Szybka porada
Architektura systemu opisuje jego główne komponenty, ich relacje (struktury) oraz ich wzajemne interakcje. Architektura i projektowanie oprogramowania obejmuje kilka czynników, takich jak strategia biznesowa, atrybuty jakości, dynamika człowieka, projektowanie i środowisko IT.

Możemy podzielić architekturę oprogramowania i projekt na dwie odrębne fazy: architekturę oprogramowania i projektowanie oprogramowania. WArchitecturedecyzje niefunkcjonalne są rzucane i rozdzielane przez wymagania funkcjonalne. W projekcie wymagania funkcjonalne są spełnione.
Architektura oprogramowania
Architektura służy jako blueprint for a system. Dostarcza abstrakcji do zarządzania złożonością systemu i ustanowienia mechanizmu komunikacji i koordynacji między komponentami.
Definiuje structured solution spełnienie wszystkich wymagań technicznych i operacyjnych, przy jednoczesnej optymalizacji wspólnych atrybutów jakości, takich jak wydajność i bezpieczeństwo.
Co więcej, obejmuje zestaw znaczących decyzji dotyczących organizacji związanych z tworzeniem oprogramowania, a każda z tych decyzji może mieć znaczący wpływ na jakość, łatwość konserwacji, wydajność i ogólny sukces produktu końcowego. Decyzje te obejmują -
Wybór elementów konstrukcyjnych i ich interfejsów, za pomocą których zbudowany jest system.
Zachowanie określone we współpracy między tymi elementami.
Skład tych elementów strukturalnych i behawioralnych w duży podsystem.
Decyzje architektoniczne są zgodne z celami biznesowymi.
Organizacją kierują się style architektoniczne.
Projektowanie Oprogramowania
Projekt oprogramowania zapewnia design planopisujący elementy systemu, ich dopasowanie i współpracę w celu spełnienia wymagań systemu. Cele posiadania planu projektu są następujące:
Negocjowanie wymagań systemowych i ustalanie oczekiwań z klientami, działem marketingu i personelem zarządzającym.
Działaj jako plan podczas procesu rozwoju.
Pokieruj zadaniami wdrożeniowymi, w tym szczegółowym projektem, kodowaniem, integracją i testowaniem.
Następuje przed szczegółowym projektem, kodowaniem, integracją i testowaniem, a także po analizie domeny, analizie wymagań i analizie ryzyka.
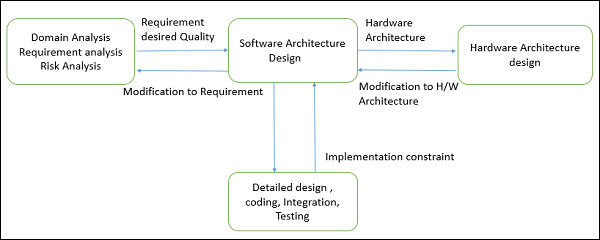
Cele architektury
Podstawowym celem architektury jest identyfikacja wymagań, które mają wpływ na strukturę aplikacji. Dobrze zaprojektowana architektura zmniejsza ryzyko biznesowe związane z budową rozwiązania technicznego i tworzy pomost między wymaganiami biznesowymi a technicznymi.
Niektóre z innych celów są następujące -
Wyeksponuj strukturę systemu, ale ukryj szczegóły jego implementacji.
Zrealizuj wszystkie przypadki użycia i scenariusze.
Spróbuj odpowiedzieć na wymagania różnych interesariuszy.
Spełniaj wymagania funkcjonalne i jakościowe.
Zmniejsz cel własności i popraw pozycję rynkową organizacji.
Popraw jakość i funkcjonalność oferowaną przez system.
Zwiększ zewnętrzne zaufanie do organizacji lub systemu.
Ograniczenia
Architektura oprogramowania jest wciąż rozwijającą się dyscypliną w inżynierii oprogramowania. Ma następujące ograniczenia -
Brak narzędzi i ustandaryzowanych sposobów przedstawiania architektury.
Brak metod analitycznych pozwalających przewidzieć, czy architektura spowoduje wdrożenie spełniające wymagania.
Brak świadomości znaczenia projektu architektonicznego dla tworzenia oprogramowania.
Brak zrozumienia roli architekta oprogramowania i słaba komunikacja między interesariuszami.
Brak zrozumienia procesu projektowania, doświadczenia projektowego i oceny projektu.
Rola architekta oprogramowania
Architekt oprogramowania zapewnia rozwiązanie, które zespół techniczny może stworzyć i zaprojektować dla całej aplikacji. Architekt oprogramowania powinien mieć doświadczenie w następujących obszarach -
Ekspertyza projektowa
Ekspert w projektowaniu oprogramowania, w tym różnych metod i podejść, takich jak projektowanie obiektowe, projektowanie sterowane zdarzeniami itp.
Kieruj zespołem programistów i koordynuj prace rozwojowe w celu zapewnienia integralności projektu.
Powinien móc przeglądać propozycje projektów i kompromis między sobą.
Ekspertyza domeny
Ekspert w zakresie opracowywanego systemu i planowania ewolucji oprogramowania.
Pomoc w procesie badania wymagań, zapewniając kompletność i spójność.
Koordynacja definicji modelu domeny dla tworzonego systemu.
Wiedza technologiczna
Ekspert w zakresie dostępnych technologii, który pomaga we wdrożeniu systemu.
Koordynuj wybór języka programowania, frameworka, platform, baz danych itp.
Ekspertyza metodologiczna
Ekspert w zakresie metodologii tworzenia oprogramowania, które mogą zostać przyjęte podczas SDLC (Software Development Life Cycle).
Wybierz odpowiednie podejście do rozwoju, które pomoże całemu zespołowi.
Ukryta rola architekta oprogramowania
Ułatwia pracę techniczną członków zespołu i wzmacnia zaufanie w zespole.
Informatyk, który dzieli się wiedzą i ma ogromne doświadczenie.
Chroń członków zespołu przed siłami zewnętrznymi, które rozpraszają ich uwagę i wniosą mniejszą wartość do projektu.
Elementy dostarczane architekta
Jasny, kompletny, spójny i możliwy do osiągnięcia zestaw celów funkcjonalnych
Funkcjonalny opis systemu, z co najmniej dwoma warstwami rozkładu
Koncepcja systemu
Projekt w postaci układu z co najmniej dwiema warstwami rozkładu
Pojęcie harmonogramu, atrybutów operatora oraz planów wdrożenia i operacji
Przestrzegany jest dokument lub proces zapewniający rozkład funkcjonalny i kontrolowana jest forma interfejsów
Atrybuty jakości
Jakość jest miarą doskonałości lub stanu wolnego od braków lub wad. Atrybuty jakości to właściwości systemu, które są niezależne od funkcjonalności systemu.
Wdrożenie atrybutów jakości ułatwia odróżnienie dobrego systemu od złego. Atrybuty to ogólne czynniki wpływające na zachowanie w czasie wykonywania, projekt systemu i doświadczenie użytkownika.
Można je sklasyfikować jako -
Statyczne atrybuty jakości
Odzwierciedlaj strukturę systemu i organizacji, bezpośrednio związaną z architekturą, projektem i kodem źródłowym. Są niewidoczne dla użytkownika końcowego, ale wpływają na koszty rozwoju i utrzymania, np .: modułowość, testowalność, łatwość konserwacji itp.
Dynamiczne atrybuty jakości
Odzwierciedlaj zachowanie systemu podczas jego wykonywania. Są bezpośrednio związane z architekturą systemu, projektem, kodem źródłowym, konfiguracją, parametrami wdrażania, środowiskiem i platformą.
Są widoczne dla użytkownika końcowego i istnieją w czasie wykonywania, np. Przepustowość, niezawodność, skalowalność itp.
Scenariusze jakości
Scenariusze dotyczące jakości określają, jak zapobiegać przekształcaniu się usterki w awarię. Można je podzielić na sześć części na podstawie ich specyfikacji atrybutów -
Source - Wewnętrzny lub zewnętrzny podmiot, taki jak ludzie, sprzęt, oprogramowanie lub infrastruktura fizyczna, które generują bodziec.
Stimulus - Stan, który należy wziąć pod uwagę, gdy pojawi się w systemie.
Environment - Bodziec występuje w określonych warunkach.
Artifact - Cały system lub jego część, np. Procesory, kanały komunikacyjne, pamięć trwała, procesy itp.
Response - Czynność podejmowana po nadejściu bodźca, taka jak wykrywanie usterek, odzyskiwanie po awarii, wyłączanie źródła zdarzenia itp.
Response measure - Powinien mierzyć pojawiające się odpowiedzi, aby można było przetestować wymagania.
Wspólne atrybuty jakości
Poniższa tabela zawiera typowe atrybuty jakości, które musi mieć architektura oprogramowania -
| Kategoria | Atrybut jakości | Opis |
|---|---|---|
| Cechy konstrukcyjne | Integralność koncepcyjna | Definiuje spójność i spójność całego projektu. Obejmuje to sposób projektowania komponentów lub modułów. |
| Konserwowalność | Zdolność systemu do łatwego wprowadzania zmian. | |
| Możliwość ponownego użycia | Definiuje zdolność komponentów i podsystemów do wykorzystania w innych aplikacjach. | |
| Jakości w czasie wykonywania | Interoperacyjność | Zdolność systemu lub różnych systemów do pomyślnego działania poprzez komunikację i wymianę informacji z innymi systemami zewnętrznymi napisanymi i obsługiwanymi przez podmioty zewnętrzne. |
| Łatwość zarządzania | Określa, jak łatwo administratorzy systemu mogą zarządzać aplikacją. | |
| Niezawodność | Zdolność systemu do utrzymania działania w czasie. | |
| Skalowalność | Zdolność systemu do radzenia sobie ze wzrostem obciążenia bez wpływu na wydajność systemu lub możliwość łatwego powiększania. | |
| Bezpieczeństwo | Zdolność systemu do zapobiegania złośliwym lub przypadkowym działaniom poza przewidzianymi zastosowaniami. | |
| Wydajność | Wskazanie czasu reakcji systemu na wykonanie dowolnej akcji w zadanym przedziale czasu. | |
| Dostępność | Określa odsetek czasu, przez który system jest funkcjonalny i działa. Można go mierzyć jako procent całkowitego przestoju systemu w zdefiniowanym okresie. | |
| Cechy systemu | Wsparcie | Zdolność systemu do dostarczania informacji pomocnych w identyfikowaniu i rozwiązywaniu problemów, gdy nie działa poprawnie. |
| Testowalność | Miara tego, jak łatwo jest stworzyć kryteria testowe dla systemu i jego komponentów. | |
| Cechy użytkownika | Użyteczność | Określa, w jakim stopniu aplikacja spełnia wymagania użytkownika i konsumenta, będąc intuicyjną. |
| Jakość architektury | Poprawność | Odpowiedzialność za spełnienie wszystkich wymagań systemu. |
| Jakość non-runtime | Ruchliwość | Zdolność systemu do pracy w różnych środowiskach obliczeniowych. |
| Integralność | Możliwość sprawienia, aby oddzielnie opracowane komponenty systemu działały poprawnie ze sobą. | |
| Modyfikowalność | Łatwość, z jaką każdy system oprogramowania może dostosowywać zmiany w swoim oprogramowaniu. | |
| Atrybuty jakości biznesowej | Koszt i harmonogram | Koszt systemu w odniesieniu do czasu wprowadzenia go na rynek, oczekiwanego czasu życia projektu i wykorzystania starszej wersji. |
| Zbywalność | Korzystanie z systemu w kontekście konkurencji rynkowej. |
Architektura oprogramowania jest opisywana jako organizacja systemu, w którym system reprezentuje zestaw komponentów realizujących określone funkcje.
Styl architektoniczny
Plik architectural style, zwany także jako architectural pattern, to zbiór zasad kształtujących aplikację. Definiuje abstrakcyjne ramy dla rodziny systemów pod względem wzorca organizacji strukturalnej.
Styl architektoniczny odpowiada za -
Zapewnij leksykon komponentów i łączników wraz z zasadami ich łączenia.
Popraw partycjonowanie i pozwól na ponowne wykorzystanie projektu, dając rozwiązania często występujących problemów.
Opisz konkretny sposób konfiguracji zbioru komponentów (modułu z dobrze zdefiniowanymi interfejsami, wielokrotnego użytku i wymiennych) i łączników (łącze komunikacyjne między modułami).
Oprogramowanie zbudowane dla systemów komputerowych wykazuje jeden z wielu stylów architektonicznych. Każdy styl opisuje kategorię systemu, która obejmuje -
Zestaw typów komponentów, które pełnią wymaganą funkcję przez system.
Zestaw łączników (wywołanie podprogramu, zdalne wywołanie procedury, strumień danych i gniazdo), które umożliwiają komunikację, koordynację i współpracę między różnymi komponentami.
Ograniczenia semantyczne, które definiują sposób integracji komponentów w celu utworzenia systemu.
Topologiczny układ komponentów wskazujący ich wzajemne relacje w czasie wykonywania.
Wspólny projekt architektoniczny
W poniższej tabeli wymieniono style architektoniczne, które można uporządkować według ich kluczowych obszarów zainteresowania -
| Kategoria | Styl architektoniczny | Opis |
|---|---|---|
| Komunikacja | Magistrala wiadomości | Zaleca użycie systemu oprogramowania, który może odbierać i wysyłać wiadomości przy użyciu jednego lub więcej kanałów komunikacji. |
| Architektura zorientowana na usługi (SOA) | Definiuje aplikacje, które udostępniają i wykorzystują funkcjonalność jako usługę przy użyciu umów i wiadomości. | |
| Rozlokowanie | Klient / serwer | Podziel system na dwie aplikacje, w których klient wysyła żądania do serwera. |
| Trzywarstwowe lub N-warstwowe | Oddziela funkcje na osobne segmenty, przy czym każdy segment jest warstwą znajdującą się na fizycznie oddzielnym komputerze. | |
| Domena | Projektowanie oparte na domenie | Koncentruje się na modelowaniu domeny biznesowej i definiowaniu obiektów biznesowych na podstawie jednostek w domenie biznesowej. |
| Struktura | Oparte na komponentach | Podziel projekt aplikacji na funkcjonalne lub logiczne komponenty wielokrotnego użytku, które udostępniają dobrze zdefiniowane interfejsy komunikacyjne. |
| Warstwowy | Podziel uwagi aplikacji na ułożone w stosy grupy (warstwy). | |
| Zorientowany obiektowo | Na podstawie podziału obowiązków aplikacji lub systemu na obiekty, z których każdy zawiera dane i zachowanie właściwe dla obiektu. |
Rodzaje architektury
Z punktu widzenia przedsiębiorstwa istnieją cztery typy architektury, które łącznie określane są jako enterprise architecture.
Business architecture - Definiuje strategię biznesową, ład korporacyjny, organizację i kluczowe procesy biznesowe w przedsiębiorstwie i koncentruje się na analizie i projektowaniu procesów biznesowych.
Application (software) architecture - Służy jako plan dla poszczególnych systemów aplikacji, ich interakcji i ich relacji z procesami biznesowymi organizacji.
Information architecture - Definiuje logiczne i fizyczne zasoby danych oraz zasoby do zarządzania danymi.
Information technology (IT) architecture - Definiuje elementy składowe sprzętu i oprogramowania, które tworzą ogólny system informacyjny organizacji.
Proces projektowania architektury
Proces projektowania architektury koncentruje się na dekompozycji systemu na różne komponenty i ich interakcjach w celu spełnienia wymagań funkcjonalnych i niefunkcjonalnych. Kluczowe dane wejściowe do projektowania architektury oprogramowania to:
Wymagania generowane przez zadania analityczne.
Architektura sprzętu (z kolei architekt oprogramowania dostarcza wymagania architektowi systemu, który konfiguruje architekturę sprzętu).
Wynikiem lub wynikiem procesu projektowania architektury jest plik architectural description. Podstawowy proces projektowania architektury składa się z następujących kroków -
Zrozum problem
Jest to najważniejszy krok, ponieważ wpływa na jakość projektu, który następuje.
Bez jasnego zrozumienia problemu nie da się stworzyć skutecznego rozwiązania.
Wiele projektów i produktów oprogramowania jest uznawanych za niepowodzenia, ponieważ w rzeczywistości nie rozwiązały one ważnego problemu biznesowego lub nie zapewniają rozpoznawalnego zwrotu z inwestycji (ROI).
Zidentyfikuj elementy projektu i ich relacje
Na tym etapie zbuduj podstawę do zdefiniowania granic i kontekstu systemu.
Rozkład systemu na główne komponenty w oparciu o wymagania funkcjonalne. Rozkład można modelować za pomocą macierzy struktury projektu (DSM), która pokazuje zależności między elementami projektu bez określania ziarnistości elementów.
Na tym etapie pierwsza weryfikacja architektury odbywa się poprzez opisanie wielu instancji systemu, a ten krok jest określany jako projekt architektoniczny oparty na funkcjonalności.
Oceń projekt architektury
Każdy atrybut jakości jest szacowany, więc w celu zebrania miar jakościowych lub danych ilościowych projekt jest oceniany.
Obejmuje ocenę architektury pod kątem zgodności z wymaganiami architektonicznymi atrybutów jakości.
Jeśli wszystkie szacunkowe atrybuty jakości są zgodne z wymaganym standardem, proces projektowania architektonicznego jest zakończony.
Jeśli nie, wkraczamy w trzecią fazę projektowania architektury oprogramowania: transformację architektury. Jeśli obserwowany atrybut jakości nie spełnia jego wymagań, należy stworzyć nowy projekt.
Przekształć projekt architektury
Ten krok jest wykonywany po ocenie projektu architektonicznego. Projekt architektoniczny należy zmieniać, aż całkowicie spełni wymagania dotyczące atrybutów jakości.
Chodzi o dobór rozwiązań projektowych w celu poprawy atrybutów jakości przy jednoczesnym zachowaniu funkcjonalności domeny.
Projekt jest przekształcany przez zastosowanie operatorów projektu, stylów lub wzorów. W przypadku transformacji weź istniejący projekt i zastosuj operator projektu, taki jak dekompozycja, replikacja, kompresja, abstrakcja i udostępnianie zasobów.
Projekt jest ponownie oceniany iw razie potrzeby ten sam proces jest powtarzany wielokrotnie, a nawet wykonywany rekurencyjnie.
Transformacje (tj. Rozwiązania optymalizujące atrybut jakości) generalnie poprawiają jeden lub kilka atrybutów jakości, podczas gdy wpływają negatywnie na inne
Kluczowe zasady architektury
Poniżej przedstawiono kluczowe zasady, które należy wziąć pod uwagę podczas projektowania architektury -
Buduj, aby się zmienić, zamiast budować do końca
Zastanów się, jak aplikacja może wymagać zmian w czasie, aby sprostać nowym wymaganiom i wyzwaniom, i skorzystaj z elastyczności, aby to wspierać.
Zmniejsz ryzyko i model do analizy
Użyj narzędzi projektowych, wizualizacji, systemów modelowania, takich jak UML, aby uchwycić wymagania i decyzje projektowe. Można również przeanalizować wpływ. Nie należy formalizować modelu w takim stopniu, w jakim utrudnia to łatwe iterowanie i dostosowywanie projektu.
Użyj modeli i wizualizacji jako narzędzi do komunikacji i współpracy
Skuteczna komunikacja projektu, decyzji i bieżących zmian w projekcie ma kluczowe znaczenie dla dobrej architektury. Użyj modeli, widoków i innych wizualizacji architektury, aby skutecznie komunikować się i udostępniać projekt wszystkim interesariuszom. Umożliwia to szybką komunikację zmian w projekcie.
Zidentyfikuj i zrozum kluczowe decyzje inżynieryjne i obszary, w których najczęściej popełniane są błędy. Zainwestuj w podejmowanie właściwych decyzji już za pierwszym razem, aby projekt był bardziej elastyczny i mniej podatny na zmiany w wyniku zmian.
Użyj podejścia przyrostowego i iteracyjnego
Zacznij od architektury bazowej, a następnie rozwijaj architektury kandydujące poprzez testowanie iteracyjne w celu ulepszenia architektury. Iteracyjnie dodawaj szczegóły do projektu w wielu przebiegach, aby uzyskać duży lub właściwy obraz, a następnie skup się na szczegółach.
Kluczowe zasady projektowania
Poniżej przedstawiono zasady projektowania, które należy wziąć pod uwagę w celu zminimalizowania kosztów, wymagań dotyczących konserwacji i maksymalizacji możliwości rozbudowy, użyteczności architektury -
Rozdzielenie problemów
Podziel komponenty systemu na określone funkcje, tak aby nie zachodziły na siebie funkcje komponentów. Zapewni to wysoką spójność i niskie sprzężenie. Takie podejście pozwala uniknąć współzależności między elementami systemu, co pomaga w łatwym utrzymaniu systemu.
Zasada pojedynczej odpowiedzialności
Każdy moduł systemu powinien mieć jedną konkretną odpowiedzialność, co pomaga użytkownikowi w zrozumieniu systemu. Powinien również pomóc w integracji komponentu z innymi komponentami.
Zasada najmniejszej wiedzy
Żaden komponent lub obiekt nie powinien mieć wiedzy o wewnętrznych szczegółach innych komponentów. Takie podejście pozwala uniknąć współzależności i ułatwia konserwację.
Minimalizuj duży projekt z góry
Zminimalizuj duży projekt z góry, jeśli wymagania aplikacji są niejasne. Jeśli istnieje możliwość modyfikacji wymagań, unikaj tworzenia dużego projektu dla całego systemu.
Nie powtarzaj funkcji
Nie powtarzaj funkcjonalności określa, że funkcjonalność komponentów nie powinna się powtarzać i dlatego fragment kodu powinien być implementowany tylko w jednym komponencie. Powielanie funkcjonalności w aplikacji może utrudniać wdrażanie zmian, zmniejszać przejrzystość i wprowadzać potencjalne niespójności.
Preferuj kompozycję zamiast dziedziczenia podczas ponownego korzystania z funkcji
Dziedziczenie tworzy zależność między klasami podrzędnymi i nadrzędnymi, a tym samym blokuje swobodne korzystanie z klas podrzędnych. Natomiast kompozycja zapewnia duży poziom swobody i redukuje hierarchie dziedziczenia.
Zidentyfikuj komponenty i pogrupuj je w warstwy logiczne
Elementy tożsamości i obszar zainteresowania, które są potrzebne w systemie, aby spełnić wymagania. Następnie pogrupuj te powiązane komponenty w warstwę logiczną, która pomoże użytkownikowi zrozumieć strukturę systemu na wysokim poziomie. Unikaj mieszania składników różnego rodzaju w tej samej warstwie.
Zdefiniuj protokół komunikacji między warstwami
Zrozum, w jaki sposób komponenty będą się ze sobą komunikować, co wymaga pełnej wiedzy na temat scenariuszy wdrażania i środowiska produkcyjnego.
Zdefiniuj format danych dla warstwy
Różne komponenty będą ze sobą współdziałać poprzez format danych. Nie mieszaj formatów danych, aby aplikacje były łatwe we wdrażaniu, rozszerzaniu i utrzymaniu. Staraj się zachować ten sam format danych dla warstwy, aby różne komponenty nie musiały kodować / dekodować danych podczas komunikacji między sobą. Zmniejsza narzut przetwarzania.
Składniki usług systemowych powinny być abstrakcyjne
Kod związany z bezpieczeństwem, komunikacją lub usługami systemowymi, takimi jak logowanie, profilowanie i konfiguracja, powinien być wyodrębniony w oddzielnych składnikach. Nie mieszaj tego kodu z logiką biznesową, ponieważ łatwo jest rozszerzyć projekt i utrzymać go.
Projektowanie wyjątków i mechanizm obsługi wyjątków
Zdefiniowanie wyjątków z wyprzedzeniem pomaga komponentom w elegancki sposób zarządzać błędami lub niepożądanymi sytuacjami. Zarządzanie wyjątkami będzie takie samo w całym systemie.
Konwencje nazewnictwa
Z góry należy zdefiniować konwencje nazewnictwa. Zapewniają spójny model, który pomaga użytkownikom łatwo zrozumieć system. Członkom zespołu łatwiej jest zweryfikować kod napisany przez innych, a tym samym zwiększy to łatwość utrzymania.
Architektura oprogramowania obejmuje wysokopoziomową strukturę abstrakcji systemu oprogramowania, wykorzystującą dekompozycję i kompozycję, ze stylem architektonicznym i atrybutami jakości. Projekt architektury oprogramowania musi być zgodny z głównymi wymaganiami dotyczącymi funkcjonalności i wydajności systemu, a także spełniać wymagania niefunkcjonalne, takie jak niezawodność, skalowalność, przenośność i dostępność.
Architektura oprogramowania musi opisywać swoją grupę komponentów, ich połączenia, interakcje między nimi oraz konfigurację wdrożenia wszystkich komponentów.
Architekturę oprogramowania można zdefiniować na wiele sposobów -
UML (Unified Modeling Language) - UML jest jednym z rozwiązań obiektowych stosowanych w modelowaniu i projektowaniu oprogramowania.
Architecture View Model (4+1 view model) - Model widoku architektury reprezentuje funkcjonalne i niefunkcjonalne wymagania aplikacji.
ADL (Architecture Description Language) - ADL definiuje architekturę oprogramowania pod względem formalnym i semantycznym.
UML
UML to skrót od Unified Modeling Language. Jest to język obrazkowy używany do tworzenia planów oprogramowania. UML został stworzony przez Object Management Group (OMG). Projekt specyfikacji UML 1.0 został zaproponowany OMG w styczniu 1997 roku. Służy jako standard do analizy wymagań oprogramowania i dokumentów projektowych, które są podstawą do tworzenia oprogramowania.
UML można opisać jako język modelowania wizualnego ogólnego przeznaczenia do wizualizacji, określania, konstruowania i dokumentowania systemu oprogramowania. Chociaż język UML jest generalnie używany do modelowania systemu oprogramowania, nie jest on ograniczony w tych granicach. Jest również używany do modelowania systemów innych niż oprogramowanie, takich jak przepływy procesów w jednostce produkcyjnej.
Elementy są jak komponenty, które można łączyć na różne sposoby, aby stworzyć pełny obraz UML, który jest znany jako diagram. Dlatego bardzo ważne jest, aby zrozumieć różne diagramy, aby wdrożyć wiedzę w rzeczywistych systemach. Mamy dwie szerokie kategorie diagramów i są one dalej podzielone na podkategorie, tjStructural Diagrams i Behavioral Diagrams.
Diagramy strukturalne
Diagramy strukturalne przedstawiają statyczne aspekty systemu. Te statyczne aspekty reprezentują te części diagramu, który tworzy główną strukturę i dlatego jest stabilny.
Te statyczne części są reprezentowane przez klasy, interfejsy, obiekty, komponenty i węzły. Diagramy strukturalne można podzielić w następujący sposób -
- Diagram klas
- Diagram obiektów
- Schemat elementów
- Diagram rozmieszczenia
- Schemat pakietu
- Struktura kompozytowa
Poniższa tabela zawiera krótki opis tych diagramów -
| Sr.No. | Schemat i opis |
|---|---|
| 1 | Class Reprezentuje orientację obiektu systemu. Pokazuje, w jaki sposób klasy są statycznie powiązane. |
| 2 | Object Reprezentuje zestaw obiektów i ich relacje w czasie wykonywania, a także reprezentuje statyczny widok systemu. |
| 3 | Component Opisuje wszystkie komponenty, ich wzajemne relacje, interakcje i interfejs systemu. |
| 4 | Composite structure Opisuje wewnętrzną strukturę komponentu, w tym wszystkie klasy, interfejsy komponentu itp. |
| 5 | Package Opisuje strukturę i organizację pakietu. Obejmuje klasy w pakiecie i pakiety w innym pakiecie. |
| 6 | Deployment Diagramy wdrożenia to zestaw węzłów i ich relacji. Te węzły to jednostki fizyczne, w których wdrażane są komponenty. |
Diagramy behawioralne
Diagramy behawioralne zasadniczo przedstawiają dynamiczny aspekt systemu. Dynamiczne aspekty to w zasadzie zmieniające się / ruchome części systemu. UML ma następujące typy diagramów behawioralnych -
- Diagram przypadków użycia
- Diagram sekwencyjny
- Schemat komunikacji
- Diagram wykresu stanu
- Diagram aktywności
- Omówienie interakcji
- Diagram sekwencji czasowej
Poniższa tabela zawiera krótki opis tego diagramu -
| Sr.No. | Schemat i opis |
|---|---|
| 1 | Use case Opisuje relacje między funkcjami i ich wewnętrznymi / zewnętrznymi kontrolerami. Te kontrolery są znane jako aktorzy. |
| 2 | Activity Opisuje przepływ sterowania w systemie. Składa się z działań i linków. Przepływ może być sekwencyjny, współbieżny lub rozgałęziony. |
| 3 | State Machine/state chart Reprezentuje sterowaną zdarzeniem zmianę stanu systemu. Zasadniczo opisuje zmianę stanu klasy, interfejsu itp. Służy do wizualizacji reakcji systemu na czynniki wewnętrzne / zewnętrzne. |
| 4 | Sequence Wizualizuje sekwencję wywołań w systemie w celu wykonania określonej funkcji. |
| 5 | Interaction Overview Łączy diagramy aktywności i sekwencji, aby zapewnić przegląd przepływu kontroli systemu i procesu biznesowego. |
| 6 | Communication To samo co diagram sekwencji, z tą różnicą, że koncentruje się na roli obiektu. Każda komunikacja jest powiązana z kolejnością sekwencji, numerem oraz przeszłymi wiadomościami. |
| 7 | Time Sequenced Opisuje zmiany za pomocą komunikatów w stanie, stanie i zdarzeniach. |
Model widoku architektury
Model to kompletny, podstawowy i uproszczony opis architektury oprogramowania, który składa się z wielu widoków z określonej perspektywy lub punktu widzenia.
Widok to reprezentacja całego systemu z perspektywy powiązanego zestawu problemów. Służy do opisu systemu z punktu widzenia różnych interesariuszy, takich jak użytkownicy końcowi, programiści, kierownicy projektów i testerzy.
Model widoku 4 + 1
Model widoku 4 + 1 został zaprojektowany przez Philippe'a Kruchtena w celu opisania architektury systemu intensywnie korzystającego z oprogramowania opartego na wykorzystaniu wielu i współbieżnych widoków. To jestmultiple viewmodel, który dotyczy różnych funkcji i problemów systemu. Ujednolica dokumenty projektowe oprogramowania i sprawia, że projekt jest łatwy do zrozumienia dla wszystkich interesariuszy.
Jest to metoda weryfikacji architektury służąca do badania i dokumentowania projektu architektury oprogramowania i obejmuje wszystkie aspekty architektury oprogramowania dla wszystkich interesariuszy. Zapewnia cztery podstawowe widoki -
The logical view or conceptual view - Opisuje model obiektowy projektu.
The process view - Opisuje działania systemu, wychwytuje aspekty współbieżności i synchronizacji projektu.
The physical view - Opisuje mapowanie oprogramowania na sprzęt i odzwierciedla jego rozproszony aspekt.
The development view - Opisuje statyczną organizację lub strukturę oprogramowania podczas tworzenia środowiska.
Ten model widoku można rozszerzyć, dodając jeszcze jeden widok o nazwie scenario view lub use case viewdla użytkowników końcowych lub klientów systemów oprogramowania. Jest spójny z innymi czterema widokami i służy do zilustrowania architektury służącej jako widok „plus jeden”, model widoku (4 + 1). Poniższy rysunek przedstawia architekturę oprogramowania przy użyciu modelu pięciu współbieżnych widoków (4 + 1).

