Kibana - Guia Rápido
Kibana é uma ferramenta de visualização baseada em navegador de código aberto usada principalmente para analisar grande volume de registros na forma de gráfico de linha, gráfico de barras, gráficos de pizza, mapas de calor, mapas de região, mapas de coordenadas, medidor, metas, cronograma etc. A visualização torna mais fácil para prever ou ver as mudanças nas tendências de erros ou outros eventos significativos da fonte de entrada. Kibana trabalha em sincronia com Elasticsearch e Logstash que juntos formam o chamado ELK pilha.
O que é ELK Stack?
ELK significa Elasticsearch, Logstash e Kibana. ELKé uma das plataformas de gerenciamento de log populares usadas em todo o mundo para análise de log. Na pilha ELK, o Logstash extrai os dados de registro ou outros eventos de diferentes fontes de entrada. Ele processa os eventos e depois os armazena no Elasticsearch.
Kibana é uma ferramenta de visualização, que acessa os registros do Elasticsearch e é capaz de exibir para o usuário na forma de gráfico de linha, gráfico de barra, gráfico de pizza, etc.
O fluxo básico do ELK Stack é mostrado na imagem aqui -
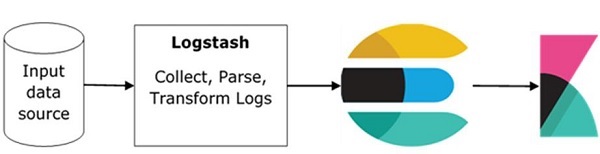
O Logstash é responsável por coletar os dados de todas as fontes remotas onde os logs são arquivados e enviar os mesmos para o Elasticsearch.
Elasticsearch atua como um banco de dados onde os dados são coletados e Kibana usa os dados do Elasticsearch para representar os dados para o usuário na forma de gráficos de barras, gráficos de pizza, mapas de calor, conforme mostrado abaixo -
Ele mostra os dados em tempo real, por exemplo, do dia ou da hora para o usuário. Kibana UI é amigável e muito fácil para um iniciante entender.
Características do Kibana
Kibana oferece aos seus usuários os seguintes recursos -
Visualização
Kibana tem muitas maneiras de visualizar dados de uma maneira fácil. Alguns dos que são comumente usados são gráfico de barra vertical, gráfico de barra horizontal, gráfico de pizza, gráfico de linha, mapa de calor, etc.
painel de controle
Quando tivermos as visualizações prontas, todas elas podem ser colocadas em um quadro - o Dashboard. Observar diferentes seções em conjunto dá a você uma ideia geral clara sobre o que exatamente está acontecendo.
Ferramentas Dev
Você pode trabalhar com seus índices usando ferramentas de desenvolvimento. Os iniciantes podem adicionar índices fictícios de ferramentas de desenvolvimento e também adicionar, atualizar, excluir os dados e usar os índices para criar a visualização.
Relatórios
Todos os dados na forma de visualização e painel podem ser convertidos em relatórios (formato CSV), embutidos no código ou na forma de URLs para serem compartilhados com outras pessoas.
Filtros e consulta de pesquisa
Você pode usar filtros e consultas de pesquisa para obter os detalhes necessários para uma entrada específica de um painel ou ferramenta de visualização.
Plugins
Você pode adicionar plug-ins de terceiros para adicionar alguma nova visualização ou também outra adição de IU no Kibana.
Mapas de Coordenadas e Regiões
Um mapa de coordenadas e região em Kibana ajuda a mostrar a visualização no mapa geográfico dando uma visão realista dos dados.
Timelion
Timelion, também chamado de timelineé mais uma ferramenta de visualização usada principalmente para análise de dados com base no tempo. Para trabalhar com a linha do tempo, precisamos usar uma linguagem de expressão simples que nos ajude a nos conectar com o índice e também realizar cálculos nos dados para obter os resultados que precisamos. Ajuda mais na comparação de dados com o ciclo anterior em termos de semana, mês, etc.
Tela de pintura
O Canvas é outro recurso poderoso do Kibana. Usando a visualização em tela, você pode representar seus dados em diferentes combinações de cores, formas, textos, várias páginas basicamente chamadas de workpad.
Vantagens de Kibana
Kibana oferece as seguintes vantagens aos seus usuários -
Contém ferramenta de visualização baseada em navegador de código aberto usada principalmente para analisar grande volume de registros na forma de gráfico de linha, gráfico de barra, gráfico de pizza, mapas de calor etc.
Simples e fácil de entender para iniciantes.
Facilidade de conversão de visualização e painel em relatórios.
A visualização em tela ajuda a analisar dados complexos de maneira fácil.
A visualização do cronograma no Kibana ajuda a comparar os dados de trás para frente para entender melhor o desempenho.
Desvantagens de Kibana
Adicionar plug-ins ao Kibana pode ser muito tedioso se houver incompatibilidade de versão.
Você tende a enfrentar problemas quando deseja atualizar de uma versão mais antiga para uma nova.
Para começar a trabalhar com Kibana, precisamos instalar Logstash, Elasticsearch e Kibana. Neste capítulo, tentaremos entender a instalação da pilha ELK aqui.
Discutiríamos as seguintes instalações aqui -
- Instalação Elasticsearch
- Instalação Logstash
- Instalação Kibana
Instalação Elasticsearch
Uma documentação detalhada sobre Elasticsearch existe em nossa biblioteca. Você pode verificar aqui a instalação do elasticsearch . Você terá que seguir as etapas mencionadas no tutorial para instalar o Elasticsearch.
Depois de concluir a instalação, inicie o servidor elasticsearch da seguinte maneira -
Passo 1
For Windows
> cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin
> elasticsearchObserve que para o usuário do Windows, a variável JAVA_HOME deve ser definida para o caminho java jdk.
For Linux
$ cd kibanaproject/elasticsearch-6.5.4/elasticsearch-6.5.4/bin $ elasticsearch
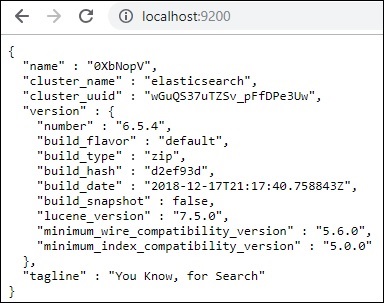
A porta padrão para elasticsearch é 9200. Uma vez feito isso, você pode verificar o elasticsearch na porta 9200 em localhost http://localhost:9200/as mostrado abaixo -
Instalação Logstash
Para a instalação Logstash, seguir esta instalação ElasticSearch que já é existente em nossa biblioteca.
Instalação Kibana
Vá para o site oficial da Kibana -https://www.elastic.co/products/kibana

Clique no link de downloads no canto superior direito e a tela será exibida da seguinte forma -
Clique no botão Download para Kibana. Por favor, note que para trabalhar com Kibana precisamos de uma máquina de 64 bits e não funcionará com 32 bits.
Neste tutorial, vamos usar o Kibana versão 6. A opção de download está disponível para Windows, Mac e Linux. Você pode baixar conforme sua escolha.
Crie uma pasta e descompacte os downloads tar / zip para o kibana. Vamos trabalhar com dados de amostra carregados em elasticsearch. Assim, por enquanto, vamos ver como iniciar o elasticsearch e o kibana. Para isso, vá até a pasta onde o Kibana está descompactado.
For Windows
> cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin
> kibanaFor Linux
$ cd kibanaproject/kibana-6.5.4/kibana-6.5.4/bin $ kibanaAssim que o Kibana for iniciado, o usuário poderá ver a seguinte tela -
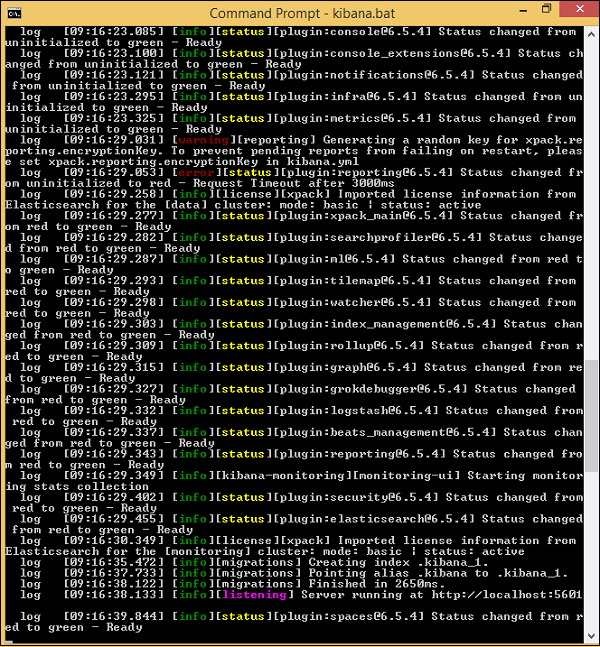
Depois de ver o sinal de pronto no console, você pode abrir o Kibana no navegador usando http://localhost:5601/.A porta padrão na qual o kibana está disponível é 5601.
A interface do usuário do Kibana é mostrada aqui -
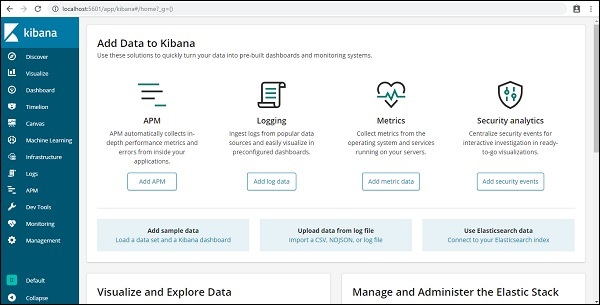
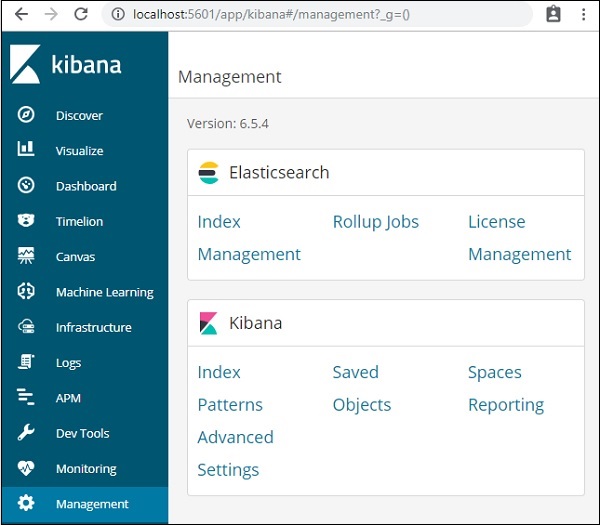
Em nosso próximo capítulo, aprenderemos como usar a IU do Kibana. Para saber a versão do Kibana na IU do Kibana, acesse a guia Gerenciamento no lado esquerdo e será exibida a versão do Kibana que estamos usando atualmente.
Kibana é uma ferramenta de visualização de código aberto usada principalmente para analisar um grande volume de registros na forma de gráfico de linha, gráfico de barras, gráficos de pizza, mapas de calor, etc. Kibana trabalha em sincronia com Elasticsearch e Logstash que juntos formam o chamado ELK pilha.
ELK significa Elasticsearch, Logstash e Kibana. ELK é uma das plataformas de gerenciamento de log populares usadas em todo o mundo para análise de log.
Na pilha ELK -
Logstashextrai os dados de registro ou outros eventos de diferentes fontes de entrada. Ele processa os eventos e depois os armazena no Elasticsearch.
Kibana é uma ferramenta de visualização, que acessa os registros do Elasticsearch e é capaz de exibir para o usuário na forma de gráfico de linha, gráfico de barra, gráfico de pizza, etc.
Neste tutorial, trabalharemos em conjunto com Kibana e Elasticsearch e visualizaremos os dados em diferentes formas.
Neste capítulo, vamos entender como trabalhar com a pilha ELK juntos. Além disso, você também verá como -
- Carregue dados CSV do Logstash para o Elasticsearch.
- Use os índices do Elasticsearch em Kibana.
Carregar dados CSV de Logstash para Elasticsearch
Vamos usar dados CSV para fazer upload de dados usando Logstash para Elasticsearch. Para trabalhar na análise de dados, podemos obter dados do site kaggle.com. O site Kaggle.com possui todos os tipos de dados carregados e os usuários podem usá-los para trabalhar na análise de dados.
Pegamos os dados de countries.csv daqui: https://www.kaggle.com/fernandol/countries-of-the-world. Você pode baixar o arquivo csv e usá-lo.
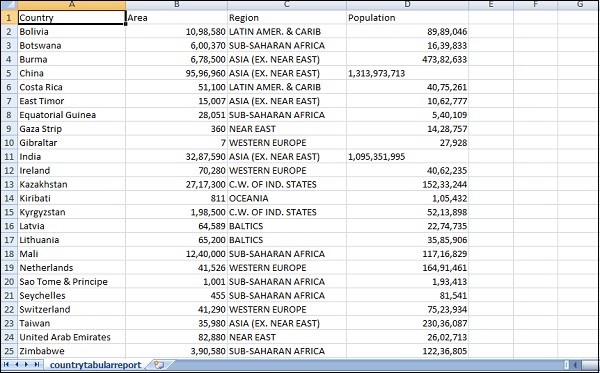
O arquivo csv que vamos usar tem os seguintes detalhes.
Nome do arquivo - countriesdata.csv
Colunas - "País", "Região", "População", "Área"
Você também pode criar um arquivo csv fictício e usá-lo. Estaremos usando logstash para despejar esses dados de countriesdata.csv para elasticsearch.
Inicie o elasticsearch e o Kibana em seu terminal e mantenha-o funcionando. Temos que criar o arquivo de configuração para logstash, que terá detalhes sobre as colunas do arquivo CSV e também outros detalhes, conforme mostrado no arquivo logstash-config fornecido abaixo -
input {
file {
path => "C:/kibanaproject/countriesdata.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns => ["Country","Region","Population","Area"]
}
mutate {convert => ["Population", "integer"]}
mutate {convert => ["Area", "integer"]}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
=> "countriesdata-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}No arquivo de configuração, criamos 3 componentes -
Entrada
Precisamos especificar o caminho do arquivo de entrada que, em nosso caso, é um arquivo csv. O caminho onde o arquivo csv está armazenado é fornecido para o campo do caminho.
Filtro
Terá o componente csv com separador usado que no nosso caso é a vírgula, e também as colunas disponíveis para o nosso arquivo csv. Como o logstash considera todos os dados que chegam como string, no caso de desejarmos que qualquer coluna seja usada como inteiro, float o mesmo deve ser especificado usando mutate, conforme mostrado acima.
Resultado
Para saída, precisamos especificar onde precisamos colocar os dados. Aqui, em nosso caso, estamos usando elasticsearch. Os dados que devem ser fornecidos ao elasticsearch são os hosts em que ele está sendo executado, mencionamos como localhost. O próximo campo em é o índice, ao qual demos o nome de países -atualidade. Temos que usar o mesmo índice no Kibana uma vez que os dados sejam atualizados no Elasticsearch.
Salve o arquivo de configuração acima como logstash_countries.config . Observe que precisamos fornecer o caminho desta configuração para o comando logstash na próxima etapa.
Para carregar os dados do arquivo csv para elasticsearch, precisamos iniciar o servidor elasticsearch -
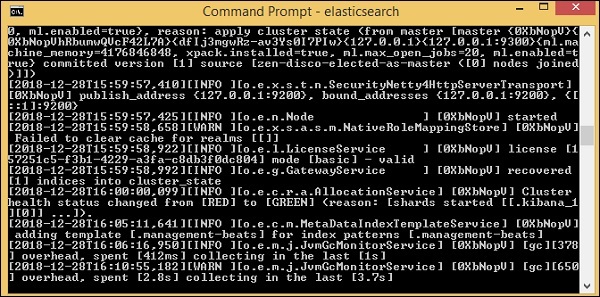
Agora corra http://localhost:9200 no navegador para confirmar se elasticsearch está sendo executado com sucesso.
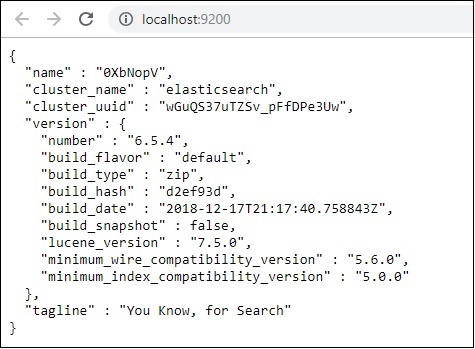
Temos elasticsearch em execução. Agora vá para o caminho onde o logstash está instalado e execute o seguinte comando para fazer upload dos dados para elasticsearch.
> logstash -f logstash_countries.conf
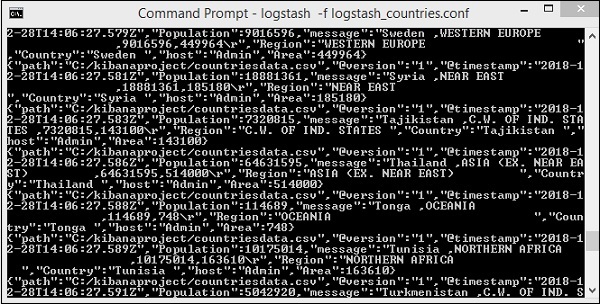
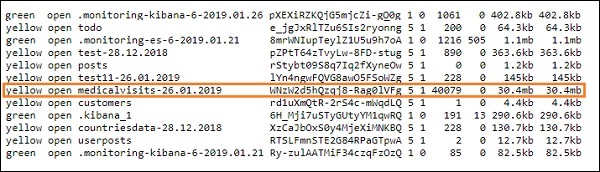
A tela acima mostra o carregamento de dados do arquivo CSV para o Elasticsearch. Para saber se temos o índice criado no Elasticsearch, podemos verificar o mesmo da seguinte maneira -
Podemos ver o índice countriesdata-28.12.2018 criado conforme mostrado acima.

