Apache MXNet - Guia rápido
Este capítulo destaca os recursos do Apache MXNet e fala sobre a versão mais recente desta estrutura de software de aprendizado profundo.
O que é MXNet?
Apache MXNet é um poderoso instrumento de estrutura de software de aprendizado profundo de código aberto que ajuda os desenvolvedores a construir, treinar e implantar modelos de aprendizado profundo. Nos últimos anos, da saúde ao transporte à fabricação e, de fato, em todos os aspectos de nossa vida diária, o impacto do aprendizado profundo foi generalizado. Hoje em dia, o deep learning é procurado por empresas para resolver alguns problemas difíceis, como reconhecimento facial, detecção de objetos, reconhecimento óptico de caracteres (OCR), reconhecimento de fala e tradução automática.
Essa é a razão pela qual o Apache MXNet é compatível com:
Algumas grandes empresas como Intel, Baidu, Microsoft, Wolfram Research, etc.
Provedores de nuvem pública, incluindo Amazon Web Services (AWS) e Microsoft Azure
Alguns grandes institutos de pesquisa como Carnegie Mellon, MIT, a Universidade de Washington e a Universidade de Ciência e Tecnologia de Hong Kong.
Por que Apache MXNet?
Existem várias plataformas de aprendizado profundo, como Torch7, Caffe, Theano, TensorFlow, Keras, Microsoft Cognitive Toolkit, etc., então você pode se perguntar por que Apache MXNet? Vamos verificar alguns dos motivos por trás disso:
O Apache MXNet resolve um dos maiores problemas das plataformas de aprendizado profundo existentes. O problema é que, para usar plataformas de aprendizado profundo, é necessário aprender outro sistema para um tipo de programação diferente.
Com a ajuda do Apache MXNet, os desenvolvedores podem explorar todos os recursos das GPUs e também da computação em nuvem.
O Apache MXNet pode acelerar qualquer computação numérica e enfatiza especialmente a aceleração do desenvolvimento e implantação de DNN (redes neurais profundas) em grande escala.
Ele fornece aos usuários os recursos de programação imperativa e simbólica.
Vários Recursos
Se você está procurando uma biblioteca flexível de aprendizado profundo para desenvolver rapidamente pesquisas de aprendizado profundo de ponta ou uma plataforma robusta para impulsionar a carga de trabalho de produção, sua busca termina no Apache MXNet. É por causa das seguintes características:
Treinamento Distribuído
Quer seja um treinamento multi-gpu ou multi-host com eficiência de escalonamento quase linear, o Apache MXNet permite que os desenvolvedores aproveitem ao máximo seu hardware. MXNet também oferece suporte à integração com Horovod, que é uma estrutura de aprendizado profundo distribuída de código aberto criada na Uber.
Para esta integração, a seguir estão algumas das APIs distribuídas comuns definidas no Horovod:
horovod.broadcast()
horovod.allgather()
horovod.allgather()
A este respeito, MXNet nos oferece os seguintes recursos:
Device Placement - Com a ajuda do MXNet podemos especificar facilmente cada estrutura de dados (DS).
Automatic Differentiation - Apache MXNet automatiza a diferenciação, ou seja, cálculos de derivadas.
Multi-GPU training - O MXNet nos permite alcançar eficiência de dimensionamento com o número de GPUs disponíveis.
Optimized Predefined Layers - Podemos codificar nossas próprias camadas no MXNet, bem como as camadas predefinidas otimizadas para velocidade também.
Hibridização
O Apache MXNet fornece a seus usuários um front-end híbrido. Com a ajuda da API Gluon Python, ele pode preencher a lacuna entre seus recursos imperativos e simbólicos. Isso pode ser feito chamando sua funcionalidade de hibridização.
Computação mais rápida
As operações lineares como dezenas ou centenas de multiplicações de matrizes são o gargalo computacional para redes neurais profundas. Para resolver esse gargalo, a MXNet fornece -
Cálculo numérico otimizado para GPUs
Computação numérica otimizada para ecossistemas distribuídos
Automação de fluxos de trabalho comuns com a ajuda dos quais o NN padrão pode ser expresso brevemente.
Ligações de idioma
MXNet tem integração profunda em linguagens de alto nível, como Python e R. Ele também fornece suporte para outras linguagens de programação, como-
Scala
Julia
Clojure
Java
C/C++
Perl
Não precisamos aprender nenhuma nova linguagem de programação, em vez do MXNet, combinado com o recurso de hibridização, permite uma transição excepcionalmente suave do Python para a implantação na linguagem de programação de nossa escolha.
Última versão MXNet 1.6.0
A Apache Software Foundation (ASF) lançou a versão estável 1.6.0 do Apache MXNet em 21 de fevereiro de 2020 sob a Licença Apache 2.0. Este é o último lançamento do MXNet para oferecer suporte ao Python 2, já que a comunidade MXNet votou para não oferecer mais suporte ao Python 2 em versões futuras. Vamos dar uma olhada em alguns dos novos recursos que este lançamento traz para seus usuários.
Interface compatível com NumPy
Devido à sua flexibilidade e generalidade, o NumPy tem sido amplamente utilizado por profissionais, cientistas e estudantes de aprendizado de máquina. Mas, como sabemos, os aceleradores de hardware atuais, como unidades de processamento gráfico (GPUs), tornaram-se cada vez mais assimilados em vários kits de ferramentas de aprendizado de máquina (ML), os usuários do NumPy, para aproveitar a velocidade das GPUs, precisam mudar para novas estruturas com sintaxe diferente.
Com o MXNet 1.6.0, o Apache MXNet está se movendo em direção a uma experiência de programação compatível com NumPy. A nova interface fornece usabilidade equivalente, bem como expressividade para os profissionais familiarizados com a sintaxe NumPy. Junto com isso, o MXNet 1.6.0 também permite que o sistema Numpy existente utilize aceleradores de hardware como GPUs para acelerar cálculos em grande escala.
Integração com Apache TVM
Apache TVM, uma pilha de compiladores de aprendizado profundo de código aberto para back-ends de hardware, como CPUs, GPUs e aceleradores especializados, visa preencher a lacuna entre as estruturas de aprendizado profundo focadas na produtividade e os back-ends de hardware orientados para o desempenho . Com a versão mais recente do MXNet 1.6.0, os usuários podem aproveitar o Apache (incubando) TVM para implementar kernels de operador de alto desempenho na linguagem de programação Python. Duas vantagens principais deste novo recurso estão a seguir -
Simplifica o antigo processo de desenvolvimento baseado em C ++.
Permite compartilhar a mesma implementação em vários back-end de hardware, como CPUs, GPUs, etc.
Melhorias em recursos existentes
Além dos recursos listados acima do MXNet 1.6.0, ele também fornece algumas melhorias em relação aos recursos existentes. As melhorias são as seguintes -
Operação de agrupamento de elementos para GPU
Como sabemos, o desempenho das operações elementares é a largura de banda da memória e essa é a razão, o encadeamento de tais operações pode reduzir o desempenho geral. O Apache MXNet 1.6.0 faz fusão de operação elementar, que realmente gera operações fundidas just-in-time como e quando possível. Essa fusão de operação por elemento também reduz as necessidades de armazenamento e melhora o desempenho geral.
Simplificando expressões comuns
MXNet 1.6.0 elimina as expressões redundantes e simplifica as expressões comuns. Esse aprimoramento também melhora o uso da memória e o tempo total de execução.
Otimizações
MXNet 1.6.0 também fornece várias otimizações para recursos e operadoras existentes, que são as seguintes:
Precisão mista automática
API Gluon Fit
MKL-DNN
Suporte de tensor grande
TensorRT integração
Suporte de gradiente de ordem superior
Operators
Perfilador de desempenho do operador
Importação / exportação ONNX
Melhorias nas APIs Gluon
Melhorias nas APIs de símbolo
Mais de 100 correções de bugs
Para começar a usar o MXNet, a primeira coisa que precisamos fazer é instalá-lo em nosso computador. O Apache MXNet funciona em praticamente todas as plataformas disponíveis, incluindo Windows, Mac e Linux.
Linux OS
Podemos instalar o MXNet no sistema operacional Linux das seguintes maneiras -
Unidade de processamento gráfico (GPU)
Aqui, usaremos vários métodos, nomeadamente Pip, Docker e Source para instalar o MXNet quando estivermos usando GPU para processamento -
Usando o método Pip
Você pode usar o seguinte comando para instalar o MXNet em seu sistema operacional Linus -
pip install mxnetO Apache MXNet também oferece pacotes MKL pip, que são muito mais rápidos quando executados em hardware Intel. Aqui por exemplomxnet-cu101mkl significa que -
O pacote é construído com CUDA / cuDNN
O pacote está habilitado para MKL-DNN
A versão CUDA é 10.1
Para outra opção, você também pode consultar https://pypi.org/project/mxnet/.
Usando Docker
Você pode encontrar as imagens do docker com MXNet em DockerHub, que está disponível em https://hub.docker.com/u/mxnet Vamos verificar as etapas abaixo para instalar o MXNet usando Docker com GPU -
Step 1- Primeiro, seguindo as instruções de instalação do docker que estão disponíveis em https://docs.docker.com/engine/install/ubuntu/. Precisamos instalar o Docker em nossa máquina.
Step 2- Para habilitar o uso de GPUs dos contêineres do docker, em seguida, precisamos instalar o nvidia-docker-plugin. Você pode seguir as instruções de instalação fornecidas emhttps://github.com/NVIDIA/nvidia-docker/wiki.
Step 3- Usando o comando a seguir, você pode puxar a imagem do docker MXNet -
$ sudo docker pull mxnet/python:gpuAgora, para ver se a extração da imagem docker mxnet / python foi bem-sucedida, podemos listar as imagens docker da seguinte maneira -
$ sudo docker imagesPara obter as velocidades de inferência mais rápidas com MXNet, é recomendável usar o MXNet mais recente com Intel MKL-DNN. Verifique os comandos abaixo -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesDa fonte
Para construir a biblioteca compartilhada MXNet da fonte com GPU, primeiro precisamos configurar o ambiente para CUDA e cuDNN da seguinte forma -
Baixe e instale o kit de ferramentas CUDA, aqui CUDA 9.2 é recomendado.
Próximo download cuDNN 7.1.4.
Agora precisamos descompactar o arquivo. Também é necessário mudar para o diretório raiz cuDNN. Mova também o cabeçalho e as bibliotecas para a pasta CUDA Toolkit local da seguinte forma -
tar xvzf cudnn-9.2-linux-x64-v7.1
sudo cp -P cuda/include/cudnn.h /usr/local/cuda/include
sudo cp -P cuda/lib64/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
sudo ldconfigDepois de configurar o ambiente para CUDA e cuDNN, siga as etapas abaixo para construir a biblioteca compartilhada MXNet a partir da fonte -
Step 1- Primeiro, precisamos instalar os pacotes de pré-requisitos. Essas dependências são necessárias no Ubuntu versão 16.04 ou posterior.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev
libopencv-dev cmakeStep 2- Nesta etapa, faremos o download da fonte MXNet e a configuração. Primeiro, vamos clonar o repositório usando o seguinte comando−
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux_gpu.cmake #for build with CUDAStep 3- Usando os seguintes comandos, você pode construir a biblioteca compartilhada central MXNet -
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Se você deseja construir a versão de depuração, especifique o seguinte -
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Para definir o número de trabalhos de compilação paralela, especifique o seguinte -
cmake --build . --parallel NDepois de construir com sucesso a biblioteca compartilhada central MXNet, no build pasta em seu MXNet project root, você encontrará libmxnet.so que é necessário para instalar ligações de idioma (opcional).
Unidade de processamento central (CPU)
Aqui, usaremos vários métodos, nomeadamente Pip, Docker e Source para instalar o MXNet quando estivermos usando a CPU para processamento -
Usando o método Pip
Você pode usar o seguinte comando para instalar o MXNet em seu Linus OS-
pip install mxnetO Apache MXNet também oferece pacotes pip habilitados para MKL-DNN que são muito mais rápidos quando executados em hardware Intel.
pip install mxnet-mklUsando Docker
Você pode encontrar as imagens do docker com MXNet em DockerHub, que está disponível em https://hub.docker.com/u/mxnet. Vamos verificar as etapas abaixo para instalar o MXNet usando Docker com CPU -
Step 1- Primeiro, seguindo as instruções de instalação do docker que estão disponíveis em https://docs.docker.com/engine/install/ubuntu/. Precisamos instalar o Docker em nossa máquina.
Step 2- Usando o seguinte comando, você pode extrair a imagem do docker MXNet:
$ sudo docker pull mxnet/pythonAgora, para ver se a extração da imagem docker mxnet / python foi bem-sucedida, podemos listar as imagens docker da seguinte maneira -
$ sudo docker imagesPara obter as velocidades de inferência mais rápidas com MXNet, é recomendável usar o MXNet mais recente com Intel MKL-DNN.
Verifique os comandos abaixo -
$ sudo docker pull mxnet/python:1.3.0_cpu_mkl $ sudo docker imagesDa fonte
Para construir a biblioteca compartilhada MXNet da fonte com CPU, siga as etapas abaixo -
Step 1- Primeiro, precisamos instalar os pacotes de pré-requisitos. Essas dependências são necessárias no Ubuntu versão 16.04 ou posterior.
sudo apt-get update
sudo apt-get install -y build-essential git ninja-build ccache libopenblas-dev libopencv-dev cmakeStep 2- Nesta etapa, faremos o download do código-fonte MXNet e a configuração. Primeiro, vamos clonar o repositório usando o seguinte comando:
git clone –recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- Usando os seguintes comandos, você pode construir a biblioteca compartilhada central MXNet:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Se você deseja construir a versão de depuração, especifique o seguinte:
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Para definir o número de trabalhos de compilação paralela, especifique o seguinte−
cmake --build . --parallel NDepois de construir com sucesso a biblioteca compartilhada central MXNet, no build pasta na raiz do projeto MXNet, você encontrará libmxnet.so, que é necessário para instalar ligações de idioma (opcional).
Mac OS
Podemos instalar MXNet no MacOS das seguintes maneiras–
Unidade de processamento gráfico (GPU)
Se você planeja construir MXNet no MacOS com GPU, NÃO há método Pip e Docker disponível. O único método neste caso é construí-lo a partir da fonte.
Da fonte
Para construir a biblioteca compartilhada MXNet a partir da fonte com GPU, primeiro precisamos configurar o ambiente para CUDA e cuDNN. Você precisa seguir oNVIDIA CUDA Installation Guide que está disponível em https://docs.nvidia.com e cuDNN Installation Guide, que está disponível em https://docs.nvidia.com/deeplearning para mac OS.
Observe que, em 2019, o CUDA parou de oferecer suporte ao macOS. Na verdade, as versões futuras do CUDA também podem não oferecer suporte ao macOS.
Depois de configurar o ambiente para CUDA e cuDNN, siga as etapas abaixo para instalar o MXNet da fonte no OS X (Mac) -
Step 1- Como precisamos de algumas dependências no OS x, primeiro, precisamos instalar os pacotes de pré-requisitos.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesTambém podemos construir MXNet sem OpenCV, pois opencv é uma dependência opcional.
Step 2- Nesta etapa, faremos o download do código-fonte MXNet e a configuração. Primeiro, vamos clonar o repositório usando o seguinte comando−
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakePara um habilitado para GPU, é necessário instalar as dependências CUDA primeiro porque quando se tenta construir uma compilação habilitada para GPU em uma máquina sem GPU, a compilação MXNet não pode detectar automaticamente sua arquitetura de GPU. Nesses casos, o MXNet terá como alvo todas as arquiteturas de GPU disponíveis.
Step 3- Usando os seguintes comandos, você pode construir a biblioteca compartilhada central MXNet -
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Dois pontos importantes em relação à etapa acima são os seguintes -
Se você deseja construir a versão de depuração, especifique o seguinte -
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Para definir o número de trabalhos de compilação paralela, especifique o seguinte:
cmake --build . --parallel NDepois de construir com sucesso a biblioteca compartilhada central MXNet, no build pasta em seu MXNet project root, você encontrará libmxnet.dylib, que é necessário para instalar ligações de idioma (opcional).
Unidade de processamento central (CPU)
Aqui, usaremos vários métodos, nomeadamente Pip, Docker e Source para instalar o MXNet quando estivermos usando CPU para processamento -
Usando o método Pip
Você pode usar o seguinte comando para instalar o MXNet em seu sistema operacional Linus
pip install mxnetUsando Docker
Você pode encontrar as imagens do docker com MXNet em DockerHub, que está disponível em https://hub.docker.com/u/mxnet. Vamos verificar as etapas abaixo para instalar o MXNet usando Docker com CPU−
Step 1- Primeiro, seguindo o docker installation instructions que estão disponíveis em https://docs.docker.com/docker-for-mac precisamos instalar o Docker em nossa máquina.
Step 2- Usando o seguinte comando, você pode puxar a imagem docker MXNet -
$ docker pull mxnet/pythonAgora, a fim de ver se o pull da imagem docker mxnet / python foi bem-sucedido, podemos listar as imagens docker da seguinte maneira−
$ docker imagesPara obter as velocidades de inferência mais rápidas com MXNet, é recomendável usar o MXNet mais recente com Intel MKL-DNN. Verifique os comandos abaixo -
$ docker pull mxnet/python:1.3.0_cpu_mkl
$ docker imagesDa fonte
Siga as etapas abaixo para instalar o MXNet da fonte no OS X (Mac) -
Step 1- Como precisamos de algumas dependências no OS x, primeiro, precisamos instalar os pacotes de pré-requisitos.
xcode-select –-install #Install OS X Developer Tools
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" #Install Homebrew
brew install cmake ninja ccache opencv # Install dependenciesTambém podemos construir MXNet sem OpenCV, pois opencv é uma dependência opcional.
Step 2- Nesta etapa, faremos o download do código-fonte MXNet e a configuração. Primeiro, vamos clonar o repositório usando o seguinte comando−
git clone –-recursive https://github.com/apache/incubator-mxnet.git mxnet
cd mxnet
cp config/linux.cmake config.cmakeStep 3- Usando os seguintes comandos, você pode construir a biblioteca compartilhada central MXNet:
rm -rf build
mkdir -p build && cd build
cmake -GNinja ..
cmake --build .Two important points regarding the above step is as follows−
Se você deseja construir a versão de depuração, especifique o seguinte -
cmake -DCMAKE_BUILD_TYPE=Debug -GNinja ..Para definir o número de trabalhos de compilação paralela, especifique o seguinte−
cmake --build . --parallel NDepois de construir com sucesso a biblioteca compartilhada central MXNet, no build pasta em seu MXNet project root, você encontrará libmxnet.dylib, que é necessário para instalar ligações de idioma (opcional).
SO Windows
Para instalar MXNet no Windows, a seguir estão os pré-requisitos–
Requisitos Mínimos do Sistema
Windows 7, 10, Server 2012 R2 ou Server 2016
Visual Studio 2015 ou 2017 (qualquer tipo)
Python 2.7 ou 3.6
pip
Requisitos de sistema recomendados
Windows 10, Server 2012 R2 ou Server 2016
Visual Studio 2017
Pelo menos uma GPU habilitada para NVIDIA CUDA
CPU habilitada para MKL: processador Intel® Xeon®, família de processadores Intel® Core ™, processador Intel Atom® ou processador Intel® Xeon Phi ™
Python 2.7 ou 3.6
pip
Unidade de processamento gráfico (GPU)
Usando o método Pip−
Se você planeja construir MXNet no Windows com GPUs NVIDIA, há duas opções para instalar MXNet com suporte CUDA com um pacote Python-
Instalar com suporte CUDA
Abaixo estão as etapas com a ajuda das quais podemos configurar o MXNet com CUDA.
Step 1- Instale primeiro o Microsoft Visual Studio 2017 ou o Microsoft Visual Studio 2015.
Step 2- Em seguida, baixe e instale o NVIDIA CUDA. Recomenda-se usar o CUDA versões 9.2 ou 9.0 porque alguns problemas com CUDA 9.1 foram identificados no passado.
Step 3- Agora, baixe e instale NVIDIA_CUDA_DNN.
Step 4- Finalmente, usando o seguinte comando pip, instale MXNet com CUDA−
pip install mxnet-cu92Instale com suporte CUDA e MKL
Abaixo estão os passos com a ajuda dos quais podemos configurar o MXNet com CUDA e MKL.
Step 1- Instale primeiro o Microsoft Visual Studio 2017 ou o Microsoft Visual Studio 2015.
Step 2- Em seguida, baixe e instale intel MKL
Step 3- Agora, baixe e instale o NVIDIA CUDA.
Step 4- Agora, baixe e instale NVIDIA_CUDA_DNN.
Step 5- Finalmente, usando o seguinte comando pip, instale o MXNet com MKL.
pip install mxnet-cu92mklDa fonte
Para construir a biblioteca central MXNet a partir da fonte com GPU, temos as duas opções a seguir -
Option 1− Build with Microsoft Visual Studio 2017
Para construir e instalar o MXNet sozinho usando o Microsoft Visual Studio 2017, você precisa das seguintes dependências.
Install/update Microsoft Visual Studio.
Se o Microsoft Visual Studio ainda não estiver instalado em sua máquina, primeiro baixe e instale-o.
Ele solicitará a instalação do Git. Instale também.
Se o Microsoft Visual Studio já estiver instalado em sua máquina, mas você quiser atualizá-lo, prossiga para a próxima etapa para modificar sua instalação. Aqui, você também terá a oportunidade de atualizar o Microsoft Visual Studio.
Siga as instruções para abrir o Visual Studio Installer disponível em https://docs.microsoft.com/en-us para modificar componentes individuais.
No aplicativo Visual Studio Installer, atualize conforme necessário. Depois disso, procure e verifiqueVC++ 2017 version 15.4 v14.11 toolset e clique Modify.
Agora, usando o seguinte comando, altere a versão do Microsoft VS2017 para v14.11−
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat" -vcvars_ver=14.11Em seguida, você precisa baixar e instalar CMake disponível em https://cmake.org/download/ Recomenda-se usar CMake v3.12.2 que está disponível em https://cmake.org/download/ porque é testado com MXNet.
Agora, baixe e execute o OpenCV pacote disponível em https://sourceforge.net/projects/opencvlibrary/que descompactará vários arquivos. Depende de você se deseja colocá-los em outro diretório ou não. Aqui, vamos usar o caminhoC:\utils(mkdir C:\utils) como nosso caminho padrão.
Em seguida, precisamos definir a variável de ambiente OpenCV_DIR para apontar para o diretório de construção OpenCV que acabamos de descompactar. Para este prompt de comando aberto e digiteset OpenCV_DIR=C:\utils\opencv\build.
Um ponto importante é que, se você não tiver o Intel MKL (Math Kernel Library) instalado, poderá instalá-lo.
Outro pacote de código aberto que você pode usar é OpenBLAS. Aqui, para obter mais instruções, presumimos que você esteja usandoOpenBLAS.
Então, baixe o OpenBlas pacote que está disponível em https://sourceforge.net e descompacte o arquivo, renomeie-o para OpenBLAS e colocá-lo sob C:\utils.
Em seguida, precisamos definir a variável de ambiente OpenBLAS_HOME para apontar para o diretório OpenBLAS que contém o include e libdiretórios. Para este prompt de comando aberto e digiteset OpenBLAS_HOME=C:\utils\OpenBLAS.
Agora, baixe e instale o CUDA disponível em https://developer.nvidia.com. Observe que, se você já tinha o CUDA e instalou o Microsoft VS2017, é necessário reinstalar o CUDA agora, para que possa obter os componentes do kit de ferramentas CUDA para integração com o Microsoft VS2017.
Em seguida, você precisa baixar e instalar cuDNN.
Em seguida, você precisa baixar e instalar o git que está em https://gitforwindows.org/ Além disso.
Depois de instalar todas as dependências necessárias, siga as etapas fornecidas abaixo para construir o código-fonte MXNet -
Step 1- Abra o prompt de comando no Windows.
Step 2- Agora, usando o seguinte comando, baixe o código-fonte MXNet do GitHub:
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 3- Em seguida, verifique o seguinte−
DCUDNN_INCLUDE and DCUDNN_LIBRARY variáveis de ambiente estão apontando para o include pasta e cudnn.lib arquivo do local de instalação do CUDA
C:\incubator-mxnet é a localização do código-fonte que você acabou de clonar na etapa anterior.
Step 4- Em seguida, usando o seguinte comando, crie um build directory e também vá para o diretório, por exemplo−
mkdir C:\incubator-mxnet\build
cd C:\incubator-mxnet\buildStep 5- Agora, usando cmake, compile o código-fonte MXNet da seguinte maneira−
cmake -G "Visual Studio 15 2017 Win64" -T cuda=9.2,host=x64 -DUSE_CUDA=1 -DUSE_CUDNN=1 -DUSE_NVRTC=1 -DUSE_OPENCV=1 -DUSE_OPENMP=1 -DUSE_BLAS=open -DUSE_LAPACK=1 -DUSE_DIST_KVSTORE=0 -DCUDA_ARCH_LIST=Common -DCUDA_TOOLSET=9.2 -DCUDNN_INCLUDE=C:\cuda\include -DCUDNN_LIBRARY=C:\cuda\lib\x64\cudnn.lib "C:\incubator-mxnet"Step 6- Depois que o CMake for concluído com sucesso, use o seguinte comando para compilar o código-fonte MXNet -
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountOption 2: Build with Microsoft Visual Studio 2015
Para construir e instalar o MXNet sozinho usando o Microsoft Visual Studio 2015, você precisa das seguintes dependências.
Instale / atualize o Microsoft Visual Studio 2015. O requisito mínimo para construir MXnet a partir da fonte é a atualização 3 do Microsoft Visual Studio 2015. Você pode usar Tools -> Extensions and Updates... | Product Updates menu para atualizá-lo.
Em seguida, você precisa baixar e instalar CMake que está disponível em https://cmake.org/download/. Recomenda-se usarCMake v3.12.2 que está em https://cmake.org/download/, porque é testado com MXNet.
Agora, baixe e execute o pacote OpenCV disponível em https://excellmedia.dl.sourceforge.netque descompactará vários arquivos. Depende de você, se deseja colocá-los em outro diretório ou não.
Em seguida, precisamos definir a variável de ambiente OpenCV_DIR apontar para o OpenCVdiretório de compilação que acabamos de descompactar. Para isso, abra o prompt de comando e digite setOpenCV_DIR=C:\opencv\build\x64\vc14\bin.
Um ponto importante é que, se você não tiver o Intel MKL (Math Kernel Library) instalado, poderá instalá-lo.
Outro pacote de código aberto que você pode usar é OpenBLAS. Aqui, para obter mais instruções, presumimos que você esteja usandoOpenBLAS.
Então, baixe o OpenBLAS pacote disponível em https://excellmedia.dl.sourceforge.net e descompacte o arquivo, renomeie-o para OpenBLAS e coloque-o em C: \ utils.
Em seguida, precisamos definir a variável de ambiente OpenBLAS_HOME para apontar para o diretório OpenBLAS que contém os diretórios include e lib. Você pode encontrar o diretório emC:\Program files (x86)\OpenBLAS\
Observe que, se você já tinha o CUDA e depois instalou o Microsoft VS2015, é necessário reinstalar o CUDA agora para obter os componentes do kit de ferramentas CUDA para integração com o Microsoft VS2017.
Em seguida, você precisa baixar e instalar cuDNN.
Agora, precisamos definir a variável de ambiente CUDACXX para apontar para o CUDA Compiler(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1\bin\nvcc.exe por exemplo).
