SQLAlchemy - Szybki przewodnik
SQLAlchemy to popularny zestaw narzędzi SQL i Object Relational Mapper. Jest napisanePythoni daje pełną moc i elastyczność SQL programiście aplikacji. To jestopen source i cross-platform software wydany na licencji MIT.
SQLAlchemy słynie z mapowania relacyjno-obiektowego (ORM), za pomocą którego klasy mogą być mapowane do bazy danych, umożliwiając w ten sposób tworzenie modelu obiektowego i schematu bazy danych w czysty odsprzężony sposób od samego początku.
Ponieważ rozmiar i wydajność baz danych SQL zaczynają mieć znaczenie, zachowują się one mniej jak zbiory obiektów. Z drugiej strony, gdy abstrakcja w kolekcjach obiektów zaczyna mieć znaczenie, zachowują się one mniej jak tabele i wiersze. SQLAlchemy ma na celu uwzględnienie obu tych zasad.
Z tego powodu przyjęła data mapper pattern (like Hibernate) rather than the active record pattern used by a number of other ORMs. Bazy danych i SQL będą oglądane z innej perspektywy przy użyciu SQLAlchemy.
Michael Bayer jest oryginalnym autorem SQLAlchemy. Jego pierwotna wersja została wydana w lutym 2006 r. Najnowsza wersja nosi numer 1.2.7, a wydana dopiero w kwietniu 2018 r.
Co to jest ORM?
ORM (Object Relational Mapping) to technika programowania służąca do konwersji danych między niekompatybilnymi systemami typów w obiektowych językach programowania. Zwykle system typów używany w języku zorientowanym obiektowo (OO), takim jak Python, zawiera typy nieskalarne. Nie można ich wyrazić jako typów pierwotnych, takich jak liczby całkowite i łańcuchy. Dlatego programista OO musi konwertować obiekty na dane skalarne, aby współdziałać z bazą danych zaplecza. Jednak typy danych w większości produktów bazodanowych, takich jak Oracle, MySQL itp., Są podstawowe.
W systemie ORM każda klasa jest odwzorowywana na tabelę w bazowej bazie danych. Zamiast samodzielnie pisać żmudny kod interfejsu bazy danych, ORM zajmuje się tymi problemami za Ciebie, podczas gdy Ty możesz skupić się na programowaniu logiki systemu.
SQLAlchemy - konfiguracja środowiska
Omówmy konfigurację środowiska wymaganą do korzystania z SQLAlchemy.
Do zainstalowania SQLAlchemy wymagana jest każda wersja Pythona wyższa niż 2.7. Najłatwiejszym sposobem instalacji jest użycie Python Package Manager,pip. To narzędzie jest dołączone do standardowej dystrybucji języka Python.
pip install sqlalchemyZa pomocą powyższego polecenia możemy pobrać plik latest released versionSQLAlchemy z python.org i zainstaluj go w swoim systemie.
W przypadku dystrybucji anaconda Pythona SQLAlchemy można zainstalować z conda terminal używając poniższego polecenia -
conda install -c anaconda sqlalchemyMożliwe jest również zainstalowanie SQLAlchemy z poniższego kodu źródłowego -
python setup.py installSQLAlchemy jest zaprojektowany do pracy z implementacją DBAPI zbudowaną dla konkretnej bazy danych. Używa systemu dialektów do komunikacji z różnymi typami implementacji DBAPI i bazami danych. Wszystkie dialekty wymagają zainstalowania odpowiedniego sterownika DBAPI.
Poniżej znajdują się dialekty zawarte -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQLite
- Sybase
Aby sprawdzić, czy SQLAlchemy jest poprawnie zainstalowany i poznać jego wersję, wprowadź następujące polecenie w wierszu polecenia Pythona -
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.2.7'Rdzeń SQLAlchemy zawiera SQL rendering engine, DBAPI integration, transaction integration, i schema description services. Rdzeń SQLAlchemy używa języka SQL Expression Language, który zapewnia rozszerzenieschema-centric usage paradygmat, podczas gdy SQLAlchemy ORM to domain-centric mode of usage.
Język SQL Expression Language przedstawia system reprezentacji struktur i wyrażeń relacyjnych baz danych przy użyciu konstrukcji Pythona. Przedstawia system przedstawiania prymitywnych konstrukcji relacyjnej bazy danych bezpośrednio, bez opinii, w przeciwieństwie do ORM, który prezentuje wysoki poziom i abstrakcyjny wzorzec użycia, który sam w sobie jest przykładem zastosowania języka wyrażeń.
Język wyrażeń jest jednym z podstawowych składników SQLAlchemy. Pozwala programiście określać instrukcje SQL w kodzie Pythona i używać ich bezpośrednio w bardziej złożonych zapytaniach. Język wyrażeń jest niezależny od zaplecza i kompleksowo obejmuje każdy aspekt surowego SQL. Jest bliżej surowego SQL niż jakikolwiek inny składnik SQLAlchemy.
Język wyrażeń bezpośrednio reprezentuje pierwotne konstrukcje relacyjnej bazy danych. Ponieważ ORM jest oparty na języku Expression, typowa aplikacja bazodanowa Python może nakładać się na oba. Aplikacja może używać samego języka wyrażeń, chociaż musi zdefiniować własny system tłumaczenia koncepcji aplikacji na indywidualne zapytania do bazy danych.
Instrukcje języka Expression zostaną przetłumaczone na odpowiednie surowe zapytania SQL przez silnik SQLAlchemy. Dowiemy się teraz, jak stworzyć silnik i za jego pomocą wykonywać różne zapytania SQL.
W poprzednim rozdziale omówiliśmy język wyrażeń w SQLAlchemy. Przejdźmy teraz do kroków związanych z łączeniem się z bazą danych.
Klasa silnika łączy a Pool and Dialect together aby zapewnić źródło bazy danych connectivity and behavior. Obiekt klasy Engine jest tworzony przy użyciu rozszerzeniacreate_engine() funkcjonować.
Funkcja create_engine () przyjmuje bazę danych jako jeden argument. Baza danych nie musi być nigdzie definiowana. Standardowy formularz wywołujący musi wysyłać adres URL jako pierwszy argument pozycyjny, zwykle jest to ciąg znaków wskazujący dialekt bazy danych i argumenty połączenia. Korzystając z podanego poniżej kodu możemy stworzyć bazę danych.
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///college.db', echo = True)Dla MySQL databaseużyj poniższego polecenia -
engine = create_engine("mysql://user:pwd@localhost/college",echo = True)Aby konkretnie wspomnieć DB-API do użycia do połączenia URL string przyjmuje następującą postać -
dialect[+driver]://user:password@host/dbnameNa przykład, jeśli używasz PyMySQL driver with MySQLużyj następującego polecenia -
mysql+pymysql://<username>:<password>@<host>/<dbname>Plik echo flagjest skrótem do konfiguracji rejestrowania SQLAlchemy, które jest realizowane za pośrednictwem standardowego modułu logowania Pythona. W kolejnych rozdziałach poznamy wszystkie wygenerowane SQL. Aby ukryć szczegółowe dane wyjściowe, ustaw atrybut echo naNone. Inne argumenty funkcji create_engine () mogą być specyficzne dla dialektu.
Funkcja create_engine () zwraca plik Engine object. Niektóre ważne metody klasy Engine to -
| Sr.No. | Metoda i opis |
|---|---|
| 1 | connect() Zwraca obiekt połączenia |
| 2 | execute() Wykonuje konstrukcję instrukcji SQL |
| 3 | begin() Zwraca menedżera kontekstu dostarczającego połączenie z ustanowioną transakcją. Po pomyślnej operacji transakcja jest zatwierdzana, w przeciwnym razie jest wycofywana |
| 4 | dispose() Usuwa pulę połączeń używaną przez Engine |
| 5 | driver() Nazwa sterownika dialektu używanego przez silnik |
| 6 | table_names() Zwraca listę wszystkich nazw tabel dostępnych w bazie danych |
| 7 | transaction() Wykonuje daną funkcję w granicach transakcji |
Omówmy teraz, jak używać funkcji tworzenia tabeli.
Język wyrażeń SQL konstruuje swoje wyrażenia na podstawie kolumn tabeli. Obiekt SQLAlchemy Column reprezentuje plikcolumn w tabeli bazy danych, która z kolei jest reprezentowana przez Tableobject. Metadane zawierają definicje tabel i powiązanych obiektów, takich jak indeks, widok, wyzwalacze itp.
Stąd obiekt klasy MetaData z SQLAlchemy Metadata jest zbiorem obiektów Table i skojarzonych z nimi konstrukcji schematu. Zawiera kolekcję obiektów Table, a także opcjonalne powiązanie z aparatem lub połączeniem.
from sqlalchemy import MetaData
meta = MetaData()Konstruktor klasy MetaData może mieć domyślne parametry bind i schema None.
Następnie definiujemy wszystkie nasze tabele w powyższym katalogu metadanych, używając the Table construct, która przypomina zwykłą instrukcję SQL CREATE TABLE.
Obiekt klasy Table reprezentuje odpowiednią tabelę w bazie danych. Konstruktor przyjmuje następujące parametry -
| Nazwa | Nazwa tabeli |
|---|---|
| Metadane | Obiekt MetaData, który będzie zawierał tę tabelę |
| Kolumna (y) | Co najmniej jeden obiekt klasy kolumnowej |
Obiekt kolumny reprezentuje plik column w database table. Konstruktor przyjmuje nazwę, typ i inne parametry, takie jak primary_key, autoincrement i inne ograniczenia.
SQLAlchemy dopasowuje dane Pythona do najlepszych możliwych generycznych typów danych kolumn w nim zdefiniowanych. Niektóre z ogólnych typów danych to -
- BigInteger
- Boolean
- Date
- DateTime
- Float
- Integer
- Numeric
- SmallInteger
- String
- Text
- Time
Stworzyć students table w bazie danych uczelni użyj następującego fragmentu -
from sqlalchemy import Table, Column, Integer, String, MetaData
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)Funkcja create_all () używa obiektu silnika do tworzenia wszystkich zdefiniowanych obiektów tabeli i przechowuje informacje w metadanych.
meta.create_all(engine)Poniżej podano pełny kod, który utworzy bazę danych SQLite college.db z tabelą studentów.
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
meta.create_all(engine)Ponieważ atrybut echo funkcji create_engine () jest ustawiony na True, konsola wyświetli rzeczywiste zapytanie SQL do tworzenia tabeli w następujący sposób -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
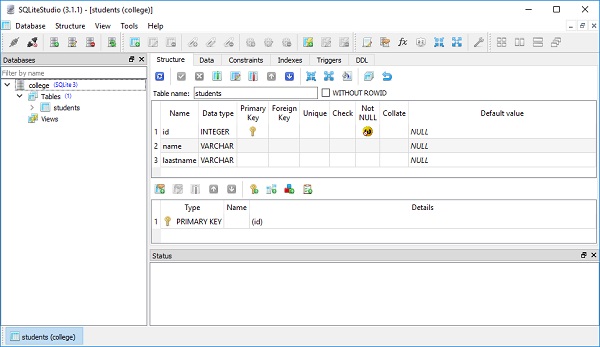
)Plik college.db zostanie utworzony w bieżącym katalogu roboczym. Aby sprawdzić, czy tabela uczniów została utworzona, możesz otworzyć bazę danych za pomocą dowolnego narzędzia SQLite GUI, takiego jakSQLiteStudio.
Poniższy obraz przedstawia tabelę uczniów utworzoną w bazie danych -
W tym rozdziale skupimy się pokrótce na wyrażeniach SQL i ich funkcjach.
Wyrażenia SQL są konstruowane przy użyciu odpowiednich metod względem obiektu tabeli docelowej. Na przykład instrukcja INSERT jest tworzona przez wykonanie metody insert () w następujący sposób -
ins = students.insert()Wynikiem powyższej metody jest wstawienie obiektu, który można zweryfikować za pomocą str()funkcjonować. Poniższy kod wstawia szczegóły, takie jak identyfikator ucznia, imię i nazwisko.
'INSERT INTO students (id, name, lastname) VALUES (:id, :name, :lastname)'Istnieje możliwość wstawienia wartości w określonym polu za pomocą values()metoda wstawiania obiektu. Kod tego samego podano poniżej -
>>> ins = users.insert().values(name = 'Karan')
>>> str(ins)
'INSERT INTO users (name) VALUES (:name)'SQL powtórzony na konsoli Pythona nie pokazuje rzeczywistej wartości (w tym przypadku 'Karan'). Zamiast tego SQLALchemy generuje parametr bind, który jest widoczny w skompilowanej formie instrukcji.
ins.compile().params
{'name': 'Karan'}Podobnie metody takie jak update(), delete() i select()utwórz odpowiednio wyrażenia UPDATE, DELETE i SELECT. Dowiemy się o nich w dalszych rozdziałach.
