KDB + - Guia rápido
Esta é uma carta completa para kdb+da kx systems, voltada principalmente para aqueles que aprendem de forma independente. O kdb +, lançado em 2003, é a nova geração do banco de dados kdb que foi projetado para capturar, analisar, comparar e armazenar dados.
Um sistema kdb + contém os seguintes dois componentes -
KDB+ - o banco de dados (k banco de dados mais)
Q - a linguagem de programação para trabalhar com kdb +
Ambos kdb+ e q são escritos em k programming language (igual a q mas menos legível).
fundo
Kdb + / q originou-se como uma linguagem acadêmica obscura, mas ao longo dos anos, ele melhorou gradualmente sua facilidade de uso.
APL (1964, A Programming Language)
A+ (1988, APL modificado por Arthur Whitney)
K (1993, versão nítida de A +, desenvolvida por A. Whitney)
Kdb (1998, banco de dados baseado em coluna na memória)
Kdb+/q (2003, q linguagem - versão mais legível de k)
Por que e onde usar KDB +
Por quê? - Se você precisa de uma solução única para dados em tempo real com análise, deve considerar o kdb +. O Kdb + armazena o banco de dados como arquivos nativos comuns, portanto, não tem nenhuma necessidade especial em relação à arquitetura de hardware e armazenamento. Vale ressaltar que o banco de dados é apenas um conjunto de arquivos, portanto, seu trabalho administrativo não será difícil.
Onde usar KDB +?- É fácil contar quais bancos de investimento NÃO estão usando kdb +, já que a maioria deles está usando atualmente ou planejando mudar de bancos de dados convencionais para kdb +. Como o volume de dados aumenta dia a dia, precisamos de um sistema que possa lidar com grandes volumes de dados. O KDB + atende a esse requisito. O KDB + não apenas armazena uma enorme quantidade de dados, mas também os analisa em tempo real.
Começando
Com todo esse conhecimento, vamos agora estabelecer e aprender como configurar um ambiente para KDB +. Começaremos explicando como fazer o download e instalar o KDB +.
Baixando e instalando KDB +
Você pode obter a versão gratuita de 32 bits do KDB +, com todas as funcionalidades da versão de 64 bits de http://kx.com/software-download.php
Aceite o contrato de licença, selecione o sistema operacional (disponível para todos os principais sistemas operacionais). Para o sistema operacional Windows, a versão mais recente é 3.2. Baixe a versão mais recente. Depois de descompactá-lo, você obterá o nome da pasta“windows” e dentro da pasta do windows, você terá outra pasta “q”. Copie o todoq pasta em sua unidade c: /.
Abra o terminal Executar, digite o local onde você armazena o qpasta; será como “c: /q/w32/q.exe”. Depois de pressionar Enter, você obterá um novo console da seguinte forma -
Na primeira linha, você pode ver o número da versão que é 3.2 e a data de lançamento como 2015.03.05
Layout de diretório
A versão de teste / gratuita geralmente é instalada em diretórios,
For linux/Mac −
~/q / main q directory (under the user’s home)
~/q/l32 / location of linux 32-bit executable
~/q/m32 / Location of mac 32-bit executableFor Windows −
c:/q / Main q directory
c:/q/w32/ / Location of windows 32-bit executableExample Files −
Depois de baixar o kdb +, a estrutura de diretórios na plataforma Windows aparecerá da seguinte maneira -
Na estrutura de diretório acima, trade.q e sp.q são os arquivos de exemplo que podemos usar como ponto de referência.
Kdb + é um banco de dados de alto volume e alto desempenho, projetado desde o início para lidar com enormes volumes de dados. É totalmente de 64 bits e possui processamento multi-core e multi-threading integrados. A mesma arquitetura é usada para dados históricos e em tempo real. O banco de dados incorpora sua própria linguagem de consulta poderosa,q, portanto, a análise pode ser executada diretamente nos dados.
kdb+tick é uma arquitetura que permite a captura, processamento e consulta de dados históricos e em tempo real.
Arquitetura Kdb + / tick
A ilustração a seguir fornece um esboço geral de uma arquitetura Kdb + / tick típica, seguida por uma breve explicação dos vários componentes e do fluxo de dados.
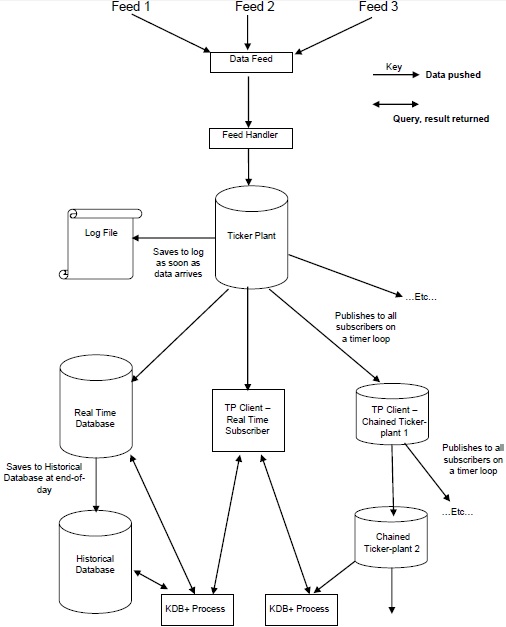
o Data Feeds são dados de séries temporais fornecidos principalmente por fornecedores de alimentação de dados, como Reuters, Bloomberg ou diretamente de bolsas.
Para obter os dados relevantes, os dados do feed de dados são analisados pelo feed handler.
Depois que os dados são analisados pelo gerenciador de feed, eles vão para o ticker-plant.
Para recuperar dados de qualquer falha, o ticker-plant primeiro atualiza / armazena os novos dados no arquivo de log e depois atualiza suas próprias tabelas.
Depois de atualizar as tabelas internas e os arquivos de log, os dados do loop on-time são continuamente enviados / publicados para o banco de dados em tempo real e todos os assinantes encadeados que solicitaram os dados.
No final de um dia útil, o arquivo de log é excluído, um novo é criado e o banco de dados em tempo real é salvo no banco de dados histórico. Depois que todos os dados são salvos no banco de dados histórico, o banco de dados em tempo real limpa suas tabelas.
Componentes da arquitetura Kdb + Tick
Feeds de dados
Os feeds de dados podem ser qualquer mercado ou outros dados de série temporal. Considere os feeds de dados como a entrada bruta para o manipulador de feeds. Os feeds podem ser diretamente da troca (dados de streaming ao vivo), de fornecedores de notícias / dados como Thomson-Reuters, Bloomberg ou quaisquer outras agências externas.
Feed Handler
Um manipulador de feed converte o fluxo de dados em um formato adequado para gravação em kdb +. Ele é conectado ao feed de dados e recupera e converte os dados do formato específico do feed em uma mensagem Kdb + que é publicada no processo ticker-plant. Geralmente, um manipulador de feed é usado para realizar as seguintes operações -
- Capture dados de acordo com um conjunto de regras.
- Traduzir (/ enriquecer) os dados de um formato para outro.
- Pegue os valores mais recentes.
Ticker Plant
Ticker Plant é o componente mais importante da arquitetura KDB +. É o ticker plant com o qual o banco de dados em tempo real ou diretamente os assinantes (clientes) estão conectados para acessar os dados financeiros. Atua empublish and subscribemecanismo. Depois de obter uma assinatura (licença), uma publicação de ticker (rotineiramente) do editor (ticker plant) é definida. Ele executa as seguintes operações -
Recebe os dados do manipulador de feed.
Imediatamente após o ticker plant receber os dados, ele armazena uma cópia como um arquivo de log e o atualiza assim que o ticker plant recebe qualquer atualização para que em caso de falha, não haja perda de dados.
Os clientes (assinantes em tempo real) podem se inscrever diretamente no ticker-plant.
No final de cada dia útil, ou seja, uma vez que o banco de dados em tempo real recebe a última mensagem, ele armazena todos os dados de hoje no banco de dados histórico e os envia a todos os assinantes que assinaram os dados de hoje. Em seguida, ele redefine todas as suas tabelas. O arquivo de registro também é excluído uma vez que os dados são armazenados no banco de dados histórico ou outro assinante diretamente vinculado ao banco de dados em tempo real (rtdb).
Como resultado, o ticker-plant, o banco de dados em tempo real e o banco de dados histórico estão operacionais 24 horas por dia, 7 dias por semana.
