Apache Tajo - Guia rápido
Sistema de Data Warehouse Distribuído
O data warehouse é um banco de dados relacional projetado para consulta e análise, e não para processamento de transações. É uma coleção de dados orientada para o assunto, integrada, variável no tempo e não volátil. Esses dados ajudam os analistas a tomar decisões informadas em uma organização, mas os volumes de dados relacionais aumentam dia a dia.
Para superar os desafios, o sistema de data warehouse distribuído compartilha dados em vários repositórios de dados para fins de processamento analítico online (OLAP). Cada data warehouse pode pertencer a uma ou mais organizações. Ele executa balanceamento de carga e escalabilidade. Os metadados são replicados e distribuídos centralmente.
Apache Tajo é um sistema de data warehouse distribuído que usa o Hadoop Distributed File System (HDFS) como a camada de armazenamento e tem seu próprio mecanismo de execução de consulta em vez da estrutura MapReduce.
Visão geral do SQL no Hadoop
Hadoop é uma estrutura de código aberto que permite armazenar e processar big data em um ambiente distribuído. É extremamente rápido e poderoso. No entanto, o Hadoop tem recursos de consulta limitados, portanto, seu desempenho pode ser ainda melhor com a ajuda do SQL no Hadoop. Isso permite que os usuários interajam com o Hadoop por meio de comandos SQL fáceis.
Alguns dos exemplos de SQL em aplicativos Hadoop são Hive, Impala, Drill, Presto, Spark, HAWQ e Apache Tajo.
O que é Apache Tajo
Apache Tajo é uma estrutura de processamento de dados distribuída e relacional. Ele foi projetado para baixa latência e análise de consulta ad-hoc escalonável.
Tajo suporta SQL padrão e vários formatos de dados. A maioria das consultas Tajo podem ser executadas sem qualquer modificação.
Tajo tem fault-tolerance por meio de um mecanismo de reinicialização para tarefas com falha e mecanismo de regravação de consulta extensível.
Tajo realiza o necessário ETL (Extract Transform and Load process)operações para resumir grandes conjuntos de dados armazenados no HDFS. É uma escolha alternativa para Hive / Pig.
A última versão do Tajo tem maior conectividade com programas Java e bancos de dados de terceiros, como Oracle e PostGreSQL.
Características do Apache Tajo
Apache Tajo tem os seguintes recursos -
- Escalabilidade superior e desempenho otimizado
- Baixa latência
- Funções definidas pelo usuário
- Estrutura de processamento de armazenamento em linha / colunar.
- Compatibilidade com HiveQL e Hive MetaStore
- Fluxo de dados simples e fácil manutenção.
Benefícios do Apache Tajo
Apache Tajo oferece os seguintes benefícios -
- Fácil de usar
- Arquitetura simplificada
- Otimização de consulta baseada em custos
- Plano de execução de consulta vetorizado
- Entrega rápida
- Mecanismo de E / S simples e suporta vários tipos de armazenamento.
- Tolerância ao erro
Casos de uso do Apache Tajo
A seguir estão alguns dos casos de uso do Apache Tajo -
Armazenamento e análise de dados
A empresa coreana SK Telecom executou o Tajo com 1,7 terabytes de dados e descobriu que poderia completar consultas com maior velocidade do que o Hive ou o Impala.
Descoberta de dados
O serviço de streaming de música coreano Melon usa Tajo para processamento analítico. O Tajo executa tarefas ETL (processo de extração-transformação-carregamento) 1,5 a 10 vezes mais rápido do que o Hive.
Análise de log
Bluehole Studio, uma empresa com sede na Coréia desenvolveu TERA - um jogo online multiplayer de fantasia. A empresa usa o Tajo para análise de registro de jogos e localização das principais causas de interrupções na qualidade do serviço.
Armazenamento e formatos de dados
Apache Tajo suporta os seguintes formatos de dados -
- JSON
- Arquivo de texto (CSV)
- Parquet
- Arquivo de Sequência
- AVRO
- Buffer de protocolo
- Apache Orc
Tajo suporta os seguintes formatos de armazenamento -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
A ilustração a seguir descreve a arquitetura do Apache Tajo.

A tabela a seguir descreve cada um dos componentes em detalhes.
| S.No. | Descrição do componente |
|---|---|
| 1 | Client Client envia as instruções SQL ao Tajo Master para obter o resultado. |
| 2 | Master Master é o daemon principal. É responsável pelo planejamento da consulta e coordenador dos trabalhadores. |
| 3 | Catalog server Mantém as descrições da tabela e do índice. Ele está embutido no daemon Master. O servidor de catálogos usa Apache Derby como a camada de armazenamento e se conecta via cliente JDBC. |
| 4 | Worker O nó mestre atribui tarefas aos nós de trabalho. TajoWorker processa dados. Conforme o número de TajoWorkers aumenta, a capacidade de processamento também aumenta linearmente. |
| 5 | Query Master O mestre tajo atribui a consulta ao mestre de consultas. O Query Master é responsável por controlar um plano de execução distribuído. Ele inicia o TaskRunner e agenda tarefas para o TaskRunner. A principal função do mestre de consultas é monitorar as tarefas em execução e relatá-las ao nó mestre. |
| 6 | Node Managers Gerencia o recurso do nó de trabalho. Ele decide sobre a alocação de solicitações ao nó. |
| 7 | TaskRunner Atua como um mecanismo de execução de consulta local. É usado para executar e monitorar o processo de consulta. O TaskRunner processa uma tarefa por vez. Tem os seguintes três atributos principais -
|
| 8 | Query Executor É usado para executar uma consulta. |
| 9 | Storage service Conecta o armazenamento de dados subjacente ao Tajo. |
Fluxo de Trabalho
Tajo usa o Hadoop Distributed File System (HDFS) como a camada de armazenamento e tem seu próprio mecanismo de execução de consulta em vez da estrutura MapReduce. Um cluster Tajo consiste em um nó mestre e vários trabalhadores em nós de cluster.
O mestre é o principal responsável pelo planejamento da consulta e o coordenador dos trabalhadores. O mestre divide uma consulta em pequenas tarefas e atribui aos trabalhadores. Cada trabalhador possui um mecanismo de consulta local que executa um gráfico acíclico direcionado de operadores físicos.
Além disso, o Tajo pode controlar o fluxo de dados distribuídos de forma mais flexível do que o MapReduce e oferece suporte a técnicas de indexação.
A interface baseada na web do Tajo tem os seguintes recursos -
- Opção para descobrir como as consultas enviadas são planejadas
- Opção para descobrir como as consultas são distribuídas entre os nós
- Opção para verificar o status do cluster e dos nós
Para instalar o Apache Tajo, você deve ter o seguinte software em seu sistema -
- Hadoop versão 2.3 ou superior
- Java versão 1.7 ou superior
- Linux ou Mac OS
Vamos agora continuar com os seguintes passos para instalar o Tajo.
Verificando a instalação do Java
Felizmente, você já instalou o Java versão 8 em sua máquina. Agora, você só precisa continuar verificando.
