Teradata - szybki przewodnik
Co to jest Teradata?
Teradata to jeden z popularnych systemów zarządzania relacyjnymi bazami danych. Nadaje się głównie do tworzenia aplikacji do hurtowni danych na dużą skalę. Teradata osiąga to dzięki koncepcji równoległości. Jest rozwijany przez firmę o nazwie Teradata.
Historia Teradata
Poniżej znajduje się krótkie podsumowanie historii Teradata, zawierające listę głównych kamieni milowych.
1979 - Teradata została włączona.
1984 - Wydanie pierwszego komputera bazodanowego DBC / 1012.
1986- Magazyn Fortune określa Teradata jako „Produkt roku”.
1999 - Największa baza danych na świecie wykorzystująca Teradata z 130 terabajtami.
2002 - Teradata V2R5 wydany z indeksem partycji i kompresją.
2006 - Wprowadzenie rozwiązania Teradata Master Data Management.
2008 - Teradata 13.0 wydany z aktywną hurtownią danych.
2011 - Przejmuje Teradata Aster i wchodzi do Advanced Analytics Space.
2012 - Wprowadzono Teradata 14.0.
2014 - Wprowadzono Teradata 15.0.
Funkcje Teradata
Oto niektóre funkcje Teradata -
Unlimited Parallelism- System bazy danych Teradata jest oparty na architekturze Massively Parallel Processing (MPP). Architektura MPP równomiernie rozdziela obciążenie w całym systemie. System Teradata dzieli zadanie między swoje procesy i uruchamia je równolegle, aby zapewnić szybkie wykonanie zadania.
Shared Nothing Architecture- Architektura Teradata nazywa się Shared Nothing Architecture. Węzły Teradata, ich procesory modułu dostępu (AMP) i dyski powiązane z AMP działają niezależnie. Nie są udostępniane innym.
Linear Scalability- Systemy Teradata są wysoce skalowalne. Mogą skalować do 2048 węzłów. Na przykład możesz podwoić pojemność systemu, podwajając liczbę AMP.
Connectivity - Teradata może łączyć się z systemami podłączonymi do kanału, takimi jak komputery mainframe lub systemy podłączone do sieci.
Mature Optimizer- Optymalizator Teradata jest jednym z dojrzałych optymalizatorów na rynku. Został zaprojektowany jako równoległy od samego początku. Został dopracowany w każdym wydaniu.
SQL- Teradata obsługuje standard branżowy SQL do interakcji z danymi przechowywanymi w tabelach. Oprócz tego zapewnia własne rozszerzenie.
Robust Utilities - Teradata zapewnia solidne narzędzia do importowania / eksportowania danych z / do systemu Teradata, takie jak FastLoad, MultiLoad, FastExport i TPT.
Automatic Distribution - Teradata automatycznie dystrybuuje dane równomiernie na dyski bez jakiejkolwiek ręcznej interwencji.
Teradata dostarcza Teradata express dla VMWARE, która jest w pełni operacyjną maszyną wirtualną Teradata. Zapewnia do 1 terabajta pamięci. Teradata zapewnia wersję VMware o pojemności 40 GB i 1 TB.
Wymagania wstępne
Ponieważ maszyna wirtualna jest 64-bitowa, Twój procesor musi obsługiwać 64-bitowy.
Kroki instalacji dla systemu Windows
Step 1 - Pobierz wymaganą wersję VM z linku, https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - Wyodrębnij plik i określ folder docelowy.
Step 3 - Pobierz odtwarzacz VMWare Workstation z linku, https://my.vmware.com/web/vmware/downloads. Jest dostępny zarówno dla systemu Windows, jak i Linux. Pobierz odtwarzacz stacji roboczej VMWARE dla systemu Windows.
Step 4 - Po zakończeniu pobierania zainstaluj oprogramowanie.
Step 5 - Po zakończeniu instalacji uruchom klienta VMWARE.
Step 6- Wybierz „Otwórz maszynę wirtualną”. Przejdź przez wyodrębniony folder Teradata VMWare i wybierz plik z rozszerzeniem .vmdk.
Step 7- Teradata VMWare jest dodawany do klienta VMWare. Wybierz dodany Teradata VMware i kliknij „Zagraj w maszynę wirtualną”.

Step 8 - Jeśli pojawi się wyskakujące okienko z aktualizacjami oprogramowania, możesz wybrać opcję „Przypomnij mi później”.
Step 9 - Wprowadź nazwę użytkownika jako root, naciśnij klawisz Tab i wprowadź hasło jako root, a następnie ponownie naciśnij Enter.
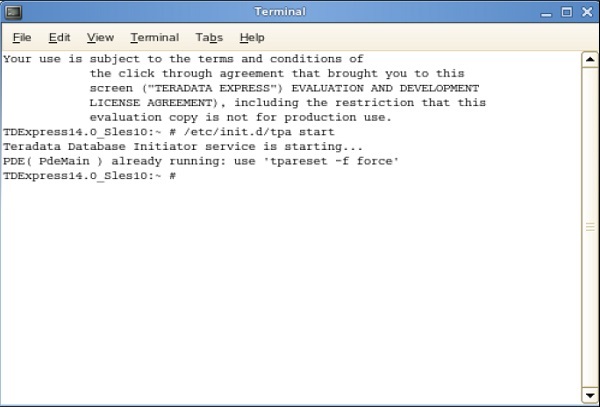
Step 10- Gdy na pulpicie pojawi się następujący ekran, kliknij dwukrotnie „katalog główny roota”. Następnie kliknij dwukrotnie „Genome's Terminal”. Spowoduje to otwarcie powłoki.

Step 11- W następnej powłoce wprowadź polecenie /etc/init.d/tpa start. Spowoduje to uruchomienie serwera Teradata.
Uruchamiam BTEQ
Narzędzie BTEQ służy do interaktywnego przesyłania zapytań SQL. Poniżej przedstawiono kroki, aby uruchomić narzędzie BTEQ.
Step 1 - Wpisz polecenie / sbin / ifconfig i zanotuj adres IP VMWare.
Step 2- Uruchom polecenie bteq. W wierszu logowania wprowadź polecenie.
Zaloguj <ipaddress> / dbc, dbc; i wprowadź W monicie o hasło wprowadź hasło jako dbc;
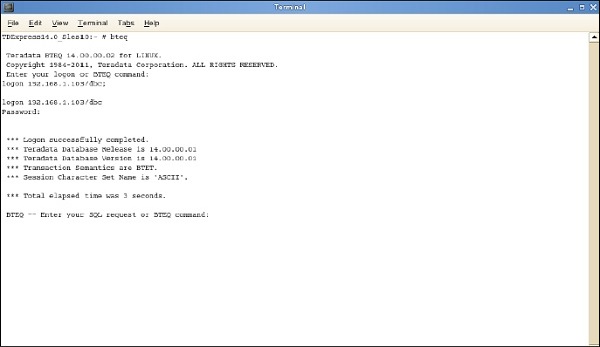
Możesz zalogować się do systemu Teradata za pomocą BTEQ i uruchamiać dowolne zapytania SQL.
Architektura Teradata jest oparta na architekturze Massively Parallel Processing (MPP). Główne składniki Teradata to Parsing Engine, BYNET i Access Module Processors (AMP). Poniższy diagram przedstawia architekturę wysokiego poziomu węzła Teradata.
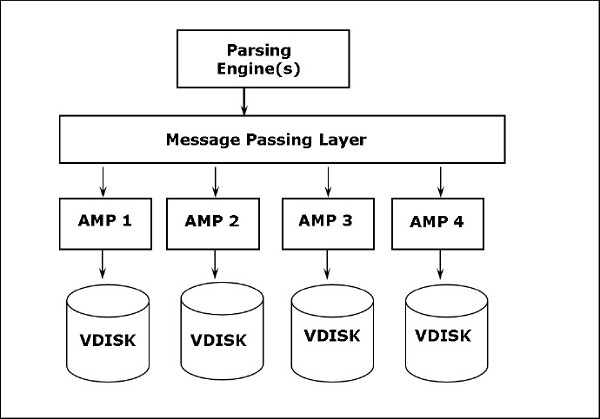
Składniki Teradata
Kluczowe składniki Teradata są następujące -
Node- Jest to podstawowa jednostka w systemie Teradata. Każdy serwer w systemie Teradata jest nazywany węzłem. Węzeł składa się z własnego systemu operacyjnego, procesora, pamięci, własnej kopii oprogramowania Teradata RDBMS i miejsca na dysku. Szafka składa się z co najmniej jednego węzła.
Parsing Engine- Parsing Engine odpowiada za przyjmowanie zapytań od klienta i przygotowanie efektywnego planu wykonania. Obowiązki silnika analizującego to:
Odbierz zapytanie SQL od klienta
Przeanalizuj sprawdzenie zapytania SQL pod kątem błędów składniowych
Sprawdź, czy użytkownik ma wymagane uprawnienia do obiektów używanych w zapytaniu SQL
Sprawdź, czy obiekty użyte w SQL rzeczywiście istnieją
Przygotuj plan wykonania zapytania SQL i przekaż go do BYNET
Odbiera wyniki z AMP i wysyła do klienta
Message Passing Layer- Warstwa przekazywania wiadomości nazywana BYNET, to warstwa sieciowa w systemie Teradata. Umożliwia komunikację między PE i AMP, a także między węzłami. Otrzymuje plan wykonania z Parsing Engine i wysyła do AMP. Podobnie otrzymuje wyniki z AMP i wysyła do mechanizmu parsującego.
Access Module Processor (AMP)- AMP, zwane procesorami wirtualnymi (vprocs), to te, które faktycznie przechowują i pobierają dane. AMP odbierają dane i plan wykonania z Parsing Engine, wykonują dowolną konwersję typów danych, agregację, filtrowanie, sortowanie i zapisywanie danych na powiązanych z nimi dyskach. Rekordy z tabel są równomiernie rozprowadzane między AMP w systemie. Każdy AMP jest powiązany z zestawem dysków, na których przechowywane są dane. Tylko ten AMP może odczytywać / zapisywać dane z dysków.
Architektura pamięci masowej
Gdy klient uruchamia zapytania w celu wstawienia rekordów, aparat analizujący wysyła rekordy do BYNET. BYNET pobiera rekordy i wysyła wiersz do docelowej strony AMP. AMP przechowuje te rekordy na swoich dyskach. Poniższy diagram przedstawia architekturę pamięci masowej Teradata.
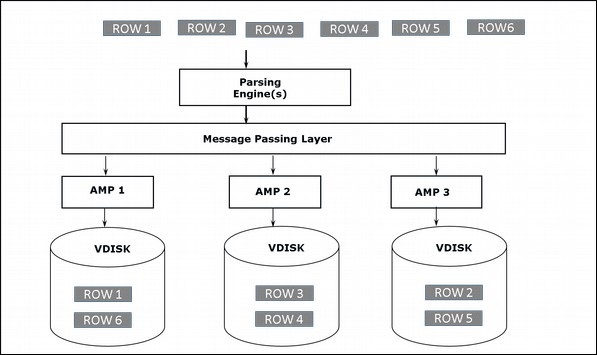
Architektura średniowieczna
Gdy klient uruchamia zapytania w celu pobrania rekordów, aparat analizujący wysyła żądanie do BYNET. BYNET wysyła żądanie pobrania do odpowiednich stron AMP. Następnie strony AMP równolegle przeszukują swoje dyski, identyfikują wymagane rekordy i wysyłają je do BYNET. Następnie BYNET wysyła rekordy do mechanizmu parsowania, który z kolei wyśle do klienta. Poniżej przedstawiono architekturę odzyskiwania Teradata.