Uma vez que o ticker-plant é um aplicativo Kdb +, suas tabelas podem ser consultadas usando qcomo qualquer outro banco de dados Kdb +. Todos os clientes do ticker plant devem ter acesso ao banco de dados apenas como assinantes.
Banco de dados em tempo real
Um banco de dados em tempo real (rdb) armazena os dados de hoje. Ele está diretamente conectado à planta do relógio. Normalmente, ele seria armazenado na memória durante o horário de mercado (um dia) e gravado no banco de dados histórico (hdb) no final do dia. Como os dados (dados rdb) são armazenados na memória, o processamento é extremamente rápido.
Como o kdb + recomenda ter um tamanho de RAM quatro ou mais vezes o tamanho esperado dos dados por dia, a consulta que roda no rdb é muito rápida e oferece desempenho superior. Como um banco de dados em tempo real contém apenas os dados de hoje, a coluna de data (parâmetro) não é necessária.
Por exemplo, podemos ter consultas rdb como,
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Banco de Dados Históricos
Se tivermos que calcular as estimativas de uma empresa, precisamos ter seus dados históricos disponíveis. Um banco de dados histórico (hdb) contém dados de transações feitas no passado. O registro de cada novo dia seria adicionado ao hdb no final do dia. As tabelas grandes no hdb são armazenadas e distribuídas (cada coluna é armazenada em seu próprio arquivo) ou são armazenadas particionadas por dados temporais. Além disso, alguns bancos de dados muito grandes podem ser particionados ainda mais usandopar.txt (Arquivo).
Essas estratégias de armazenamento (distribuídas, particionadas, etc.) são eficientes ao pesquisar ou acessar os dados de uma grande mesa.
Um banco de dados histórico também pode ser usado para fins de relatórios internos e externos, ou seja, para análises. Por exemplo, suponha que desejemos obter as negociações da empresa da IBM para um determinado dia a partir do nome da tabela de negociação (ou qualquer), precisamos escrever uma consulta da seguinte forma -
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Escreveremos todas essas consultas assim que tivermos uma visão geral do q língua.
Kdb + vem com sua linguagem de programação integrada que é conhecida como q. Ele incorpora um superconjunto de SQL padrão que é estendido para análise de série temporal e oferece muitas vantagens em relação à versão padrão. Qualquer pessoa familiarizada com SQL pode aprenderq em questão de dias e ser capaz de escrever rapidamente suas próprias consultas ad hoc.
Iniciando o Ambiente “q”
Para começar a usar o kdb +, você precisa iniciar o qsessão. Existem três maneiras de iniciar umq sessão -
Basta digitar “c: /q/w32/q.exe” em seu terminal de execução.
Inicie o terminal de comando do MS-DOS e digite q.
Copie o q.exe arquivo em “C: \ Windows \ System32” e no terminal de execução, basta digitar “q”.
Aqui, estamos assumindo que você está trabalhando em uma plataforma Windows.
Tipos de dados
A tabela a seguir fornece uma lista de tipos de dados suportados -
| Nome | Exemplo | Caracteres | Tipo | Tamanho |
|---|---|---|---|---|
| boleano | 1b | b | 1 | 1 |
| byte | 0xff | x | 4 | 1 |
| baixo | 23h | h | 5 | 2 |
| int | 23i | Eu | 6 | 4 |
| grandes | 23j | j | 7 | 8 |
| real | 2.3e | e | 8 | 4 |
| flutuador | 2.3f | f | 9 | 8 |
| Caracteres | "uma" | c | 10 | 1 |
| varchar | `ab | s | 11 | * |
| mês | 2003,03m | m | 13 | 4 |
| encontro | 17.03.2015T18: 01: 40.134 | z | 15 | 8 |
| minuto | 08:31 | você | 17 | 4 |
| segundo | 08:31:53 | v | 18 | 4 |
| Tempo | 18: 03: 18.521 | t | 19 | 4 |
| enum | `u $` b, onde u: `a`b | * | 20 | 4 |
Formação de átomos e listas
Os átomos são entidades únicas, por exemplo, um único número, um caractere ou um símbolo. Na tabela acima (de diferentes tipos de dados), todos os tipos de dados suportados são átomos. Uma lista é uma sequência de átomos ou outros tipos, incluindo listas.
Passar um átomo de qualquer tipo para a função do tipo monádica (ou seja, função de argumento único) retornará um valor negativo, ou seja, –n, ao passo que passar uma lista simples desses átomos para a função de tipo retornará um valor positivo n.
Exemplo 1 - Formação de átomos e listas
/ Note that the comments begin with a slash “ / ” and cause the parser
/ to ignore everything up to the end of the line.
x: `mohan / `mohan is a symbol, assigned to a variable x
type x / let’s check the type of x
-11h / -ve sign, because it’s single element.
y: (`abc;`bca;`cab) / list of three symbols, y is the variable name.
type y
11h / +ve sign, as it contain list of atoms (symbol).
y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon
y2: (`$”symbols may have interior blanks”) / string to symbol conversion
y[0] / return `abc
y 0 / same as y[0], also returns `abc
y 0 2 / returns `abc`cab, same as does y[0 2]
z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types,
z 2 0 / returns (`a`b; `abc),
z[2;0] / return `a. first element of z[2]
x: “Hello World!” / list of character, a string
x 4 0 / returns “oH” i.e. 4th and 0th(first)
elementFreqüentemente, é necessário alterar o tipo de dados de alguns dados de um tipo para outro. A função de fundição padrão é o “$”dyadic operator.
Três abordagens são usadas para lançar de um tipo para outro (exceto para string) -
- Especifique o tipo de dados desejado por seu nome de símbolo
- Especifique o tipo de dados desejado por seu caractere
- Especifique o tipo de dados desejado por seu valor curto.
Fundição de inteiros para flutuadores
No exemplo a seguir de conversão de inteiros em flutuantes, todas as três formas diferentes de conversão são equivalentes -
q)a:9 18 27
q)$[`float;a] / Specify desired data type by its symbol name, 1st way
9 18 27f
q)$["f";a] / Specify desired data type by its character, 2nd way
9 18 27f
q)$[9h;a] / Specify desired data type by its short value, 3rd way
9 18 27fVerifique se todas as três operações são equivalentes,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a])
1bFundindo Strings em Símbolos
Transformar string em símbolos e vice-versa funciona de maneira um pouco diferente. Vamos verificar com um exemplo -
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorldA tentativa de converter strings para símbolos usando o símbolo de palavras-chave `ou 11h irá falhar com o erro de tipo -
q)b
"Hello"
"World"
"HelloWorld"
q)`symbol$b
'type
q)11h$b
'typeFundindo Strings em Non-Symbols
A conversão de strings para um tipo de dados diferente de símbolo é realizada da seguinte maneira -
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above 57 48 48i q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900iPortanto, para converter uma string inteira (a lista de caracteres) em um único átomo de tipo de dados x exige que especifiquemos a letra maiúscula que representa o tipo de dados x como o primeiro argumento para o $operador. Se você especificar o tipo de dados dex de qualquer outra forma, resulta na aplicação do elenco a cada caractere da string.
o q a linguagem tem muitas maneiras diferentes de representar e manipular dados temporais, como horas e datas.
Encontro
Uma data em kdb + é armazenada internamente como o número inteiro de dias desde que nossa data de referência é 01Jan2000. Uma data posterior a essa data é armazenada internamente como um número positivo e uma data anterior é referenciada como um número negativo.
Por padrão, uma data é escrita no formato “AAAA.MM.DD”
q)x:2015.01.22 / This is how we write 22nd Jan 2015
q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date
2015i
q)x.year / Another way of extracting year
2015i
q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date
22i
q)x.dd / Another way of extracting day
22iArithmetic and logical operations pode ser realizado diretamente nas datas.
q)x+1 / Add one day
2015.01.23
q)x-7 / Subtract 7 days
2015.01.15O primeiro de janeiro de 2000 caiu em um sábado. Portanto, qualquer sábado da história ou no futuro, quando dividido por 7, renderia um resto de 0, o domingo dá 1, o rendimento de segunda-feira 2.
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6Vezes
Uma hora é armazenada internamente como o número inteiro de milissegundos desde a meia-noite. Uma hora é escrita no formato HH: MM: SS.MSS
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM
q)tt1
03:30:00.000
q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time
3i
q)tt1.hh
3i
q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time
0i
q)tt1.ss
0iComo no caso das datas, a aritmética pode ser realizada diretamente nas horas.
