AVRO - Guia Rápido
Para transferir dados em uma rede ou para seu armazenamento persistente, você precisa serializar os dados. Antes doserialization APIs fornecido por Java e Hadoop, temos um utilitário especial, chamado Avro, uma técnica de serialização baseada em esquema.
Este tutorial ensina como serializar e desserializar os dados usando Avro. Avro fornece bibliotecas para várias linguagens de programação. Neste tutorial, demonstramos os exemplos usando a biblioteca Java.
O que é Avro?
Apache Avro é um sistema de serialização de dados com neutralidade de idioma. Foi desenvolvido por Doug Cutting, o pai do Hadoop. Como as classes graváveis do Hadoop não possuem portabilidade de idioma, o Avro se torna bastante útil, pois lida com formatos de dados que podem ser processados por vários idiomas. Avro é a ferramenta preferencial para serializar dados no Hadoop.
Avro tem um sistema baseado em esquema. Um esquema independente de linguagem está associado a suas operações de leitura e gravação. Avro serializa os dados que têm um esquema integrado. Avro serializa os dados em um formato binário compacto, que pode ser desserializado por qualquer aplicativo.
Avro usa o formato JSON para declarar as estruturas de dados. Atualmente, ele oferece suporte a linguagens como Java, C, C ++, C #, Python e Ruby.
Esquemas Avro
Avro depende muito de seu schema. Ele permite que todos os dados sejam gravados sem nenhum conhecimento prévio do esquema. Ele serializa rapidamente e os dados serializados resultantes são menores em tamanho. O esquema é armazenado junto com os dados do Avro em um arquivo para qualquer processamento posterior.
No RPC, o cliente e o servidor trocam esquemas durante a conexão. Essa troca ajuda na comunicação entre os mesmos campos nomeados, campos ausentes, campos extras, etc.
Os esquemas Avro são definidos com JSON, o que simplifica sua implementação em linguagens com bibliotecas JSON.
Como Avro, existem outros mecanismos de serialização no Hadoop, como Sequence Files, Protocol Buffers, e Thrift.
Comparação com Thrift e Buffers de protocolo
Thrift e Protocol Bufferssão as bibliotecas mais competentes com Avro. Avro difere dessas estruturas nas seguintes maneiras:
Avro oferece suporte a tipos dinâmicos e estáticos de acordo com os requisitos. Buffers de protocolo e Thrift usam linguagem de definição de interface (IDLs) para especificar esquemas e seus tipos. Esses IDLs são usados para gerar código para serialização e desserialização.
Avro é construído no ecossistema Hadoop. Buffers de Thrift e Protocol não são construídos no ecossistema Hadoop.
Ao contrário do Thrift e do Protocol Buffer, a definição de esquema do Avro está em JSON e não em qualquer IDL proprietário.
| Propriedade | Avro | Thrift & Protocol Buffer |
|---|---|---|
| Esquema dinâmico | sim | Não |
| Integrado ao Hadoop | sim | Não |
| Esquema em JSON | sim | Não |
| Não há necessidade de compilar | sim | Não |
| Não há necessidade de declarar IDs | sim | Não |
| Borda sangrando | sim | Não |
Características do Avro
Listados abaixo estão algumas das características proeminentes do Avro -
Avro é um language-neutral sistema de serialização de dados.
Ele pode ser processado por várias linguagens (atualmente C, C ++, C #, Java, Python e Ruby).
Avro cria formato binário estruturado que é compressible e splittable. Portanto, ele pode ser usado de maneira eficiente como entrada para tarefas Hadoop MapReduce.
Avro fornece rich data structures. Por exemplo, você pode criar um registro que contém uma matriz, um tipo enumerado e um sub-registro. Esses tipos de dados podem ser criados em qualquer idioma, podem ser processados no Hadoop e os resultados podem ser enviados para um terceiro idioma.
Avro schemas definido em JSON, facilite a implementação nas linguagens que já possuem bibliotecas JSON.
Avro cria um arquivo autoexplicativo denominado Avro Data File, no qual armazena dados junto com seu esquema na seção de metadados.
Avro também é usado em chamadas de procedimento remoto (RPCs). Durante o RPC, o cliente e o servidor trocam esquemas no handshake de conexão.