W poprzednim rozdziale nauczyliśmy się wyrażeń SQL. W tym rozdziale przyjrzymy się wykonaniu tych wyrażeń.
Aby wykonać wynikowe wyrażenia SQL, musimy to zrobić obtain a connection object representing an actively checked out DBAPI connection resource i wtedy feed the expression object jak pokazano na poniższym kodzie.
conn = engine.connect()Następujący obiekt insert () może służyć do metody execute () -
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
result = conn.execute(ins)Konsola pokazuje wynik wykonania wyrażenia SQL jak poniżej -
INSERT INTO students (name, lastname) VALUES (?, ?)
('Ravi', 'Kapoor')
COMMITPoniżej znajduje się cały fragment, który pokazuje wykonanie zapytania INSERT przy użyciu podstawowej techniki SQLAlchemy -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
ins = students.insert()
ins = students.insert().values(name = 'Ravi', lastname = 'Kapoor')
conn = engine.connect()
result = conn.execute(ins)Wynik można zweryfikować, otwierając bazę danych za pomocą SQLite Studio, jak pokazano na poniższym zrzucie ekranu -

Zmienna wynikowa jest znana jako ResultProxy object. Jest to analogiczne do obiektu kursora DBAPI. Możemy uzyskać informacje o wartościach klucza podstawowego, które zostały wygenerowane z naszego oświadczenia za pomocąResultProxy.inserted_primary_key jak pokazano poniżej -
result.inserted_primary_key
[1]Aby wydać wiele wstawień przy użyciu metody execute many () DBAPI, możemy wysłać listę słowników, z których każdy zawiera odrębny zestaw parametrów do wstawienia.
conn.execute(students.insert(), [
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
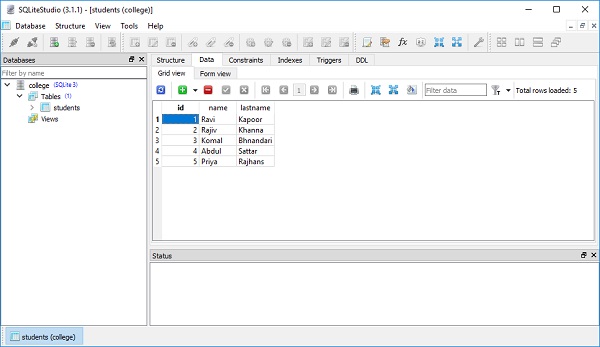
])Znajduje to odzwierciedlenie w widoku danych tabeli, jak pokazano na poniższym rysunku -
W tym rozdziale omówimy koncepcję wybierania wierszy w obiekcie tabeli.
Umożliwia nam to metoda select () obiektu tabeli construct SELECT expression.
s = students.select()Zaznaczony obiekt jest tłumaczony na SELECT query by str(s) function jak pokazano poniżej -
'SELECT students.id, students.name, students.lastname FROM students'Możemy użyć tego obiektu select jako parametru do wykonania () metody obiektu połączenia, jak pokazano w kodzie poniżej -
result = conn.execute(s)Po wykonaniu powyższej instrukcji powłoka Pythona powtarza następujące równoważne wyrażenie SQL -
SELECT students.id, students.name, students.lastname
FROM studentsWynikowa zmienna jest odpowiednikiem kursora w DBAPI. Możemy teraz pobierać rekordy za pomocąfetchone() method.
row = result.fetchone()Wszystkie zaznaczone wiersze w tabeli można wydrukować za pomocą pliku for loop jak podano poniżej -
for row in result:
print (row)Pełny kod do wydrukowania wszystkich wierszy z tabeli uczniów jest pokazany poniżej -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
s = students.select()
conn = engine.connect()
result = conn.execute(s)
for row in result:
print (row)Dane wyjściowe pokazane w powłoce Pythona są następujące -
(1, 'Ravi', 'Kapoor')
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Klauzulę WHERE zapytania SELECT można zastosować przy użyciu Select.where(). Na przykład, jeśli chcemy wyświetlić wiersze o id> 2
s = students.select().where(students.c.id>2)
result = conn.execute(s)
for row in result:
print (row)Tutaj c attribute is an alias for column. Następujące dane wyjściowe zostaną wyświetlone w powłoce -
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')Tutaj musimy zauważyć, że obiekt select można również uzyskać za pomocą funkcji select () w module sqlalchemy.sql. Funkcja select () wymaga obiektu tabeli jako argumentu.
from sqlalchemy.sql import select
s = select([users])
result = conn.execute(s)SQLAlchemy pozwala po prostu używać ciągów znaków w przypadkach, gdy SQL jest już znany i nie ma silnej potrzeby, aby instrukcja obsługiwała funkcje dynamiczne. Konstrukcja text () jest używana do tworzenia instrukcji tekstowej, która jest przekazywana do bazy danych w większości niezmieniona.
Konstruuje nowe TextClause, reprezentujący bezpośrednio tekstowy ciąg znaków SQL, jak pokazano w poniższym kodzie -
from sqlalchemy import text
t = text("SELECT * FROM students")
result = connection.execute(t)Zalety text() zapewnia ponad zwykły ciąg to -
- obsługa neutralna dla zaplecza dla parametrów wiązania
- opcje wykonywania instrukcji
- zachowanie pisania w kolumnie wynikowej
Funkcja text () wymaga parametrów Bound w nazwanym formacie dwukropka. Są spójne niezależnie od zaplecza bazy danych. Aby wysłać wartości parametrów, przekazujemy je do metody execute () jako dodatkowe argumenty.
Poniższy przykład używa parametrów powiązanych w tekstowym języku SQL -
from sqlalchemy.sql import text
s = text("select students.name, students.lastname from students where students.name between :x and :y")
conn.execute(s, x = 'A', y = 'L').fetchall()Funkcja text () konstruuje wyrażenie SQL w następujący sposób -
select students.name, students.lastname from students where students.name between ? and ?Wartości x = „A” i y = „L” są przekazywane jako parametry. Wynik to lista wierszy o nazwach od „A” do „L” -
[('Komal', 'Bhandari'), ('Abdul', 'Sattar')]Konstrukcja text () obsługuje wstępnie ustalone wartości powiązane przy użyciu metody TextClause.bindparams (). Parametry można również jawnie wpisać w następujący sposób -
stmt = text("SELECT * FROM students WHERE students.name BETWEEN :x AND :y")
stmt = stmt.bindparams(
bindparam("x", type_= String),
bindparam("y", type_= String)
)
result = conn.execute(stmt, {"x": "A", "y": "L"})
The text() function also be produces fragments of SQL within a select() object that
accepts text() objects as an arguments. The “geometry” of the statement is provided by
select() construct , and the textual content by text() construct. We can build a statement
without the need to refer to any pre-established Table metadata.
from sqlalchemy.sql import select
s = select([text("students.name, students.lastname from students")]).where(text("students.name between :x and :y"))
conn.execute(s, x = 'A', y = 'L').fetchall()Możesz także użyć and_() funkcja, aby połączyć wiele warunków w klauzuli WHERE utworzonej za pomocą funkcji text ().
from sqlalchemy import and_
from sqlalchemy.sql import select
s = select([text("* from students")]) \
.where(
and_(
text("students.name between :x and :y"),
text("students.id>2")
)
)
conn.execute(s, x = 'A', y = 'L').fetchall()Powyższy kod pobiera wiersze o nazwach od „A” do „L” o identyfikatorze większym niż 2. Dane wyjściowe kodu podano poniżej -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar')]Alias w języku SQL odpowiada „zmienionej nazwie” wersji tabeli lub instrukcji SELECT, która pojawia się za każdym razem, gdy powiesz „SELECT * FROM table1 AS a”. AS tworzy nową nazwę dla tabeli. Aliasy umożliwiają odwoływanie się do dowolnej tabeli lub podzapytania za pomocą unikalnej nazwy.
W przypadku tabeli umożliwia to wielokrotne nazwanie tej samej tabeli w klauzuli FROM. Zawiera nazwę nadrzędną dla kolumn reprezentowanych przez instrukcję, umożliwiając odwoływanie się do nich względem tej nazwy.
W SQLAlchemy dowolną konstrukcję Table, select () lub inny wybieralny obiekt można przekształcić w alias za pomocą From Clause.alias()metoda, która tworzy konstrukcję Alias. Funkcja alias () w module sqlalchemy.sql reprezentuje alias, zwykle stosowany do dowolnej tabeli lub podwyboru w instrukcji SQL przy użyciu słowa kluczowego AS.
from sqlalchemy.sql import alias
st = students.alias("a")Ten alias może być teraz używany w konstrukcji select () do odwoływania się do tabeli uczniów -
s = select([st]).where(st.c.id>2)Przekłada się to na wyrażenie SQL w następujący sposób -
SELECT a.id, a.name, a.lastname FROM students AS a WHERE a.id > 2Możemy teraz wykonać to zapytanie SQL za pomocą metody execute () obiektu connection. Kompletny kod wygląda następująco -
from sqlalchemy.sql import alias, select
st = students.alias("a")
s = select([st]).where(st.c.id > 2)
conn.execute(s).fetchall()Po wykonaniu powyższej linii kodu generuje następujące dane wyjściowe -
[(3, 'Komal', 'Bhandari'), (4, 'Abdul', 'Sattar'), (5, 'Priya', 'Rajhans')]Plik update() Metoda na docelowym obiekcie tabeli konstruuje równoważne wyrażenie SQL UPDATE.
table.update().where(conditions).values(SET expressions)Plik values()Metoda na wynikowym obiekcie aktualizacji jest używana do określenia warunków SET dla UPDATE. W przypadku pozostawienia wartości Brak warunki SET są określane na podstawie parametrów przekazanych do instrukcji podczas wykonywania i / lub kompilacji instrukcji.
Klauzula where jest wyrażeniem opcjonalnym opisującym warunek WHERE instrukcji UPDATE.
Poniższy fragment kodu zmienia wartość kolumny „nazwisko” z „Khanna” na „Kapoor” w tabeli uczniów -
stmt = students.update().where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')Obiekt stmt jest obiektem aktualizacji, który przekłada się na -
'UPDATE students SET lastname = :lastname WHERE students.lastname = :lastname_1'Powiązany parametr lastname_1 zostanie zastąpiony, gdy execute()wywoływana jest metoda. Pełny kod aktualizacji znajduje się poniżej -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students',
meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt=students.update().where(students.c.lastname=='Khanna').values(lastname='Kapoor')
conn.execute(stmt)
s = students.select()
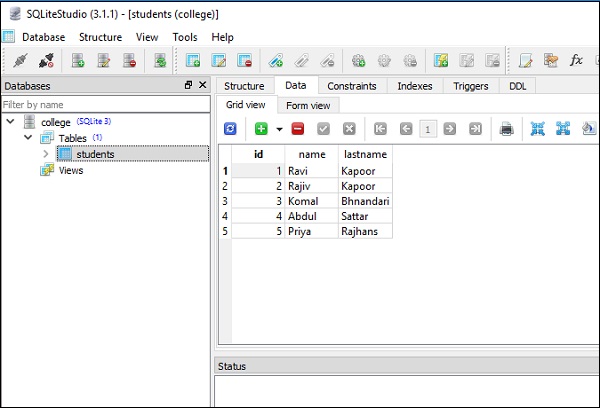
conn.execute(s).fetchall()Powyższy kod wyświetla następujące dane wyjściowe z drugim wierszem pokazującym efekt operacji aktualizacji, jak na podanym zrzucie ekranu -
[
(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(4, 'Abdul', 'Sattar'),
(5, 'Priya', 'Rajhans')
]
Należy pamiętać, że podobną funkcjonalność można również osiągnąć, używając update() funkcja w module sqlalchemy.sql.expression, jak pokazano poniżej -
from sqlalchemy.sql.expression import update
stmt = update(students).where(students.c.lastname == 'Khanna').values(lastname = 'Kapoor')W poprzednim rozdziale zrozumieliśmy, czym jest plik Updatewyrażenie to robi. Następnym wyrażeniem, którego się nauczymy, jestDelete.
Operację usuwania można wykonać, uruchamiając metodę delete () na docelowym obiekcie tabeli, jak podano w poniższej instrukcji -
stmt = students.delete()W przypadku tabeli studentów powyższa linia kodu konstruuje wyrażenie SQL w następujący sposób -
'DELETE FROM students'Spowoduje to jednak usunięcie wszystkich wierszy w tabeli uczniów. Zwykle zapytanie DELETE jest skojarzone z wyrażeniem logicznym określonym przez klauzulę WHERE. Poniższa instrukcja pokazuje, gdzie parametr -
stmt = students.delete().where(students.c.id > 2)Wynikowe wyrażenie SQL będzie miało powiązany parametr, który zostanie podstawiony w czasie wykonywania, gdy instrukcja jest wykonywana.
