Apache Flume - Guia rápido
O que é Flume?
Apache Flume é uma ferramenta / serviço / mecanismo de ingestão de dados para coletar, agregar e transportar grandes quantidades de dados de streaming, como arquivos de log, eventos (etc ...) de várias fontes para um armazenamento de dados centralizado.
O Flume é uma ferramenta altamente confiável, distribuída e configurável. Ele é projetado principalmente para copiar dados de streaming (dados de log) de vários servidores da web para o HDFS.
Aplicações de Flume
Suponha que um aplicativo da web de e-commerce deseja analisar o comportamento do cliente de uma determinada região. Para fazer isso, eles precisariam mover os dados de log disponíveis para o Hadoop para análise. Aqui, o Apache Flume vem em nosso resgate.
O Flume é usado para mover os dados de log gerados pelos servidores de aplicativos para o HDFS em uma velocidade mais alta.
Vantagens do Flume
Aqui estão as vantagens de usar o Flume -
Usando o Apache Flume, podemos armazenar os dados em qualquer um dos armazenamentos centralizados (HBase, HDFS).
Quando a taxa de entrada de dados excede a taxa na qual os dados podem ser gravados no destino, o Flume atua como um mediador entre os produtores de dados e os armazenamentos centralizados e fornece um fluxo constante de dados entre eles.
Flume fornece o recurso de contextual routing.
As transações no Flume são baseadas em canais, onde duas transações (um remetente e um receptor) são mantidas para cada mensagem. Ele garante uma entrega confiável de mensagens.
O Flume é confiável, tolerante a falhas, escalonável, gerenciável e personalizável.
Características do Flume
Algumas das características notáveis do Flume são as seguintes -
O Flume ingere dados de log de vários servidores da web em um armazenamento centralizado (HDFS, HBase) com eficiência.
Usando o Flume, podemos obter os dados de vários servidores imediatamente para o Hadoop.
Junto com os arquivos de log, o Flume também é usado para importar grandes volumes de dados de eventos produzidos por sites de redes sociais como Facebook e Twitter, e sites de comércio eletrônico como Amazon e Flipkart.
O Flume oferece suporte a um grande conjunto de tipos de fontes e destinos.
O Flume suporta fluxos de vários saltos, fluxos fan-in fan-out, roteamento contextual, etc.
O canal pode ser dimensionado horizontalmente.
Big Data,como sabemos, é uma coleção de grandes conjuntos de dados que não podem ser processados usando técnicas de computação tradicionais. Big Data, quando analisado, dá resultados valiosos.Hadoop é uma estrutura de código aberto que permite armazenar e processar Big Data em um ambiente distribuído entre clusters de computadores usando modelos de programação simples.
Dados de streaming / registro
Geralmente, a maioria dos dados a serem analisados será produzida por várias fontes de dados, como servidores de aplicativos, sites de redes sociais, servidores em nuvem e servidores corporativos. Esses dados estarão na forma delog files e events.
Log file - Em geral, um arquivo de log é um fileque lista eventos / ações que ocorrem em um sistema operacional. Por exemplo, os servidores da web listam todas as solicitações feitas ao servidor nos arquivos de log.
Ao coletar esses dados de registro, podemos obter informações sobre -
- o desempenho do aplicativo e localize várias falhas de software e hardware.
- o comportamento do usuário e obter melhores percepções de negócios.
O método tradicional de transferência de dados para o sistema HDFS é usar o putcomando. Vamos ver como usar oput comando.
HDFS put Command
O principal desafio em lidar com os dados de log é mover esses logs produzidos por vários servidores para o ambiente Hadoop.
Hadoop File System Shellfornece comandos para inserir dados no Hadoop e ler a partir dele. Você pode inserir dados no Hadoop usando oput comando como mostrado abaixo.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the fileProblema com o comando put
Podemos usar o putcomando do Hadoop para transferir dados dessas fontes para o HDFS. Mas, ele sofre das seguintes desvantagens -
Usando put comando, podemos transferir only one file at a timeenquanto os geradores de dados geram dados em uma taxa muito mais alta. Como a análise feita em dados mais antigos é menos precisa, precisamos ter uma solução para transferir dados em tempo real.
Se usarmos putcomando, os dados precisam ser empacotados e devem estar prontos para o upload. Como os servidores da web geram dados continuamente, é uma tarefa muito difícil.
O que precisamos aqui é de soluções que possam superar as desvantagens de put comande e transfira os "dados de streaming" dos geradores de dados para armazenamentos centralizados (especialmente HDFS) com menos atraso.
Problema com HDFS
No HDFS, o arquivo existe como uma entrada de diretório e o comprimento do arquivo será considerado zero até que seja fechado. Por exemplo, se uma fonte está gravando dados no HDFS e a rede foi interrompida no meio da operação (sem fechar o arquivo), os dados gravados no arquivo serão perdidos.
Portanto, precisamos de um sistema confiável, configurável e sustentável para transferir os dados de log para o HDFS.
Note- No sistema de arquivos POSIX, sempre que estamos acessando um arquivo (digamos, executando uma operação de gravação), outros programas ainda podem ler esse arquivo (pelo menos a parte salva do arquivo). Isso ocorre porque o arquivo existe no disco antes de ser fechado.
Soluções Disponíveis
Para enviar dados de streaming (arquivos de log, eventos, etc.) de várias fontes para o HDFS, temos as seguintes ferramentas disponíveis -
Escriba do Facebook
Scribe é uma ferramenta imensamente popular usada para agregar e transmitir dados de log. Ele foi projetado para ser dimensionado para um número muito grande de nós e ser robusto para falhas de rede e de nós.