Para verificar, use o seguinte comando -
$ java -versionSe o Java for instalado com sucesso em sua máquina, você poderá ver a versão atual do Java instalado. Se o Java não estiver instalado, siga estas etapas para instalar o Java 8 em sua máquina.
Baixar JDK
Baixe a versão mais recente do JDK visitando o link a seguir e, em seguida, baixe a versão mais recente.
https://www.oracle.com
A última versão é JDK 8u 92 e o arquivo é “jdk-8u92-linux-x64.tar.gz”. Faça download do arquivo em sua máquina. Em seguida, extraia os arquivos e mova-os para um diretório específico. Agora, defina as alternativas Java. Finalmente, o Java é instalado em sua máquina.
Verificando a instalação do Hadoop
Você já instalou Hadoopem seu sistema. Agora, verifique-o usando o seguinte comando -
$ hadoop versionSe tudo estiver bem com sua configuração, você poderá ver a versão do Hadoop. Se o Hadoop não estiver instalado, baixe e instale o Hadoop visitando o seguinte link -https://www.apache.org
Instalação Apache Tajo
O Apache Tajo fornece dois modos de execução - modo local e modo totalmente distribuído. Depois de verificar a instalação do Java e do Hadoop, prossiga com as etapas a seguir para instalar o cluster Tajo em sua máquina. Uma instância Tajo de modo local requer configurações muito fáceis.
Baixe a versão mais recente do Tajo visitando o seguinte link - https://www.apache.org/dyn/closer.cgi/tajo
Agora você pode baixar o arquivo “tajo-0.11.3.tar.gz” de sua máquina.
Extrair arquivo tar
Extraia o arquivo tar usando o seguinte comando -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Definir Variável de Ambiente
Adicione as seguintes alterações a “conf/tajo-env.sh” Arquivo
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Aqui, você deve especificar o caminho Hadoop e Java para “tajo-env.sh”Arquivo. Depois que as alterações forem feitas, salve o arquivo e saia do terminal.
Iniciar servidor Tajo
Para iniciar o servidor Tajo, execute o seguinte comando -
$ bin/start-tajo.shVocê receberá uma resposta semelhante à seguinte -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Agora, digite o comando “jps” para ver os daemons em execução.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterLançar Tajo Shell (Tsql)
Para iniciar o cliente shell Tajo, use o seguinte comando -
$ bin/tsqlVocê receberá a seguinte saída -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Saia da Tajo Shell
Execute o seguinte comando para sair do Tsql -
default> \q
bye!Aqui, o padrão se refere ao catálogo no Tajo.
IU da web
Digite o seguinte URL para iniciar a IU da web do Tajo - http://localhost:26080/
Agora você verá a tela a seguir, que é semelhante à opção ExecuteQuery.

Pare Tajo
Para parar o servidor Tajo, use o seguinte comando -
$ bin/stop-tajo.shVocê receberá a seguinte resposta -
localhost: stopping worker
stopping masterA configuração do Tajo é baseada no sistema de configuração do Hadoop. Este capítulo explica as definições de configuração do Tajo em detalhes.
Configurações básicas
Tajo usa os seguintes dois arquivos de configuração -
- catalog-site.xml - configuração para o servidor de catálogos.
- tajo-site.xml - configuração para outros módulos Tajo.
Configuração de modo distribuído
A configuração do modo distribuído é executada no Hadoop Distributed File System (HDFS). Vamos seguir as etapas para configurar a configuração do modo distribuído Tajo.
tajo-site.xml
Este arquivo está disponível @ /path/to/tajo/confdiretório e atua como configuração para outros módulos Tajo. Para acessar o Tajo em um modo distribuído, aplique as seguintes alterações a“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Configuração do Nó Mestre
Tajo usa HDFS como tipo de armazenamento primário. A configuração é a seguinte e deve ser adicionada ao“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Configuração do Catálogo
Se você deseja customizar o serviço de catálogo, copie $path/to/Tajo/conf/catalogsite.xml.template para $path/to/Tajo/conf/catalog-site.xml e adicione qualquer uma das configurações a seguir, conforme necessário.
Por exemplo, se você usar “Hive catalog store” para acessar o Tajo, a configuração deve ser como a seguinte -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Se você precisa armazenar MySQL catálogo e, em seguida, aplique as seguintes alterações -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Da mesma forma, você pode registrar os outros catálogos suportados pelo Tajo no arquivo de configuração.
Configuração de trabalhador
Por padrão, o TajoWorker armazena dados temporários no sistema de arquivos local. É definido no arquivo “tajo-site.xml” da seguinte forma -
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Para aumentar a capacidade de execução de tarefas de cada recurso do trabalhador, escolha a seguinte configuração -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Para fazer o trabalhador Tajo funcionar em um modo dedicado, escolha a seguinte configuração -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>Neste capítulo, entenderemos os comandos do Tajo Shell em detalhes.
Para executar os comandos do shell Tajo, você precisa iniciar o servidor Tajo e o shell Tajo usando os seguintes comandos -
Iniciar servidor
$ bin/start-tajo.shIniciar Shell
$ bin/tsqlOs comandos acima agora estão prontos para execução.
Meta Comandos
Vamos agora discutir o Meta Commands. Os meta comandos Tsql começam com uma barra invertida(‘\’).
Comando de ajuda
“\?” O comando é usado para mostrar a opção de ajuda.
Query
default> \?Result
O de cima \?O comando lista todas as opções básicas de uso no Tajo. Você receberá a seguinte saída -
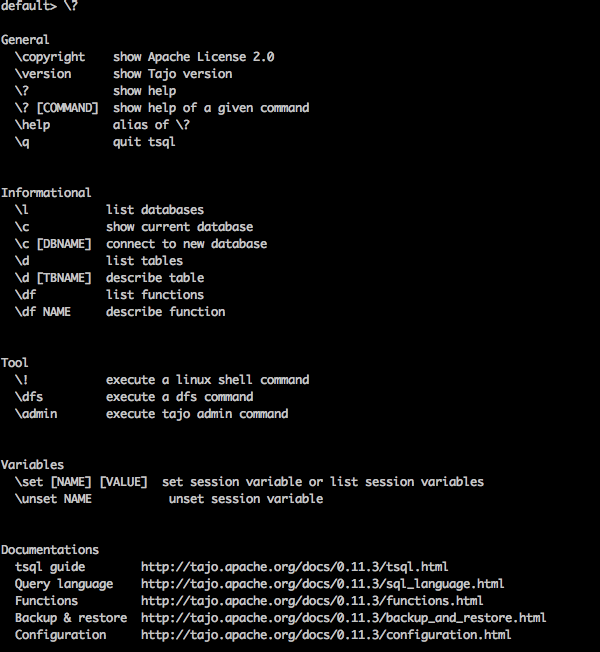
Lista de banco de dados
Para listar todos os bancos de dados no Tajo, use o seguinte comando -
Query
default> \lResult
Você receberá a seguinte saída -
information_schema
defaultNo momento, não criamos nenhum banco de dados, portanto ele mostra dois bancos de dados Tajo integrados.
