Apache Spark - Programação Principal
Spark Core é a base de todo o projeto. Ele fornece despacho distribuído de tarefas, agendamento e funcionalidades básicas de E / S. O Spark usa uma estrutura de dados fundamental especializada conhecida como RDD (Resilient Distributed Datasets), que é uma coleção lógica de dados particionados entre máquinas. Os RDDs podem ser criados de duas maneiras; uma é fazendo referência a conjuntos de dados em sistemas de armazenamento externos e a segunda é aplicando transformações (por exemplo, mapa, filtro, redutor, junção) em RDDs existentes.
A abstração RDD é exposta por meio de uma API integrada à linguagem. Isso simplifica a complexidade da programação porque a maneira como os aplicativos manipulam RDDs é semelhante à manipulação de coleções locais de dados.
Spark Shell
O Spark fornece um shell interativo - uma ferramenta poderosa para analisar dados interativamente. Ele está disponível em linguagem Scala ou Python. A abstração primária do Spark é uma coleção distribuída de itens chamada Resilient Distributed Dataset (RDD). Os RDDs podem ser criados a partir de formatos de entrada do Hadoop (como arquivos HDFS) ou transformando outros RDDs.
Abra o Spark Shell
O seguinte comando é usado para abrir o shell do Spark.
$ spark-shellCrie um RDD simples
Vamos criar um RDD simples a partir do arquivo de texto. Use o seguinte comando para criar um RDD simples.
scala> val inputfile = sc.textFile(“input.txt”)A saída para o comando acima é
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12A API Spark RDD apresenta alguns Transformations e poucos Actions para manipular RDD.
Transformações RDD
As transformações RDD retornam o ponteiro para o novo RDD e permitem que você crie dependências entre os RDDs. Cada RDD na cadeia de dependências (String de Dependências) possui uma função para calcular seus dados e possui um ponteiro (dependência) para seu RDD pai.
O Spark é preguiçoso, então nada será executado a menos que você chame alguma transformação ou ação que acione a criação e execução do job. Veja o seguinte trecho do exemplo de contagem de palavras.
Portanto, a transformação RDD não é um conjunto de dados, mas uma etapa em um programa (pode ser a única etapa) dizendo ao Spark como obter dados e o que fazer com eles.
A seguir está uma lista de transformações RDD.
| S.Não | Transformações e significado |
|---|---|
| 1 | map(func) Retorna um novo conjunto de dados distribuído, formado pela passagem de cada elemento da fonte por meio de uma função func. |
| 2 | filter(func) Retorna um novo conjunto de dados formado selecionando os elementos da fonte em que func retorna verdadeiro. |
| 3 | flatMap(func) Semelhante ao map, mas cada item de entrada pode ser mapeado para 0 ou mais itens de saída (portanto, func deve retornar um Seq em vez de um único item). |
| 4 | mapPartitions(func) Semelhante ao map, mas é executado separadamente em cada partição (bloco) do RDD, então func deve ser do tipo Iterator <T> ⇒ Iterator <U> quando executado em um RDD do tipo T. |
| 5 | mapPartitionsWithIndex(func) Semelhante às partições de mapas, mas também fornece func com um valor inteiro representando o índice da partição, então func deve ser do tipo (Int, Iterator <T>) ⇒ Iterator <U> ao executar em um RDD do tipo T. |
| 6 | sample(withReplacement, fraction, seed) Experimente um fraction dos dados, com ou sem substituição, usando uma determinada semente do gerador de número aleatório. |
| 7 | union(otherDataset) Retorna um novo conjunto de dados que contém a união dos elementos no conjunto de dados de origem e o argumento. |
| 8 | intersection(otherDataset) Retorna um novo RDD que contém a interseção de elementos no conjunto de dados de origem e o argumento. |
| 9 | distinct([numTasks]) Retorna um novo conjunto de dados que contém os elementos distintos do conjunto de dados de origem. |
| 10 | groupByKey([numTasks]) Quando chamado em um conjunto de dados de pares (K, V), retorna um conjunto de dados de pares (K, Iteráveis <V>). Note - Se você estiver agrupando para realizar uma agregação (como uma soma ou média) em cada chave, o uso de reduceByKey ou aggregateByKey resultará em um desempenho muito melhor. |
| 11 | reduceByKey(func, [numTasks]) Quando chamado em um conjunto de dados de (K, V) pares, retorna um conjunto de dados de (K, V) pares onde os valores de cada chave são agregados usando a função de redução fornecida func , que deve ser do tipo (V, V) ⇒ V Como em groupByKey, o número de tarefas de redução é configurável por meio de um segundo argumento opcional. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) Quando chamado em um conjunto de dados de pares (K, V), retorna um conjunto de dados de pares (K, U) onde os valores de cada chave são agregados usando as funções de combinação fornecidas e um valor neutro "zero". Permite um tipo de valor agregado diferente do tipo de valor de entrada, evitando alocações desnecessárias. Como em groupByKey, o número de tarefas de redução é configurável por meio de um segundo argumento opcional. |