Apache Kafka
Kafka foi desenvolvido pela Apache Software Foundation. É um corretor de mensagens de código aberto. Usando Kafka, podemos lidar com feeds com alto rendimento e baixa latência.
Apache Flume
Apache Flume é uma ferramenta / serviço / mecanismo de ingestão de dados para coletar, agregar e transportar grandes quantidades de dados de streaming, como dados de log, eventos (etc ...) de vários servidores da web para um armazenamento de dados centralizado.
É uma ferramenta altamente confiável, distribuída e configurável, projetada principalmente para transferir dados de streaming de várias fontes para o HDFS.
Neste tutorial, discutiremos em detalhes como usar o Flume com alguns exemplos.
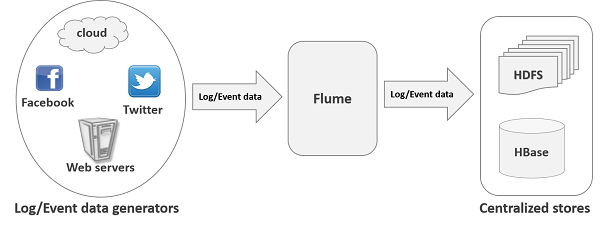
A ilustração a seguir descreve a arquitetura básica do Flume. Conforme mostrado na ilustração,data generators (como Facebook, Twitter) geram dados que são coletados por Flume individual agentscorrendo sobre eles. Depois disso, umdata collector (que também é um agente) coleta os dados dos agentes que são agregados e colocados em um armazenamento centralizado, como HDFS ou HBase.

Flume Event
A event é a unidade básica dos dados transportados dentro Flume. Ele contém uma carga útil de matriz de bytes que deve ser transportada da origem para o destino, acompanhada de cabeçalhos opcionais. Um evento típico de Flume teria a seguinte estrutura -

Agente Flume
A agenté um processo daemon independente (JVM) no Flume. Ele recebe os dados (eventos) de clientes ou outros agentes e os encaminha para seu próximo destino (coletor ou agente). Flume pode ter mais de um agente. O diagrama a seguir representa umFlume Agent

Conforme mostrado no diagrama, um Flume Agent contém três componentes principais, a saber, source, channel, e sink.
Fonte
UMA source é o componente de um Agente que recebe dados dos geradores de dados e os transfere para um ou mais canais na forma de eventos Flume.
O Apache Flume suporta vários tipos de fontes e cada fonte recebe eventos de um gerador de dados especificado.
Example - Fonte Avro, fonte Thrift, fonte twitter 1% etc.
Canal
UMA channelé um armazenamento temporário que recebe os eventos da fonte e os armazena até que sejam consumidos pelos sumidouros. Ele atua como uma ponte entre as fontes e os sumidouros.
Esses canais são totalmente transacionais e podem funcionar com qualquer número de fontes e sumidouros.
Example - Canal JDBC, canal do sistema de arquivos, canal de memória, etc.
Pia
UMA sinkarmazena os dados em armazenamentos centralizados como HBase e HDFS. Ele consome os dados (eventos) dos canais e os entrega ao destino. O destino do coletor pode ser outro agente ou os armazenamentos centrais.
Example - pia HDFS
Note- Um agente de fluxo pode ter várias fontes, sumidouros e canais. Listamos todas as fontes, sumidouros e canais suportados no capítulo de configuração do Flume deste tutorial.
Componentes Adicionais do Agente Flume
O que discutimos acima são os componentes primitivos do agente. Além disso, temos mais alguns componentes que desempenham um papel vital na transferência dos eventos do gerador de dados para os armazenamentos centralizados.
Interceptores
Interceptadores são usados para alterar / inspecionar eventos de canal que são transferidos entre a fonte e o canal.
Seletores de canal
Eles são usados para determinar qual canal deve ser escolhido para transferir os dados no caso de vários canais. Existem dois tipos de seletores de canal -
Default channel selectors - Também conhecidos como seletores de canal de replicação, eles replicam todos os eventos em cada canal.
Multiplexing channel selectors - Decide o canal para enviar um evento com base no endereço no cabeçalho desse evento.
Sink Processors
Eles são usados para invocar um coletor específico do grupo selecionado de coletores. Eles são usados para criar caminhos de failover para seus coletores ou eventos de equilíbrio de carga em vários coletores de um canal.
Flume é uma estrutura usada para mover dados de log para o HDFS. Geralmente, os eventos e dados de log são gerados pelos servidores de log e esses servidores têm agentes Flume em execução neles. Esses agentes recebem os dados dos geradores de dados.
Os dados nesses agentes serão coletados por um nó intermediário conhecido como Collector. Assim como os agentes, pode haver vários coletores em Flume.
Finalmente, os dados de todos esses coletores serão agregados e enviados para um armazenamento centralizado, como HBase ou HDFS. O diagrama a seguir explica o fluxo de dados no Flume.
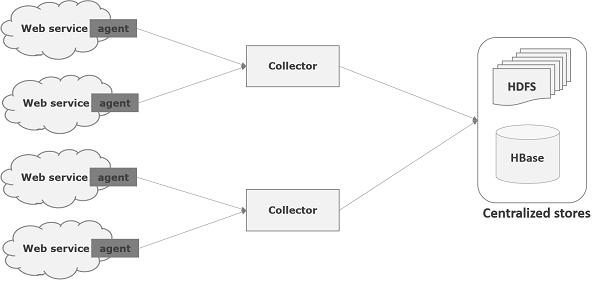
Fluxo Multi-hop
No Flume, pode haver vários agentes e antes de chegar ao destino final, um evento pode passar por mais de um agente. Isso é conhecido comomulti-hop flow.
