Apache Presto - Guia rápido
A análise de dados é o processo de análise de dados brutos para reunir informações relevantes para uma melhor tomada de decisão. É usado principalmente em muitas organizações para tomar decisões de negócios. Bem, a análise de big data envolve uma grande quantidade de dados e esse processo é bastante complexo, portanto, as empresas usam estratégias diferentes.
Por exemplo, o Facebook é uma das maiores empresas de armazenamento de dados orientadas a dados do mundo. Os dados de warehouse do Facebook são armazenados no Hadoop para computação em grande escala. Mais tarde, quando os dados do warehouse cresceram para petabytes, eles decidiram desenvolver um novo sistema com baixa latência. No ano de 2012, os membros da equipe do Facebook criaram“Presto” para análise de consulta interativa que operaria rapidamente mesmo com petabytes de dados.
O que é Apache Presto?
Apache Presto é um mecanismo de execução de consulta paralela distribuído, otimizado para baixa latência e análise de consulta interativa. Presto executa consultas facilmente e escala sem tempo de inatividade, mesmo de gigabytes a petabytes.
Uma única consulta Presto pode processar dados de várias fontes, como HDFS, MySQL, Cassandra, Hive e muitas outras fontes de dados. Presto é construído em Java e fácil de integrar com outros componentes de infraestrutura de dados. Presto é poderoso, e empresas líderes como Airbnb, DropBox, Groupon, Netflix o estão adotando.
Presto - Recursos
Presto contém os seguintes recursos -
- Arquitetura simples e extensível.
- Conectores plugáveis - Presto oferece suporte a conectores plugáveis para fornecer metadados e dados para consultas.
- Execuções pipelined - evita sobrecarga de latência de E / S desnecessária.
- Funções definidas pelo usuário - os analistas podem criar funções personalizadas definidas pelo usuário para migrar facilmente.
- Processamento colunar vetorizado.
Presto - Benefícios
Aqui está uma lista de benefícios que o Apache Presto oferece -
- Operações SQL especializadas
- Fácil de instalar e depurar
- Abstração de armazenamento simples
- Escala dados de petabytes rapidamente com baixa latência
Presto - Aplicativos
O Presto oferece suporte à maioria das melhores aplicações industriais da atualidade. Vamos dar uma olhada em alguns dos aplicativos notáveis.
Facebook- Facebook construiu Presto para necessidades de análise de dados. O Presto dimensiona facilmente grandes velocidades de dados.
Teradata- A Teradata fornece soluções ponta a ponta em análise de Big Data e armazenamento de dados. A contribuição da Teradata para o Presto torna mais fácil para mais empresas atender a todas as necessidades analíticas.
Airbnb- O Presto é parte integrante da infraestrutura de dados do Airbnb. Bem, centenas de funcionários estão executando consultas todos os dias com a tecnologia.
Por que Presto?
O Presto suporta ANSI SQL padrão, o que o torna muito fácil para analistas de dados e desenvolvedores. Embora seja construído em Java, ele evita problemas típicos de código Java relacionados à alocação de memória e coleta de lixo. O Presto tem uma arquitetura de conector compatível com Hadoop. Ele permite conectar facilmente sistemas de arquivos.
O Presto é executado em várias distribuições do Hadoop. Além disso, o Presto pode acessar a partir de uma plataforma Hadoop para consultar o Cassandra, bancos de dados relacionais ou outros armazenamentos de dados. Esse recurso analítico de plataforma cruzada permite que os usuários do Presto extraiam o máximo valor comercial de gigabytes a petabytes de dados.
A arquitetura do Presto é quase semelhante à arquitetura DBMS MPP (processamento massivamente paralelo) clássica. O diagrama a seguir ilustra a arquitetura do Presto.

O diagrama acima consiste em diferentes componentes. A tabela a seguir descreve cada um dos componentes em detalhes.
| S.No | Descrição do componente |
|---|---|
| 1 | Client O cliente (Presto CLI) envia instruções SQL a um coordenador para obter o resultado. |
| 2 | Coordinator O coordenador é um daemon mestre. O coordenador inicialmente analisa as consultas SQL e, em seguida, analisa e planeja a execução da consulta. O Scheduler executa a execução do pipeline, atribui o trabalho ao nó mais próximo e monitora o progresso. |
| 3 - | Connector Os plug-ins de armazenamento são chamados de conectores. Hive, HBase, MySQL, Cassandra e muitos outros atuam como um conector; caso contrário, você também pode implementar um personalizado. O conector fornece metadados e dados para consultas. O coordenador usa o conector para obter metadados para construir um plano de consulta. |
| 4 - | Worker O coordenador atribui tarefas aos nós de trabalho. Os trabalhadores obtêm dados reais do conector. Finalmente, o nó do trabalhador entrega o resultado ao cliente. |
Presto - Fluxo de Trabalho
Presto é um sistema distribuído que funciona em um cluster de nós. O mecanismo de consulta distribuído do Presto é otimizado para análise interativa e oferece suporte a ANSI SQL padrão, incluindo consultas complexas, agregações, junções e funções de janela. A arquitetura do Presto é simples e extensível. O cliente Presto (CLI) envia instruções SQL para um coordenador mestre daemon.
O planejador se conecta por meio do pipeline de execução. O planejador atribui trabalho aos nós que estão mais próximos dos dados e monitora o progresso. O coordenador atribui tarefas a vários nós de trabalho e, finalmente, o nó de trabalho entrega o resultado de volta ao cliente. O cliente extrai dados do processo de saída. A extensibilidade é o design chave. Conectores plugáveis como Hive, HBase, MySQL, etc., fornecem metadados e dados para consultas. O Presto foi projetado com uma “abstração de armazenamento simples” que torna fácil fornecer capacidade de consulta SQL contra esses diferentes tipos de fontes de dados.
Modelo de Execução
Presto oferece suporte a consulta personalizada e mecanismo de execução com operadores projetados para oferecer suporte à semântica SQL. Além da programação aprimorada, todo o processamento fica na memória e é canalizado pela rede entre os diferentes estágios. Isso evita sobrecarga de latência de E / S desnecessária.
