HSQLDB - Guia rápido
O Banco de Dados HyperSQL (HSQLDB) é um gerenciador de banco de dados relacional moderno que está em conformidade com o padrão SQL: 2011 e especificações JDBC 4. Ele suporta todos os recursos básicos e RDBMS. HSQLDB é usado para desenvolvimento, teste e implantação de aplicativos de banco de dados.
O recurso principal e exclusivo do HSQLDB é a conformidade padrão. Ele pode fornecer acesso ao banco de dados dentro do processo de aplicativo do usuário, em um servidor de aplicativos ou como um processo de servidor separado.
Recursos do HSQLDB
HSQLDB usa a estrutura na memória para operações rápidas no servidor de banco de dados. Ele usa a persistência de disco de acordo com a flexibilidade do usuário, com uma recuperação de falhas confiável.
HSQLDB também é adequado para business intelligence, ETL e outros aplicativos que processam grandes conjuntos de dados.
HSQLDB tem uma ampla gama de opções de implantação corporativa, como transações XA, fontes de dados de pool de conexão e autenticação remota.
HSQLDB é escrito na linguagem de programação Java e executado em uma Java Virtual Machine (JVM). Ele suporta a interface JDBC para acesso ao banco de dados.
Componentes de HSQLDB
Existem três componentes diferentes no pacote jar HSQLDB.
HyperSQL RDBMS Engine (HSQLDB)
Driver HyperSQL JDBC
Database Manager (ferramenta de acesso a banco de dados GUI, com versões Swing e AWT)
HyperSQL RDBMS e JDBC Driver fornecem a funcionalidade principal. Os gerenciadores de banco de dados são ferramentas de acesso a banco de dados de propósito geral que podem ser usados com qualquer mecanismo de banco de dados que tenha um driver JDBC.
Um jar adicional denominado sqltool.jar contém o Sql Tool, que é uma ferramenta de acesso ao banco de dados de linha de comando. Este é um comando de propósito geral. Ferramenta de acesso ao banco de dados de linha que também pode ser usada com outros mecanismos de banco de dados.
HSQLDB é um sistema de gerenciamento de banco de dados relacional implementado em Java puro. Você pode incorporar facilmente esse banco de dados ao seu aplicativo usando JDBC. Ou você pode usar as operações separadamente.
Pré-requisitos
Siga as instalações de software de pré-requisito para HSQLDB.
Verifique a instalação do Java
Como o HSQLDB é um sistema de gerenciamento de banco de dados relacional implementado em Java puro, você deve instalar o software JDK (Java Development Kit) antes de instalar o HSQLDB. Se você já tem a instalação do JDK em seu sistema, tente o seguinte comando para verificar a versão do Java.
java –versionSe o JDK for instalado com sucesso em seu sistema, você obterá a seguinte saída.
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)Se você não tiver o JDK instalado em seu sistema, visite o seguinte link para Instalar o JDK.
Instalação HSQLDB
A seguir estão as etapas para instalar o HSQLDB.
Step 1 − Download HSQLDB bundle
Baixe a versão mais recente do banco de dados HSQLDB no seguinte link https://sourceforge.net/projects/hsqldb/files/. Depois de clicar no link, você obterá a seguinte captura de tela.

Clique em HSQLDB e o download começará imediatamente. Finalmente, você obterá o arquivo zip chamadohsqldb-2.3.4.zip.
Step 2 − Extract the HSQLDB zip file
Extraia o arquivo zip e coloque-o no C:\diretório. Após a extração, você obterá uma estrutura de arquivo conforme mostrado na imagem a seguir.
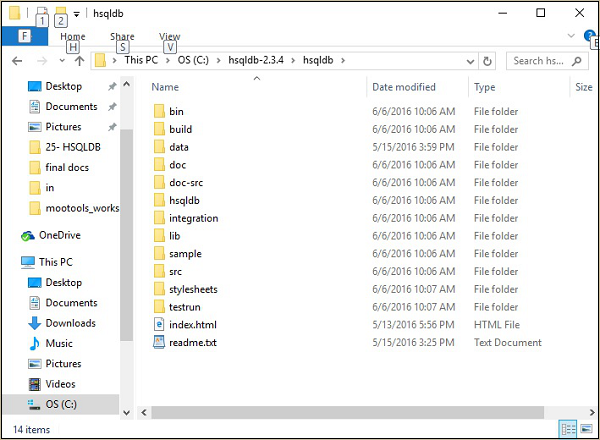
Step 3 − Create a default database
Não há banco de dados padrão para HSQLDB, portanto, você precisa criar um banco de dados para HSQLDB. Vamos criar um arquivo de propriedades chamadoserver.properties que define um novo banco de dados chamado demodb. Dê uma olhada nas seguintes propriedades do servidor de banco de dados.
server.database.0 = file:hsqldb/demodb
server.dbname.0 = testdbColoque este arquivo server.properties no diretório inicial HSQLDB que é C:\hsqldb- 2.3.4\hsqldb\.
Agora execute o seguinte comando no prompt de comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.ServerApós a execução do comando acima, você receberá o status do servidor conforme mostrado na imagem a seguir.
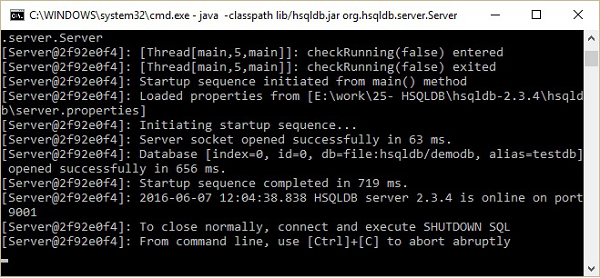
Posteriormente, você encontrará a seguinte estrutura de pastas do diretório hsqldb no diretório inicial HSQLDB que é C:\hsqldb-2.3.4\hsqldb. Esses arquivos são arquivo temporário, arquivo lck, arquivo de log, arquivo de propriedades e arquivo de script do banco de dados demodb criado pelo servidor de banco de dados HSQLDB.
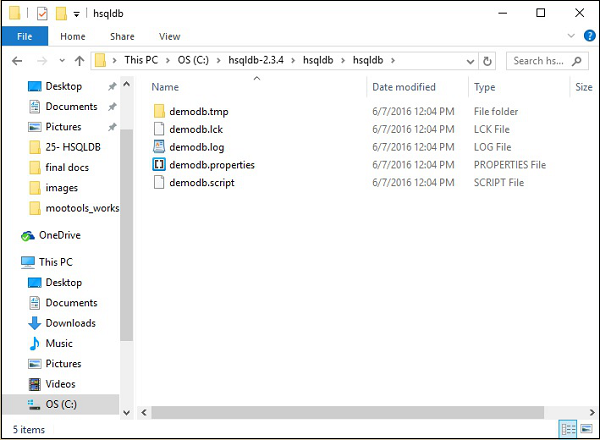
Step 4 − Start the database server
Depois de criar um banco de dados, você deve iniciá-lo usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbApós a execução do comando acima, você obtém o seguinte status.