Fluxo de Fan-out
O fluxo de dados de uma fonte para vários canais é conhecido como fan-out flow. É de dois tipos -
Replicating - O fluxo de dados onde os dados serão replicados em todos os canais configurados.
Multiplexing - O fluxo de dados onde os dados serão enviados para um canal selecionado que é mencionado no cabeçalho do evento.
Fluxo Fan-in
O fluxo de dados em que os dados serão transferidos de muitas fontes para um canal é conhecido como fan-in flow.
Tratamento de Falhas
No Flume, para cada evento, duas transações ocorrem: uma no emissor e outra no receptor. O remetente envia eventos ao destinatário. Logo após receber os dados, o receptor confirma sua própria transação e envia um sinal de “recebido” ao remetente. Depois de receber o sinal, o remetente confirma sua transação. (O remetente não confirmará sua transação até que receba um sinal do receptor.)
Já discutimos a arquitetura do Flume no capítulo anterior. Neste capítulo, vamos ver como baixar e configurar o Apache Flume.
Antes de prosseguir, você precisa ter um ambiente Java em seu sistema. Portanto, antes de mais nada, certifique-se de ter o Java instalado em seu sistema. Para alguns exemplos neste tutorial, usamos o Hadoop HDFS (como coletor). Portanto, recomendamos que você instale o Hadoop junto com o Java. Para coletar mais informações, acesse o link -http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Instalando Flume
Em primeiro lugar, baixe a versão mais recente do software Apache Flume do site https://flume.apache.org/.
Passo 1
Abra o site. Clique nodownloadlink no lado esquerdo da página inicial. Isso o levará à página de download do Apache Flume.
Passo 2
Na página de download, você pode ver os links para arquivos binários e de origem do Apache Flume. Clique no link apache-flume-1.6.0-bin.tar.gz
Você será redirecionado para uma lista de mirrors, onde poderá iniciar o download clicando em qualquer um desses mirrors. Da mesma forma, você pode baixar o código-fonte do Apache Flume clicando em apache-flume-1.6.0-src.tar.gz .
etapa 3
Crie um diretório com o nome Flume no mesmo diretório onde os diretórios de instalação do Hadoop, HBase, e outro software foi instalado (se você já tiver instalado algum) conforme mostrado abaixo.
$ mkdir FlumePasso 4
Extraia os arquivos tar baixados conforme mostrado abaixo.
$ cd Downloads/
$ tar zxvf apache-flume-1.6.0-bin.tar.gz
$ tar zxvf apache-flume-1.6.0-src.tar.gzEtapa 5
Mova o conteúdo do apache-flume-1.6.0-bin.tar arquivo para o Flumediretório criado anteriormente, conforme mostrado abaixo. (Suponha que criamos o diretório Flume no usuário local chamado Hadoop.)
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/Configurando Flume
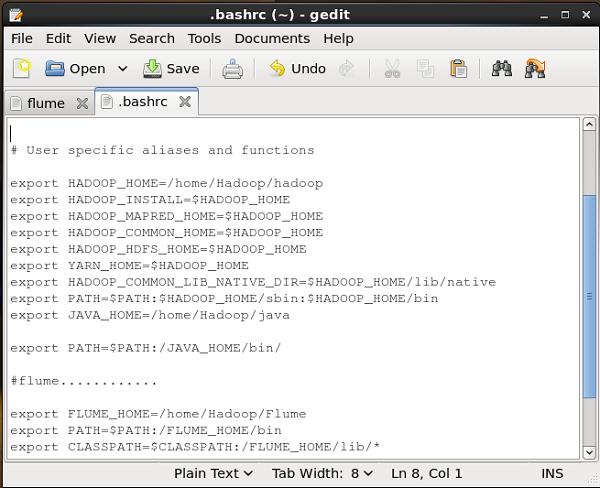
Para configurar o Flume, temos que modificar três arquivos, a saber, flume-env.sh, flumeconf.properties, e bash.rc.
Configurando o Caminho / Classpath
No .bashrc arquivo, defina a pasta inicial, o caminho e o caminho de classe para Flume como mostrado abaixo.
pasta conf
Se você abrir o conf pasta do Apache Flume, você terá os seguintes quatro arquivos -
- flume-conf.properties.template,
- flume-env.sh.template,
- flume-env.ps1.template e
- log4j.properties.

Agora renomear
flume-conf.properties.template arquivo como flume-conf.properties e
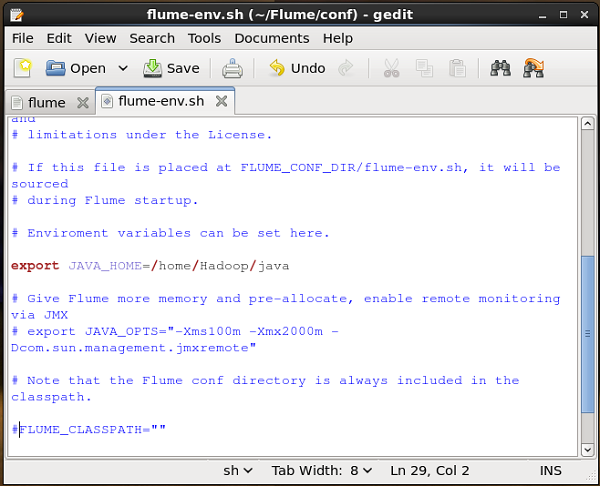
flume-env.sh.template Como flume-env.sh
flume-env.sh
Abrir flume-env.sh arquivo e definir o JAVA_Home para a pasta onde o Java foi instalado em seu sistema.