Dlaczego nazywa się to 4 + 1 zamiast 5?
Plik use case viewma szczególne znaczenie, ponieważ wyszczególnia wymagania systemu na wysokim poziomie, podczas gdy inne przedstawia szczegóły - w jaki sposób te wymagania są realizowane. Gdy wszystkie pozostałe cztery widoki są ukończone, jest to faktycznie zbędne. Jednak bez niego żadne inne widoki nie byłyby możliwe. Poniższy obraz i tabela przedstawiają szczegółowo widok 4 + 1 -
| Logiczny | Proces | Rozwój | Fizyczny | Scenariusz | |
|---|---|---|---|---|---|
| Opis | Pokazuje komponent (obiekt) systemu oraz ich interakcję | Pokazuje procesy / zasady przepływu pracy w systemie i sposób komunikacji tych procesów, koncentruje się na dynamicznym widoku systemu | Zawiera widoki blokowe systemu i opisuje statyczną organizację modułów systemu | Pokazuje instalację, konfigurację i wdrażanie aplikacji | Pokazuje, że projekt jest ukończony, wykonując weryfikację i ilustrację |
| Widz / posiadacz stawki | Użytkownik końcowy, analitycy i projektant | Integratorzy i programiści | Programista i kierownicy projektów oprogramowania | Inżynier systemowy, operatorzy, administratorzy systemów i instalatorzy systemów | Wszystkie opinie ich opinii i oceniających |
| Rozważać | Wymagania funkcjonalne | Wymagania niefunkcjonalne | Organizacja modułu oprogramowania (ponowne wykorzystanie zarządzania oprogramowaniem, ograniczenie narzędzi) | Niefunkcjonalne wymaganie dotyczące podstawowego sprzętu | Spójność i ważność systemu |
| UML - Diagram | Klasa, stan, obiekt, sekwencja, diagram komunikacji | Diagram aktywności | Schemat komponentów, pakietów | Diagram rozmieszczenia | Diagram przypadków użycia |
Języki opisu architektury (ADL)
ADL to język, który zapewnia składnię i semantykę do definiowania architektury oprogramowania. Jest to specyfikacja notacji, która zapewnia funkcje modelowania architektury koncepcyjnej systemu oprogramowania, w odróżnieniu od implementacji systemu.
ADL muszą obsługiwać komponenty architektury, ich połączenia, interfejsy i konfiguracje, które są budulcem opisu architektury. Jest formą wyrażenia używaną w opisach architektury i zapewnia możliwość dekompozycji komponentów, łączenia komponentów i definiowania interfejsów komponentów.
Język opisu architektury to formalny język specyfikacji, który opisuje funkcje oprogramowania, takie jak procesy, wątki, dane i podprogramy, a także komponenty sprzętowe, takie jak procesory, urządzenia, magistrale i pamięć.
Trudno jest sklasyfikować lub rozróżnić ADL od języka programowania lub języka modelowania. Istnieją jednak następujące wymagania, aby język został sklasyfikowany jako ADL -
Powinien być odpowiedni do komunikowania architektury wszystkim zainteresowanym stronom.
Powinien być odpowiedni do zadań związanych z tworzeniem, udoskonalaniem i sprawdzaniem architektury.
Powinien stanowić podstawę do dalszej implementacji, więc musi być w stanie dodawać informacje do specyfikacji ADL, aby umożliwić wyprowadzenie ostatecznej specyfikacji systemu z ADL.
Powinien mieć możliwość reprezentowania większości popularnych stylów architektonicznych.
Powinien wspierać możliwości analityczne lub zapewniać szybkie generowanie implementacji prototypów.
Paradygmat obiektowy (OO) wziął swój kształt z początkowej koncepcji nowego podejścia do programowania, podczas gdy zainteresowanie metodami projektowania i analizy pojawiło się znacznie później. Paradygmat analizy obiektowej i projektowania jest logicznym wynikiem szerokiego zastosowania języków programowania obiektowych.
Pierwszym językiem zorientowanym obiektowo był Simula (Symulacja rzeczywistych systemów), który został opracowany w 1960 r. Przez naukowców z Norweskiego Centrum Obliczeniowego.
W 1970 roku Alan Kay i jego grupa badawcza w Xerox PARC stworzyła komputer osobisty o nazwie Dynabook oraz pierwszy czysty obiektowy język programowania (OOPL) - Smalltalk, do programowania Dynabook.
W 1980, Grady Boochopublikował artykuł zatytułowany Object Oriented Design, w którym przedstawiono głównie projekt języka programowania Ada. W kolejnych edycjach rozszerzył swoje pomysły na kompletną metodę projektowania obiektowego.
W latach dziewięćdziesiątych, Coad włączył pomysły behawioralne do metod zorientowanych obiektowo.
Innymi znaczącymi innowacjami były techniki modelowania obiektów (OMT) autorstwa James Rum Baugh oraz Object-Oriented Software Engineering (OOSE) autorstwa Ivar Jacobson.
Wprowadzenie do paradygmatu OO
Paradygmat OO jest znaczącą metodologią tworzenia dowolnego oprogramowania. Większość stylów lub wzorców architektury, takich jak potok i filtr, repozytorium danych i oparta na komponentach, można zaimplementować przy użyciu tego paradygmatu.
Podstawowe pojęcia i terminologie systemów obiektowych -
Obiekt
Obiekt to element świata rzeczywistego w środowisku obiektowym, który może istnieć fizycznie lub koncepcyjnie. Każdy obiekt ma -
Tożsamość, która odróżnia go od innych obiektów w systemie.
Stan określający charakterystyczne właściwości obiektu, a także wartości właściwości, które posiada obiekt.
Zachowanie, które reprezentuje widoczne z zewnątrz czynności wykonywane przez obiekt pod względem zmian jego stanu.
Obiekty można modelować zgodnie z potrzebami aplikacji. Obiekt może istnieć fizycznie, jak klient, samochód itp .; lub niematerialne istnienie pojęciowe, takie jak projekt, proces itp.
Klasa
Klasa reprezentuje zbiór obiektów o tych samych charakterystycznych właściwościach, które wykazują typowe zachowanie. Daje plan lub opis obiektów, które można z niego stworzyć. Tworzenie obiektu jako członka klasy nazywa się tworzeniem instancji. Zatem obiekt jestinstance klasy.
Składnikami klasy są -
Zestaw atrybutów obiektów, które mają zostać utworzone z klasy. Ogólnie rzecz biorąc, różne obiekty klasy mają pewne różnice w wartościach atrybutów. Atrybuty są często określane jako dane klas.
Zestaw operacji, które przedstawiają zachowanie obiektów klasy. Operacje są również określane jako funkcje lub metody.
Example
Rozważmy prostą klasę Circle, która reprezentuje geometryczny okrąg figury w dwuwymiarowej przestrzeni. Atrybuty tej klasy można zidentyfikować w następujący sposób -
- x – współrzędna, aby oznaczyć x – współrzędną środka
- y – współrzędna, aby oznaczyć y – współrzędną środka
- a, aby oznaczyć promień okręgu
Niektóre z jego operacji można zdefiniować następująco:
- findArea (), metoda obliczania powierzchni
- findCircumference (), metoda obliczania obwodu
- scale (), metoda zwiększania lub zmniejszania promienia
Kapsułkowanie
Hermetyzacja to proces wiązania razem atrybutów i metod w klasie. Dzięki hermetyzacji wewnętrzne szczegóły klasy można ukryć przed zewnętrzem. Pozwala na dostęp do elementów klasy z zewnątrz tylko za pośrednictwem interfejsu udostępnionego przez klasę.
Wielopostaciowość
Polimorfizm jest pierwotnie greckim słowem, które oznacza zdolność do przyjmowania wielu form. W paradygmacie zorientowanym obiektowo polimorfizm implikuje używanie operacji na różne sposoby, w zależności od instancji, na których operują. Polimorfizm umożliwia obiektom o różnych strukturach wewnętrznych posiadanie wspólnego interfejsu zewnętrznego. Polimorfizm jest szczególnie skuteczny przy wdrażaniu dziedziczenia.
Example
Rozważmy dwie klasy, Circle i Square, z których każda ma metodę findArea (). Chociaż nazwa i przeznaczenie metod w klasach są takie same, wewnętrzna implementacja, tj. Procedura obliczania obszaru, jest inna dla każdej klasy. Gdy obiekt klasy Circle wywołuje swoją metodę findArea (), operacja odnajduje obszar koła bez konfliktu z metodą findArea () klasy Square.
Relationships
Aby opisać system, należy podać zarówno dynamiczną (behawioralną), jak i statyczną (logiczną) specyfikację systemu. Specyfikacja dynamiczna opisuje relacje między obiektami, np. Przekazywanie wiadomości. Specyfikacje statyczne opisują relacje między klasami, np. Agregację, asocjację i dziedziczenie.
Przekazywanie wiadomości
Każda aplikacja wymaga harmonijnej interakcji wielu obiektów. Obiekty w systemie mogą komunikować się ze sobą za pomocą przekazywania komunikatów. Załóżmy, że system ma dwa obiekty - obj1 i obj2. Obiekt obj1 wysyła komunikat do obiektu obj2, jeśli obiekt obj1 chce, aby obj2 wykonał jedną ze swoich metod.
Kompozycja lub agregacja
Agregacja lub kompozycja to relacja między klasami, dzięki której klasa może się składać z dowolnej kombinacji obiektów innych klas. Pozwala na umieszczanie obiektów bezpośrednio w treści innych klas. Agregacja jest określana jako relacja „część” lub „ma”, z możliwością przechodzenia od całości do jej części. Obiekt zagregowany to obiekt składający się z co najmniej jednego innego obiektu.
Stowarzyszenie
Skojarzenie to grupa połączeń o wspólnej strukturze i wspólnym zachowaniu. Skojarzenie przedstawia związek między obiektami jednej lub kilku klas. Łącze można zdefiniować jako instancję powiązania. Stopień asocjacji oznacza liczbę klas zaangażowanych w połączenie. Stopień może być jednoargumentowy, binarny lub trójskładnikowy.
- Jednoargumentowa relacja łączy obiekty tej samej klasy.
- Relacja binarna łączy obiekty dwóch klas.
- Relacja trójskładnikowa łączy obiekty trzech lub więcej klas.
Dziedzictwo
Jest to mechanizm, który umożliwia tworzenie nowych klas z istniejących klas poprzez rozszerzanie i udoskonalanie jego możliwości. Istniejące klasy nazywane są klasami podstawowymi / klasami nadrzędnymi / superklasami, a nowe klasy nazywane są klasami pochodnymi / klasami potomnymi / podklasami.
Podklasa może dziedziczyć lub wyprowadzać atrybuty i metody superklasy (-ów), o ile pozwala na to superklasa. Poza tym podklasa może dodawać własne atrybuty i metody oraz może modyfikować dowolne metody nadklasy. Dziedziczenie definiuje relację „jest - a”.
Example
Z klasy Mammal można wyprowadzić szereg klas, takich jak człowiek, kot, pies, krowa itp. Ludzie, koty, psy i krowy mają odrębne cechy charakterystyczne dla ssaków. Ponadto każdy ma swoje szczególne cechy. Można powiedzieć, że krowa „jest” ssakiem.
Analiza obiektowa
W fazie analizy obiektowej tworzenia oprogramowania określa się wymagania systemowe, identyfikuje klasy i potwierdza relacje między klasami. Celem analizy OO jest zrozumienie dziedziny aplikacji i specyficznych wymagań systemu. Wynikiem tej fazy jest określenie wymagań i wstępna analiza struktury logicznej i wykonalności systemu.
Trzy techniki analizy, które są używane w połączeniu ze sobą w analizie zorientowanej obiektowo, to modelowanie obiektowe, modelowanie dynamiczne i modelowanie funkcjonalne.
Modelowanie obiektów
Modelowanie obiektowe rozwija statyczną strukturę systemu oprogramowania w kategoriach obiektów. Identyfikuje obiekty, klasy, do których można je grupować oraz relacje między obiektami. Określa również główne atrybuty i operacje, które charakteryzują każdą klasę.
Proces modelowania obiektów można zwizualizować w następujących krokach -
- Identyfikuj obiekty i grupuj w klasy
- Zidentyfikuj relacje między klasami
- Utwórz diagram modelu obiektów użytkownika
- Zdefiniuj atrybuty obiektu użytkownika
- Zdefiniuj operacje, które powinny zostać wykonane na klasach
Modelowanie dynamiczne
Po przeanalizowaniu statycznego zachowania systemu należy zbadać jego zachowanie względem czasu i zmian zewnętrznych. Taki jest cel modelowania dynamicznego.
Modelowanie dynamiczne można zdefiniować jako „sposób opisania, w jaki sposób pojedynczy obiekt reaguje na zdarzenia, albo zdarzenia wewnętrzne wyzwalane przez inne obiekty, albo zdarzenia zewnętrzne wyzwalane przez świat zewnętrzny”.
Proces modelowania dynamicznego można wizualizować w następujących krokach -
- Zidentyfikuj stany każdego obiektu
- Identyfikuj zdarzenia i analizuj zastosowanie działań
- Skonstruuj diagram modelu dynamicznego, składający się z diagramów przejść stanów
- Wyraź każdy stan za pomocą atrybutów obiektu
- Sprawdź poprawność narysowanych diagramów stanów
Modelowanie funkcjonalne
Modelowanie funkcjonalne jest ostatnim elementem analizy zorientowanej obiektowo. Model funkcjonalny pokazuje procesy, które są wykonywane w obiekcie i jak zmieniają się dane podczas przemieszczania się między metodami. Określa znaczenie operacji modelowania obiektów i działań modelowania dynamicznego. Model funkcjonalny odpowiada schematowi przepływu danych tradycyjnej analizy strukturalnej.
Proces modelowania funkcjonalnego można zwizualizować w następujących krokach -
- Zidentyfikuj wszystkie wejścia i wyjścia
- Skonstruuj diagramy przepływu danych pokazujące zależności funkcjonalne
- Podaj cel każdej funkcji
- Zidentyfikuj ograniczenia
- Określ kryteria optymalizacji
Projektowanie zorientowane obiektowo
Po fazie analizy model koncepcyjny jest dalej rozwijany w model zorientowany obiektowo przy użyciu projektowania zorientowanego obiektowo (OOD). W OOD koncepcje niezależne od technologii w modelu analizy są mapowane na klasy implementujące, identyfikowane są ograniczenia i projektowane są interfejsy, w wyniku czego powstaje model domeny rozwiązania. Głównym celem projektowania OO jest opracowanie architektury strukturalnej systemu.
Etapy projektowania zorientowanego obiektowo można określić jako -
- Definiowanie kontekstu systemu
- Projektowanie architektury systemu
- Identyfikacja obiektów w systemie
- Budowa modeli projektowych
- Specyfikacja interfejsów obiektów
Projekt OO można podzielić na dwa etapy - Projekt koncepcyjny i Projekt szczegółowy.
Conceptual design
Na tym etapie identyfikowane są wszystkie klasy potrzebne do zbudowania systemu. Ponadto każdej klasie przypisane są określone obowiązki. Diagram klas służy do wyjaśnienia relacji między klasami, a diagram interakcji służy do pokazania przepływu zdarzeń. Jest również znany jakohigh-level design.
Detailed design
Na tym etapie atrybuty i operacje są przypisywane do każdej klasy na podstawie ich diagramu interakcji. Diagram maszyny stanów został opracowany w celu opisania dalszych szczegółów projektu. Jest również znany jakolow-level design.
Zasady projektowania
Poniżej przedstawiono główne zasady projektowania -
Principle of Decoupling
Trudno jest utrzymać system z zestawem wysoce współzależnych klas, ponieważ modyfikacja w jednej klasie może skutkować kaskadowymi aktualizacjami innych klas. W projekcie OO ścisłe powiązanie można wyeliminować, wprowadzając nowe klasy lub dziedziczenie.
Ensuring Cohesion
Klasa spójna pełni zestaw ściśle powiązanych funkcji. Brak spójności oznacza - klasa pełni niezwiązane ze sobą funkcje, choć nie ma to wpływu na działanie całego systemu. To sprawia, że cała struktura oprogramowania jest trudna do zarządzania, rozbudowy, utrzymania i zmiany.
Open-closed Principle
Zgodnie z tą zasadą system powinien mieć możliwość rozbudowy w celu spełnienia nowych wymagań. Istniejąca implementacja i kod systemu nie powinny być modyfikowane w wyniku rozbudowy systemu. Ponadto następujące wytyczne muszą być przestrzegane na zasadzie otwarte-zamknięte -
Dla każdej konkretnej klasy należy zachować oddzielny interfejs i implementacje.
W środowisku wielowątkowym zachowaj prywatność atrybutów.
Zminimalizuj użycie zmiennych globalnych i zmiennych klas.
W architekturze przepływu danych cały system oprogramowania jest postrzegany jako seria przekształceń na kolejnych elementach lub zestawie danych wejściowych, w których dane i operacje są od siebie niezależne. W tym podejściu dane wchodzą do systemu, a następnie przepływają przez moduły pojedynczo, aż zostaną przypisane do jakiegoś miejsca docelowego (wyjście lub magazyn danych).
Połączenia między komponentami lub modułami mogą być realizowane jako strumień we / wy, bufory we / wy, połączenia potokowe lub inne typy połączeń. Dane mogą być przepuszczane w topologii grafu z cyklami, w strukturze liniowej bez cykli lub w strukturze drzewiastej.
Głównym celem tego podejścia jest osiągnięcie cech ponownego wykorzystania i możliwości modyfikacji. Jest odpowiedni dla aplikacji, które obejmują dobrze zdefiniowaną serię niezależnych transformacji danych lub obliczeń na uporządkowanych danych wejściowych i wyjściowych, takich jak kompilatory i aplikacje do przetwarzania danych biznesowych. Istnieją trzy typy sekwencji wykonania między modułami
- Partia sekwencyjna
- Tryb potoków i filtrów lub niesekwencyjny tryb rurociągów
- Kontrola procesu
Batch Sequential
Batch sequential to klasyczny model przetwarzania danych, w którym podsystem transformacji danych może zainicjować swój proces dopiero po całkowitym przejściu poprzedniego podsystemu -
Przepływ danych przenosi pakiet danych jako całości z jednego podsystemu do drugiego.
Komunikacja między modułami odbywa się za pośrednictwem tymczasowych plików pośrednich, które mogą być usuwane przez kolejne podsystemy.
Ma zastosowanie do tych aplikacji, w których dane są grupowane, a każdy podsystem odczytuje powiązane pliki wejściowe i zapisuje pliki wyjściowe.
Typowe zastosowanie tej architektury obejmuje przetwarzanie danych biznesowych, takie jak bankowość i rachunki za media.