Trabalho Geral da Avro
Para usar o Avro, você precisa seguir o fluxo de trabalho fornecido -
Step 1- Crie esquemas. Aqui você precisa projetar o esquema Avro de acordo com seus dados.
Step 2- Leia os esquemas em seu programa. Isso é feito de duas maneiras -
By Generating a Class Corresponding to Schema- Compile o esquema usando Avro. Isso gera um arquivo de classe correspondente ao esquema
By Using Parsers Library - Você pode ler diretamente o esquema usando a biblioteca de analisadores.
Step 3 - Serialize os dados usando a API de serialização fornecida para Avro, que se encontra no package org.apache.avro.specific.
Step 4 - Desserialize os dados usando a API de desserialização fornecida para Avro, que se encontra no package org.apache.avro.specific.
Os dados são serializados para dois objetivos -
Para armazenamento persistente
Para transportar os dados pela rede
O que é serialização?
A serialização é o processo de traduzir estruturas de dados ou estado de objetos em forma binária ou textual para transportar os dados pela rede ou para armazenar em algum armazenamento persistente. Depois que os dados são transportados pela rede ou recuperados do armazenamento persistente, eles precisam ser desserializados novamente. A serialização é denominada comomarshalling e a desserialização é denominada como unmarshalling.
Serialização em Java
Java fornece um mecanismo, chamado object serialization onde um objeto pode ser representado como uma sequência de bytes que inclui os dados do objeto, bem como informações sobre o tipo do objeto e os tipos de dados armazenados no objeto.
Depois que um objeto serializado é gravado em um arquivo, ele pode ser lido do arquivo e desserializado. Ou seja, as informações de tipo e bytes que representam o objeto e seus dados podem ser usados para recriar o objeto na memória.
ObjectInputStream e ObjectOutputStream classes são usadas para serializar e desserializar um objeto respectivamente em Java.
Serialização em Hadoop
Geralmente em sistemas distribuídos como Hadoop, o conceito de serialização é usado para Interprocess Communication e Persistent Storage.
Comunicação entre processos
Para estabelecer a comunicação entre processos entre os nós conectados em uma rede, foi utilizada a técnica RPC.
O RPC usou a serialização interna para converter a mensagem em formato binário antes de enviá-la ao nó remoto pela rede. Na outra extremidade, o sistema remoto desserializa o fluxo binário na mensagem original.
O formato de serialização RPC deve ser o seguinte -
Compact - Fazer o melhor uso da largura de banda da rede, que é o recurso mais escasso em um data center.
Fast - Como a comunicação entre os nós é crucial em sistemas distribuídos, o processo de serialização e desserialização deve ser rápido, produzindo menos overhead.
Extensible - Os protocolos mudam com o tempo para atender a novos requisitos, portanto, deve ser simples evoluir o protocolo de uma maneira controlada para clientes e servidores.
Interoperable - O formato da mensagem deve suportar os nós que são escritos em diferentes idiomas.
Armazenamento persistente
O Persistent Storage é uma instalação de armazenamento digital que não perde seus dados com a perda de alimentação. Arquivos, pastas, bancos de dados são exemplos de armazenamento persistente.
Interface gravável
Esta é a interface no Hadoop que fornece métodos para serialização e desserialização. A tabela a seguir descreve os métodos -
| S.No. | Métodos e Descrição |
|---|---|
| 1 | void readFields(DataInput in) Este método é usado para desserializar os campos de um determinado objeto. |
| 2 | void write(DataOutput out) Este método é usado para serializar os campos de um determinado objeto. |
Interface gravável comparável
É a combinação de Writable e Comparableinterfaces. Esta interface herdaWritable interface do Hadoop, bem como Comparableinterface de Java. Portanto, ele fornece métodos para serialização, desserialização e comparação de dados.
