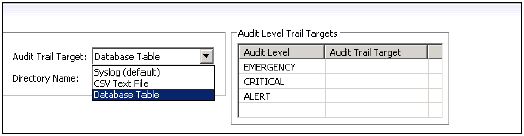
Możesz również utworzyć nową politykę inspekcji w obszarze Zasady inspekcji → wybierz opcję Utwórz nową politykę. Wprowadź nazwę polityki i czynności do kontroli.
Zapisz nową politykę za pomocą przycisku Wdróż. Nowa polityka jest włączana automatycznie, gdy spełniony jest warunek akcji, w tabeli dziennika inspekcji tworzony jest wpis inspekcji. Możesz wyłączyć politykę, zmieniając jej stan, aby wyłączyć, lub możesz również usunąć politykę.
SAP HANA Replication umożliwia migrację danych z systemów źródłowych do bazy danych SAP HANA. Prostym sposobem na przeniesienie danych z istniejącego systemu SAP do HANA jest użycie różnych technik replikacji danych.
Replikację systemu można skonfigurować na konsoli za pomocą wiersza poleceń lub za pomocą HANA Studio. Podczas tego procesu podstawowe ECC lub systemy transakcyjne mogą pozostawać online. Mamy trzy rodzaje metod replikacji danych w systemie HANA -
- Metoda replikacji SAP LT
- Narzędzie ETL Metoda SAP Business Object Data Service (BODS)
- Metoda bezpośredniego podłączenia wyciągu (DXC)
Metoda replikacji SAP LT
SAP Landscape Transformation Replication to metoda replikacji danych w systemie HANA oparta na wyzwalaczach. Jest to idealne rozwiązanie do replikacji danych w czasie rzeczywistym lub replikacji opartej na harmonogramie ze źródeł SAP i innych niż SAP. Posiada serwer replikacji SAP LT, który obsługuje wszystkie żądania wyzwalaczy. Serwer replikacji można zainstalować jako serwer autonomiczny lub można go uruchomić w dowolnym systemie SAP z oprogramowaniem SAP NW 7.02 lub nowszym.
Pomiędzy HANA DB a systemem transakcyjnym ECC istnieje połączenie Trusted RFC, które umożliwia replikację danych w oparciu o wyzwalacze w środowisku systemu HANA.

Zalety replikacji SLT
Metoda replikacji SLT umożliwia replikację danych z wielu systemów źródłowych do jednego systemu HANA, a także z jednego systemu źródłowego do wielu systemów HANA.
SAP LT wykorzystuje podejście oparte na wyzwalaczu. Nie ma to mierzalnego wpływu na wydajność w systemie źródłowym.
Zapewnia również możliwość transformacji i filtrowania danych przed załadowaniem do bazy danych HANA.
Umożliwia replikację danych w czasie rzeczywistym, replikując tylko istotne dane do HANA z systemów źródłowych SAP i innych niż SAP.
Jest w pełni zintegrowany z systemem HANA i studiem HANA.
Tworzenie zaufanego połączenia RFC w systemie ECC
W źródłowym systemie SAP AA1 chcesz skonfigurować zaufany RFC dla systemu docelowego BB1. Gdy zostanie to zrobione, oznaczałoby to, że kiedy jesteś zalogowany do AA1 i twój użytkownik ma wystarczającą autoryzację w BB1, możesz użyć połączenia RFC i zalogować się do BB1 bez konieczności ponownego wprowadzania użytkownika i hasła.
Korzystając z relacji zaufanych / zaufanych RFC między dwoma systemami SAP, RFC z systemu zaufanego do systemu ufającego, hasło nie jest wymagane do zalogowania się do systemu ufającego.
Otwórz system SAP ECC przy użyciu logowania SAP. Wprowadź numer transakcji sm59 → to jest numer transakcji, aby utworzyć nowe połączenie Zaufane RFC → Kliknij trzecią ikonę, aby otworzyć kreatora nowego połączenia → kliknij Utwórz, a otworzy się nowe okno.
RFC Destination ECCHANA (wprowadź nazwę miejsca docelowego RFC) Connection Type - 3 (dla systemu ABAP)
Przejdź do ustawień technicznych
Wpisz Host docelowy - nazwa systemu ECC, adres IP i wprowadź numer systemu.
Przejdź do zakładki Logowanie i zabezpieczenia, wprowadź język, klienta, nazwę użytkownika i hasło systemu ECC.
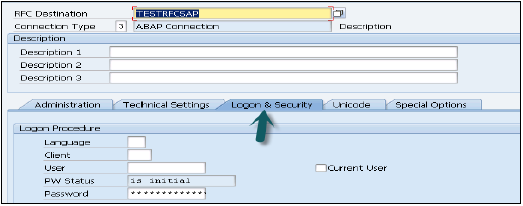
Kliknij opcję Zapisz u góry.

Kliknij Testuj połączenie i pomyślnie przetestuje połączenie.
Aby skonfigurować połączenie RFC
Uruchom transakcję - ltr (aby skonfigurować połączenie RFC) → Otworzy się nowa przeglądarka → wprowadź nazwę użytkownika i hasło do systemu ECC oraz zaloguj się.

Kliknij Nowy → Otworzy się nowe okno → Wprowadź nazwę konfiguracji → Kliknij Dalej → Wprowadź miejsce docelowe RFC (nazwa połączenia utworzonego wcześniej), Użyj opcji wyszukiwania, wybierz nazwę i kliknij Dalej.
W obszarze Określ system docelowy wprowadź nazwę użytkownika i hasło administratora systemu HANA, nazwę hosta, numer wystąpienia i kliknij przycisk Dalej. Wpisz liczbę zadań transferu danych, np. 007 (nie może to być 000) → Dalej → Utwórz konfigurację.
Teraz przejdź do HANA Studio, aby użyć tego połączenia -
Przejdź do HANA Studio → kliknij Data Provisioning → wybierz system HANA
Wybierz system źródłowy (nazwa zaufanego połączenia RFC) i nazwę schematu docelowego, do którego chcesz załadować tabele z systemu ECC. Wybierz tabele, które chcesz przenieść do bazy danych HANA → DODAJ → Zakończ.

Wybrane tabele zostaną przeniesione do wybranego schematu w bazie danych HANA.
Replikacja oparta na SAP HANA ETL wykorzystuje usługi SAP Data Services do migracji danych z systemu źródłowego SAP lub innego niż SAP do docelowej bazy danych HANA. System BODS jest narzędziem ETL używanym do wyodrębniania, transformacji i ładowania danych z systemu źródłowego do systemu docelowego.
Umożliwia odczyt danych biznesowych w warstwie aplikacji. Musisz zdefiniować przepływy danych w usługach danych, zaplanować zadanie replikacji oraz zdefiniować system źródłowy i docelowy w magazynie danych w projektancie usług danych.
Jak korzystać z replikacji opartej na ETL usług danych SAP HANA?
Zaloguj się do projektanta usług danych (wybierz Repozytorium) → Utwórz magazyn danych
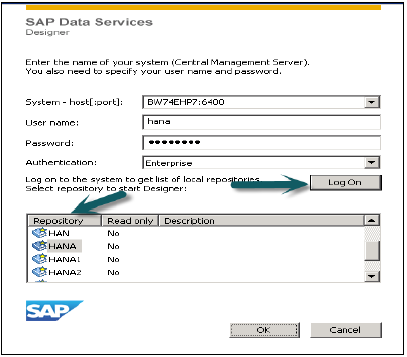
W przypadku systemu SAP ECC wybierz bazę danych jako Aplikacje SAP, wprowadź nazwę serwera ECC, nazwę użytkownika i hasło do systemu ECC, zakładkę Zaawansowane wybierz szczegóły, takie jak numer instancji, numer klienta itp. I zastosuj.
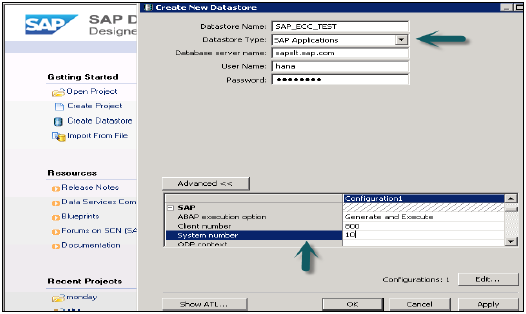
Ta składnica danych znajdzie się w lokalnej bibliotece obiektów, jeśli ją rozwiniesz, nie będzie w niej żadnej tabeli.
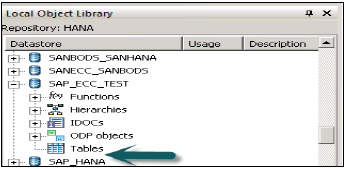
Kliknij prawym przyciskiem myszy na Tabela → Importuj według nazwy → Wejdź do tabeli ECC, aby zaimportować z systemu ECC (MARA jest domyślną tabelą w systemie ECC) → Importuj → Teraz rozwiń tabelę → MARA → Kliknij prawym przyciskiem Wyświetl dane. Jeśli wyświetlane są dane, połączenie ze składnicą danych jest prawidłowe.
Teraz, aby wybrać system docelowy jako bazę danych HANA, utwórz nowy magazyn danych. Utwórz magazyn danych → Nazwa magazynu danych SAP_HANA_TEST → Typ magazynu danych (baza danych) → Typ bazy danych SAP HANA → Wersja bazy danych HANA 1.x.
Wpisz nazwę serwera HANA, nazwę użytkownika i hasło do systemu HANA i OK.
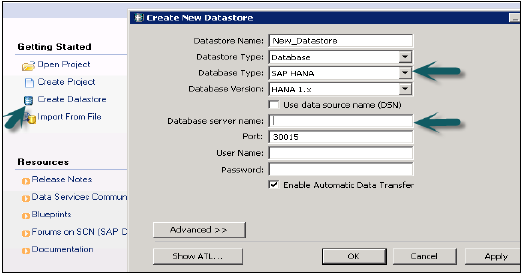
Ta składnica danych zostanie dodana do lokalnej biblioteki obiektów. Możesz dodać tabelę, jeśli chcesz przenieść dane z tabeli źródłowej do określonej tabeli w bazie danych HANA. Należy zauważyć, że tabela docelowa powinna mieć podobny typ danych jak tabela źródłowa.
Tworzenie zadania replikacji
Utwórz nowy projekt → Wprowadź nazwę projektu → Kliknij prawym przyciskiem myszy nazwę projektu → Nowe zadanie wsadowe → Wprowadź nazwę zadania.
