Apache Kafka - Guia rápido
Em Big Data, um enorme volume de dados é usado. Em relação aos dados, temos dois desafios principais. O primeiro desafio é como coletar um grande volume de dados e o segundo desafio é analisar os dados coletados. Para superar esses desafios, você precisa de um sistema de mensagens.
O Kafka é projetado para sistemas distribuídos de alto rendimento. O Kafka tende a funcionar muito bem como um substituto para um corretor de mensagens mais tradicional. Em comparação com outros sistemas de mensagens, o Kafka tem melhor rendimento, particionamento integrado, replicação e tolerância a falhas inerente, o que o torna uma boa opção para aplicativos de processamento de mensagens em grande escala.
O que é um sistema de mensagens?
Um Sistema de Mensagens é responsável por transferir dados de um aplicativo para outro, para que os aplicativos possam se concentrar nos dados, mas não se preocupem em como compartilhá-los. O sistema de mensagens distribuído é baseado no conceito de enfileiramento de mensagens confiável. As mensagens são enfileiradas de forma assíncrona entre os aplicativos clientes e o sistema de mensagens. Dois tipos de padrões de mensagens estão disponíveis - um é ponto a ponto e o outro é o sistema de mensagens publicar-assinar (pub-sub). A maioria dos padrões de mensagens seguepub-sub.
Sistema de mensagens ponto a ponto
Em um sistema ponto a ponto, as mensagens são mantidas em uma fila. Um ou mais consumidores podem consumir as mensagens na fila, mas uma determinada mensagem pode ser consumida por no máximo um consumidor apenas. Depois que um consumidor lê uma mensagem na fila, ela desaparece dessa fila. O exemplo típico desse sistema é um Sistema de Processamento de Pedidos, onde cada pedido será processado por um Processador de Pedidos, mas vários Processadores de Pedidos também podem funcionar ao mesmo tempo. O diagrama a seguir descreve a estrutura.

Sistema de Mensagens Publicar-Assinar
No sistema publicar-assinar, as mensagens são mantidas em um tópico. Ao contrário do sistema ponto a ponto, os consumidores podem se inscrever em um ou mais tópicos e consumir todas as mensagens naquele tópico. No sistema Publicar-Assinar, os produtores de mensagens são chamados de publicadores e os consumidores de mensagens são chamados de assinantes. Um exemplo da vida real é a Dish TV, que publica diferentes canais como esportes, filmes, música, etc., e qualquer pessoa pode se inscrever em seu próprio conjunto de canais e obtê-los sempre que seus canais assinados estiverem disponíveis.

O que é Kafka?
Apache Kafka é um sistema de mensagens de publicação-assinatura distribuído e uma fila robusta que pode lidar com um alto volume de dados e permite que você passe mensagens de um terminal para outro. Kafka é adequado para consumo de mensagens offline e online. As mensagens Kafka são mantidas no disco e replicadas dentro do cluster para evitar perda de dados. O Kafka foi criado com base no serviço de sincronização ZooKeeper. Ele se integra muito bem com Apache Storm e Spark para análise de dados de streaming em tempo real.
Benefícios
A seguir estão alguns benefícios do Kafka -
Reliability - Kafka é distribuído, particionado, replicado e com tolerância a falhas.
Scalability - O sistema de mensagens Kafka é dimensionado facilmente, sem tempo de inatividade.
Durability- O Kafka usa o
log de commit distribuído, o
que significa que as mensagens persistem no disco o mais rápido possível, portanto, é durável.Performance- Kafka tem alto rendimento para publicação e assinatura de mensagens. Ele mantém o desempenho estável, mesmo muitos TB de mensagens são armazenados.
O Kafka é muito rápido e garante tempo de inatividade zero e perda de dados zero.
Casos de Uso
O Kafka pode ser usado em muitos casos de uso. Alguns deles estão listados abaixo -
Metrics- Kafka é freqüentemente usado para dados de monitoramento operacional. Isso envolve a agregação de estatísticas de aplicativos distribuídos para produzir feeds centralizados de dados operacionais.
Log Aggregation Solution - O Kafka pode ser usado em uma organização para coletar logs de vários serviços e disponibilizá-los em um formato padrão para vários consumidores.
Stream Processing- Estruturas populares como Storm e Spark Streaming leem dados de um tópico, os processam e gravam dados processados em um novo tópico, onde se tornam disponíveis para usuários e aplicativos. A forte durabilidade do Kafka também é muito útil no contexto de processamento de fluxo.
Necessidade de Kafka
Kafka é uma plataforma unificada para lidar com todos os feeds de dados em tempo real. O Kafka oferece suporte para entrega de mensagens de baixa latência e oferece garantia de tolerância a falhas na presença de falhas na máquina. Ele tem a capacidade de atender a um grande número de consumidores diversos. Kafka é muito rápido, executa 2 milhões de gravações / s. O Kafka mantém todos os dados no disco, o que essencialmente significa que todas as gravações vão para o cache de página do SO (RAM). Isso torna muito eficiente a transferência de dados do cache de página para um soquete de rede.
Antes de se aprofundar no Kafka, você deve estar ciente das principais terminologias como tópicos, corretores, produtores e consumidores. O diagrama a seguir ilustra as principais terminologias e a tabela descreve os componentes do diagrama em detalhes.
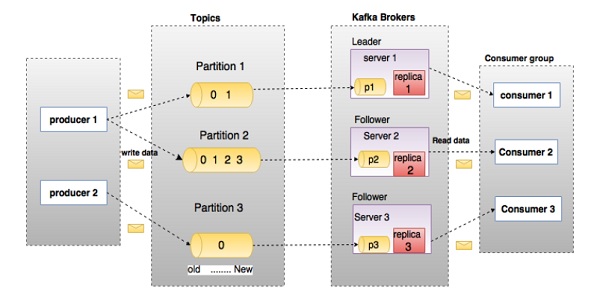
No diagrama acima, um tópico é configurado em três partições. A partição 1 tem dois fatores de deslocamento 0 e 1. A partição 2 tem quatro fatores de deslocamento 0, 1, 2 e 3. A partição 3 tem um fator de deslocamento 0. O id da réplica é igual ao id do servidor que a hospeda.
