Impala - Guia Rápido
O que é Impala?
Impala é um mecanismo de consulta MPP (Massive Parallel Processing) SQL para processar grandes volumes de dados armazenados no cluster do Hadoop. É um software de código aberto escrito em C ++ e Java. Ele fornece alto desempenho e baixa latência em comparação com outros mecanismos SQL para Hadoop.
Em outras palavras, o Impala é o mecanismo SQL de melhor desempenho (proporcionando experiência semelhante a RDBMS), que fornece a maneira mais rápida de acessar dados armazenados no Hadoop Distributed File System.
Por que Impala?
O Impala combina o suporte SQL e o desempenho multiusuário de um banco de dados analítico tradicional com a escalabilidade e flexibilidade do Apache Hadoop, utilizando componentes padrão como HDFS, HBase, Metastore, YARN e Sentry.
Com o Impala, os usuários podem se comunicar com o HDFS ou HBase usando consultas SQL de maneira mais rápida em comparação com outros mecanismos SQL como o Hive.
O Impala pode ler quase todos os formatos de arquivo, como Parquet, Avro, RCFile usados pelo Hadoop.
O Impala usa os mesmos metadados, sintaxe SQL (Hive SQL), driver ODBC e interface de usuário (Hue Beeswax) que o Apache Hive, fornecendo uma plataforma familiar e unificada para consultas em lote ou em tempo real.
Ao contrário do Apache Hive, Impala is not based on MapReduce algorithms. Ele implementa uma arquitetura distribuída baseada emdaemon processes que são responsáveis por todos os aspectos da execução da consulta que são executados nas mesmas máquinas.
Portanto, ele reduz a latência de utilização do MapReduce e torna o Impala mais rápido do que o Apache Hive.
Vantagens do Impala
Aqui está uma lista de algumas vantagens notáveis do Cloudera Impala.
Usando o impala, você pode processar dados armazenados no HDFS na velocidade da luz com conhecimento de SQL tradicional.
Como o processamento de dados é realizado onde os dados residem (no cluster Hadoop), a transformação e movimentação de dados não são necessárias para os dados armazenados no Hadoop, durante o trabalho com o Impala.
Usando o Impala, você pode acessar os dados armazenados no HDFS, HBase e Amazon s3 sem o conhecimento de Java (trabalhos MapReduce). Você pode acessá-los com uma ideia básica de consultas SQL.
Para escrever consultas em ferramentas de negócios, os dados devem passar por um complicado ciclo de extração-transformação-carregamento (ETL). Mas, com o Impala, esse procedimento é abreviado. Os estágios demorados de carregamento e reorganização são superados com as novas técnicas, comoexploratory data analysis & data discovery tornando o processo mais rápido.
A Impala é pioneira no uso do formato de arquivo Parquet, um layout de armazenamento colunar que é otimizado para consultas em grande escala típicas em cenários de data warehouse.
Características do Impala
A seguir estão as características do cloudera Impala -
O Impala está disponível gratuitamente como código aberto sob a licença Apache.
O Impala oferece suporte ao processamento de dados na memória, ou seja, ele acessa / analisa os dados armazenados nos nós de dados do Hadoop sem movimentação de dados.
Você pode acessar dados usando o Impala usando consultas semelhantes a SQL.
O Impala fornece acesso mais rápido aos dados no HDFS quando comparado a outros mecanismos SQL.
Usando o Impala, você pode armazenar dados em sistemas de armazenamento como HDFS, Apache HBase e Amazon s3.
Você pode integrar o Impala com ferramentas de inteligência de negócios como Tableau, Pentaho, Micro estratégia e dados de Zoom.
O Impala oferece suporte a vários formatos de arquivo, como LZO, Sequence File, Avro, RCFile e Parquet.
O Impala usa metadados, driver ODBC e sintaxe SQL do Apache Hive.
Bancos de dados relacionais e Impala
O Impala usa uma linguagem de consulta semelhante a SQL e HiveQL. A tabela a seguir descreve algumas das principais diferenças entre as linguagens SQL e Impala Query.
| Impala | Bancos de dados relacionais |
|---|---|
| O Impala usa uma linguagem de consulta semelhante ao SQL que é semelhante ao HiveQL. | Os bancos de dados relacionais usam a linguagem SQL. |
| No Impala, você não pode atualizar ou excluir registros individuais. | Em bancos de dados relacionais, é possível atualizar ou excluir registros individuais. |
| O Impala não oferece suporte a transações. | Bancos de dados relacionais oferecem suporte a transações. |
| Impala não oferece suporte para indexação. | Bancos de dados relacionais suportam indexação. |
| O Impala armazena e gerencia grandes quantidades de dados (petabytes). | Os bancos de dados relacionais lidam com quantidades menores de dados (terabytes) quando comparados ao Impala. |
Hive, Hbase e Impala
Embora o Cloudera Impala use a mesma linguagem de consulta, metastore e a interface do usuário do Hive, ele difere do Hive e do HBase em certos aspectos. A tabela a seguir apresenta uma análise comparativa entre HBase, Hive e Impala.
| HBase | Colmeia | Impala |
|---|---|---|
| HBase é um banco de dados de armazenamento de colunas largas baseado no Apache Hadoop. Ele usa os conceitos de BigTable. | Hive é um software de data warehouse. Usando isso, podemos acessar e gerenciar grandes conjuntos de dados distribuídos, construídos no Hadoop. | Impala é uma ferramenta para gerenciar e analisar dados armazenados no Hadoop. |
| O modelo de dados do HBase é um amplo armazenamento de colunas. | O Hive segue o modelo relacional. | Impala segue o modelo relacional. |
| O HBase é desenvolvido em linguagem Java. | O Hive é desenvolvido em linguagem Java. | O Impala é desenvolvido em C ++. |
| O modelo de dados do HBase não tem esquema. | O modelo de dados do Hive é baseado em esquema. | O modelo de dados do Impala é baseado em esquema. |
| HBase fornece APIs Java, RESTful e Thrift. | O Hive fornece JDBC, ODBC, APIs Thrift. | A Impala fornece APIs JDBC e ODBC. |
| Suporta linguagens de programação como C, C #, C ++, Groovy, Java PHP, Python e Scala. | Suporta linguagens de programação como C ++, Java, PHP e Python. | O Impala oferece suporte a todos os idiomas com suporte a JDBC / ODBC. |
| HBase oferece suporte para gatilhos. | O Hive não oferece suporte para gatilhos. | O Impala não oferece suporte para gatilhos. |
Todos esses três bancos de dados -
São bancos de dados NOSQL.
Disponível como código aberto.
Suporte a scripts do lado do servidor.
Siga as propriedades do ACID, como durabilidade e simultaneidade.
Usar sharding para partitioning.
Desvantagens do Impala
Algumas das desvantagens de usar o Impala são as seguintes -
- O Impala não oferece suporte para serialização e desserialização.
- O Impala só pode ler arquivos de texto, não arquivos binários personalizados.
- Sempre que novos registros / arquivos são adicionados ao diretório de dados no HDFS, a tabela precisa ser atualizada.
Este capítulo explica os pré-requisitos para instalar o Impala, como baixar, instalar e configurar Impala em seu sistema.
Semelhante ao Hadoop e seu software de ecossistema, precisamos instalar o Impala no sistema operacional Linux. Uma vez que a cloudera despachou o Impala, ele está disponível comCloudera Quick Start VM.
Este capítulo descreve como fazer o download Cloudera Quick Start VM e inicie o Impala.
Baixando Cloudera Quick Start VM
Siga as etapas abaixo para baixar a versão mais recente do Cloudera QuickStartVM.
Passo 1
Abra a página inicial do site da cloudera http://www.cloudera.com/. Você obterá a página conforme mostrado abaixo.

Passo 2
Clique no Sign in link na página inicial da cloudera, que o redirecionará para a página de login, conforme mostrado abaixo.

Se você ainda não se cadastrou, clique no Register Now link que vai te dar Account RegistrationFormato. Registre-se lá e faça login na conta cloudera.
etapa 3
Após o login, abra a página de download do site da cloudera clicando no Downloads link destacado no instantâneo a seguir.
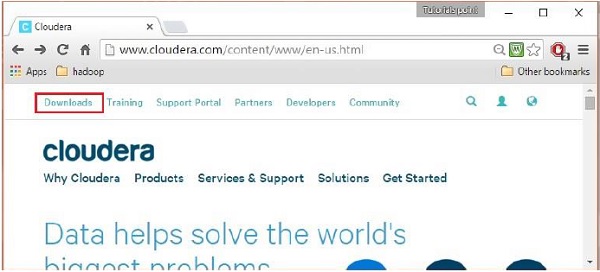
Etapa 4 - Baixe QuickStartVM
Baixe o cloudera QuickStartVM clicando no Download Now botão, conforme destacado no seguinte instantâneo
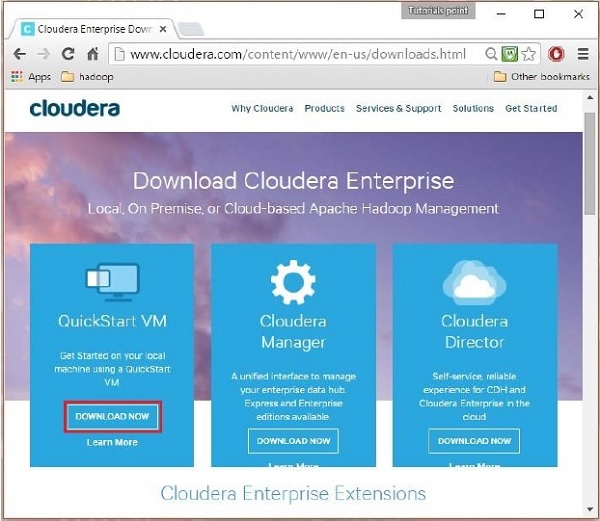
Isso irá redirecioná-lo para a página de download de QuickStart VM.
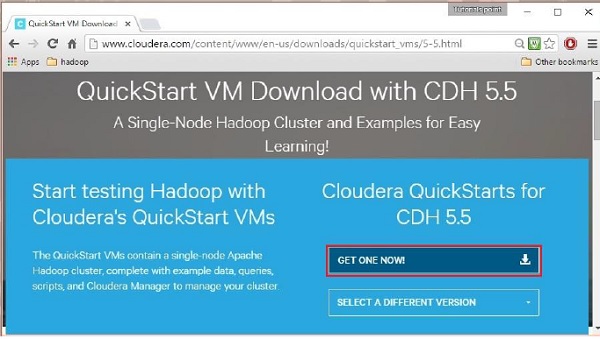
Clique no Get ONE NOW , aceite o contrato de licença e clique no botão enviar conforme mostrado abaixo.
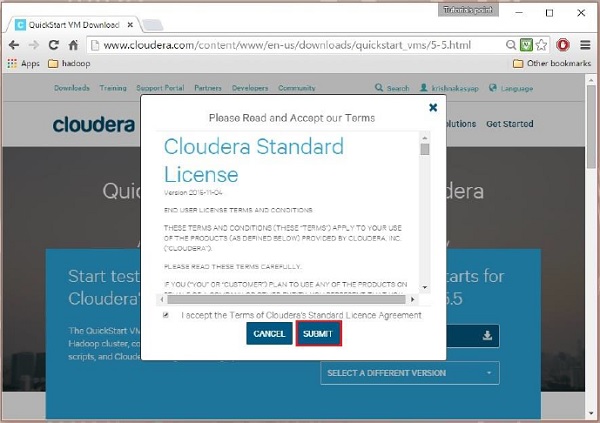
A Cloudera fornece VMware, KVM e VIRTUALBOX compatível com VM. Selecione a versão necessária. Aqui em nosso tutorial, estamos demonstrando oCloudera QuickStartVM configuração usando a caixa virtual, portanto, clique no VIRTUALBOX DOWNLOAD botão, como mostrado no instantâneo fornecido abaixo.