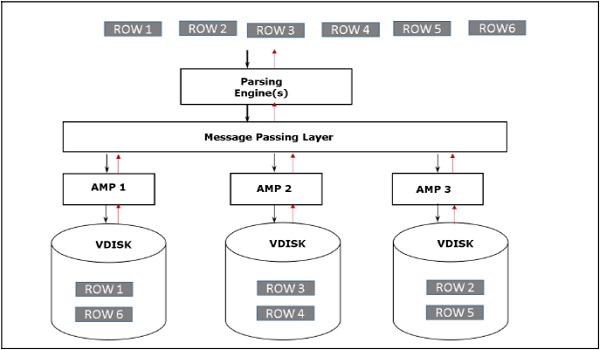
System zarządzania relacyjnymi bazami danych (RDBMS) to oprogramowanie DBMS, które pomaga w interakcji z bazami danych. Używają języka SQL (Structured Query Language) do interakcji z danymi przechowywanymi w tabelach.
Baza danych
Baza danych to zbiór powiązanych logicznie danych. Dostęp do nich ma wielu użytkowników w różnych celach. Na przykład baza danych sprzedaży zawiera wszystkie informacje o sprzedaży, które są przechowywane w wielu tabelach.
Tabele
Tabele to podstawowa jednostka w RDBMS, w której przechowywane są dane. Tabela to zbiór wierszy i kolumn. Poniżej znajduje się przykład tabeli pracowników.
| Pracownik numer | Imię | Nazwisko | Data urodzenia |
|---|---|---|---|
| 101 | Mikrofon | James | 05.01.1980 |
| 104 | Alex | Stuart | 06.11.1984 |
| 102 | Robert | Williams | 05.03.1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Piotr | Paweł | 01.04.1983 |
Kolumny
Kolumna zawiera podobne dane. Na przykład kolumna Data urodzenia w tabeli Pracownik zawiera informacje dotyczące daty urodzenia wszystkich pracowników.
| Data urodzenia |
|---|
| 05.01.1980 |
| 06.11.1984 |
| 05.03.1983 |
| 12/1/1984 |
| 01.04.1983 |
Rząd
Wiersz jest jednym wystąpieniem wszystkich kolumn. Na przykład w tabeli pracowników jeden wiersz zawiera informacje o pojedynczym pracowniku.
| Pracownik numer | Imię | Nazwisko | Data urodzenia |
|---|---|---|---|
| 101 | Mikrofon | James | 05.01.1980 |
Klucz podstawowy
Klucz podstawowy służy do jednoznacznej identyfikacji wiersza w tabeli. Żadne zduplikowane wartości nie są dozwolone w kolumnie klucza podstawowego i nie mogą akceptować wartości NULL. To jest obowiązkowe pole w tabeli.
Klucz obcy
Klucze obce służą do budowania relacji między tabelami. Klucz obcy w tabeli podrzędnej jest definiowany jako klucz podstawowy w tabeli nadrzędnej. Tabela może mieć więcej niż jeden klucz obcy. Może akceptować zduplikowane wartości, a także wartości null. W tabeli klucze obce są opcjonalne.
Każda kolumna w tabeli jest powiązana z typem danych. Typy danych określają, jakie wartości będą przechowywane w kolumnie. Teradata obsługuje kilka typów danych. Poniżej przedstawiono niektóre z często używanych typów danych.
| Typy danych | Długość (w bajtach) | Zakres wartości |
|---|---|---|
| BYTEINT | 1 | -128 do +127 |
| SMALLINT | 2 | -32768 do +32767 |
| LICZBA CAŁKOWITA | 4 | -2,147,483,648 do +2147,483,647 |
| BIGINT | 8 | -9.233.372.036.854.775,80 8 do +9.233.372.036.854.775,8 07 |
| DZIESIĘTNY | 1-16 | |
| NUMERYCZNE | 1-16 | |
| PŁYWAK | 8 | Format IEEE |
| ZWĘGLAĆ | Naprawiono format | 1-64 000 |
| VARCHAR | Zmienna | 1-64 000 |
| DATA | 4 | RRRRMMDD |
| CZAS | 6 lub 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| ZNAK CZASU | 10 lub 12 | YYMMDDHHMMSS.nnnnnn or YYMMDDHHMMSS.nnnnnn + HHMM |
Tabele w modelu relacyjnym są definiowane jako zbiór danych. Są reprezentowane jako wiersze i kolumny.
Typy tabel
Typy Teradata obsługuje różne typy tabel.
Permanent Table - To jest domyślna tabela, która zawiera dane wstawione przez użytkownika i przechowuje dane na stałe.
Volatile Table- Dane wstawione do niestabilnej tabeli są zachowywane tylko podczas sesji użytkownika. Tabela i dane są usuwane na koniec sesji. Tabele te są używane głównie do przechowywania danych pośrednich podczas transformacji danych.
Global Temporary Table - Definicje tabeli Global Temporary są trwałe, ale dane w tabeli są usuwane po zakończeniu sesji użytkownika.
Derived Table- Tabela pochodna zawiera wyniki pośrednie zapytania. Ich żywotność jest zawarta w zapytaniu, w którym są tworzone, używane i upuszczane.
Zestaw Versus Multiset
Teradata klasyfikuje tabele jako tabele SET lub MULTISET na podstawie sposobu obsługi zduplikowanych rekordów. Tabela zdefiniowana jako tabela SET nie przechowuje zduplikowanych rekordów, podczas gdy tabela MULTISET może przechowywać zduplikowane rekordy.
| Sr.No | Tabela poleceń i opis |
|---|---|
| 1 | Utwórz tabelę Polecenie CREATE TABLE służy do tworzenia tabel w Teradata. |
| 2 | Alter Table Polecenie ALTER TABLE służy do dodawania lub usuwania kolumn z istniejącej tabeli. |
| 3 | Drop Table Polecenie DROP TABLE służy do usuwania tabeli. |
W tym rozdziale przedstawiono polecenia SQL używane do manipulowania danymi przechowywanymi w tabelach programu Teradata.
Wstaw rekordy
Instrukcja INSERT INTO służy do wstawiania rekordów do tabeli.
Składnia
Poniżej znajduje się ogólna składnia INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);Przykład
Poniższy przykład wstawia rekordy do tabeli pracowników.
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);Po wstawieniu powyższego zapytania możesz użyć instrukcji SELECT, aby wyświetlić rekordy z tabeli.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
Wstaw z innego stołu
Instrukcja INSERT SELECT służy do wstawiania rekordów z innej tabeli.
Składnia
Poniżej znajduje się ogólna składnia INSERT INTO.
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;Przykład
Poniższy przykład wstawia rekordy do tabeli pracowników. Utwórz tabelę o nazwie Employee_Bkup z taką samą definicją kolumny jak tabela pracowników przed uruchomieniem następującego zapytania wstawiającego.
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;Wykonanie powyższego zapytania spowoduje wstawienie wszystkich rekordów z tabeli pracowników do tabeli Employer_bkup.
Zasady
Liczba kolumn określona na liście VALUES powinna być zgodna z kolumnami określonymi w klauzuli INSERT INTO.
Wartości są obowiązkowe dla kolumn NOT NULL.
Jeśli nie określono żadnych wartości, dla pól dopuszczających wartość null wstawiana jest wartość NULL.
Typy danych kolumn określone w klauzuli VALUES powinny być zgodne z typami danych kolumn w klauzuli INSERT.
Zaktualizuj rekordy
Instrukcja UPDATE służy do aktualizowania rekordów z tabeli.
Składnia
Poniżej znajduje się ogólna składnia UPDATE.
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];Przykład
Poniższy przykład aktualizuje dział pracowników do 03 dla pracownika 101.
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;Na poniższym wyjściu widać, że numer działu jest aktualizowany z 1 do 3 dla numeru pracownika 101.
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3Zasady
Możesz zaktualizować jedną lub więcej wartości w tabeli.
Jeśli warunek WHERE nie zostanie określony, ma to wpływ na wszystkie wiersze tabeli.
Możesz zaktualizować tabelę wartościami z innej tabeli.
Usuń rekordy
Instrukcja DELETE FROM służy do aktualizacji rekordów z tabeli.
Składnia
Poniżej znajduje się ogólna składnia DELETE FROM.
DELETE FROM <tablename>
[WHERE condition];Przykład
Poniższy przykład usuwa pracownika 101 z tabeli pracownika.
DELETE FROM Employee
WHERE EmployeeNo = 101;W poniższym wyniku widać, że pracownik 101 został usunięty z tabeli.
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.Zasady
Możesz zaktualizować jeden lub więcej rekordów tabeli.
Jeśli warunek WHERE nie zostanie określony, wszystkie wiersze tabeli zostaną usunięte.
Możesz zaktualizować tabelę wartościami z innej tabeli.
Instrukcja SELECT służy do pobierania rekordów z tabeli.
Składnia
Poniżej znajduje się podstawowa składnia instrukcji SELECT.
SELECT
column 1, column 2, .....
FROM
tablename;Przykład
Rozważ poniższą tabelę pracowników.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Poniżej znajduje się przykład instrukcji SELECT.
SELECT EmployeeNo,FirstName,LastName
FROM Employee;Kiedy to zapytanie jest wykonywane, pobiera kolumny EmployeeNo, FirstName i LastName z tabeli pracowników.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulJeśli chcesz pobrać wszystkie kolumny z tabeli, możesz użyć następującego polecenia zamiast wypisywać wszystkie kolumny.
SELECT * FROM Employee;Powyższe zapytanie pobierze wszystkie rekordy z tabeli pracowników.
Klauzula GDZIE
Klauzula WHERE służy do filtrowania rekordów zwracanych przez instrukcję SELECT. Warunek jest powiązany z klauzulą WHERE. Zwracane są tylko rekordy, które spełniają warunek w klauzuli WHERE.
Składnia
Poniżej znajduje się składnia instrukcji SELECT z klauzulą WHERE.
SELECT * FROM tablename
WHERE[condition];Przykład
Następujące zapytanie pobiera rekordy, w których EmployeeNo to 101.
SELECT * FROM Employee
WHERE EmployeeNo = 101;Po wykonaniu tego zapytania zwraca następujące rekordy.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesZAMÓW PRZEZ
Po wykonaniu instrukcji SELECT zwracane wiersze nie są w określonej kolejności. Klauzula ORDER BY służy do porządkowania rekordów w porządku rosnącym / malejącym w dowolnych kolumnach.
Składnia
Poniżej znajduje się składnia instrukcji SELECT z klauzulą ORDER BY.
SELECT * FROM tablename
ORDER BY column 1, column 2..;Przykład
Następujące zapytanie pobiera rekordy z tabeli pracowników i porządkuje wyniki według FirstName.
SELECT * FROM Employee
ORDER BY FirstName;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesGRUPUJ WEDŁUG
Klauzula GROUP BY jest używana z instrukcją SELECT i porządkuje podobne rekordy w grupy.
Składnia
Poniżej znajduje się składnia instrukcji SELECT z klauzulą GROUP BY.
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;Przykład
Poniższy przykład grupuje rekordy według kolumny DepartmentNo i identyfikuje łączną liczbę z każdego działu.