Os detalhes do índice - países-28.12.2018 são os seguintes -
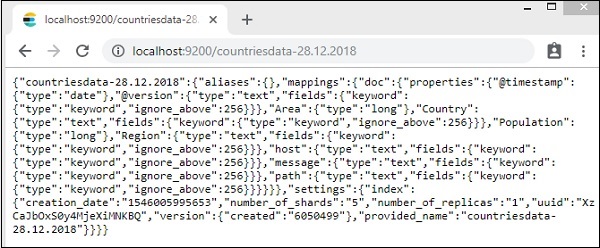
Observe que os detalhes de mapeamento com propriedades são criados quando os dados são carregados de logstash para elasticsearch.
Use dados do Elasticsearch em Kibana
Atualmente, temos Kibana em execução no localhost, porta 5601 - http://localhost:5601. A IU do Kibana é mostrada aqui -
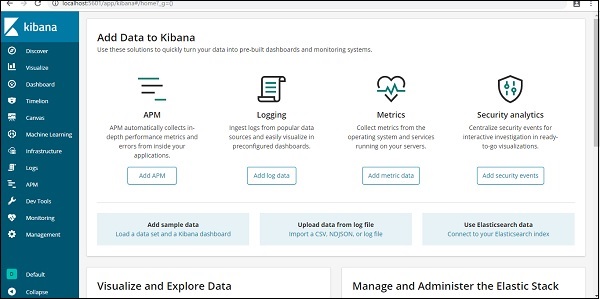
Observe que já temos Kibana conectado ao Elasticsearch e devemos ser capazes de ver index :countries-28.12.2018 dentro de Kibana.
Na IU Kibana, clique na opção Menu de gerenciamento no lado esquerdo -
Agora, clique em Gerenciamento de índice -
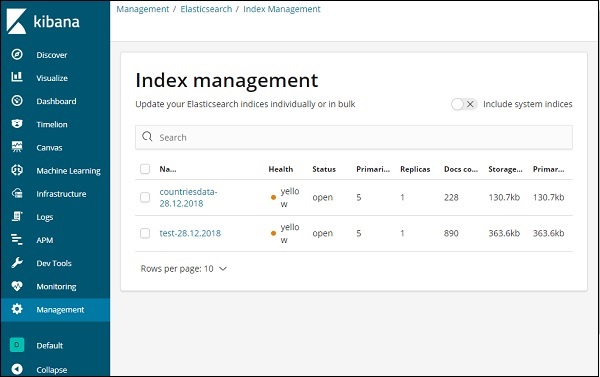
Os índices presentes no Elasticsearch são exibidos no gerenciamento de índice. O índice que vamos usar em Kibana é o país de 28/12/2018.
Assim, como já temos o índice de pesquisa elástica em Kibana, a seguir entenderemos como usar o índice em Kibana para visualizar dados na forma de gráfico de pizza, gráfico de barras, gráfico de linha etc.
Vimos como fazer upload de dados do logstash para o elasticsearch. Faremos upload de dados usando logstash e elasticsearch aqui. Mas sobre os dados que possuem campos de data, longitude e latitude que precisamos usar, aprenderemos nos próximos capítulos. Também veremos como fazer upload de dados diretamente no Kibana, se não tivermos um arquivo CSV.
Neste capítulo, cobriremos os seguintes tópicos -
- Usando Logstash, faça upload de dados com campos de data, longitude e latitude no Elasticsearch
- Usando ferramentas Dev para fazer upload de dados em massa
Usando o upload do Logstash para dados com campos no Elasticsearch
Vamos usar os dados no formato CSV e o mesmo é retirado do Kaggle.com que trata de dados que você pode usar para uma análise.
Os dados de visitas médicas domiciliares a serem usados aqui são obtidos no site Kaggle.com.
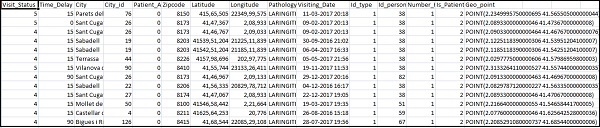
A seguir estão os campos disponíveis para o arquivo CSV -
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude","Longitude",
"Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]O Home_visits.csv é o seguinte -
A seguir está o arquivo conf a ser usado com logstash -
input {
file {
path => "C:/kibanaproject/home_visits.csv"
start_position => "beginning"
sincedb_path => "NUL"
}
}
filter {
csv {
separator => ","
columns =>
["Visit_Status","Time_Delay","City","City_id","Patient_Age",
"Zipcode","Latitude","Longitude","Pathology","Visiting_Date",
"Id_type","Id_personal","Number_Home_Visits","Is_Patient_Minor","Geo_point"]
}
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "medicalvisits-%{+dd.MM.YYYY}"
}
stdout {codec => json_lines }
}Por padrão, o logstash considera tudo a ser carregado em elasticsearch como string. Caso seu arquivo CSV tenha um campo de data, você precisa fazer o seguinte para obter o formato de data.
For date field −
date {
match => ["Visiting_Date","dd-MM-YYYY HH:mm"]
target => "Visiting_Date"
}No caso de localização geográfica, elasticsearch entende o mesmo que -
"location": {
"lat":41.565505000000044,
"lon": 2.2349995750000695
}Portanto, precisamos ter certeza de que temos Longitude e Latitude no formato que o elasticsearch precisa. Portanto, primeiro precisamos converter longitude e latitude em flutuante e, posteriormente, renomeá-la para que esteja disponível como parte delocation objeto json com lat e lon. O código para o mesmo é mostrado aqui -
mutate {
convert => { "Longitude" => "float" }
convert => { "Latitude" => "float" }
}
mutate {
rename => {
"Longitude" => "[location][lon]"
"Latitude" => "[location][lat]"
}
}Para converter campos em inteiros, use o seguinte código -
mutate {convert => ["Number_Home_Visits", "integer"]}
mutate {convert => ["City_id", "integer"]}
mutate {convert => ["Id_personal", "integer"]}
mutate {convert => ["Id_type", "integer"]}
mutate {convert => ["Zipcode", "integer"]}
mutate {convert => ["Patient_Age", "integer"]}Depois de cuidar dos campos, execute o seguinte comando para fazer upload dos dados no elasticsearch -
- Vá para dentro do diretório bin Logstash e execute o seguinte comando.
logstash -f logstash_homevisists.conf- Uma vez feito isso, você deve ver o índice mencionado no arquivo conf logstash no elasticsearch conforme mostrado abaixo -
Agora podemos criar um padrão de índice no índice acima carregado e usá-lo posteriormente para criar a visualização.
Usando ferramentas Dev para fazer upload de dados em massa
Vamos usar as Dev Tools da Kibana UI. Dev Tools é útil para fazer upload de dados no Elasticsearch, sem usar o Logstash. Podemos postar, colocar, deletar, pesquisar os dados que queremos no Kibana usando Dev Tools.
Nesta seção, tentaremos carregar dados de amostra no próprio Kibana. Podemos usá-lo para praticar com os dados de amostra e brincar com os recursos do Kibana para obter um bom entendimento do Kibana.
Vamos pegar os dados json do seguinte url e carregá-los no Kibana. Da mesma forma, você pode tentar qualquer amostra de dados json a ser carregada dentro do Kibana.
Antes de começar a fazer upload dos dados de amostra, precisamos ter os dados json com índices a serem usados na pesquisa elástica. Quando fazemos upload usando o logstash, o logstash se preocupa em adicionar os índices e o usuário não precisa se preocupar com os índices exigidos pelo elasticsearch.
Dados Json normais
[
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"},
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"SCENE I.London. The palace."},
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the
EARL of WESTMORELAND, SIR WALTER BLUNT, and others"}
]O código json a ser usado com Kibana deve ser indexado da seguinte forma -
{"index":{"_index":"shakespeare","_id":0}}
{"type":"act","line_id":1,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":"ACT I"}
{"index":{"_index":"shakespeare","_id":1}}
{"type":"scene","line_id":2,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"",
"text_entry":"SCENE I. London. The palace."}
{"index":{"_index":"shakespeare","_id":2}}
{"type":"line","line_id":3,"play_name":"Henry IV",
"speech_number":"","line_number":"","speaker":"","text_entry":
"Enter KING HENRY, LORD JOHN OF LANCASTER, the EARL
of WESTMORELAND, SIR WALTER BLUNT, and others"}Observe que há dados adicionais incluídos no arquivo json -{"index":{"_index":"nameofindex","_id":key}}.
Para converter qualquer arquivo json de amostra compatível com elasticsearch, aqui temos um pequeno código em php que produzirá o arquivo json fornecido no formato desejado por elasticsearch -
Código PHP
<?php
$myfile = fopen("todo.json", "r") or die("Unable to open file!"); // your json file here $alldata = fread($myfile,filesize("todo.json")); fclose($myfile);
$farray = json_decode($alldata);
$afinalarray = []; $index_name = "todo";
$i=0; $myfile1 = fopen("todonewfile.json", "w") or die("Unable to open file!"); //
writes a new file to be used in kibana dev tool
foreach ($farray as $a => $value) { $_index = json_decode('{"index": {"_index": "'.$index_name.'", "_id": "'.$i.'"}}');
fwrite($myfile1, json_encode($_index));
fwrite($myfile1, "\n"); fwrite($myfile1, json_encode($value)); fwrite($myfile1, "\n");
$i++;
}
?>Pegamos o arquivo todo json de https://jsonplaceholder.typicode.com/todos e usar o código php para converter para o formato que precisamos carregar no Kibana.
Para carregar os dados de amostra, abra a guia de ferramentas de desenvolvimento conforme mostrado abaixo -
Agora vamos usar o console conforme mostrado acima. Pegaremos os dados json que obtivemos após executá-los por meio do código php.
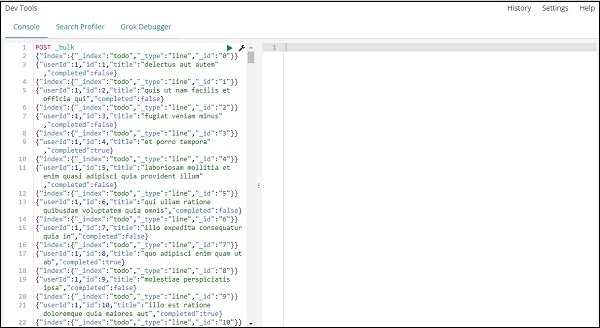
O comando a ser usado nas ferramentas de desenvolvimento para fazer upload dos dados json é -
POST _bulkObserve que o nome do índice que estamos criando é todo .