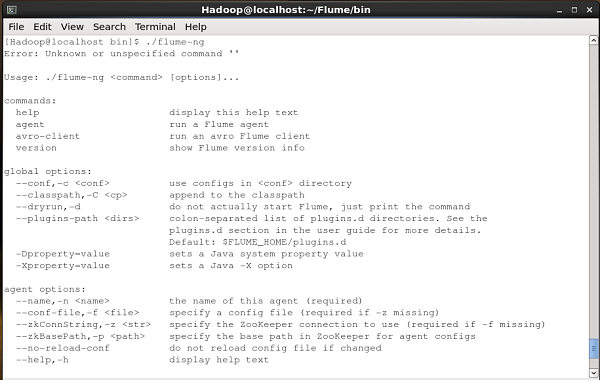
Verificando a instalação
Verifique a instalação do Apache Flume navegando pelo bin pasta e digitando o seguinte comando.
$ ./flume-ngSe você instalou o Flume com sucesso, receberá um prompt de ajuda do Flume conforme mostrado abaixo.
Depois de instalar o Flume, precisamos configurá-lo usando o arquivo de configuração, que é um arquivo de propriedade Java com key-value pairs. Precisamos passar valores para as chaves no arquivo.
No arquivo de configuração do Flume, precisamos -
- Nomeie os componentes do agente atual.
- Descreva / configure a fonte.
- Descreva / configure o coletor.
- Descreva / configure o canal.
- Vincule a fonte e o coletor ao canal.
Normalmente podemos ter vários agentes em Flume. Podemos diferenciar cada agente usando um nome exclusivo. E usando esse nome, temos que configurar cada agente.
Nomeando os componentes
Em primeiro lugar, é necessário nomear / listar os componentes como fontes, coletores e canais do agente, conforme mostrado a seguir.
agent_name.sources = source_name
agent_name.sinks = sink_name
agent_name.channels = channel_nameO Flume oferece suporte a várias fontes, pias e canais. Eles estão listados na tabela abaixo.
| Fontes | Canais | Pias |
|---|---|---|
|
|
|
Você pode usar qualquer um deles. Por exemplo, se você estiver transferindo dados do Twitter usando a fonte do Twitter por meio de um canal de memória para um coletor de HDFS e o ID do nome do agenteTwitterAgent, então
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFSDepois de listar os componentes do agente, você deve descrever a (s) fonte (s), coletor (es) e canal (is), fornecendo valores para suas propriedades.
Descrevendo a fonte
Cada fonte terá uma lista separada de propriedades. A propriedade chamada “tipo” é comum a todas as fontes e é usada para especificar o tipo de fonte que estamos usando.
Junto com a propriedade “tipo”, é necessário fornecer os valores de todos os required propriedades de uma determinada fonte para configurá-lo, conforme mostrado abaixo.
agent_name.sources. source_name.type = value
agent_name.sources. source_name.property2 = value
agent_name.sources. source_name.property3 = valuePor exemplo, se considerarmos o twitter source, a seguir estão as propriedades para as quais devemos fornecer valores para configurá-lo.
TwitterAgent.sources.Twitter.type = Twitter (type name)
TwitterAgent.sources.Twitter.consumerKey =
TwitterAgent.sources.Twitter.consumerSecret =
TwitterAgent.sources.Twitter.accessToken =
TwitterAgent.sources.Twitter.accessTokenSecret =Descrevendo o Sink
Assim como a fonte, cada coletor terá uma lista separada de propriedades. A propriedade denominada “type” é comum a todos os dissipadores e é usada para especificar o tipo de dissipador que estamos usando. Junto com a propriedade “tipo”, é necessário fornecer valores para todos osrequired propriedades de um coletor específico para configurá-lo, conforme mostrado abaixo.
agent_name.sinks. sink_name.type = value
agent_name.sinks. sink_name.property2 = value
agent_name.sinks. sink_name.property3 = valuePor exemplo, se considerarmos HDFS sink, a seguir estão as propriedades para as quais devemos fornecer valores para configurá-lo.
TwitterAgent.sinks.HDFS.type = hdfs (type name)
TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the dataDescrevendo o canal
O Flume oferece vários canais para transferir dados entre fontes e coletores. Portanto, junto com as fontes e os canais, é necessário descrever o canal usado no agente.
Para descrever cada canal, você precisa definir as propriedades necessárias, conforme mostrado abaixo.
agent_name.channels.channel_name.type = value
agent_name.channels.channel_name. property2 = value
agent_name.channels.channel_name. property3 = valuePor exemplo, se considerarmos memory channel, a seguir estão as propriedades para as quais devemos fornecer valores para configurá-lo.
TwitterAgent.channels.MemChannel.type = memory (type name)Vinculando a fonte e o coletor ao canal
Uma vez que os canais conectam as fontes e coletores, é necessário vincular ambos ao canal, conforme mostrado abaixo.
agent_name.sources.source_name.channels = channel_name
agent_name.sinks.sink_name.channels = channel_nameO exemplo a seguir mostra como vincular as fontes e os coletores a um canal. Aqui, nós consideramostwitter source, memory channel, e HDFS sink.
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channels = MemChannelIniciando um Agente Flume
Após a configuração, temos que iniciar o agente Flume. É feito da seguinte forma -
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentonde -
agent - Comando para iniciar o agente Flume
--conf ,-c<conf> - Use o arquivo de configuração no diretório conf
-f<file> - Especifica um caminho de arquivo de configuração, se ausente
--name, -n <name> - Nome do agente do Twitter
-D property =value - Define um valor de propriedade do sistema Java.
Usando o Flume, podemos buscar dados de vários serviços e transportá-los para armazenamentos centralizados (HDFS e HBase). Este capítulo explica como buscar dados do serviço Twitter e armazená-los no HDFS usando o Apache Flume.