Suponha que, se o fator de replicação do tópico for definido como 3, o Kafka criará 3 réplicas idênticas de cada partição e as colocará no cluster para disponibilizá-las para todas as suas operações. Para equilibrar uma carga no cluster, cada corretor armazena uma ou mais dessas partições. Vários produtores e consumidores podem publicar e recuperar mensagens ao mesmo tempo.
| S.No | Componentes e Descrição |
|---|---|
| 1 | Topics Um fluxo de mensagens pertencentes a uma categoria específica é chamado de tópico. Os dados são armazenados em tópicos. Os tópicos são divididos em partições. Para cada tópico, o Kafka mantém um mínimo de uma partição. Cada partição contém mensagens em uma sequência ordenada imutável. Uma partição é implementada como um conjunto de arquivos de segmento de tamanhos iguais. |
| 2 | Partition Os tópicos podem ter muitas partições, portanto, podem lidar com uma quantidade arbitrária de dados. |
| 3 | Partition offset Cada mensagem particionada tem um id de sequência exclusivo chamado de |
| 4 | Replicas of partition As réplicas nada mais são do que |
| 5 | Brokers
|
| 6 | Kafka Cluster O fato de Kafka ter mais de um corretor é chamado de cluster Kafka. Um cluster Kafka pode ser expandido sem tempo de inatividade. Esses clusters são usados para gerenciar a persistência e a replicação dos dados da mensagem. |
| 7 | Producers Os produtores são os editores de mensagens para um ou mais tópicos do Kafka. Os produtores enviam dados aos corretores Kafka. Cada vez que um produtor publica uma mensagem para um corretor, o corretor simplesmente anexa a mensagem ao último arquivo de segmento. Na verdade, a mensagem será anexada a uma partição. O produtor também pode enviar mensagens para uma partição de sua escolha. |
| 8 | Consumers Os consumidores leem dados de corretores. Os consumidores assinam um ou mais tópicos e consomem mensagens publicadas puxando dados dos corretores. |
| 9 | Leader
|
| 10 | Follower O nó que segue as instruções do líder é chamado de seguidor. Se o líder falhar, um dos seguidores se tornará automaticamente o novo líder. Um seguidor atua como consumidor normal, puxa mensagens e atualiza seu próprio armazenamento de dados. |
Dê uma olhada na ilustração a seguir. Ele mostra o diagrama de cluster de Kafka.

A tabela a seguir descreve cada um dos componentes mostrados no diagrama acima.
| S.No | Componentes e Descrição |
|---|---|
| 1 | Broker O cluster Kafka geralmente consiste em vários brokers para manter o equilíbrio de carga. Os corretores Kafka não têm estado, portanto, usam o ZooKeeper para manter o estado do cluster. Uma instância do broker Kafka pode lidar com centenas de milhares de leituras e gravações por segundo e cada bro-ker pode lidar com TB de mensagens sem impacto no desempenho. A eleição do líder do corretor Kafka pode ser feita pelo ZooKeeper. |
| 2 | ZooKeeper O ZooKeeper é usado para gerenciar e coordenar o corretor Kafka. O serviço ZooKeeper é usado principalmente para notificar o produtor e o consumidor sobre a presença de qualquer novo corretor no sistema Kafka ou falha do corretor no sistema Kafka. De acordo com a notificação recebida pelo Zookeeper sobre a presença ou falha do corretor, o produtor e o consumidor tomam a decisão e começam a coordenar suas tarefas com algum outro corretor. |
| 3 | Producers Os produtores enviam dados aos corretores. Quando o novo broker é iniciado, todos os produtores o procuram e automaticamente enviam uma mensagem para esse novo broker. O produtor Kafka não espera por confirmações do corretor e envia mensagens tão rápido quanto o corretor pode manipular. |
| 4 | Consumers Como os corretores Kafka são sem estado, o que significa que o consumidor precisa manter quantas mensagens foram consumidas usando o deslocamento de partição. Se o consumidor reconhece um deslocamento de mensagem específico, isso implica que o consumidor consumiu todas as mensagens anteriores. O consumidor emite uma solicitação de pull assíncrona ao broker para ter um buffer de bytes pronto para consumir. Os consumidores podem retroceder ou pular para qualquer ponto em uma partição simplesmente fornecendo um valor de deslocamento. O valor de compensação do consumidor é notificado pelo ZooKeeper. |
A partir de agora, discutimos os principais conceitos de Kafka. Vamos agora lançar algumas luzes sobre o fluxo de trabalho de Kafka.
Kafka é simplesmente uma coleção de tópicos divididos em uma ou mais partições. Uma partição Kafka é uma sequência de mensagens ordenada linearmente, em que cada mensagem é identificada por seu índice (chamado de deslocamento). Todos os dados em um cluster Kafka são a união desarticulada de partições. As mensagens de entrada são gravadas no final de uma partição e as mensagens são lidas sequencialmente pelos consumidores. A durabilidade é fornecida pela replicação de mensagens para diferentes corretores.
O Kafka fornece sistema de mensagens baseado em fila e pub-sub de maneira rápida, confiável, persistente, com tolerância a falhas e tempo de inatividade zero. Em ambos os casos, os produtores simplesmente enviam a mensagem a um tópico e o consumidor pode escolher qualquer tipo de sistema de mensagens, dependendo de sua necessidade. Vamos seguir as etapas na próxima seção para entender como o consumidor pode escolher o sistema de mensagens de sua escolha.
Fluxo de trabalho de mensagens Pub-Sub
A seguir está o fluxo de trabalho detalhado do Pub-Sub Messaging -
Os produtores enviam mensagens para um tópico em intervalos regulares.
O broker Kafka armazena todas as mensagens nas partições configuradas para esse tópico específico. Isso garante que as mensagens sejam compartilhadas igualmente entre as partições. Se o produtor enviar duas mensagens e houver duas partições, o Kafka armazenará uma mensagem na primeira partição e a segunda na segunda partição.
O consumidor se inscreve em um tópico específico.
Depois que o consumidor assina um tópico, Kafka fornecerá o deslocamento atual do tópico para o consumidor e também salvará o deslocamento no conjunto Zookeeper.
O consumidor solicitará o Kafka em um intervalo regular (como 100 ms) para novas mensagens.
Assim que o Kafka recebe as mensagens dos produtores, ele as encaminha para os consumidores.
O consumidor receberá a mensagem e a processará.
Assim que as mensagens forem processadas, o consumidor enviará uma confirmação ao corretor Kafka.
Depois que Kafka recebe uma confirmação, ele altera o deslocamento para o novo valor e o atualiza no Zookeeper. Uma vez que os offsets são mantidos no Zookeeper, o consumidor pode ler a próxima mensagem corretamente, mesmo durante os ataques do servidor.
Este fluxo acima se repetirá até que o consumidor interrompa a solicitação.
O consumidor tem a opção de retroceder / pular para o deslocamento desejado de um tópico a qualquer momento e ler todas as mensagens subsequentes.
Fluxo de trabalho da fila de mensagens / grupo de consumidores
Em um sistema de mensagens em fila, em vez de um único consumidor, um grupo de consumidores com o mesmo ID de Grupo
se inscreverá em um tópico. Em termos simples, os consumidores que se inscrevem em um tópico com o mesmo ID de grupo
são considerados como um único grupo e as mensagens são compartilhadas entre eles. Vamos verificar o fluxo de trabalho real deste sistema.
