XML DOM - Guia rápido
o Documento Objeto Model (DOM) é um padrão W3C. Ele define um padrão para acessar documentos como HTML e XML.
A definição de DOM conforme colocada pelo W3C é -
O Document Object Model (DOM) é uma interface de programação de aplicativo (API) para documentos HTML e XML. Ele define a estrutura lógica dos documentos e a maneira como um documento é acessado e manipulado.
DOM define os objetos e propriedades e métodos (interface) para acessar todos os elementos XML. Ele é separado em 3 partes / níveis diferentes -
Core DOM - modelo padrão para qualquer documento estruturado
XML DOM - modelo padrão para documentos XML
HTML DOM - modelo padrão para documentos HTML
XML DOM é um modelo de objeto padrão para XML. Os documentos XML possuem uma hierarquia de unidades de informação denominadas nós ; DOM é uma interface de programação padrão que descreve esses nós e as relações entre eles.
Como XML DOM também fornece uma API que permite ao desenvolvedor adicionar, editar, mover ou remover nós em qualquer ponto da árvore para criar um aplicativo.
A seguir está o diagrama para a estrutura DOM. O diagrama mostra que o analisador avalia um documento XML como uma estrutura DOM, percorrendo cada nó.
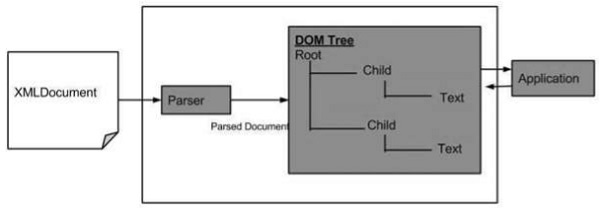
Vantagens do XML DOM
A seguir estão as vantagens do XML DOM.
XML DOM é independente de linguagem e plataforma.
DOM XML é traversable - As informações em XML DOM são organizadas em uma hierarquia que permite ao desenvolvedor navegar pela hierarquia procurando por informações específicas.
DOM XML é modifiable - É de natureza dinâmica, fornecendo ao desenvolvedor um escopo para adicionar, editar, mover ou remover nós em qualquer ponto da árvore.
Desvantagens do XML DOM
Ele consome mais memória (se a estrutura XML for grande), pois o programa escrito uma vez permanece na memória o tempo todo até e a menos que seja explicitamente removido.
Devido ao uso extensivo de memória, sua velocidade operacional, em comparação com SAX, é mais lenta.
Agora que sabemos o que significa DOM, vamos ver o que é uma estrutura DOM. Um documento DOM é uma coleção de nós ou pedaços de informação, organizados em uma hierarquia. Alguns tipos de nós podem ter nós filhos de vários tipos e outros são nós folha que não podem ter nada abaixo deles na estrutura do documento. A seguir está uma lista dos tipos de nós, com uma lista de tipos de nós que eles podem ter como filhos -
Document - Elemento (máximo de um), ProcessingInstruction, Comment, DocumentType (máximo de um)
DocumentFragment - Elemento, Instrução de Processamento, Comentário, Texto, CDATASection, EntityReference
EntityReference - Elemento, Instrução de Processamento, Comentário, Texto, CDATASection, EntityReference
Element - Elemento, Texto, Comentário, Instrução de Processamento, CDATASection, EntityReference
Attr - Texto, EntityReference
ProcessingInstruction - Sem filhos
Comment - Sem filhos
Text - Sem filhos
CDATASection - Sem filhos
Entity - Elemento, Instrução de Processamento, Comentário, Texto, CDATASection, EntityReference
Notation - Sem filhos
Exemplo
Considere a representação DOM do seguinte documento XML node.xml.
<?xml version = "1.0"?>
<Company>
<Employee category = "technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "non-technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>O modelo de objeto de documento do documento XML acima seria o seguinte -

A partir do fluxograma acima, podemos inferir -
O objeto de nó pode ter apenas um objeto de nó pai . Isso ocupa a posição acima de todos os nós. Aqui está a empresa .
O nó pai pode ter vários nós chamados de nós filhos . Esses nós filhos podem ter nós adicionais chamados de nós de atributo . No exemplo acima, temos dois nós de atributo Técnico e Não Técnico . O nó de atributo não é realmente um filho do nó de elemento, mas ainda está associado a ele.
Esses nós filhos , por sua vez, podem ter vários nós filhos. O texto dentro dos nós é chamado de nó de texto .
Os objetos de nó no mesmo nível são chamados de irmãos.
O DOM identifica -
os objetos para representar a interface e manipular o documento.
a relação entre os objetos e interfaces.
Neste capítulo, estudaremos sobre os nós XML DOM . Cada XML DOM contém as informações em unidades hierárquicas chamadas de nós e o DOM descreve esses nós e a relação entre eles.
Tipos de Nó
O fluxograma a seguir mostra todos os tipos de nós -
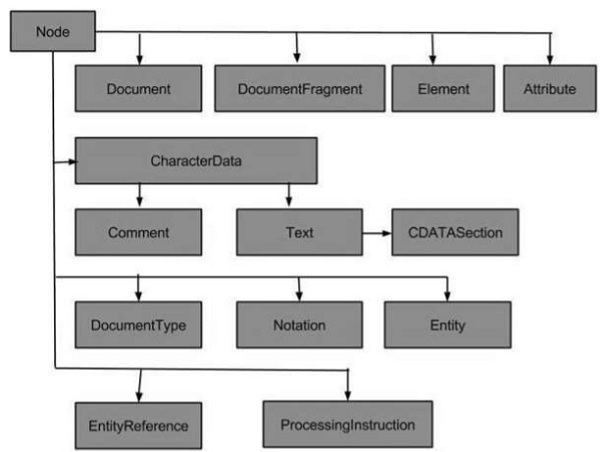
Os tipos mais comuns de nós em XML são -
Document Node- A estrutura completa do documento XML é um nó de documento .
Element Node- Cada elemento XML é um nó de elemento . Este também é o único tipo de nó que pode ter atributos.
Attribute Node- Cada atributo é considerado um nó de atributo . Ele contém informações sobre um nó de elemento, mas não é realmente considerado filho do elemento.
Text Node- Os textos do documento são considerados como nó de texto . Pode consistir em mais informações ou apenas espaço em branco.
Alguns tipos menos comuns de nós são -
CData Node- Este nó contém informações que não devem ser analisadas pelo analisador. Em vez disso, deve apenas ser transmitido como texto simples.
Comment Node - Este nó inclui informações sobre os dados e geralmente é ignorado pelo aplicativo.
Processing Instructions Node - Este nó contém informações destinadas especificamente ao aplicativo.
Document Fragments Node
Entities Node
Entity reference nodes
Notations Node
Neste capítulo, estudaremos sobre a árvore de nós XML DOM . Em um documento XML, as informações são mantidas em estrutura hierárquica; essa estrutura hierárquica é conhecida como Árvore de Nó . Essa hierarquia permite que um desenvolvedor navegue pela árvore em busca de informações específicas, portanto, os nós têm permissão para acessar. O conteúdo desses nós pode então ser atualizado.
A estrutura da árvore de nós começa com o elemento raiz e se espalha para os elementos filhos até o nível mais baixo.
Exemplo
O exemplo a seguir demonstra um documento XML simples, cuja árvore de nós é a estrutura mostrada no diagrama abaixo -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
</Employee>
</Company>Como pode ser visto no exemplo acima, cuja representação pictórica (de seu DOM) é como mostrado abaixo -
O nó superior de uma árvore é chamado de root. orooto nó é <Company>, que por sua vez contém os dois nós de <Employee>. Esses nós são chamados de nós filhos.
O nó filho <Employee> do nó raiz <Company>, por sua vez, consiste em seu próprio nó filho (<FirstName>, <LastName>, <ContactNo>).
Os dois nós filhos, <Employee>, têm valores de atributo técnicos e não técnicos, são chamados de nós de atributo .
O texto dentro de cada nó é chamado de nó de texto .
XML DOM - Métodos
O DOM como uma API contém interfaces que representam diferentes tipos de informação que podem ser encontrados em um documento XML, como elementos e texto. Essas interfaces incluem os métodos e propriedades necessários para trabalhar com esses objetos. As propriedades definem a característica do nó, enquanto os métodos fornecem a maneira de manipular os nós.
A tabela a seguir lista as classes e interfaces DOM -
| S.No. | Interface e descrição |
|---|---|
| 1 | DOMImplementation Ele fornece vários métodos para executar operações que são independentes de qualquer instância particular do modelo de objeto de documento. |
| 2 | DocumentFragment É o objeto de documento "leve" ou "mínimo" e (como a superclasse de Documento) ancora a árvore XML / HTML em um documento completo. |
| 3 | Document Ele representa o nó de nível superior do documento XML, que fornece acesso a todos os nós do documento, incluindo o elemento raiz. |
| 4 | Node Ele representa o nó XML. |
| 5 | NodeList Ele representa uma lista somente leitura de objetos Node . |
| 6 | NamedNodeMap Ele representa coleções de nós que podem ser acessados por nome. |
| 7 | Data Ele estende o Node com um conjunto de atributos e métodos para acessar dados de caracteres no DOM. |
| 8 | Attribute Ele representa um atributo em um objeto Element. |
| 9 | Element Ele representa o nó do elemento. Deriva do Nó. |
| 10 | Text Ele representa o nó de texto. Deriva de CharacterData. |
| 11 | Comment Ele representa o nó de comentário. Deriva de CharacterData. |
| 12 | ProcessingInstruction Ele representa uma "instrução de processamento". Ele é usado em XML como uma forma de manter informações específicas do processador no texto do documento. |
| 13 | CDATA Section Representa a Seção CDATA. Deriva do texto. |
| 14 | Entity Ele representa uma entidade. Deriva do Nó. |
| 15 | EntityReference Isso representa uma referência de entidade na árvore. Deriva do Nó. |
Estaremos discutindo métodos e propriedades de cada uma das interfaces acima em seus respectivos capítulos.