| S.No. | Métodos e Descrição |
|---|---|
| 1 | int compareTo(class obj) Este método compara o objeto atual com o objeto fornecido obj. |
Além dessas classes, o Hadoop oferece suporte a várias classes de wrapper que implementam a interface WritableComparable. Cada classe envolve um tipo primitivo Java. A hierarquia de classes de serialização do Hadoop é fornecida abaixo -
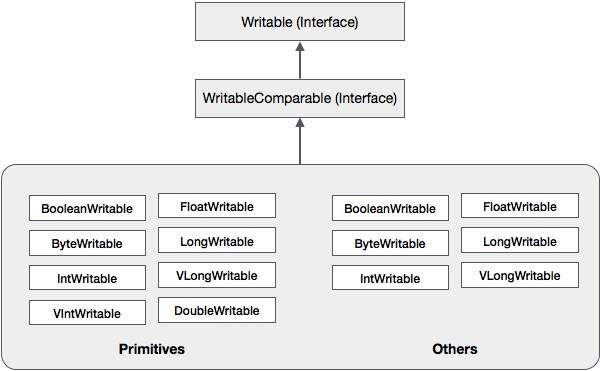
Essas classes são úteis para serializar vários tipos de dados no Hadoop. Por exemplo, vamos considerar oIntWritableclasse. Vamos ver como essa classe é usada para serializar e desserializar os dados no Hadoop.
Classe IntWritable
Esta classe implementa Writable, Comparable, e WritableComparableinterfaces. Ele envolve um tipo de dados inteiro nele. Esta classe fornece métodos usados para serializar e desserializar tipos de dados inteiros.
Construtores
| S.No. | Resumo |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
Métodos
| S.No. | Resumo |
|---|---|
| 1 | int get() Usando este método, você pode obter o valor inteiro presente no objeto atual. |
| 2 | void readFields(DataInput in) Este método é usado para desserializar os dados no dado DataInput objeto. |
| 3 | void set(int value) Este método é usado para definir o valor da corrente IntWritable objeto. |
| 4 | void write(DataOutput out) Este método é usado para serializar os dados no objeto atual para o dado DataOutput objeto. |
Serializando os dados no Hadoop
O procedimento para serializar o tipo inteiro de dados é discutido abaixo.
Instanciar IntWritable classe envolvendo um valor inteiro nela.
Instanciar ByteArrayOutputStream classe.
Instanciar DataOutputStream classe e passar o objeto de ByteArrayOutputStream classe para isso.
Serializar o valor inteiro no objeto IntWritable usando write()método. Este método precisa de um objeto da classe DataOutputStream.
Os dados serializados serão armazenados no objeto de matriz de bytes que é passado como parâmetro para o DataOutputStreamclasse no momento da instanciação. Converta os dados do objeto em uma matriz de bytes.
Exemplo
O exemplo a seguir mostra como serializar dados do tipo inteiro no Hadoop -
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Desserializando os dados no Hadoop
O procedimento para desserializar o tipo inteiro de dados é discutido abaixo -
Instanciar IntWritable classe envolvendo um valor inteiro nela.
Instanciar ByteArrayOutputStream classe.
Instanciar DataOutputStream classe e passar o objeto de ByteArrayOutputStream classe para isso.
Desserialize os dados no objeto de DataInputStream usando readFields() método da classe IntWritable.
Os dados desserializados serão armazenados no objeto da classe IntWritable. Você pode recuperar esses dados usandoget() método desta classe.
Exemplo
O exemplo a seguir mostra como desserializar os dados do tipo inteiro no Hadoop -
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Vantagem do Hadoop sobre a serialização Java
A serialização baseada em gravável do Hadoop é capaz de reduzir a sobrecarga de criação de objeto ao reutilizar os objetos graváveis, o que não é possível com a estrutura de serialização nativa do Java.
Desvantagens da serialização Hadoop
Para serializar dados do Hadoop, existem duas maneiras -
Você pode usar o Writable classes, fornecidas pela biblioteca nativa do Hadoop.
Você também pode usar Sequence Files que armazenam os dados em formato binário.
A principal desvantagem desses dois mecanismos é que Writables e SequenceFiles possuem apenas uma API Java e não podem ser escritos ou lidos em qualquer outra linguagem.
Portanto, qualquer um dos arquivos criados no Hadoop com os dois mecanismos acima não podem ser lidos por qualquer outro terceiro idioma, o que torna o Hadoop uma caixa limitada. Para resolver esta desvantagem, Doug Cutting criouAvro, que é um language independent data structure.
O Apache Software Foundation fornece ao Avro várias versões. Você pode baixar a versão necessária dos espelhos do Apache. Vamos ver como configurar o ambiente para trabalhar com Avro -
Baixando Avro
Para baixar o Apache Avro, prossiga com o seguinte -
Abra a página da web Apache.org . Você verá a página inicial do Apache Avro conforme mostrado abaixo -
Clique em projeto → versões. Você receberá uma lista de lançamentos.