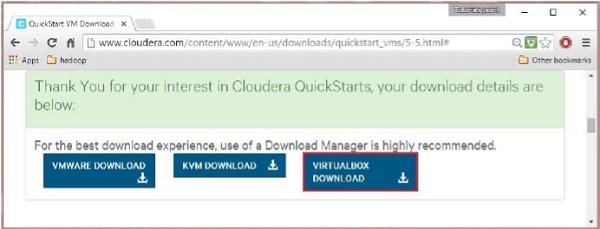
Isso iniciará o download de um arquivo chamado cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf que é um arquivo de imagem de caixa virtual.
Importando o Cloudera QuickStartVM
Depois de baixar o cloudera-quickstart-vm-5.5.0-0-virtualbox.ovfarquivo, precisamos importá-lo usando a caixa virtual. Para isso, em primeiro lugar, você precisa instalar a caixa virtual em seu sistema. Siga as etapas abaixo para importar o arquivo de imagem baixado.
Passo 1
Baixe a caixa virtual a partir do link a seguir e instale-a https://www.virtualbox.org/
Passo 2
Abra o software da caixa virtual. CliqueFile e escolher Import Appliance, como mostrado abaixo.
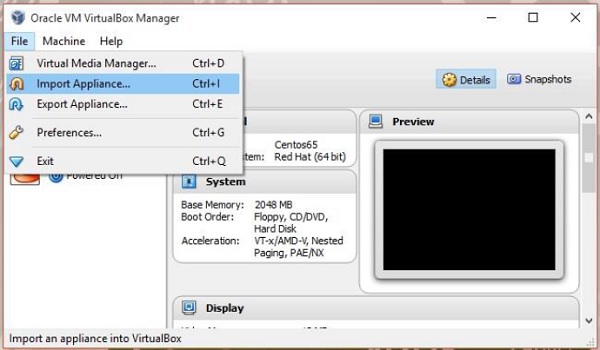
etapa 3
Ao clicar Import Appliance, você obterá a janela Import Virtual Appliance. Selecione o local do arquivo de imagem baixado conforme mostrado abaixo.
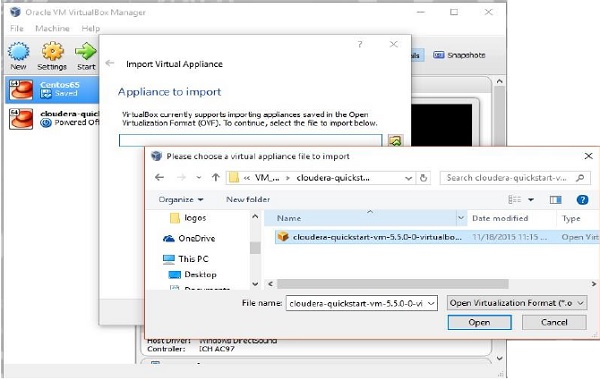
Depois de importar Cloudera QuickStartVMimagem, inicie a máquina virtual. Esta máquina virtual possui Hadoop, cloudera Impala e todos os softwares necessários instalados. O instantâneo da VM é mostrado abaixo.

Iniciando Impala Shell
Para iniciar o Impala, abra o terminal e execute o seguinte comando.
[cloudera@quickstart ~] $ impala-shellIsso iniciará o Impala Shell, exibindo a seguinte mensagem.
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
********************************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Press TAB twice to see a list of available commands.
********************************************************************************
[quickstart.cloudera:21000] >Note - Discutiremos todos os comandos do impala-shell em capítulos posteriores.
Editor de consultas Impala
Além de Impala shell, você pode se comunicar com o Impala usando o navegador Hue. Após instalar o CDH5 e iniciar o Impala, se você abrir seu navegador, obterá a página inicial do cloudera conforme mostrado abaixo.
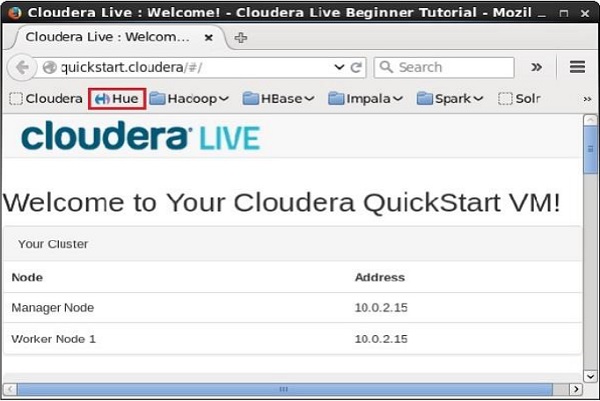
Agora, clique no favorito Huepara abrir o navegador Hue. Ao clicar, você pode ver a página de login do Hue Browser, logando com as credenciais cloudera e cloudera.
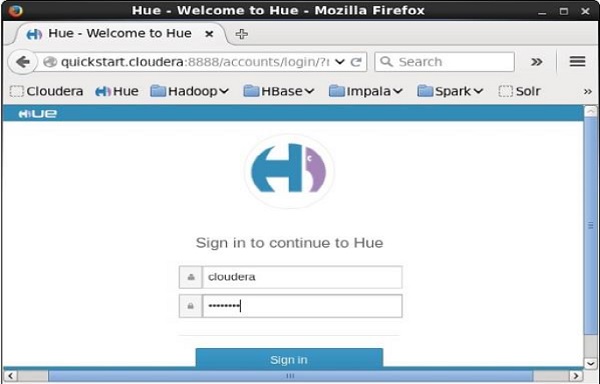
Assim que você fizer logon no navegador Hue, poderá ver o Assistente de início rápido do navegador Hue conforme mostrado abaixo.
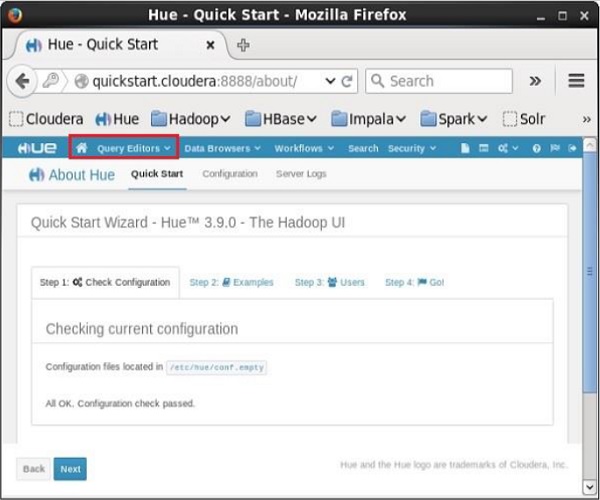
Ao clicar no Query Editors No menu suspenso, você obterá a lista de editores compatíveis com o Impala, conforme mostrado na imagem a seguir.
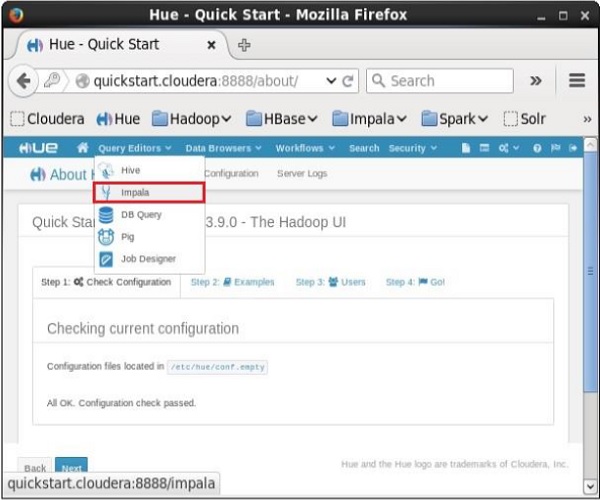
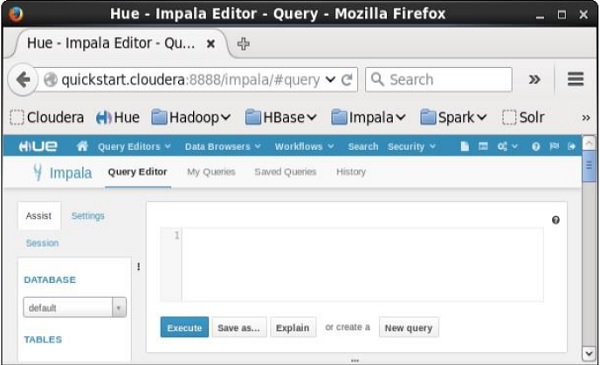
Ao clicar Impala no menu suspenso, você obterá o editor de consultas Impala conforme mostrado abaixo.
Impala é um mecanismo de execução de consulta MPP (Massive Parallel Processing) que é executado em vários sistemas no cluster Hadoop. Ao contrário dos sistemas de armazenamento tradicionais, o impala é desacoplado de seu mecanismo de armazenamento. Ele tem três componentes principais, a saber, Impala daemon (Impalad) , Impala Statestore e metadados ou metastore do Impala.
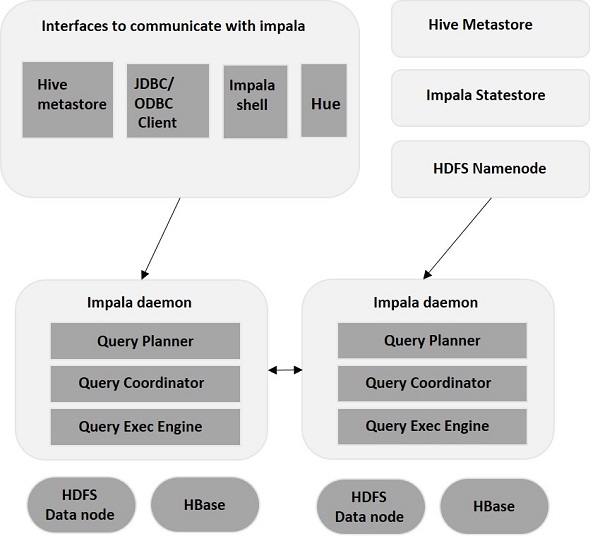
Impala daemon ( Impalad )
Daemon Impala (também conhecido como impalad) é executado em cada nó onde o Impala está instalado. Ele aceita as consultas de várias interfaces, como impala shell, hue browser, etc. ... e as processa.
Sempre que uma consulta é submetida a um impalad em um nó específico, esse nó serve como um “coordinator node”Para essa consulta. Várias consultas são atendidas pelo Impalad em execução em outros nós também. Depois de aceitar a consulta, o Impalad lê e grava em arquivos de dados e paraleliza as consultas distribuindo o trabalho para os outros nós do Impala no cluster do Impala. Quando as consultas estão sendo processadas em várias instâncias do Impalad , todas elas retornam o resultado para o nó de coordenação central.
Dependendo do requisito, as consultas podem ser enviadas para um Impalad dedicado ou de maneira balanceada para outro Impalad em seu cluster.
Impala State Store
O Impala tem outro componente importante chamado armazenamento de estado do Impala, que é responsável por verificar a integridade de cada Impalad e, em seguida, retransmitir a integridade de cada daemon do Impala para os outros daemons com frequência. Isso pode ser executado no mesmo nó onde o servidor Impala ou outro nó dentro do cluster está sendo executado.
O nome do processo daemon de armazenamento do Impala State é State stored . O Impalad relata seu status de integridade ao daemon de armazenamento de estado do Impala, ou seja, estado armazenado .
No caso de falha de um nó devido a qualquer motivo, o Statestore atualiza todos os outros nós sobre essa falha e, uma vez que tal notificação esteja disponível para o outro impalad , nenhum outro daemon Impala atribui qualquer outra consulta ao nó afetado.