Os produtores enviam mensagens para um tópico em intervalos regulares.
O Kafka armazena todas as mensagens nas partições configuradas para esse tópico específico, semelhante ao cenário anterior.
Um único consumidor assina um tópico específico, suponha que
Topic-01
comID de
Grupo
sejaGrupo-1
.Interage Kafka com o consumidor da mesma forma como Pub-Sub Messaging até novo consumidor subscreve o mesmo tema,
tópico-01
com a mesmaID do grupo
comoGrupo-1
.Assim que o novo consumidor chega, Kafka muda sua operação para o modo de compartilhamento e compartilha os dados entre os dois consumidores. Esse compartilhamento continuará até que o número de consumidores atinja o número de partição configurada para aquele tópico específico.
Assim que o número de consumidores exceder o número de partições, o novo consumidor não receberá mais nenhuma mensagem até que qualquer um dos consumidores existentes cancele a assinatura. Este cenário surge porque cada consumidor no Kafka receberá no mínimo uma partição e, uma vez que todas as partições sejam atribuídas aos consumidores existentes, os novos consumidores terão que esperar.
Esse recurso também é chamado de
Grupo de Consumidores
. Da mesma forma, Kafka irá fornecer o melhor de ambos os sistemas de uma forma muito simples e eficiente.
Papel do ZooKeeper
Uma dependência crítica do Apache Kafka é o Apache Zookeeper, que é um serviço de configuração e sincronização distribuído. O Zookeeper serve como interface de coordenação entre os corretores e consumidores Kafka. Os servidores Kafka compartilham informações por meio de um cluster Zookeeper. O Kafka armazena metadados básicos no Zookeeper, como informações sobre tópicos, corretores, compensações do consumidor (leitores de fila) e assim por diante.
Como todas as informações críticas são armazenadas no Zookeeper e ele normalmente replica esses dados em seu conjunto, a falha do Kafka broker / Zookeeper não afeta o estado do cluster Kafka. Kafka irá restaurar o estado assim que o Zookeeper for reiniciado. Isso dá tempo de inatividade zero para Kafka. A eleição do líder entre o corretor Kafka também é feita usando o Zookeeper em caso de falha do líder.
Para saber mais sobre Zookeeper, consulte zookeeper
Vamos continuar como instalar o Java, ZooKeeper e Kafka em sua máquina no próximo capítulo.
A seguir estão as etapas para instalar o Java em sua máquina.
Etapa 1 - Verificando a instalação do Java
Esperamos que você já tenha instalado o java na sua máquina agora, então apenas verifique-o usando o seguinte comando.
$ java -versionSe o java for instalado com sucesso em sua máquina, você poderá ver a versão do Java instalado.
Etapa 1.1 - Baixe o JDK
Se o Java não for baixado, baixe a versão mais recente do JDK visitando o link a seguir e baixe a versão mais recente.
http://www.oracle.com/technetwork/java/javase/downloads/index.htmlAgora, a versão mais recente é JDK 8u 60 e o arquivo é “jdk-8u60-linux-x64.tar.gz”. Faça download do arquivo em sua máquina.
Etapa 1.2 - Extrair arquivos
Geralmente, os arquivos baixados são armazenados na pasta de downloads, verifique e extraia a configuração do tar usando os seguintes comandos.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzEtapa 1.3 - Mover para Opt Directory
Para disponibilizar o java a todos os usuários, mova o conteúdo java extraído para a pasta usr / local / java
/.
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Etapa 1.4 - Definir caminho
Para definir as variáveis de caminho e JAVA_HOME, adicione os seguintes comandos ao arquivo ~ / .bashrc.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binAgora aplique todas as alterações no sistema em execução atual.
$ source ~/.bashrcEtapa 1.5 - Alternativas Java
Use o seguinte comando para alterar as alternativas Java.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 - Agora verifique o java usando o comando de verificação (java -version) explicado na Etapa 1.
Etapa 2 - Instalação do ZooKeeper Framework
Etapa 2.1 - Baixe o ZooKeeper
Para instalar a estrutura do ZooKeeper em sua máquina, visite o link a seguir e baixe a versão mais recente do ZooKeeper.
http://zookeeper.apache.org/releases.htmlA partir de agora, a última versão do ZooKeeper é a 3.4.6 (ZooKeeper-3.4.6.tar.gz).
Etapa 2.2 - Extrair arquivo tar
Extraia o arquivo tar usando o seguinte comando
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataEtapa 2.3 - Criar arquivo de configuração
Abra o arquivo de configuração denominado conf / zoo.cfg
usando o comando vi “conf / zoo.cfg” e todos os parâmetros a seguir para definir como ponto de partida.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Uma vez que o arquivo de configuração foi salvo com sucesso e retornar ao terminal novamente, você pode iniciar o servidor zookeeper.
Etapa 2.4 - Iniciar o ZooKeeper Server
$ bin/zkServer.sh startDepois de executar este comando, você obterá uma resposta conforme mostrado abaixo -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDEtapa 2.5 - Iniciar CLI
$ bin/zkCli.shDepois de digitar o comando acima, você será conectado ao servidor zookeeper e receberá a resposta abaixo.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Etapa 2.6 - Pare o servidor Zookeeper
Depois de conectar o servidor e realizar todas as operações, você pode parar o servidor zookeeper com o seguinte comando -
$ bin/zkServer.sh stopAgora você instalou com sucesso o Java e o ZooKeeper em sua máquina. Vamos ver as etapas para instalar o Apache Kafka.
Etapa 3 - Instalação do Apache Kafka
Vamos continuar com as etapas a seguir para instalar o Kafka em sua máquina.
Etapa 3.1 - Baixe o Kafka
Para instalar o Kafka em sua máquina, clique no link abaixo -
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgzAgora, a versão mais recente, ou seja, - kafka_2.11_0.9.0.0.tgz será baixado em sua máquina.
Etapa 3.2 - Extrair o arquivo tar
Extraia o arquivo tar usando o seguinte comando -
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0Agora você baixou a versão mais recente do Kafka em sua máquina.
Etapa 3.3 - Iniciar o servidor
Você pode iniciar o servidor dando o seguinte comando -
$ bin/kafka-server-start.sh config/server.propertiesDepois que o servidor for iniciado, você verá a resposta abaixo em sua tela -
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….Etapa 4 - Pare o servidor
Depois de realizar todas as operações, você pode parar o servidor usando o seguinte comando -
$ bin/kafka-server-stop.sh config/server.propertiesAgora que já discutimos a instalação do Kafka, podemos aprender como realizar operações básicas no Kafka no próximo capítulo.