Neste capítulo, estudaremos sobre carregamento e análise de XML .
Para descrever as interfaces fornecidas pela API, o W3C usa uma linguagem abstrata chamada Interface Definition Language (IDL). A vantagem de usar IDL é que o desenvolvedor aprende como usar o DOM com sua linguagem favorita e pode alternar facilmente para uma linguagem diferente.
A desvantagem é que, por ser abstrato, o IDL não pode ser usado diretamente por desenvolvedores da web. Devido às diferenças entre as linguagens de programação, eles precisam ter mapeamento - ou ligação - entre as interfaces abstratas e suas linguagens concretas. DOM foi mapeado para linguagens de programação como Javascript, JScript, Java, C, C ++, PLSQL, Python e Perl.
Nas seções e capítulos seguintes, usaremos Javascript como nossa linguagem de programação para carregar o arquivo XML.
Parser
Um analisador é um aplicativo de software desenvolvido para analisar um documento, no nosso caso, um documento XML, e fazer algo específico com as informações. Alguns dos analisadores baseados em DOM estão listados na tabela a seguir -
| S.No | Analisador e Descrição |
|---|---|
| 1 | JAXP API Java da Sun Microsystem para análise XML (JAXP) |
| 2 | XML4J Analisador de XML da IBM para Java (XML4J) |
| 3 | msxml O analisador XML da Microsoft (msxml) versão 2.0 está integrado ao Internet Explorer 5.5 |
| 4 | 4DOM 4DOM é um analisador para a linguagem de programação Python |
| 5 | XML::DOM XML :: DOM é um módulo Perl para manipular documentos XML usando Perl |
| 6 | Xerces Analisador Xerces Java do Apache |
Em uma API baseada em árvore como o DOM, o analisador percorre o arquivo XML e cria os objetos DOM correspondentes. Em seguida, você pode percorrer a estrutura DOM para frente e para trás.
Carregando e analisando XML
Ao carregar um documento XML, o conteúdo XML pode vir em duas formas -
- Diretamente como arquivo XML
- Como string XML
Conteúdo como arquivo XML
O exemplo a seguir demonstra como carregar dados XML ( node.xml ) usando Ajax e Javascript quando o conteúdo XML é recebido como um arquivo XML. Aqui, a função Ajax obtém o conteúdo de um arquivo xml e o armazena em XML DOM. Depois que o objeto DOM é criado, ele é analisado.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>ContactNo:</b> <span id = "ContactNo"></span><br>
<b>Email:</b> <span id = "Email"></span>
</div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) { // Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp = new XMLHttpRequest();
} else { // code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
xmlDoc = xmlhttp.responseXML;
//parsing the DOM object
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("ContactNo").innerHTML =
xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0].nodeValue;
document.getElementById("Email").innerHTML =
xmlDoc.getElementsByTagName("Email")[0].childNodes[0].nodeValue;
</script>
</body>
</html>node.xml
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>A maioria dos detalhes do código está no código do script.
O Internet Explorer usa o ActiveXObject ("Microsoft.XMLHTTP") para criar uma instância do objeto XMLHttpRequest, outros navegadores usam o método XMLHttpRequest () .
o responseXML transforma o conteúdo XML diretamente em XML DOM.
Depois que o conteúdo XML é transformado em JavaScript XML DOM, você pode acessar qualquer elemento XML usando os métodos e propriedades JS DOM. Usamos as propriedades DOM, como childNodes , nodeValue e métodos DOM, como getElementsById (ID), getElementsByTagName (tags_name).
Execução
Salve este arquivo como loadingexample.html e abra-o em seu navegador. Você receberá a seguinte saída -

Conteúdo como string XML
O exemplo a seguir demonstra como carregar dados XML usando Ajax e Javascript quando o conteúdo XML é recebido como arquivo XML. Aqui, a função Ajax obtém o conteúdo de um arquivo xml e o armazena em XML DOM. Depois que o objeto DOM é criado, ele é analisado.
<!DOCTYPE html>
<html>
<head>
<script>
// loads the xml string in a dom object
function loadXMLString(t) { // for non IE browsers
if (window.DOMParser) {
// create an instance for xml dom object parser = new DOMParser();
xmlDoc = parser.parseFromString(t,"text/xml");
}
// code for IE
else { // create an instance for xml dom object
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
xmlDoc.loadXML(t);
}
return xmlDoc;
}
</script>
</head>
<body>
<script>
// a variable with the string
var text = "<Employee>";
text = text+"<FirstName>Tanmay</FirstName>";
text = text+"<LastName>Patil</LastName>";
text = text+"<ContactNo>1234567890</ContactNo>";
text = text+"<Email>[email protected]</Email>";
text = text+"</Employee>";
// calls the loadXMLString() with "text" function and store the xml dom in a variable
var xmlDoc = loadXMLString(text);
//parsing the DOM object
y = xmlDoc.documentElement.childNodes;
for (i = 0;i<y.length;i++) {
document.write(y[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>A maioria dos detalhes do código está no código do script.
O Internet Explorer usa ActiveXObject ("Microsoft.XMLDOM") para carregar dados XML em um objeto DOM, outros navegadores usam a função DOMParser () e o método parseFromString (text, 'text / xml') .
O texto da variável deve conter uma string com conteúdo XML.
Depois que o conteúdo XML é transformado em JavaScript XML DOM, você pode acessar qualquer elemento XML usando métodos e propriedades JS DOM. Usamos propriedades DOM, como childNodes , nodeValue .
Execução
Salve este arquivo como loadingexample.html e abra-o em seu navegador. Você verá a seguinte saída -

Agora que vimos como o conteúdo XML se transforma em JavaScript XML DOM, agora você pode acessar qualquer elemento XML usando os métodos XML DOM.
Neste capítulo, discutiremos o XML DOM Traversing. Estudamos no capítulo anterior como carregar um documento XML e analisar o objeto DOM assim obtido. Este objeto DOM analisado pode ser percorrido. Traversing é um processo no qual o loop é feito de maneira sistemática, percorrendo cada um dos elementos passo a passo em uma árvore de nós.
Exemplo
O exemplo a seguir (traverse_example.htm) demonstra a travessia de DOM. Aqui, atravessamos cada nó filho do elemento <Employee>.
<!DOCTYPE html>
<html>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center">
<tr>
<th>Employee Category</th>
<th>FirstName</th>
<th>LastName</th>
<th>ContactNo</th>
<th>Email</th>
</tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr>
<td>'+ employee_cat+ '</td>
<td>'+ employee_firstName+ '</td>
<td>'+ employee_lastName+ '</td>
<td>'+ employee_contactno+ '</td>
<td>'+ employee_email+ '</td>
</tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>Este código carrega node.xml .
O conteúdo XML é transformado em objeto JavaScript XML DOM.
O array de elementos (com tag Element) usando o método getElementsByTagName () é obtido.
Em seguida, percorremos essa matriz e exibimos os valores dos nós filhos em uma tabela.
Execução
Salve este arquivo como traverse_example.html no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Você receberá a seguinte saída -

Até agora, estudamos a estrutura do DOM, como carregar e analisar o objeto XML DOM e atravessar os objetos DOM. Aqui, veremos como podemos navegar entre os nós em um objeto DOM. O XML DOM consiste em várias propriedades dos nós que nos ajudam a navegar pelos nós, como -
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
A seguir está um diagrama de uma árvore de nós mostrando seu relacionamento com os outros nós.
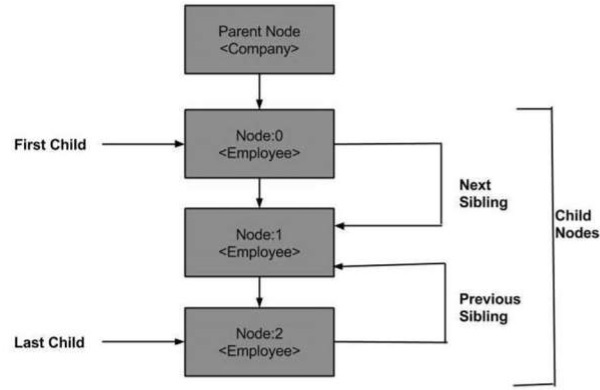
DOM - Nó Pai
Esta propriedade especifica o nó pai como um objeto de nó.
Exemplo
O exemplo a seguir (navigate_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM. Em seguida, o objeto DOM é navegado para o nó pai através do nó filho -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
var y = xmlDoc.getElementsByTagName("Employee")[0];
document.write(y.parentNode.nodeName);
</script>
</body>
</html>Como você pode ver no exemplo acima, o nó filho Employee navega para seu nó pai.
Execução
Salve este arquivo como navigate_example.html no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o nó pai de Employee , ou seja, Company .
Primeiro filho
Esta propriedade é do tipo Node e representa o primeiro nome do filho presente na NodeList.
Exemplo
O exemplo a seguir (first_node_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e, em seguida, navega para o primeiro nó filho presente no objeto DOM.
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_firstChild(p) {
a = p.firstChild;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var firstchild = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(firstchild.nodeName);
</script>
</body>
</html>A função get_firstChild (p) é usada para evitar os nós vazios. Isso ajuda a obter o elemento firstChild da lista de nós.
x = get_firstChild(xmlDoc.getElementsByTagName("Employee")[0])busca o primeiro nó filho para o nome da marca Employee .
Execução
Salve este arquivo como first_node_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o primeiro nó filho de Employee, ou seja, FirstName .