Datetimes
Uma data e hora é a combinação de uma data e uma hora, separadas por 'T' como no formato padrão ISO. Um valor datetime armazena a contagem de dias fracionários a partir da meia-noite de 1º de janeiro de 2000.
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012
q)type dt
-15h
q)dt
2012.12.20T04:54:59.000
9
q)`float$dt
4737.205A contagem de dias fracionários subjacente pode ser obtida lançando para float.
As listas são os blocos básicos de construção de q language, portanto, um entendimento completo das listas é muito importante. Uma lista é simplesmente uma coleção ordenada de átomos (elementos atômicos) e outras listas (grupo de um ou mais átomos).
Tipos de lista
UMA general listenvolve seus itens entre parênteses correspondentes e os separa com ponto e vírgula. Por exemplo -
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")Se uma lista contém átomos do mesmo tipo, ela é conhecida como uniform list. Caso contrário, é conhecido como umgeneral list (tipo misto).
Contagem
Podemos obter o número de itens em uma lista por meio de sua contagem.
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list
q)count l1 / Calculating number of items in the list l1
4Exemplos de lista simples
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"**Note − A simple list of char is called a string.
Uma lista contém átomos ou listas. To create a single item list, usamos -
q)singleton:enlist 42
q)singleton
,42To distinguish between an atom and the equivalent singleton, examine o sinal de seu tipo.
q)signum type 42
-1i
q)signum type enlist 42
1iUma lista é ordenada da esquerda para a direita pela posição de seus itens. O deslocamento de um item desde o início da lista é chamado deindex. Assim, o primeiro item tem um índice 0, o segundo item (se houver) tem um índice 1, etc. Uma lista de contagemn tem domínio de índice de 0 para n–1.
Notação de índice
Dada uma lista L, o item no índice i é acessado por L[i]. A recuperação de um item pelo seu índice é chamadaitem indexing. Por exemplo,
q)L:(99;98.7e;`b;`abc;"z")
q)L[0]
99
q)L[1]
98.7e
q)L[4]
"zAtribuição Indexada
Os itens em uma lista também podem ser atribuídos por meio da indexação de itens. Portanto,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66Listas de variáveis
q)l1:(9;8;40;200)
q)l2:(1 4 3; `abc`xyz)
q)l:(l1;l2) / combining the two list l1 and l2
q)l
9 8 40 200
(1 4 3;`abc`xyz)Aderir a listas
A operação mais comum em duas listas é juntá-las para formar uma lista maior. Mais precisamente, o operador de junção (,) anexa seu operando direito ao final do operando esquerdo e retorna o resultado. Ele aceita um átomo em qualquer argumento.
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6Nesting
A complexidade dos dados é construída usando listas como itens de listas.
Profundidade
O número de níveis de aninhamento de uma lista é chamado de profundidade. Os átomos têm uma profundidade de 0 e as listas simples têm uma profundidade de 1.
q)l1:(9;8;(99;88))
q)count l1
3Aqui está uma lista de profundidade 3 com dois itens -
q)l5
9
(90;180;900 1800 2700 3600)
q)count l5
2
q)count l5[1]
3Indexando em profundidade
É possível indexar diretamente nos itens de uma lista aninhada.
Repeated Item Indexing
A recuperação de um item por meio de um único índice sempre recupera um item superior de uma lista aninhada.
q)L:(1;(100;200;(300;400;500;600)))
q)L[0]
1
q)L[1]
100
200
300 400 500 600Desde o resultado L[1] é uma lista, podemos recuperar seus elementos usando um único índice.
q)L[1][2]
300 400 500 600Podemos repetir a indexação única mais uma vez para recuperar um item da lista aninhada mais interna.
q)L[1][2][0]
300Você pode ler isso como,
Obtenha o item no índice 1 de L, e dele recupere o item no índice 2, e dele recupere o item no índice 0.
Notation for Indexing at Depth
Há uma notação alternativa para indexação repetida nos constituintes de uma lista aninhada. A última recuperação também pode ser escrita como,
q)L[1;2;0]
300A atribuição via índice também funciona em profundidade.
q)L[1;2;1]:900
q)L
1
(100;200;300 900 500 600)Índices Elididos
Eliding Indices for a General List
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"Interpret L[;1;] as,
Recupere todos os itens na segunda posição de cada lista no nível superior.
Interpret L[;;2] as,
Recupere os itens na terceira posição para cada lista no segundo nível.
Os dicionários são uma extensão das listas que fornecem a base para a criação de tabelas. Em termos matemáticos, o dicionário cria o
“Domínio → intervalo”
ou em geral (resumido) cria
“Chave → valor”
relação entre os elementos.
Um dicionário é uma coleção ordenada de pares chave-valor que é aproximadamente equivalente a uma tabela hash. Um dicionário é um mapeamento definido por uma associação de E / S explícita entre uma lista de domínio e uma lista de intervalo por meio de correspondência posicional. A criação de um dicionário usa a primitiva "xkey" (!)
ListOfDomain ! ListOfRangeO dicionário mais básico mapeia uma lista simples para uma lista simples.
| Entrada (I) | Saída (O) |
|---|---|
| `Nome | `John |
| `Idade | 36 |
| `Sexo | “M” |
| Peso | 60,3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d
q)d
Name | `John
Age | 36
Sex | "M"
Weight | 60.3
q)count d / To get the number of rows in a dictionary.
4
q)key d / The function key returns the domain
`Name`Age`Sex`Weight
q)value d / The function value returns the range.
`John
36
"M"
60.3
q)cols d / The function cols also returns the domain.
`Name`Age`Sex`WeightOlho para cima
Encontrar o valor de saída do dicionário correspondente a um valor de entrada é chamado looking up a entrada.
q)d[`Name] / Accessing the value of domain `Name
`John
q)d[`Name`Sex] / extended item-wise to a simple list of keys
`John
"M"Pesquisa com Verbo @
q)d1:`one`two`three!9 18 27
q)d1[`two]
18
q)d1@`two
18Operações em dicionários
Emendar e Upsert
Tal como acontece com as listas, os itens de um dicionário podem ser modificados por meio de atribuição indexada.
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3Os dicionários podem ser estendidos por meio da atribuição de índice.
q)d[`Height]:"182 Ft"
q)d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
Height | "182 Ft"Pesquisa reversa com Localizar (?)
O operador find (?) É usado para realizar a pesquisa reversa mapeando uma gama de elementos para seu elemento de domínio.
q)d2:`x`y`z!99 88 77
q)d2?77
`zCaso os elementos de uma lista não sejam únicos, o find retorna o primeiro mapeamento de item da lista de domínio.
Removendo entradas
Para remover uma entrada de um dicionário, o delete ( _ ) functioné usado. O operando esquerdo de (_) é o dicionário e o operando direito é um valor-chave.
q)d2:`x`y`z!99 88 77
q)d2 _`z
x| 99
y| 88É necessário espaço em branco à esquerda de _ se o primeiro operando for uma variável.
q)`x`y _ d2 / Deleting multiple entries
z| 77Dicionários de coluna
Dicionários de coluna são básicos para a criação de tabelas. Considere o seguinte exemplo -
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27Invertendo um dicionário
O efeito líquido de inverter um dicionário de coluna é simplesmente inverter a ordem dos índices. Isso é logicamente equivalente a transpor as linhas e colunas.
Flip em um dicionário de coluna
A transposição de um dicionário é obtida aplicando o operador unário flip. Dê uma olhada no seguinte exemplo -
q)scores
name | John Jenny Jonathan
id | 9 18 27
q)flip scores
name id
---------------
John 9
Jenny 18
Jonathan 27Inverter um dicionário de coluna invertido
Se você transpõe um dicionário duas vezes, obtém o dicionário original,
q)scores ~ flip flip scores
1bAs tabelas são o cerne do kdb +. Uma tabela é uma coleção de colunas nomeadas implementadas como um dicionário.q tables são orientados por colunas.
Criação de tabelas
As tabelas são criadas usando a seguinte sintaxe -
q)trade:([]time:();sym:();price:();size:())
q)trade
time sym price size
-------------------No exemplo acima, não especificamos o tipo de cada coluna. Isso será definido pela primeira inserção na tabela.
Outra forma, podemos especificar o tipo de coluna na inicialização -
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())Ou também podemos definir tabelas não vazias -
q)trade:([]sym:(`a`b);price:(1 2))
q)trade
sym price
-------------
a 1
b 2Se não houver colunas entre colchetes, como nos exemplos acima, a tabela é unkeyed.