'DELETE FROM students WHERE students.id > :id_1'Poniższy przykład kodu usunie te wiersze z tabeli uczniów o nazwisku „Khanna” -
from sqlalchemy.sql.expression import update
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn = engine.connect()
stmt = students.delete().where(students.c.lastname == 'Khanna')
conn.execute(stmt)
s = students.select()
conn.execute(s).fetchall()Aby zweryfikować wynik, odśwież widok danych tabeli uczniów w SQLiteStudio.
Jedną z ważnych cech RDBMS jest ustanawianie relacji między tabelami. Operacje SQL, takie jak SELECT, UPDATE i DELETE, można wykonywać na powiązanych tabelach. W tej sekcji opisano te operacje przy użyciu SQLAlchemy.
W tym celu w naszej bazie danych SQLite (college.db) tworzone są dwie tabele. Tabela uczniów ma taką samą strukturę jak podana w poprzedniej sekcji; podczas gdy tabela adresów mast_id kolumna, na którą jest mapowana id column in students table używając ograniczenia klucza obcego.
Poniższy kod utworzy dwie tabele w college.db -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo=True)
meta = MetaData()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer, ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String))
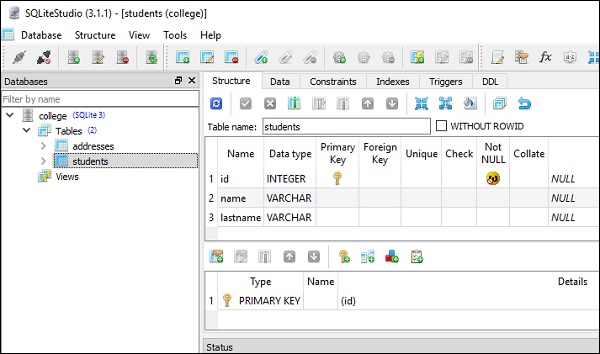
meta.create_all(engine)Powyższy kod zostanie przetłumaczony na zapytania CREATE TABLE dla uczniów i tabelę adresów, jak poniżej -
CREATE TABLE students (
id INTEGER NOT NULL,
name VARCHAR,
lastname VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE addresses (
id INTEGER NOT NULL,
st_id INTEGER,
postal_add VARCHAR,
email_add VARCHAR,
PRIMARY KEY (id),
FOREIGN KEY(st_id) REFERENCES students (id)
)Poniższe zrzuty ekranu bardzo wyraźnie przedstawiają powyższy kod -
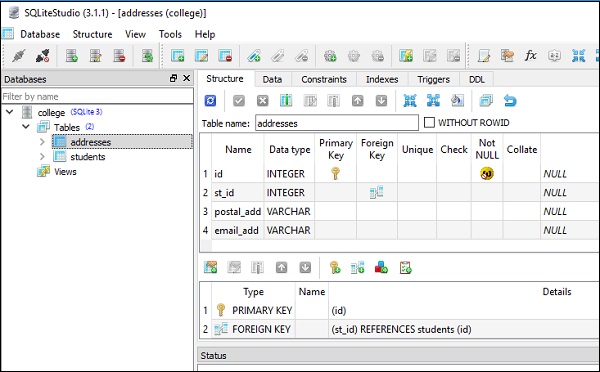
Te tabele są wypełniane danymi przez wykonanie insert() methodobiektów tabeli. Aby wstawić 5 wierszy w tabeli uczniów, możesz użyć kodu podanego poniżej -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
conn.execute(students.insert(), [
{'name':'Ravi', 'lastname':'Kapoor'},
{'name':'Rajiv', 'lastname' : 'Khanna'},
{'name':'Komal','lastname' : 'Bhandari'},
{'name':'Abdul','lastname' : 'Sattar'},
{'name':'Priya','lastname' : 'Rajhans'},
])Rows są dodawane do tabeli adresów za pomocą następującego kodu -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
conn.execute(addresses.insert(), [
{'st_id':1, 'postal_add':'Shivajinagar Pune', 'email_add':'[email protected]'},
{'st_id':1, 'postal_add':'ChurchGate Mumbai', 'email_add':'[email protected]'},
{'st_id':3, 'postal_add':'Jubilee Hills Hyderabad', 'email_add':'[email protected]'},
{'st_id':5, 'postal_add':'MG Road Bangaluru', 'email_add':'[email protected]'},
{'st_id':2, 'postal_add':'Cannought Place new Delhi', 'email_add':'[email protected]'},
])Zauważ, że kolumna st_id w tabeli adresów odnosi się do kolumny id w tabeli studentów. Możemy teraz użyć tej relacji do pobrania danych z obu tabel. Chcemy pobieraćname i lastname z tabeli studentów odpowiadającej st_id w tabeli adresów.
from sqlalchemy.sql import select
s = select([students, addresses]).where(students.c.id == addresses.c.st_id)
result = conn.execute(s)
for row in result:
print (row)Zaznaczone obiekty skutecznie przełożą się na następujące wyrażenie SQL łączące dwie tabele we wspólnej relacji -
SELECT students.id,
students.name,
students.lastname,
addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM students, addresses
WHERE students.id = addresses.st_idSpowoduje to wyodrębnienie odpowiednich danych z obu tabel w następujący sposób -
(1, 'Ravi', 'Kapoor', 1, 1, 'Shivajinagar Pune', '[email protected]')
(1, 'Ravi', 'Kapoor', 2, 1, 'ChurchGate Mumbai', '[email protected]')
(3, 'Komal', 'Bhandari', 3, 3, 'Jubilee Hills Hyderabad', '[email protected]')
(5, 'Priya', 'Rajhans', 4, 5, 'MG Road Bangaluru', '[email protected]')
(2, 'Rajiv', 'Khanna', 5, 2, 'Cannought Place new Delhi', '[email protected]')W poprzednim rozdziale omówiliśmy sposób korzystania z wielu tabel. Więc idziemy o krok dalej i uczymy sięmultiple table updates w tym rozdziale.
Używając obiektu table SQLAlchemy, można określić więcej niż jedną tabelę w klauzuli WHERE metody update (). PostgreSQL i Microsoft SQL Server obsługują instrukcje UPDATE, które odnoszą się do wielu tabel. To implementuje“UPDATE FROM”składnia, która aktualizuje jedną tabelę naraz. Jednak do dodatkowych tabel można odwoływać się bezpośrednio w dodatkowej klauzuli „FROM” w klauzuli WHERE. Poniższe wiersze kodów wyjaśniają pojęciemultiple table updates Wyraźnie.
stmt = students.update().\
values({
students.c.name:'xyz',
addresses.c.email_add:'[email protected]'
}).\
where(students.c.id == addresses.c.id)Obiekt aktualizacji jest odpowiednikiem następującego zapytania UPDATE -
UPDATE students
SET email_add = :addresses_email_add, name = :name
FROM addresses
WHERE students.id = addresses.idJeśli chodzi o dialekt MySQL, wiele tabel można osadzić w jednej instrukcji UPDATE oddzielonej przecinkiem, jak podano poniżej -
stmt = students.update().\
values(name = 'xyz').\
where(students.c.id == addresses.c.id)Poniższy kod przedstawia wynikową kwerendę UPDATE -
'UPDATE students SET name = :name
FROM addresses
WHERE students.id = addresses.id'Jednak dialekt SQLite nie obsługuje kryteriów z wieloma tabelami w ramach UPDATE i wyświetla następujący błąd -
NotImplementedError: This backend does not support multiple-table criteria within UPDATEZapytanie UPDATE surowego kodu SQL ma klauzulę SET. Jest renderowany przez konstrukcję update () przy użyciu kolejności kolumn podanej w pierwotnym obiekcie Table. Dlatego konkretna instrukcja UPDATE z określonymi kolumnami będzie za każdym razem renderowana tak samo. Ponieważ same parametry są przekazywane do metody Update.values () jako klucze słownika Pythona, nie ma innej ustalonej kolejności.
W niektórych przypadkach kolejność parametrów renderowanych w klauzuli SET ma znaczenie. W MySQL aktualizacja wartości kolumn jest oparta na innych wartościach kolumn.
Wynik następującego oświadczenia -
UPDATE table1 SET x = y + 10, y = 20będzie miał inny wynik niż -
UPDATE table1 SET y = 20, x = y + 10Klauzula SET w MySQL jest oceniana na podstawie wartości, a nie na podstawie wiersza. W tym celupreserve_parameter_orderjest używany. Lista 2-krotek w Pythonie jest podawana jako argument funkcjiUpdate.values() metoda -
stmt = table1.update(preserve_parameter_order = True).\
values([(table1.c.y, 20), (table1.c.x, table1.c.y + 10)])Obiekt List jest podobny do słownika, z tą różnicą, że jest uporządkowany. Gwarantuje to, że najpierw zostanie wyświetlona klauzula SET kolumny „y”, a następnie klauzula SET kolumny „x”.
W tym rozdziale przyjrzymy się wyrażeniu Multiple Table Deletes, które jest podobne do funkcji Multiple Table Updates.
W klauzuli WHERE instrukcji DELETE w wielu dialektach DBMS można odwołać się do więcej niż jednej tabeli. W przypadku PG i MySQL używana jest składnia „DELETE USING”; aw przypadku programu SQL Server wyrażenie „USUŃ Z” odnosi się do więcej niż jednej tabeli. SQLAlchemydelete() Konstrukcja obsługuje oba te tryby niejawnie, określając wiele tabel w klauzuli WHERE w następujący sposób -
stmt = users.delete().\
where(users.c.id == addresses.c.id).\
where(addresses.c.email_address.startswith('xyz%'))
conn.execute(stmt)Na zapleczu PostgreSQL wynikowy kod SQL z powyższej instrukcji byłby renderowany jako -
DELETE FROM users USING addresses
WHERE users.id = addresses.id
AND (addresses.email_address LIKE %(email_address_1)s || '%%')Jeśli ta metoda jest używana z bazą danych, która nie obsługuje tego zachowania, kompilator zgłosi błąd NotImplementedError.
W tym rozdziale nauczymy się, jak używać połączeń w SQLAlchemy.
Efekt połączenia uzyskuje się po prostu umieszczając dwie tabele w pliku columns clause albo where clausekonstrukcji select (). Teraz używamy metod join () i externaljoin ().
Metoda join () zwraca obiekt join z jednego obiektu tabeli do drugiego.
join(right, onclause = None, isouter = False, full = False)Funkcje parametrów wymienionych w powyższym kodzie są następujące -
right- prawa strona połączenia; to jest dowolny obiekt tabeli
onclause- wyrażenie SQL reprezentujące klauzulę ON w złączeniu. W przypadku pozostawienia opcji Brak próbuje połączyć dwie tabele na podstawie relacji klucza obcego
isouter - jeśli True, renderuje LEFT OUTER JOIN zamiast JOIN
full - jeśli True, renderuje FULL OUTER JOIN zamiast LEFT OUTER JOIN
Na przykład użycie metody join () automatycznie spowoduje złączenie na podstawie klucza obcego.
>>> print(students.join(addresses))Jest to równoważne z następującym wyrażeniem SQL -
students JOIN addresses ON students.id = addresses.st_idMożesz wyraźnie wspomnieć o kryteriach dołączania w następujący sposób -
j = students.join(addresses, students.c.id == addresses.c.st_id)Jeśli teraz zbudujemy poniższą konstrukcję wybierz, używając tego sprzężenia jako -
stmt = select([students]).select_from(j)Spowoduje to następujące wyrażenie SQL -
SELECT students.id, students.name, students.lastname
FROM students JOIN addresses ON students.id = addresses.st_idJeśli instrukcja ta zostanie wykonana przy użyciu połączenia reprezentującego silnik, wyświetlone zostaną dane należące do wybranych kolumn. Kompletny kod wygląda następująco -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer,ForeignKey('students.id')),
Column('postal_add', String),
Column('email_add', String)
)
from sqlalchemy import join
from sqlalchemy.sql import select
j = students.join(addresses, students.c.id == addresses.c.st_id)
stmt = select([students]).select_from(j)
result = conn.execute(stmt)
result.fetchall()Poniżej przedstawiono wynik powyższego kodu -
[
(1, 'Ravi', 'Kapoor'),
(1, 'Ravi', 'Kapoor'),
(3, 'Komal', 'Bhandari'),
(5, 'Priya', 'Rajhans'),
(2, 'Rajiv', 'Khanna')
]Koniunkcje to funkcje w module SQLAlchemy, które implementują operatory relacyjne używane w klauzuli WHERE wyrażeń SQL. Operatory AND, OR, NOT itd. Służą do tworzenia wyrażenia złożonego łączącego dwa pojedyncze wyrażenia logiczne. Prosty przykład użycia AND w instrukcji SELECT jest następujący -
SELECT * from EMPLOYEE WHERE salary>10000 AND age>30Funkcje SQLAlchemy i_ (), or_ () i not_ () odpowiednio implementują operatory AND, OR i NOT.
and_ () funkcja
Tworzy koniunkcję wyrażeń połączonych AND. Poniżej podano przykład dla lepszego zrozumienia -
from sqlalchemy import and_
print(
and_(
students.c.name == 'Ravi',
students.c.id <3
)
)To przekłada się na -
students.name = :name_1 AND students.id < :id_1Aby użyć and_ () w konstrukcji select () w tabeli uczniów, użyj następującego wiersza kodu -
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))Zostanie skonstruowana instrukcja SELECT o następującym charakterze -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1 AND students.id < :id_1Pełny kod, który wyświetla dane wyjściowe powyższego zapytania SELECT, jest następujący:
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import and_, or_
stmt = select([students]).where(and_(students.c.name == 'Ravi', students.c.id <3))
result = conn.execute(stmt)
print (result.fetchall())Następujący wiersz zostanie wybrany przy założeniu, że tabela uczniów jest wypełniona danymi używanymi w poprzednim przykładzie -
[(1, 'Ravi', 'Kapoor')]funkcja or_ ()
Tworzy koniunkcję wyrażeń połączonych OR. Zastąpimy obiekt stmt w powyższym przykładzie następującym za pomocą or_ ()
stmt = select([students]).where(or_(students.c.name == 'Ravi', students.c.id <3))Który będzie efektywnie równoważny z następującym zapytaniem SELECT -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.name = :name_1
OR students.id < :id_1Po dokonaniu podstawienia i uruchomieniu powyższego kodu w wyniku otrzymamy dwa wiersze mieszczące się w warunku OR -
[(1, 'Ravi', 'Kapoor'),
(2, 'Rajiv', 'Khanna')]funkcja asc ()
Tworzy rosnącą klauzulę ORDER BY. Funkcja przyjmuje kolumnę, aby zastosować funkcję jako parametr.