Último filho
Esta propriedade é do tipo Node e representa o último nome do filho presente na NodeList.
Exemplo
O exemplo a seguir (last_node_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e, a seguir, navega até o último nó filho presente no objeto xml DOM.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_lastChild(p) {
a = p.lastChild;
while (a.nodeType != 1){
a = a.previousSibling;
}
return a;
}
var lastchild = get_lastChild(xmlDoc.getElementsByTagName("Employee")[0]);
document.write(lastchild.nodeName);
</script>
</body>
</html>Execução
Salve este arquivo como last_node_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o último nó filho de Employee, ou seja, Email .
Próximo irmão
Esta propriedade é do tipo Node e representa o próximo filho, ou seja, o próximo irmão do elemento filho especificado presente na NodeList.
Exemplo
O exemplo a seguir (nextSibling_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM que navega imediatamente para o próximo nó presente no documento xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
}
else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_nextSibling(p) {
a = p.nextSibling;
while (a.nodeType != 1) {
a = a.nextSibling;
}
return a;
}
var nextsibling = get_nextSibling(xmlDoc.getElementsByTagName("FirstName")[0]);
document.write(nextsibling.nodeName);
</script>
</body>
</html>Execução
Salve este arquivo como nextSibling_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o próximo nó irmão de FirstName, ou seja, LastName .
Irmão anterior
Esta propriedade é do tipo Node e representa o filho anterior, ou seja, o irmão anterior do elemento filho especificado presente na NodeList.
Exemplo
O exemplo a seguir (previoussibling_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e, em seguida, navega no nó anterior do último nó filho presente no documento xml.
<!DOCTYPE html>
<body>
<script>
if (window.XMLHttpRequest)
{
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
function get_previousSibling(p) {
a = p.previousSibling;
while (a.nodeType != 1) {
a = a.previousSibling;
}
return a;
}
prevsibling = get_previousSibling(xmlDoc.getElementsByTagName("Email")[0]);
document.write(prevsibling.nodeName);
</script>
</body>
</html>Execução
Salve este arquivo como previoussibling_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o nó irmão anterior de Email, ou seja, ContactNo .
Neste capítulo, estudaremos como acessar os nós XML DOM, que são considerados unidades de informação do documento XML. A estrutura de nós do XML DOM permite ao desenvolvedor navegar pela árvore em busca de informações específicas e, simultaneamente, acessar as informações.
Nós de acesso
A seguir estão as três maneiras pelas quais você pode acessar os nós -
Usando o getElementsByTagName () método
Fazendo um loop ou atravessando a árvore de nós
Navegando na árvore do nó, usando os relacionamentos do nó
getElementsByTagName ()
Este método permite acessar as informações de um nó especificando o nome do nó. Também permite acessar as informações da Lista de Nós e Comprimento da Lista de Nós.
Sintaxe
O método getElementByTagName () tem a seguinte sintaxe -
node.getElementByTagName("tagname");Onde,
nó - é o nó do documento.
tagname - contém o nome do nó cujo valor você deseja obter.
Exemplo
A seguir está um programa simples que ilustra o uso do método getElementByTagName.
<!DOCTYPE html>
<html>
<body>
<div>
<b>FirstName:</b> <span id = "FirstName"></span><br>
<b>LastName:</b> <span id = "LastName"></span><br>
<b>Category:</b> <span id = "Employee"></span><br>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
document.getElementById("FirstName").innerHTML =
xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0].nodeValue;
document.getElementById("LastName").innerHTML =
xmlDoc.getElementsByTagName("LastName")[0].childNodes[0].nodeValue;
document.getElementById("Employee").innerHTML =
xmlDoc.getElementsByTagName("Employee")[0].attributes[0].nodeValue;
</script>
</body>
</html>No exemplo acima, estamos acessando as informações dos nós FirstName , LastName e Employee .
xmlDoc.getElementsByTagName ("FirstName") [0] .childNodes [0] .nodeValue; Esta linha acessa o valor do nó filho FirstName usando o método getElementByTagName ().
xmlDoc.getElementsByTagName ("Employee") [0] .attributes [0] .nodeValue; Esta linha acessa o valor do atributo do método getElementByTagName () do nó Employee .
Atravessando nós
Isso é abordado no capítulo Traversing de DOM com exemplos.
Navegando pelos nós
Isso é abordado no capítulo Navegação no DOM com exemplos.
Neste capítulo, estudaremos como obter o valor do nó de um objeto XML DOM. Os documentos XML possuem uma hierarquia de unidades de informação denominadas nós. O objeto Node possui uma propriedade nodeValue , que retorna o valor do elemento.
Nas seções a seguir, discutiremos -
Obtendo o valor do nó de um elemento
Obtendo valor de atributo de um nó
O node.xml usado em todos os exemplos a seguir é o seguinte -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Obter valor do nó
O método getElementsByTagName () retorna uma NodeList de todos os elementos na ordem do documento com um determinado nome de tag.
Exemplo
O exemplo a seguir (getnode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e extrai o valor do nó do nó filho Firstname (índice em 0) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else{
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('FirstName')[0]
y = x.childNodes[0];
document.write(y.nodeValue);
</script>
</body>
</html>Execução
Salve este arquivo como getnode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do nó como Tanmay .
Obtenha o valor do atributo
Os atributos fazem parte dos elementos do nó XML. Um elemento de nó pode ter vários atributos exclusivos. O atributo fornece mais informações sobre os elementos do nó XML. Para ser mais preciso, eles definem propriedades dos elementos do nó. Um atributo XML é sempre um par nome-valor. Este valor do atributo é chamado de nó de atributo .
O método getAttribute () recupera um valor de atributo por nome de elemento.
Exemplo
O exemplo a seguir (get_attribute_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e extrai o valor do atributo da categoria Funcionário (índice em 2) -
<!DOCTYPE html>
<html>
<body>
<script>
if (window.XMLHttpRequest) {
xmlhttp = new XMLHttpRequest();
} else {
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/dom/node.xml",false);
xmlhttp.send();
xmlDoc = xmlhttp.responseXML;
x = xmlDoc.getElementsByTagName('Employee')[2];
document.write(x.getAttribute('category'));
</script>
</body>
</html>Execução
Salve este arquivo como get_attribute_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo como Gerenciamento .
Neste capítulo, estudaremos como alterar os valores dos nós em um objeto XML DOM. O valor do nó pode ser alterado da seguinte forma -
var value = node.nodeValue;Se o nó for um Atributo , a variável de valor será o valor do atributo; se o nó for um nó de Texto , será o conteúdo do texto; se o nó for um elemento, ele será nulo .
As seções a seguir demonstrarão a configuração do valor do nó para cada tipo de nó (atributo, nó de texto e elemento).
O node.xml usado em todos os exemplos a seguir é o seguinte -
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Alterar o valor do nó de texto
Quando, digamos, o valor de alteração do elemento Node, queremos dizer editar o conteúdo de texto de um elemento (que também é chamado de nó de texto ). O exemplo a seguir demonstra como alterar o nó de texto de um elemento.
Exemplo
O exemplo a seguir (set_text_node_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e altera o valor do nó de texto de um elemento. Neste caso, envie o e- mail de cada Funcionário para [email protected] e imprima os valores.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Email");
for(i = 0;i<x.length;i++) {
x[i].childNodes[0].nodeValue = "[email protected]";
document.write(i+');
document.write(x[i].childNodes[0].nodeValue);
document.write('<br>');
}
</script>
</body>
</html>Execução
Salve este arquivo como set_text_node_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Você receberá a seguinte saída -
0) [email protected]
1) [email protected]
2) [email protected]Alterar o valor do nó de atributo
O exemplo a seguir demonstra como alterar o nó de atributo de um elemento.
Exemplo
O exemplo a seguir (set_attribute_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e altera o valor do nó de atributo de um elemento. Neste caso, a Categoria de cada Funcionário para admin-0, admin-1, admin-2 respectivamente e imprime os valores.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("Employee");
for(i = 0 ;i<x.length;i++){
newcategory = x[i].getAttributeNode('category');
newcategory.nodeValue = "admin-"+i;
document.write(i+');
document.write(x[i].getAttributeNode('category').nodeValue);
document.write('<br>');
}
</script>
</body>
</html>Execução
Salve este arquivo como set_node_attribute_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). O resultado seria o seguinte -
0) admin-0
1) admin-1
2) admin-2Neste capítulo, discutiremos como criar novos nós usando alguns métodos do objeto de documento. Esses métodos fornecem um escopo para criar um novo nó de elemento, nó de texto, nó de comentário, nó de seção CDATA e nó de atributo . Se o nó recém-criado já existir no objeto do elemento, ele será substituído pelo novo. As seções a seguir demonstram isso com exemplos.
Criar novo nó de elemento
O método createElement () cria um novo nó de elemento. Se o nó do elemento recém-criado existir no objeto do elemento, ele será substituído pelo novo.
Sintaxe
A sintaxe para usar o método createElement () é a seguinte -
var_name = xmldoc.createElement("tagname");Onde,
var_name - é o nome da variável definida pelo usuário que contém o nome do novo elemento.
("tagname") - é o nome do novo nó de elemento a ser criado.
Exemplo
O exemplo a seguir (createnewelement_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria um novo nó de elemento PhoneNo no documento XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
new_element = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(new_element);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>new_element = xmlDoc.createElement ("PhoneNo"); cria o novo nó de elemento <PhoneNo>
x.appendChild (novo_elemento); x contém o nome do nó filho especificado <FirstName> ao qual o novo nó de elemento é anexado.
Execução
Salve este arquivo como createnewelement_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo como PhoneNo .
Criar novo nó de texto
O método createTextNode () cria um novo nó de texto.
