Git - conceitos básicos
Sistema de controle de versão
Version Control System (VCS) é um software que ajuda os desenvolvedores de software a trabalhar juntos e manter um histórico completo de seu trabalho.
Listadas abaixo estão as funções de um VCS -
- Permite que os desenvolvedores trabalhem simultaneamente.
- Não permite sobrescrever as alterações uns dos outros.
- Mantém um histórico de cada versão.
A seguir estão os tipos de VCS -
- Sistema de controle de versão centralizado (CVCS).
- Sistema de controle de versão distribuído / descentralizado (DVCS).
Neste capítulo, vamos nos concentrar apenas no sistema de controle de versão distribuído e especialmente no Git. Git se enquadra no sistema de controle de versão distribuído.
Sistema de controle de versão distribuída
O sistema de controle de versão centralizado (CVCS) usa um servidor central para armazenar todos os arquivos e permite a colaboração em equipe. Mas a principal desvantagem do CVCS é seu ponto único de falha, ou seja, falha do servidor central. Infelizmente, se o servidor central ficar inativo por uma hora, durante essa hora, ninguém poderá colaborar. E mesmo na pior das hipóteses, se o disco do servidor central for corrompido e o backup adequado não tiver sido feito, você perderá todo o histórico do projeto. Aqui, o sistema de controle de versão distribuída (DVCS) entra em cena.
Os clientes DVCS não apenas verificam o instantâneo mais recente do diretório, mas também espelham totalmente o repositório. Se o servidor cair, o repositório de qualquer cliente pode ser copiado de volta para o servidor para restaurá-lo. Cada checkout é um backup completo do repositório. Git não depende do servidor central e é por isso que você pode realizar muitas operações quando está offline. Você pode confirmar alterações, criar ramificações, visualizar logs e executar outras operações quando estiver offline. Você precisa de conexão de rede apenas para publicar suas alterações e fazer as alterações mais recentes.
Vantagens do Git
Livre e de código aberto
Git é lançado sob a licença de código aberto GPL. Ele está disponível gratuitamente na Internet. Você pode usar o Git para gerenciar projetos de propriedade sem pagar um único centavo. Por ser um código aberto, você pode baixar seu código-fonte e também realizar alterações de acordo com suas necessidades.
Rápido e pequeno
Como a maioria das operações é realizada localmente, isso traz um grande benefício em termos de velocidade. O Git não depende do servidor central; por isso, não há necessidade de interagir com o servidor remoto para cada operação. A parte central do Git é escrita em C, o que evita sobrecargas de tempo de execução associadas a outras linguagens de alto nível. Embora o Git espelhe o repositório inteiro, o tamanho dos dados no lado do cliente é pequeno. Isso ilustra a eficiência do Git em compactar e armazenar dados no lado do cliente.
Backup implícito
As chances de perda de dados são muito raras quando há várias cópias deles. Os dados presentes em qualquer lado do cliente refletem o repositório, portanto, podem ser usados no caso de uma falha ou corrupção de disco.
Segurança
O Git usa uma função hash criptográfica comum chamada função hash segura (SHA1), para nomear e identificar objetos em seu banco de dados. Cada arquivo e confirmação são somados à verificação e recuperados por sua soma de verificação no momento do checkout. Isso implica que é impossível alterar o arquivo, a data e a mensagem de confirmação e quaisquer outros dados do banco de dados Git sem conhecer o Git.
Não há necessidade de hardware poderoso
No caso do CVCS, o servidor central precisa ser poderoso o suficiente para atender às solicitações de toda a equipe. Para equipes menores, não é um problema, mas conforme o tamanho da equipe aumenta, as limitações de hardware do servidor podem ser um gargalo de desempenho. No caso do DVCS, os desenvolvedores não interagem com o servidor, a menos que precisem enviar ou receber alterações. Todo o trabalho pesado acontece no lado do cliente, portanto, o hardware do servidor pode ser muito simples.
Ramificação mais fácil
O CVCS usa o mecanismo de cópia barata. Se criarmos uma nova ramificação, ele copiará todos os códigos para a nova ramificação, por isso é demorado e não eficiente. Além disso, a exclusão e a fusão de ramificações no CVCS são complicadas e demoradas. Mas o gerenciamento de filiais com Git é muito simples. Leva apenas alguns segundos para criar, excluir e mesclar branches.
Terminologias DVCS
Repositório Local
Cada ferramenta VCS fornece um local de trabalho privado como uma cópia de trabalho. Os desenvolvedores fazem alterações em seus locais de trabalho privados e, após a confirmação, essas alterações se tornam parte do repositório. Git dá um passo adiante, fornecendo a eles uma cópia privada de todo o repositório. Os usuários podem realizar muitas operações com este repositório, como adicionar arquivo, remover arquivo, renomear arquivo, mover arquivo, confirmar alterações e muito mais.