Este capítulo explicará como instalar o Presto em sua máquina. Vamos examinar os requisitos básicos do Presto,
- Linux ou Mac OS
- Java versão 8
Agora, vamos continuar as etapas a seguir para instalar o Presto em sua máquina.
Verificando a instalação do Java
Felizmente, você já instalou o Java versão 8 em sua máquina agora, então apenas verifique-o usando o seguinte comando.
$ java -versionSe o Java for instalado com sucesso em sua máquina, você poderá ver a versão do Java instalado. Se o Java não estiver instalado, siga as etapas subsequentes para instalar o Java 8 em sua máquina.
Baixe o JDK. Baixe a versão mais recente do JDK visitando o link a seguir.
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
A versão mais recente é JDK 8u 92 e o arquivo é “jdk-8u92-linux-x64.tar.gz”. Faça download do arquivo em sua máquina.
Depois disso, extraia os arquivos e vá para o diretório específico.
Em seguida, defina alternativas Java. Finalmente, o Java será instalado em sua máquina.
Instalação do Apache Presto
Baixe a versão mais recente do Presto visitando o seguinte link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.149/
Agora, a última versão de “presto-server-0.149.tar.gz” será baixada em sua máquina.
Extrair arquivos tar
Extraia o tar arquivo usando o seguinte comando -
$ tar -zxf presto-server-0.149.tar.gz
$ cd presto-server-0.149Definições de configuração
Crie um diretório de “dados”
Crie um diretório de dados fora do diretório de instalação, que será usado para armazenar logs, metadados, etc., para que seja facilmente preservado ao atualizar o Presto. É definido usando o seguinte código -
$ cd
$ mkdir dataPara visualizar o caminho onde está localizado, use o comando “pwd”. Este local será designado no próximo arquivo node.properties.
Crie o diretório “etc”
Crie um diretório etc dentro do diretório de instalação do Presto usando o seguinte código -
$ cd presto-server-0.149
$ mkdir etcEste diretório manterá os arquivos de configuração. Vamos criar cada arquivo um por um.
Propriedades do nó
O arquivo de propriedades do nó Presto contém a configuração ambiental específica para cada nó. Ele é criado dentro do diretório etc (etc / node.properties) usando o seguinte código -
$ cd etc
$ vi node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/../workspace/PrestoDepois de fazer todas as alterações, salve o arquivo e saia do terminal. Aquinode.data é o caminho do local do diretório de dados criado acima. node.id representa o identificador exclusivo de cada nó.
Configuração JVM
Crie um arquivo “jvm.config” dentro do diretório etc (etc / jvm.config). Este arquivo contém uma lista de opções de linha de comando usadas para iniciar a Java Virtual Machine.
$ cd etc
$ vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize = 32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError = kill -9 %pDepois de fazer todas as alterações, salve o arquivo e saia do terminal.
Propriedades de configuração
Crie um arquivo “config.properties” dentro do diretório etc (etc / config.properties). Este arquivo contém a configuração do servidor Presto. Se você estiver configurando uma única máquina para teste, o servidor Presto pode funcionar apenas como o processo de coordenação, conforme definido usando o código a seguir -
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Aqui,
coordinator - nó mestre.
node-scheduler.include-coordinator - Permite agendamento de trabalho no coordenador.
http-server.http.port - Especifica a porta para o servidor HTTP.
query.max-memory=5GB - A quantidade máxima de memória distribuída.
query.max-memory-per-node=1GB - A quantidade máxima de memória por nó.
discovery-server.enabled - O Presto usa o serviço Discovery para encontrar todos os nós do cluster.
discovery.uri - o URI para o servidor Discovery.
Se você estiver configurando um servidor Presto de várias máquinas, o Presto funcionará como um processo de coordenação e de trabalho. Use esta definição de configuração para testar o servidor Presto em várias máquinas.
Configuração para Coordenador
$ cd etc
$ vi config.properties
coordinator = true
node-scheduler.include-coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = http://localhost:8080Configuração para trabalhador
$ cd etc
$ vi config.properties
coordinator = false
http-server.http.port = 8080
query.max-memory = 50GB
query.max-memory-per-node = 1GB
discovery.uri = http://localhost:8080Propriedades de log
Crie um arquivo “log.properties” dentro do diretório etc (etc / log.properties). Este arquivo contém o nível mínimo de log para hierarquias de logger nomeadas. É definido usando o seguinte código -
$ cd etc
$ vi log.properties
com.facebook.presto = INFOSalve o arquivo e saia do terminal. Aqui, quatro níveis de log são usados, como DEBUG, INFO, WARN e ERROR. O nível de registro padrão é INFO.
Propriedades do Catálogo
Crie um diretório “catálogo” dentro do diretório etc (etc / catalog). Isso será usado para montar dados. Por exemplo, crieetc/catalog/jmx.properties com o seguinte conteúdo para montar o jmx connector como o catálogo jmx -
$ cd etc
$ mkdir catalog $ cd catalog
$ vi jmx.properties
connector.name = jmxIniciar Presto
O Presto pode ser iniciado usando o seguinte comando,
$ bin/launcher startEntão você verá uma resposta semelhante a esta,
Started as 840Execute o Presto
Para iniciar o servidor Presto, use o seguinte comando -
$ bin/launcher runDepois de iniciar o servidor Presto com sucesso, você pode encontrar os arquivos de log no diretório “var / log”.
launcher.log - Este log é criado pelo ativador e conectado aos fluxos stdout e stderr do servidor.
server.log - Este é o principal arquivo de log usado pelo Presto.
http-request.log - Solicitação HTTP recebida pelo servidor.
A partir de agora, você instalou com êxito as definições de configuração do Presto em sua máquina. Vamos continuar as etapas para instalar o Presto CLI.
Instale o Presto CLI
O Presto CLI fornece um shell interativo baseado em terminal para a execução de consultas.
Baixe o Presto CLI visitando o seguinte link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.149/
Agora, “presto-cli-0.149-executable.jar” será instalado em sua máquina.