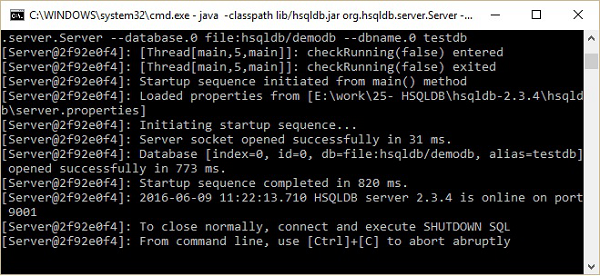
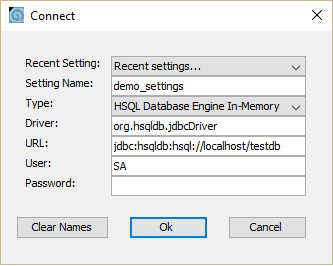
Agora, você pode abrir a tela inicial do banco de dados que é runManagerSwing.bat de C:\hsqldb-2.3.4\hsqldb\binlocalização. Este arquivo bat abrirá o arquivo GUI para o banco de dados HSQLDB. Antes disso, ele solicitará as configurações do banco de dados por meio de uma caixa de diálogo. Dê uma olhada na imagem a seguir. Nesta caixa de diálogo, insira o Nome da configuração, URL conforme mostrado acima e clique em OK.
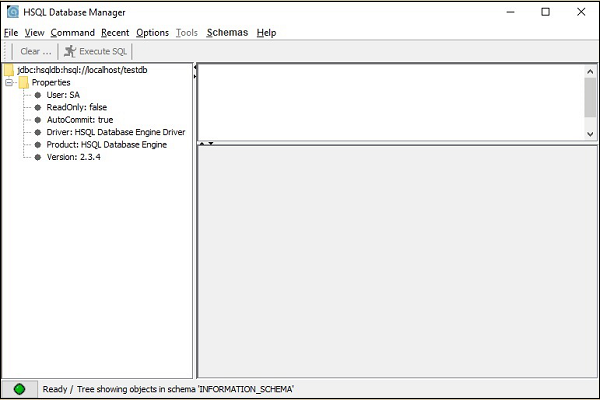
Você obterá a tela GUI do banco de dados HSQLDB conforme mostrado na captura de tela a seguir.
No capítulo de instalação, discutimos como conectar o banco de dados manualmente. Neste capítulo, discutiremos como conectar o banco de dados programaticamente (usando a programação Java).
Dê uma olhada no programa a seguir, que iniciará o servidor e criará uma conexão entre o aplicativo Java e o banco de dados.
Exemplo
import java.sql.Connection;
import java.sql.DriverManager;
public class ConnectDatabase {
public static void main(String[] args) {
Connection con = null;
try {
//Registering the HSQLDB JDBC driver
Class.forName("org.hsqldb.jdbc.JDBCDriver");
//Creating the connection with HSQLDB
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
if (con!= null){
System.out.println("Connection created successfully");
}else{
System.out.println("Problem with creating connection");
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Salve este código em ConnectDatabase.javaArquivo. Você terá que iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbVocê pode usar o seguinte comando para compilar e executar o código.
\>javac ConnectDatabase.java
\>java ConnectDatabaseApós a execução do comando acima, você receberá a seguinte saída -
Connection created successfullyEste capítulo explica os diferentes tipos de dados de HSQLDB. O servidor HSQLDB oferece seis categorias de tipos de dados.
Tipos de dados numéricos exatos
| Tipo de dados | De | Para |
|---|---|---|
| bigint | -9.223.372.036.854.775.808 | 9.223.372.036.854.775.807 |
| int | -2.147.483.648 | 2.147.483.647 |
| smallint | -32.768 | 32.767 |
| tinyint | 0 | 255 |
| mordeu | 0 | 1 |
| decimal | -10 ^ 38 +1 | 10 ^ 38 -1 |
| numérico | -10 ^ 38 +1 | 10 ^ 38 -1 |
| dinheiro | -922.337.203.685.477.5808 | +922.337.203.685.477.5807 |
| dinheirinho | -214.748,3648 | +214.748.3647 |
Tipos de dados numéricos aproximados
| Tipo de dados | De | Para |
|---|---|---|
| flutuador | -1,79E + 308 | 1,79E + 308 |
| real | -3,40E + 38 | 3,40E + 38 |
Tipos de dados de data e hora
| Tipo de dados | De | Para |
|---|---|---|
| data hora | 1º de janeiro de 1753 | 31 de dezembro de 9999 |
| smalldatetime | 1 de janeiro de 1900 | 6 de junho de 2079 |
| encontro | Armazena uma data como 30 de junho de 1991 | |
| Tempo | Armazena uma hora do dia como 12h30 | |
Note - Aqui, o datetime tem uma precisão de 3,33 milissegundos, enquanto o datetime pequeno tem uma precisão de 1 minuto.
Tipos de dados de strings de caracteres
| Tipo de dados | Descrição |
|---|---|
| Caracteres | Comprimento máximo de 8.000 caracteres (caracteres não Unicode de comprimento fixo) |
| varchar | Máximo de 8.000 caracteres (dados não Unicode de comprimento variável) |
| varchar (max) | Comprimento máximo de 231 caracteres, dados não Unicode de comprimento variável (somente SQL Server 2005) |
| texto | Dados não Unicode de comprimento variável com comprimento máximo de 2.147.483.647 caracteres |
Tipos de dados de strings de caracteres Unicode
| Tipo de dados | Descrição |
|---|---|
| nchar | Comprimento máximo de 4.000 caracteres (Unicode de comprimento fixo) |
| nvarchar | Comprimento máximo de 4.000 caracteres (Unicode de comprimento variável) |
| nvarchar (max) | Comprimento máximo de 231 caracteres (apenas SQL Server 2005), (Unicode de comprimento variável) |
| ntext | Comprimento máximo de 1.073.741.823 caracteres (Unicode de comprimento variável) |
Tipos de dados binários
| Tipo de dados | Descrição |
|---|---|
| binário | Comprimento máximo de 8.000 bytes (dados binários de comprimento fixo) |
| varbinary | Comprimento máximo de 8.000 bytes (dados binários de comprimento variável) |
| varbinary (max) | Comprimento máximo de 231 bytes (apenas SQL Server 2005), (dados binários de comprimento variável) |
| imagem | Comprimento máximo de 2.147.483.647 bytes (dados binários de comprimento variável) |
Tipos de dados diversos
| Tipo de dados | Descrição |
|---|---|
| sql_variant | Armazena valores de vários tipos de dados com suporte do SQL Server, exceto text, ntext e timestamp |
| timestamp | Armazena um número exclusivo em todo o banco de dados que é atualizado toda vez que uma linha é atualizada |
| identificador único | Armazena um identificador globalmente exclusivo (GUID) |
| xml | Armazena dados XML. Você pode armazenar instâncias xml em uma coluna ou variável (somente SQL Server 2005) |
| cursor | Referência a um objeto cursor |
| mesa | Armazena um conjunto de resultados para processamento posterior |
Os requisitos básicos obrigatórios para criar uma tabela são o nome da tabela, os nomes dos campos e os tipos de dados desses campos. Opcionalmente, você também pode fornecer as principais restrições à tabela.
Sintaxe
Dê uma olhada na seguinte sintaxe.
CREATE TABLE table_name (column_name column_type);Exemplo
Vamos criar uma tabela chamada tutorials_tbl com os nomes dos campos como id, title, author e submit_date. Dê uma olhada na seguinte consulta.
CREATE TABLE tutorials_tbl (
id INT NOT NULL,
title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL,
submission_date DATE,
PRIMARY KEY (id)
);Após a execução da consulta acima, você receberá a seguinte saída -
(0) rows effectedHSQLDB - Programa JDBC
A seguir está o programa JDBC usado para criar uma tabela chamada tutorials_tbl no banco de dados HSQLDB. Salve o programa emCreateTable.java Arquivo.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class CreateTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("CREATE TABLE tutorials_tbl (
id INT NOT NULL, title VARCHAR(50) NOT NULL,
author VARCHAR(20) NOT NULL, submission_date DATE,
PRIMARY KEY (id));
");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table created successfully");
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac CreateTable.java
\>java CreateTableApós a execução do comando acima, você receberá a seguinte saída -
Table created successfullyÉ muito fácil eliminar uma tabela HSQLDB existente. No entanto, você precisa ter muito cuidado ao excluir qualquer tabela existente, pois os dados perdidos não serão recuperados após a exclusão de uma tabela.