| 13 | sortByKey([ascending], [numTasks]) Quando chamado em um conjunto de dados de pares (K, V) onde K implementa Ordered, retorna um conjunto de dados de pares (K, V) classificados por chaves em ordem crescente ou decrescente, conforme especificado no argumento ascendente booleano. |
| 14 | join(otherDataset, [numTasks]) Quando chamado em conjuntos de dados do tipo (K, V) e (K, W), retorna um conjunto de dados de pares (K, (V, W)) com todos os pares de elementos para cada chave. As junções externas são suportadas por leftOuterJoin, rightOuterJoin e fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks]) Quando chamado em conjuntos de dados do tipo (K, V) e (K, W), retorna um conjunto de dados de tuplas (K, (Iterable <V>, Iterable <W>)). Esta operação também é chamada de grupo com. |
| 16 | cartesian(otherDataset) Quando chamado em conjuntos de dados dos tipos T e U, retorna um conjunto de dados de pares (T, U) (todos os pares de elementos). |
| 17 | pipe(command, [envVars]) Canalize cada partição do RDD por meio de um comando shell, por exemplo, um script Perl ou bash. Os elementos RDD são gravados no stdin do processo e as linhas de saída do stdout são retornadas como um RDD de strings. |
| 18 | coalesce(numPartitions) Diminua o número de partições no RDD para numPartitions. Útil para executar operações com mais eficiência após filtrar um grande conjunto de dados. |
| 19 | repartition(numPartitions) Reorganize os dados no RDD aleatoriamente para criar mais ou menos partições e equilibrá-los entre elas. Isso sempre embaralha todos os dados pela rede. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Reparticione o RDD de acordo com o particionador fornecido e, dentro de cada partição resultante, classifique os registros por suas chaves. Isso é mais eficiente do que chamar a repartição e, em seguida, classificar dentro de cada partição, porque pode empurrar a classificação para o mecanismo de embaralhamento. |
Ações
A tabela a seguir fornece uma lista de ações, que retornam valores.
| S.Não | Ação e Significado |
|---|---|
| 1 | reduce(func) Agregue os elementos do conjunto de dados usando uma função func(que recebe dois argumentos e retorna um). A função deve ser comutativa e associativa para que possa ser calculada corretamente em paralelo. |
| 2 | collect() Retorna todos os elementos do conjunto de dados como uma matriz no programa de driver. Isso geralmente é útil após um filtro ou outra operação que retorna um subconjunto suficientemente pequeno de dados. |
| 3 | count() Retorna o número de elementos no conjunto de dados. |
| 4 | first() Retorna o primeiro elemento do conjunto de dados (semelhante a take (1)). |
| 5 | take(n) Retorna uma matriz com o primeiro n elementos do conjunto de dados. |
| 6 | takeSample (withReplacement,num, [seed]) Retorna uma matriz com uma amostra aleatória de num elementos do conjunto de dados, com ou sem substituição, opcionalmente pré-especificando uma semente do gerador de número aleatório. |
| 7 | takeOrdered(n, [ordering]) Retorna o primeiro n elementos do RDD usando sua ordem natural ou um comparador personalizado. |
| 8 | saveAsTextFile(path) Grava os elementos do conjunto de dados como um arquivo de texto (ou conjunto de arquivos de texto) em um determinado diretório no sistema de arquivos local, HDFS ou qualquer outro sistema de arquivos compatível com Hadoop. Spark chama toString em cada elemento para convertê-lo em uma linha de texto no arquivo. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Grava os elementos do conjunto de dados como um Hadoop SequenceFile em um determinado caminho no sistema de arquivos local, HDFS ou qualquer outro sistema de arquivos compatível com Hadoop. Isso está disponível em RDDs de pares chave-valor que implementam a interface gravável do Hadoop. No Scala, ele também está disponível em tipos que são implicitamente conversíveis em graváveis (o Spark inclui conversões para tipos básicos como Int, Double, String, etc.). |
| 10 | saveAsObjectFile(path) (Java and Scala) Grava os elementos do conjunto de dados em um formato simples usando serialização Java, que pode então ser carregado usando SparkContext.objectFile (). |
| 11 | countByKey() Disponível apenas em RDDs do tipo (K, V). Retorna um hashmap de pares (K, Int) com a contagem de cada chave. |
| 12 | foreach(func) Executa uma função funcem cada elemento do conjunto de dados. Isso geralmente é feito para efeitos colaterais, como atualizar um acumulador ou interagir com sistemas de armazenamento externos. Note- modificar variáveis diferentes de Accumulators fora de foreach () pode resultar em comportamento indefinido. Consulte Noções básicas sobre fechamentos para obter mais detalhes. |
Programação com RDD
Vejamos as implementações de algumas transformações e ações RDD na programação RDD com a ajuda de um exemplo.
Exemplo
Considere um exemplo de contagem de palavras - conta cada palavra que aparece em um documento. Considere o seguinte texto como uma entrada e é salvo como uminput.txt arquivo em um diretório inicial.
input.txt - arquivo de entrada.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Siga o procedimento fornecido a seguir para executar o exemplo fornecido.