Executar CLI
Depois de baixar o presto-cli, copie-o para o local de onde deseja executá-lo. Este local pode ser qualquer nó que tenha acesso à rede para o coordenador. Primeiro altere o nome do arquivo Jar para Presto. Em seguida, torne-o executável comchmod + x comando usando o seguinte código -
$ mv presto-cli-0.149-executable.jar presto
$ chmod +x prestoAgora execute a CLI usando o seguinte comando,
./presto --server localhost:8080 --catalog jmx --schema default
Here jmx(Java Management Extension) refers to catalog and default referes to schema.Você verá a seguinte resposta,
presto:default>Agora digite o comando “jps” em seu terminal e você verá os daemons em execução.
Pare Presto
Depois de ter realizado todas as execuções, você pode parar o servidor presto usando o seguinte comando -
$ bin/launcher stopEste capítulo irá discutir as configurações do Presto.
Verificador Presto
O Presto Verifier pode ser usado para testar o Presto em relação a outro banco de dados (como MySQL) ou para testar dois clusters Presto entre si.
Criar banco de dados em MySQL
Abra o servidor MySQL e crie um banco de dados usando o seguinte comando.
create database testAgora você criou o banco de dados de “teste” no servidor. Crie a tabela e carregue-a com a seguinte consulta.
CREATE TABLE verifier_queries(
id INT NOT NULL AUTO_INCREMENT,
suite VARCHAR(256) NOT NULL,
name VARCHAR(256),
test_catalog VARCHAR(256) NOT NULL,
test_schema VARCHAR(256) NOT NULL,
test_prequeries TEXT,
test_query TEXT NOT NULL,
test_postqueries TEXT,
test_username VARCHAR(256) NOT NULL default 'verifier-test',
test_password VARCHAR(256),
control_catalog VARCHAR(256) NOT NULL,
control_schema VARCHAR(256) NOT NULL,
control_prequeries TEXT,
control_query TEXT NOT NULL,
control_postqueries TEXT,
control_username VARCHAR(256) NOT NULL default 'verifier-test',
control_password VARCHAR(256),
session_properties_json TEXT,
PRIMARY KEY (id)
);Adicionar configurações de configuração
Crie um arquivo de propriedades para configurar o verificador -
$ vi config.properties
suite = mysuite
query-database = jdbc:mysql://localhost:3306/tutorials?user=root&password=pwd
control.gateway = jdbc:presto://localhost:8080
test.gateway = jdbc:presto://localhost:8080
thread-count = 1Aqui no query-database campo, digite os seguintes detalhes - nome do banco de dados mysql, nome de usuário e senha.
Baixar arquivo JAR
Baixe o arquivo jar do Presto-verifier visitando o seguinte link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-verifier/0.149/
Agora a versão “presto-verifier-0.149-executable.jar” é baixado em sua máquina.
Executar JAR
Execute o arquivo JAR usando o seguinte comando,
$ mv presto-verifier-0.149-executable.jar verifier
$ chmod+x verifierExecutar verificador
Execute o verificador usando o seguinte comando,
$ ./verifier config.propertiesCriar a tabela
Vamos criar uma tabela simples em “test” banco de dados usando a seguinte consulta.
create table product(id int not null, name varchar(50))Insira a tabela
Depois de criar uma tabela, insira dois registros usando a seguinte consulta,
insert into product values(1,’Phone')
insert into product values(2,’Television’)Executar consulta do verificador
Execute a seguinte consulta de amostra no terminal do verificador (./verifier config.propeties) para verificar o resultado do verificador.
Consulta de amostra
insert into verifier_queries (suite, test_catalog, test_schema, test_query,
control_catalog, control_schema, control_query) values
('mysuite', 'mysql', 'default', 'select * from mysql.test.product',
'mysql', 'default', 'select * from mysql.test.product');Aqui, select * from mysql.test.product consulta refere-se ao catálogo mysql, test é o nome do banco de dados e producté o nome da tabela. Desta forma, você pode acessar o conector mysql usando o servidor Presto.
Aqui, duas mesmas consultas selecionadas são testadas entre si para ver o desempenho. Da mesma forma, você pode executar outras consultas para testar os resultados de desempenho. Você também pode conectar dois clusters Presto para verificar os resultados de desempenho.
Neste capítulo, discutiremos as ferramentas de administração usadas no Presto. Vamos começar com a interface da Web do Presto.
Interface web
O Presto oferece uma interface web para monitorar e gerenciar consultas. Ele pode ser acessado a partir do número da porta especificado nas Propriedades de configuração do coordenador.
Inicie o servidor Presto e o Presto CLI. Em seguida, você pode acessar a interface da web a partir do seguinte url -http://localhost:8080/
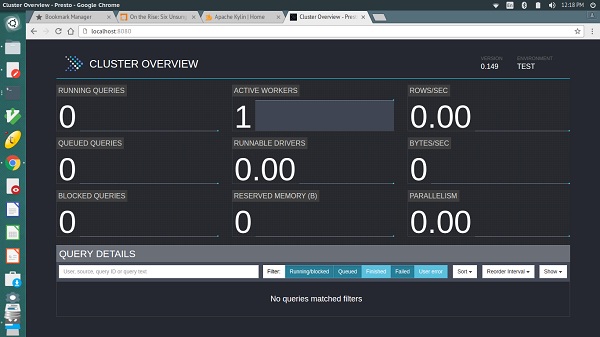
A saída será semelhante à tela acima.
Aqui, a página principal tem uma lista de consultas junto com informações como ID exclusivo da consulta, texto da consulta, estado da consulta, porcentagem concluída, nome de usuário e fonte de origem da consulta. As consultas mais recentes são executadas primeiro e, em seguida, as consultas concluídas ou não concluídas são exibidas na parte inferior.
Ajustando o desempenho no Presto
Se o cluster Presto estiver tendo problemas relacionados ao desempenho, altere suas configurações padrão para as configurações a seguir.
Propriedades de configuração
task. info -refresh-max-wait - Reduz a carga de trabalho do coordenador.
task.max-worker-threads - Divide o processo e atribui a cada nó de trabalho.
distributed-joins-enabled - Junções distribuídas baseadas em hash.
node-scheduler.network-topology - Define a topologia da rede para o planejador.
Configurações JVM
Altere suas configurações JVM padrão para as configurações a seguir. Isso será útil para diagnosticar problemas de coleta de lixo.