Sintaxe
A seguir está uma sintaxe SQL genérica para descartar uma tabela HSQLDB.
DROP TABLE table_name;Exemplo
Vamos considerar um exemplo para remover uma tabela chamada funcionário do servidor HSQLDB. A seguir está a consulta para descartar uma tabela chamada funcionário.
DROP TABLE employee;Após a execução da consulta acima, você receberá a seguinte saída -
(0) rows effectedHSQLDB - Programa JDBC
A seguir está o programa JDBC usado para retirar o funcionário da mesa do servidor HSQLDB.
Salve o seguinte código em DropTable.java Arquivo.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DropTable {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection("jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("DROP TABLE employee");
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println("Table dropped successfully");
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac DropTable.java
\>java DropTableApós a execução do comando acima, você receberá a seguinte saída -
Table dropped successfullyVocê pode obter a instrução de consulta Insert em HSQLDB usando o comando INSERT INTO. Você deve fornecer os dados definidos pelo usuário seguindo a ordem dos campos da coluna da tabela.
Sintaxe
A seguir está a sintaxe genérica para INSERT uma consulta.
INSERT INTO table_name (field1, field2,...fieldN)
VALUES (value1, value2,...valueN );Para inserir dados do tipo string em uma tabela, você terá que usar aspas duplas ou simples para fornecer o valor da string na instrução de consulta de inserção.
Exemplo
Vamos considerar um exemplo que insere um registro em uma tabela chamada tutorials_tbl com os valores id = 100, title = Learn PHP, Author = John Poul, e a data de envio é a data atual.
A seguir está a consulta para o exemplo fornecido.
INSERT INTO tutorials_tbl VALUES (100,'Learn PHP', 'John Poul', NOW());Após a execução da consulta acima, você receberá a seguinte saída -
1 row effectedHSQLDB - Programa JDBC
Aqui está o programa JDBC para inserir o registro na tabela com os valores fornecidos, id = 100, title = Learn PHP, Author = John Poul, e a data de envio é a data atual. Dê uma olhada no programa fornecido. Salve o código noInserQuery.java Arquivo.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class InsertQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate("INSERT INTO tutorials_tbl
VALUES (100,'Learn PHP', 'John Poul', NOW())");
con.commit();
}catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" rows effected");
System.out.println("Rows inserted successfully");
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac InsertQuery.java
\>java InsertQueryApós a execução do comando acima, você receberá a seguinte saída -
1 rows effected
Rows inserted successfullyTente inserir os seguintes registros no tutorials_tbl mesa usando o INSERT INTO comando.
| Eu iria | Título | Autor | Data de submissão |
|---|---|---|---|
| 101 | Aprenda C | Yaswanth | Agora() |
| 102 | Aprenda MySQL | Abdul S | Agora() |
| 103 | Aprenda Excel | Bavya Kanna | Agora() |
| 104 | Aprenda JDB | Ajith Kumar | Agora() |
| 105 | Aprenda Junit | Sathya Murthi | Agora() |
O comando SELECT é usado para buscar os dados de registro do banco de dados HSQLDB. Aqui, você precisa mencionar a lista de campos obrigatórios na instrução Select.
Sintaxe
Aqui está a sintaxe genérica para a consulta Select.
SELECT field1, field2,...fieldN table_name1, table_name2...
[WHERE Clause]
[OFFSET M ][LIMIT N]Você pode buscar um ou mais campos em um único comando SELECT.
Você pode especificar asterisco (*) no lugar dos campos. Nesse caso, SELECT retornará todos os campos.
Você pode especificar qualquer condição usando a cláusula WHERE.
Você pode especificar um deslocamento usando OFFSET de onde SELECT começará a retornar registros. Por padrão, o deslocamento é zero.
Você pode limitar o número de devoluções usando o atributo LIMIT.
Exemplo
Aqui está um exemplo que busca campos de id, título e autor de todos os registros de tutorials_tblmesa. Podemos conseguir isso usando a instrução SELECT. A seguir está a consulta para o exemplo.
SELECT id, title, author FROM tutorials_tblApós a execução da consulta acima, você receberá a seguinte saída.
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 100 | Learn PHP | John Poul |
| 101 | Learn C | Yaswanth |
| 102 | Learn MySQL | Abdul S |
| 103 | Learn Excell | Bavya kanna |
| 104 | Learn JDB | Ajith kumar |
| 105 | Learn Junit | Sathya Murthi |
+------+----------------+-----------------+HSQLDB - Programa JDBC
Aqui está o programa JDBC que buscará os campos de id, título e autor de todos os registros de tutorials_tblmesa. Salve o seguinte código noSelectQuery.java Arquivo.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class SelectQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl");
while(result.next()){
System.out.println(result.getInt("id")+" | "+
result.getString("title")+" | "+
result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o código acima usando o seguinte comando.
\>javac SelectQuery.java
\>java SelectQueryApós a execução do comando acima, você receberá a seguinte saída -
100 | Learn PHP | John Poul
101 | Learn C | Yaswanth
102 | Learn MySQL | Abdul S
103 | Learn Excell | Bavya Kanna
104 | Learn JDB | Ajith kumar
105 | Learn Junit | Sathya MurthiGeralmente, usamos o comando SELECT para buscar dados da tabela HSQLDB. Podemos usar a cláusula condicional WHERE para filtrar os dados resultantes. Usando WHERE, podemos especificar os critérios de seleção para selecionar os registros necessários de uma tabela.
Sintaxe
A seguir está a sintaxe da cláusula WHERE do comando SELECT para buscar dados da tabela HSQLDB.
SELECT field1, field2,...fieldN table_name1, table_name2...
[WHERE condition1 [AND [OR]] condition2.....Você pode usar uma ou mais tabelas separadas por vírgula para incluir várias condições usando uma cláusula WHERE, mas a cláusula WHERE é uma parte opcional do comando SELECT.
Você pode especificar qualquer condição usando a cláusula WHERE.
Você pode especificar mais de uma condição usando os operadores AND ou OR.
Uma cláusula WHERE também pode ser usada junto com o comando DELETE ou UPDATE SQL para especificar uma condição.
Podemos filtrar os dados do registro usando condições. Estamos usando operadores diferentes na cláusula WHERE condicional. Aqui está a lista de operadores, que podem ser usados com a cláusula WHERE.
| Operador | Descrição | Exemplo |
|---|---|---|
| = | Verifica se os valores dos dois operandos são iguais ou não, caso positivo a condição torna-se verdadeira. | (A = B) não é verdade |
| ! = | Verifica se os valores de dois operandos são iguais ou não; se os valores não são iguais, a condição se torna verdadeira. | (A! = B) é verdade |
| > | Verifica se o valor do operando esquerdo é maior que o valor do operando direito, se sim a condição torna-se verdadeira. | (A> B) não é verdade |
| < | Verifica se o valor do operando esquerdo é menor que o valor do operando direito, se sim a condição torna-se verdadeira. | (A <B) é verdade |
| > = | Verifica se o valor do operando esquerdo é maior ou igual ao valor do operando direito, se sim a condição torna-se verdadeira. | (A> = B) não é verdade |
| <= | Verifica se o valor do operando esquerdo é menor ou igual ao valor do operando direito, se sim a condição torna-se verdadeira. | (A <= B) é verdadeiro |
Exemplo
Aqui está um exemplo que recupera os detalhes como id, título e o autor do livro intitulado "Aprenda C". Isso é possível usando a cláusula WHERE no comando SELECT. A seguir está a consulta para o mesmo.