Impala Metadata & Meta Store
Os metadados e meta store do Impala são outro componente importante. O Impala usa bancos de dados MySQL ou PostgreSQL tradicionais para armazenar definições de tabela. Os detalhes importantes, como tabela e informações de coluna e definições de tabela, são armazenados em um banco de dados centralizado conhecido como meta store.
Cada nó do Impala armazena em cache todos os metadados localmente. Ao lidar com uma quantidade extremamente grande de dados e / ou muitas partições, obter metadados específicos da tabela pode levar um tempo significativo. Portanto, um cache de metadados armazenado localmente ajuda a fornecer essas informações instantaneamente.
Quando uma definição de tabela ou os dados da tabela são atualizados, outros daemons do Impala devem atualizar seu cache de metadados, recuperando os metadados mais recentes antes de emitir uma nova consulta na tabela em questão.
Interfaces de processamento de consulta
Para processar consultas, o Impala fornece três interfaces conforme listado abaixo.
Impala-shell - Depois de configurar o Impala usando o Cloudera VM, você pode iniciar o shell do Impala digitando o comando impala-shellno editor. Discutiremos mais sobre o shell Impala nos próximos capítulos.
Hue interface- Você pode processar consultas do Impala usando o navegador Hue. No navegador Hue, você tem o editor de consulta Impala, onde pode digitar e executar as consultas impala. Para acessar este editor, em primeiro lugar, você precisa fazer o login no navegador Hue.
ODBC/JDBC drivers- Assim como outros bancos de dados, o Impala fornece drivers ODBC / JDBC. Usando esses drivers, você pode se conectar ao impala por meio de linguagens de programação que oferecem suporte a esses drivers e criar aplicativos que processam consultas no impala usando essas linguagens de programação.
Procedimento de execução de consulta
Sempre que os usuários passam uma consulta usando qualquer uma das interfaces fornecidas, isso é aceito por um dos Impalads no cluster. Este Impalad é tratado como um coordenador dessa consulta específica.
Após receber a consulta, o coordenador da consulta verifica se a consulta é adequada, usando o Table Schemada meta store do Hive. Posteriormente, ele coleta as informações sobre a localização dos dados que são necessários para executar a consulta, do nó do nome HDFS e envia essas informações para outros impalads a fim de executar a consulta.
Todos os outros daemons do Impala leem o bloco de dados especificado e processam a consulta. Assim que todos os daemons concluem suas tarefas, o coordenador de consulta coleta o resultado de volta e o entrega ao usuário.
Nos capítulos anteriores, vimos a instalação do Impala usando cloudera e sua arquitetura.
- Shell do Impala (prompt de comando)
- Hue (interface do usuário)
- ODBC e JDBC (bibliotecas de terceiros)
Este capítulo explica como iniciar o Impala Shell e as várias opções do shell.
Referência de comandos do Impala Shell
Os comandos do shell Impala são classificados como general commands, query specific options, e table and database specific options, conforme explicado abaixo.
Comandos Gerais
- help
- version
- history
- shell (ou)!
- connect
- sair | Sair
Opções específicas de consulta
- Set/unset
- Profile
- Explain
Opções específicas de tabela e banco de dados
- Alter
- describe
- drop
- insert
- select
- show
- use
Iniciando Impala Shell
Abra o terminal da cloudera, faça login como superusuário e digite cloudera como senha conforme mostrado abaixo.
[cloudera@quickstart ~]$ su
Password: cloudera
[root@quickstart cloudera]#Inicie o shell do Impala digitando o seguinte comando -
[root@quickstart cloudera] # impala-shell
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE
(build 0c891d79aa38f297d244855a32f1e17280e2129b)
*********************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Want to know what version of Impala you're connected to? Run the VERSION command to
find out!
*********************************************************************
[quickstart.cloudera:21000] >Impala - Comandos de uso geral
Os comandos de propósito geral do Impala são explicados abaixo -
comando de ajuda
o help comando do shell do Impala fornece uma lista dos comandos disponíveis no Impala -
[quickstart.cloudera:21000] > help;
Documented commands (type help <topic>):
========================================================
compute describe insert set unset with version
connect explain quit show values use
exit history profile select shell tip
Undocumented commands:
=========================================
alter create desc drop help load summarycomando de versão
o version comando fornece a versão atual do Impala, conforme mostrado abaixo.
[quickstart.cloudera:21000] > version;
Shell version: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9
12:18:12 PST 2015
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)comando de história
o historyO comando do Impala exibe os últimos 10 comandos executados no shell. A seguir está o exemplo dohistorycomando. Aqui, executamos 5 comandos, a saber, version, help, show, use e history.
[quickstart.cloudera:21000] > history;
[1]:version;
[2]:help;
[3]:show databases;
[4]:use my_db;
[5]:history;comando sair / sair
Você pode sair do shell do Impala usando o quit ou exit comando, como mostrado abaixo.
[quickstart.cloudera:21000] > exit;
Goodbye clouderacomando de conexão
o connectcomando é usado para conectar a uma determinada instância do Impala. Caso você não especifique nenhuma instância, ele se conecta à porta padrão21000 como mostrado abaixo.
[quickstart.cloudera:21000] > connect;
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)Opções específicas de consulta do Impala
Os comandos específicos de consulta do Impala aceitam uma consulta. Eles são explicados abaixo -
Explicar
o explain comando retorna o plano de execução para a consulta fornecida.
[quickstart.cloudera:21000] > explain select * from sample;
Query: explain select * from sample
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| Estimated Per-Host Requirements: Memory = 48.00MB VCores = 1 |
| WARNING: The following tables are missing relevant table and/or column statistics. |
| my_db.customers |
| 01:EXCHANGE [UNPARTITIONED] |
| 00:SCAN HDFS [my_db.customers] |
| partitions = 1/1 files = 6 size = 148B |
+------------------------------------------------------------------------------------+
Fetched 7 row(s) in 0.17sPerfil
o profilecomando exibe as informações de baixo nível sobre a consulta recente. Este comando é usado para diagnóstico e ajuste de desempenho de uma consulta. A seguir está o exemplo de umprofilecomando. Neste cenário, oprofile comando retorna as informações de baixo nível de explain inquerir.
[quickstart.cloudera:21000] > profile;
Query Runtime Profile:
Query (id=164b1294a1049189:a67598a6699e3ab6):
Summary:
Session ID: e74927207cd752b5:65ca61e630ad3ad
Session Type: BEESWAX
Start Time: 2016-04-17 23:49:26.08148000 End Time: 2016-04-17 23:49:26.2404000
Query Type: EXPLAIN
Query State: FINISHED
Query Status: OK
Impala Version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d77280e2129b)
User: cloudera
Connected User: cloudera
Delegated User:
Network Address:10.0.2.15:43870
Default Db: my_db
Sql Statement: explain select * from sample
Coordinator: quickstart.cloudera:22000
: 0ns
Query Timeline: 167.304ms
- Start execution: 41.292us (41.292us) - Planning finished: 56.42ms (56.386ms)
- Rows available: 58.247ms (1.819ms)
- First row fetched: 160.72ms (101.824ms)
- Unregister query: 166.325ms (6.253ms)
ImpalaServer:
- ClientFetchWaitTimer: 107.969ms
- RowMaterializationTimer: 0nsOpções específicas de tabela e banco de dados
A tabela a seguir lista as opções específicas de tabela e dados no Impala.
| Sr. Não | Comando e Explicação |
|---|---|
| 1 | Alter o alter O comando é usado para alterar a estrutura e o nome de uma tabela no Impala. |
| 2 | Describe o describeO comando do Impala fornece os metadados de uma tabela. Ele contém informações como colunas e seus tipos de dados. odescribe comando tem desc como um atalho. |
| 3 | Drop o drop O comando é usado para remover uma construção do Impala, onde uma construção pode ser uma tabela, uma visão ou uma função de banco de dados. |
| 4 | insert o insert comando do Impala é usado para,
|
| 5 | select o selectdeclaração é usada para executar uma operação desejada em um conjunto de dados específico. Ele especifica o conjunto de dados no qual alguma ação deve ser concluída. Você pode imprimir ou armazenar (em um arquivo) o resultado da instrução select. |
| 6 | show o show declaração do Impala é usado para exibir o metastore de várias construções, como tabelas, bancos de dados e tabelas. |
| 7 | use o use declaração do Impala é usada para alterar o contexto atual para o banco de dados desejado. |
Tipos de dados Impala
A tabela a seguir descreve os tipos de dados Impala.
| Sr. Não | Tipo de dados e descrição |
|---|---|
| 1 | BIGINT Este tipo de dados armazena valores numéricos e o intervalo deste tipo de dados é -9223372036854775808 a 9223372036854775807. Este tipo de dados é usado em criar tabela e alterar instruções de tabela. |
| 2 | BOOLEAN Este tipo de dados armazena apenas true ou false valores e é usado na definição da coluna da instrução de criação de tabela. |
| 3 | CHAR Este tipo de dados é um armazenamento de comprimento fixo, é preenchido com espaços, você pode armazenar até o comprimento máximo de 255. |
| 4 | DECIMAL Este tipo de dados é usado para armazenar valores decimais e para criar tabelas e alterar instruções de tabelas. |
| 5 | DOUBLE Este tipo de dados é usado para armazenar os valores de ponto flutuante na faixa de 4,94065645841246544e-324d positivo ou negativo -1,79769313486231570e + 308. |
| 6 | FLOAT Este tipo de dados é usado para armazenar tipos de dados de valor flutuante de precisão única na faixa de positivo ou negativo 1.40129846432481707e-45 .. 3.40282346638528860e + 38. |
| 7 | INT Este tipo de dados é usado para armazenar inteiros de 4 bytes até o intervalo de -2147483648 a 2147483647. |
| 8 | SMALLINT Este tipo de dados é usado para armazenar inteiros de 2 bytes até o intervalo de -32768 a 32767. |
| 9 | STRING Isso é usado para armazenar valores de string. |
| 10 | TIMESTAMP Este tipo de dados é usado para representar um ponto em um tempo. |
| 11 | TINYINT Este tipo de dados é usado para armazenar valores inteiros de 1 byte até o intervalo de -128 a 127. |
| 12 | VARCHAR Este tipo de dados é usado para armazenar caracteres de comprimento variável até o comprimento máximo de 65.535. |
| 13 | ARRAY Este é um tipo de dados complexo e é usado para armazenar um número variável de elementos ordenados. |
| 14 | Map Este é um tipo de dados complexo e é usado para armazenar um número variável de pares de valores-chave. |
| 15 | Struct Este é um tipo de dados complexo e usado para representar vários campos de um único item. |
Comentários no Impala
Os comentários no Impala são semelhantes aos do SQL. Em geral, temos dois tipos de comentários em linguagens de programação, a saber, Comentários de uma linha e Comentários de várias linhas.
Single-line comments- Cada linha seguida por "-" é considerada um comentário no Impala. A seguir está um exemplo de comentários de uma linha no Impala.
-- Hello welcome to tutorials point.Multiline comments - Todas as linhas entre /* e */são considerados como comentários de várias linhas no Impala. A seguir está um exemplo de comentários de várias linhas no Impala.
/*
Hi this is an example
Of multiline comments in Impala
*/Os operadores no Impala são semelhantes aos do SQL. Consulte nosso tutorial SQL clicando no link a seguiroperadores sql.
Impala - Crie um banco de dados
No Impala, um banco de dados é uma construção que contém tabelas, visualizações e funções relacionadas em seus namespaces. É representado como uma árvore de diretório no HDFS; ele contém partições de tabelas e arquivos de dados. Este capítulo explica como criar um banco de dados no Impala.
Instrução CREATE DATABASE
o CREATE DATABASE Statement é usado para criar um novo banco de dados no Impala.
Sintaxe
A seguir está a sintaxe do CREATE DATABASE Declaração.
