Montagem - Guia Rápido
O que é linguagem Assembly?
Cada computador pessoal possui um microprocessador que gerencia as atividades aritméticas, lógicas e de controle do computador.
Cada família de processadores tem seu próprio conjunto de instruções para lidar com várias operações, como obter dados do teclado, exibir informações na tela e realizar vários outros trabalhos. Esse conjunto de instruções é chamado de 'instruções em linguagem de máquina'.
Um processador entende apenas instruções em linguagem de máquina, que são cadeias de 1's e 0's. No entanto, a linguagem de máquina é muito obscura e complexa para ser usada no desenvolvimento de software. Portanto, a linguagem assembly de baixo nível é projetada para uma família específica de processadores que representa várias instruções em código simbólico e de uma forma mais compreensível.
Vantagens da linguagem assembly
Ter uma compreensão da linguagem assembly torna-o ciente de -
- Como os programas fazem interface com o sistema operacional, processador e BIOS;
- Como os dados são representados na memória e em outros dispositivos externos;
- Como o processador acessa e executa a instrução;
- Como as instruções acessam e processam os dados;
- Como um programa acessa dispositivos externos.
Outras vantagens de usar a linguagem assembly são -
Requer menos memória e tempo de execução;
Ele permite trabalhos complexos específicos de hardware de uma maneira mais fácil;
É adequado para trabalhos urgentes;
É mais adequado para escrever rotinas de serviço de interrupção e outros programas residentes na memória.
Recursos básicos do hardware do PC
O hardware interno principal de um PC consiste em processador, memória e registros. Os registros são componentes do processador que armazenam dados e endereços. Para executar um programa, o sistema o copia do dispositivo externo para a memória interna. O processador executa as instruções do programa.
A unidade fundamental de armazenamento do computador é um pouco; pode ser ON (1) ou OFF (0) e um grupo de 8 bits relacionados cria um byte na maioria dos computadores modernos.
Portanto, o bit de paridade é usado para tornar ímpar o número de bits em um byte. Se a paridade for uniforme, o sistema presume que houve um erro de paridade (embora raro), que pode ter sido causado devido a falha de hardware ou distúrbio elétrico.
O processador suporta os seguintes tamanhos de dados -
- Word: um item de dados de 2 bytes
- Palavra dupla: um item de dados de 4 bytes (32 bits)
- Quadword: um item de dados de 8 bytes (64 bits)
- Parágrafo: uma área de 16 bytes (128 bits)
- Quilobyte: 1024 bytes
- Megabyte: 1.048.576 bytes
Sistema de número binário
Todo sistema numérico usa notação posicional, ou seja, cada posição em que um dígito é escrito tem um valor posicional diferente. Cada posição é a potência da base, que é 2 para o sistema numérico binário, e essas potências começam em 0 e aumentam em 1.
A tabela a seguir mostra os valores posicionais para um número binário de 8 bits, onde todos os bits são definidos como ON.
| Valor de bit | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|---|---|---|---|---|---|---|---|---|
| Valor da posição como uma potência de base 2 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
| Número de bits | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
O valor de um número binário é baseado na presença de 1 bits e seu valor posicional. Portanto, o valor de um determinado número binário é -
1 + 2 + 4 + 8 +16 + 32 + 64 + 128 = 255
que é o mesmo que 2 8 - 1.
Sistema numérico hexadecimal
O sistema numérico hexadecimal usa a base 16. Os dígitos neste sistema variam de 0 a 15. Por convenção, as letras de A a F são usadas para representar os dígitos hexadecimais correspondentes aos valores decimais de 10 a 15.
Os números hexadecimais na computação são usados para abreviar representações binárias extensas. Basicamente, o sistema numérico hexadecimal representa um dado binário dividindo cada byte pela metade e expressando o valor de cada meio byte. A tabela a seguir fornece os equivalentes decimais, binários e hexadecimais -
| Número decimal | Representação binária | Representação hexadecimal |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
| 2 | 10 | 2 |
| 3 | 11 | 3 |
| 4 | 100 | 4 |
| 5 | 101 | 5 |
| 6 | 110 | 6 |
| 7 | 111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | UMA |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
Para converter um número binário em seu equivalente hexadecimal, divida-o em grupos de 4 grupos consecutivos cada, começando da direita, e escreva esses grupos sobre os dígitos correspondentes do número hexadecimal.
Example - O número binário 1000 1100 1101 0001 é equivalente a hexadecimal - 8CD1
Para converter um número hexadecimal em binário, basta escrever cada dígito hexadecimal em seu equivalente binário de 4 dígitos.
Example - O número hexadecimal FAD8 é equivalente ao binário - 1111 1010 1101 1000
Aritmética Binária
A tabela a seguir ilustra quatro regras simples para adição binária -
| (Eu) | (ii) | (iii) | (iv) |
|---|---|---|---|
| 1 | |||
| 0 | 1 | 1 | 1 |
| +0 | +0 | +1 | +1 |
| = 0 | = 1 | = 10 | = 11 |
As regras (iii) e (iv) mostram um transporte de 1 bit para a próxima posição à esquerda.
Example
| Decimal | Binário |
|---|---|
| 60 | 00111100 |
| +42 | 00101010 |
| 102 | 01100110 |
Um valor binário negativo é expresso em two's complement notation. De acordo com essa regra, converter um número binário em seu valor negativo é reverter seus valores de bit e adicionar 1 .
Example
| Número 53 | 00110101 |
| Inverta os bits | 11001010 |
| Adicionar 1 | 0000000 1 |
| Número -53 | 11001011 |
Para subtrair um valor de outro, converta o número que está sendo subtraído para o formato de complemento de dois e some os números .
Example
Subtraia 42 de 53
| Número 53 | 00110101 |
| Número 42 | 00101010 |
| Inverta os bits de 42 | 11010101 |
| Adicionar 1 | 0000000 1 |
| Número -42 | 11010110 |
| 53 - 42 = 11 | 00001011 |
O estouro do último 1 bit é perdido.
Endereçando dados na memória
O processo pelo qual o processador controla a execução das instruções é conhecido como o fetch-decode-execute cycle ou o execution cycle. Consiste em três etapas contínuas -
- Buscando a instrução da memória
- Decodificando ou identificando a instrução
- Executando a instrução
O processador pode acessar um ou mais bytes de memória por vez. Vamos considerar um número hexadecimal 0725H. Este número exigirá dois bytes de memória. O byte de ordem superior ou byte mais significativo é 07 e o byte de ordem inferior é 25.
O processador armazena dados em seqüência de byte reverso, ou seja, um byte de ordem inferior é armazenado em um endereço de memória baixa e um byte de ordem alta no endereço de memória alta. Portanto, se o processador traz o valor 0725H do registro para a memória, ele irá transferir 25 primeiro para o endereço de memória inferior e 07 para o próximo endereço de memória.
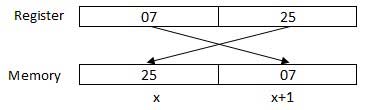
x: endereço de memória
Quando o processador obtém os dados numéricos da memória para registrar, ele reverte os bytes novamente. Existem dois tipos de endereços de memória -
Endereço absoluto - uma referência direta do local específico.
Endereço do segmento (ou deslocamento) - endereço inicial de um segmento de memória com o valor do deslocamento.
Configuração de ambiente local
A linguagem assembly depende do conjunto de instruções e da arquitetura do processador. Neste tutorial, nos concentramos em processadores Intel-32 como o Pentium. Para seguir este tutorial, você precisará de -
- Um IBM PC ou qualquer computador compatível equivalente
- Uma cópia do sistema operacional Linux
- Uma cópia do programa NASM assembler
Existem muitos programas bons em assembler, como -
- Microsoft Assembler (MASM)
- Borland Turbo Assembler (TASM)
- O GNU assembler (GAS)
Usaremos o montador NASM, como ele é -
- Livre. Você pode baixá-lo de várias fontes da web.
- Bem documentado e você obterá muitas informações na rede.
- Pode ser usado em Linux e Windows.
Instalando NASM
Se você selecionar "Ferramentas de Desenvolvimento" durante a instalação do Linux, poderá obter o NASM instalado junto com o sistema operacional Linux e não precisará fazer o download e instalá-lo separadamente. Para verificar se você já tem NASM instalado, execute as seguintes etapas -
Abra um terminal Linux.
Tipo whereis nasm e pressione ENTER.
Se já estiver instalado, uma linha como nasm: / usr / bin / nasm aparecerá. Caso contrário, você verá apenas nasm:, então você precisa instalar o NASM.
Para instalar o NASM, execute as seguintes etapas -
Verifique o site do The netwide assembler (NASM) para obter a versão mais recente.
Baixe o arquivo de origem do Linux
nasm-X.XX.ta.gz, ondeX.XXé o número da versão NASM no arquivo.Descompacte o arquivo em um diretório que crie um subdiretório
nasm-X. XX.cd para
nasm-X.XXe digite./configure. Este script de shell encontrará o melhor compilador C para usar e configurar os Makefiles de acordo.Tipo make para construir os binários nasm e ndisasm.
Tipo make install para instalar o nasm e ndisasm em / usr / local / bin e para instalar as páginas de manual.
Isso deve instalar o NASM em seu sistema. Alternativamente, você pode usar uma distribuição RPM para o Fedora Linux. Esta versão é mais simples de instalar, basta clicar duas vezes no arquivo RPM.
Um programa de montagem pode ser dividido em três seções -
o data seção,
o bss seção, e
o text seção.
A seção de dados
o dataseção é usada para declarar dados ou constantes inicializados. Esses dados não mudam em tempo de execução. Você pode declarar vários valores constantes, nomes de arquivo ou tamanho do buffer, etc., nesta seção.
A sintaxe para declarar a seção de dados é -
section.dataA seção bss
o bssseção é usada para declarar variáveis. A sintaxe para declarar a seção bss é -
section.bssA seção de texto
o textseção é usada para manter o código real. Esta seção deve começar com a declaraçãoglobal _start, que informa ao kernel onde a execução do programa começa.