Depois de clicar no botão verde, os dados são carregados, você pode verificar se o índice foi criado ou não no elasticsearch da seguinte maneira -

Você pode verificar o mesmo nas próprias ferramentas de desenvolvimento da seguinte maneira -
Command −
GET /_cat/indices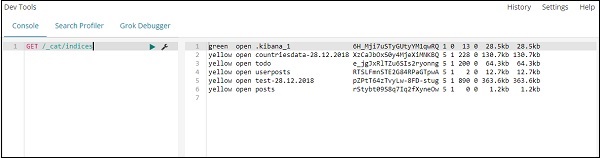
Se você deseja pesquisar algo em seu índice: todo, você pode fazer isso conforme mostrado abaixo -
Command in dev tool
GET /todo/_search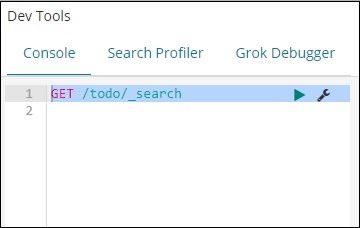
O resultado da pesquisa acima é mostrado abaixo -

Ele fornece todos os registros presentes no todoindex. O total de registros que estamos obtendo é 200.
Procure um registro no índice de tarefas
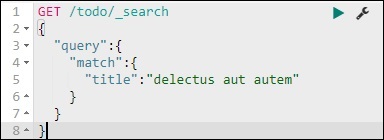
Podemos fazer isso usando o seguinte comando -
GET /todo/_search
{
"query":{
"match":{
"title":"delectusautautem"
}
}
}

Podemos obter os registros que correspondem ao título que demos.
A seção Gerenciamento no Kibana é usada para gerenciar os padrões de índice. Neste capítulo, discutiremos o seguinte -
- Criar padrão de índice sem campo de filtro de tempo
- Criar padrão de índice com campo de filtro de tempo
Criar padrão de índice sem campo de filtro de tempo
Para fazer isso, vá para Kibana UI e clique em Gerenciamento -
Para trabalhar com Kibana, primeiro temos que criar um índice que é preenchido a partir de elasticsearch. Você pode obter todos os índices disponíveis em Elasticsearch → Gerenciamento de índices conforme mostrado -
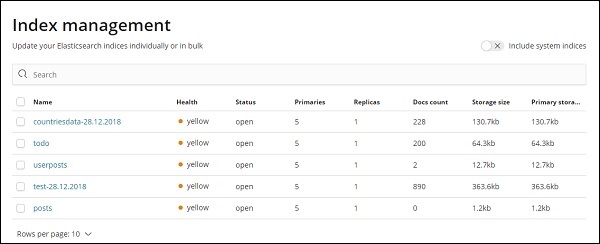
No momento, a elasticsearch tem os índices acima. A contagem de documentos informa o número de registros disponíveis em cada um dos índices. Se houver algum índice atualizado, a contagem de documentos continuará mudando. O armazenamento primário informa o tamanho de cada índice carregado.
Para criar um novo índice em Kibana, precisamos clicar em Padrões de índice como mostrado abaixo -

Depois de clicar em Padrões de índice, obtemos a seguinte tela -
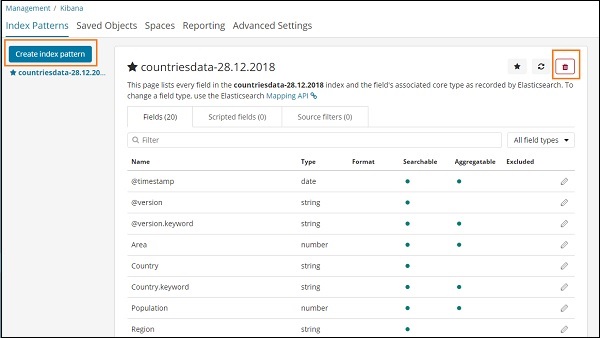
Observe que o botão Criar padrão de índice é usado para criar um novo índice. Lembre-se de que já temos countriesdata-28.12.2018 criado bem no início do tutorial.
Criar padrão de índice com campo de filtro de tempo
Clique em Criar padrão de índice para criar um novo índice.
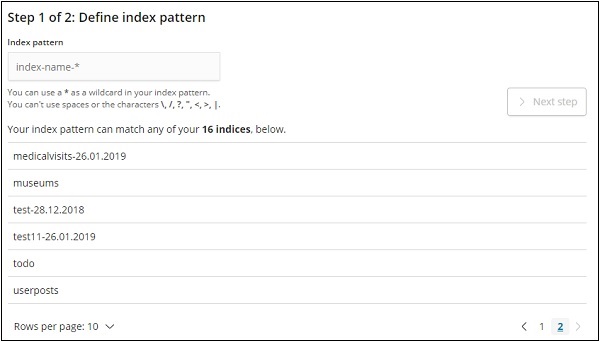
Os índices de elasticsearch são exibidos, selecione um para criar um novo índice.
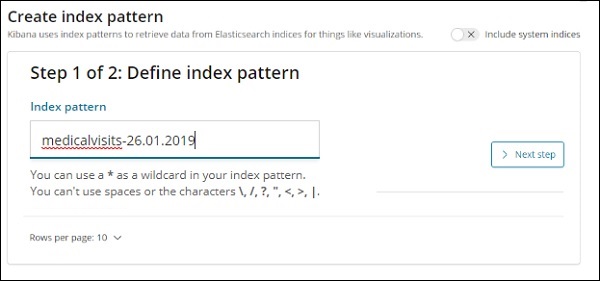
Agora, clique em Próxima etapa .
A próxima etapa é definir a configuração, onde você precisa inserir o seguinte -
O nome do campo de filtro de tempo é usado para filtrar dados com base no tempo. A lista suspensa exibirá todos os campos relacionados a hora e data do índice.
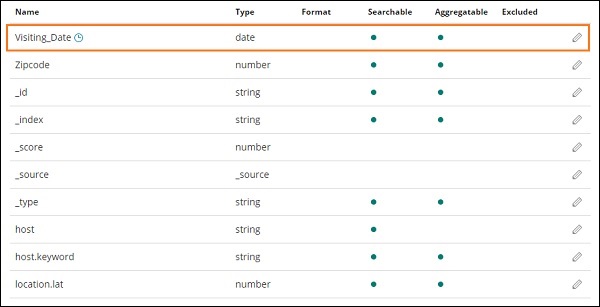
Na imagem mostrada abaixo, temos Visiting_Date como um campo de data. Selecione Visiting_Date como o nome do campo Filtro de tempo.
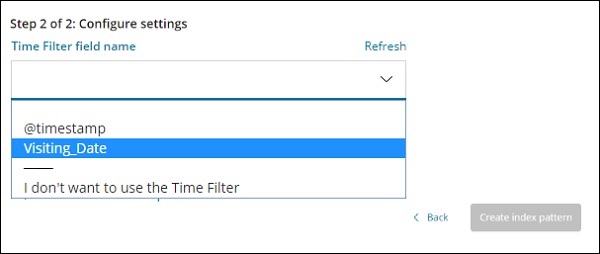
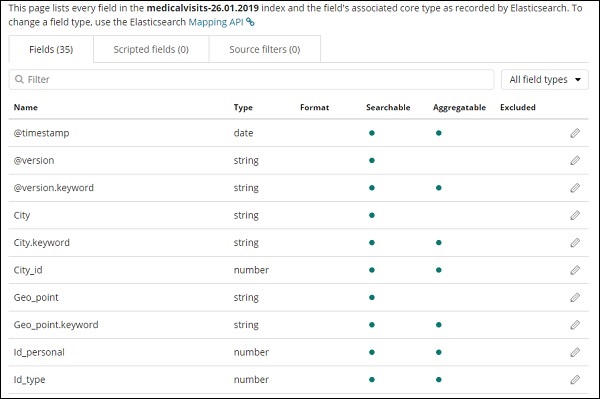
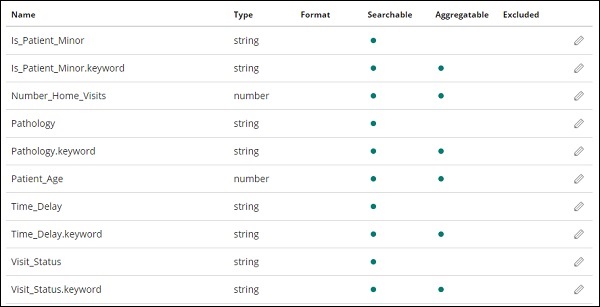
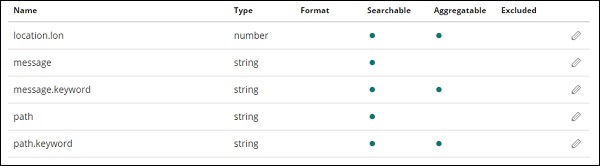
Clique Create index patternbotão para criar o índice. Uma vez feito isso, ele exibirá todos os campos presentes em seu índice medicalvisits-26.01.2019 conforme mostrado abaixo -
Temos os seguintes campos no índice medicalvisits-26.01.2019 -
["Visit_Status","Time_Delay","City","City_id","Patient_Age","Zipcode","Latitude
","Longitude","Pathology","Visiting_Date","Id_type","Id_personal","Number_Home_
Visits","Is_Patient_Minor","Geo_point"].O índice contém todos os dados das visitas médicas domiciliares. Existem alguns campos adicionais adicionados por elasticsearch quando inserido do logstash.
Este capítulo discute a guia Descobrir na IU do Kibana. Aprenderemos em detalhes sobre os seguintes conceitos -
- Índice sem campo de data
- Índice com campo de data
Índice sem campo de data
Selecione Descobrir no menu do lado esquerdo conforme mostrado abaixo -
No lado direito, exibe os detalhes dos dados disponíveis em countriesdata- 28.12.2018 índice que criamos no capítulo anterior.
No canto superior esquerdo, mostra o número total de registros disponíveis -

Podemos obter os detalhes dos dados dentro do índice (countriesdata-28.12.2018)nesta guia. No canto superior esquerdo da tela mostrada acima, podemos ver botões como Novo, Salvar, Abrir, Compartilhar, Inspecionar e Atualizar automaticamente.
Se você clicar em Atualização automática, a tela será exibida conforme mostrado abaixo -
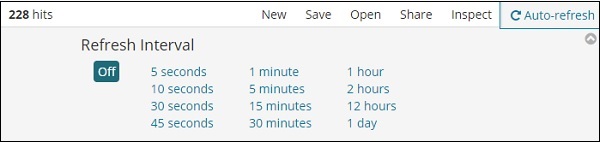
Você pode definir o intervalo de atualização automática clicando nos segundos, minutos ou horas acima. Kibana atualizará automaticamente a tela e obterá novos dados após cada cronômetro de intervalo definido.
Os dados de index:countriesdata-28.12.2018 é exibido como mostrado abaixo -
Todos os campos junto com os dados são mostrados por linha. Clique na seta para expandir a linha e ela fornecerá detalhes em formato de tabela ou formato JSON