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))Instrukcja implementuje następujące wyrażenie SQL -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.name ASCPoniższy kod wyświetla wszystkie rekordy w tabeli uczniów w rosnącej kolejności według kolumny nazw -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, ForeignKey, select
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
students = Table(
'students', meta,
Column('id', Integer, primary_key = True),
Column('name', String),
Column('lastname', String),
)
from sqlalchemy import asc
stmt = select([students]).order_by(asc(students.c.name))
result = conn.execute(stmt)
for row in result:
print (row)Powyższy kod daje następujące dane wyjściowe -
(4, 'Abdul', 'Sattar')
(3, 'Komal', 'Bhandari')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')desc (), funkcja
Podobnie funkcja desc () generuje malejącą klauzulę ORDER BY w następujący sposób -
from sqlalchemy import desc
stmt = select([students]).order_by(desc(students.c.lastname))Równoważne wyrażenie SQL to -
SELECT students.id,
students.name,
students.lastname
FROM students
ORDER BY students.lastname DESCWynik dla powyższych wierszy kodu to -
(4, 'Abdul', 'Sattar')
(5, 'Priya', 'Rajhans')
(2, 'Rajiv', 'Khanna')
(1, 'Ravi', 'Kapoor')
(3, 'Komal', 'Bhandari')between () funkcja
Tworzy klauzulę predykatu BETWEEN. Jest to zwykle używane do sprawdzania, czy wartość określonej kolumny mieści się w zakresie. Na przykład poniższy kod wybiera wiersze, dla których kolumna id zawiera się w przedziale od 2 do 4 -
from sqlalchemy import between
stmt = select([students]).where(between(students.c.id,2,4))
print (stmt)Wynikowe wyrażenie SQL przypomina -
SELECT students.id,
students.name,
students.lastname
FROM students
WHERE students.id
BETWEEN :id_1 AND :id_2a wynik jest następujący -
(2, 'Rajiv', 'Khanna')
(3, 'Komal', 'Bhandari')
(4, 'Abdul', 'Sattar')W tym rozdziale omówiono niektóre z ważnych funkcji używanych w SQLAlchemy.
Standardowy SQL zaleca wiele funkcji, które są zaimplementowane w większości dialektów. Zwracają pojedynczą wartość na podstawie przekazanych argumentów. Niektóre funkcje SQL przyjmują kolumny jako argumenty, podczas gdy inne są ogólne.Thefunc keyword in SQLAlchemy API is used to generate these functions.
W SQL now () jest funkcją ogólną. Następujące instrukcje renderują funkcję now () za pomocą func -
from sqlalchemy.sql import func
result = conn.execute(select([func.now()]))
print (result.fetchone())Przykładowy wynik powyższego kodu może wyglądać tak, jak pokazano poniżej -
(datetime.datetime(2018, 6, 16, 6, 4, 40),)Z drugiej strony funkcja count (), która zwraca liczbę wierszy wybranych z tabeli, jest renderowana przez użycie funkcji func -
from sqlalchemy.sql import func
result = conn.execute(select([func.count(students.c.id)]))
print (result.fetchone())Z powyższego kodu zostanie pobrana liczba wierszy w tabeli uczniów.
Niektóre wbudowane funkcje SQL przedstawiono za pomocą tabeli Employee z następującymi danymi -
| ID | Nazwa | Znaki |
|---|---|---|
| 1 | Kamal | 56 |
| 2 | Fernandez | 85 |
| 3 | Sunil | 62 |
| 4 | Bhaskar | 76 |
Funkcja max () jest implementowana poprzez użycie funkcji func z SQLAlchemy, co da w wyniku 85, łączną maksymalną uzyskaną ocenę -
from sqlalchemy.sql import func
result = conn.execute(select([func.max(employee.c.marks)]))
print (result.fetchone())Podobnie funkcja min (), która zwróci 56 znaków minimum, zostanie wyrenderowana przez następujący kod -
from sqlalchemy.sql import func
result = conn.execute(select([func.min(employee.c.marks)]))
print (result.fetchone())Tak więc funkcję AVG () można również zaimplementować za pomocą poniższego kodu -
from sqlalchemy.sql import func
result = conn.execute(select([func.avg(employee.c.marks)]))
print (result.fetchone())
Functions are normally used in the columns clause of a select statement.
They can also be given label as well as a type. A label to function allows the result
to be targeted in a result row based on a string name, and a type is required when
you need result-set processing to occur.from sqlalchemy.sql import func
result = conn.execute(select([func.max(students.c.lastname).label('Name')]))
print (result.fetchone())W ostatnim rozdziale poznaliśmy różne funkcje, takie jak max (), min (), count (), itp., Tutaj dowiemy się o operacjach na zbiorach i ich zastosowaniach.
Operacje na zbiorach, takie jak UNION i INTERSECT, są obsługiwane przez standardowy SQL i większość jego dialektu. SQLAlchemy implementuje je za pomocą następujących funkcji -
unia()
Podczas łączenia wyników dwóch lub więcej instrukcji SELECT, UNION eliminuje duplikaty z zestawu wyników. Liczba kolumn i typ danych muszą być takie same w obu tabelach.
Funkcja union () zwraca obiekt CompoundSelect z wielu tabel. Poniższy przykład demonstruje jego użycie -
from sqlalchemy import create_engine, MetaData, Table, Column, Integer, String, union
engine = create_engine('sqlite:///college.db', echo = True)
meta = MetaData()
conn = engine.connect()
addresses = Table(
'addresses', meta,
Column('id', Integer, primary_key = True),
Column('st_id', Integer),
Column('postal_add', String),
Column('email_add', String)
)
u = union(addresses.select().where(addresses.c.email_add.like('%@gmail.com addresses.select().where(addresses.c.email_add.like('%@yahoo.com'))))
result = conn.execute(u)
result.fetchall()Konstrukcja unii przekłada się na następujące wyrażenie SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?W naszej tabeli adresów następujące wiersze przedstawiają operację unii -
[
(1, 1, 'Shivajinagar Pune', '[email protected]'),
(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]'),
(4, 5, 'MG Road Bangaluru', '[email protected]')
]union_all ()
Operacja UNION ALL nie może usunąć duplikatów i nie może sortować danych w zestawie wyników. Na przykład w powyższym zapytaniu UNION jest zastępowany przez UNION ALL, aby zobaczyć efekt.
u = union_all(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.email_add.like('%@yahoo.com')))Odpowiednie wyrażenie SQL jest następujące -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? UNION ALL SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ?z wyjątkiem_()
SQL EXCEPTklauzula / operator służy do łączenia dwóch instrukcji SELECT i zwracania wierszy z pierwszej instrukcji SELECT, które nie są zwracane przez drugą instrukcję SELECT. Funkcja except_ () generuje wyrażenie SELECT z klauzulą EXCEPT.
W poniższym przykładzie funkcja except_ () zwraca tylko te rekordy z tabeli adresów, które mają „gmail.com” w polu email_add, ale wyklucza te, które mają „Pune” jako część pola postal_add.
u = except_(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))Rezultatem powyższego kodu jest następujące wyrażenie SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? EXCEPT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Zakładając, że tabela adresów zawiera dane użyte we wcześniejszych przykładach, wyświetli następujące dane wyjściowe -
[(2, 1, 'ChurchGate Mumbai', '[email protected]'),
(3, 3, 'Jubilee Hills Hyderabad', '[email protected]')]krzyżować()
Używając operatora INTERSECT, SQL wyświetla wspólne wiersze z obu instrukcji SELECT. Funkcja intersect () implementuje to zachowanie.
W poniższych przykładach dwie konstrukcje SELECT są parametrami funkcji intersect (). Jeden zwraca wiersze zawierające „gmail.com” jako część kolumny email_add, a inne zwraca wiersze zawierające „Pune” jako część kolumny postal_add. Wynikiem będą wspólne wiersze z obu zestawów wyników.
u = intersect(addresses.select().where(addresses.c.email_add.like('%@gmail.com')), addresses.select().where(addresses.c.postal_add.like('%Pune')))W efekcie jest to równoważne z następującą instrukcją SQL -
SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.email_add LIKE ? INTERSECT SELECT addresses.id,
addresses.st_id,
addresses.postal_add,
addresses.email_add
FROM addresses
WHERE addresses.postal_add LIKE ?Dwa powiązane parametry „% gmail.com” i „% Pune” generują pojedynczy wiersz z oryginalnych danych w tabeli adresów, jak pokazano poniżej -
[(1, 1, 'Shivajinagar Pune', '[email protected]')]Głównym celem Object Relational Mapper API SQLAlchemy jest ułatwienie kojarzenia zdefiniowanych przez użytkownika klas języka Python z tabelami bazy danych oraz obiektów tych klas z wierszami w odpowiadających im tabelach. Zmiany stanów obiektów i wierszy są do siebie dopasowywane synchronicznie. SQLAlchemy umożliwia wyrażanie zapytań do bazy danych w zakresie klas zdefiniowanych przez użytkownika i ich zdefiniowanych relacji.
ORM jest zbudowany w oparciu o język wyrażeń SQL. Jest to wysokopoziomowy i abstrakcyjny wzór użytkowania. W rzeczywistości ORM jest stosowanym użyciem języka wyrażeń.
Chociaż pomyślna aplikacja może zostać skonstruowana wyłącznie przy użyciu Object Relational Mapper, czasami aplikacja zbudowana za pomocą ORM może używać języka wyrażeń bezpośrednio, gdy wymagane są określone interakcje z bazą danych.
Zadeklaruj mapowanie
Przede wszystkim wywoływana jest funkcja create_engine () w celu skonfigurowania obiektu silnika, który jest następnie używany do wykonywania operacji SQL. Funkcja ma dwa argumenty, jeden to nazwa bazy danych, a drugi to parametr echo, gdy ustawiono wartość True, wygeneruje dziennik aktywności. Jeśli nie istnieje, baza danych zostanie utworzona. W poniższym przykładzie tworzona jest baza danych SQLite.
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)Silnik ustanawia rzeczywiste połączenie DBAPI z bazą danych, gdy wywoływana jest metoda, taka jak Engine.execute () lub Engine.connect (). Następnie jest używany do emitowania kodu SQLORM, który nie korzysta bezpośrednio z silnika; zamiast tego jest używany za kulisami przez ORM.
W przypadku ORM proces konfiguracyjny rozpoczyna się od opisu tabel bazy danych, a następnie definiowania klas, które zostaną odwzorowane na te tabele. W SQLAlchemy te dwa zadania są wykonywane razem. Odbywa się to za pomocą systemu deklaratywnego; utworzone klasy zawierają dyrektywy opisujące rzeczywistą tabelę bazy danych, na którą są odwzorowane.
Klasa bazowa przechowuje katalog klas i mapowanych tabel w systemie deklaratywnym. Nazywa się to deklaratywną klasą bazową. Zwykle będzie tylko jedno wystąpienie tej bazy w powszechnie importowanym module. Funkcja declarative_base () służy do tworzenia klasy bazowej. Ta funkcja jest zdefiniowana w module sqlalchemy.ext.declarative.
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()Po zadeklarowaniu klasy bazowej można zdefiniować w jej ramach dowolną liczbę mapowanych klas. Poniższy kod definiuje klasę klienta. Zawiera tabelę, na którą ma zostać zmapowana, oraz nazwy i typy danych kolumn w niej.