Conforme discutido na Arquitetura do Flume, um servidor da web gera dados de log e esses dados são coletados por um agente no Flume. O canal armazena esses dados em um coletor, que finalmente os empurra para armazenamentos centralizados.
No exemplo fornecido neste capítulo, criaremos um aplicativo e obteremos os tweets dele usando a fonte experimental do Twitter fornecida pelo Apache Flume. Usaremos o canal de memória para armazenar esses tweets e coletor de HDFS para enviar esses tweets para o HDFS.

Para buscar dados do Twitter, teremos que seguir as etapas abaixo -
- Crie um aplicativo do Twitter
- Instalar / iniciar HDFS
- Configurar Flume
Criação de um aplicativo do Twitter
Para obter os tweets do Twitter, é necessário criar um aplicativo Twitter. Siga as etapas fornecidas abaixo para criar um aplicativo Twitter.
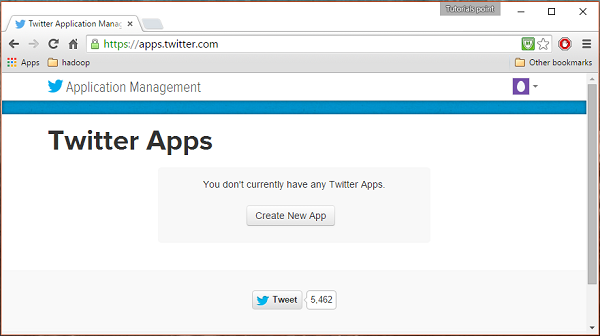
Passo 1
Para criar um aplicativo do Twitter, clique no link a seguir https://apps.twitter.com/. Faça login em sua conta do Twitter. Você terá uma janela de gerenciamento de aplicativos do Twitter onde pode criar, excluir e gerenciar aplicativos do Twitter.
Passo 2
Clique no Create New Appbotão. Você será redirecionado para uma janela onde obterá um formulário de inscrição no qual deverá preencher seus dados para criar o Aplicativo. Ao preencher o endereço do site, forneça o padrão de URL completo, por exemplo,http://example.com.
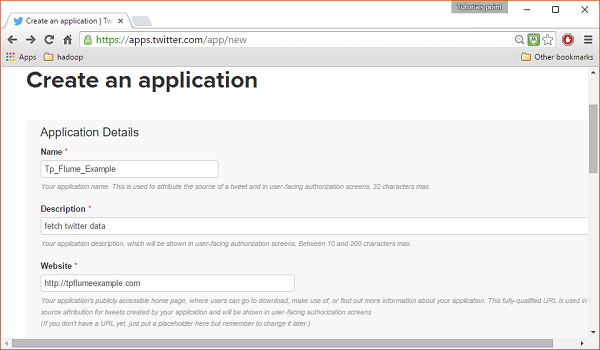
etapa 3
Preencha os detalhes, aceite o Developer Agreement quando terminar, clique no Create your Twitter application buttonque está na parte inferior da página. Se tudo correr bem, um aplicativo será criado com os detalhes fornecidos, conforme mostrado abaixo.
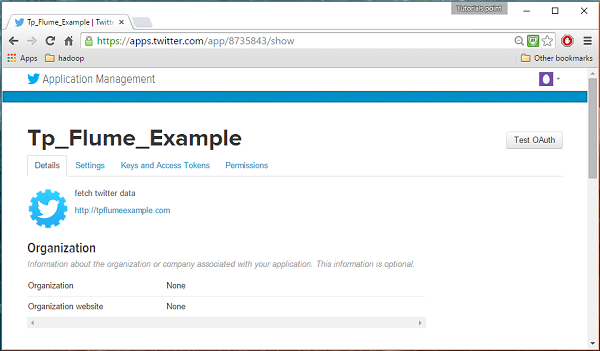
Passo 4
Sob keys and Access Tokens guia na parte inferior da página, você pode observar um botão chamado Create my access token. Clique nele para gerar o token de acesso.
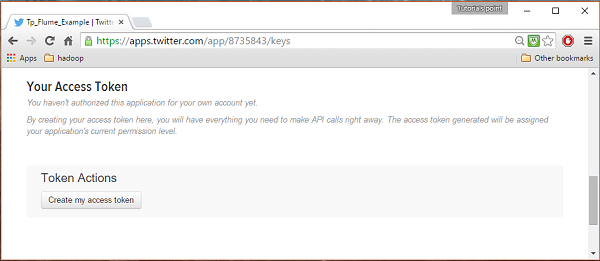
Etapa 5
Por fim, clique no Test OAuthbotão que está no topo do lado direito da página. Isso levará a uma página que exibe o seuConsumer key, Consumer secret, Access token, e Access token secret. Copie esses detalhes. Eles são úteis para configurar o agente no Flume.

Iniciando HDFS
Como estamos armazenando os dados no HDFS, precisamos instalar / verificar o Hadoop. Inicie o Hadoop e crie uma pasta nele para armazenar os dados do Flume. Siga as etapas fornecidas abaixo antes de configurar o Flume.
Etapa 1: instalar / verificar o Hadoop
Instale o Hadoop . Se o Hadoop já estiver instalado em seu sistema, verifique a instalação usando o comando de versão do Hadoop, conforme mostrado abaixo.
$ hadoop versionSe o seu sistema contém Hadoop, e se você definiu a variável de caminho, você obterá a seguinte saída -
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarEtapa 2: Iniciando o Hadoop
Navegue pelo sbin diretório do Hadoop e inicie yarn e Hadoop dfs (sistema de arquivos distribuído) conforme mostrado abaixo.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outEtapa 3: crie um diretório no HDFS
No Hadoop DFS, você pode criar diretórios usando o comando mkdir. Navegue por ele e crie um diretório com o nometwitter_data no caminho necessário conforme mostrado abaixo.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataConfigurando Flume
Temos que configurar a fonte, o canal e o coletor usando o arquivo de configuração no confpasta. O exemplo dado neste capítulo usa uma fonte experimental fornecida pelo Apache Flume chamadaTwitter 1% Firehose Canal de memória e coletor de HDFS.