Selecione a versão mais recente que leva a um link de download.
mirror.nexcess é um dos links onde você pode encontrar a lista de todas as bibliotecas de diferentes linguagens que Avro suporta, conforme mostrado abaixo -

Você pode selecionar e baixar a biblioteca para qualquer um dos idiomas fornecidos. Neste tutorial, usamos Java. Portanto, baixe os arquivos jaravro-1.7.7.jar e avro-tools-1.7.7.jar.
Avro com Eclipse
Para usar Avro no ambiente Eclipse, você precisa seguir as etapas abaixo -
Step 1. Eclipse aberto.
Step 2. Crie um projeto.
Step 3.Clique com o botão direito no nome do projeto. Você obterá um menu de atalho.
Step 4. Clique em Build Path. Isso leva você a outro menu de atalho.
Step 5. Clique em Configure Build Path... Você pode ver a janela Propriedades do seu projeto como mostrado abaixo -

Step 6. Na guia Bibliotecas, clique em ADD EXternal JARs... botão.
Step 7. Selecione o arquivo jar avro-1.77.jar você baixou.
Step 8. Clique em OK.
Avro com Maven
Você também pode obter a biblioteca Avro em seu projeto usando o Maven. A seguir está o arquivo pom.xml para Avro.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>Configurando Classpath
Para trabalhar com Avro no ambiente Linux, baixe os seguintes arquivos jar -
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- og4j-core-2.0.beta9.jar.
Copie esses arquivos em uma pasta e defina o caminho de classe para a pasta, no./bashrc arquivo como mostrado abaixo.
#class path for Avro
export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
Avro, sendo um utilitário de serialização baseado em esquema, aceita esquemas como entrada. Apesar de vários esquemas estarem disponíveis, Avro segue seus próprios padrões de definição de esquemas. Esses esquemas descrevem os seguintes detalhes -
- tipo de arquivo (registro por padrão)
- localização do registro
- nome do registro
- campos no registro com seus tipos de dados correspondentes
Usando esses esquemas, você pode armazenar valores serializados em formato binário usando menos espaço. Esses valores são armazenados sem metadados.
Criação de esquemas Avro
O esquema Avro é criado no formato de documento JavaScript Object Notation (JSON), que é um formato leve de intercâmbio de dados baseado em texto. Ele é criado de uma das seguintes maneiras -
- Uma string JSON
- Um objeto JSON
- Uma matriz JSON
Example - O exemplo a seguir mostra um esquema, que define um documento, sob o namespace Tutorialspoint, com o nome Employee, tendo os campos name e age.
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}Neste exemplo, você pode observar que existem quatro campos para cada registro -
type - Este campo está incluído no documento, bem como no campo denominado campos.
No caso de documento, mostra o tipo do documento, geralmente um registro porque há vários campos.
Quando é um campo, o tipo descreve o tipo de dados.
namespace - Este campo descreve o nome do namespace no qual o objeto reside.
name - Este campo está incluído no documento, bem como no campo denominado campos.
No caso de documento, descreve o nome do esquema. Este nome de esquema, juntamente com o namespace, identifica exclusivamente o esquema dentro da loja (Namespace.schema name) No exemplo acima, o nome completo do esquema será Tutorialspoint.Employee.
No caso de campos, descreve o nome do campo.
Tipos de dados primitivos de Avro
O esquema Avro possui tipos de dados primitivos, bem como tipos de dados complexos. A tabela a seguir descreve oprimitive data types de Avro -
| Tipo de dados | Descrição |
|---|---|
| nulo | Nulo é um tipo sem valor. |
| int | Número inteiro assinado de 32 bits. |
| grandes | Inteiro assinado de 64 bits. |
| flutuador | Número de ponto flutuante IEEE 754 de precisão única (32 bits). |
| em dobro | Número de ponto flutuante IEEE 754 de precisão dupla (64 bits). |
| bytes | seqüência de bytes não assinados de 8 bits. |
| corda | Sequência de caracteres Unicode. |
Tipos de dados complexos do Avro
Junto com tipos de dados primitivos, Avro fornece seis tipos de dados complexos, nomeadamente registros, enums, matrizes, mapas, uniões e fixos.