CREATE DATABASE IF NOT EXISTS database_name;Aqui, IF NOT EXISTSé uma cláusula opcional. Se usarmos esta cláusula, um banco de dados com o nome dado é criado, apenas se não houver nenhum banco de dados existente com o mesmo nome.
Exemplo
A seguir está um exemplo do create database statement. Neste exemplo, criamos um banco de dados com o nomemy_database.
[quickstart.cloudera:21000] > CREATE DATABASE IF NOT EXISTS my_database;Ao executar a consulta acima em cloudera impala-shell, você obterá a seguinte saída.
Query: create DATABASE my_database
Fetched 0 row(s) in 0.21sVerificação
o SHOW DATABASES consulta fornece a lista de bancos de dados no Impala, portanto, você pode verificar se o banco de dados é criado, usando o SHOWInstrução DATABASES. Aqui você pode observar o banco de dados recém-criadomy_db na lista.
[quickstart.cloudera:21000] > show databases;
Query: show databases
+-----------------------------------------------+
| name |
+-----------------------------------------------+
| _impala_builtins |
| default |
| my_db |
+-----------------------------------------------+
Fetched 3 row(s) in 0.20s
[quickstart.cloudera:21000] >Caminho Hdfs
Para criar um banco de dados no sistema de arquivos HDFS, você precisa especificar o local onde o banco de dados deve ser criado.
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;Criação de um banco de dados usando o navegador Hue
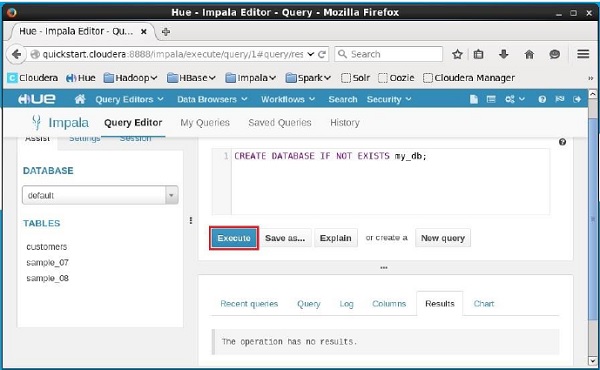
Abra o editor de consultas Impala e digite o CREATE DATABASEdeclaração nele. Depois disso, clique no botão executar conforme mostrado na imagem a seguir.
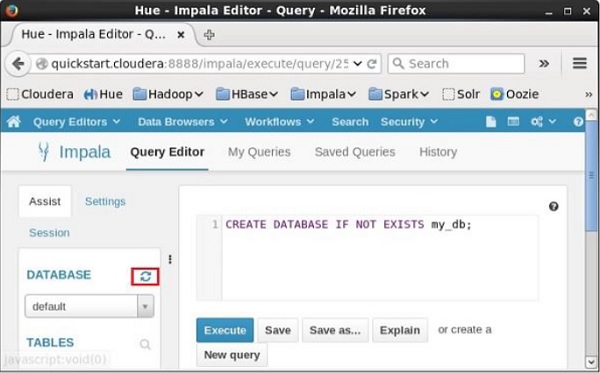
Depois de executar a consulta, mova suavemente o cursor para o topo do menu suspenso e você encontrará um símbolo de atualização. Se você clicar no símbolo de atualização, a lista de bancos de dados será atualizada e as alterações recentes serão aplicadas a ela.
Verificação
Clique no drop-down box sob o título DATABASEno lado esquerdo do editor. Lá você pode ver uma lista de bancos de dados no sistema. Aqui você pode observar o banco de dados recém-criadomy_db como mostrado abaixo.
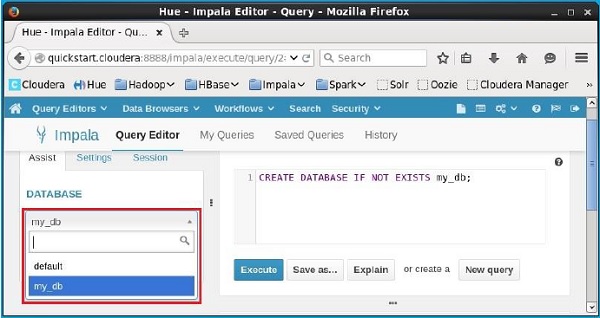
Se você observar cuidadosamente, poderá ver apenas um banco de dados, ou seja, my_db na lista junto com o banco de dados padrão.
o DROP DATABASE Statementdo Impala é usado para remover um banco de dados do Impala. Antes de excluir o banco de dados, é recomendável remover todas as tabelas dele.
Sintaxe
A seguir está a sintaxe de DROP DATABASE Declaração.
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT |
CASCADE] [LOCATION hdfs_path];Aqui, IF EXISTSé uma cláusula opcional. Se usarmos esta cláusula quando um banco de dados com o nome fornecido existir, ele será excluído. E se não houver um banco de dados existente com o nome fornecido, nenhuma operação será executada.
Exemplo
A seguir está um exemplo de DROP DATABASEdeclaração. Suponha que você tenha um banco de dados no Impala com o nomesample_database.
E, se você verificar a lista de bancos de dados usando o SHOW DATABASES declaração, você observará o nome nela.
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11sAgora, você pode excluir este banco de dados usando o DROP DATABASE Statement como mostrado abaixo.
< DROP DATABASE IF EXISTS sample_database;Isso excluirá o banco de dados especificado e fornecerá a seguinte saída.
Query: drop DATABASE IF EXISTS sample_database;Verificação
Você pode verificar se o banco de dados fornecido foi excluído, usando o SHOW DATABASESdeclaração. Aqui você pode observar que o banco de dados denominadosample_database é removido da lista de bancos de dados.
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+----------------------+
| name |
+----------------------+
| _impala_builtins |
| default |
| my_db |
+----------------------+
Fetched 3 row(s) in 0.10s
[quickstart.cloudera:21000] >Cascata
Em geral, para excluir um banco de dados, você precisa remover todas as tabelas nele manualmente. Se você usar cascata, o Impala remove as tabelas do banco de dados especificado antes de excluí-lo.
Exemplo
Suponha que haja um banco de dados no Impala chamado sample, e contém duas tabelas, a saber, student e test. Se você tentar remover este banco de dados diretamente, obterá um erro conforme mostrado abaixo.
[quickstart.cloudera:21000] > DROP database sample;
Query: drop database sample
ERROR:
ImpalaRuntimeException: Error making 'dropDatabase' RPC to Hive Metastore:
CAUSED BY: InvalidOperationException: Database sample is not empty. One or more
tables exist.Usando cascade, você pode excluir este banco de dados diretamente (sem excluir seu conteúdo manualmente) conforme mostrado abaixo.
[quickstart.cloudera:21000] > DROP database sample cascade;
Query: drop database sample cascadeNote - Você não pode excluir o “current database”No Impala. Portanto, antes de excluir um banco de dados, você precisa se certificar de que o contexto atual está definido para o banco de dados diferente daquele que você deseja excluir.
Excluindo um banco de dados usando o navegador Hue
Abra o editor de consultas Impala e digite o DELETE DATABASEdeclaração nele e clique no botão executar como mostrado abaixo. Suponha que existam três bancos de dados, a saber,my_db, my_database, e sample_databasejunto com o banco de dados padrão. Aqui, estamos excluindo o banco de dados denominado my_database.

Depois de executar a consulta, mova suavemente o cursor para o topo do menu suspenso. Em seguida, você encontrará um símbolo de atualização conforme mostrado na imagem abaixo. Se você clicar no símbolo de atualização, a lista de bancos de dados será atualizada e as alterações recentes feitas serão aplicadas a ela.
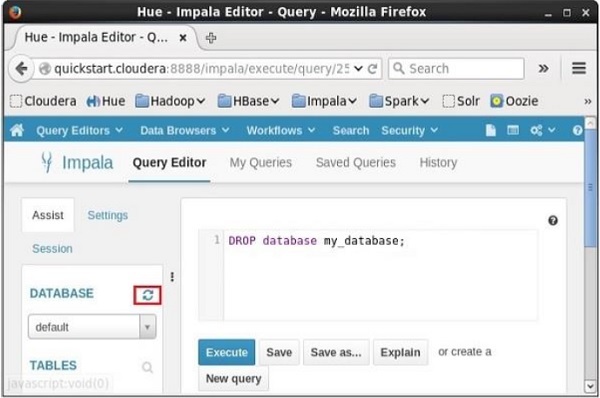
Verificação
Clique no drop down sob o título DATABASEno lado esquerdo do editor. Lá, você pode ver uma lista de bancos de dados no sistema. Aqui você pode observar o banco de dados recém-criadomy_db como mostrado abaixo.
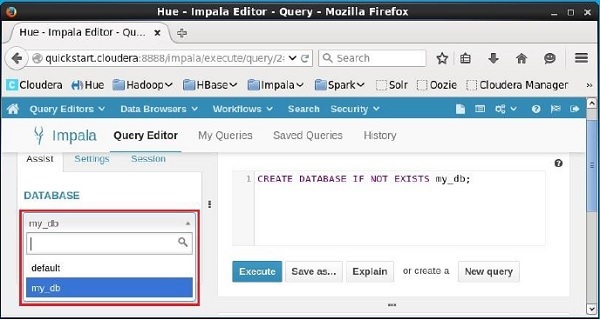
Se você observar cuidadosamente, poderá ver apenas um banco de dados, ou seja, my_db na lista junto com o banco de dados padrão.
Depois de se conectar ao Impala, é necessário selecionar um entre os bancos de dados disponíveis. oUSE DATABASE Statement do Impala é usado para mudar a sessão atual para outro banco de dados.
Sintaxe
A seguir está a sintaxe de USE Declaração.
USE db_name;Exemplo
A seguir está um exemplo de USE statement. Em primeiro lugar, vamos criar um banco de dados com o nomesample_database como mostrado abaixo.
> CREATE DATABASE IF NOT EXISTS sample_database;Isso criará um novo banco de dados e fornecerá a seguinte saída.
Query: create DATABASE IF NOT EXISTS my_db2
Fetched 0 row(s) in 2.73sSe você verificar a lista de bancos de dados usando o SHOW DATABASES declaração, você pode observar o nome do banco de dados recém-criado nele.
> SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11sAgora, vamos mudar a sessão para o banco de dados recém-criado (sample_database) usando o USE Declaração conforme mostrado abaixo.
> USE sample_database;Isso mudará o contexto atual para sample_database e exibirá uma mensagem conforme mostrado abaixo.
Query: use sample_databaseSelecionando um banco de dados usando o Hue Browser
No lado esquerdo do Query Editor do Impala, você encontrará um menu suspenso conforme mostrado na imagem a seguir.
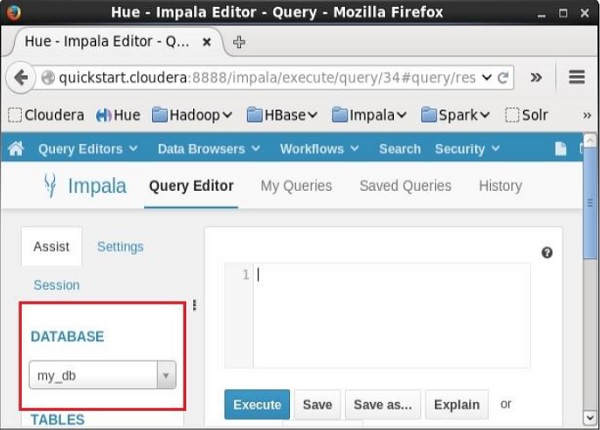
Se você clicar no menu suspenso, encontrará a lista de todos os bancos de dados do Impala conforme mostrado abaixo.