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCCause
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintReferenceGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintClassHistogramBeforeFullGC
-XX:PrintFLSStatistics = 2
-XX:+PrintAdaptiveSizePolicy
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount = 1Neste capítulo, discutiremos como criar e executar consultas no Presto. Vamos examinar os tipos de dados básicos suportados pelo Presto.
Tipos de dados básicos
A tabela a seguir descreve os tipos de dados básicos do Presto.
| S.No | Tipo de dados e descrição |
|---|---|
| 1 | VARCHAR Dados de caracteres de comprimento variável |
| 2 | BIGINT Um inteiro assinado de 64 bits |
| 3 - | DOUBLE Um valor de dupla precisão de ponto flutuante de 64 bits |
| 4 - | DECIMAL Um número decimal de precisão fixa. Por exemplo DECIMAL (10,3) - 10 é a precisão, ou seja, o número total de dígitos e 3 é o valor da escala representado como um ponto fracionário. A escala é opcional e o valor padrão é 0 |
| 5 | BOOLEAN Valores booleanos verdadeiros e falsos |
| 6 | VARBINARY Dados binários de comprimento variável |
| 7 | JSON Dados JSON |
| 8 | DATE Tipo de dados de data representado como ano-mês-dia |
| 9 | TIME, TIMESTAMP, TIMESTAMP with TIME ZONE TIME - hora do dia (hora-min-seg-milissegundo) TIMESTAMP - Data e hora do dia TIMESTAMP com TIME ZONE - Data e hora do dia com fuso horário do valor |
| 10 | INTERVAL Amplie ou amplie os tipos de dados de data e hora |
| 11 | ARRAY Matriz do tipo de componente fornecido. Por exemplo, ARRAY [5,7] |
| 12 | MAP Mapeie entre os tipos de componentes fornecidos. Por exemplo, MAP (ARRAY ['um', 'dois'], ARRAY [5,7]) |
| 13 | ROW Estrutura de linha composta de campos nomeados |
Presto - Operadores
Os operadores Presto estão listados na tabela a seguir.
| S.No | Operador e descrição |
|---|---|
| 1 | Operador aritmético Presto suporta operadores aritméticos como +, -, *, /,% |
| 2 | Operador relacional <,>, <=,> =, =, <> |
| 3 - | Operador lógico AND, OR, NOT |
| 4 - | Operador de alcance O operador de intervalo é usado para testar o valor em um intervalo específico. Presto suporta BETWEEN, IS NULL, IS NOT NULL, GREATEST e MENOS |
| 5 | Operador decimal O operador decimal aritmético binário executa a operação aritmética binária para o tipo decimal Operador decimal unário - O - operator realiza negação |
| 6 | Operador string o ‘||’ operator realiza concatenação de strings |
| 7 | Operador de data e hora Executa operações aritméticas de adição e subtração em tipos de dados de data e hora |
| 8 | Operador de matriz Operador subscrito [] - acessa um elemento de uma matriz Operador de concatenação || - concatenar uma matriz com uma matriz ou um elemento do mesmo tipo |
| 9 | Operador de mapa Operador de subscrito do mapa [] - recupera o valor correspondente a uma determinada chave de um mapa |
No momento, estávamos discutindo a execução de algumas consultas básicas simples no Presto. Este capítulo discutirá as funções SQL importantes.
Funções Matemáticas
As funções matemáticas operam em fórmulas matemáticas. A tabela a seguir descreve a lista de funções em detalhes.
| S.No. | Descrição da função |
|---|---|
| 1 | abs (x) Retorna o valor absoluto de x |
| 2 | cbrt (x) Retorna a raiz cúbica de x |
| 3 - | teto (x) Retorna o x valor arredondado para o número inteiro mais próximo |
| 4 - | ceil(x) Alias para teto (x) |
| 5 | graus (x) Retorna o valor do grau para x |
| 6 | ex) Devolve o valor duplo do número de Euler |
| 7 | exp(x) Retorna o valor expoente do número de Euler |
| 8 | andar (x) Devoluções x arredondado para baixo para o número inteiro mais próximo |
| 9 | from_base(string,radix) Retorna o valor da string interpretado como um número base-raiz |
| 10 | ln(x) Retorna o logaritmo natural de x |
| 11 | log2 (x) Retorna o logaritmo de base 2 de x |
| 12 | log10(x) Retorna o logaritmo de base 10 de x |
| 13 | log(x,y) Retorna a base y logaritmo de x |
| 14 | mod (n, m) Retorna o módulo (resto) de n dividido por m |
| 15 | pi() Retorna o valor de pi. O resultado será devolvido como um valor duplo |
| 16 | potência (x, p) Retorna poder de valor ‘p’ ao x valor |
| 17 | pow(x,p) Alias para potência (x, p) |
| 18 | radianos (x) converte o ângulo x em graus radianos |
| 19 | rand() Alias para radianos () |
| 20 | aleatória() Retorna o valor pseudo-aleatório |
| 21 | rand(n) Alias para aleatório () |
| 22 | rodada (x) Retorna o valor arredondado para x |
| 23 | round(x,d) x valor arredondado para o ‘d’ casas decimais |
| 24 | sign(x) Retorna a função signum de x, ou seja, 0 se o argumento for 0 1 se o argumento for maior que 0 -1 se o argumento for menor que 0 Para argumentos duplos, a função retorna adicionalmente - NaN se o argumento for NaN 1 se o argumento for + Infinito -1 se o argumento for -Infinity |
| 25 | sqrt (x) Retorna a raiz quadrada de x |
| 26 | to_base (x, raiz) O tipo de retorno é arqueiro. O resultado é retornado como a raiz de base parax |
| 27 | truncar (x) Trunca o valor de x |
| 28 | largura_bucket (x, limite1, limite2, n) Retorna o número do compartimento de x limites de limite1 e limite2 especificados e número n de intervalos |
| 29 | width_bucket (x, bins) Retorna o número do compartimento de x de acordo com os bins especificados pelos bins do array |
Funções trigonométricas
Os argumentos das funções trigonométricas são representados como radianos (). A tabela a seguir lista as funções.