SELECT id, title, author FROM tutorials_tbl WHERE title = 'Learn C';Após a execução da consulta acima, você receberá a seguinte saída.
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 101 | Learn C | Yaswanth |
+------+----------------+-----------------+HSQLDB - Programa JDBC
Aqui está o programa JDBC que recupera os dados do registro da tabela tutorials_tblhaving the title Learn C. Salve o seguinte código emWhereClause.java.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class WhereClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author FROM tutorials_tbl
WHERE title = 'Learn C'");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o código acima usando o seguinte comando.
\>javac WhereClause.java
\>java WhereClauseApós a execução do comando acima, você receberá a seguinte saída.
101 | Learn C | YaswanthSempre que quiser modificar os valores de uma tabela, pode-se usar o comando UPDATE. Isso modificará qualquer valor de campo de qualquer tabela HSQLDB.
Sintaxe
Aqui está a sintaxe genérica para o comando UPDATE.
UPDATE table_name SET field1 = new-value1, field2 = new-value2 [WHERE Clause]- Você pode atualizar um ou mais campos completamente.
- Você pode especificar qualquer condição usando a cláusula WHERE.
- Você pode atualizar os valores em uma única tabela por vez.
Exemplo
Vamos considerar um exemplo que atualiza o título do tutorial de "Aprenda C" para "C e Estruturas de Dados" com um id "101". A seguir está a consulta para a atualização.
UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101;Após a execução da consulta acima, você receberá a seguinte saída.
(1) Rows effectedHSQLDB - Programa JDBC
Aqui está o programa JDBC que irá atualizar um título de tutorial de Learn C para C and Data Structures ter um id 101. Salve o seguinte programa noUpdateQuery.java Arquivo.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class UpdateQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"UPDATE tutorials_tbl SET title = 'C and Data Structures' WHERE id = 101");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac UpdateQuery.java
\>java UpdateQueryApós a execução do comando acima, você receberá a seguinte saída -
1 Rows effectedSempre que quiser excluir um registro de qualquer tabela HSQLDB, você pode usar o comando DELETE FROM.
Sintaxe
Aqui está a sintaxe genérica para o comando DELETE para excluir dados de uma tabela HSQLDB.
DELETE FROM table_name [WHERE Clause]Se a cláusula WHERE não for especificada, todos os registros serão excluídos da tabela MySQL fornecida.
Você pode especificar qualquer condição usando a cláusula WHERE.
Você pode excluir registros em uma única tabela por vez.
Exemplo
Vamos considerar um exemplo que exclui os dados do registro da tabela chamada tutorials_tbl tendo id 105. A seguir está a consulta que implementa o exemplo fornecido.
DELETE FROM tutorials_tbl WHERE id = 105;Após a execução da consulta acima, você receberá a seguinte saída -
(1) rows effectedHSQLDB - Programa JDBC
Aqui está o programa JDBC que implementa o exemplo fornecido. Salve o seguinte programa emDeleteQuery.java.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
public class DeleteQuery {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
int result = 0;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeUpdate(
"DELETE FROM tutorials_tbl WHERE id=105");
} catch (Exception e) {
e.printStackTrace(System.out);
}
System.out.println(result+" Rows effected");
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac DeleteQuery.java
\>java DeleteQueryApós a execução do comando acima, você receberá a seguinte saída -
1 Rows effectedExiste uma cláusula WHERE na estrutura RDBMS. Você pode usar a cláusula WHERE com um sinal de igual (=) onde queremos fazer uma correspondência exata. Mas pode haver um requisito em que queremos filtrar todos os resultados em que o nome do autor deve conter "john". Isso pode ser tratado usando a cláusula SQL LIKE junto com a cláusula WHERE.
Se a cláusula SQL LIKE for usada junto com os caracteres%, ela funcionará como um metacaractere (*) no UNIX ao listar todos os arquivos ou diretórios no prompt de comando.
Sintaxe
A seguir está a sintaxe SQL genérica da cláusula LIKE.
SELECT field1, field2,...fieldN table_name1, table_name2...
WHERE field1 LIKE condition1 [AND [OR]] filed2 = 'somevalue'Você pode especificar qualquer condição usando a cláusula WHERE.
Você pode usar a cláusula LIKE junto com a cláusula WHERE.
Você pode usar a cláusula LIKE no lugar do sinal de igual.
Quando a cláusula LIKE é usada junto com o sinal%, ela funciona como uma pesquisa de metacaracteres.
Você pode especificar mais de uma condição usando os operadores AND ou OR.
Uma cláusula WHERE ... LIKE pode ser usada junto com o comando DELETE ou UPDATE SQL para especificar uma condição.
Exemplo
Vamos considerar um exemplo que recupera a lista de dados de tutoriais onde o nome do autor começa com John. A seguir está a consulta HSQLDB para o exemplo fornecido.
SELECT * from tutorials_tbl WHERE author LIKE 'John%';Após a execução da consulta acima, você receberá a seguinte saída.
+-----+----------------+-----------+-----------------+
| id | title | author | submission_date |
+-----+----------------+-----------+-----------------+
| 100 | Learn PHP | John Poul | 2016-06-20 |
+-----+----------------+-----------+-----------------+HSQLDB - Programa JDBC
A seguir está o programa JDBC que recupera a lista de dados de tutoriais onde o nome do autor começa com John. Salve o código emLikeClause.java.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class LikeClause {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT * from tutorials_tbl WHERE author LIKE 'John%';");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author")+" |
"+result.getDate("submission_date"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o código acima usando o seguinte comando.
\>javac LikeClause.java
\>java LikeClauseApós a execução do seguinte comando, você receberá a seguinte saída.
100 | Learn PHP | John Poul | 2016-06-20O comando SQL SELECT busca dados da tabela HSQLDB sempre que houver um requisito que segue uma ordem específica durante a recuperação e exibição de registros. Nesse caso, podemos usar oORDER BY cláusula.
Sintaxe
Aqui está a sintaxe do comando SELECT junto com a cláusula ORDER BY para classificar dados de HSQLDB.
SELECT field1, field2,...fieldN table_name1, table_name2...
ORDER BY field1, [field2...] [ASC [DESC]]Você pode classificar o resultado retornado em qualquer campo, desde que esse campo esteja sendo listado.
Você pode classificar o resultado em mais de um campo.
Você pode usar a palavra-chave ASC ou DESC para obter o resultado em ordem crescente ou decrescente. Por padrão, está em ordem crescente.
Você pode usar a cláusula WHERE ... LIKE de uma maneira usual para colocar uma condição.
Exemplo
Vamos considerar um exemplo que busca e classifica os registros de tutorials_tbltabela ordenando o nome do autor em ordem crescente. A seguir está a consulta para o mesmo.
SELECT id, title, author from tutorials_tbl ORDER BY author ASC;Após a execução da consulta acima, você receberá a seguinte saída.