Sintaxe
A sintaxe para usar createTextNode () é a seguinte -
var_name = xmldoc.createTextNode("tagname");Onde,
var_name - é o nome da variável definida pelo usuário que contém o nome do novo nó de texto.
("tagname") - entre parênteses está o nome do novo nó de texto a ser criado.
Exemplo
O exemplo a seguir (createtextnode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria um novo nó de texto Im novo nó de texto no documento XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
create_t = xmlDoc.createTextNode("Im new text node");
create_e.appendChild(create_t);
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_e);
document.write(" PhoneNO: ");
document.write(x.getElementsByTagName("PhoneNo")[0].childNodes[0].nodeValue);
</script>
</body>
</html>Os detalhes do código acima são os seguintes -
create_e = xmlDoc.createElement ("PhoneNo"); cria um novo elemento < PhoneNo >.
create_t = xmlDoc.createTextNode ("Im novo nó de texto"); cria um novo nó de texto "Im novo nó de texto" .
x.appendChild (criar_e); o nó de texto, "Im novo nó de texto" é anexado ao elemento, < PhoneNo >.
document.write (x.getElementsByTagName ("PhoneNo") [0] .childNodes [0] .nodeValue); grava o novo valor do nó de texto no elemento <PhoneNo>.
Execução
Salve este arquivo como createtextnode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo como, por exemplo, PhoneNO: Im new text node .
Criar novo nó de comentário
O método createComment () cria um novo nó de comentário. O nó de comentário está incluído no programa para facilitar a compreensão da funcionalidade do código.
Sintaxe
A sintaxe para usar createComment () é a seguinte -
var_name = xmldoc.createComment("tagname");Onde,
var_name - é o nome da variável definida pelo usuário que contém o nome do novo nó de comentário.
("tagname") - é o nome do novo nó de comentário a ser criado.
Exemplo
O exemplo a seguir (createcommentnode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria um novo nó de comentário, "Company is the parent node" no documento XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_comment = xmlDoc.createComment("Company is the parent node");
x = xmlDoc.getElementsByTagName("Company")[0];
x.appendChild(create_comment);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>No exemplo acima -
create_comment = xmlDoc.createComment ("Company is the parent node") creates a specified comment line.
x.appendChild (create_comment) Nesta linha, 'x' contém o nome do elemento <Company> ao qual a linha de comentário é anexada.
Execução
Salve este arquivo como createcommentnode_example.htm no caminho do servidor (este arquivo e o node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo, pois Company é o nó pai .
Criar novo nó de seção CDATA
O método createCDATASection () cria um novo nó de seção CDATA. Se o nó de seção CDATA recém-criado existir no objeto de elemento, ele será substituído pelo novo.
Sintaxe
A sintaxe para usar createCDATASection () é a seguinte -
var_name = xmldoc.createCDATASection("tagname");Onde,
var_name - é o nome da variável definida pelo usuário que contém o nome do novo nó da seção CDATA.
("tagname") - é o nome do novo nó de seção CDATA a ser criado.
Exemplo
O exemplo a seguir (createcdatanode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria um novo nó de seção CDATA, "Criar Exemplo CDATA" no documento XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
}
else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_CDATA = xmlDoc.createCDATASection("Create CDATA Example");
x = xmlDoc.getElementsByTagName("Employee")[0];
x.appendChild(create_CDATA);
document.write(x.lastChild.nodeValue);
</script>
</body>
</html>No exemplo acima -
create_CDATA = xmlDoc.createCDATASection ("Criar exemplo CDATA") cria um novo nó de seção CDATA, "Criar exemplo CDATA"
x.appendChild (create_CDATA) aqui, x contém o elemento especificado <Employee> indexado em 0 ao qual o valor do nó CDATA é anexado.
Execução
Salve este arquivo como createcdatanode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo como Criar Exemplo CDATA .
Criar novo nó de atributo
Para criar um novo nó de atributo, o método setAttributeNode () é usado. Se o nó de atributo recém-criado existir no objeto de elemento, ele será substituído pelo novo.
Sintaxe
A sintaxe para usar o método createElement () é a seguinte -
var_name = xmldoc.createAttribute("tagname");Onde,
var_name - é o nome da variável definida pelo usuário que contém o nome do novo nó de atributo.
("tagname") - é o nome do novo nó de atributo a ser criado.
Exemplo
O exemplo a seguir (createattributenode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria uma nova seção de nó de atributo no documento XML.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_a = xmlDoc.createAttribute("section");
create_a.nodeValue = "A";
x = xmlDoc.getElementsByTagName("Employee");
x[0].setAttributeNode(create_a);
document.write("New Attribute: ");
document.write(x[0].getAttribute("section"));
</script>
</body>
</html>No exemplo acima -
create_a = xmlDoc.createAttribute ("Category") cria um atributo com o nome <seção>.
create_a.nodeValue = "Management" cria o valor "A" para o atributo <seção>.
x [0] .setAttributeNode (create_a) este valor de atributo é definido para o elemento de nó <Employee> indexado em 0.
Neste capítulo, discutiremos os nós do elemento existente. Ele fornece um meio para -
anexar novos nós filhos antes ou depois dos nós filhos existentes
insira dados dentro do nó de texto
adicionar nó de atributo
Os métodos a seguir podem ser usados para adicionar / anexar os nós a um elemento em um DOM -
- appendChild()
- insertBefore()
- insertData()
appendChild ()
O método appendChild () adiciona o novo nó filho após o nó filho existente.
Sintaxe
A sintaxe do método appendChild () é a seguinte -
Node appendChild(Node newChild) throws DOMExceptionOnde,
newChild - é o nó a ser adicionado
Este método retorna o Nó adicionado.
Exemplo
O exemplo a seguir (appendchildnode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e anexa o novo filho PhoneNo ao elemento <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("PhoneNo");
x = xmlDoc.getElementsByTagName("FirstName")[0];
x.appendChild(create_e);
document.write(x.getElementsByTagName("PhoneNo")[0].nodeName);
</script>
</body>
</html>No exemplo acima -
usando o método createElement (), um novo elemento PhoneNo é criado.
O novo elemento PhoneNo é adicionado ao elemento FirstName usando o método appendChild ().
Execução
Salve este arquivo como appendchildnode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Na saída, obtemos o valor do atributo como PhoneNo .
insertBefore ()
O método insertBefore () insere os novos nós filhos antes dos nós filhos especificados.
Sintaxe
A sintaxe do método insertBefore () é a seguinte -
Node insertBefore(Node newChild, Node refChild) throws DOMExceptionOnde,
newChild - é o nó a ser inserido
refChild - É o nó de referência, ou seja, o nó antes do qual o novo nó deve ser inserido.
Este método retorna o Nó que está sendo inserido.
Exemplo
O exemplo a seguir (insertnodebefore_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e insere um novo Email filho antes do elemento especificado <Email>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
create_e = xmlDoc.createElement("Email");
x = xmlDoc.documentElement;
y = xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements before inserting was: " + y.length);
document.write("<br>");
x.insertBefore(create_e,y[3]);
y=xmlDoc.getElementsByTagName("Email");
document.write("No of Email elements after inserting is: " + y.length);
</script>
</body>
</html>No exemplo acima -
usando o método createElement (), um novo elemento Email é criado.
O novo elemento Email é adicionado antes do elemento Email usando o método insertBefore ().
y.length fornece o número total de elementos adicionados antes e depois do novo elemento.
Execução
Salve este arquivo como insertnodebefore_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Receberemos a seguinte saída -
No of Email elements before inserting was: 3
No of Email elements after inserting is: 4insertData ()
O método insertData () insere uma string no deslocamento da unidade de 16 bits especificada.
Sintaxe
O insertData () tem a seguinte sintaxe -
void insertData(int offset, java.lang.String arg) throws DOMExceptionOnde,
deslocamento - é o deslocamento de caractere no qual inserir.
arg - é a palavra-chave para inserir os dados. Ele inclui os dois parâmetros offset e string entre parênteses separados por vírgula.
Exemplo
O exemplo a seguir (addtext_example.htm) analisa um documento XML (" node.xml ") em um objeto XML DOM e insere novos dados MiddleName na posição especificada para o elemento <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0].childNodes[0];
document.write(x.nodeValue);
x.insertData(6,"MiddleName");
document.write("<br>");
document.write(x.nodeValue);
</script>
</body>
</html>x.insertData(6,"MiddleName");- Aqui, x contém o nome do filho especificado, ou seja, <FirstName>. Em seguida, inserimos neste nó de texto os dados "MiddleName" a partir da posição 6.
Execução
Salve este arquivo como addtext_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Receberemos o seguinte na saída -
Tanmay
TanmayMiddleNameNeste capítulo, estudaremos sobre a operação de substituição de nó em um objeto XML DOM. Como sabemos, tudo no DOM é mantido em uma unidade hierárquica informativa conhecida como nó e o nó substituto fornece outra maneira de atualizar esses nós especificados ou um nó de texto.
A seguir estão os dois métodos para substituir os nós.
- replaceChild()
- replaceData()
replaceChild ()
O método replaceChild () substitui o nó especificado pelo novo nó.
Sintaxe
O insertData () tem a seguinte sintaxe -
Node replaceChild(Node newChild, Node oldChild) throws DOMExceptionOnde,
newChild - é o novo nó a ser colocado na lista de filhos.
oldChild - é o nó sendo substituído na lista.
Este método retorna o nó substituído.