Fonte 1% Firehose no Twitter
Esta fonte é altamente experimental. Ele se conecta ao Firehose do Twitter de 1% de amostra usando API de streaming e baixa tweets continuamente, converte-os para o formato Avro e envia eventos Avro para um coletor de fluxo de fluxo.
Obteremos essa fonte por padrão junto com a instalação do Flume. ojar os arquivos correspondentes a esta fonte podem ser localizados no lib pasta conforme mostrado abaixo.

Configurando o classpath
Colocou o classpath variável para o lib pasta do Flume em Flume-env.sh arquivo como mostrado abaixo.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Esta fonte precisa de detalhes como Consumer key, Consumer secret, Access token, e Access token secretde um aplicativo do Twitter. Ao configurar esta fonte, você deve fornecer valores para as seguintes propriedades -
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - A chave do consumidor OAuth
consumerSecret - segredo do consumidor OAuth
accessToken - token de acesso OAuth
accessTokenSecret - segredo do token OAuth
maxBatchSize- Número máximo de mensagens do Twitter que devem estar em um lote do Twitter. O valor padrão é 1000 (opcional).
maxBatchDurationMillis- Número máximo de milissegundos a aguardar antes de fechar um lote. O valor padrão é 1000 (opcional).
Canal
Estamos usando o canal de memória. Para configurar o canal de memória, você deve fornecer um valor para o tipo de canal.
type- Contém o tipo de canal. Em nosso exemplo, o tipo éMemChannel.
Capacity- É o número máximo de eventos armazenados no canal. Seu valor padrão é 100 (opcional).
TransactionCapacity- É o número máximo de eventos que o canal aceita ou envia. Seu valor padrão é 100 (opcional).
HDFS Sink
Este coletor grava dados no HDFS. Para configurar este coletor, você deve fornecer os seguintes detalhes.
Channel
type - hdfs
hdfs.path - o caminho do diretório no HDFS onde os dados devem ser armazenados.
E podemos fornecer alguns valores opcionais com base no cenário. Abaixo estão as propriedades opcionais do coletor HDFS que estamos configurando em nosso aplicativo.
fileType - Este é o formato de arquivo necessário para nosso arquivo HDFS. SequenceFile, DataStream e CompressedStreamsão os três tipos disponíveis com este fluxo. Em nosso exemplo, estamos usando oDataStream.
writeFormat - Pode ser texto ou gravável.
batchSize- É o número de eventos gravados em um arquivo antes de ser descarregado no HDFS. Seu valor padrão é 100.
rollsize- É o tamanho do arquivo para desencadear um rolo. Seu valor padrão é 100.
rollCount- É o número de eventos gravados no arquivo antes de rolá-lo. Seu valor padrão é 10.
Exemplo - arquivo de configuração
A seguir está um exemplo do arquivo de configuração. Copie este conteúdo e salve comotwitter.conf na pasta conf do Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelExecução
Navegue pelo diretório inicial do Flume e execute o aplicativo conforme mostrado abaixo.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentSe tudo correr bem, o streaming de tweets para HDFS começará. A seguir está o instantâneo da janela do prompt de comando durante a busca de tweets.
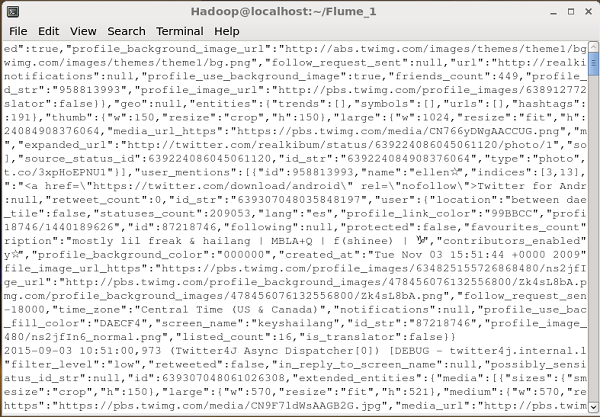
Verificando HDFS
Você pode acessar a Hadoop Administration Web UI usando o URL fornecido a seguir.
http://localhost:50070/Clique na lista suspensa chamada Utilitiesno lado direito da página. Você pode ver duas opções, conforme mostrado no instantâneo fornecido abaixo.
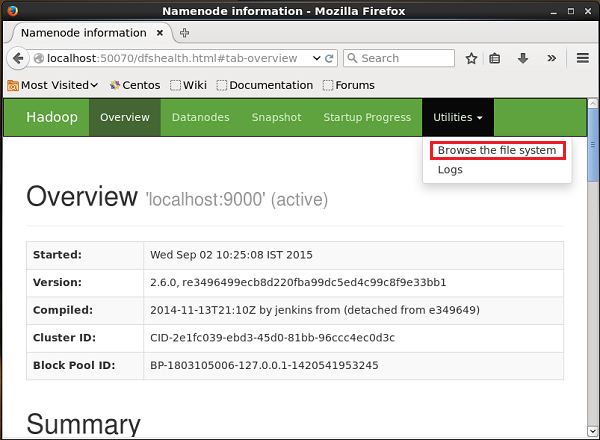
Clique em Browse the file systeme digite o caminho do diretório HDFS onde você armazenou os tweets. Em nosso exemplo, o caminho será/user/Hadoop/twitter_data/. Em seguida, você pode ver a lista de arquivos de log do Twitter armazenados no HDFS conforme mostrado abaixo.