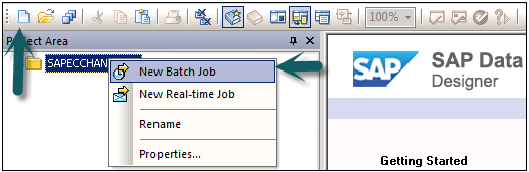
Z prawej strony wybierz przepływ pracy → Wprowadź nazwę przepływu pracy → Kliknij dwukrotnie, aby dodać go do zadania wsadowego → Wprowadź przepływ danych → Wprowadź nazwę przepływu danych → Kliknij dwukrotnie, aby dodać go pod zadaniem wsadowym w obszarze Projekt Opcja Zapisz wszystko u góry.

Przeciągnij tabelę z First Data Store ECC (MARA) do obszaru roboczego. Wybierz go i kliknij prawym przyciskiem myszy → Dodaj nowy → Tabela szablonów, aby utworzyć nową tabelę z podobnymi typami danych w HANA DB → Wprowadź nazwę tabeli, Magazyn danych ECC_HANA_TEST2 → Nazwa właściciela (nazwa schematu) → OK
Przeciągnij stół na przód i połącz oba tabele → zapisz wszystko. Teraz przejdź do zadania wsadowego → Kliknij prawym przyciskiem myszy → Wykonaj → Tak → OK
Po wykonaniu zadania replikacji otrzymasz potwierdzenie, że zadanie zostało zakończone pomyślnie.
Przejdź do studia HANA → Rozwiń schemat → Tabele → Weryfikuj dane. Jest to ręczne wykonanie zadania wsadowego.
Planowanie zadań wsadowych
Możesz również zaplanować zadanie wsadowe, przechodząc do konsoli zarządzania usługami danych. Zaloguj się do konsoli zarządzania usługami danych.
Wybierz repozytorium z lewej strony → Przejdź do zakładki `` Konfiguracja zadań wsadowych '', gdzie zobaczysz listę zadań → Z zadaniem, które chcesz zaplanować → kliknij dodaj harmonogram → Wprowadź `` nazwę harmonogramu '' i ustaw parametry takie jak ( godzina, data, powtórka itp.) i kliknij `` Zastosuj ''.
Jest to również znane jako replikacja Sybase w systemie HANA. Głównymi komponentami tej metody replikacji są Sybase Replication Agent, który jest częścią źródłowego systemu aplikacji SAP, agent replikacji oraz Sybase Replication Server, który ma zostać wdrożony w systemie SAP HANA.
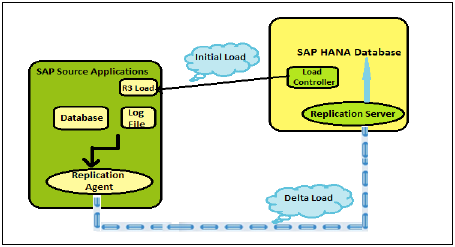
Metoda Initial Load in Sybase Replication jest inicjowana przez Load Controller i wyzwalana przez administratora w SAP HANA. Informuje R3 Load o przeniesieniu obciążenia początkowego do bazy danych HANA. Obciążenie R3 w systemie źródłowym eksportuje dane dla wybranych tabel w systemie źródłowym i przenosi te dane do komponentów obciążenia R3 w systemie HANA. Obciążenie R3 w systemie docelowym importuje dane do bazy danych SAP HANA.
Agent hosta SAP zarządza uwierzytelnianiem między systemem źródłowym a systemem docelowym, który jest częścią systemu źródłowego. Agent Sybase Replication wykrywa wszelkie zmiany danych podczas początkowego ładowania i zapewnia, że każda zmiana została zakończona. W przypadku zmiany, aktualizacji lub usunięcia wpisów tabeli w systemie źródłowym tworzony jest dziennik tabeli. Ten dziennik tabeli przenosi dane z systemu źródłowego do bazy danych HANA.
Replikacja delta po wstępnym załadowaniu
Replikacja delta rejestruje zmiany danych w systemie źródłowym w czasie rzeczywistym po zakończeniu wstępnego ładowania i replikacji. Wszystkie dalsze zmiany w systemie źródłowym są przechwytywane i replikowane z systemu źródłowego do bazy danych HANA przy użyciu powyższej metody.
Ta metoda była częścią początkowej oferty replikacji SAP HANA, ale nie jest już pozycjonowana / obsługiwana z powodu problemów licencyjnych i złożoności, a także SLT zapewnia te same funkcje.
Note - Ta metoda obsługuje tylko system SAP ERP jako źródło danych i bazę danych DB2.
Replikacja danych Direct Extractor Connection ponownie wykorzystuje istniejący mechanizm ekstrakcji, transformacji i ładowania wbudowany w systemy SAP Business Suite za pośrednictwem prostego połączenia HTTP (S) z SAP HANA. Jest to technika replikacji danych oparta na partiach. Jest uważana za metodę ekstrakcji, transformacji i ładowania z ograniczonymi możliwościami wyodrębniania danych.
DXC jest procesem wsadowym, a ekstrakcja danych przy użyciu DXC w określonych odstępach czasu jest wystarczająca w wielu przypadkach. Możesz ustawić interwał wykonywania zadania wsadowego, na przykład: co 20 minut, aw większości przypadków wystarczy wyodrębnić dane za pomocą tych zadań wsadowych w określonych odstępach czasu.
Zalety replikacji danych DXC
Ta metoda nie wymaga dodatkowego serwera ani aplikacji w środowisku systemu SAP HANA.
Metoda DXC zmniejsza złożoność modelowania danych w SAP HANA, ponieważ dane są wysyłane do HANA po zastosowaniu wszystkich logiki ekstraktora biznesowego w systemie źródłowym.
Przyspiesza terminy realizacji projektu wdrożenia SAP HANA
Dostarcza bogate semantycznie dane z SAP Business Suite do SAP HANA
Ponownie wykorzystuje istniejący zastrzeżony mechanizm ekstrakcji, transformacji i ładowania wbudowany w systemy SAP Business Suite za pośrednictwem prostego połączenia HTTP (S) z SAP HANA.
Ograniczenia replikacji danych DXC
Źródło danych musi mieć predefiniowany mechanizm ekstrakcji, transformacji i ładowania, a jeśli nie, to musimy go zdefiniować.
Wymaga systemu Business Suite opartego na oprogramowaniu Net Weaver 7.0 lub nowszym z co najmniej SP: Release 700 SAPKW70021 (SP stack 19, od listopada 2008).
Konfigurowanie replikacji danych DXC
Enabling XS Engine service in Configuration tab in HANA Studio- Przejdź do zakładki Administrator w studiu systemu HANA. Przejdź do Konfiguracja → xsengine.ini i ustaw wartość instancji na 1.
Enabling ICM Web Dispatcher service in HANA Studio - Przejdź do Konfiguracja → webdispatcher.ini i ustaw wartość instancji na 1.
Umożliwia obsługę ICM Web Dispatcher w systemie HANA. Dyspozytor sieciowy wykorzystuje metodę ICM do odczytu i ładowania danych w systemie HANA.
Setup SAP HANA Direct Extractor Connection- Pobierz jednostkę dostarczania DXC do SAP HANA. Możesz zaimportować urządzenie w lokalizacji / usr / sap / HDB / SYS / global / hdb / content.
Zaimportuj jednostkę za pomocą okna dialogowego importu w węźle zawartości SAP HANA → Skonfiguruj serwer aplikacji XS do korzystania z DXC → Zmień wartość application_container na libxsdxc
Creating a HTTP connection in SAP BW - Teraz musimy utworzyć połączenie http w SAP BW przy użyciu kodu transakcji SM59.
Input Parameters - Wprowadź nazwę połączenia RFC, nazwę hosta HANA i <numer wystąpienia>
W zakładce Log on Security wprowadź użytkownika DXC utworzonego w studio HANA przy użyciu podstawowej metody uwierzytelniania -
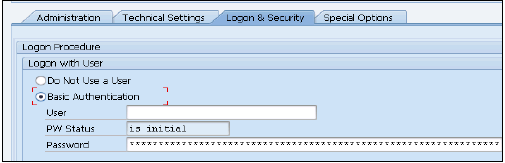
Setting up BW Parameters for HANA - Należy ustawić następujące parametry w BW przy użyciu transakcji SE 38. Lista parametrów -
PSA_TO_HDB_DESTINATION - musimy wspomnieć, gdzie musimy przenieść dane przychodzące (nazwa połączenia utworzona za pomocą SM 59)
PSA_TO_HDB_SCHEMA - Do którego schematu należy przypisać replikowane dane
PSA_TO_HDB- GLOBALNA replikacja wszystkich źródeł danych na platformę HANA. SYSTEM - Określeni klienci do korzystania z DXC. DATASOURCE - tylko określone źródło danych jest używane dla
PSA_TO_HDB_DATASOURCETABLE - Trzeba podać nazwę tabeli zawierającą listę źródeł danych, które są używane dla DXC.
Replikacja źródła danych
Zainstaluj źródło danych w ECC przy użyciu RSA5.
Zreplikuj metadane przy użyciu określonego komponentu aplikacji (wersja źródła danych Wymagana do 7.0, jeśli mamy źródło danych w wersji 3.5, musimy to zmigrować. Aktywuj źródło danych w SAP BW. Po aktywowaniu źródła danych w SAP BW zostanie utworzona następująca tabela w zdefiniowanym schemacie -
/ BIC / A <źródło danych> 00 - IMDSO Active Table
/ BIC / A <źródło danych> 40 - kolejka aktywacji IMDSO
/ BIC / A <źródło danych> 70 - Tabela obsługi trybu nagrywania
/ BIC / A <źródło danych> 80 - Tabela informacji o żądaniach i identyfikatorach pakietów
/ BIC / A <źródło danych> A0 - Tabela datowników żądań
RSODSO_IMOLOG - tabela powiązana z IMDSO. Przechowuje informacje o wszystkich źródłach danych związanych z DXC.
Teraz dane są pomyślnie ładowane do tabeli / BIC / A0FI_AA_2000 po ich aktywacji.
Otwórz SAP HANA Studio → Utwórz schemat na karcie Katalog. <Zacznij tutaj>
Przygotuj dane i zapisz je w formacie csv. Teraz utwórz plik z rozszerzeniem „ctl” o następującej składni -
---------------------------------------
import data into table Schema."Table name"
from 'file.csv'
records delimited by '\n'
fields delimited by ','
Optionally enclosed by '"'
error log 'table.err'
-----------------------------------------Przenieś ten plik „ctl” na FTP i uruchom ten plik, aby zaimportować dane -
import z „table.ctl”
Sprawdź dane w tabeli przechodząc do HANA Studio → Katalog → Schemat → Tabele → Wyświetl zawartość
MDX Provider służy do połączenia MS Excel z systemem bazodanowym SAP HANA. Dostarcza sterownik do połączenia systemu HANA z Excelem i jest dalej wykorzystywany do modelowania danych. Możesz użyć Microsoft Office Excel 2010/2013 do łączności z HANA zarówno dla 32-bitowego, jak i 64-bitowego systemu Windows.