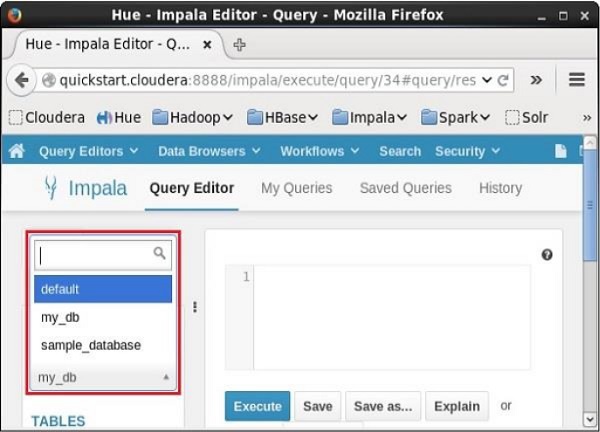
Simplesmente selecione o banco de dados para o qual você precisa alterar o contexto atual.
o CREATE TABLEA instrução é usada para criar uma nova tabela no banco de dados necessário no Impala. Criar uma tabela básica envolve nomear a tabela e definir suas colunas e o tipo de dados de cada coluna.
Sintaxe
A seguir está a sintaxe do CREATE TABLEDeclaração. Aqui,IF NOT EXISTSé uma cláusula opcional. Se usarmos esta cláusula, uma tabela com o nome fornecido será criada, apenas se não houver uma tabela existente no banco de dados especificado com o mesmo nome.
create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);CREATE TABLE é a palavra-chave que instrui o sistema de banco de dados a criar uma nova tabela. O nome ou identificador exclusivo da tabela segue a instrução CREATE TABLE. Opcionalmente, você pode especificardatabase_name junto com table_name.
Exemplo
A seguir está um exemplo da instrução create table. Neste exemplo, criamos uma tabela chamadastudent no banco de dados my_db.
[quickstart.cloudera:21000] > CREATE TABLE IF NOT EXISTS my_db.student
(name STRING, age INT, contact INT );Ao executar a instrução acima, uma tabela com o nome especificado será criada, exibindo a seguinte saída.
Query: create table student (name STRING, age INT, phone INT)
Fetched 0 row(s) in 0.48sVerificação
o show Tablesconsulta fornece uma lista de tabelas no banco de dados atual no Impala. Portanto, você pode verificar se a tabela é criada, usando oShow Tables declaração.
Em primeiro lugar, você precisa mudar o contexto para o banco de dados no qual a tabela necessária existe, conforme mostrado abaixo.
[quickstart.cloudera:21000] > use my_db;
Query: use my_dbEntão, se você obtiver a lista de tabelas usando o show tables consulta, você pode observar a tabela chamada student nele como mostrado abaixo.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| student |
+-----------+
Fetched 1 row(s) in 0.10sCaminho HDFS
Para criar um banco de dados no sistema de arquivos HDFS, você precisa especificar o local onde o banco de dados deve ser criado, conforme mostrado abaixo.
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;Criação de um banco de dados usando o navegador Hue
Abra o editor de consultas impala e digite o CREATE TableDeclaração nele. E clique no botão executar conforme mostrado na imagem a seguir.
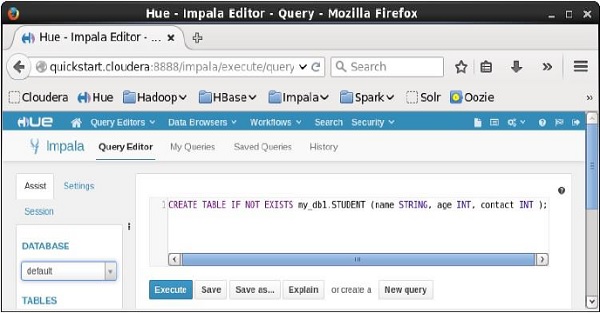
Depois de executar a consulta, mova suavemente o cursor para o topo do menu suspenso e você encontrará um símbolo de atualização. Se você clicar no símbolo de atualização, a lista de bancos de dados será atualizada e as alterações recentes feitas serão aplicadas a ela.
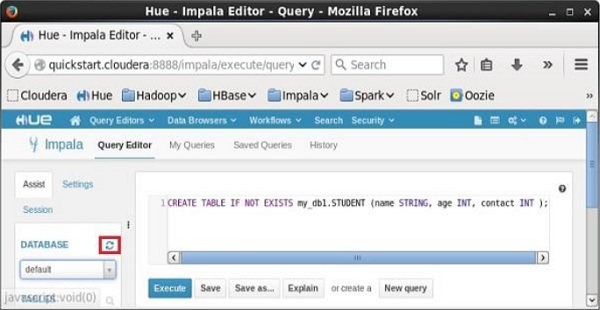
Verificação
Clique no drop down sob o título DATABASEno lado esquerdo do editor. Lá você pode ver uma lista de bancos de dados. Selecione o banco de dadosmy_db como mostrado abaixo.
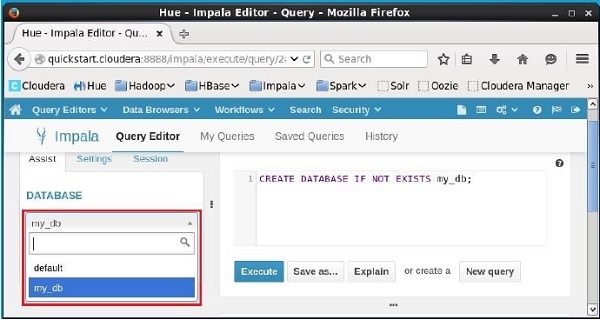
Ao selecionar o banco de dados my_dbvocê pode ver uma lista de tabelas como mostrado abaixo. Aqui você pode encontrar a tabela recém-criadastudent como mostrado abaixo.

o INSERT Declaração da Impala tem duas cláusulas - into e overwrite. Inserir declaração cominto cláusula é usada para adicionar novos registros em uma tabela existente em um banco de dados.
Sintaxe
Existem duas sintaxes básicas de INSERT declaração da seguinte forma -
insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN);Aqui, coluna1, coluna2, ... colunaN são os nomes das colunas na tabela na qual você deseja inserir dados.
Você também pode adicionar valores sem especificar os nomes das colunas, mas, para isso, você precisa se certificar de que a ordem dos valores está na mesma ordem das colunas na tabela, conforme mostrado abaixo.
Insert into table_name values (value1, value2, value2);CREATE TABLE é a palavra-chave que diz ao sistema de banco de dados para criar uma nova tabela. O nome ou identificador exclusivo da tabela segue a instrução CREATE TABLE. Opcionalmente, você pode especificardatabase_name juntamente com o table_name.
Exemplo
Suponha que criamos uma tabela chamada student no Impala como mostrado abaixo.
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);A seguir está um exemplo de criação de um registro na tabela chamada employee.
[quickstart.cloudera:21000] > insert into employee
(ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );Ao executar a instrução acima, um registro é inserido na tabela chamada employee exibindo a seguinte mensagem.
Query: insert into employee (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh',
32, 'Ahmedabad', 20000 )
Inserted 1 row(s) in 1.32sVocê pode inserir outro registro sem especificar os nomes das colunas conforme mostrado abaixo.
[quickstart.cloudera:21000] > insert into employee values (2, 'Khilan', 25,
'Delhi', 15000 );Ao executar a instrução acima, um registro é inserido na tabela chamada employee exibindo a seguinte mensagem.
Query: insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 )
Inserted 1 row(s) in 0.31sVocê pode inserir mais alguns registros na tabela de funcionários, conforme mostrado abaixo.
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );Após inserir os valores, o employee tabela no Impala será como mostrado abaixo.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+Substituindo os dados em uma tabela
Podemos substituir os registros de uma tabela usando a cláusula overwrite. Os registros sobrescritos serão excluídos permanentemente da tabela. A seguir está a sintaxe de uso da cláusula overwrite.
Insert overwrite table_name values (value1, value2, value2);Exemplo
A seguir está um exemplo de uso da cláusula overwrite.
[quickstart.cloudera:21000] > Insert overwrite employee values (1, 'Ram', 26,
'Vishakhapatnam', 37000 );Ao executar a consulta acima, isso irá sobrescrever os dados da tabela com o registro especificado exibindo a seguinte mensagem.
Query: insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 )
Inserted 1 row(s) in 0.31sAo verificar a tabela, você pode observar que todos os registros da tabela employee são substituídos por novos registros, conforme mostrado abaixo.
+----+------+-----+---------------+--------+
| id | name | age | address | salary |
+----+------+-----+---------------+--------+
| 1 | Ram | 26 | Vishakhapatnam| 37000 |
+----+------+-----+---------------+--------+Inserindo dados usando o navegador Hue
Abra o editor de consultas Impala e digite o insertDeclaração nele. E clique no botão executar conforme mostrado na imagem a seguir.

Depois de executar a consulta / instrução, este registro é adicionado à tabela.
Impala SELECTinstrução é usada para buscar os dados de uma ou mais tabelas em um banco de dados. Esta consulta retorna dados na forma de tabelas.
Sintaxe
A seguir está a sintaxe do Impala select declaração.
SELECT column1, column2, columnN from table_name;Aqui, coluna1, coluna2 ... são os campos de uma tabela cujos valores você deseja buscar. Se você deseja buscar todos os campos disponíveis no campo, você pode usar a seguinte sintaxe -
SELECT * FROM table_name;Exemplo
Suponha que temos uma mesa chamada customers no Impala, com os seguintes dados -
ID NAME AGE ADDRESS SALARY
--- ------- --- ---------- -------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000Você pode buscar o id, name, e age de todos os registros do customers mesa usando select declaração conforme mostrado abaixo -
[quickstart.cloudera:21000] > select id, name, age from customers;Ao executar a consulta acima, o Impala busca id, nome, idade de todos os registros da tabela especificada e os exibe como mostrado abaixo.
Query: select id,name,age from customers
+----+----------+-----+
| id | name | age |
| 1 | Ramesh | 32 |
| 2 | Khilan | 25 |
| 3 | Hardik | 27 |
| 4 | Chaitali | 25 |
| 5 | kaushik | 23 |
| 6 | Komal | 22 |
+----+----------+-----+
Fetched 6 row(s) in 0.66sVocê também pode buscar all os registros do customers mesa usando o select consulta conforme mostrado abaixo.
[quickstart.cloudera:21000] > select name, age from customers;
Query: select * from customersAo executar a consulta acima, o Impala busca e exibe todos os registros da tabela especificada conforme mostrado abaixo.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.66sBuscando os Registros usando Hue
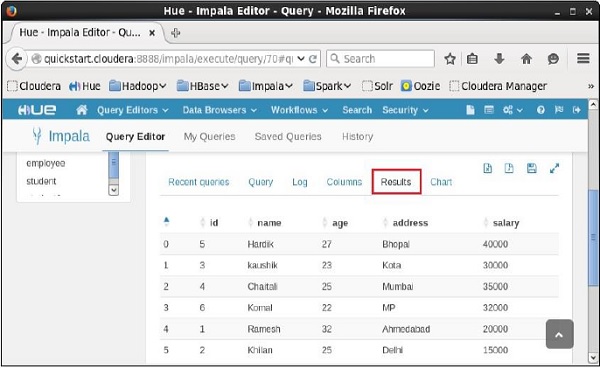
Abra o editor de consultas Impala e digite o selectDeclaração nele. E clique no botão executar conforme mostrado na imagem a seguir.