Zalety
Zapewnia prostsze podziały na podsystemy.
Każdy podsystem może być niezależnym programem pracującym na danych wejściowych i wytwarzającym dane wyjściowe.
Niedogodności
Zapewnia duże opóźnienia i niską przepustowość.
Nie zapewnia współbieżności i interaktywnego interfejsu.
Do wdrożenia wymagana jest kontrola zewnętrzna.
Architektura rur i filtrów
Podejście to kładzie nacisk na przyrostową transformację danych przez kolejny składnik. W tym podejściu przepływ danych jest sterowany przez dane, a cały system jest rozkładany na komponenty źródła danych, filtry, potoki i ujścia danych.
Połączenia między modułami to strumień danych będący buforem pierwszego wejścia / pierwszego wyjścia, który może być strumieniem bajtów, znaków lub dowolnego innego rodzaju. Główną cechą tej architektury jest jednoczesne i przyrostowe wykonywanie.
Filtr
Filtr to niezależny transformator strumienia danych lub przetworniki strumienia. Przekształca dane wejściowego strumienia danych, przetwarza je i zapisuje przekształcony strumień danych w potoku w celu przetworzenia przez następny filtr. Działa w trybie przyrostowym, w którym zaczyna działać, gdy tylko dane dotrą przez podłączony potok. Istnieją dwa rodzaje filtrów -active filter i passive filter.
Active filter
Aktywny filtr umożliwia podłączonym rurom pobieranie danych i wypychanie przekształconych danych. Działa z pasywnym potokiem, który zapewnia mechanizmy odczytu / zapisu dla ciągnięcia i pchania. Ten tryb jest używany w mechanizmach potoków i filtrów systemu UNIX.
Passive filter
Filtr pasywny umożliwia podłączonym rurom wpychanie i pobieranie danych. Działa z aktywnym potokiem, który pobiera dane z filtru i wypycha dane do następnego filtru. Musi zapewniać mechanizm odczytu / zapisu.