A sintaxe para declarar a seção de texto é -
section.text
global _start
_start:Comentários
O comentário da linguagem assembly começa com um ponto e vírgula (;). Ele pode conter qualquer caractere imprimível, incluindo espaços em branco. Ele pode aparecer em uma linha sozinho, como -
; This program displays a message on screenou, na mesma linha junto com uma instrução, como -
add eax, ebx ; adds ebx to eaxDeclarações da linguagem assembly
Os programas de linguagem assembly consistem em três tipos de declarações -
- Instruções executáveis ou instruções,
- Diretivas Assembler ou pseudo-ops, e
- Macros.
o executable instructions ou simplesmente instructionsdiga ao processador o que fazer. Cada instrução consiste em umoperation code(Código de operação). Cada instrução executável gera uma instrução em linguagem de máquina.
o assembler directives ou pseudo-opsdiga ao montador sobre os vários aspectos do processo de montagem. Eles não são executáveis e não geram instruções em linguagem de máquina.
Macros são basicamente um mecanismo de substituição de texto.
Sintaxe de declarações da linguagem Assembly
As instruções da linguagem assembly são inseridas uma instrução por linha. Cada declaração segue o seguinte formato -
[label] mnemonic [operands] [;comment]Os campos entre colchetes são opcionais. Uma instrução básica possui duas partes, a primeira é o nome da instrução (ou o mnemônico), que deve ser executada, e a segunda são os operandos ou parâmetros do comando.
A seguir estão alguns exemplos de declarações típicas de linguagem assembly -
INC COUNT ; Increment the memory variable COUNT
MOV TOTAL, 48 ; Transfer the value 48 in the
; memory variable TOTAL
ADD AH, BH ; Add the content of the
; BH register into the AH register
AND MASK1, 128 ; Perform AND operation on the
; variable MASK1 and 128
ADD MARKS, 10 ; Add 10 to the variable MARKS
MOV AL, 10 ; Transfer the value 10 to the AL registerO Programa Hello World em Assembleia
O seguinte código de linguagem assembly exibe a string 'Hello World' na tela -
section .text
global _start ;must be declared for linker (ld)
_start: ;tells linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Hello, world!', 0xa ;string to be printed
len equ $ - msg ;length of the stringQuando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello, world!Compilando e vinculando um programa de montagem em NASM
Certifique-se de ter definido o caminho de nasm e ldbinários em sua variável de ambiente PATH. Agora, execute as seguintes etapas para compilar e vincular o programa acima -
Digite o código acima usando um editor de texto e salve-o como hello.asm.
Certifique-se de que você está no mesmo diretório onde salvou hello.asm.
Para montar o programa, digite nasm -f elf hello.asm
Se houver algum erro, você será avisado sobre isso nesta fase. Caso contrário, um arquivo de objeto do seu programa chamadohello.o Será criado.
Para vincular o arquivo objeto e criar um arquivo executável chamado hello, digite ld -m elf_i386 -s -o hello hello.o
Execute o programa digitando ./hello
Se você fez tudo corretamente, será exibido 'Olá, mundo!' na tela.
Já discutimos as três seções de um programa de montagem. Essas seções também representam vários segmentos de memória.
Curiosamente, se você substituir a palavra-chave da seção por segmento, obterá o mesmo resultado. Experimente o seguinte código -
segment .text ;code segment
global _start ;must be declared for linker
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
segment .data ;data segment
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear stringQuando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello, world!Segmentos de Memória
Um modelo de memória segmentada divide a memória do sistema em grupos de segmentos independentes referenciados por ponteiros localizados nos registradores de segmento. Cada segmento é usado para conter um tipo específico de dados. Um segmento é usado para conter códigos de instrução, outro segmento armazena os elementos de dados e um terceiro segmento mantém a pilha do programa.
À luz da discussão acima, podemos especificar vários segmentos de memória como -
Data segment - É representado por .data seção e o .bss. A seção .data é usada para declarar a região da memória, onde os elementos de dados são armazenados para o programa. Esta seção não pode ser expandida depois que os elementos de dados são declarados e permanece estática em todo o programa.
A seção .bss também é uma seção de memória estática que contém buffers para os dados a serem declarados posteriormente no programa. Esta memória buffer é preenchida com zeros.
Code segment - É representado por .textseção. Isso define uma área na memória que armazena os códigos de instrução. Esta também é uma área fixa.
Stack - Este segmento contém valores de dados passados para funções e procedimentos dentro do programa.
As operações do processador envolvem principalmente o processamento de dados. Esses dados podem ser armazenados na memória e acessados a partir dela. No entanto, ler e armazenar dados na memória retarda o processador, pois envolve processos complicados de enviar a solicitação de dados pelo barramento de controle e para a unidade de armazenamento de memória e obter os dados pelo mesmo canal.
Para acelerar as operações do processador, o processador inclui alguns locais de armazenamento de memória interna, chamados registers.
Os registradores armazenam elementos de dados para processamento sem ter que acessar a memória. Um número limitado de registros é integrado ao chip do processador.
Registros do processador
Existem dez registros de processador de 32 bits e seis de 16 bits na arquitetura IA-32. Os registros são agrupados em três categorias -
- Registros Gerais,
- Registros de controle e
- Registros de segmento.
Os registros gerais são divididos nos seguintes grupos -
- Registros de dados,
- O ponteiro registra e
- Registradores de índice.
Registros de dados
Quatro registradores de dados de 32 bits são usados para operações aritméticas, lógicas e outras. Esses registros de 32 bits podem ser usados de três maneiras -
Como registradores de dados completos de 32 bits: EAX, EBX, ECX, EDX.
As metades inferiores dos registros de 32 bits podem ser usadas como quatro registros de dados de 16 bits: AX, BX, CX e DX.
As metades inferior e superior dos quatro registros de 16 bits mencionados acima podem ser usadas como oito registros de dados de 8 bits: AH, AL, BH, BL, CH, CL, DH e DL.

Alguns desses registros de dados têm uso específico em operações aritméticas.
AX is the primary accumulator; ele é usado na entrada / saída e na maioria das instruções aritméticas. Por exemplo, na operação de multiplicação, um operando é armazenado no registro EAX ou AX ou AL de acordo com o tamanho do operando.
BX is known as the base register, pois poderia ser usado no endereçamento indexado.
CX is known as the count register, como o ECX, os registradores CX armazenam a contagem do loop em operações iterativas.
DX is known as the data register. Ele também é usado em operações de entrada / saída. Ele também é usado com o registro AX junto com DX para operações de multiplicação e divisão envolvendo grandes valores.
Pointer Registers
Os registros de ponteiro são registros EIP, ESP e EBP de 32 bits e as partes direitas de 16 bits correspondentes IP, SP e BP. Existem três categorias de registradores de ponteiro -
Instruction Pointer (IP)- O registro IP de 16 bits armazena o endereço de deslocamento da próxima instrução a ser executada. IP em associação com o registro CS (como CS: IP) fornece o endereço completo da instrução atual no segmento de código.
Stack Pointer (SP)- O registro SP de 16 bits fornece o valor de deslocamento dentro da pilha do programa. SP em associação com o registro SS (SS: SP) refere-se à posição atual dos dados ou endereço na pilha do programa.
Base Pointer (BP)- O registro BP de 16 bits ajuda principalmente a referenciar as variáveis de parâmetro passadas para uma sub-rotina. O endereço no registro SS é combinado com o deslocamento no BP para obter a localização do parâmetro. BP também pode ser combinado com DI e SI como base registradora para endereçamento especial.
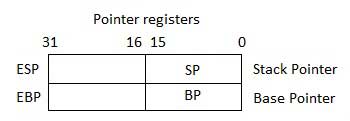
Registros de índice
Os registradores de índice de 32 bits, ESI e EDI, e suas partes mais à direita de 16 bits. SI e DI são usados para endereçamento indexado e às vezes usados em adição e subtração. Existem dois conjuntos de indicadores de índice -
Source Index (SI) - É usado como índice de origem para operações de string.
Destination Index (DI) - É usado como índice de destino para operações de string.

Registros de controle
O registrador de ponteiro de instrução de 32 bits e o registrador de sinalizadores de 32 bits combinados são considerados os registradores de controle.
Muitas instruções envolvem comparações e cálculos matemáticos e mudam o status dos sinalizadores e algumas outras instruções condicionais testam o valor desses sinalizadores de status para levar o fluxo de controle para outro local.
Os bits de sinalização comuns são:
Overflow Flag (OF) - Indica o estouro de um bit de ordem superior (bit mais à esquerda) de dados após uma operação aritmética assinada.
Direction Flag (DF)- Determina a direção esquerda ou direita para mover ou comparar os dados da string. Quando o valor DF é 0, a operação da string segue a direção da esquerda para a direita e quando o valor é definido como 1, a operação da string segue a direção da direita para a esquerda.
Interrupt Flag (IF)- Determina se as interrupções externas como entrada de teclado, etc., devem ser ignoradas ou processadas. Desabilita a interrupção externa quando o valor é 0 e habilita interrupções quando ajustado para 1.
Trap Flag (TF)- Permite configurar o funcionamento do processador em modo de passo único. O programa DEBUG que usamos define o sinalizador de trap, para que pudéssemos avançar na execução de uma instrução por vez.
Sign Flag (SF)- Mostra o sinal do resultado de uma operação aritmética. Este sinalizador é definido de acordo com o sinal de um item de dados após a operação aritmética. O sinal é indicado pela ordem superior do bit mais à esquerda. Um resultado positivo limpa o valor de SF para 0 e um resultado negativo define para 1.
Zero Flag (ZF)- Indica o resultado de uma operação aritmética ou de comparação. Um resultado diferente de zero limpa o sinalizador zero para 0 e um resultado zero define-o como 1.
Auxiliary Carry Flag (AF)- Contém o transporte do bit 3 para o bit 4 após uma operação aritmética; usado para aritmética especializada. O AF é definido quando uma operação aritmética de 1 byte causa um transporte do bit 3 para o bit 4.
Parity Flag (PF)- Indica o número total de bits 1 no resultado obtido em uma operação aritmética. Um número par de bits 1 limpa o sinalizador de paridade para 0 e um número ímpar de bits 1 define o sinalizador de paridade para 1.
Carry Flag (CF)- Contém o transporte de 0 ou 1 de um bit de ordem superior (mais à esquerda) após uma operação aritmética. Ele também armazena o conteúdo do último bit de uma operação de deslocamento ou rotação .
A tabela a seguir indica a posição dos bits de sinalização no registro Sinalizadores de 16 bits:
| Bandeira: | O | D | Eu | T | S | Z | UMA | P | C | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bit não: | 15 | 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
Registros de segmento
Os segmentos são áreas específicas definidas em um programa para conter dados, código e pilha. Existem três segmentos principais -
Code Segment- Contém todas as instruções a serem executadas. Um registro de segmento de código de 16 bits ou registro CS armazena o endereço inicial do segmento de código.