Primeiro, vamos começar a implementar a configuração de broker de nó único
e, então, migraremos nossa configuração para a configuração de brokers de nó único e múltiplos.
Com sorte, você já deve ter instalado o Java, o ZooKeeper e o Kafka em sua máquina. Antes de passar para a configuração do cluster Kafka, primeiro você precisa iniciar o ZooKeeper porque o cluster Kafka usa o ZooKeeper.
Inicie o ZooKeeper
Abra um novo terminal e digite o seguinte comando -
bin/zookeeper-server-start.sh config/zookeeper.propertiesPara iniciar o Kafka Broker, digite o seguinte comando -
bin/kafka-server-start.sh config/server.propertiesDepois de iniciar o Kafka Broker, digite o comando jps
no terminal ZooKeeper e você verá a seguinte resposta -
821 QuorumPeerMain
928 Kafka
931 JpsAgora você pode ver dois daemons em execução no terminal onde QuorumPeerMain é o daemon ZooKeeper e outro é o daemon Kafka.
Configuração de Nó Único - Agente Único
Nesta configuração, você tem uma única instância do ZooKeeper e do ID do corretor. A seguir estão as etapas para configurá-lo -
Creating a Kafka Topic- Kafka fornece um utilitário de linha de comando chamado kafka-topics.sh
para criar tópicos no servidor. Abra o novo terminal e digite o exemplo abaixo.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-KafkaAcabamos de criar um tópico chamado Hello-Kafka
com uma única partição e um fator de réplica. A saída criada acima será semelhante à seguinte saída -
Output- Criado tópico Hello-Kafka
Depois de criar o tópico, você pode obter a notificação na janela do terminal do broker Kafka e o log do tópico criado especificado em “/ tmp / kafka-logs /“ no arquivo config / server.properties.
Lista de Tópicos
Para obter uma lista de tópicos no servidor Kafka, você pode usar o seguinte comando -
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-KafkaComo criamos um tópico, ele listará apenas Hello-Kafka
. Suponha que, se você criar mais de um tópico, obterá os nomes dos tópicos na saída.
Comece o produtor a enviar mensagens
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-nameA partir da sintaxe acima, dois parâmetros principais são necessários para o cliente de linha de comando do produtor -
Broker-list- A lista de corretores para os quais queremos enviar as mensagens. Neste caso, temos apenas um corretor. O arquivo Config / server.properties contém o id da porta do broker, pois sabemos que nosso broker está escutando na porta 9092, então você pode especificá-lo diretamente.
Nome do tópico - Aqui está um exemplo para o nome do tópico.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-KafkaO produtor aguardará a entrada de stdin e publicará no cluster Kafka. Por padrão, cada nova linha é publicada como uma nova mensagem, em seguida, as propriedades do produtor padrão são especificadas no arquivo config / producer.properties
. Agora você pode digitar algumas linhas de mensagens no terminal, conforme mostrado abaixo.
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageComece o consumidor a receber mensagens
Semelhante ao produtor, as propriedades do consumidor padrão são especificadas no arquivo config / consumer.proper-ties
. Abra um novo terminal e digite a sintaxe abaixo para consumir mensagens.
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second messageFinalmente, você pode inserir mensagens do terminal do produtor e vê-las aparecendo no terminal do consumidor. A partir de agora, você tem um bom conhecimento sobre o cluster de nó único com um único broker. Vamos agora passar para a configuração de vários corretores.
Configuração de Nó Único-Múltiplos Brokers
Antes de passar para a configuração de cluster de vários brokers, primeiro inicie o servidor ZooKeeper.
Create Multiple Kafka Brokers- Já temos uma instância do broker Kafka em con-fig / server.properties. Agora precisamos de várias instâncias do broker, então copie o arquivo server.prop-erties existente em dois novos arquivos de configuração e renomeie-o como server-one.properties e server-two.prop-erties. Em seguida, edite os novos arquivos e atribua as seguintes alterações -
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers- Após todas as alterações terem sido feitas em três servidores, abra três novos terminais para iniciar cada corretor, um por um.
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesAgora temos três corretores diferentes em execução na máquina. Experimente você mesmo para verificar todos os daemons digitandojps no terminal ZooKeeper, então você veria a resposta.
Criando um Tópico
Vamos atribuir o valor do fator de replicação como três para este tópico, porque temos três corretores diferentes em execução. Se você tiver dois corretores, o valor de réplica atribuído será dois.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”O comando Descrever
é usado para verificar qual corretor está ouvindo no tópico atual criado, conforme mostrado abaixo -
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1A partir da saída acima, podemos concluir que a primeira linha fornece um resumo de todas as partições, mostrando o nome do tópico, a contagem de partições e o fator de replicação que já escolhemos. Na segunda linha, cada nó será o líder para uma parte selecionada aleatoriamente das partições.
Em nosso caso, vemos que nosso primeiro corretor (com broker.id 0) é o líder. Then Replicas: 0,2,1 significa que todos os brokers replicam o tópico finalmente Isr
é o conjunto de réplicas sincronizadas
. Bem, este é o subconjunto de réplicas que estão atualmente vivas e capturadas pelo líder.
Comece o produtor a enviar mensagens
Este procedimento permanece o mesmo que na configuração do corretor único.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageComece o consumidor a receber mensagens
Este procedimento permanece o mesmo mostrado na configuração do corretor único.
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second messageOperações Básicas de Tópico
Neste capítulo, discutiremos as várias operações básicas de tópicos.
Modificando um Tópico
Como você já entendeu como criar um tópico no Kafka Cluster. Agora vamos modificar um tópico criado usando o seguinte comando
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!Excluindo um Tópico
Para excluir um tópico, você pode usar a seguinte sintaxe.
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −Isso não terá impacto se delete.topic.enable não está definido como verdadeiro
Vamos criar um aplicativo para publicar e consumir mensagens usando um cliente Java. O cliente produtor Kafka consiste nas seguintes APIs.
API KafkaProducer
Vamos entender o conjunto mais importante de API do produtor Kafka nesta seção. A parte central da API KafkaProducer
é a classe KafkaProducer
. A classe KafkaProducer fornece uma opção para conectar um broker Kafka em seu construtor com os métodos a seguir.
A classe KafkaProducer fornece o método send para enviar mensagens de forma assíncrona para um tópico. A assinatura de send () é a seguinte
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord - O produtor gerencia um buffer de registros aguardando para serem enviados.
Callback - Um retorno de chamada fornecido pelo usuário a ser executado quando o registro tiver sido reconhecido pelo servidor (nulo indica nenhum retorno de chamada).