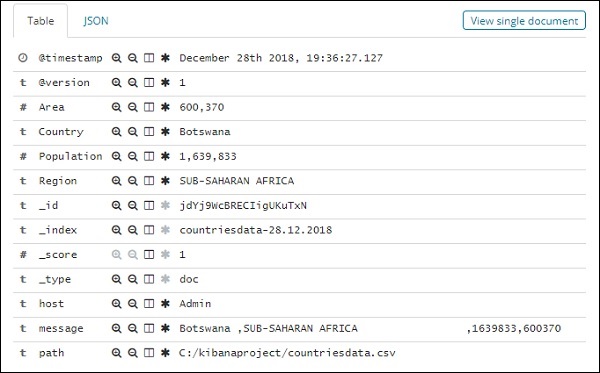
Formato JSON
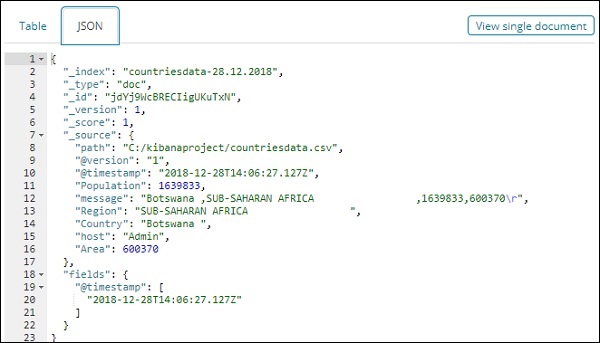
Há um botão no lado esquerdo chamado Exibir documento único.
Se você clicar nele, ele exibirá a linha ou os dados presentes na linha dentro da página, conforme mostrado abaixo -
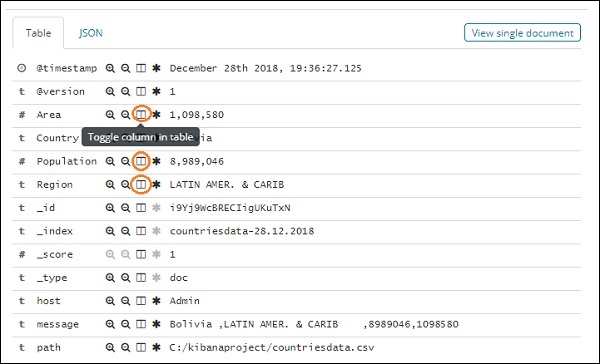
Embora estejamos obtendo todos os detalhes dos dados aqui, é difícil examinar cada um deles.
Agora, vamos tentar obter os dados em formato tabular. Uma maneira de expandir uma das linhas e clicar na opção de alternar coluna disponível em cada campo é mostrada abaixo -
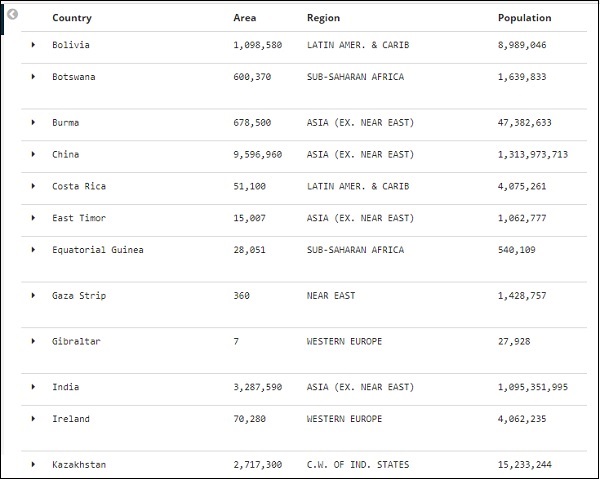
Clique na opção Alternar coluna na tabela disponível para cada um e você notará os dados sendo mostrados no formato de tabela -

Aqui, selecionamos os campos País, Área, Região e População. Recolha a linha expandida e você deverá ver todos os dados em formato tabular agora.
Os campos que selecionamos são exibidos no lado esquerdo da tela, conforme mostrado abaixo -
Observe que existem 2 opções - Campos selecionados e Campos disponíveis . Os campos que selecionamos para mostrar em formato tabular fazem parte dos campos selecionados. Caso queira remover algum campo, você pode fazê-lo clicando no botão remover que será visto ao longo do nome do campo na opção de campo selecionado.
Uma vez removido, o campo estará disponível dentro dos Campos disponíveis onde você pode adicionar novamente clicando no botão adicionar que será mostrado no campo que você deseja. Você também pode usar este método para obter seus dados em formato tabular, escolhendo os campos obrigatórios em Campos disponíveis .
Temos uma opção de pesquisa disponível no Discover, que podemos usar para pesquisar dados dentro do índice. Vamos tentar exemplos relacionados à opção de pesquisa aqui -
Suponha que você queira pesquisar o país Índia, você pode fazer o seguinte -
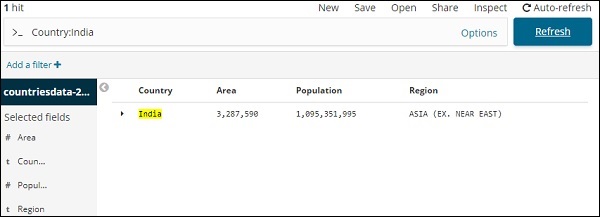
Você pode digitar os detalhes de sua pesquisa e clicar no botão Atualizar. Se você deseja pesquisar países começando com Aus, você pode fazer o seguinte -

Clique em Atualizar para ver os resultados
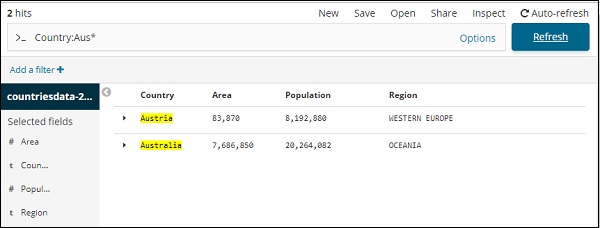
Aqui, temos dois países começando com Aus *. O campo de pesquisa possui um botão Opções conforme mostrado acima. Quando um usuário clica nele, ele exibe um botão de alternância que, quando ligado, ajuda a escrever a consulta de pesquisa.
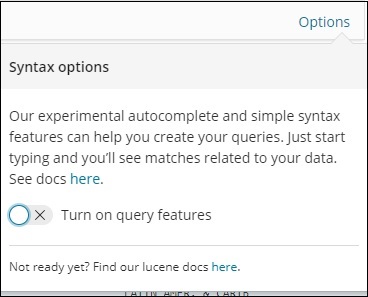
Ative os recursos de consulta e digite o nome do campo na pesquisa, ele exibirá as opções disponíveis para aquele campo.
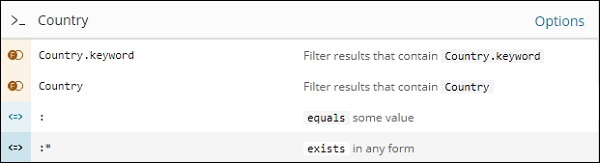
Por exemplo, o campo País é uma string e exibe as seguintes opções para o campo string -
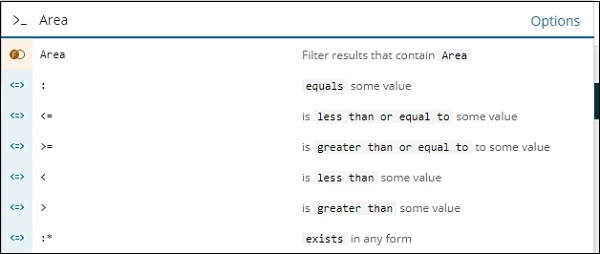
Da mesma forma, Área é um campo Número e exibe as seguintes opções para o campo Número -
Você pode experimentar combinações diferentes e filtrar os dados de acordo com sua escolha no campo Descobrir. Os dados dentro da guia Descobrir podem ser salvos usando o botão Salvar, para que você possa usá-los para fins futuros.
Para salvar os dados dentro do Discover, clique no botão Salvar no canto superior direito conforme mostrado abaixo -
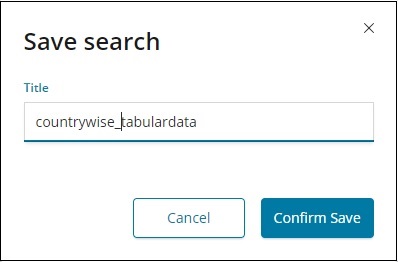
Dê um título à sua pesquisa e clique em Confirmar Salvar para salvá-la. Depois de salvos, na próxima vez que visitar a guia Descobrir, você pode clicar no botão Abrir no canto superior direito para obter os títulos salvos conforme mostrado abaixo -
Você também pode compartilhar os dados com outras pessoas usando o botão Compartilhar disponível no canto superior direito. Se clicar nele, você encontrará as opções de compartilhamento conforme mostrado abaixo -
Você pode compartilhá-lo usando relatórios CSV ou na forma de links permanentes.
A opção disponível ao clicar em Relatórios CSV são -
Clique em Gerar CSV para que o relatório seja compartilhado com outras pessoas.
As opções disponíveis ao clicar nos links permanentes são as seguintes -

A opção Instantâneo fornecerá um link Kibana que exibirá os dados disponíveis na pesquisa atualmente.
A opção Objeto salvo fornecerá um link Kibana que exibirá os dados recentes disponíveis em sua pesquisa.
Instantâneo - http://localhost:5601/goto/309a983483fccd423950cfb708fabfa5 Objeto salvo: http: // localhost: 5601 / app / kibana # / discover / 40bd89d0-10b1-11e9-9876-4f3d759b471e? _G = ()
Você pode trabalhar com a guia Descobrir e as opções de pesquisa disponíveis e o resultado obtido pode ser salvo e compartilhado com outras pessoas.
Índice com campo de data
Vá para a guia Descobrir e selecione o índice:medicalvisits-26.01.2019
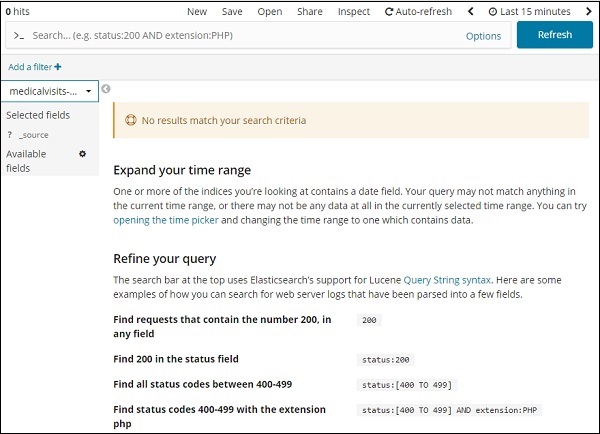
Ele exibiu a mensagem - “Nenhum resultado corresponde aos seus critérios de pesquisa”, nos últimos 15 minutos no índice que selecionamos. O índice tem dados para os anos de 2015,2016,2017 e 2018.
Altere o intervalo de tempo conforme mostrado abaixo -
Clique na guia Absoluto.
Selecione a data De - 1º de janeiro de 2017 e Até - 31 de dezembro de 2017, pois analisaremos os dados para o ano de 2017.
Clique no botão Ir para adicionar o intervalo de tempo. Ele exibirá os dados e o gráfico de barras da seguinte forma -
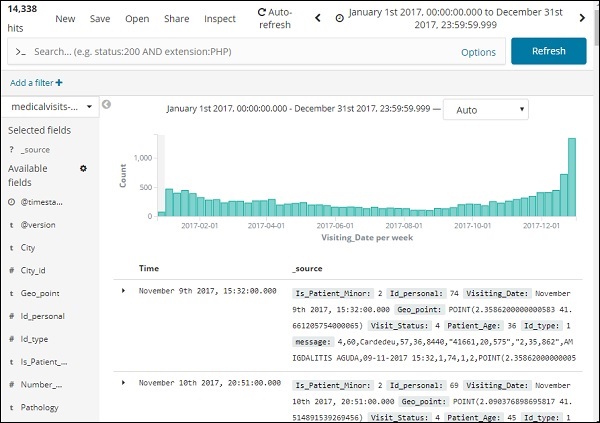
Estes são os dados mensais do ano de 2017 -
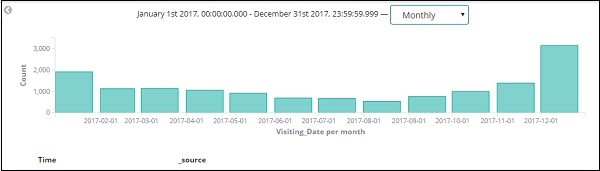
Como também temos o tempo armazenado junto com a data, podemos filtrar os dados por horas e minutos também.
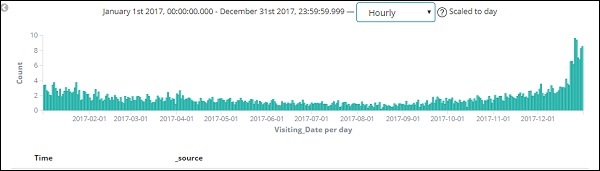
A figura mostrada acima exibe os dados horários para o ano de 2017.
Aqui, os campos exibidos a partir do índice - medicalvisits-26.01.2019