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)Klasa w Declarative musi mieć rozszerzenie __tablename__ atrybut i co najmniej jeden Columnktóry jest częścią klucza podstawowego. Deklaratywne zastępuje wszystkieColumn obiekty ze specjalnymi akcesoriami Pythona znanymi jako descriptors. Ten proces jest znany jako instrumentacja, która zapewnia środki odwoływania się do tabeli w kontekście SQL i umożliwia utrwalanie i ładowanie wartości kolumn z bazy danych.
Ta odwzorowana klasa, podobnie jak normalna klasa Pythona, ma atrybuty i metody zgodnie z wymaganiami.
Informacje o klasie w systemie deklaratywnym nazywane są metadanymi tabeli. SQLAlchemy używa obiektu Table do reprezentowania tych informacji dla określonej tabeli utworzonej przez Declarative. Obiekt Table jest tworzony zgodnie ze specyfikacjami i jest powiązany z klasą poprzez utworzenie obiektu Mapper. Ten obiekt mapowania nie jest używany bezpośrednio, ale jest używany wewnętrznie jako interfejs między mapowaną klasą a tabelą.
Każdy obiekt Table jest członkiem większej kolekcji znanej jako MetaData i ten obiekt jest dostępny przy użyciu rozszerzenia .metadataatrybut deklaratywnej klasy bazowej. PlikMetaData.create_all()metoda polega na przekazaniu do naszego silnika jako źródła połączenia z bazą danych. Dla wszystkich tabel, które nie zostały jeszcze utworzone, wysyła instrukcje CREATE TABLE do bazy danych.
Base.metadata.create_all(engine)Pełny skrypt do tworzenia bazy danych i tabeli oraz mapowania klasy Pythona jest podany poniżej -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
Base.metadata.create_all(engine)Po uruchomieniu konsola Pythona wyświetli echo po wykonywaniu wyrażenia SQL -
CREATE TABLE customers (
id INTEGER NOT NULL,
name VARCHAR,
address VARCHAR,
email VARCHAR,
PRIMARY KEY (id)
)Jeśli otworzymy Sales.db za pomocą narzędzia graficznego SQLiteStudio, wyświetli się w nim tabela klientów o powyższej strukturze.

Aby móc współdziałać z bazą danych, musimy uzyskać jej uchwyt. Obiekt sesji jest uchwytem do bazy danych. Klasa sesji jest definiowana za pomocą sessionmaker () - konfigurowalnej metody fabryki sesji, która jest powiązana z utworzonym wcześniej obiektem silnika.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)Obiekt sesji jest następnie konfigurowany przy użyciu jego domyślnego konstruktora w następujący sposób -
session = Session()Poniżej wymieniono niektóre z często wymaganych metod klas sesji -
| Sr.No. | Metoda i opis |
|---|---|
| 1 | begin() rozpoczyna transakcję w tej sesji |
| 2 | add() umieszcza obiekt w sesji. Jego stan jest utrwalany w bazie danych podczas następnej operacji opróżniania |
| 3 | add_all() dodaje kolekcję obiektów do sesji |
| 4 | commit() opróżnia wszystkie elementy i wszystkie trwające transakcje |
| 5 | delete() oznacza transakcję jako usuniętą |
| 6 | execute() wykonuje wyrażenie SQL |
| 7 | expire() oznacza atrybuty instancji jako nieaktualne |
| 8 | flush() opróżnia wszystkie zmiany obiektów do bazy danych |
| 9 | invalidate() zamyka sesję za pomocą unieważnienia połączenia |
| 10 | rollback() wycofuje bieżącą transakcję w toku |
| 11 | close() Zamyka bieżącą sesję, usuwając wszystkie pozycje i kończąc transakcję w toku |
W poprzednich rozdziałach SQLAlchemy ORM dowiedzieliśmy się, jak deklarować mapowanie i tworzyć sesje. W tym rozdziale dowiemy się, jak dodawać obiekty do tabeli.
Zadeklarowaliśmy klasę Customer, która została zmapowana do tabeli klientów. Musimy zadeklarować obiekt tej klasy i na stałe dodać go do tablicy metodą add () obiektu sesji.
c1 = Sales(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)Zauważ, że ta transakcja jest w toku, dopóki nie zostanie opróżniona przy użyciu metody commit ().
session.commit()Poniżej znajduje się kompletny skrypt dodawania rekordu w tabeli klientów -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key=True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
c1 = Customers(name = 'Ravi Kumar', address = 'Station Road Nanded', email = '[email protected]')
session.add(c1)
session.commit()Aby dodać wiele rekordów, możemy użyć add_all() metoda klasy sesji.
session.add_all([
Customers(name = 'Komal Pande', address = 'Koti, Hyderabad', email = '[email protected]'),
Customers(name = 'Rajender Nath', address = 'Sector 40, Gurgaon', email = '[email protected]'),
Customers(name = 'S.M.Krishna', address = 'Budhwar Peth, Pune', email = '[email protected]')]
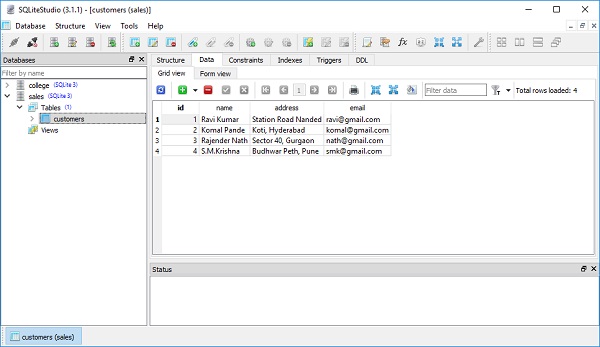
)
session.commit()Widok tabeli SQLiteStudio pokazuje, że rekordy są trwale dodawane do tabeli klientów. Poniższy obraz przedstawia wynik -
Wszystkie instrukcje SELECT generowane przez SQLAlchemy ORM są konstruowane przez obiekt Query. Zapewnia interfejs generatywny, stąd kolejne wywołania zwracają nowy obiekt Query, kopię poprzedniego z dodatkowymi kryteriami i powiązanymi z nim opcjami.
Obiekty zapytania są początkowo generowane przy użyciu metody query () sesji w następujący sposób -
q = session.query(mapped class)Poniższe stwierdzenie jest również równoważne powyższemu stwierdzeniu -
q = Query(mappedClass, session)Obiekt zapytania posiada metodę all (), która zwraca zestaw wyników w postaci listy obiektów. Jeśli wykonamy to na stole naszych klientów -
result = session.query(Customers).all()Ta instrukcja jest efektywnie równoważna z następującym wyrażeniem SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customersPrzez obiekt wynikowy można przejść za pomocą pętli For, jak poniżej, aby uzyskać wszystkie rekordy w podstawowej tabeli klientów. Oto pełny kod do wyświetlania wszystkich rekordów w tabeli Klienci -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).all()
for row in result:
print ("Name: ",row.name, "Address:",row.address, "Email:",row.email)Konsola Pythona pokazuje listę rekordów jak poniżej -
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]
Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Obiekt Query ma również następujące przydatne metody -
| Sr.No. | Metoda i opis |
|---|---|
| 1 | add_columns() Dodaje jedno lub więcej wyrażeń kolumnowych do listy zwracanych kolumn wynikowych. |
| 2 | add_entity() Dodaje mapowaną jednostkę do listy zwracanych kolumn wynikowych. |
| 3 | count() Zwraca liczbę wierszy, które zwróciłoby to zapytanie. |
| 4 | delete() Wykonuje zapytanie do usuwania zbiorczego. Usuwa z bazy danych wiersze dopasowane przez to zapytanie. |
| 5 | distinct() Stosuje klauzulę DISTINCT do zapytania i zwraca nowo powstałe zapytanie. |
| 6 | filter() Stosuje dane kryterium filtrowania do kopii tego zapytania, używając wyrażeń SQL. |
| 7 | first() Zwraca pierwszy wynik tego zapytania lub None, jeśli wynik nie zawiera żadnego wiersza. |
| 8 | get() Zwraca instancję na podstawie podanego identyfikatora klucza podstawowego, zapewniając bezpośredni dostęp do mapy tożsamości sesji będącej właścicielem. |
| 9 | group_by() Stosuje jedno lub więcej kryterium GROUP BY do zapytania i zwraca nowo wynikowe zapytanie |
| 10 | join() Tworzy JOIN SQL na podstawie kryterium tego obiektu zapytania i stosuje się je generatywnie, zwracając nowo wynikowe zapytanie. |
| 11 | one() Zwraca dokładnie jeden wynik lub zgłasza wyjątek. |
| 12 | order_by() Stosuje do zapytania jedno lub więcej kryteriów ORDER BY i zwraca nowo wynikowe zapytanie. |
| 13 | update() Wykonuje zapytanie zbiorcze aktualizujące i aktualizuje wiersze dopasowane przez to zapytanie w bazie danych. |
W tym rozdziale zobaczymy, jak zmodyfikować lub zaktualizować tabelę o żądane wartości.
Aby zmodyfikować dane określonego atrybutu dowolnego obiektu, musimy przypisać mu nową wartość i zatwierdzić zmiany, aby zmiana stała się trwała.
Pobierzmy obiekt z tabeli, której identyfikator klucza podstawowego znajduje się w naszej tabeli Klienci o ID = 2. Możemy użyć metody sesji get () w następujący sposób -
x = session.query(Customers).get(2)Możemy wyświetlić zawartość wybranego obiektu za pomocą poniższego kodu -
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Z tabeli naszych klientów powinno zostać wyświetlone następujące wyjście -
Name: Komal Pande Address: Koti, Hyderabad Email: [email protected]Teraz musimy zaktualizować pole Adres, przypisując nową wartość, jak podano poniżej -
x.address = 'Banjara Hills Secunderabad'
session.commit()Zmiana zostanie trwale odzwierciedlona w bazie danych. Teraz pobieramy obiekt odpowiadający pierwszemu wierszowi tabeli za pomocąfirst() method w następujący sposób -
x = session.query(Customers).first()Spowoduje to wykonanie następującego wyrażenia SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Powiązanymi parametrami będą odpowiednio LIMIT = 1 i OFFSET = 0, co oznacza, że zostanie wybrany pierwszy wiersz.
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Teraz wynik dla powyższego kodu wyświetlającego pierwszy wiersz jest następujący:
Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]Teraz zmień atrybut nazwy i wyświetl zawartość za pomocą poniższego kodu -
x.name = 'Ravi Shrivastava'
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Wynik powyższego kodu to -
Name: Ravi Shrivastava Address: Station Road Nanded Email: [email protected]Mimo że zmiana jest wyświetlana, nie jest zatwierdzona. Możesz zachować wcześniejszą stałą pozycję za pomocąrollback() method z poniższym kodem.
session.rollback()
print ("Name: ", x.name, "Address:", x.address, "Email:", x.email)Zostanie wyświetlona oryginalna zawartość pierwszego rekordu.
W przypadku aktualizacji zbiorczych będziemy używać metody update () obiektu Query. Spróbujmy podać przedrostek „Mr.” nazwać w każdym wierszu (z wyjątkiem ID = 2). Odpowiednia instrukcja update () jest następująca -
session.query(Customers).filter(Customers.id! = 2).
update({Customers.name:"Mr."+Customers.name}, synchronize_session = False)The update() method requires two parameters as follows −
Słownik par klucz-wartość, w którym klucz to atrybut do zaktualizowania, a wartość to nowa zawartość atrybutu.
atrybut synchronize_session zawierający wzmiankę o strategii aktualizowania atrybutów w sesji. Poprawne wartości to false: aby nie synchronizować sesji, fetch: wykonuje zapytanie wybierające przed aktualizacją w celu znalezienia obiektów, które są zgodne z zapytaniem aktualizującym; i oceniaj: oceniaj kryteria obiektów w sesji.
Trzy z 4 wierszy w tabeli będą miały nazwę z przedrostkiem „Pan”. Jednak zmiany nie zostaną zatwierdzone i dlatego nie zostaną odzwierciedlone w widoku tabeli SQLiteStudio. Zostanie odświeżony dopiero po zatwierdzeniu sesji.
W tym rozdziale omówimy, jak zastosować filtr, a także niektóre operacje filtrujące wraz z ich kodami.
Zestaw wyników reprezentowany przez obiekt Query może zostać poddany określonym kryteriom za pomocą metody filter (). Ogólne użycie metody filtrowania jest następujące -
session.query(class).filter(criteria)W poniższym przykładzie zestaw wyników uzyskany przez zapytanie SELECT w tabeli Klienci jest filtrowany według warunku (ID> 2) -
result = session.query(Customers).filter(Customers.id>2)Ta instrukcja zostanie przetłumaczona na następujące wyrażenie SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ?Ponieważ powiązany parametr (?) Ma wartość 2, zostaną wyświetlone tylko wiersze z kolumną ID> 2. Pełny kod znajduje się poniżej -
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Customers(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
result = session.query(Customers).filter(Customers.id>2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Dane wyjściowe wyświetlane w konsoli Pythona są następujące -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Teraz nauczymy się operacji filtrowania z ich odpowiednimi kodami i danymi wyjściowymi.