SAP HANA obsługuje oba języki zapytań - SQL i MDX. Można używać obu języków: JDBC i ODBC dla SQL i ODBO jest używane do przetwarzania MDX. Tabele przestawne programu Excel używają języka MDX jako języka zapytań do odczytywania danych z systemu SAP HANA. MDX jest zdefiniowany jako część specyfikacji ODBO (OLE DB for OLAP) firmy Microsoft i jest używany do wyboru danych, obliczeń i układu. MDX obsługuje wielowymiarowy model danych i obsługuje wymagania dotyczące raportowania i analizy.
Dostawca MDX umożliwia korzystanie z widoków informacji zdefiniowanych w HANA Studio przez narzędzia raportowania SAP i inne niż SAP. Istniejące fizyczne tabele i schematy stanowią podstawę danych dla modeli informacyjnych.
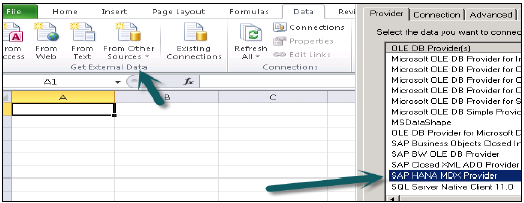
Po wybraniu dostawcy SAP HANA MDX z listy źródeł danych, z którymi chcesz się połączyć, przekaż szczegóły systemu HANA, takie jak nazwa hosta, numer wystąpienia, nazwa użytkownika i hasło.
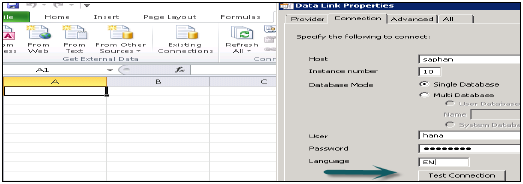
Po pomyślnym nawiązaniu połączenia możesz wybrać opcję Nazwa pakietu → Widoki modelowania HANA, aby wygenerować tabele przestawne.
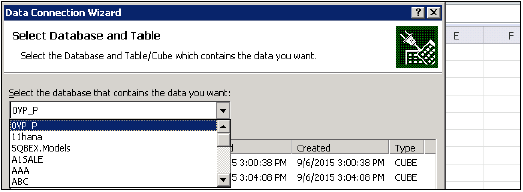
MDX jest ściśle zintegrowany z bazą danych HANA. Zarządzanie połączeniami i sesjami w bazie danych HANA obsługuje instrukcje wykonywane przez platformę HANA. Po wykonaniu tych instrukcji są one analizowane przez interfejs MDX i generowany jest model obliczeniowy dla każdej instrukcji MDX. Ten model obliczeniowy tworzy plan wykonania, który generuje standardowe wyniki dla MDX. Te wyniki są bezpośrednio używane przez klientów OLAP.
Aby nawiązać połączenie MDX z bazą danych HANA, wymagane są narzędzia klienckie HANA. Możesz pobrać to narzędzie klienckie z rynku SAP. Po zakończeniu instalacji klienta HANA na liście źródeł danych w MS Excel pojawi się opcja dostawcy SAP HANA MDX.
Monitorowanie alertów SAP HANA służy do monitorowania stanu zasobów systemowych i usług, które działają w systemie HANA. Monitorowanie alertów służy do obsługi alertów krytycznych, takich jak użycie procesora, zapełnienie dysku, przekroczenie progu FS itp. Komponent monitorujący systemu HANA w sposób ciągły gromadzi informacje o stanie, wykorzystaniu i wydajności wszystkich komponentów bazy danych HANA. Podnosi alarm, gdy którykolwiek ze składników przekroczy ustawioną wartość progową.
Priorytet alertu zgłaszanego w systemie HANA informuje o krytyczności problemu i zależy od sprawdzenia, które jest wykonywane na komponencie. Przykład - jeśli użycie procesora wynosi 80%, zostanie podniesiony alert o niskim priorytecie. Jeśli jednak osiągnie 96%, system podniesie alert o wysokim priorytecie.
Monitor systemu to najpopularniejszy sposób monitorowania systemu HANA i sprawdzania dostępności wszystkich komponentów systemu SAP HANA. Monitor systemu służy do sprawdzania wszystkich kluczowych komponentów i usług systemu HANA.

W Edytorze administracyjnym można również przejść do szczegółów dotyczących poszczególnych systemów. Mówi o dysku danych, dysku dziennika, dysku śledzenia, alarmach o wykorzystaniu zasobów z priorytetem.

Zakładka Alert w edytorze Administrator służy do sprawdzania aktualnych i wszystkich alertów w systemie HANA.
Zawiera również informacje o czasie, w którym wystąpił alert, opisie ostrzeżenia, priorytecie ostrzeżenia itp.
Pulpit monitorujący SAP HANA informuje o kluczowych aspektach kondycji i konfiguracji systemu -
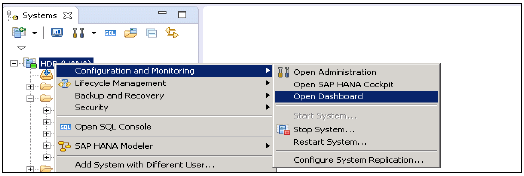
- Alerty o wysokim i średnim priorytecie.
- Wykorzystanie pamięci i procesora
- Kopie zapasowe danych
Warstwa trwałości bazy danych SAP HANA jest odpowiedzialna za zarządzanie dziennikami wszystkich transakcji w celu zapewnienia standardowych kopii zapasowych danych i funkcji przywracania systemu.
Zapewnia przywrócenie bazy danych do ostatniego zatwierdzonego stanu po ponownym uruchomieniu lub po awarii systemu, a transakcje są wykonywane całkowicie lub całkowicie cofnięte. SAP HANA Persistent Layer jest częścią serwera Index i zawiera woluminy danych i dzienników transakcji dla systemu HANA, a dane w pamięci są regularnie zapisywane w tych woluminach. Istnieją usługi w systemie HANA, które mają swoją trwałość. Zapewnia również punkty składowania i dzienniki dla wszystkich transakcji bazy danych od ostatniego punktu zapisu.
Dlaczego baza danych SAP HANA potrzebuje trwałej warstwy?
Pamięć główna jest ulotna, dlatego dane są tracone podczas restartu lub zaniku zasilania.
Dane muszą być przechowywane na trwałym nośniku.
Kopia zapasowa i przywracanie jest dostępne.
Zapewnia przywrócenie bazy danych do ostatniego zatwierdzonego stanu po ponownym uruchomieniu oraz całkowite wykonanie lub cofnięcie transakcji.
Woluminy danych i dzienników transakcji
Bazę danych można zawsze przywrócić do jej najnowszego stanu, aby zapewnić regularne kopiowanie tych zmian danych w bazie danych na dysk. Pliki dziennika zawierające zmiany danych i niektóre zdarzenia transakcji są również regularnie zapisywane na dysku. Dane i dzienniki systemu są przechowywane w woluminach dziennika.
Woluminy danych przechowują dane SQL i informacje o cofnięciu dziennika, a także dane modelowania informacji SAP HANA. Informacje te są przechowywane na stronach danych, zwanych blokami. Bloki te są zapisywane w woluminach danych w regularnych odstępach czasu, co jest znane jako punkt zapisu.
Woluminy dziennika przechowują informacje o zmianach danych. Zmiany wprowadzone między dwoma punktami dziennika są zapisywane w woluminach dziennika i nazywane wpisami dziennika. Są one zapisywane w buforze dziennika po zatwierdzeniu transakcji.
Savepoints
W bazie danych SAP HANA zmienione dane są automatycznie zapisywane z pamięci na dysk. Te regularne interwały nazywane są punktami zapisu i domyślnie są ustawione tak, aby następowały co pięć minut. Warstwa trwałości w bazie danych SAP HANA wykonuje te punkty zapisu w regularnych odstępach czasu. Podczas tej operacji zmienione dane są zapisywane na dysku, a dzienniki powtórek są również zapisywane na dysku.
Dane należące do punktu zapisu informują o spójnym stanie danych na dysku i pozostają tam do zakończenia następnej operacji punktu zapisu. Ponów wpisy dziennika są zapisywane w woluminach dziennika dla wszystkich zmian w trwałych danych. W przypadku ponownego uruchomienia bazy danych można odczytać dane z ostatniego zakończonego punktu zapisu z woluminów danych i powtórzyć wpisy dziennika zapisane w woluminach dziennika.
Częstotliwość zapisu punktu można skonfigurować za pomocą pliku global.ini. Punkty zapisu mogą być inicjowane przez inne operacje, takie jak zamknięcie bazy danych lub ponowne uruchomienie systemu. Możesz także uruchomić punkt zapisu, wykonując poniższe polecenie -
ALTER System SAVEPOINT
Aby zapisać dane i powtórzyć dzienniki w woluminach dziennika, należy upewnić się, że na dysku jest wystarczająco dużo miejsca, aby je przechwycić, w przeciwnym razie system wyświetli zdarzenie zapełnienia dysku i baza danych przestanie działać.
Podczas instalacji systemu HANA jako miejsce przechowywania woluminów danych i dzienników tworzone są następujące domyślne katalogi -
- /usr/sap/<SID>/SYS/global/hdb/data
- /usr/sap/<SID>/SYS/global/hdb/log
Te katalogi są zdefiniowane w pliku global.ini i można je zmienić na późniejszym etapie.
Należy pamiętać, że punkty Savepoints nie wpływają na wydajność transakcji realizowanych w systemie HANA. Podczas operacji punktu zapisu transakcje działają normalnie. Przy systemie HANA działającym na odpowiednim sprzęcie wpływ punktów zapisu na wydajność systemu jest znikomy.
Kopia zapasowa i odzyskiwanie SAP HANA służy do wykonywania kopii zapasowych systemu HANA oraz odzyskiwania systemu w przypadku awarii dowolnej bazy danych.
Karta Przegląd
Informuje o stanie aktualnie wykonywanej kopii zapasowej danych i ostatniej pomyślnej kopii zapasowej danych.
Opcja Utwórz kopię zapasową teraz może zostać użyta do uruchomienia kreatora tworzenia kopii zapasowych danych.
Zakładka Konfiguracja
Zawiera informacje o ustawieniach interwału tworzenia kopii zapasowych, ustawieniach kopii zapasowych danych w plikach i ustawieniach tworzenia kopii zapasowych na podstawie dziennika.

Ustawienia interwału kopii zapasowych
Ustawienia kopii zapasowej umożliwiają użycie narzędzia innej firmy do przechowywania danych i tworzenia kopii zapasowych dziennika z konfiguracją agenta zapasowego.
Skonfiguruj połączenie z narzędziem do tworzenia kopii zapasowych innej firmy, określając plik parametrów dla agenta Backint.