Para criar um keyed table, inserimos a (s) coluna (s) da chave entre colchetes.
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$())
q)trade
sym | time price size
----- | ---------------Também é possível definir os tipos de coluna definindo os valores como listas nulas de vários tipos -
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)Obtendo Informações da Tabela
Vamos criar uma mesa de negociação -
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow)
q)cols trade / column names of a table
`sym`mcap`ex
q)trade.sym / Retrieves the value of column sym
`ibm`msft`apple`samsung
q)show meta trade / Get the meta data of a table trade.
c | t f a
----- | -----
Sym | s
Mcap | j
ex | sChaves primárias e tabelas codificadas
Mesa Chaveada
Uma tabela com chave é um dicionário que mapeia cada linha em uma tabela de chaves exclusivas para uma linha correspondente em uma tabela de valores. Vamos dar um exemplo -
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eidAgora crie uma tabela com chave simples contendo eid como chave,
q)valid: id ! val
q)valid / table name valid, having key as eid
eid | name id
--- | ---------------
99 | John 9
198 | Jenny 18
297 | Jonathan 27ForeignKeys
UMA foreign key define um mapeamento das linhas da tabela em que está definido para as linhas da tabela com o correspondente primary key.
Chaves estrangeiras fornecem referential integrity. Em outras palavras, uma tentativa de inserir um valor de chave estrangeira que não esteja na chave primária falhará.
Considere os seguintes exemplos. No primeiro exemplo, definiremos uma chave estrangeira explicitamente na inicialização. No segundo exemplo, usaremos a busca de chave estrangeira, que não assume nenhuma relação anterior entre as duas tabelas.
Example 1 − Define foreign key on initialization
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000)
q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f)
q)show meta tab
c | t f a
------ | ----------
sym | s sector
price | f
q)show select from tab where sym.ex=`N
sym price
----------------
APPLE 4.65382
APPLE 4.643817
APPLE 3.659978Example 2 − no pre-defined relationship between tables
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000)
tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)Para usar a busca de chave estrangeira, devemos criar uma tabela para digitar no setor.
q)show update mc:(sector([]symb:sym))[`MC] from tab
sym price mc
--------------------------
IBM 7.065297 1000
MSFT 4.812387 2000
MSFT 6.400545 2000
HSBC 3.704373 3000
HSBC 4.438651 3000Notação geral para uma chave estrangeira predefinida -
selecione ab de c onde a é a chave estrangeira (sym), b é a
campo na tabela de chave primária (ind), c é o
tabela de chave estrangeira (comércio)
Manipulando tabelas
Vamos criar uma tabela de negociação e verificar o resultado de diferentes expressões de tabela -
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365))
q)trade
sym price size time
-----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842Vamos agora dar uma olhada nas instruções que são usadas para manipular tabelas usando q língua.
Selecione
A sintaxe para usar um Select declaração é a seguinte -
select [columns] [by columns] from table [where clause]Vamos agora dar um exemplo para demonstrar como usar a instrução Select -
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006Inserir
A sintaxe para usar um Insert declaração é a seguinte -
`tablename insert (values)
Insert[`tablename; values]Vamos agora dar um exemplo para demonstrar como usar a instrução Insert -
q)/ Insert expression example
q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000)
5 6
q)trade
sym price size time
------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
q)/Insert another value
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000]
']
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)]
,7
q)trade
sym price size time
----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000Excluir
A sintaxe para usar um Delete declaração é a seguinte -
delete columns from table
delete from table where clauseVamos agora dar um exemplo para demonstrar como usar a instrução Delete -
q)/Delete expression example
q)delete price from trade
sym size time
-------------------------------
msft 3162 02:32:17.036
msft 2917 01:44:56.936
hsbc 1492 00:25:23.210
samsung 1983 00:29:38.945
ibm 4006 07:24:26.842
hsbc 3020 09:30:17.004
apple 3012 09:15:00.000
samsung 3333 10:30:00.000
q)delete from trade where price > 3000
sym price size time
-------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000
q)delete from trade where price > 500
sym price size time
-----------------------------------------
samsung 278.3498 1983 00:29:38.945
hsbc 302 3020 09:30:17.004
samsung 302 3333 10:30:00.000Atualizar
A sintaxe para usar um Update declaração é a seguinte -
update column: newValue from table where ….Use a seguinte sintaxe para atualizar o formato / tipo de dados de uma coluna usando a função de conversão -
update column:newValue from `table where …Vamos agora dar um exemplo para demonstrar como usar Update declaração -
q)/Update expression example
q)update size:9000 from trade where price > 600
sym price size time
------------------------------------------
msft 743.8592 9000 02:32:17.036
msft 641.7307 9000 01:44:56.936
hsbc 838.2311 9000 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 9000 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 9000 09:15:00.000
samsung 302 3333 10:30:00.000
q)/Update the datatype of a column using the cast function
q)meta trade
c | t f a
----- | --------
sym | s
price| f
size | j
time | t
q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade
`trade
q)meta trade
c | t f a
------ | --------
sym | s
price | f
size | f
time | tKdb + tem substantivos, verbos e advérbios. Todos os objetos de dados e funções sãonouns. Verbs aprimore a legibilidade reduzindo o número de colchetes e parênteses nas expressões. Adverbsmodifique funções e verbos diádicos (2 argumentos) para produzir novos verbos relacionados. As funções produzidas por advérbios são chamadasderived functions ou derived verbs.
Cada
O advérbio each, denotado por (`), modifica funções diádicas e verbos para aplicar aos itens de listas em vez das próprias listas. Dê uma olhada no seguinte exemplo -
q)1, (2 3 5) / Join
1 2 3 5
q)1, '( 2 3 4) / Join each
1 2
1 3
1 4Existe uma forma de Eachpara funções monádicas que usam a palavra-chave “cada”. Por exemplo,
q)reverse ( 1 2 3; "abc") /Reverse
a b c
1 2 3
q)each [reverse] (1 2 3; "abc") /Reverse-Each
3 2 1
c b a
q)'[reverse] ( 1 2 3; "abc")
3 2 1
c b aCada Esquerda e Cada Direita
Existem duas variantes de cada para funções diádicas chamadas Each-Left (\ :) e Each-Right(/ :). O exemplo a seguir explica como usá-los.
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40Dentro qlinguagem, temos diferentes tipos de junções com base nas tabelas de entrada fornecidas e o tipo de tabelas associadas que desejamos. Uma junção combina dados de duas tabelas. Além da busca de chave estrangeira, existem quatro outras maneiras de unir tabelas -
- Junção simples
- Assim que entrar
- Associação à esquerda
- União
Aqui, neste capítulo, discutiremos cada uma dessas junções em detalhes.
Junção Simples
A junção simples é o tipo mais básico de junção, executada com uma vírgula ','. Neste caso, as duas tabelas devem sertype conformant, ou seja, ambas as tabelas têm o mesmo número de colunas na mesma ordem e mesma chave.
table1,:table2 / table1 is assigned the value of table2Podemos usar junção de cada vírgula para tabelas com o mesmo comprimento para junção lateral. Uma das tabelas pode ser codificada aqui,
Table1, `Table2Asof Join (aj)
É a junção mais poderosa que é usada para obter o valor de um campo em uma tabela a partir do momento em outra tabela. Geralmente é usado para obter a oferta e solicitação prevalecentes no momento de cada negociação.
Formato geral
aj[joinColumns;tbl1;tbl2]Por exemplo,
aj[`sym`time;trade;quote]Exemplo
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show aj[`a`b;tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Junção à esquerda (lj)
É um caso especial de aj onde o segundo argumento é uma tabela com chave e o primeiro argumento contém as colunas da chave do argumento correto.
Formato geral
table1 lj Keyed-tableExemplo
q)/Left join- syntax table1 lj table2 or lj[table1;table2]
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6))
q)show lj[tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Union Join (uj)
Permite criar uma união de duas tabelas com esquemas distintos. É basicamente uma extensão da junção simples (,)
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show uj[tab1;tab2]
a b d c
------------
1 2 6
2 3 7
3 4 8
4 5 9
2 3 4
3 4 5
4 5 6Se você estiver usando uj em tabelas chaveadas, as chaves primárias devem corresponder.