Da mesma forma, também precisamos definir a variável de ambiente CUDNN_ROOT apontar para o cuDNN diretório que contém o include, lib e bin diretórios (C:\Downloads\cudnn-9.1-windows7-x64-v7\cuda por exemplo).
Depois de instalar todas as dependências necessárias, siga as etapas fornecidas abaixo para construir o código-fonte MXNet -
Step 1- Primeiro, baixe o código-fonte MXNet do GitHub−
cd C:\
git clone https://github.com/apache/incubator-mxnet.git --recursiveStep 2- Em seguida, use o CMake para criar um Visual Studio em ./build.
Step 3- Agora, no Visual Studio, precisamos abrir o arquivo de solução,.slne compilá-lo. Esses comandos irão produzir uma biblioteca chamadamxnet.dll no ./build/Release/ or ./build/Debug pasta
Step 4- Depois que o CMake for concluído com sucesso, use o seguinte comando para compilar o código-fonte MXNet
msbuild mxnet.sln /p:Configuration=Release;Platform=x64 /maxcpucountUnidade de processamento central (CPU)
Aqui, usaremos vários métodos, nomeadamente Pip, Docker e Source para instalar o MXNet quando estivermos usando CPU para processamento -
Usando o método Pip
Se você planeja construir MXNet no Windows com CPUs, há duas opções para instalar MXNet usando um pacote Python -
Install with CPUs
Use o seguinte comando para instalar MXNet com CPU com Python−
pip install mxnetInstall with Intel CPUs
Conforme discutido acima, MXNet tem suporte experimental para Intel MKL, bem como MKL-DNN. Use o seguinte comando para instalar MXNet com CPU Intel com Python−
pip install mxnet-mklUsando Docker
Você pode encontrar as imagens do docker com MXNet em DockerHub, disponível em https://hub.docker.com/u/mxnet Vamos verificar as etapas abaixo, para instalar o MXNet usando Docker com CPU−
Step 1- Primeiro, seguindo as instruções de instalação do docker, que podem ser lidas em https://docs.docker.com/docker-for-mac/install. Precisamos instalar o Docker em nossa máquina.
Step 2- Usando o seguinte comando, você pode puxar a imagem docker MXNet -
$ docker pull mxnet/pythonAgora, a fim de ver se o pull da imagem docker mxnet / python foi bem-sucedido, podemos listar as imagens docker da seguinte maneira−
$ docker imagesPara obter as velocidades de inferência mais rápidas com MXNet, é recomendável usar o MXNet mais recente com Intel MKL-DNN.
Verifique os comandos abaixo -
$ docker pull mxnet/python:1.3.0_cpu_mkl $ docker imagesInstalando MXNet na nuvem e dispositivos
Esta seção destaca como instalar o Apache MXNet na nuvem e em dispositivos. Vamos começar aprendendo sobre a instalação do MXNet na nuvem.
Instalando MXNet On Cloud
Você também pode obter o Apache MXNet em vários provedores de nuvem com Graphical Processing Unit (GPU)Apoio, suporte. Dois outros tipos de suporte que você pode encontrar são os seguintes-
- Suporte híbrido de GPU / CPU para casos de uso como inferência escalonável.
- Suporte a GPU fatorial com AWS Elastic Inference.
A seguir estão os provedores de nuvem que fornecem suporte de GPU com diferentes máquinas virtuais para Apache MXNet−
O console Alibaba
Você pode criar o NVIDIA GPU Cloud Virtual Machine (VM) disponível em https://docs.nvidia.com/ngc com o console Alibaba e use o Apache MXNet.
Amazon Web Services
Ele também fornece suporte de GPU e fornece os seguintes serviços para Apache MXNet−
Amazon SageMaker
Ele gerencia o treinamento e a implantação de modelos Apache MXNet.
AWS Deep Learning AMI
Ele fornece um ambiente Conda pré-instalado para Python 2 e Python 3 com Apache MXNet, CUDA, cuDNN, MKL-DNN e AWS Elastic Inference.
Treinamento dinâmico na AWS
Ele fornece o treinamento para a configuração manual experimental do EC2, bem como para a configuração semi-automatizada do CloudFormation.
Você pode usar NVIDIA VM disponível em https://aws.amazon.com com os serviços da Web da Amazon.
Google Cloud Platform
O Google também está fornecendo NVIDIA GPU cloud image que está disponível em https://console.cloud.google.com para trabalhar com Apache MXNet.
Microsoft Azure
O Microsoft Azure Marketplace também oferece NVIDIA GPU cloud image disponível em https://azuremarketplace.microsoft.com para trabalhar com Apache MXNet.
Oracle Cloud
A Oracle também está fornecendo NVIDIA GPU cloud image disponível em https://docs.cloud.oracle.com para trabalhar com Apache MXNet.
Unidade de processamento central (CPU)
O Apache MXNet funciona em todas as instâncias somente de CPU do provedor de nuvem. Existem vários métodos de instalação, como -
Instruções de instalação do pip Python.
Instruções do Docker.
Opção pré-instalada como Amazon Web Services, que fornece AWS Deep Learning AMI (com ambiente Conda pré-instalado para Python 2 e Python 3 com MXNet e MKL-DNN).
Instalando MXNet em Dispositivos
Vamos aprender como instalar MXNet em dispositivos.
Raspberry Pi
Você também pode executar o Apache MXNet em dispositivos Raspberry Pi 3B, pois o MXNet também oferece suporte ao sistema operacional baseado em ARM da Respbian. Para executar o MXNet sem problemas no Raspberry Pi3, é recomendável ter um dispositivo com mais de 1 GB de RAM e um cartão SD com pelo menos 4 GB de espaço livre.
A seguir estão as maneiras com a qual você pode construir MXNet para o Raspberry Pi e instalar os vínculos Python para a biblioteca também -
Instalação rápida
A roda Python pré-construída pode ser usada em um Raspberry Pi 3B com Stretch para instalação rápida. Um dos problemas importantes com esse método é que precisamos instalar várias dependências para fazer o Apache MXNet funcionar.
Instalação do Docker
Você pode seguir as instruções de instalação do docker, que estão disponíveis em https://docs.docker.com/engine/install/ubuntu/para instalar o Docker em sua máquina. Para este propósito, podemos instalar e usar o Community Edition (CE) também.
Compilação nativa (da fonte)
Para instalar o MXNet a partir da fonte, precisamos seguir as duas etapas a seguir -
Passo 1
Build the shared library from the Apache MXNet C++ source code
Para construir a biblioteca compartilhada na versão Raspberry Wheezy e posterior, precisamos das seguintes dependências:
Git- É necessário extrair o código do GitHub.
Libblas- É necessário para operações algébricas lineares.
Libopencv- É necessário para operações relacionadas à visão computacional. No entanto, é opcional se você quiser economizar sua RAM e espaço em disco.
C++ Compiler- É necessário para compilar e construir o código-fonte do MXNet. A seguir estão os compiladores suportados que suportam C ++ 11−
G ++ (4.8 ou versão posterior)
Clang(3.9-6)
Use os seguintes comandos para instalar as dependências mencionadas acima−
sudo apt-get update
sudo apt-get -y install git cmake ninja-build build-essential g++-4.9 c++-4.9 liblapack*
libblas* libopencv*
libopenblas* python3-dev python-dev virtualenvEm seguida, precisamos clonar o repositório de código-fonte MXNet. Para isso, use o seguinte comando git em seu diretório home−
git clone https://github.com/apache/incubator-mxnet.git --recursive
cd incubator-mxnetAgora, com a ajuda dos seguintes comandos, construa a biblioteca compartilhada:
mkdir -p build && cd build
cmake \
-DUSE_SSE=OFF \
-DUSE_CUDA=OFF \
-DUSE_OPENCV=ON \
-DUSE_OPENMP=ON \
-DUSE_MKL_IF_AVAILABLE=OFF \
-DUSE_SIGNAL_HANDLER=ON \
-DCMAKE_BUILD_TYPE=Release \
-GNinja ..
ninja -j$(nproc)Depois de executar os comandos acima, o processo de construção será iniciado, o que levará algumas horas para terminar. Você receberá um arquivo chamadolibmxnet.so no diretório de construção.
Passo 2
Install the supported language-specific packages for Apache MXNet
Nesta etapa, iremos instalar ligações MXNet Pythin. Para fazer isso, precisamos executar o seguinte comando no diretório MXNet -
cd python
pip install --upgrade pip
pip install -e .Como alternativa, com o seguinte comando, você também pode criar um whl package instalável com pip-
ci/docker/runtime_functions.sh build_wheel python/ $(realpath build)Dispositivos NVIDIA Jetson
Você também pode executar o Apache MXNet em dispositivos NVIDIA Jetson, como TX2 ou Nanocomo MXNet também suporta o sistema operacional baseado em Ubuntu Arch64. Para executar o MXNet sem problemas nos dispositivos NVIDIA Jetson, é necessário ter CUDA instalado em seu dispositivo Jetson.
A seguir estão as maneiras com as quais você pode construir MXNet para dispositivos NVIDIA Jetson:
Usando uma roda de pip Jetson MXNet para desenvolvimento Python
Da fonte
Mas, antes de construir MXNet de qualquer uma das formas mencionadas acima, você precisa instalar as seguintes dependências em seus dispositivos Jetson-
Dependências Python
Para usar a API Python, precisamos das seguintes dependências−
sudo apt update
sudo apt -y install \
build-essential \
git \
graphviz \
libatlas-base-dev \
libopencv-dev \
python-pip
sudo pip install --upgrade \
pip \
setuptools
sudo pip install \
graphviz==0.8.4 \
jupyter \
numpy==1.15.2Clone o repositório de código-fonte MXNet
Usando o seguinte comando git em seu diretório inicial, clone o repositório de código-fonte MXNet -
git clone --recursive https://github.com/apache/incubator-mxnet.git mxnetVariáveis de ambiente de configuração
Adicione o seguinte em seu .profile arquivo em seu diretório home−
export PATH=/usr/local/cuda/bin:$PATH export MXNET_HOME=$HOME/mxnet/
export PYTHONPATH=$MXNET_HOME/python:$PYTHONPATHAgora, aplique a mudança imediatamente com o seguinte comando−
source .profileConfigurar CUDA
Antes de configurar o CUDA, com o nvcc, você precisa verificar qual versão do CUDA está em execução -
nvcc --versionSuponha que, se mais de uma versão CUDA estiver instalada no seu dispositivo ou computador e você quiser trocar as versões CUDA, use o seguinte e substitua o link simbólico para a versão que você deseja -
sudo rm /usr/local/cuda
sudo ln -s /usr/local/cuda-10.0 /usr/local/cudaO comando acima mudará para CUDA 10.0, que é pré-instalado no dispositivo NVIDIA Jetson Nano.
Depois de concluir os pré-requisitos mencionados acima, agora você pode instalar o MXNet nos dispositivos NVIDIA Jetson. Então, vamos entender as maneiras com a qual você pode instalar o MXNet−
By using a Jetson MXNet pip wheel for Python development- Se você quiser usar uma roda Python preparada, faça o download do seguinte em seu Jetson e execute-o−
MXNet 1.4.0 (para Python 3) disponível em https://docs.docker.com
MXNet 1.4.0 (para Python 2) disponível em https://docs.docker.com
Compilação nativa (da fonte)
Para instalar o MXNet a partir da fonte, precisamos seguir as duas etapas a seguir -
Passo 1
Build the shared library from the Apache MXNet C++ source code
Para construir a biblioteca compartilhada a partir do código-fonte Apache MXNet C ++, você pode usar o método Docker ou fazê-lo manualmente
Método Docker
Neste método, primeiro você precisa instalar o Docker e ser capaz de executá-lo sem sudo (o que também é explicado nas etapas anteriores). Uma vez feito isso, execute o seguinte para executar a compilação cruzada via Docker−
$MXNET_HOME/ci/build.py -p jetsonManual
Neste método, você precisa editar o Makefile (com o comando abaixo) para instalar o MXNet com ligações CUDA para aproveitar as unidades de processamento gráfico (GPU) em dispositivos NVIDIA Jetson:
cp $MXNET_HOME/make/crosscompile.jetson.mk config.mkDepois de editar o Makefile, você precisa editar o arquivo config.mk para fazer algumas alterações adicionais no dispositivo NVIDIA Jetson.
Para isso, atualize as seguintes configurações–
Atualize o caminho CUDA: USE_CUDA_PATH = / usr / local / cuda
Adicione -gencode arch = compute-63, code = sm_62 à configuração CUDA_ARCH.
Atualize as configurações de NVCC: NVCCFLAGS: = -m64
Ligue o OpenCV: USE_OPENCV = 1
Agora, para garantir que o MXNet seja construído com a aceleração de baixa precisão de nível de hardware de Pascal, precisamos editar o Makefile Mshadow como segue−
MSHADOW_CFLAGS += -DMSHADOW_USE_PASCAL=1Finalmente, com a ajuda do seguinte comando, você pode construir a biblioteca Apache MXNet completa -
cd $MXNET_HOME make -j $(nproc)Depois de executar os comandos acima, o processo de construção será iniciado, o que levará algumas horas para terminar. Você receberá um arquivo chamadolibmxnet.so no mxnet/lib directory.
Passo 2
Install the Apache MXNet Python Bindings
Nesta etapa, instalaremos os vínculos MXNet Python. Para fazer isso, precisamos executar o seguinte comando no diretório MXNet -
cd $MXNET_HOME/python
sudo pip install -e .Depois de concluir as etapas acima, você agora está pronto para executar o MXNet em seus dispositivos NVIDIA Jetson TX2 ou Nano. Pode ser verificado com o seguinte comando−
import mxnet
mxnet.__version__Ele retornará o número da versão se tudo estiver funcionando corretamente.
Para apoiar a pesquisa e o desenvolvimento de aplicativos de aprendizado profundo em muitos campos, o Apache MXNet nos fornece um rico ecossistema de kits de ferramentas, bibliotecas e muito mais. Deixe-nos explorá-los -
Kits de ferramentas
A seguir estão alguns dos kits de ferramentas mais usados e importantes fornecidos pelo MXNet -
GluonCV
Como o nome indica, o GluonCV é um kit de ferramentas Gluon para visão computacional desenvolvido por MXNet. Ele fornece implementação de algoritmos DL (Deep Learning) de última geração em visão computacional (CV). Com a ajuda do kit de ferramentas GluonCV, engenheiros, pesquisadores e alunos podem validar novas ideias e aprender CV facilmente.
Abaixo estão alguns dos features of GluonCV -
Ele treina scripts para reproduzir resultados de última geração relatados nas pesquisas mais recentes.
Mais de 170 modelos pré-treinados de alta qualidade.
Adote um padrão de desenvolvimento flexível.
O GluonCV é fácil de otimizar. Podemos implantá-lo sem reter uma estrutura DL de peso.
Ele fornece APIs cuidadosamente projetadas que reduzem muito a complexidade da implementação.
Suporte da comunidade.
Implementações fáceis de entender.
A seguir estão os supported applications por GluonCV toolkit:
Classificação de imagens
Detecção de Objetos
Segmentação Semântica
Segmentação de instância
Estimativa de pose
Reconhecimento de ação de vídeo
Podemos instalar o GluonCV usando o pip da seguinte forma -
pip install --upgrade mxnet gluoncvGluonNLP
Como o nome indica, GluonNLP é um kit de ferramentas Gluon para Processamento de Linguagem Natural (NLP) desenvolvido por MXNet. Ele fornece a implementação de modelos de DL (Deep Learning) de última geração em PNL.
Com a ajuda de engenheiros do kit de ferramentas GluonNLP, pesquisadores e alunos podem construir blocos para pipelines de dados de texto e modelos. Com base nesses modelos, eles podem criar um protótipo rapidamente das ideias de pesquisa e do produto.
A seguir estão alguns dos recursos do GluonNLP:
Ele treina scripts para reproduzir resultados de última geração relatados nas pesquisas mais recentes.
Conjunto de modelos pré-treinados para tarefas comuns de PNL.
Ele fornece APIs cuidadosamente projetadas que reduzem muito a complexidade da implementação.
Suporte da comunidade.
Ele também fornece tutoriais para ajudá-lo a iniciar novas tarefas de PNL.
A seguir estão as tarefas de PNL que podemos implementar com o kit de ferramentas GluonNLP -
Word Embedding
Modelo de linguagem
Maquina de tradução
Classificação de Texto
Análise de sentimentos
Inferência de linguagem natural
Geração de Texto
Análise de Dependência
Reconhecimento de entidade nomeada
Classificação de Intenção e Rotulagem de Slot
Podemos instalar o GluonNLP usando pip da seguinte forma -
pip install --upgrade mxnet gluonnlpGluonTS
Como o nome indica, GluonTS é um kit de ferramentas Gluon para Modelagem Probabilística de Séries Temporais desenvolvido por MXNet.
Ele fornece os seguintes recursos -
Modelos de aprendizado profundo de última geração (SOTA) prontos para serem treinados.
Os utilitários para carregar e iterar em conjuntos de dados de série temporal.
Blocos de construção para definir seu próprio modelo.
Com a ajuda do kit de ferramentas GluonTS, engenheiros, pesquisadores e estudantes podem treinar e avaliar qualquer um dos modelos integrados em seus próprios dados, experimentar rapidamente diferentes soluções e apresentar uma solução para suas tarefas de série temporal.
Eles também podem usar as abstrações e blocos de construção fornecidos para criar modelos de série temporal personalizados e compará-los rapidamente com os algoritmos de linha de base.
Podemos instalar o GluonTS usando pip da seguinte maneira -
pip install gluontsGluonFR
Como o nome indica, é um kit de ferramentas Apache MXNet Gluon para FR (Face Recognition). Ele fornece os seguintes recursos -
Modelos de aprendizado profundo de última geração (SOTA) em reconhecimento facial.
A implementação de SoftmaxCrossEntropyLoss, ArcLoss, TripletLoss, RingLoss, CosLoss / AMsoftmax, L2-Softmax, A-Softmax, CenterLoss, ContrastiveLoss e LGM Loss, etc.
Para instalar o Gluon Face, precisamos do Python 3.5 ou posterior. Também precisamos primeiro instalar o GluonCV e o MXNet da seguinte forma -
pip install gluoncv --pre
pip install mxnet-mkl --pre --upgrade
pip install mxnet-cuXXmkl --pre –upgrade # if cuda XX is installedDepois de instalar as dependências, você pode usar o seguinte comando para instalar o GluonFR -
From Source
pip install git+https://github.com/THUFutureLab/gluon-face.git@masterPip
pip install gluonfrEcossistema
Agora vamos explorar as ricas bibliotecas, pacotes e estruturas do MXNet -
Treinador RL
Coach, uma estrutura Python Reinforcement Learning (RL) criada pelo laboratório Intel AI. Ele permite uma fácil experimentação com algoritmos RL de última geração. O Coach RL oferece suporte ao Apache MXNet como back-end e permite a integração simples de um novo ambiente para solução.
Para estender e reutilizar componentes existentes facilmente, o Coach RL desacoplou muito bem os componentes básicos de aprendizagem por reforço, como algoritmos, ambientes, arquiteturas NN, políticas de exploração.
A seguir estão os agentes e algoritmos suportados para a estrutura Coach RL -
Agentes de otimização de valor
Deep Q Network (DQN)
Rede Double Deep Q (DDQN)
Dueling Q Network
Monte Carlo Misto (MMC)
Persistent Advantage Learning (PAL)
Rede categórica Deep Q (C51)
Rede Q profunda de regressão de quantis (QR-DQN)
N-Step Q Learning
Controle Episódico Neural (NEC)
Funções Normalized Advantage (NAF)
Rainbow
Agentes de otimização de política
Gradientes de política (PG)
Ator-crítico do Asynchronous Advantage (A3C)
Gradientes de política determinísticos profundos (DDPG)
Otimização de Política Proximal (PPO)
Otimização de Política Proximal Cortada (CPPO)
Estimativa de vantagem generalizada (GAE)
Amostra de ator-crítico eficiente com repetição de experiência (ACER)
Crítico de Soft Actor (SAC)
Gradiente de política determinística profunda com atraso duplo (TD3)
Agentes Gerais
Previsão direta do futuro (DFP)
Agentes de Imitação de Aprendizagem
Clonagem Comportamental (BC)
Aprendizagem de imitação condicional
Agentes de Aprendizagem por Reforço Hierárquico
Crítico de Ator Hierárquico (HAC)
Biblioteca Deep Graph
Deep Graph Library (DGL), desenvolvida pelas equipes da NYU e da AWS, em Xangai, é um pacote Python que fornece implementações fáceis de Redes Neurais de Grafo (GNNs) no topo do MXNet. Também fornece implementação fácil de GNNs em cima de outras bibliotecas de aprendizado profundo existentes, como PyTorch, Gluon, etc.
Deep Graph Library é um software livre. Ele está disponível em todas as distribuições Linux posteriores ao Ubuntu 16.04, macOS X e Windows 7 ou posterior. Também requer a versão Python 3.5 ou posterior.
A seguir estão os recursos do DGL -
No Migration cost - Não há custo de migração para o uso de DGL, pois ele é criado com base em estruturas DL existentes.
Message Passing- DGL fornece passagem de mensagem e tem controle versátil sobre ela. A transmissão de mensagens varia de operações de baixo nível, como envio ao longo de bordas selecionadas, até controle de alto nível, como atualizações de recursos em todo o gráfico.
Smooth Learning Curve - É muito fácil aprender e usar o DGL, pois as poderosas funções definidas pelo usuário são flexíveis e fáceis de usar.
Transparent Speed Optimization - DGL fornece otimização de velocidade transparente, fazendo lotes automáticos de cálculos e multiplicação de matrizes esparsas.
High performance - Para atingir a eficiência máxima, o DGL agrupa automaticamente o treinamento DNN (redes neurais profundas) em um ou mais gráficos juntos.
Easy & friendly interface - DGL nos fornece interfaces fáceis e amigáveis para acesso a recursos de borda, bem como manipulação de estrutura de gráfico.
InsightFace
InsightFace, um kit de ferramentas de aprendizado profundo para análise facial que fornece implementação de algoritmo de análise facial SOTA (estado da arte) em visão computacional com tecnologia MXNet. Ele fornece -
Grande conjunto de modelos pré-treinados de alta qualidade.
Roteiros de treinamento de última geração (SOTA).
O InsightFace é fácil de otimizar. Podemos implantá-lo sem reter uma estrutura DL de peso.
Ele fornece APIs cuidadosamente projetadas que reduzem muito a complexidade da implementação.
Blocos de construção para definir seu próprio modelo.
Podemos instalar o InsightFace usando pip da seguinte maneira -
pip install --upgrade insightfaceObserve que antes de instalar o InsightFace, instale o pacote MXNet correto de acordo com a configuração do sistema.
Keras-MXNet
Como sabemos que Keras é uma API de Rede Neural (NN) de alto nível escrita em Python, Keras-MXNet nos fornece um suporte de back-end para Keras. Ele pode ser executado em cima da estrutura Apache MXNet DL escalonável e de alto desempenho.
Os recursos do Keras-MXNet são mencionados abaixo -
Permite aos usuários uma prototipagem fácil, suave e rápida. Tudo acontece por meio da facilidade de uso, modularidade e extensibilidade.
Suporta tanto CNN (Redes Neurais Convolucionais) e RNN (Redes Neurais Recorrentes), bem como a combinação de ambos também.
Funciona perfeitamente na unidade de processamento central (CPU) e unidade de processamento gráfico (GPU).
Pode ser executado em uma ou várias GPUs.
Para trabalhar com este back-end, você primeiro precisa instalar o keras-mxnet da seguinte maneira -
pip install keras-mxnetAgora, se você estiver usando GPUs, instale o MXNet com suporte CUDA 9 da seguinte maneira -
pip install mxnet-cu90Mas se você estiver usando apenas CPU, instale o MXNet básico da seguinte forma -
pip install mxnetMXBoard
MXBoard é uma ferramenta de registro, escrita em Python, que é usada para registrar frames de dados MXNet e exibi-los no TensorBoard. Em outras palavras, o MXBoard deve seguir a API tensorboard-pytorch. Ele é compatível com a maioria dos tipos de dados do TensorBoard.
Alguns deles são mencionados abaixo -
Graph
Scalar
Histogram
Embedding
Image
Text
Audio
Curva de Rechamada de Precisão
MXFusion
MXFusion é uma biblioteca de programação probabilística modular com aprendizado profundo. O MXFusion nos permite explorar totalmente a modularidade, que é um recurso-chave das bibliotecas de aprendizado profundo, para programação probabilística. É simples de usar e fornece aos usuários uma interface conveniente para projetar modelos probabilísticos e aplicá-los aos problemas do mundo real.
MXFusion é verificado no Python versão 3.4 e mais no MacOS e Linux OS. Para instalar o MXFusion, precisamos primeiro instalar as seguintes dependências -
MXNet> = 1,3
Networkx> = 2,1
Com a ajuda do seguinte comando pip, você pode instalar MXFusion -
pip install mxfusionTVM
Apache TVM, uma pilha de compiladores de aprendizado profundo de código aberto para back-ends de hardware, como CPUs, GPUs e aceleradores especializados, visa preencher a lacuna entre as estruturas de aprendizado profundo focadas na produtividade e os back-ends de hardware orientados para o desempenho . Com a versão mais recente do MXNet 1.6.0, os usuários podem aproveitar o Apache (incubando) TVM para implementar kernels de operador de alto desempenho na linguagem de programação Python.
O Apache TVM realmente começou como um projeto de pesquisa no grupo SAMPL da Escola Paul G. Allen de Ciência da Computação e Engenharia da Universidade de Washington e agora é um esforço em incubação na The Apache Software Foundation (ASF) que é conduzido por um OSC ( comunidade de código aberto) que envolve várias indústrias, bem como instituições acadêmicas sob o modelo Apache.
A seguir estão as principais características do Apache (incubando) TVM -
Simplifica o antigo processo de desenvolvimento baseado em C ++.
Permite compartilhar a mesma implementação em vários back-ends de hardware, como CPUs, GPUs, etc.
TVM fornece compilação de modelos DL em várias estruturas, como Kears, MXNet, PyTorch, Tensorflow, CoreML, DarkNet em módulos implantáveis mínimos em diversos back-ends de hardware.
Ele também nos fornece a infraestrutura para gerar e otimizar automaticamente os operadores de tensores com melhor desempenho.
XFer
Xfer, um framework de aprendizagem por transferência, é escrito em Python. Basicamente, ele pega um modelo MXNet e treina um metamodelo ou também modifica o modelo para um novo conjunto de dados de destino.
Em palavras simples, Xfer é uma biblioteca Python que permite aos usuários uma transferência rápida e fácil de conhecimento armazenado em DNN (redes neurais profundas).
Xfer pode ser usado -
Para a classificação de dados de formato numérico arbitrário.
Para os casos comuns de imagens ou dados de texto.
Como um pipeline que envia spams desde a extração de recursos até o treinamento de um redirecionador (um objeto que realiza a classificação na tarefa de destino).
A seguir estão os recursos do Xfer:
Eficiência de recursos
Eficiência de dados
Fácil acesso a redes neurais
Modelagem de incerteza
Prototipagem rápida
Utilitários para extração de recursos do NN
Este capítulo o ajudará a entender a arquitetura do sistema MXNet. Vamos começar aprendendo sobre os Módulos MXNet.
Módulos MXNet
O diagrama abaixo é a arquitetura do sistema MXNet e mostra os principais módulos e componentes do MXNet modules and their interaction.

No diagrama acima -
Os módulos nas caixas de cor azul são User Facing Modules.
Os módulos em caixas de cor verde são System Modules.
A seta sólida representa alta dependência, ou seja, depende muito da interface.