Zalety
Zapewnia współbieżność i wysoką przepustowość w przypadku nadmiernego przetwarzania danych.
Zapewnia możliwość ponownego użycia i upraszcza konserwację systemu.
Zapewnia modyfikowalność i niskie sprzężenie między filtrami.
Zapewnia prostotę, oferując wyraźne podziały między dowolnymi dwoma filtrami połączonymi rurami.
Zapewnia elastyczność dzięki obsłudze wykonywania sekwencyjnego i równoległego.
Niedogodności
Nie nadaje się do dynamicznych interakcji.
Do transmisji danych w formatach ASCII potrzebny jest niski wspólny mianownik.
Narzut związany z transformacją danych między filtrami.
Nie zapewnia możliwości współpracy filtrów w celu rozwiązania problemu.
Trudne do dynamicznej konfiguracji tej architektury.
Rura
Potoki są bezstanowe i przenoszą strumień binarny lub znakowy, który istnieje między dwoma filtrami. Może przenosić strumień danych z jednego filtra do drugiego. Potoki używają niewielkiej ilości informacji kontekstowych i nie zachowują żadnych informacji o stanie między wystąpieniami.
Architektura sterowania procesami
Jest to typ architektury przepływu danych, w którym dane nie są ani sekwencyjnym, ani potokowym strumieniem wsadowym. Przepływ danych pochodzi ze zbioru zmiennych, które sterują przebiegiem procesu. Rozkłada cały system na podsystemy lub moduły i łączy je.
Rodzaje podsystemów
Architektura sterowania procesem miałaby rozszerzenie processing unit do zmiany zmiennych sterujących procesem oraz a controller unit do obliczania ilości zmian.
Jednostka sterująca musi mieć następujące elementy -
Controlled Variable- Zmienna kontrolowana zawiera wartości dla systemu bazowego i powinna być mierzona przez czujniki. Na przykład prędkość w tempomacie.
Input Variable- Mierzy wkład w proces. Na przykład temperatura powietrza powrotnego w układzie regulacji temperatury
Manipulated Variable - Wartość zmiennej manipulowanej jest regulowana lub zmieniana przez sterownik.
Process Definition - Zawiera mechanizmy manipulowania niektórymi zmiennymi procesowymi.
Sensor - Uzyskuje wartości zmiennych procesowych związanych ze sterowaniem i może służyć jako odniesienie zwrotne do ponownego obliczenia zmiennych manipulowanych.
Set Point - Jest to żądana wartość zmiennej kontrolowanej.
Control Algorithm - Służy do podejmowania decyzji, jak manipulować zmiennymi procesowymi.
Obszary zastosowań
Architektura sterowania procesami jest odpowiednia w następujących dziedzinach -
Projektowanie oprogramowania systemu wbudowanego, w którym manipuluje się systemem za pomocą zmiennych danych sterujących procesem.
Zastosowania, których celem jest utrzymanie określonych właściwości wyników procesu przy zadanych wartościach odniesienia.
Ma zastosowanie do tempomatu samochodowego i systemów kontroli temperatury w budynku.
Oprogramowanie systemowe czasu rzeczywistego do sterowania samochodowymi hamulcami przeciwblokującymi, elektrowniami jądrowymi itp.
W architekturze zorientowanej na dane dane są scentralizowane i często używane przez inne komponenty, które modyfikują dane. Głównym celem tego stylu jest osiągnięcie integralności danych. Architektura skoncentrowana na danych składa się z różnych komponentów, które komunikują się poprzez współdzielone repozytoria danych. Komponenty mają dostęp do wspólnej struktury danych i są względnie niezależne, w tym sensie, że oddziałują tylko za pośrednictwem magazynu danych.
Najbardziej znanymi przykładami architektury zorientowanej na dane jest architektura bazy danych, w której wspólny schemat bazy danych jest tworzony z protokołem definicji danych - na przykład zestaw powiązanych tabel z polami i typami danych w RDBMS.
Innym przykładem architektur zorientowanych na dane jest architektura sieciowa, która ma wspólny schemat danych (tj. Meta-strukturę sieci) i podąża za modelem danych hipermedialnych, a procesy komunikują się za pośrednictwem współdzielonych usług danych internetowych.

Rodzaje komponentów
Istnieją dwa rodzaje komponentów -
ZA central datastruktura lub magazyn danych lub repozytorium danych, które jest odpowiedzialne za zapewnienie trwałego przechowywania danych. Przedstawia stan obecny.
ZA data accessor lub zbiór niezależnych komponentów, które działają w centralnym magazynie danych, wykonują obliczenia i mogą odłożyć wyniki.
Interakcje lub komunikacja między akcesorami danych odbywa się tylko za pośrednictwem magazynu danych. Dane są jedynym środkiem komunikacji między klientami. Przepływ kontroli dzieli architekturę na dwie kategorie -
- Styl architektury repozytorium
- Styl architektury tablicy
Styl architektury repozytorium
W stylu architektury repozytorium magazyn danych jest pasywny, a klienci (komponenty oprogramowania lub agenci) magazynu danych są aktywni, którzy kontrolują przepływ logiki. Uczestniczące komponenty sprawdzają magazyn danych pod kątem zmian.
Klient wysyła do systemu żądanie wykonania czynności (np. Wprowadzenia danych).
Procesy obliczeniowe są niezależne i wyzwalane przez przychodzące żądania.
Jeżeli typy transakcji w strumieniu wejściowym transakcji wyzwalają wybór procesów do wykonania, to jest to tradycyjna architektura bazodanowa lub repozytorium, bądź repozytorium pasywne.
Podejście to jest szeroko stosowane w DBMS, systemie informacji bibliotecznej, repozytorium interfejsów w CORBA, kompilatorach i środowiskach CASE (wspomagana komputerowo inżynieria oprogramowania).

Zalety
Zapewnia integralność danych, funkcje tworzenia kopii zapasowych i przywracania.
Zapewnia skalowalność i możliwość ponownego wykorzystania agentów, ponieważ nie komunikują się oni bezpośrednio ze sobą.
Zmniejsza narzut danych przejściowych między składnikami oprogramowania.
Niedogodności
Jest bardziej podatny na awarie i możliwa jest replikacja lub duplikacja danych.
Duża zależność między strukturą danych magazynu danych a jego agentami.
Zmiany w strukturze danych mają duży wpływ na klientów.
Ewolucja danych jest trudna i kosztowna.
Koszt przenoszenia danych w sieci dla danych rozproszonych.
Styl architektury tablicy
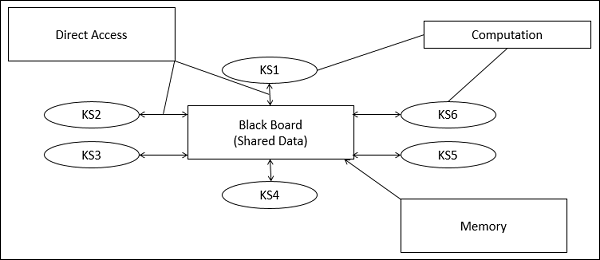
W stylu architektury Blackboard magazyn danych jest aktywny, a jego klienci są pasywni. Dlatego przepływ logiczny jest określany przez bieżący stan danych w magazynie danych. Posiada komponent tablicy, działający jako centralne repozytorium danych, a wewnętrzna reprezentacja jest budowana i przetwarzana przez różne elementy obliczeniowe.
Na tablicy przechowywanych jest wiele komponentów, które działają niezależnie od wspólnej struktury danych.
W tym stylu komponenty oddziałują tylko poprzez tablicę. Magazyn danych ostrzega klientów o każdej zmianie w magazynie danych.
Bieżący stan rozwiązania jest przechowywany w tablicy, a stan tablicy uruchamia przetwarzanie.
System wysyła powiadomienia znane jako trigger oraz dane klientom, gdy nastąpią zmiany w danych.
Podejście to można znaleźć w niektórych aplikacjach AI i złożonych aplikacjach, takich jak rozpoznawanie mowy, rozpoznawanie obrazu, system bezpieczeństwa, systemy zarządzania zasobami biznesowymi itp.
Jeśli aktualny stan centralnej struktury danych jest głównym wyzwalaczem wyboru procesów do wykonania, repozytorium może być tablicą, a to współdzielone źródło danych jest aktywnym agentem.
Główna różnica w porównaniu z tradycyjnymi systemami baz danych polega na tym, że wywołanie elementów obliczeniowych w architekturze tablicy jest wyzwalane przez bieżący stan tablicy, a nie przez zewnętrzne dane wejściowe.
Części modelu tablicy
Model tablicy zwykle składa się z trzech głównych części -
Knowledge Sources (KS)
Źródła wiedzy, znane również jako Listeners lub Subscriberssą odrębnymi i niezależnymi jednostkami. Rozwiązują części problemu i agregują częściowe wyniki. Interakcja między źródłami wiedzy odbywa się wyjątkowo poprzez tablicę.
Blackboard Data Structure
Dane o stanie rozwiązywania problemów są zorganizowane w hierarchię zależną od aplikacji. Źródła wiedzy wprowadzają zmiany na tablicy, które stopniowo prowadzą do rozwiązania problemu.
Control
Control zarządza zadaniami i sprawdza stan pracy.
Zalety
Zapewnia skalowalność, która zapewnia łatwe dodawanie lub aktualizowanie źródła wiedzy.
Zapewnia współbieżność, która umożliwia równoległą pracę wszystkich źródeł wiedzy, ponieważ są one od siebie niezależne.
Wspiera eksperymentowanie dla hipotez.
Obsługuje możliwość ponownego wykorzystania agentów źródła wiedzy.
Niedogodności
Zmiana struktury tablicy może mieć znaczący wpływ na wszystkich jej agentów, ponieważ istnieje ścisła zależność między tablicą a źródłem wiedzy.
Trudno jest zdecydować, kiedy zakończyć rozumowanie, ponieważ oczekuje się jedynie przybliżonego rozwiązania.
Problemy z synchronizacją wielu agentów.
Główne wyzwania w projektowaniu i testowaniu systemu.
Architektura hierarchiczna postrzega cały system jako strukturę hierarchiczną, w której system oprogramowania jest rozłożony na logiczne moduły lub podsystemy na różnych poziomach w hierarchii. Podejście to jest zwykle używane przy projektowaniu oprogramowania systemowego, takiego jak protokoły sieciowe i systemy operacyjne.
W projektowaniu hierarchii oprogramowania systemowego podsystem niskiego poziomu zapewnia usługi sąsiednim podsystemom wyższego poziomu, które wywołują metody na niższym poziomie. Niższa warstwa zapewnia bardziej specyficzne funkcje, takie jak usługi we / wy, transakcje, planowanie, usługi bezpieczeństwa itp. Warstwa środkowa zapewnia funkcje bardziej zależne od domeny, takie jak logika biznesowa i podstawowe usługi przetwarzania. Górna warstwa zapewnia bardziej abstrakcyjną funkcjonalność w postaci interfejsu użytkownika, takiego jak GUI, narzędzia programowania powłoki itp.
Jest również używany do organizacji bibliotek klas, takich jak biblioteka klas .NET w hierarchii przestrzeni nazw. Wszystkie typy projektów mogą implementować tę hierarchiczną architekturę i często łączą się z innymi stylami architektury.
Hierarchiczne style architektoniczne są podzielone na -
- Main-subroutine
- Master-slave
- Maszyna wirtualna
Główny podprogram
Celem tego stylu jest ponowne wykorzystanie modułów i swobodne opracowywanie poszczególnych modułów lub podprogramów. W tym stylu system oprogramowania jest podzielony na podprogramy za pomocą udoskonalenia odgórnego zgodnie z pożądaną funkcjonalnością systemu.
Te udoskonalenia prowadzą pionowo, aż zdekomponowane moduły są na tyle proste, że ponoszą wyłączną niezależną odpowiedzialność. Funkcjonalność może być ponownie wykorzystywana i współdzielona przez wielu abonentów w wyższych warstwach.
Istnieją dwa sposoby przekazywania danych jako parametrów do podprogramów, a mianowicie -
Pass by Value - Podprogramy wykorzystują tylko poprzednie dane, ale nie mogą ich modyfikować.
Pass by Reference - Podprogramy wykorzystują, jak również zmieniają wartość danych, do których odwołuje się parametr.