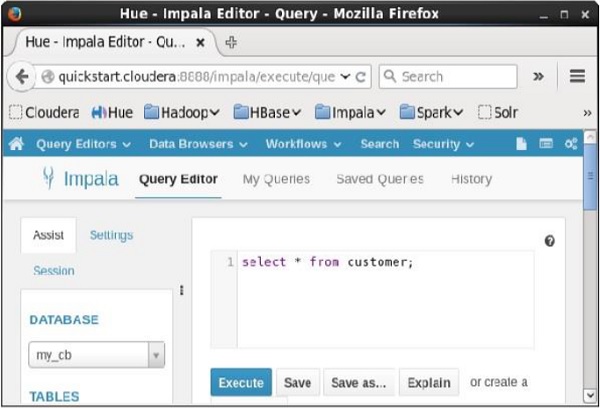
Depois de executar a consulta, se você rolar para baixo e selecionar o Results guia, você pode ver a lista dos registros da tabela especificada conforme mostrado abaixo.
o describedeclaração no Impala é usada para fornecer a descrição da tabela. O resultado dessa instrução contém as informações sobre uma tabela, como os nomes das colunas e seus tipos de dados.
Sintaxe
A seguir está a sintaxe do Impala describe declaração.
Describe table_name;Exemplo
Por exemplo, suponha que temos uma tabela chamada customer no Impala, com os seguintes dados -
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- -----------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000Você pode obter a descrição do customer mesa usando o describe declaração conforme mostrado abaixo -
[quickstart.cloudera:21000] > describe customer;Ao executar a consulta acima, o Impala busca o metadata da tabela especificada e a exibe conforme mostrado abaixo.
Query: describe customer
+---------+--------+---------+
| name | type | comment |
+---------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
+---------+--------+---------+
Fetched 5 row(s) in 0.51sDescrevendo os registros usando matiz
Abra o editor de consultas Impala e digite o describe declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
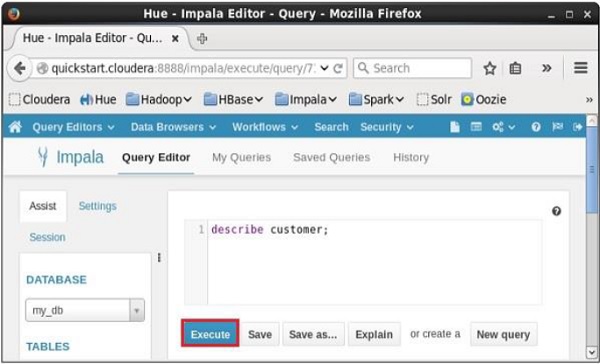
Depois de executar a consulta, se você rolar para baixo e selecionar o Results guia, você pode ver os metadados da tabela conforme mostrado abaixo.

A instrução Alter table no Impala é usada para realizar alterações em uma determinada tabela. Usando essa instrução, podemos adicionar, excluir ou modificar colunas em uma tabela existente e também podemos renomeá-la.
Este capítulo explica vários tipos de instruções alter com sintaxe e exemplos. Em primeiro lugar, suponha que temos uma tabela chamadacustomers no my_db banco de dados no Impala, com os seguintes dados
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000E, se você obtiver a lista de tabelas no banco de dados my_db, você pode encontrar o customers tabela como mostrado abaixo.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
| student1 |
+-----------+Alterar o nome de uma mesa
Sintaxe
A sintaxe básica de ALTER TABLE renomear uma tabela existente é o seguinte -
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_nameExemplo
A seguir está um exemplo de alteração do nome da tabela usando o alterdeclaração. Aqui estamos mudando o nome da mesacustomers para os usuários.
[quickstart.cloudera:21000] > ALTER TABLE my_db.customers RENAME TO my_db.users;Após executar a consulta acima, o Impala altera o nome da tabela conforme necessário, exibindo a seguinte mensagem.
Query: alter TABLE my_db.customers RENAME TO my_db.usersVocê pode verificar a lista de tabelas no banco de dados atual usando o show tablesdeclaração. Você pode encontrar a mesa chamadausers ao invés de customers.
Query: show tables
+----------+
| name |
+----------+
| employee |
| student |
| student1 |
| users |
+----------+
Fetched 4 row(s) in 0.10sAdicionando colunas a uma tabela
Sintaxe
A sintaxe básica de ALTER TABLE adicionar colunas a uma tabela existente é o seguinte -
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])Exemplo
A consulta a seguir é um exemplo que demonstra como adicionar colunas a uma tabela existente. Aqui, estamos adicionando duas colunas account_no e phone_number (ambos são do tipo de dados bigint) aousers mesa.
[quickstart.cloudera:21000] > ALTER TABLE users ADD COLUMNS (account_no BIGINT,
phone_no BIGINT);Ao executar a consulta acima, ele adicionará as colunas especificadas à tabela chamada student, exibindo a seguinte mensagem.
Query: alter TABLE users ADD COLUMNS (account_no BIGINT, phone_no BIGINT)Se você verificar o esquema da tabela users, você pode encontrar as colunas recém-adicionadas conforme mostrado abaixo.
quickstart.cloudera:21000] > describe users;
Query: describe users
+------------+--------+---------+
| name | type | comment |
+------------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| account_no | bigint | |
| phone_no | bigint | |
+------------+--------+---------+
Fetched 7 row(s) in 0.20sEliminando colunas de uma tabela
Sintaxe
A sintaxe básica de ALTER TABLE para DROP COLUMN em uma tabela existente é o seguinte -
ALTER TABLE name DROP [COLUMN] column_nameExemplo
A consulta a seguir é um exemplo de exclusão de colunas de uma tabela existente. Aqui estamos excluindo a coluna chamadaaccount_no.
[quickstart.cloudera:21000] > ALTER TABLE users DROP account_no;Ao executar a consulta acima, o Impala exclui a coluna chamada account_no exibindo a seguinte mensagem.
Query: alter TABLE users DROP account_noSe você verificar o esquema da tabela users, você não pode encontrar a coluna chamada account_no desde que foi excluído.
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11sAlterar o nome e o tipo de uma coluna
Sintaxe
A sintaxe básica de ALTER TABLE para change the name and datatype de uma coluna em uma tabela existente é a seguinte -
ALTER TABLE name CHANGE column_name new_name new_typeExemplo
A seguir está um exemplo de alteração do nome e tipo de dados de uma coluna usando a instrução alter. Aqui estamos mudando o nome da colunaphone_no to email e seu tipo de dados para string.
[quickstart.cloudera:21000] > ALTER TABLE users CHANGE phone_no e_mail string;Ao executar a consulta acima, o Impala faz as alterações especificadas, exibindo a seguinte mensagem.
Query: alter TABLE users CHANGE phone_no e_mail stringVocê pode verificar os metadados dos usuários da tabela usando o describedeclaração. Você pode observar que o Impala fez as alterações necessárias na coluna especificada.
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11sAlterando uma Tabela usando Hue
Abra o editor de consulta Impala e digite o alter declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
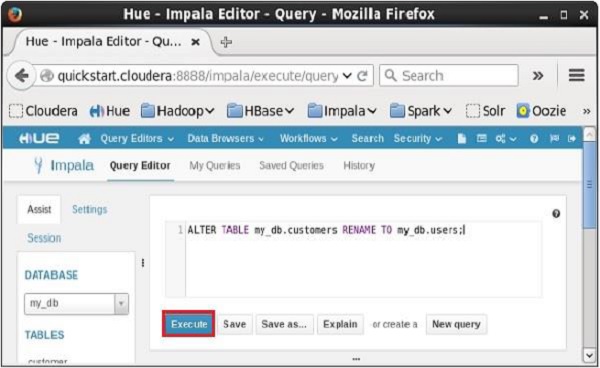
Ao executar a consulta acima, mudará o nome da tabela customers para users. Da mesma forma, podemos executar todas asalter consultas.
The Impala drop tabledeclaração é usada para excluir uma tabela existente no Impala. Esta declaração também exclui os arquivos HDFS subjacentes para tabelas internas
NOTE - Você deve ter cuidado ao usar este comando porque uma vez que uma tabela é excluída, todas as informações disponíveis na tabela também serão perdidas para sempre.
Sintaxe
A seguir está a sintaxe do DROP TABLEDeclaração. Aqui,IF EXISTSé uma cláusula opcional. Se usarmos esta cláusula, uma tabela com o nome fornecido será excluída, apenas se ela existir. Caso contrário, nenhuma operação será realizada.
DROP table database_name.table_name;Se você tentar excluir uma tabela que não existe sem a cláusula IF EXISTS, um erro será gerado. Opcionalmente, você pode especificardatabase_name junto com table_name.
Exemplo
Vamos primeiro verificar a lista de tabelas no banco de dados my_db como mostrado abaixo.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+------------+
| name |
+------------+
| customers |
| employee |
| student |
+------------+
Fetched 3 row(s) in 0.11sA partir do resultado acima, você pode observar que o banco de dados my_db contém 3 tabelas
A seguir está um exemplo do drop table statement. Neste exemplo, estamos excluindo a tabela chamadastudent do banco de dados my_db.
[quickstart.cloudera:21000] > drop table if exists my_db.student;Ao executar a consulta acima, uma tabela com o nome especificado será excluída, exibindo a seguinte saída.
Query: drop table if exists studentVerificação
o show Tablesconsulta fornece uma lista das tabelas no banco de dados atual no Impala. Portanto, você pode verificar se uma tabela foi excluída, usando oShow Tables declaração.
Em primeiro lugar, você precisa mudar o contexto para o banco de dados no qual a tabela necessária existe, conforme mostrado abaixo.
[quickstart.cloudera:21000] > use my_db;
Query: use my_dbEntão, se você obtiver a lista de tabelas usando o show tables consulta, você pode observar a tabela chamada student não está na lista.
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
+-----------+
Fetched 3 row(s) in 0.11sCriação de um banco de dados usando o navegador Hue
Abra o editor de consultas Impala e digite o drop TableDeclaração nele. E clique no botão executar conforme mostrado na imagem a seguir.
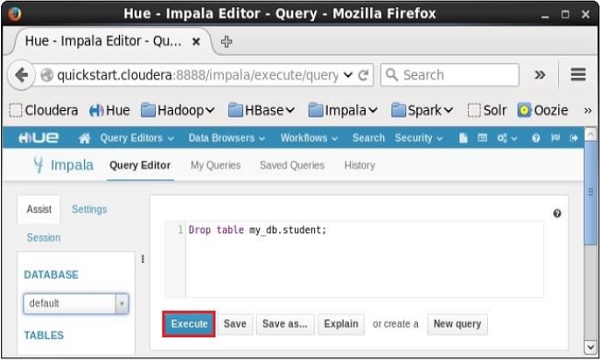
Depois de executar a consulta, mova suavemente o cursor para o topo do menu suspenso e você encontrará um símbolo de atualização. Se você clicar no símbolo de atualização, a lista de bancos de dados será atualizada e as alterações recentes feitas serão aplicadas a ela.
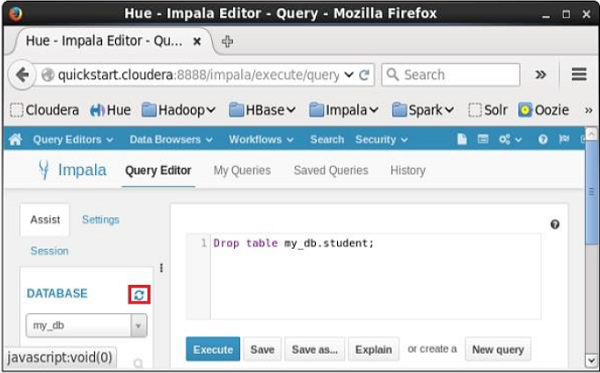
Verificação
Clique no drop down sob o título DATABASEno lado esquerdo do editor. Lá você pode ver uma lista de bancos de dados; selecione o banco de dadosmy_db como mostrado abaixo.
