Spark SQL - wprowadzenie
Spark wprowadza moduł programowania do przetwarzania danych strukturalnych o nazwie Spark SQL. Zapewnia abstrakcję programowania o nazwie DataFrame i może działać jako rozproszony silnik zapytań SQL.
Funkcje Spark SQL
Oto funkcje Spark SQL -
Integrated- Bezproblemowo mieszaj zapytania SQL z programami Spark. Spark SQL umożliwia wykonywanie zapytań dotyczących danych strukturalnych jako rozproszonego zestawu danych (RDD) w Spark, ze zintegrowanymi interfejsami API w językach Python, Scala i Java. Ta ścisła integracja ułatwia uruchamianie zapytań SQL wraz ze złożonymi algorytmami analitycznymi.
Unified Data Access- Ładowanie i przeszukiwanie danych z różnych źródeł. Schema-RDD zapewnia jeden interfejs do wydajnej pracy z danymi strukturalnymi, w tym tabelami Apache Hive, plikami parkietów i plikami JSON.
Hive Compatibility- Uruchom niezmodyfikowane zapytania Hive na istniejących magazynach. Spark SQL ponownie wykorzystuje interfejs Hive i MetaStore, zapewniając pełną zgodność z istniejącymi danymi, zapytaniami i funkcjami UDF programu Hive. Po prostu zainstaluj go obok Hive.
Standard Connectivity- Połącz przez JDBC lub ODBC. Spark SQL zawiera tryb serwera ze standardowymi łączami JDBC i ODBC.
Scalability- Używaj tego samego silnika do zapytań interaktywnych i długich. Spark SQL wykorzystuje model RDD do obsługi odporności na błędy w trakcie zapytania, umożliwiając skalowanie również do dużych zadań. Nie martw się o użycie innego silnika dla danych historycznych.
Architektura Spark SQL
Poniższa ilustracja wyjaśnia architekturę Spark SQL -
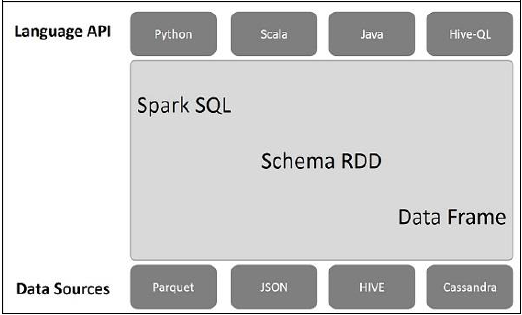
Ta architektura zawiera trzy warstwy, a mianowicie język API, schemat RDD i źródła danych.
Language API- Spark jest kompatybilny z różnymi językami i Spark SQL. Jest również obsługiwany przez te języki - API (python, scala, java, HiveQL).
Schema RDD- Spark Core został zaprojektowany ze specjalną strukturą danych zwaną RDD. Generalnie Spark SQL działa na schematach, tabelach i rekordach. Dlatego możemy użyć Schema RDD jako tabeli tymczasowej. Możemy nazwać ten schemat RDD jako ramkę danych.
Data Sources- Zwykle źródłem danych dla Spark-core jest plik tekstowy, plik Avro itp. Jednak źródła danych dla Spark SQL są inne. Są to plik Parquet, dokument JSON, tabele HIVE i baza danych Cassandra.
Więcej na ten temat omówimy w następnych rozdziałach.