Równa się
Zwykle używany operator to == i stosuje kryteria do sprawdzenia równości.
result = session.query(Customers).filter(Customers.id == 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)SQLAlchemy wyśle następujące wyrażenie SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Dane wyjściowe dla powyższego kodu są następujące -
ID: 2 Name: Komal Pande Address: Banjara Hills Secunderabad Email: [email protected]Nie równa się
Operator użyty do wyrażenia nie równa się to! = I podaje kryterium nie równa się.
result = session.query(Customers).filter(Customers.id! = 2)
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Wynikowe wyrażenie SQL to -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id != ?Dane wyjściowe dla powyższych wierszy kodu są następujące -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Lubić
like () sama generuje kryteria LIKE dla klauzuli WHERE w wyrażeniu SELECT.
result = session.query(Customers).filter(Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Powyższy kod SQLAlchemy jest odpowiednikiem następującego wyrażenia SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name LIKE ?Wynik dla powyższego kodu to -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]W
Ten operator sprawdza, czy wartość kolumny należy do kolekcji elementów na liście. Zapewnia to metoda in_ ().
result = session.query(Customers).filter(Customers.id.in_([1,3]))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Tutaj wyrażenie SQL oceniane przez silnik SQLite będzie wyglądać następująco:
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id IN (?, ?)Dane wyjściowe dla powyższego kodu są następujące -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]I
Ta koniunkcja jest generowana przez obie putting multiple commas separated criteria in the filter or using and_() method jak podano poniżej -
result = session.query(Customers).filter(Customers.id>2, Customers.name.like('Ra%'))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)from sqlalchemy import and_
result = session.query(Customers).filter(and_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)Oba powyższe podejścia skutkują podobnym wyrażeniem SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? AND customers.name LIKE ?Dane wyjściowe dla powyższych wierszy kodu to -
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]LUB
To połączenie jest implementowane przez or_() method.
from sqlalchemy import or_
result = session.query(Customers).filter(or_(Customers.id>2, Customers.name.like('Ra%')))
for row in result:
print ("ID:", row.id, "Name: ",row.name, "Address:",row.address, "Email:",row.email)W rezultacie silnik SQLite otrzymuje następujące równoważne wyrażenie SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id > ? OR customers.name LIKE ?Dane wyjściowe dla powyższego kodu są następujące -
ID: 1 Name: Ravi Kumar Address: Station Road Nanded Email: [email protected]
ID: 3 Name: Rajender Nath Address: Sector 40, Gurgaon Email: [email protected]
ID: 4 Name: S.M.Krishna Address: Budhwar Peth, Pune Email: [email protected]Istnieje wiele metod obiektu Query, które natychmiast powodują wyświetlenie kodu SQL i zwrócenie wartości zawierającej wyniki załadowanej bazy danych.
Oto krótkie podsumowanie listy powracających i skalarów -
wszystko()
Zwraca listę. Poniżej podano wiersz kodu funkcji all ().
session.query(Customers).all()Konsola Pythona wyświetla następujące wyemitowane wyrażenie SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customerspierwszy()
Stosuje limit jeden i zwraca pierwszy wynik jako skalar.
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
LIMIT ? OFFSET ?Powiązane parametry dla LIMIT to 1, a dla OFFSET to 0.
jeden()
To polecenie w pełni pobiera wszystkie wiersze, a jeśli w wyniku nie ma dokładnie jednej tożsamości obiektu lub złożonego wiersza, generuje błąd.
session.query(Customers).one()W przypadku znalezienia wielu wierszy -
MultipleResultsFound: Multiple rows were found for one()Bez znalezionych wierszy -
NoResultFound: No row was found for one()Metoda one () jest przydatna w systemach, które oczekują odmiennego traktowania „nie znaleziono elementów” i „wielu znalezionych elementów”.
skalarny()
Wywołuje metodę one (), a po pomyślnym zakończeniu zwraca pierwszą kolumnę wiersza w następujący sposób -
session.query(Customers).filter(Customers.id == 3).scalar()To generuje następującą instrukcję SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?Wcześniej tekstowy SQL korzystający z funkcji text () został wyjaśniony z perspektywy podstawowego języka wyrażeń SQLAlchemy. Teraz omówimy to z punktu widzenia ORM.
Ciągów literałów można elastycznie używać z obiektem Query, określając ich użycie za pomocą konstrukcji text (). Większość odpowiednich metod to akceptuje. Na przykład filter () i order_by ().
W poniższym przykładzie metoda filter () tłumaczy ciąg „id <3” na WHERE id <3
from sqlalchemy import text
for cust in session.query(Customers).filter(text("id<3")):
print(cust.name)Wygenerowane surowe wyrażenie SQL pokazuje konwersję filtru do klauzuli WHERE z kodem przedstawionym poniżej -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id<3Z naszych przykładowych danych w tabeli Klienci zostaną wybrane dwa wiersze, a kolumna z nazwą zostanie wydrukowana w następujący sposób -
Ravi Kumar
Komal PandeAby określić parametry wiązania za pomocą łańcuchowego kodu SQL, użyj dwukropka, a aby określić wartości, użyj metody params ().
cust = session.query(Customers).filter(text("id = :value")).params(value = 1).one()Efektywny SQL wyświetlany na konsoli Pythona będzie taki, jak podano poniżej -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE id = ?Aby użyć instrukcji całkowicie opartej na ciągach znaków, konstrukcję text () reprezentującą kompletną instrukcję można przekazać do funkcji from_statement ().
session.query(Customers).from_statement(text("SELECT * FROM customers")).all()Wynikiem powyższego kodu będzie podstawowa instrukcja SELECT, jak podano poniżej -
SELECT * FROM customersOczywiście zostaną wybrane wszystkie rekordy w tabeli klientów.
Konstrukcja text () umożliwia pozycjonowanie jego tekstowego SQL z wyrażeniami kolumnowymi Core lub odwzorowanymi na ORM. Możemy to osiągnąć, przekazując wyrażenia kolumnowe jako argumenty pozycyjne do metody TextClause.columns ().
stmt = text("SELECT name, id, name, address, email FROM customers")
stmt = stmt.columns(Customers.id, Customers.name)
session.query(Customers.id, Customers.name).from_statement(stmt).all()Kolumny id i name we wszystkich wierszach zostaną zaznaczone, mimo że silnik SQLite wykona następujące wyrażenie wygenerowane przez powyższy kod pokazuje wszystkie kolumny w metodzie text () -
SELECT name, id, name, address, email FROM customersTa sesja opisuje tworzenie kolejnej tabeli, która jest powiązana z już istniejącą w naszej bazie danych. Tabela klientów zawiera dane podstawowe klientów. Teraz musimy utworzyć tabelę faktur, która może zawierać dowolną liczbę faktur należących do klienta. To jest przypadek relacji jeden do wielu.
Używając deklaratywnych, definiujemy tę tabelę wraz z jej mapowaną klasą, Faktury, jak podano poniżej -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")
Base.metadata.create_all(engine)Spowoduje to wysłanie zapytania CREATE TABLE do silnika SQLite, jak poniżej -
CREATE TABLE invoices (
id INTEGER NOT NULL,
custid INTEGER,
invno INTEGER,
amount INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(custid) REFERENCES customers (id)
)Możemy sprawdzić, czy nowa tabela została utworzona w sales.db za pomocą narzędzia SQLiteStudio.
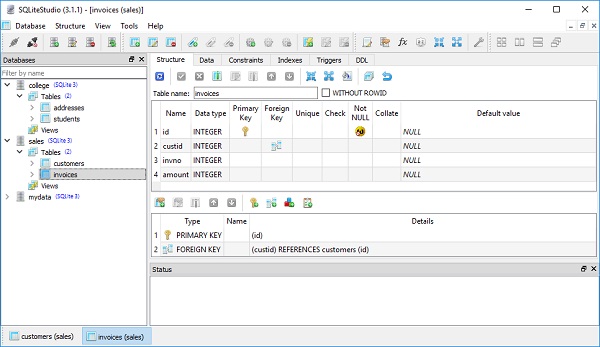
Klasa faktur stosuje konstrukcję ForeignKey dla atrybutu custid. Ta dyrektywa wskazuje, że wartości w tej kolumnie powinny być ograniczone tak, aby były wartościami obecnymi w kolumnie identyfikatora w tabeli klientów. Jest to podstawowa cecha relacyjnych baz danych i jest „klejem”, który przekształca niepołączony zbiór tabel w celu uzyskania bogatych, nakładających się relacji.
Druga dyrektywa, zwana relacją (), informuje ORM, że klasa faktury powinna być połączona z klasą Customer przy użyciu atrybutu Invoice.customer. Relacja () używa relacji klucza obcego między dwiema tabelami, aby określić charakter tego powiązania, określając, że jest to wiele do jednego.
Dodatkowa dyrektywa relations () jest umieszczana w odwzorowanej klasie Customer w atrybucie Customer.invoices. Parametr relations.back_populate jest przypisany do odwoływania się do uzupełniających się nazw atrybutów, dzięki czemu każda relacja () może podejmować inteligentne decyzje dotyczące tej samej relacji, co wyrażono odwrotnie. Z jednej strony Invoices.customer odwołuje się do instancji Invoices, a z drugiej strony Customer.invoices do listy instancji Klientów.
Funkcja relacji jest częścią Relationship API pakietu SQLAlchemy ORM. Zapewnia relację między dwiema mapowanymi klasami. Odpowiada to relacji nadrzędny-podrzędny lub tabeli asocjacyjnej.
Poniżej przedstawiono podstawowe znalezione wzorce relacji -
Jeden za dużo
Relacja jeden do wielu odnosi się do rodzica za pomocą klucza obcego na stole podrzędnym. Relacja () jest następnie określana na rodzicu, jako odwołanie do kolekcji elementów reprezentowanych przez dziecko. Parametr relacji.back_populate służy do ustanowienia relacji dwukierunkowej w trybie jeden-do-wielu, gdzie strona „odwrotna” to wiele do jednego.
Wiele do jednego
Z drugiej strony, relacja Wiele do jednego umieszcza klucz obcy w tabeli nadrzędnej w celu odniesienia się do dziecka. relacja () jest zadeklarowana w rodzicu, gdzie zostanie utworzony nowy atrybut trzymający wartość skalarną. Tutaj ponownie parametr relations.back_populate jest używany dla zachowania dwukierunkowego.
Jeden na jednego
Relacja jeden do jednego jest z natury relacją dwukierunkową. Flaga uselist wskazuje na umieszczenie atrybutu skalarnego zamiast zbioru po stronie „wiele” relacji. Aby przekonwertować relację jeden-do-wielu na typ relacji jeden-do-jednego, ustaw parametr uselist na false.
Wiele do wielu
Relację wiele do wielu ustanawia się przez dodanie tabeli asocjacji związanej z dwiema klasami poprzez zdefiniowanie atrybutów za pomocą ich kluczy obcych. Wskazuje na to drugi argument relacji (). Zwykle tabela używa obiektu MetaData skojarzonego z deklaratywną klasą bazową, dzięki czemu dyrektywy ForeignKey mogą zlokalizować zdalne tabele, z którymi mają zostać połączone. Parametr relacji.back_populate dla każdej relacji () ustanawia relację dwukierunkową. Obie strony relacji zawierają kolekcję.
W tym rozdziale skupimy się na powiązanych obiektach w SQLAlchemy ORM.
Teraz, gdy utworzymy obiekt Customer, pusty zestaw faktur będzie obecny w postaci listy Pythona.
c1 = Customer(name = "Gopal Krishna", address = "Bank Street Hydarebad", email = "[email protected]")Atrybut faktury faktur c1 będzie pustą listą. Możemy przypisać pozycje na liście jako -
c1.invoices = [Invoice(invno = 10, amount = 15000), Invoice(invno = 14, amount = 3850)]Zatwierdźmy ten obiekt w bazie danych za pomocą obiektu Session w następujący sposób -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(c1)
session.commit()Spowoduje to automatyczne wygenerowanie zapytań INSERT dla klientów i tabel faktur -
INSERT INTO customers (name, address, email) VALUES (?, ?, ?)
('Gopal Krishna', 'Bank Street Hydarebad', '[email protected]')
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 10, 15000)
INSERT INTO invoices (custid, invno, amount) VALUES (?, ?, ?)