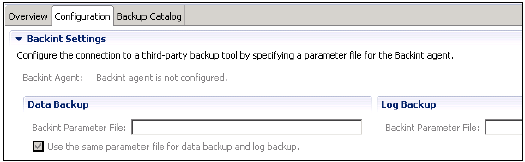
Ustawienia kopii zapasowej danych w oparciu o pliki i dzienniki
Ustawienie kopii zapasowej danych na podstawie pliku informuje o folderze, w którym chcesz zapisać kopię zapasową danych w systemie HANA. Możesz zmienić folder kopii zapasowej.
Możesz także ograniczyć rozmiar plików kopii zapasowych danych. Jeśli kopia zapasowa danych systemowych przekracza ten ustawiony rozmiar pliku, zostanie podzielona na wiele plików.
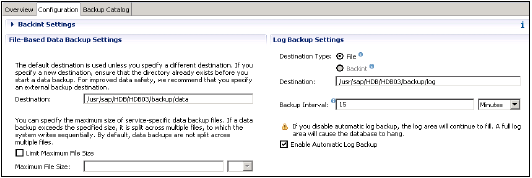
Ustawienia kopii zapasowej dziennika wskazują folder docelowy, w którym chcesz zapisać kopię zapasową dziennika na serwerze zewnętrznym. Możesz wybrać typ miejsca docelowego kopii zapasowej dziennika
Plik - zapewnia wystarczającą ilość miejsca w systemie do przechowywania kopii zapasowych
Backint - czy specjalny potok nazwany istnieje w systemie plików, ale nie wymaga miejsca na dysku.
Możesz wybrać interwał tworzenia kopii zapasowych z listy rozwijanej. Podaje najdłuższy czas, jaki może upłynąć, zanim zostanie zapisana kopia zapasowa nowego dziennika. Backup Interval: może być w sekundach, minutach lub godzinach.
Włącz opcję Automatycznej kopii zapasowej dziennika: pomaga utrzymać wolny obszar dziennika. Jeśli wyłączysz ten dziennik, obszar ten będzie się nadal wypełniał, co może spowodować zawieszenie się bazy danych.
Open Backup Wizard - aby uruchomić kopię zapasową systemu.
Kreator kopii zapasowych służy do określania ustawień tworzenia kopii zapasowych. Informuje o typie kopii zapasowej, typie miejsca docelowego, folderze docelowym kopii zapasowej, prefiksie kopii zapasowej, rozmiarze kopii zapasowej itp.
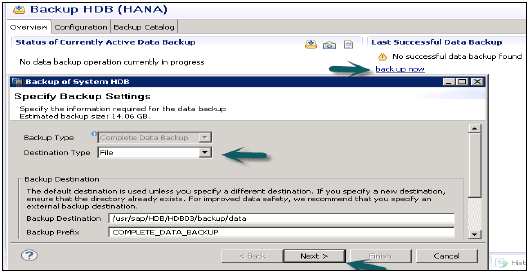
Po kliknięciu Dalej → Przejrzyj ustawienia kopii zapasowej → Zakończ
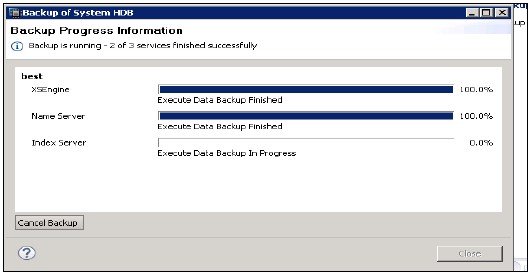
Uruchamia kopie zapasowe systemu i informuje o czasie wykonania kopii zapasowej dla każdego serwera.
Odzyskiwanie systemu HANA
Aby odzyskać bazę danych SAP HANA, bazę danych należy zamknąć. Dlatego podczas odzyskiwania użytkownicy końcowi lub aplikacje SAP nie mogą uzyskać dostępu do bazy danych.
Odzyskiwanie bazy danych SAP HANA jest wymagane w następujących sytuacjach -
Dysk w obszarze danych jest bezużyteczny lub dysk w obszarze dziennika nie nadaje się do użytku.
W wyniku błędu logicznego baza danych musi zostać zresetowana do jej stanu w określonym momencie.
Chcesz utworzyć kopię bazy danych.
Jak odzyskać system HANA?
Wybierz system HANA → Kliknij prawym przyciskiem myszy → Back and Recovery → Recover System
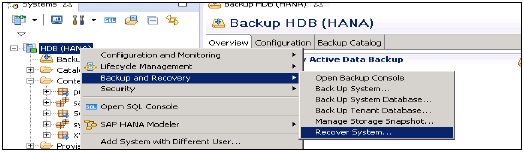
Rodzaje odzyskiwania w systemie HANA
Most Recent State- Służy do odzyskiwania bazy danych do czasu jak najbardziej zbliżonego do aktualnego czasu. Do tego przywracania kopia zapasowa danych i kopia zapasowa dziennika muszą być dostępne, ponieważ ostatnia kopia zapasowa danych i obszar dziennika są wymagane do wykonania powyższego odzyskiwania.
Point in Time- Służy do odzyskiwania bazy danych do określonego punktu w czasie. Aby to odzyskać, kopia zapasowa danych i kopia zapasowa dziennika muszą być dostępne, ponieważ ostatnia kopia zapasowa danych i obszar dziennika są wymagane do wykonania powyższego odzyskiwania
Specific Data Backup- Służy do odzyskiwania bazy danych do określonej kopii zapasowej danych. W przypadku powyższej opcji odzyskiwania wymagana jest określona kopia zapasowa danych.
Specific Log Position - Ten typ odzyskiwania jest opcją zaawansowaną, której można użyć w wyjątkowych przypadkach, gdy poprzednie odzyskiwanie nie powiodło się.
Note - Aby uruchomić kreatora odzyskiwania, należy mieć uprawnienia administratora w systemie HANA.
SAP HANA zapewnia mechanizm zapewniający ciągłość biznesową i odzyskiwanie po awarii w przypadku błędów systemowych i błędów oprogramowania. Wysoka dostępność w systemie HANA definiuje zestaw praktyk, które pomagają osiągnąć ciągłość biznesową w przypadku katastrof, takich jak awarie zasilania w centrach danych, klęski żywiołowe, takie jak pożar, powódź, itp. Czy awarie sprzętu.
Wysoka dostępność SAP HANA zapewnia odporność na awarie i możliwość wznowienia działania systemu po awarii przy minimalnych stratach biznesowych.
Na poniższej ilustracji przedstawiono fazy wysokiej dostępności w systemie HANA -
Pierwsza faza jest przygotowywana na awarię. Usterkę można wykryć automatycznie lub w wyniku działania administracyjnego. Dane są zabezpieczane, a systemy w trybie gotowości przejmują operacje. Rozpoczęcie procesu odzyskiwania obejmuje naprawę wadliwego systemu i przywrócenie oryginalnego systemu do poprzedniej konfiguracji.
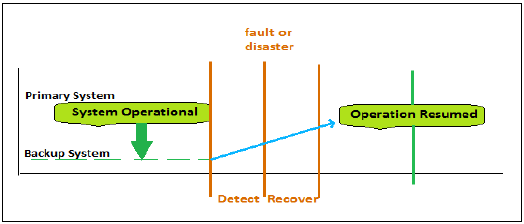
Aby uzyskać wysoką dostępność w systemie HANA, kluczowe jest włączenie dodatkowych komponentów, które nie są niezbędne do działania i wykorzystania w przypadku awarii innych komponentów. Obejmuje redundancję sprzętową, sieciową i centrum danych. SAP HANA zapewnia kilka poziomów nadmiarowości sprzętu i oprogramowania, jak poniżej -
Nadmiarowość sprzętu systemu HANA
Dostawcy urządzeń SAP HANA oferują wiele warstw nadmiarowego sprzętu, oprogramowania i komponentów sieciowych, takich jak nadmiarowe zasilacze i wentylatory, pamięci korygujące błędy, w pełni nadmiarowe przełączniki i routery sieciowe oraz nieprzerwane zasilanie (UPS). System pamięci dyskowej gwarantuje zapis nawet w przypadku awarii zasilania i wykorzystuje funkcje rozłożenia i dublowania w celu zapewnienia nadmiarowości w celu automatycznego odzyskiwania po awarii dysku.
Nadmiarowość oprogramowania SAP HANA
SAP HANA jest oparty na SUSE Linux Enterprise 11 for SAP i obejmuje wstępne konfiguracje zabezpieczeń.
Oprogramowanie systemu SAP HANA zawiera funkcję watchdog, która automatycznie restartuje skonfigurowane usługi (serwer indeksu, serwer nazw itp.) W przypadku wykrycia przestoju (zabity lub zawieszony).
SAP HANA Persistence Redundancy
SAP HANA zapewnia trwałość dzienników transakcji, punktów zapisu i migawek, aby wspierać ponowne uruchamianie systemu i odzyskiwanie po awarii, z minimalnym opóźnieniem i bez utraty danych.
Stan wstrzymania i przełączania awaryjnego systemu HANA
System SAP HANA obejmuje oddzielne hosty rezerwowe, które są używane do przełączania awaryjnego w przypadku awarii systemu podstawowego. Poprawia to dostępność systemu HANA, skracając czas odzyskiwania po awarii.
System SAP HANA rejestruje wszystkie transakcje zmieniające dane aplikacji lub katalog bazy danych we wpisach dziennika i przechowuje je w obszarze dziennika. Używa tych wpisów dziennika w obszarze dziennika do wycofywania lub powtarzania instrukcji SQL. Pliki dziennika są dostępne w systemie HANA i można do nich uzyskać dostęp poprzez HANA Studio na stronie Pliki diagnostyczne w edytorze Administrator.
Podczas tworzenia kopii zapasowej dziennika tylko rzeczywiste dane segmentów dziennika są zapisywane z obszaru dziennika do plików kopii zapasowych dziennika specyficznych dla usługi lub do narzędzia do tworzenia kopii zapasowych innej firmy.
Po awarii systemu może być konieczne ponowne wykonanie wpisów dziennika z kopii zapasowych dziennika, aby przywrócić bazę danych do żądanego stanu.
Jeśli usługa bazy danych z trwałością zostanie zatrzymana, należy upewnić się, że została ponownie uruchomiona, w przeciwnym razie odzyskanie będzie możliwe tylko do punktu przed zatrzymaniem usługi.
Konfigurowanie limitu czasu kopii zapasowej dziennika
Limit czasu kopii zapasowej dziennika określa interwał tworzenia kopii zapasowych segmentów dziennika, jeśli zatwierdzenie miało miejsce w tym interwale. Limit czasu kopii zapasowej dziennika można skonfigurować za pomocą Backup Console w SAP HANA Studio -
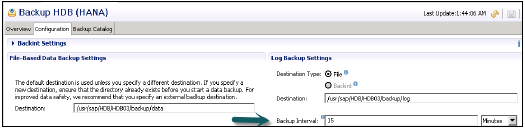
Możesz także skonfigurować interwał log_backup_timeout_s w pliku konfiguracyjnym global.ini.
