Data Warehousing - Estratégia de Particionamento
O particionamento é feito para melhorar o desempenho e facilitar o gerenciamento de dados. O particionamento também ajuda a equilibrar os vários requisitos do sistema. Ele otimiza o desempenho do hardware e simplifica o gerenciamento do data warehouse, particionando cada tabela de fatos em várias partições separadas. Neste capítulo, discutiremos diferentes estratégias de particionamento.
Por que é necessário particionar?
O particionamento é importante pelos seguintes motivos -
- Para facilitar o gerenciamento,
- Para auxiliar o backup / recuperação,
- Para melhorar o desempenho.
Para fácil gerenciamento
A tabela de fatos em um data warehouse pode crescer até centenas de gigabytes. Esse tamanho enorme de tabela de fatos é muito difícil de gerenciar como uma entidade única. Portanto, ele precisa de particionamento.
Para auxiliar o backup / recuperação
Se não particionarmos a tabela de fatos, teremos que carregar a tabela de fatos completa com todos os dados. O particionamento nos permite carregar apenas os dados necessários regularmente. Reduz o tempo de carregamento e também melhora o desempenho do sistema.
Note- Para reduzir o tamanho do backup, todas as partições, exceto a partição atual, podem ser marcadas como somente leitura. Podemos então colocar essas partições em um estado em que não possam ser modificadas. Em seguida, eles podem ser copiados. Isso significa que apenas a partição atual deve ser copiada.
Para melhorar o desempenho
Ao particionar a tabela de fatos em conjuntos de dados, os procedimentos de consulta podem ser aprimorados. O desempenho da consulta é aprimorado porque agora a consulta verifica apenas as partições que são relevantes. Não é necessário verificar todos os dados.
Particionamento Horizontal
Existem várias maneiras de particionar uma tabela de fatos. No particionamento horizontal, devemos ter em mente os requisitos de gerenciamento do data warehouse.
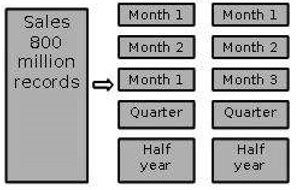
Particionamento por tempo em segmentos iguais
Nessa estratégia de particionamento, a tabela de fatos é particionada com base no período de tempo. Aqui, cada período de tempo representa um período de retenção significativo dentro da empresa. Por exemplo, se o usuário consultarmonth to date dataentão, é apropriado particionar os dados em segmentos mensais. Podemos reutilizar as tabelas particionadas removendo os dados delas.
Partição por tempo em segmentos de tamanhos diferentes
Esse tipo de partição é feito onde os dados antigos são acessados com pouca frequência. É implementado como um conjunto de pequenas partições para dados relativamente atuais, partição maior para dados inativos.
Pontos a serem observados
As informações detalhadas permanecem disponíveis online.
O número de tabelas físicas é mantido relativamente pequeno, o que reduz o custo operacional.
Essa técnica é adequada quando uma combinação de dados que mergulham no histórico recente e mineração de dados em todo o histórico é necessária.
Essa técnica não é útil onde o perfil de particionamento muda regularmente, porque o reparticionamento aumentará o custo operacional do data warehouse.
Partição em uma dimensão diferente
A tabela de fatos também pode ser particionada com base em outras dimensões além do tempo, como grupo de produtos, região, fornecedor ou qualquer outra dimensão. Vamos dar um exemplo.
Suponha que uma função de mercado tenha sido estruturada em departamentos regionais distintos, como em um state by statebase. Se cada região deseja consultar as informações capturadas em sua região, seria mais eficaz particionar a tabela de fatos em partições regionais. Isso fará com que as consultas sejam mais rápidas, porque não exige a verificação de informações que não são relevantes.
Pontos a serem observados
A consulta não precisa verificar dados irrelevantes, o que acelera o processo de consulta.
Esta técnica não é apropriada onde as dimensões provavelmente não mudarão no futuro. Portanto, vale a pena determinar que a dimensão não muda no futuro.
Se a dimensão for alterada, toda a tabela de fatos deverá ser reparticionada.
Note - Recomendamos executar a partição apenas com base na dimensão de tempo, a menos que você tenha certeza de que o agrupamento de dimensão sugerido não mudará durante a vida útil do data warehouse.
Partição por tamanho da mesa
Quando não há uma base clara para particionar a tabela de fatos em qualquer dimensão, devemos partition the fact table on the basis of their size.Podemos definir o tamanho predeterminado como um ponto crítico. Quando a tabela excede o tamanho predeterminado, uma nova partição de tabela é criada.