Tipos de funções
As funções podem ser classificadas de várias maneiras. Aqui, nós os classificamos com base no número e tipo de argumento que assumem e no tipo de resultado. As funções podem ser,
Atomic - Onde os argumentos são atômicos e produzem resultados atômicos
Aggregate - átomo da lista
Uniform (list from list)- Ampliou o conceito de átomo conforme se aplica a listas. A contagem da lista de argumentos é igual à contagem da lista de resultados.
Other - se a função não pertencer à categoria acima.
Operações binárias em matemática são chamadas dyadic functionsem q; por exemplo, “+”. Da mesma forma, as operações unárias são chamadasmonadic functions; por exemplo, “abs” ou “chão”.
Funções frequentemente utilizadas
Existem algumas funções usadas com frequência em qprogramação. Aqui, nesta seção, veremos o uso de algumas funções populares -
abdômen
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number
9.9todos
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value
0bMáx (&), Mín (|) e Não (!)
q) /And, Or, and Logical Negation
q) 1b & 1b / And (Max)
1b
q) 1b|0b / Or (Min)
1b
q) not 1b /Logical Negate (Not)
0basc
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for groupedmédia
q)avg 3 4 5 6 7 / Return average of a list of numeric values
5f
q)/Create on trade table
q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)de
q)/ by - Groups rows in a table at given sym
q)select sum price by sym from trade / find total price for each sym
sym | price
------ | --------
apple | 140.2165
ibm | 16.11385cols
q)cols trade / Lists columns of a table
`time`sym`price`sizecontagem
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9porta
q)\p 9999 / assign port number
q)/csv - This command allows queries in a browser to be exported to
excel by prefixing the query, such as http://localhost:9999/.csv?select from trade where sym =`ibmcortar
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"Excluir
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97Distinto
q)/distinct - Returns the distinct element of a list
q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number
1 2 3 4 5alistar
q)/enlist - Creates one-item list.
q)enlist 37
,37
q)type 37 / -ve type value
-7h
q)type enlist 37 / +ve type value
7hPreencher (^)
q)/fill - used with nulls. There are three functions for processing null values.
The dyadic function named fill replaces null values in the right argument with the atomic left argument.
q)100 ^ 3 4 0N 0N -5
3 4 100 100 -5
q)`Hello^`jack`herry``john`
`jack`herry`Hello`john`HelloPreenche
q)/fills - fills in nulls with the previous not null value.
q)fills 1 0N 2 0N 0N 2 3 0N -5 0N
1 1 2 2 2 2 3 3 -5 -5Primeiro
q)/first - returns the first atom of a list
q)first 1 3 34 5 3
1Giro
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97iasc
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list.
q)iasc 5 4 0 3 4 9
2 3 1 4 0 5Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list
q)idesc 0 1 3 4
3 2 1 0dentro
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents.
q)(2 4) in 1 2 3
10binserir
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99chave
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary.
q)key 9
0 1 2 3 4 5 6 7 8
q)key `:c:
`$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..mais baixo
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`symMáx e Mín (ou seja, | e &)
q)/Max and Min / a|b and a&b
q)9|7
9
q)9&5
5nulo
q)/null - return 1b if the atom is a null else 0b from the argument list
q)null 1 3 3 0N
0001bpêssego
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31Anterior
q)/prev - returns the previous element i.e. pushes list forwards
q)prev 0 1 3 4 5 7
0N 0 1 3 4 5Aleatória( ?)
q)/random - syntax - n?list, gives random sequences of ints and floats
q)9?5
0 0 4 0 3 2 2 0 1
q)3?9.9
0.2426823 1.674133 3.901671Arrasar
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4leia 0
q)/read0 - Read in a text file
q)read0 `:c:/q/README.txt / gives the contents of *.txt fileread1
q)/read1 - Read in a q data file
q)read1 `:c:/q/t1
0xff016200630b000500000073796d0074696d6500707269636…reverter
q)/reverse - Reverse a list
q)reverse 2 30 29 1 3 4
4 3 1 29 30 2
q)reverse "HelloWorld"
"dlroWolleH"conjunto
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99ssr
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with]
q)ssr["HelloWorld";"o";"O"]
"HellOWOrld"corda
q)/string - converts to string, converts all types to a string format.
q)string (1 2 3; `abc;"XYZ";0b)
(,"1";,"2";,"3")
"abc"
(,"X";,"Y";,"Z")
,"0"SV
q)/sv - Scalar from vector, performs different tasks dependent on its arguments.
It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters.
q)24 60 60 sv 11 30 49
41449 / number of seconds elapsed in a day at 11:30:49sistema
q)/system - allows a system command to be sent,
q)system "dir *.py"
" Volume in drive C is New Volume"
" Volume Serial Number is 8CD2-05B2"
""
" Directory of C:\\Users\\myaccount-raj"
""
"09/14/2014 06:32 PM 22 hello1.py"
" 1 File(s) 22 bytes"mesas
q)/tables - list all tables
q)tables `
`s#`tab1`tab2`tradeAté
q)/til - Enumerate
q)til 5
0 1 2 3 4aparar
q)/trim - Eliminate string spaces
q)trim " John "
"John"vs
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity
q)"|" vs "20150204|msft|20.45"
"20150204"
"msft"
"20.45"xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99xcols
q)/xcols - Reorders the columns of a table,
q)`size`price xcols trade
size price time sym
-----------------------------------------------------------
36 72.05742 2009.06.18T06:04:42.919 apple
12 16.11385 2009.11.14T12:42:34.653 ibm
97 68.15909 2009.12.27T17:02:11.518 apple
99 48.35 2015.04.06T10:03:36.738 samsung
99 48.35 2015.04.06T10:03:47.540 samsung
99 48.35 2015.04.06T10:04:44.844 samsungxdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12xgroup
q)/xgroup - Creates nested table
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40)
'length
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10)
x | y
---- | -----------
9 | 10 10 40 10
18 | 20 20
27 | ,30xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99Comandos do Sistema
Os comandos do sistema controlam o qmeio Ambiente. Eles têm o seguinte formato -
\cmd [p] where p may be optionalAlguns dos comandos de sistema populares foram discutidos abaixo -
\ a [namespace] - lista as tabelas no namespace fornecido
q)/Tables in default namespace
q)\a
,`trade
q)\a .o / table in .o namespace.
,`TI\ b - Ver dependências
q)/ views/dependencies
q)a:: x+y / global assingment
q)b:: x+1
q)\b
`s#`a`b\ B - Vistas / dependências pendentes
q)/ Pending views/dependencies
q)a::x+1 / a depends on x
q)\B / the dependency is pending
' / the dependency is pending
q)\B
`s#`a`b
q)\b
`s#`a`b
q)b
29
q)a
29
q)\B
`symbol$()\ cd - Alterar diretório
q)/change directory, \cd [name]
q)\cd
"C:\\Users\\myaccount-raj"
q)\cd ../new-account
q)\cd
"C:\\Users\\new-account"\ d - define o namespace atual
q)/ sets current namespace \d [namespace]
q)\d /default namespace
'
q)\d .o /change to .o
q.o)\d
`.o
q.o)\d . / return to default
q)key ` /lists namespaces other than .z
`q`Q`h`j`o
q)\d .john /change to non-existent namespace
q.john)\d
`.john
q.john)\d .
q)\d
`.\ l - carregar arquivo ou diretório do banco de dados
q)/ Load file or directory, \l
q)\l test2.q / loading test2.q which is stored in current path.
ric | date ex openP closeP MCap
----------- | -------------------------------------------------
JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876
HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559
JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557
HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366
JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390
ric | date ex openP closeP MCap
---------- | ------------------------------------------------
INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375
RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201
SBIN | 2008.02.14 DOW 1.830857 9.006485 15465
INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143
SBIN | 2010.07.05 DOW 18.55637 10.54082 15873\ p - número da porta
q)/ assign port number, \p
q)\p
5001i
q)\p 8888
q)\p
8888i\\ - Saia do q console
\\ - exit
Exit form q.o qlinguagem de programação tem um conjunto de funções integradas ricas e poderosas. Uma função integrada pode ser dos seguintes tipos -
String function - Pega uma string como entrada e retorna uma string.
Aggregate function - Obtém uma lista como entrada e retorna um átomo.
Uniform function - Obtém uma lista e retorna uma lista da mesma contagem.
Mathematical function - Pega um argumento numérico e retorna um argumento numérico.
Miscellaneous function - Todas as funções além das mencionadas acima.