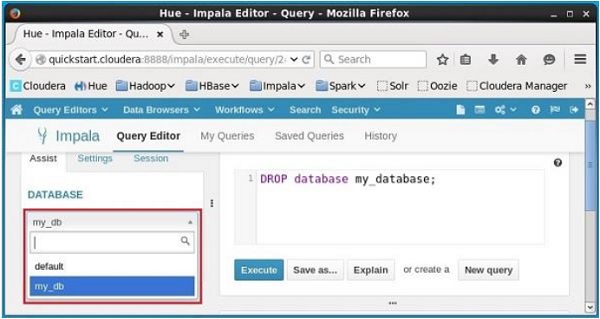
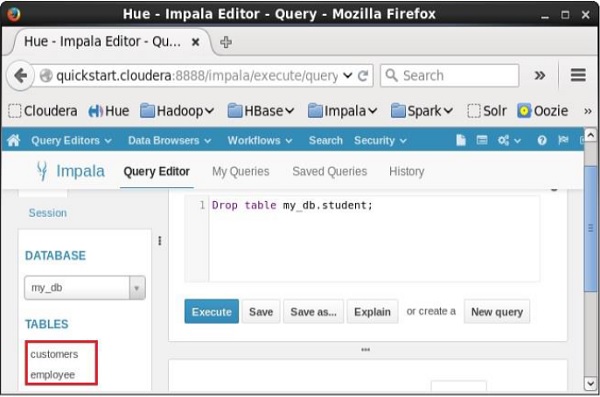
Ao selecionar o banco de dados my_db, você pode ver uma lista de tabelas como mostrado abaixo. Aqui você não consegue encontrar a tabela excluídastudent na lista conforme mostrado abaixo.
o Truncate Table A declaração do Impala é usada para remover todos os registros de uma tabela existente.
Você também pode usar o comando DROP TABLE para excluir uma tabela completa, mas removeria a estrutura completa da tabela do banco de dados e você precisaria recriar esta tabela mais uma vez se desejar armazenar alguns dados.
Sintaxe
A seguir está a sintaxe da instrução truncate table.
truncate table_name;Exemplo
Suponha que temos uma tabela chamada customersno Impala, e se você verificar seu conteúdo, obterá o seguinte resultado. Isso significa que a tabela de clientes contém 6 registros.
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+--------+
| id | name | age | address | salary | e_mail |
+----+----------+-----+-----------+--------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 | NULL |
| 2 | Khilan | 25 | Delhi | 15000 | NULL |
| 3 | kaushik | 23 | Kota | 30000 | NULL |
| 4 | Chaitali | 25 | Mumbai | 35000 | NULL |
| 5 | Hardik | 27 | Bhopal | 40000 | NULL |
| 6 | Komal | 22 | MP | 32000 | NULL |
+----+----------+-----+-----------+--------+--------+A seguir está um exemplo de truncamento de uma tabela no Impala usando truncate statement. Aqui estamos removendo todos os registros da tabela chamadacustomers.
[quickstart.cloudera:21000] > truncate customers;Ao executar a instrução acima, o Impala exclui todos os registros da tabela especificada, exibindo a seguinte mensagem.
Query: truncate customers
Fetched 0 row(s) in 0.37sVerificação
Se você verificar o conteúdo da tabela de clientes, após a operação de exclusão, usando select declaração, você obterá uma linha vazia conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
Fetched 0 row(s) in 0.12sTruncar uma tabela usando o navegador Hue
Abra o editor de consultas Impala e digite o truncateDeclaração nele. E clique no botão executar conforme mostrado na imagem a seguir.
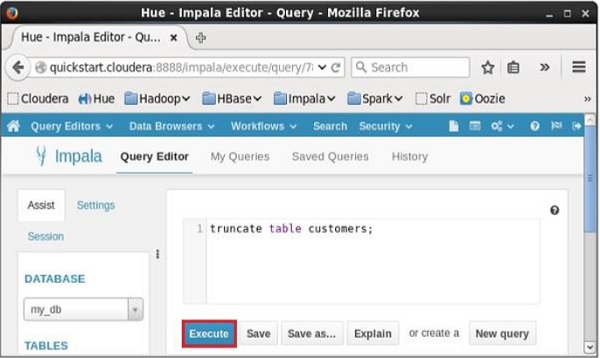
Após a execução da consulta / instrução, todos os registros da tabela são excluídos.
o show tables instrução no Impala é usada para obter a lista de todas as tabelas existentes no banco de dados atual.
Exemplo
A seguir está um exemplo do show tablesdeclaração. Se você deseja obter a lista de tabelas em um banco de dados específico, em primeiro lugar, altere o contexto para o banco de dados necessário e obtenha a lista de tabelas nele usandoshow tables declaração conforme mostrado abaixo.
[quickstart.cloudera:21000] > use my_db;
Query: use my_db
[quickstart.cloudera:21000] > show tables;Ao executar a consulta acima, o Impala busca a lista de todas as tabelas no banco de dados especificado e a exibe conforme mostrado abaixo.
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
+-----------+
Fetched 2 row(s) in 0.10sListando as tabelas usando o matiz
Abra o editor de consultas impala, selecione o contexto como my_db e digite o show tables declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
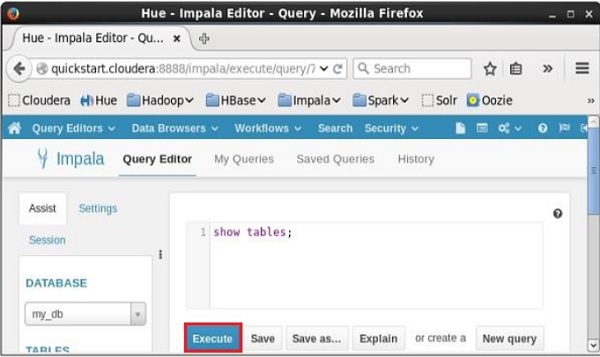
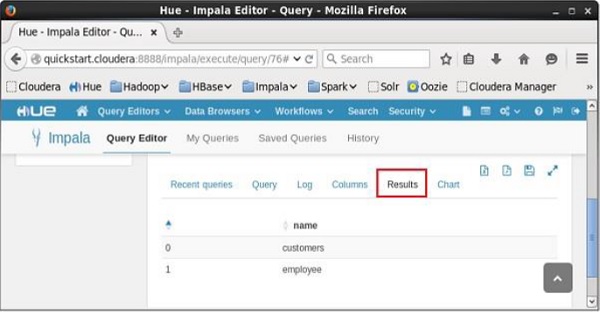
Depois de executar a consulta, se você rolar para baixo e selecionar o Results guia, você pode ver a lista das tabelas conforme mostrado abaixo.
Uma visualização nada mais é do que uma declaração da linguagem de consulta do Impala armazenada no banco de dados com um nome associado. É a composição de uma tabela na forma de uma consulta SQL predefinida.
Uma visão pode conter todas as linhas de uma tabela ou algumas selecionadas. Uma visão pode ser criada a partir de uma ou várias tabelas. As visualizações permitem que os usuários -
Estruture os dados de uma forma que os usuários ou classes de usuários considerem natural ou intuitiva.
Restrinja o acesso aos dados de forma que um usuário possa ver e (às vezes) modificar exatamente o que precisa e nada mais.
Resuma os dados de várias tabelas que podem ser usadas para gerar relatórios.
Você pode criar uma visualização usando o Create View declaração do Impala.
Sintaxe
A seguir está a sintaxe da instrução create view. IF NOT EXISTSé uma cláusula opcional. Se usarmos esta cláusula, uma tabela com o nome fornecido será criada, apenas se não houver uma tabela existente no banco de dados especificado com o mesmo nome.
Create View IF NOT EXISTS view_name as Select statementExemplo
Por exemplo, suponha que temos uma tabela chamada customers no my_db banco de dados no Impala, com os seguintes dados.
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 MP 32000A seguir está um exemplo de Create View Statement. Neste exemplo, estamos criando uma visualização comocustomers tabela que contém as colunas, nome e idade.
[quickstart.cloudera:21000] > CREATE VIEW IF NOT EXISTS customers_view AS
select name, age from customers;Ao executar a consulta acima, é criada uma visão com as colunas desejadas, exibindo a seguinte mensagem.
Query: create VIEW IF NOT EXISTS sample AS select * from customers
Fetched 0 row(s) in 0.33sVerificação
Você pode verificar o conteúdo da visualização recém-criada, usando o select declaração conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers_view;Isso produzirá o seguinte resultado.
Query: select * from customers_view
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+
Fetched 6 row(s) in 4.80sCriação de uma vista usando matiz
Abra o editor de consultas Impala, selecione o contexto como my_db, e digite o Create View declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
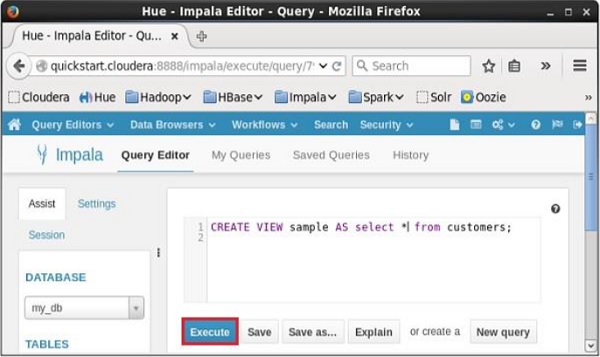
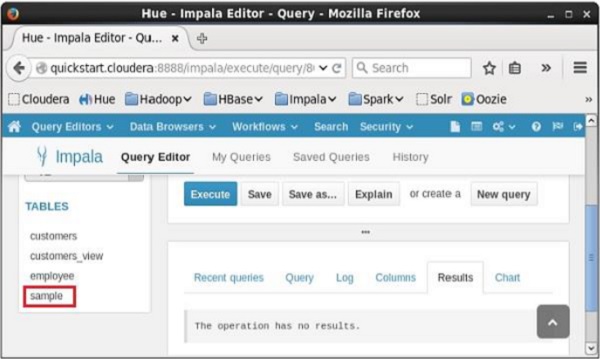
Depois de executar a consulta, se você rolar para baixo, pode ver o view nomeado sample criado na lista de tabelas conforme mostrado abaixo.
o Alter Viewdeclaração do Impala é usada para mudar uma visão. Usando essa instrução, você pode alterar o nome de uma visualização, alterar o banco de dados e a consulta associada a ele.
Desde um view é uma construção lógica, nenhum dado físico será afetado pelo alter view inquerir.
Sintaxe
A seguir está a sintaxe do Alter View declaração
ALTER VIEW database_name.view_name as Select statementExemplo
Por exemplo, suponha que temos uma visão chamada customers_view no my_db base de dados no Impala com os seguintes conteúdos.
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+A seguir está um exemplo de Alter View Statement. Neste exemplo, estamos incluindo as colunas id, nome e salário em vez de nome e idade para ocustomers_view.
[quickstart.cloudera:21000] > Alter view customers_view as select id, name,
salary from customers;Ao executar a consulta acima, o Impala faz as alterações especificadas no customers_view, exibindo a seguinte mensagem.
Query: alter view customers_view as select id, name, salary from customersVerificação
Você pode verificar o conteúdo do view nomeado customers_view, usando o select declaração conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers_view;
Query: select * from customers_viewIsso produzirá o seguinte resultado.
+----+----------+--------+
| id | name | salary |
+----+----------+--------+
| 3 | kaushik | 30000 |
| 2 | Khilan | 15000 |
| 5 | Hardik | 40000 |
| 6 | Komal | 32000 |
| 1 | Ramesh | 20000 |
| 4 | Chaitali | 35000 |
+----+----------+--------+
Fetched 6 row(s) in 0.69sAlterando uma visualização usando o matiz
Abra o editor de consultas Impala, selecione o contexto como my_db, e digite o Alter View declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
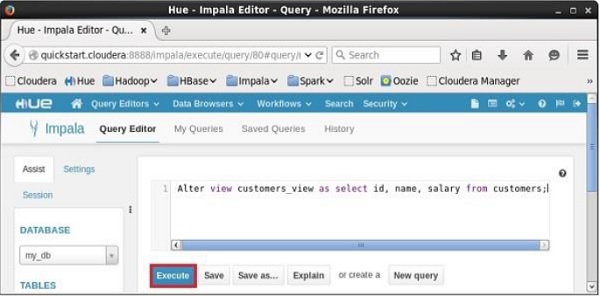
Depois de executar a consulta, o view nomeado sample será alterado em conformidade.
o Drop ViewA consulta do Impala é usada para excluir uma visualização existente. Desde umview é uma construção lógica, nenhum dado físico será afetado pelo drop view inquerir.