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata obsługuje następujące operatory logiczne i warunkowe. Te operatory służą do porównywania i łączenia wielu warunków.
| Składnia | Znaczenie |
|---|---|
| > | Lepszy niż |
| < | Mniej niż |
| >= | Większe bądź równe |
| <= | Mniejszy lub równy |
| = | Równy |
| BETWEEN | Jeśli wartości mieszczą się w zakresie |
| IN | Jeśli wartości w <expression> |
| NOT IN | Jeśli wartości nie są w <expression> |
| IS NULL | Jeśli wartość wynosi NULL |
| IS NOT NULL | Jeśli wartość NIE jest NULL |
| AND | Połącz wiele warunków. Zwraca wartość true tylko wtedy, gdy wszystkie warunki są spełnione |
| OR | Połącz wiele warunków. Zwraca wartość true tylko wtedy, gdy jeden z warunków jest spełniony. |
| NOT | Odwraca znaczenie warunku |
POMIĘDZY
Polecenie BETWEEN służy do sprawdzania, czy wartość mieści się w zakresie wartości.
Przykład
Rozważ poniższą tabelę pracowników.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Poniższy przykład pobiera rekordy z numerami pracowników z zakresu od 101,102 do 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;Po wykonaniu powyższego zapytania zwraca rekordy pracowników z numerem pracownika od 101 do 103.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterW
Polecenie IN służy do sprawdzania wartości z podaną listą wartości.
Przykład
Poniższy przykład pobiera rekordy z numerami pracowników 101, 102 i 103.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);Powyższe zapytanie zwraca następujące rekordy.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterNIE W
Polecenie NOT IN odwraca wynik polecenia IN. Pobiera rekordy z wartościami, które nie pasują do podanej listy.
Przykład
Poniższy przykład pobiera rekordy z numerami pracowników spoza 101, 102 i 103.
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);Powyższe zapytanie zwraca następujące rekordy.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesOperatory SET łączą wyniki z wielu instrukcji SELECT. Może to wyglądać podobnie do Łączenia, ale łączenia łączy kolumny z wielu tabel, podczas gdy operatory SET łączą wiersze z wielu wierszy.
Zasady
Liczba kolumn z każdej instrukcji SELECT powinna być taka sama.
Typy danych z każdego polecenia SELECT muszą być zgodne.
ORDER BY należy uwzględnić tylko w końcowej instrukcji SELECT.
UNIA
Instrukcja UNION służy do łączenia wyników z wielu instrukcji SELECT. Ignoruje duplikaty.
Składnia
Poniżej znajduje się podstawowa składnia instrukcji UNION.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Przykład
Weź pod uwagę poniższą tabelę pracowników i tabelę wynagrodzeń.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
Poniższe zapytanie UNION łączy wartość EmployeeNo z tabeli Employee i Salary.
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;Gdy zapytanie jest wykonywane, generuje następujące dane wyjściowe.
EmployeeNo
-----------
101
102
103
104
105UNIA WSZYSTKO
Instrukcja UNION ALL jest podobna do UNION, łączy wyniki z wielu tabel, w tym zduplikowanych wierszy.
Składnia
Poniżej znajduje się podstawowa składnia instrukcji UNION ALL.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Przykład
Poniżej znajduje się przykład instrukcji UNION ALL.
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Widać, że zwraca również duplikaty.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103KRZYŻOWAĆ
Polecenie INTERSECT służy również do łączenia wyników z wielu instrukcji SELECT. Zwraca wiersze z pierwszej instrukcji SELECT, która ma odpowiednie dopasowanie w drugiej instrukcji SELECT. Innymi słowy, zwraca wiersze, które istnieją w obu instrukcjach SELECT.
Składnia
Poniżej znajduje się podstawowa składnia instrukcji INTERSECT.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Przykład
Poniżej znajduje się przykład instrukcji INTERSECT. Zwraca wartości EmployeeNo, które istnieją w obu tabelach.
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;Po wykonaniu powyższego zapytania zwraca następujące rekordy. Pracownik nr 105 jest wykluczony, ponieważ nie istnieje w tabeli WYNAGRODZENIE.
EmployeeNo
-----------
101
104
102
103MINUS / EXCEPT
Polecenia MINUS / EXCEPT łączą wiersze z wielu tabel i zwracają wiersze, które znajdują się w pierwszym SELECT, ale nie w drugim SELECT. Oba zwracają te same wyniki.
Składnia
Poniżej znajduje się podstawowa składnia instrukcji MINUS.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Przykład
Poniżej znajduje się przykład instrukcji MINUS.
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;Po wykonaniu tego zapytania zwraca następujący rekord.
EmployeeNo
-----------
105Teradata udostępnia kilka funkcji do manipulowania napisami. Funkcje te są zgodne ze standardem ANSI.
| Sr.No | Funkcja i opis łańcucha |
|---|---|
| 1 | || Łączy ze sobą ciągi znaków |
| 2 | SUBSTR Wyodrębnia część ciągu (rozszerzenie Teradata) |
| 3 | SUBSTRING Wyodrębnia część ciągu (standard ANSI) |
| 4 | INDEX Lokalizuje pozycję znaku w ciągu (rozszerzenie Teradata) |
| 5 | POSITION Lokalizuje pozycję znaku w ciągu (standard ANSI) |
| 6 | TRIM Przycina puste miejsca ze sznurka |
| 7 | UPPER Konwertuje ciąg na wielkie litery |
| 8 | LOWER Konwertuje ciąg na małe litery |
Przykład
Poniższa tabela zawiera listę niektórych funkcji łańcuchowych wraz z wynikami.
| Funkcja ciągu | Wynik |
|---|---|
| WYBIERZ PODCIĄG ('magazyn' OD 1 DO 4) | towar |
| SELECT SUBSTR ('magazyn', 1,4) | towar |
| WYBIERZ „dane” || '' || 'magazyn' | hurtownia danych |
| WYBIERZ GÓRNE („dane”) | DANE |
| WYBIERZ NIŻSZE („DANE”) | dane |
W tym rozdziale omówiono funkcje daty / czasu dostępne w programie Teradata.
Przechowywanie daty
Daty są wewnętrznie przechowywane jako liczby całkowite przy użyciu następującego wzoru.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYMożesz użyć następującego zapytania, aby sprawdzić, jak przechowywane są daty.
SELECT CAST(CURRENT_DATE AS INTEGER);Ponieważ daty są przechowywane jako liczby całkowite, można na nich wykonać pewne operacje arytmetyczne. Teradata udostępnia funkcje do wykonywania tych operacji.
WYCIĄG
Funkcja EXTRACT wyodrębnia części dnia, miesiąca i roku z wartości DATA. Ta funkcja jest również używana do wyodrębnienia godziny, minuty i sekundy z wartości TIME / TIMESTAMP.
Przykład
Poniższe przykłady pokazują, jak wyodrębnić wartości roku, miesiąca, daty, godziny, minuty i sekundy z wartości daty i znacznika czasu.
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000INTERWAŁ
Teradata zapewnia funkcję INTERVAL do wykonywania operacji arytmetycznych na wartościach DATA i CZAS. Istnieją dwa typy funkcji INTERVAL.
Odstęp rok-miesiąc
- YEAR
- ROK DO MIESIĄCA
- MONTH
Przedział dzienny
- DAY
- DZIEŃ DO GODZIN
- DZIEŃ DO MINUT
- DZIEŃ DO DRUGI
- HOUR
- GODZINA DO MINUT
- GODZINA DO SEKUND
- MINUTE
- MINUTA DO SEKUNDY
- SECOND
Przykład
Poniższy przykład dodaje 3 lata do bieżącej daty.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01Poniższy przykład dodaje 3 lata i 01 miesiąca do bieżącej daty.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01Poniższy przykład dodaje 01 dzień, 05 godzin i 10 minut do bieżącego znacznika czasu.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata zapewnia wbudowane funkcje, które są rozszerzeniami języka SQL. Poniżej przedstawiono typowe funkcje wbudowane.
| Funkcjonować | Wynik |
|---|---|
| WYBIERZ DATĘ; | Data -------- 16/01/01 |
| SELECT CURRENT_DATE; | Data -------- 16/01/01 |
| WYBIERZ CZAS; | Czas -------- 04:50:29 |
| SELECT CURRENT_TIME; | Czas -------- 04:50:29 |
| SELECT CURRENT_TIMESTAMP; | Aktualny czas (6) -------------------------------- 2016-01-01 04: 51: 06.990000 + 00: 00 |
| SELECT DATABASE; | Baza danych ------------------------------ TDUSER |
Teradata obsługuje typowe funkcje agregujące. Można ich używać z instrukcją SELECT.
COUNT - Liczy rzędy
SUM - sumuje wartości z określonych kolumn
MAX - Zwraca dużą wartość określonej kolumny
MIN - Zwraca minimalną wartość określonej kolumny
AVG - Zwraca średnią wartość z określonej kolumny
Przykład
Rozważ poniższą tabelę wynagrodzeń.
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 104 | 75 000 | 5000 | 70 000 |
| 102 | 80 000 | 6000 | 74 000 |
| 105 | 70 000 | 4000 | 66.000 |
| 103 | 90 000 | 7,000 | 83 000 |
LICZYĆ
Poniższy przykład zlicza liczbę rekordów w tabeli Salary.
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
Poniższy przykład zwraca maksymalną wartość wynagrodzenia netto pracownika.
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
Poniższy przykład zwraca minimalną wartość wynagrodzenia netto pracownika z tabeli Wynagrodzenie.
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000ŚR
Poniższy przykład zwraca średnią wartość wynagrodzenia netto pracowników z tabeli.
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800SUMA
Poniższy przykład oblicza sumę wynagrodzenia netto pracowników ze wszystkich rekordów tabeli wynagrodzeń.
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000W tym rozdziale wyjaśniono funkcje CASE i COALESCE programu Teradata.
Wyrażenie CASE
Wyrażenie CASE ocenia każdy wiersz pod kątem warunku lub klauzuli WHEN i zwraca wynik pierwszego dopasowania. Jeśli nie ma dopasowań, zwrócony został wynik z części ELSE.
Składnia
Poniżej znajduje się składnia wyrażenia CASE.
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDPrzykład
Rozważ poniższą tabelę Pracownik.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Poniższy przykład ocenia kolumnę DepartmentNo i zwraca wartość 1, jeśli numer działu to 1; zwraca wartość 2, jeśli numer działu to 3; w przeciwnym razie zwraca wartość jako nieprawidłowy dział.
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITPowyższe wyrażenie CASE można również zapisać w następującej formie, co da taki sam wynik jak powyżej.
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;ŁĄCZYĆ
COALESCE jest instrukcją, która zwraca pierwszą niezerową wartość wyrażenia. Zwraca NULL, jeśli wszystkie argumenty wyrażenia mają wartość NULL. Poniżej znajduje się składnia.
Składnia
COALESCE(expression 1, expression 2, ....)Przykład
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
Instrukcja NULLIF zwraca NULL, jeśli argumenty są równe.
Składnia
Poniżej znajduje się składnia instrukcji NULLIF.
NULLIF(expression 1, expression 2)Przykład
Poniższy przykład zwraca wartość NULL, jeśli DepartmentNo jest równe 3. W przeciwnym razie zwraca wartość DepartmentNo.
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;Powyższe zapytanie zwraca następujące rekordy. Widać, że pracownik 105 ma dział nr. jako NULL.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2Indeks podstawowy służy do określenia, gdzie dane znajdują się w Teradata. Służy do określenia, które AMP ma pobrać wiersz danych. Każda tabela w Teradata musi mieć zdefiniowany indeks podstawowy. Jeśli indeks podstawowy nie jest zdefiniowany, Teradata automatycznie przypisuje indeks podstawowy. Indeks podstawowy zapewnia najszybszy sposób dostępu do danych. Podstawowy może mieć maksymalnie 64 kolumny.
