Hadoop - Soluções de Big Data
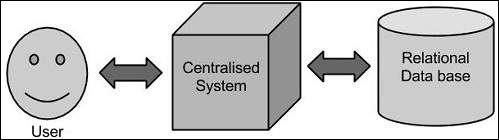
Abordagem tradicional
Nessa abordagem, uma empresa terá um computador para armazenar e processar big data. Para fins de armazenamento, os programadores terão a ajuda de sua escolha de fornecedores de banco de dados, como Oracle, IBM, etc. Nesta abordagem, o usuário interage com o aplicativo, que por sua vez lida com a parte de armazenamento e análise de dados.
Limitação
Essa abordagem funciona bem com os aplicativos que processam dados menos volumosos que podem ser acomodados por servidores de banco de dados padrão ou até o limite do processador que está processando os dados. Mas, quando se trata de lidar com grandes quantidades de dados escaláveis, é uma tarefa agitada processar esses dados por meio de um único gargalo de banco de dados.
Solução do Google
O Google resolveu esse problema usando um algoritmo chamado MapReduce. Este algoritmo divide a tarefa em pequenas partes e as atribui a vários computadores, e coleta os resultados deles que, quando integrados, formam o conjunto de dados de resultados.

Hadoop
Usando a solução fornecida pelo Google, Doug Cutting e sua equipe desenvolveu um projeto de código aberto chamado HADOOP.
O Hadoop executa aplicativos usando o algoritmo MapReduce, onde os dados são processados em paralelo com outros. Resumindo, o Hadoop é usado para desenvolver aplicativos que podem realizar análises estatísticas completas em grandes quantidades de dados.