Zalety
Łatwy do rozłożenia systemu w oparciu o udoskonalenie hierarchii.
Może być używany w podsystemie projektowania obiektowego.
Niedogodności
Podatny, ponieważ zawiera dane udostępniane globalnie.
Ścisłe połączenie może powodować bardziej tętniące efekty zmian.
Master-Slave
Podejście to stosuje zasadę „dziel i zwyciężaj” oraz wspiera obliczenia błędów i dokładność obliczeń. Jest to modyfikacja architektury głównego podprogramu, która zapewnia niezawodność systemu i odporność na uszkodzenia.
W tej architekturze slave zapewniają zduplikowane usługi dla mastera, a master wybiera określony wynik spośród slaveów za pomocą określonej strategii wyboru. Slaverzy mogą wykonywać to samo zadanie funkcjonalne za pomocą różnych algorytmów i metod lub całkowicie odmiennych funkcji. Obejmuje obliczenia równoległe, w których wszystkie urządzenia podrzędne mogą być wykonywane równolegle.

Implementacja wzorca Master-Slave obejmuje pięć kroków -
Określ, w jaki sposób obliczenia zadania można podzielić na zestaw równych podzadań i określ usługi podrzędne, które są potrzebne do przetworzenia pod-zadania.
Określ, jak można obliczyć ostateczny wynik całej usługi za pomocą wyników uzyskanych z przetwarzania poszczególnych podzadań.
Zdefiniuj interfejs dla usługi podrzędnej określonej w kroku 1. Zostanie on zaimplementowany przez slave i użyty przez mastera do delegowania przetwarzania poszczególnych podzadań.
Zaimplementuj komponenty podrzędne zgodnie ze specyfikacjami opracowanymi w poprzednim kroku.
Zaimplementuj wzorzec zgodnie ze specyfikacjami opracowanymi w krokach od 1 do 3.
Aplikacje
Nadaje się do zastosowań, w których niezawodność oprogramowania ma krytyczne znaczenie.
Szerokie zastosowanie w obszarach obliczeń równoległych i rozproszonych.
Zalety
Szybsze obliczenia i łatwa skalowalność.
Zapewnia niezawodność, ponieważ slave mogą być duplikowane.
Slave można zaimplementować na różne sposoby, aby zminimalizować błędy semantyczne.
Niedogodności
Koszty komunikacji.
Nie wszystkie problemy można podzielić.
Problem trudny do wdrożenia i przenoszenia.
Architektura maszyny wirtualnej
Architektura maszyny wirtualnej udaje funkcje, które nie są natywne dla sprzętu i / lub oprogramowania, na którym jest zaimplementowana. Maszyna wirtualna jest zbudowana na istniejącym systemie i zapewnia wirtualną abstrakcję, zestaw atrybutów i operacji.
W architekturze maszyny wirtualnej urządzenie nadrzędne wykorzystuje „tę samą„ usługę podrzędną ”co urządzenie podrzędne i wykonuje takie funkcje, jak podział pracy, wywoływanie urządzeń podrzędnych i łączenie wyników. Pozwala programistom symulować i testować platformy, które nie zostały jeszcze zbudowane, a także symulować tryby „katastrofy”, które byłyby zbyt złożone, kosztowne lub niebezpieczne, aby przetestować je w rzeczywistym systemie.
W większości przypadków maszyna wirtualna oddziela język programowania lub środowisko aplikacji od platformy wykonawczej. Głównym celem jest zapewnienieportability. Interpretacja określonego modułu za pośrednictwem maszyny wirtualnej może być postrzegana jako -
Silnik interpretacyjny wybiera instrukcję z interpretowanego modułu.
Na podstawie instrukcji silnik aktualizuje stan wewnętrzny maszyny wirtualnej i powyższy proces jest powtarzany.
Poniższy rysunek przedstawia architekturę standardowej infrastruktury maszyn wirtualnych na pojedynczym komputerze fizycznym.

Plik hypervisor, zwany także virtual machine monitor, działa w systemie operacyjnym hosta i przydziela dopasowane zasoby do każdego systemu gościa. Gdy gość wykonuje wywołanie systemowe, hiperwizor przechwytuje je i tłumaczy na odpowiednie wywołanie systemowe obsługiwane przez system operacyjny hosta. Hiperwizor kontroluje dostęp każdej maszyny wirtualnej do procesora, pamięci, pamięci trwałej, urządzeń we / wy i sieci.
Aplikacje
Architektura maszyny wirtualnej jest odpowiednia w następujących domenach -
Nadaje się do rozwiązywania problemu za pomocą symulacji lub tłumaczenia, jeśli nie ma bezpośredniego rozwiązania.
Przykładowe aplikacje obejmują interpretery mikroprogramowania, przetwarzania XML, wykonywania skryptów w języku poleceń, wykonywania systemu opartego na regułach, języka programowania typu Smalltalk i interpretera Java.
Typowymi przykładami maszyn wirtualnych są interpretery, systemy oparte na regułach, powłoki składniowe i procesory języka poleceń.
Zalety
Mobilność i niezależność od platformy maszyny.
Prostota tworzenia oprogramowania.
Zapewnia elastyczność dzięki możliwości przerywania i wysyłania zapytań do programu.
Symulacja dla modelu pracy po katastrofie.
Wprowadź modyfikacje w czasie wykonywania.
Niedogodności
Powolne wykonywanie pracy przez tłumacza ze względu na charakter tłumacza.
Występuje koszt wydajności z powodu dodatkowych obliczeń związanych z wykonaniem.
Styl warstwowy
W tym podejściu system jest rozkładany na kilka wyższych i niższych warstw w hierarchii, a każda warstwa ponosi wyłączną odpowiedzialność w systemie.
Każda warstwa składa się z grupy powiązanych klas, które są zawarte w pakiecie, we wdrożonym komponencie lub jako grupa podprogramów w formacie biblioteki metod lub pliku nagłówka.
Każda warstwa dostarcza usługi warstwie powyżej i służy jako klient warstwie poniżej, tj. Żądanie do warstwy i +1 wywołuje usługi świadczone przez warstwę i za pośrednictwem interfejsu warstwy i. Odpowiedź może wrócić do warstwy i +1, jeśli zadanie zostanie zakończone; w przeciwnym razie warstwa i stale wywołuje usługi z warstwy i -1 poniżej.
Aplikacje
Styl warstwowy jest odpowiedni w następujących obszarach -
Aplikacje, które obejmują różne klasy usług, które można uporządkować hierarchicznie.
Dowolna aplikacja, którą można rozłożyć na części specyficzne dla aplikacji i platformy.
Aplikacje z wyraźnym podziałem na usługi podstawowe, usługi krytyczne i usługi interfejsu użytkownika itp.
Zalety
Projektowanie w oparciu o przyrostowe poziomy abstrakcji.
Zapewnia niezależność ulepszeń, ponieważ zmiany funkcji jednej warstwy wpływają na co najwyżej dwie inne warstwy.
Rozdzielenie standardowego interfejsu i jego implementacja.
Wdrożony przy użyciu technologii opartej na komponentach, dzięki czemu system jest znacznie łatwiejszy i umożliwia podłączenie nowych komponentów.
Każda warstwa może być abstrakcyjną maszyną wdrożoną niezależnie, która obsługuje przenośność.
Łatwy w dekompozycji system w oparciu o definicję zadań w sposób odgórny
Różne implementacje (z identycznymi interfejsami) tej samej warstwy mogą być używane zamiennie
Niedogodności
Wiele aplikacji lub systemów nie ma łatwej struktury warstwowej.
Niższa wydajność w czasie wykonywania, ponieważ żądanie klienta lub odpowiedź do klienta musi przejść przez potencjalnie kilka warstw.
Istnieją również problemy z wydajnością związane z narzutem na organizowanie i buforowanie danych przez każdą warstwę.
Otwarcie komunikacji międzywarstwowej może spowodować zakleszczenie, a „mostkowanie” może spowodować szczelne sprzężenie.
Wyjątki i obsługa błędów jest problemem w architekturze warstwowej, ponieważ błędy w jednej warstwie muszą rozprzestrzeniać się w górę na wszystkie warstwy wywołujące
Podstawowym celem architektury zorientowanej na interakcję jest oddzielenie interakcji użytkownika od abstrakcji i przetwarzania danych biznesowych. Architektura oprogramowania zorientowana na interakcję rozkłada system na trzy główne partycje -
Data module - Moduł danych zapewnia abstrakcję danych i całą logikę biznesową.
Control module - Moduł sterujący identyfikuje przepływ działań kontrolnych i konfiguracyjnych systemu.
View presentation module - Moduł prezentacji widoku jest odpowiedzialny za wizualną lub dźwiękową prezentację danych wyjściowych, a także zapewnia interfejs do wprowadzania danych przez użytkownika.
Architektura zorientowana na interakcję ma dwa główne style - Model-View-Controller (MVC) i Presentation-Abstraction-Control(PAC). Zarówno MVC, jak i PAC proponują dekompozycję trzech komponentów i są używane w aplikacjach interaktywnych, takich jak aplikacje internetowe z wieloma rozmowami i interakcjami użytkownika. Różnią się przepływem kontroli i organizacją. PAC jest hierarchiczną architekturą opartą na agentach, ale MVC nie ma jasnej struktury hierarchicznej.
Kontroler widoku modelu (MVC)
MVC rozkłada daną aplikację na trzy połączone ze sobą części, które pomagają w oddzieleniu wewnętrznych reprezentacji informacji od informacji przedstawionych użytkownikowi lub zaakceptowanych przez użytkownika.
| Moduł | Funkcjonować |
|---|---|
| Model | Hermetyzacja danych i logiki biznesowej |
| Kontroler | Reaguj na działanie użytkownika i kieruj przepływem aplikacji |
| Widok | Formatuje i przedstawia dane z modelu użytkownikowi. |
Model
Model jest centralnym komponentem MVC, który bezpośrednio zarządza danymi, logiką i ograniczeniami aplikacji. Składa się z komponentów danych, które utrzymują surowe dane aplikacji i logikę aplikacji dla interfejsu.
Jest to niezależny interfejs użytkownika i rejestruje zachowanie domeny, w której występują problemy z aplikacjami.
Jest to specyficzna dla domeny symulacja oprogramowania lub implementacja centralnej struktury aplikacji.
Gdy nastąpiła zmiana w jego stanie, wysyła powiadomienie do skojarzonego z nim widoku, aby wygenerować zaktualizowane wyjście, a sterownik do zmiany dostępnego zestawu poleceń.
Widok
Widok może służyć do przedstawiania dowolnych danych wyjściowych w formie graficznej, takiej jak diagram lub wykres. Składa się z komponentów prezentacji, które zapewniają wizualną reprezentację danych
Widoki żądają informacji ze swojego modelu i generują reprezentację wyjściową dla użytkownika.
Możliwych jest wiele widoków tych samych informacji, takich jak wykres słupkowy do zarządzania i widok tabelaryczny dla księgowych.
Kontroler
Kontroler akceptuje dane wejściowe i konwertuje je na polecenia dla modelu lub widoku. Składa się z komponentów przetwarzania danych wejściowych, które obsługują dane wejściowe od użytkownika poprzez modyfikację modelu.
Działa jako interfejs między skojarzonymi modelami i widokami a urządzeniami wejściowymi.
Może wysyłać polecenia do modelu, aby zaktualizować stan modelu i do skojarzonego z nim widoku, aby zmienić prezentację modelu w widoku.

MVC - I
Jest to prosta wersja architektury MVC, w której system jest podzielony na dwa podsystemy -
The Controller-View - Widok kontrolera działa jako interfejs wejścia / wyjścia i przetwarzanie jest zakończone.
The Model - Model zapewnia wszystkie usługi związane z danymi i domenami.
MVC-I Architecture
Moduł modelowy powiadamia moduł widoku sterownika o wszelkich zmianach danych, dzięki czemu wszelkie wyświetlane dane graficzne zostaną odpowiednio zmienione. Administrator podejmuje również odpowiednie działania w przypadku zmian.

Połączenie między widokiem kontrolera a modelem można zaprojektować według wzoru (jak pokazano na powyższym obrazku) powiadomienia o subskrypcji, w którym widok kontrolera subskrybuje model, a model powiadamia widok kontrolera o wszelkich zmianach.
MVC - II
MVC-II jest rozszerzeniem architektury MVC-I, w której moduł widoku i moduł kontrolera są oddzielne. Moduł modelowy odgrywa aktywną rolę, podobnie jak w MVC-I, zapewniając wszystkie podstawowe funkcje i dane obsługiwane przez bazę danych.
Moduł widoku prezentuje dane, podczas gdy moduł kontrolera przyjmuje żądanie wejścia, weryfikuje dane wejściowe, inicjuje model, widok, ich połączenie, a także wysyła zadanie.
MVC-II Architecture

Aplikacje MVC
Aplikacje MVC są efektywne w przypadku aplikacji interaktywnych, w których dla jednego modelu danych potrzeba wielu widoków i można je łatwo podłączyć do nowego lub zmienić widok interfejsu.
Aplikacje MVC są odpowiednie dla aplikacji, w których istnieją wyraźne podziały między modułami, dzięki czemu można przypisać różnych specjalistów do jednoczesnej pracy nad różnymi aspektami takich aplikacji.
Advantages
Dostępnych jest wiele zestawów narzędzi dla dostawców MVC.
Wiele widoków zsynchronizowanych z tym samym modelem danych.
Łatwe do podłączenia nowe lub zastąpienia widoków interfejsu.
Służy do tworzenia aplikacji, w których specjaliści od grafiki, specjaliści od programowania i specjaliści ds. Rozwoju baz danych pracują w zaprojektowanym zespole projektowym.
Disadvantages
Nie nadaje się do aplikacji zorientowanych na agentów, takich jak interaktywne aplikacje mobilne i robotyka.
Wiele par kontrolerów i widoków opartych na tym samym modelu danych powoduje, że każda zmiana modelu danych jest kosztowna.
W niektórych przypadkach podział między View a Controller nie jest jasny.
Kontrola prezentacji-abstrakcji (PAC)
W PAC system jest zorganizowany w hierarchię wielu współpracujących agentów (triad). Został opracowany z MVC w celu obsługi wymagań aplikacji wielu agentów oprócz wymagań interaktywnych.
Każdy agent składa się z trzech elementów -
The presentation component - Formatuje wizualną i dźwiękową prezentację danych.
The abstraction component - Pobiera i przetwarza dane.
The control component - Obsługuje zadania, takie jak przepływ kontroli i komunikacja między pozostałymi dwoma komponentami.
Architektura PAC jest podobna do MVC, w tym sensie, że moduł prezentacji jest podobny do modułu widoku MVC. Moduł abstrakcji wygląda jak moduł modelowy MVC, a moduł sterujący jest podobny do modułu kontrolera MVC, ale różnią się przepływem kontroli i organizacją.
W każdym agencie nie ma bezpośrednich połączeń między komponentem abstrakcji a komponentem prezentacji. Komponent kontrolny każdego agenta odpowiada za komunikację z innymi agentami.
Poniższy rysunek przedstawia schemat blokowy pojedynczego agenta w projekcie PAC.

PAC z wieloma agentami
W poświadczeniach dostępu zabezpieczonego składających się z wielu agentów agent najwyższego poziomu zapewnia podstawowe dane i logikę biznesową. Agenci najniższego poziomu definiują szczegółowe dane i prezentacje. Agent średniego lub średniego szczebla działa jako koordynator agentów niskiego poziomu.
Każdy agent ma swoje przypisane zadanie.
W przypadku niektórych agentów średniego poziomu prezentacje interaktywne nie są wymagane, więc nie mają komponentu prezentacji.
Komponent kontrolny jest wymagany dla wszystkich agentów, za pośrednictwem których wszyscy agenci komunikują się ze sobą.
Poniższy rysunek przedstawia wielu agentów biorących udział w PAC.