No capítulo anterior, vimos como buscar dados da fonte do Twitter para o HDFS. Este capítulo explica como buscar dados deSequence generator.
Pré-requisitos
Para executar o exemplo fornecido neste capítulo, você precisa instalar HDFS junto com Flume. Portanto, verifique a instalação do Hadoop e inicie o HDFS antes de prosseguir. (Consulte o capítulo anterior para saber como iniciar o HDFS).
Configurando Flume
Temos que configurar a fonte, o canal e o coletor usando o arquivo de configuração no confpasta. O exemplo dado neste capítulo usa umsequence generator source, uma memory channel, e um HDFS sink.
Fonte do gerador de sequência
É a fonte que gera os eventos continuamente. Ele mantém um contador que começa em 0 e aumenta em 1. É usado para fins de teste. Ao configurar esta fonte, você deve fornecer valores para as seguintes propriedades -
Channels
Source type - seq
Canal
Estamos usando o memorycanal. Para configurar o canal de memória, você deve fornecer um valor para o tipo de canal. Dada abaixo está a lista de propriedades que você precisa fornecer ao configurar o canal de memória -
type- Contém o tipo de canal. Em nosso exemplo, o tipo é MemChannel.
Capacity- É o número máximo de eventos armazenados no canal. Seu valor padrão é 100. (opcional)
TransactionCapacity- É o número máximo de eventos que o canal aceita ou envia. Seu padrão é 100. (opcional).
HDFS Sink
Este coletor grava dados no HDFS. Para configurar este coletor, você deve fornecer os seguintes detalhes.
Channel
type - hdfs
hdfs.path - o caminho do diretório no HDFS onde os dados devem ser armazenados.
E podemos fornecer alguns valores opcionais com base no cenário. Abaixo estão as propriedades opcionais do coletor HDFS que estamos configurando em nosso aplicativo.
fileType - Este é o formato de arquivo necessário para nosso arquivo HDFS. SequenceFile, DataStream e CompressedStreamsão os três tipos disponíveis com este fluxo. Em nosso exemplo, estamos usando oDataStream.
writeFormat - Pode ser texto ou gravável.
batchSize- É o número de eventos gravados em um arquivo antes de ser descarregado no HDFS. Seu valor padrão é 100.
rollsize- É o tamanho do arquivo para desencadear um rolo. Seu valor padrão é 100.
rollCount- É o número de eventos gravados no arquivo antes de rolá-lo. Seu valor padrão é 10.
Exemplo - arquivo de configuração
A seguir está um exemplo do arquivo de configuração. Copie este conteúdo e salve comoseq_gen .conf na pasta conf do Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelExecução
Navegue pelo diretório inicial do Flume e execute o aplicativo conforme mostrado abaixo.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentSe tudo correr bem, a fonte começa a gerar números de sequência que serão colocados no HDFS na forma de arquivos de log.
A seguir, é fornecido um instantâneo da janela do prompt de comando que busca os dados gerados pelo gerador de sequência no HDFS.

Verificando o HDFS
Você pode acessar a IU da Web de administração do Hadoop usando o seguinte URL -
http://localhost:50070/Clique na lista suspensa chamada Utilitiesno lado direito da página. Você pode ver duas opções conforme mostrado no diagrama abaixo.
Clique em Browse the file system e insira o caminho do diretório HDFS onde você armazenou os dados gerados pelo gerador de sequência.
Em nosso exemplo, o caminho será /user/Hadoop/ seqgen_data /. Em seguida, você pode ver a lista de arquivos de log gerados pelo gerador de sequência, armazenados no HDFS conforme fornecido a seguir.
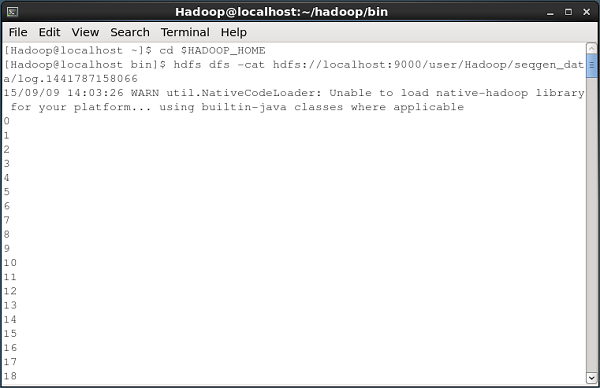
Verificando o conteúdo do arquivo
Todos esses arquivos de log contêm números em formato sequencial. Você pode verificar o conteúdo desses arquivos no sistema de arquivos usando ocat comando como mostrado abaixo.
Este capítulo dá um exemplo para explicar como você pode gerar eventos e, subsequentemente, registrá-los no console. Para isso, estamos usando oNetCat fonte e o logger Pia.
Pré-requisitos
Para executar o exemplo fornecido neste capítulo, você precisa instalar Flume.
Configurando Flume
Temos que configurar a fonte, o canal e o coletor usando o arquivo de configuração no confpasta. O exemplo dado neste capítulo usa umNetCat Source, Memory channel, e um logger sink.
Fonte NetCat
Ao configurar a fonte NetCat, temos que especificar uma porta ao configurar a fonte. Agora a fonte (fonte NetCat) escuta a porta dada e recebe cada linha que inserimos nessa porta como um evento individual e a transfere para o coletor através do canal especificado.
Ao configurar esta fonte, você deve fornecer valores para as seguintes propriedades -
channels
Source type - netcat
bind - Nome do host ou endereço IP para vincular.
port - Número da porta que queremos que a fonte escute.