Kopia zapasowa dziennika do „Plik” i tryb kopii zapasowej „NORMALNY” to domyślne ustawienia funkcji automatycznego tworzenia kopii zapasowej dziennika po zainstalowaniu systemu SAP HANA. Automatyczna kopia zapasowa dziennika działa tylko wtedy, gdy została wykonana przynajmniej jedna pełna kopia zapasowa danych.
Po wykonaniu pierwszej pełnej kopii zapasowej danych funkcja automatycznego tworzenia kopii zapasowej dziennika jest aktywna. SAP HANA studio może służyć do włączania / wyłączania funkcji automatycznego tworzenia kopii zapasowych dziennika. Zaleca się, aby automatyczne tworzenie kopii zapasowych dziennika było włączone, w przeciwnym razie obszar dziennika będzie nadal wypełniony. Pełny obszar dziennika może spowodować zawieszenie bazy danych w systemie HANA.
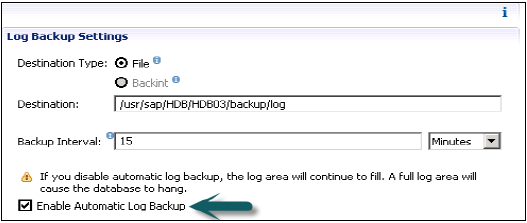
Możesz także zmienić parametr enable_auto_log_backup w sekcji trwałości pliku konfiguracyjnego global.ini.
SQL to skrót od Structured Query Language.
Jest to ustandaryzowany język do komunikacji z bazą danych. SQL służy do pobierania danych, przechowywania lub manipulowania danymi w bazie danych.
Instrukcje SQL wykonują następujące funkcje -
- Definicja i manipulowanie danymi
- Zarządzanie systemem
- Zarządzanie sesjami
- Zarządzanie transakcjami
- Definicja i manipulacja schematem
Nazywa się zestaw rozszerzeń SQL, które umożliwiają programistom wypychanie danych do bazy danych SQL scripts.
Język manipulacji danymi (DML)
Instrukcje DML służą do zarządzania danymi w obiektach schematu. Kilka przykładów -
SELECT - pobrać dane z bazy danych
INSERT - wstaw dane do tabeli
UPDATE - aktualizuje istniejące dane w tabeli
Język definicji danych (DDL)
Instrukcje DDL służą do definiowania struktury lub schematu bazy danych. Kilka przykładów -
CREATE - do tworzenia obiektów w bazie danych
ALTER - zmienia strukturę bazy danych
DROP - usuń obiekty z bazy danych
Język kontroli danych (DCL)
Oto kilka przykładów instrukcji DCL:
GRANT - daje użytkownikowi uprawnienia dostępu do bazy danych
REVOKE - cofnąć uprawnienia dostępu nadane komendą GRANT
Dlaczego potrzebujemy SQL?
Kiedy tworzymy widoki informacji w SAP HANA Modeler, tworzymy je na wierzchu niektórych aplikacji OLTP. Wszystko to działa na zapleczu SQL. Baza danych obsługuje tylko ten język.
Aby sprawdzić, czy nasz raport spełnia wymagania biznesowe, musimy uruchomić instrukcję SQL w bazie danych, jeśli dane wyjściowe są zgodne z wymaganiem.
Widoki obliczeń HANA można tworzyć na dwa sposoby - graficznie lub przy użyciu skryptu SQL. Podczas tworzenia bardziej złożonych widoków obliczeń może być konieczne użycie bezpośrednich skryptów SQL.
Jak otworzyć konsolę SQL w HANA Studio?
Wybierz system HANA i kliknij opcję konsoli SQL w widoku systemu. Możesz także otworzyć konsolę SQL, klikając prawym przyciskiem myszy kartę Katalog lub dowolną nazwę schematu.
SAP HANA może działać zarówno jako relacyjna, jak i jako baza danych OLAP. Kiedy używamy BW na HANA, tworzymy kostki w BW i HANA, które działają jak relacyjna baza danych i zawsze generują instrukcję SQL. Gdy jednak uzyskamy bezpośredni dostęp do widoków HANA za pomocą połączenia OLAP, będzie on działał jako baza danych OLAP i zostanie wygenerowany MDX.
Możesz tworzyć tabele magazynu wierszy lub kolumn w SAP HANA za pomocą opcji tworzenia tabeli. Tabelę można utworzyć, wykonując instrukcję tworzenia tabeli definicji danych lub korzystając z opcji graficznej w HANA Studio.
Tworząc tabelę, musisz również zdefiniować atrybuty wewnątrz niej.
SQL statement to create a table in HANA Studio SQL Console -
Create column Table TEST (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);Creating a table in HANA studio using GUI option -
Podczas tworzenia tabeli musisz zdefiniować nazwy kolumn i typy danych SQL. Pole Wymiar informuje o długości wartości, a opcja Klucz umożliwia zdefiniowanie jej jako klucza podstawowego.
SAP HANA obsługuje następujące typy danych w tabeli -
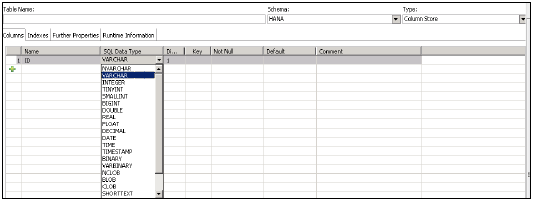
SAP HANA obsługuje 7 kategorii typów danych SQL i zależy to od typu danych, które musisz przechowywać w kolumnie.
- Numeric
- Łańcuch znaków
- Boolean
- Data i godzina
- Binary
- Duże obiekty
- Multi-Valued
Poniższa tabela zawiera listę typów danych w każdej kategorii -

Data i godzina
Te typy danych służą do przechowywania daty i godziny w tabeli w bazie danych HANA.
DATE- typ danych składa się z informacji o roku, miesiącu i dniu, aby przedstawić wartość daty w kolumnie. Domyślny format danych typu Data to RRRR-MM-DD.
TIME- typ danych składa się z wartości godzin, minut i sekund w tabeli w bazie danych HANA. Domyślny format danych typu Czas to HH: MI: SS.
SECOND DATE- typ danych składa się z roku, miesiąca, dnia, godziny, minuty, drugiej wartości w tabeli w bazie HANA. Domyślny format danych typu SECONDDATE to RRRR-MM-DD GG: MM: SS.
TIMESTAMP- typ danych składa się z informacji o dacie i godzinie w tabeli w bazie danych HANA. Domyślny format danych typu TIMESTAMP to RRRR-MM-DD GG: MM: SS: FFn, gdzie FFn oznacza ułamek sekundy.
Numeryczne
TinyINT- przechowuje 8-bitową liczbę całkowitą bez znaku. Wartość minimalna: 0 i wartość maksymalna: 255
SMALLINT- przechowuje 16-bitową liczbę całkowitą ze znakiem. Wartość minimalna: -32768 i wartość maksymalna: 32767
Integer- przechowuje 32-bitową liczbę całkowitą ze znakiem. Wartość minimalna: -2 147 483 648, a wartość maksymalna: 2 147 483 648
BIGINT- przechowuje 64-bitową liczbę całkowitą ze znakiem. Wartość minimalna: -9 223 372 036 854 775 808, a maksymalna: 9 223 372 036 854 775 808
SMALL - Dziesiętne i dziesiętne: wartość minimalna: -10 ^ 38 +1 i wartość maksymalna: 10 ^ 38 -1
REAL - Wartość minimalna: -3,40E + 38 i maksymalna wartość: 3,40E + 38
DOUBLE- przechowuje 64-bitową liczbę zmiennoprzecinkową. Wartość minimalna: -1,7976931348623157E308 i wartość maksymalna: 1,7976931348623157E308
Boolean
Typy danych Boolean przechowują wartości Boolean, które są TRUE, FALSE
Postać
Varchar - maksymalnie 8000 znaków.
Nvarchar - maksymalna długość 4000 znaków
ALPHANUM- przechowuje znaki alfanumeryczne. Wartość liczby całkowitej wynosi od 1 do 127.
SHORTTEXT - przechowuje ciąg znaków o zmiennej długości, który obsługuje funkcje wyszukiwania tekstu i funkcje wyszukiwania ciągów.
Dwójkowy
Typy binarne służą do przechowywania bajtów danych binarnych.
VARBINARY- przechowuje dane binarne w bajtach. Maksymalna długość całkowita wynosi od 1 do 5000.
Duże obiekty
LARGEOBJECTS służą do przechowywania dużej ilości danych, takich jak dokumenty tekstowe i obrazy.
NCLOB - przechowuje duży obiekt znakowy UNICODE.
BLOB - przechowuje dużą ilość danych binarnych.
CLOB - przechowuje dużą ilość danych w postaci znaków ASCII.
TEXT- umożliwia wyszukiwanie tekstu. Ten typ danych można zdefiniować tylko dla tabel kolumn, a nie dla tabel magazynu wierszy.
BINTEXT - obsługuje funkcje wyszukiwania tekstu, ale możliwe jest wstawianie danych binarnych.
Wielowartościowe
Wielowartościowe typy danych służą do przechowywania kolekcji wartości o tym samym typie danych.
Szyk
Tablice przechowują zbiory wartości o tym samym typie danych. Mogą również zawierać wartości null.
Operator to specjalny znak używany głównie w instrukcjach SQL z klauzulą WHERE do wykonywania operacji, takich jak porównania i operacje arytmetyczne. Służą do przekazywania warunków w zapytaniu SQL.