A seta pontilhada representa a dependência de luz, ou seja, estrutura de dados usada para conveniência e consistência da interface. Na verdade, ele pode ser substituído pelas alternativas.
Vamos discutir mais sobre módulos de sistema e voltados para o usuário.
Módulos voltados para o usuário
Os módulos voltados para o usuário são os seguintes -
NDArray- Fornece programas imperativos flexíveis para Apache MXNet. Eles são arrays n-dimensionais dinâmicos e assíncronos.
KVStore- Atua como interface para sincronização eficiente de parâmetros. Em KVStore, KV significa Key-Value. Portanto, é uma interface de armazenamento de valor-chave.
Data Loading (IO) - Este módulo voltado para o usuário é usado para carregamento e aumento de dados distribuídos eficientes.
Symbol Execution- É um executor de gráfico estático simbólico. Ele fornece execução e otimização de gráficos simbólicos eficientes.
Symbol Construction - Este módulo voltado para o usuário fornece ao usuário uma maneira de construir um gráfico de computação, ou seja, configuração de rede.
Módulos de sistema
Os módulos do sistema são os seguintes -
Storage Allocator - Este módulo de sistema, como o nome sugere, aloca e recicla blocos de memória de forma eficiente no host, ou seja, CPU e diferentes dispositivos, como GPUs.
Runtime Dependency Engine - O módulo do mecanismo de dependência de tempo de execução programa, bem como executa as operações de acordo com sua dependência de leitura / gravação.
Resource Manager - Módulo de sistema Resource Manager (RM) gerencia recursos globais como o gerador de números aleatórios e espaço temporal.
Operator - O módulo do sistema do operador consiste em todos os operadores que definem o cálculo progressivo e gradiente estático, ou seja, a retropropagação.
Aqui, os componentes do sistema no Apache MXNet são explicados em detalhes. Primeiramente, estudaremos sobre o mecanismo de execução no MXNet.
Execution Engine
O mecanismo de execução do Apache MXNet é muito versátil. Podemos usá-lo para aprendizado profundo, bem como para qualquer problema específico de domínio: execute um monte de funções seguindo suas dependências. Ele é projetado de forma que as funções com dependências sejam serializadas, enquanto as funções sem dependências podem ser executadas em paralelo.
Interface central
A API fornecida abaixo é a interface principal para o mecanismo de execução do Apache MXNet -
virtual void PushSync(Fn exec_fun, Context exec_ctx,
std::vector<VarHandle> const& const_vars,
std::vector<VarHandle> const& mutate_vars) = 0;A API acima tem o seguinte -
exec_fun - A API da interface principal do MXNet nos permite enviar a função chamada exec_fun, junto com suas informações de contexto e dependências, para o mecanismo de execução.
exec_ctx - As informações de contexto em que a função exec_fun mencionada acima deve ser executada.
const_vars - Estas são as variáveis das quais a função lê.
mutate_vars - Estas são as variáveis que devem ser modificadas.
O mecanismo de execução fornece a seu usuário a garantia de que a execução de quaisquer duas funções que modificam uma variável comum seja serializada em sua ordem de push.
Função
A seguir está o tipo de função do mecanismo de execução do Apache MXNet -
using Fn = std::function<void(RunContext)>;Na função acima, RunContextcontém as informações de tempo de execução. As informações de tempo de execução devem ser determinadas pelo mecanismo de execução. A sintaxe deRunContext é o seguinte
struct RunContext {
// stream pointer which could be safely cast to
// cudaStream_t* type
void *stream;
};Abaixo estão alguns pontos importantes sobre as funções do mecanismo de execução -
Todas as funções são executadas pelos threads internos do mecanismo de execução do MXNet.
Não é bom empurrar o bloqueio da função para o mecanismo de execução porque, com isso, a função ocupará o thread de execução e também reduzirá o rendimento total.
Para este MXNet fornece outra função assíncrona como segue−
using Callback = std::function<void()>;
using AsyncFn = std::function<void(RunContext, Callback)>;Nisso AsyncFn podemos passar a parte pesada de nossos threads, mas o mecanismo de execução não considera a função concluída até que chamemos o callback função.
Contexto
Dentro Context, podemos especificar o contexto da função a ser executada. Isso geralmente inclui o seguinte -
Se a função deve ser executada em uma CPU ou GPU.
Se especificarmos GPU no Contexto, qual GPU usar.
Há uma grande diferença entre Context e RunContext. Context tem o tipo de dispositivo e o id do dispositivo, enquanto RunContext tem as informações que podem ser decididas apenas durante o tempo de execução.
VarHandle
VarHandle, usado para especificar as dependências de funções, é como um token (especialmente fornecido pelo mecanismo de execução) que podemos usar para representar os recursos externos que a função pode modificar ou usar.
Mas surge a pergunta: por que precisamos usar VarHandle? É porque o motor Apache MXNet foi projetado para se separar de outros módulos MXNet.
A seguir estão alguns pontos importantes sobre VarHandle -
É leve, portanto, criar, excluir ou copiar uma variável incorre em poucos custos operacionais.
Precisamos especificar as variáveis imutáveis, ou seja, as variáveis que serão usadas no const_vars.
Precisamos especificar as variáveis mutáveis, ou seja, as variáveis que serão modificadas no mutate_vars.
A regra usada pelo mecanismo de execução para resolver as dependências entre as funções é que a execução de quaisquer duas funções quando uma delas modifica pelo menos uma variável comum é serializada em sua ordem de push.
Para criar uma nova variável, podemos usar o NewVar() API.
Para excluir uma variável, podemos usar o PushDelete API.
Vamos entender seu funcionamento com um exemplo simples -
Suponha que temos duas funções, a saber F1 e F2, e ambas alteram a variável V2. Nesse caso, F2 é garantido para ser executado após F1 se F2 for pressionado após F1. Por outro lado, se F1 e F2 usam V2, então sua ordem de execução real pode ser aleatória.
Empurre e espere
Push e wait são duas APIs de mecanismo de execução mais úteis.
A seguir estão dois recursos importantes do Push API:
Todas as APIs Push são assíncronas, o que significa que a chamada da API retorna imediatamente, independentemente de a função push ter sido concluída ou não.
Push API não é thread-safe, o que significa que apenas um thread deve fazer chamadas de API do mecanismo por vez.
Agora, se falamos sobre API Wait, os seguintes pontos representam -
Se um usuário deseja aguardar a conclusão de uma função específica, ele deve incluir uma função de retorno de chamada no encerramento. Depois de incluído, chame a função no final da função.
Por outro lado, se um usuário quiser esperar que todas as funções que envolvem uma determinada variável terminem, ele deve usar WaitForVar(var) API.
Se alguém quiser esperar que todas as funções enviadas terminem, use o WaitForAll () API.
Usado para especificar as dependências de funções, é como um token.
Operadores
Operator no Apache MXNet é uma classe que contém a lógica de computação real, bem como informações auxiliares e ajuda o sistema a realizar a otimização.
Interface de operador
Forward é a interface principal do operador, cuja sintaxe é a seguinte:
virtual void Forward(const OpContext &ctx,
const std::vector<TBlob> &in_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &out_data,
const std::vector<TBlob> &aux_states) = 0;A estrutura de OpContext, definido em Forward() é o seguinte:
struct OpContext {
int is_train;
RunContext run_ctx;
std::vector<Resource> requested;
}o OpContextdescreve o estado do operador (seja em fase de trem ou de teste), em qual dispositivo o operador deve operar e também os recursos solicitados. duas APIs mais úteis do mecanismo de execução.
De cima Forward interface principal, podemos entender os recursos solicitados da seguinte forma -
in_data e out_data representam os tensores de entrada e saída.
req denota como o resultado da computação é escrito no out_data.
o OpReqType pode ser definido como -
enum OpReqType {
kNullOp,
kWriteTo,
kWriteInplace,
kAddTo
};Como Forward operador, podemos opcionalmente implementar o Backward interface da seguinte forma -
virtual void Backward(const OpContext &ctx,
const std::vector<TBlob> &out_grad,
const std::vector<TBlob> &in_data,
const std::vector<TBlob> &out_data,
const std::vector<OpReqType> &req,
const std::vector<TBlob> &in_grad,
const std::vector<TBlob> &aux_states);Várias tarefas
Operator interface permite que os usuários façam as seguintes tarefas -
O usuário pode especificar atualizações no local e pode reduzir o custo de alocação de memória
Para torná-lo mais limpo, o usuário pode ocultar alguns argumentos internos do Python.
O usuário pode definir a relação entre os tensores e os tensores de saída.
Para realizar a computação, o usuário pode adquirir espaço temporário adicional do sistema.
Propriedade do operador
Como sabemos, na rede neural convolucional (CNN), uma convolução tem várias implementações. Para obter o melhor desempenho deles, podemos alternar entre essas várias convoluções.
Essa é a razão, o Apache MXNet separa a interface semântica do operador da interface de implementação. Essa separação é feita na forma deOperatorProperty classe que consiste no seguinte
InferShape - A interface InferShape tem duas finalidades, conforme mostrado abaixo:
O primeiro objetivo é dizer ao sistema o tamanho de cada tensor de entrada e saída para que o espaço possa ser alocado antes Forward e Backward ligar.
O segundo objetivo é realizar uma verificação de tamanho para garantir que não haja nenhum erro antes de executar.
A sintaxe é fornecida abaixo -
virtual bool InferShape(mxnet::ShapeVector *in_shape,
mxnet::ShapeVector *out_shape,
mxnet::ShapeVector *aux_shape) const = 0;Request Resource- E se o seu sistema puder gerenciar o espaço de trabalho de computação para operações como cudnnConvolutionForward? Seu sistema pode realizar otimizações como reutilizar o espaço e muito mais. Aqui, o MXNet consegue isso facilmente com a ajuda das duas interfaces a seguir
virtual std::vector<ResourceRequest> ForwardResource(
const mxnet::ShapeVector &in_shape) const;
virtual std::vector<ResourceRequest> BackwardResource(
const mxnet::ShapeVector &in_shape) const;Mas, e se o ForwardResource e BackwardResourceretornar matrizes não vazias? Nesse caso, o sistema oferece recursos correspondentes por meio dectx parâmetro no Forward e Backward interface de Operator.
Backward dependency - Apache MXNet segue duas assinaturas de operador diferentes para lidar com a dependência reversa -
void FullyConnectedForward(TBlob weight, TBlob in_data, TBlob out_data);
void FullyConnectedBackward(TBlob weight, TBlob in_data, TBlob out_grad, TBlob in_grad);
void PoolingForward(TBlob in_data, TBlob out_data);
void PoolingBackward(TBlob in_data, TBlob out_data, TBlob out_grad, TBlob in_grad);Aqui, os dois pontos importantes a serem observados -
O out_data em FullyConnectedForward não é usado por FullyConnectedBackward, e
PoolingBackward requer todos os argumentos de PoolingForward.
É por isso que para FullyConnectedForward, a out_datatensor uma vez consumido pode ser liberado com segurança porque a função de retrocesso não vai precisar dele. Com a ajuda desse sistema conseguiu coletar alguns tensores o mais cedo possível.
In place Option- O Apache MXNet fornece outra interface aos usuários para economizar o custo de alocação de memória. A interface é apropriada para operações elementares nas quais os tensores de entrada e saída têm a mesma forma.
A seguir está a sintaxe para especificar a atualização in-loco -
Exemplo para criar um operador
Com a ajuda de OperatorProperty, podemos criar um operador. Para fazer isso, siga as etapas abaixo -
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::ForwardInplaceOption(
const std::vector<int> &in_data,
const std::vector<void*> &out_data)
const {
return { {in_data[0], out_data[0]} };
}
virtual std::vector<std::pair<int, void*>> ElewiseOpProperty::BackwardInplaceOption(
const std::vector<int> &out_grad,
const std::vector<int> &in_data,
const std::vector<int> &out_data,
const std::vector<void*> &in_grad)
const {
return { {out_grad[0], in_grad[0]} }
}Passo 1
Create Operator
Primeiro, implemente a seguinte interface em OperatorProperty:
virtual Operator* CreateOperator(Context ctx) const = 0;O exemplo é dado abaixo -
class ConvolutionOp {
public:
void Forward( ... ) { ... }
void Backward( ... ) { ... }
};
class ConvolutionOpProperty : public OperatorProperty {
public:
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp;
}
};Passo 2
Parameterize Operator
Se você for implementar um operador de convolução, é obrigatório saber o tamanho do kernel, o tamanho da passada, o tamanho do preenchimento e assim por diante. Por que, porque esses parâmetros devem ser passados para a operadora antes de chamar qualquerForward ou backward interface.
Para isso, precisamos definir um ConvolutionParam estrutura como abaixo -
#include <dmlc/parameter.h>
struct ConvolutionParam : public dmlc::Parameter<ConvolutionParam> {
mxnet::TShape kernel, stride, pad;
uint32_t num_filter, num_group, workspace;
bool no_bias;
};Agora, precisamos colocar isso em ConvolutionOpProperty e passe para o operador da seguinte forma -
class ConvolutionOp {
public:
ConvolutionOp(ConvolutionParam p): param_(p) {}
void Forward( ... ) { ... }
void Backward( ... ) { ... }
private:
ConvolutionParam param_;
};
class ConvolutionOpProperty : public OperatorProperty {
public:
void Init(const vector<pair<string, string>& kwargs) {
// initialize param_ using kwargs
}
Operator* CreateOperator(Context ctx) const {
return new ConvolutionOp(param_);
}
private:
ConvolutionParam param_;
};etapa 3
Register the Operator Property Class and the Parameter Class to Apache MXNet
Por fim, precisamos registrar a Operator Property Class e a Parameter Class no MXNet. Isso pode ser feito com a ajuda das seguintes macros -
DMLC_REGISTER_PARAMETER(ConvolutionParam);
MXNET_REGISTER_OP_PROPERTY(Convolution, ConvolutionOpProperty);Na macro acima, o primeiro argumento é a string de nome e o segundo é o nome da classe de propriedade.
Este capítulo fornece informações sobre a interface de programação de aplicativo (API) do operador unificada no Apache MXNet.
SimpleOp
SimpleOp é uma nova API de operador unificada que unifica diferentes processos de invocação. Depois de invocado, ele retorna aos elementos fundamentais dos operadores. O operador unificado é especialmente projetado para operações unárias e binárias. É porque a maioria dos operadores matemáticos atende a um ou dois operandos e mais operandos tornam a otimização, relacionada à dependência, útil.
Estaremos entendendo seu operador unificado SimpleOp trabalhando com a ajuda de um exemplo. Neste exemplo, estaremos criando um operador que funciona como umsmooth l1 loss, que é uma mistura de perda de l1 e l2. Podemos definir e escrever a perda conforme abaixo -
loss = outside_weight .* f(inside_weight .* (data - label))
grad = outside_weight .* inside_weight .* f'(inside_weight .* (data - label))Aqui, no exemplo acima,
. * significa multiplicação por elemento
f, f’ é a função de perda suave l1 que estamos assumindo está em mshadow.
Parece impossível implementar esta perda específica como um operador unário ou binário, mas o MXNet fornece aos seus usuários diferenciação automática na execução simbólica que simplifica a perda para f e f 'diretamente. É por isso que podemos certamente implementar essa perda particular como um operador unário.
Definindo formas
Como sabemos, MXNet's mshadow libraryrequer alocação de memória explícita, portanto, precisamos fornecer todas as formas de dados antes que qualquer cálculo ocorra. Antes de definir funções e gradiente, precisamos fornecer consistência da forma de entrada e forma de saída da seguinte forma:
typedef mxnet::TShape (*UnaryShapeFunction)(const mxnet::TShape& src,
const EnvArguments& env);
typedef mxnet::TShape (*BinaryShapeFunction)(const mxnet::TShape& lhs,
const mxnet::TShape& rhs,
const EnvArguments& env);A função mxnet :: Tshape é usada para verificar o formato dos dados de entrada e o formato dos dados de saída designados. No caso, se você não definir esta função, o formato de saída padrão será o mesmo que o formato de entrada. Por exemplo, no caso do operador binário, a forma de lhs e rhs é marcada como igual por padrão.
Agora vamos passar para o nosso smooth l1 loss example. Para isso, precisamos definir uma XPU para cpu ou gpu na implementação do cabeçalho smooth_l1_unary-inl.h. O motivo é reutilizar o mesmo código em smooth_l1_unary.cc e smooth_l1_unary.cu.
#include <mxnet/operator_util.h>
#if defined(__CUDACC__)
#define XPU gpu
#else
#define XPU cpu
#endifComo em nosso smooth l1 loss example,a saída tem a mesma forma que a fonte, podemos usar o comportamento padrão. Pode ser escrito da seguinte forma -
inline mxnet::TShape SmoothL1Shape_(const mxnet::TShape& src,const EnvArguments& env) {
return mxnet::TShape(src);
}Definindo Funções
Podemos criar uma função unária ou binária com uma entrada da seguinte maneira -
typedef void (*UnaryFunction)(const TBlob& src,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);
typedef void (*BinaryFunction)(const TBlob& lhs,
const TBlob& rhs,
const EnvArguments& env,
TBlob* ret,
OpReqType req,
RunContext ctx);A seguir está o RunContext ctx struct que contém as informações necessárias durante o tempo de execução para execução -
struct RunContext {
void *stream; // the stream of the device, can be NULL or Stream<gpu>* in GPU mode
template<typename xpu> inline mshadow::Stream<xpu>* get_stream() // get mshadow stream from Context
} // namespace mxnetAgora, vamos ver como podemos escrever os resultados do cálculo em ret.
enum OpReqType {
kNullOp, // no operation, do not write anything
kWriteTo, // write gradient to provided space
kWriteInplace, // perform an in-place write
kAddTo // add to the provided space
};Agora, vamos prosseguir para o nosso smooth l1 loss example. Para isso, usaremos UnaryFunction para definir a função deste operador da seguinte maneira:
template<typename xpu>
void SmoothL1Forward_(const TBlob& src,
const EnvArguments& env,
TBlob *ret,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(ret->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> out = ret->get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> in = src.get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(out, req,
F<mshadow_op::smooth_l1_loss>(in, ScalarExp<DType>(sigma2)));
});
}Definindo Gradientes
Exceto Input, TBlob, e OpReqTypesão duplicados, as funções de gradientes de operadores binários têm uma estrutura semelhante. Vamos verificar abaixo, onde criamos uma função gradiente com vários tipos de entrada:
// depending only on out_grad
typedef void (*UnaryGradFunctionT0)(const OutputGrad& out_grad,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on out_value
typedef void (*UnaryGradFunctionT1)(const OutputGrad& out_grad,
const OutputValue& out_value,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);
// depending only on in_data
typedef void (*UnaryGradFunctionT2)(const OutputGrad& out_grad,
const Input0& in_data0,
const EnvArguments& env,
TBlob* in_grad,
OpReqType req,
RunContext ctx);Conforme definido acima Input0, Input, OutputValue, e OutputGrad todos compartilham a estrutura de GradientFunctionArgument. É definido da seguinte forma -
struct GradFunctionArgument {
TBlob data;
}Agora vamos passar para o nosso smooth l1 loss example. Para que isso ative a regra da cadeia de gradiente, precisamos multiplicarout_grad do topo ao resultado de in_grad.
template<typename xpu>
void SmoothL1BackwardUseIn_(const OutputGrad& out_grad, const Input0& in_data0,
const EnvArguments& env,
TBlob *in_grad,
OpReqType req,
RunContext ctx) {
using namespace mshadow;
using namespace mshadow::expr;
mshadow::Stream<xpu> *s = ctx.get_stream<xpu>();
real_t sigma2 = env.scalar * env.scalar;
MSHADOW_TYPE_SWITCH(in_grad->type_flag_, DType, {
mshadow::Tensor<xpu, 2, DType> src = in_data0.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> ograd = out_grad.data.get<xpu, 2, DType>(s);
mshadow::Tensor<xpu, 2, DType> igrad = in_grad->get<xpu, 2, DType>(s);
ASSIGN_DISPATCH(igrad, req,
ograd * F<mshadow_op::smooth_l1_gradient>(src, ScalarExp<DType>(sigma2)));
});
}Registre SimpleOp para MXNet
Depois de criar a forma, a função e o gradiente, precisamos restaurá-los em um operador NDArray e em um operador simbólico. Para isso, podemos usar a macro de registro da seguinte forma -
MXNET_REGISTER_SIMPLE_OP(Name, DEV)
.set_shape_function(Shape)
.set_function(DEV::kDevMask, Function<XPU>, SimpleOpInplaceOption)
.set_gradient(DEV::kDevMask, Gradient<XPU>, SimpleOpInplaceOption)
.describe("description");o SimpleOpInplaceOption pode ser definido como segue -
enum SimpleOpInplaceOption {
kNoInplace, // do not allow inplace in arguments
kInplaceInOut, // allow inplace in with out (unary)
kInplaceOutIn, // allow inplace out_grad with in_grad (unary)
kInplaceLhsOut, // allow inplace left operand with out (binary)
kInplaceOutLhs // allow inplace out_grad with lhs_grad (binary)
};Agora vamos passar para o nosso smooth l1 loss example. Para isso, temos uma função gradiente que depende dos dados de entrada para que a função não possa ser escrita no local.
MXNET_REGISTER_SIMPLE_OP(smooth_l1, XPU)
.set_function(XPU::kDevMask, SmoothL1Forward_<XPU>, kNoInplace)
.set_gradient(XPU::kDevMask, SmoothL1BackwardUseIn_<XPU>, kInplaceOutIn)
.set_enable_scalar(true)
.describe("Calculate Smooth L1 Loss(lhs, scalar)");SimpleOp em EnvArguments
Como sabemos, algumas operações podem precisar do seguinte -
Um escalar como entrada, como uma escala de gradiente
Um conjunto de argumentos de palavras-chave controlando o comportamento
Um espaço temporário para agilizar os cálculos.
A vantagem de usar EnvArguments é que ele fornece argumentos e recursos adicionais para tornar os cálculos mais escalonáveis e eficientes.
Exemplo
Primeiro, vamos definir a estrutura conforme abaixo -
struct EnvArguments {
real_t scalar; // scalar argument, if enabled
std::vector<std::pair<std::string, std::string> > kwargs; // keyword arguments
std::vector<Resource> resource; // pointer to the resources requested
};Em seguida, precisamos solicitar recursos adicionais, como mshadow::Random<xpu> e espaço de memória temporário de EnvArguments.resource. Isso pode ser feito da seguinte forma -
struct ResourceRequest {
enum Type { // Resource type, indicating what the pointer type is
kRandom, // mshadow::Random<xpu> object
kTempSpace // A dynamic temp space that can be arbitrary size
};
Type type; // type of resources
};Agora, o registro irá solicitar a solicitação de recurso declarada de mxnet::ResourceManager. Depois disso, ele colocará os recursos em std::vector<Resource> resource in EnvAgruments.
Podemos acessar os recursos com a ajuda do seguinte código -
auto tmp_space_res = env.resources[0].get_space(some_shape, some_stream);
auto rand_res = env.resources[0].get_random(some_stream);Se você ver em nosso exemplo de perda suave l1, uma entrada escalar é necessária para marcar o ponto de viragem de uma função de perda. É por isso que, no processo de registro, usamosset_enable_scalar(true), e env.scalar em declarações de função e gradiente.
Operação do tensor de construção
Aqui surge a pergunta: por que precisamos criar operações de tensor? As razões são as seguintes -
A computação utiliza a biblioteca mshadow e às vezes não temos funções disponíveis.
Se uma operação não for realizada de maneira elementar, como softmax loss e gradiente.
Exemplo
Aqui, estamos usando o exemplo de perda suave l1 acima. Estaremos criando dois mapeadores, a saber, os casos escalares de perda suave l1 e gradiente:
namespace mshadow_op {
struct smooth_l1_loss {
// a is x, b is sigma2
MSHADOW_XINLINE static real_t Map(real_t a, real_t b) {
if (a > 1.0f / b) {
return a - 0.5f / b;
} else if (a < -1.0f / b) {
return -a - 0.5f / b;
} else {
return 0.5f * a * a * b;
}
}
};
}Este capítulo é sobre o treinamento distribuído no Apache MXNet. Vamos começar entendendo quais são os modos de computação no MXNet.
Modos de Computação
MXNet, uma biblioteca de ML multilíngue, oferece aos seus usuários os seguintes dois modos de computação -
Modo imperativo
Este modo de computação expõe uma interface como a API NumPy. Por exemplo, no MXNet, use o seguinte código imperativo para construir um tensor de zeros na CPU e também na GPU -
import mxnet as mx
tensor_cpu = mx.nd.zeros((100,), ctx=mx.cpu())
tensor_gpu= mx.nd.zeros((100,), ctx=mx.gpu(0))Como vemos no código acima, MXNets especifica o local onde manter o tensor, seja na CPU ou no dispositivo GPU. No exemplo acima, ele está no local 0. O MXNet alcança uma utilização incrível do dispositivo, porque todos os cálculos acontecem preguiçosamente em vez de instantaneamente.
Modo simbólico
Embora o modo imperativo seja bastante útil, uma das desvantagens deste modo é sua rigidez, ou seja, todos os cálculos precisam ser conhecidos de antemão junto com as estruturas de dados predefinidas.
Por outro lado, o modo Simbólico expõe um gráfico de computação como o TensorFlow. Ele remove a desvantagem da API imperativa, permitindo que o MXNet trabalhe com símbolos ou variáveis em vez de estruturas de dados fixas / predefinidas. Posteriormente, os símbolos podem ser interpretados como um conjunto de operações da seguinte forma -
import mxnet as mx
x = mx.sym.Variable(“X”)
y = mx.sym.Variable(“Y”)
z = (x+y)
m = z/100Tipos de paralelismo
Apache MXNet oferece suporte a treinamento distribuído. Ele nos permite alavancar várias máquinas para um treinamento mais rápido e eficaz.
A seguir estão as duas maneiras pelas quais podemos distribuir a carga de trabalho de treinamento de um NN em vários dispositivos, CPU ou dispositivo GPU -
Paralelismo de dados
Nesse tipo de paralelismo, cada dispositivo armazena uma cópia completa do modelo e trabalha com uma parte diferente do conjunto de dados. Os dispositivos também atualizam um modelo compartilhado coletivamente. Podemos localizar todos os dispositivos em uma única máquina ou em várias máquinas.
Paralelismo de modelo
É outro tipo de paralelismo, que é útil quando os modelos são tão grandes que não cabem na memória do dispositivo. No paralelismo do modelo, diferentes dispositivos são atribuídos a tarefa de aprender diferentes partes do modelo. O ponto importante a ser observado aqui é que atualmente o Apache MXNet oferece suporte ao paralelismo de modelo em uma única máquina apenas.
Trabalho de treinamento distribuído
Os conceitos fornecidos abaixo são a chave para entender o funcionamento do treinamento distribuído no Apache MXNet -
Tipos de processos
Os processos se comunicam entre si para realizar o treinamento de um modelo. Apache MXNet tem os seguintes três processos -
Trabalhador
O trabalho do nó trabalhador é realizar o treinamento em um lote de amostras de treinamento. Os nós de trabalho puxarão pesos do servidor antes de processar cada lote. Os nós de trabalho enviarão gradientes ao servidor, assim que o lote for processado.
Servidor
O MXNet pode ter vários servidores para armazenar os parâmetros do modelo e para se comunicar com os nós de trabalho.
Agendador
A função do planejador é configurar o cluster, o que inclui esperar por mensagens de que cada nó foi ativado e em qual porta o nó está atendendo. Depois de configurar o cluster, o planejador permite que todos os processos saibam sobre todos os outros nós do cluster. É porque os processos podem se comunicar uns com os outros. Existe apenas um agendador.
