DBMS - Indexação
Sabemos que os dados são armazenados na forma de registros. Cada registro possui um campo-chave, que o ajuda a ser reconhecido de forma única.
A indexação é uma técnica de estrutura de dados para recuperar registros dos arquivos de banco de dados com eficiência, com base em alguns atributos nos quais a indexação foi feita. A indexação em sistemas de banco de dados é semelhante ao que vemos nos livros.
A indexação é definida com base em seus atributos de indexação. A indexação pode ser dos seguintes tipos -
Primary Index- O índice primário é definido em um arquivo de dados ordenado. O arquivo de dados é ordenado em umkey field. O campo chave é geralmente a chave primária da relação.
Secondary Index - O índice secundário pode ser gerado a partir de um campo que é uma chave candidata e tem um valor único em cada registro, ou uma não chave com valores duplicados.
Clustering Index- O índice de clustering é definido em um arquivo de dados ordenado. O arquivo de dados é ordenado em um campo não chave.
A indexação ordenada é de dois tipos -
- Índice Denso
- Índice Esparso
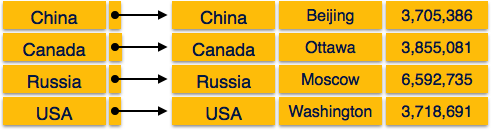
Índice Denso
No índice denso, há um registro de índice para cada valor de chave de pesquisa no banco de dados. Isso torna a pesquisa mais rápida, mas requer mais espaço para armazenar os próprios registros de índice. Os registros de índice contêm o valor da chave de pesquisa e um ponteiro para o registro real no disco.
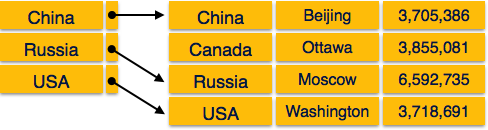
Índice Esparso
No índice esparso, os registros do índice não são criados para todas as chaves de pesquisa. Um registro de índice aqui contém uma chave de pesquisa e um ponteiro real para os dados no disco. Para pesquisar um registro, primeiro procedemos por registro de índice e chegamos à localização real dos dados. Se os dados que estamos procurando não estiverem onde alcançamos diretamente, seguindo o índice, o sistema inicia a busca sequencial até que os dados desejados sejam encontrados.
Índice Multinível
Os registros de índice incluem valores de chave de pesquisa e indicadores de dados. O índice multinível é armazenado no disco junto com os arquivos de banco de dados reais. Conforme o tamanho do banco de dados aumenta, também aumenta o tamanho dos índices. É imensa a necessidade de manter os registros do índice na memória principal para agilizar as operações de busca. Se o índice de nível único for usado, um índice de tamanho grande não pode ser mantido na memória, o que leva a vários acessos ao disco.
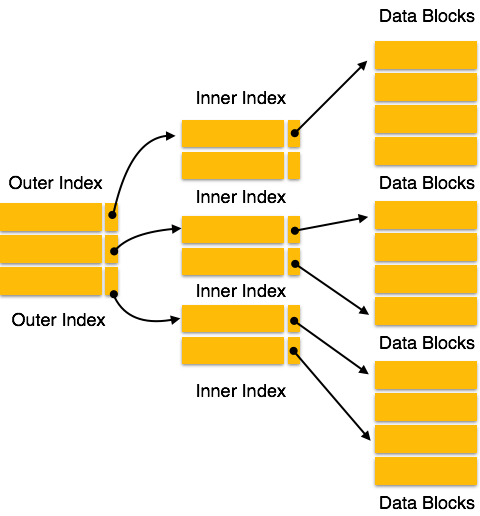
O índice multinível ajuda a quebrar o índice em vários índices menores, a fim de tornar o nível mais externo tão pequeno que possa ser salvo em um único bloco de disco, que pode ser facilmente acomodado em qualquer lugar da memória principal.
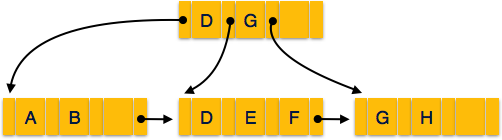
Árvore B +
A árvore AB + é uma árvore de pesquisa binária balanceada que segue um formato de índice multinível. Os nós folha de uma árvore B + denotam ponteiros de dados reais. A árvore B + garante que todos os nós das folhas permaneçam na mesma altura, portanto equilibrados. Além disso, os nós folha são vinculados por meio de uma lista de links; portanto, uma árvore B + pode suportar acesso aleatório, bem como acesso sequencial.
Estrutura da Árvore B +
Cada nó folha está a uma distância igual do nó raiz. A árvore AB + é da ordemn Onde né fixo para cada árvore B + .
Internal nodes -
- Nós internos (não-folha) contêm pelo menos ⌈n / 2⌉ ponteiros, exceto o nó raiz.
- No máximo, um nó interno pode conter n ponteiros.
Leaf nodes -
- Os nós de folha contêm pelo menos ⌈n / 2⌉ ponteiros de registro e valores-chave ⌈n / 2⌉.
- No máximo, um nó folha pode conter n pontos de registro e n valores-chave.
- Cada nó folha contém um ponteiro de bloco P para apontar para o próximo nó folha e formar uma lista vinculada.
Inserção de árvore B +
As árvores B + são preenchidas a partir da parte inferior e cada entrada é feita no nó folha.
- Se um nó folha estourar -
Divida o nó em duas partes.
Partição em i = ⌊(m+1)/2⌋.
Primeiro i as entradas são armazenadas em um nó.
O resto das entradas (i + 1 em diante) são movidas para um novo nó.
ith a chave é duplicada no pai da folha.
Se um nó não folha estourar -
Divida o nó em duas partes.
Particionar o nó em i = ⌈(m+1)/2⌉.
Inscrições até i são mantidos em um nó.
O resto das entradas são movidas para um novo nó.
Exclusão da árvore B +
As entradas da árvore B + são excluídas nos nós folha.
A entrada de destino é pesquisada e excluída.
Se for um nó interno, exclua e substitua pela entrada da posição esquerda.
Após a exclusão, o underflow é testado,
Se ocorrer estouro negativo, distribua as entradas dos nós restantes.
Se a distribuição não for possível da esquerda, então
Distribua dos nós diretamente para ele.
Se a distribuição não for possível da esquerda ou da direita, então
Mescle o nó com a esquerda e a direita.