Podane poniżej typy operatorów mogą być używane w instrukcjach SQL w HANA -
- Operatory arytmetyczne
- Operatory porównania / relacyjne
- Operatory logiczne
- Operatory zbioru
Operatory arytmetyczne
Operatory arytmetyczne służą do wykonywania prostych funkcji obliczeniowych, takich jak dodawanie, odejmowanie, mnożenie, dzielenie i procent.
| Operator | Opis |
|---|---|
| + | Dodawanie - dodaje wartości po obu stronach operatora |
| - | Odejmowanie - odejmuje operand prawej ręki od operandu lewej ręki |
| * | Mnożenie - mnoży wartości po obu stronach operatora |
| / | Dzielenie - dzieli operand lewej ręki przez operand prawej ręki |
| % | Moduł - dzieli operand lewej ręki przez operand prawej ręki i zwraca resztę |
Operatory porównania
Operatory porównania służą do porównywania wartości w instrukcji SQL.
| Operator | Opis |
|---|---|
| = | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli tak, warunek staje się prawdziwy. |
| ! = | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli wartości nie są równe, warunek staje się prawdziwy. |
| <> | Sprawdza, czy wartości dwóch operandów są równe, czy nie, jeśli wartości nie są równe, warunek staje się prawdziwy. |
| > | Sprawdza, czy wartość lewego operandu jest większa niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. |
| < | Sprawdza, czy wartość lewego operandu jest mniejsza niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. |
| > = | Sprawdza, czy wartość lewego operandu jest większa lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. |
| <= | Sprawdza, czy wartość lewego operandu jest mniejsza lub równa wartości prawego operandu, jeśli tak, warunek staje się prawdziwy. |
| ! < | Sprawdza, czy wartość lewego operandu nie jest mniejsza niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. |
| !> | Sprawdza, czy wartość lewego operandu nie jest większa niż wartość prawego operandu, jeśli tak, warunek staje się prawdziwy. |
Operatory logiczne
Operatory logiczne są używane do przekazywania wielu warunków w instrukcji SQL lub do manipulowania wynikami warunków.
| Operator | Opis |
|---|---|
| WSZYSTKO | Operator ALL służy do porównywania wartości ze wszystkimi wartościami w innym zestawie wartości. |
| I | Operator AND dopuszcza istnienie wielu warunków w klauzuli WHERE instrukcji SQL. |
| KAŻDY | Operator ANY służy do porównywania wartości z dowolną odpowiednią wartością na liście zgodnie z warunkiem. |
| POMIĘDZY | Operator BETWEEN służy do wyszukiwania wartości mieszczących się w zbiorze wartości, dla których określono wartość minimalną i maksymalną. |
| ISTNIEJE | Operator EXISTS służy do wyszukiwania obecności wiersza w określonej tabeli, który spełnia określone kryteria. |
| W | Operator IN służy do porównywania wartości z listą wartości literałów, które zostały określone. |
| LUBIĆ | Operator LIKE służy do porównywania wartości z podobnymi wartościami za pomocą operatorów symboli wieloznacznych. |
| NIE | Operator NOT odwraca znaczenie operatora logicznego, z którym jest używany. Np. - NIE ISTNIEJE, NIE MA MIĘDZY, NIE MA W itd.This is a negate operator. |
| LUB | Operator OR służy do porównywania wielu warunków w klauzuli WHERE instrukcji SQL. |
| JEST NULL | Operator NULL służy do porównywania wartości z wartością NULL. |
| WYJĄTKOWY | Operator UNIQUE przeszukuje każdy wiersz określonej tabeli pod kątem unikalności (bez duplikatów). |
Operatory zbioru
Operatory zbiorów służą do łączenia wyników dwóch zapytań w jeden wynik. Typ danych powinien być taki sam dla obu tabel.
UNION- Łączy wyniki dwóch lub więcej instrukcji Select. Jednak wyeliminuje zduplikowane wiersze.
UNION ALL - Ten operator jest podobny do Union, ale pokazuje również zduplikowane wiersze.
INTERSECT- Operacja przecięcia służy do łączenia dwóch instrukcji SELECT i zwraca rekordy, które są wspólne dla obu instrukcji SELECT. W przypadku Przecięcia liczba kolumn i typ danych muszą być takie same w obu tabelach.
MINUS - Operacja minus łączy wynik dwóch instrukcji SELECT i zwraca tylko te wyniki, które należą do pierwszego zestawu wyników i eliminuje wiersze z drugiej instrukcji z wyniku pierwszego.
Baza danych SAP HANA udostępnia różne funkcje SQL -
- Funkcje numeryczne
- Funkcje łańcuchowe
- Funkcje pełnotekstowe
- Funkcje daty i godziny
- Funkcje agregujące
- Funkcje konwersji typu danych
- Funkcje okna
- Funkcje danych szeregowych
- Różne funkcje
Funkcje numeryczne
Są to wbudowane funkcje numeryczne w języku SQL i używane w skryptach. Pobiera wartości numeryczne lub ciągi znaków ze znakami numerycznymi i zwraca wartości liczbowe.
ABS - Zwraca wartość bezwzględną argumentu liczbowego.
Example − SELECT ABS (-1) "abs" FROM TEST;
abs
1ACOS, ASIN, ATAN, ATAN2 (te funkcje zwracają wartość trygonometryczną argumentu)
BINTOHEX - Konwertuje wartość binarną na wartość szesnastkową.
BITAND - Wykonuje operację AND na bitach przekazanego argumentu.
BITCOUNT - Oblicza liczbę ustawionych bitów w argumencie.
BITNOT - Wykonuje bitową operację NOT na bitach argumentu.
BITOR - Wykonuje operację OR na bitach przekazanego argumentu.
BITSET - Służy do ustawiania bitów na 1 w <target_num> z pozycji <start_bit>.
BITUNSET - Służy do ustawiania bitów na 0 w <target_num> z pozycji <start_bit>.
BITXOR - Wykonuje operację XOR na bitach przekazanego argumentu.
CEIL - Zwraca pierwszą liczbę całkowitą większą lub równą przekazanej wartości.
COS, COSH, COT ((te funkcje zwracają wartość trygonometryczną argumentu)
EXP - Zwraca wynik podstawy logarytmów naturalnych e podniesionych do potęgi podanej wartości.
FLOOR - Zwraca największą liczbę całkowitą nie większą niż argument numeryczny.
HEXTOBIN - Konwertuje wartość szesnastkową na wartość binarną.
LN - Zwraca logarytm naturalny argumentu.
LOG- Zwraca wartość algorytmu przekazanej wartości dodatniej. Zarówno wartość podstawowa, jak i logarytmiczna powinny być dodatnie.
Można również użyć różnych innych funkcji numerycznych - MOD, POWER, RAND, ROUND, SIGN, SIN, SINH, SQRT, TAN, TANH, UMINUS
Funkcje łańcuchowe
W HANA można używać różnych funkcji tekstowych SQL ze skryptami SQL. Najpopularniejsze funkcje łańcuchowe to -
ASCII - Zwraca całkowitą wartość ASCII przekazanego ciągu.
CHAR - Zwraca znak powiązany z przekazaną wartością ASCII.
CONCAT - Jest to operator konkatenacji i zwraca połączone przekazane ciągi.
LCASE - Konwertuje wszystkie znaki ciągu na małe litery.
LEFT - Zwraca pierwsze znaki przekazanego ciągu zgodnie z podaną wartością.
LENGTH - Zwraca liczbę znaków w przekazanym ciągu.
LOCATE - Zwraca pozycję podciągu w przekazanym ciągu.
LOWER - Konwertuje wszystkie znaki w ciągu na małe litery.
NCHAR - Zwraca znak Unicode z przekazaną wartością całkowitą.
REPLACE - Przeszukuje w przekazanym oryginalnym łańcuchu wszystkie wystąpienia szukanego ciągu i zastępuje je ciągiem zastępującym.
RIGHT - Zwraca skrajnie prawe przekazane znaki wartości wspomnianego ciągu.
UPPER - Konwertuje wszystkie znaki w przekazanym ciągu na wielkie litery.
UCASE- Jest identyczny z funkcją UPPER. Konwertuje wszystkie znaki w przekazanym ciągu na wielkie litery.
Inne funkcje tekstowe, których można użyć to - LPAD, LTRIM, RTRIM, STRTOBIN, SUBSTR_AFTER, SUBSTR_BEFORE, SUBSTRING, TRIM, UNICODE, RPAD, BINTOSTR
Funkcje daty i godziny
Istnieją różne funkcje związane z datą i godziną, których można używać w środowisku HANA w skryptach SQL. Najpopularniejsze funkcje daty i godziny to -
CURRENT_DATE - Zwraca aktualną lokalną datę systemową.
CURRENT_TIME - Zwraca aktualny lokalny czas systemowy.
CURRENT_TIMESTAMP - Zwraca szczegóły dotyczące aktualnego czasu systemu lokalnego (RRRR-MM-DD GG: MM: SS: FF).
CURRENT_UTCDATE - Zwraca aktualną datę UTC (średnia data Greenwich).
CURRENT_UTCTIME - Zwraca aktualny czas UTC (Greenwich Mean Time).
CURRENT_UTCTIMESTAMP
DAYOFMONTH - Zwraca wartość całkowitą dnia w przekazanej dacie w argumencie.
HOUR - Zwraca wartość całkowitą godziny w przekazanym czasie w argumencie.
YEAR - Zwraca wartość roku dla minionej daty.
Inne funkcje związane z datą i godziną to - DAYOFYEAR, DAYNAME, DAYS_BETWEEN, EXTRACT, NANO100_BETWEEN, NEXT_DAY, NOW, QUARTER, SECOND, SECONDS_BETWEEN, UTCTOLOCAL, WEEK, WEEKDAY, WORKDAYS_BETWEEN, NEXT_DAY, NOW, QUARTER, SECOND, SECONDS_BETWEEN, UTCTOLOCAL, WEEK, WEEKDAY, WORKDAYS_BETWEEN, ADOCTHON, MONOCTHON, MONOCTHON, MONOCTHONDA, LASMONDAY ADD_SECONDS, ADD_WORKDAYS
Funkcje konwersji typu danych
Funkcje te służą do konwersji jednego typu danych na inny lub do sprawdzenia, czy konwersja jest możliwa, czy nie.
Najpopularniejsze funkcje konwersji typów danych używane w HANA w skryptach SQL -
CAST - Zwraca wartość wyrażenia przekonwertowanego na podany typ danych.
TO_ALPHANUM - Konwertuje przekazaną wartość na typ danych ALPHANUM
TO_REAL - Konwertuje wartość na typ danych REAL.
TO_TIME - Konwertuje przekazany ciąg czasu na typ danych TIME.
TO_CLOB - Konwertuje wartość na typ danych CLOB.
Inne podobne funkcje konwersji typu danych to: - TO_BIGINT, TO_BINARY, TO_BLOB, TO_DATE, TO_DATS, TO_DECIMAL, TO_DOUBLE, TO_FIXEDCHAR, TO_INT, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TO_TIMESTAMP, TO_TINYOND_DOUBLE, TO_FIXEDCHAR, TO_INT, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TO_TIMESTAMP, TO_TINYOND_DOUBLE, TO_FIXEDCHAR, TO_INT, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TO_TIMESTAMP, TO_TECMONDAR, TO_TIMESTAM
Istnieją również różne funkcje systemu Windows i inne różne funkcje, których można używać w skryptach HANA SQL.
Current_Schema - Zwraca ciąg zawierający aktualną nazwę schematu.
Session_User - Zwraca nazwę użytkownika z bieżącej sesji
Wyrażenie służy do oceny klauzuli w celu zwrócenia wartości. Istnieją różne wyrażenia SQL, których można używać w HANA -
- Wyrażenia wielkości liter
- Wyrażenia funkcyjne
- Wyrażenia agregujące
- Podzapytania w wyrażeniach
Wyrażenie wielkości liter
Służy do przekazywania wielu warunków w wyrażeniu SQL. Pozwala na użycie logiki IF-ELSE-THEN bez stosowania procedur w instrukcjach SQL.