| S.No | Funções e descrição |
|---|---|
| 1 | acos (x) Retorna o valor cosseno inverso (x) |
| 2 | asin(x) Retorna o valor do seno inverso (x) |
| 3 - | atan(x) Retorna o valor tangente inverso (x) |
| 4 - | atan2 (y, x) Retorna o valor tangente inverso (y / x) |
| 5 | cos(x) Retorna o valor do cosseno (x) |
| 6 | cosh (x) Retorna o valor do cosseno hiperbólico (x) |
| 7 | sin (x) Retorna o valor do seno (x) |
| 8 | tan(x) Retorna o valor tangente (x) |
| 9 | tanh(x) Retorna o valor da tangente hiperbólica (x) |
Funções bit a bit
A tabela a seguir lista as funções Bitwise.
| S.No | Funções e descrição |
|---|---|
| 1 | bit_count (x, bits) Conte o número de bits |
| 2 | bitwise_and (x, y) Execute a operação AND bit a bit para dois bits, x e y |
| 3 - | bitwise_or (x, y) Operação OR bit a bit entre dois bits x, y |
| 4 - | bitwise_not (x) Não operação bit a bit para bit x |
| 5 | bitwise_xor (x, y) Operação XOR para bits x, y |
Funções de String
A tabela a seguir lista as funções de String.
| S.No | Funções e descrição |
|---|---|
| 1 | concat (string1, ..., stringN) Concatenar as strings fornecidas |
| 2 | comprimento (string) Retorna o comprimento da string dada |
| 3 - | inferior (corda) Retorna o formato de minúsculas para a string |
| 4 - | superior (corda) Retorna o formato em maiúsculas para a string dada |
| 5 | lpad (corda, tamanho, corda) Preenchimento esquerdo para a string dada |
| 6 | ltrim (string) Remove o espaço em branco inicial da string |
| 7 | substituir (string, pesquisar, substituir) Substitui o valor da string |
| 8 | reverso (string) Reverte a operação realizada para a string |
| 9 | rpad (string, tamanho, padstring) Preenchimento correto para a string dada |
| 10 | rtrim (string) Remove o espaço em branco à direita da string |
| 11 | divisão (string, delimitador) Divide a string no delimitador e retorna uma matriz de tamanho no máximo |
| 12 | split_part (string, delimitador, índice) Divide a string no delimitador e retorna o índice do campo |
| 13 | strpos (string, substring) Retorna a posição inicial da substring na string |
| 14 | substr (string, início) Retorna a substring para a string fornecida |
| 15 | substr (string, início, comprimento) Retorna a substring para a string dada com o comprimento específico |
| 16 | trim (string) Remove o espaço em branco à esquerda e à direita da string |
Funções de data e hora
A tabela a seguir lista as funções de data e hora.
| S.No | Funções e descrição |
|---|---|
| 1 | data atual Retorna a data atual |
| 2 | hora atual Retorna a hora atual |
| 3 - | current_timestamp Retorna o carimbo de data / hora atual |
| 4 - | current_timezone () Retorna o fuso horário atual |
| 5 | agora() Retorna a data atual, timestamp com o fuso horário |
| 6 | horário local Retorna a hora local |
| 7 | localtimestamp Retorna o timestamp local |
Funções de expressão regular
A tabela a seguir lista as funções de Expressão Regular.
| S.No | Funções e descrição |
|---|---|
| 1 | regexp_extract_all (string, padrão) Retorna a string correspondente à expressão regular do padrão |
| 2 | regexp_extract_all (string, padrão, grupo) Retorna a string correspondida pela expressão regular para o padrão e o grupo |
| 3 - | regexp_extract (string, padrão) Retorna a primeira substring correspondida pela expressão regular do padrão |
| 4 - | regexp_extract (string, padrão, grupo) Retorna a primeira substring correspondida pela expressão regular para o padrão e o grupo |
| 5 | regexp_like (string, padrão) Retorna as correspondências de string para o padrão. Se a string for retornada, o valor será verdadeiro, caso contrário, será falso |
| 6 | regexp_replace (string, padrão) Substitui a instância da string correspondida à expressão pelo padrão |
| 7 | regexp_replace (string, padrão, substituição) Substitua a instância da string correspondente à expressão pelo padrão e substituição |
| 8 | regexp_split (string, padrão) Divide a expressão regular para o padrão fornecido |
Funções JSON
The following table lists out JSON functions.
| S.No | Functions & Description |
|---|---|
| 1. | json_array_contains(json, value) Check the value exists in a json array. If the value exists it will return true, otherwise false |
| 2. | json_array_get(json_array, index) Get the element for index in json array |
| 3. | json_array_length(json) Returns the length in json array |
| 4. | json_format(json) Returns the json structure format |
| 5. | json_parse(string) Parses the string as a json |
| 6. | json_size(json, json_path) Returns the size of the value |
URL Functions
The following table lists out the URL functions.
| S.No | Functions & Description |
|---|---|
| 1. | url_extract_host(url) Returns the URL’s host |
| 2. | url_extract_path(url) Returns the URL’s path |
| 3. | url_extract_port(url) Returns the URL’s port |
| 4. | url_extract_protocol(url) Returns the URL’s protocol |
| 5. | url_extract_query(url) Returns the URL’s query string |
Aggregate Functions
The following table lists out the Aggregate functions.
| S.No | Functions & Description |
|---|---|
| 1. | avg(x) Returns average for the given value |
| 2. | min(x,n) Returns the minimum value from two values |
| 3. | max(x,n) Returns the maximum value from two values |
| 4. | sum(x) Returns the sum of value |
| 5. | count(*) Returns the number of input rows |
| 6. | count(x) Returns the count of input values |
| 7. | checksum(x) Returns the checksum for x |
| 8. | arbitrary(x) Returns the arbitrary value for x |
Color Functions
Following table lists out the Color functions.