A classe KafkaProducer fornece um método flush para garantir que todas as mensagens enviadas anteriormente foram realmente concluídas. A sintaxe do método flush é a seguinte -
public void flush()A classe KafkaProducer fornece o método partitionFor, que ajuda a obter os metadados da partição para um determinado tópico. Isso pode ser usado para particionamento personalizado. A assinatura deste método é a seguinte -
public Map metrics()Ele retorna o mapa de métricas internas mantidas pelo produtor.
public void close () - A classe KafkaProducer fornece blocos de método de fechamento até que todas as solicitações enviadas anteriormente sejam concluídas.
API do produtor
A parte central da API Producer
é a classe Producer
. A classe do produtor fornece uma opção para conectar o broker Kafka em seu construtor pelos métodos a seguir.
A classe do produtor
A classe produtora fornece método de envio para send mensagens para um ou vários tópicos usando as seguintes assinaturas.
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);Existem dois tipos de produtores - Sync e Async.
A mesma configuração de API se aplica ao produtor de sincronização
também. A diferença entre eles é que um produtor de sincronização envia mensagens diretamente, mas envia mensagens em segundo plano. O produtor assíncrono é preferível quando você deseja um rendimento mais alto. Nas versões anteriores, como 0.8, um produtor assíncrono não tem um retorno de chamada para send () para registrar manipuladores de erro. Isso está disponível apenas na versão atual do 0.9.
public void close ()
A classe de produtor fornece close método para fechar as conexões do conjunto de produtores para todos os bro-kers Kafka.
Definições de configuração
As principais definições de configuração da API do Produtor estão listadas na tabela a seguir para melhor compreensão -
| S.No | Definições de configuração e descrição |
|---|---|
| 1 | client.id identifica a aplicação do produtor |
| 2 | producer.type sincronizar ou async |
| 3 | acks A configuração de acks controla os critérios em que as solicitações do produtor são consideradas concluídas. |
| 4 | retries Se a solicitação do produtor falhar, tente novamente automaticamente com um valor específico. |
| 5 | bootstrap.servers lista de bootstrapping de corretores. |
| 6 | linger.ms se você deseja reduzir o número de solicitações, pode definir linger.ms para algo maior do que algum valor. |
| 7 | key.serializer Chave para a interface do serializador. |
| 8 | value.serializer valor para a interface do serializador. |
| 9 | batch.size Tamanho do buffer. |
| 10 | buffer.memory controla a quantidade total de memória disponível para o produtor para armazenamento em buffer. |
API ProducerRecord
ProducerRecord é um par de chave / valor enviado ao construtor da classe Kafka cluster.ProducerRecord para criar um registro com pares de partição, chave e valor usando a assinatura a seguir.
public ProducerRecord (string topic, int partition, k key, v value)Topic - nome do tópico definido pelo usuário que será anexado ao registro.
Partition - contagem de partição
Key - A chave que será incluída no registro.
- Value - Gravar conteúdos
public ProducerRecord (string topic, k key, v value)O construtor da classe ProducerRecord é usado para criar um registro com chave, pares de valor e sem partição.
Topic - Crie um tópico para atribuir registro.
Key - chave para o registro.
Value - conteúdo do registro.
public ProducerRecord (string topic, v value)A classe ProducerRecord cria um registro sem partição e chave.
Topic - crie um tópico.
Value - conteúdo do registro.
Os métodos da classe ProducerRecord estão listados na tabela a seguir -
| S.No | Métodos de classe e descrição |
|---|---|
| 1 | public string topic() O tópico será anexado ao registro. |
| 2 | public K key() Chave que será incluída no registro. Se não houver essa chave, null será devolvido aqui. |
| 3 | public V value() Conteúdo do registro. |
| 4 | partition() Contagem de partição para o registro |
Aplicativo SimpleProducer
Antes de criar o aplicativo, primeiro inicie o ZooKeeper e o corretor Kafka e, em seguida, crie seu próprio tópico no corretor Kafka usando o comando criar tópico. Depois disso, crie uma classe java chamada Sim-pleProducer.java
e digite a seguinte codificação.
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation - O aplicativo pode ser compilado usando o seguinte comando.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution - O aplicativo pode ser executado usando o seguinte comando.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10Exemplo de consumidor simples
A partir de agora, criamos um produtor para enviar mensagens ao cluster Kafka. Agora vamos criar um consumidor para consumir mensagens do cluster Kafka. A API KafkaConsumer é usada para consumir mensagens do cluster Kafka. O construtor da classe KafkaConsumer é definido a seguir.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs - Retorne um mapa de configurações do consumidor.
A classe KafkaConsumer tem os seguintes métodos significativos listados na tabela a seguir.
| S.No | Método e Descrição |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() Obtenha o conjunto de partições atualmente atribuídas pelo consumidor. |
| 2 | public string subscription() Inscreva-se na lista de tópicos fornecida para obter partições atribuídas dinamicamente. |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) Inscreva-se na lista de tópicos fornecida para obter partições atribuídas dinamicamente. |
| 4 | public void unsubscribe() Cancele a assinatura dos tópicos da lista de partições fornecida. |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) Inscreva-se na lista de tópicos fornecida para obter partições atribuídas dinamicamente. Se a lista de tópicos fornecida estiver vazia, ela será tratada da mesma forma que unsubscribe (). |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) O padrão de argumento refere-se ao padrão de assinatura no formato de expressão regular e o argumento do listener obtém notificações do padrão de assinatura. |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) Atribua manualmente uma lista de partições ao cliente. |
| 8 | poll() Busque dados para os tópicos ou partições especificados usando uma das APIs de inscrição / atribuição. Isso retornará um erro, se os tópicos não forem inscritos antes da pesquisa de dados. |
| 9 | public void commitSync() Compita os deslocamentos retornados na última enquete () para toda a lista de tópicos e partições assinada. A mesma operação é aplicada a commitAsyn (). |
| 10 | public void seek(TopicPartition partition, long offset) Busque o valor de deslocamento atual que o consumidor usará no próximo método poll (). |
| 11 | public void resume() Retome as partições pausadas. |
| 12 | public void wakeup() Desperte o consumidor. |
API ConsumerRecord
A API ConsumerRecord é usada para receber registros do cluster Kafka. Esta API consiste em um nome de tópico, número de partição, a partir do qual o registro está sendo recebido e um deslocamento que aponta para o registro em uma partição Kafka. A classe ConsumerRecord é usada para criar um registro de consumidor com nome de tópico específico, contagem de partição e pares <chave, valor>. Possui a seguinte assinatura.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic - O nome do tópico para registro do consumidor recebido do cluster Kafka.
Partition - Partição para o tópico.
Key - A chave do registro, se nenhuma chave existir, será retornado nulo.
Value - Grave conteúdos.
API ConsumerRecords
A API ConsumerRecords atua como um contêiner para ConsumerRecord. Esta API é usada para manter a lista de ConsumerRecord por partição para um tópico específico. Seu construtor é definido a seguir.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition - Retorne um mapa de partição para um tópico específico.