Data Segment- Contém dados, constantes e áreas de trabalho. Um registro de segmento de dados de 16 bits ou registro DS armazena o endereço inicial do segmento de dados.
Stack Segment- Contém dados e endereços de retorno de procedimentos ou sub-rotinas. É implementado como uma estrutura de dados 'pilha'. O registrador Stack Segment ou SS armazena o endereço inicial da pilha.
Além dos registros DS, CS e SS, existem outros registros de segmento extra - ES (segmento extra), FS e GS, que fornecem segmentos adicionais para armazenamento de dados.
Na programação de montagem, um programa precisa acessar os locais de memória. Todos os locais de memória dentro de um segmento são relativos ao endereço inicial do segmento. Um segmento começa em um endereço divisível uniformemente por 16 ou hexadecimal 10. Portanto, o dígito hexadecimal mais à direita em todos esses endereços de memória é 0, que geralmente não é armazenado nos registradores de segmento.
O registrador de segmento armazena os endereços iniciais de um segmento. Para obter a localização exata dos dados ou instrução dentro de um segmento, um valor de deslocamento (ou deslocamento) é necessário. Para fazer referência a qualquer localização da memória em um segmento, o processador combina o endereço do segmento no registro do segmento com o valor de deslocamento da localização.
Exemplo
Veja o programa simples a seguir para entender o uso de registradores na programação de assembly. Este programa exibe 9 estrelas na tela junto com uma mensagem simples -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,9 ;message length
mov ecx,s2 ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'Displaying 9 stars',0xa ;a message
len equ $ - msg ;length of message
s2 times 9 db '*'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Displaying 9 stars
*********As chamadas do sistema são APIs para a interface entre o espaço do usuário e o espaço do kernel. Já usamos as chamadas de sistema. sys_write e sys_exit, para escrever na tela e sair do programa, respectivamente.
Chamadas de sistema Linux
Você pode fazer uso de chamadas de sistema Linux em seus programas de montagem. Você precisa seguir os seguintes passos para usar chamadas de sistema Linux em seu programa -
- Coloque o número de chamada do sistema no registro EAX.
- Armazene os argumentos para a chamada do sistema nos registros EBX, ECX, etc.
- Ligue para a interrupção relevante (80h).
- O resultado geralmente é retornado no registro EAX.
Existem seis registradores que armazenam os argumentos da chamada de sistema usada. São EBX, ECX, EDX, ESI, EDI e EBP. Esses registros recebem os argumentos consecutivos, começando com o registro EBX. Se houver mais de seis argumentos, a localização da memória do primeiro argumento é armazenada no registrador EBX.
O seguinte snippet de código mostra o uso da chamada do sistema sys_exit -
mov eax,1 ; system call number (sys_exit)
int 0x80 ; call kernelO seguinte snippet de código mostra o uso da chamada de sistema sys_write -
mov edx,4 ; message length
mov ecx,msg ; message to write
mov ebx,1 ; file descriptor (stdout)
mov eax,4 ; system call number (sys_write)
int 0x80 ; call kernelTodas as syscalls estão listadas em /usr/include/asm/unistd.h , junto com seus números (o valor a ser colocado em EAX antes de chamar int 80h).
A tabela a seguir mostra algumas das chamadas do sistema usadas neste tutorial -
| % eax | Nome | % ebx | % ecx | % edx | % esx | % edi |
|---|---|---|---|---|---|---|
| 1 | sys_exit | int | - | - | - | - |
| 2 | sys_fork | struct pt_regs | - | - | - | - |
| 3 | sys_read | int não assinado | Caracteres * | size_t | - | - |
| 4 | sys_write | int não assinado | const char * | size_t | - | - |
| 5 | sys_open | const char * | int | int | - | - |
| 6 | sys_close | int não assinado | - | - | - | - |
Exemplo
O exemplo a seguir lê um número do teclado e o exibe na tela -
section .data ;Data segment
userMsg db 'Please enter a number: ' ;Ask the user to enter a number
lenUserMsg equ $-userMsg ;The length of the message
dispMsg db 'You have entered: '
lenDispMsg equ $-dispMsg
section .bss ;Uninitialized data
num resb 5
section .text ;Code Segment
global _start
_start: ;User prompt
mov eax, 4
mov ebx, 1
mov ecx, userMsg
mov edx, lenUserMsg
int 80h
;Read and store the user input
mov eax, 3
mov ebx, 2
mov ecx, num
mov edx, 5 ;5 bytes (numeric, 1 for sign) of that information
int 80h
;Output the message 'The entered number is: '
mov eax, 4
mov ebx, 1
mov ecx, dispMsg
mov edx, lenDispMsg
int 80h
;Output the number entered
mov eax, 4
mov ebx, 1
mov ecx, num
mov edx, 5
int 80h
; Exit code
mov eax, 1
mov ebx, 0
int 80hQuando o código acima é compilado e executado, ele produz o seguinte resultado -
Please enter a number:
1234
You have entered:1234A maioria das instruções em linguagem assembly requer que operandos sejam processados. Um endereço de operando fornece o local onde os dados a serem processados são armazenados. Algumas instruções não exigem um operando, enquanto outras instruções podem exigir um, dois ou três operandos.
Quando uma instrução requer dois operandos, o primeiro operando é geralmente o destino, que contém dados em um registro ou local de memória e o segundo operando é a fonte. A origem contém os dados a serem entregues (endereçamento imediato) ou o endereço (no registro ou na memória) dos dados. Geralmente, os dados de origem permanecem inalterados após a operação.
Os três modos básicos de endereçamento são -
- Registrar endereçamento
- Endereçamento imediato
- Endereçamento de memória
Registrar Endereçamento
Neste modo de endereçamento, um registro contém o operando. Dependendo da instrução, o registro pode ser o primeiro operando, o segundo operando ou ambos.
Por exemplo,
MOV DX, TAX_RATE ; Register in first operand
MOV COUNT, CX ; Register in second operand
MOV EAX, EBX ; Both the operands are in registersComo o processamento de dados entre registradores não envolve memória, ele fornece processamento de dados mais rápido.
Endereçamento Imediato
Um operando imediato possui um valor constante ou uma expressão. Quando uma instrução com dois operandos usa endereçamento imediato, o primeiro operando pode ser um registro ou localização na memória, e o segundo operando é uma constante imediata. O primeiro operando define o comprimento dos dados.
Por exemplo,
BYTE_VALUE DB 150 ; A byte value is defined
WORD_VALUE DW 300 ; A word value is defined
ADD BYTE_VALUE, 65 ; An immediate operand 65 is added
MOV AX, 45H ; Immediate constant 45H is transferred to AXEndereçamento Direto de Memória
Quando operandos são especificados no modo de endereçamento de memória, é necessário acesso direto à memória principal, geralmente ao segmento de dados. Essa forma de abordar resulta em um processamento mais lento dos dados. Para localizar a localização exata dos dados na memória, precisamos do endereço inicial do segmento, que normalmente é encontrado no registro DS e um valor de deslocamento. Este valor de deslocamento também é chamadoeffective address.
No modo de endereçamento direto, o valor de deslocamento é especificado diretamente como parte da instrução, geralmente indicado pelo nome da variável. O montador calcula o valor de deslocamento e mantém uma tabela de símbolos, que armazena os valores de deslocamento de todas as variáveis usadas no programa.
No endereçamento de memória direto, um dos operandos se refere a uma localização de memória e o outro operando faz referência a um registrador.
Por exemplo,
ADD BYTE_VALUE, DL ; Adds the register in the memory location
MOV BX, WORD_VALUE ; Operand from the memory is added to registerEndereçamento de deslocamento direto
Este modo de endereçamento usa os operadores aritméticos para modificar um endereço. Por exemplo, observe as seguintes definições que definem tabelas de dados -
BYTE_TABLE DB 14, 15, 22, 45 ; Tables of bytes
WORD_TABLE DW 134, 345, 564, 123 ; Tables of wordsAs seguintes operações acessam dados das tabelas na memória em registros -
MOV CL, BYTE_TABLE[2] ; Gets the 3rd element of the BYTE_TABLE
MOV CL, BYTE_TABLE + 2 ; Gets the 3rd element of the BYTE_TABLE
MOV CX, WORD_TABLE[3] ; Gets the 4th element of the WORD_TABLE
MOV CX, WORD_TABLE + 3 ; Gets the 4th element of the WORD_TABLEEndereçamento de memória indireta
Este modo de endereçamento utiliza a capacidade do computador de Segmento: Endereçamento de deslocamento . Geralmente, os registradores de base EBX, EBP (ou BX, BP) e os registradores de índice (DI, SI), codificados entre colchetes para referências de memória, são usados para esse propósito.
O endereçamento indireto é geralmente usado para variáveis que contêm vários elementos, como arrays. O endereço inicial do array é armazenado, digamos, no registrador EBX.
O trecho de código a seguir mostra como acessar diferentes elementos da variável.
MY_TABLE TIMES 10 DW 0 ; Allocates 10 words (2 bytes) each initialized to 0
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110
ADD EBX, 2 ; EBX = EBX +2
MOV [EBX], 123 ; MY_TABLE[1] = 123A Instrução MOV
Já usamos a instrução MOV que é usada para mover dados de um espaço de armazenamento para outro. A instrução MOV leva dois operandos.
Sintaxe
A sintaxe da instrução MOV é -
MOV destination, sourceA instrução MOV pode ter uma das seguintes cinco formas -
MOV register, register
MOV register, immediate
MOV memory, immediate
MOV register, memory
MOV memory, registerObserve que -
- Ambos os operandos em operação MOV devem ser do mesmo tamanho
- O valor do operando de origem permanece inalterado
A instrução MOV às vezes causa ambigüidade. Por exemplo, olhe para as declarações -
MOV EBX, [MY_TABLE] ; Effective Address of MY_TABLE in EBX
MOV [EBX], 110 ; MY_TABLE[0] = 110Não está claro se você deseja mover um equivalente de byte ou equivalente de palavra do número 110. Nesses casos, é aconselhável usar um type specifier.