Indeks podstawowy jest definiowany podczas tworzenia tabeli. Istnieją 2 typy indeksów podstawowych.
- Unikalny indeks podstawowy (UPI)
- Nieunikalny indeks podstawowy (NUPI)
Unikalny indeks podstawowy (UPI)
Jeśli tabela jest zdefiniowana jako posiadająca UPI, wówczas kolumna uznana za UPI nie powinna mieć żadnych zduplikowanych wartości. Jeśli zostaną wstawione zduplikowane wartości, zostaną odrzucone.
Utwórz unikalny indeks podstawowy
Poniższy przykład tworzy tabelę Salary z kolumną EmployeeNo jako unikalny indeks podstawowy.
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Niepowtarzalny indeks podstawowy (NUPI)
Jeśli tabela jest zdefiniowana jako zawierająca NUPI, wówczas kolumna uznawana za UPI może akceptować zduplikowane wartości.
Utwórz nieunikalny indeks główny
Poniższy przykład tworzy tabelę kont pracowników z kolumną EmployeeNo jako Non Unique Primary Index. Numer pracownika jest zdefiniowany jako nieunikalny indeks podstawowy, ponieważ pracownik może mieć wiele kont w tabeli; jeden do konta wynagrodzeń, a drugi do konta zwrotnego.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Łączenie służy do łączenia rekordów z więcej niż jednej tabeli. Tabele są łączone na podstawie wspólnych kolumn / wartości z tych tabel.
Dostępne są różne typy połączeń.
- Połączenie wewnętrzne
- Lewe połączenie zewnętrzne
- Prawe połączenie zewnętrzne
- Pełne połączenie zewnętrzne
- Dołącz do siebie
- Łączenie krzyżowe
- Dołączenie produkcji kartezjańskiej
WEWNĘTRZNE DOŁĄCZENIE
Łączenie wewnętrzne łączy rekordy z wielu tabel i zwraca wartości istniejące w obu tabelach.
Składnia
Poniżej znajduje się składnia instrukcji INNER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Przykład
Weź pod uwagę poniższą tabelę pracowników i tabelę wynagrodzeń.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentNo | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
Następujące zapytanie łączy tabelę Employee i Salary we wspólnej kolumnie EmployeeNo. Do każdej tabeli przypisany jest alias A i B, a odwołania do kolumn są wskazywane przez właściwy alias.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);Po wykonaniu powyższego zapytania zwraca następujące rekordy. Pracownik 105 nie jest uwzględniany w wyniku, ponieważ nie ma pasujących rekordów w tabeli Wynagrodzenie.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000ZEWNĘTRZNE DOŁĄCZ
LEFT OUTER JOIN i RIGHT OUTER JOIN również łączą wyniki z wielu tabel.
LEFT OUTER JOIN zwraca wszystkie rekordy z lewej tabeli i zwraca tylko pasujące rekordy z prawej tabeli.
RIGHT OUTER JOIN zwraca wszystkie rekordy z prawej tabeli i zwraca tylko pasujące wiersze z lewej tabeli.
FULL OUTER JOINłączy wyniki LEWEJ ZEWNĘTRZNEJ i PRAWEJ ZEWNĘTRZNEJ STAWY Zwraca zarówno pasujące, jak i niepasujące wiersze z połączonych tabel.
Składnia
Poniżej przedstawiono składnię instrukcji OUTER JOIN. Musisz użyć jednej z opcji LEFT OUTER JOIN, RIGHT OUTER JOIN lub FULL OUTER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Przykład
Rozważmy następujący przykład zapytania LEFT OUTER JOIN. Zwraca wszystkie rekordy z tabeli Pracownik i pasujące rekordy z tabeli Wynagrodzenie.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Dla pracownika 105 wartość NetPay wynosi NULL, ponieważ nie ma pasujących rekordów w tabeli wynagrodzeń.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?CROSS JOIN
Łączenie krzyżowe łączy każdy wiersz z lewej tabeli do każdego wiersza z prawej tabeli.
Składnia
Poniżej znajduje się składnia instrukcji CROSS JOIN.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Pracownik nr 101 z tabeli Pracownik łączy się z każdym rekordem z Tabeli wynagrodzeń.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000Podzapytanie zwraca rekordy z jednej tabeli na podstawie wartości z innej tabeli. Jest to zapytanie SELECT w ramach innego zapytania. Zapytanie SELECT wywołane jako zapytanie wewnętrzne jest wykonywane jako pierwsze, a wynik jest używany przez zapytanie zewnętrzne. Niektóre z jego najważniejszych cech to:
Zapytanie może mieć wiele podzapytań, a podzapytania mogą zawierać inne podzapytanie.
Podzapytania nie zwracają zduplikowanych rekordów.
Jeśli podzapytanie zwraca tylko jedną wartość, możesz użyć operatora =, aby użyć go z zapytaniem zewnętrznym. Jeśli zwraca wiele wartości, możesz użyć IN lub NOT IN.
Składnia
Poniżej znajduje się ogólna składnia podzapytań.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Przykład
Rozważ poniższą tabelę wynagrodzeń.
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
Poniższe zapytanie identyfikuje numer pracownika z najwyższym wynagrodzeniem. Wewnętrzny SELECT wykonuje funkcję agregującą w celu zwrócenia maksymalnej wartości NetPay, a zewnętrzne zapytanie SELECT używa tej wartości do zwrócenia rekordu pracownika o tej wartości.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);Gdy to zapytanie jest wykonywane, generuje następujące dane wyjściowe.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata obsługuje następujące typy tabel do przechowywania danych tymczasowych.
- Tabela pochodna
- Volatile Table
- Globalna tabela tymczasowa
Tabela pochodna
Tabele pochodne są tworzone, używane i upuszczane w zapytaniu. Służą do przechowywania wyników pośrednich w zapytaniu.
Przykład
Poniższy przykład tworzy tabelę pochodną EmpSal z rekordami pracowników z wynagrodzeniem powyżej 75000.
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;Po wykonaniu powyższego zapytania zwraca pracowników z wynagrodzeniem powyżej 75000.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000Volatile Table
Tabele niestabilne są tworzone, używane i usuwane w ramach sesji użytkownika. Ich definicja nie jest przechowywana w słowniku danych. Przechowują dane pośrednie zapytania, które jest często używane. Poniżej znajduje się składnia.
Składnia
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSPrzykład
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
*** Table has been created.
*** Total elapsed time was 1 second.Globalna tabela tymczasowa
Definicja tabeli Global Temporary jest przechowywana w słowniku danych i może być używana przez wielu użytkowników / sesje. Ale dane załadowane do globalnej tabeli tymczasowej są zachowywane tylko podczas sesji. Możesz zmaterializować do 2000 globalnych tabel tymczasowych na sesję. Poniżej znajduje się składnia.
Składnia
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>Przykład
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);Wykonanie powyższego zapytania daje następujące dane wyjściowe.
*** Table has been created.
*** Total elapsed time was 1 second.W Teradata dostępne są trzy rodzaje przestrzeni.
Stała przestrzeń
Stała przestrzeń to maksymalna ilość miejsca dostępna dla użytkownika / bazy danych do przechowywania wierszy danych. Stałe tabele, kroniki, tabele rezerwowe i pomocnicze tabele indeksowe zajmują stałą przestrzeń.
Stała przestrzeń nie jest wstępnie przydzielana dla bazy danych / użytkownika. Są one definiowane jako maksymalna ilość miejsca, jaką baza danych / użytkownik może wykorzystać. Ilość stałego miejsca jest podzielona przez liczbę stron AMP. Za każdym razem, gdy limit na AMP przekracza, generowany jest komunikat o błędzie.
Spool Space
Przestrzeń bufora to nieużywana stała przestrzeń, która jest używana przez system do przechowywania pośrednich wyników zapytania SQL. Użytkownicy bez przestrzeni buforowania nie mogą wykonywać żadnych zapytań.
Podobnie jak w przypadku miejsca stałego, przestrzeń szpuli określa maksymalną ilość miejsca, którą może wykorzystać użytkownik. Przestrzeń szpuli jest podzielona przez liczbę AMP. Za każdym razem, gdy limit na AMP przekracza, użytkownik otrzyma błąd miejsca na szpulę.
Temp Space
Przestrzeń tymczasowa to nieużywana stała przestrzeń używana przez tabele Global Temporary. Przestrzeń tymczasowa jest również podzielona przez liczbę AMP.
Tabela może zawierać tylko jeden indeks podstawowy. Częściej spotkasz scenariusze, w których tabela zawiera inne kolumny, za pomocą których dane są często używane. Teradata wykona pełne skanowanie tabeli dla tych zapytań. Indeksy pomocnicze rozwiązują ten problem.
Indeksy pomocnicze to alternatywna ścieżka dostępu do danych. Istnieją pewne różnice między indeksem podstawowym i wtórnym.
Indeks pomocniczy nie bierze udziału w dystrybucji danych.
Wartości indeksu wtórnego są przechowywane w tabelach podrzędnych. Te tabele są wbudowane we wszystkich AMP.
Indeksy pomocnicze są opcjonalne.
Można je utworzyć podczas tworzenia tabeli lub po utworzeniu tabeli.
Zajmują dodatkową przestrzeń, ponieważ tworzą tabele podrzędne, a także wymagają konserwacji, ponieważ tabele podrzędne muszą być aktualizowane dla każdego nowego wiersza.
Istnieją dwa typy indeksów pomocniczych -
- Unikalny indeks pomocniczy (USI)
- Nieunikalny indeks wtórny (NUSI)
Unikalny indeks pomocniczy (USI)
Unikalny indeks pomocniczy dopuszcza tylko unikalne wartości dla kolumn zdefiniowanych jako USI. Dostęp do wiersza przez USI to operacja na dwóch amperach.
Utwórz unikalny indeks dodatkowy
Poniższy przykład tworzy USI w kolumnie EmployeeNo tabeli pracownika.
CREATE UNIQUE INDEX(EmployeeNo) on employee;Nieunikalny indeks pomocniczy (NUSI)
Niepowtarzalny indeks pomocniczy umożliwia zduplikowane wartości dla kolumn zdefiniowanych jako NUSI. Dostęp do wiersza przez NUSI jest operacją na wszystkich wzmacniaczach.
Utwórz nieunikalny indeks dodatkowy
Poniższy przykład tworzy NUSI w kolumnie FirstName w tabeli pracowników.
CREATE INDEX(FirstName) on Employee;Optymalizator Teradata opracowuje strategię wykonywania dla każdego zapytania SQL. Ta strategia wykonywania jest oparta na statystykach zebranych w tabelach używanych w zapytaniu SQL. Statystyki dotyczące tabeli zbierane są za pomocą polecenia ZBIERZ STATYSTYKI. Optymalizator wymaga informacji o środowisku i danych demograficznych, aby opracować optymalną strategię wykonania.
Informacje o środowisku
- Liczba węzłów, procesorów AMP i procesorów
- Ilość pamięci
Dane demograficzne
- Liczba rzędów
- Rozmiar rzędu
- Zakres wartości w tabeli
- Liczba wierszy na wartość
- Liczba zer
Istnieją trzy sposoby zbierania statystyk na stole.
- Losowe próbkowanie AMP
- Pełne zbieranie statystyk
- Korzystanie z opcji SAMPLE
Zbieranie statystyk
Polecenie COLLECT STATISTICS służy do zbierania statystyk dotyczących tabeli.