Exemplo
O exemplo a seguir (replaceenode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e substitui o nó especificado <FirstName> pelo novo nó <Name>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.documentElement;
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element before replace operation</b><br>");
for (i=0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
//create a Employee element, FirstName element and a text node
newNode = xmlDoc.createElement("Employee");
newTitle = xmlDoc.createElement("Name");
newText = xmlDoc.createTextNode("MS Dhoni");
//add the text node to the title node,
newTitle.appendChild(newText);
//add the title node to the book node
newNode.appendChild(newTitle);
y = xmlDoc.getElementsByTagName("Employee")[0]
//replace the first book node with the new node
x.replaceChild(newNode,y);
z = xmlDoc.getElementsByTagName("FirstName");
document.write("<b>Content of FirstName element after replace operation</b><br>");
for (i = 0;i<z.length;i++) {
document.write(z[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>Execução
Salve este arquivo como replaceenode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obteremos a saída conforme mostrado abaixo -
Content of FirstName element before replace operation
Tanmay
Taniya
Tanisha
Content of FirstName element after replace operation
Taniya
TanishareplaceData ()
O método replaceData () substitui os caracteres começando no deslocamento da unidade de 16 bits especificada pela string especificada.
Sintaxe
O replaceData () tem a seguinte sintaxe -
void replaceData(int offset, int count, java.lang.String arg) throws DOMExceptionOnde
deslocamento - é o deslocamento a partir do qual iniciar a substituição.
contagem - é o número de unidades de 16 bits a serem substituídas. Se a soma do deslocamento e da contagem exceder o comprimento, todas as unidades de 16 bits até o final dos dados serão substituídas.
arg - o DOMString com o qual o intervalo deve ser substituído.
Exemplo
O exemplo a seguir ( overrata_example.htm ) analisa um documento XML ( node.xml ) em um objeto XML DOM e o substitui.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("ContactNo")[0].childNodes[0];
document.write("<b>ContactNo before replace operation:</b> "+x.nodeValue);
x.replaceData(1,5,"9999999");
document.write("<br>");
document.write("<b>ContactNo after replace operation:</b> "+x.nodeValue);
</script>
</body>
</html>No exemplo acima -
x.replaceData (2,3, "999"); - Aqui x contém o texto do elemento especificado <ContactNo> cujo texto é substituído pelo novo texto "9999999" , começando da posição 1 até o comprimento de 5 .
Execução
Salve o arquivo como replacedata_example.htm no caminho do servidor (este arquivo e node.xml deve estar no mesmo caminho no seu servidor). Obteremos a saída conforme mostrado abaixo -
ContactNo before replace operation: 1234567890
ContactNo after replace operation: 199999997890Neste capítulo, estudaremos sobre a operação XML DOM Remove Node . A operação de remoção do nó remove o nó especificado do documento. Esta operação pode ser implementada para remover os nós como nó de texto, nó de elemento ou um nó de atributo.
A seguir estão os métodos que são usados para a operação de remoção do nó -
removeChild()
removeAttribute()
removeChild ()
O método removeChild () remove o nó filho indicado por oldChild da lista de filhos e o retorna. Remover um nó filho é equivalente a remover um nó de texto. Portanto, a remoção de um nó filho remove o nó de texto associado a ele.
Sintaxe
A sintaxe para usar removeChild () é a seguinte -
Node removeChild(Node oldChild) throws DOMExceptionOnde,
oldChild - é o nó que está sendo removido.
Este método retorna o nó removido.
Exemplo - Remover Nó Atual
O exemplo a seguir (removecurrentnode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e remove o nó especificado <ContactNo> do nó pai.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
document.write("<b>Before remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
document.write("<br>");
x = xmlDoc.getElementsByTagName("ContactNo")[0];
x.parentNode.removeChild(x);
document.write("<b>After remove operation, total ContactNo elements: </b>");
document.write(xmlDoc.getElementsByTagName("ContactNo").length);
</script>
</body>
</html>No exemplo acima -
x = xmlDoc.getElementsByTagName ("ContactNo") [0] obtém o elemento <ContactNo> indexado em 0.
x.parentNode.removeChild (x); remove o elemento <ContactNo> indexado em 0 do nó pai.
Execução
Salve este arquivo como removecurrentnode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obtemos o seguinte resultado -
Before remove operation, total ContactNo elements: 3
After remove operation, total ContactNo elements: 2Exemplo - Remover Nó de Texto
O exemplo a seguir (removetextNode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e remove o nó filho especificado <FirstName>.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName("FirstName")[0];
document.write("<b>Text node of child node before removal is:</b> ");
document.write(x.childNodes.length);
document.write("<br>");
y = x.childNodes[0];
x.removeChild(y);
document.write("<b>Text node of child node after removal is:</b> ");
document.write(x.childNodes.length);
</script>
</body>
</html>No exemplo acima -
x = xmlDoc.getElementsByTagName ("FirstName") [0]; - obtém o primeiro elemento <FirstName> ax indexado em 0.
y = x.nodos filhos [0]; - nesta linha, y contém o nó filho a ser removido.
x.removeChild (y); - remove o nó filho especificado.
Execução
Salve este arquivo como removetextNode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obtemos o seguinte resultado -
Text node of child node before removal is: 1
Text node of child node after removal is: 0removeAttribute ()
O método removeAttribute () remove um atributo de um elemento por nome.
Sintaxe
A sintaxe para usar removeAttribute () é a seguinte -
void removeAttribute(java.lang.String name) throws DOMExceptionOnde,
nome - é o nome do atributo a ser removido.
Exemplo
O exemplo a seguir (removeelementattribute_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e remove o nó de atributo especificado.
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee');
document.write(x[1].getAttribute('category'));
document.write("<br>");
x[1].removeAttribute('category');
document.write(x[1].getAttribute('category'));
</script>
</body>
</html>No exemplo acima -
document.write (x [1] .getAttribute ('categoria')); - o valor da categoria de atributo indexado na 1ª posição é invocado.
x [1] .removeAttribute ('categoria'); - remove o valor do atributo.
Execução
Salve este arquivo como removeelementattribute_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obtemos o seguinte resultado -
Non-Technical
nullNeste capítulo, iremos discutir a operação Clone Node no objeto XML DOM. A operação do nó clone é usada para criar uma cópia duplicada do nó especificado. cloneNode () é usado para esta operação.
cloneNode ()
Este método retorna uma duplicata deste nó, ou seja, serve como um construtor de cópia genérico para nós. O nó duplicado não tem pai (parentNode é nulo) e nenhum dado do usuário.
Sintaxe
O método cloneNode () tem a seguinte sintaxe -
Node cloneNode(boolean deep)deep - se true, clona recursivamente a subárvore no nó especificado; se falso, clona apenas o próprio nó (e seus atributos, se for um Elemento).
Este método retorna o nó duplicado.
Exemplo
O exemplo a seguir (clonenode_example.htm) analisa um documento XML ( node.xml ) em um objeto XML DOM e cria uma cópia profunda do primeiro elemento Employee .
<!DOCTYPE html>
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
xmlDoc = loadXMLDoc("/dom/node.xml");
x = xmlDoc.getElementsByTagName('Employee')[0];
clone_node = x.cloneNode(true);
xmlDoc.documentElement.appendChild(clone_node);
firstname = xmlDoc.getElementsByTagName("FirstName");
lastname = xmlDoc.getElementsByTagName("LastName");
contact = xmlDoc.getElementsByTagName("ContactNo");
email = xmlDoc.getElementsByTagName("Email");
for (i = 0;i < firstname.length;i++) {
document.write(firstname[i].childNodes[0].nodeValue+'
'+lastname[i].childNodes[0].nodeValue+',
'+contact[i].childNodes[0].nodeValue+', '+email[i].childNodes[0].nodeValue);
document.write("<br>");
}
</script>
</body>
</html>Como você pode ver no exemplo acima, definimos o parâmetro cloneNode () como true . Conseqüentemente, cada elemento filho no elemento Employee é copiado ou clonado.
Execução
Salve este arquivo como clonenode_example.htm no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obteremos a saída conforme mostrado abaixo -
Tanmay Patil, 1234567890, [email protected]
Taniya Mishra, 1234667898, [email protected]
Tanisha Sharma, 1234562350, [email protected]
Tanmay Patil, 1234567890, [email protected]Você notará que o primeiro elemento Employee foi clonado completamente.
A interface do nó é o tipo de dados principal para todo o Document Object Model. O nó é usado para representar um único elemento XML em toda a árvore do documento.
Um nó pode ser qualquer tipo que seja um nó de atributo, um nó de texto ou qualquer outro nó. Os atributos nodeName, nodeValue e atributos são incluídos como um mecanismo para obter as informações do nó sem efetuar cast down para a interface derivada específica.