Loja KV
Lojas KV significa Key-Valueloja. É um componente crítico usado para treinamento em vários dispositivos. É importante porque a comunicação de parâmetros entre dispositivos em uma única máquina ou em várias máquinas é transmitida por meio de um ou mais servidores com um KVStore para os parâmetros. Vamos entender o funcionamento do KVStore com a ajuda dos seguintes pontos -
Cada valor em KVStore é representado por um key e um value.
Cada array de parâmetros na rede é atribuído a um key e os pesos dessa matriz de parâmetro são referidos por value.
Depois disso, os nós de trabalho pushgradientes após o processamento de um lote. Eles tambémpull pesos atualizados antes de processar um novo lote.
A noção de servidor KVStore existe apenas durante o treinamento distribuído e o modo distribuído dele é habilitado chamando mxnet.kvstore.create função com um argumento string contendo a palavra dist -
kv = mxnet.kvstore.create(‘dist_sync’)Distribuição de Chaves
Não é necessário que todos os servidores armazenem todas as matrizes ou chaves de parâmetros, mas eles são distribuídos em diferentes servidores. Essa distribuição de chaves em diferentes servidores é tratada de forma transparente pelo KVStore e a decisão de qual servidor armazena uma chave específica é feita aleatoriamente.
KVStore, conforme discutido acima, garante que sempre que a chave for puxada, sua solicitação seja enviada para aquele servidor, que possui o valor correspondente. E se o valor de alguma chave for grande? Nesse caso, ele pode ser compartilhado entre diferentes servidores.
Divida os dados de treinamento
Como sendo os usuários, queremos que cada máquina trabalhe em diferentes partes do conjunto de dados, especialmente, ao executar o treinamento distribuído no modo paralelo de dados. Sabemos que, para dividir um lote de amostras fornecidas pelo iterador de dados para treinamento paralelo de dados em um único trabalhador, podemos usarmxnet.gluon.utils.split_and_load e, em seguida, carregue cada parte do lote no dispositivo que irá processá-lo posteriormente.
Por outro lado, no caso de treinamento distribuído, no início precisamos dividir o conjunto de dados em npartes diferentes para que cada trabalhador receba uma parte diferente. Uma vez obtido, cada trabalhador pode usarsplit_and_loadpara dividir novamente essa parte do conjunto de dados entre diferentes dispositivos em uma única máquina. Tudo isso acontece por meio do iterador de dados.mxnet.io.MNISTIterator e mxnet.io.ImageRecordIter são dois desses iteradores no MXNet que oferecem suporte a esse recurso.
Atualização de pesos
Para atualizar os pesos, KVStore suporta os seguintes dois modos -
O primeiro método agrega os gradientes e atualiza os pesos usando esses gradientes.
No segundo método, o servidor agrega apenas gradientes.
Se você estiver usando o Gluon, há uma opção de escolher entre os métodos mencionados acima, passando update_on_kvstorevariável. Vamos entender isso criando otrainer objeto da seguinte forma -
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd',
optimizer_params={'learning_rate': opt.lr,
'wd': opt.wd,
'momentum': opt.momentum,
'multi_precision': True},
kvstore=kv,
update_on_kvstore=True)Modos de treinamento distribuído
Se a string de criação do KVStore contiver a palavra dist, significa que o treinamento distribuído está ativado. A seguir estão os diferentes modos de treinamento distribuído que podem ser ativados usando diferentes tipos de KVStore -
dist_sync
Como o nome indica, denota treinamento distribuído síncrono. Nesse caso, todos os trabalhadores usam o mesmo conjunto sincronizado de parâmetros do modelo no início de cada lote.
A desvantagem desse modo é que, após cada lote, o servidor deve esperar para receber gradientes de cada trabalhador antes de atualizar os parâmetros do modelo. Isso significa que, se um trabalhador travar, o progresso de todos os trabalhadores será interrompido.
dist_async
Como o nome indica, denota treinamento distribuído síncrono. Neste, o servidor recebe gradientes de um trabalhador e atualiza imediatamente seu armazenamento. O servidor usa o armazenamento atualizado para responder a quaisquer solicitações adicionais.
A vantagem, em comparação com dist_sync mode, é que um trabalhador que conclui o processamento de um lote pode obter os parâmetros atuais do servidor e iniciar o próximo lote. O trabalhador pode fazer isso, mesmo que o outro trabalhador ainda não tenha concluído o processamento do lote anterior. Também é mais rápido do que o modo dist_sync porque pode levar mais épocas para convergir sem nenhum custo de sincronização.
dist_sync_device
Este modo é o mesmo que dist_syncmodo. A única diferença é que, quando há várias GPUs sendo usadas em cada nódist_sync_device agrega gradientes e atualiza pesos na GPU, enquanto, dist_sync agrega gradientes e atualiza pesos na memória da CPU.
Ele reduz a comunicação cara entre GPU e CPU. É por isso que é mais rápido do quedist_sync. A desvantagem é que aumenta o uso de memória na GPU.
dist_async_device
Este modo funciona da mesma forma que dist_sync_device modo, mas no modo assíncrono.
Neste capítulo, aprenderemos sobre os pacotes Python disponíveis no Apache MXNet.
Pacotes importantes do MXNet Python
MXNet tem os seguintes pacotes Python importantes que iremos discutir um por um -
Autograd (diferenciação automática)
NDArray
KVStore
Gluon
Visualization
Primeiro vamos começar com Autograd Pacote Python para Apache MXNet.
Autograd
Autograd apoia automatic differentiationusado para retropropagar os gradientes da métrica de perda de volta para cada um dos parâmetros. Junto com a retropropagação, ele usa uma abordagem de programação dinâmica para calcular os gradientes com eficiência. É também chamado de diferenciação automática de modo reverso. Essa técnica é muito eficiente em situações de 'fan-in', onde muitos parâmetros afetam uma única métrica de perda.
O que são gradientes?
Os gradientes são os fundamentos do processo de treinamento da rede neural. Basicamente, eles nos dizem como alterar os parâmetros da rede para melhorar seu desempenho.
Como sabemos, as redes neurais (NN) são compostas por operadores como somas, produto, convoluções, etc. Esses operadores, para seus cálculos, utilizam parâmetros como os pesos nos kernels de convolução. Devemos ter que encontrar os valores ideais para esses parâmetros e gradientes nos mostra o caminho e nos leva à solução também.
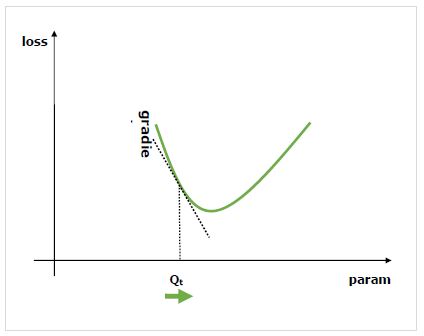
Estamos interessados no efeito da alteração de um parâmetro no desempenho da rede e os gradientes nos dizem o quanto uma determinada variável aumenta ou diminui quando alteramos uma variável da qual depende. O desempenho é geralmente definido usando uma métrica de perda que tentamos minimizar. Por exemplo, para regressão, podemos tentar minimizarL2 perda entre nossas previsões e valor exato, ao passo que para a classificação podemos minimizar o cross-entropy loss.
Depois de calcularmos o gradiente de cada parâmetro com referência à perda, podemos usar um otimizador, como a descida gradiente estocástica.
Como calcular gradientes?
Temos as seguintes opções para calcular gradientes -
Symbolic Differentiation- A primeira opção é a diferenciação simbólica, que calcula as fórmulas para cada gradiente. A desvantagem desse método é que ele levará rapidamente a fórmulas incrivelmente longas conforme a rede se torna mais profunda e as operadoras mais complexas.
Finite Differencing- Outra opção é usar a diferenciação finita, que tenta pequenas diferenças em cada parâmetro e ver como a métrica de perda responde. A desvantagem desse método é que ele seria caro do ponto de vista computacional e pode ter uma precisão numérica pobre.
Automatic differentiation- A solução para as desvantagens dos métodos acima é usar a diferenciação automática para retropropagar os gradientes da métrica de perda de volta para cada um dos parâmetros. A propagação nos permite uma abordagem de programação dinâmica para calcular com eficiência os gradientes. Esse método também é chamado de diferenciação automática no modo reverso.
Diferenciação automática (autograd)
Aqui, entenderemos em detalhes o funcionamento do autograd. Basicamente, funciona seguindo duas etapas -
Stage 1 - Esta fase é chamada ‘Forward Pass’de treinamento. Como o nome indica, nesta etapa ele cria o registro da operadora utilizado pela rede para fazer previsões e calcular a métrica de perda.
Stage 2 - Esta fase é chamada ‘Backward Pass’de treinamento. Como o nome indica, neste estágio ele funciona de trás para frente neste registro. Retrocedendo, avalia as derivadas parciais de cada operadora, voltando ao parâmetro da rede.
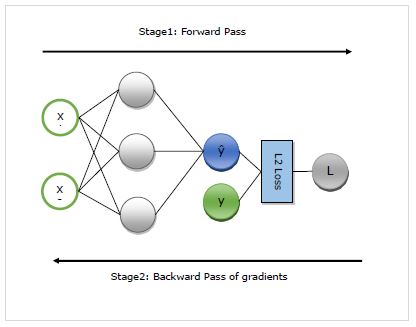
Vantagens do autograd
A seguir estão as vantagens de usar a diferenciação automática (autograd) -
Flexible- A flexibilidade que nos dá na hora de definir nossa rede é um dos grandes benefícios de usar o autograd. Podemos mudar as operações em cada iteração. Eles são chamados de gráficos dinâmicos, que são muito mais complexos de implementar em estruturas que requerem gráfico estático. O Autograd, mesmo em tais casos, ainda será capaz de retropropagar os gradientes corretamente.
Automatic- O autograd é automático, ou seja, as complexidades do procedimento de retropropagação são atendidas por ele para você. Precisamos apenas especificar quais gradientes estamos interessados em calcular.
Efficient - O Autogard calcula os gradientes de forma muito eficiente.
Can use native Python control flow operators- Podemos usar os operadores de fluxo de controle nativos do Python, como if condition e while loop. O autograd ainda será capaz de retropropagar os gradientes de forma eficiente e correta.
Usando autograd no MXNet Gluon
Aqui, com a ajuda de um exemplo, veremos como podemos usar autograd em MXNet Gluon.
Exemplo de Implementação
No exemplo a seguir, implementaremos o modelo de regressão com duas camadas. Após a implementação, usaremos o autograd para calcular automaticamente o gradiente da perda com referência a cada um dos parâmetros de peso -
Primeiro importe o autogrard e outros pacotes necessários da seguinte forma -
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2LossAgora, precisamos definir a rede da seguinte maneira -
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()Agora precisamos definir a perda da seguinte forma -
loss_function = L2Loss()Em seguida, precisamos criar os dados fictícios da seguinte forma -
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])Agora, estamos prontos para nossa primeira passagem para frente pela rede. Queremos autograd para registrar o gráfico computacional para que possamos calcular os gradientes. Para isso, precisamos executar o código de rede no escopo deautograd.record contexto da seguinte forma -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)Agora, estamos prontos para a passagem para trás, que começamos chamando o método para trás na quantidade de juros. A quantidade de interesse em nosso exemplo é perda porque estamos tentando calcular o gradiente de perda com referência aos parâmetros -
loss.backward()Agora, temos gradientes para cada parâmetro da rede, que serão usados pelo otimizador para atualizar o valor do parâmetro para melhorar o desempenho. Vamos verificar os gradientes da 1ª camada da seguinte forma -
N_net[0].weight.grad()Output
A saída é a seguinte−
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>Exemplo de implementação completo
A seguir está o exemplo de implementação completo.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()Neste capítulo, iremos discutir sobre o formato de array multidimensional do MXNet chamado ndarray.
Tratamento de dados com NDArray
Primeiro, veremos como podemos lidar com os dados com NDArray. A seguir estão os pré-requisitos para o mesmo -
Pré-requisitos
Para entender como podemos lidar com dados com este formato de matriz multidimensional, precisamos cumprir os seguintes pré-requisitos:
MXNet instalado em um ambiente Python
Python 2.7.x ou Python 3.x
Exemplo de Implementação
Vamos entender a funcionalidade básica com a ajuda de um exemplo dado abaixo -
Primeiro, precisamos importar MXNet e ndarray do MXNet da seguinte maneira -
import mxnet as mx
from mxnet import ndAssim que importarmos as bibliotecas necessárias, iremos com as seguintes funcionalidades básicas:
Uma matriz 1-D simples com uma lista python
Example
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
O resultado é como mencionado abaixo -
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Uma matriz 2-D com uma lista python
Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
A saída é conforme indicado abaixo -
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>Criação de um NDArray sem qualquer inicialização
Aqui, criaremos uma matriz com 3 linhas e 4 colunas usando .emptyfunção. Também usaremos.full , que terá um operador adicional para o valor que você deseja preencher na matriz.
Example
x = nd.empty((3, 4))
print(x)
x = nd.full((3,4), 8)
print(x)Output
O resultado é dado abaixo -
[[0.000e+00 0.000e+00 0.000e+00 0.000e+00]
[0.000e+00 0.000e+00 2.887e-42 0.000e+00]
[0.000e+00 0.000e+00 0.000e+00 0.000e+00]]
<NDArray 3x4 @cpu(0)>
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]]
<NDArray 3x4 @cpu(0)>Matriz de todos os zeros com a função .zeros
Example
x = nd.zeros((3, 8))
print(x)Output
O resultado é o seguinte -
[[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 3x8 @cpu(0)>Matriz de todos com a função .ones
Example
x = nd.ones((3, 8))
print(x)Output
A saída é mencionada abaixo -
[[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1. 1. 1. 1.]]
<NDArray 3x8 @cpu(0)>Criação de matriz cujos valores são amostrados aleatoriamente
Example
y = nd.random_normal(0, 1, shape=(3, 4))
print(y)Output
O resultado é dado abaixo -
[[ 1.2673576 -2.0345826 -0.32537818 -1.4583491 ]
[-0.11176403 1.3606371 -0.7889914 -0.17639421]
[-0.2532185 -0.42614475 -0.12548696 1.4022992 ]]
<NDArray 3x4 @cpu(0)>Encontrando a dimensão de cada NDArray
Example
y.shapeOutput
O resultado é o seguinte -
(3, 4)Encontrar o tamanho de cada NDArray
Example
y.sizeOutput
12Encontrar o tipo de dados de cada NDArray
Example
y.dtypeOutput
numpy.float32Operações NDArray
Nesta seção, apresentaremos as operações de array do MXNet. O NDArray oferece suporte a um grande número de operações matemáticas padrão e também no local.
Operações Matemáticas Padrão
A seguir estão as operações matemáticas padrão suportadas pelo NDArray -
Adição elementar
Primeiro, precisamos importar MXNet e ndarray do MXNet da seguinte maneira:
import mxnet as mx
from mxnet import nd
x = nd.ones((3, 5))
y = nd.random_normal(0, 1, shape=(3, 5))
print('x=', x)
print('y=', y)
x = x + y
print('x = x + y, x=', x)Output
A saída é fornecida aqui -
x=
[[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]
[1. 1. 1. 1. 1.]]
<NDArray 3x5 @cpu(0)>
y=
[[-1.0554522 -1.3118273 -0.14674698 0.641493 -0.73820823]
[ 2.031364 0.5932667 0.10228804 1.179526 -0.5444829 ]
[-0.34249446 1.1086396 1.2756858 -1.8332436 -0.5289873 ]]
<NDArray 3x5 @cpu(0)>
x = x + y, x=
[[-0.05545223 -0.3118273 0.853253 1.6414931 0.26179177]
[ 3.031364 1.5932667 1.102288 2.1795259 0.4555171 ]
[ 0.6575055 2.1086397 2.2756858 -0.8332436 0.4710127 ]]
<NDArray 3x5 @cpu(0)>Multiplicação elementar
Example
x = nd.array([1, 2, 3, 4])
y = nd.array([2, 2, 2, 1])
x * yOutput
Você verá a seguinte saída−
[2. 4. 6. 4.]
<NDArray 4 @cpu(0)>Exponenciação
Example
nd.exp(x)Output
Ao executar o código, você verá a seguinte saída:
[ 2.7182817 7.389056 20.085537 54.59815 ]
<NDArray 4 @cpu(0)>Matriz transposta para calcular o produto matriz-matriz
Example
nd.dot(x, y.T)Output
A seguir está a saída do código -
[16.]
<NDArray 1 @cpu(0)>Operações no local
Cada vez que, no exemplo acima, executamos uma operação, alocamos uma nova memória para hospedar seu resultado.
Por exemplo, se escrevermos A = A + B, vamos desreferenciar a matriz para a qual A costumava apontar e, em vez disso, apontá-la para a memória recém-alocada. Vamos entender isso com o exemplo dado abaixo, usando a função id () do Python -
print('y=', y)
print('id(y):', id(y))
y = y + x
print('after y=y+x, y=', y)
print('id(y):', id(y))Output
Após a execução, você receberá a seguinte saída -
y=
[2. 2. 2. 1.]
<NDArray 4 @cpu(0)>
id(y): 2438905634376
after y=y+x, y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
id(y): 2438905685664Na verdade, também podemos atribuir o resultado a uma matriz previamente alocada da seguinte forma -
print('x=', x)
z = nd.zeros_like(x)
print('z is zeros_like x, z=', z)
print('id(z):', id(z))
print('y=', y)
z[:] = x + y
print('z[:] = x + y, z=', z)
print('id(z) is the same as before:', id(z))Output
O resultado é mostrado abaixo -
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)>
z is zeros_like x, z=
[0. 0. 0. 0.]
<NDArray 4 @cpu(0)>
id(z): 2438905790760
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)>
z[:] = x + y, z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)>
id(z) is the same as before: 2438905790760Pela saída acima, podemos ver que x + y ainda alocará um buffer temporário para armazenar o resultado antes de copiá-lo para z. Portanto, agora podemos realizar operações no local para fazer melhor uso da memória e evitar buffer temporário. Para fazer isso, especificaremos o argumento de palavra-chave out que cada operador suporta da seguinte forma -
print('x=', x, 'is in id(x):', id(x))
print('y=', y, 'is in id(y):', id(y))
print('z=', z, 'is in id(z):', id(z))
nd.elemwise_add(x, y, out=z)
print('after nd.elemwise_add(x, y, out=z), x=', x, 'is in id(x):', id(x))
print('after nd.elemwise_add(x, y, out=z), y=', y, 'is in id(y):', id(y))
print('after nd.elemwise_add(x, y, out=z), z=', z, 'is in id(z):', id(z))Output
Ao executar o programa acima, você obterá o seguinte resultado -
x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760
after nd.elemwise_add(x, y, out=z), x=
[1. 2. 3. 4.]
<NDArray 4 @cpu(0)> is in id(x): 2438905791152
after nd.elemwise_add(x, y, out=z), y=
[3. 4. 5. 5.]
<NDArray 4 @cpu(0)> is in id(y): 2438905685664
after nd.elemwise_add(x, y, out=z), z=
[4. 6. 8. 9.]
<NDArray 4 @cpu(0)> is in id(z): 2438905790760Contextos NDArray
No Apache MXNet, cada array tem um contexto e um contexto pode ser a CPU, enquanto outros contextos podem ser várias GPUs. As coisas podem ficar ainda piores, quando implantamos o trabalho em vários servidores. É por isso que precisamos atribuir matrizes a contextos de maneira inteligente. Isso irá minimizar o tempo gasto na transferência de dados entre dispositivos.
Por exemplo, tente inicializar uma matriz da seguinte maneira -
from mxnet import nd
z = nd.ones(shape=(3,3), ctx=mx.cpu(0))
print(z)Output
Ao executar o código acima, você verá a seguinte saída -
[[1. 1. 1.]
[1. 1. 1.]
[1. 1. 1.]]
<NDArray 3x3 @cpu(0)>Podemos copiar o NDArray fornecido de um contexto para outro, usando o método copyto () da seguinte maneira -
x_gpu = x.copyto(gpu(0))
print(x_gpu)Matriz NumPy vs. NDArray
Todos nós estamos familiarizados com arrays NumPy, mas o Apache MXNet oferece sua própria implementação de array chamada NDArray. Na verdade, ele foi inicialmente projetado para ser semelhante ao NumPy, mas há uma diferença fundamental -
A principal diferença está na maneira como os cálculos são executados em NumPy e NDArray. Toda manipulação de NDArray em MXNet é feita de forma assíncrona e não bloqueadora, o que significa que, quando escrevemos código como c = a * b, a função é enviada para oExecution Engine, que iniciará o cálculo.
Aqui, aeb são ambos NDArrays. A vantagem de usá-lo é que a função retorna imediatamente e a thread do usuário pode continuar a execução, apesar do cálculo anterior ainda não ter sido concluído.
Funcionamento do mecanismo de execução
Se falamos sobre o funcionamento do mecanismo de execução, ele constrói o gráfico de computação. O gráfico de computação pode reordenar ou combinar alguns cálculos, mas sempre respeita a ordem de dependência.
Por exemplo, se houver outra manipulação com 'X' feita posteriormente no código de programação, o Execution Engine começará a fazê-las assim que o resultado de 'X' estiver disponível. O mecanismo de execução tratará de alguns trabalhos importantes para os usuários, como escrever callbacks para iniciar a execução do código subsequente.
No Apache MXNet, com a ajuda de NDArray, para obter o resultado da computação, precisamos apenas acessar a variável resultante. O fluxo do código será bloqueado até que os resultados do cálculo sejam atribuídos à variável resultante. Dessa forma, ele aumenta o desempenho do código enquanto ainda oferece suporte ao modo de programação imperativo.
Convertendo NDArray em NumPy Array
Vamos aprender como podemos converter NDArray em NumPy Array em MXNet.
Combining higher-level operator with the help of few lower-level operators
Às vezes, podemos montar um operador de nível superior usando os operadores existentes. Um dos melhores exemplos disso é onp.full_like()operador, que não existe na API NDArray. Ele pode ser facilmente substituído por uma combinação de operadores existentes da seguinte forma:
from mxnet import nd
import numpy as np
np_x = np.full_like(a=np.arange(7, dtype=int), fill_value=15)
nd_x = nd.ones(shape=(7,)) * 15
np.array_equal(np_x, nd_x.asnumpy())Output
Obteremos uma saída semelhante à seguinte -
TrueFinding similar operator with different name and/or signature
Entre todos os operadores, alguns deles têm nome ligeiramente diferente, mas são semelhantes em termos de funcionalidade. Um exemplo disso énd.ravel_index() com np.ravel()funções. Da mesma forma, alguns operadores podem ter nomes semelhantes, mas têm assinaturas diferentes. Um exemplo disso énp.split() e nd.split() são similares.
Vamos entender isso com o seguinte exemplo de programação:
def pad_array123(data, max_length):
data_expanded = data.reshape(1, 1, 1, data.shape[0])
data_padded = nd.pad(data_expanded,
mode='constant',
pad_width=[0, 0, 0, 0, 0, 0, 0, max_length - data.shape[0]],
constant_value=0)
data_reshaped_back = data_padded.reshape(max_length)
return data_reshaped_back
pad_array123(nd.array([1, 2, 3]), max_length=10)Output
O resultado é declarado abaixo -
[1. 2. 3. 0. 0. 0. 0. 0. 0. 0.]
<NDArray 10 @cpu(0)>Minimizando o impacto do bloqueio de chamadas
Em alguns casos, temos que usar .asnumpy() ou .asscalar()métodos, mas isso forçará o MXNet a bloquear a execução, até que o resultado possa ser recuperado. Podemos minimizar o impacto de uma chamada de bloqueio chamando.asnumpy() ou .asscalar() métodos no momento, quando pensamos que o cálculo deste valor já está feito.
Exemplo de Implementação
Example
from __future__ import print_function
import mxnet as mx
from mxnet import gluon, nd, autograd
from mxnet.ndarray import NDArray
from mxnet.gluon import HybridBlock
import numpy as np
class LossBuffer(object):
"""
Simple buffer for storing loss value
"""
def __init__(self):
self._loss = None
def new_loss(self, loss):
ret = self._loss
self._loss = loss
return ret
@property
def loss(self):
return self._loss
net = gluon.nn.Dense(10)
ce = gluon.loss.SoftmaxCELoss()
net.initialize()
data = nd.random.uniform(shape=(1024, 100))
label = nd.array(np.random.randint(0, 10, (1024,)), dtype='int32')
train_dataset = gluon.data.ArrayDataset(data, label)
train_data = gluon.data.DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=2)
trainer = gluon.Trainer(net.collect_params(), optimizer='sgd')
loss_buffer = LossBuffer()
for data, label in train_data:
with autograd.record():
out = net(data)
# This call saves new loss and returns previous loss
prev_loss = loss_buffer.new_loss(ce(out, label))
loss_buffer.loss.backward()
trainer.step(data.shape[0])
if prev_loss is not None:
print("Loss: {}".format(np.mean(prev_loss.asnumpy())))Output
O resultado é citado abaixo:
Loss: 2.3373236656188965
Loss: 2.3656985759735107
Loss: 2.3613128662109375
Loss: 2.3197104930877686
Loss: 2.3054862022399902
Loss: 2.329197406768799
Loss: 2.318927526473999Outro pacote MXNet Python mais importante é o Gluon. Neste capítulo, iremos discutir este pacote. O Gluon fornece uma API clara, concisa e simples para projetos DL. Ele permite que o Apache MXNet crie protótipos, construa e treine modelos DL sem perder a velocidade de treinamento.
Blocos
Os blocos formam a base de projetos de rede mais complexos. Em uma rede neural, conforme a complexidade da rede neural aumenta, precisamos passar do projeto de camadas simples para camadas inteiras de neurônios. Por exemplo, o design NN como o ResNet-152 tem um grau muito razoável de regularidade ao consistir emblocks de camadas repetidas.
Exemplo
No exemplo dado abaixo, iremos escrever um bloco simples de código, a saber, um bloco para um perceptron multicamadas.
from mxnet import nd
from mxnet.gluon import nn
x = nd.random.uniform(shape=(2, 20))
N_net = nn.Sequential()
N_net.add(nn.Dense(256, activation='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
Isso produz a seguinte saída:
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>Etapas necessárias para ir desde a definição de camadas até a definição de blocos de uma ou mais camadas -
Step 1 - Bloco recebe os dados como entrada.
Step 2- Agora, os blocos irão armazenar o estado na forma de parâmetros. Por exemplo, no exemplo de codificação acima, o bloco contém duas camadas ocultas e precisamos de um local para armazenar seus parâmetros.
Step 3- O próximo bloco invocará a função direta para realizar a propagação direta. Também é chamado de computação direta. Como parte da primeira chamada de encaminhamento, os blocos inicializam os parâmetros de maneira lenta.
Step 4- Por fim, os blocos invocarão a função de retrocesso e calcularão o gradiente com referência à sua entrada. Normalmente, esta etapa é executada automaticamente.
Bloco Sequencial
Um bloco sequencial é um tipo especial de bloco no qual os dados fluem por uma sequência de blocos. Neste, cada bloco aplicado à saída de um antes com o primeiro bloco sendo aplicado aos próprios dados de entrada.