Składnia
Poniżej przedstawiono podstawową składnię do zbierania statystyk w tabeli.
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;Przykład
Poniższy przykład zbiera statystyki dotyczące kolumny EmployeeNo tabeli Employee.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.Przeglądanie statystyk
Zebrane statystyki można wyświetlić za pomocą komendy HELP STATISTICS.
Składnia
Poniżej przedstawiono składnię służącą do przeglądania zebranych statystyk.
HELP STATISTICS <tablename>;Przykład
Poniżej znajduje się przykład przeglądania statystyk zebranych w tabeli Pracownik.
HELP STATISTICS employee;Wykonanie powyższego zapytania daje następujący wynik.
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoKompresja służy do zmniejszenia pamięci używanej przez tabele. W Teradata kompresja może skompresować do 255 różnych wartości, w tym NULL. Ponieważ pamięć jest ograniczona, Teradata może przechowywać więcej rekordów w bloku. Skutkuje to skróceniem czasu odpowiedzi na zapytanie, ponieważ każda operacja we / wy może przetwarzać więcej wierszy na blok. Kompresję można dodać podczas tworzenia tabeli za pomocą polecenia CREATE TABLE lub po utworzeniu tabeli za pomocą polecenia ALTER TABLE.
Ograniczenia
- W jednej kolumnie można skompresować tylko 255 wartości.
- Nie można skompresować kolumny indeksu podstawowego.
- Tabel niestabilnych nie można kompresować.
Kompresja wielowartościowa (MVC)
Poniższa tabela kompresuje pole DepatmentNo dla wartości 1, 2 i 3. W przypadku zastosowania kompresji do kolumny wartości dla tej kolumny nie są przechowywane w wierszu. Zamiast tego wartości są przechowywane w nagłówku tabeli w każdym AMP i tylko bity obecności są dodawane do wiersza, aby wskazać wartość.
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);Kompresji wielu wartości można użyć, gdy w dużej tabeli znajduje się kolumna o skończonych wartościach.
Polecenie EXPLAIN zwraca plan wykonania silnika parsującego w języku angielskim. Można go używać z dowolną instrukcją SQL z wyjątkiem innego polecenia EXPLAIN. Gdy zapytanie jest poprzedzone poleceniem EXPLAIN, plan wykonania silnika analizującego jest zwracany do użytkownika zamiast AMP.
Przykłady EXPLAIN
Rozważmy tabelę Pracownik z następującą definicją.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );Poniżej podano kilka przykładów planu EXPLAIN.
Pełne skanowanie tabeli (FTS)
Jeśli w instrukcji SELECT nie określono żadnych warunków, optymalizator może zdecydować się na użycie pełnego skanowania tabeli, w którym uzyskiwany jest dostęp do każdego wiersza tabeli.
Przykład
Poniżej znajduje się przykładowe zapytanie, w którym optymalizator może wybrać FTS.
EXPLAIN SELECT * FROM employee;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Jak widać, optymalizator wybiera dostęp do wszystkich stron AMP i wszystkich wierszy w AMP.
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.Unikalny indeks podstawowy
Gdy dostęp do wierszy uzyskuje się za pomocą Unique Primary Index, jest to jedna operacja AMP.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Jak widać, jest to pobieranie pojedynczego AMP, a optymalizator używa unikalnego indeksu podstawowego, aby uzyskać dostęp do wiersza.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Unikalny indeks pomocniczy
Gdy dostęp do rzędów uzyskuje się za pomocą Unique Secondary Index, jest to operacja z dwoma amperami.
Przykład
Rozważ tabelę Wynagrodzenie z następującą definicją.
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Rozważ następującą instrukcję SELECT.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Jak widać, optymalizator pobiera wiersz w trybie pracy z dwoma amperami przy użyciu unikalnego indeksu dodatkowego.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Dodatkowe warunki
Poniżej znajduje się lista terminów często występujących w planie EXPLAIN.
... (Last Use) …
Zbiór buforowy nie jest już potrzebny i zostanie zwolniony po zakończeniu tego kroku.
... with no residual conditions …
Wszystkie obowiązujące warunki zostały zastosowane do wierszy.
... END TRANSACTION …
Blokady transakcji są zwalniane, a zmiany są zatwierdzane.
... eliminating duplicate rows ...
Zduplikowane wiersze istnieją tylko w plikach buforowania, a nie w tabelach zestawów. Wykonywanie operacji DISTINCT.
... by way of a traversal of index #n extracting row ids only …
Tworzony jest zbiór buforowy zawierający identyfikatory wierszy znalezione w indeksie dodatkowym (indeks nr n)
... we do a SMS (set manipulation step) …
Łączenie wierszy za pomocą operatora UNION, MINUS lub INTERSECT.
... which is redistributed by hash code to all AMPs.
Redystrybucja danych w ramach przygotowań do łączenia.
... which is duplicated on all AMPs.
Powielanie danych z mniejszej tabeli (pod względem SPOOL) w ramach przygotowań do łączenia.
... (one_AMP) or (group_AMPs)
Wskazuje, że zamiast wszystkich stron AMP zostanie użyty jeden AMP lub podzbiór stron AMP.
Wiersz jest przypisywany do określonej strony AMP na podstawie wartości indeksu podstawowego. Teradata używa algorytmu mieszania, aby określić, która strona AMP otrzyma wiersz.
Poniżej znajduje się diagram wysokiego poziomu dotyczący algorytmu mieszania.

Poniżej przedstawiono kroki, aby wstawić dane.
Klient przesyła zapytanie.
Parser odbiera zapytanie i przekazuje wartość PI rekordu do algorytmu haszującego.
Algorytm haszujący haszuje wartość indeksu podstawowego i zwraca 32-bitową liczbę o nazwie Row Hash.
Bity wyższego rzędu skrótu wiersza (pierwsze 16 bitów) są używane do identyfikacji wpisu mapy skrótu. Mapa skrótów zawiera jeden numer AMP. Mapa skrótów to tablica zasobników, która zawiera określony numer AMP.
BYNET wysyła dane do zidentyfikowanej strony AMP.
AMP używa 32-bitowego skrótu Row do zlokalizowania wiersza na swoim dysku.
Jeśli istnieje jakikolwiek rekord z tym samym hashem wiersza, zwiększa on identyfikator unikalności, który jest liczbą 32-bitową. W przypadku nowego skrótu wiersza identyfikator unikalności jest przypisywany jako 1 i jest zwiększany za każdym razem, gdy zostanie wstawiony rekord z tym samym hashem wiersza.
Połączenie skrótu wiersza i identyfikatora unikalności jest nazywane identyfikatorem wiersza.
Identyfikator wiersza stanowi przedrostek każdego rekordu na dysku.
Każdy wiersz tabeli w AMP jest logicznie sortowany według ich identyfikatorów wierszy.
Jak przechowywane są tabele
Tabele są sortowane według ich identyfikatora wiersza (skrót wiersza + identyfikator unikalności), a następnie przechowywane w AMP. Identyfikator wiersza jest przechowywany w każdym wierszu danych.
| Row Hash | Identyfikator unikalności | Pracownik numer | Imię | Nazwisko |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mikrofon | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Piotr | Paweł |
JOIN INDEX to zmaterializowany widok. Jego definicja jest trwale przechowywana, a dane są aktualizowane za każdym razem, gdy aktualizowane są tabele podstawowe, do których odnosi się indeks łączenia. JOIN INDEX może zawierać jedną lub więcej tabel, a także wstępnie zagregowane dane. Indeksy złączeń służą głównie do poprawiania wydajności.
Dostępne są różne typy indeksów złączeń.
- Indeks łączenia pojedynczej tabeli (STJI)
- Wskaźnik łączenia wielu tabel (MTJI)
- Aggregated Join Index (AJI)
Indeks łączenia pojedynczej tabeli
Indeks łączenia pojedynczej tabeli umożliwia podzielenie dużej tabeli na podstawie innych kolumn indeksu podstawowego niż ta z tabeli podstawowej.
Składnia
Poniżej znajduje się składnia JOIN INDEX.
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;Przykład
Weź pod uwagę poniższe tabele pracowników i wynagrodzeń.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Poniżej znajduje się przykład, który tworzy indeks Join o nazwie Employee_JI w tabeli Employee.
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);Jeśli użytkownik wyśle zapytanie z klauzulą WHERE w polu EmployeeNo, system wyśle zapytanie do tabeli Employee przy użyciu unikalnego indeksu podstawowego. Jeśli użytkownik zapyta tabelę pracowników używając nazwa_pracownika, wtedy system może uzyskać dostęp do indeksu dołączenia Employee_JI używając Employee_name. Wiersze indeksu złączenia są haszowane w kolumnie nazwa_pracownika. Jeśli indeks łączenia nie jest zdefiniowany, a nazwa_pracownika nie jest zdefiniowana jako indeks pomocniczy, system wykona pełne skanowanie tabeli w celu uzyskania dostępu do wierszy, co jest czasochłonne.
Możesz uruchomić następujący plan EXPLAIN i zweryfikować plan optymalizacji. W poniższym przykładzie widać, że optymalizator używa indeksu łączenia zamiast podstawowej tabeli Employee, gdy tabela wysyła zapytanie za pomocą kolumny Employee_Name.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.Indeks łączenia wielu tabel
Indeks łączenia wielu tabel jest tworzony przez połączenie więcej niż jednej tabeli. Indeks łączenia wielu tabel może służyć do przechowywania zestawu wyników często łączonych tabel w celu poprawy wydajności.
Przykład
Poniższy przykład tworzy JOIN INDEX o nazwie Employee_Salary_JI, łącząc tabele Employee i Salary.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);Za każdym razem, gdy aktualizowane są podstawowe tabele Pracownik lub Wynagrodzenie, automatycznie aktualizowany jest również indeks Dołącz do Employee_Salary_JI. Jeśli uruchamiasz zapytanie łączące tabele pracowników i wynagrodzeń, optymalizator może wybrać bezpośredni dostęp do danych z Employee_Salary_JI zamiast dołączać do tabel. Plan EXPLAIN zapytania może być użyty do sprawdzenia, czy optymalizator wybierze tabelę bazową lub indeks sprzężenia.
Indeks łącznych połączeń
Jeśli tabela jest konsekwentnie agregowana w określonych kolumnach, można zdefiniować indeks łączenia zagregowanego w tabeli, aby poprawić wydajność. Jednym z ograniczeń indeksu łączenia zagregowanego jest to, że obsługuje on tylko funkcje SUMA i COUNT.
Przykład
W poniższym przykładzie pracownik i wynagrodzenie są łączone, aby określić łączne wynagrodzenie na dział.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);Widoki to obiekty bazy danych, które są tworzone przez zapytanie. Widoki można budować za pomocą pojedynczej tabeli lub wielu tabel za pomocą łączenia. Ich definicja jest trwale przechowywana w słowniku danych, ale nie przechowują kopii danych. Dane do widoku są budowane dynamicznie.
Widok może zawierać podzbiór wierszy tabeli lub podzbiór kolumn tabeli.
Utwórz widok
Widoki są tworzone za pomocą instrukcji CREATE VIEW.
Składnia
Poniżej znajduje się składnia tworzenia widoku.
CREATE/REPLACE VIEW <viewname>
AS
<select query>;Przykład
Rozważ poniższą tabelę Pracownik.
| Pracownik numer | Imię | Nazwisko | Data urodzenia |
|---|---|---|---|
| 101 | Mikrofon | James | 05.01.1980 |
| 104 | Alex | Stuart | 06.11.1984 |
| 102 | Robert | Williams | 05.03.1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Piotr | Paweł | 01.04.1983 |
Poniższy przykład tworzy widok w tabeli Employee.