A tabela a seguir mostra alguns dos especificadores de tipo comuns -
| Especificador de tipo | Bytes endereçados |
|---|---|
| BYTE | 1 |
| PALAVRA | 2 |
| DWORD | 4 |
| QWORD | 8 |
| TBYTE | 10 |
Exemplo
O programa a seguir ilustra alguns dos conceitos discutidos acima. Ele armazena um nome 'Zara Ali' na seção de dados da memória e, em seguida, altera seu valor para outro nome 'Nuha Ali' programaticamente e exibe ambos os nomes.
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
;writing the name 'Zara Ali'
mov edx,9 ;message length
mov ecx, name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov [name], dword 'Nuha' ; Changed the name to Nuha Ali
;writing the name 'Nuha Ali'
mov edx,8 ;message length
mov ecx,name ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
name db 'Zara Ali 'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Zara Ali Nuha AliNASM fornece vários define directivespara reservar espaço de armazenamento para variáveis. A diretiva define assembler é usada para alocação de espaço de armazenamento. Pode ser usado para reservar e também para inicializar um ou mais bytes.
Alocando espaço de armazenamento para dados inicializados
A sintaxe para declaração de alocação de armazenamento para dados inicializados é -
[variable-name] define-directive initial-value [,initial-value]...Onde, nome-da-variável é o identificador de cada espaço de armazenamento. O montador associa um valor de deslocamento para cada nome de variável definido no segmento de dados.
Existem cinco formas básicas da diretiva define -
| Diretriz | Objetivo | Espaço de armazenamento |
|---|---|---|
| DB | Definir Byte | aloca 1 byte |
| DW | Definir palavra | aloca 2 bytes |
| DD | Definir palavra dupla | aloca 4 bytes |
| DQ | Definir Quadword | aloca 8 bytes |
| DT | Defina dez bytes | aloca 10 bytes |
A seguir estão alguns exemplos de uso de diretivas de definição -
choice DB 'y'
number DW 12345
neg_number DW -12345
big_number DQ 123456789
real_number1 DD 1.234
real_number2 DQ 123.456Observe que -
Cada byte de caractere é armazenado como seu valor ASCII em hexadecimal.
Cada valor decimal é automaticamente convertido em seu equivalente binário de 16 bits e armazenado como um número hexadecimal.
O processador usa a ordem de bytes little-endian.
Os números negativos são convertidos em sua representação de complemento de 2.
Números de ponto flutuante curtos e longos são representados usando 32 ou 64 bits, respectivamente.
O programa a seguir mostra o uso da diretiva define -
section .text
global _start ;must be declared for linker (gcc)
_start: ;tell linker entry point
mov edx,1 ;message length
mov ecx,choice ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
choice DB 'y'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
yAlocando espaço de armazenamento para dados não inicializados
As diretivas de reserva são usadas para reservar espaço para dados não inicializados. As diretivas de reserva usam um único operando que especifica o número de unidades de espaço a serem reservadas. Cada diretiva define tem uma diretiva de reserva relacionada.
Existem cinco formas básicas da diretiva de reserva -
| Diretriz | Objetivo |
|---|---|
| RESB | Reserve um Byte |
| RESW | Reserve uma palavra |
| RESD | Reserve uma palavra dupla |
| RESQ | Reserve um Quadword |
| DESCANSAR | Reserve dez bytes |
Múltiplas Definições
Você pode ter várias instruções de definição de dados em um programa. Por exemplo -
choice DB 'Y' ;ASCII of y = 79H
number1 DW 12345 ;12345D = 3039H
number2 DD 12345679 ;123456789D = 75BCD15HO montador aloca memória contígua para múltiplas definições de variáveis.
Múltiplas inicializações
A diretiva TIMES permite várias inicializações com o mesmo valor. Por exemplo, uma matriz chamada marcas de tamanho 9 pode ser definida e inicializada como zero usando a seguinte instrução -
marks TIMES 9 DW 0A diretiva TIMES é útil na definição de arrays e tabelas. O programa a seguir exibe 9 asteriscos na tela -
section .text
global _start ;must be declared for linker (ld)
_start: ;tell linker entry point
mov edx,9 ;message length
mov ecx, stars ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
stars times 9 db '*'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
*********Existem várias diretivas fornecidas pelo NASM que definem constantes. Já usamos a diretiva EQU em capítulos anteriores. Vamos discutir particularmente três diretivas -
- EQU
- %assign
- %define
A Diretiva EQU
o EQUdiretiva é usada para definir constantes. A sintaxe da diretiva EQU é a seguinte -
CONSTANT_NAME EQU expressionPor exemplo,
TOTAL_STUDENTS equ 50Você pode então usar este valor constante em seu código, como -
mov ecx, TOTAL_STUDENTS
cmp eax, TOTAL_STUDENTSO operando de uma instrução EQU pode ser uma expressão -
LENGTH equ 20
WIDTH equ 10
AREA equ length * widthO segmento de código acima definiria ÁREA como 200.
Exemplo
O exemplo a seguir ilustra o uso da diretiva EQU -
SYS_EXIT equ 1
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
mov eax,SYS_EXIT ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1
msg2 db 'Welcome to the world of,', 0xA,0xD
len2 equ $ - msg2 msg3 db 'Linux assembly programming! ' len3 equ $- msg3Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!A% designar diretiva
o %assignpode ser usada para definir constantes numéricas como a diretiva EQU. Esta diretiva permite redefinição. Por exemplo, você pode definir o TOTAL constante como -
%assign TOTAL 10Posteriormente no código, você pode redefini-lo como -
%assign TOTAL 20Esta diretiva diferencia maiúsculas de minúsculas.
A% define a diretiva
o %definediretiva permite definir constantes numéricas e de string. Esta diretiva é semelhante a #define em C. Por exemplo, você pode definir o PTR constante como -
%define PTR [EBP+4]O código acima substitui PTR por [EBP + 4].
Essa diretiva também permite a redefinição e faz distinção entre maiúsculas e minúsculas.
A Instrução INC
A instrução INC é usada para incrementar um operando em um. Ele funciona em um único operando que pode estar em um registro ou na memória.
Sintaxe
A instrução INC tem a seguinte sintaxe -
INC destinationO destino do operando pode ser um operando de 8, 16 ou 32 bits.
Exemplo
INC EBX ; Increments 32-bit register
INC DL ; Increments 8-bit register
INC [count] ; Increments the count variableA Instrução DEC
A instrução DEC é usada para diminuir um operando em um. Ele funciona em um único operando que pode estar em um registro ou na memória.
Sintaxe
A instrução DEC tem a seguinte sintaxe -
DEC destinationO destino do operando pode ser um operando de 8, 16 ou 32 bits.
Exemplo
segment .data
count dw 0
value db 15
segment .text
inc [count]
dec [value]
mov ebx, count
inc word [ebx]
mov esi, value
dec byte [esi]As instruções ADD e SUB
As instruções ADD e SUB são usadas para realizar adição / subtração simples de dados binários em tamanho de byte, palavra e palavra dupla, ou seja, para adicionar ou subtrair operandos de 8, 16 ou 32 bits, respectivamente.
Sintaxe
As instruções ADD e SUB têm a seguinte sintaxe -
ADD/SUB destination, sourceA instrução ADD / SUB pode ocorrer entre -
- Cadastre-se para se registrar
- Memória para registrar
- Registre-se na memória
- Registre-se para dados constantes
- Memória para dados constantes
No entanto, como outras instruções, as operações de memória para memória não são possíveis usando as instruções ADD / SUB. Uma operação ADD ou SUB define ou limpa os sinalizadores de overflow e carry.
Exemplo
O exemplo a seguir pedirá dois dígitos ao usuário, armazenará os dígitos no registrador EAX e EBX, respectivamente, adicionará os valores, armazenará o resultado em um local de memória ' res ' e finalmente exibirá o resultado.
SYS_EXIT equ 1
SYS_READ equ 3
SYS_WRITE equ 4
STDIN equ 0
STDOUT equ 1
segment .data
msg1 db "Enter a digit ", 0xA,0xD
len1 equ $- msg1 msg2 db "Please enter a second digit", 0xA,0xD len2 equ $- msg2
msg3 db "The sum is: "
len3 equ $- msg3
segment .bss
num1 resb 2
num2 resb 2
res resb 1
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg1
mov edx, len1
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num1
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg2
mov edx, len2
int 0x80
mov eax, SYS_READ
mov ebx, STDIN
mov ecx, num2
mov edx, 2
int 0x80
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, msg3
mov edx, len3
int 0x80
; moving the first number to eax register and second number to ebx
; and subtracting ascii '0' to convert it into a decimal number
mov eax, [num1]
sub eax, '0'
mov ebx, [num2]
sub ebx, '0'
; add eax and ebx
add eax, ebx
; add '0' to to convert the sum from decimal to ASCII
add eax, '0'
; storing the sum in memory location res
mov [res], eax
; print the sum
mov eax, SYS_WRITE
mov ebx, STDOUT
mov ecx, res
mov edx, 1
int 0x80
exit:
mov eax, SYS_EXIT
xor ebx, ebx
int 0x80Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Enter a digit:
3
Please enter a second digit:
4
The sum is:
7The program with hardcoded variables −
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The sum is:
7A Instrução MUL / IMUL
Existem duas instruções para multiplicar dados binários. A instrução MUL (Multiply) lida com dados não assinados e o IMUL (Integer Multiply) lida com dados assinados. Ambas as instruções afetam o sinalizador Carry e Overflow.
Sintaxe
A sintaxe para as instruções MUL / IMUL é a seguinte -
MUL/IMUL multiplierMultiplicando em ambos os casos estará em um acumulador, dependendo do tamanho do multiplicando e do multiplicador e o produto gerado também é armazenado em dois registradores dependendo do tamanho dos operandos. A seção a seguir explica as instruções do MUL com três casos diferentes -
| Sr. Não. | Cenários |
|---|---|
| 1 | When two bytes are multiplied − O multiplicando está no registrador AL, e o multiplicador é um byte na memória ou em outro registrador. O produto está em AX. Os 8 bits de ordem superior do produto são armazenados em AH e os 8 bits de ordem inferior são armazenados em AL.

|
| 2 | When two one-word values are multiplied − O multiplicando deve estar no registrador AX, e o multiplicador é uma palavra na memória ou outro registrador. Por exemplo, para uma instrução como MUL DX, você deve armazenar o multiplicador em DX e o multiplicando em AX. O produto resultante é uma palavra dupla, que precisará de dois registros. A parte de ordem superior (extrema esquerda) é armazenada em DX e a parte de ordem inferior (extrema direita) é armazenada em AX.