+------+----------------+-----------------+
| id | title | author |
+------+----------------+-----------------+
| 102 | Learn MySQL | Abdul S |
| 104 | Learn JDB | Ajith kumar |
| 103 | Learn Excell | Bavya kanna |
| 100 | Learn PHP | John Poul |
| 105 | Learn Junit | Sathya Murthi |
| 101 | Learn C | Yaswanth |
+------+----------------+-----------------+HSQLDB - Programa JDBC
Aqui está o programa JDBC que busca e classifica os registros de tutorials_tbltabela ordenando o nome do autor em ordem crescente. Salve o seguinte programa emOrderBy.java.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class OrderBy {
public static void main(String[] args) {
Connection con = null;
Statement stmt = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt = con.createStatement();
result = stmt.executeQuery(
"SELECT id, title, author from tutorials_tbl
ORDER BY author ASC");
while(result.next()){
System.out.println(result.getInt("id")+" |
"+result.getString("title")+" |
"+result.getString("author"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Você pode iniciar o banco de dados usando o seguinte comando.
\>cd C:\hsqldb-2.3.4\hsqldb
hsqldb>java -classpath lib/hsqldb.jar org.hsqldb.server.Server --database.0
file:hsqldb/demodb --dbname.0 testdbCompile e execute o programa acima usando o seguinte comando.
\>javac OrderBy.java
\>java OrderByApós a execução do comando acima, você receberá a seguinte saída.
102 | Learn MySQL | Abdul S
104 | Learn JDB | Ajith kumar
103 | Learn Excell | Bavya Kanna
100 | Learn PHP | John Poul
105 | Learn Junit | Sathya Murthi
101 | C and Data Structures | YaswanthSempre que houver um requisito para recuperar dados de várias tabelas usando uma única consulta, você pode usar JOINS do RDBMS. Você pode usar várias tabelas em sua única consulta SQL. O ato de ingressar em HSQLDB refere-se a quebrar duas ou mais tabelas em uma única tabela.
Considere as seguintes tabelas Clientes e Pedidos.
Customer:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
Orders:
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+Agora, vamos tentar recuperar os dados dos clientes e o valor do pedido que o respetivo cliente efetuou. Isso significa que estamos recuperando os dados de registro da tabela de clientes e pedidos. Podemos conseguir isso usando o conceito JOINS no HSQLDB. A seguir está a consulta JOIN para o mesmo.
SELECT ID, NAME, AGE, AMOUNT FROM CUSTOMERS, ORDERS WHERE CUSTOMERS.ID =
ORDERS.CUSTOMER_ID;Após a execução da consulta acima, você receberá a seguinte saída.
+----+----------+-----+--------+
| ID | NAME | AGE | AMOUNT |
+----+----------+-----+--------+
| 3 | kaushik | 23 | 3000 |
| 3 | kaushik | 23 | 1500 |
| 2 | Khilan | 25 | 1560 |
| 4 | Chaitali | 25 | 2060 |
+----+----------+-----+--------+Tipos de JOIN
Existem diferentes tipos de junções disponíveis no HSQLDB.
INNER JOIN - Retorna as linhas quando há uma correspondência em ambas as tabelas.
LEFT JOIN - Retorna todas as linhas da tabela da esquerda, mesmo se não houver correspondências na tabela da direita.
RIGHT JOIN - Retorna todas as linhas da tabela da direita, mesmo se não houver correspondências na tabela da esquerda.
FULL JOIN - Retorna as linhas quando há uma correspondência em uma das tabelas.
SELF JOIN - Usado para juntar uma tabela a si mesma como se a tabela fosse duas tabelas, renomeando temporariamente pelo menos uma tabela na instrução SQL.
Junção interna
A junção mais freqüentemente usada e importante é a INNER JOIN. Ele também é conhecido como EQUIJOIN.
O INNER JOIN cria uma nova tabela de resultados combinando os valores das colunas de duas tabelas (tabela1 e tabela2) com base no predicado de junção. A consulta compara cada linha da tabela1 com cada linha da tabela2 para encontrar todos os pares de linhas que satisfazem o predicado de junção. Quando o predicado de junção é satisfeito, os valores da coluna para cada par correspondente de linhas A e B são combinados em uma linha de resultado.
Sintaxe
A sintaxe básica de INNER JOIN é a seguinte.
SELECT table1.column1, table2.column2...
FROM table1
INNER JOIN table2
ON table1.common_field = table2.common_field;Exemplo
Considere as duas tabelas a seguir, uma intitulada como tabela CUSTOMERS e outra intitulada tabela ORDERS da seguinte forma -
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+Agora, vamos juntar essas duas tabelas usando a consulta INNER JOIN da seguinte maneira -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
INNER JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;Após a execução da consulta acima, você receberá a seguinte saída.
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+----+----------+--------+---------------------+Associação à esquerda
O HSQLDB LEFT JOIN retorna todas as linhas da tabela à esquerda, mesmo se não houver correspondências na tabela à direita. Isso significa que se a cláusula ON corresponder a 0 (zero) registros na tabela certa, a junção ainda retornará uma linha no resultado, mas com NULL em cada coluna da tabela certa.
Isso significa que uma junção à esquerda retorna todos os valores da tabela à esquerda, mais os valores correspondentes da tabela à direita ou NULL no caso de nenhum predicado de junção correspondente.
Sintaxe
A sintaxe básica de LEFT JOIN é a seguinte -
SELECT table1.column1, table2.column2...
FROM table1
LEFT JOIN table2
ON table1.common_field = table2.common_field;Aqui, a condição fornecida pode ser qualquer expressão com base em seus requisitos.
Exemplo
Considere as duas tabelas a seguir, uma intitulada como tabela CUSTOMERS e outra intitulada tabela ORDERS da seguinte forma -
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+Agora, vamos juntar essas duas tabelas usando a consulta LEFT JOIN da seguinte maneira -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
LEFT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;Após a execução da consulta acima, você receberá a seguinte saída -
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
+----+----------+--------+---------------------+Junção certa
O HSQLDB RIGHT JOIN retorna todas as linhas da tabela da direita, mesmo se não houver correspondências na tabela da esquerda. Isso significa que se a cláusula ON corresponder a 0 (zero) registros na tabela à esquerda, a junção ainda retornará uma linha no resultado, mas com NULL em cada coluna da tabela à esquerda.
Isso significa que uma junção à direita retorna todos os valores da tabela à direita, mais os valores correspondentes da tabela à esquerda ou NULL no caso de nenhum predicado de junção correspondente.
Sintaxe
A sintaxe básica de RIGHT JOIN é o seguinte -
SELECT table1.column1, table2.column2...
FROM table1
RIGHT JOIN table2
ON table1.common_field = table2.common_field;Exemplo
Considere as duas tabelas a seguir, uma intitulada como tabela CUSTOMERS e outra intitulada tabela ORDERS da seguinte forma -
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+Agora, vamos juntar essas duas tabelas usando a consulta RIGHT JOIN da seguinte maneira -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
RIGHT JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;Após a execução da consulta acima, você receberá o seguinte resultado.
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+Full Join
O HSQLDB FULL JOIN combina os resultados das junções externas esquerda e direita.
A tabela associada conterá todos os registros de ambas as tabelas e preencherá NULLs para as correspondências ausentes em ambos os lados.
Sintaxe
A sintaxe básica de FULL JOIN é a seguinte -
SELECT table1.column1, table2.column2...
FROM table1
FULL JOIN table2
ON table1.common_field = table2.common_field;Aqui, a condição fornecida pode ser qualquer expressão com base em seus requisitos.
Exemplo
Considere as duas tabelas a seguir, uma intitulada como tabela CUSTOMERS e outra intitulada tabela ORDERS da seguinte forma -
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------++-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+Agora, vamos juntar essas duas tabelas usando a consulta FULL JOIN da seguinte maneira -
SELECT ID, NAME, AMOUNT, DATE FROM CUSTOMERS
FULL JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;Após a execução da consulta acima, você receberá o seguinte resultado.