Abra o Spark-Shell
O seguinte comando é usado para abrir o shell do Spark. Geralmente, o Spark é construído usando Scala. Portanto, um programa Spark é executado no ambiente Scala.
$ spark-shellSe o shell do Spark abrir com êxito, você encontrará a seguinte saída. Observe a última linha da saída "Contexto do Spark disponível como sc" significa que o contêiner do Spark é criado automaticamente para o objeto de contexto do Spark com o nomesc. Antes de iniciar a primeira etapa de um programa, o objeto SparkContext deve ser criado.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Crie um RDD
Primeiro, temos que ler o arquivo de entrada usando a API Spark-Scala e criar um RDD.
O comando a seguir é usado para ler um arquivo de um determinado local. Aqui, um novo RDD é criado com o nome de inputfile. O String que é fornecido como um argumento no método textFile (“”) é o caminho absoluto para o nome do arquivo de entrada. No entanto, se apenas o nome do arquivo for fornecido, isso significa que o arquivo de entrada está no local atual.
scala> val inputfile = sc.textFile("input.txt")Executar transformação de contagem de palavras
Nosso objetivo é contar as palavras em um arquivo. Crie um mapa plano para dividir cada linha em palavras (flatMap(line ⇒ line.split(“ ”))
Em seguida, leia cada palavra como uma chave com um valor ‘1’ (<chave, valor> = <palavra, 1>) usando a função de mapa (map(word ⇒ (word, 1))
Por fim, reduza essas chaves adicionando valores de chaves semelhantes (reduceByKey(_+_))
O seguinte comando é usado para executar a lógica de contagem de palavras. Depois de executar isso, você não encontrará nenhuma saída porque esta não é uma ação, é uma transformação; apontar um novo RDD ou dizer à centelha o que fazer com os dados fornecidos)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);RDD atual
Ao trabalhar com o RDD, se desejar saber sobre o RDD atual, use o seguinte comando. Ele mostrará a descrição sobre o RDD atual e suas dependências para depuração.
scala> counts.toDebugStringArmazenando as Transformações em Cache
Você pode marcar um RDD para ser persistido usando os métodos persist () ou cache () nele. Na primeira vez em que for computado em uma ação, ele será mantido na memória dos nós. Use o seguinte comando para armazenar as transformações intermediárias na memória.
scala> counts.cache()Aplicando a Ação
Aplicar uma ação, como armazenar todas as transformações, resulta em um arquivo de texto. O argumento String para o método saveAsTextFile (“”) é o caminho absoluto da pasta de saída. Tente o seguinte comando para salvar a saída em um arquivo de texto. No exemplo a seguir, a pasta 'output' está no local atual.
scala> counts.saveAsTextFile("output")Verificando o resultado
Abra outro terminal para ir para o diretório inicial (onde o spark é executado no outro terminal). Use os seguintes comandos para verificar o diretório de saída.
[hadoop@localhost ~]$ cd output/
[hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSO seguinte comando é usado para ver a saída de Part-00000 arquivos.
[hadoop@localhost output]$ cat part-00000Resultado
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)O seguinte comando é usado para ver a saída de Part-00001 arquivos.
[hadoop@localhost output]$ cat part-00001Resultado
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)ONU Persiste o Armazenamento
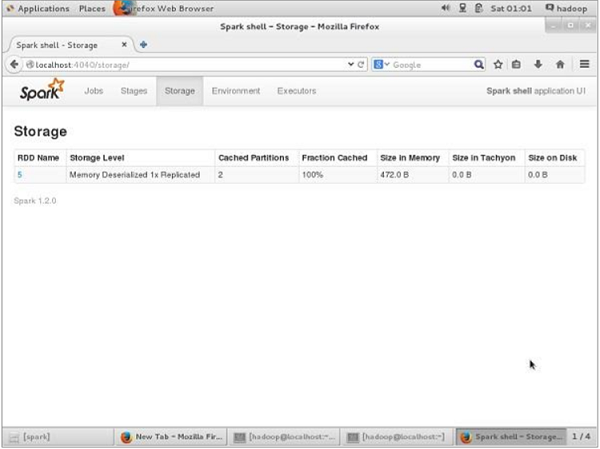
Antes de persistir com o UN, se quiser ver o espaço de armazenamento usado para este aplicativo, use a seguinte URL em seu navegador.
http://localhost:4040Você verá a tela a seguir, que mostra o espaço de armazenamento usado para o aplicativo, que está sendo executado no shell do Spark.

Se você deseja UN-persistir o espaço de armazenamento de um RDD específico, use o seguinte comando.
Scala> counts.unpersist()Você verá a saída da seguinte forma -
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Para verificar o espaço de armazenamento no navegador, use a seguinte URL.
http://localhost:4040/Você verá a seguinte tela. Ele mostra o espaço de armazenamento usado para o aplicativo, que está sendo executado no shell do Spark.