| S.No | Functions & Description |
|---|---|
| 1. | bar(x, width) Renders a single bar using rgb low_color and high_color |
| 2. | bar(x, width, low_color, high_color) Renders a single bar for the specified width |
| 3. | color(string) Returns the color value for the entered string |
| 4. | render(x, color) Renders value x using the specific color using ANSI color codes |
| 5. | render(b) Accepts boolean value b and renders a green true or a red false using ANSI color codes |
| 6. | rgb(red, green, blue) Returns a color value capturing the RGB value of three component color values supplied as int parameters ranging from 0 to 255 |
Array Functions
The following table lists out the Array functions.
| S.No | Functions & Description |
|---|---|
| 1. | array_max(x) Finds the max element in an array |
| 2. | array_min(x) Finds the min element in an array |
| 3. | array_sort(x) Sorts the elements in an array |
| 4. | array_remove(x,element) Removes the specific element from an array |
| 5. | concat(x,y) Concatenates two arrays |
| 6. | contains(x,element) Finds the given elements in an array. True will be returned if it is present, otherwise false |
| 7. | array_position(x,element) Find the position of the given element in an array |
| 8. | array_intersect(x,y) Performs an intersection between two arrays |
| 9. | element_at(array,index) Returns the array element position |
| 10. | slice(x,start,length) Slices the array elements with the specific length |
Teradata Functions
The following table lists out Teradata functions.
| S.No | Functions & Description |
|---|---|
| 1. | index(string,substring) Returns the index of the string with the given substring |
| 2. | substring(string,start) Returns the substring of the given string. You can specify the start index here |
| 3. | substring(string,start,length) Returns the substring of the given string for the specific start index and length of the string |
The MySQL connector is used to query an external MySQL database.
Prerequisites
MySQL server installation.
Configuration Settings
Hopefully you have installed mysql server on your machine. To enable mysql properties on Presto server, you must create a file “mysql.properties” in “etc/catalog” directory. Issue the following command to create a mysql.properties file.
$ cd etc $ cd catalog
$ vi mysql.properties
connector.name = mysql
connection-url = jdbc:mysql://localhost:3306
connection-user = root
connection-password = pwdSave the file and quit the terminal. In the above file, you must enter your mysql password in connection-password field.
Create Database in MySQL Server
Open MySQL server and create a database using the following command.
create database tutorialsNow you have created “tutorials” database in the server. To enable database type, use the command “use tutorials” in the query window.
Create Table
Let’s create a simple table on “tutorials” database.
create table author(auth_id int not null, auth_name varchar(50),topic varchar(100))Insert Table
After creating a table, insert three records using the following query.
insert into author values(1,'Doug Cutting','Hadoop')
insert into author values(2,’James Gosling','java')
insert into author values(3,'Dennis Ritchie’,'C')Select Records
To retrieve all the records, type the following query.
Query
select * from authorResult
auth_id auth_name topic
1 Doug Cutting Hadoop
2 James Gosling java
3 Dennis Ritchie CAs of now, you have queried data using MySQL server. Let’s connect Mysql storage plugin to Presto server.
Connect Presto CLI
Type the following command to connect MySql plugin on Presto CLI.
./presto --server localhost:8080 --catalog mysql --schema tutorialsYou will receive the following response.
presto:tutorials>Here “tutorials” refers to schema in mysql server.
List Schemas
To list out all the schemas in mysql, type the following query in Presto server.
Query
presto:tutorials> show schemas from mysql;Result
Schema
--------------------
information_schema
performance_schema
sys
tutorialsFrom this result, we can conclude the first three schemas as predefined and the last one as created by yourself.
List Tables from Schema
Following query lists out all the tables in tutorials schema.
Query
presto:tutorials> show tables from mysql.tutorials;Result
Table
--------
authorWe have created only one table in this schema. If you have created multiple tables, it will list out all the tables.
Describe Table
To describe the table fields, type the following query.
Query
presto:tutorials> describe mysql.tutorials.author;Result
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Show Columns from Table
Query
presto:tutorials> show columns from mysql.tutorials.author;Result
Column | Type | Comment
-----------+--------------+---------
auth_id | integer |
auth_name | varchar(50) |
topic | varchar(100) |Access Table Records
To fetch all the records from mysql table, issue the following query.
Query
presto:tutorials> select * from mysql.tutorials.author;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CFrom this result, you can retrieve mysql server records in Presto.
Create Table Using as Command
Mysql connector doesn’t support create table query but you can create a table using as command.
Query
presto:tutorials> create table mysql.tutorials.sample as
select * from mysql.tutorials.author;Result
CREATE TABLE: 3 rowsYou can’t insert rows directly because this connector has some limitations. It cannot support the following queries −
- create
- insert
- update
- delete
- drop
To view the records in the newly created table, type the following query.
Query
presto:tutorials> select * from mysql.tutorials.sample;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CJava Management Extensions (JMX) gives information about the Java Virtual Machine and software running inside JVM. The JMX connector is used to query JMX information in Presto server.
As we have already enabled “jmx.properties” file under “etc/catalog” directory. Now connect Prest CLI to enable JMX plugin.
Presto CLI
Query
$ ./presto --server localhost:8080 --catalog jmx --schema jmxResult
You will receive the following response.
presto:jmx>JMX Schema
To list out all the schemas in “jmx”, type the following query.
Query
presto:jmx> show schemas from jmx;Result
Schema
--------------------
information_schema
currentShow Tables
To view the tables in the “current” schema, use the following command.
Query 1
presto:jmx> show tables from jmx.current;Result
Table
------------------------------------------------------------------------------
com.facebook.presto.execution.scheduler:name = nodescheduler
com.facebook.presto.execution:name = queryexecution
com.facebook.presto.execution:name = querymanager
com.facebook.presto.execution:name = remotetaskfactory
com.facebook.presto.execution:name = taskexecutor
com.facebook.presto.execution:name = taskmanager
com.facebook.presto.execution:type = queryqueue,name = global,expansion = global
………………
……………….Query 2
presto:jmx> select * from jmx.current.”java.lang:type = compilation";Result
node | compilationtimemonitoringsupported | name | objectname | totalcompilationti
--------------------------------------+------------------------------------+--------------------------------+----------------------------+-------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | true | HotSpot 64-Bit Tiered Compilers | java.lang:type=Compilation | 1276Query 3
presto:jmx> select * from jmx.current."com.facebook.presto.server:name = taskresource";Result
node | readfromoutputbuffertime.alltime.count
| readfromoutputbuffertime.alltime.max | readfromoutputbuffertime.alltime.maxer
--------------------------------------+---------------------------------------+--------------------------------------+---------------------------------------
ffffffff-ffff-ffff-ffff-ffffffffffff | 92.0 | 1.009106149 |The Hive connector allows querying data stored in a Hive data warehouse.