Applications
Skuteczny dla systemu interaktywnego, w którym system można rozłożyć na wielu współpracujących agentów w sposób hierarchiczny.
Skuteczny, gdy oczekuje się, że sprzężenie między czynnikami będzie luźne, aby zmiany w czynniku nie wpływały na innych.
Skuteczny dla systemów rozproszonych, w których wszyscy agenci są zdalnie rozproszeni, a każdy z nich ma własne funkcjonalności z danymi i interaktywnym interfejsem.
Nadaje się do aplikacji z bogatymi komponentami GUI, w których każdy z nich przechowuje własne bieżące dane i interaktywny interfejs oraz musi komunikować się z innymi komponentami.
Zalety
Obsługa wielozadaniowości i wielu widoków
Obsługa możliwości ponownego użycia i rozszerzania agentów
Łatwo podłączyć nowego agenta lub zmienić istniejącego
Obsługa współbieżności, w której wielu agentów działa równolegle w różnych wątkach lub na różnych urządzeniach lub komputerach
Niedogodności
Koszty ogólne ze względu na pomost kontrolny między prezentacją a abstrakcją oraz komunikacją kontroli między agentami.
Trudno jest określić właściwą liczbę agentów ze względu na luźne powiązania i dużą niezależność między agentami.
Całkowite oddzielenie prezentacji i abstrakcji przez kontrolę w każdym agencie generuje złożoność programowania, ponieważ komunikacja między agentami odbywa się tylko między kontrolkami agentów
W architekturze rozproszonej komponenty są prezentowane na różnych platformach, a kilka komponentów może współpracować ze sobą w sieci komunikacyjnej w celu osiągnięcia określonego celu lub celu.
W tej architekturze przetwarzanie informacji nie ogranicza się do jednej maszyny, ale jest rozłożone na kilka niezależnych komputerów.
Rozproszony system można zademonstrować poprzez architekturę klient-serwer, która stanowi podstawę dla architektur wielowarstwowych; alternatywami są architektura brokera, taka jak CORBA, oraz architektura zorientowana na usługi (SOA).
Istnieje kilka platform technologicznych obsługujących architektury rozproszone, w tym .NET, J2EE, CORBA, .NET Web services, AXIS Java Web services i Globus Grid.
Oprogramowanie pośredniczące to infrastruktura, która odpowiednio obsługuje tworzenie i wykonywanie aplikacji rozproszonych. Zapewnia bufor między aplikacjami a siecią.
Znajduje się w środku systemu i zarządza różnymi komponentami rozproszonego systemu lub obsługuje je. Przykładami są monitory przetwarzania transakcji, konwertery danych i kontrolery komunikacji itp.
Oprogramowanie pośredniczące jako infrastruktura dla systemu rozproszonego

Podstawą rozproszonej architektury jest jej przejrzystość, niezawodność i dostępność.
W poniższej tabeli wymieniono różne formy przejrzystości w systemie rozproszonym -
| Sr.No. | Przejrzystość i opis |
|---|---|
| 1 | Access Ukrywa sposób uzyskiwania dostępu do zasobów i różnice w platformie danych. |
| 2 | Location Ukrywa lokalizację zasobów. |
| 3 | Technology Ukrywa przed użytkownikiem różne technologie, takie jak język programowania i system operacyjny. |
| 4 | Migration / Relocation Ukryj zasoby, które można przenieść w inne używane miejsce. |
| 5 | Replication Ukryj zasoby, które można skopiować w kilku miejscach. |
| 6 | Concurrency Ukryj zasoby, które mogą być udostępniane innym użytkownikom. |
| 7 | Failure Ukrywa awarie i odzyskiwanie zasobów przed użytkownikiem. |
| 8 | Persistence Ukrywa, czy zasób (oprogramowanie) znajduje się w pamięci, czy na dysku. |
Zalety
Resource sharing - Współdzielenie zasobów sprzętowych i programowych.
Openness - Elastyczność użytkowania sprzętu i oprogramowania różnych dostawców.
Concurrency - Jednoczesne przetwarzanie w celu zwiększenia wydajności.
Scalability - Zwiększona przepustowość poprzez dodanie nowych zasobów.
Fault tolerance - Możliwość kontynuowania pracy po wystąpieniu błędu.
Niedogodności
Complexity - Są bardziej złożone niż systemy scentralizowane.
Security - Bardziej podatny na atak zewnętrzny.
Manageability - Większy wysiłek wymagany do zarządzania systemem.
Unpredictability - Nieprzewidywalne reakcje w zależności od organizacji systemu i obciążenia sieci.
System scentralizowany a system rozproszony
| Kryteria | Scentralizowany system | System rozproszony |
|---|---|---|
| Ekonomia | Niska | Wysoki |
| Dostępność | Niska | Wysoki |
| Złożoność | Niska | Wysoki |
| Konsystencja | Prosty | Wysoki |
| Skalowalność | Ubogi | Dobry |
| Technologia | Jednorodny | Heterogeniczny |
| Bezpieczeństwo | Wysoki | Niska |
Architektura klient-serwer
Architektura klient-serwer jest najpopularniejszą architekturą systemu rozproszonego, która rozkłada system na dwa główne podsystemy lub procesy logiczne -
Client - Jest to pierwszy proces, który wysyła żądanie do drugiego procesu, tj. Serwera.
Server - To jest drugi proces, który odbiera żądanie, wykonuje je i wysyła odpowiedź do klienta.
W tej architekturze aplikacja jest modelowana jako zestaw usług dostarczanych przez serwery i zestaw klientów korzystających z tych usług. Serwery nie muszą wiedzieć o klientach, ale klienci muszą znać tożsamość serwerów, a mapowanie procesorów do procesów niekoniecznie jest 1: 1

Architekturę klient-serwer można podzielić na dwa modele w zależności od funkcjonalności klienta -
Model cienkiego klienta
W modelu cienkiego klienta całe przetwarzanie aplikacji i zarządzanie danymi jest realizowane przez serwer. Klient jest po prostu odpowiedzialny za uruchomienie oprogramowania do prezentacji.
Używane, gdy starsze systemy są migrowane do architektur klienta-serwera, w których starszy system działa jako sam serwer z interfejsem graficznym zaimplementowanym na kliencie
Główną wadą jest to, że powoduje duże obciążenie przetwarzania zarówno na serwerze, jak i w sieci.
Model grubego / grubego klienta
W modelu grubego klienta serwer odpowiada tylko za zarządzanie danymi. Oprogramowanie na kliencie implementuje logikę aplikacji i interakcje z użytkownikiem systemu.
Najbardziej odpowiedni dla nowych systemów C / S, w których możliwości systemu klienta są znane z góry
Bardziej złożony niż model cienkiego klienta, zwłaszcza do zarządzania. Nowe wersje aplikacji muszą być zainstalowane na wszystkich klientach.
Zalety
Rozdzielenie obowiązków, takich jak prezentacja interfejsu użytkownika i przetwarzanie logiki biznesowej.
Możliwość ponownego wykorzystania składników serwera i możliwość współbieżności
Upraszcza projektowanie i tworzenie aplikacji rozproszonych
Ułatwia migrację lub integrację istniejących aplikacji w środowisku rozproszonym.
Efektywnie wykorzystuje również zasoby, gdy duża liczba klientów uzyskuje dostęp do serwera o wysokiej wydajności.
Niedogodności
Brak heterogenicznej infrastruktury do obsługi zmian wymagań.
Komplikacje dotyczące bezpieczeństwa.
Ograniczona dostępność i niezawodność serwera.
Ograniczona testowalność i skalowalność.
Grubi klienci z prezentacją i logiką biznesową razem.
Architektura wielowarstwowa (architektura n-warstwowa)
Architektura wielowarstwowa to architektura klient-serwer, w której funkcje takie jak prezentacja, przetwarzanie aplikacji i zarządzanie danymi są fizycznie oddzielone. Dzieląc aplikację na warstwy, programiści uzyskują możliwość zmiany lub dodania określonej warstwy, zamiast przerabiania całej aplikacji. Zapewnia model, za pomocą którego programiści mogą tworzyć elastyczne i wielokrotnego użytku aplikacje.

Najbardziej ogólnym zastosowaniem architektury wielowarstwowej jest architektura trójwarstwowa. Architektura trójwarstwowa zazwyczaj składa się z warstwy prezentacji, warstwy aplikacji i warstwy przechowywania danych i może być wykonywana na oddzielnym procesorze.
Poziom prezentacji
Warstwa prezentacji to najwyższy poziom aplikacji, za pomocą którego użytkownicy mogą uzyskać bezpośredni dostęp, na przykład do strony internetowej lub GUI systemu operacyjnego (graficzny interfejs użytkownika). Podstawową funkcją tej warstwy jest przetłumaczenie zadań i wyników na coś zrozumiałego dla użytkownika. Komunikuje się z innymi warstwami, dzięki czemu umieszcza wyniki w warstwie przeglądarki / klienta i wszystkich innych warstwach w sieci.
Poziom aplikacji (logika biznesowa, warstwa logiki lub warstwa środkowa)
Poziom aplikacji koordynuje aplikację, przetwarza polecenia, podejmuje logiczne decyzje, ocenia i wykonuje obliczenia. Kontroluje funkcjonalność aplikacji, wykonując szczegółowe przetwarzanie. Przenosi również i przetwarza dane między dwiema otaczającymi warstwami.
Poziom danych
W tej warstwie informacje są przechowywane i pobierane z bazy danych lub systemu plików. Informacje są następnie przekazywane z powrotem do przetwarzania, a następnie z powrotem do użytkownika. Obejmuje mechanizmy trwałości danych (serwery baz danych, udziały plików itp.) I zapewnia API (interfejs programowania aplikacji) do warstwy aplikacji, która zapewnia metody zarządzania przechowywanymi danymi.
Advantages
Lepsza wydajność niż podejście „cienkiego klienta” i prostsze zarządzanie niż podejście „grubego klienta”.
Zwiększa możliwość ponownego użycia i skalowalność - wraz ze wzrostem wymagań można dodać dodatkowe serwery.
Zapewnia obsługę wielowątkowości, a także zmniejsza ruch w sieci.
Zapewnia łatwość konserwacji i elastyczność
Disadvantages
Niezadowalająca testowalność z powodu braku narzędzi testujących.
Bardziej krytyczna niezawodność i dostępność serwera.
Styl architektoniczny brokera
Broker Architectural Style to architektura oprogramowania pośredniego używana w obliczeniach rozproszonych do koordynowania i umożliwiania komunikacji między zarejestrowanymi serwerami a klientami. Tutaj komunikacja obiektowa odbywa się za pośrednictwem systemu oprogramowania pośredniego zwanego brokerem żądań obiektów (magistrala oprogramowania).
Klient i serwer nie współdziałają bezpośrednio ze sobą. Klient i serwer mają bezpośrednie połączenie ze swoim proxy, które komunikuje się z pośrednikiem-brokerem.
Serwer świadczy usługi, rejestrując i publikując swoje interfejsy z brokerem, a klienci mogą żądać usług od brokera statycznie lub dynamicznie za pomocą wyszukiwania.
CORBA (Common Object Request Broker Architecture) jest dobrym przykładem implementacji architektury brokera.
Elementy stylu architektonicznego brokera
Składowe stylu architektonicznego brokera są omawiane w następujących głowach:
Broker
Broker jest odpowiedzialny za koordynację komunikacji, na przykład przekazywanie i rozsyłanie wyników oraz wyjątków. Może to być usługa zorientowana na wywołania, dokument lub broker zorientowany na komunikaty, do którego klienci wysyłają wiadomość.
Odpowiada za pośrednictwo w żądaniach usług, lokalizowanie odpowiedniego serwera, przesyłanie żądań i wysyłanie odpowiedzi z powrotem do klientów.
Zachowuje informacje rejestracyjne serwerów, w tym ich funkcjonalność i usługi, a także informacje o lokalizacji.
Zapewnia interfejsy API do żądania przez klientów, serwery do odpowiadania, rejestrowanie lub wyrejestrowywanie składników serwera, przesyłanie wiadomości i lokalizowanie serwerów.
Stub
Stuby są generowane w czasie kompilacji statycznej, a następnie wdrażane po stronie klienta, która jest używana jako serwer proxy dla klienta. Proxy po stronie klienta działa jako mediator między klientem a brokerem i zapewnia dodatkową przejrzystość między nimi a klientem; zdalny obiekt wygląda jak lokalny.
Proxy ukrywa IPC (komunikację międzyprocesową) na poziomie protokołu i wykonuje organizowanie wartości parametrów oraz cofanie wyników z serwera.
Skeleton
Szkielet jest generowany przez kompilację interfejsu usługi, a następnie wdrażany po stronie serwera, który jest używany jako serwer proxy dla serwera. Serwer proxy po stronie serwera hermetyzuje funkcje sieciowe niskiego poziomu specyficzne dla systemu i zapewnia interfejsy API wysokiego poziomu do pośredniczenia między serwerem a brokerem.
Odbiera żądania, rozpakowuje żądania, usuwa argumenty metody, wywołuje odpowiednią usługę, a także organizuje wynik przed wysłaniem go z powrotem do klienta.
Bridge
Most może łączyć dwie różne sieci w oparciu o różne protokoły komunikacyjne. Pośredniczy w obsłudze różnych brokerów, w tym brokerów DCOM, .NET remote i Java CORBA.
Mosty są komponentem opcjonalnym, który ukrywa szczegóły implementacji, gdy dwóch brokerów współpracuje i przyjmuje żądania i parametry w jednym formacie oraz tłumaczy je na inny format.

Broker implementation in CORBA
CORBA to międzynarodowy standard dla Object Request Broker - oprogramowania pośredniczącego do zarządzania komunikacją między rozproszonymi obiektami zdefiniowanymi przez OMG (grupa zarządzania obiektami).

Architektura zorientowana na usługi (SOA)
Usługa jest składnikiem funkcjonalności biznesowej, który jest dobrze zdefiniowany, samodzielny, niezależny, opublikowany i dostępny do użycia za pośrednictwem standardowego interfejsu programistycznego. Połączenia między usługami są realizowane przez powszechne i uniwersalne protokoły zorientowane na komunikaty, takie jak protokół usługi sieci Web SOAP, który może luźno dostarczać żądania i odpowiedzi między usługami.
Architektura zorientowana na usługi to projekt typu klient / serwer, który wspiera biznesowe podejście IT, w którym aplikacja składa się z usług oprogramowania i odbiorców usług oprogramowania (zwanych również klientami lub requesterami usług).
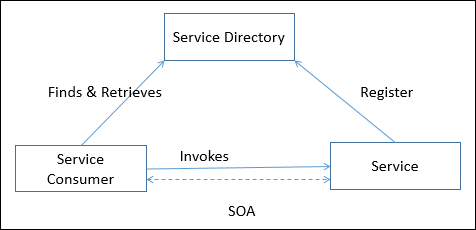
Cechy SOA
Architektura zorientowana na usługi zapewnia następujące funkcje -
Distributed Deployment - Ujawnij dane przedsiębiorstwa i logikę biznesową jako luźne, powiązane, wykrywalne, ustrukturyzowane, oparte na standardach, gruboziarniste, bezstanowe jednostki funkcjonalności zwane usługami.
Composability - Zbierz nowe procesy z istniejących usług, które są udostępniane z pożądaną szczegółowością za pośrednictwem dobrze zdefiniowanych, opublikowanych i standardowych interfejsów skarg.
Interoperability - Dziel się możliwościami i ponownie wykorzystuj współdzielone usługi w sieci niezależnie od bazowych protokołów lub technologii implementacji.
Reusability - Wybierz dostawcę usług i dostęp do istniejących zasobów udostępnianych jako usługi.
Operacja SOA
Poniższy rysunek przedstawia sposób działania SOA -