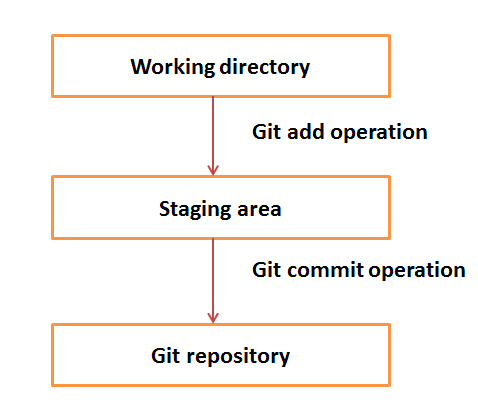
Diretório de trabalho e área de teste ou índice
O diretório de trabalho é o local onde os arquivos são retirados. Em outro CVCS, os desenvolvedores geralmente fazem modificações e enviam suas alterações diretamente para o repositório. Mas o Git usa uma estratégia diferente. O Git não rastreia todos os arquivos modificados. Sempre que você confirma uma operação, o Git procura os arquivos presentes na área de teste. Apenas os arquivos presentes na área de teste são considerados para confirmação e não todos os arquivos modificados.
Vamos ver o fluxo de trabalho básico do Git.
Step 1 - Você modifica um arquivo do diretório de trabalho.
Step 2 - Você adiciona esses arquivos à área de teste.
Step 3- Você executa a operação de confirmação que move os arquivos da área de teste. Após a operação push, ele armazena as alterações permanentemente no repositório Git.
Suponha que você modificou dois arquivos, a saber “sort.c” e “search.c” e deseja dois commits diferentes para cada operação. Você pode adicionar um arquivo na área de teste e fazer o commit. Após o primeiro commit, repita o mesmo procedimento para outro arquivo.
# First commit
[bash]$ git add sort.c
# adds file to the staging area
[bash]$ git commit –m “Added sort operation”
# Second commit
[bash]$ git add search.c
# adds file to the staging area
[bash]$ git commit –m “Added search operation”Blobs
Blob significa Binário Large Object. Cada versão de um arquivo é representada por blob. Um blob contém os dados do arquivo, mas não contém nenhum metadado sobre o arquivo. É um arquivo binário e, no banco de dados Git, é denominado como hash SHA1 desse arquivo. No Git, os arquivos não são endereçados por nomes. Tudo é endereçado ao conteúdo.
Árvores
Tree é um objeto que representa um diretório. Ele contém blobs e também outros subdiretórios. Uma árvore é um arquivo binário que armazena referências a blobs e árvores que também são nomeadas comoSHA1 hash do objeto árvore.
Compromissos
Commit mantém o estado atual do repositório. Um commit também é nomeado porSHA1cerquilha. Você pode considerar um objeto de confirmação como um nó da lista vinculada. Cada objeto de confirmação tem um ponteiro para o objeto de confirmação pai. De um determinado commit, você pode retroceder olhando para o ponteiro pai para ver o histórico do commit. Se um commit tem vários commits pais, então esse commit particular foi criado pela fusão de dois branches.
Ramos
Ramificações são usadas para criar outra linha de desenvolvimento. Por padrão, Git tem um branch master, que é o mesmo que o tronco no Subversion. Normalmente, uma ramificação é criada para trabalhar em um novo recurso. Uma vez que o recurso é concluído, ele é mesclado de volta com o branch master e excluímos o branch. Cada branch é referenciado por HEAD, que aponta para o último commit no branch. Sempre que você faz um commit, o HEAD é atualizado com o commit mais recente.
Tag
A tag atribui um nome significativo com uma versão específica no repositório. As tags são muito semelhantes aos branches, mas a diferença é que as tags são imutáveis. Isso significa que tag é um branch que ninguém pretende modificar. Uma vez que uma tag é criada para um commit particular, mesmo se você criar um novo commit, ele não será atualizado. Normalmente, os desenvolvedores criam tags para lançamentos de produtos.
Clone
A operação de clonagem cria a instância do repositório. A operação de clonagem não apenas verifica a cópia de trabalho, mas também reflete o repositório completo. Os usuários podem realizar várias operações com este repositório local. O único momento em que a rede se envolve é quando as instâncias do repositório estão sendo sincronizadas.
Puxar
A operação pull copia as alterações de uma instância de repositório remoto para uma local. A operação pull é usada para sincronização entre duas instâncias do repositório. É o mesmo que a operação de atualização no Subversion.
Empurrar
A operação push copia as alterações de uma instância do repositório local para uma remota. Isso é usado para armazenar as alterações permanentemente no repositório Git. Isso é o mesmo que a operação de confirmação no Subversion.
CABEÇA
HEAD é um ponteiro, que sempre aponta para o último commit no branch. Sempre que você faz um commit, o HEAD é atualizado com o commit mais recente. As cabeças das filiais são armazenadas em.git/refs/heads/ diretório.
[CentOS]$ ls -1 .git/refs/heads/
master
[CentOS]$ cat .git/refs/heads/master
570837e7d58fa4bccd86cb575d884502188b0c49Revisão
Revisão representa a versão do código-fonte. As revisões no Git são representadas por commits. Esses commits são identificados porSHA1 hashes seguros.
URL
URL representa a localização do repositório Git. O URL do Git é armazenado no arquivo de configuração.
[tom@CentOS tom_repo]$ pwd
/home/tom/tom_repo
[tom@CentOS tom_repo]$ cat .git/config
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
[remote "origin"]
url = [email protected]:project.git
fetch = +refs/heads/*:refs/remotes/origin/*