+------+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+------+----------+--------+---------------------+
| 1 | Ramesh | NULL | NULL |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
| 5 | Hardik | NULL | NULL |
| 6 | Komal | NULL | NULL |
| 7 | Muffy | NULL | NULL |
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+------+----------+--------+---------------------+Self Join
O SQL SELF JOIN é usado para juntar uma tabela a si mesma como se a tabela fosse duas tabelas, renomeando temporariamente pelo menos uma tabela na instrução SQL.
Sintaxe
A sintaxe básica de SELF JOIN é a seguinte -
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_field = b.common_field;Aqui, a cláusula WHERE pode ser qualquer expressão com base em seus requisitos.
Exemplo
Considere as duas tabelas a seguir, uma intitulada como tabela CUSTOMERS e outra intitulada tabela ORDERS da seguinte forma -
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+Agora, vamos juntar esta tabela usando a consulta SELF JOIN da seguinte maneira -
SELECT a.ID, b.NAME, a.SALARY FROM CUSTOMERS a, CUSTOMERS b
WHERE a.SALARY > b.SALARY;Após a execução da consulta acima, você receberá a seguinte saída -
+----+----------+---------+
| ID | NAME | SALARY |
+----+----------+---------+
| 2 | Ramesh | 1500.00 |
| 2 | kaushik | 1500.00 |
| 1 | Chaitali | 2000.00 |
| 2 | Chaitali | 1500.00 |
| 3 | Chaitali | 2000.00 |
| 6 | Chaitali | 4500.00 |
| 1 | Hardik | 2000.00 |
| 2 | Hardik | 1500.00 |
| 3 | Hardik | 2000.00 |
| 4 | Hardik | 6500.00 |
| 6 | Hardik | 4500.00 |
| 1 | Komal | 2000.00 |
| 2 | Komal | 1500.00 |
| 3 | Komal | 2000.00 |
| 1 | Muffy | 2000.00 |
| 2 | Muffy | 1500.00 |
| 3 | Muffy | 2000.00 |
| 4 | Muffy | 6500.00 |
| 5 | Muffy | 8500.00 |
| 6 | Muffy | 4500.00 |
+----+----------+---------+SQL NULL é um termo usado para representar um valor ausente. Um valor NULL em uma tabela é um valor em um campo que parece estar em branco. Sempre que tentamos fornecer uma condição que compara o valor do campo ou coluna com NULL, ela não funciona corretamente.
Podemos lidar com os valores NULL usando as três coisas.
IS NULL - O operador retorna verdadeiro se o valor da coluna for NULL.
IS NOT NULL - O operador retorna verdadeiro se o valor da coluna for NOT NULL.
<=> - O operador compara valores, o que (ao contrário do operador =) é verdadeiro mesmo para dois valores NULL.
Para procurar colunas NULL ou NOT NULL, use IS NULL ou IS NOT NULL respectivamente.
Exemplo
Vamos considerar um exemplo onde há uma mesa tcount_tblque contém duas colunas, autor e tutorial_count. Podemos fornecer valores NULL para o tutorial_count indica que o autor não publicou nem mesmo um tutorial. Portanto, o valor tutorial_count para esse respectivo autor é NULL.
Execute as seguintes consultas.
create table tcount_tbl(author varchar(40) NOT NULL, tutorial_count INT);
INSERT INTO tcount_tbl values ('Abdul S', 20);
INSERT INTO tcount_tbl values ('Ajith kumar', 5);
INSERT INTO tcount_tbl values ('Jen', NULL);
INSERT INTO tcount_tbl values ('Bavya kanna', 8);
INSERT INTO tcount_tbl values ('mahran', NULL);
INSERT INTO tcount_tbl values ('John Poul', 10);
INSERT INTO tcount_tbl values ('Sathya Murthi', 6);Use o seguinte comando para exibir todos os registros do tcount_tbl mesa.
select * from tcount_tbl;Após a execução do comando acima, você receberá a seguinte saída.
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Abdul S | 20 |
| Ajith kumar | 5 |
| Jen | NULL |
| Bavya kanna | 8 |
| mahran | NULL |
| John Poul | 10 |
| Sathya Murthi | 6 |
+-----------------+----------------+Para localizar os registros em que a coluna tutorial_count É NULL, a seguir está a consulta.
SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;Após a execução da consulta, você receberá a seguinte saída.
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Jen | NULL |
| mahran | NULL |
+-----------------+----------------+Para localizar os registros em que a coluna tutorial_count NÃO É NULL, a seguir está a consulta.
SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;Após a execução da consulta, você receberá a seguinte saída.
+-----------------+----------------+
| author | tutorial_count |
+-----------------+----------------+
| Abdul S | 20 |
| Ajith kumar | 5 |
| Bavya kanna | 8 |
| John Poul | 10 |
| Sathya Murthi | 6 |
+-----------------+----------------+HSQLDB - Programa JDBC
Aqui está o programa JDBC que recupera os registros separadamente da tabela tcount_tbl em que tutorial_ count é NULL e tutorial_count NÃO é NULL. Salve o seguinte programa emNullValues.java.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class NullValues {
public static void main(String[] args) {
Connection con = null;
Statement stmt_is_null = null;
Statement stmt_is_not_null = null;
ResultSet result = null;
try {
Class.forName("org.hsqldb.jdbc.JDBCDriver");
con = DriverManager.getConnection(
"jdbc:hsqldb:hsql://localhost/testdb", "SA", "");
stmt_is_null = con.createStatement();
stmt_is_not_null = con.createStatement();
result = stmt_is_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NULL;");
System.out.println("Records where the tutorial_count is NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
result = stmt_is_not_null.executeQuery(
"SELECT * FROM tcount_tbl WHERE tutorial_count IS NOT NULL;");
System.out.println("Records where the tutorial_count is NOT NULL");
while(result.next()){
System.out.println(result.getString("author")+" |
"+result.getInt("tutorial_count"));
}
} catch (Exception e) {
e.printStackTrace(System.out);
}
}
}Compile e execute o programa acima usando o seguinte comando.
\>javac NullValues.java
\>Java NullValuesApós a execução do comando acima, você receberá a seguinte saída.
Records where the tutorial_count is NULL
Jen | 0
mahran | 0
Records where the tutorial_count is NOT NULL
Abdul S | 20
Ajith kumar | 5
Bavya kanna | 8
John Poul | 10
Sathya Murthi | 6HSQLDB suporta alguns símbolos especiais para operação de correspondência de padrões com base em expressões regulares e o operador REGEXP.
A seguir está a tabela de padrões, que pode ser usada junto com o operador REGEXP.
| padronizar | O que o padrão corresponde |
|---|---|
| ^ | Começo da corda |
| $ | Fim da corda |
| . | Qualquer personagem |
| [...] | Qualquer caractere listado entre colchetes |
| [^ ...] | Qualquer caractere não listado entre colchetes |
| p1 | p2 | p3 | Alternação; corresponde a qualquer um dos padrões p1, p2 ou p3 |
| * | Zero ou mais instâncias do elemento anterior |
| + | Uma ou mais instâncias do elemento anterior |
| {n} | n instâncias do elemento anterior |
| {m, n} | m a n instâncias do elemento anterior |
Exemplo
Vamos tentar diferentes exemplos de consultas para atender aos nossos requisitos. Dê uma olhada nas seguintes consultas fornecidas.
Experimente esta Consulta para encontrar todos os autores cujo nome comece com '^ A'.
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^A.*');Após a execução da consulta acima, você receberá a seguinte saída.