Banco de Dados Atual
\c opção é usada para exibir o nome do banco de dados atual.
Query
default> \cResult
Agora você está conectado ao banco de dados "padrão" como usuário “nome de usuário”.
Listar funções integradas
Para listar todas as funções integradas, digite a consulta da seguinte forma -
Query
default> \dfResult
Você receberá a seguinte saída -

Descrever Função
\df function name - Esta consulta retorna a descrição completa da função fornecida.
Query
default> \df sqrtResult
Você receberá a seguinte saída -

Sair do Terminal
Para sair do terminal, digite a seguinte consulta -
Query
default> \qResult
Você receberá a seguinte saída -
bye!Comandos de Admin
Concha tajo fornece \admin opção de listar todos os recursos de administrador.
Query
default> \adminResult
Você receberá a seguinte saída -

Informação do Cluster
Para exibir as informações do cluster no Tajo, use a seguinte consulta
Query
default> \admin -clusterResult
Você receberá a seguinte saída -

Mostrar mestre
A consulta a seguir exibe as informações mestre atuais.
Query
default> \admin -showmastersResult
localhostDa mesma forma, você pode tentar outros comandos de administrador.
Variáveis de Sessão
O cliente Tajo se conecta ao Master por meio de uma id de sessão exclusiva. A sessão está ativa até que o cliente seja desconectado ou expire.
O seguinte comando é usado para listar todas as variáveis de sessão.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'o \set key val irá definir a variável de sessão chamada key com o valor val. Por exemplo,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Aqui, você pode atribuir a chave e o valor no \setcomando. Se você precisar reverter as alterações, use o\unset comando.
Para executar uma consulta em um shell Tajo, abra seu terminal e vá para o diretório instalado do Tajo e digite o seguinte comando -
$ bin/tsqlAgora você verá a resposta conforme mostrado no programa a seguir -
default>Agora você pode executar suas consultas. Caso contrário, você pode executar suas consultas por meio do aplicativo de console da web para o seguinte URL -http://localhost:26080/
Tipos de dados primitivos
Apache Tajo suporta a seguinte lista de tipos de dados primitivos -
| S.No. | Tipo de dados e descrição |
|---|---|
| 1 | integer Usado para armazenar o valor inteiro com 4 bytes de armazenamento. |
| 2 | tinyint O valor inteiro minúsculo é 1 byte |
| 3 | smallint Usado para armazenar valores inteiros de 2 bytes de tamanho pequeno. |
| 4 | bigint O valor inteiro de grande alcance tem 8 bytes de armazenamento. |
| 5 | boolean Retorna verdadeiro / falso. |
| 6 | real Usado para armazenar valor real. O tamanho é 4 bytes. |
| 7 | float Valor de precisão de ponto flutuante que possui 4 ou 8 bytes de espaço de armazenamento. |
| 8 | double Valor de precisão de ponto duplo armazenado em 8 bytes. |
| 9 | char[(n)] Valor do personagem. |
| 10 | varchar[(n)] Dados não Unicode de comprimento variável. |
| 11 | number Valores decimais. |
| 12 | binary Valores binários. |
| 13 | date Data do calendário (ano, mês, dia). Example - DATA '2016-08-22' |
| 14 | time Hora do dia (hora, minuto, segundo, milissegundo) sem fuso horário. Valores desse tipo são analisados e renderizados no fuso horário da sessão. |
| 15 | timezone Hora do dia (hora, minuto, segundo, milissegundo) com um fuso horário. Valores desse tipo são renderizados usando o fuso horário do valor. Example - TIME '01: 02: 03.456 Asia / kolkata ' |
| 16 | timestamp Instantâneo no tempo que inclui a data e a hora do dia sem fuso horário. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Texto Unicode de comprimento variável. |
Os seguintes operadores são usados no Tajo para realizar as operações desejadas.
| S.No. | Operador e descrição |
|---|---|
| 1 | Operadores aritméticos Presto suporta operadores aritméticos como +, -, *, /,%. |
| 2 | Operadores relacionais <,>, <=,> =, =, <> |
| 3 | Operadores lógicos AND, OR, NOT |
| 4 | Operadores de string O '||' operador executa concatenação de string. |
| 5 | Operadores de alcance O operador de intervalo é usado para testar o valor em um intervalo específico. Tajo suporta os operadores BETWEEN, IS NULL, IS NOT NULL. |
A partir de agora, você estava ciente de executar consultas básicas simples no Tajo. Nos próximos capítulos subsequentes, discutiremos as seguintes funções SQL -
- Funções Matemáticas
- Funções de String
- Funções DateTime
- Funções JSON
As funções matemáticas operam em fórmulas matemáticas. A tabela a seguir descreve a lista de funções em detalhes.
| S.No. | Descrição da função |
|---|---|
| 1 | abs (x) Retorna o valor absoluto de x. |
| 2 | cbrt (x) Retorna a raiz cúbica de x. |
| 3 | ceil (x) Retorna o valor x arredondado para o número inteiro mais próximo. |
| 4 | andar (x) Retorna x arredondado para o número inteiro mais próximo. |
| 5 | pi () Retorna o valor de pi. O resultado será retornado como valor duplo. |
| 6 | radianos (x) converte o ângulo x em radianos de graus. |
| 7 | graus (x) Retorna o valor de grau para x. |
| 8 | pow (x, p) Retorna a potência do valor 'p' para o valor x. |
| 9 | div (x, y) Retorna o resultado da divisão para os dois valores inteiros x, y fornecidos. |
| 10 | exp (x) Retorna o número de Euler e elevado à potência de um número. |
| 11 | sqrt (x) Retorna a raiz quadrada de x. |
| 12 | sinal (x) Retorna a função signum de x, ou seja -
|
| 13 | mod (n, m) Retorna o módulo (resto) de n dividido por m. |
| 14 | rodada (x) Retorna o valor arredondado para x. |
| 15 | cos (x) Retorna o valor do cosseno (x). |
| 16 | asin (x) Retorna o valor do seno inverso (x). |
| 17 | acos (x) Retorna o valor do cosseno inverso (x). |
| 18 | atan (x) Retorna o valor da tangente inversa (x). |
| 19 | atan2 (y, x) Retorna o valor da tangente inversa (y / x). |
Funções de tipo de dados
A tabela a seguir lista as funções de tipo de dados disponíveis no Apache Tajo.
| S.No. | Descrição da função |
|---|---|
| 1 | to_bin (x) Retorna a representação binária do inteiro. |
| 2 | to_char (int, texto) Converte inteiro em string. |
| 3 | to_hex (x) Converte o valor x em hexadecimal. |
A tabela a seguir lista as funções de string no Tajo.