Registro
Um tipo de dados de registro no Avro é uma coleção de vários atributos. Suporta os seguintes atributos -
name - O valor deste campo contém o nome do registro.
namespace - O valor deste campo contém o nome do namespace onde o objeto está armazenado.
type - O valor deste atributo contém o tipo do documento (registro) ou o tipo de dados do campo no esquema.
fields - Este campo contém uma matriz JSON, que contém a lista de todos os campos do esquema, cada um com o nome e os atributos de tipo.
Example
A seguir está o exemplo de um registro.
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}Enum
Uma enumeração é uma lista de itens em uma coleção, a enumeração Avro oferece suporte aos seguintes atributos -
name - O valor deste campo contém o nome da enumeração.
namespace - O valor deste campo contém a string que qualifica o nome da Enumeração.
symbols - O valor deste campo contém os símbolos do enum como uma matriz de nomes.
Example
A seguir está o exemplo de uma enumeração.
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}Arrays
Este tipo de dados define um campo de matriz com itens de um único atributo. Este atributo de itens especifica o tipo de itens na matriz.
Example
{ " type " : " array ", " items " : " int " }Mapas
O tipo de dados do mapa é uma matriz de pares de valores-chave e organiza os dados como pares de valores-chave. A chave para um mapa Avro deve ser uma string. Os valores de um mapa contêm o tipo de dados do conteúdo do mapa.
Example
{"type" : "map", "values" : "int"}Sindicatos
Um tipo de dados de união é usado sempre que o campo tem um ou mais tipos de dados. Eles são representados como matrizes JSON. Por exemplo, se um campo que pode ser int ou nulo, a união é representada como ["int", "nulo"].
Example
Abaixo está um exemplo de documento usando sindicatos -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}Fixo
Este tipo de dados é usado para declarar um campo de tamanho fixo que pode ser usado para armazenar dados binários. Possui nome de campo e dados como atributos. Nome contém o nome do campo e o tamanho contém o tamanho do campo.
Example
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}No capítulo anterior, descrevemos o tipo de entrada do Avro, ou seja, os esquemas Avro. Neste capítulo, explicaremos as classes e métodos usados na serialização e desserialização de esquemas Avro.
Classe SpecificDatumWriter
Esta classe pertence ao pacote org.apache.avro.specific. Ele implementa oDatumWriter interface que converte objetos Java em um formato serializado na memória.
Construtor
| S.No. | Descrição |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
Método
| S.No. | Descrição |
|---|---|
| 1 | SpecificData getSpecificData() Retorna a implementação SpecificData usada por este escritor. |
Classe SpecificDatumReader
Esta classe pertence ao pacote org.apache.avro.specific. Ele implementa oDatumReader interface que lê os dados de um esquema e determina a representação dos dados na memória. SpecificDatumReader é a classe que suporta classes java geradas.
Construtor
| S.No. | Descrição |
|---|---|
| 1 | SpecificDatumReader(Schema schema) Construa onde os esquemas do escritor e do leitor são os mesmos. |
Métodos
| S.No. | Descrição |
|---|---|
| 1 | SpecificData getSpecificData() Retorna o SpecificData contido. |
| 2 | void setSchema(Schema actual) Este método é usado para definir o esquema do escritor. |
DataFileWriter
Instancia DataFileWrite para empclasse. Essa classe grava uma seqüência de registros serializados de dados em conformidade com um esquema, junto com o esquema em um arquivo.
Construtor
| S.No. | Descrição |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
Métodos
| S.No | Descrição |
|---|---|
| 1 | void append(D datum) Anexa um datum a um arquivo. |
| 2 | DataFileWriter<D> appendTo(File file) Este método é usado para abrir um gravador anexando a um arquivo existente. |
Data FileReader
Esta classe fornece acesso aleatório a arquivos escritos com DataFileWriter. Herda a classeDataFileStream.
Construtor
| S.No. | Descrição |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
Métodos
| S.No. | Descrição |
|---|---|
| 1 | next() Lê o próximo dado no arquivo. |
| 2 | Boolean hasNext() Retorna verdadeiro se mais entradas permanecerem neste arquivo. |
Classe Schema.parser
Esta classe é um analisador para esquemas de formato JSON. Ele contém métodos para analisar o esquema. Isso pertence aorg.apache.avro pacote.