+-----------------+
| author |
+-----------------+
| Abdul S |
| Ajith kumar |
+-----------------+Tente esta Consulta para encontrar todos os autores cujo nome termina com 'ul $'.
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*ul$');Após a execução da consulta acima, você receberá a seguinte saída.
+-----------------+
| author |
+-----------------+
| John Poul |
+-----------------+Tente esta consulta para encontrar todos os autores cujo nome contém 'th'.
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'.*th.*');Após a execução da consulta acima, você receberá a seguinte saída.
+-----------------+
| author |
+-----------------+
| Ajith kumar |
| Abdul S |
+-----------------+Tente esta consulta para encontrar todos os autores cujo nome comece com vogal (a, e, i, o, u).
SELECT author FROM tcount_tbl WHERE REGEXP_MATCHES(author,'^[AEIOU].*');Após a execução da consulta acima, você receberá a seguinte saída.
+-----------------+
| author |
+-----------------+
| Abdul S |
| Ajith kumar |
+-----------------+UMA Transactioné um grupo sequencial de operações de manipulação de banco de dados, que é executado e considerado como uma única unidade de trabalho. Em outras palavras, quando todas as operações forem executadas com sucesso, somente então toda a transação será concluída. Se alguma operação dentro da transação falhar, a transação inteira falhará.
Propriedades das transações
Basicamente, a transação oferece suporte a 4 propriedades padrão. Eles podem ser referidos como propriedades ACID.
Atomicity - Todas as operações nas transações são executadas com sucesso, caso contrário, a transação é abortada no ponto de falha e as operações anteriores são revertidas para sua posição anterior.
Consistency - O banco de dados muda de estado corretamente após uma transação confirmada com sucesso.
Isolation - Permite que a transação opere de forma independente e transparente entre si.
Durability - O resultado ou efeito de uma transação confirmada persiste em caso de falha do sistema.
Commit, Rollback e Savepoint
Essas palavras-chave são usadas principalmente para transações HSQLDB.
Commit- Sempre a transação bem-sucedida deve ser concluída executando o comando COMMIT.
Rollback - Se ocorrer uma falha na transação, o comando ROLLBACK deve ser executado para retornar todas as tabelas referenciadas na transação ao seu estado anterior.
Savepoint - Cria um ponto dentro do grupo de transações no qual reverter.
Exemplo
O exemplo a seguir explica o conceito de transações junto com commit, rollback e Savepoint. Vamos considerar a tabela Clientes com as colunas id, nome, idade, endereço e salário.
| Eu iria | Nome | Era | Endereço | Salário |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2.000,00 |
| 2 | Karun | 25 | Délhi | 1500,00 |
| 3 | Kaushik | 23 | Kota | 2.000,00 |
| 4 | Chaitanya | 25 | Mumbai | 6.500,00 |
| 5 | Harish | 27 | Bhopal | 8.500,00 |
| 6 | Kamesh | 22 | MP | 1500,00 |
| 7 | Murali | 24 | Indore | 10.000,00 |
Use os seguintes comandos para criar a tabela de clientes ao longo das linhas dos dados acima.
CREATE TABLE Customer (id INT NOT NULL, name VARCHAR(100) NOT NULL, age INT NOT
NULL, address VARCHAR(20), Salary INT, PRIMARY KEY (id));
Insert into Customer values (1, "Ramesh", 32, "Ahmedabad", 2000);
Insert into Customer values (2, "Karun", 25, "Delhi", 1500);
Insert into Customer values (3, "Kaushik", 23, "Kota", 2000);
Insert into Customer values (4, "Chaitanya", 25, "Mumbai", 6500);
Insert into Customer values (5, "Harish", 27, "Bhopal", 8500);
Insert into Customer values (6, "Kamesh", 22, "MP", 1500);
Insert into Customer values (7, "Murali", 24, "Indore", 10000);Exemplo para COMMIT
A consulta a seguir exclui linhas da tabela com idade = 25 e usa o comando COMMIT para aplicar essas alterações no banco de dados.
DELETE FROM CUSTOMERS WHERE AGE = 25;
COMMIT;Após a execução da consulta acima, você receberá a seguinte saída.
2 rows effectedApós a execução bem-sucedida do comando acima, verifique os registros da tabela do cliente executando o comando fornecido abaixo.
Select * from Customer;Após a execução da consulta acima, você receberá a seguinte saída.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000 |
| 3 | kaushik | 23 | Kota | 2000 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+Exemplo para reversão
Vamos considerar a mesma tabela de clientes como entrada.
| Eu iria | Nome | Era | Endereço | Salário |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2.000,00 |
| 2 | Karun | 25 | Délhi | 1500,00 |
| 3 | Kaushik | 23 | Kota | 2.000,00 |
| 4 | Chaitanya | 25 | Mumbai | 6.500,00 |
| 5 | Harish | 27 | Bhopal | 8.500,00 |
| 6 | Kamesh | 22 | MP | 1500,00 |
| 7 | Murali | 24 | Indore | 10.000,00 |
Aqui está o exemplo de consulta que explica sobre a funcionalidade de Rollback, excluindo registros da tabela com idade = 25 e, em seguida, ROLLBACK as alterações no banco de dados.
DELETE FROM CUSTOMERS WHERE AGE = 25;
ROLLBACK;Após a execução bem-sucedida das duas consultas acima, você pode visualizar os dados do registro na tabela do Cliente usando o seguinte comando.
Select * from Customer;Após a execução do comando acima, você receberá a seguinte saída.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000 |
| 2 | Karun | 25 | Delhi | 1500 |
| 3 | Kaushik | 23 | Kota | 2000 |
| 4 | Chaitanya| 25 | Mumbai | 6500 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+A consulta de exclusão exclui os dados de registro de clientes com idade = 25. O comando Rollback, reverte essas alterações na tabela Customer.
Exemplo para Savepoint
O ponto de salvamento é um ponto em uma transação em que você pode reverter a transação para um determinado ponto sem reverter toda a transação.
Vamos considerar a mesma tabela de clientes como entrada.
| Eu iria | Nome | Era | Endereço | Salário |
|---|---|---|---|---|
| 1 | Ramesh | 32 | Ahmedabad | 2.000,00 |
| 2 | Karun | 25 | Délhi | 1500,00 |
| 3 | Kaushik | 23 | Kota | 2.000,00 |
| 4 | Chaitanya | 25 | Mumbai | 6.500,00 |
| 5 | Harish | 27 | Bhopal | 8.500,00 |
| 6 | Kamesh | 22 | MP | 1500,00 |
| 7 | Murali | 24 | Indore | 10.000,00 |
Vamos considerar neste exemplo, você planeja excluir os três registros diferentes da tabela Clientes. Você deseja criar um Savepoint antes de cada exclusão, de modo que possa reverter para qualquer Savepoint a qualquer momento para retornar os dados apropriados ao seu estado original.
Aqui está a série de operações.
SAVEPOINT SP1;
DELETE FROM CUSTOMERS WHERE ID = 1;
SAVEPOINT SP2;
DELETE FROM CUSTOMERS WHERE ID = 2;
SAVEPOINT SP3;
DELETE FROM CUSTOMERS WHERE ID = 3;Agora, você criou três pontos de salvamento e excluiu três registros. Nesta situação, se você deseja reverter os registros com Id 2 e 3, use o seguinte comando Rollback.
ROLLBACK TO SP2;Observe que apenas a primeira exclusão ocorreu desde a reversão para o SP2. Use a seguinte consulta para exibir todos os registros dos clientes.