Pontos a serem observados
Esse particionamento é complexo de gerenciar.
Requer metadados para identificar quais dados são armazenados em cada partição.
Dimensões de particionamento
Se uma dimensão contiver um grande número de entradas, será necessário particionar as dimensões. Aqui temos que verificar o tamanho de uma dimensão.
Considere um design grande que muda com o tempo. Se precisarmos armazenar todas as variações para aplicar comparações, essa dimensão pode ser muito grande. Isso definitivamente afetaria o tempo de resposta.
Partições Round Robin
Na técnica round robin, quando uma nova partição é necessária, a antiga é arquivada. Ele usa metadados para permitir que a ferramenta de acesso do usuário se refira à partição correta da tabela.
Essa técnica facilita a automação dos recursos de gerenciamento de tabelas no data warehouse.
Partição Vertical
Particionamento vertical, divide os dados verticalmente. As imagens a seguir mostram como o particionamento vertical é feito.
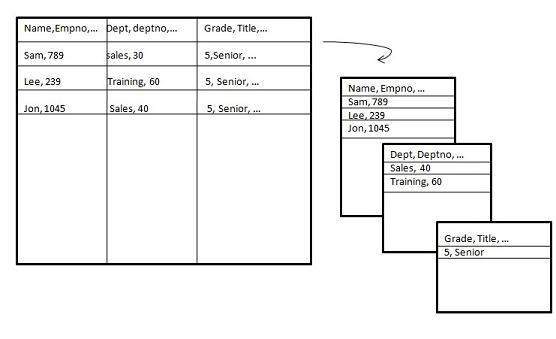
O particionamento vertical pode ser executado das seguintes maneiras -
- Normalization
- Divisão de linha
Normalização
A normalização é o método relacional padrão de organização de banco de dados. Neste método, as linhas são recolhidas em uma única linha, portanto, reduz o espaço. Dê uma olhada nas tabelas a seguir que mostram como a normalização é realizada.
Tabela antes da normalização
| ID do produto | Qty | Valor | data_de_venda | Store_id | Nome da loja | Localização | Região |
|---|---|---|---|---|---|---|---|
| 30 | 5 | 3,67 | 3 de agosto de 13 | 16 | ensolarado | Bangalore | S |
| 35 | 4 | 5,33 | 3-set-13 | 16 | ensolarado | Bangalore | S |
| 40 | 5 | 2,50 | 3-set-13 | 64 | san | Mumbai | W |
| 45 | 7 | 5,66 | 3-set-13 | 16 | ensolarado | Bangalore | S |
Tabela após normalização
| Store_id | Nome da loja | Localização | Região |
|---|---|---|---|
| 16 | ensolarado | Bangalore | W |
| 64 | san | Mumbai | S |
| ID do produto | Quantidade | Valor | data_de_venda | Store_id |
|---|---|---|---|---|
| 30 | 5 | 3,67 | 3 de agosto de 13 | 16 |
| 35 | 4 | 5,33 | 3-set-13 | 16 |
| 40 | 5 | 2,50 | 3-set-13 | 64 |
| 45 | 7 | 5,66 | 3-set-13 | 16 |
Divisão de linha
A divisão de linha tende a deixar um mapa um-para-um entre as partições. O motivo da divisão de linha é acelerar o acesso a uma mesa grande, reduzindo seu tamanho.
Note - Ao usar o particionamento vertical, certifique-se de que não haja nenhum requisito para realizar uma operação de junção principal entre duas partições.
Identificar a chave para a partição
É muito importante escolher a chave de partição correta. A escolha de uma chave de partição errada levará à reorganização da tabela de fatos. Vamos dar um exemplo. Suponha que desejamos particionar a tabela a seguir.
Account_Txn_Table
transaction_id
account_id
transaction_type
value
transaction_date
region
branch_namePodemos escolher particionar em qualquer chave. As duas chaves possíveis podem ser
- region
- transaction_date
Suponha que a empresa esteja organizada em 30 regiões geográficas e cada região tenha um número diferente de filiais. Isso nos dará 30 partições, o que é razoável. Esse particionamento é bom o suficiente porque nossa captura de requisitos mostrou que a grande maioria das consultas é restrita à própria região de negócios do usuário.
Se particionarmos por transaction_date em vez de região, a última transação de cada região estará em uma partição. Agora, o usuário que deseja examinar os dados de sua própria região precisa consultar várias partições.
Portanto, vale a pena determinar a chave de particionamento correta.