Advantages
Luźne powiązanie orientacji na usługi zapewnia przedsiębiorstwom dużą elastyczność w korzystaniu ze wszystkich dostępnych zasobów usług, niezależnie od platform i ograniczeń technologicznych.
Każdy składnik usługi jest niezależny od innych usług ze względu na funkcję usługi bezstanowej.
Implementacja usługi nie wpłynie na aplikację usługi, o ile ujawniony interfejs nie zostanie zmieniony.
Klient lub dowolna usługa może uzyskać dostęp do innych usług niezależnie od platformy, technologii, dostawców lub implementacji językowej.
Możliwość ponownego wykorzystania zasobów i usług, ponieważ klienci usługi muszą znać tylko jej interfejsy publiczne, skład usługi.
Tworzenie aplikacji biznesowych opartych na architekturze SOA jest znacznie bardziej wydajne pod względem czasu i kosztów.
Zwiększa skalowalność i zapewnia standardowe połączenie między systemami.
Wydajne i efektywne wykorzystanie „usług biznesowych”.
Integracja staje się znacznie łatwiejsza i poprawia wewnętrzną interoperacyjność.
Abstrakcyjna złożoność dla programistów i pobudzanie procesów biznesowych bliżej użytkowników końcowych.
Architektura oparta na komponentach skupia się na dekompozycji projektu na poszczególne komponenty funkcjonalne lub logiczne, które reprezentują dobrze zdefiniowane interfejsy komunikacyjne zawierające metody, zdarzenia i właściwości. Zapewnia wyższy poziom abstrakcji i dzieli problem na podproblemy, z których każdy jest powiązany z partycjami składowymi.
Podstawowym celem architektury opartej na komponentach jest zapewnienie component reusability. Komponent hermetyzuje funkcjonalność i zachowanie elementu oprogramowania w jednostce binarnej wielokrotnego użytku i samodzielnego wdrażania. Istnieje wiele standardowych struktur składowych, takich jak COM / DCOM, JavaBean, EJB, CORBA, .NET, usługi sieciowe i usługi gridowe. Technologie te są szeroko stosowane w projektowaniu lokalnych aplikacji GUI na komputery stacjonarne, takich jak graficzne komponenty JavaBean, komponenty MS ActiveX i komponenty COM, które można ponownie wykorzystać, po prostu przeciągając i upuszczając.
Projektowanie oprogramowania zorientowanego na komponenty ma wiele zalet w porównaniu z tradycyjnymi podejściami obiektowymi, takimi jak -
Skrócony czas na rynku i koszty rozwoju dzięki ponownemu wykorzystaniu istniejących komponentów.
Zwiększona niezawodność dzięki ponownemu wykorzystaniu istniejących komponentów.
Co to jest komponent?
Komponent to modułowy, przenośny, wymienny i wielokrotnego użytku zestaw dobrze zdefiniowanych funkcji, który zawiera jego implementację i eksportuje jako interfejs wyższego poziomu.
Komponent to obiekt oprogramowania, przeznaczony do interakcji z innymi komponentami, obejmujący określoną funkcjonalność lub zestaw funkcji. Ma wyraźnie zdefiniowany interfejs i jest zgodny z zalecanym zachowaniem, wspólnym dla wszystkich komponentów w architekturze.
Komponent oprogramowania można zdefiniować jako jednostkę kompozycji z interfejsem określonym w umowie i tylko jawnymi zależnościami kontekstowymi. Oznacza to, że komponent oprogramowania może być wdrażany niezależnie i podlega kompozycji stron trzecich.
Widoki komponentu
Komponent może mieć trzy różne widoki - widok obiektowy, widok konwencjonalny i widok związany z procesem.
Object-oriented view
Komponent jest postrzegany jako zbiór jednej lub więcej współpracujących klas. Każda klasa domeny problemu (analiza) i klasa infrastruktury (projekt) są wyjaśnione w celu zidentyfikowania wszystkich atrybutów i operacji, które mają zastosowanie do jej implementacji. Obejmuje również zdefiniowanie interfejsów, które umożliwiają klasom komunikację i współpracę.
Conventional view
Jest postrzegany jako element funkcjonalny lub moduł programu, który integruje logikę przetwarzania, wewnętrzne struktury danych wymagane do implementacji logiki przetwarzania oraz interfejs, który umożliwia wywołanie komponentu i przekazanie do niego danych.
Process-related view
W tym widoku, zamiast tworzyć każdy komponent od podstaw, system buduje z istniejących komponentów utrzymywanych w bibliotece. W trakcie formułowania architektury oprogramowania komponenty są wybierane z biblioteki i wykorzystywane do zapełnienia architektury.
Komponent interfejsu użytkownika (UI) zawiera siatki, przyciski nazywane kontrolkami, a komponenty narzędziowe udostępniają określony podzbiór funkcji używanych w innych komponentach.
Inne typowe typy komponentów to te, które wymagają dużej ilości zasobów, nie są często używane i muszą być aktywowane przy użyciu podejścia just-in-time (JIT).
Wiele komponentów jest niewidocznych, które są rozpowszechniane w aplikacjach biznesowych przedsiębiorstwa i aplikacjach internetowych, takich jak Enterprise JavaBean (EJB), komponenty .NET i komponenty CORBA.
Charakterystyka elementów
Reusability- Komponenty są zwykle projektowane do ponownego wykorzystania w różnych sytuacjach w różnych zastosowaniach. Jednak niektóre komponenty mogą być zaprojektowane do określonego zadania.
Replaceable - Komponenty można dowolnie zastępować innymi podobnymi komponentami.
Not context specific - Komponenty są zaprojektowane do działania w różnych środowiskach i kontekstach.
Extensible - Komponent można rozszerzyć z istniejących komponentów, aby zapewnić nowe zachowanie.
Encapsulated - Komponent AA przedstawia interfejsy, które pozwalają dzwoniącemu na korzystanie z jego funkcjonalności i nie ujawniają szczegółów procesów wewnętrznych ani żadnych wewnętrznych zmiennych lub stanów.
Independent - Komponenty są zaprojektowane tak, aby mieć minimalne zależności od innych komponentów.
Zasady projektowania opartego na komponentach
Projekt na poziomie komponentu można przedstawić za pomocą pewnej reprezentacji pośredniej (np. Graficznej, tabelarycznej lub tekstowej), którą można przetłumaczyć na kod źródłowy. Projekt struktur danych, interfejsów i algorytmów powinien być zgodny z dobrze ugruntowanymi wytycznymi, aby pomóc nam uniknąć wprowadzania błędów.
System oprogramowania jest rozkładany na nadające się do wielokrotnego użytku, spójne i zamknięte w obudowie jednostki.
Każdy składnik ma własny interfejs, który określa wymagane porty i dostarczone porty; każdy komponent ukrywa swoją szczegółową implementację.
Komponent powinien zostać rozbudowany bez konieczności wprowadzania kodu wewnętrznego lub modyfikacji projektu istniejących części komponentu.
Składnik zależny od abstrakcji nie zależy od innych konkretnych składników, które zwiększają trudność w zbędności.
Łączniki łączy komponenty, określając i regulując interakcję między komponentami. Typ interakcji jest określony przez interfejsy komponentów.
Interakcja komponentów może przybrać formę wywołań metod, wywołań asynchronicznych, emisji, interakcji opartych na komunikatach, komunikacji strumieniowej danych i innych interakcji specyficznych dla protokołu.
W przypadku klasy serwerów należy utworzyć wyspecjalizowane interfejsy do obsługi głównych kategorii klientów. W interfejsie należy określić tylko te operacje, które są istotne dla określonej kategorii klientów.
Komponent może rozszerzać się na inne komponenty i nadal oferować własne punkty rozszerzeń. Jest to koncepcja architektury opartej na wtyczkach. Dzięki temu wtyczka może oferować inny interfejs API wtyczki.

Wytyczne dotyczące projektowania na poziomie komponentów
Tworzy konwencje nazewnictwa dla komponentów, które są określone jako część modelu architektonicznego, a następnie udoskonala lub rozwija jako część modelu na poziomie komponentów.
Pobiera nazwy komponentów architektonicznych z domeny problemu i zapewnia, że mają one znaczenie dla wszystkich interesariuszy, którzy przeglądają model architektoniczny.
Wyodrębnia jednostki procesu biznesowego, które mogą istnieć niezależnie, bez skojarzonej zależności od innych jednostek.
Rozpoznaje i odkrywa te niezależne jednostki jako nowe komponenty.
Używa nazw składników infrastruktury, które odzwierciedlają ich znaczenie specyficzne dla implementacji.
Modeluje wszelkie zależności od lewej do prawej i dziedziczenie od góry (klasa bazowa) do dołu (klasy pochodne).
Modeluj wszystkie zależności komponentów jako interfejsy, zamiast przedstawiać je jako bezpośrednią zależność między komponentami.
Przeprowadzanie projektowania na poziomie komponentów
Rozpoznaje wszystkie klasy projektowe, które odpowiadają domenie problemu zdefiniowanej w modelu analitycznym i modelu architektonicznym.
Rozpoznaje wszystkie klasy projektowe, które odpowiadają domenie infrastruktury.
Opisuje wszystkie klasy projektowe, które nie są nabywane jako komponenty wielokrotnego użytku, i określa szczegóły komunikatu.
Identyfikuje odpowiednie interfejsy dla każdego komponentu i opracowuje atrybuty oraz definiuje typy danych i struktury danych wymagane do ich wdrożenia.
Opisuje szczegółowo przepływ przetwarzania w ramach każdej operacji za pomocą pseudokodu lub diagramów aktywności UML.
Opisuje trwałe źródła danych (bazy danych i pliki) i identyfikuje klasy wymagane do zarządzania nimi.
Opracowuje i opracowuje reprezentacje behawioralne dla klasy lub komponentu. Można to zrobić, opracowując diagramy stanu UML utworzone dla modelu analitycznego i badając wszystkie przypadki użycia, które są istotne dla klasy projektu.
Opracowuje diagramy wdrażania, aby zapewnić dodatkowe szczegóły implementacji.
Pokazuje lokalizację pakietów kluczy lub klas komponentów w systemie za pomocą instancji klas i wyznaczając określony sprzęt i środowisko systemu operacyjnego.
Ostateczną decyzję można podjąć, stosując ustalone zasady i wytyczne projektowe. Doświadczeni projektanci rozważają wszystkie (lub większość) alternatywnych rozwiązań projektowych przed ustaleniem ostatecznego modelu projektowego.
Zalety
Ease of deployment - Wraz z pojawieniem się nowych kompatybilnych wersji łatwiej jest zastąpić istniejące wersje bez wpływu na inne komponenty lub system jako całość.
Reduced cost - Zastosowanie komponentów firm trzecich pozwala rozłożyć koszty rozwoju i utrzymania.
Ease of development - Komponenty implementują dobrze znane interfejsy w celu zapewnienia określonej funkcjonalności, umożliwiając rozwój bez wpływu na inne części systemu.
Reusable - Stosowanie komponentów wielokrotnego użytku oznacza, że można je wykorzystać do rozłożenia kosztów rozwoju i utrzymania na kilka aplikacji lub systemów.
Modification of technical complexity - Komponent modyfikuje złożoność poprzez użycie kontenera komponentów i jego usług.
Reliability - Ogólna niezawodność systemu wzrasta, ponieważ niezawodność każdego pojedynczego komponentu zwiększa niezawodność całego systemu poprzez ponowne użycie.
System maintenance and evolution - Łatwa zmiana i aktualizacja implementacji bez wpływu na resztę systemu.
Independent- Niezależność i elastyczna łączność komponentów. Niezależny rozwój komponentów przez różne grupy równolegle. Produktywność w zakresie tworzenia oprogramowania i przyszłego rozwoju oprogramowania.
Interfejs użytkownika to pierwsze wrażenie systemu oprogramowania z punktu widzenia użytkownika. Dlatego każdy system oprogramowania musi spełniać wymagania użytkownika. Interfejs użytkownika pełni głównie dwie funkcje -
Akceptacja danych wejściowych użytkownika
Wyświetlanie wyjścia
Interfejs użytkownika odgrywa kluczową rolę w każdym systemie oprogramowania. Jest to prawdopodobnie jedyny widoczny aspekt systemu oprogramowania, ponieważ -
Użytkownicy początkowo zobaczą architekturę zewnętrznego interfejsu użytkownika systemu oprogramowania bez uwzględnienia jego architektury wewnętrznej.
Dobry interfejs użytkownika musi zachęcać użytkownika do korzystania z systemu oprogramowania bez błędów. Powinien pomóc użytkownikowi w łatwym zrozumieniu systemu oprogramowania bez wprowadzających w błąd informacji. Zły interfejs użytkownika może spowodować niepowodzenie rynkowe w stosunku do konkurencji systemu oprogramowania.
Interfejs użytkownika ma swoją składnię i semantykę. Składnia obejmuje typy komponentów, takie jak tekstowe, ikona, przycisk itp., A użyteczność podsumowuje semantykę interfejsu użytkownika. Jakość interfejsu użytkownika charakteryzuje się wyglądem i działaniem (składnia) oraz użytecznością (semantyką).
Istnieją zasadniczo dwa główne rodzaje interfejsów użytkownika - a) tekstowy b) graficzny.
Oprogramowanie w różnych domenach może wymagać innego stylu interfejsu użytkownika, np. Kalkulator potrzebuje tylko małego obszaru do wyświetlania liczb liczbowych, ale dużego obszaru dla poleceń, Strona internetowa potrzebuje formularzy, linków, zakładek itp.
Graficzny interfejs użytkownika
Graficzny interfejs użytkownika jest obecnie najpopularniejszym typem interfejsu użytkownika. Jest bardzo przyjazny dla użytkownika, ponieważ wykorzystuje obrazy, grafikę i ikony - stąd nazywany jest „graficznym”.
Jest również znany jako WIMP interface ponieważ wykorzystuje -
Windows - Prostokątny obszar na ekranie, w którym działają często używane aplikacje.
Icons - Obraz lub symbol, który jest używany do reprezentowania aplikacji lub urządzenia sprzętowego.
Menus - Lista opcji, z których użytkownik może wybrać to, czego potrzebuje.
Pointers- Symbol, taki jak strzałka, który porusza się po ekranie, gdy użytkownik porusza myszą. Pomaga użytkownikowi wybierać obiekty.
Projekt interfejsu użytkownika
Rozpoczyna się od analizy zadań, która rozumie podstawowe zadania użytkownika i dziedzinę problemów. Powinien być zaprojektowany pod kątem terminologii Użytkownika i początków jego pracy, a nie programisty.
Aby przeprowadzić analizę interfejsu użytkownika, lekarz musi przestudiować i zrozumieć cztery elementy -
Plik users kto będzie wchodził w interakcję z systemem za pośrednictwem interfejsu
Plik tasks że użytkownicy końcowi muszą wykonywać swoją pracę
Plik content który jest prezentowany jako część interfejsu
Plik work environment w którym te zadania będą realizowane
Właściwy lub dobry projekt interfejsu użytkownika opiera się na możliwościach i ograniczeniach użytkownika, a nie na maszynach. Przy projektowaniu UI ważna jest również znajomość natury pracy i środowiska użytkownika.
Zadanie do wykonania można następnie podzielić, które są przypisane do użytkownika lub maszyny, w oparciu o znajomość możliwości i ograniczeń każdego z nich. Projekt interfejsu użytkownika jest często podzielony na cztery różne poziomy -
The conceptual level - Opisuje podstawowe podmioty uwzględniające pogląd użytkownika na system i możliwe na nim działania.
The semantic level - Opisuje funkcje wykonywane przez system, tj. Opis wymagań funkcjonalnych systemu, ale nie dotyczy sposobu, w jaki użytkownik będzie wywoływał funkcje.
The syntactic level - Opisuje sekwencje wejść i wyjść wymaganych do wywołania opisanych funkcji.
The lexical level - Określa, w jaki sposób wejścia i wyjścia są faktycznie tworzone z prymitywnych operacji sprzętowych.
Projektowanie interfejsu użytkownika to proces iteracyjny, w którym cała iteracja wyjaśnia i poprawia informacje opracowane w poprzednich krokach. Ogólne kroki projektowania interfejsu użytkownika
Definiuje obiekty i akcje interfejsu użytkownika (operacje).
Definiuje zdarzenia (akcje użytkownika), które spowodują zmianę stanu interfejsu użytkownika.
Wskazuje, jak użytkownik interpretuje stan systemu na podstawie informacji dostarczonych przez interfejs.
Opisz każdy stan interfejsu tak, jak będzie wyglądał dla użytkownika końcowego.
Stworzony przez użytkownika lub inżyniera oprogramowania, który ustala profil użytkowników końcowych systemu na podstawie wieku, płci, sprawności fizycznej, wykształcenia, motywacji, celów i osobowości.
Uwzględnia składniową i semantyczną wiedzę użytkownika i klasyfikuje użytkowników jako nowicjuszy, posiadających wiedzę sporadycznych i posiadających dużą wiedzę częstych użytkowników.
Stworzony przez inżyniera oprogramowania, który obejmuje dane, architekturę, interfejs i proceduralne reprezentacje oprogramowania.
Wyprowadzony z modelu analizy wymagań i kontrolowany przez informacje zawarte w specyfikacji wymagań, które pomagają w zdefiniowaniu użytkownika systemu.
Stworzony przez wdrażających oprogramowanie, którzy pracują nad wyglądem i działaniem interfejsu w połączeniu ze wszystkimi pomocniczymi informacjami (książki, filmy, pliki pomocy) opisującymi składnię i semantykę systemu.
Służy jako tłumaczenie modelu projektowego i stara się uzgodnić model mentalny użytkownika, tak aby użytkownicy czuli się komfortowo z oprogramowaniem i efektywnie z niego korzystali.
Tworzone przez użytkownika podczas interakcji z aplikacją. Zawiera obraz systemu, który użytkownicy noszą w głowach.
Często nazywany percepcją systemu użytkownika i poprawność opisu zależy od profilu użytkownika i ogólnej znajomości oprogramowania w domenie aplikacji.
- Na początku określ cele związane z architekturą.
- Zidentyfikuj konsumenta naszej architektury.
- Zidentyfikuj ograniczenia.
Często przeglądaj architekturę na głównych etapach projektu oraz w odpowiedzi na inne znaczące zmiany architektoniczne.
Głównym celem przeglądu architektury jest określenie wykonalności architektur bazowych i kandydujących, które prawidłowo weryfikują architekturę.
Łączy wymagania funkcjonalne i cechy jakościowe z proponowanym rozwiązaniem technicznym. Pomaga również zidentyfikować problemy i rozpoznać obszary wymagające poprawy
Proces tworzenia interfejsu użytkownika
Jest to proces spiralny, jak pokazano na poniższym schemacie -