Select * from Customer;Após a execução da consulta acima, você receberá a seguinte saída.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 2 | Karun | 25 | Delhi | 1500 |
| 3 | Kaushik | 23 | Kota | 2000 |
| 4 | Chaitanya| 25 | Mumbai | 6500 |
| 5 | Harish | 27 | Bhopal | 8500 |
| 6 | Kamesh | 22 | MP | 4500 |
| 7 | Murali | 24 | Indore | 10000 |
+----+----------+-----+-----------+----------+Liberar ponto de salvamento
Podemos liberar o Savepoint usando o comando RELEASE. A seguir está a sintaxe genérica.
RELEASE SAVEPOINT SAVEPOINT_NAME;Sempre que houver necessidade de alterar o nome de uma tabela ou de um campo, alterar a ordem dos campos, alterar o tipo de dados dos campos ou qualquer estrutura da tabela, pode-se fazer o mesmo com o comando ALTER.
Exemplo
Vamos considerar um exemplo que explica o comando ALTER usando diferentes cenários.
Use a seguinte consulta para criar uma tabela chamada testalter_tbl com os campos ' id e name.
//below given query is to create a table testalter_tbl table.
create table testalter_tbl(id INT, name VARCHAR(10));
//below given query is to verify the table structure testalter_tbl.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';Após a execução da consulta acima, você receberá a seguinte saída.
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+Eliminando ou Adicionando uma Coluna
Sempre que quiser DROP em uma coluna existente da tabela HSQLDB, você pode usar a cláusula DROP junto com o comando ALTER.
Use a seguinte consulta para eliminar uma coluna (name) da tabela testalter_tbl.
ALTER TABLE testalter_tbl DROP name;Após a execução bem-sucedida da consulta acima, você pode saber se o campo de nome foi eliminado da tabela testalter_tbl usando o seguinte comando.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';Após a execução do comando acima, você receberá a seguinte saída.
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
+------------+-------------+------------+-----------+-----------+------------+Sempre que desejar adicionar qualquer coluna à tabela HSQLDB, você pode usar a cláusula ADD junto com o comando ALTER.
Use a seguinte consulta para adicionar uma coluna chamada NAME para a mesa testalter_tbl.
ALTER TABLE testalter_tbl ADD name VARCHAR(10);Após a execução bem-sucedida da consulta acima, você pode saber se o campo de nome foi adicionado à tabela testalter_tbl usando o seguinte comando.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';Após a execução da consulta acima, você receberá a seguinte saída.
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | INTEGER | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+Alteração de uma definição ou nome de coluna
Sempre que houver um requisito de alterar a definição da coluna, use o MODIFY ou CHANGE cláusula junto com a ALTER comando.
Vamos considerar um exemplo que explicará como usar a cláusula CHANGE. A mesatestalter_tblcontém dois campos - id e nome - tendo tipos de dados int e varchar respectivamente. Agora vamos tentar mudar o tipo de dados de id de INT para BIGINT. A seguir está a consulta para fazer a mudança.
ALTER TABLE testalter_tbl CHANGE id id BIGINT;Após a execução bem-sucedida da consulta acima, a estrutura da tabela pode ser verificada usando o seguinte comando.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';Após a execução do comando acima, você receberá a seguinte saída.
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 10 |
+------------+-------------+------------+-----------+-----------+------------+Agora, vamos tentar aumentar o tamanho da coluna NOME de 10 para 20 no testalter_tblmesa. A seguir está a consulta para conseguir isso usando a cláusula MODIFY junto com o comando ALTER.
ALTER TABLE testalter_tbl MODIFY name VARCHAR(20);Após a execução bem-sucedida da consulta acima, a estrutura da tabela pode ser verificada usando o seguinte comando.
Select * From INFORMATION_SCHEMA.SYSTEM_COLUMNS as C Where C.TABLE_SCHEM =
'PUBLIC' AND C.TABLE_NAME = 'TESTALTER_TBL';Após a execução do comando acima, você receberá a seguinte saída.
+------------+-------------+------------+-----------+-----------+------------+
|TABLE_SCHEM | TABLE_NAME | COLUMN_NAME| DATA_TYPE | TYPE_NAME | COLUMN_SIZE|
+------------+-------------+------------+-----------+-----------+------------+
| PUBLIC |TESTALTER_TBL| ID | 4 | BIGINT | 4 |
| PUBLIC |TESTALTER_TBL| NAME | 12 | VARCHAR | 20 |
+------------+-------------+------------+-----------+-----------+------------+UMA database indexé uma estrutura de dados que melhora a velocidade das operações em uma tabela. Os índices podem ser criados usando uma ou mais colunas, fornecendo a base para pesquisas aleatórias rápidas e ordenação eficiente de acesso aos registros.
Ao criar um índice, deve-se considerar quais são as colunas que serão usadas para fazer consultas SQL e criar um ou mais índices nessas colunas.
Praticamente, os índices também são tipos de tabelas, que mantêm a chave primária ou o campo do índice e um ponteiro para cada registro na tabela real.
Os usuários não podem ver os índices. Eles são usados apenas para acelerar as consultas e serão usados pelo Mecanismo de pesquisa de banco de dados para localizar registros rapidamente.
As instruções INSERT e UPDATE demoram mais em tabelas com índices, enquanto as instruções SELECT são executadas mais rapidamente nessas tabelas. O motivo é que, ao inserir ou atualizar, o banco de dados também precisa inserir ou atualizar os valores do índice.
Índice Simples e Único
Você pode criar um índice exclusivo em uma tabela. UMAunique indexsignifica que duas linhas não podem ter o mesmo valor de índice. A seguir está a sintaxe para criar um índice em uma tabela.
CREATE UNIQUE INDEX index_name
ON table_name (column1, column2,...);Você pode usar uma ou mais colunas para criar um índice. Por exemplo, crie um índice em tutorials_tbl usando tutorial_author.
CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author)Você pode criar um índice simples em uma tabela. Apenas omita a palavra-chave UNIQUE da consulta para criar um índice simples. UMAsimple index permite valores duplicados em uma tabela.
Se quiser indexar os valores em uma coluna em ordem decrescente, você pode adicionar a palavra reservada DESC após o nome da coluna.
CREATE UNIQUE INDEX AUTHOR_INDEX
ON tutorials_tbl (tutorial_author DESC)Comando ALTER para adicionar e descartar INDEX
Existem quatro tipos de instruções para adicionar índices a uma tabela -
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list) - Esta instrução adiciona uma PRIMARY KEY, o que significa que os valores indexados devem ser exclusivos e não podem ser NULL.
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list) - Esta instrução cria um índice para o qual os valores devem ser únicos (com exceção dos valores NULL, que podem aparecer várias vezes).
ALTER TABLE tbl_name ADD INDEX index_name (column_list) - Isso adiciona um índice comum no qual qualquer valor pode aparecer mais de uma vez.
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list) - Isso cria um índice FULLTEXT especial que é usado para fins de pesquisa de texto.
A seguir está a consulta para adicionar índice em uma tabela existente.
ALTER TABLE testalter_tbl ADD INDEX (c);Você pode eliminar qualquer INDEX usando a cláusula DROP junto com o comando ALTER. A seguir está a consulta para descartar o índice criado acima.
ALTER TABLE testalter_tbl DROP INDEX (c);Exibindo informações INDEX
Você pode usar o comando SHOW INDEX para listar todos os índices associados a uma tabela. A saída de formato vertical (especificada por \ G) geralmente é útil com essa instrução, para evitar o contorno de linhas longas.
A seguir está a sintaxe genérica para exibir as informações de índice sobre uma tabela.
SHOW INDEX FROM table_name\G