| S.No. | Descrição da função |
|---|---|
| 1 | concat (string1, ..., stringN) Concatene as strings fornecidas. |
| 2 | comprimento (string) Retorna o comprimento da string fornecida. |
| 3 | inferior (corda) Retorna o formato de minúsculas para a string. |
| 4 | superior (corda) Retorna o formato em maiúsculas para a string fornecida. |
| 5 | ascii (texto da string) Retorna o código ASCII do primeiro caractere do texto. |
| 6 | bit_length (texto da string) Retorna o número de bits em uma string. |
| 7 | char_length (texto da string) Retorna o número de caracteres em uma string. |
| 8 | octet_length (texto da string) Retorna o número de bytes em uma string. |
| 9 | resumo (texto de entrada, texto do método) Calcula o Digesthash de string. Aqui, o segundo método arg refere-se ao método hash. |
| 10 | initcap (texto de string) Converte a primeira letra de cada palavra em maiúsculas. |
| 11 | md5 (texto da string) Calcula o MD5 hash de string. |
| 12 | esquerda (texto da string, tamanho interno) Retorna os primeiros n caracteres da string. |
| 13 | direita (texto da string, tamanho interno) Retorna os últimos n caracteres da string. |
| 14 | localizar (texto de origem, texto de destino, start_index) Retorna a localização da substring especificada. |
| 15 | strposb (texto fonte, texto alvo) Retorna a localização binária da substring especificada. |
| 16 | substr (texto de origem, índice inicial, comprimento) Retorna a substring para o comprimento especificado. |
| 17 | trim (texto da string [, texto dos caracteres]) Remove os caracteres (um espaço por padrão) do início / fim / ambas as extremidades da string. |
| 18 | split_part (string text, delimiter text, field int) Divide uma string no delimitador e retorna o campo fornecido (contando a partir de um). |
| 19 | regexp_replace (texto de string, texto de padrão, texto de substituição) Substitui substrings correspondentes a um determinado padrão de expressão regular. |
| 20 | reverso (string) Operação reversa realizada para a string. |
Apache Tajo suporta as seguintes funções DateTime.
| S.No. | Descrição da função |
|---|---|
| 1 | add_days (data data ou timestamp, int dia Retorna a data adicionada pelo valor do dia fornecido. |
| 2 | add_months (data data ou timestamp, int mês) Retorna a data adicionada pelo valor do mês fornecido. |
| 3 | data atual() Retorna a data de hoje. |
| 4 | hora atual() Retorna a hora de hoje. |
| 5 | extrair (século da data / carimbo de data / hora) Extrai o século do parâmetro fornecido. |
| 6 | extrair (dia da data / carimbo de hora) Extrai o dia do parâmetro fornecido. |
| 7 | extrair (década a partir da data / carimbo de data / hora) Extrai a década do parâmetro fornecido. |
| 8 | extrair (data / hora do dia de baixa) Extrai o dia da semana do parâmetro fornecido. |
| 9 | extrair (doy de data / carimbo de data / hora) Extrai o dia do ano do parâmetro fornecido. |
| 10 | selecionar extrato (hora do carimbo de data / hora) Extrai a hora do parâmetro fornecido. |
| 11 | selecionar extração (isodow do carimbo de data / hora) Extrai o dia da semana do parâmetro fornecido. É idêntico ao dow, exceto no domingo. Corresponde à numeração do dia da semana ISO 8601. |
| 12 | selecionar extrato (isoyear from date) Extrai o ano ISO da data especificada. O ano ISO pode ser diferente do ano gregoriano. |
| 13 | extrair (microssegundos do tempo) Extrai microssegundos do parâmetro fornecido. O campo dos segundos, incluindo as partes fracionárias, multiplicado por 1 000 000; |
| 14 | extrair (milênio do timestamp) Extrai milênio do parâmetro fornecido. Um milênio corresponde a 1000 anos. Portanto, o terceiro milênio começou em 1º de janeiro de 2001. |
| 15 | extrair (milissegundos a partir do tempo) Extrai milissegundos do parâmetro fornecido. |
| 16 | extrair (minuto do carimbo de data / hora) Extrai minuto do parâmetro fornecido. |
| 17 | extrair (trimestre do carimbo de data / hora) Extrai o trimestre do ano (1 - 4) do parâmetro fornecido. |
| 18 | date_part (texto do campo, data de origem ou carimbo de data / hora ou hora) Extrai o campo de data do texto. |
| 19 | agora() Retorna o carimbo de data / hora atual. |
| 20 | to_char (carimbo de data / hora, formato de texto) Converte o carimbo de data / hora em texto. |
| 21 | to_date (texto src, formato de texto) Converte o texto em data. |
| 22 | to_timestamp (texto src, formato de texto) Converte texto em carimbo de data / hora. |
As funções JSON estão listadas na tabela a seguir -
| S.No. | Descrição da função |
|---|---|
| 1 | json_extract_path_text (js no texto, texto json_path) Extrai a string JSON de uma string JSON com base no caminho json especificado. |
| 2 | json_array_get (texto json_array, índice int4) Retorna o elemento no índice especificado na matriz JSON. |
| 3 | json_array_contains (texto da matriz json_, valor qualquer) Determine se o valor fornecido existe na matriz JSON. |
| 4 | json_array_length (texto json_ar ray) Retorna o comprimento da matriz json. |
Esta seção explica os comandos Tajo DDL. Tajo tem um banco de dados integrado chamadodefault.
Criar declaração de banco de dados
Create Databaseé uma instrução usada para criar um banco de dados no Tajo. A sintaxe para esta declaração é a seguinte -
CREATE DATABASE [IF NOT EXISTS] <database_name>Inquerir
default> default> create database if not exists test;Resultado
A consulta acima irá gerar o seguinte resultado.
OKO banco de dados é o namespace no Tajo. Um banco de dados pode conter várias tabelas com um nome exclusivo.
Mostrar banco de dados atual
Para verificar o nome do banco de dados atual, emita o seguinte comando -
Inquerir
default> \cResultado
A consulta acima irá gerar o seguinte resultado.
You are now connected to database "default" as user “user1".
default>Conectar ao banco de dados
A partir de agora, você criou um banco de dados denominado “teste”. A seguinte sintaxe é usada para conectar o banco de dados de “teste”.
\c <database name>Inquerir
default> \c testResultado
A consulta acima irá gerar o seguinte resultado.
You are now connected to database "test" as user “user1”.
test>Agora você pode ver as mudanças de prompt do banco de dados padrão para o banco de dados de teste.
Drop Database
Para eliminar um banco de dados, use a seguinte sintaxe -
DROP DATABASE <database-name>Inquerir
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Resultado
A consulta acima irá gerar o seguinte resultado.
OKUma tabela é uma visão lógica de uma fonte de dados. Ele consiste em um esquema lógico, partições, URL e várias propriedades. Uma tabela Tajo pode ser um diretório no HDFS, um único arquivo, uma tabela HBase ou uma tabela RDBMS.
Tajo suporta os seguintes dois tipos de tabelas -
- mesa externa
- mesa interna
Mesa Externa
A tabela externa precisa da propriedade local quando a tabela é criada. Por exemplo, se seus dados já estiverem lá como arquivos Texto / JSON ou tabela HBase, você pode registrá-los como tabela externa Tajo.
A consulta a seguir é um exemplo de criação de tabela externa.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Aqui,
External keyword- Isso é usado para criar uma tabela externa. Isso ajuda a criar uma mesa no local especificado.
Amostra refere-se ao nome da tabela.