Records - Lista de retorno de ConsumerRecord.
A classe ConsumerRecords possui os seguintes métodos definidos.
| S.No | Métodos e Descrição |
|---|---|
| 1 | public int count() O número de registros para todos os tópicos. |
| 2 | public Set partitions() O conjunto de partições com dados neste conjunto de registros (se nenhum dado foi retornado, o conjunto está vazio). |
| 3 | public Iterator iterator() Iterator permite que você percorra uma coleção, obtendo ou removendo elementos. |
| 4 | public List records() Obtenha uma lista de registros para a partição fornecida. |
Definições de configuração
As definições de configuração para as principais definições de configuração da API do cliente consumidor estão listadas abaixo -
| S.No | Configurações e descrição |
|---|---|
| 1 | bootstrap.servers Lista de bootstrapping de corretores. |
| 2 | group.id Atribui um consumidor individual a um grupo. |
| 3 | enable.auto.commit Habilite a confirmação automática para deslocamentos se o valor for verdadeiro, caso contrário, não confirmada. |
| 4 | auto.commit.interval.ms Retorne com que frequência os deslocamentos consumidos atualizados são gravados no ZooKeeper. |
| 5 | session.timeout.ms Indica quantos milissegundos o Kafka aguardará até que o ZooKeeper responda a uma solicitação (leitura ou gravação) antes de desistir e continuar a consumir mensagens. |
Aplicativo SimpleConsumer
As etapas do aplicativo do produtor permanecem as mesmas aqui. Primeiro, inicie seu corretor ZooKeeper e Kafka. Em seguida, crie um aplicativo SimpleConsumer
com a classe java chamada SimpleCon-sumer.java
e digite o código a seguir.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation - O aplicativo pode ser compilado usando o seguinte comando.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − O aplicativo pode ser executado usando o seguinte comando
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input- Abra a CLI do produtor e envie algumas mensagens para o tópico. Você pode colocar a entrada smple como 'Olá, consumidor'.
Output - A seguir será a saída.
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello ConsumerGrupo de consumidores é um consumo multi-threaded ou multi-máquina de tópicos Kafka.
Grupo de Consumidores
Os consumidores podem ingressar em um grupo usando o mesmo
group.id.
O paralelismo máximo de um grupo é que o número de consumidores no grupo ← não de partições.
O Kafka atribui as partições de um tópico ao consumidor em um grupo, de modo que cada partição seja consumida por exatamente um consumidor no grupo.
Kafka garante que uma mensagem só é lida por um único consumidor no grupo.
Os consumidores podem ver a mensagem na ordem em que foram armazenadas no log.
Reequilíbrio de um consumidor
Adicionar mais processos / threads fará com que o Kafka se reequilibre. Se algum consumidor ou corretor falhar em enviar pulsação ao ZooKeeper, ele poderá ser reconfigurado por meio do cluster Kafka. Durante esse reequilíbrio, o Kafka atribuirá as partições disponíveis aos threads disponíveis, possivelmente movendo uma partição para outro processo.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilação
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.javaExecução
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupAqui, criamos um nome de grupo de amostra como my-group
com dois consumidores. Da mesma forma, você pode criar seu grupo e o número de consumidores no grupo.
Entrada
Abra a CLI do produtor e envie algumas mensagens como -
Test consumer group 01
Test consumer group 02Saída do Primeiro Processo
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01Saída do segundo processo
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02Esperamos que você tenha entendido SimpleConsumer e ConsumeGroup usando a demonstração do cliente Java. Agora você tem uma ideia sobre como enviar e receber mensagens usando um cliente Java. Vamos continuar a integração do Kafka com tecnologias de big data no próximo capítulo.
Neste capítulo, aprenderemos como integrar o Kafka ao Apache Storm.
Sobre Storm
Storm foi originalmente criado por Nathan Marz e equipe da BackType. Em pouco tempo, o Apache Storm se tornou um padrão para sistema de processamento distribuído em tempo real que permite processar um grande volume de dados. Storm é muito rápido e um benchmark o registrou em mais de um milhão de tuplas processadas por segundo por nó. O Apache Storm é executado continuamente, consumindo dados das fontes configuradas (Spouts) e passa os dados pelo pipeline de processamento (Bolts). Combinados, bicos e parafusos formam uma topologia.
Integração com Storm
Kafka e Storm se complementam naturalmente, e sua poderosa cooperação permite análises de streaming em tempo real para big data em movimento rápido. A integração do Kafka e do Storm torna mais fácil para os desenvolvedores ingerir e publicar fluxos de dados de topologias do Storm.
Fluxo conceitual
Um bico é uma fonte de riachos. Por exemplo, um spout pode ler tuplas de um Tópico Kafka e emiti-las como um fluxo. Um bolt consome fluxos de entrada, processa e possivelmente emite novos fluxos. Bolts podem fazer qualquer coisa, desde executar funções, filtrar tuplas, fazer agregações de streaming, junções de streaming, conversar com bancos de dados e muito mais. Cada nó em uma topologia Storm é executado em paralelo. Uma topologia é executada indefinidamente até que você a encerre. Storm irá reatribuir automaticamente quaisquer tarefas com falha. Além disso, Storm garante que não haverá perda de dados, mesmo que as máquinas parem e as mensagens sejam descartadas.
Vamos examinar as APIs de integração Kafka-Storm em detalhes. Existem três classes principais para integrar o Kafka com o Storm. Eles são os seguintes -
BrokerHosts - ZkHosts e StaticHosts
BrokerHosts é uma interface e ZkHosts e StaticHosts são suas duas principais implementações. ZkHosts é usado para rastrear os corretores Kafka dinamicamente, mantendo os detalhes no ZooKeeper, enquanto StaticHosts é usado para definir manualmente / estaticamente os corretores Kafka e seus detalhes. ZkHosts é a maneira simples e rápida de acessar o corretor Kafka.
A assinatura da ZkHosts é a seguinte -
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)Onde brokerZkStr é o host do ZooKeeper e brokerZkPath é o caminho do ZooKeeper para manter os detalhes do corretor Kafka.
API KafkaConfig
Esta API é usada para definir as configurações do cluster Kafka. A assinatura de Kafka Con-fig é definida como segue
public KafkaConfig(BrokerHosts hosts, string topic)Hosts - Os BrokerHosts podem ser ZkHosts / StaticHosts.
Topic - nome do tópico.
API SpoutConfig
Spoutconfig é uma extensão do KafkaConfig que suporta informações adicionais do ZooKeeper.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts - O BrokerHosts pode ser qualquer implementação da interface BrokerHosts
Topic - nome do tópico.
zkRoot - Caminho de raiz do ZooKeeper.
id −O bico armazena o estado das compensações consumidas no Zookeeper. O id deve identificar exclusivamente o seu bico.