|
| 3 | When two doubleword values are multiplied − Quando dois valores de palavra dupla são multiplicados, o multiplicando deve estar em EAX e o multiplicador é um valor de palavra dupla armazenado na memória ou em outro registro. O produto gerado é armazenado nos registros EDX: EAX, ou seja, os 32 bits de ordem superior são armazenados no registro EDX e os 32 bits de ordem inferior são armazenados no registro EAX.

|
Exemplo
MOV AL, 10
MOV DL, 25
MUL DL
...
MOV DL, 0FFH ; DL= -1
MOV AL, 0BEH ; AL = -66
IMUL DLExemplo
O exemplo a seguir multiplica 3 por 2 e exibe o resultado -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al,'3'
sub al, '0'
mov bl, '2'
sub bl, '0'
mul bl
add al, '0'
mov [res], al
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The result is:
6As instruções DIV / IDIV
A operação de divisão gera dois elementos - um quotient e um remainder. No caso de multiplicação, o estouro não ocorre porque registros de comprimento duplo são usados para manter o produto. No entanto, em caso de divisão, pode ocorrer estouro. O processador gera uma interrupção se ocorrer estouro.
A instrução DIV (Divide) é usada para dados sem sinal e o IDIV (Integer Divide) é usado para dados assinados.
Sintaxe
O formato da instrução DIV / IDIV -
DIV/IDIV divisorO dividendo está em um acumulador. Ambas as instruções podem funcionar com operandos de 8, 16 ou 32 bits. A operação afeta todos os seis sinalizadores de status. A seção a seguir explica três casos de divisão com diferentes tamanhos de operando -
| Sr. Não. | Cenários |
|---|---|
| 1 | When the divisor is 1 byte − O dividendo é assumido como estando no registrador AX (16 bits). Após a divisão, o quociente vai para o registrador AL e o restante vai para o registrador AH.

|
| 2 | When the divisor is 1 word − O dividendo é assumido como tendo 32 bits de comprimento e nos registros DX: AX. Os 16 bits de ordem superior estão em DX e os 16 bits de ordem inferior estão em AX. Após a divisão, o quociente de 16 bits vai para o registrador AX e o restante de 16 bits vai para o registrador DX.
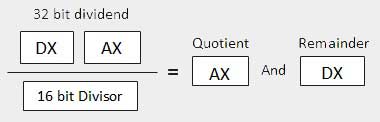
|
| 3 | When the divisor is doubleword − O dividendo é assumido como tendo 64 bits de comprimento e nos registradores EDX: EAX. Os 32 bits de ordem superior estão em EDX e os 32 bits de ordem inferior estão em EAX. Após a divisão, o quociente de 32 bits vai para o registrador EAX e o restante de 32 bits vai para o registrador EDX.
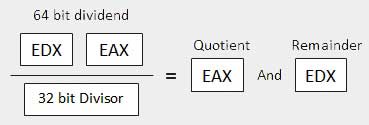
|
Exemplo
O exemplo a seguir divide 8 com 2. O dividend 8 é armazenado no 16-bit AX register e a divisor 2 é armazenado no 8-bit BL register.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax,'8'
sub ax, '0'
mov bl, '2'
sub bl, '0'
div bl
add ax, '0'
mov [res], ax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,res
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The result is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The result is:
4O conjunto de instruções do processador fornece as instruções AND, OR, XOR, TEST e NOT lógica booleana, que testa, configura e apaga os bits de acordo com a necessidade do programa.
O formato dessas instruções -
| Sr. Não. | Instrução | Formato |
|---|---|---|
| 1 | E | AND operand1, operand2 |
| 2 | OU | OU operando1, operando2 |
| 3 | XOR | Operando 1 XOR, operando 2 |
| 4 | TESTE | TEST operando 1, operando 2 |
| 5 | NÃO | NÃO operando1 |
O primeiro operando em todos os casos pode estar no registro ou na memória. O segundo operando pode estar no registro / memória ou em um valor imediato (constante). No entanto, as operações de memória para memória não são possíveis. Essas instruções comparam ou combinam bits dos operandos e definem os sinalizadores CF, OF, PF, SF e ZF.
A instrução AND
A instrução AND é usada para oferecer suporte a expressões lógicas, executando a operação AND bit a bit. A operação AND bit a bit retorna 1, se os bits correspondentes de ambos os operandos são 1, caso contrário, retorna 0. Por exemplo -
Operand1: 0101
Operand2: 0011
----------------------------
After AND -> Operand1: 0001A operação AND pode ser usada para limpar um ou mais bits. Por exemplo, digamos que o registrador BL contenha 0011 1010. Se você precisar limpar os bits de ordem superior para zero, faça o AND com 0FH.
AND BL, 0FH ; This sets BL to 0000 1010Vamos pegar outro exemplo. Se você quiser verificar se um determinado número é ímpar ou par, um teste simples seria verificar o bit menos significativo do número. Se for 1, o número é ímpar, caso contrário, o número é par.
Supondo que o número esteja no registro AL, podemos escrever -
AND AL, 01H ; ANDing with 0000 0001
JZ EVEN_NUMBERO programa a seguir ilustra isso -
Exemplo
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ax, 8h ;getting 8 in the ax
and ax, 1 ;and ax with 1
jz evnn
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, odd_msg ;message to write
mov edx, len2 ;length of message
int 0x80 ;call kernel
jmp outprog
evnn:
mov ah, 09h
mov eax, 4 ;system call number (sys_write)
mov ebx, 1 ;file descriptor (stdout)
mov ecx, even_msg ;message to write
mov edx, len1 ;length of message
int 0x80 ;call kernel
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
even_msg db 'Even Number!' ;message showing even number
len1 equ $ - even_msg odd_msg db 'Odd Number!' ;message showing odd number len2 equ $ - odd_msgQuando o código acima é compilado e executado, ele produz o seguinte resultado -
Even Number!Altere o valor no registro ax com um dígito ímpar, como -
mov ax, 9h ; getting 9 in the axO programa exibiria:
Odd Number!Da mesma forma, para limpar todo o registro, você pode fazer o AND com 00H.
A instrução OR
A instrução OR é usada para dar suporte à expressão lógica executando a operação OR bit a bit. O operador OR bit a bit retorna 1, se os bits correspondentes de um ou de ambos os operandos forem um. Ele retorna 0, se ambos os bits forem zero.
Por exemplo,
Operand1: 0101
Operand2: 0011
----------------------------
After OR -> Operand1: 0111A operação OR pode ser usada para definir um ou mais bits. Por exemplo, vamos supor que o registro AL contém 0011 1010, você precisa definir os quatro bits de ordem inferior, você pode fazer OR com um valor 0000 1111, ou seja, FH.
OR BL, 0FH ; This sets BL to 0011 1111Exemplo
O exemplo a seguir demonstra a instrução OR. Vamos armazenar os valores 5 e 3 nos registradores AL e BL, respectivamente, então a instrução,
OR AL, BLdeve armazenar 7 no registro AL -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov al, 5 ;getting 5 in the al
mov bl, 3 ;getting 3 in the bl
or al, bl ;or al and bl registers, result should be 7
add al, byte '0' ;converting decimal to ascii
mov [result], al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
result resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
7A Instrução XOR
A instrução XOR implementa a operação XOR bit a bit. A operação XOR define o bit resultante para 1, se e somente se os bits dos operandos forem diferentes. Se os bits dos operandos forem iguais (ambos 0 ou 1), o bit resultante é zerado para 0.
Por exemplo,
Operand1: 0101
Operand2: 0011
----------------------------
After XOR -> Operand1: 0110XORing um operando com ele mesmo muda o operando para 0. Isso é usado para limpar um registro.
XOR EAX, EAXA Instrução TEST
A instrução TEST funciona da mesma forma que a operação AND, mas ao contrário da instrução AND, ela não altera o primeiro operando. Portanto, se precisarmos verificar se um número em um registro é par ou ímpar, também podemos fazer isso usando a instrução TEST sem alterar o número original.
TEST AL, 01H
JZ EVEN_NUMBERA instrução NOT
A instrução NOT implementa a operação NOT bit a bit. A operação NOT inverte os bits em um operando. O operando pode estar em um registro ou na memória.
Por exemplo,
Operand1: 0101 0011
After NOT -> Operand1: 1010 1100A execução condicional em linguagem assembly é realizada por várias instruções de loop e ramificação. Essas instruções podem alterar o fluxo de controle em um programa. A execução condicional é observada em dois cenários -
| Sr. Não. | Instruções Condicionais |
|---|---|
| 1 | Unconditional jump Isso é executado pela instrução JMP. A execução condicional frequentemente envolve uma transferência de controle para o endereço de uma instrução que não segue a instrução atualmente em execução. A transferência de controle pode ser direta, para executar um novo conjunto de instruções, ou para trás, para reexecutar as mesmas etapas. |
| 2 | Conditional jump Isso é executado por um conjunto de instruções de salto j <condição> dependendo da condição. As instruções condicionais transferem o controle interrompendo o fluxo sequencial e o fazem alterando o valor de deslocamento no IP. |
Vamos discutir a instrução CMP antes de discutir as instruções condicionais.
Instrução CMP
A instrução CMP compara dois operandos. Geralmente é usado em execução condicional. Essa instrução basicamente subtrai um operando do outro para comparar se os operandos são iguais ou não. Não perturba os operandos de destino ou origem. É usado junto com a instrução de salto condicional para a tomada de decisão.
Sintaxe
CMP destination, sourceCMP compara dois campos de dados numéricos. O operando de destino pode estar no registro ou na memória. O operando de origem pode ser um dado constante (imediato), registro ou memória.
Exemplo
CMP DX, 00 ; Compare the DX value with zero
JE L7 ; If yes, then jump to label L7
.
.
L7: ...CMP é freqüentemente usado para comparar se um valor de contador atingiu o número de vezes que um loop precisa ser executado. Considere a seguinte condição típica -
INC EDX
CMP EDX, 10 ; Compares whether the counter has reached 10
JLE LP1 ; If it is less than or equal to 10, then jump to LP1Salto Incondicional
Conforme mencionado anteriormente, isso é executado pela instrução JMP. A execução condicional frequentemente envolve uma transferência de controle para o endereço de uma instrução que não segue a instrução atualmente em execução. A transferência de controle pode ser direta, para executar um novo conjunto de instruções, ou para trás, para reexecutar as mesmas etapas.