Funções de String
Semelhante - correspondência de padrão
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b
q)"John" like "J??n"
1b
q)"John My Name" like "J*"
1bltrim - remove os espaços em branco à esquerda
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks
q)ltrim " Rick "
"Rick "rtrim - remove espaços em branco à direita
q)/rtrim - takes string argument, returns the result of removing trailing blanks
q)rtrim " Rick "
" Rick"ss - pesquisa de string
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source.
q)"Life is beautiful" ss "i"
1 5 13trim - remove os espaços em branco à esquerda e à direita
q)/trim - takes string argument, returns the result of removing leading & trailing blanks
q)trim " John "
"John"Funções Matemáticas
acos - inverso do cos
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi
q)acos 1
0f
q)acos -1
3.141593
q)acos 0
1.570796cor - dá correlação
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments
q)27 18 18 9 0 cor 27 36 45 54 63
-0.9707253cruzado - produto cartesiano
q)/cross - takes atoms or lists as arguments and returns their Cartesian product
q)9 18 cross `x`y`z
9 `x
9 `y
9 `z
18 `x
18 `y
18 `zvar - variância
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items
q)var 45
0f
q)var 9 18 27 36
101.25wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument.
q)1 2 3 4 wavg 200 300 400 500
400fFunções de agregação
tudo - e operação
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items.
q)all 0b
0b
q)all 9 18 27 36
1b
q)all 10 20 30
1bQualquer - | Operação
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items
q)any 20 30 40 50
1b
q)any 20012.02.12 2013.03.11
'20012.02.12prd - produto aritmético
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product.
q)prd `x`y`z! 10 20 30
6000
q)prd ((1 2; 3 4);(10 20; 30 40))
10 40
90 160Soma - soma aritmética
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum.
q)sum 2 3 4 5 6
20
q)sum (1 2; 4 5)
5 7Funções Uniformes
Deltas - diferença do item anterior.
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor.
q)deltas 2 3 5 7 9
2 1 2 2 2
q)deltas `x`y`z!9 18 27
x | 9
y | 9
z | 9preenche - preenche o valor nulo
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls
q)fills 1 0N 2 0N 4
1 1 2 2 4
q)fills `a`b`c`d! 10 0N 30 0N
a | 10
b | 10
c | 30
d | 30maxs - máximo cumulativo
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items.
q)maxs 1 2 4 3 9 13 2
1 2 4 4 9 13 13
q)maxs `a`b`c`d!9 18 0 36
a | 9
b | 18
c | 18
d | 36Funções Diversas
Contagem - número de retorno do elemento
q)/count - returns the number of entities in its argument.
q)count 10 30 30
3
q)count (til 9)
9
q)count ([]a:9 18 27;b:1.1 2.2 3.3)
3Distinto - retorna entidades distintas
q)/distinct - monadic, returns the distinct entities in its argument
q)distinct 1 2 3 4 2 3 4 5 6 9
1 2 3 4 5 6 9Exceto - elemento não presente no segundo argumento.
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument
q)1 2 3 4 3 1 except 1
2 3 4 3fill - preenche nulo com o primeiro argumento
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target
q)42^ 9 18 0N 27 0N 36
9 18 42 27 42 36
q)";"^"Life is Beautiful"
"Life;is;Beautiful"Consultas em qsão mais curtos e simples e estendem as capacidades do sql. A principal expressão de consulta é a 'expressão selecionada', que em sua forma mais simples extrai subtabelas, mas também pode criar novas colunas.
A forma geral de um Select expression é o seguinte -
Select columns by columns from table where conditions**Note − by & where as frases são opcionais, apenas a 'expressão de origem' é obrigatória.
Em geral, a sintaxe será -
select [a] [by b] from t [where c]
update [a] [by b] from t [where c]A sintaxe de q expressões parecem bastante semelhantes ao SQL, mas qas expressões são simples e poderosas. Uma expressão sql equivalente para o acimaq expressão seria a seguinte -
select [b] [a] from t [where c] [group by b order by b]
update t set [a] [where c]Todas as cláusulas são executadas nas colunas e, portanto, qpode tirar vantagem da ordem. Como as consultas Sql não são baseadas na ordem, elas não podem aproveitar essa vantagem.
qas consultas relacionais geralmente são muito menores em tamanho em comparação ao sql correspondente. Consultas ordenadas e funcionais fazem coisas que são difíceis no sql.
Em um banco de dados histórico, a ordem do wherecláusula é muito importante porque afeta o desempenho da consulta. opartition variável (data / mês / dia) sempre vem primeiro, seguida pela coluna classificada e indexada (geralmente a coluna sym).
Por exemplo,
select from table where date in d, sym in sé muito mais rápido do que,
select from table where sym in s, date in dConsultas básicas
Vamos escrever um script de consulta no bloco de notas (como abaixo), salvar (como * .q) e, em seguida, carregá-lo.
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination @[dst;`sym;:;sym]; n:1000000; trade:([]sym:n?`sym;time:10:30:00.0+til n;price:n?3.3e;size:n?9;ex:n?ex); quote:([]sym:n?`sym;time:10:30:00.0+til n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex); {@[;`sym;`p#]`sym xasc x}each`trade`quote; d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.Consultas com restrições
* Denotes HDB query
Select all IBM trades
select from trade where sym in `IBM*Select all IBM trades on a certain day
thisday: 2014.08.11
select from trade where date=thisday,sym=`IBMSelect all IBM trades with a price > 100
select from trade where sym=`IBM, price > 100.0Select all IBM trades with a price less than or equal to 100
select from trade where sym=`IBM,not price > 100.0*Select all IBM trades between 10.30 and 10.40, in the morning, on a certain date
thisday: 2014.08.11
select from trade where
date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000Select all IBM trades in ascending order of price
`price xasc select from trade where sym =`IBM*Select all IBM trades in descending order of price in a certain time frame
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBMComposite sort − sort ascending order by sym and then sort the result in descending order of price
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5Select all IBM or MSFT trades
select from trade where sym in `IBM`MSFT*Calculate count of all symbols in ascending order within a certain time frame
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11*Calculate count of all symbols in descending order within a certain time frame
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11* What is the maximum price of IBM stock within a certain time frame, and when does this first happen?
select time,ask from quote where date within 2014.08.07 2014.08.11,
sym =`IBM, ask = exec first ask from select max ask from quote where
sym =`IBMSelect the last price for each sym in hourly buckets
select last price by hour:time.hh, sym from tradeConsultas com agregações
* Calculate vwap (Volume Weighted Average Price) of all symbols
select vwap:size wavg price by sym from trade* Count the number of records (in millions) for a certain month
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m* HLOC – Daily High, Low, Open and Close for CSCO in a certain month
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO* Daily Vwap for CSCO in a certain month
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO* Calculate the hourly mean, variance and standard deviation of the price for AIG
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIGSelect the price range in hourly buckets
select range:max[price] – min price by date,sym,hour:time.hh from trade* Daily Spread (average bid-ask) for CSCO in a certain month
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO* Daily Traded Values for all syms in a certain month
select dtv:sum size by date,sym from trade where date.month = 2014.08mExtract a 5 minute vwap for CSCO
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO* Extract 10 minute bars for CSCO
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO* Find the times when the price exceeds 100 basis points (100e-4) over the last price for CSCO for a certain day
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price* Full Day Price and Volume for MSFT in 1 Minute Intervals for the last date in the database
select last price,last size by time.minute from trade where date = last date, sym = `MSFTO KDB + permite que um processo se comunique com outro processo por meio da comunicação entre processos. Os processos Kdb + podem se conectar a qualquer outro kdb + no mesmo computador, na mesma rede ou mesmo remotamente. Precisamos apenas especificar a porta e então os clientes podem conversar com ela. Qualquerq processo pode se comunicar com qualquer outro q processo, desde que esteja acessível na rede e esteja ouvindo conexões.
um processo de servidor escuta conexões e processa quaisquer solicitações
um processo cliente inicia a conexão e envia comandos para serem executados
O cliente e o servidor podem estar na mesma máquina ou em máquinas diferentes. Um processo pode ser um cliente e um servidor.