(2, 14, 3850)Przyjrzyjmy się teraz zawartości tabeli klientów i tabeli faktur w widoku tabeli SQLiteStudio -

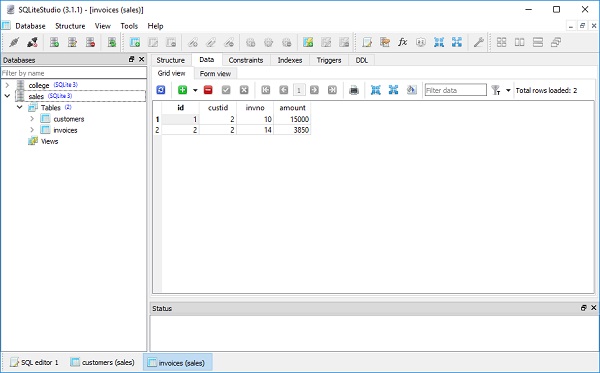
Możesz skonstruować obiekt Customer, dostarczając mapowany atrybut faktur w samym konstruktorze za pomocą poniższego polecenia -
c2 = [
Customer(
name = "Govind Pant",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 3, amount = 10000),
Invoice(invno = 4, amount = 5000)]
)
]Lub lista obiektów do dodania za pomocą funkcji add_all () obiektu sesji, jak pokazano poniżej -
rows = [
Customer(
name = "Govind Kala",
address = "Gulmandi Aurangabad",
email = "[email protected]",
invoices = [Invoice(invno = 7, amount = 12000), Invoice(invno = 8, amount = 18500)]),
Customer(
name = "Abdul Rahman",
address = "Rohtak",
email = "[email protected]",
invoices = [Invoice(invno = 9, amount = 15000),
Invoice(invno = 11, amount = 6000)
])
]
session.add_all(rows)
session.commit()Teraz, gdy mamy dwie tabele, zobaczymy, jak tworzyć zapytania w obu tabelach jednocześnie. Aby skonstruować proste niejawne sprzężenie między klientem a fakturą, możemy użyć Query.filter () do zrównania ich powiązanych kolumn. Poniżej wczytujemy jednocześnie podmioty Klient i Faktura za pomocą tej metody -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for c, i in session.query(Customer, Invoice).filter(Customer.id == Invoice.custid).all():
print ("ID: {} Name: {} Invoice No: {} Amount: {}".format(c.id,c.name, i.invno, i.amount))Wyrażenie SQL emitowane przez SQLAlchemy jest następujące -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM customers, invoices
WHERE customers.id = invoices.custidWynik powyższych wierszy kodu jest następujący -
ID: 2 Name: Gopal Krishna Invoice No: 10 Amount: 15000
ID: 2 Name: Gopal Krishna Invoice No: 14 Amount: 3850
ID: 3 Name: Govind Pant Invoice No: 3 Amount: 10000
ID: 3 Name: Govind Pant Invoice No: 4 Amount: 5000
ID: 4 Name: Govind Kala Invoice No: 7 Amount: 12000
ID: 4 Name: Govind Kala Invoice No: 8 Amount: 8500
ID: 5 Name: Abdul Rahman Invoice No: 9 Amount: 15000
ID: 5 Name: Abdul Rahman Invoice No: 11 Amount: 6000Rzeczywistą składnię SQL JOIN można łatwo uzyskać za pomocą metody Query.join () w następujący sposób -
session.query(Customer).join(Invoice).filter(Invoice.amount == 8500).all()Na konsoli zostanie wyświetlone wyrażenie SQL dotyczące łączenia -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers JOIN invoices ON customers.id = invoices.custid
WHERE invoices.amount = ?Możemy powtórzyć wynik za pomocą pętli for -
result = session.query(Customer).join(Invoice).filter(Invoice.amount == 8500)
for row in result:
for inv in row.invoices:
print (row.id, row.name, inv.invno, inv.amount)Z 8500 jako parametrem powiązania, wyświetlane są następujące dane wyjściowe -
4 Govind Kala 8 8500Query.join () wie, jak łączyć te tabele, ponieważ między nimi jest tylko jeden klucz obcy. Jeśli nie było kluczy obcych lub więcej kluczy obcych, Query.join () działa lepiej, gdy używana jest jedna z następujących form -
| query.join (Faktura, id == Adres.custid) | wyraźny warunek |
| query.join (Customer.invoices) | określ relację od lewej do prawej |
| query.join (faktura, faktury klienta) | to samo, z wyraźnym celem |
| query.join ('faktury') | to samo, używając ciągu |
Podobnie, funkcja externaljoin () jest dostępna do uzyskania lewostronnego sprzężenia zewnętrznego.
query.outerjoin(Customer.invoices)Metoda subquery () generuje wyrażenie SQL reprezentujące instrukcję SELECT osadzoną w aliasie.
from sqlalchemy.sql import func
stmt = session.query(
Invoice.custid, func.count('*').label('invoice_count')
).group_by(Invoice.custid).subquery()Obiekt stmt będzie zawierał instrukcję SQL, jak poniżej -
SELECT invoices.custid, count(:count_1) AS invoice_count FROM invoices GROUP BY invoices.custidKiedy już mamy naszą instrukcję, zachowuje się ona jak konstrukcja Table. Kolumny w instrukcji są dostępne za pośrednictwem atrybutu o nazwie c, jak pokazano w poniższym kodzie -
for u, count in session.query(Customer, stmt.c.invoice_count).outerjoin(stmt, Customer.id == stmt.c.custid).order_by(Customer.id):
print(u.name, count)Powyższa pętla for wyświetla liczbę faktur według nazwy w następujący sposób -
Arjun Pandit None
Gopal Krishna 2
Govind Pant 2
Govind Kala 2
Abdul Rahman 2W tym rozdziale omówimy operatory, które opierają się na relacjach.
__eq __ ()
Powyższy operator to porównanie „równa się” wiele do jednego. Linia kodu tego operatora jest pokazana poniżej -
s = session.query(Customer).filter(Invoice.invno.__eq__(12))Równoważne zapytanie SQL dla powyższego wiersza kodu to -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.invno = ?__ne __ ()
Ten operator jest porównaniem „wiele do jednego” „nie równa się”. Linia kodu tego operatora jest pokazana poniżej -
s = session.query(Customer).filter(Invoice.custid.__ne__(2))Odpowiednik zapytania SQL dla powyższej linii kodu podano poniżej -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers, invoices
WHERE invoices.custid != ?zawiera ()
Ten operator jest używany dla kolekcji jeden do wielu, a poniżej podany jest kod zawiera () -
s = session.query(Invoice).filter(Invoice.invno.contains([3,4,5]))Równoważne zapytanie SQL dla powyższego wiersza kodu to -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE (invoices.invno LIKE '%' + ? || '%')każdy()
dowolny operator () jest używany do kolekcji, jak pokazano poniżej -
s = session.query(Customer).filter(Customer.invoices.any(Invoice.invno==11))Równoważne zapytanie SQL dla powyższego wiersza kodu pokazano poniżej -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE EXISTS (
SELECT 1
FROM invoices
WHERE customers.id = invoices.custid
AND invoices.invno = ?)ma ()
Ten operator jest używany do odwołań skalarnych w następujący sposób -
s = session.query(Invoice).filter(Invoice.customer.has(name = 'Arjun Pandit'))Równoważne zapytanie SQL dla powyższego wiersza kodu to -
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE EXISTS (
SELECT 1
FROM customers
WHERE customers.id = invoices.custid
AND customers.name = ?)Chętne ładowanie zmniejsza liczbę zapytań. SQLAlchemy oferuje funkcje szybkiego ładowania wywoływane przez opcje zapytania, które dają dodatkowe instrukcje zapytaniu. Te opcje określają sposób ładowania różnych atrybutów za pomocą metody Query.options ().
Ładowanie podzapytania
Chcemy, aby faktury Klienta były szybko ładowane. Opcja orm.subqueryload () daje drugą instrukcję SELECT, która w pełni ładuje kolekcje powiązane z właśnie załadowanymi wynikami. Nazwa „podzapytanie” powoduje, że instrukcja SELECT jest konstruowana bezpośrednio przez zapytanie ponownie użyte i osadzone jako podzapytanie w SELECT względem powiązanej tabeli.
from sqlalchemy.orm import subqueryload
c1 = session.query(Customer).options(subqueryload(Customer.invoices)).filter_by(name = 'Govind Pant').one()Powoduje to dwa następujące wyrażenia SQL -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?
('Govind Pant',)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount, anon_1.customers_id
AS anon_1_customers_id
FROM (
SELECT customers.id
AS customers_id
FROM customers
WHERE customers.name = ?)
AS anon_1
JOIN invoices
ON anon_1.customers_id = invoices.custid
ORDER BY anon_1.customers_id, invoices.id 2018-06-25 18:24:47,479
INFO sqlalchemy.engine.base.Engine ('Govind Pant',)Aby uzyskać dostęp do danych z dwóch tabel, możemy skorzystać z poniższego programu -
print (c1.name, c1.address, c1.email)
for x in c1.invoices:
print ("Invoice no : {}, Amount : {}".format(x.invno, x.amount))Wynik powyższego programu jest następujący -
Govind Pant Gulmandi Aurangabad [email protected]
Invoice no : 3, Amount : 10000
Invoice no : 4, Amount : 5000Połączone obciążenie
Druga funkcja nazywa się orm.joinedload (). To emituje LEWE POŁĄCZENIE ZEWNĘTRZNE. Obiekt wiodący oraz powiązany obiekt lub kolekcja są ładowane w jednym kroku.
from sqlalchemy.orm import joinedload
c1 = session.query(Customer).options(joinedload(Customer.invoices)).filter_by(name='Govind Pant').one()To emituje następujące wyrażenie dające taki sam wynik jak powyżej -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email, invoices_1.id
AS invoices_1_id, invoices_1.custid
AS invoices_1_custid, invoices_1.invno
AS invoices_1_invno, invoices_1.amount
AS invoices_1_amount
FROM customers
LEFT OUTER JOIN invoices
AS invoices_1
ON customers.id = invoices_1.custid
WHERE customers.name = ? ORDER BY invoices_1.id
('Govind Pant',)ZEWNĘTRZNE JOIN spowodowało powstanie dwóch wierszy, ale zwraca jedno wystąpienie klienta. Dzieje się tak, ponieważ Query stosuje strategię „unikatową”, opartą na tożsamości obiektu, do zwracanych jednostek. Dołączone przyspieszone ładowanie można zastosować bez wpływu na wyniki zapytania.
Subqueryload () jest bardziej odpowiednia do ładowania powiązanych kolekcji, podczas gdy joinload () lepiej nadaje się do relacji wiele do jednego.
Operację usuwania można łatwo wykonać na pojedynczej tabeli. Wszystko, co musisz zrobić, to usunąć obiekt zamapowanej klasy z sesji i zatwierdzić akcję. Jednak operacja usuwania na wielu powiązanych tabelach jest trochę skomplikowana.
W naszej bazie danych sales.db klasy Klient i Faktura są mapowane na tabelę klientów i faktur z jednym do wielu typów relacji. Spróbujemy usunąć obiekt klienta i zobaczyć wynik.
W skrócie poniżej znajdują się definicje klas klienta i faktury -
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///sales.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
class Invoice(Base):
__tablename__ = 'invoices'
id = Column(Integer, primary_key = True)
custid = Column(Integer, ForeignKey('customers.id'))
invno = Column(Integer)
amount = Column(Integer)
customer = relationship("Customer", back_populates = "invoices")
Customer.invoices = relationship("Invoice", order_by = Invoice.id, back_populates = "customer")Konfigurujemy sesję i uzyskujemy obiekt klienta, odpytując go o podstawowy identyfikator za pomocą poniższego programu -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
x = session.query(Customer).get(2)W naszej przykładowej tabeli x.name to „Gopal Krishna”. Usuńmy ten x z sesji i policzmy wystąpienie tej nazwy.
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()Wynikowe wyrażenie SQL zwróci 0.
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',) 0Jednak powiązane obiekty faktury z x nadal tam są. Można to zweryfikować za pomocą następującego kodu -
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Tutaj 10 i 14 to numery faktur należące do klienta Gopal Krishna. Wynik powyższego zapytania to 2, co oznacza, że powiązane obiekty nie zostały usunięte.
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14) 2Dzieje się tak, ponieważ SQLAlchemy nie zakłada usunięcia kaskady; musimy wydać polecenie usunięcia go.
Aby zmienić zachowanie, konfigurujemy opcje kaskadowe w relacji Użytkownik.adresy. Zamknijmy trwającą sesję, użyjmy nowej declarative_base () i ponownie zadeklarujmy klasę User, dodając relację adresów, w tym konfigurację kaskadową.
Atrybut kaskady w funkcji relacji jest rozdzieloną przecinkami listą reguł kaskadowych, która określa, w jaki sposób operacje sesji powinny być „kaskadowane” od rodzica do podrzędnego. Domyślnie jest to False, co oznacza, że jest to „zapisz-aktualizacja, scal”.
Dostępne kaskady są następujące -
- save-update
- merge
- expunge
- delete
- delete-orphan
- refresh-expire
Często używaną opcją jest „wszystkie, usuń-osierocone”, aby wskazać, że powiązane obiekty powinny we wszystkich przypadkach towarzyszyć obiektowi nadrzędnemu i zostać usunięte po usunięciu skojarzenia.