SchemeAsMultiScheme
SchemeAsMultiScheme é uma interface que determina como o ByteBuffer consumido de Kafka é transformado em uma tupla de tempestade. É derivado de MultiScheme e aceita a implementação da classe Scheme. Existem muitas implementações da classe Scheme e uma dessas implementações é StringScheme, que analisa o byte como uma string simples. Ele também controla a nomenclatura de seu campo de saída. A assinatura é definida da seguinte forma.
public SchemeAsMultiScheme(Scheme scheme)Scheme - buffer de byte consumido do kafka.
API KafkaSpout
KafkaSpout é nossa implementação de spout, que se integrará ao Storm. Ele busca as mensagens do tópico kafka e as emite no ecossistema Storm como tuplas. O KafkaSpout obtém seus detalhes de configuração em SpoutConfig.
Abaixo está um exemplo de código para criar um bico Kafka simples.
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Criação de Parafuso
Bolt é um componente que recebe tuplas como entrada, processa a tupla e produz novas tuplas como saída. Bolts implementará a interface IRichBolt. Neste programa, duas classes de bolt WordSplitter-Bolt e WordCounterBolt são utilizadas para realizar as operações.
A interface IRichBolt tem os seguintes métodos -
Prepare- Fornece ao parafuso um ambiente para execução. Os executores irão executar este método para inicializar o spout.
Execute - Processa uma única tupla de entrada.
Cleanup - Chamado quando um parafuso vai desligar.
declareOutputFields - Declara o esquema de saída da tupla.
Vamos criar SplitBolt.java, que implementa a lógica para dividir uma frase em palavras e CountBolt.java, que implementa a lógica para separar palavras únicas e contar sua ocorrência.
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Enviando para topologia
A topologia Storm é basicamente uma estrutura Thrift. A classe TopologyBuilder fornece métodos simples e fáceis para criar topologias complexas. A classe TopologyBuilder possui métodos para definir spout (setSpout) e para definir bolt (setBolt). Finalmente, TopologyBuilder tem createTopology para criar to-pology. Os métodos shuffleGrouping e fieldsGrouping ajudam a definir o agrupamento de fluxos para spout e bolts.
Local Cluster- Para fins de desenvolvimento, podemos criar um cluster local usando LocalCluster
objeto e, em seguida, enviar a topologia usando submitTopology
método de LocalCluster
classe.
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}Antes de mover a compilação, a integração Kakfa-Storm precisa da biblioteca Java do curador ZooKeeper. O Curator versão 2.9.1 oferece suporte ao Apache Storm versão 0.9.5 (que usamos neste tutorial). Baixe os arquivos jar especificados abaixo e coloque-os no caminho de classe java.
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
Depois de incluir os arquivos de dependência, compile o programa usando o seguinte comando,
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.javaExecução
Inicie a CLI do Kafka Producer (explicado no capítulo anterior), crie um novo tópico chamado my-first-topic
e forneça algumas mensagens de amostra, conforme mostrado abaixo -
hello
kafka
storm
spark
test message
another test messageAgora execute o aplicativo usando o seguinte comando -
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleO exemplo de saída deste aplicativo é especificado abaixo -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2Neste capítulo, discutiremos sobre como integrar o Apache Kafka com a API Spark Streaming.
Sobre o Spark
A API Spark Streaming permite o processamento escalonável, de alto rendimento e tolerante a falhas de fluxos de dados ao vivo. Os dados podem ser ingeridos de muitas fontes, como Kafka, Flume, Twitter, etc., e podem ser processados usando algoritmos complexos, como funções de alto nível, como mapear, reduzir, juntar e janela. Finalmente, os dados processados podem ser enviados para sistemas de arquivos, bancos de dados e painéis dinâmicos. Resilient Distributed Datasets (RDD) é uma estrutura de dados fundamental do Spark. É uma coleção imutável de objetos distribuídos. Cada conjunto de dados em RDD é dividido em partições lógicas, que podem ser calculadas em diferentes nós do cluster.
Integração com Spark
Kafka é uma plataforma potencial de mensagens e integração para streaming do Spark. O Kafka atua como o hub central para fluxos de dados em tempo real e são processados usando algoritmos complexos no Spark Streaming. Depois que os dados são processados, o Spark Streaming pode publicar os resultados em outro tópico do Kafka ou armazenar em HDFS, bancos de dados ou painéis. O diagrama a seguir descreve o fluxo conceitual.

Agora, vamos examinar em detalhes a API do Kafka-Spark.
API SparkConf
Ele representa a configuração de um aplicativo Spark. Usado para definir vários parâmetros do Spark como pares de valor-chave.
A
classe SparkConf
tem os seguintes métodos -
set(string key, string value) - definir variável de configuração.
remove(string key) - remove a chave da configuração.
setAppName(string name) - definir o nome do aplicativo para seu aplicativo.
get(string key) - pegue a chave
API StreamingContext
Este é o principal ponto de entrada para a funcionalidade do Spark. Um SparkContext representa a conexão com um cluster Spark e pode ser usado para criar RDDs, acumuladores e variáveis de transmissão no cluster. A assinatura é definida conforme mostrado abaixo.
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master - URL do cluster ao qual se conectar (por exemplo, mesos: // host: porta, spark: // host: porta, local [4]).
appName - um nome para seu trabalho, para exibir na IU da web do cluster
batchDuration - o intervalo de tempo em que os dados de streaming serão divididos em lotes
public StreamingContext(SparkConf conf, Duration batchDuration)Crie um StreamingContext fornecendo a configuração necessária para um novo SparkContext.
conf - Parâmetros do Spark
batchDuration - o intervalo de tempo em que os dados de streaming serão divididos em lotes
API KafkaUtils
A API KafkaUtils é usada para conectar o cluster Kafka ao streaming do Spark. Esta API possui a assinatura do método createStream significativa
definida como abaixo.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)O método mostrado acima é usado para criar um fluxo de entrada que extrai mensagens dos Kafka Brokers.
ssc - Objeto StreamingContext.
zkQuorum - Quorum do Zookeeper.
groupId - O ID do grupo para este consumidor.
topics - retorna um mapa de tópicos para consumir.
storageLevel - Nível de armazenamento a ser usado para armazenar os objetos recebidos.
A API KafkaUtils tem outro método createDirectStream, que é usado para criar um fluxo de entrada que extrai mensagens diretamente dos Kafka Brokers sem usar nenhum receptor. Esse fluxo pode garantir que cada mensagem de Kafka seja incluída nas transformações exatamente uma vez.