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;Korzystanie z widoków
Możesz użyć zwykłej instrukcji SELECT, aby pobrać dane z widoków.
Przykład
Poniższy przykład pobiera rekordy z Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulModyfikowanie widoków
Istniejący widok można zmodyfikować za pomocą instrukcji REPLACE VIEW.
Poniżej przedstawiono składnię służącą do modyfikowania widoku.
REPLACE VIEW <viewname>
AS
<select query>;Przykład
Poniższy przykład modyfikuje widok Employee_View w celu dodania dodatkowych kolumn.
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Upuść widok
Istniejący widok można usunąć za pomocą instrukcji DROP VIEW.
Składnia
Poniżej znajduje się składnia DROP VIEW.
DROP VIEW <viewname>;Przykład
Poniżej znajduje się przykład usunięcia widoku Employee_View.
DROP VIEW Employee_View;Zalety widoków
Widoki zapewniają dodatkowy poziom bezpieczeństwa, ograniczając wiersze lub kolumny tabeli.
Użytkownicy mogą mieć dostęp tylko do widoków zamiast do tabel podstawowych.
Upraszcza korzystanie z wielu tabel, łącząc je wstępnie za pomocą widoków.
Makro to zestaw instrukcji SQL, które są przechowywane i wykonywane przez wywołanie nazwy makra. Definicja makr jest przechowywana w słowniku danych. Użytkownicy potrzebują tylko uprawnienia EXEC, aby wykonać makro. Użytkownicy nie potrzebują oddzielnych uprawnień do obiektów bazy danych używanych wewnątrz makra. Deklaracje makr są wykonywane jako pojedyncza transakcja. Jeśli jedna z instrukcji SQL w makrze nie powiedzie się, wszystkie instrukcje są wycofywane. Makra mogą akceptować parametry. Makra mogą zawierać instrukcje DDL, ale powinna to być ostatnia instrukcja w makrze.
Utwórz makra
Makra są tworzone za pomocą instrukcji CREATE MACRO.
Składnia
Poniżej znajduje się ogólna składnia polecenia CREATE MACRO.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);Przykład
Rozważ poniższą tabelę Pracownik.
| Pracownik numer | Imię | Nazwisko | Data urodzenia |
|---|---|---|---|
| 101 | Mikrofon | James | 05.01.1980 |
| 104 | Alex | Stuart | 06.11.1984 |
| 102 | Robert | Williams | 05.03.1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Piotr | Paweł | 01.04.1983 |
Poniższy przykład tworzy makro o nazwie Get_Emp. Zawiera instrukcję wyboru służącą do pobierania rekordów z tabeli pracowników.
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);Wykonywanie makr
Makra są wykonywane za pomocą polecenia EXEC.
Składnia
Poniżej znajduje się składnia polecenia EXECUTE MACRO.
EXEC <macroname>;Przykład
Poniższy przykład wykonuje nazwy makr Get_Emp; Wykonanie następującego polecenia powoduje pobranie wszystkich rekordów z tabeli pracowników.
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert JamesSparametryzowane makra
Makra Teradata mogą akceptować parametry. Wewnątrz makra do tych parametrów odwołuje się; (średnik).
Poniżej znajduje się przykład makra, które akceptuje parametry.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);Wykonywanie sparametryzowanych makr
Makra są wykonywane za pomocą polecenia EXEC. Do wykonywania makr potrzebne są uprawnienia EXEC.
Składnia
Poniżej znajduje się składnia instrukcji EXECUTE MACRO.
EXEC <macroname>(value);Przykład
Poniższy przykład wykonuje nazwy makr Get_Emp; Przyjmuje pracownika nr jako parametr i wyodrębnia rekordy z tabeli pracowników dla tego pracownika.
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000Procedura składowana zawiera zestaw instrukcji SQL i instrukcji proceduralnych. Mogą zawierać tylko oświadczenia proceduralne. Definicja procedury składowanej jest przechowywana w bazie danych, a parametry są przechowywane w tabelach słownika danych.
Zalety
Procedury składowane zmniejszają obciążenie sieci między klientem a serwerem.
Zapewnia większe bezpieczeństwo, ponieważ dostęp do danych odbywa się za pośrednictwem procedur składowanych zamiast bezpośredniego dostępu.
Zapewnia lepszą konserwację, ponieważ logika biznesowa jest testowana i przechowywana na serwerze.
Procedura tworzenia
Procedury składowane są tworzone za pomocą instrukcji CREATE PROCEDURE.
Składnia
Poniżej przedstawiono ogólną składnię instrukcji CREATE PROCEDURE.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;Przykład
Rozważ poniższą tabelę wynagrodzeń.
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
Poniższy przykład tworzy procedurę składowaną o nazwie InsertSalary w celu zaakceptowania wartości i wstawienia do tabeli wynagrodzeń.
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;Wykonywanie procedur
Procedury składowane są wykonywane za pomocą instrukcji CALL.
Składnia
Poniżej znajduje się ogólna składnia instrukcji CALL.
CALL <procedure name> [(parameter values)];Przykład
Poniższy przykład wywołuje procedurę składowaną InsertSalary i wstawia rekordy do tabeli wynagrodzeń.
CALL InsertSalary(105,20000,2000,18000);Po wykonaniu powyższego zapytania generuje następujące dane wyjściowe i można zobaczyć wstawiony wiersz w tabeli wynagrodzeń.
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
| 105 | 20 000 | 2000 | 18 000 |
W tym rozdziale omówiono różne strategie JOIN dostępne w Teradata.
Połącz metody
Teradata używa różnych metod łączenia do wykonywania operacji łączenia. Niektóre z powszechnie używanych metod łączenia to -
- Połącz Połącz
- Połączenie zagnieżdżone
- Dołącz produkt
Połącz Połącz
Metoda Merge Join ma miejsce, gdy sprzężenie jest oparte na warunku równości. Funkcja Merge Join wymaga, aby łączące się wiersze znajdowały się na tej samej stronie AMP. Wiersze są łączone na podstawie ich wartości skrótu. Merge Join używa różnych strategii łączenia, aby przenieść wiersze do tej samej strony AMP.
Strategia nr 1
Jeśli kolumny łączenia są głównymi indeksami odpowiednich tabel, to łączące się wiersze znajdują się już w tym samym AMP. W takim przypadku dystrybucja nie jest wymagana.
Weź pod uwagę następujące tabele pracowników i wynagrodzeń.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Gdy te dwie tabele są połączone w kolumnie EmployeeNo, redystrybucja nie ma miejsca, ponieważ EmployeeNo jest głównym indeksem obu tabel, które są łączone.
Strategia nr 2
Rozważ poniższe tabele pracowników i działów.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );Jeśli te dwie tabele są połączone w kolumnie DeparmentNo, wiersze muszą zostać ponownie rozłożone, ponieważ DepartmentNo jest indeksem podstawowym w jednej tabeli i indeksem innym niż podstawowy w innej tabeli. W tym scenariuszu łączenie wierszy może nie znajdować się na tej samej stronie AMP. W takim przypadku Teradata może redystrybuować tabelę pracowników w kolumnie DepartmentNo.
Strategia nr 3
W przypadku powyższych tabel Pracownik i Dział Teradata może powielić tabelę Dział na wszystkich AMP, jeśli rozmiar tabeli Dział jest mały.
Połączenie zagnieżdżone
Zagnieżdżone łączenie nie używa wszystkich stron AMP. Aby zagnieżdżone sprzężenie miało miejsce, jednym z warunków powinna być równość w unikalnym indeksie podstawowym jednej tabeli, a następnie połączenie tej kolumny z dowolnym indeksem w drugiej tabeli.
W tym scenariuszu system pobierze jeden wiersz przy użyciu Unique Primary index jednej tabeli i użyje tego skrótu wiersza do pobrania pasujących rekordów z innej tabeli. Łączenie zagnieżdżone jest najbardziej wydajną ze wszystkich metod łączenia.
Dołącz produkt
Łączenie produktu porównuje każdy kwalifikujący się wiersz z jednej tabeli z każdym kwalifikującym wierszem z innej tabeli. Dołączenie produktu może nastąpić z powodu niektórych z następujących czynników -
- Gdzie brakuje warunku.
- Warunek łączenia nie jest oparty na warunku równości.
- Aliasy tabel są nieprawidłowe.
- Wiele warunków łączenia.
Partycjonowany indeks podstawowy (PPI) to mechanizm indeksujący, który jest przydatny w poprawianiu wydajności niektórych zapytań. Kiedy wiersze są wstawiane do tabeli, są przechowywane w AMP i uporządkowane według ich kolejności mieszania wierszy. Gdy tabela jest zdefiniowana za pomocą PPI, wiersze są sortowane według numeru partycji. W każdej partycji są uporządkowane według wartości hash w wierszu. Wiersze są przypisywane do partycji na podstawie zdefiniowanego wyrażenia partycji.
Zalety
Unikaj pełnego skanowania tabeli dla niektórych zapytań.
Unikaj używania indeksu pomocniczego, który wymaga dodatkowej struktury fizycznej i dodatkowej obsługi we / wy.
Uzyskaj szybki dostęp do podzbioru dużej tabeli.
Szybko upuść stare dane i dodaj nowe.
Przykład
Rozważ poniższą tabelę zamówień z indeksem podstawowym w zamówieniu nr.
| Numer sklepu | Nr zamówienia | Data zamówienia | Suma zamówienia |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1200 |
| 102 | 7503 | 2015-10-02 | 3000 |
| 102 | 7504 | 2015-10-03 | 2,454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2,454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
Załóżmy, że rekordy są dystrybuowane między stronami AMP, jak pokazano w poniższych tabelach. Nagrane pliki są przechowywane w AMP, posortowane na podstawie skrótu wiersza.
| RowHash | Nr zamówienia | Data zamówienia |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | Nr zamówienia | Data zamówienia |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
Jeśli uruchomisz zapytanie, aby wyodrębnić zamówienia z określonej daty, optymalizator może wybrać opcję pełnego skanowania tabeli, a następnie uzyskasz dostęp do wszystkich rekordów w AMP. Aby tego uniknąć, możesz zdefiniować datę zamówienia jako partycjonowany indeks podstawowy. Kiedy wiersze są wstawiane do tabeli zamówień, są one dzielone według daty zamówienia. W każdej partycji zostaną uporządkowane według wartości hash wiersza.
Poniższe dane pokazują, jak rekordy będą przechowywane w AMP, jeśli są podzielone według daty zamówienia. Jeśli zostanie uruchomione zapytanie w celu uzyskania dostępu do rekordów według daty zamówienia, uzyskany zostanie dostęp tylko do partycji zawierającej rekordy dla tego konkretnego zamówienia.
| Przegroda | RowHash | Nr zamówienia | Data zamówienia |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| Przegroda | RowHash | Nr zamówienia | Data zamówienia |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
Poniżej znajduje się przykład tworzenia tabeli z indeksem podstawowym partycji. Klauzula PARTITION BY służy do definiowania partycji.
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);W powyższym przykładzie tabela jest podzielona na partycje według kolumny OrderDate. Każdego dnia będzie osobna partycja.
Funkcje OLAP są podobne do funkcji agregujących, z tą różnicą, że funkcje agregujące zwracają tylko jedną wartość, podczas gdy funkcja OLAP udostępnia oprócz agregatów również pojedyncze wiersze.