Interface analysis
Koncentruje się lub koncentruje się na użytkownikach, zadaniach, treści i środowisku pracy, którzy będą współpracować z systemem. Definiuje zadania zorientowane na człowieka i komputer, które są wymagane do osiągnięcia funkcji systemu.
Interface design
Definiuje zestaw obiektów interfejsu, akcji i ich reprezentacji na ekranie, które umożliwiają użytkownikowi wykonanie wszystkich zdefiniowanych zadań w sposób spełniający każdy cel użyteczności zdefiniowany dla systemu.
Interface construction
Rozpoczyna się prototypem, który umożliwia ocenę scenariuszy użytkowania, i kontynuuje z narzędziami programistycznymi do ukończenia budowy.
Interface validation
Koncentruje się na zdolności interfejsu do poprawnej realizacji każdego zadania użytkownika, dostosowania się do wszystkich wariantów zadań, spełnienia wszystkich ogólnych wymagań użytkownika oraz stopnia, w jakim interfejs jest łatwy w użyciu i łatwy do nauczenia.
User Interface Models
Podczas analizy i projektowania interfejsu użytkownika używane są cztery modele -
User profile model
Design model
Implementation model
User's mental model
Rozważania projektowe dotyczące interfejsu użytkownika
Skoncentrowany na użytkowniku
Interfejs użytkownika musi być produktem zorientowanym na użytkownika, który angażuje użytkowników przez cały cykl rozwoju produktu. Prototyp interfejsu użytkownika powinien być dostępny dla użytkowników, a informacje zwrotne od użytkowników powinny zostać włączone do produktu końcowego.
Proste i intuicyjne
Interfejs użytkownika zapewnia prostotę i intuicyjność, dzięki czemu można go używać szybko i skutecznie bez instrukcji. Graficzny interfejs użytkownika jest lepszy niż tekstowy interfejs użytkownika, ponieważ składa się z menu, okien i przycisków i jest obsługiwany za pomocą myszy.
Umieść użytkowników pod kontrolą
Nie zmuszaj użytkowników do wykonywania predefiniowanych sekwencji. Daj im opcje — anulowania lub zapisania i powrotu do miejsca, w którym przerwały. W całym interfejsie używaj terminów zrozumiałych dla użytkowników, a nie terminów dotyczących systemu lub programistów.
Zapewnij użytkownikom pewne wskazania, że akcja została wykonana, pokazując im wyniki działania lub potwierdzając, że akcja została wykonana pomyślnie.
Przezroczystość
Interfejs użytkownika musi być przejrzysty, aby użytkownicy mieli wrażenie, że sięgają bezpośrednio przez komputer i bezpośrednio manipulują obiektami, z którymi pracują. Interfejs można uczynić przezroczystym, udostępniając użytkownikom obiekty robocze zamiast obiektów systemowych. Na przykład użytkownicy powinni zrozumieć, że ich hasło systemowe musi mieć co najmniej 6 znaków, a nie ile bajtów musi mieć hasło.
Używaj stopniowego ujawniania
Zawsze zapewniaj łatwy dostęp do typowych funkcji i często używanych działań. Ukryj mniej typowe funkcje i czynności i pozwól użytkownikom na poruszanie się po nich. Nie próbuj umieszczać wszystkich informacji w jednym głównym oknie. Użyj dodatkowego okna dla informacji, które nie są informacjami kluczowymi.
Konsystencja
Interfejs użytkownika zachowuje spójność w obrębie produktu i między nimi, utrzymuje te same wyniki interakcji, polecenia i menu interfejsu użytkownika powinny mieć ten sam format, znaki interpunkcyjne poleceń powinny być podobne, a parametry należy przekazywać do wszystkich poleceń w ten sam sposób. Interfejs użytkownika nie powinien mieć zachowań, które mogą zaskoczyć użytkowników i powinien zawierać mechanizmy, które pozwalają użytkownikom odzyskać siły po popełnieniu błędów.
Integracja
System oprogramowania powinien płynnie integrować się z innymi aplikacjami, takimi jak MS Notatnik i MS-Office. Może używać poleceń schowka bezpośrednio do wykonywania wymiany danych.
Zorientowany na komponenty
Projekt interfejsu użytkownika musi być modułowy i zawierać architekturę zorientowaną na komponenty, tak aby projekt interfejsu użytkownika miał takie same wymagania, jak projekt głównej części systemu oprogramowania. Moduły można łatwo modyfikować i wymieniać bez wpływu na inne części systemu.
Możliwość dostosowania
Architektura całego systemu oprogramowania zawiera moduły typu plug-in, które pozwalają wielu różnym osobom na samodzielne rozszerzanie oprogramowania. Umożliwia indywidualnym użytkownikom wybór spośród różnych dostępnych formularzy w celu dostosowania ich do osobistych preferencji i potrzeb.
Zmniejsz obciążenie pamięci użytkownika
Nie zmuszaj użytkowników do pamiętania i powtarzania tego, co komputer powinien dla nich robić. Na przykład podczas wypełniania formularzy online, nazwy klientów, adresy i numery telefonów powinny zostać zapamiętane przez system po wprowadzeniu ich przez użytkownika lub po otwarciu rekordu klienta.
Interfejsy użytkownika obsługują odzyskiwanie pamięci długoterminowej, udostępniając użytkownikom elementy do rozpoznania zamiast przywoływania informacji.
Separacja
Interfejs użytkownika musi być oddzielony od logiki systemu poprzez jego implementację w celu zwiększenia możliwości ponownego użycia i utrzymania.
Podejście iteracyjne i przyrostowe
Jest to podejście iteracyjne i przyrostowe, składające się z pięciu głównych kroków, które pomaga w generowaniu kandydujących rozwiązań. To proponowane rozwiązanie można dalej udoskonalać, powtarzając te kroki i ostatecznie tworząc projekt architektoniczny, który najlepiej pasuje do naszej aplikacji. Na koniec procesu możemy przejrzeć naszą architekturę i zakomunikować ją wszystkim zainteresowanym stronom.
To tylko jedno możliwe podejście. Istnieje wiele innych bardziej formalnych podejść do definiowania, przeglądu i komunikowania architektury.
Zidentyfikuj cel architektury
Zidentyfikuj cel architektury, który tworzy architekturę i proces projektowania. Bezbłędne i zdefiniowane cele kładą nacisk na architekturę, rozwiązują właściwe problemy w projekcie i pomagają określić, kiedy bieżąca faza się zakończyła i jest gotowa do przejścia do następnej fazy.
Ten krok obejmuje następujące czynności -
Przykłady działań związanych z architekturą obejmują tworzenie prototypu w celu uzyskania informacji zwrotnej na temat interfejsu użytkownika przetwarzania zamówień dla aplikacji sieci Web, tworzenie aplikacji do śledzenia zamówień klientów oraz projektowanie architektury uwierzytelniania i autoryzacji dla aplikacji w celu przeprowadzenia przeglądu bezpieczeństwa.
Kluczowe scenariusze
Ten krok kładzie nacisk na projekt, który ma największe znaczenie. Scenariusz to obszerny i obejmujący opis interakcji użytkownika z systemem.
Scenariusze kluczowe to te, które są uważane za najważniejsze scenariusze sukcesu Twojej aplikacji. Pomaga w podejmowaniu decyzji dotyczących architektury. Celem jest osiągnięcie równowagi między celami użytkownika, biznesowymi i systemowymi. Na przykład uwierzytelnianie użytkownika jest scenariuszem kluczowym, ponieważ jest to skrzyżowanie atrybutu jakości (bezpieczeństwa) z ważną funkcjonalnością (sposobem logowania użytkownika do systemu).
Przegląd aplikacji
Zbuduj przegląd aplikacji, dzięki czemu architektura będzie bardziej dotykalna, łącząc ją z rzeczywistymi ograniczeniami i decyzjami. Składa się z następujących czynności -
Zidentyfikuj typ aplikacji
Zidentyfikuj typ aplikacji, niezależnie od tego, czy jest to aplikacja mobilna, bogaty klient, bogata aplikacja internetowa, usługa, aplikacja internetowa, czy też kombinacja tych typów.
Zidentyfikuj ograniczenia wdrażania
Wybierz odpowiednią topologię wdrażania i rozwiąż konflikty między aplikacją a infrastrukturą docelową.
Zidentyfikuj ważne style projektowania architektury
Zidentyfikuj ważne style projektowania architektury, takie jak klient / serwer, warstwowy, magistrala komunikatów, projekt oparty na domenie itp., Aby poprawić partycjonowanie i promować ponowne wykorzystanie projektu, zapewniając rozwiązania często powtarzających się problemów. Aplikacje często używają kombinacji stylów.
Zidentyfikuj odpowiednie technologie
Zidentyfikuj odpowiednie technologie, biorąc pod uwagę typ aplikacji, którą tworzymy, nasze preferowane opcje topologii wdrażania aplikacji i style architektoniczne. Wybór technologii będzie również zależał od zasad organizacji, ograniczeń infrastruktury, umiejętności zasobów i tak dalej.
Kluczowe problemy lub kluczowe punkty aktywne
Podczas projektowania aplikacji hotspoty to strefy, w których najczęściej popełniane są błędy. Zidentyfikuj kluczowe problemy na podstawie atrybutów jakości i zagadnień przekrojowych. Potencjalne problemy obejmują pojawienie się nowych technologii i krytycznych wymagań biznesowych.
Atrybuty jakości to ogólne cechy architektury, które wpływają na zachowanie w czasie wykonywania, projekt systemu i wrażenia użytkownika. Kwestie dotyczące przekrojów to cechy naszego projektu, które mogą dotyczyć wszystkich warstw, komponentów i poziomów.
Są to również obszary, w których najczęściej popełniane są poważne błędy projektowe. Przykładami problemów przekrojowych są uwierzytelnianie i autoryzacja, komunikacja, zarządzanie konfiguracją, zarządzanie wyjątkami i walidacja itp.
Rozwiązania kandydujące
Po zdefiniowaniu kluczowych punktów aktywnych zbuduj początkową architekturę bazową lub pierwszy projekt wysokiego poziomu, a następnie zacznij wypełniać szczegóły, aby wygenerować architekturę kandydującą.
Architektura kandydata obejmuje typ aplikacji, architekturę wdrażania, styl architektoniczny, wybór technologii, atrybuty jakości i zagadnienia przekrojowe. Jeśli architektura kandydata jest ulepszeniem, może stać się punktem odniesienia, na podstawie którego można tworzyć i testować nowe architektury kandydujące.
Sprawdź poprawność projektu rozwiązania kandydata pod kątem kluczowych scenariuszy i wymagań, które zostały już zdefiniowane, przed iteracyjnym wykonaniem cyklu i ulepszeniem projektu.
Możemy wykorzystać szpilki architektoniczne, aby odkryć określone obszary projektu lub zweryfikować nowe koncepcje. Impulsy architektoniczne to prototypy projektowe, które określają wykonalność określonej ścieżki projektowej, zmniejszają ryzyko i szybko określają wykonalność różnych podejść. Testuj skoki architektoniczne w kluczowych scenariuszach i hotspotach.
Przegląd architektury
Przegląd architektury jest najważniejszym zadaniem w celu zmniejszenia kosztów błędów oraz jak najszybszego znalezienia i rozwiązania problemów architektonicznych. Jest to ugruntowany, efektywny kosztowo sposób na obniżenie kosztów projektu i prawdopodobieństwa niepowodzenia projektu.
Ewaluacje oparte na scenariuszach to dominująca metoda przeglądu projektu architektury, która koncentruje się na scenariuszach, które są najważniejsze z punktu widzenia biznesowego i które mają największy wpływ na architekturę.
Metoda analizy architektury oprogramowania (SAAM)
Pierwotnie był przeznaczony do oceny modyfikowalności, ale później został rozszerzony na przegląd architektury pod kątem atrybutów jakości.
Metoda analizy kompromisów architektury (ATAM)
Jest to dopracowana i ulepszona wersja programu SAAM, który analizuje decyzje architektoniczne pod kątem wymagań dotyczących atrybutów jakości oraz tego, jak dobrze spełniają one określone cele jakościowe.
Active Design Review (ADR)
Najlepiej nadaje się do niekompletnych lub będących w toku architektur, które bardziej koncentrują się na zestawie problemów lub poszczególnych sekcji architektury naraz, niż na wykonywaniu ogólnego przeglądu.
Aktywne recenzje projektów pośrednich (ARID)
Łączy w sobie aspekt ADR polegający na przeglądaniu architektury będącej w toku z naciskiem na zestaw problemów oraz podejście ATAM i SAAM do przeglądu opartego na scenariuszach, koncentrującego się na atrybutach jakości.
Metoda analizy kosztów i korzyści (CBAM)
Koncentruje się na analizie kosztów, korzyści i skutków decyzji architektonicznych dotyczących harmonogramu.
Analiza zmian na poziomie architektury (ALMA)
Szacuje modyfikowalność architektury systemów informacji biznesowej (BIS).
Metoda oceny architektury rodzinnej (FAAM)
Szacuje architektury rodziny systemów informacyjnych pod kątem interoperacyjności i rozszerzalności.
Komunikowanie projektu architektury
Po ukończeniu projektu architektury musimy przekazać go innym interesariuszom, w tym zespołowi programistom, administratorom systemu, operatorom, właścicielom firm i innym zainteresowanym stronom.
Istnieje kilka dobrze znanych metod opisywania architektury innym: -
Model 4 + 1
To podejście wykorzystuje pięć widoków całej architektury. Wśród nich cztery widoki (pliklogical view, the process view, the physical view, i development view) opisują architekturę z różnych podejść. Piąty widok przedstawia scenariusze i przypadki użycia oprogramowania. Pozwala interesariuszom zobaczyć cechy architektury, które ich szczególnie interesują.
Język opisu architektury (ADL)
Podejście to służy do opisu architektury oprogramowania przed wdrożeniem systemu. Dotyczy następujących problemów - zachowanie, protokół i złącze.
Główną zaletą ADL jest to, że możemy przeanalizować architekturę pod kątem kompletności, spójności, niejednoznaczności i wydajności przed formalnym rozpoczęciem korzystania z projektu.
Modelowanie zwinne
To podejście jest zgodne z koncepcją, że „treść jest ważniejsza niż przedstawienie”. Zapewnia, że utworzone modele są proste i łatwe do zrozumienia, wystarczająco dokładne, szczegółowe i spójne.
Dokumenty modelu Agile są skierowane do określonych klientów i spełniają wysiłki tego klienta. Prostota dokumentu zapewnia aktywny udział interesariuszy w modelowaniu artefaktu.
IEEE 1471
IEEE 1471 to skrócona nazwa normy znanej formalnie jako ANSI / IEEE 1471-2000, „Zalecana praktyka dotycząca opisu architektury systemów intensywnie korzystających z oprogramowania”. IEEE 1471 wzbogaca treść opisu architektonicznego, w szczególności nadając określone znaczenie kontekstowi, widokom i punktom widzenia.
Język Unified Modeling Language (UML)
To podejście przedstawia trzy widoki modelu systemu. Plikfunctional requirements view (wymagania funkcjonalne systemu z punktu widzenia użytkownika, w tym przypadki użycia); the static structural view(obiekty, atrybuty, relacje i operacje, w tym diagramy klas); idynamic behavior view (współpraca między obiektami i zmiany stanu wewnętrznego obiektów, w tym diagramy sekwencji, aktywności i stanu).