Prerequisites
- Hadoop
- Hive
Hopefully you have installed Hadoop and Hive on your machine. Start all the services one by one in the new terminal. Then, start hive metastore using the following command,
hive --service metastorePresto uses Hive metastore service to get the hive table’s details.
Configuration Settings
Create a file “hive.properties” under “etc/catalog” directory. Use the following command.
$ cd etc $ cd catalog
$ vi hive.properties
connector.name = hive-cdh4
hive.metastore.uri = thrift://localhost:9083After making all the changes, save the file and quit the terminal.
Create Database
Create a database in Hive using the following query −
Query
hive> CREATE SCHEMA tutorials;After the database is created, you can verify it using the “show databases” command.
Create Table
Create Table is a statement used to create a table in Hive. For example, use the following query.
hive> create table author(auth_id int, auth_name varchar(50),
topic varchar(100) STORED AS SEQUENCEFILE;Insert Table
Following query is used to insert records in hive’s table.
hive> insert into table author values (1,’ Doug Cutting’,Hadoop),
(2,’ James Gosling’,java),(3,’ Dennis Ritchie’,C);Start Presto CLI
You can start Presto CLI to connect Hive storage plugin using the following command.
$ ./presto --server localhost:8080 --catalog hive —schema tutorials;You will receive the following response.
presto:tutorials >List Schemas
To list out all the schemas in Hive connector, type the following command.
Query
presto:tutorials > show schemas from hive;Result
default
tutorialsList Tables
To list out all the tables in “tutorials” schema, use the following query.
Query
presto:tutorials > show tables from hive.tutorials;Result
authorFetch Table
Following query is used to fetch all the records from hive’s table.
Query
presto:tutorials > select * from hive.tutorials.author;Result
auth_id | auth_name | topic
---------+----------------+--------
1 | Doug Cutting | Hadoop
2 | James Gosling | java
3 | Dennis Ritchie | CThe Kafka Connector for Presto allows to access data from Apache Kafka using Presto.
Prerequisites
Download and install the latest version of the following Apache projects.
- Apache ZooKeeper
- Apache Kafka
Start ZooKeeper
Start ZooKeeper server using the following command.
$ bin/zookeeper-server-start.sh config/zookeeper.propertiesNow, ZooKeeper starts port on 2181.
Start Kafka
Start Kafka in another terminal using the following command.
$ bin/kafka-server-start.sh config/server.propertiesAfter kafka starts, it uses the port number 9092.
TPCH Data
Download tpch-kafka
$ curl -o kafka-tpch
https://repo1.maven.org/maven2/de/softwareforge/kafka_tpch_0811/1.0/kafka_tpch_
0811-1.0.shNow you have downloaded the loader from Maven central using the above command. You will get a similar response as the following.
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:01 --:--:-- 0
5 21.6M 5 1279k 0 0 83898 0 0:04:30 0:00:15 0:04:15 129k
6 21.6M 6 1407k 0 0 86656 0 0:04:21 0:00:16 0:04:05 131k
24 21.6M 24 5439k 0 0 124k 0 0:02:57 0:00:43 0:02:14 175k
24 21.6M 24 5439k 0 0 124k 0 0:02:58 0:00:43 0:02:15 160k
25 21.6M 25 5736k 0 0 128k 0 0:02:52 0:00:44 0:02:08 181k
………………………..Then, make it executable using the following command,
$ chmod 755 kafka-tpchRun tpch-kafka
Run the kafka-tpch program to preload a number of topics with tpch data using the following command.
Query
$ ./kafka-tpch load --brokers localhost:9092 --prefix tpch. --tpch-type tinyResultado
2016-07-13T16:15:52.083+0530 INFO main io.airlift.log.Logging Logging
to stderr
2016-07-13T16:15:52.124+0530 INFO main de.softwareforge.kafka.LoadCommand
Processing tables: [customer, orders, lineitem, part, partsupp, supplier,
nation, region]
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-1
de.softwareforge.kafka.LoadCommand Loading table 'customer' into topic 'tpch.customer'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-2
de.softwareforge.kafka.LoadCommand Loading table 'orders' into topic 'tpch.orders'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-3
de.softwareforge.kafka.LoadCommand Loading table 'lineitem' into topic 'tpch.lineitem'...
2016-07-13T16:15:52.834+0530 INFO pool-1-thread-4
de.softwareforge.kafka.LoadCommand Loading table 'part' into topic 'tpch.part'...
………………………
……………………….Agora, as tabelas Kafka de clientes, pedidos, fornecedor, etc., são carregadas usando tpch.
Adicionar configurações de configuração
Vamos adicionar as seguintes configurações do conector Kafka no servidor Presto.
connector.name = kafka
kafka.nodes = localhost:9092
kafka.table-names = tpch.customer,tpch.orders,tpch.lineitem,tpch.part,tpch.partsupp,
tpch.supplier,tpch.nation,tpch.region
kafka.hide-internal-columns = falseNa configuração acima, as tabelas Kafka são carregadas usando o programa Kafka-tpch.
Iniciar Presto CLI
Inicie o Presto CLI usando o seguinte comando,
$ ./presto --server localhost:8080 --catalog kafka —schema tpch;Aqui “tpch" é um esquema para o conector Kafka e você receberá a seguinte resposta.
presto:tpch>Listar tabelas
A consulta a seguir lista todas as tabelas em “tpch” esquema.
Inquerir
presto:tpch> show tables;Resultado
Table
----------
customer
lineitem
nation
orders
part
partsupp
region
supplierDescrever a tabela do cliente
A consulta a seguir descreve “customer” mesa.