Location- É um diretório para HDFS, Amazon S3, HBase ou sistema de arquivos local. Para atribuir uma propriedade de localização para diretórios, use os exemplos de URI abaixo -
HDFS - hdfs: // localhost: porta / caminho / para / tabela
Amazon S3 - s3: // nome do intervalo / tabela
local file system - arquivo: /// caminho / para / tabela
Openstack Swift - swift: // nome do balde / tabela
Propriedades da Tabela
Uma tabela externa possui as seguintes propriedades -
TimeZone - Os usuários podem especificar um fuso horário para ler ou escrever uma tabela.
Compression format- Usado para tornar o tamanho dos dados compacto. Por exemplo, o arquivo text / json usacompression.codec propriedade.
Mesa Interna
Uma tabela interna também é chamada de Managed Table. Ele é criado em um local físico predefinido chamado Tablespace.
Sintaxe
create table table1(col1 int,col2 text);Por padrão, o Tajo usa “tajo.warehouse.directory” localizado em “conf / tajo-site.xml”. Para atribuir um novo local para a tabela, você pode usar a configuração do Tablespace.
Tablespace
O espaço de tabela é usado para definir locais no sistema de armazenamento. É compatível apenas com tabelas internas. Você pode acessar os espaços de tabela por seus nomes. Cada espaço de tabela pode usar um tipo de armazenamento diferente. Se você não especificar os espaços de tabela, o Tajo usará o espaço de tabela padrão no diretório raiz.
Configuração de Tablespace
Você tem “conf/tajo-site.xml.template”em Tajo. Copie o arquivo e renomeie-o para“storagesite.json”. Este arquivo funcionará como uma configuração para Tablespaces. Os formatos de dados Tajo usam a seguinte configuração -
Configuração HDFS
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Configuração HBase
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Configuração de arquivo de texto
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Criação de Tablespace
Os registros da tabela interna do Tajo podem ser acessados somente de outra tabela. Você pode configurá-lo com o espaço de tabela.
Sintaxe
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Aqui,
IF NOT EXISTS - Isso evita um erro se a mesma tabela ainda não tiver sido criada.
TABLESPACE - Esta cláusula é usada para atribuir o nome do espaço de tabela.
Storage type - Os dados Tajo suportam formatos como texto, JSON, HBase, Parquet, Sequencefile e ORC.
AS select statement - Selecione registros de outra tabela.
Configurar Tablespace
Inicie seus serviços Hadoop e abra o arquivo “conf/storage-site.json”e adicione as seguintes alterações -
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Aqui, Tajo irá se referir aos dados da localização do HDFS e space1é o nome do espaço de tabela. Se você não iniciar os serviços Hadoop, não poderá registrar o espaço de tabela.
Inquerir
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;A consulta acima cria uma tabela chamada “tabela1” e “espaço1” refere-se ao nome do espaço de tabela.
Formatos de dados
Tajo suporta formatos de dados. Vamos examinar cada um dos formatos, um por um, em detalhes.
Texto
Um arquivo de texto simples de valores separados por caracteres representa um conjunto de dados tabular que consiste em linhas e colunas. Cada linha é uma linha de texto simples.
Criando mesa
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Aqui, “customers.csv” arquivo refere-se a um arquivo de valor separado por vírgula localizado no diretório de instalação do Tajo.
Para criar uma tabela interna usando formato de texto, use a seguinte consulta -
default> create table customer(id int,name text,address text,age int) using text;Na consulta acima, você não atribuiu nenhum espaço de tabela, portanto, ele usará o espaço de tabela padrão de Tajo.
Propriedades
Um formato de arquivo de texto tem as seguintes propriedades -
text.delimiter- Este é um caractere delimitador. O padrão é '|'.
compression.codec- Este é um formato de compressão. Por padrão, ele está desabilitado. você pode alterar as configurações usando o algoritmo especificado.
timezone - A mesa usada para ler ou escrever.
text.error-tolerance.max-num - O número máximo de níveis de tolerância.
text.skip.headerlines - O número de linhas de cabeçalho por omitido.
text.serde - Esta é uma propriedade de serialização.
JSON
Apache Tajo suporta o formato JSON para consulta de dados. Tajo trata um objeto JSON como registro SQL. Um objeto é igual a uma linha em uma tabela Tajo. Vamos considerar “array.json” da seguinte forma -
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}Depois de criar esse arquivo, alterne para o shell Tajo e digite a seguinte consulta para criar uma tabela usando o formato JSON.
Inquerir
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Lembre-se sempre de que os dados do arquivo devem corresponder ao esquema da tabela. Caso contrário, você pode omitir os nomes das colunas e usar * que não requer lista de colunas.
Para criar uma tabela interna, use a seguinte consulta -
default> create table sample (num1 int,num2 text,num3 float) using json;Parquet
Parquet é um formato de armazenamento colunar. Tajo usa o formato Parquet para um acesso fácil, rápido e eficiente.
Criação de mesa
A consulta a seguir é um exemplo de criação de tabela -
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;O formato de arquivo Parquet tem as seguintes propriedades -
parquet.block.size - tamanho de um grupo de linhas sendo armazenado em buffer na memória.
parquet.page.size - O tamanho da página é para compressão.
parquet.compression - O algoritmo de compressão usado para comprimir páginas.
parquet.enable.dictionary - O valor booleano serve para ativar / desativar a codificação do dicionário.
RCFile
RCFile é o arquivo colunar do registro. Consiste em pares binários de chave / valor.
Criação de mesa
A consulta a seguir é um exemplo de criação de tabela -
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile tem as seguintes propriedades -
rcfile.serde - classe desserializadora personalizada.
compression.codec - algoritmo de compressão.
rcfile.null - caractere NULL.
SequenceFile
SequenceFile é um formato de arquivo básico no Hadoop que consiste em pares de chave / valor.
Criação de mesa
A consulta a seguir é um exemplo de criação de tabela -
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;Este arquivo de sequência é compatível com Hive. Isso pode ser escrito no Hive como,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) é um formato de armazenamento colunar do Hive.
Criação de mesa
A consulta a seguir é um exemplo de criação de tabela -
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;O formato ORC tem as seguintes propriedades -
orc.max.merge.distance - O arquivo ORC é lido, ele se funde quando a distância é menor.
orc.stripe.size - Este é o tamanho de cada faixa.
orc.buffer.size - O padrão é 256 KB.
orc.rowindex.stride - Este é o avanço do índice ORC em número de linhas.
No capítulo anterior, você entendeu como criar tabelas no Tajo. Este capítulo explica sobre a instrução SQL no Tajo.
Criar declaração de tabela
Antes de começar a criar uma tabela, crie um arquivo de texto “students.csv” no caminho do diretório de instalação do Tajo da seguinte maneira -
students.csv
| Eu iria | Nome | Endereço | Era | Marcas |
|---|---|---|---|---|
| 1 | Adão | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Prumo | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Maria | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
Após a criação do arquivo, vá para o terminal e inicie o servidor Tajo e o shell, um por um.