Składnia
Poniżej przedstawiono ogólną składnię funkcji OLAP.
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)Funkcje agregacji mogą mieć wartości SUMA, COUNT, MAX, MIN, AVG.
Przykład
Rozważ poniższą tabelę wynagrodzeń.
| Pracownik numer | obrzydliwy | Odliczenie | Płaca netto |
|---|---|---|---|
| 101 | 40 000 | 4000 | 36.000 |
| 102 | 80 000 | 6000 | 74 000 |
| 103 | 90 000 | 7,000 | 83 000 |
| 104 | 75 000 | 5000 | 70 000 |
Poniżej znajduje się przykład znalezienia skumulowanej sumy lub sumy bieżącej NetPay w tabeli wynagrodzeń. Rekordy są sortowane według numeru pracownika, a skumulowana suma jest obliczana w kolumnie NetPay.
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000RANGA
Funkcja RANK porządkuje rekordy na podstawie podanej kolumny. Funkcja RANK może również filtrować liczbę zwracanych rekordów na podstawie rangi.
Składnia
Poniżej przedstawiono ogólną składnię używaną w funkcji POZYCJA.
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])Przykład
Rozważ poniższą tabelę Pracownik.
| Pracownik numer | Imię | Nazwisko | JoinedDate | DepartmentID | Data urodzenia |
|---|---|---|---|---|---|
| 101 | Mikrofon | James | 27.03.2005 | 1 | 05.01.1980 |
| 102 | Robert | Williams | 25.04.2007 | 2 | 05.03.1983 |
| 103 | Piotr | Paweł | 21.03.2007 | 2 | 01.04.1983 |
| 104 | Alex | Stuart | 01.02.2008 | 2 | 06.11.1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Następujące zapytanie porządkuje rekordy tabeli pracowników według daty dołączenia i przypisuje ranking na dzień dołączenia.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;Wykonanie powyższego zapytania daje następujące dane wyjściowe.
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5Klauzula PARTITION BY grupuje dane według kolumn zdefiniowanych w klauzuli PARTITION BY i wykonuje funkcję OLAP w każdej grupie. Poniżej znajduje się przykład kwerendy używającej klauzuli PARTITION BY.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;Wykonanie powyższego zapytania daje następujące dane wyjściowe. Jak widać, ranga jest resetowana dla każdego działu.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1W tym rozdziale omówiono funkcje dostępne do ochrony danych w Teradata.
Dziennik przejściowy
Teradata używa Transient Journal do ochrony danych przed niepowodzeniami transakcji. Za każdym razem, gdy uruchamiane są jakiekolwiek transakcje, dziennik przejściowy przechowuje kopię obrazów wcześniejszych wierszy, których dotyczy problem, do momentu pomyślnego zakończenia transakcji lub jej wycofania. Następnie poprzednie obrazy są odrzucane. Dziennik przejściowy jest przechowywany w każdym AMP. Jest to proces automatyczny i nie można go wyłączyć.
Rezerwowa
Funkcja rezerwowa chroni dane tabeli, przechowując drugą kopię wierszy tabeli na innej stronie AMP o nazwie Fallback AMP. Jeśli jedna strona AMP ulegnie awarii, uzyskuje się dostęp do wierszy zastępczych. Dzięki temu nawet jeśli jedna strona AMP ulegnie awarii, dane są nadal dostępne za pośrednictwem zastępczej strony AMP. Opcji rezerwowej można użyć podczas tworzenia tabeli lub po jej utworzeniu. Funkcja rezerwowa zapewnia, że druga kopia wierszy tabeli jest zawsze przechowywana w innym AMP, aby chronić dane przed awarią AMP. Jednak rezerwa zajmuje dwa razy więcej miejsca niż pamięć i operacje we / wy na potrzeby wstawiania / usuwania / aktualizacji.
Poniższy diagram pokazuje, jak zastępcza kopia wierszy jest przechowywana w innej witrynie AMP.
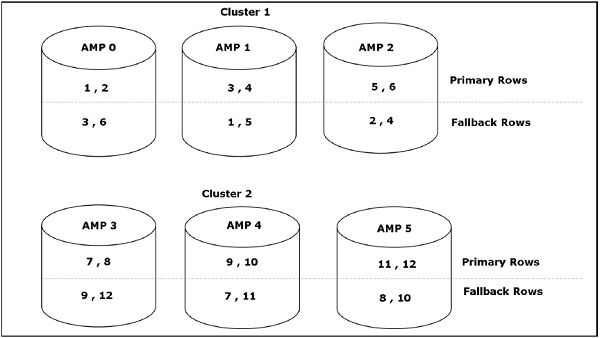
W dół dziennika odzyskiwania AMP
Dziennik odzyskiwania Down AMP jest aktywowany, gdy AMP nie powiedzie się, a tabela jest zabezpieczona awaryjnie. Ten dziennik śledzi wszystkie zmiany w danych nieudanego AMP. Dziennik jest aktywowany na pozostałych AMP w klastrze. Jest to proces automatyczny i nie można go wyłączyć. Gdy uszkodzony AMP jest aktywny, dane z dziennika odzyskiwania Down AMP są synchronizowane z AMP. Po wykonaniu tej czynności dziennik jest odrzucany.
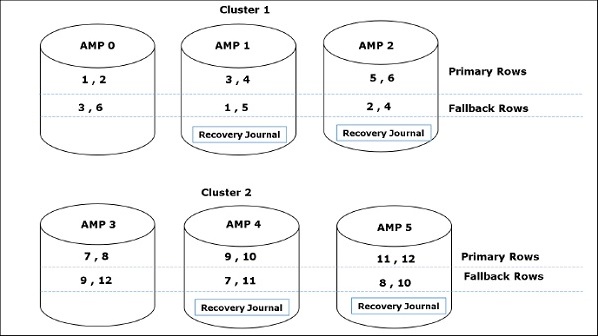
Kliki
Clique to mechanizm używany przez Teradata do ochrony danych przed awariami węzłów. Klika to nic innego jak zbiór węzłów Teradata, które mają wspólny zestaw macierzy dyskowych. Gdy węzeł ulegnie awarii, vproc z tego węzła zostaną przeniesione do innych węzłów kliki i nadal będą uzyskiwać dostęp do swoich macierzy dyskowych.
Węzeł w trybie pełnej gotowości
Węzeł w trybie pełnej gotowości to węzeł, który nie uczestniczy w środowisku produkcyjnym. Jeśli węzeł ulegnie awarii, vprocs z uszkodzonych węzłów zostaną przeniesione do węzła w trybie hot standby. Po odzyskaniu uszkodzonego węzła staje się on węzłem w stanie gotowości. Węzły w trybie pełnej gotowości służą do utrzymania wydajności w przypadku awarii węzła.
NALOT
Redundant Array of Independent Disks (RAID) to mechanizm używany do ochrony danych przed awariami dysków. Macierz dyskowa składa się z zestawu dysków, które są zgrupowane jako jednostka logiczna. Jednostka ta może wyglądać dla użytkownika jak pojedyncza jednostka, ale mogą być rozmieszczone na kilku dyskach.
RAID 1 jest powszechnie używany w Teradata. W RAID 1 każdy dysk jest powiązany z dyskiem lustrzanym. Wszelkie zmiany danych na dysku głównym są również odzwierciedlane w kopii lustrzanej. Jeśli dysk podstawowy ulegnie awarii, można uzyskać dostęp do danych z dysku lustrzanego.

W tym rozdziale omówiono różne strategie zarządzania użytkownikami w programie Teradata.
Użytkownicy
Użytkownik jest tworzony za pomocą polecenia CREATE USER. W Teradata użytkownik jest również podobny do bazy danych. Oba mogą mieć przypisaną przestrzeń i zawierać obiekty bazy danych, z wyjątkiem tego, że użytkownik ma przypisane hasło.
Składnia
Poniżej znajduje się składnia CREATE USER.
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;Podczas tworzenia użytkownika wartości nazwy użytkownika, miejsca stałego i hasła są obowiązkowe. Pozostałe pola są opcjonalne.
Przykład
Poniżej znajduje się przykład tworzenia użytkownika TD01.
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;Konta
Tworząc nowego użytkownika, można go przypisać do konta. Do przypisania konta służy opcja KONTO w UTWÓRZ UŻYTKOWNIKA. Użytkownik może być przypisany do wielu kont.
Składnia
Poniżej znajduje się składnia polecenia UTWÓRZ UŻYTKOWNIKA z opcją konta.
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidPrzykład
Poniższy przykład tworzy użytkownika TD02 i przypisuje mu konto jako IT i Admin.
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);Użytkownik może określić identyfikator konta podczas logowania do systemu Teradata lub po zalogowaniu się do systemu za pomocą polecenia SET SESSION.
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidPrzyznaj uprawnienia
Polecenie GRANT służy do przypisywania jednego lub więcej uprawnień dotyczących obiektów bazy danych użytkownikowi lub bazie danych.
Składnia
Poniżej znajduje się składnia polecenia GRANT.
GRANT privileges ON objectname TO username;Dostępne uprawnienia to INSERT, SELECT, UPDATE, REFERENCES.
Przykład
Poniżej znajduje się przykład instrukcji GRANT.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;Odwołaj uprawnienia
Polecenie REVOKE usuwa uprawnienia z użytkowników lub baz danych. Polecenie REVOKE może usunąć tylko jawne uprawnienia.
Składnia
Poniżej przedstawiono podstawową składnię polecenia REVOKE.
REVOKE [ALL|privileges] ON objectname FROM username;Przykład
Poniżej znajduje się przykład polecenia REVOKE.
REVOKE INSERT,SELECT ON Employee FROM TD01;W tym rozdziale omówiono procedurę dostrajania wydajności w programie Teradata.
Wyjaśnić
Pierwszym krokiem w dostrajaniu wydajności jest użycie EXPLAIN w zapytaniu. Plan EXPLAIN zawiera szczegółowe informacje o tym, jak optymalizator wykona Twoje zapytanie. W planie wyjaśnienia sprawdź słowa kluczowe, takie jak poziom zaufania, zastosowana strategia łączenia, rozmiar pliku buforowania, redystrybucja itp.
Zbieraj statystyki
Optymalizator wykorzystuje dane demograficzne do opracowania skutecznej strategii wykonania. Polecenie ZBIERZ STATYSTYKI służy do zbierania danych demograficznych tabeli. Upewnij się, że statystyki zebrane w kolumnach są aktualne.
Zbierz statystyki dotyczące kolumn używanych w klauzuli WHERE oraz kolumn używanych w warunku łączenia.
Zbierz statystyki w kolumnach Unique Primary Index.
Zbierz statystyki dotyczące nieunikalnych kolumn indeksu dodatkowego. Optimizer zdecyduje, czy może używać NUSI czy pełnego skanowania tabeli.
Zbieraj statystyki dotyczące indeksu łączenia, chociaż gromadzone są statystyki dotyczące tabeli bazowej.
Zbierz statystyki dotyczące kolumn partycjonowania.
Typy danych
Upewnij się, że używane są odpowiednie typy danych. Pozwoli to uniknąć nadmiernego przechowywania, niż jest to wymagane.
Konwersja
Upewnij się, że typy danych kolumn używanych w warunku sprzężenia są zgodne, aby uniknąć jawnych konwersji danych.
Sortować
Usuń niepotrzebne klauzule ORDER BY, chyba że jest to wymagane.