Temos os campos disponíveis no lado esquerdo conforme mostrado abaixo -
Você pode selecionar os campos dos campos disponíveis e converter os dados em formato tabular, conforme mostrado abaixo. Aqui, selecionamos os seguintes campos -
Os dados tabulares para os campos acima são mostrados aqui -
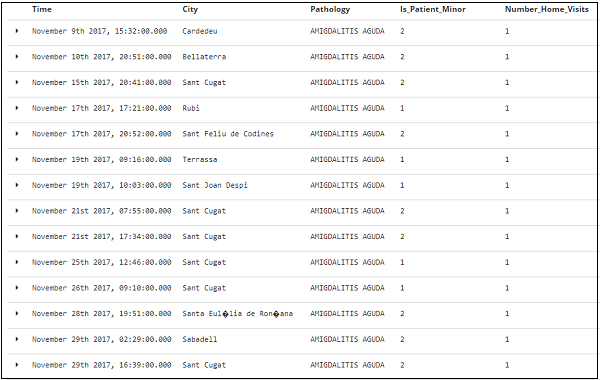
Os dois termos que você encontra com frequência durante o aprendizado de Kibana são Bucket e Metrics Aggregation. Este capítulo discute o papel que eles desempenham no Kibana e mais detalhes sobre eles.
O que é agregação Kibana?
A agregação se refere à coleção de documentos ou a um conjunto de documentos obtido de uma consulta de pesquisa ou filtro específico. A agregação constitui o conceito principal para construir a visualização desejada no Kibana.
Sempre que você realiza qualquer visualização, você precisa decidir os critérios, o que significa de que forma você deseja agrupar os dados para realizar a métrica sobre eles.
Nesta seção, discutiremos dois tipos de agregação -
- Agregação de balde
- Agregação métrica
Agregação de balde
Um balde consiste principalmente em uma chave e um documento. Quando a agregação é executada, os documentos são colocados no respectivo depósito. Portanto, no final, você deve ter uma lista de baldes, cada um com uma lista de documentos. A lista de Bucket Aggregation que você verá ao criar a visualização no Kibana é mostrada abaixo -
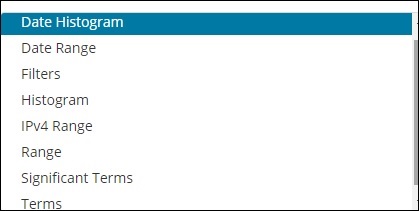
Agregação de intervalo tem a seguinte lista -
- Histograma de data
- Intervalo de datas
- Filters
- Histogram
- Intervalo IPv4
- Range
- Termos Significativos
- Terms
Ao criar, você precisa decidir um deles para Agregação de Bucket, ou seja, agrupar os documentos dentro dos buckets.
Como exemplo, para análise, considere os dados dos países que carregamos no início deste tutorial. Os campos disponíveis no índice de países são nome do país, área, população, região. Nos dados dos países, temos o nome do país junto com sua população, região e área.
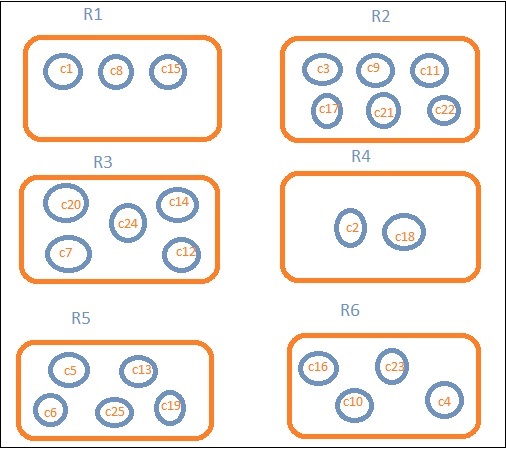
Vamos supor que queremos dados regionais. Então, os países disponíveis em cada região passam a ser nossa consulta de pesquisa, então neste caso a região formará nossos baldes. O diagrama de blocos abaixo mostra que R1, R2, R3, R4, R5 e R6 são os depósitos que obtivemos e c1, c2 ..c25 são a lista de documentos que fazem parte dos depósitos R1 a R6.
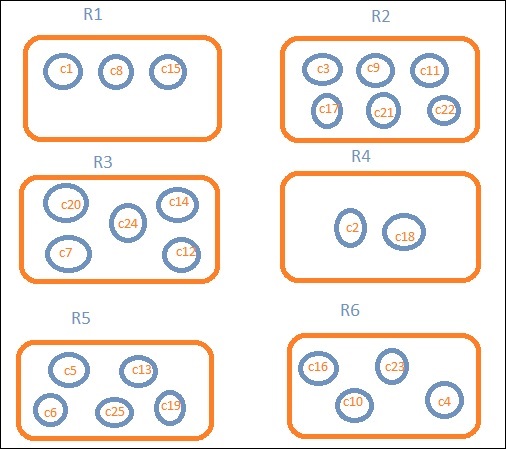
Podemos ver que existem alguns círculos em cada um dos baldes. Eles são conjuntos de documentos com base nos critérios de pesquisa e considerados como pertencentes a cada um dos baldes. No intervalo R1, temos os documentos c1, c8 e c15. Esses documentos são os países que se enquadram naquela região, o mesmo para outros. Portanto, se contarmos os países no intervalo R1, é 3, 6 para R2, 6 para R3, 2 para R4, 5 para R5 e 4 para R6.
Portanto, por meio da agregação de buckets, podemos agregar o documento em buckets e ter uma lista de documentos nesses buckets, conforme mostrado acima.
A lista de Bucket Aggregation que temos até agora é -
- Histograma de data
- Intervalo de datas
- Filters
- Histogram
- Intervalo IPv4
- Range
- Termos Significativos
- Terms
Vamos agora discutir como formar esses baldes um por um em detalhes.
Histograma de data
A agregação de histograma de data é usada em um campo de data. Portanto, o índice que você usa para visualizar, se você tiver campo de data nesse índice, então apenas este tipo de agregação pode ser usado. Esta é uma agregação de vários baldes, o que significa que você pode ter alguns dos documentos como parte de mais de 1 balde. Há um intervalo a ser usado para esta agregação e os detalhes são mostrados abaixo -
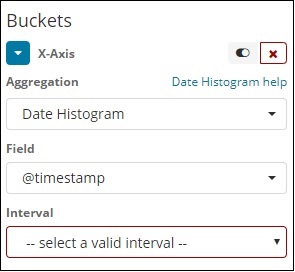
Ao selecionar Agregação de Buckets como Histograma de Data, será exibida a opção Campo que fornecerá apenas os campos relacionados à data. Depois de selecionar seu campo, você precisa selecionar o intervalo que contém os seguintes detalhes -
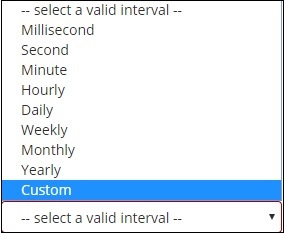
Portanto, os documentos do índice escolhido e com base no campo e intervalo escolhidos irão categorizar os documentos em buckets. Por exemplo, se você escolheu o intervalo como mensal, os documentos baseados na data serão convertidos em baldes e com base no mês, ou seja, Jan-Dez, os documentos serão colocados nos baldes. Aqui, janeiro, fevereiro, ... dezembro serão os baldes.
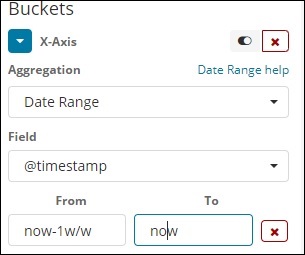
Intervalo de datas
Você precisa de um campo de data para usar este tipo de agregação. Aqui teremos um intervalo de datas, ou seja, a partir da data e a data a ser fornecida. Os buckets terão seus documentos baseados no formulário e na data fornecidos.
Filtros
Com a agregação do tipo Filtros, os depósitos serão formados com base no filtro. Aqui você obterá um balde múltiplo formado com base nos critérios de filtro, um documento pode existir em um ou mais baldes.
Usando filtros, os usuários podem escrever suas consultas na opção de filtro, conforme mostrado abaixo -
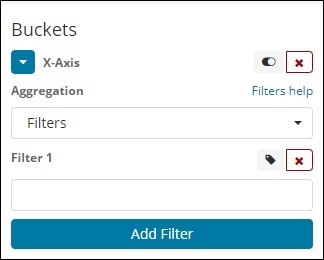
Você pode adicionar vários filtros de sua escolha usando o botão Adicionar filtro.
Histograma
Este tipo de agregação é aplicado em um campo numérico e agrupará os documentos em um bucket com base no intervalo aplicado. Por exemplo, 0-50,50-100,100-150 etc.
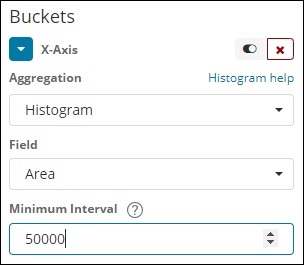
Intervalo IPv4
Esse tipo de agregação é usado e principalmente usado para endereços IP.
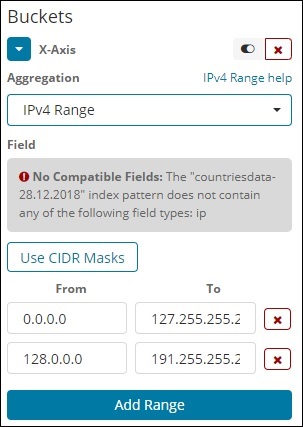
O índice que temos que é o contriesdata-28.12.2018 não possui campo do tipo IP por isso exibe uma mensagem conforme mostrado acima. Se acontecer de você ter o campo IP, você pode especificar os valores De e Para nele, conforme mostrado acima.
Alcance
Este tipo de agregação precisa que os campos sejam do tipo número. Você precisa especificar o intervalo e os documentos serão listados nos baldes que caem no intervalo.
Você pode adicionar mais intervalo, se necessário, clicando no botão Adicionar intervalo.
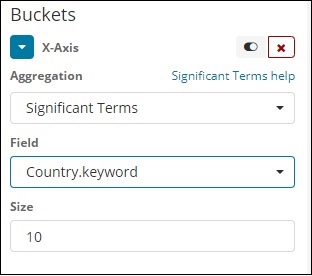
Termos Significativos
Este tipo de agregação é usado principalmente nos campos de string.
Termos
Este tipo de agregação é usado em todos os campos disponíveis a saber, número, string, data, booleano, endereço IP, carimbo de data / hora, etc. Observe que esta é a agregação que vamos usar em todas as nossas visualizações que vamos trabalhar neste tutorial.
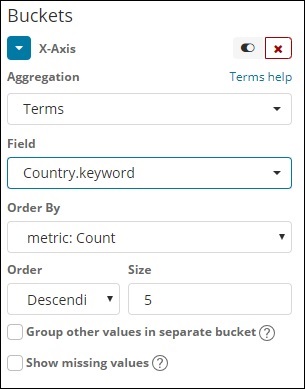
Temos uma ordem de opções pela qual agruparemos os dados com base na métrica que selecionarmos. O tamanho se refere ao número de intervalos que você deseja exibir na visualização.
A seguir, vamos falar sobre agregação métrica.
Agregação métrica
A agregação da métrica se refere principalmente ao cálculo matemático feito nos documentos presentes no balde. Por exemplo, se você escolher um campo de número, o cálculo da métrica que você pode fazer nele é COUNT, SUM, MIN, MAX, AVERAGE etc.
Uma lista de agregação de métricas que discutiremos é fornecida aqui -
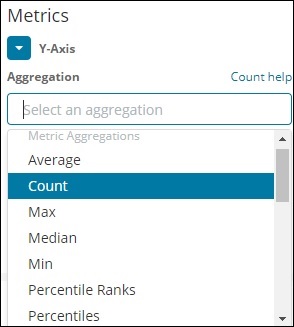
Nesta seção, vamos discutir os importantes que vamos usar com frequência -
- Average
- Count
- Max
- Min
- Sum
A métrica será aplicada à agregação de intervalo individual que já discutimos acima.
A seguir, vamos discutir a lista de agregação de métricas aqui -
Média
Isso dará a média dos valores dos documentos presentes nos baldes. Por exemplo -
R1 a R6 são os baldes. Em R1, temos c1, c8 e c15. Considere que o valor de c1 é 300, c8 é 500 e c15 é 700. Agora, para obter o valor médio do intervalo R1
R1 = valor de c1 + valor de c8 + valor de c15 / 3 = 300 + 500 + 700/3 = 500.
A média é 500 para o intervalo R1. Aqui, o valor do documento pode ser qualquer coisa como, se você considerar os dados dos países, pode ser a área do país naquela região.
Contagem
Isso dará a contagem de documentos presentes no Balde. Suponha que você queira a contagem dos países presentes na região, será o total de documentos presentes nos baldes. Por exemplo, R1 será 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 e R6 = 4.
Max
Isso fornecerá o valor máximo do documento presente no balde. Considerando o exemplo acima, se tivermos dados de países da área inteligente no intervalo da região. O máximo para cada região será o país com a área máxima. Portanto, terá um país de cada região, ou seja, R1 a R6.
dentro
Isso fornecerá o valor mínimo do documento presente no balde. Considerando o exemplo acima, se tivermos dados de países da área sábia no intervalo da região. O mínimo para cada região será o país com a área mínima. Portanto, terá um país de cada região, ou seja, R1 a R6.
Soma
Isso dará a soma dos valores do documento presente no balde. Por exemplo, se você considerar o exemplo acima se quisermos a área total ou países da região, será a soma dos documentos presentes na região.
Por exemplo, para saber o total de países na região R1, será 3, R2 = 6, R3 = 5, R4 = 2, R5 = 5 e R6 = 4.
Caso tenhamos documentos com área na região então R1 a R6 terão a área do país somada para a região.
Podemos visualizar os dados que temos na forma de gráficos de barras, gráficos de linhas, gráficos de setores circulares, etc. Neste capítulo, entenderemos como criar visualização.
Criar visualização
Vá para Kibana Visualization conforme mostrado abaixo -