Construtor
| S.No. | Descrição |
|---|---|
| 1 | Schema.Parser() |
Métodos
| S.No. | Descrição |
|---|---|
| 1 | parse (File file) Analisa o esquema fornecido no file. |
| 2 | parse (InputStream in) Analisa o esquema fornecido no InputStream. |
| 3 | parse (String s) Analisa o esquema fornecido no String. |
Interface GenricRecord
Essa interface fornece métodos para acessar os campos por nome e também por índice.
Métodos
| S.No. | Descrição |
|---|---|
| 1 | Object get(String key) Retorna o valor de um campo fornecido. |
| 2 | void put(String key, Object v) Define o valor de um campo dado seu nome. |
Classe GenericData.Record
Construtor
| S.No. | Descrição |
|---|---|
| 1 | GenericData.Record(Schema schema) |
Métodos
| S.No. | Descrição |
|---|---|
| 1 | Object get(String key) Retorna o valor de um campo com o nome fornecido. |
| 2 | Schema getSchema() Retorna o esquema desta instância. |
| 3 | void put(int i, Object v) Define o valor de um campo de acordo com sua posição no esquema. |
| 4 | void put(String key, Object value) Define o valor de um campo dado seu nome. |
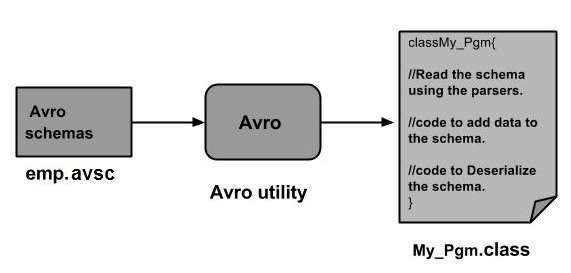
Pode-se ler um esquema Avro no programa gerando uma classe correspondente a um esquema ou usando a biblioteca de analisadores. Este capítulo descreve como ler o esquemaby generating a class e Serializing os dados usando o Avr.

Serialização pela geração de uma classe
Para serializar os dados usando Avro, siga as etapas fornecidas abaixo -
Escreva um esquema Avro.
Compile o esquema usando o utilitário Avro. Você obtém o código Java correspondente a esse esquema.
Preencha o esquema com os dados.
Serialize-o usando a biblioteca Avro.
Definindo um Esquema
Suponha que você queira um esquema com os seguintes detalhes -
| Field | Nome | Eu iria | era | salário | endereço |
| type | Corda | int | int | int | corda |
Crie um esquema Avro conforme mostrado abaixo.
Salvar como emp.avsc.
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}Compilando o Esquema
Depois de criar um esquema Avro, você precisa compilar o esquema criado usando ferramentas Avro. avro-tools-1.7.7.jar é o jarro que contém as ferramentas.
Sintaxe para compilar um esquema Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>Abra o terminal na pasta inicial.
Crie um novo diretório para trabalhar com Avro, conforme mostrado abaixo -
$ mkdir Avro_WorkNo diretório recém-criado, crie três subdiretórios -
Primeiro nomeado schema, para colocar o esquema.
Segundo nome with_code_gen, para colocar o código gerado.
Terceiro nomeado jars, para colocar os arquivos jar.
$ mkdir schema
$ mkdir with_code_gen
$ mkdir jarsA captura de tela a seguir mostra como seu Avro_work pasta deve ficar parecida após a criação de todos os diretórios.
Agora /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar é o caminho para o diretório onde você baixou o arquivo avro-tools-1.7.7.jar.
/home/Hadoop/Avro_work/schema/ é o caminho para o diretório onde o arquivo de esquema emp.avsc está armazenado.
/home/Hadoop/Avro_work/with_code_gen é o diretório onde você deseja que os arquivos de classe gerados sejam armazenados.
Agora compile o esquema conforme mostrado abaixo -
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_genApós a compilação, um pacote de acordo com o espaço de nomes do esquema é criado no diretório de destino. Dentro deste pacote, o código-fonte Java com o nome do esquema é criado. Este código-fonte gerado é o código Java do esquema fornecido, que pode ser usado diretamente nos aplicativos.
Por exemplo, neste caso, um pacote / pasta, denominado tutorialspoint é criado que contém outra pasta chamada com (já que o espaço de nome é tutorialspoint.com) e dentro dela, você pode observar o arquivo gerado emp.java. O instantâneo a seguir mostraemp.java -

Esta classe é útil para criar dados de acordo com o esquema.