Vamos ver como sequential trabalhos de classe -
from mxnet import nd
from mxnet.gluon import nn
class MySequential(nn.Block):
def __init__(self, **kwargs):
super(MySequential, self).__init__(**kwargs)
def add(self, block):
self._children[block.name] = block
def forward(self, x):
for block in self._children.values():
x = block(x)
return x
x = nd.random.uniform(shape=(2, 20))
N_net = MySequential()
N_net.add(nn.Dense(256, activation
='relu'))
N_net.add(nn.Dense(10))
N_net.initialize()
N_net(x)Output
A saída é fornecida aqui -
[[ 0.09543004 0.04614332 -0.00286655 -0.07790346 -0.05130241 0.02942038
0.08696645 -0.0190793 -0.04122177 0.05088576]
[ 0.0769287 0.03099706 0.00856576 -0.044672 -0.06926838 0.09132431
0.06786592 -0.06187843 -0.03436674 0.04234696]]
<NDArray 2x10 @cpu(0)>Bloco Personalizado
Podemos facilmente ir além da concatenação com bloco sequencial conforme definido acima. Mas, se quisermos fazer personalizações, oBlockclasse também nos fornece a funcionalidade necessária. A classe de bloco tem um construtor de modelo fornecido no módulo nn. Podemos herdar esse construtor de modelo para definir o modelo que queremos.
No exemplo a seguir, o MLP class substitui o __init__ e funções de encaminhamento da classe Block.
Vamos ver como funciona.
class MLP(nn.Block):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Dense(256, activation='relu') # Hidden layer
self.output = nn.Dense(10) # Output layer
def forward(self, x):
hidden_out = self.hidden(x)
return self.output(hidden_out)
x = nd.random.uniform(shape=(2, 20))
N_net = MLP()
N_net.initialize()
N_net(x)Output
Ao executar o código, você verá a seguinte saída:
[[ 0.07787763 0.00216403 0.01682201 0.03059879 -0.00702019 0.01668715
0.04822846 0.0039432 -0.09300035 -0.04494302]
[ 0.08891078 -0.00625484 -0.01619131 0.0380718 -0.01451489 0.02006172
0.0303478 0.02463485 -0.07605448 -0.04389168]]
<NDArray 2x10 @cpu(0)>Camadas Personalizadas
A API Gluon do Apache MXNet vem com um número modesto de camadas predefinidas. Mas ainda em algum ponto, podemos descobrir que uma nova camada é necessária. Podemos facilmente adicionar uma nova camada na API Gluon. Nesta seção, veremos como podemos criar uma nova camada do zero.
A Camada Personalizada Mais Simples
Para criar uma nova camada na API Gluon, devemos criar uma classe herda da classe Block que fornece a funcionalidade mais básica. Podemos herdar todas as camadas predefinidas diretamente ou por meio de outras subclasses.
Para criar a nova camada, o único método de instância necessário para ser implementado é forward (self, x). Este método define o que exatamente nossa camada fará durante a propagação direta. Conforme discutido anteriormente, a passagem de propagação reversa para blocos será feita pelo próprio Apache MXNet automaticamente.
Exemplo
No exemplo abaixo, iremos definir uma nova camada. Também iremos implementarforward() método para normalizar os dados de entrada ajustando-os em um intervalo de [0, 1].
from __future__ import print_function
import mxnet as mx
from mxnet import nd, gluon, autograd
from mxnet.gluon.nn import Dense
mx.random.seed(1)
class NormalizationLayer(gluon.Block):
def __init__(self):
super(NormalizationLayer, self).__init__()
def forward(self, x):
return (x - nd.min(x)) / (nd.max(x) - nd.min(x))
x = nd.random.uniform(shape=(2, 20))
N_net = NormalizationLayer()
N_net.initialize()
N_net(x)Output
Ao executar o programa acima, você obterá o seguinte resultado -
[[0.5216355 0.03835821 0.02284337 0.5945146 0.17334817 0.69329053
0.7782702 1. 0.5508242 0. 0.07058554 0.3677264
0.4366546 0.44362497 0.7192635 0.37616986 0.6728799 0.7032008
0.46907538 0.63514024]
[0.9157533 0.7667402 0.08980197 0.03593295 0.16176797 0.27679572
0.07331014 0.3905285 0.6513384 0.02713427 0.05523694 0.12147208
0.45582628 0.8139887 0.91629887 0.36665893 0.07873632 0.78268915
0.63404864 0.46638715]]
<NDArray 2x20 @cpu(0)>Hibridização
Pode ser definido como um processo usado pelo Apache MXNet para criar um gráfico simbólico de uma computação direta. A hibridização permite que o MXNet aumente o desempenho de computação otimizando o gráfico simbólico computacional. Em vez de herdar diretamente deBlock, na verdade, podemos descobrir que, ao implementar as camadas existentes, um bloco herda de um HybridBlock.
A seguir estão as razões para isso -
Allows us to write custom layers: HybridBlock nos permite escrever camadas personalizadas que podem ser usadas posteriormente na programação imperativa e simbólica.
Increase computation performance- HybridBlock otimiza o gráfico simbólico computacional que permite ao MXNet aumentar o desempenho computacional.
Exemplo
Neste exemplo, estaremos reescrevendo nossa camada de exemplo, criada acima, usando HybridBlock:
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self):
super(NormalizationHybridLayer, self).__init__()
def hybrid_forward(self, F, x):
return F.broadcast_div(F.broadcast_sub(x, F.min(x)), (F.broadcast_sub(F.max(x), F.min(x))))
layer_hybd = NormalizationHybridLayer()
layer_hybd(nd.array([1, 2, 3, 4, 5, 6], ctx=mx.cpu()))Output
O resultado é declarado abaixo:
[0. 0.2 0.4 0.6 0.8 1. ]
<NDArray 6 @cpu(0)>A hibridização não tem nada a ver com computação na GPU e pode-se treinar redes hibridizadas ou não hibridizadas na CPU e na GPU.
Diferença entre Block e HybridBlock
Se compararmos o Block Classe e HybridBlock, nós veremos isso HybridBlock já tem o seu forward() método implementado. HybridBlock define um hybrid_forward()método que precisa ser implementado durante a criação das camadas. O argumento F cria a principal diferença entreforward() e hybrid_forward(). Na comunidade MXNet, o argumento F é conhecido como back-end. F pode se referir amxnet.ndarray API (usado para programação imperativa) ou mxnet.symbol API (usado para programação simbólica).
Como adicionar camada personalizada a uma rede?
Em vez de usar camadas personalizadas separadamente, essas camadas são usadas com camadas predefinidas. Podemos usar qualquer umSequential ou HybridSequentialcontêineres de uma rede neural sequencial. Conforme discutido anteriormente também,Sequential recipiente herda de Bloco e HybridSequential herdar de HybridBlock respectivamente.
Exemplo
No exemplo abaixo, estaremos criando uma rede neural simples com uma camada personalizada. A saída deDense (5) camada será a entrada de NormalizationHybridLayer. A saída deNormalizationHybridLayer se tornará a entrada de Dense (1) camada.
net = gluon.nn.HybridSequential()
with net.name_scope():
net.add(Dense(5))
net.add(NormalizationHybridLayer())
net.add(Dense(1))
net.initialize(mx.init.Xavier(magnitude=2.24))
net.hybridize()
input = nd.random_uniform(low=-10, high=10, shape=(10, 2))
net(input)Output
Você verá a seguinte saída -
[[-1.1272651]
[-1.2299833]
[-1.0662932]
[-1.1805027]
[-1.3382034]
[-1.2081106]
[-1.1263978]
[-1.2524893]
[-1.1044774]
[-1.316593 ]]
<NDArray 10x1 @cpu(0)>Parâmetros de camada personalizados
Em uma rede neural, uma camada possui um conjunto de parâmetros associados a ela. Às vezes nos referimos a eles como pesos, que é o estado interno de uma camada. Esses parâmetros desempenham papéis diferentes -
Às vezes, esses são os que queremos aprender durante a etapa de retropropagação.
Às vezes, essas são apenas constantes que queremos usar durante o passe para frente.
Se falamos sobre o conceito de programação, esses parâmetros (pesos) de um bloco são armazenados e acessados via ParameterDict classe que ajuda na inicialização, atualização, salvamento e carregamento deles.
Exemplo
No exemplo abaixo, vamos definir dois conjuntos de parâmetros a seguir -
Parameter weights- Isso é treinável e sua forma é desconhecida durante a fase de construção. Isso será inferido na primeira execução da propagação direta.
Parameter scale- Esta é uma constante cujo valor não muda. Ao contrário dos pesos dos parâmetros, sua forma é definida durante a construção.
class NormalizationHybridLayer(gluon.HybridBlock):
def __init__(self, hidden_units, scales):
super(NormalizationHybridLayer, self).__init__()
with self.name_scope():
self.weights = self.params.get('weights',
shape=(hidden_units, 0),
allow_deferred_init=True)
self.scales = self.params.get('scales',
shape=scales.shape,
init=mx.init.Constant(scales.asnumpy()),
differentiable=False)
def hybrid_forward(self, F, x, weights, scales):
normalized_data = F.broadcast_div(F.broadcast_sub(x, F.min(x)),
(F.broadcast_sub(F.max(x), F.min(x))))
weighted_data = F.FullyConnected(normalized_data, weights, num_hidden=self.weights.shape[0], no_bias=True)
scaled_data = F.broadcast_mul(scales, weighted_data)
return scaled_dataEste capítulo trata dos pacotes Python KVStore e visualização.
Pacote KVStore
Lojas KV significa armazenamento de valor-chave. É um componente crítico usado para treinamento em vários dispositivos. É importante porque a comunicação de parâmetros entre dispositivos em uma única máquina ou em várias máquinas é transmitida por meio de um ou mais servidores com um KVStore para os parâmetros.
Vamos entender o funcionamento do KVStore com a ajuda dos seguintes pontos:
Cada valor em KVStore é representado por um key e um value.
Cada array de parâmetros na rede é atribuído a um key e os pesos dessa matriz de parâmetro são referidos por value.
Depois disso, os nós de trabalho pushgradientes após o processamento de um lote. Eles tambémpull pesos atualizados antes de processar um novo lote.
Em palavras simples, podemos dizer que KVStore é um lugar para compartilhamento de dados onde, cada dispositivo pode enviar e retirar dados.
Data Push-In e Pull-Out
O KVStore pode ser considerado como um único objeto compartilhado por diferentes dispositivos, como GPUs e computadores, onde cada dispositivo é capaz de inserir e extrair dados.
A seguir estão as etapas de implementação que precisam ser seguidas por dispositivos para inserir e retirar dados:
Etapas de implementação
Initialisation- O primeiro passo é inicializar os valores. Aqui, para nosso exemplo, estaremos inicializando um par (int, NDArray) em KVStrore e depois retirando os valores -
import mxnet as mx
kv = mx.kv.create('local') # create a local KVStore.
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())Output
Isso produz a seguinte saída -
[[2. 2. 2.]
[2. 2. 2.]
[2. 2. 2.]]Push, Aggregate, and Update - Uma vez inicializado, podemos colocar um novo valor no KVStore com a mesma forma da chave -
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a)
print(a.asnumpy())Output
O resultado é dado abaixo -
[[8. 8. 8.]
[8. 8. 8.]
[8. 8. 8.]]Os dados usados para envio podem ser armazenados em qualquer dispositivo, como GPUs ou computadores. Também podemos inserir vários valores na mesma chave. Neste caso, o KVStore primeiro soma todos esses valores e, em seguida, envia o valor agregado da seguinte forma -
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())Output
Você verá a seguinte saída -
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Para cada push que você aplicou, o KVStore combinará o valor enviado com o valor já armazenado. Isso será feito com a ajuda de um atualizador. Aqui, o atualizador padrão é ASSIGN.
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv.set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())Output
Ao executar o código acima, você verá a seguinte saída -
[[4. 4. 4.]
[4. 4. 4.]
[4. 4. 4.]]Example
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())Output
A seguir está a saída do código -
update on key: 3
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Pull - Assim como Push, também podemos extrair o valor de vários dispositivos com uma única chamada, da seguinte forma -
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Output
O resultado é declarado abaixo -
[[6. 6. 6.]
[6. 6. 6.]
[6. 6. 6.]]Exemplo de implementação completo
Abaixo está o exemplo de implementação completo -
import mxnet as mx
kv = mx.kv.create('local')
shape = (3,3)
kv.init(3, mx.nd.ones(shape)*2)
a = mx.nd.zeros(shape)
kv.pull(3, out = a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape)*8)
kv.pull(3, out = a) # pull out the value
print(a.asnumpy())
contexts = [mx.cpu(i) for i in range(4)]
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.push(3, b)
kv.pull(3, out = a)
print(a.asnumpy())
def update(key, input, stored):
print("update on key: %d" % key)
stored += input * 2
kv._set_updater(update)
kv.pull(3, out=a)
print(a.asnumpy())
kv.push(3, mx.nd.ones(shape))
kv.pull(3, out=a)
print(a.asnumpy())
b = [mx.nd.ones(shape, ctx) for ctx in contexts]
kv.pull(3, out = b)
print(b[1].asnumpy())Lidando com pares de valores-chave
Todas as operações que implementamos acima envolvem uma única chave, mas o KVStore também fornece uma interface para a list of key-value pairs -
Para um único dispositivo
A seguir está um exemplo para mostrar uma interface KVStore para uma lista de pares chave-valor para um único dispositivo -
keys = [5, 7, 9]
kv.init(keys, [mx.nd.ones(shape)]*len(keys))
kv.push(keys, [mx.nd.ones(shape)]*len(keys))
b = [mx.nd.zeros(shape)]*len(keys)
kv.pull(keys, out = b)
print(b[1].asnumpy())Output
Você receberá a seguinte saída -
update on key: 5
update on key: 7
update on key: 9
[[3. 3. 3.]
[3. 3. 3.]
[3. 3. 3.]]Para vários dispositivos
A seguir está um exemplo para mostrar uma interface KVStore para uma lista de pares chave-valor para vários dispositivos -
b = [[mx.nd.ones(shape, ctx) for ctx in contexts]] * len(keys)
kv.push(keys, b)
kv.pull(keys, out = b)
print(b[1][1].asnumpy())Output
Você verá a seguinte saída -
update on key: 5
update on key: 7
update on key: 9
[[11. 11. 11.]
[11. 11. 11.]
[11. 11. 11.]]Pacote de visualização
O pacote de visualização é o pacote Apache MXNet usado para representar a rede neural (NN) como um gráfico de computação que consiste em nós e arestas.
Visualize a rede neural
No exemplo abaixo, usaremos mx.viz.plot_networkpara visualizar a rede neural. A seguir são os pré-requisitos para isso -
Prerequisites
Caderno Jupyter
Biblioteca Graphviz
Exemplo de Implementação
No exemplo abaixo, iremos visualizar um NN de amostra para fatoração de matriz linear -
import mxnet as mx
user = mx.symbol.Variable('user')
item = mx.symbol.Variable('item')
score = mx.symbol.Variable('score')
# Set the dummy dimensions
k = 64
max_user = 100
max_item = 50
# The user feature lookup
user = mx.symbol.Embedding(data = user, input_dim = max_user, output_dim = k)
# The item feature lookup
item = mx.symbol.Embedding(data = item, input_dim = max_item, output_dim = k)
# predict by the inner product and then do sum
N_net = user * item
N_net = mx.symbol.sum_axis(data = N_net, axis = 1)
N_net = mx.symbol.Flatten(data = N_net)
# Defining the loss layer
N_net = mx.symbol.LinearRegressionOutput(data = N_net, label = score)
# Visualize the network
mx.viz.plot_network(N_net)Este capítulo explica a biblioteca ndarray que está disponível no Apache MXNet.
Mxnet.ndarray
A biblioteca NDArray do Apache MXNet define o núcleo DS (estruturas de dados) para todos os cálculos matemáticos. Duas tarefas fundamentais do NDArray são as seguintes -
Ele oferece suporte à execução rápida em uma ampla gama de configurações de hardware.
Ele paralela automaticamente várias operações em todo o hardware disponível.
O exemplo dado abaixo mostra como se pode criar um NDArray usando 1-D e 2-D 'array' de uma lista Python regular -
import mxnet as mx
from mxnet import nd
x = nd.array([1,2,3,4,5,6,7,8,9,10])
print(x)Output
O resultado é fornecido abaixo:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
<NDArray 10 @cpu(0)>Example
y = nd.array([[1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10], [1,2,3,4,5,6,7,8,9,10]])
print(y)Output
Isso produz a seguinte saída -
[[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]]
<NDArray 3x10 @cpu(0)>Agora vamos discutir em detalhes sobre as classes, funções e parâmetros da API ndarray do MXNet.
Aulas
A tabela a seguir consiste nas classes da API ndarray do MXNet -
| Classe | Definição |
|---|---|
| CachedOp (sym [, sinalizadores]) | É usado para identificador de operador em cache. |
| NDArray (identificador [, gravável]) | É usado como um objeto de matriz que representa uma matriz homogênea e multidimensional de itens de tamanho fixo. |
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos pela API mxnet.ndarray -
| Função e seus parâmetros | Definição |
|---|---|
| Activation([dados, act_type, saída, nome]) | Ele aplica uma função de ativação a nível de elemento para a entrada. Suporta funções de ativação relu, sigmóide, tanh, softrelu e softsign. |
| BatchNorm([dados, gama, beta, média_movente, ...]) | É usado para normalização de lote. Esta função normaliza um lote de dados por média e variância. Ele aplica uma escala gama e deslocamento beta. |
| BilinearSampler([dados, grade, cudnn_off, ...]) | Esta função aplica a amostragem bilinear ao mapa de características de entrada. Na verdade, é a chave de “Redes de Transformadores Espaciais”. Se você está familiarizado com a função de remapeamento em OpenCV, o uso desta função é bastante semelhante a isso. A única diferença é que ele tem o passe para trás. |
| BlockGrad ([data, out, name]) | Como o nome especifica, esta função interrompe a computação de gradiente. Isso basicamente impede que o gradiente acumulado das entradas flua através desse operador na direção inversa. |
| elenco ([data, dtype, out, name]) | Esta função irá converter todos os elementos da entrada para um novo tipo. |
Exemplos de implementação
No exemplo abaixo, usaremos a função BilinierSampler () para diminuir o zoom dos dados duas vezes e deslocar os dados horizontalmente em -1 pixel -
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
affine_matrix = nd.array([[2, 0, 0],
[0, 2, 0]])
affine_matrix = nd.reshape(affine_matrix, shape=(1, 6))
grid = nd.GridGenerator(data=affine_matrix, transform_type='affine', target_shape=(4, 4))
output = nd.BilinearSampler(data, grid)Output
Ao executar o código acima, você verá a seguinte saída:
[[[[0. 0. 0. 0. ]
[0. 4.0000005 6.25 0. ]
[0. 1.5 4. 0. ]
[0. 0. 0. 0. ]]]]
<NDArray 1x1x4x4 @cpu(0)>A saída acima mostra a redução dos dados duas vezes.
O exemplo de deslocamento dos dados em -1 pixel é o seguinte -
import mxnet as mx
from mxnet import nd
data = nd.array([[[[2, 5, 3, 6],
[1, 8, 7, 9],
[0, 4, 1, 8],
[2, 0, 3, 4]]]])
warp_matrix = nd.array([[[[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 1]],
[[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]]]])
grid = nd.GridGenerator(data=warp_matrix, transform_type='warp')
output = nd.BilinearSampler(data, grid)Output
O resultado é declarado abaixo -
[[[[5. 3. 6. 0.]
[8. 7. 9. 0.]
[4. 1. 8. 0.]
[0. 3. 4. 0.]]]]
<NDArray 1x1x4x4 @cpu(0)>Da mesma forma, o exemplo a seguir mostra o uso da função cast () -
nd.cast(nd.array([300, 10.1, 15.4, -1, -2]), dtype='uint8')Output
Após a execução, você receberá a seguinte saída -
[ 44 10 15 255 254]
<NDArray 5 @cpu(0)>ndarray.contrib
A API Contrib NDArray é definida no pacote ndarray.contrib. Normalmente fornece muitas APIs experimentais úteis para novos recursos. Esta API funciona como um local para a comunidade onde eles podem experimentar os novos recursos. O colaborador do recurso também receberá o feedback.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.ndarray.contrib API -
| Função e seus parâmetros | Definição |
|---|---|
| rand_zipfian(true_classes, num_sampled, ...) | Esta função extrai amostras aleatórias de uma distribuição aproximadamente Zipfian. A distribuição básica desta função é a distribuição Zipfian. Esta função amostra aleatoriamente num_sampled candidatos e os elementos de sampled_candidates são extraídos da distribuição de base fornecida acima. |
| foreach(corpo, dados, init_states) | Como o nome indica, essa função executa um loop for com computação definida pelo usuário sobre NDArrays na dimensão 0. Essa função simula um loop for e o corpo tem o cálculo para uma iteração do loop for. |
| while_loop (cond, func, loop_vars [, ...]) | Como o nome indica, esta função executa um loop while com computação definida pelo usuário e condição de loop. Esta função simula um loop while que literalmente faz cálculos personalizados se a condição for satisfeita. |
| cond(pred, then_func, else_func) | Como o nome indica, essa função executa um if-then-else usando condição e computação definidas pelo usuário. Esta função simula uma ramificação semelhante a if que escolhe fazer um dos dois cálculos personalizados de acordo com a condição especificada. |
| isinf(dados) | Esta função executa uma verificação de elemento para determinar se o NDArray contém um elemento infinito ou não. |
| getnnz([dados, eixo, saída, nome]) | Esta função nos dá o número de valores armazenados para um tensor esparso. Também inclui zeros explícitos. Ele suporta apenas matriz CSR na CPU. |
| requantize ([data, min_range, max_range,…]) | Esta função requantiza os dados fornecidos que são quantizados em int32 e os limites correspondentes, em int8, usando os limites mínimo e máximo calculados em tempo de execução ou a partir da calibração. |
Exemplos de implementação
No exemplo abaixo, usaremos a função rand_zipfian para extrair amostras aleatórias de uma distribuição aproximadamente Zipfian -
import mxnet as mx
from mxnet import nd
trueclass = mx.nd.array([2])
samples, exp_count_true, exp_count_sample = mx.nd.contrib.rand_zipfian(trueclass, 3, 4)
samplesOutput
Você verá a seguinte saída -
[0 0 1]
<NDArray 3 @cpu(0)>Example
exp_count_trueOutput
O resultado é fornecido abaixo:
[0.53624076]
<NDArray 1 @cpu(0)>Example
exp_count_sampleOutput
Isso produz a seguinte saída:
[1.29202967 1.29202967 0.75578891]
<NDArray 3 @cpu(0)>No exemplo abaixo, estaremos usando a função while_loop para executar um loop while para computação definida pelo usuário e condição de loop:
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_var = (mx.nd.array([0], dtype="int64"), mx.nd.array([1], dtype="int64"))
outputs, states = mx.nd.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
outputsOutput
O resultado é mostrado abaixo -
[
[[ 1]
[ 2]
[ 4]
[ 7]
[ 11]
[ 16]
[ 22]
[ 29]
[3152434450384]
[ 257]]
<NDArray 10x1 @cpu(0)>]Example
StatesOutput
Isso produz a seguinte saída -
[
[8]
<NDArray 1 @cpu(0)>,
[29]
<NDArray 1 @cpu(0)>]ndarray.image
A API Image NDArray é definida no pacote ndarray.image. Como o nome indica, normalmente é usado para imagens e seus recursos.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.ndarray.image API-
| Função e seus parâmetros | Definição |
|---|---|
| adjust_lighting([dados, alfa, saída, nome]) | Como o nome indica, esta função ajusta o nível de iluminação da entrada. Segue o estilo AlexNet. |
| crop([dados, x, y, largura, altura, saída, nome]) | Com a ajuda desta função, podemos recortar uma imagem NDArray de forma (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. |
| normalize([dados, média, padrão, saída, nome]) | Ele normalizará um tensor de forma (C x H x W) ou (N x C x H x W) com mean e standard deviation(SD). |
| random_crop ([data, xrange, yrange, width, ...]) | Semelhante a crop (), ele corta aleatoriamente uma imagem NDArray de formato (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. Isso aumentará a amostra do resultado se src for menor que o tamanho. |
| random_lighting([dados, alfa_std, saída, nome]) | Como o nome indica, esta função adiciona o ruído PCA aleatoriamente. Também segue o estilo AlexNet. |
| random_resized_crop([data, xrange, yrange, ...]) | Ele também corta uma imagem aleatoriamente NDArray de forma (A x L x C) ou (N x A x L x C) para o tamanho fornecido. Isso aumentará a amostra do resultado, se src for menor que o tamanho. Ele irá randomizar a área e a proporção também. |
| resize([dados, tamanho, keep_ratio, interp, ...]) | Como o nome indica, esta função irá redimensionar uma imagem NDArray de formato (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. |
| to_tensor([dados, saída, nome]) | Ele converte uma imagem NDArray de forma (H x W x C) ou (N x A x W x C) com os valores no intervalo [0, 255] em um tensor NDArray de forma (C x H x W) ou ( N x C x H x W) com os valores no intervalo [0, 1]. |
Exemplos de implementação
No exemplo abaixo, estaremos usando a função to_tensor para converter NDArray de imagem de forma (H x W x C) ou (N x H x W x C) com os valores no intervalo [0, 255] para um tensor NDArray de forma (C x H x W) ou (N x C x A x W) com os valores no intervalo [0, 1].
import numpy as np
img = mx.nd.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
Você verá a seguinte saída -
[[[0.972549 0.5058824 ]
[0.6039216 0.01960784]
[0.28235295 0.35686275]
[0.11764706 0.8784314 ]]
[[0.8745098 0.9764706 ]
[0.4509804 0.03529412]
[0.9764706 0.29411766]
[0.6862745 0.4117647 ]]
[[0.46666667 0.05490196]
[0.7372549 0.4392157 ]
[0.11764706 0.47843137]
[0.31764707 0.91764706]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.nd.image.to_tensor(img)Output
Ao executar o código, você verá a seguinte saída -
[[[[0.0627451 0.5647059 ]
[0.2627451 0.9137255 ]
[0.57254905 0.27450982]
[0.6666667 0.64705884]]
[[0.21568628 0.5647059 ]
[0.5058824 0.09019608]
[0.08235294 0.31764707]
[0.8392157 0.7137255 ]]
[[0.6901961 0.8627451 ]
[0.52156866 0.91764706]
[0.9254902 0.00784314]
[0.12941177 0.8392157 ]]]
[[[0.28627452 0.39607844]
[0.01960784 0.36862746]
[0.6745098 0.7019608 ]
[0.9607843 0.7529412 ]]
[[0.2627451 0.58431375]
[0.16470589 0.00392157]
[0.5686275 0.73333335]
[0.43137255 0.57254905]]
[[0.18039216 0.54901963]
[0.827451 0.14509805]
[0.26666668 0.28627452]
[0.24705882 0.39607844]]]]
<NDArgt;ray 2x3x4x2 @cpu(0)>No exemplo abaixo, estaremos usando a função normalize para normalizar um tensor de forma (C x H x W) ou (N x C x H x W) com mean e standard deviation(SD).