Não temos nenhuma visualização criada, por isso aparece em branco e existe um botão para criar uma.
Clique no botão Create a visualization conforme mostrado na tela acima e isso o levará para a tela mostrada abaixo -
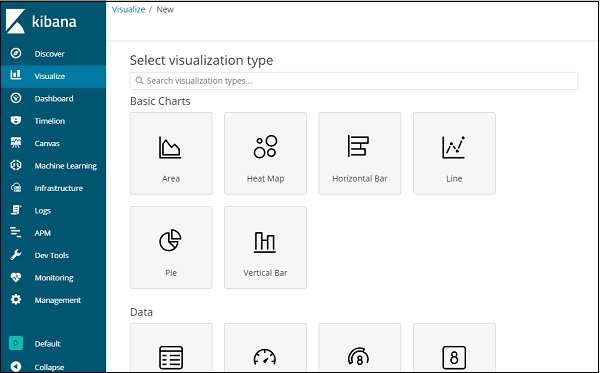
Aqui você pode selecionar a opção necessária para visualizar seus dados. Vamos entender cada um deles em detalhes nos próximos capítulos. Neste momento, selecionarei o gráfico de pizza para começar.
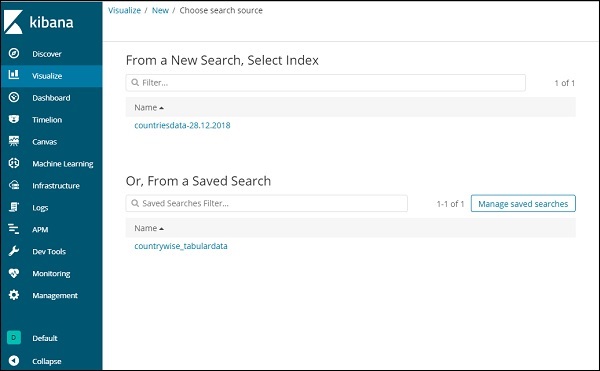
Depois de selecionar o tipo de visualização, agora você precisa selecionar o índice no qual deseja trabalhar, e ele irá levá-lo à tela conforme mostrado abaixo -

Agora temos um gráfico de pizza padrão. Usaremos os paísesdata-28.12.2018 para obter a contagem das regiões disponíveis nos dados dos países em formato de gráfico de pizza.
Bucket and Metric Aggregation
O lado esquerdo contém métricas, que selecionaremos como contagem. Em Buckets, existem 2 opções Dividir fatias e dividir gráfico. Usaremos a opção Dividir fatias.
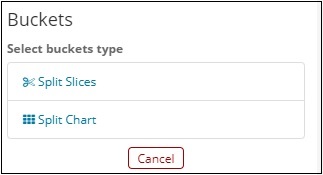
Agora, selecione Split Slices e ele exibirá as seguintes opções -
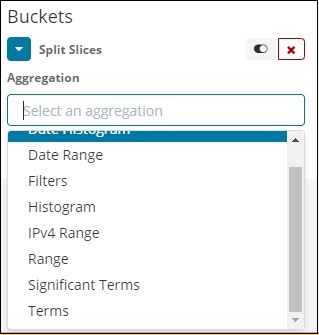
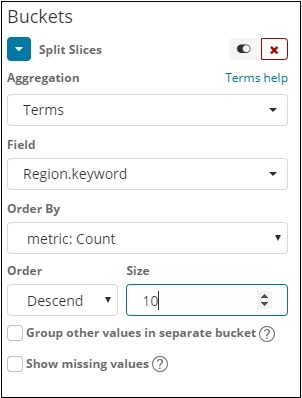
Agora, selecione a agregação como termos e ela exibirá mais opções a serem inseridas da seguinte forma -

A lista suspensa Campos terá todos os campos do índice: paísesdados escolhidos. Escolhemos o campo Região e Ordenar por. Observe que escolhemos a métrica Contagem para Ordenar por. Iremos ordená-lo em ordem decrescente e o tamanho que tomamos como 10. Isso significa que aqui obteremos a contagem das 10 principais regiões do índice de países.
Agora, clique no botão analisar conforme destacado abaixo e você deverá ver o gráfico de pizza atualizado no lado direito.
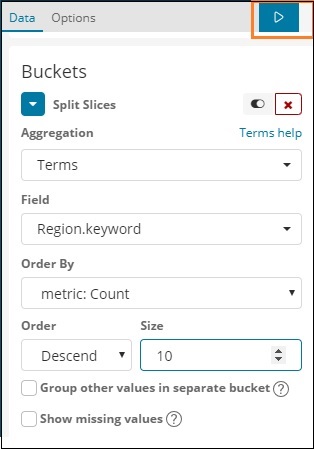
Gráfico de pizza
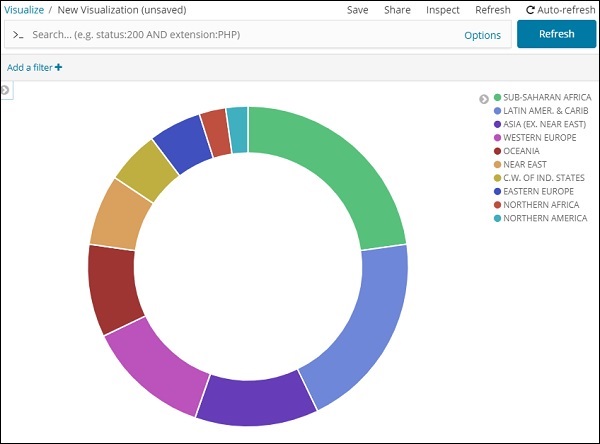
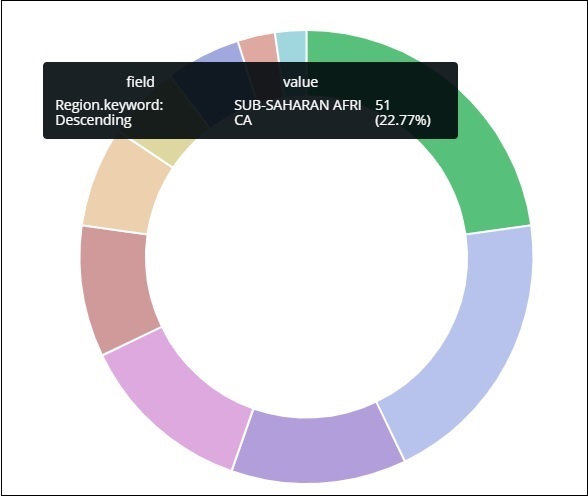
Todas as regiões são listadas no canto superior direito com cores e a mesma cor é mostrada no gráfico de pizza. Se você passar o mouse sobre o gráfico de pizza, ele fornecerá a contagem da região e também o nome da região como mostrado abaixo -
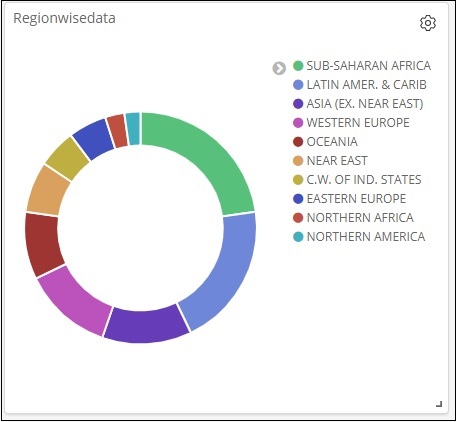
Portanto, isso nos diz que 22,77% da região está ocupada pela África Subsaariana de acordo com os dados dos países que carregamos.
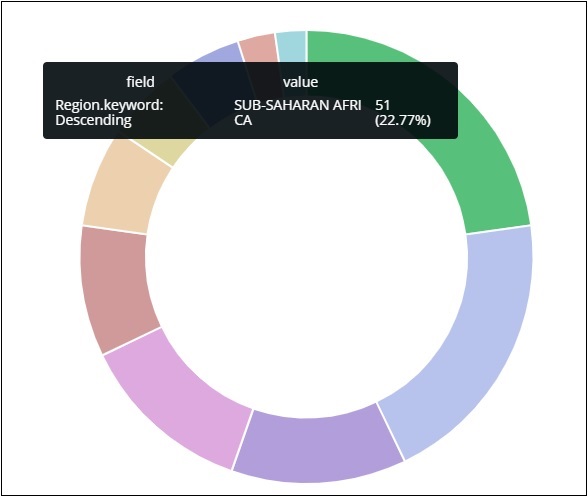

A região da Ásia cobre 12,5% e a contagem é de 28.
Agora podemos salvar a visualização clicando no botão Salvar no canto superior direito, conforme mostrado abaixo -

Agora, salve a visualização para que possa ser usada posteriormente.
Também podemos obter os dados que quisermos usando a opção de pesquisa conforme mostrado abaixo -
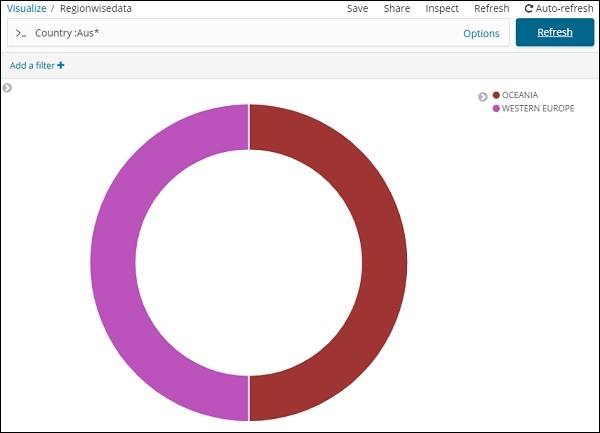
Filtramos dados para países começando com Aus *. Compreenderemos mais sobre gráfico de pizza e outras visualizações nos próximos capítulos.
Vamos explorar e compreender os gráficos mais comumente usados na visualização.
- Gráfico de Barras Horizontais
- Gráfico de Barras Verticais
- Gráfico de pizza
A seguir estão as etapas a serem seguidas para criar a visualização acima. Vamos começar com a barra horizontal.
Gráfico de Barras Horizontais
Abra o Kibana e clique na guia Visualizar no lado esquerdo, conforme mostrado abaixo -
Clique no botão + para criar uma nova visualização -
Clique na barra horizontal listada acima. Você terá que fazer uma seleção do índice que deseja visualizar.
Selecione os countriesdata-28.12.2018índice como mostrado acima. Ao selecionar o índice, ele exibe uma tela conforme mostrado abaixo -
Mostra uma contagem padrão. Agora, vamos traçar um gráfico horizontal onde podemos ver os dados das 10 principais populações do país.
Para isso, precisamos selecionar o que queremos nos eixos Y e X. Portanto, selecione o intervalo e a agregação métrica -
Agora, se você clicar no eixo Y, ele exibirá a tela conforme mostrado abaixo -
Agora, selecione a agregação que deseja nas opções mostradas aqui -
Observe que aqui selecionaremos a agregação Máx, pois queremos exibir os dados de acordo com a população máxima disponível.
Em seguida, temos que selecionar o campo cujo valor máximo é obrigatório. No índice countriesdata-28.12.2018 , temos apenas 2 campos de números - área e população.
Como queremos a população máxima, selecionamos o campo População conforme mostrado abaixo -
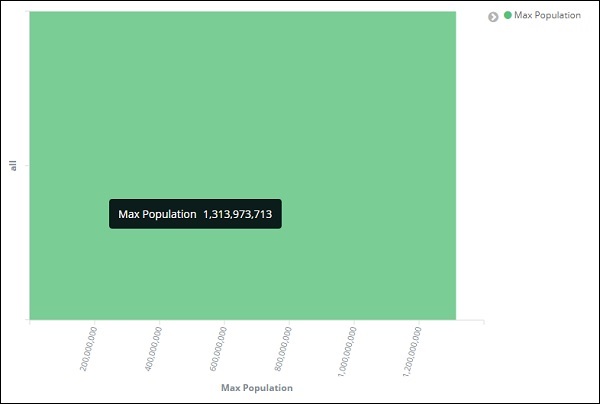
Com isso, terminamos com o eixo Y. A saída que obtemos para o eixo Y é mostrada abaixo -
Agora vamos selecionar o eixo X conforme mostrado abaixo -
Se você selecionar X-Axis, obterá a seguinte saída -
Escolha agregação como termos.
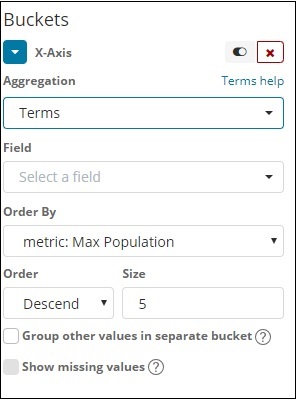
Escolha o campo no menu suspenso. Queremos a população do país, então selecione o campo do país. Ordem por, temos as seguintes opções -
Vamos escolher a ordem por População máxima conforme queremos que o país com a maior população seja exibido primeiro e assim por diante. Assim que os dados que queremos forem adicionados, clique no botão aplicar alterações na parte superior dos dados de métricas, conforme mostrado abaixo -