Canal
Estamos usando o memorycanal. Para configurar o canal de memória, você deve fornecer um valor para o tipo de canal. Dada abaixo está a lista de propriedades que você precisa fornecer ao configurar o canal de memória -
type- Contém o tipo de canal. Em nosso exemplo, o tipo éMemChannel.
Capacity- É o número máximo de eventos armazenados no canal. Seu valor padrão é 100. (opcional)
TransactionCapacity- É o número máximo de eventos que o canal aceita ou envia. Seu valor padrão é 100. (opcional).
Logger Sink
Este coletor registra todos os eventos passados para ele. Geralmente, é usado para fins de teste ou depuração. Para configurar este coletor, você deve fornecer os seguintes detalhes.
Channel
type - logger
Arquivo de configuração de exemplo
A seguir está um exemplo do arquivo de configuração. Copie este conteúdo e salve comonetcat.conf na pasta conf do Flume.
# Naming the components on the current agent
NetcatAgent.sources = Netcat
NetcatAgent.channels = MemChannel
NetcatAgent.sinks = LoggerSink
# Describing/Configuring the source
NetcatAgent.sources.Netcat.type = netcat
NetcatAgent.sources.Netcat.bind = localhost
NetcatAgent.sources.Netcat.port = 56565
# Describing/Configuring the sink
NetcatAgent.sinks.LoggerSink.type = logger
# Describing/Configuring the channel
NetcatAgent.channels.MemChannel.type = memory
NetcatAgent.channels.MemChannel.capacity = 1000
NetcatAgent.channels.MemChannel.transactionCapacity = 100
# Bind the source and sink to the channel
NetcatAgent.sources.Netcat.channels = MemChannel
NetcatAgent.sinks. LoggerSink.channel = MemChannelExecução
Navegue pelo diretório inicial do Flume e execute o aplicativo conforme mostrado abaixo.
$ cd $FLUME_HOME
$ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf
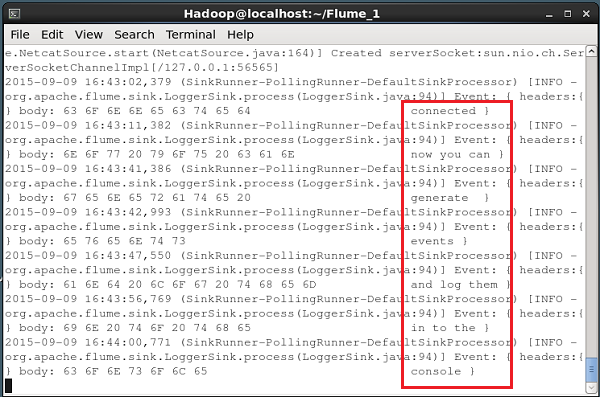
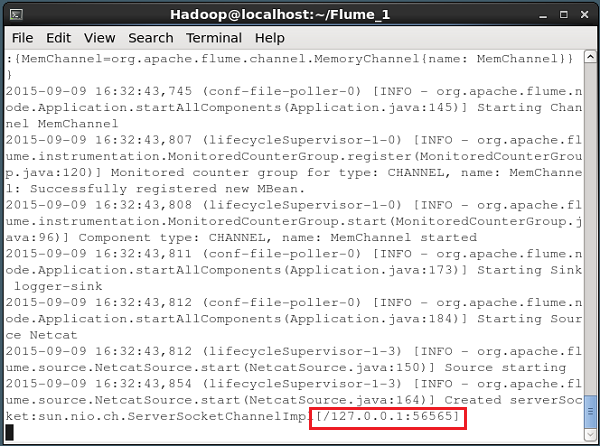
--name NetcatAgent -Dflume.root.logger=INFO,consoleSe tudo correr bem, a fonte começa a escutar a porta fornecida. Neste caso, é56565. A seguir está o instantâneo da janela do prompt de comando de uma fonte NetCat que foi iniciada e está ouvindo a porta 56565.
Passando dados para a fonte
Para passar dados para a fonte NetCat, você deve abrir a porta fornecida no arquivo de configuração. Abra um terminal separado e conecte-o à fonte (56565) usando ocurlcomando. Quando a conexão for bem-sucedida, você receberá a mensagem “connected" como mostrado abaixo.
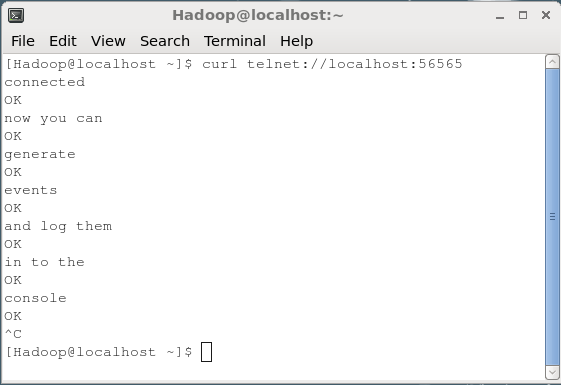
$ curl telnet://localhost:56565
connectedAgora você pode inserir seus dados linha por linha (após cada linha, você deve pressionar Enter). A fonte NetCat recebe cada linha como um evento individual e você receberá uma mensagem recebida “OK”.
Sempre que terminar de passar os dados, você pode sair do console pressionando (Ctrl+C) Dada a seguir está o instantâneo do console onde nos conectamos à fonte usando ocurl comando.
Cada linha inserida no console acima será recebida como um evento individual pela fonte. Desde que usamos oLogger coletor, esses eventos serão registrados no console (console de origem) por meio do canal especificado (canal de memória neste caso).
O instantâneo a seguir mostra o console NetCat onde os eventos são registrados.