Atributos
A tabela a seguir lista os atributos do objeto Node -
| Atributo | Tipo | Descrição |
|---|---|---|
| atributos | NamedNodeMap | É do tipo NamedNodeMap contendo os atributos deste nó (se for um Elemento) ou nulo caso contrário. Isso foi removido. Consulte as especificações |
| baseURI | DOMString | É usado para especificar o URI de base absoluta do nó. |
| childNodes | NodeList | É uma NodeList que contém todos os filhos deste nó. Se não houver filhos, é uma NodeList que não contém nós. |
| primeiro filho | Nó | Ele especifica o primeiro filho de um nó. |
| lastChild | Nó | Ele especifica o último filho de um nó. |
| localName | DOMString | É usado para especificar o nome da parte local de um nó. Isso foi removido. Consulte as especificações . |
| namespaceURI | DOMString | Ele especifica o URI do namespace de um nó. Isso foi removido. Consulte as especificações |
| próximo irmão | Nó | Ele retorna o nó imediatamente após este nó. Se não houver tal nó, retorna nulo. |
| nodeName | DOMString | O nome deste nó, dependendo de seu tipo. |
| nodeType | curto sem sinal | É um código que representa o tipo do objeto subjacente. |
| nodeValue | DOMString | É usado para especificar o valor de um nó dependendo de seus tipos. |
| ownerDocument | Documento | Ele especifica o objeto Document associado ao nó. |
| parentNode | Nó | Esta propriedade especifica o nó pai de um nó. |
| prefixo | DOMString | Esta propriedade retorna o prefixo do namespace de um nó. Isso foi removido. Consulte as especificações |
| irmão anterior | Nó | Isso especifica o nó imediatamente anterior ao nó atual. |
| textContent | DOMString | Isso especifica o conteúdo textual de um nó. |
Tipos de Nó
Listamos os tipos de nós conforme abaixo -
- ELEMENT_NODE
- ATTRIBUTE_NODE
- ENTITY_NODE
- ENTITY_REFERENCE_NODE
- DOCUMENT_FRAGMENT_NODE
- TEXT_NODE
- CDATA_SECTION_NODE
- COMMENT_NODE
- PROCESSING_INSTRUCTION_NODE
- DOCUMENT_NODE
- DOCUMENT_TYPE_NODE
- NOTATION_NODE
Métodos
A tabela abaixo lista os diferentes métodos de objeto de nó -
| S.No. | Método e Descrição |
|---|---|
| 1 | appendChild (Node newChild) Este método adiciona um nó após o último nó filho do nó do elemento especificado. Ele retorna o nó adicionado. |
| 2 | cloneNode (profundidade booleana) Este método é usado para criar um nó duplicado, quando substituído em uma classe derivada. Ele retorna o nó duplicado. |
| 3 | compareDocumentPosition (Node other) Este método é usado para comparar a posição do nó atual em relação a um nó especificado de acordo com a ordem do documento. Retorna curto sem sinal , como o nó está posicionado em relação ao nó de referência. |
| 4 | getFeature(DOMString feature, DOMString version) Retorna o objeto DOM que implementa as APIs especializadas do recurso e versão especificados, se houver, ou null se não houver objeto. Isso foi removido. Consulte as especificações . |
| 5 | getUserData(DOMString key) Recupera o objeto associado a uma chave neste nó. O objeto deve primeiro ter sido definido para este nó chamando setUserData com a mesma chave. Retorna o DOMUserData associado à chave fornecida neste nó, ou nulo se não houver nenhuma. Isso foi removido. Consulte as especificações . |
| 6 | hasAttributes() Retorna se este nó (se for um elemento) possui algum atributo ou não. Retorna verdadeiro se algum atributo estiver presente no nó especificado, caso contrário, retorna falso . Isso foi removido. Consulte as especificações . |
| 7 | hasChildNodes () Retorna se este nó possui algum filho. Este método retorna verdadeiro se o nó atual tiver nós filhos, caso contrário, será falso . |
| 8 | insertBefore (Node newChild, Node refChild) Este método é usado para inserir um novo nó como filho deste nó, diretamente antes de um filho existente deste nó. Ele retorna o nó que está sendo inserido. |
| 9 | isDefaultNamespace (DOMString namespaceURI) Este método aceita um URI de namespace como um argumento e retorna um Booleano com um valor true se o namespace for o namespace padrão no nó fornecido ou false se não for. |
| 10 | isEqualNode (Node arg) Este método testa se dois nós são iguais. Retorna verdadeiro se os nós são iguais, falso caso contrário. |
| 11 | isSameNode(Node other) Este método retorna se o nó atual é o mesmo nó que o dado. Retorna verdadeiro se os nós são iguais e falso caso contrário. Isso foi removido. Consulte as especificações . |
| 12 | isSupported(DOMString feature, DOMString version) Este método retorna se o módulo DOM especificado é suportado pelo nó atual. Retorna verdadeiro se o recurso especificado é suportado neste nó, falso caso contrário. Isso foi removido. Consulte as especificações . |
| 13 | lookupNamespaceURI (prefixo DOMString) Este método obtém o URI do namespace associado ao prefixo do namespace. |
| 14 | lookupPrefix (DOMString namespaceURI) Este método retorna o prefixo mais próximo definido no namespace atual para o URI do namespace. Retorna um prefixo de namespace associado se encontrado ou nulo se nenhum for encontrado. |
| 15 | normalizar() A normalização adiciona todos os nós de texto, incluindo nós de atributo que definem uma forma normal onde a estrutura dos nós que contém elementos, comentários, instruções de processamento, seções CDATA e referências de entidade separa os nós de texto, ou seja, nem nós de texto adjacentes nem nós de Texto vazios. |
| 16 | removeChild (Node oldChild) Este método é usado para remover um nó filho especificado do nó atual. Isso retorna o nó removido. |
| 17 | replaceChild (Node newChild, Node oldChild) Este método é usado para substituir o antigo nó filho por um novo nó. Isso retorna o nó substituído. |
| 18 | setUserData(DOMString key, DOMUserData data, UserDataHandler handler) Este método associa um objeto a uma chave neste nó. O objeto pode ser posteriormente recuperado deste nó chamando getUserData com a mesma chave. Isso retorna o DOMUserData previamente associado à chave fornecida neste nó. Isso foi removido. Consulte as especificações . |
O objeto NodeList especifica a abstração de uma coleção ordenada de nós. Os itens na NodeList são acessíveis por meio de um índice integral, começando em 0.
Atributos
A tabela a seguir lista os atributos do objeto NodeList -
| Atributo | Tipo | Descrição |
|---|---|---|
| comprimento | longo sem sinal | Fornece o número de nós na lista de nós. |
Métodos
O seguinte é o único método do objeto NodeList.
| S.No. | Método e Descrição |
|---|---|
| 1 | item() Ele retorna o índice o item da coleção. Se o índice for maior ou igual ao número de nós na lista, isso retornará nulo. |
O objeto NamedNodeMap é usado para representar coleções de nós que podem ser acessados por nome.
Atributos
A tabela a seguir lista a propriedade do objeto NamedNodeMap.
| Atributo | Tipo | Descrição |
|---|---|---|
| comprimento | longo sem sinal | Fornece o número de nós neste mapa. O intervalo de índices de nós filhos válidos é de 0 a 1, inclusive. |
Métodos
A tabela a seguir lista os métodos do objeto NamedNodeMap .
| S.No. | Métodos e Descrição |
|---|---|
| 1 | getNamedItem () Recupera o nó especificado por nome. |
| 2 | getNamedItemNS () Recupera um nó especificado por nome local e URI de namespace. |
| 3 | item () Retorna o índice do item do mapa. Se o índice for maior ou igual ao número de nós neste mapa, isso retornará nulo. |
| 4 | removeNamedItem () Remove um nó especificado por nome. |
| 5 | removeNamedItemNS () Remove um nó especificado por nome local e URI de namespace. |
| 6 | setNamedItem () Adiciona um nó usando seu atributo nodeName . Se um nó com esse nome já estiver presente neste mapa, ele será substituído pelo novo. |
| 7 | setNamedItemNS () Adiciona um nó usando seu namespaceURI e localName . Se um nó com esse URI de namespace e esse nome local já estiver presente neste mapa, ele será substituído pelo novo. Substituir um nó por si só não tem efeito. |
O objeto DOMImplementation fornece vários métodos para executar operações que são independentes de qualquer instância particular do modelo de objeto de documento.
Métodos
A tabela a seguir lista os métodos do objeto DOMImplementation -
| S.No. | Método e Descrição |
|---|---|
| 1 | createDocument (namespaceURI, relevantName, doctype) Ele cria um objeto DOM Document do tipo especificado com seu elemento de documento. |
| 2 | createDocumentType (relevantName, publicId, systemId) Ele cria um nó DocumentType vazio . |
| 3 | getFeature(feature, version) Este método retorna um objeto especializado que implementa as APIs especializadas do recurso e versão especificados. Isso foi removido. Consulte as especificações . |
| 4 | hasFeature (recurso, versão) Este método testa se a implementação do DOM implementa um recurso e uma versão específicos. |
Os objetos DocumentType são a chave para acessar os dados do documento e, no documento, o atributo doctype pode ter o valor nulo ou o valor do objeto DocumentType. Esses objetos DocumentType atuam como uma interface para as entidades descritas para um documento XML.
Atributos
A tabela a seguir lista os atributos do objeto DocumentType -
| Atributo | Tipo | Descrição |
|---|---|---|
| nome | DOMString | Ele retorna o nome do DTD que está escrito imediatamente ao lado da palavra-chave! DOCTYPE. |
| entidades | NamedNodeMap | Ele retorna um objeto NamedNodeMap contendo as entidades gerais, externas e internas, declaradas no DTD. |
| notações | NamedNodeMap | Ele retorna um NamedNodeMap contendo as notações declaradas no DTD. |
| internalSubset | DOMString | Ele retorna um subconjunto interno como uma string ou nulo se não houver nenhum. Isso foi removido. Consulte as especificações . |
| publicId | DOMString | Ele retorna o identificador público do subconjunto externo. |
| systemId | DOMString | Ele retorna o identificador do sistema do subconjunto externo. Este pode ser um URI absoluto ou não. |
Métodos
DocumentType herda métodos de seu pai, Node , e implementa a interface ChildNode .
ProcessingInstruction fornece as informações específicas do aplicativo que geralmente estão incluídas na seção do prólogo do documento XML.
As instruções de processamento (PIs) podem ser usadas para passar informações aos aplicativos. Os PIs podem aparecer em qualquer lugar do documento fora da marcação. Eles podem aparecer no prólogo, incluindo a definição do tipo de documento (DTD), no conteúdo textual ou após o documento.
Um PI começa com uma tag especial <? e termina com ?>. O processamento do conteúdo termina imediatamente após a string?> é encontrado.
Atributos
A tabela a seguir lista os atributos do objeto ProcessingInstruction -
| Atributo | Tipo | Descrição |
|---|---|---|
| dados | DOMString | É um caractere que descreve as informações para o aplicativo processar imediatamente antes de?>. |
| alvo | DOMString | Isso identifica o aplicativo para o qual a instrução ou os dados são direcionados. |
A interface de entidade representa uma entidade conhecida, analisada ou não, em um documento XML. O atributo nodeName que é herdado de Node contém o nome da entidade.