A classe gerada contém -
- Construtor padrão e construtor parametrizado que aceita todas as variáveis do esquema.
- Os métodos setter e getter para todas as variáveis no esquema.
- Método Get () que retorna o esquema.
- Métodos Builder.
Criação e serialização dos dados
Em primeiro lugar, copie o arquivo java gerado usado neste projeto para o diretório atual ou importe-o de onde ele está localizado.
Agora podemos escrever um novo arquivo Java e instanciar a classe no arquivo gerado (emp) para adicionar dados de funcionários ao esquema.
Vamos ver o procedimento para criar dados de acordo com o esquema usando o apache Avro.
Passo 1
Instancie o gerado emp classe.
emp e1=new emp( );Passo 2
Usando métodos setter, insira os dados do primeiro funcionário. Por exemplo, criamos os detalhes do funcionário chamado Omar.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);Da mesma forma, preencha todos os detalhes do funcionário usando métodos setter.
etapa 3
Crie um objeto de DatumWriter interface usando o SpecificDatumWriterclasse. Isso converte objetos Java em formato serializado na memória. O exemplo a seguir instanciaSpecificDatumWriter objeto de classe para emp classe.
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Passo 4
Instanciar DataFileWriter para empclasse. Essa classe grava uma seqüência de registros serializados de dados em conformidade com um esquema, junto com o próprio esquema, em um arquivo. Esta aula requer oDatumWriter objeto, como um parâmetro para o construtor.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);Etapa 5
Abra um novo arquivo para armazenar os dados correspondentes ao esquema fornecido usando create()método. Este método requer o esquema e o caminho do arquivo onde os dados devem ser armazenados como parâmetros.
No exemplo a seguir, o esquema é passado usando getSchema() método, e o arquivo de dados é armazenado no caminho - /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));Etapa 6
Adicione todos os registros criados ao arquivo usando append() método como mostrado abaixo -
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Exemplo - serialização gerando uma classe
O seguinte programa completo mostra como serializar dados em um arquivo usando o Apache Avro -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}Navegue pelo diretório onde o código gerado é colocado. Neste caso, emhome/Hadoop/Avro_work/with_code_gen.
In Terminal −
$ cd home/Hadoop/Avro_work/with_code_gen/In GUI −
Agora copie e salve o programa acima no arquivo chamado Serialize.java
Compile e execute-o conforme mostrado abaixo -
$ javac Serialize.java
$ java SerializeResultado
data successfully serializedSe você verificar o caminho fornecido no programa, poderá encontrar o arquivo serializado gerado conforme mostrado abaixo.
Conforme descrito anteriormente, é possível ler um esquema Avro em um programa gerando uma classe correspondente ao esquema ou usando a biblioteca de analisadores. Este capítulo descreve como ler o esquemaby generating a class e Deserialize os dados usando Avro.
Desserialização pela geração de uma classe
Os dados serializados são armazenados no arquivo emp.avro. Você pode desserializar e ler usando Avro.

Siga o procedimento abaixo para desserializar os dados serializados de um arquivo.
Passo 1
Crie um objeto de DatumReader interface usando SpecificDatumReader classe.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);Passo 2
Instanciar DataFileReader para empclasse. Esta classe lê dados serializados de um arquivo. Requer oDataumeader objeto e caminho do arquivo onde os dados serializados existem, como um parâmetro para o construtor.
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);etapa 3
Imprima os dados desserializados, usando os métodos de DataFileReader.
o hasNext() método retornará um booleano se houver algum elemento no Reader.
o next() método de DataFileReader retorna os dados no Reader.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Exemplo - desserialização gerando uma classe
O programa completo a seguir mostra como desserializar os dados em um arquivo usando Avro.
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}Navegue até o diretório onde o código gerado é colocado. Neste caso, emhome/Hadoop/Avro_work/with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/Agora, copie e salve o programa acima no arquivo chamado DeSerialize.java. Compile e execute-o conforme mostrado abaixo -
$ javac Deserialize.java
$ java DeserializeResultado
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}Pode-se ler um esquema Avro em um programa gerando uma classe correspondente a um esquema ou usando a biblioteca de analisadores. No Avro, os dados são sempre armazenados com seu esquema correspondente. Portanto, sempre podemos ler um esquema sem geração de código.