Uma comunicação pode ser,
Synchronous (aguarde o resultado ser retornado)
Asynchronous (sem espera e nenhum resultado retornado)
Inicializar servidor
UMA q servidor é inicializado especificando a porta para escutar,
q –p 5001 / command line
\p 5001 / session commandIdentificador de Comunicação
Um identificador de comunicação é um símbolo que começa com “:” e tem a forma -
`:[server]:port-numberExemplo
`::5001 / server and client on same machine
`:jack:5001 / server on machine jack
`:192.168.0.156 / server on specific IP address
`:www.myfx.com:5001 / server at www.myfx.comPara iniciar a conexão, usamos a função “hopen” que retorna um identificador de conexão inteiro. Este identificador é usado para todas as solicitações subsequentes do cliente. Por exemplo -
q)h:hopen `::5001
q)h"til 5"
0 1 2 3 4
q)hclose hMensagens síncronas e assíncronas
Assim que tivermos um identificador, podemos enviar uma mensagem de forma síncrona ou assíncrona.
Synchronous Message- Depois que uma mensagem é enviada, ela aguarda e retorna o resultado. Seu formato é o seguinte -
handle “message”Asynchronous Message- Depois de enviar uma mensagem, comece a processar a próxima instrução imediatamente, sem ter que esperar e retornar um resultado. Seu formato é o seguinte -
neg[handle] “message”As mensagens que requerem uma resposta, por exemplo, chamadas de função ou instruções de seleção, normalmente usarão a forma síncrona; enquanto as mensagens que não precisam retornar uma saída, por exemplo, inserir atualizações em uma tabela, serão assíncronas.
Quando um q processo se conecta a outro qprocesso via comunicação entre processos, ele é processado por manipuladores de mensagens. Esses manipuladores de mensagens têm um comportamento padrão. Por exemplo, no caso de tratamento de mensagens síncronas, o manipulador retorna o valor da consulta. O manipulador síncrono, neste caso, é.z.pg, que podemos substituir de acordo com o requisito.
Os processos Kdb + têm vários gerenciadores de mensagens predefinidos. Os manipuladores de mensagens são importantes para configurar o banco de dados. Alguns dos usos incluem -
Logging - Registrar mensagens recebidas (útil em caso de qualquer erro fatal),
Security- Permitir / proibir o acesso ao banco de dados, certas chamadas de função, etc., com base no nome de usuário / endereço IP. Ele ajuda a fornecer acesso apenas a assinantes autorizados.
Handle connections/disconnections de outros processos.
Manipuladores de mensagens predefinidos
Alguns dos manipuladores de mensagens predefinidos são discutidos abaixo.
.z.pg
É um manipulador de mensagens síncrono (processo get). Esta função é chamada automaticamente sempre que uma mensagem de sincronização é recebida em uma instância kdb +.
O parâmetro é a string / chamada de função a ser executada, ou seja, a mensagem passada. Por padrão, é definido da seguinte forma -
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle.z.ps
É um manipulador de mensagens assíncronas (conjunto de processos). É o manipulador equivalente para mensagens assíncronas. O parâmetro é a string / chamada de função a ser executada. Por padrão, é definido como,
.z.pg : {value x} / Can be overriden for a customized action.A seguir está o gerenciador de mensagens personalizado para mensagens assíncronas, onde usamos a execução protegida,
.z.pg: {@[value; x; errhandler x]}Aqui errhandler é uma função usada em caso de algum erro inesperado.
.z.po []
É um manipulador de conexão aberta (processo aberto). É executado quando um processo remoto abre uma conexão. Para ver o identificador quando uma conexão com um processo é aberta, podemos definir o .z.po como,
.z.po : {Show “Connection opened by” , string h: .z.h}.z.pc []
É um manipulador de conexão fechada (fechamento do processo). É chamado quando uma conexão é fechada. Podemos criar nosso próprio manipulador de fechamento, que pode redefinir o identificador de conexão global para 0 e emitir um comando para definir o cronômetro para disparar (executar) a cada 3 segundos (3000 milissegundos).
.z.pc : { h::0; value “\\t 3000”}O manipulador do cronômetro (.z.ts) tenta reabrir a conexão. Em caso de sucesso, desliga o cronômetro.
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }.z.pi []
PI significa entrada do processo. É chamado para qualquer tipo de entrada. Pode ser usado para controlar a entrada do console ou entrada do cliente remoto. Usando .z.pi [], pode-se validar a entrada do console ou substituir a exibição padrão. Além disso, pode ser usado para qualquer tipo de operação de registro.
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9.z.pw
É um manipulador de conexão de validação (autenticação do usuário). Ele adiciona um retorno de chamada extra quando uma conexão está sendo aberta para uma sessão kdb +. Ele é chamado após as verificações –u / -U e antes de .z.po (porta aberta).
.z.pw : {[user_id;passwd] 1b}Entradas são userid (símbolo) e password (texto).
Listas, dicionários ou colunas de uma tabela podem ter atributos aplicados a eles. Os atributos impõem certas propriedades na lista. Alguns atributos podem desaparecer na modificação.
Tipos de Atributos
Ordenado (`s #)
`s # significa que a lista está classificada em ordem crescente. Se uma lista for explicitamente classificada por asc (ou xasc), a lista terá automaticamente o conjunto de atributos classificado.
q)L1: asc 40 30 20 50 9 4
q)L1
`s#4 9 20 30 40 50Uma lista que é conhecida por ser classificada também pode ter o atributo definido explicitamente. Q irá verificar se a lista está classificada e, se não estiver, um s-fail erro será lançado.
q)L2:30 40 24 30 2
q)`s#L2
's-failO atributo classificado será perdido em um anexo não classificado.
Parted (`p #)
`p # significa que a lista é dividida e itens idênticos são armazenados contiguamente.
O alcance é um int ou temporal type tendo um valor int subjacente, como anos, meses, dias, etc. Você também pode particionar sobre um símbolo, desde que seja enumerado.
Aplicar o atributo parted cria um dicionário de índice que mapeia cada valor de saída exclusivo para a posição de sua primeira ocorrência. Quando uma lista é dividida, a pesquisa é muito mais rápida, já que a pesquisa linear é substituída pela pesquisa com hashtable.
q)L:`p# 99 88 77 1 2 3
q)L
`p#99 88 77 1 2 3
q)L,:3
q)L
99 88 77 1 2 3 3Note −
O atributo parted não é preservado em uma operação na lista, mesmo se a operação preserva o particionamento.
O atributo parted deve ser considerado quando o número de entidades atingir um bilhão e a maioria das partições for de tamanho substancial, ou seja, houver repetição significativa.
Agrupado (`g #)
`g # significa que a lista está agrupada. Um dicionário interno é construído e mantido que mapeia cada item único para cada um de seus índices, exigindo um espaço de armazenamento considerável. Para uma lista de comprimentoL contendo u itens únicos de tamanho s, isto será (L × 4) + (u × s) bytes.
O agrupamento pode ser aplicado a uma lista quando nenhuma outra suposição pode ser feita sobre sua estrutura.
O atributo pode ser aplicado a qualquer lista digitada. É mantido em anexos, mas perdido em exclusões.
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6
q)L,:9
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6 9
q)L _:2
q)L
1 2 4 5 4 2 3 1 4 5 6 9Único (`#u)
Aplicar o atributo exclusivo (`u #) a uma lista indica que os itens da lista são distintos. Saber que os elementos de uma lista são únicos acelera drasticamentedistinct e permite q para executar algumas comparações antecipadamente.
Quando uma lista é sinalizada como exclusiva, um mapa hash interno é criado para cada item da lista. As operações na lista devem preservar a exclusividade ou o atributo será perdido.
q)LU:`u#`MSFT`SAMSUNG`APPLE
q)LU
`u#`MSFT`SAMSUNG`APPLE
q)LU,:`IBM /Uniqueness preserved
q)LU
`u#`MSFT`SAMSUNG`APPLE`IBM
q)LU,:`SAMSUNG / Attribute lost
q)LU
`MSFT`SAMSUNG`APPLE`IBM`SAMSUNGNote −
`u # é preservado em concatenações que preservam a exclusividade. Ele se perde em exclusões e concatenações não exclusivas.
As pesquisas nas listas `u # são feitas por meio de uma função hash.
Removendo Atributos
Os atributos podem ser removidos aplicando `#.
Aplicando Atributos
Três formatos de aplicação de atributos são -
L: `s# 14 2 3 3 9/ Especificar durante a criação da lista
@[ `.; `L ; `s#]/ Funcional aplicar, ou seja, para a lista de variáveis L
/ no namespace padrão (ou seja, `.) se aplica
/ o atributo `s # classificado
Update `s#time from `tab
/ Atualize a tabela (guia) para aplicar o
/ atributo.
Vamos aplicar os três formatos diferentes acima com exemplos.