Um objeto Entity não possui nenhum nó pai e todos os seus nós sucessores são somente leitura.
Atributos
A tabela a seguir lista os atributos do objeto Entidade -
| Atributo | Tipo | Descrição |
|---|---|---|
| inputEncoding | DOMString | Isso especifica a codificação usada pela entidade externa analisada. Seu valor é nulo se for uma entidade do subconjunto interno ou se for desconhecido. |
| notationName | DOMString | Para entidades não analisadas, fornece o nome da notação e seu valor é nulo para as entidades analisadas. |
| publicId | DOMString | Fornece o nome do identificador público associado à entidade. |
| systemId | DOMString | Fornece o nome do identificador do sistema associado à entidade. |
| xmlEncoding | DOMString | Ele fornece a codificação xml incluída como parte da declaração de texto para a entidade externa analisada, caso contrário, null. |
| xmlVersion | DOMString | Fornece a versão xml incluída como parte da declaração de texto para a entidade externa analisada, caso contrário, null. |
Os objetos EntityReference são as referências gerais da entidade que são inseridas no documento XML, fornecendo escopo para substituir o texto. O objeto EntityReference não funciona para as entidades predefinidas, pois elas são consideradas expandidas pelo processador HTML ou XML.
Esta interface não possui propriedades ou métodos próprios, mas herda de Node .
Neste capítulo, estudaremos sobre o objeto XML DOM Notation . A propriedade do objeto de notação fornece um escopo para reconhecer o formato de elementos com um atributo de notação, uma instrução de processamento particular ou dados não XML. As propriedades e métodos do Objeto de Nó podem ser executados no Objeto de Notação, uma vez que também é considerado um Nó.
Este objeto herda métodos e propriedades de Node . Seu nodeName é o nome da notação. Não tem pai.
Atributos
A tabela a seguir lista os atributos do objeto Notation -
| Atributo | Tipo | Descrição |
|---|---|---|
| publicID | DOMString | Fornece o nome do identificador público associado à notação. |
| systemID | DOMString | Fornece o nome do identificador do sistema associado à notação. |
Os elementos XML podem ser definidos como blocos de construção de XML. Os elementos podem se comportar como contêineres para conter texto, elementos, atributos, objetos de mídia ou todos eles. Sempre que o analisador analisa um documento XML em relação à boa formação, o analisador navega por um nó de elemento. Um nó de elemento contém o texto dentro dele, que é chamado de nó de texto.
O objeto Element herda as propriedades e os métodos do objeto Node, pois o objeto element também é considerado um Node. Além das propriedades e métodos do objeto de nó, ele possui as seguintes propriedades e métodos.
Propriedades
A tabela a seguir lista os atributos do objeto Element -
| Atributo | Tipo | Descrição |
|---|---|---|
| tagName | DOMString | Fornece o nome da tag para o elemento especificado. |
| schemaTypeInfo | TypeInfo | Ele representa as informações de tipo associadas a este elemento. Isso foi removido. Consulte as especificações . |
Métodos
A tabela abaixo lista os métodos de objeto de elemento -
| Métodos | Tipo | Descrição |
|---|---|---|
| getAttribute () | DOMString | Recupera o valor do atributo, se existir para o elemento especificado. |
| getAttributeNS () | DOMString | Recupera um valor de atributo por nome local e URI de namespace. |
| getAttributeNode () | Attr | Recupera o nome do nó de atributo do elemento atual. |
| getAttributeNodeNS () | Attr | Recupera um nó Attr por nome local e URI de namespace. |
| getElementsByTagName () | NodeList | Retorna uma NodeList de todos os elementos descendentes com um determinado nome de tag, na ordem do documento. |
| getElementsByTagNameNS () | NodeList | Retorna uma NodeList de todos os elementos descendentes com um determinado nome local e URI de namespace na ordem do documento. |
| hasAttribute () | boleano | Retorna verdadeiro quando um atributo com um determinado nome é especificado neste elemento ou possui um valor padrão; caso contrário, retorna falso. |
| hasAttributeNS () | boleano | Retorna verdadeiro quando um atributo com um determinado nome local e URI de namespace é especificado neste elemento ou tem um valor padrão; caso contrário, é falso. |
| removeAttribute () | Sem valor de retorno | Remove um atributo por nome. |
| removeAttributeNS | Sem valor de retorno | Remove um atributo por nome local e URI de namespace. |
| removeAttributeNode () | Attr | O nó de atributo especificado é removido do elemento. |
| setAttribute () | Sem valor de retorno | Define um novo valor de atributo para o elemento existente. |
| setAttributeNS () | Sem valor de retorno | Adiciona um novo atributo. Se um atributo com o mesmo nome local e URI de espaço de nomes já estiver presente no elemento, seu prefixo será alterado para ser a parte do prefixo do nome qualificado e seu valor será alterado para ser o parâmetro de valor. |
| setAttributeNode () | Attr | Define um novo nó de atributo para o elemento existente. |
| setAttributeNodeNS | Attr | Adiciona um novo atributo. Se um atributo com esse nome local e esse URI de namespace já estiver presente no elemento, ele será substituído pelo novo. |
| setIdAttribute | Sem valor de retorno | Se o parâmetro isId for verdadeiro, este método declara o atributo especificado como um atributo de ID determinado pelo usuário. Isso foi removido. Consulte as especificações . |
| setIdAttributeNS | Sem valor de retorno | Se o parâmetro isId for verdadeiro, este método declara o atributo especificado como um atributo de ID determinado pelo usuário. Isso foi removido. Consulte as especificações . |
A interface Attr representa um atributo em um objeto Element. Normalmente, os valores permitidos para o atributo são definidos em um esquema associado ao documento. Os objetos Attr não são considerados como parte da árvore do documento, pois eles não são realmente nós filhos do elemento que descrevem. Portanto, para os nós filhos parentNode , previousSibling e nextSibling, o valor do atributo é nulo .
Atributos
A tabela a seguir lista os atributos do objeto Atributo -
| Atributo | Tipo | Descrição |
|---|---|---|
| nome | DOMString | Isso fornece o nome do atributo. |
| Especificadas | boleano | É um valor booleano que retorna verdadeiro se o valor do atributo existir no documento. |
| valor | DOMString | Retorna o valor do atributo. |
| ownerElement | Elemento | Fornece o nó ao qual o atributo está associado ou nulo se o atributo não estiver em uso. |
| isId | boleano | Ele retorna se o atributo é conhecido por ser do tipo ID (ou seja, por conter um identificador para seu elemento proprietário) ou não. |
Neste capítulo, estudaremos sobre o XML DOM CDATASection Object . O texto presente em um documento XML é analisado ou não, dependendo do que é declarado. Se o texto for declarado como Dados de caractere de análise (PCDATA), ele será analisado pelo analisador para converter um documento XML em um objeto XML DOM. Por outro lado, se o texto for declarado como dados de caracteres não analisados (CDATA), o texto dentro não será analisado pelo analisador XML. Eles não são considerados marcação e não irão expandir as entidades.
O objetivo de usar o objeto CDATASection é escapar dos blocos de texto que contêm caracteres que, de outra forma, seriam considerados como marcação. "]]>", este é o único delimitador reconhecido em uma seção CDATA que termina a seção CDATA.
O atributo CharacterData.data contém o texto contido na seção CDATA. Essa interface herda a interface CharatcterData por meio da interface de texto .
Não há métodos e atributos definidos para o objeto CDATASection. Ele apenas implementa diretamente a interface de texto .
Neste capítulo, estudaremos sobre o objeto Comentário . Os comentários são adicionados como notas ou linhas para entender o propósito de um código XML. Os comentários podem ser usados para incluir links, informações e termos relacionados. Eles podem aparecer em qualquer lugar no código XML.
A interface de comentário herda a interface CharacterData que representa o conteúdo do comentário.
Sintaxe
O comentário XML tem a seguinte sintaxe -
<!-------Your comment----->Um comentário começa com <! - e termina com ->. Você pode adicionar notas textuais como comentários entre os personagens. Você não deve aninhar um comentário dentro do outro.
Não há métodos e atributos definidos para o objeto Comentário. Ele herda os de seu pai, CharacterData , e indiretamente os de Node .
O objeto XMLHttpRequest estabelece um meio entre o lado do cliente e o lado do servidor de uma página da Web que pode ser usado por muitas linguagens de script como JavaScript, JScript, VBScript e outro navegador da Web para transferir e manipular os dados XML.
Com o objeto XMLHttpRequest é possível atualizar parte de uma página web sem recarregar toda a página, solicitar e receber os dados de um servidor após o carregamento da página e enviar os dados para o servidor.