Este capítulo descreve como ler o esquema by using parsers library e para serialize os dados usando Avro.

Serialização usando a biblioteca de analisadores
Para serializar os dados, precisamos ler o esquema, criar dados de acordo com o esquema e serializar o esquema usando a API Avro. O procedimento a seguir serializa os dados sem gerar nenhum código -
Passo 1
Em primeiro lugar, leia o esquema do arquivo. Para fazer isso, useSchema.Parserclasse. Esta classe fornece métodos para analisar o esquema em diferentes formatos.
Instancie o Schema.Parser classe passando o caminho do arquivo onde o esquema está armazenado.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Passo 2
Crie o objeto de GenericRecord interface, instanciando GenericData.Recordclasse como mostrado abaixo. Passe o objeto de esquema criado acima para seu construtor.
GenericRecord e1 = new GenericData.Record(schema);etapa 3
Insira os valores no esquema usando o put() método do GenericData classe.
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");Passo 4
Crie um objeto de DatumWriter interface usando o SpecificDatumWriterclasse. Ele converte objetos Java em formato serializado na memória. O exemplo a seguir instanciaSpecificDatumWriter objeto de classe para emp classe -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Etapa 5
Instanciar DataFileWriter para empclasse. Essa classe grava registros serializados de dados em conformidade com um esquema, junto com o próprio esquema, em um arquivo. Esta aula requer oDatumWriter objeto, como um parâmetro para o construtor.
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);Etapa 6
Abra um novo arquivo para armazenar os dados correspondentes ao esquema fornecido usando create()método. Este método requer o esquema e o caminho do arquivo onde os dados devem ser armazenados como parâmetros.
No exemplo abaixo, o esquema é passado usando getSchema() método e o arquivo de dados é armazenado no caminho
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));Etapa 7
Adicione todos os registros criados ao arquivo usando append( ) método conforme mostrado abaixo.
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Exemplo - serialização usando analisadores
O programa completo a seguir mostra como serializar os dados usando analisadores -
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}Navegue até o diretório onde o código gerado é colocado. Neste caso, emhome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/
Agora copie e salve o programa acima no arquivo chamado Serialize.java. Compile e execute-o conforme mostrado abaixo -
$ javac Serialize.java
$ java SerializeResultado
data successfully serializedSe você verificar o caminho fornecido no programa, poderá encontrar o arquivo serializado gerado conforme mostrado abaixo.
Como mencionado anteriormente, pode-se ler um esquema Avro em um programa gerando uma classe correspondente a um esquema ou usando a biblioteca de analisadores. No Avro, os dados são sempre armazenados com seu esquema correspondente. Portanto, sempre podemos ler um item serializado sem geração de código.
Este capítulo descreve como ler o esquema using parsers library e Deserializing os dados usando Avro.
Desserialização usando a biblioteca de analisadores
Os dados serializados são armazenados no arquivo mydata.txt. Você pode desserializar e ler usando Avro.
Siga o procedimento abaixo para desserializar os dados serializados de um arquivo.
Passo 1
Em primeiro lugar, leia o esquema do arquivo. Para fazer isso, useSchema.Parserclasse. Esta classe fornece métodos para analisar o esquema em diferentes formatos.
Instancie o Schema.Parser classe passando o caminho do arquivo onde o esquema está armazenado.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Passo 2
Crie um objeto de DatumReader interface usando SpecificDatumReader classe.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);etapa 3
Instanciar DataFileReaderclasse. Esta classe lê dados serializados de um arquivo. Requer oDatumReader objeto e caminho do arquivo onde os dados serializados existem, como um parâmetro para o construtor.
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);Passo 4
Imprima os dados desserializados, usando os métodos de DataFileReader.
o hasNext() método retorna um booleano se houver algum elemento no Reader.
o next() método de DataFileReader retorna os dados no Reader.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Exemplo - desserialização usando a biblioteca de analisadores
O programa completo a seguir mostra como desserializar os dados serializados usando a biblioteca Parsers -
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}Navegue até o diretório onde o código gerado é colocado. Neste caso, é emhome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/Agora copie e salve o programa acima no arquivo chamado DeSerialize.java. Compile e execute-o conforme mostrado abaixo -
$ javac Deserialize.java
$ java DeserializeResultado
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}