Sintaxe
A instrução JMP fornece um nome de rótulo onde o fluxo de controle é transferido imediatamente. A sintaxe da instrução JMP é -
JMP labelExemplo
O seguinte trecho de código ilustra a instrução JMP -
MOV AX, 00 ; Initializing AX to 0
MOV BX, 00 ; Initializing BX to 0
MOV CX, 01 ; Initializing CX to 1
L20:
ADD AX, 01 ; Increment AX
ADD BX, AX ; Add AX to BX
SHL CX, 1 ; shift left CX, this in turn doubles the CX value
JMP L20 ; repeats the statementsSalto Condicional
Se alguma condição especificada for satisfeita no salto condicional, o fluxo de controle é transferido para uma instrução de destino. Existem várias instruções de salto condicional, dependendo da condição e dos dados.
A seguir estão as instruções de salto condicional usadas em dados assinados usados para operações aritméticas -
| Instrução | Descrição | Bandeiras testadas |
|---|---|---|
| JE / JZ | Jump Equal ou Jump Zero | ZF |
| JNE / JNZ | Jump Not Equal ou Jump Not Zero | ZF |
| JG / JNLE | Jump Greater or Jump Not Less / Equal | OF, SF, ZF |
| JGE / JNL | Salto maior / igual ou não menor | OF, SF |
| JL / JNGE | Salte menos ou não salte maior / igual | OF, SF |
| JLE / JNG | Salto menos / igual ou não maior | OF, SF, ZF |
A seguir estão as instruções de salto condicional usadas em dados não assinados usados para operações lógicas -
| Instrução | Descrição | Bandeiras testadas |
|---|---|---|
| JE / JZ | Jump Equal ou Jump Zero | ZF |
| JNE / JNZ | Jump Not Equal ou Jump Not Zero | ZF |
| JA / JNBE | Saltar acima ou não abaixo / igual | CF, ZF |
| JAE / JNB | Saltar acima / igual ou não abaixo | CF |
| JB / JNAE | Saltar abaixo ou não acima / igual | CF |
| JBE / JNA | Saltar abaixo / igual ou não acima | AF, CF |
As seguintes instruções de salto condicional têm usos especiais e verificam o valor dos sinalizadores -
| Instrução | Descrição | Bandeiras testadas |
|---|---|---|
| JXCZ | Pule se CX for Zero | Nenhum |
| JC | Jump If Carry | CF |
| JNC | Pule se não houver transporte | CF |
| JO | Saltar se estouro | DO |
| JNO | Saltar se não houver estouro | DO |
| JP / JPE | Jump Parity ou Jump Parity Even | PF |
| JNP / JPO | Jump No Parity ou Jump Parity Odd | PF |
| JS | Sinal de salto (valor negativo) | SF |
| JNS | Salto sem sinal (valor positivo) | SF |
A sintaxe para o conjunto de instruções J <condition> -
Exemplo,
CMP AL, BL
JE EQUAL
CMP AL, BH
JE EQUAL
CMP AL, CL
JE EQUAL
NON_EQUAL: ...
EQUAL: ...Exemplo
O programa a seguir exibe a maior das três variáveis. As variáveis são variáveis de dois dígitos. As três variáveis num1, num2 e num3 têm valores 47, 22 e 31, respectivamente -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx, [num1]
cmp ecx, [num2]
jg check_third_num
mov ecx, [num2]
check_third_num:
cmp ecx, [num3]
jg _exit
mov ecx, [num3]
_exit:
mov [largest], ecx
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,largest
mov edx, 2
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1
int 80h
section .data
msg db "The largest digit is: ", 0xA,0xD
len equ $- msg
num1 dd '47'
num2 dd '22'
num3 dd '31'
segment .bss
largest resb 2Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The largest digit is:
47A instrução JMP pode ser usada para implementar loops. Por exemplo, o seguinte trecho de código pode ser usado para executar o corpo do loop 10 vezes.
MOV CL, 10
L1:
<LOOP-BODY>
DEC CL
JNZ L1O conjunto de instruções do processador, no entanto, inclui um grupo de instruções de loop para implementar a iteração. A instrução LOOP básica tem a seguinte sintaxe -
LOOP labelOnde, rótulo é o rótulo de destino que identifica a instrução de destino como nas instruções de salto. A instrução LOOP assume que oECX register contains the loop count. Quando a instrução de loop é executada, o registro ECX é decrementado e o controle salta para o rótulo de destino, até o valor do registro ECX, ou seja, o contador atinge o valor zero.
O snippet de código acima pode ser escrito como -
mov ECX,10
l1:
<loop body>
loop l1Exemplo
O programa a seguir imprime o número de 1 a 9 na tela -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,10
mov eax, '1'
l1:
mov [num], eax
mov eax, 4
mov ebx, 1
push ecx
mov ecx, num
mov edx, 1
int 0x80
mov eax, [num]
sub eax, '0'
inc eax
add eax, '0'
pop ecx
loop l1
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .bss
num resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
123456789:Os dados numéricos são geralmente representados no sistema binário. As instruções aritméticas operam em dados binários. Quando os números são exibidos na tela ou inseridos no teclado, eles estão no formato ASCII.
Até agora, convertemos esses dados de entrada no formato ASCII para binário para cálculos aritméticos e convertemos o resultado de volta para binário. O código a seguir mostra isso -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax,'3'
sub eax, '0'
mov ebx, '4'
sub ebx, '0'
add eax, ebx
add eax, '0'
mov [sum], eax
mov ecx,msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx,sum
mov edx, 1
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db "The sum is:", 0xA,0xD
len equ $ - msg
segment .bss
sum resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The sum is:
7Essas conversões, no entanto, têm uma sobrecarga, e a programação em linguagem assembly permite o processamento de números de maneira mais eficiente, na forma binária. Os números decimais podem ser representados em duas formas -
- Formulário ASCII
- BCD ou forma decimal codificada em binário
Representação ASCII
Na representação ASCII, os números decimais são armazenados como string de caracteres ASCII. Por exemplo, o valor decimal 1234 é armazenado como -
31 32 33 34HOnde, 31H é o valor ASCII para 1, 32H é o valor ASCII para 2 e assim por diante. Existem quatro instruções para processar números na representação ASCII -
AAA - Ajuste ASCII após a adição
AAS - Ajuste ASCII após a subtração
AAM - Ajuste ASCII após a multiplicação
AAD - Ajuste ASCII antes da divisão
Essas instruções não levam nenhum operando e assumem que o operando necessário está no registro AL.
O exemplo a seguir usa a instrução AAS para demonstrar o conceito -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
sub ah, ah
mov al, '9'
sub al, '3'
aas
or al, 30h
mov [res], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,res ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Result is:',0xa
len equ $ - msg
section .bss
res resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The Result is:
6Representação BCD
Existem dois tipos de representação BCD -
- Representação BCD descompactada
- Representação BCD embalada
Na representação BCD não compactada, cada byte armazena o equivalente binário de um dígito decimal. Por exemplo, o número 1234 é armazenado como -
01 02 03 04HExistem duas instruções para processar esses números -
AAM - Ajuste ASCII após a multiplicação
AAD - Ajuste ASCII antes da divisão
As quatro instruções de ajuste ASCII, AAA, AAS, AAM e AAD, também podem ser usadas com representação BCD desempacotada. Na representação BCD compactada, cada dígito é armazenado usando quatro bits. Dois dígitos decimais são compactados em um byte. Por exemplo, o número 1234 é armazenado como -
12 34HExistem duas instruções para processar esses números -
DAA - Ajuste decimal após adição
DAS - Ajuste decimal após a subtração
Não há suporte para multiplicação e divisão na representação BCD compactada.
Exemplo
O programa a seguir adiciona dois números decimais de 5 dígitos e exibe a soma. Ele usa os conceitos acima -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov esi, 4 ;pointing to the rightmost digit
mov ecx, 5 ;num of digits
clc
add_loop:
mov al, [num1 + esi]
adc al, [num2 + esi]
aaa
pushf
or al, 30h
popf
mov [sum + esi], al
dec esi
loop add_loop
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,5 ;message length
mov ecx,sum ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg db 'The Sum is:',0xa
len equ $ - msg
num1 db '12345'
num2 db '23456'
sum db ' 'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The Sum is:
35801Já usamos strings de comprimento variável em nossos exemplos anteriores. As strings de comprimento variável podem ter quantos caracteres forem necessários. Geralmente, especificamos o comprimento da string por uma das duas maneiras -
- Armazenar explicitamente o comprimento da corda
- Usando um personagem sentinela
Podemos armazenar o comprimento da string explicitamente usando o símbolo do contador $ location que representa o valor atual do contador local. No exemplo a seguir -
msg db 'Hello, world!',0xa ;our dear string
len equ $ - msg ;length of our dear string$ aponta para o byte após o último caractere da variável de string msg . Portanto,$-msgdá o comprimento da corda. Nós também podemos escrever
msg db 'Hello, world!',0xa ;our dear string
len equ 13 ;length of our dear stringComo alternativa, você pode armazenar strings com um caractere de sentinela final para delimitar uma string em vez de armazenar o comprimento da string explicitamente. O caractere sentinela deve ser um caractere especial que não aparece em uma string.
Por exemplo -
message DB 'I am loving it!', 0Instruções de string
Cada instrução de string pode exigir um operando de origem, um operando de destino ou ambos. Para segmentos de 32 bits, as instruções de string usam registradores ESI e EDI para apontar para os operandos de origem e destino, respectivamente.
Para segmentos de 16 bits, entretanto, os registros SI e DI são usados para apontar para a origem e o destino, respectivamente.
Existem cinco instruções básicas para o processamento de strings. Eles são -
MOVS - Esta instrução move 1 byte, palavra ou palavra dupla de dados do local da memória para outro.
LODS- Esta instrução é carregada da memória. Se o operando for de um byte, ele é carregado no registro AL, se o operando for uma palavra, ele é carregado no registro AX e uma palavra dupla é carregada no registro EAX.
STOS - Esta instrução armazena dados do registrador (AL, AX ou EAX) na memória.
CMPS- Esta instrução compara dois itens de dados na memória. Os dados podem ser de tamanho de byte, palavra ou palavra dupla.