Criar banco de dados
Crie um novo banco de dados usando o seguinte comando -
Inquerir
default> create database sampledb;
OKConecte-se ao banco de dados “sampledb” que agora foi criado.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Em seguida, crie uma tabela em “sampledb” da seguinte forma -
Inquerir
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Resultado
A consulta acima irá gerar o seguinte resultado.
OKAqui, a tabela externa é criada. Agora, você só precisa inserir a localização do arquivo. Se você tiver que atribuir a tabela a partir de hdfs, use hdfs em vez de arquivo.
A seguir, o “students.csv”arquivo contém valores separados por vírgula. otext.delimiter campo é atribuído com ','.
Agora você criou “mytable” com sucesso em “sampledb”.
Mostrar mesa
Para mostrar tabelas no Tajo, use a seguinte consulta.
Inquerir
sampledb> \d
mytable
sampledb> \d mytableResultado
A consulta acima irá gerar o seguinte resultado.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4Tabela de lista
Para buscar todos os registros da tabela, digite a seguinte consulta -
Inquerir
sampledb> select * from mytable;Resultado
A consulta acima irá gerar o seguinte resultado.

Inserir declaração de tabela
Tajo usa a seguinte sintaxe para inserir registros na tabela.
Sintaxe
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;A instrução de inserção de Tajo é semelhante ao INSERT INTO SELECT declaração de SQL.
Inquerir
Vamos criar uma tabela para sobrescrever os dados da tabela de uma tabela existente.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Cláusula Where
A cláusula Where é usada para filtrar registros da tabela.
Inquerir
sampledb> select * from mytable where id > 5;Resultado
A consulta acima irá gerar o seguinte resultado.
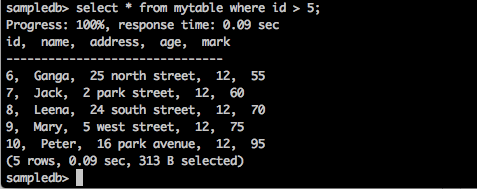
A consulta retorna os registros dos alunos cujo id é maior que 5.
Inquerir
sampledb> select * from mytable where name = ‘Peter’;Resultado
A consulta acima irá gerar o seguinte resultado.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12O resultado filtra apenas os registros de Peter.
Cláusula Distinta
Uma coluna da tabela pode conter valores duplicados. A palavra-chave DISTINCT pode ser usada para retornar apenas valores distintos (diferentes).
Sintaxe
SELECT DISTINCT column1,column2 FROM table_name;Inquerir
sampledb> select distinct age from mytable;Resultado
A consulta acima irá gerar o seguinte resultado.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12A consulta retorna a idade distinta dos alunos de mytable.
Grupo por cláusula
A cláusula GROUP BY é usada em colaboração com a instrução SELECT para organizar dados idênticos em grupos.
Sintaxe
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Inquerir
select age,sum(mark) as sumofmarks from mytable group by age;Resultado
A consulta acima irá gerar o seguinte resultado.
age, sumofmarks
-------------------------------
13, 145
12, 610Aqui, a coluna “minha tabela” tem dois tipos de idades - 12 e 13 anos. Agora, a consulta agrupa os registros por idade e produz a soma das notas para as idades correspondentes dos alunos.
Ter Cláusula
A cláusula HAVING permite que você especifique condições que filtram quais resultados de grupo aparecem nos resultados finais. A cláusula WHERE coloca condições nas colunas selecionadas, enquanto a cláusula HAVING coloca condições nos grupos criados pela cláusula GROUP BY.
Sintaxe
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Inquerir
sampledb> select age from mytable group by age having sum(mark) > 200;Resultado
A consulta acima irá gerar o seguinte resultado.
age
-------------------------------
12A consulta agrupa os registros por idade e retorna a idade quando a soma do resultado da condição (marca)> 200.
Ordem por cláusula
A cláusula ORDER BY é usada para classificar os dados em ordem crescente ou decrescente, com base em uma ou mais colunas. O banco de dados Tajo classifica os resultados da consulta em ordem crescente por padrão.
Sintaxe
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Inquerir
sampledb> select * from mytable where mark > 60 order by name desc;Resultado
A consulta acima irá gerar o seguinte resultado.

A consulta retorna os nomes dos alunos em ordem decrescente cujas notas são maiores que 60.
Criar declaração de índice
A instrução CREATE INDEX é usada para criar índices em tabelas. O índice é usado para recuperação rápida de dados. A versão atual suporta o índice apenas para formatos de texto simples armazenados em HDFS.
Sintaxe
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Inquerir
create index student_index on mytable(id);Resultado
A consulta acima irá gerar o seguinte resultado.
id
———————————————Para visualizar o índice atribuído à coluna, digite a seguinte consulta.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Aqui, o método TWO_LEVEL_BIN_TREE é usado por padrão no Tajo.
Declaração de abandono de mesa
A instrução Eliminar Tabela é usada para eliminar uma tabela do banco de dados.
Sintaxe
drop table table name;Inquerir
sampledb> drop table mytable;Para verificar se a tabela foi eliminada da tabela, digite a seguinte consulta.
sampledb> \d mytable;Resultado
A consulta acima irá gerar o seguinte resultado.
ERROR: relation 'mytable' does not existVocê também pode verificar a consulta usando o comando “\ d” para listar as tabelas Tajo disponíveis.
Este capítulo explica as funções de agregação e janela em detalhes.
Funções de Agregação
As funções agregadas produzem um único resultado de um conjunto de valores de entrada. A tabela a seguir descreve a lista de funções agregadas em detalhes.
| S.No. | Descrição da função |
|---|---|
| 1 | AVG (exp) Calcula a média de uma coluna de todos os registros em uma fonte de dados. |
| 2 | CORR (expressão1, expressão2) Retorna o coeficiente de correlação entre um conjunto de pares de números. |
| 3 | CONTAGEM() Retorna o número de linhas. |
| 4 | MAX (expressão) Retorna o maior valor da coluna selecionada. |
| 5 | MIN (expressão) Retorna o menor valor da coluna selecionada. |
| 6 | SUM (expressão) Retorna a soma da coluna fornecida. |
| 7 | LAST_VALUE (expressão) Retorna o último valor da coluna fornecida. |
Função de janela
As funções Window são executadas em um conjunto de linhas e retornam um único valor para cada linha da consulta. O termo janela tem o significado de conjunto de linhas para a função.
A função Window em uma consulta define a janela usando a cláusula OVER ().
o OVER() cláusula tem os seguintes recursos -
- Define partições de janela para formar grupos de linhas. (Cláusula PARTITION BY)
- Ordena as linhas dentro de uma partição. (Cláusula ORDER BY)
A tabela a seguir descreve as funções da janela em detalhes.
| Função | Tipo de retorno | Descrição |
|---|---|---|
| classificação() | int | Retorna a classificação da linha atual com lacunas. |
| row_num () | int | Retorna a linha atual em sua partição, contando a partir de 1. |
| lead (valor [, deslocamento inteiro [, padrão qualquer]]) | Igual ao tipo de entrada | Retorna o valor avaliado na linha que está deslocada nas linhas após a linha atual na partição. Se não houver tal linha, o valor padrão será retornado. |
| lag (valor [, número inteiro de deslocamento [, padrão qualquer]]) | Igual ao tipo de entrada | Retorna o valor avaliado na linha que está deslocada antes da linha atual dentro da partição. |
| first_value (valor) | Igual ao tipo de entrada | Retorna o primeiro valor das linhas de entrada. |
| last_value (valor) | Igual ao tipo de entrada | Retorna o último valor das linhas de entrada. |
Este capítulo explica sobre as seguintes consultas significativas.
