Apache Flink - Arquitetura
Apache Flink trabalha na arquitetura Kappa. A arquitetura Kappa possui um único processador - stream, que trata todas as entradas como stream e o mecanismo de streaming processa os dados em tempo real. Os dados em lote na arquitetura kappa são um caso especial de streaming.
O diagrama a seguir mostra o Apache Flink Architecture.
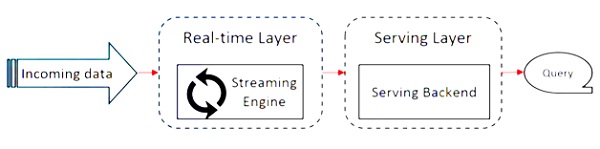
A ideia principal na arquitetura Kappa é lidar com dados em lote e em tempo real por meio de um único mecanismo de processamento de fluxo.
A maior parte da estrutura de big data funciona na arquitetura Lambda, que possui processadores separados para dados em lote e streaming. Na arquitetura Lambda, você tem bases de código separadas para visualizações em lote e fluxo. Para consultar e obter o resultado, as bases de código precisam ser mescladas. Não manter bases de código / visualizações separadas e mesclá-las é uma dor, mas a arquitetura Kappa resolve esse problema, pois tem apenas uma visualização - em tempo real, portanto a mesclagem da base de código não é necessária.
Isso não significa que a arquitetura Kappa substitui a arquitetura Lambda, ela depende completamente do caso de uso e do aplicativo que decide qual arquitetura seria preferível.
O diagrama a seguir mostra a arquitetura de execução de trabalho do Apache Flink.

Programa
É um trecho de código, que você executa no Flink Cluster.
Cliente
Ele é responsável por pegar o código (programa) e construir o gráfico do fluxo de dados do trabalho e, em seguida, passá-lo para o JobManager. Ele também recupera os resultados do trabalho.
JobManager
Após receber o Job Dataflow Graph do Client, ele é responsável por criar o gráfico de execução. Ele atribui o trabalho a TaskManagers no cluster e supervisiona a execução do trabalho.
Gerenciador de tarefas
É responsável por executar todas as tarefas atribuídas pelo JobManager. Todos os TaskManagers executam as tarefas em seus slots separados no paralelismo especificado. É responsável por enviar o status das tarefas ao JobManager.
Recursos do Apache Flink
Os recursos do Apache Flink são os seguintes -
Possui um processador de streaming, que pode executar programas em lote e stream.
Ele pode processar dados em alta velocidade.
APIs disponíveis em Java, Scala e Python.
Fornece APIs para todas as operações comuns, o que é muito fácil para os programadores usarem.
Processa dados em baixa latência (nanossegundos) e alta taxa de transferência.
É tolerante a falhas. Se um nó, aplicativo ou hardware falhar, isso não afetará o cluster.
Pode se integrar facilmente com Apache Hadoop, Apache MapReduce, Apache Spark, HBase e outras ferramentas de big data.
O gerenciamento in-memory pode ser personalizado para melhor computação.
É altamente escalonável e pode escalar até milhares de nós em um cluster.
O janelamento é muito flexível no Apache Flink.
Fornece processamento de gráficos, aprendizado de máquina e bibliotecas de processamento de eventos complexos.