Depois de clicar em aplicar alterações, temos o gráfico horizontal em que podemos ver que a China é o país com maior população, seguido pela Índia, Estados Unidos etc.
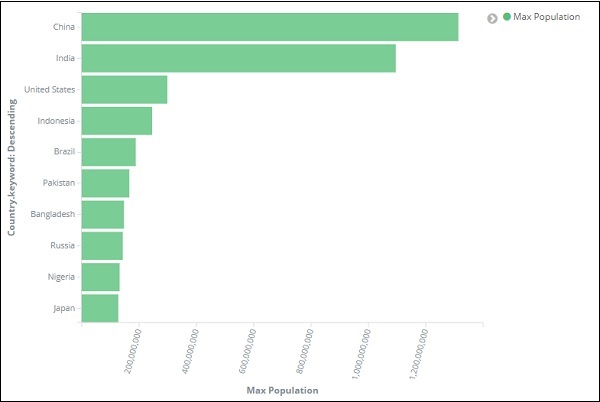
Da mesma forma, você pode traçar gráficos diferentes, escolhendo o campo desejado. A seguir, salvaremos esta visualização como max_population para ser usado posteriormente para a criação do painel.
Na próxima seção, criaremos um gráfico de barras verticais.
Gráfico de Barras Verticais
Clique na guia Visualizar e crie uma nova visualização usando a barra vertical e o índice como countriesdata-28.12.2018.
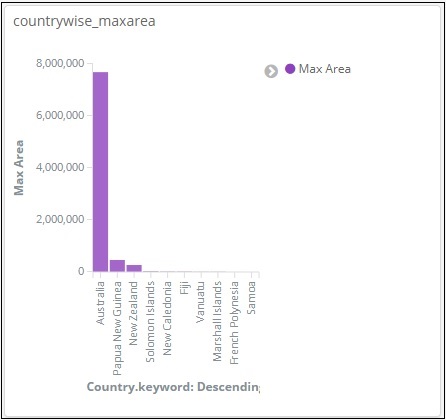
Nesta visualização da barra vertical, criaremos um gráfico de barras com a área dos países, ou seja, os países serão exibidos com a área mais alta.
Então, vamos selecionar os eixos Y e X conforme mostrado abaixo -
Eixo Y
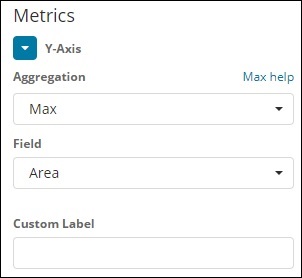
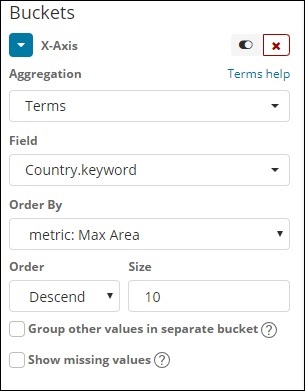
Eixo X
Quando aplicamos as alterações aqui, podemos ver a saída conforme mostrado abaixo -

No gráfico, podemos ver que a Rússia tem a área mais alta, seguida por Canadá e Estados Unidos. Observe que esses dados são coletados dos dados dos países do índice e de seus dados fictícios, portanto, os números podem não estar corretos com os dados reais.
Vamos salvar esta visualização como countrywise_maxarea para ser usada com o painel posteriormente.
A seguir, vamos trabalhar no gráfico de pizza.
Gráfico de pizza
Portanto, primeiro crie uma visualização e selecione o gráfico de pizza com o índice como dados do país. Vamos exibir a contagem de regiões disponíveis nos dados de países em formato de gráfico de pizza.
O lado esquerdo tem métricas que darão conta. Em Buckets, há 2 opções: Dividir fatias e dividir gráfico. Agora, usaremos a opção Dividir fatias.
Agora, se você selecionar Dividir fatias, ele exibirá as seguintes opções -

Selecione a agregação como termos e exibirá mais opções a serem inseridas da seguinte forma -
A lista suspensa Campos terá todos os campos do índice escolhido. Selecionamos o campo Região e Ordem por que selecionamos como Contagem. Iremos ordená-lo em ordem decrescente e o tamanho será 10. Portanto, aqui obteremos a contagem de 10 regiões do índice de países.
Agora, clique no botão reproduzir conforme destacado abaixo e você deverá ver o gráfico de pizza atualizado no lado direito.
Gráfico de pizza

Todas as regiões são listadas no canto superior direito com cores e a mesma cor é mostrada no gráfico de pizza. Se você passar o mouse sobre o gráfico de pizza, ele fornecerá a contagem da região e também o nome da região como mostrado abaixo -

Assim, diz-nos que 22,77% da região é ocupada pela África Subsariana nos dados dos países que carregamos.
No gráfico de pizza, observe que a região da Ásia cobre 12,5% e a contagem é 28.
Agora podemos salvar a visualização clicando no botão Salvar no canto superior direito, conforme mostrado abaixo -

Agora, salve a visualização para que possa ser usada posteriormente no painel.
Neste capítulo, discutiremos os dois tipos de gráficos usados na visualização -
- Gráfico de linha
- Area
Gráfico de linha
Para começar, vamos criar uma visualização, escolhendo um gráfico de linha para exibir os dados e usar contriesdata como o índice. Precisamos criar o eixo Y e o eixo X e os detalhes para os mesmos são mostrados abaixo -
Para eixo Y
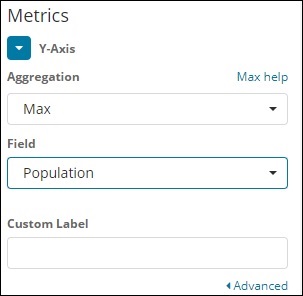
Observe que consideramos Max como a agregação. Portanto, aqui vamos mostrar a apresentação dos dados em um gráfico de linha. Agora, traçaremos um gráfico que mostrará a população máxima do país. O campo que escolhemos é População, pois precisamos de população máxima em cada país.
Para eixo X
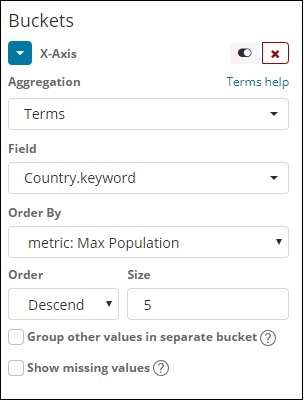
No eixo x, consideramos os termos como agregação, país. palavra-chave como campo e métrica: população máxima para ordenar por e o tamanho do pedido é 5. Portanto, ele representará os 5 principais países com população máxima. Depois de aplicar as alterações, você pode ver o gráfico de linha conforme mostrado abaixo -
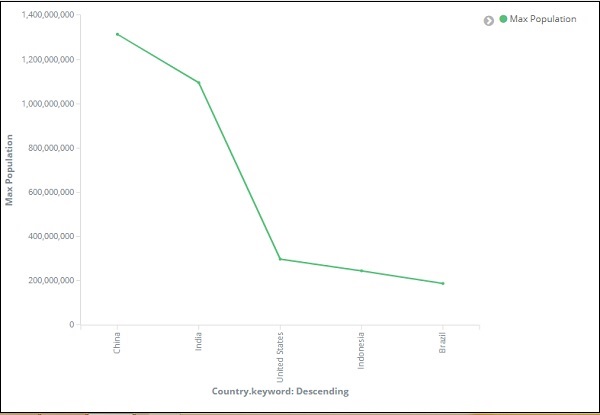
Portanto, temos a população máxima na China, seguida pela Índia, Estados Unidos, Indonésia e Brasil como os 5 principais países em população.
Agora, vamos salvar este gráfico de linha para que possamos usar no painel mais tarde.
Clique em Confirmar Salvar e você pode salvar a visualização.
Gráfico de Área
Vá para a visualização e escolha a área com índice como dados de países. Precisamos selecionar o eixo Y e o eixo X. Faremos um gráfico de área para a área máxima para o país.
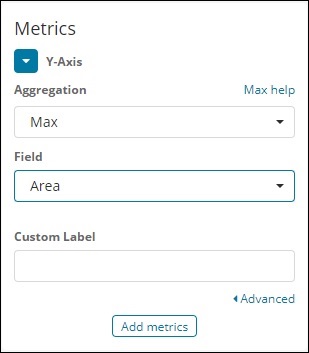
Então, aqui o eixo X e o eixo Y serão como mostrado abaixo -

Depois de clicar no botão Aplicar alterações, o resultado que podemos ver é o mostrado abaixo -
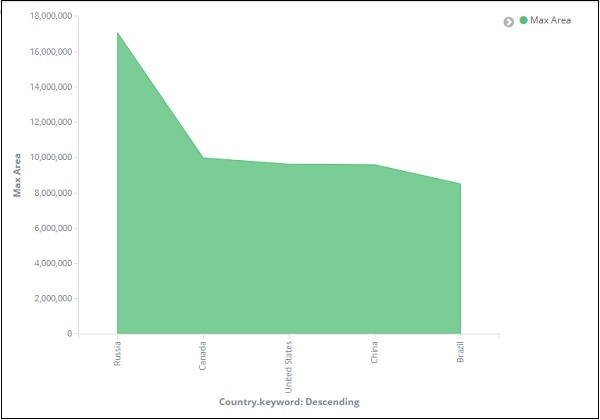
No gráfico, podemos observar que a Rússia possui a maior área, seguida de Canadá, Estados Unidos, China e Brasil. Salve a visualização para usá-la mais tarde.
Neste capítulo, entenderemos como trabalhar com mapa de calor. O mapa de calor mostrará a apresentação dos dados em cores diferentes para o intervalo selecionado nas métricas de dados.
Introdução ao Mapa de Calor
Para começar, precisamos criar a visualização clicando na guia de visualização no lado esquerdo, conforme mostrado abaixo -

Selecione o tipo de visualização como mapa de calor, conforme mostrado acima. Ele pedirá que você escolha o índice conforme mostrado abaixo -
Selecione o índice countriesdata-28.12.2018 conforme mostrado acima. Uma vez que o índice é selecionado, temos os dados a serem selecionados conforme mostrado abaixo -
Selecione as métricas conforme mostrado abaixo -

Selecione Max Aggregation na lista suspensa conforme mostrado abaixo -
Selecionamos Max, pois queremos traçar a área máxima por país.
Agora selecionará os valores para Buckets conforme mostrado abaixo -
Agora, vamos selecionar o eixo X conforme mostrado abaixo -
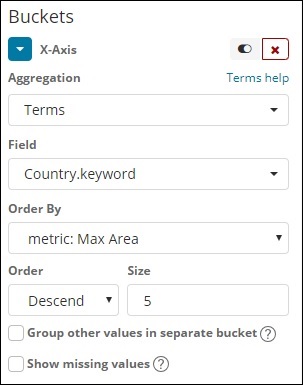
Usamos agregação como termos, campo como país e ordem por área máxima. Clique em Aplicar alterações conforme mostrado abaixo -
Se você clicar em Aplicar alterações, o mapa de calor terá a aparência mostrada abaixo -
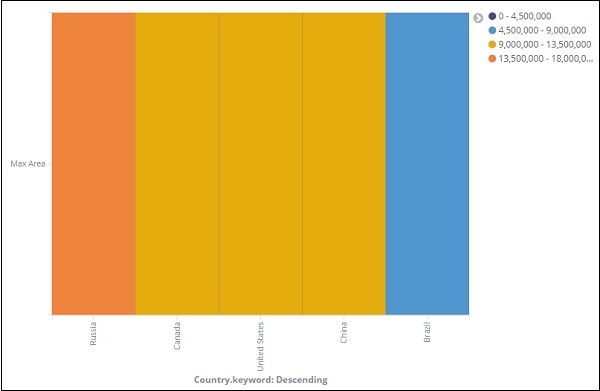
O mapa de calor é mostrado com cores diferentes e a gama de áreas é exibida no lado direito. Você pode alterar a cor clicando nos pequenos círculos ao lado da faixa de área conforme mostrado abaixo -