W związku z tym ponownie zadeklarowana klasa klienta jest pokazana poniżej -
class Customer(Base):
__tablename__ = 'customers'
id = Column(Integer, primary_key = True)
name = Column(String)
address = Column(String)
email = Column(String)
invoices = relationship(
"Invoice",
order_by = Invoice.id,
back_populates = "customer",
cascade = "all,
delete, delete-orphan"
)Usuńmy klienta z nazwą Gopal Krishna za pomocą poniższego programu i zobaczmy liczbę powiązanych z nim obiektów faktur -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
x = session.query(Customer).get(2)
session.delete(x)
session.query(Customer).filter_by(name = 'Gopal Krishna').count()
session.query(Invoice).filter(Invoice.invno.in_([10,14])).count()Liczba wynosi teraz 0, a następujący kod SQL jest emitowany przez powyższy skrypt -
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.id = ?
(2,)
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE ? = invoices.custid
ORDER BY invoices.id (2,)
DELETE FROM invoices
WHERE invoices.id = ? ((1,), (2,))
DELETE FROM customers
WHERE customers.id = ? (2,)
SELECT count(*)
AS count_1
FROM (
SELECT customers.id
AS customers_id, customers.name
AS customers_name, customers.address
AS customers_address, customers.email
AS customers_email
FROM customers
WHERE customers.name = ?)
AS anon_1('Gopal Krishna',)
SELECT count(*)
AS count_1
FROM (
SELECT invoices.id
AS invoices_id, invoices.custid
AS invoices_custid, invoices.invno
AS invoices_invno, invoices.amount
AS invoices_amount
FROM invoices
WHERE invoices.invno IN (?, ?))
AS anon_1(10, 14)
0Many to Many relationshipmiędzy dwiema tabelami uzyskuje się poprzez dodanie tabeli asocjacyjnej, która ma dwa klucze obce - po jednym z klucza podstawowego każdej tabeli. Ponadto klasy odwzorowujące te dwie tabele mają atrybut ze zbiorem obiektów innych tabel asocjacyjnych przypisany jako drugorzędny atrybut funkcji relations ().
W tym celu stworzymy bazę danych SQLite (mycollege.db) z dwiema tabelami - dział i pracownik. W tym przypadku zakładamy, że pracownik jest częścią więcej niż jednego działu, a dział ma więcej niż jednego pracownika. Stanowi to relację wiele do wielu.
Definicja klas Pracownik i Dział odwzorowanych na dział i tabelę pracowników jest następująca:
from sqlalchemy import create_engine, ForeignKey, Column, Integer, String
engine = create_engine('sqlite:///mycollege.db', echo = True)
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy.orm import relationship
class Department(Base):
__tablename__ = 'department'
id = Column(Integer, primary_key = True)
name = Column(String)
employees = relationship('Employee', secondary = 'link')
class Employee(Base):
__tablename__ = 'employee'
id = Column(Integer, primary_key = True)
name = Column(String)
departments = relationship(Department,secondary='link')Teraz zdefiniujemy klasę Link. Jest powiązany z tabelą linków i zawiera atrybuty id_działów i identyfikator_pracownika odnoszące się odpowiednio do kluczy podstawowych działu i tabeli pracowników.
class Link(Base):
__tablename__ = 'link'
department_id = Column(
Integer,
ForeignKey('department.id'),
primary_key = True)
employee_id = Column(
Integer,
ForeignKey('employee.id'),
primary_key = True)W tym miejscu należy zaznaczyć, że klasa Department ma atrybut workers powiązany z klasą Employee. Drugorzędnemu atrybutowi funkcji relacji przypisano łącze jako wartość.
Podobnie klasa Employee ma atrybut działów powiązany z klasą działu. Drugorzędnemu atrybutowi funkcji relacji przypisano łącze jako wartość.
Wszystkie te trzy tabele są tworzone po wykonaniu poniższej instrukcji -
Base.metadata.create_all(engine)Konsola Pythona emituje następujące zapytania CREATE TABLE -
CREATE TABLE department (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE employee (
id INTEGER NOT NULL,
name VARCHAR,
PRIMARY KEY (id)
)
CREATE TABLE link (
department_id INTEGER NOT NULL,
employee_id INTEGER NOT NULL,
PRIMARY KEY (department_id, employee_id),
FOREIGN KEY(department_id) REFERENCES department (id),
FOREIGN KEY(employee_id) REFERENCES employee (id)
)Możemy to sprawdzić, otwierając mycollege.db za pomocą SQLiteStudio, jak pokazano na zrzutach ekranu podanych poniżej -
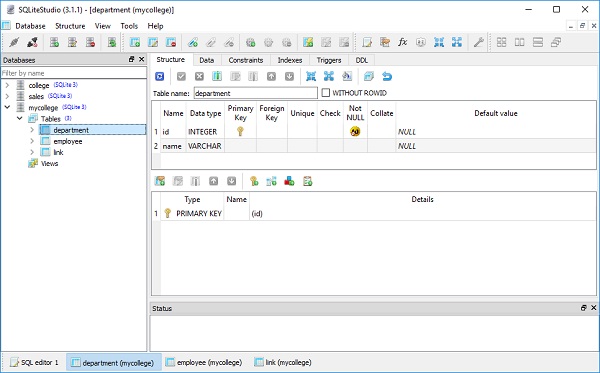
Następnie tworzymy trzy obiekty klasy Dział i trzy obiekty klasy Pracownik, jak pokazano poniżej -
d1 = Department(name = "Accounts")
d2 = Department(name = "Sales")
d3 = Department(name = "Marketing")
e1 = Employee(name = "John")
e2 = Employee(name = "Tony")
e3 = Employee(name = "Graham")Każda tabela ma atrybut kolekcji z metodą append (). Możemy dodawać obiekty Employee do kolekcji Employees obiektu Department. Podobnie możemy dodać obiekty działu do atrybutu kolekcji działów obiektów pracownika.
e1.departments.append(d1)
e2.departments.append(d3)
d1.employees.append(e3)
d2.employees.append(e2)
d3.employees.append(e1)
e3.departments.append(d2)Wszystko, co musimy teraz zrobić, to ustawić obiekt sesji, dodać do niego wszystkie obiekty i zatwierdzić zmiany, jak pokazano poniżej -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
session.add(e1)
session.add(e2)
session.add(d1)
session.add(d2)
session.add(d3)
session.add(e3)
session.commit()Następujące instrukcje SQL zostaną wyemitowane na konsoli Pythona -
INSERT INTO department (name) VALUES (?) ('Accounts',)
INSERT INTO department (name) VALUES (?) ('Sales',)
INSERT INTO department (name) VALUES (?) ('Marketing',)
INSERT INTO employee (name) VALUES (?) ('John',)
INSERT INTO employee (name) VALUES (?) ('Graham',)
INSERT INTO employee (name) VALUES (?) ('Tony',)
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 2), (3, 1), (2, 3))
INSERT INTO link (department_id, employee_id) VALUES (?, ?) ((1, 1), (2, 2), (3, 3))Aby sprawdzić efekt powyższych operacji, użyj SQLiteStudio i przejrzyj dane w tabelach działu, pracowników i linków -
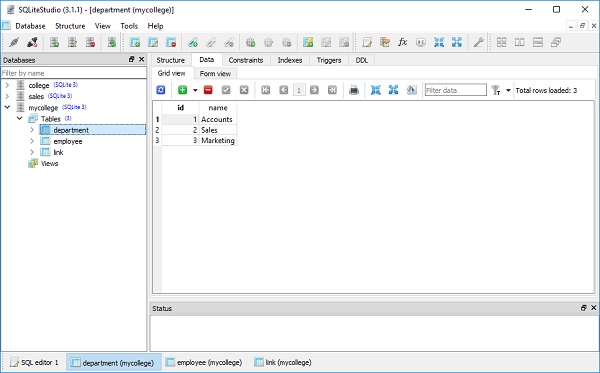
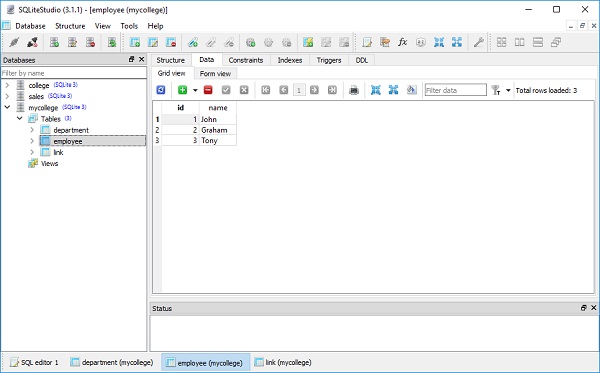
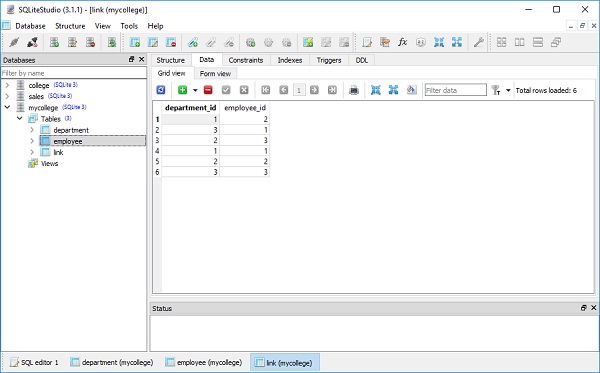
Aby wyświetlić dane, uruchom następującą instrukcję zapytania -
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind = engine)
session = Session()
for x in session.query( Department, Employee).filter(Link.department_id == Department.id,
Link.employee_id == Employee.id).order_by(Link.department_id).all():
print ("Department: {} Name: {}".format(x.Department.name, x.Employee.name))Zgodnie z danymi podanymi w naszym przykładzie, dane wyjściowe zostaną wyświetlone jak poniżej -
Department: Accounts Name: John
Department: Accounts Name: Graham
Department: Sales Name: Graham
Department: Sales Name: Tony
Department: Marketing Name: John
Department: Marketing Name: TonySQLAlchemy wykorzystuje system dialektów do komunikacji z różnymi typami baz danych. Każda baza danych ma odpowiednią otokę DBAPI. Wszystkie dialekty wymagają zainstalowania odpowiedniego sterownika DBAPI.
Następujące dialekty są zawarte w SQLAlchemy API -
- Firebird
- Microsoft SQL Server
- MySQL
- Oracle
- PostgreSQL
- SQL
- Sybase
Obiekt Engine oparty na adresie URL jest tworzony przez funkcję create_engine (). Te adresy URL mogą zawierać nazwę użytkownika, hasło, nazwę hosta i nazwę bazy danych. Mogą istnieć opcjonalne argumenty słów kluczowych dla dodatkowej konfiguracji. W niektórych przypadkach akceptowana jest ścieżka do pliku, aw innych „nazwa źródła danych” zastępuje części „host” i „baza danych”. Typowa forma adresu URL bazy danych jest następująca -
dialect+driver://username:password@host:port/databasePostgreSQL
Dialekt PostgreSQL używa psycopg2jako domyślny DBAPI. pg8000 jest również dostępny jako substytut w czystym Pythonie, jak pokazano poniżej:
# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')MySQL
Dialekt MySQL używa mysql-pythonjako domyślny DBAPI. Dostępnych jest wiele interfejsów DBAPI MySQL, takich jak MySQL-connector-python w następujący sposób -
# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysql-python
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# MySQL-connector-python
engine = create_engine('mysql+mysqlconnector://scott:tiger@localhost/foo')Wyrocznia
Dialekt Oracle używa cx_oracle jako domyślny DBAPI w następujący sposób -
engine = create_engine('oracle://scott:[email protected]:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')Microsoft SQL Server
Dialekt SQL Server używa pyodbcjako domyślny DBAPI. pymssql jest również dostępny.
# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')SQLite
SQLite łączy się z bazami danych opartymi na plikach za pomocą wbudowanego modułu Pythona sqlite3domyślnie. Ponieważ SQLite łączy się z plikami lokalnymi, format adresu URL jest nieco inny. Część adresu URL „plik” to nazwa pliku bazy danych. W przypadku względnej ścieżki pliku wymaga to trzech ukośników, jak pokazano poniżej -
engine = create_engine('sqlite:///foo.db')W przypadku bezwzględnej ścieżki do pliku po trzech ukośnikach następuje ścieżka bezwzględna, jak podano poniżej -
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')Aby użyć bazy danych SQLite: memory: database, podaj pusty adres URL, jak podano poniżej -
engine = create_engine('sqlite://')Wniosek
W pierwszej części tego samouczka nauczyliśmy się, jak używać języka wyrażeń do wykonywania instrukcji SQL. Język wyrażeń osadza konstrukcje SQL w kodzie Pythona. W drugiej części omówiliśmy możliwości mapowania relacji obiektów w SQLAlchemy. ORM API mapuje tabele SQL na klasy Pythona.