Sintaxe
Um objeto XMLHttpRequest pode ser instanciado da seguinte maneira -
xmlhttp = new XMLHttpRequest();Para lidar com todos os navegadores, incluindo IE5 e IE6, verifique se o navegador oferece suporte ao objeto XMLHttpRequest conforme abaixo -
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}Exemplos para carregar um arquivo XML usando o objeto XMLHttpRequest podem ser consultados aqui
Métodos
A tabela a seguir lista os métodos do objeto XMLHttpRequest -
| S.No. | Método e Descrição |
|---|---|
| 1 | abort() Encerra a solicitação atual feita. |
| 2 | getAllResponseHeaders() Retorna todos os cabeçalhos de resposta como uma string ou null se nenhuma resposta foi recebida. |
| 3 | getResponseHeader() Retorna a string que contém o texto do cabeçalho especificado ou null se a resposta ainda não foi recebida ou o cabeçalho não existe na resposta. |
| 4 | open(method,url,async,uname,pswd) É usado em conjugação com o método Send para enviar o pedido ao servidor. O método aberto especifica os seguintes parâmetros -
|
| 5 | send(string) É utilizado para enviar a solicitação trabalhando em conjugação com o método Open. |
| 6 | setRequestHeader() O cabeçalho contém o par rótulo / valor para o qual a solicitação é enviada. |
Atributos
A tabela a seguir lista os atributos do objeto XMLHttpRequest -
| S.No. | Atributo e descrição |
|---|---|
| 1 | onreadystatechange É uma propriedade baseada em evento que é ativada a cada mudança de estado. |
| 2 | readyState Isso descreve o estado atual do objeto XMLHttpRequest. Existem cinco estados possíveis da propriedade readyState -
|
| 3 | responseText Esta propriedade é usada quando a resposta do servidor é um arquivo de texto. |
| 4 | responseXML Esta propriedade é usada quando a resposta do servidor é um arquivo XML. |
| 5 | status Fornece o status do objeto de solicitação Http como um número. Por exemplo, "404" ou "200". |
| 6 | statusText Fornece o status do objeto de solicitação Http como uma string. Por exemplo, "Não encontrado" ou "OK". |
Exemplos
O conteúdo do node.xml é o seguinte -
<?xml version = "1.0"?>
<Company>
<Employee category = "Technical">
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Taniya</FirstName>
<LastName>Mishra</LastName>
<ContactNo>1234667898</ContactNo>
<Email>[email protected]</Email>
</Employee>
<Employee category = "Management">
<FirstName>Tanisha</FirstName>
<LastName>Sharma</LastName>
<ContactNo>1234562350</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>Recupere informações específicas de um arquivo de recurso
O exemplo a seguir demonstra como recuperar informações específicas de um arquivo de recurso usando o método getResponseHeader () e a propriedade readState .
<!DOCTYPE html>
<html>
<head>
<meta http-equiv = "content-type" content = "text/html; charset = iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
}
else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getResponseHeader("Content-length");
}
}
}
</script>
</head>
<body>
<button type = "button" onclick="makerequest('/dom/node.xml', 'ID')">Click me to get the specific ResponseHeader</button>
<div id = "ID">Specific header information is returned.</div>
</body>
</html>Execução
Salve este arquivo como elementattribute_removeAttributeNS.htm no caminho do servidor (este arquivo e node_ns.xml devem estar no mesmo caminho em seu servidor). Obteremos a saída conforme mostrado abaixo -
Before removing the attributeNS: en
After removing the attributeNS: nullRecuperar informações de cabeçalho de um arquivo de recurso
O exemplo a seguir demonstra como recuperar as informações do cabeçalho de um arquivo de recurso, usando o método getAllResponseHeaders() usando a propriedade readyState.
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="content-type" content="text/html; charset=iso-8859-2" />
<script>
function loadXMLDoc() {
var xmlHttp = null;
if(window.XMLHttpRequest) // for Firefox, IE7+, Opera, Safari, ... {
xmlHttp = new XMLHttpRequest();
} else if(window.ActiveXObject) // for Internet Explorer 5 or 6 {
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
return xmlHttp;
}
function makerequest(serverPage, myDiv) {
var request = loadXMLDoc();
request.open("GET", serverPage);
request.send(null);
request.onreadystatechange = function() {
if (request.readyState == 4) {
document.getElementById(myDiv).innerHTML = request.getAllResponseHeaders();
}
}
}
</script>
</head>
<body>
<button type = "button" onclick = "makerequest('/dom/node.xml', 'ID')">
Click me to load the AllResponseHeaders</button>
<div id = "ID"></div>
</body>
</html>Execução
Salve este arquivo como http_allheader.html no caminho do servidor (este arquivo e node.xml devem estar no mesmo caminho em seu servidor). Obteremos a saída conforme mostrado abaixo (depende do navegador) -
Date: Sat, 27 Sep 2014 07:48:07 GMT Server: Apache Last-Modified:
Wed, 03 Sep 2014 06:35:30 GMT Etag: "464bf9-2af-50223713b8a60" Accept-Ranges: bytes Vary: Accept-Encoding,User-Agent
Content-Encoding: gzip Content-Length: 256 Content-Type: text/xmlA DOMException representa um evento anormal que ocorre quando um método ou propriedade é usado.
Propriedades
A tabela abaixo lista as propriedades do objeto DOMException
| S.No. | Descrição da Propriedade |
|---|---|
| 1 | name Retorna um DOMString que contém uma das strings associadas a uma constante de erro (conforme visto na tabela abaixo). |
Tipos de Erro
| S.No. | Tipo e descrição |
|---|---|
| 1 | IndexSizeError O índice não está no intervalo permitido. Por exemplo, isso pode ser lançado pelo objeto Range. (Valor do código legado: 1 e nome da constante legada: INDEX_SIZE_ERR) |
| 2 | HierarchyRequestError A hierarquia da árvore de nós não está correta. (Valor do código legado: 3 e nome da constante legada: HIERARCHY_REQUEST_ERR) |
| 3 | WrongDocumentError O objeto está no documento errado. (Valor do código legado: 4 e nome da constante legada: WRONG_DOCUMENT_ERR) |
| 4 | InvalidCharacterError A string contém caracteres inválidos. (Valor do código legado: 5 e nome da constante legada: INVALID_CHARACTER_ERR) |
| 5 | NoModificationAllowedError O objeto não pode ser modificado. (Valor do código legado: 7 e nome da constante legada: NO_MODIFICATION_ALLOWED_ERR) |
| 6 | NotFoundError O objeto não pode ser encontrado aqui. (Valor do código legado: 8 e nome da constante legada: NOT_FOUND_ERR) |
| 7 | NotSupportedError A operação não é compatível. (Valor do código legado: 9 e nome da constante legada: NOT_SUPPORTED_ERR) |
| 8 | InvalidStateError O objeto está em um estado inválido. (Valor do código legado: 11 e nome da constante legada: INVALID_STATE_ERR) |
| 9 | SyntaxError A string não corresponde ao padrão esperado. (Valor do código legado: 12 e nome da constante legada: SYNTAX_ERR) |
| 10 | InvalidModificationError O objeto não pode ser modificado desta forma. (Valor do código legado: 13 e nome da constante legada: INVALID_MODIFICATION_ERR) |
| 11 | NamespaceError A operação não é permitida por namespaces em XML. (Valor do código legado: 14 e nome da constante legada: NAMESPACE_ERR) |
| 12 | InvalidAccessError O objeto não suporta a operação ou argumento. (Valor do código legado: 15 e nome da constante legada: INVALID_ACCESS_ERR) |
| 13 | TypeMismatchError O tipo do objeto não corresponde ao tipo esperado. (Valor do código legado: 17 e nome da constante legada: TYPE_MISMATCH_ERR) Este valor está obsoleto, a exceção JavaScript TypeError agora é gerada em vez de uma DOMException com este valor. |
| 14 | SecurityError A operação é insegura. (Valor do código legado: 18 e nome da constante legada: SECURITY_ERR) |
| 15 | NetworkError Ocorreu um erro de rede. (Valor do código legado: 19 e nome da constante legada: NETWORK_ERR) |
| 16 | AbortError A operação foi abortada. (Valor do código legado: 20 e nome da constante legada: ABORT_ERR) |
| 17 | URLMismatchError O URL fornecido não corresponde a outro URL. (Valor do código legado: 21 e nome da constante legada: URL_MISMATCH_ERR) |
| 18 | QuotaExceededError A cota foi excedida. (Valor do código legado: 22 e nome da constante legada: QUOTA_EXCEEDED_ERR) |
| 19 | TimeoutError A operação expirou. (Valor do código legado: 23 e nome da constante legada: TIMEOUT_ERR) |
| 20 | InvalidNodeTypeError O nó está incorreto ou possui um ancestral incorreto para esta operação. (Valor do código legado: 24 e nome da constante legada: INVALID_NODE_TYPE_ERR) |
| 21 | DataCloneError O objeto não pode ser clonado. (Valor do código legado: 25 e nome da constante legada: DATA_CLONE_ERR) |
| 22 | EncodingError A operação de codificação, sendo uma codificação ou decodificação, falhou (nenhum valor de código legado e nome constante). |
| 23 | NotReadableError A operação de leitura de entrada / saída falhou (nenhum valor de código legado e nome de constante). |
Exemplo
O exemplo a seguir demonstra como o uso de um documento XML mal formado causa uma DOMException.
O conteúdo do error.xml é o seguinte -
<?xml version = "1.0" encoding = "UTF-8" standalone = "no" ?>
<Company id = "companyid">
<Employee category = "Technical" id = "firstelement" type = "text/html">
<FirstName>Tanmay</first>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>[email protected]</Email>
</Employee>
</Company>O exemplo a seguir demonstra o uso do atributo name -
<html>
<head>
<script>
function loadXMLDoc(filename) {
if (window.XMLHttpRequest) {
xhttp = new XMLHttpRequest();
} else // code for IE5 and IE6 {
xhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xhttp.open("GET",filename,false);
xhttp.send();
return xhttp.responseXML;
}
</script>
</head>
<body>
<script>
try {
xmlDoc = loadXMLDoc("/dom/error.xml");
var node = xmlDoc.getElementsByTagName("to").item(0);
var refnode = node.nextSibling;
var newnode = xmlDoc.createTextNode('That is why you fail.');
node.insertBefore(newnode, refnode);
} catch(err) {
document.write(err.name);
}
</script>
</body>
</html>Execução
Salve este arquivo como domexcption_name.html no caminho do servidor (este arquivo e error.xml devem estar no mesmo caminho em seu servidor). Obteremos a saída conforme mostrado abaixo -
TypeError