SCAS - Esta instrução compara o conteúdo de um registro (AL, AX ou EAX) com o conteúdo de um item na memória.
Cada uma das instruções acima tem uma versão de byte, palavra e palavra dupla, e as instruções de string podem ser repetidas usando um prefixo de repetição.
Essas instruções usam o par de registradores ES: DI e DS: SI, onde os registradores DI e SI contêm endereços de deslocamento válidos que se referem aos bytes armazenados na memória. SI está normalmente associado a DS (segmento de dados) e DI está sempre associado a ES (segmento extra).
Os registradores DS: SI (ou ESI) e ES: DI (ou EDI) apontam para os operandos origem e destino, respectivamente. Presume-se que o operando de origem esteja em DS: SI (ou ESI) e o operando de destino em ES: DI (ou EDI) na memória.
Para endereços de 16 bits, os registros SI e DI são usados, e para endereços de 32 bits, os registros ESI e EDI são usados.
A tabela a seguir fornece várias versões de instruções de string e o espaço assumido dos operandos.
| Instrução Básica | Operandos em | Operação de Byte | Operação de Palavra | Operação de palavra dupla |
|---|---|---|---|---|
| MOVS | ES: DI, DS: SI | MOVSB | MOVSW | MOVSD |
| LODS | AX, DS: SI | LODSB | LODSW | LODSD |
| STOS | ES: DI, AX | STOSB | STOSW | STOSD |
| CMPS | DS: SI, ES: DI | CMPSB | CMPSW | CMPSD |
| SCAS | ES: DI, AX | SCASB | SCASW | SCASD |
Prefixos de repetição
O prefixo REP, quando definido antes de uma instrução de string, por exemplo - REP MOVSB, causa a repetição da instrução com base em um contador colocado no registrador CX. REP executa a instrução, diminui CX em 1 e verifica se CX é zero. Ele repete o processamento da instrução até que CX seja zero.
A Bandeira de Direção (DF) determina a direção da operação.
- Use CLD (Clear Direction Flag, DF = 0) para fazer a operação da esquerda para a direita.
- Use STD (Definir Bandeira de Direção, DF = 1) para fazer a operação da direita para a esquerda.
O prefixo REP também tem as seguintes variações:
REP: É a repetição incondicional. Ele repete a operação até que CX seja zero.
REPE ou REPZ: É uma repetição condicional. Ele repete a operação enquanto o sinalizador zero indica igual / zero. Ele para quando ZF indica diferente de / zero ou quando CX é zero.
REPNE ou REPNZ: Também é uma repetição condicional. Ele repete a operação enquanto o sinalizador zero indica diferente de / zero. Ele para quando ZF indica igual / zero ou quando CX é decrementado para zero.
Já discutimos que as diretivas de definição de dados para o montador são usadas para alocar armazenamento para variáveis. A variável também pode ser inicializada com algum valor específico. O valor inicializado pode ser especificado na forma hexadecimal, decimal ou binária.
Por exemplo, podemos definir uma variável de palavra 'meses' de uma das seguintes maneiras -
MONTHS DW 12
MONTHS DW 0CH
MONTHS DW 0110BAs diretivas de definição de dados também podem ser usadas para definir uma matriz unidimensional. Vamos definir uma matriz unidimensional de números.
NUMBERS DW 34, 45, 56, 67, 75, 89A definição acima declara uma matriz de seis palavras, cada uma inicializada com os números 34, 45, 56, 67, 75, 89. Isso aloca 2x6 = 12 bytes de espaço de memória consecutivo. O endereço simbólico do primeiro número será NÚMEROS e o do segundo número será NÚMEROS + 2 e assim por diante.
Tomemos outro exemplo. Você pode definir um array denominado inventário de tamanho 8 e inicializar todos os valores com zero, como -
INVENTORY DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0
DW 0Que pode ser abreviado como -
INVENTORY DW 0, 0 , 0 , 0 , 0 , 0 , 0 , 0A diretiva TIMES também pode ser usada para várias inicializações com o mesmo valor. Usando TIMES, a matriz INVENTORY pode ser definida como:
INVENTORY TIMES 8 DW 0Exemplo
O exemplo a seguir demonstra os conceitos acima definindo uma matriz x de 3 elementos, que armazena três valores: 2, 3 e 4. Ele adiciona os valores na matriz e exibe a soma 9 -
section .text
global _start ;must be declared for linker (ld)
_start:
mov eax,3 ;number bytes to be summed
mov ebx,0 ;EBX will store the sum
mov ecx, x ;ECX will point to the current element to be summed
top: add ebx, [ecx]
add ecx,1 ;move pointer to next element
dec eax ;decrement counter
jnz top ;if counter not 0, then loop again
done:
add ebx, '0'
mov [sum], ebx ;done, store result in "sum"
display:
mov edx,1 ;message length
mov ecx, sum ;message to write
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax, 1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
global x
x:
db 2
db 4
db 3
sum:
db 0Quando o código acima é compilado e executado, ele produz o seguinte resultado -
9Os procedimentos ou sub-rotinas são muito importantes na linguagem assembly, pois os programas em linguagem assembly tendem a ser grandes. Os procedimentos são identificados por um nome. Seguindo esse nome, é descrito o corpo do procedimento que realiza um trabalho bem definido. O fim do procedimento é indicado por uma instrução de retorno.
Sintaxe
A seguir está a sintaxe para definir um procedimento -
proc_name:
procedure body
...
retO procedimento é chamado de outra função usando a instrução CALL. A instrução CALL deve ter o nome do procedimento chamado como um argumento conforme mostrado abaixo -
CALL proc_nameO procedimento chamado retorna o controle para o procedimento de chamada usando a instrução RET.
Exemplo
Vamos escrever um procedimento muito simples denominado soma que adiciona as variáveis armazenadas no registro ECX e EDX e retorna a soma no registro EAX -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov ecx,'4'
sub ecx, '0'
mov edx, '5'
sub edx, '0'
call sum ;call sum procedure
mov [res], eax
mov ecx, msg
mov edx, len
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov ecx, res
mov edx, 1
mov ebx, 1 ;file descriptor (stdout)
mov eax, 4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
sum:
mov eax, ecx
add eax, edx
add eax, '0'
ret
section .data
msg db "The sum is:", 0xA,0xD
len equ $- msg
segment .bss
res resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
The sum is:
9Estrutura de dados de pilhas
Uma pilha é uma estrutura de dados semelhante a um array na memória na qual os dados podem ser armazenados e removidos de um local denominado 'topo' da pilha. Os dados que precisam ser armazenados são 'colocados' na pilha e os dados a serem recuperados são 'retirados' da pilha. Stack é uma estrutura de dados LIFO, ou seja, os dados armazenados primeiro são recuperados por último.
A linguagem assembly fornece duas instruções para operações de pilha: PUSH e POP. Essas instruções têm sintaxes como -
PUSH operand
POP address/registerO espaço de memória reservado no segmento da pilha é usado para implementar a pilha. Os registros SS e ESP (ou SP) são usados para implementar a pilha. O topo da pilha, que aponta para o último item de dados inserido na pilha, é apontado pelo registro SS: ESP, onde o registro SS aponta para o início do segmento da pilha e o SP (ou ESP) fornece o deslocamento para o segmento da pilha.
A implementação da pilha tem as seguintes características -
Somente words ou doublewords pode ser salvo na pilha, não em um byte.
A pilha cresce na direção inversa, ou seja, em direção ao endereço de memória inferior
O topo da pilha aponta para o último item inserido na pilha; ele aponta para o byte inferior da última palavra inserida.
Conforme discutimos sobre como armazenar os valores dos registradores na pilha antes de usá-los para algum uso; isso pode ser feito da seguinte maneira -
; Save the AX and BX registers in the stack
PUSH AX
PUSH BX
; Use the registers for other purpose
MOV AX, VALUE1
MOV BX, VALUE2
...
MOV VALUE1, AX
MOV VALUE2, BX
; Restore the original values
POP BX
POP AXExemplo
O programa a seguir exibe todo o conjunto de caracteres ASCII. O programa principal chama um procedimento denominado display , que exibe o conjunto de caracteres ASCII.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
call display
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
display:
mov ecx, 256
next:
push ecx
mov eax, 4
mov ebx, 1
mov ecx, achar
mov edx, 1
int 80h
pop ecx
mov dx, [achar]
cmp byte [achar], 0dh
inc byte [achar]
loop next
ret
section .data
achar db '0'Quando o código acima é compilado e executado, ele produz o seguinte resultado -
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}
...
...Um procedimento recursivo é aquele que chama a si mesmo. Existem dois tipos de recursão: direta e indireta. Na recursão direta, o procedimento chama a si mesmo e na recursão indireta, o primeiro procedimento chama um segundo procedimento, que por sua vez chama o primeiro procedimento.
A recursão pode ser observada em vários algoritmos matemáticos. Por exemplo, considere o caso de calcular o fatorial de um número. O fatorial de um número é dado pela equação -
Fact (n) = n * fact (n-1) for n > 0Por exemplo: fatorial de 5 é 1 x 2 x 3 x 4 x 5 = 5 x fatorial de 4 e este pode ser um bom exemplo de como mostrar um procedimento recursivo. Todo algoritmo recursivo deve ter uma condição de término, ou seja, a chamada recursiva do programa deve ser interrompida quando uma condição for satisfeita. No caso do algoritmo fatorial, a condição final é alcançada quando n é 0.
O programa a seguir mostra como o fatorial n é implementado em linguagem assembly. Para manter o programa simples, calcularemos o fatorial 3.
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov bx, 3 ;for calculating factorial 3
call proc_fact
add ax, 30h
mov [fact], ax
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov edx,1 ;message length
mov ecx,fact ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
proc_fact:
cmp bl, 1
jg do_calculation
mov ax, 1
ret
do_calculation:
dec bl
call proc_fact
inc bl
mul bl ;ax = al * bl
ret
section .data
msg db 'Factorial 3 is:',0xa
len equ $ - msg
section .bss
fact resb 1Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Factorial 3 is:
6Escrever uma macro é outra maneira de garantir a programação modular em linguagem assembly.
Uma macro é uma sequência de instruções, atribuída por um nome e pode ser usada em qualquer parte do programa.
No NASM, as macros são definidas com %macro e %endmacro diretivas.
A macro começa com a diretiva% macro e termina com a diretiva% endmacro.