Przykład
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1,
COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2,
COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;Ta instrukcja zwróci count1, count2, count3 z wartością całkowitą zgodnie z przekazanym warunkiem.
Wyrażenia funkcyjne
Wyrażenia funkcyjne obejmują wbudowane funkcje SQL, które mają być używane w wyrażeniach.
Wyrażenia agregujące
Funkcje agregujące służą do wykonywania złożonych obliczeń, takich jak Suma, Procent, Min, Max, Liczba, Tryb, Mediana itp. Funkcja Aggregate Expression używa funkcji agregujących do obliczania pojedynczej wartości z wielu wartości.
Aggregate Functions- Suma, liczba, minimum, maksimum. Są one stosowane do wartości miar (faktów) i są zawsze związane z wymiarem.
Typowe funkcje agregujące obejmują -
- Średnia ()
- Liczba ()
- Maksymalna ()
- Mediana ()
- Minimalna ()
- Tryb ()
- Suma ()
Podzapytania w wyrażeniach
Podzapytanie jako wyrażenie to instrukcja Select. Gdy jest używany w wyrażeniu, zwraca zero lub pojedynczą wartość.
Podzapytanie służy do zwracania danych, które zostaną użyte w zapytaniu głównym jako warunek dalszego ograniczenia pobieranych danych.
Podzapytań można używać z instrukcjami SELECT, INSERT, UPDATE i DELETE wraz z operatorami takimi jak =, <,>,> =, <=, IN, BETWEEN itp.
Istnieje kilka zasad, których muszą przestrzegać podzapytania -
Podzapytania muszą być zawarte w nawiasach.
Podzapytanie może mieć tylko jedną kolumnę w klauzuli SELECT, chyba że w głównym zapytaniu dla podzapytania znajduje się wiele kolumn w celu porównania wybranych kolumn.
ORDER BY nie może być użyte w podzapytaniu, chociaż główne zapytanie może używać ORDER BY. Funkcja GROUP BY może być używana do wykonywania tej samej funkcji, co ORDER BY w podzapytaniu.
Podkwerendy, które zwracają więcej niż jeden wiersz, mogą być używane tylko z wieloma operatorami wartości, takimi jak operator IN.
Lista SELECT nie może zawierać żadnych odniesień do wartości, których wynikiem jest BLOB, ARRAY, CLOB lub NCLOB.
Podzapytania nie można od razu zamknąć w funkcji zestawu.
Operator BETWEEN nie może być używany z podzapytaniem; jednak operator BETWEEN może być używany w podzapytaniu.
Podzapytania z instrukcją SELECT
Podkwerendy są najczęściej używane z instrukcją SELECT. Podstawowa składnia jest następująca -
Przykład
SELECT * FROM CUSTOMERS
WHERE ID IN (SELECT ID
FROM CUSTOMERS
WHERE SALARY > 4500) ;+----+----------+-----+---------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+---------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+---------+----------+Procedura umożliwia zgrupowanie instrukcji SQL w pojedynczy blok. Procedury składowane służą do osiągnięcia określonych wyników w aplikacjach. Zestaw instrukcji SQL i logika używana do wykonania określonego zadania są przechowywane w procedurach składowanych SQL. Te procedury składowane są wykonywane przez aplikacje w celu wykonania tego zadania.
Procedury składowane mogą zwracać dane w postaci parametrów wyjściowych (liczba całkowita lub znak) lub zmiennej kursora. Może również skutkować zestawem instrukcji Select, które są używane przez inne procedury składowane.
Procedury składowane są również używane do optymalizacji wydajności, ponieważ zawierają serie instrukcji SQL, a wyniki z jednego zestawu instrukcji określają następny zestaw instrukcji do wykonania. Procedury składowane uniemożliwiają użytkownikom zobaczenie złożoności i szczegółów tabel w bazie danych. Ponieważ procedury składowane zawierają pewną logikę biznesową, użytkownicy muszą wykonać lub wywołać nazwę procedury.
Nie ma potrzeby ponownego wydawania poszczególnych oświadczeń, ale można odwołać się do procedury bazy danych.
Przykładowa instrukcja tworzenia procedur
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP")
as
begin
opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ;
end;Sekwencja to zbiór liczb całkowitych 1, 2, 3, które są generowane w kolejności na żądanie. Sekwencje są często używane w bazach danych, ponieważ wiele aplikacji wymaga, aby każdy wiersz w tabeli zawierał unikalną wartość, a sekwencje zapewniają łatwy sposób ich generowania.
Używam kolumny AUTO_INCREMENT
Najprostszym sposobem użycia sekwencji w MySQL jest zdefiniowanie kolumny jako AUTO_INCREMENT i pozostawienie całej sprawy MySQL.
Przykład
Wypróbuj następujący przykład. Spowoduje to utworzenie tabeli, a następnie wstawi kilka wierszy w tej tabeli, w których nie jest wymagane podawanie identyfikatora rekordu, ponieważ jest on automatycznie zwiększany przez MySQL.
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO INSECT (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM INSECT ORDER BY id;+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)Uzyskaj wartości AUTO_INCREMENT
LAST_INSERT_ID () jest funkcją SQL, więc można jej używać z poziomu dowolnego klienta, który rozumie, jak wydawać instrukcje SQL. W przeciwnym razie skrypty PERL i PHP zapewniają ekskluzywne funkcje do pobierania automatycznie zwiększonej wartości ostatniego rekordu.
Przykład PERL
Użyj atrybutu mysql_insertid, aby uzyskać wartość AUTO_INCREMENT wygenerowaną przez zapytanie. Dostęp do tego atrybutu uzyskuje się przez uchwyt bazy danych lub uchwyt instrukcji, w zależności od sposobu wysłania zapytania. Poniższy przykład odwołuje się do niego za pośrednictwem uchwytu bazy danych -
$dbh->do ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')"); my $seq = $dbh->{mysql_insertid};Przykład PHP
Po wysłaniu zapytania, które generuje wartość AUTO_INCREMENT, pobierz wartość, wywołując mysql_insert_id () -
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);Zmiana numeracji istniejącej sekwencji
Może się zdarzyć, że usunąłeś wiele rekordów z tabeli i chcesz zmienić kolejność wszystkich rekordów. Można to zrobić za pomocą prostej sztuczki, ale powinieneś być bardzo ostrożny, jeśli twój stół ma łączenie z innym stołem.
Jeśli stwierdzisz, że ponowne sekwencjonowanie kolumny AUTO_INCREMENT jest nieuniknione, sposobem na to jest usunięcie kolumny z tabeli, a następnie dodanie jej ponownie. Poniższy przykład pokazuje, jak przenumerować wartości identyfikatorów w tabeli owadów za pomocą tej techniki -
mysql> ALTER TABLE INSECT DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);Rozpoczynanie sekwencji o określonej wartości
Domyślnie MySQL rozpocznie sekwencję od 1, ale możesz podać również dowolną inną liczbę w momencie tworzenia tabeli. Poniżej znajduje się przykład, w którym MySQL rozpocznie sekwencję od 100.
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);Alternatywnie możesz utworzyć tabelę, a następnie ustawić początkową wartość sekwencji za pomocą ALTER TABLE.
Wyzwalacze to zapisane programy, które są automatycznie wykonywane lub uruchamiane, gdy wystąpią jakieś zdarzenia. Wyzwalacze są w rzeczywistości napisane do wykonania w odpowiedzi na którekolwiek z następujących zdarzeń -
Instrukcja manipulacji bazą danych (DML) (DELETE, INSERT lub UPDATE).
Instrukcja definicji bazy danych (DDL) (CREATE, ALTER lub DROP).
Operacja bazy danych (SERVERERROR, LOGON, LOGOFF, STARTUP lub SHUTDOWN).
Wyzwalacze można zdefiniować w tabeli, widoku, schemacie lub bazie danych, z którą skojarzone jest zdarzenie.
Korzyści z wyzwalaczy
Wyzwalacze można pisać w następujących celach -
- Automatyczne generowanie niektórych wartości kolumn pochodnych
- Wymuszanie więzów integralności
- Rejestrowanie zdarzeń i przechowywanie informacji o dostępie do tabeli
- Auditing
- Synchroniczna replikacja tabel
- Nakładanie uprawnień bezpieczeństwa
- Zapobieganie nieprawidłowym transakcjom
Synonimy SQL to alias dla tabeli lub obiektu schematu w bazie danych. Służą do ochrony aplikacji klienckich przed zmianami nazwy lub lokalizacji obiektu.
Synonimy pozwalają aplikacjom działać niezależnie od tego, kto jest właścicielem tabeli i która baza danych zawiera tabelę lub obiekt.
Instrukcja Utwórz synonim służy do tworzenia synonimu dla tabeli, widoku, pakietu, procedury, obiektów itp.
Przykład
Na serwerze Server1 znajduje się tabela Customer of efashion. Aby uzyskać do niego dostęp z serwera 2, aplikacja kliencka musiałaby użyć nazwy jako Serwer1.efashion.Customer. Teraz zmieniamy lokalizację tabeli Customer, aplikacja klienta musiałaby zostać zmodyfikowana, aby odzwierciedlić zmianę.
Aby rozwiązać te problemy, możemy utworzyć synonim tabeli Customer Cust_Table na serwerze2 dla tabeli na serwerze1. Dlatego aplikacja kliencka musi teraz używać nazwy pojedynczej części Cust_Table do odwoływania się do tej tabeli. Teraz, jeśli lokalizacja tej tabeli ulegnie zmianie, będziesz musiał zmodyfikować synonim, aby wskazywał na nową lokalizację tabeli.
Ponieważ nie ma instrukcji ALTER SYNONYM, musisz usunąć synonim Cust_Table, a następnie ponownie utworzyć synonim o tej samej nazwie i wskazać synonim nowej lokalizacji tabeli Customer.
Synonimy publiczne
Synonimy publiczne są własnością schematu PUBLIC w bazie danych. Wszyscy użytkownicy bazy danych mogą odwoływać się do publicznych synonimów. Są tworzone przez właściciela aplikacji dla tabel i innych obiektów, takich jak procedury i pakiety, aby użytkownicy aplikacji mogli je zobaczyć.
Składnia
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;Aby utworzyć PUBLICZNY synonim, musisz użyć słowa kluczowego PUBLIC, jak pokazano.
Synonimy prywatne
Synonimy prywatne są używane w schemacie bazy danych w celu ukrycia prawdziwej nazwy tabeli, procedury, widoku lub dowolnego innego obiektu bazy danych.
Do prywatnych synonimów można się odwoływać tylko w schemacie, do którego należy tabela lub obiekt.
Składnia
CREATE SYNONYM Cust_table FOR efashion.Customer;Upuść synonim
Synonimy można usunąć za pomocą polecenia DROP Synonym. Jeśli upuszczasz publiczny synonim, musisz użyć słowa kluczowegopublic w instrukcji drop.