O aplicativo de amostra é feito em Scala. Para compilar o aplicativo, baixe e instale o sbt
, ferramenta de construção scala (semelhante ao maven). O código do aplicativo principal é apresentado a seguir.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}Script de construção
A integração spark-kafka depende do jarro de integração spark, spark streaming e spark Kafka. Crie um novo arquivo build.sbt
e especifique os detalhes do aplicativo e sua dependência. O sbt baixará
o jar necessário enquanto compila e empacota o aplicativo.
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"Compilação / embalagem
Execute o seguinte comando para compilar e empacotar o arquivo jar do aplicativo. Precisamos enviar o arquivo jar para o console do Spark para executar o aplicativo.
sbt packageEnviando para o Spark
Inicie a CLI do Kafka Producer (explicado no capítulo anterior), crie um novo tópico chamado my-first-topic
e forneça algumas mensagens de amostra, conforme mostrado abaixo.
Another spark test messageExecute o seguinte comando para enviar o aplicativo ao console do Spark.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>O exemplo de saída deste aplicativo é mostrado abaixo.
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..Vamos analisar um aplicativo em tempo real para obter os feeds do Twitter mais recentes e suas hashtags. Anteriormente, vimos a integração do Storm e do Spark com o Kafka. Em ambos os cenários, criamos um Produtor Kafka (usando cli) para enviar mensagem ao ecossistema Kafka. Em seguida, a integração de tempestade e faísca lê as mensagens usando o consumidor Kafka e o injeta no ecossistema de tempestade e faísca, respectivamente. Então, praticamente precisamos criar um Produtor Kafka, que deve -
- Leia os feeds do Twitter usando “Twitter Streaming API”,
- Processe os feeds,
- Extraia as HashTags e
- Envie para Kafka.
Assim que os HashTags
são recebidos pelo Kafka, a integração do Storm / Spark recebe as informações e as envia ao ecossistema Storm / Spark.
Twitter Streaming API
A “Twitter Streaming API” pode ser acessada em qualquer linguagem de programação. O “twitter4j” é uma biblioteca Java não oficial de código aberto, que fornece um módulo baseado em Java para acessar facilmente a “API de streaming do Twitter”. O “twitter4j” fornece uma estrutura baseada em ouvinte para acessar os tweets. Para acessar a “Twitter Streaming API”, precisamos entrar na conta de desenvolvedor do Twitter e deve obter o seguinteOAuth detalhes de autenticação.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Assim que a conta do desenvolvedor for criada, baixe os arquivos jar “twitter4j” e coloque-os no caminho da classe java.
A codificação completa do produtor Kafka do Twitter (KafkaTwitterProducer.java) está listada abaixo -
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}Compilação
Compile o aplicativo usando o seguinte comando -
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.javaExecução
Abra dois consoles. Execute o aplicativo compilado acima conforme mostrado abaixo em um console.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic foodExecute qualquer um dos aplicativos Spark / Storm explicados no capítulo anterior em outra janela. O principal ponto a ser observado é que o tópico usado deve ser o mesmo em ambos os casos. Aqui, usamos “meu-primeiro-tópico” como o nome do tópico.
Resultado
A saída deste aplicativo dependerá das palavras-chave e do feed atual do Twitter. Um exemplo de saída é especificado abaixo (integração de tempestade).
. . .
food : 1
foodie : 2
burger : 1
. . .Ferramenta Kafka empacotada em “org.apache.kafka.tools. *. As ferramentas são categorizadas em ferramentas de sistema e ferramentas de replicação.
Ferramentas do sistema
As ferramentas do sistema podem ser executadas a partir da linha de comando usando o script de classe de execução. A sintaxe é a seguinte -
bin/kafka-run-class.sh package.class - - optionsAlgumas das ferramentas do sistema são mencionadas abaixo -
Kafka Migration Tool - Esta ferramenta é usada para migrar um broker de uma versão para outra.
Mirror Maker - Esta ferramenta é usada para fornecer espelhamento de um cluster Kafka para outro.
Consumer Offset Checker - Esta ferramenta exibe Grupo de Consumidores, Tópico, Partições, Off-set, logSize, Proprietário para o conjunto especificado de Tópicos e Grupo de Consumidores.
Ferramenta de Replicação
A replicação do Kafka é uma ferramenta de design de alto nível. O objetivo de adicionar a ferramenta de replicação é para maior durabilidade e maior disponibilidade. Algumas das ferramentas de replicação são mencionadas abaixo -
Create Topic Tool - Isso cria um tópico com um número padrão de partições, fator de replicação e usa o esquema padrão de Kafka para fazer a atribuição de réplicas.
List Topic Tool- Esta ferramenta lista as informações para uma determinada lista de tópicos. Se nenhum tópico for fornecido na linha de comando, a ferramenta consulta o Zookeeper para obter todos os tópicos e lista as informações para eles. Os campos que a ferramenta exibe são nome do tópico, partição, líder, réplicas, isr.
Add Partition Tool- Criação de um tópico, o número de partições para o tópico deve ser especificado. Mais tarde, mais partições podem ser necessárias para o tópico, quando o volume do tópico aumentará. Esta ferramenta ajuda a adicionar mais partições para um tópico específico e também permite a atribuição manual de réplicas das partições adicionadas.
Kafka oferece suporte a muitas das melhores aplicações industriais da atualidade. Forneceremos uma breve visão geral de algumas das aplicações mais notáveis do Kafka neste capítulo.
O Twitter é um serviço de rede social online que fornece uma plataforma para enviar e receber tweets de usuários. Usuários registrados podem ler e postar tweets, mas usuários não registrados podem apenas ler tweets. O Twitter usa Storm-Kafka como parte de sua infraestrutura de processamento de stream.
Apache Kafka é usado no LinkedIn para dados de fluxo de atividades e métricas operacionais. O sistema de mensagens Kafka ajuda o LinkedIn com vários produtos como LinkedIn Newsfeed, LinkedIn Today para consumo de mensagens online e, além de sistemas analíticos offline, como Hadoop. A forte durabilidade de Kafka também é um dos fatores-chave em conexão com o LinkedIn.
Netflix
A Netflix é uma fornecedora multinacional americana de mídia de streaming de Internet sob demanda. A Netflix usa o Kafka para monitoramento em tempo real e processamento de eventos.
Mozilla
Mozilla é uma comunidade de software livre, criada em 1998 por membros da Netscape. Kafka logo substituirá uma parte do atual sistema de produção da Mozilla para coletar dados de desempenho e uso do navegador do usuário final para projetos como Telemetria, Piloto de Teste, etc.
Oráculo
A Oracle fornece conectividade nativa ao Kafka a partir de seu produto Enterprise Service Bus chamado OSB (Oracle Service Bus), que permite aos desenvolvedores aproveitar os recursos de mediação integrados do OSB para implementar pipelines de dados em estágios.