Sintaxe
A seguir está a sintaxe da instrução drop view.
DROP VIEW database_name.view_name;Exemplo
Por exemplo, suponha que temos uma visão chamada customers_view no my_db base de dados no Impala com os seguintes conteúdos.
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+A seguir está um exemplo de Drop View Statement. Neste exemplo, estamos tentando excluir oview nomeado customers_view usando o drop view inquerir.
[quickstart.cloudera:21000] > Drop view customers_view;Ao executar a consulta acima, o Impala exclui a visualização especificada, exibindo a seguinte mensagem.
Query: drop view customers_viewVerificação
Se você verificar a lista de tabelas usando show tables declaração, você pode observar que o view nomeado customers_view esta deletado.
[quickstart.cloudera:21000] > show tables;Isso produzirá o seguinte resultado.
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| sample |
+-----------+
Fetched 3 row(s) in 0.10sEliminando uma visualização usando matiz
Abra o editor de consultas Impala, selecione o contexto como my_db, e digite o Drop view declaração nele e clique no botão executar conforme mostrado na imagem a seguir.
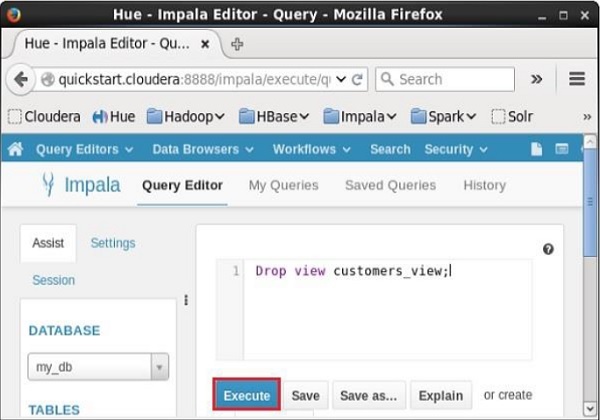
Depois de executar a consulta, se você rolar para baixo, verá uma lista chamada TABLES. Esta lista contém todos ostables e viewsno banco de dados atual. A partir desta lista, você pode descobrir que o especificadoview Foi apagado.
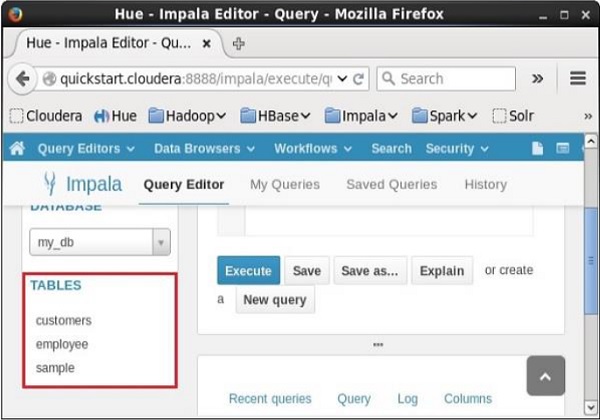
The Impala ORDER BYcláusula é usada para classificar os dados em ordem crescente ou decrescente, com base em uma ou mais colunas. Alguns bancos de dados classificam os resultados da consulta em ordem crescente por padrão.
Sintaxe
A seguir está a sintaxe da cláusula ORDER BY.
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]Você pode organizar os dados na tabela em ordem crescente ou decrescente usando as palavras-chave ASC ou DESC respectivamente.
Da mesma forma, se usarmos NULLS FIRST, todos os valores nulos da tabela serão organizados nas linhas superiores; e se usarmos NULLS LAST, as linhas contendo valores nulos serão organizadas por último.
Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 6 | Komal | 22 | MP | 32000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51sA seguir está um exemplo de organização dos dados no customers mesa, em ordem crescente de sua id’s usando o order by cláusula.
[quickstart.cloudera:21000] > Select * from customers ORDER BY id asc;Na execução, a consulta acima produz a seguinte saída.
Query: select * from customers ORDER BY id asc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.56sDa mesma forma, você pode organizar os dados de customers tabela em ordem decrescente usando o order by cláusula conforme mostrado abaixo.
[quickstart.cloudera:21000] > Select * from customers ORDER BY id desc;Na execução, a consulta acima produz a seguinte saída.
Query: select * from customers ORDER BY id desc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.54sThe Impala GROUP BY cláusula é usada em colaboração com a instrução SELECT para organizar dados idênticos em grupos.
Sintaxe
A seguir está a sintaxe da cláusula GROUP BY.
select data from table_name Group BY col_name;Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51sVocê pode obter o valor total do salário de cada cliente usando a consulta GROUP BY conforme mostrado abaixo.
[quickstart.cloudera:21000] > Select name, sum(salary) from customers Group BY name;Na execução, a consulta acima fornece a seguinte saída.
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 20000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 35000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75sSuponha que esta tabela tenha vários registros, conforme mostrado abaixo.
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Ramesh | 32 | Ahmedabad | 1000| |
| 3 | Khilan | 25 | Delhi | 15000 |
| 4 | kaushik | 23 | Kota | 30000 |
| 5 | Chaitali | 25 | Mumbai | 35000 |
| 6 | Chaitali | 25 | Mumbai | 2000 |
| 7 | Hardik | 27 | Bhopal | 40000 |
| 8 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+Agora, novamente, você pode obter o valor total dos salários dos funcionários, considerando as entradas repetidas de registros, usando o Group By cláusula conforme mostrado abaixo.
Select name, sum(salary) from customers Group BY name;Na execução, a consulta acima fornece a seguinte saída.
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 21000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 37000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75so Having A cláusula no Impala permite que você especifique as condições que filtram quais resultados de grupo aparecem nos resultados finais.
Em geral, o Having cláusula é usada junto com group bycláusula; ele coloca condições em grupos criados pela cláusula GROUP BY.
Sintaxe
A seguir está a sintaxe do Havingcláusula.
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-------------+--------+
| id | name | age | address | salary |
+----+----------+-----+-------------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | rahim | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sA seguir está um exemplo de uso Having cláusula no Impala -
[quickstart.cloudera:21000] > select max(salary) from customers group by age having max(salary) > 20000;Esta consulta agrupa inicialmente a tabela por idade e seleciona os salários máximos de cada grupo e exibe esses salários, que são superiores a 20.000, conforme mostrado abaixo.
20000
+-------------+
| max(salary) |
+-------------+
| 30000 |
| 35000 |
| 40000 |
| 32000 |
+-------------+
Fetched 4 row(s) in 1.30so limit A cláusula no Impala é usada para restringir o número de linhas de um conjunto de resultados a um número desejado, ou seja, o conjunto de resultados da consulta não contém os registros além do limite especificado.
Sintaxe
A seguir está a sintaxe do Limit cláusula no Impala.
select * from table_name order by id limit numerical_expression;Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sVocê pode organizar os registros na tabela em ordem crescente de seus ids usando o order by cláusula conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers order by id;
Query: select * from customers order by id
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.54sAgora, usando o limit cláusula, você pode restringir o número de registros da saída a 4, usando o limit cláusula conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers order by id limit 4;Na execução, a consulta acima fornece a seguinte saída.
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64sEm geral, as linhas no conjunto de resultados de um select consulta começa em 0. Usando o offsetcláusula, podemos decidir de onde a saída deve ser considerada. Por exemplo, se escolhermos o deslocamento como 0, o resultado será como de costume e se escolhermos o deslocamento como 5, o resultado começa na quinta linha.
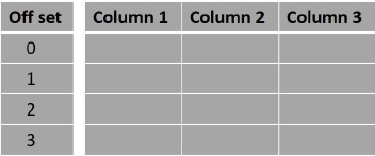
Sintaxe
A seguir está a sintaxe do offsetcláusula no Impala.
select data from table_name Group BY col_name;Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51sVocê pode organizar os registros na tabela em ordem crescente de seus ids e limitar o número de registros a 4, usando limit e order by cláusulas conforme mostrado abaixo.
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64sA seguir está um exemplo do offsetcláusula. Aqui, estamos obtendo os registros nocustomerstabela na ordem de seus ids e imprimindo as primeiras quatro linhas começando na 0ª linha.
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 0;Na execução, a consulta acima fornece o seguinte resultado.
Query: select * from customers order by id limit 4 offset 0
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.62sDa mesma forma, você pode obter quatro registros do customers tabela começando na linha com deslocamento 5, conforme mostrado abaixo.
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 5;
Query: select * from customers order by id limit 4 offset 5
+----+--------+-----+----------+--------+
| id | name | age | address | salary |
+----+--------+-----+----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+--------+-----+----------+--------+
Fetched 4 row(s) in 0.52sVocê pode combinar os resultados de duas consultas usando o Union cláusula do Impala.
Sintaxe
A seguir está a sintaxe do Union cláusula no Impala.
query1 union query2;Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59sDa mesma forma, suponha que temos outra tabela chamada employee e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59sA seguir está um exemplo do unioncláusula no Impala. Neste exemplo, organizamos os registros em ambas as tabelas na ordem de seus ids e limitamos seu número em 3 usando duas consultas separadas e juntando essas consultas usando oUNION cláusula.
[quickstart.cloudera:21000] > select * from customers order by id limit 3
union select * from employee order by id limit 3;Na execução, a consulta acima fornece a seguinte saída.
Query: select * from customers order by id limit 3 union select
* from employee order by id limit 3
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 3.11sNo caso de uma consulta ser muito complexa, podemos definir aliases para partes complexas e incluí-los na consulta usando o with cláusula do Impala.
Sintaxe
A seguir está a sintaxe do with cláusula no Impala.
with x as (select 1), y as (select 2) (select * from x union y);Exemplo
Suponha que temos uma mesa chamada customers no banco de dados my_db e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59sDa mesma forma, suponha que temos outra tabela chamada employee e seu conteúdo é o seguinte -
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59sA seguir está um exemplo do withcláusula no Impala. Neste exemplo, estamos exibindo os registros de ambosemployee e customers cuja idade é maior que 25 usando with cláusula.
[quickstart.cloudera:21000] >
with t1 as (select * from customers where age>25),
t2 as (select * from employee where age>25)
(select * from t1 union select * from t2);Na execução, a consulta acima fornece a seguinte saída.
Query: with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25)
(select * from t1 union select * from t2)
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 1.73so distinct operador no Impala é usado para obter os valores exclusivos, removendo duplicatas.
Sintaxe
A seguir está a sintaxe do distinct operador.
select distinct columns… from table_name;Exemplo
Suponha que temos uma tabela chamada customers no Impala e seus conteúdos são os seguintes -
[quickstart.cloudera:21000] > select distinct id, name, age, salary from customers;
Query: select distinct id, name, age, salary from customersAqui você pode observar o salário dos clientes Ramesh e Chaitali cadastrados duas vezes e utilizando o distinct operador, podemos selecionar os valores exclusivos conforme mostrado abaixo.
[quickstart.cloudera:21000] > select distinct name, age, address from customers;Na execução, a consulta acima fornece a seguinte saída.
Query: select distinct id, name from customers
+----------+-----+-----------+
| name | age | address |
+----------+-----+-----------+
| Ramesh | 32 | Ahmedabad |
| Khilan | 25 | Delhi |
| kaushik | 23 | Kota |
| Chaitali | 25 | Mumbai |
| Hardik | 27 | Bhopal |
| Komal | 22 | MP |
+----------+-----+-----------+
Fetched 9 row(s) in 1.46s