img = mx.nd.random.uniform(0, 1, (3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Isso produz a seguinte saída -
[[[ 0.29391178 0.3218054 ]
[ 0.23084386 0.19615503]
[ 0.24175143 0.21988946]
[ 0.16710812 0.1777354 ]]
[[-0.02195817 -0.3847335 ]
[-0.17800489 -0.30256534]
[-0.28807247 -0.19059572]
[-0.19680339 -0.26256624]]
[[-1.9808068 -1.5298678 ]
[-1.6984252 -1.2839255 ]
[-1.3398265 -1.712009 ]
[-1.7099224 -1.6165378 ]]]
<NDArray 3x4x2 @cpu(0)>Example
img = mx.nd.random.uniform(0, 1, (2, 3, 4, 2))
mx.nd.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
Ao executar o código acima, você verá a seguinte saída -
[[[[ 2.0600514e-01 2.4972327e-01]
[ 1.4292289e-01 2.9281738e-01]
[ 4.5158025e-02 3.4287784e-02]
[ 9.9427439e-02 3.0791296e-02]]
[[-2.1501756e-01 -3.2297665e-01]
[-2.0456362e-01 -2.2409186e-01]
[-2.1283737e-01 -4.8318747e-01]
[-1.7339960e-01 -1.5519112e-02]]
[[-1.3478968e+00 -1.6790028e+00]
[-1.5685816e+00 -1.7787373e+00]
[-1.1034534e+00 -1.8587360e+00]
[-1.6324382e+00 -1.9027401e+00]]]
[[[ 1.4528830e-01 3.2801408e-01]
[ 2.9730779e-01 8.6780310e-02]
[ 2.6873133e-01 1.7900752e-01]
[ 2.3462953e-01 1.4930873e-01]]
[[-4.4988656e-01 -4.5021546e-01]
[-4.0258706e-02 -3.2384416e-01]
[-1.4287934e-01 -2.6537544e-01]
[-5.7649612e-04 -7.9429924e-02]]
[[-1.8505517e+00 -1.0953522e+00]
[-1.1318740e+00 -1.9624406e+00]
[-1.8375070e+00 -1.4916846e+00]
[-1.3844404e+00 -1.8331525e+00]]]]
<NDArray 2x3x4x2 @cpu(0)>ndarray.random
A API Random NDArray é definida no pacote ndarray.random. Como o nome indica, é o gerador de distribuição aleatória NDArray API do MXNet.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.ndarray.random API -
| Função e seus parâmetros | Definição |
|---|---|
| uniforme ([baixo, alto, forma, tipo d, ctx, fora]) | Ele gera amostras aleatórias de uma distribuição uniforme. |
| normal ([local, escala, forma, tipo d, ctx, saída]) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana). |
| randn (* forma, ** kwargs) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana). |
| exponencial ([escala, forma, tipo d, ctx, saída]) | Ele gera amostras de uma distribuição exponencial. |
| gama ([alpha, beta, shape, dtype, ctx, out]) | Ele gera amostras aleatórias de uma distribuição gama. |
| multinomial (dados [, forma, get_prob, out, dtype]) | Ele gera amostragem simultânea de várias distribuições multinomiais. |
| binomial_ negativo ([k, p, forma, tipo d, ctx, saída]) | Ele gera amostras aleatórias de uma distribuição binomial negativa. |
| generalized_negative_binomial ([mu, alpha, ...]) | Ele gera amostras aleatórias de uma distribuição binomial negativa generalizada. |
| embaralhar (dados, ** kwargs) | Ele embaralha os elementos aleatoriamente. |
| randint (baixo, alto [, forma, tipo d, ctx, fora]) | Ele gera amostras aleatórias de uma distribuição uniforme discreta. |
| exponential_like ([data, lam, out, name]) | Ele gera amostras aleatórias de uma distribuição exponencial de acordo com a forma da matriz de entrada. |
| gamma_like ([dados, alfa, beta, saída, nome]) | Ele gera amostras aleatórias de uma distribuição gama de acordo com a forma da matriz de entrada. |
| generalized_negative_binomial_like ([dados, ...]) | Ele gera amostras aleatórias de uma distribuição binomial negativa generalizada, de acordo com a forma da matriz de entrada. |
| negative_binomial_like ([data, k, p, out, name]) | Ele gera amostras aleatórias de uma distribuição binomial negativa, de acordo com a forma da matriz de entrada. |
| normal_like ([dados, loc, escala, saída, nome]) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana), de acordo com a forma da matriz de entrada. |
| poisson_like ([data, lam, out, name]) | Ele gera amostras aleatórias de uma distribuição de Poisson, de acordo com a forma do array de entrada. |
| uniform_like ([dados, baixo, alto, fora, nome]) | Ele gera amostras aleatórias a partir de uma distribuição uniforme, de acordo com a forma da matriz de entrada. |
Exemplos de implementação
No exemplo abaixo, vamos tirar amostras aleatórias de uma distribuição uniforme. Para isso estarei usando a funçãouniform().
mx.nd.random.uniform(0, 1)Output
A saída é mencionada abaixo -
[0.12381998]
<NDArray 1 @cpu(0)>Example
mx.nd.random.uniform(-1, 1, shape=(2,))Output
O resultado é dado abaixo -
[0.558102 0.69601643]
<NDArray 2 @cpu(0)>Example
low = mx.nd.array([1,2,3])
high = mx.nd.array([2,3,4])
mx.nd.random.uniform(low, high, shape=2)Output
Você verá a seguinte saída -
[[1.8649333 1.8073189]
[2.4113967 2.5691009]
[3.1399727 3.4071832]]
<NDArray 3x2 @cpu(0)>No exemplo abaixo, vamos extrair amostras aleatórias de uma distribuição binomial negativa generalizada. Para isso, estaremos usando a funçãogeneralized_negative_binomial().
mx.nd.random.generalized_negative_binomial(10, 0.5)Output
Ao executar o código acima, você verá a seguinte saída -
[1.]
<NDArray 1 @cpu(0)>Example
mx.nd.random.generalized_negative_binomial(10, 0.5, shape=(2,))Output
A saída é fornecida aqui -
[16. 23.]
<NDArray 2 @cpu(0)>Example
mu = mx.nd.array([1,2,3])
alpha = mx.nd.array([0.2,0.4,0.6])
mx.nd.random.generalized_negative_binomial(mu, alpha, shape=2)Output
A seguir está a saída do código -
[[0. 0.]
[4. 1.]
[9. 3.]]
<NDArray 3x2 @cpu(0)>ndarray.utils
O utilitário NDArray API é definido no pacote ndarray.utils. Como o nome indica, ele fornece as funções de utilitário para NDArray e BaseSparseNDArray.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.ndarray.utils API -
| Função e seus parâmetros | Definição |
|---|---|
| zeros (forma [, ctx, dtype, stype]) | Esta função retornará um novo array de forma e tipo fornecidos, preenchido com zeros. |
| vazio (forma [, ctx, dtype, stype]) | Ele retornará uma nova matriz com a forma e o tipo fornecidos, sem inicializar as entradas. |
| array (source_array [, ctx, dtype]) | Como o nome indica, essa função criará um array a partir de qualquer objeto que exponha a interface do array. |
| carregar (fname) | Ele irá carregar um array do arquivo. |
| load_frombuffer (buf) | Como o nome indica, esta função irá carregar um dicionário de array ou lista de um buffer |
| salvar (fname, data) | Esta função salvará uma lista de arrays ou um dicionário de str-> array para arquivo. |
Exemplos de implementação
No exemplo abaixo, vamos retornar um novo array de forma e tipo dados, preenchido com zeros. Para isso, estaremos usando a funçãozeros().
mx.nd.zeros((1,2), mx.cpu(), stype='csr')Output
Isso produz a seguinte saída -
<CSRNDArray 1x2 @cpu(0)>Example
mx.nd.zeros((1,2), mx.cpu(), 'float16', stype='row_sparse').asnumpy()Output
Você receberá a seguinte saída -
array([[0., 0.]], dtype=float16)No exemplo abaixo, vamos salvar uma lista de arrays e um dicionário de strings. Para isso, estaremos usando a funçãosave().
Example
x = mx.nd.zeros((2,3))
y = mx.nd.ones((1,4))
mx.nd.save('list', [x,y])
mx.nd.save('dict', {'x':x, 'y':y})
mx.nd.load('list')Output
Após a execução, você receberá a seguinte saída -
[
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>,
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>]Example
mx.nd.load('my_dict')Output
O resultado é mostrado abaixo -
{'x':
[[0. 0. 0.]
[0. 0. 0.]]
<NDArray 2x3 @cpu(0)>, 'y':
[[1. 1. 1. 1.]]
<NDArray 1x4 @cpu(0)>}Como já discutimos nos capítulos anteriores, o MXNet Gluon fornece uma API clara, concisa e simples para projetos DL. Ele permite que o Apache MXNet crie protótipos, construa e treine modelos DL sem perder a velocidade de treinamento.
Módulos principais
Vamos aprender os módulos principais do gluon da interface de programação de aplicativos (API) Apache MXNet Python.
gluon.nn
O Gluon fornece um grande número de camadas NN integradas no módulo gluon.nn. Essa é a razão pela qual é chamado de módulo principal.
Métodos e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos por mxnet.gluon.nn módulo central -
| Métodos e seus parâmetros | Definição |
|---|---|
| Ativação (ativação, ** kwargs) | Como o nome indica, este método aplica uma função de ativação à entrada. |
| AvgPool1D ([pool_size, strides, padding, ...]) | Esta é a operação de agrupamento média para dados temporais. |
| AvgPool2D ([pool_size, strides, padding, ...]) | Esta é a operação média de agrupamento de dados espaciais. |
| AvgPool3D ([pool_size, strides, padding, ...]) | Esta é a operação média de pooling para dados 3D. Os dados podem ser espaciais ou espaço-temporais. |
| BatchNorm ([eixo, momento, épsilon, centro, ...]) | Ele representa a camada de normalização do lote. |
| BatchNormReLU ([eixo, momento, épsilon, ...]) | Também representa a camada de normalização em lote, mas com função de ativação Relu. |
| Bloco ([prefixo, parâmetros]) | Ele fornece a classe base para todas as camadas e modelos de rede neural. |
| Conv1D (canais, kernel_size [, passos, ...]) | Este método é usado para camada de convolução 1-D. Por exemplo, convolução temporal. |
| Conv1DTranspose (canais, kernel_size [,…]) | Este método é usado para a camada de convolução 1D transposta. |
| Conv2D (canais, kernel_size [, passos, ...]) | Este método é usado para camada de convolução 2D. Por exemplo, convolução espacial sobre imagens). |
| Conv2DTranspose (canais, kernel_size [,…]) | Este método é usado para a camada de convolução 2D transposta. |
| Conv3D (canais, kernel_size [, passos, ...]) | Este método é usado para camada de convolução 3D. Por exemplo, convolução espacial sobre volumes. |
| Conv3DTranspose (canais, kernel_size [,…]) | Este método é usado para a camada de convolução 3D transposta. |
| Denso (unidades [, ativação, use_bias, ...]) | Este método representa para sua camada NN densamente conectada regular. |
| Dropout (taxa [, eixos]) | Como o nome indica, o método aplica Dropout à entrada. |
| ELU ([alfa]) | Este método é usado para Unidade Linear Exponencial (ELU). |
| Incorporação (input_dim, output_dim [, dtype, ...]) | Ele transforma inteiros não negativos em vetores densos de tamanho fixo. |
| Flatten (** kwargs) | Este método nivela a entrada para 2-D. |
| GELU (** kwargs) | Este método é usado para a Unidade Linear Exponencial Gaussiana (GELU). |
| GlobalAvgPool1D ([layout]) | Com a ajuda deste método, podemos fazer uma operação global de agrupamento médio para dados temporais. |
| GlobalAvgPool2D ([layout]) | Com a ajuda deste método, podemos fazer uma operação global de agrupamento médio para dados espaciais. |
| GlobalAvgPool3D ([layout]) | Com a ajuda desse método, podemos fazer a operação global de agrupamento médio para dados 3-D. |
| GlobalMaxPool1D ([layout]) | Com a ajuda deste método, podemos fazer a operação global max pooling para dados 1-D. |
| GlobalMaxPool2D ([layout]) | Com a ajuda desse método, podemos fazer a operação global max pooling para dados 2-D. |
| GlobalMaxPool3D ([layout]) | Com a ajuda desse método, podemos fazer a operação global max pooling para dados 3-D. |
| GroupNorm ([núm_grupos, épsilon, centro, ...]) | Este método aplica a normalização de grupo à matriz de entrada nD. |
| HybridBlock ([prefixo, parâmetros]) | Este método suporta encaminhamento com ambos Symbol e NDArray. |
| HybridLambda(função [, prefixo]) | Com a ajuda deste método, podemos envolver um operador ou uma expressão como um objeto HybridBlock. |
| HybridSequential ([prefixo, params]) | Ele empilha HybridBlocks sequencialmente. |
| InstanceNorm ([eixo, épsilon, centro, escala, ...]) | Este método aplica a normalização da instância ao array de entrada nD. |
Exemplos de implementação
No exemplo abaixo, vamos usar Block () que fornece a classe base para todas as camadas e modelos de rede neural.
from mxnet.gluon import Block, nn
class Model(Block):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = mx.nd.relu(self.dense0(x))
return mx.nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
Você verá a seguinte saída -
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)*gt;No exemplo abaixo, usaremos HybridBlock () que oferece suporte ao encaminhamento com Symbol e NDArray.
import mxnet as mx
from mxnet.gluon import HybridBlock, nn
class Model(HybridBlock):
def __init__(self, **kwargs):
super(Model, self).__init__(**kwargs)
# use name_scope to give child Blocks appropriate names.
with self.name_scope():
self.dense0 = nn.Dense(20)
self.dense1 = nn.Dense(20)
def forward(self, x):
x = nd.relu(self.dense0(x))
return nd.relu(self.dense1(x))
model = Model()
model.initialize(ctx=mx.cpu(0))
model.hybridize()
model(mx.nd.zeros((5, 5), ctx=mx.cpu(0)))Output
A saída é mencionada abaixo -
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
<NDArray 5x20 @cpu(0)>gluon.rnn
Gluon fornece um grande número de componentes recurrent neural network(RNN) camadas no módulo gluon.rnn. É por isso que é chamado de módulo principal.
Métodos e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos por mxnet.gluon.nn módulo principal:
| Métodos e seus parâmetros | Definição |
|---|---|
| BidirectionalCell (l_cell, r_cell [, ...]) | É usado para células de Rede Neural Recorrente Bidirecional (RNN). |
| DropoutCell (taxa [, eixos, prefixo, parâmetros]) | Este método aplicará dropout na entrada fornecida. |
| GRU (oculto_size [, núm_camadas, layout, ...]) | Ele aplica uma unidade recorrente com portas multicamadas (GRU) RNN a uma determinada sequência de entrada. |
| GRUCell (oculto_size [,…]) | É usado para célula de rede Gated Rectified Unit (GRU). |
| HybridRecurrentCell ([prefixo, params]) | Este método oferece suporte a hibridização. |
| HybridSequentialRNNCell ([prefixo, params]) | Com a ajuda deste método, podemos empilhar sequencialmente várias células HybridRNN. |
| LSTM (oculto_size [, núm_camadas, layout, ...]) 0 | Ele aplica um RNN de memória longa de curto prazo multicamadas (LSTM) a uma determinada sequência de entrada. |
| LSTMCell (oculto_size [,…]) | É usado para a célula de rede Long-Short Term Memory (LSTM). |
| ModifierCell (base_cell) | É a classe base para células modificadoras. |
| RNN (oculto_size [, núm_camadas, ativação, ...]) | Ele aplica um Elman RNN multicamadas com tanh ou ReLU não linearidade para uma determinada sequência de entrada. |
| RNNCell (oculto_size [, ativação, ...]) | É usado para células de rede neural recorrente Elman RNN. |
| RecurrentCell ([prefixo, params]) | Ele representa a classe base abstrata para células RNN. |
| SequentialRNNCell ([prefixo, params]) | Com a ajuda deste método, podemos empilhar sequencialmente várias células RNN. |
| ZoneoutCell (base_cell [, zoneout_outputs,…]) | Este método aplica Zoneout na célula base. |
Exemplos de implementação
No exemplo abaixo, vamos usar GRU (), que aplica uma unidade recorrente com portas multicamadas (GRU) RNN a uma determinada sequência de entrada.
layer = mx.gluon.rnn.GRU(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq, h0)
out_seqOutput
Isso produz a seguinte saída -
[[[ 1.50152072e-01 5.19012511e-01 1.02390535e-01 ... 4.35803324e-01
1.30406499e-01 3.30152437e-02]
[ 2.91542172e-01 1.02243155e-01 1.73325196e-01 ... 5.65296151e-02
1.76546033e-02 1.66693389e-01]
[ 2.22257316e-01 3.76294643e-01 2.11277917e-01 ... 2.28903517e-01
3.43954474e-01 1.52770668e-01]]
[[ 1.40634328e-01 2.93247789e-01 5.50393537e-02 ... 2.30207980e-01
6.61415309e-02 2.70989928e-02]
[ 1.11081995e-01 7.20834285e-02 1.08342394e-01 ... 2.28330195e-02
6.79589901e-03 1.25501186e-01]
[ 1.15944080e-01 2.41565228e-01 1.18612610e-01 ... 1.14908054e-01
1.61080107e-01 1.15969211e-01]]
………………………….Example
hnOutput
Isso produz a seguinte saída -
[[[-6.08105101e-02 3.86217088e-02 6.64453954e-03 8.18805695e-02
3.85607071e-02 -1.36945639e-02 7.45836645e-03 -5.46515081e-03
9.49622393e-02 6.39371723e-02 -6.37890724e-03 3.82240303e-02
9.11015049e-02 -2.01375950e-02 -7.29381144e-02 6.93765879e-02
2.71829776e-02 -6.64435029e-02 -8.45306814e-02 -1.03075653e-01
6.72040805e-02 -7.06537142e-02 -3.93818803e-02 5.16211614e-03
-4.79770005e-02 1.10734522e-01 1.56721435e-02 -6.93409378e-03
1.16915874e-01 -7.95962065e-02 -3.06530762e-02 8.42394680e-02
7.60370195e-02 2.17055440e-01 9.85361822e-03 1.16660878e-01
4.08297703e-02 1.24978097e-02 8.25245082e-02 2.28673983e-02
-7.88266212e-02 -8.04114193e-02 9.28791538e-02 -5.70827350e-03
-4.46166918e-02 -6.41122833e-02 1.80885363e-02 -2.37745279e-03
4.37298454e-02 1.28888980e-01 -3.07202265e-02 2.50503756e-02
4.00907174e-02 3.37077095e-03 -1.78839862e-02 8.90695080e-02
6.30150884e-02 1.11416787e-01 2.12221760e-02 -1.13236710e-01
5.39616570e-02 7.80710578e-02 -2.28817668e-02 1.92073174e-02
………………………….No exemplo abaixo, vamos usar LSTM (), que aplica uma memória de longo-curto prazo (LSTM) RNN a uma determinada sequência de entrada.
layer = mx.gluon.rnn.LSTM(100, 3)
layer.initialize()
input_seq = mx.nd.random.uniform(shape=(5, 3, 10))
out_seq = layer(input_seq)
h0 = mx.nd.random.uniform(shape=(3, 3, 100))
c0 = mx.nd.random.uniform(shape=(3, 3, 100))
out_seq, hn = layer(input_seq,[h0,c0])
out_seqOutput
A saída é mencionada abaixo -
[[[ 9.00025964e-02 3.96071747e-02 1.83841765e-01 ... 3.95872220e-02
1.25569820e-01 2.15555862e-01]
[ 1.55962542e-01 -3.10300849e-02 1.76772922e-01 ... 1.92474753e-01
2.30574399e-01 2.81707942e-02]
[ 7.83204585e-02 6.53361529e-03 1.27262697e-01 ... 9.97719541e-02
1.28254429e-01 7.55299702e-02]]
[[ 4.41036932e-02 1.35250352e-02 9.87644792e-02 ... 5.89378644e-03
5.23949116e-02 1.00922674e-01]
[ 8.59075040e-02 -1.67027581e-02 9.69351009e-02 ... 1.17763653e-01
9.71239135e-02 2.25218050e-02]
[ 4.34580036e-02 7.62207608e-04 6.37005866e-02 ... 6.14888743e-02
5.96345589e-02 4.72368896e-02]]
……………Example
hnOutput
Ao executar o código, você verá a seguinte saída -
[
[[[ 2.21408084e-02 1.42750628e-02 9.53067932e-03 -1.22849066e-02
1.78788435e-02 5.99269159e-02 5.65306023e-02 6.42553642e-02
6.56616641e-03 9.80876666e-03 -1.15729487e-02 5.98640442e-02
-7.21173314e-03 -2.78371759e-02 -1.90690923e-02 2.21447181e-02
8.38765781e-03 -1.38521893e-02 -9.06938594e-03 1.21346042e-02
6.06449470e-02 -3.77471633e-02 5.65885007e-02 6.63008019e-02
-7.34188128e-03 6.46054149e-02 3.19911093e-02 4.11194898e-02
4.43960279e-02 4.92892228e-02 1.74766723e-02 3.40303481e-02
-5.23341820e-03 2.68163737e-02 -9.43402853e-03 -4.11836170e-02
1.55221792e-02 -5.05655073e-02 4.24557598e-03 -3.40388380e-02
……………………Módulos de treinamento
Os módulos de treinamento no Gluon são os seguintes -
gluon.loss
Dentro mxnet.gluon.lossmódulo, Gluon fornece função de perda pré-definida. Basicamente, tem as perdas para treinar a rede neural. É por isso que é chamado de módulo de treinamento.
Métodos e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos por mxnet.gluon.loss módulo de treinamento:
| Métodos e seus parâmetros | Definição |
|---|---|
| Perda (peso, lote_eixo, ** kwargs) | Isso atua como a classe base para perdas. |
| L2Loss ([peso, lote_eixo]) | Ele calcula o erro quadrático médio (MSE) entre label e prediction(pred). |
| L1Loss ([weight, batch_axis]) | Ele calcula o erro absoluto médio (MAE) entre label e pred. |
| SigmoidBinaryCrossEntropyLoss ([...]) | Este método é usado para a perda de entropia cruzada para classificação binária. |
| SigmoidBCELoss | Este método é usado para a perda de entropia cruzada para classificação binária. |
| SoftmaxCrossEntropyLoss ([eixo, ...]) | Ele calcula a perda de entropia cruzada softmax (CEL). |
| SoftmaxCELoss | Ele também calcula a perda de entropia cruzada softmax. |
| KLDivLoss ([from_logits, eixo, peso, ...]) | É usado para a perda de divergência de Kullback-Leibler. |
| CTCLoss ([layout, label_layout, weight]) | É usado para perda de classificação temporal (TCL) conexionista. |
| HuberLoss ([rho, weight, batch_axis]) | Ele calcula a perda L1 suavizada. A perda L1 suavizada será igual à perda L1 se o erro absoluto exceder rho, mas será igual à perda L2 caso contrário. |
| HingeLoss ([margem, peso, lote_eixo]) | Este método calcula a função de perda de dobradiça frequentemente usada em SVMs: |
| SquaredHingeLoss ([margin, weight, batch_axis]) | Este método calcula a função de perda de margem suave usada em SVMs: |
| LogisticLoss ([weight, batch_axis, label_format]) | Este método calcula a perda logística. |
| TripletLoss ([margem, peso, lote_eixo]) | Este método calcula a perda de tripleto dados três tensores de entrada e uma margem positiva. |
| PoissonNLLLoss ([peso, from_logits, ...]) | A função calcula a perda de probabilidade de log negativo. |
| CosineEmbeddingLoss ([weight, batch_axis, margin]) | A função calcula a distância cosseno entre os vetores. |
| SDMLLoss ([smoothing_parameter, weight, ...]) | Este método calcula a perda de aprendizado métrico profundo suavizado em lote (SDML), dados dois tensores de entrada e um peso de suavização SDM Loss. Ele aprende a semelhança entre amostras emparelhadas usando amostras não emparelhadas no minibatch como exemplos negativos em potencial. |
Exemplo
Como sabemos isso mxnet.gluon.loss.lossirá calcular o MSE (erro quadrático médio) entre o rótulo e a previsão (pred). Isso é feito com a ajuda da seguinte fórmula:

gluon.parameter
mxnet.gluon.parameter é um contêiner que contém os parâmetros, ou seja, pesos dos blocos.
Métodos e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos por mxnet.gluon.parameter módulo de treinamento -
| Métodos e seus parâmetros | Definição |
|---|---|
| elenco (tipo d) | Este método lançará dados e gradiente deste parâmetro para um novo tipo de dados. |
| dados ([ctx]) | Este método retornará uma cópia deste parâmetro em um contexto. |
| grad ([ctx]) | Este método retornará um buffer de gradiente para este parâmetro em um contexto. |
| inicializar ([init, ctx, default_init, ...]) | Este método inicializará matrizes de parâmetros e gradientes. |
| list_ctx () | Este método retornará uma lista de contextos nos quais este parâmetro foi inicializado. |
| list_data () | Este método retornará cópias deste parâmetro em todos os contextos. Isso será feito na mesma ordem da criação. |
| list_grad () | Este método retornará buffers de gradiente em todos os contextos. Isso será feito na mesma ordem quevalues(). |
| list_row_sparse_data (row_id) | Este método retornará cópias do parâmetro 'row_sparse' em todos os contextos. Isso será feito na mesma ordem da criação. |
| reset_ctx (ctx) | Este método irá reatribuir Parameter a outros contextos. |
| row_sparse_data (row_id) | Este método retornará uma cópia do parâmetro 'row_sparse' no mesmo contexto que row_id's. |
| set_data (dados) | Este método irá definir o valor deste parâmetro em todos os contextos. |
| var () | Este método retornará um símbolo que representa este parâmetro. |
| zero_grad () | Este método definirá o buffer de gradiente em todos os contextos como 0. |
Exemplo de Implementação
No exemplo abaixo, inicializaremos os parâmetros e as matrizes de gradientes usando o método initialize () da seguinte maneira -
weight = mx.gluon.Parameter('weight', shape=(2, 2))
weight.initialize(ctx=mx.cpu(0))
weight.data()Output
A saída é mencionada abaixo -
[[-0.0256899 0.06511251]
[-0.00243821 -0.00123186]]
<NDArray 2x2 @cpu(0)>Example
weight.grad()Output
O resultado é dado abaixo -
[[0. 0.]
[0. 0.]]
<NDArray 2x2 @cpu(0)>Example
weight.initialize(ctx=[mx.gpu(0), mx.gpu(1)])
weight.data(mx.gpu(0))Output
Você verá a seguinte saída -
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(0)>Example
weight.data(mx.gpu(1))Output
Ao executar o código acima, você verá a seguinte saída -
[[-0.00873779 -0.02834515]
[ 0.05484822 -0.06206018]]
<NDArray 2x2 @gpu(1)>gluon.trainer
mxnet.gluon.trainer aplica um Otimizador em um conjunto de parâmetros. Deve ser usado junto com o autograd.
Métodos e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos por mxnet.gluon.trainer módulo de treinamento -
| Métodos e seus parâmetros | Definição |
|---|---|
| allreduce_grads () | Este método irá reduzir os gradientes de diferentes contextos para cada parâmetro (peso). |
| load_states (fname) | Como o nome indica, este método carregará os estados do treinador. |
| save_states (fname) | Como o nome indica, esse método salvará os estados do treinador. |
| set_learning_rate (lr) | Este método definirá uma nova taxa de aprendizado do otimizador. |
| etapa (batch_size [, ignore_stale_grad]) | Este método fará uma etapa de atualização do parâmetro. Deve ser chamado apósautograd.backward() e fora de record() escopo. |
| atualizar (batch_size [, ignore_stale_grad]) | Este método também fará uma etapa de atualização do parâmetro. Deve ser chamado apósautograd.backward() e fora de record() escopo e depois de trainer.update (). |
Módulos de Dados
Os módulos de dados do Gluon são explicados abaixo -
gluon.data
O Gluon fornece um grande número de utilitários de conjunto de dados integrados no módulo gluon.data. É por isso que é chamado de módulo de dados.
Classes e seus parâmetros
A seguir estão alguns dos métodos importantes e seus parâmetros cobertos pelo módulo principal mxnet.gluon.data. Esses métodos geralmente estão relacionados a Datasets, Sampling e DataLoader.