- Predicates
- Explain
- Join
Vamos prosseguir e realizar as consultas.
Predicados
Predicado é uma expressão que é usada para avaliar valores verdadeiro / falso e DESCONHECIDO. Os predicados são usados na condição de pesquisa de cláusulas WHERE e cláusulas HAVING e outras construções onde um valor booleano é necessário.
Predicado IN
Determina se o valor da expressão a ser testada corresponde a qualquer valor na subconsulta ou na lista. A subconsulta é uma instrução SELECT comum que possui um conjunto de resultados de uma coluna e uma ou mais linhas. Esta coluna ou todas as expressões na lista devem ter o mesmo tipo de dados que a expressão a ser testada.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
A consulta acima irá gerar o seguinte resultado.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueA consulta retorna registros de mytable para os alunos id 2,3 e 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
A consulta acima irá gerar o seguinte resultado.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueA consulta acima retorna registros de mytable onde os alunos não estão em 2,3 e 4.
Como predicado
O predicado LIKE compara a string especificada na primeira expressão para calcular o valor da string, que é referido como um valor a ser testado, com o padrão que é definido na segunda expressão para calcular o valor da string.
O padrão pode conter qualquer combinação de curingas, como -
Símbolo de sublinhado (_), que pode ser usado em vez de qualquer caractere único no valor a ser testado.
Sinal de porcentagem (%), que substitui qualquer string de zero ou mais caracteres no valor a ser testado.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
A consulta acima irá gerar o seguinte resultado.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95A consulta retorna registros de minha tabela daqueles alunos cujos nomes começam com 'A'.
Query
select * from mytable where name like ‘_a%';Result
A consulta acima irá gerar o seguinte resultado.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75A consulta retorna registros de mytable daqueles alunos cujos nomes começam com 'a' como o segundo caractere.
Usando valor NULL nas condições de pesquisa
Vamos agora entender como usar o valor NULL nas condições de pesquisa.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
A consulta acima irá gerar o seguinte resultado.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Aqui, o resultado é verdadeiro, então ele retorna todos os nomes da tabela.
Query
Vamos agora verificar a consulta com a condição NULL.
default> select name from mytable where name is null;Result
A consulta acima irá gerar o seguinte resultado.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Explicar
Explainé usado para obter um plano de execução de consulta. Ele mostra a execução de um plano lógico e global de uma instrução.
Consulta de plano lógico
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
A consulta acima irá gerar o seguinte resultado.

O resultado da consulta mostra um formato de plano lógico para a tabela fornecida. O plano lógico retorna os três resultados a seguir -
- Lista de alvos
- Nosso esquema
- No esquema
Consulta de plano global
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
A consulta acima irá gerar o seguinte resultado.

Aqui, o plano global mostra o ID do bloco de execução, a ordem de execução e suas informações.
Junta-se
As junções SQL são usadas para combinar linhas de duas ou mais tabelas. A seguir estão os diferentes tipos de junções SQL -
- Junção interna
- {LEFT | DIREITO | FULL} OUTER JOIN
- Junção cruzada
- Autoinserir
- Junção natural
Considere as duas tabelas a seguir para realizar operações de junção.
Tabela1 - Clientes
| Eu iria | Nome | Endereço | Era |
|---|---|---|---|
| 1 | Cliente 1 | 23 Old Street | 21 |
| 2 | Cliente 2 | 12 New Street | 23 |
| 3 | Cliente 3 | 10 Express Avenue | 22 |
| 4 | Cliente 4 | 15 Express Avenue | 22 |
| 5 | Cliente 5 | 20 Garden Street | 33 |
| 6 | Cliente 6 | 21 North Street | 25 |
Tabela2 - pedido do cliente
| Eu iria | Id do pedido | Id Emp |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Vamos agora prosseguir e realizar as operações de junção SQL nas duas tabelas acima.
Junção interna
A junção interna seleciona todas as linhas de ambas as tabelas quando há uma correspondência entre as colunas em ambas as tabelas.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
A consulta acima irá gerar o seguinte resultado.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105A consulta corresponde a cinco linhas de ambas as tabelas. Portanto, ele retorna a idade das linhas correspondentes da primeira tabela.
União Externa Esquerda
Uma junção externa esquerda retém todas as linhas da tabela “esquerda”, independentemente de haver uma linha que corresponda à tabela “direita” ou não.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
A consulta acima irá gerar o seguinte resultado.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Aqui, a junção externa esquerda retorna linhas de coluna de nome da tabela de clientes (esquerda) e linhas correspondentes de coluna vazia da tabela customer_order (direita).
Junção Externa Direita
Uma junção externa direita retém todas as linhas da tabela “direita”, independentemente de haver uma linha que corresponda à tabela “esquerda”.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
A consulta acima irá gerar o seguinte resultado.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Aqui, o Right Outer Join retorna as linhas vazias da tabela customer_order (direita) e as linhas correspondentes da coluna de nome da tabela customers.
Full Outer Join
A Full Outer Join retém todas as linhas da tabela à esquerda e à direita.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
A consulta acima irá gerar o seguinte resultado.

A consulta retorna todas as linhas correspondentes e não correspondentes das tabelas clientes e customer_order.
Cross Join
Isso retorna o produto cartesiano dos conjuntos de registros de duas ou mais tabelas unidas.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
A consulta acima irá gerar o seguinte resultado.
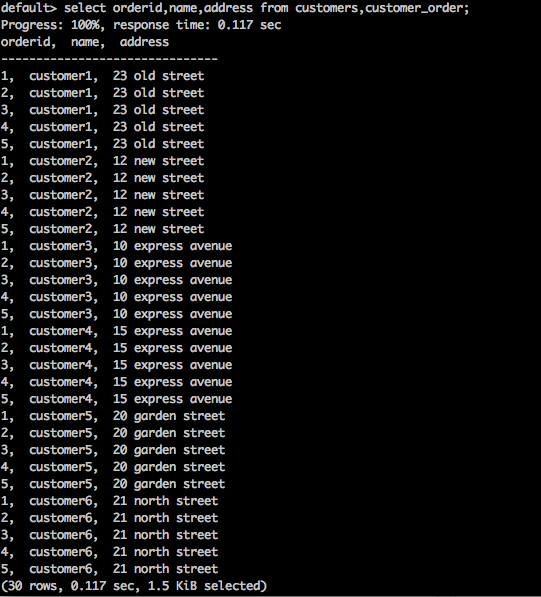
A consulta acima retorna o produto cartesiano da tabela.