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).Consultas funcionais (dinâmicas) permitem especificar nomes de colunas como símbolos para colunas q-sql select / exec / delete típicas. É muito útil quando queremos especificar nomes de coluna dinamicamente.
As formas funcionais são -
?[t;c;b;a] / for select
![t;c;b;a] / for updateOnde
t é uma mesa;
a é um dicionário de agregados;
bo by-frase; e
c é uma lista de restrições.
Nota -
Todos q entidades em a, b, e c deve ser referenciado por nome, ou seja, como símbolos contendo os nomes das entidades.
As formas sintáticas de seleção e atualização são analisadas em suas formas funcionais equivalentes pelo q intérprete, portanto, não há diferença de desempenho entre os dois formulários.
Seleção funcional
O bloco de código a seguir mostra como usar functional select -
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38Exemplo 1
Vamos começar com o caso mais fácil, a versão funcional do “select from t” vai se parecer com -
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54Exemplo 2
No exemplo a seguir, usamos a função enlist para criar singletons para garantir que as entidades apropriadas sejam listas.
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54Exemplo 3
q)groupby: enlist[`p] ! enlist `p
q)selcols: enlist [`n]!enlist `n
q)?[ `t;(); groupby;selcols] / select n by p from t
p | n
----- | -------
38 | msft
40 | ibm
45 | samsung
54 | appleExec Funcional
A forma funcional do exec é uma forma simplificada de select.
q)?[t;();();`n] / exec n from t (functional form of exec)
`ibm`msft`samsung`apple
q)?[t;();`n;`p] / exec p by n from t (functional exec)
apple | 54
ibm | 40
msft | 38
samsung | 45Atualização Funcional
A forma funcional de atualização é completamente análoga à de select. No exemplo a seguir, o uso de enlist é para criar singletons, para garantir que as entidades de entrada sejam listas.
q)c:enlist (>;`p;0)
q)b: (enlist `n)!enlist `n
q)a: (enlist `p) ! enlist (max;`p)
q)![t;c;b;a]
n p
-------------
ibm 40
msft 38
samsung 45
apple 54Exclusão funcional
A exclusão funcional é uma forma simplificada de atualização funcional. Sua sintaxe é a seguinte -
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column namesVamos agora dar um exemplo para mostrar como funciona a exclusão funcional -
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54Neste capítulo, aprenderemos como operar com dicionários e tabelas. Vamos começar com dicionários -
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d
q)/ key of this dictionary (d) is given by
q)key d
`u`v`x`y`z
q)/and the value by
q)value d
9 18 27 36 45
q)/a specific value
q)d`x
27
q)d[`x]
27
q)/values can be manipulated by using the arithmetic operator +-*% as,
q)45 + d[`x`y]
72 81Se for necessário alterar os valores do dicionário, a formulação de alteração pode ser -
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)] 0 1 2 3 4 5 6 7 8 9 q)`time xasc `tab `tab q)/ to get particular column from table tab q)tab[`size] 12 10 1 90 73 90 43 90 84 63 q)tab[`size]+9 21 19 10 99 82 99 52 99 93 72 q)/Example table tab q)tab:([]sym:`;time:0#0nt;price:0n;size:0N) q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75Os dados em seu disco rígido (também chamado de banco de dados histórico) podem ser salvos em três formatos diferentes - Arquivos Simples, Tabelas Splayed e Tabelas Particionadas. Aqui, aprenderemos como usar esses três formatos para salvar dados.
Arquivo plano
Os arquivos simples são totalmente carregados na memória, por isso seu tamanho (área de cobertura da memória) deve ser pequeno. As tabelas são salvas no disco inteiramente em um arquivo (portanto, o tamanho é importante).
As funções usadas para manipular essas tabelas são set/get -
`:path_to_file/filename set tablenameVamos dar um exemplo para demonstrar como funciona -
q)tables `.
`s#`t`tab`tab1
q)`:c:/q/w32/tab1_test set tab1
`:c:/q/w32/tab1_testNo ambiente Windows, os arquivos simples são salvos no local - C:\q\w32
Obtenha o arquivo simples do seu disco (banco de dados histórico) e use o get comando da seguinte forma -
q)tab2: get `:c:/q/w32/tab1_test
q)tab2
sym | time price size
--------- | -------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73Uma nova tabela é criada tab2 com seu conteúdo armazenado em tab1_test Arquivo.
Mesas Espalhadas
Se houver muitas colunas em uma tabela, então armazenamos tais tabelas no formato espalhado, ou seja, nós as salvamos em disco em um diretório. Dentro do diretório, cada coluna é salva em um arquivo separado com o mesmo nome da coluna. Cada coluna é salva como uma lista do tipo correspondente em um arquivo kdb + binário.
Salvar uma tabela no formato espalhado é muito útil quando temos que acessar apenas algumas colunas frequentemente de suas muitas colunas. Um diretório de tabela espalhada contém.d arquivo binário que contém a ordem das colunas.
Muito parecido com um arquivo simples, uma tabela pode ser salva como espalhada usando o setcomando. Para salvar uma tabela como espalhada, o caminho do arquivo deve terminar com uma folga -
`:path_to_filename/filename/ set tablenamePara ler uma tabela espalhada, podemos usar o get função -
tablename: get `:path_to_file/filenameNote - Para que uma tabela seja salva como espalhada, ela deve ser liberada e enumerada.
No ambiente Windows, sua estrutura de arquivos aparecerá da seguinte maneira -
Tabelas particionadas
As tabelas particionadas fornecem um meio eficiente de gerenciar tabelas enormes contendo volumes significativos de dados. As tabelas particionadas são tabelas distribuídas em mais partições (diretórios).
Dentro de cada partição, uma tabela terá seu próprio diretório, com a estrutura de uma tabela espalhada. As tabelas podem ser divididas em uma base dia / mês / ano para fornecer acesso otimizado ao seu conteúdo.
Para obter o conteúdo de uma tabela particionada, use o seguinte bloco de código -
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder
quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0
0 0 0….
trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 ….Vamos tentar obter o conteúdo de uma tabela de negociação -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 ANote - O modo particionado é adequado para tabelas com milhões de registros por dia (ou seja, dados de série temporal)
Arquivo Sym
O arquivo sym é um arquivo kdb + binário que contém a lista de símbolos de todas as tabelas distribuídas e particionadas. Pode ser lido com,
get `:symarquivo par.txt (opcional)
Este é um arquivo de configuração, usado quando as partições são espalhadas em vários diretórios / drives de disco e contém os caminhos para as partições de disco.
.Q.en
.Q.ené uma função diádica que ajuda a espalhar uma tabela enumerando uma coluna de símbolo. É especialmente útil quando estamos lidando com banco de dados histórico (splayed, tabelas de partição, etc.). -
.Q.en[`:directory;table]Onde directory é o diretório inicial do banco de dados histórico onde sym file está localizado e table é a tabela a ser enumerada.
A enumeração manual das tabelas não é necessária para salvá-las como tabelas distribuídas, pois isso será feito por -
.Q.en[`:directory_where_symbol_file_stored]table_name.Q.dpft
o .Q.dpftfunção ajuda na criação de tabelas particionadas e segmentadas. É uma forma avançada de.Q.en, já que não apenas distribui a tabela, mas também cria uma tabela de partição.
Existem quatro argumentos usados em .Q.dpft -
identificador de arquivo simbólico do banco de dados onde queremos criar uma partição,
q valor de dados com o qual vamos particionar a tabela,
nome do campo com o qual o atributo parted (`p #) será aplicado (geralmente` sym), e
o nome da tabela.
Vamos dar um exemplo para ver como funciona -
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25)
q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab]
`tab
q)delete tab from `
'type
q)delete tab from `/
'type
q)delete tab from .
'type
q)delete tab from `.
`.
q)tab
'tabNós deletamos a tabela tabda memória. Vamos agora carregá-lo do banco de dados
q)\l c:/q/2014.08.24/
q)\a
,`tab
q)tab
sym time price
-------------------------------
hsbc 07:38:13 15.64201
hsbc 07:21:05 5.387037
msft 06:16:58 11.88076
msft 08:09:26 12.30159
samsung 04:57:56 15.60838.Q.chk
.Q.chk é uma função monádica cujo único parâmetro é o identificador de arquivo simbólico do diretório raiz. Ele cria tabelas vazias em uma partição, sempre que necessário, examinando cada subdiretório de partição na raiz.
.Q.chk `:directoryOnde directory é o diretório inicial do banco de dados histórico.