Składnia
DROP PUBLIC Synonym Cust_table;
DROP Synonym Cust_table;Plany wyjaśniania SQL służą do generowania szczegółowych wyjaśnień instrukcji SQL. Służą one do oceny planu wykonania, zgodnie z którym baza danych SAP HANA wykonuje instrukcje SQL.
Wyniki planu wyjaśniania są przechowywane w EXPLAIN_PLAN_TABLE w celu oceny. Aby użyć planu wyjaśniania, przekazane zapytanie SQL musi być językiem manipulacji danymi (DML).
Typowe instrukcje DML
SELECT - pobrać dane z bazy danych
INSERT - wstaw dane do tabeli
UPDATE - aktualizuje istniejące dane w tabeli
Planów SQL Explain nie można używać z instrukcjami DDL i DCL SQL.
WYJAŚNIJ TABELĘ PLANÓW w bazie danych
EXPLAIN PLAN_TABLE w bazie danych składa się z wielu kolumn. Kilka typowych nazw kolumn - OPERATOR_NAME, OPERATOR_ID, PARENT_OPERATOR_ID, LEVEL i POSITION itd.
Wartość COLUMN SEARCH określa pozycję początkową operatorów silnika kolumnowego.
Wartość ROW SEARCH określa pozycję początkową operatorów silników rzędowych.
Aby utworzyć EXPLAIN PLAN STATEMENT dla zapytania SQL
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>Aby zobaczyć wartości w WYJAŚNIENIU TABELI PLANÓW
SELECT Operator_Name, Operator_ID
FROM explain_plan_table
WHERE statement_name = 'statement_name';Aby usunąć instrukcję w EXPLAIN PLAN TABLE
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';Zadanie profilowania danych SQL służy do zrozumienia i analizy danych z wielu źródeł danych. Służy do usuwania nieprawidłowych, niekompletnych danych i zapobiegania problemom z jakością danych przed załadowaniem ich do Hurtowni danych.
Oto zalety zadań profilowania danych SQL -
Pomaga efektywniej analizować dane źródłowe.
Pomaga w lepszym zrozumieniu danych źródłowych.
Usuwa nieprawidłowe, niekompletne dane i poprawia jakość danych, zanim zostaną załadowane do hurtowni danych.
Jest używany z zadaniami ekstrakcji, transformacji i ładowania.
Zadanie Profilowanie danych sprawdza profile, które pomagają zrozumieć źródło danych i zidentyfikować problemy w danych, które należy naprawić.
Możesz użyć zadania Data Profiling w pakiecie Integration Services, aby profilować dane przechowywane w SQL Server i identyfikować potencjalne problemy z jakością danych.
Note - Zadanie profilowania danych działa tylko ze źródłami danych SQL Server i nie obsługuje żadnych innych źródeł danych opartych na plikach ani stron trzecich.
Wymaganie dostępu
Aby uruchomić pakiet zawierający zadanie profilowania danych, konto użytkownika musi mieć uprawnienia do odczytu / zapisu z uprawnieniami do tworzenia tabeli w bazie danych tempdb.
Przeglądarka Data Profiler
Przeglądarka profili danych służy do przeglądania danych wyjściowych programu profilującego. Przeglądarka profili danych obsługuje również możliwość przechodzenia do szczegółów, aby pomóc Ci zrozumieć problemy z jakością danych, które są zidentyfikowane w danych wyjściowych profilu. Ta możliwość przechodzenia do szczegółów wysyła zapytania na żywo do oryginalnego źródła danych.
Konfiguracja i przeglądanie zadania profilowania danych
Konfigurowanie zadania profilowania danych
Obejmuje wykonanie pakietu zawierającego zadanie profilowania danych w celu obliczenia profili. Zadanie zapisuje dane wyjściowe w formacie XML do pliku lub zmiennej pakietu.
Przegląd profili
Aby wyświetlić profile danych, wyślij dane wyjściowe do pliku, a następnie użyj przeglądarki profili danych. Ta przeglądarka jest samodzielnym narzędziem wyświetlającym dane wyjściowe profilu w formacie podsumowania i szczegółów z opcjonalną możliwością przechodzenia do szczegółów.
Profilowanie danych - opcje konfiguracji
Zadanie profilowania danych ma te wygodne opcje konfiguracji -
Kolumny z symbolami wieloznacznymi
Podczas konfigurowania żądania profilu zadanie akceptuje symbol wieloznaczny „*” zamiast nazwy kolumny. Upraszcza to konfigurację i ułatwia odkrywanie cech nieznanych danych. Po uruchomieniu zadania zadanie profiluje każdą kolumnę, która ma odpowiedni typ danych.
Szybki profil
Możesz wybrać Szybki profil, aby szybko skonfigurować zadanie. Szybki profil profiluje tabelę lub widok przy użyciu wszystkich domyślnych profili i ustawień.
Zadanie profilowania danych może obliczyć osiem różnych profili danych. Pięć z tych profili może sprawdzać poszczególne kolumny, a pozostałe trzy analizować - wiele kolumn lub relacje między kolumnami.
Profilowanie danych - wyniki zadań
Zadanie Profilowanie danych wyprowadza wybrane profile do formatu XML, który ma strukturę podobną do schematu DataProfile.xsd.
Możesz zapisać lokalną kopię schematu i wyświetlić lokalną kopię schematu w programie Microsoft Visual Studio lub innym edytorze schematów, w edytorze XML lub w edytorze tekstów, takim jak Notatnik.
Zestaw instrukcji SQL dla bazy danych HANA, który umożliwia programistom przekazywanie złożonej logiki do bazy danych, nazywa się SQL Script. Skrypt SQL jest znany jako zbiór rozszerzeń SQL. Te rozszerzenia to rozszerzenia danych, rozszerzenia funkcji i rozszerzenie procedury.
Skrypt SQL obsługuje przechowywane funkcje i procedury oraz umożliwia wypychanie złożonych części logiki aplikacji do bazy danych.
Główną zaletą używania skryptu SQL jest umożliwienie wykonywania złożonych obliczeń w bazie danych SAP HANA. Używanie skryptów SQL zamiast pojedynczego zapytania umożliwia funkcjom zwracanie wielu wartości. Złożone funkcje SQL można dalej rozłożyć na mniejsze funkcje. Skrypt SQL zapewnia logikę sterowania, która nie jest dostępna w pojedynczej instrukcji SQL.
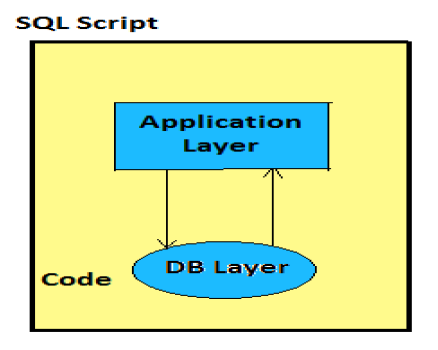
Skrypty SQL służą do optymalizacji wydajności w HANA poprzez wykonywanie skryptów w warstwie DB -
Wykonując skrypty SQL w warstwie bazy danych, eliminuje konieczność przesyłania dużej ilości danych z bazy danych do aplikacji.
Obliczenia są wykonywane w warstwie bazy danych, aby uzyskać korzyści płynące z bazy danych HANA, takie jak operacje kolumnowe, równoległe przetwarzanie zapytań itp.
Integracja z Information Modeler
Podczas korzystania ze skryptów SQL w programie Information Modeler podane poniżej mają zastosowanie do procedur -
- Parametry wejściowe mogą być skalarne lub tabelaryczne.
- Parametry wyjściowe muszą należeć do typów tabel.
- Typy tabel wymagane do podpisu są generowane automatycznie.
Skrypty SQL z widokami obliczeń
Skrypty SQL są używane do tworzenia widoków obliczeń opartych na skryptach. Wpisz instrukcje SQL względem istniejących surowych tabel lub magazynu kolumn. Zdefiniuj strukturę wyjściową, aktywacja widoku tworzy typ tabeli zgodnie ze strukturą.
Jak stworzyć widok obliczeń za pomocą skryptu SQL?
Launch SAP HANA studio. Rozwiń węzeł zawartości → Wybierz pakiet, w którym chcesz utworzyć nowy widok Obliczenia. Kliknięcie prawym przyciskiem → Nowy widok obliczeń Koniec ścieżki nawigacji → Podaj nazwę i opis.
Select calculation view type → z listy rozwijanej Typ wybierz opcję Skrypt SQL → Ustaw rozróżnianie wielkości liter parametru na Prawda lub Fałsz w zależności od tego, jak chcesz zastosować konwencję nazewnictwa dla parametrów wyjściowych widoku obliczeń → Wybierz Zakończ.
Select default schema - Wybierz węzeł Semantyka → Wybierz kartę Właściwości widoku → Z listy rozwijanej Domyślny schemat wybierz domyślny schemat.
Choose SQL Script node in the Semantics node→ Zdefiniuj strukturę wyników. W okienku danych wyjściowych wybierz opcję Utwórz cel. Dodaj wymagane parametry wyjściowe oraz określ ich długość i typ.

Aby dodać wiele kolumn, które są częścią istniejących widoków informacji lub tabel katalogów lub funkcji tabel do struktury wyjściowej widoków obliczeń opartych na skryptach -
W panelu Wyjście wybierz Początek ścieżki nawigacji Nowy Następny krok nawigacji Dodaj kolumny od końca ścieżki nawigacji → Nazwa obiektu zawierającego kolumny, które chcesz dodać do wyniku → Wybierz jeden lub więcej obiektów z rozwijanej listy → Wybierz Dalej.
W panelu Źródło wybierz kolumny, które chcesz dodać do wyniku → Aby dodać kolumny selektywne do wyniku, zaznacz te kolumny i wybierz Dodaj. Aby dodać wszystkie kolumny obiektu do wyniku, zaznacz obiekt i wybierz Dodaj → Zakończ.
Activate the script-based calculation view- W perspektywie SAP HANA Modeler - Zapisz i aktywuj - aby aktywować bieżący widok i ponownie wdrożyć obiekty, na które ma to wpływ, jeśli istnieje aktywna wersja danego obiektu. W przeciwnym razie aktywowany jest tylko bieżący widok.
Save and activate all - aby aktywować aktualny widok wraz z wymaganymi i zmienionymi obiektami.
In the SAP HANA Development perspective- W widoku Eksploratora projektów wybierz wymagany obiekt. W menu kontekstowym wybierz Początek ścieżki nawigacji Zespół Następny krok nawigacji Aktywuj Koniec ścieżki nawigacji.
Skrypty SQL w HANA Information Modeler służą do tworzenia złożonych widoków obliczeniowych, których nie można utworzyć za pomocą opcji GUI.