A sintaxe para definição de macro -
%macro macro_name number_of_params
<macro body>
%endmacroOnde, number_of_params especifica os parâmetros numéricos, macro_name especifica o nome da macro.
A macro é chamada usando o nome da macro junto com os parâmetros necessários. Quando você precisa usar alguma sequência de instruções muitas vezes em um programa, pode colocar essas instruções em uma macro e usá-la em vez de escrever as instruções o tempo todo.
Por exemplo, uma necessidade muito comum de programas é escrever uma sequência de caracteres na tela. Para exibir uma sequência de caracteres, você precisa da seguinte sequência de instruções -
mov edx,len ;message length
mov ecx,msg ;message to write
mov ebx,1 ;file descriptor (stdout)
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernelNo exemplo acima de exibição de uma string de caracteres, os registros EAX, EBX, ECX e EDX foram usados pela chamada de função INT 80H. Portanto, cada vez que você precisa exibir na tela, você precisa salvar esses registros na pilha, invocar INT 80H e, em seguida, restaurar o valor original dos registros da pilha. Portanto, pode ser útil escrever duas macros para salvar e restaurar dados.
Observamos que, algumas instruções como IMUL, IDIV, INT, etc., precisam que algumas das informações sejam armazenadas em alguns registros particulares e até mesmo retornem valores em alguns registros específicos. Se o programa já estava usando esses registros para manter dados importantes, os dados existentes desses registros devem ser salvos na pilha e restaurados após a execução da instrução.
Exemplo
O exemplo a seguir mostra como definir e usar macros -
; A macro with two parameters
; Implements the write system call
%macro write_string 2
mov eax, 4
mov ebx, 1
mov ecx, %1
mov edx, %2
int 80h
%endmacro
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
write_string msg1, len1
write_string msg2, len2
write_string msg3, len3
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
msg1 db 'Hello, programmers!',0xA,0xD
len1 equ $ - msg1 msg2 db 'Welcome to the world of,', 0xA,0xD len2 equ $- msg2
msg3 db 'Linux assembly programming! '
len3 equ $- msg3Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Hello, programmers!
Welcome to the world of,
Linux assembly programming!O sistema considera qualquer entrada ou saída de dados como fluxo de bytes. Existem três fluxos de arquivo padrão -
- Entrada padrão (stdin),
- Saída padrão (stdout) e
- Erro padrão (stderr).
Descritor de arquivo
UMA file descriptoré um inteiro de 16 bits atribuído a um arquivo como um id de arquivo. Quando um novo arquivo é criado ou um arquivo existente é aberto, o descritor de arquivo é usado para acessar o arquivo.
Descritor de arquivo dos fluxos de arquivo padrão - stdin, stdout e stderr são 0, 1 e 2, respectivamente.
Ponteiro de Arquivo
UMA file pointerespecifica o local para uma operação de leitura / gravação subsequente no arquivo em termos de bytes. Cada arquivo é considerado uma sequência de bytes. Cada arquivo aberto está associado a um ponteiro de arquivo que especifica um deslocamento em bytes, em relação ao início do arquivo. Quando um arquivo é aberto, o ponteiro do arquivo é definido como zero.
Arquivo de tratamento de chamadas do sistema
A tabela a seguir descreve resumidamente as chamadas de sistema relacionadas ao tratamento de arquivos -
| % eax | Nome | % ebx | % ecx | % edx |
|---|---|---|---|---|
| 2 | sys_fork | struct pt_regs | - | - |
| 3 | sys_read | int não assinado | Caracteres * | size_t |
| 4 | sys_write | int não assinado | const char * | size_t |
| 5 | sys_open | const char * | int | int |
| 6 | sys_close | int não assinado | - | - |
| 8 | sys_creat | const char * | int | - |
| 19 | sys_lseek | int não assinado | off_t | int não assinado |
As etapas necessárias para usar as chamadas do sistema são as mesmas, conforme discutimos anteriormente -
- Coloque o número de chamada do sistema no registro EAX.
- Armazene os argumentos para a chamada do sistema nos registros EBX, ECX, etc.
- Ligue para a interrupção relevante (80h).
- O resultado geralmente é retornado no registro EAX.
Criando e abrindo um arquivo
Para criar e abrir um arquivo, execute as seguintes tarefas -
- Coloque a chamada de sistema sys_creat () número 8, no registro EAX.
- Coloque o nome do arquivo no registro EBX.
- Coloque as permissões do arquivo no registro ECX.
A chamada do sistema retorna o descritor do arquivo criado no registro EAX, em caso de erro, o código do erro está no registro EAX.
Abrindo um arquivo existente
Para abrir um arquivo existente, execute as seguintes tarefas -
- Coloque a chamada de sistema sys_open () número 5, no registro EAX.
- Coloque o nome do arquivo no registro EBX.
- Coloque o modo de acesso ao arquivo no registro ECX.
- Coloque as permissões do arquivo no registro EDX.
A chamada do sistema retorna o descritor do arquivo criado no registro EAX, em caso de erro, o código do erro está no registro EAX.
Entre os modos de acesso a arquivos, os mais comumente usados são: somente leitura (0), somente gravação (1) e leitura / gravação (2).
Lendo de um arquivo
Para ler um arquivo, execute as seguintes tarefas -
Coloque a chamada de sistema sys_read () número 3, no registro EAX.
Coloque o descritor de arquivo no registro EBX.
Coloque o ponteiro para o buffer de entrada no registro ECX.
Coloque o tamanho do buffer, ou seja, o número de bytes a serem lidos, no registro EDX.
A chamada do sistema retorna a quantidade de bytes lidos no registro EAX, em caso de erro, o código do erro está no registro EAX.
Gravando em um Arquivo
Para gravar em um arquivo, execute as seguintes tarefas -
Coloque a chamada de sistema sys_write () número 4, no registro EAX.
Coloque o descritor de arquivo no registro EBX.
Coloque o ponteiro para o buffer de saída no registro ECX.
Coloque o tamanho do buffer, ou seja, o número de bytes a serem escritos, no registrador EDX.
A chamada do sistema retorna o número real de bytes escritos no registro EAX, em caso de erro, o código de erro está no registro EAX.
Fechando um Arquivo
Para fechar um arquivo, execute as seguintes tarefas -
- Coloque a chamada de sistema sys_close () número 6, no registro EAX.
- Coloque o descritor de arquivo no registro EBX.
A chamada do sistema retorna, em caso de erro, o código de erro no registro EAX.
Atualizando um arquivo
Para atualizar um arquivo, execute as seguintes tarefas -
- Coloque a chamada de sistema sys_lseek () número 19, no registro EAX.
- Coloque o descritor de arquivo no registro EBX.
- Coloque o valor de deslocamento no registro ECX.
- Coloque a posição de referência para o deslocamento no registro EDX.
A posição de referência pode ser:
- Início do arquivo - valor 0
- Posição atual - valor 1
- Fim do arquivo - valor 2
A chamada do sistema retorna, em caso de erro, o código de erro no registro EAX.
Exemplo
O programa a seguir cria e abre um arquivo chamado myfile.txt e grava um texto 'Bem-vindo ao Ponto de Tutoriais' neste arquivo. Em seguida, o programa lê o arquivo e armazena os dados em um buffer denominado info . Por último, exibe o texto conforme armazenado nas informações .
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
;create the file
mov eax, 8
mov ebx, file_name
mov ecx, 0777 ;read, write and execute by all
int 0x80 ;call kernel
mov [fd_out], eax
; write into the file
mov edx,len ;number of bytes
mov ecx, msg ;message to write
mov ebx, [fd_out] ;file descriptor
mov eax,4 ;system call number (sys_write)
int 0x80 ;call kernel
; close the file
mov eax, 6
mov ebx, [fd_out]
; write the message indicating end of file write
mov eax, 4
mov ebx, 1
mov ecx, msg_done
mov edx, len_done
int 0x80
;open the file for reading
mov eax, 5
mov ebx, file_name
mov ecx, 0 ;for read only access
mov edx, 0777 ;read, write and execute by all
int 0x80
mov [fd_in], eax
;read from file
mov eax, 3
mov ebx, [fd_in]
mov ecx, info
mov edx, 26
int 0x80
; close the file
mov eax, 6
mov ebx, [fd_in]
int 0x80
; print the info
mov eax, 4
mov ebx, 1
mov ecx, info
mov edx, 26
int 0x80
mov eax,1 ;system call number (sys_exit)
int 0x80 ;call kernel
section .data
file_name db 'myfile.txt'
msg db 'Welcome to Tutorials Point'
len equ $-msg
msg_done db 'Written to file', 0xa
len_done equ $-msg_done
section .bss
fd_out resb 1
fd_in resb 1
info resb 26Quando o código acima é compilado e executado, ele produz o seguinte resultado -
Written to file
Welcome to Tutorials Pointo sys_brk()chamada de sistema é fornecida pelo kernel, para alocar memória sem a necessidade de movê-la posteriormente. Essa chamada aloca memória logo atrás da imagem do aplicativo na memória. Esta função do sistema permite definir o endereço mais alto disponível na seção de dados.
Esta chamada de sistema usa um parâmetro, que é o endereço de memória mais alto que precisa ser definido. Este valor é armazenado no registro EBX.
Em caso de qualquer erro, sys_brk () retorna -1 ou retorna o próprio código de erro negativo. O exemplo a seguir demonstra a alocação dinâmica de memória.
Exemplo
O programa a seguir aloca 16kb de memória usando a chamada de sistema sys_brk () -
section .text
global _start ;must be declared for using gcc
_start: ;tell linker entry point
mov eax, 45 ;sys_brk
xor ebx, ebx
int 80h
add eax, 16384 ;number of bytes to be reserved
mov ebx, eax
mov eax, 45 ;sys_brk
int 80h
cmp eax, 0
jl exit ;exit, if error
mov edi, eax ;EDI = highest available address
sub edi, 4 ;pointing to the last DWORD
mov ecx, 4096 ;number of DWORDs allocated
xor eax, eax ;clear eax
std ;backward
rep stosd ;repete for entire allocated area
cld ;put DF flag to normal state
mov eax, 4
mov ebx, 1
mov ecx, msg
mov edx, len
int 80h ;print a message
exit:
mov eax, 1
xor ebx, ebx
int 80h
section .data
msg db "Allocated 16 kb of memory!", 10
len equ $ - msgQuando o código acima é compilado e executado, ele produz o seguinte resultado -
Allocated 16 kb of memory!