Sqoop - Wprowadzenie
Tradycyjny system zarządzania aplikacjami, czyli interakcja aplikacji z relacyjną bazą danych z wykorzystaniem RDBMS, jest jednym ze źródeł generujących Big Data. Takie Big Data, generowane przez RDBMS, są przechowywane w RelationalDatabase Servers w strukturze relacyjnej bazy danych.
Kiedy pojawiły się magazyny i analizatory Big Data, takie jak MapReduce, Hive, HBase, Cassandra, Pig itp. Ekosystemu Hadoop, potrzebowały narzędzia do interakcji z serwerami relacyjnych baz danych w celu importu i eksportu znajdujących się w nich Big Data. Tutaj Sqoop zajmuje miejsce w ekosystemie Hadoop, aby zapewnić wykonalną interakcję między serwerem relacyjnej bazy danych a HDFS Hadoop.
Sqoop - „SQL na Hadoop i Hadoop na SQL”
Sqoop to narzędzie przeznaczone do przesyłania danych między Hadoop a serwerami relacyjnych baz danych. Służy do importowania danych z relacyjnych baz danych, takich jak MySQL, Oracle do Hadoop HDFS oraz eksportu z systemu plików Hadoop do relacyjnych baz danych. Jest dostarczany przez Apache Software Foundation.
Jak działa Sqoop?
Poniższy obraz przedstawia przepływ pracy Sqoop.
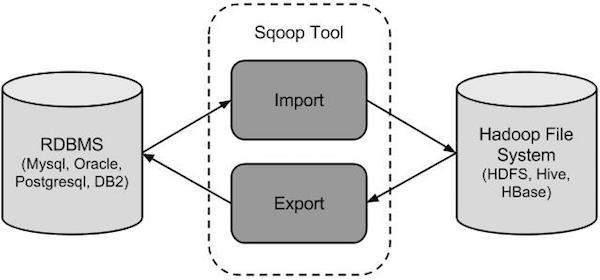
Import Sqoop
Narzędzie importu importuje pojedyncze tabele z RDBMS do HDFS. Każdy wiersz w tabeli jest traktowany jako rekord w systemie plików HDFS. Wszystkie rekordy są przechowywane jako dane tekstowe w plikach tekstowych lub jako dane binarne w plikach Avro i Sequence.
Eksport Sqoop
Narzędzie eksportu eksportuje zestaw plików z HDFS z powrotem do RDBMS. Pliki podane jako dane wejściowe do Sqoop zawierają rekordy, które są nazywane wierszami w tabeli. Są one odczytywane i analizowane w zestawie rekordów i rozdzielane ogranicznikiem określonym przez użytkownika.