Conjunto de Dados| Métodos e seus parâmetros | Definição |
|---|---|
| ArrayDataset (* args) | Este método representa um conjunto de dados que combina dois ou mais de dois objetos semelhantes a conjuntos de dados. Por exemplo, conjuntos de dados, listas, matrizes, etc. |
| BatchSampler (sampler, batch_size [, last_batch]) | Este método envolve outro Sampler. Depois de embalado, ele retorna os mini lotes de amostras. |
| DataLoader (dataset [, batch_size, shuffle, ...]) | Semelhante ao BatchSampler, mas este método carrega dados de um conjunto de dados. Uma vez carregado, ele retorna os minilotes de dados. |
| Isso representa a classe abstrata do conjunto de dados. | |
| FilterSampler (fn, conjunto de dados) | Este método representa os elementos de amostra de um conjunto de dados para o qual fn (função) retorna True. |
| RandomSampler (comprimento) | Este método representa elementos de amostra de [0, comprimento) aleatoriamente sem substituição. |
| RecordFileDataset (nome do arquivo) | Ele representa um conjunto de dados envolvendo um arquivo RecordIO. A extensão do arquivo é.rec. |
| Sampler | Esta é a classe base para amostradores. |
| SequentialSampler (comprimento [, início]) | Ele representa os elementos da amostra do conjunto [início, início + comprimento) sequencialmente. |
| Ele representa os elementos da amostra do conjunto [início, início + comprimento) sequencialmente. | Isso representa o invólucro do Conjunto de dados simples, especialmente para listas e matrizes. |
Exemplos de implementação
No exemplo abaixo, vamos usar gluon.data.BatchSampler()API, que envolve outro amostrador. Ele retorna os mini lotes de amostras.
import mxnet as mx
from mxnet.gluon import data
sampler = mx.gluon.data.SequentialSampler(15)
batch_sampler = mx.gluon.data.BatchSampler(sampler, 4, 'keep')
list(batch_sampler)Output
A saída é mencionada abaixo -
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14]]gluon.data.vision.datasets
Gluon fornece um grande número de funções de conjunto de dados de visão predefinidos em gluon.data.vision.datasets módulo.
Classes e seus parâmetros
MXNet nos fornece conjuntos de dados úteis e importantes, cujas classes e parâmetros são fornecidos abaixo -
| Classes e seus parâmetros | Definição |
|---|---|
| MNIST ([root, treinar, transformar]) | Este é um conjunto de dados útil que nos fornece os dígitos manuscritos. O url para o conjunto de dados MNIST é http://yann.lecun.com/exdb/mnist |
| FashionMNIST ([root, treinar, transformar]) | Este conjunto de dados consiste em imagens de artigos de Zalando que consistem em produtos de moda. É uma substituição imediata do conjunto de dados MNIST original. Você pode obter este conjunto de dados em https://github.com/zalandoresearch/fashion-mnist |
| CIFAR10 ([root, treinar, transformar]) | Este é um conjunto de dados de classificação de imagens de https://www.cs.toronto.edu/~kriz/cifar.html. Neste conjunto de dados, cada amostra é uma imagem com forma (32, 32, 3). |
| CIFAR100 ([root, fine_label, treinar, transformar]) | Este é o conjunto de dados de classificação de imagem CIFAR100 de https://www.cs.toronto.edu/~kriz/cifar.html. Também tem cada amostra é uma imagem com forma (32, 32, 3). |
| ImageRecordDataset (nome do arquivo [, sinalizar, transformar]) | Este conjunto de dados está envolvendo um arquivo RecordIO que contém imagens. Neste, cada amostra é uma imagem com seu rótulo correspondente. |
| ImageFolderDataset (root [, sinalizar, transformar]) | Este é um conjunto de dados para carregar arquivos de imagem armazenados em uma estrutura de pastas. |
| ImageListDataset ([root, imglist, flag]) | Este é um conjunto de dados para carregar arquivos de imagem que são especificados por uma lista de entradas. |
Exemplo
No exemplo abaixo, vamos mostrar o uso de ImageListDataset (), que é usado para carregar arquivos de imagem que são especificados por uma lista de entradas -
# written to text file *.lst
0 0 root/cat/0001.jpg
1 0 root/cat/xxxa.jpg
2 0 root/cat/yyyb.jpg
3 1 root/dog/123.jpg
4 1 root/dog/023.jpg
5 1 root/dog/wwww.jpg
# A pure list, each item is a list [imagelabel: float or list of float, imgpath]
[[0, root/cat/0001.jpg]
[0, root/cat/xxxa.jpg]
[0, root/cat/yyyb.jpg]
[1, root/dog/123.jpg]
[1, root/dog/023.jpg]
[1, root/dog/wwww.jpg]]Módulos Utilitários
Os módulos utilitários no Gluon são os seguintes -
gluon.utils
O Gluon fornece um grande número de otimizadores de utilitário de paralelização integrados no módulo gluon.utils. Ele fornece vários utilitários para treinamento. É por isso que é chamado de módulo de utilitário.
Funções e seus parâmetros
A seguir estão as funções e seus parâmetros que consistem neste módulo de utilitário denominado gluon.utils −
| Funções e seus parâmetros | Definição |
|---|---|
| split_data (data, num_slice [, batch_axis,…]) | Esta função é normalmente usada para paralelismo de dados e cada fatia é enviada para um dispositivo, ou seja, GPU. Ele divide um NDArray emnum_slice fatias junto batch_axis. |
| split_and_load (dados, ctx_list [, batch_axis,…]) | Esta função divide um NDArray em len(ctx_list) fatias junto batch_axis. A única diferença da função split_data () acima é que ela também carrega cada fatia para um contexto em ctx_list. |
| clip_global_norm (matrizes, max_norm [,…]) | O trabalho desta função é redimensionar NDArrays de tal forma que a soma de sua norma 2 seja menor que max_norm. |
| check_sha1 (nome do arquivo, sha1_hash) | Esta função irá verificar se o hash sha1 do conteúdo do arquivo corresponde ao hash esperado ou não. |
| download (url [, caminho, sobrescrever, sha1_hash, ...]) | Como o nome especifica, esta função fará o download de um determinado URL. |
| substituir_arquivo (src, dst) | Esta função irá implementar atômicas os.replace. isso será feito com Linux e OSX. |
Este capítulo trata da API de autograd e inicializador no MXNet.
mxnet.autograd
Esta é a API de autograd do MXNet para NDArray. Tem a seguinte classe -
Classe: Function ()
É usado para diferenciação personalizada em autograd. Pode ser escrito comomxnet.autograd.Function. Se, por qualquer motivo, o usuário não quiser usar os gradientes que são calculados pela regra em cadeia padrão, ele / ela pode usar a classe Function de mxnet.autograd para personalizar a diferenciação para computação. Ele tem dois métodos: Forward () e Backward ().
Vamos entender o funcionamento desta aula com a ajuda dos seguintes pontos -
Primeiro, precisamos definir nosso cálculo no método direto.
Em seguida, precisamos fornecer a diferenciação personalizada no método reverso.
Agora, durante o cálculo do gradiente, em vez da função retrógrada definida pelo usuário, mxnet.autograd usará a função retrógrada definida pelo usuário. Também podemos converter para numpy array e back para algumas operações para frente e para trás.
Example
Antes de usar a classe mxnet.autograd.function, vamos definir uma função sigmóide estável com métodos para trás e para a frente como segue -
class sigmoid(mx.autograd.Function):
def forward(self, x):
y = 1 / (1 + mx.nd.exp(-x))
self.save_for_backward(y)
return y
def backward(self, dy):
y, = self.saved_tensors
return dy * y * (1-y)Agora, a classe de função pode ser usada da seguinte maneira -
func = sigmoid()
x = mx.nd.random.uniform(shape=(10,))
x.attach_grad()
with mx.autograd.record():
m = func(x)
m.backward()
dx_grad = x.grad.asnumpy()
dx_gradOutput
Ao executar o código, você verá a seguinte saída -
array([0.21458015, 0.21291625, 0.23330082, 0.2361367 , 0.23086983,
0.24060014, 0.20326573, 0.21093895, 0.24968489, 0.24301809],
dtype=float32)Métodos e seus parâmetros
A seguir estão os métodos e seus parâmetros da classe mxnet.autogard.function -
| Métodos e seus parâmetros | Definição |
|---|---|
| forward (heads [, head_grads, reter_graph, ...]) | Este método é usado para computação direta. |
| para trás (cabeças [, cabeça_grads, retém_grafo, ...]) | Este método é usado para computação retroativa. Ele calcula os gradientes de cabeças em relação às variáveis previamente marcadas. Este método usa tantas entradas quanto a saída de forward. Ele também retorna tantos NDArray quanto entradas de encaminhamento. |
| get_symbol (x) | Este método é usado para recuperar o histórico de computação registrado como Symbol. |
| grad (cabeças, variáveis [, cabeça_grads, ...]) | Este método calcula os gradientes de cabeças em relação às variáveis. Depois de computados, em vez de armazenar em variable.grad, os gradientes serão retornados como novos NDArrays. |
| is_recording () | Com a ajuda desse método, podemos obter o status da gravação e não da gravação. |
| is_training () | Com a ajuda desse método, podemos obter o status do treinamento e da previsão. |
| mark_variables (variáveis, gradientes [, grad_reqs]) | Este método marcará NDArrays como variáveis para calcular gradiente para autograd. Este método é o mesmo que a função .attach_grad () em uma variável, mas a única diferença é que com essa chamada podemos definir o gradiente para qualquer valor. |
| pausar ([train_mode]) | Este método retorna um contexto de escopo a ser usado na instrução 'with' para códigos que não precisam de gradientes para serem calculados. |
| Predict_mode () | Este método retorna um contexto de escopo a ser usado na instrução 'with' em que o comportamento de encaminhamento é definido para o modo de inferência, sem alterar os estados de gravação. |
| registro ([train_mode]) | Ele retornará um autograd registro do contexto do escopo a ser usado na instrução 'com' e captura o código que precisa de gradientes para serem calculados. |
| set_recording (is_recording) | Semelhante a is_recoring (), com a ajuda deste método podemos obter o status da gravação e não da gravação. |
| set_training (is_training) | Semelhante a is_traininig (), com a ajuda deste método podemos definir o status para treinamento ou previsão. |
| train_mode () | Este método retornará um contexto de escopo a ser usado na instrução 'with' em que o comportamento de encaminhamento é definido para o modo de treinamento, sem alterar os estados de gravação. |
Exemplo de Implementação
No exemplo a seguir, estaremos usando o método mxnet.autograd.grad () para calcular o gradiente de cabeça em relação às variáveis -
x = mx.nd.ones((2,))
x.attach_grad()
with mx.autograd.record():
z = mx.nd.elemwise_add(mx.nd.exp(x), x)
dx_grad = mx.autograd.grad(z, [x], create_graph=True)
dx_gradOutput
A saída é mencionada abaixo -
[
[3.7182817 3.7182817]
<NDArray 2 @cpu(0)>]Podemos usar o método mxnet.autograd.predict_mode () para retornar um escopo a ser usado na instrução 'with' -
with mx.autograd.record():
y = model(x)
with mx.autograd.predict_mode():
y = sampling(y)
backward([y])mxnet.intializer
Esta é a API MXNet para o inicializador de pesagem. Tem as seguintes classes -
Classes e seus parâmetros
A seguir estão os métodos e seus parâmetros de mxnet.autogard.function classe:
| Classes e seus parâmetros | Definição |
|---|---|
| Bilinear () | Com a ajuda desta classe, podemos inicializar o peso para camadas de up-sampling. |
| Valor constante) | Essa classe inicializa os pesos para um determinado valor. O valor pode ser um escalar, bem como um NDArray que corresponde à forma do parâmetro a ser definido. |
| FusedRNN (init, num_hidden, num_layers, modo) | Como o nome indica, esta classe inicializa parâmetros para as camadas da Rede Neural Recorrente (RNN) fundida. |
| InitDesc | Ele atua como o descritor do padrão de inicialização. |
| Inicializador (** kwargs) | Esta é a classe base de um inicializador. |
| LSTMBias ([esquecer_bias]) | Esta classe inicializa todas as polarizações de um LSTMCell para 0,0, mas exceto para a porta de esquecimento, cuja polarização é definida como um valor personalizado. |
| Carregar (param [, default_init, verbose]) | Esta classe inicializa as variáveis carregando dados do arquivo ou dicionário. |
| MSRAPrelu ([fator_tipo, inclinação]) | Como o nome indica, esta classe inicializa a gramatura de acordo com um papel MSRA. |
| Misto (padrões, inicializadores) | Ele inicializa os parâmetros usando vários inicializadores. |
| Normal ([sigma]) | A classe Normal () inicializa os pesos com valores aleatórios amostrados a partir de uma distribuição normal com uma média de zero e desvio padrão (SD) de sigma. |
| 1() | Ele inicializa os pesos do parâmetro para um. |
| Ortogonal ([escala, tipo_rand]) | Como o nome indica, esta classe inicializa o peso como uma matriz ortogonal. |
| Uniforme ([escala]) | Ele inicializa pesos com valores aleatórios que são amostrados uniformemente de um determinado intervalo. |
| Xavier ([rnd_type, factor_type, magnitude]) | Na verdade, ele retorna um inicializador que executa a inicialização “Xavier” para pesos. |
| Zero() | Ele inicializa os pesos do parâmetro para zero. |
Exemplo de Implementação
No exemplo a seguir, usaremos a classe mxnet.init.Normal () para criar um inicializador e recuperar seus parâmetros -
init = mx.init.Normal(0.8)
init.dumps()Output
O resultado é dado abaixo -
'["normal", {"sigma": 0.8}]'Example
init = mx.init.Xavier(factor_type="in", magnitude=2.45)
init.dumps()Output
O resultado é mostrado abaixo -
'["xavier", {"rnd_type": "uniform", "factor_type": "in", "magnitude": 2.45}]'No exemplo a seguir, usaremos a classe mxnet.initializer.Mixed () para inicializar parâmetros usando vários inicializadores -
init = mx.initializer.Mixed(['bias', '.*'], [mx.init.Zero(),
mx.init.Uniform(0.1)])
module.init_params(init)
for dictionary in module.get_params():
for key in dictionary:
print(key)
print(dictionary[key].asnumpy())Output
O resultado é mostrado abaixo -
fullyconnected1_weight
[[ 0.0097627 0.01856892 0.04303787]]
fullyconnected1_bias
[ 0.]Neste capítulo, aprenderemos sobre uma interface no MXNet que é denominada como Símbolo.
Mxnet.ndarray
A API Symbol do Apache MXNet é uma interface para programação simbólica. A API Symbol apresenta o uso do seguinte -
Gráficos computacionais
Uso de memória reduzido
Otimização da função pré-uso
O exemplo a seguir mostra como criar uma expressão simples usando a API de símbolos do MXNet -
Um NDArray usando 'array' 1-D e 2-D de uma lista Python regular -
import mxnet as mx
# Two placeholders namely x and y will be created with mx.sym.variable
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
# The symbol here is constructed using the plus ‘+’ operator.
z = x + yOutput
Você verá a seguinte saída -
<Symbol _plus0>Example
(x, y, z)Output
O resultado é dado abaixo -
(<Symbol x>, <Symbol y>, <Symbol _plus0>)Agora vamos discutir em detalhes sobre as classes, funções e parâmetros da API ndarray do MXNet.
Aulas
A tabela a seguir consiste nas classes da API Symbol do MXNet -
| Classe | Definição |
|---|---|
| Símbolo (alça) | Este símbolo de classe é o gráfico simbólico do Apache MXNet. |
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos pela API mxnet.Symbol -
| Função e seus parâmetros | Definição |
|---|---|
| Ativação ([data, act_type, out, name]) | Ele aplica uma função de ativação a nível de elemento para a entrada. Suportarelu, sigmoid, tanh, softrelu, softsign funções de ativação. |
| BatchNorm ([data, gamma, beta, moving_mean, ...]) | É usado para normalização de lote. Esta função normaliza um lote de dados por média e variância. Aplica uma escalagamma e compensar beta. |
| BilinearSampler ([dados, grade, cudnn_off, ...]) | Esta função aplica a amostragem bilinear ao mapa de características de entrada. Na verdade, é a chave de “Redes de Transformadores Espaciais”. Se você está familiarizado com a função de remapeamento em OpenCV, o uso desta função é bastante semelhante a isso. A única diferença é que ele tem o passe para trás. |
| BlockGrad ([data, out, name]) | Como o nome especifica, esta função interrompe a computação de gradiente. Isso basicamente impede que o gradiente acumulado das entradas flua através desse operador na direção inversa. |
| elenco ([data, dtype, out, name]) | Esta função irá converter todos os elementos da entrada para um novo tipo. |
| Esta função irá converter todos os elementos da entrada para um novo tipo. | Esta função, conforme o nome especificado, retorna um novo símbolo de forma e tipo dados, preenchido com zeros. |
| uns (forma [, tipo]) | Esta função, com o nome especificado, retorna um novo símbolo de forma e tipo dados, preenchido com uns. |
| cheio (forma, val [, dtipo]) | Esta função, conforme o nome especificado, retorna um novo array de forma e tipo dados, preenchido com o valor fornecido val. |
| arange (iniciar [, parar, passo, repetir, ...]) | Ele retornará valores com espaçamento uniforme em um determinado intervalo. Os valores são gerados dentro do intervalo de meio aberto [iniciar, parar) o que significa que o intervalo incluistart mas exclui stop. |
| linspace (iniciar, parar, num [, ponto final, nome, ...]) | Ele retornará números com espaçamento uniforme dentro de um intervalo especificado. Semelhante à função organize (), os valores são gerados dentro do intervalo de meia abertura [iniciar, parar) o que significa que o intervalo incluistart mas exclui stop. |
| histograma (a [, bins, intervalo]) | Como o nome indica, esta função calculará o histograma dos dados de entrada. |
| potência (base, exp) | Como o nome indica, esta função retornará o resultado elemento a elemento de base elemento elevado a potências de expelemento. Ambas as entradas, ou seja, base e exp, podem ser Symbol ou escalar. Aqui, observe que a transmissão não é permitida. Você pode usarbroadcast_pow se você quiser usar o recurso de transmissão. |
| SoftmaxActivation ([dados, modo, nome, atributo, saída]) | Esta função aplica a ativação do softmax à entrada. Destina-se a camadas internas. Na verdade, está obsoleto, podemos usarsoftmax() em vez de. |
Exemplos de implementação
No exemplo abaixo, estaremos usando a função power() que retornará o resultado do elemento a nível do elemento base elevado às potências do elemento exp:
import mxnet as mx
mx.sym.power(3, 5)Output
Você verá a seguinte saída -
243Example
x = mx.sym.Variable('x')
y = mx.sym.Variable('y')
z = mx.sym.power(x, 3)
z.eval(x=mx.nd.array([1,2]))[0].asnumpy()Output
Isso produz a seguinte saída -
array([1., 8.], dtype=float32)Example
z = mx.sym.power(4, y)
z.eval(y=mx.nd.array([2,3]))[0].asnumpy()Output
Ao executar o código acima, você verá a seguinte saída -
array([16., 64.], dtype=float32)Example
z = mx.sym.power(x, y)
z.eval(x=mx.nd.array([4,5]), y=mx.nd.array([2,3]))[0].asnumpy()Output
A saída é mencionada abaixo -
array([ 16., 125.], dtype=float32)No exemplo abaixo, estaremos usando a função SoftmaxActivation() (or softmax()) que será aplicado à entrada e se destina a camadas internas.
input_data = mx.nd.array([[2., 0.9, -0.5, 4., 8.], [4., -.7, 9., 2., 0.9]])
soft_max_act = mx.nd.softmax(input_data)
print (soft_max_act.asnumpy())Output
Você verá a seguinte saída -
[[2.4258138e-03 8.0748333e-04 1.9912292e-04 1.7924475e-02 9.7864312e-01]
[6.6843745e-03 6.0796250e-05 9.9204916e-01 9.0463174e-04 3.0112563e-04]]symbol.contrib
A API Contrib NDArray é definida no pacote symbol.contrib. Normalmente fornece muitas APIs experimentais úteis para novos recursos. Esta API funciona como um local para a comunidade onde eles podem experimentar os novos recursos. O colaborador do recurso também receberá o feedback.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.symbol.contrib API -
| Função e seus parâmetros | Definição |
|---|---|
| rand_zipfian (true_classes, num_sampled, ...) | Esta função extrai amostras aleatórias de uma distribuição aproximadamente Zipfian. A distribuição básica desta função é a distribuição Zipfian. Esta função amostra aleatoriamente num_sampled candidatos e os elementos de sampled_candidates são extraídos da distribuição de base fornecida acima. |
| foreach (corpo, dados, init_states) | Como o nome indica, essa função executa um loop com computação definida pelo usuário sobre NDArrays na dimensão 0. Essa função simula um loop for e o corpo tem o cálculo para uma iteração do loop for. |
| while_loop (cond, func, loop_vars [, ...]) | Como o nome indica, esta função executa um loop while com computação definida pelo usuário e condição de loop. Esta função simula um loop while que literalmente faz cálculos personalizados se a condição for satisfeita. |
| cond (pred, then_func, else_func) | Como o nome indica, essa função executa um if-then-else usando condição e computação definidas pelo usuário. Esta função simula uma ramificação semelhante a if que escolhe fazer um dos dois cálculos personalizados de acordo com a condição especificada. |
| getnnz ([dados, eixo, saída, nome]) | Esta função nos dá o número de valores armazenados para um tensor esparso. Também inclui zeros explícitos. Ele suporta apenas matriz CSR na CPU. |
| requantize ([data, min_range, max_range,…]) | Esta função requantiza os dados fornecidos que são quantizados em int32 e os limites correspondentes, em int8 usando os limites mínimo e máximo calculados em tempo de execução ou a partir da calibração. |
| index_copy ([old_tensor, index_vector, ...]) | Esta função copia os elementos de um new_tensor into the old_tensor by selecting the indices in the order given in index. The output of this operator will be a new tensor that contains the rest elements of old tensor and the copied elements of new tensor. |
| interleaved_matmul_encdec_qk ([consultas,…]) | Este operador calcula a multiplicação da matriz entre as projeções de consultas e chaves no uso de atenção múltipla como codificador-decodificador. A condição é que as entradas sejam um tensor de projeções de consultas que seguem o layout: (comprimento_seq, tamanho_do_ lote, número_de_heads *, head_dim). |
Exemplos de implementação
No exemplo abaixo, estaremos usando a função rand_zipfian para desenhar amostras aleatórias de uma distribuição aproximadamente Zipfian -
import mxnet as mx
true_cls = mx.sym.Variable('true_cls')
samples, exp_count_true, exp_count_sample = mx.sym.contrib.rand_zipfian(true_cls, 5, 6)
samples.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
Você verá a seguinte saída -
array([4, 0, 2, 1, 5], dtype=int64)Example
exp_count_true.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
A saída é mencionada abaixo -
array([0.57336551])Example
exp_count_sample.eval(true_cls=mx.nd.array([3]))[0].asnumpy()Output
Você verá a seguinte saída -
array([1.78103594, 0.46847373, 1.04183923, 0.57336551, 1.04183923])No exemplo abaixo, estaremos usando a função while_loop para executar um loop while para computação definida pelo usuário e condição de loop -
cond = lambda i, s: i <= 7
func = lambda i, s: ([i + s], [i + 1, s + i])
loop_vars = (mx.sym.var('i'), mx.sym.var('s'))
outputs, states = mx.sym.contrib.while_loop(cond, func, loop_vars, max_iterations=10)
print(outputs)Output
O resultado é fornecido abaixo:
[<Symbol _while_loop0>]Example
Print(States)Output
Isso produz a seguinte saída -
[<Symbol _while_loop0>, <Symbol _while_loop0>]No exemplo abaixo, estaremos usando a função index_copy que copia os elementos de new_tensor para o old_tensor.
import mxnet as mx
a = mx.nd.zeros((6,3))
b = mx.nd.array([[1,2,3],[4,5,6],[7,8,9]])
index = mx.nd.array([0,4,2])
mx.nd.contrib.index_copy(a, index, b)Output
Ao executar o código acima, você verá a seguinte saída -
[[1. 2. 3.]
[0. 0. 0.]
[7. 8. 9.]
[0. 0. 0.]
[4. 5. 6.]
[0. 0. 0.]]
<NDArray 6x3 @cpu(0)>symbol.image
A API Image Symbol é definida no pacote symbol.image. Como o nome indica, normalmente é usado para imagens e seus recursos.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.symbol.image API -
| Função e seus parâmetros | Definição |
|---|---|
| Adjust_lighting ([data, alpha, out, name]) | Como o nome indica, esta função ajusta o nível de iluminação da entrada. Segue o estilo AlexNet. |
| cortar ([dados, x, y, largura, altura, saída, nome]) | Com a ajuda desta função, podemos cortar uma imagem NDArray de forma (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. |
| normalizar ([dados, média, padrão, saída, nome]) | Ele normalizará um tensor de forma (C x H x W) ou (N x C x H x W) com mean e standard deviation(SD). |
| random_crop ([data, xrange, yrange, width, ...]) | Semelhante a crop (), ele corta aleatoriamente uma imagem NDArray de formato (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. Isso vai aumentar a amostra do resultado sesrc é menor que o size. |
| random_lighting([dados, alfa_std, saída, nome]) | Como o nome indica, esta função adiciona o ruído PCA aleatoriamente. Também segue o estilo AlexNet. |
| random_resized_crop ([data, xrange, yrange, ...]) | Ele também corta uma imagem aleatoriamente NDArray de forma (A x L x C) ou (N x A x L x C) para o tamanho fornecido. Isso aumentará a amostra do resultado se src for menor que o tamanho. Ele irá randomizar a área e a proporção de aspecto também. |
| resize ([data, size, keep_ratio, interp, ...]) | Como o nome indica, esta função irá redimensionar uma imagem NDArray de formato (A x L x C) ou (N x A x L x C) para o tamanho fornecido pelo usuário. |
| to_tensor ([dados, saída, nome]) | Ele converte uma imagem NDArray de forma (H x W x C) ou (N x A x W x C) com os valores no intervalo [0, 255] em um tensor NDArray de forma (C x H x W) ou ( N x C x H x W) com os valores no intervalo [0, 1]. |
Exemplos de implementação
No exemplo abaixo, estaremos usando a função to_tensor para converter NDArray de imagem de forma (H x W x C) ou (N x H x W x C) com os valores no intervalo [0, 255] para um tensor NDArray de forma (C x H x W) ou (N x C x A x W) com os valores no intervalo [0, 1].
import numpy as np
img = mx.sym.random.uniform(0, 255, (4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
O resultado é declarado abaixo -
<Symbol to_tensor4>Example
img = mx.sym.random.uniform(0, 255, (2, 4, 2, 3)).astype(dtype=np.uint8)
mx.sym.image.to_tensor(img)Output
O resultado é mencionado abaixo:
<Symbol to_tensor5>No exemplo abaixo, estaremos usando a função normalize () para normalizar um tensor de forma (C x H x W) ou (N x C x H x W) com mean e standard deviation(SD).
img = mx.sym.random.uniform(0, 1, (3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
A seguir está a saída do código -
<Symbol normalize0>Example
img = mx.sym.random.uniform(0, 1, (2, 3, 4, 2))
mx.sym.image.normalize(img, mean=(0, 1, 2), std=(3, 2, 1))Output
O resultado é mostrado abaixo -
<Symbol normalize1>symbol.random
A API Random Symbol é definida no pacote symbol.random. Como o nome indica, é o gerador de distribuição aleatória Symbol API do MXNet.