União Natural
Uma junção natural não usa nenhum operador de comparação. Não concatena da mesma forma que um produto cartesiano. Podemos realizar uma junção natural apenas se houver pelo menos um atributo comum entre as duas relações.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
A consulta acima irá gerar o seguinte resultado.

Aqui, há um id de coluna comum entre duas tabelas. Usando essa coluna comum, oNatural Join junta-se a ambas as tabelas.
Self Join
O SQL SELF JOIN é usado para juntar uma tabela a si mesma como se a tabela fosse duas tabelas, renomeando temporariamente pelo menos uma tabela na instrução SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
A consulta acima irá gerar o seguinte resultado.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6A consulta associa uma tabela de clientes a si mesma.
Tajo suporta vários formatos de armazenamento. Para registrar a configuração do plugin de armazenamento, você deve adicionar as alterações ao arquivo de configuração “storage-site.json”.
storage-site.json
A estrutura é definida da seguinte forma -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Cada instância de armazenamento é identificada por URI.
Manipulador de armazenamento PostgreSQL
Tajo suporta o gerenciador de armazenamento PostgreSQL. Ele permite que as consultas do usuário acessem objetos do banco de dados no PostgreSQL. É o gerenciador de armazenamento padrão no Tajo, portanto, você pode configurá-lo facilmente.
configuração
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Aqui, “database1” refere-se a postgreSQL banco de dados que é mapeado para o banco de dados “sampledb” em Tajo.
Apache Tajo oferece suporte à integração com HBase. Isso nos permite acessar tabelas HBase no Tajo. HBase é um banco de dados orientado a coluna distribuído construído sobre o sistema de arquivos Hadoop. É uma parte do ecossistema Hadoop que fornece acesso aleatório de leitura / gravação em tempo real aos dados no Hadoop File System. As etapas a seguir são necessárias para configurar a integração do HBase.
Definir Variável de Ambiente
Adicione as seguintes alterações ao arquivo “conf / tajo-env.sh”.
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseDepois de incluir o caminho do HBase, Tajo configurará o arquivo da biblioteca do HBase para o caminho de classe.
Crie uma tabela externa
Crie uma tabela externa usando a seguinte sintaxe -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Para acessar as tabelas do HBase, você deve configurar o local do espaço de tabela.
Aqui,
Table- Definir o nome da tabela de origem hbase. Se você deseja criar uma tabela externa, a tabela deve existir no HBase.
Columns- A chave refere-se à chave de linha do HBase. O número de entradas de colunas deve ser igual ao número de colunas da tabela Tajo.
hbase.zookeeper.quorum - Defina o endereço do quorum do zookeeper.
hbase.zookeeper.property.clientPort - Definir a porta do cliente zookeeper.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Aqui, o campo de caminho de localização define o id da porta do cliente zookeeper. Se você não definir a porta, Tajo fará referência à propriedade do arquivo hbase-site.xml.
Criar tabela no HBase
Você pode iniciar o shell interativo do HBase usando o comando “shell hbase” conforme mostrado na consulta a seguir.
Query
/bin/hbase shellResult
A consulta acima irá gerar o seguinte resultado.
hbase(main):001:0>Etapas para consultar o HBase
Para consultar o HBase, você deve concluir as seguintes etapas -
Step 1 - Canalize os seguintes comandos para o shell do HBase para criar uma tabela “tutorial”.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Agora, emita o seguinte comando no shell hbase para carregar os dados em uma tabela.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Agora, retorne ao shell Tajo e execute o seguinte comando para visualizar os metadados da tabela -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Para buscar os resultados da tabela, use a seguinte consulta -
Query
default> select * from studentsResult
A consulta acima irá buscar o seguinte resultado -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo suporta o HiveCatalogStore para integração com o Apache Hive. Essa integração permite que Tajo acesse tabelas no Apache Hive.
Definir Variável de Ambiente
Adicione as seguintes alterações ao arquivo “conf / tajo-env.sh”.
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveDepois de incluir o caminho do Hive, Tajo configurará o arquivo da biblioteca do Hive como o caminho de classe.
Configuração do Catálogo
Adicione as seguintes alterações ao arquivo “conf / catalog-site.xml”.
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>Assim que o HiveCatalogStore estiver configurado, você pode acessar a tabela do Hive no Tajo.
Swift é um armazenamento de objeto / blob distribuído e consistente. Swift oferece software de armazenamento em nuvem para que você possa armazenar e recuperar muitos dados com uma API simples. Tajo suporta integração Swift.
A seguir estão os pré-requisitos da integração Swift -
- Swift
- Hadoop
Core-site.xml
Adicione as seguintes alterações ao arquivo hadoop “core-site.xml” -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Isso será usado para o Hadoop acessar os objetos Swift. Depois de fazer todas as alterações, vá para o diretório Tajo para definir a variável de ambiente Swift.
conf / tajo-env.h
Abra o arquivo de configuração Tajo e adicione definir a variável de ambiente da seguinte maneira -
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarAgora, Tajo será capaz de consultar os dados usando o Swift.
Criar a tabela
Vamos criar uma tabela externa para acessar objetos Swift no Tajo da seguinte maneira -
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Após a criação da tabela, você pode executar as consultas SQL.
Apache Tajo fornece interface JDBC para conectar e executar consultas. Podemos usar a mesma interface JDBC para conectar Tajo de nosso aplicativo baseado em Java. Vamos agora entender como conectar o Tajo e executar os comandos em nosso aplicativo Java de amostra usando a interface JDBC nesta seção.
Baixe o driver JDBC
Baixe o driver JDBC visitando o seguinte link - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Agora, o arquivo “tajo-jdbc-0.11.3.jar” foi baixado em sua máquina.
Definir caminho da classe
Para usar o driver JDBC em seu programa, defina o caminho da classe da seguinte maneira -
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHConecte-se ao Tajo
Apache Tajo fornece um driver JDBC como um único arquivo jar e está disponível @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
A string de conexão para conectar o Apache Tajo tem o seguinte formato -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseAqui,
host - O nome do host do TajoMaster.
port- O número da porta que o servidor está escutando. O número da porta padrão é 26002.
database- O nome do banco de dados. O nome do banco de dados padrão é o padrão.
Aplicativo Java
Vamos agora entender o aplicativo Java.
Codificação
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}O aplicativo pode ser compilado e executado usando os seguintes comandos.
Compilação
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaExecução
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleResultado
Os comandos acima irão gerar o seguinte resultado -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo oferece suporte a funções definidas pelo usuário / personalizadas (UDFs). As funções personalizadas podem ser criadas em python.
As funções personalizadas são funções simples do Python com decorador “@output_type(<tajo sql datatype>)” como segue -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Os scripts python com UDFs podem ser registrados adicionando a configuração abaixo em “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Assim que os scripts forem registrados, reinicie o cluster e os UDFs estarão disponíveis diretamente na consulta SQL da seguinte forma -
select sum_py(10, 10) as pyfn;Apache Tajo também oferece suporte a funções de agregação definidas pelo usuário, mas não oferece suporte a funções de janela definidas pelo usuário.