Problem z przestrzenią szpulową
Błąd miejsca w buforze jest generowany, jeśli zapytanie przekracza limit miejsca na buforowanie AMP dla tego użytkownika. Sprawdź plan wyjaśniania i zidentyfikuj krok, który zajmuje więcej miejsca na buforowanie. Te zapytania pośrednie można podzielić i umieścić oddzielnie w celu utworzenia tabel tymczasowych.
Indeks podstawowy
Upewnij się, że indeks podstawowy jest poprawnie zdefiniowany dla tabeli. Podstawowa kolumna indeksu powinna równomiernie rozprowadzać dane i powinna być często używana do uzyskiwania dostępu do danych.
Zestaw tabeli
Jeśli zdefiniujesz tabelę SET, optymalizator sprawdzi, czy rekord jest zduplikowany dla każdego wstawionego rekordu. Aby usunąć zduplikowany warunek sprawdzenia, możesz zdefiniować unikalny indeks pomocniczy dla tabeli.
UPDATE na dużym stole
Aktualizacja dużej tabeli będzie czasochłonna. Zamiast aktualizować tabelę, możesz usunąć rekordy i wstawić rekordy ze zmodyfikowanymi wierszami.
Upuszczanie tabel tymczasowych
Usuń tabele tymczasowe (tabele pomostowe) i składniki lotne, jeśli nie są już potrzebne. To zwolni stałą przestrzeń i miejsce na szpulę.
Stół MULTISET
Jeśli masz pewność, że rekordy wejściowe nie będą miały zduplikowanych rekordów, możesz zdefiniować tabelę docelową jako tabelę MULTISET, aby uniknąć sprawdzania zduplikowanych wierszy używanego przez tabelę SET.
Narzędzie FastLoad służy do ładowania danych do pustych tabel. Ponieważ nie korzysta z dzienników przejściowych, dane mogą być ładowane szybko. Nie ładuje zduplikowanych wierszy, nawet jeśli tabela docelowa jest tabelą MULTISET.
Ograniczenie
Tabela docelowa nie powinna mieć indeksu dodatkowego, indeksu łączenia i odniesienia do klucza obcego.
Jak działa FastLoad
FastLoad jest wykonywany w dwóch fazach.
Faza 1
Silniki analizujące odczytują rekordy z pliku wejściowego i wysyłają blok do każdej strony AMP.
Każdy AMP przechowuje bloki rekordów.
Następnie strony AMP haszują każdy rekord i redystrybuują je do właściwej strony AMP.
Pod koniec fazy 1 każda strona AMP ma swoje wiersze, ale nie są one w sekwencji skrótów wierszy.
Faza 2
Faza 2 rozpoczyna się, gdy FastLoad otrzyma instrukcję END LOADING.
Każda strona AMP sortuje rekordy według skrótu wiersza i zapisuje je na dysku.
Blokady w tabeli docelowej są zwalniane, a tabele błędów są usuwane.
Przykład
Utwórz plik tekstowy z następującymi rekordami i nazwij plik pracownik.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Poniżej znajduje się przykładowy skrypt FastLoad, który ładuje powyższy plik do tabeli Employee_Stg.
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;Wykonywanie skryptu FastLoad
Po utworzeniu pliku wejściowego Employee.txt i nazwie skryptu FastLoad jako EmployeeLoad.fl, można uruchomić skrypt FastLoad za pomocą następującego polecenia w systemach UNIX i Windows.
FastLoad < EmployeeLoad.fl;Po wykonaniu powyższego polecenia skrypt FastLoad zostanie uruchomiony i utworzy dziennik. W dzienniku można zobaczyć liczbę rekordów przetworzonych przez FastLoad oraz kod statusu.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsWarunki FastLoad
Poniżej znajduje się lista często używanych terminów używanych w skrypcie FastLoad.
LOGON - Loguje się do Teradata i inicjuje jedną lub więcej sesji.
DATABASE - Ustawia domyślną bazę danych.
BEGIN LOADING - Identyfikuje tabelę do załadowania.
ERRORFILES - Identyfikuje 2 tabele błędów, które należy utworzyć / zaktualizować.
CHECKPOINT - Określa, kiedy wziąć punkt kontrolny.
SET RECORD - Określa, czy format pliku wejściowego jest sformatowany, binarny, tekstowy czy niesformatowany.
DEFINE - Określa układ pliku wejściowego.
FILE - Określa nazwę i ścieżkę pliku wejściowego.
INSERT - Wstawia rekordy z pliku wejściowego do tabeli docelowej.
END LOADING- Inicjuje fazę 2 FastLoad. Dystrybuuje rekordy do tabeli docelowej.
LOGOFF - Kończy wszystkie sesje i kończy FastLoad.
MultiLoad może ładować wiele tabel jednocześnie, a także może wykonywać różne typy zadań, takie jak INSERT, DELETE, UPDATE i UPSERT. Może załadować jednocześnie do 5 tabel i wykonać do 20 operacji DML w skrypcie. Tabela docelowa nie jest wymagana w przypadku MultiLoad.
MultiLoad obsługuje dwa tryby -
- IMPORT
- DELETE
MultiLoad wymaga tabeli roboczej, tabeli dziennika i dwóch tabel błędów oprócz tabeli docelowej.
Log Table - Służy do utrzymywania punktów kontrolnych przyjętych podczas ładowania, które będą używane do ponownego uruchomienia.
Error Tables- Te tabele są wstawiane podczas ładowania, gdy wystąpi błąd. Pierwsza tabela błędów przechowuje błędy konwersji, podczas gdy druga tabela błędów przechowuje zduplikowane rekordy.
Log Table - Zachowuje wyniki z każdej fazy MultiLoad w celu ponownego uruchomienia.
Work table- Skrypt MultiLoad tworzy jedną tabelę roboczą na tabelę docelową. Tabela robocza służy do przechowywania zadań DML i danych wejściowych.
Ograniczenie
MultiLoad ma pewne ograniczenia.
- Unikalny indeks pomocniczy nie jest obsługiwany w tabeli docelowej.
- Więzy integralności nie są obsługiwane.
- Wyzwalacze nie są obsługiwane.
Jak działa MultiLoad
Import MultiLoad ma pięć faz -
Phase 1 - Faza wstępna - wykonuje podstawowe czynności konfiguracyjne.
Phase 2 - Faza transakcji DML - weryfikuje składnię instrukcji DML i przenosi je do systemu Teradata.
Phase 3 - Faza pozyskiwania - przenosi dane wejściowe do tabel roboczych i blokuje tabelę.
Phase 4 - Faza aplikacji - stosuje wszystkie operacje DML.
Phase 5 - Faza czyszczenia - Zwalnia blokadę tabeli.
Kroki wymagane w skrypcie MultiLoad to -
Step 1 - Skonfiguruj tabelę dziennika.
Step 2 - Zaloguj się do Teradata.
Step 3 - Określ tabele celu, pracy i błędów.
Step 4 - Zdefiniuj układ pliku INPUT.
Step 5 - Zdefiniuj zapytania DML.
Step 6 - Nazwij plik IMPORT.
Step 7 - Określ LAYOUT, który ma być używany.
Step 8 - Zainicjuj ładowanie.
Step 9 - Zakończ ładowanie i zakończ sesje.
Przykład
Utwórz plik tekstowy z następującymi rekordami i nazwij plik pracownik.txt.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Poniższy przykład to skrypt MultiLoad, który odczytuje rekordy z tabeli pracowników i ładuje je do tabeli Employee_Stg.
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;Wykonywanie skryptu MultiLoad
Po utworzeniu pliku wejściowego Employee.txt i nazwie skryptu multiload jako EmployeeLoad.ml, można uruchomić skrypt Multiload za pomocą następującego polecenia w systemach UNIX i Windows.
Multiload < EmployeeLoad.ml;Narzędzie FastExport służy do eksportowania danych z tabel Teradata do plików płaskich. Może również generować dane w formacie raportu. Dane można wyodrębnić z jednej lub wielu tabel za pomocą funkcji Połącz. Ponieważ FastExport eksportuje dane w blokach 64K, jest przydatny do wyodrębniania dużych ilości danych.
Przykład
Rozważ poniższą tabelę Pracownik.
| Pracownik numer | Imię | Nazwisko | Data urodzenia |
|---|---|---|---|
| 101 | Mikrofon | James | 05.01.1980 |
| 104 | Alex | Stuart | 06.11.1984 |
| 102 | Robert | Williams | 05.03.1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Piotr | Paweł | 01.04.1983 |
Poniżej znajduje się przykład skryptu FastExport. Eksportuje dane z tabeli pracowników i zapisuje do pliku Employeedata.txt.
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;Wykonywanie skryptu FastExport
Po napisaniu skryptu i nazwie go jako worker.fx, możesz użyć następującego polecenia, aby wykonać skrypt.
fexp < employee.fxPo wykonaniu powyższego polecenia otrzymasz następujące dane wyjściowe w pliku Employeedata.txt.
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06Warunki FastExport
Poniżej znajduje się lista terminów powszechnie używanych w skrypcie FastExport.
LOGTABLE - Określa tabelę dziennika w celu ponownego uruchomienia.
LOGON - Loguje się do Teradata i inicjuje jedną lub więcej sesji.
DATABASE - Ustawia domyślną bazę danych.
BEGIN EXPORT - Wskazuje początek eksportu.
EXPORT - Określa plik docelowy i format eksportu.
SELECT - Określa zapytanie wybierające do wyeksportowania danych.
END EXPORT - Określa koniec FastExport.
LOGOFF - Kończy wszystkie sesje i kończy FastExport.
Narzędzie BTEQ to potężne narzędzie w Teradata, które może być używane zarówno w trybie wsadowym, jak i interaktywnym. Może być używany do uruchamiania dowolnej instrukcji DDL, instrukcji DML, tworzenia makr i procedur składowanych. BTEQ może służyć do importowania danych do tabel Teradata z pliku płaskiego, a także do wyodrębniania danych z tabel do plików lub raportów.
Warunki BTEQ
Poniżej znajduje się lista terminów powszechnie używanych w skryptach BTEQ.
LOGON - Służy do logowania się do systemu Teradata.
ACTIVITYCOUNT - Zwraca liczbę wierszy, na które miało wpływ poprzednie zapytanie.
ERRORCODE - Zwraca kod stanu poprzedniego zapytania.
DATABASE - Ustawia domyślną bazę danych.
LABEL - przypisuje etykietę do zestawu poleceń SQL.
RUN FILE - Wykonuje zapytanie zawarte w pliku.
GOTO - Przenosi kontrolę na etykietę.
LOGOFF - Wylogowuje się z bazy danych i kończy wszystkie sesje.
IMPORT - Określa ścieżkę do pliku wejściowego.
EXPORT - Określa ścieżkę pliku wyjściowego i inicjuje eksport.
Przykład
Poniżej znajduje się przykładowy skrypt BTEQ.
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;Powyższy skrypt wykonuje następujące zadania.
Loguje się do systemu Teradata.
Ustawia domyślną bazę danych.
Tworzy tabelę o nazwie Employer_bkup.
Wybiera jeden rekord z tabeli Employee, aby sprawdzić, czy tabela zawiera jakieś rekordy.
Porzuca tabelę Employer_bkup, jeśli jest pusta.
Przenosi kontrolę do Label InsertEmployee, który wstawia rekordy do tabeli Employer_bkup
Sprawdza ERRORCODE, aby upewnić się, że instrukcja zakończyła się powodzeniem, po każdej instrukcji SQL.
ACTIVITYCOUNT zwraca liczbę rekordów wybranych / na które miało wpływ poprzednie zapytanie SQL.