Funções e seus parâmetros
A seguir estão algumas das funções importantes e seus parâmetros cobertos por mxnet.symbol.random API -
| Função e seus parâmetros | Definição |
|---|---|
| uniforme ([baixo, alto, forma, tipo d, ctx, fora]) | Ele gera amostras aleatórias de uma distribuição uniforme. |
| normal ([local, escala, forma, tipo d, ctx, saída]) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana). |
| randn (* forma, ** kwargs) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana). |
| poisson ([lam, shape, dtype, ctx, out]) | Ele gera amostras aleatórias de uma distribuição de Poisson. |
| exponencial ([escala, forma, tipo d, ctx, saída]) | Ele gera amostras de uma distribuição exponencial. |
| gama ([alpha, beta, shape, dtype, ctx, out]) | Ele gera amostras aleatórias de uma distribuição gama. |
| multinomial (dados [, forma, get_prob, out, dtype]) | Ele gera amostragem simultânea de várias distribuições multinomiais. |
| binomial_ negativo ([k, p, forma, tipo d, ctx, saída]) | Ele gera amostras aleatórias de uma distribuição binomial negativa. |
| generalized_negative_binomial ([mu, alpha, ...]) | Ele gera amostras aleatórias de uma distribuição binomial negativa generalizada. |
| embaralhar (dados, ** kwargs) | Ele embaralha os elementos aleatoriamente. |
| randint (baixo, alto [, forma, tipo d, ctx, fora]) | Ele gera amostras aleatórias de uma distribuição uniforme discreta. |
| exponential_like ([data, lam, out, name]) | Ele gera amostras aleatórias de uma distribuição exponencial de acordo com a forma da matriz de entrada. |
| gamma_like ([dados, alfa, beta, saída, nome]) | Ele gera amostras aleatórias de uma distribuição gama de acordo com a forma da matriz de entrada. |
| generalized_negative_binomial_like ([dados, ...]) | Ele gera amostras aleatórias de uma distribuição binomial negativa generalizada de acordo com a forma da matriz de entrada. |
| negative_binomial_like ([data, k, p, out, name]) | Ele gera amostras aleatórias de uma distribuição binomial negativa de acordo com a forma da matriz de entrada. |
| normal_like ([dados, loc, escala, saída, nome]) | Ele gera amostras aleatórias de uma distribuição normal (Gaussiana) de acordo com a forma da matriz de entrada. |
| poisson_like ([data, lam, out, name]) | Ele gera amostras aleatórias de uma distribuição de Poisson de acordo com a forma da matriz de entrada. |
| uniform_like ([dados, baixo, alto, fora, nome]) | Ele gera amostras aleatórias de uma distribuição uniforme de acordo com a forma da matriz de entrada. |
Exemplos de implementação
No exemplo abaixo, vamos embaralhar os elementos aleatoriamente usando a função shuffle (). Ele irá embaralhar a matriz ao longo do primeiro eixo.
data = mx.nd.array([[0, 1, 2], [3, 4, 5], [6, 7, 8],[9,10,11]])
x = mx.sym.Variable('x')
y = mx.sym.random.shuffle(x)
y.eval(x=data)Output
Você verá a seguinte saída:
[
[[ 9. 10. 11.]
[ 0. 1. 2.]
[ 6. 7. 8.]
[ 3. 4. 5.]]
<NDArray 4x3 @cpu(0)>]Example
y.eval(x=data)Output
Ao executar o código acima, você verá a seguinte saída -
[
[[ 6. 7. 8.]
[ 0. 1. 2.]
[ 3. 4. 5.]
[ 9. 10. 11.]]
<NDArray 4x3 @cpu(0)>]No exemplo abaixo, vamos extrair amostras aleatórias de uma distribuição binomial negativa generalizada. Para isso estarei usando a funçãogeneralized_negative_binomial().
mx.sym.random.generalized_negative_binomial(10, 0.1)Output
O resultado é dado abaixo -
<Symbol _random_generalized_negative_binomial0>symbol.sparse
O Sparse Symbol API é definido no pacote mxnet.symbol.sparse. Como o nome indica, ele fornece gráficos de rede neural esparsos e autodiferenciação na CPU.
Funções e seus parâmetros
A seguir estão algumas das funções importantes (inclui rotinas de criação de símbolos, rotinas de manipulação de símbolos, funções matemáticas, função trigonométrica, funções hiperbólicas, funções de redução, arredondamento, poderes, rede neural) e seus parâmetros cobertos por mxnet.symbol.sparse API -
| Função e seus parâmetros | Definição |
|---|---|
| ElementWiseSum (* args, ** kwargs) | Esta função adicionará todos os argumentos de entrada em termos de elemento. Por exemplo, _ (1,2,… = 1 + 2 + ⋯ +). Aqui, podemos ver que add_n é potencialmente mais eficiente do que chamar add por n vezes. |
| Incorporação ([dados, peso, entrada_dim, ...]) | Ele irá mapear os índices inteiros para representações vetoriais, ou seja, embeddings. Na verdade, ele mapeia palavras para vetores de valor real no espaço de alta dimensão, que é chamado de embeddings de palavras. |
| LinearRegressionOutput ([dados, rótulo, ...]) | Ele calcula e otimiza a perda quadrática durante a propagação para trás, fornecendo apenas dados de saída durante a propagação para frente. |
| LogisticRegressionOutput ([data, label, ...]) | Aplica uma função logística que também é chamada de função sigmóide à entrada. A função é calculada como 1/1 + exp (−x). |
| MAERegressionOutput ([data, label, ...]) | Este operador calcula o erro absoluto médio da entrada. MAE é na verdade uma métrica de risco correspondente ao valor esperado do erro absoluto. |
| abs ([data, name, attr, out]) | Como o nome indica, esta função retornará o valor absoluto elemento a elemento da entrada. |
| adagrad_update ([peso, graduação, história, lr, ...]) | É uma função de atualização para AdaGrad optimizer. |
| adam_update ([peso, grad, média, var, lr, ...]) | É uma função de atualização para Adam optimizer. |
| add_n (* args, ** kwargs) | Como o nome indica, ele adicionará todos os argumentos de entrada a nível de elemento. |
| arccos ([data, name, attr, out]) | Esta função retornará cosseno inverso elemento a elemento da matriz de entrada. |
| ponto ([lhs, rhs, transpose_a, transpose_b, ...]) | Como o nome indica, ele fornecerá o produto escalar de duas matrizes. Dependerá da dimensão da matriz de entrada: 1-D: produto interno dos vetores 2-D: multiplicação da matriz ND: Um produto da soma sobre o último eixo da primeira entrada e o primeiro eixo da segunda entrada. |
| elemwise_add ([lhs, rhs, nome, attr, out]) | Como o nome indica, vai add argumentos elemento sábio. |
| elemwise_div ([lhs, rhs, nome, attr, out]) | Como o nome indica, vai divide argumentos elemento sábio. |
| elemwise_mul ([lhs, rhs, nome, attr, out]) | Como o nome indica, vai Multiply argumentos elemento sábio. |
| elemwise_sub ([lhs, rhs, nome, attr, out]) | Como o nome indica, ele subtrairá os argumentos em termos de elemento. |
| exp ([data, name, attr, out]) | Esta função retornará o valor exponencial elemento a elemento da entrada fornecida. |
| sgd_update ([peso, grad, lr, wd, ...]) | Ele atua como uma função de atualização para o otimizador Stochastic Gradient Descent. |
| sigmóide ([data, name, attr, out]) | Como o nome indica, irá computar sigmoid de x elemento sábio. |
| sinal ([data, name, attr, out]) | Ele retornará o sinal do elemento sábio da entrada fornecida. |
| sin ([data, name, attr, out]) | Como o nome indica, esta função calcula o seno do elemento sábio da matriz de entrada fornecida. |
Exemplo de Implementação
No exemplo abaixo, vamos embaralhar os elementos aleatoriamente usando ElementWiseSum()função. Ele irá mapear índices inteiros para representações vetoriais, ou seja, embeddings de palavras.
input_dim = 4
output_dim = 5Example
/* Here every row in weight matrix y represents a word. So, y = (w0,w1,w2,w3)
y = [[ 0., 1., 2., 3., 4.],
[ 5., 6., 7., 8., 9.],
[ 10., 11., 12., 13., 14.],
[ 15., 16., 17., 18., 19.]]
/* Here input array x represents n-grams(2-gram). So, x = [(w1,w3), (w0,w2)]
x = [[ 1., 3.],
[ 0., 2.]]
/* Now, Mapped input x to its vector representation y.
Embedding(x, y, 4, 5) = [[[ 5., 6., 7., 8., 9.],
[ 15., 16., 17., 18., 19.]],
[[ 0., 1., 2., 3., 4.],
[ 10., 11., 12., 13., 14.]]]O módulo API do Apache MXNet é como um modelo FeedForward e é mais fácil de compor semelhante ao módulo Torch. Consiste nas seguintes classes -
BaseModule ([logger])
Ele representa a classe base de um módulo. Um módulo pode ser considerado um componente de computação ou máquina de computação. O trabalho de um módulo é executar passes para frente e para trás. Ele também atualiza parâmetros em um modelo.
Métodos
A tabela a seguir mostra os métodos consistidos em BaseModule class-
Este método obterá estados de todos os dispositivos| Métodos | Definição |
|---|---|
| para trás ([out_grads]) | Como o nome indica, este método implementa o backward computação. |
| vincular (data_shapes [, label_shapes, ...]) | Ele vincula os símbolos para construir executores e é necessário antes que se possa realizar cálculos com o módulo. |
| fit (train_data [, eval_data, eval_metric, ...]) | Este método treina os parâmetros do módulo. |
| forward (data_batch [, is_train]) | Como o nome indica, este método implementa o cálculo Forward. Este método oferece suporte a lotes de dados com várias formas, como tamanhos de lote diferentes ou tamanhos de imagem diferentes. |
| forward_backward (data_batch) | É uma função conveniente, como o nome indica, que chama tanto para frente quanto para trás. |
| get_input_grads ([merge_multi_context]) | Este método obterá os gradientes para as entradas que são calculadas no cálculo retroativo anterior. |
| get_outputs ([merge_multi_context]) | Como o nome indica, este método obterá resultados da computação direta anterior. |
| get_params () | Ele obtém os parâmetros, especialmente aqueles que são potencialmente cópias dos parâmetros reais usados para fazer cálculos no dispositivo. |
| get_states ([merge_multi_context]) | |
| init_optimizer ([kvstore, otimizer, ...]) | Este método instala e inicializa os otimizadores. Ele também inicializakvstore para distribuir o treinamento. |
| init_params ([initializer, arg_params,…]) | Como o nome indica, este método inicializará os parâmetros e estados auxiliares. |
| install_monitor (mon) | Este método instalará o monitor em todos os executores. |
| iter_predict (eval_data [, num_batch, reset, ...]) | Este método irá iterar sobre as previsões. |
| load_params (fname) | Ele irá, como o nome especifica, carregar os parâmetros do modelo do arquivo. |
| prever (eval_data [, num_batch,…]) | Ele executará a previsão e também coletará os resultados. |
| preparar (data_batch [, sparse_row_id_fn]) | O operador prepara o módulo para processar um determinado lote de dados. |
| save_params (fname) | Como o nome especifica, esta função salvará os parâmetros do modelo em um arquivo. |
| pontuação (eval_data, eval_metric [, num_batch, ...]) | Ele executa a previsão em eval_data e também avalia o desempenho de acordo com as eval_metric. |
| set_params (arg_params, aux_params [,…]) | Este método atribuirá o parâmetro e os valores do estado auxiliar. |
| set_states ([estados, valor]) | Este método, como o nome indica, define o valor dos estados. |
| atualizar() | Este método atualiza os parâmetros fornecidos de acordo com o otimizador instalado. Ele também atualiza os gradientes calculados no lote anterior para frente e para trás. |
| update_metric (eval_metric, labels [, pre_sliced]) | Este método, como o nome indica, avalia e acumula a métrica de avaliação nas saídas da última computação direta. |
| para trás ([out_grads]) | Como o nome indica, este método implementa o backward computação. |
| vincular (data_shapes [, label_shapes, ...]) | Ele configura os depósitos e vincula o executor à chave do depósito padrão. Este método representa a ligação para umBucketingModule. |
| forward (data_batch [, is_train]) | Como o nome indica, este método implementa o cálculo Forward. Este método oferece suporte a lotes de dados com várias formas, como tamanhos de lote diferentes ou tamanhos de imagem diferentes. |
| get_input_grads ([merge_multi_context]) | Este método obterá os gradientes para as entradas que são calculadas no cálculo retroativo anterior. |
| get_outputs ([merge_multi_context]) | Como o nome indica, este método obterá resultados da computação direta anterior. |
| get_params () | Ele obtém os parâmetros atuais, especialmente aqueles que são potencialmente cópias dos parâmetros reais usados para fazer cálculos no dispositivo. |
| get_states ([merge_multi_context]) | Este método obterá estados de todos os dispositivos. |
| init_optimizer ([kvstore, otimizer, ...]) | Este método instala e inicializa os otimizadores. Ele também inicializakvstore para distribuir o treinamento. |
| init_params ([initializer, arg_params,…]) | Como o nome indica, este método inicializará os parâmetros e estados auxiliares. |
| install_monitor (mon) | Este método instalará o monitor em todos os executores. |
| carregar (prefixo, época [, sym_gen, ...]) | Este método criará um modelo a partir do ponto de verificação salvo anteriormente. |
| load_dict ([sym_dict, sym_gen,…]) | Este método irá criar um modelo a partir de um mapeamento de dicionário (dict) bucket_keyaos símbolos. Também compartilhaarg_params e aux_params. |
| preparar (data_batch [, sparse_row_id_fn]) | O operador prepara o módulo para processar um determinado lote de dados. |
| save_checkpoint (prefixo, epoch [, remove_amp_cast]) | Este método, como o nome indica, salva o progresso atual no ponto de verificação para todos os buckets em BucketingModule. É recomendável usar mx.callback.module_checkpoint como epoch_end_callback para salvar durante o treinamento. |
| set_params (arg_params, aux_params [,…]) | Como o nome especifica, esta função atribuirá parâmetros e valores de estado de pausa. |
| set_states ([estados, valor]) | Este método, como o nome indica, define o valor dos estados. |
| switch_bucket (bucket_key, data_shapes [,…]) | Ele mudará para um balde diferente. |
| atualizar() | Este método atualiza os parâmetros fornecidos de acordo com o otimizador instalado. Ele também atualiza os gradientes calculados no lote anterior para frente e para trás. |
| update_metric (eval_metric, labels [, pre_sliced]) | Este método, como o nome indica, avalia e acumula a métrica de avaliação nas saídas da última computação direta. |
Atributos
A tabela a seguir mostra os atributos que consistem nos métodos de BaseModule classe -
| Atributos | Definição |
|---|---|
| data_names | Consiste na lista de nomes para os dados exigidos por este módulo. |
| data_shapes | Consiste na lista de pares (nome, forma) especificando as entradas de dados para este módulo. |
| label_shapes | Ele mostra a lista de pares (nome, forma) especificando as entradas de rótulo para este módulo. |
| output_names | Consiste na lista de nomes para as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
| símbolo | Conforme o nome especificado, este atributo obtém o símbolo associado a este módulo. |
data_shapes: Você pode consultar o link disponível em https://mxnet.apache.orgpara detalhes. output_shapes: Mais
output_shapes: Mais informações estão disponíveis em https://mxnet.apache.org/api/python
BucketingModule (sym_gen […])
Representa o Bucketingmodule classe de um módulo que ajuda a lidar de forma eficiente com entradas de comprimento variável.
Métodos
A tabela a seguir mostra os métodos consistidos em BucketingModule class -
Atributos
A tabela a seguir mostra os atributos que consistem nos métodos de BaseModule class -
| Atributos | Definição |
|---|---|
| data_names | Consiste na lista de nomes para os dados exigidos por este módulo. |
| data_shapes | Consiste na lista de pares (nome, forma) especificando as entradas de dados para este módulo. |
| label_shapes | Ele mostra a lista de pares (nome, forma) especificando as entradas de rótulo para este módulo. |
| output_names | Consiste na lista de nomes para as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
| Símbolo | Conforme o nome especificado, este atributo obtém o símbolo associado a este módulo. |
data_shapes - Você pode consultar o link em https://mxnet.apache.org/api/python/docs Para maiores informações.
output_shapes- Você pode consultar o link em https://mxnet.apache.org/api/python/docs Para maiores informações.
Módulo (símbolo [, data_names, label_names, ...])
Ele representa um módulo básico que envolve um symbol.
Métodos
A tabela a seguir mostra os métodos consistidos em Module class -
| Métodos | Definição |
|---|---|
| para trás ([out_grads]) | Como o nome indica, este método implementa o backward computação. |
| vincular (data_shapes [, label_shapes, ...]) | Ele vincula os símbolos para construir executores e é necessário antes que se possa realizar cálculos com o módulo. |
| borrow_optimizer (shared_module) | Como o nome indica, esse método pegará emprestado o otimizador de um módulo compartilhado. |
| forward (data_batch [, is_train]) | Como o nome indica, este método implementa o Forwardcomputação. Este método oferece suporte a lotes de dados com várias formas, como tamanhos de lote diferentes ou tamanhos de imagem diferentes. |
| get_input_grads ([merge_multi_context]) | Este método obterá os gradientes para as entradas que são calculadas no cálculo retroativo anterior. |
| get_outputs ([merge_multi_context]) | Como o nome indica, este método obterá resultados da computação direta anterior. |
| get_params () | Ele obtém os parâmetros, especialmente aqueles que são potencialmente cópias dos parâmetros reais usados para fazer cálculos no dispositivo. |
| get_states ([merge_multi_context]) | Este método obterá estados de todos os dispositivos |
| init_optimizer ([kvstore, otimizer, ...]) | Este método instala e inicializa os otimizadores. Ele também inicializakvstore para distribuir o treinamento. |
| init_params ([initializer, arg_params,…]) | Como o nome indica, este método inicializará os parâmetros e estados auxiliares. |
| install_monitor (mon) | Este método instalará o monitor em todos os executores. |
| carregar (prefixo, época [, sym_gen, ...]) | Este método criará um modelo a partir do ponto de verificação salvo anteriormente. |
| load_optimizer_states (fname) | Este método carregará um otimizador, ou seja, o estado do atualizador de um arquivo. |
| preparar (data_batch [, sparse_row_id_fn]) | O operador prepara o módulo para processar um determinado lote de dados. |
| remodelar (data_shapes [, label_shapes]) | Este método, como o nome indica, remodela o módulo para novas formas de entrada. |
| save_checkpoint (prefixo, época [,…]) | Ele salva o progresso atual para o ponto de verificação. |
| save_optimizer_states (fname) | Este método salva o otimizador ou o estado do atualizador em um arquivo. |
| set_params (arg_params, aux_params [,…]) | Como o nome especifica, esta função atribuirá parâmetros e valores de estado de pausa. |
| set_states ([estados, valor]) | Este método, como o nome indica, define o valor dos estados. |
| atualizar() | Este método atualiza os parâmetros fornecidos de acordo com o otimizador instalado. Ele também atualiza os gradientes calculados no lote anterior para frente e para trás. |
| update_metric (eval_metric, labels [, pre_sliced]) | Este método, como o nome indica, avalia e acumula a métrica de avaliação nas saídas da última computação direta. |
Atributos
A tabela a seguir mostra os atributos que consistem nos métodos de Module class -
| Atributos | Definição |
|---|---|
| data_names | Consiste na lista de nomes para os dados exigidos por este módulo. |
| data_shapes | Consiste na lista de pares (nome, forma) especificando as entradas de dados para este módulo. |
| label_shapes | Ele mostra a lista de pares (nome, forma) especificando as entradas de rótulo para este módulo. |
| output_names | Consiste na lista de nomes para as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
| label_names | Consiste na lista de nomes para rótulos exigidos por este módulo. |
data_shapes: Visite o link https://mxnet.apache.org/api/python/docs/api/module para mais detalhes.
output_shapes: O link fornecido aqui https://mxnet.apache.org/api/python/docs/api/module/index.html oferecerá outras informações importantes.
PythonLossModule ([name, data_names, ...])
A base desta classe é mxnet.module.python_module.PythonModule. A classe PythonLossModule é uma classe de módulo conveniente que implementa todas ou muitas das APIs de módulo como funções vazias.
Métodos
A tabela a seguir mostra os métodos consistidos em PythonLossModule classe:
| Métodos | Definição |
|---|---|
| para trás ([out_grads]) | Como o nome indica, este método implementa o backward computação. |
| forward (data_batch [, is_train]) | Como o nome indica, este método implementa o Forwardcomputação. Este método oferece suporte a lotes de dados com várias formas, como tamanhos de lote diferentes ou tamanhos de imagem diferentes. |
| get_input_grads ([merge_multi_context]) | Este método obterá os gradientes para as entradas que são calculadas no cálculo retroativo anterior. |
| get_outputs ([merge_multi_context]) | Como o nome indica, este método obterá resultados da computação direta anterior. |
| install_monitor (mon) | Este método instalará o monitor em todos os executores. |
PythonModule ([data_names, label_names ...])
A base desta classe é mxnet.module.base_module.BaseModule. A classe PythonModule também é uma classe de módulo conveniente que implementa todas ou muitas das APIs de módulo como funções vazias.
Métodos
A tabela a seguir mostra os métodos consistidos em PythonModule classe -
| Métodos | Definição |
|---|---|
| vincular (data_shapes [, label_shapes, ...]) | Ele vincula os símbolos para construir executores e é necessário antes que se possa realizar cálculos com o módulo. |
| get_params () | Ele obtém os parâmetros, especialmente aqueles que são potencialmente cópias dos parâmetros reais usados para fazer cálculos no dispositivo. |
| init_optimizer ([kvstore, otimizer, ...]) | Este método instala e inicializa os otimizadores. Ele também inicializakvstore para distribuir o treinamento. |
| init_params ([initializer, arg_params,…]) | Como o nome indica, este método inicializará os parâmetros e estados auxiliares. |
| atualizar() | Este método atualiza os parâmetros fornecidos de acordo com o otimizador instalado. Ele também atualiza os gradientes calculados no lote anterior para frente e para trás. |
| update_metric (eval_metric, labels [, pre_sliced]) | Este método, como o nome indica, avalia e acumula a métrica de avaliação nas saídas da última computação direta. |
Atributos
A tabela a seguir mostra os atributos que consistem nos métodos de PythonModule classe -
| Atributos | Definição |
|---|---|
| data_names | Consiste na lista de nomes para os dados exigidos por este módulo. |
| data_shapes | Consiste na lista de pares (nome, forma) especificando as entradas de dados para este módulo. |
| label_shapes | Ele mostra a lista de pares (nome, forma) especificando as entradas de rótulo para este módulo. |
| output_names | Consiste na lista de nomes para as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
data_shapes - Siga o link https://mxnet.apache.org para detalhes.
output_shapes - Para mais detalhes, visite o link disponível em https://mxnet.apache.org
SequentialModule ([logger])
A base desta classe é mxnet.module.base_module.BaseModule. A classe SequentialModule também é um módulo de contêiner que pode encadear mais de dois (múltiplos) módulos juntos.
Métodos
A tabela a seguir mostra os métodos consistidos em SequentialModule classe
| Métodos | Definição |
|---|---|
| adicionar (módulo, ** kwargs) | Esta é a função mais importante desta classe. Ele adiciona um módulo à cadeia. |
| para trás ([out_grads]) | Como o nome indica, este método implementa o cálculo retroativo. |
| vincular (data_shapes [, label_shapes, ...]) | Ele vincula os símbolos para construir executores e é necessário antes que se possa realizar cálculos com o módulo. |
| forward (data_batch [, is_train]) | Como o nome indica, este método implementa o cálculo Forward. Este método oferece suporte a lotes de dados com várias formas, como tamanhos de lote diferentes ou tamanhos de imagem diferentes. |
| get_input_grads ([merge_multi_context]) | Este método obterá os gradientes para as entradas que são calculadas no cálculo retroativo anterior. |
| get_outputs ([merge_multi_context]) | Como o nome indica, este método obterá resultados da computação direta anterior. |
| get_params () | Ele obtém os parâmetros, especialmente aqueles que são potencialmente cópias dos parâmetros reais usados para fazer cálculos no dispositivo. |
| init_optimizer ([kvstore, otimizer, ...]) | Este método instala e inicializa os otimizadores. Ele também inicializakvstore para distribuir o treinamento. |
| init_params ([initializer, arg_params,…]) | Como o nome indica, este método inicializará os parâmetros e estados auxiliares. |
| install_monitor (mon) | Este método instalará o monitor em todos os executores. |
| atualizar() | Este método atualiza os parâmetros fornecidos de acordo com o otimizador instalado. Ele também atualiza os gradientes calculados no lote anterior para frente e para trás. |
| update_metric (eval_metric, labels [, pre_sliced]) | Este método, como o nome indica, avalia e acumula a métrica de avaliação nas saídas da última computação direta. |
Atributos
A tabela a seguir mostra os atributos consistidos nos métodos da classe BaseModule -
| Atributos | Definição |
|---|---|
| data_names | Consiste na lista de nomes para os dados exigidos por este módulo. |
| data_shapes | Consiste na lista de pares (nome, forma) especificando as entradas de dados para este módulo. |
| label_shapes | Ele mostra a lista de pares (nome, forma) especificando as entradas de rótulo para este módulo. |
| output_names | Consiste na lista de nomes para as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
| output_shapes | Consiste na lista de pares (nome, forma) especificando as saídas deste módulo. |
data_shapes - O link fornecido aqui https://mxnet.apache.org irá ajudá-lo a compreender o atributo em muitos detalhes.
output_shapes - Siga o link disponível em https://mxnet.apache.org/api para detalhes.
Exemplos de implementação
No exemplo abaixo, vamos criar um mxnet módulo.
import mxnet as mx
input_data = mx.symbol.Variable('input_data')
f_connected1 = mx.symbol.FullyConnected(data, name='f_connected1', num_hidden=128)
activation_1 = mx.symbol.Activation(f_connected1, name='relu1', act_type="relu")
f_connected2 = mx.symbol.FullyConnected(activation_1, name = 'f_connected2', num_hidden = 64)
activation_2 = mx.symbol.Activation(f_connected2, name='relu2',
act_type="relu")
f_connected3 = mx.symbol.FullyConnected(activation_2, name='fc3', num_hidden=10)
out = mx.symbol.SoftmaxOutput(f_connected3, name = 'softmax')
mod = mx.mod.Module(out)
print(out)Output
A saída é mencionada abaixo -
<Symbol softmax>Example
print(mod)Output
O resultado é mostrado abaixo -
<mxnet.module.module.Module object at 0x00000123A9892F28>Neste exemplo abaixo, iremos implementar computação progressiva
import mxnet as mx
from collections import namedtuple
Batch = namedtuple('Batch', ['data'])
data = mx.sym.Variable('data')
out = data * 2
mod = mx.mod.Module(symbol=out, label_names=None)
mod.bind(data_shapes=[('data', (1, 10))])
mod.init_params()
data1 = [mx.nd.ones((1, 10))]
mod.forward(Batch(data1))
print (mod.get_outputs()[0].asnumpy())Output
Ao executar o código acima, você verá a seguinte saída -
[[2. 2. 2. 2. 2. 2. 2. 2. 2. 2.]]Example
data2 = [mx.nd.ones((3, 5))]
mod.forward(Batch(data2))
print (mod.get_outputs()[0].asnumpy())Output
A seguir está a saída do código -
[[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]
[2. 2. 2. 2. 2.]]