Inquerir
presto:tpch> describe customer;Resultado
Column | Type | Comment
-------------------+---------+---------------------------------------------
_partition_id | bigint | Partition Id
_partition_offset | bigint | Offset for the message within the partition
_segment_start | bigint | Segment start offset
_segment_end | bigint | Segment end offset
_segment_count | bigint | Running message count per segment
_key | varchar | Key text
_key_corrupt | boolean | Key data is corrupt
_key_length | bigint | Total number of key bytes
_message | varchar | Message text
_message_corrupt | boolean | Message data is corrupt
_message_length | bigint | Total number of message bytesA interface JDBC do Presto é usada para acessar o aplicativo Java.
Pré-requisitos
Instale presto-jdbc-0.150.jar
Você pode baixar o arquivo JDBC jar visitando o seguinte link,
https://repo1.maven.org/maven2/com/facebook/presto/presto-jdbc/0.150/
Após o download do arquivo jar, adicione-o ao caminho de classe do seu aplicativo Java.
Crie um aplicativo simples
Vamos criar um aplicativo Java simples usando a interface JDBC.
Codificação - PrestoJdbcSample.java
import java.sql.*;
import com.facebook.presto.jdbc.PrestoDriver;
//import presto jdbc driver packages here.
public class PrestoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("com.facebook.presto.jdbc.PrestoDriver");
connection = DriverManager.getConnection(
"jdbc:presto://localhost:8080/mysql/tutorials", "tutorials", “");
//connect mysql server tutorials database here
statement = connection.createStatement();
String sql;
sql = "select auth_id, auth_name from mysql.tutorials.author”;
//select mysql table author table two columns
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("auth_id");
String name = resultSet.getString(“auth_name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Salve o arquivo e feche o aplicativo. Agora, inicie o servidor Presto em um terminal e abra um novo terminal para compilar e executar o resultado. A seguir estão as etapas -
Compilação
~/Workspace/presto/presto-jdbc $ javac -cp presto-jdbc-0.149.jar PrestoJdbcSample.javaExecução
~/Workspace/presto/presto-jdbc $ java -cp .:presto-jdbc-0.149.jar PrestoJdbcSampleResultado
INFO: Logging initialized @146ms
ID: 1;
Name: Doug Cutting
ID: 2;
Name: James Gosling
ID: 3;
Name: Dennis RitchieCrie um projeto Maven para desenvolver a função personalizada do Presto.
SimpleFunctionsFactory.java
Crie a classe SimpleFunctionsFactory para implementar a interface FunctionFactory.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.metadata.FunctionListBuilder;
import com.facebook.presto.metadata.SqlFunction;
import com.facebook.presto.spi.type.TypeManager;
import java.util.List;
public class SimpleFunctionFactory implements FunctionFactory {
private final TypeManager typeManager;
public SimpleFunctionFactory(TypeManager typeManager) {
this.typeManager = typeManager;
}
@Override
public List<SqlFunction> listFunctions() {
return new FunctionListBuilder(typeManager)
.scalar(SimpleFunctions.class)
.getFunctions();
}
}SimpleFunctionsPlugin.java
Crie uma classe SimpleFunctionsPlugin para implementar a interface Plugin.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.metadata.FunctionFactory;
import com.facebook.presto.spi.Plugin;
import com.facebook.presto.spi.type.TypeManager;
import com.google.common.collect.ImmutableList;
import javax.inject.Inject;
import java.util.List;
import static java.util.Objects.requireNonNull;
public class SimpleFunctionsPlugin implements Plugin {
private TypeManager typeManager;
@Inject
public void setTypeManager(TypeManager typeManager) {
this.typeManager = requireNonNull(typeManager, "typeManager is null”);
//Inject TypeManager class here
}
@Override
public <T> List<T> getServices(Class<T> type){
if (type == FunctionFactory.class) {
return ImmutableList.of(type.cast(new SimpleFunctionFactory(typeManager)));
}
return ImmutableList.of();
}
}Adicionar arquivo de recurso
Crie um arquivo de recursos que é especificado no pacote de implementação.
(com.tutorialspoint.simple.functions.SimpleFunctionsPlugin)Agora vá para a localização do arquivo de recursos @ / path / to / resource /
Em seguida, adicione as alterações,
com.facebook.presto.spi.Pluginpom.xml
Adicione as seguintes dependências ao arquivo pom.xml.
<?xml version = "1.0"?>
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.tutorialspoint.simple.functions</groupId>
<artifactId>presto-simple-functions</artifactId>
<packaging>jar</packaging>
<version>1.0</version>
<name>presto-simple-functions</name>
<description>Simple test functions for Presto</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-spi</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>com.facebook.presto</groupId>
<artifactId>presto-main</artifactId>
<version>0.149</version>
</dependency>
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
</dependencies>
<build>
<finalName>presto-simple-functions</finalName>
<plugins>
<!-- Make this jar executable -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.3.2</version>
</plugin>
</plugins>
</build>
</project>SimpleFunctions.java
Crie a classe SimpleFunctions usando atributos Presto.
package com.tutorialspoint.simple.functions;
import com.facebook.presto.operator.Description;
import com.facebook.presto.operator.scalar.ScalarFunction;
import com.facebook.presto.operator.scalar.StringFunctions;
import com.facebook.presto.spi.type.StandardTypes;
import com.facebook.presto.type.LiteralParameters;
import com.facebook.presto.type.SqlType;
public final class SimpleFunctions {
private SimpleFunctions() {
}
@Description("Returns summation of two numbers")
@ScalarFunction(“mysum")
//function name
@SqlType(StandardTypes.BIGINT)
public static long sum(@SqlType(StandardTypes.BIGINT) long num1,
@SqlType(StandardTypes.BIGINT) long num2) {
return num1 + num2;
}
}Depois que o aplicativo for criado, compile e execute o aplicativo. Ele produzirá o arquivo JAR. Copie o arquivo e mova o arquivo JAR para o diretório de plug-in do servidor Presto de destino.
Compilação
mvn compileExecução
mvn packageAgora reinicie o servidor Presto e conecte o cliente Presto. Em seguida, execute o aplicativo de função personalizada conforme explicado abaixo,
$ ./presto --catalog mysql --schema defaultInquerir
presto:default> select mysum(10,10);Resultado
_col0
-------
20