Os mapas de coordenadas em Kibana mostrarão a área geográfica e marcarão a área com círculos com base na agregação que você especificar.
Criar Índice para Mapa de Coordenadas
A agregação Bucket usada para o mapa de coordenadas é a agregação geohash. Para este tipo de agregação, o índice que você vai usar deve ter um campo do tipo ponto geográfico. O geo ponto é uma combinação de latitude e longitude.
Criaremos um índice usando as ferramentas de desenvolvimento Kibana e adicionaremos dados em massa a ele. Vamos adicionar o mapeamento e adicionar o tipo de geo_point que precisamos.
Os dados que vamos usar são mostrados aqui -
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.39327140161001", "city": "Esplugas de Llobregat"}Agora, execute os seguintes comandos no Kibana Dev Tools, conforme mostrado abaixo -
PUT /cities
{
"mappings": {
"_doc": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
}
POST /cities/_city/_bulk?refresh
{"index":{"_id":1}}
{"location": "2.089330000000046,41.47367000000008", "city": "SantCugat"}
{"index":{"_id":2}}
{"location": "2.2947825000000677,41.601800991000076", "city": "Granollers"}
{"index":{"_id":3}}
{"location": "2.1105957495300474,41.5496295760424", "city": "Sabadell"}
{"index":{"_id":4}}
{"location": "2.132605678083895,41.5370461908878", "city": "Barbera"}
{"index":{"_id":5}}
{"location": "2.151270020052683,41.497779918345415", "city": "Cerdanyola"}
{"index":{"_id":6}}
{"location": "2.1364609496220606,41.371303520399344", "city": "Barcelona"}
{"index":{"_id":7}}
{"location": "2.0819450306711165,41.385491966414705", "city": "Sant Just Desvern"}
{"index":{"_id":8}}
{"location": "2.00532082278266,41.542294286427385", "city": "Rubi"}
{"index":{"_id":9}}
{"location": "1.9560805366930398,41.56142635214226", "city": "Viladecavalls"}
{"index":{"_id":10}}
{"location": "2.09205348251486,41.3s9327140161001", "city": "Esplugas de Llobregat"}Agora, execute os comandos acima nas ferramentas de desenvolvimento Kibana -
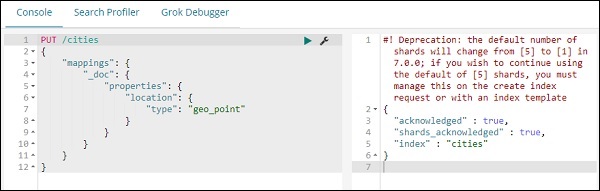
O acima irá criar cidades de nome de índice do tipo _doc e a localização do campo é do tipo geo_point.
Agora vamos adicionar dados ao índice: cidades -

Concluímos a criação de citações de nome de índice com dados. Agora vamos criar um padrão de índice para cidades usando a guia Gerenciamento.
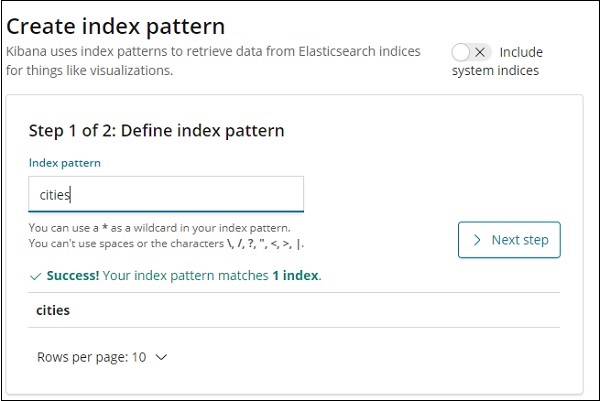
Os detalhes dos campos dentro do índice de cidades são mostrados aqui -

Podemos ver que a localização é do tipo geo_point. Agora podemos usá-lo para criar visualização.
Introdução ao Maps Coordinate
Vá para Visualização e selecione os mapas de coordenadas.
Selecione as cidades do padrão de índice e configure a métrica de agregação e o intervalo conforme mostrado abaixo -

Se você clicar no botão Analisar, poderá ver a seguinte tela -
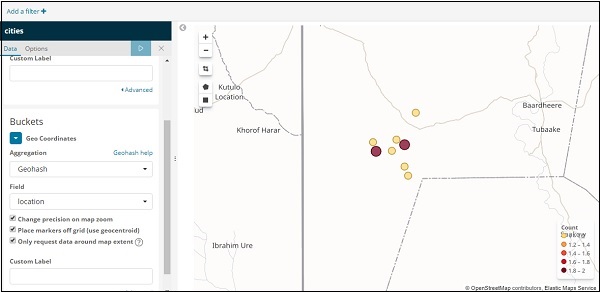
Com base na longitude e latitude, os círculos são plotados no mapa conforme mostrado acima.
Com esta visualização, você vê os dados representados no mapa mundial geográfico. Neste capítulo, vamos ver isso em detalhes.
Criar Índice para Mapa de Região
Vamos criar um novo índice para trabalhar com a visualização do mapa da região. Os dados que vamos enviar são mostrados aqui -
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
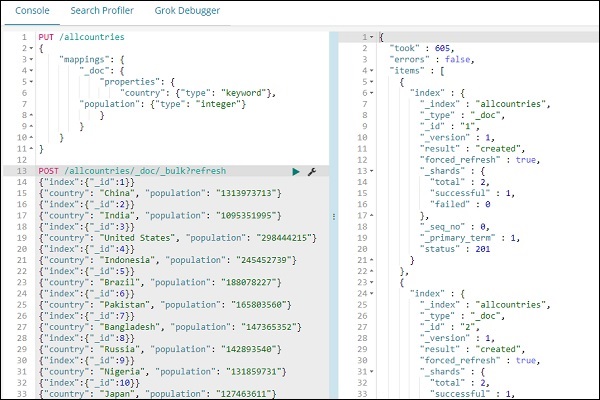
{"country": "Japan", "population": "127463611"}Observe que usaremos _bulk upload nas ferramentas de desenvolvimento para fazer o upload dos dados.
Agora, vá para Kibana Dev Tools e execute as seguintes consultas -
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}
POST /allcountries/_doc/_bulk?refresh
{"index":{"_id":1}}
{"country": "China", "population": "1313973713"}
{"index":{"_id":2}}
{"country": "India", "population": "1095351995"}
{"index":{"_id":3}}
{"country": "United States", "population": "298444215"}
{"index":{"_id":4}}
{"country": "Indonesia", "population": "245452739"}
{"index":{"_id":5}}
{"country": "Brazil", "population": "188078227"}
{"index":{"_id":6}}
{"country": "Pakistan", "population": "165803560"}
{"index":{"_id":7}}
{"country": "Bangladesh", "population": "147365352"}
{"index":{"_id":8}}
{"country": "Russia", "population": "142893540"}
{"index":{"_id":9}}
{"country": "Nigeria", "population": "131859731"}
{"index":{"_id":10}}
{"country": "Japan", "population": "127463611"}A seguir, vamos criar um índice para todos os países. Especificamos o tipo de campo do país comokeyword -
PUT /allcountries
{
"mappings": {
"_doc": {
"properties": {
"country": {"type": "keyword"},
"population": {"type": "integer"}
}
}
}
}Note - Para trabalhar com mapas de região, precisamos especificar o tipo de campo a ser usado com agregação como tipo e palavra-chave.
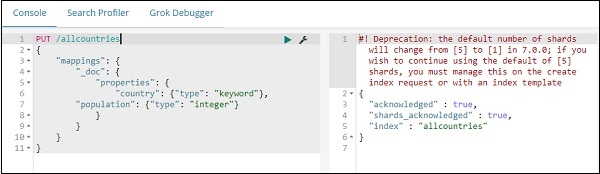
Uma vez feito isso, carregue os dados usando o comando _bulk.
Agora vamos criar um padrão de índice. Vá para a guia Kibana Management e selecione criar padrão de índice.

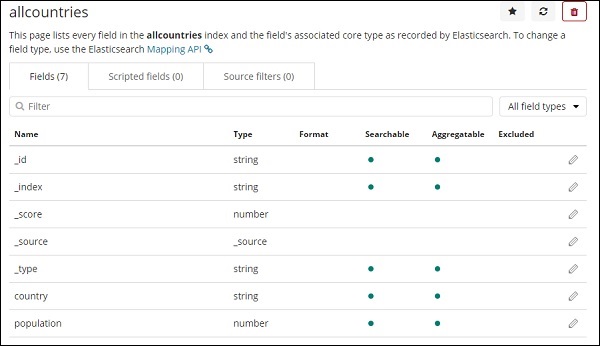
Aqui estão os campos exibidos no índice de todos os países.
Primeiros passos com mapas de região
Agora vamos criar a visualização usando Mapas de Região. Vá para Visualização e selecione Mapas de Região.
Uma vez feito isso, selecione o índice como todos os países e prossiga.
Selecione Métricas de agregação e Métricas de intervalo conforme mostrado abaixo -
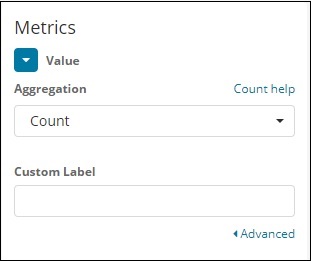
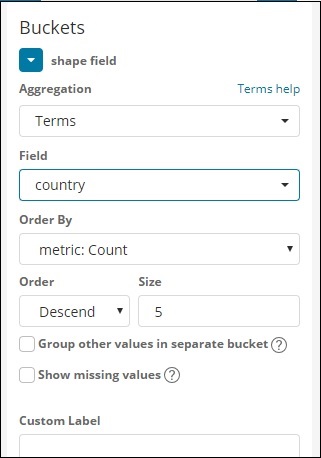
Aqui selecionamos o campo como país, pois quero mostrar o mesmo no mapa mundial.
Mapa vetorial e campo de junção para mapa regional
Para mapas de região, precisamos também selecionar as guias de opções, conforme mostrado abaixo -

A guia de opções possui configurações de Layer Settings, que são necessárias para plotar os dados no mapa mundial.
Um mapa vetorial tem as seguintes opções -
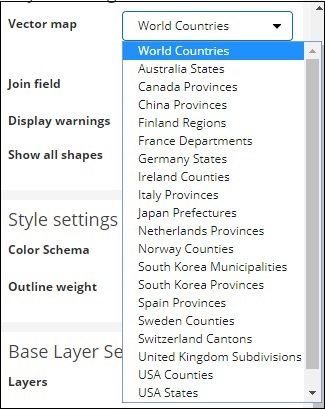
Aqui, selecionaremos os países do mundo, pois tenho os dados dos países.
O campo Join tem os seguintes detalhes -
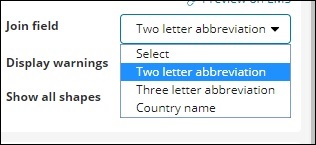
Em nosso índice, temos o nome do país, portanto, selecionaremos o nome do país.
Nas configurações de estilo, você pode escolher a cor a ser exibida para os países -
Vamos selecionar Reds. Não tocaremos no resto dos detalhes.
Agora, clique no botão Analisar para ver os detalhes dos países plotados no mapa mundial conforme mostrado abaixo -
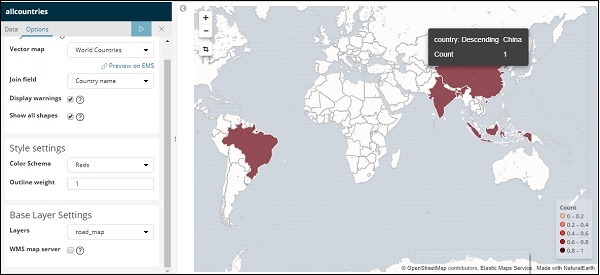
Mapa vetorial auto-hospedado e campo de junção em Kibana
Você também pode adicionar suas próprias configurações Kibana para mapa vetorial e campo de junção. Para fazer isso, vá para kibana.yml na pasta de configuração kibana e adicione os seguintes detalhes -
regionmap:
includeElasticMapsService: false
layers:
- name: "Countries Data"
url: "http://localhost/kibana/worldcountries.geojson"
attribution: "INRAP"
fields:
- name: "Country"
description: "country names"O mapa vetorial da guia de opções terá os dados acima preenchidos em vez do padrão. Observe que o URL fornecido deve estar habilitado para CORS para que Kibana possa fazer o download do mesmo. O arquivo json utilizado deve estar de forma que as coordenadas fiquem em continuação. Por exemplo -
https://vector.maps.elastic.co/blob/5659313586569216?elastic_tile_service_tos=agreeA guia de opções quando os detalhes do mapa vetorial do mapa da região são auto-hospedados é mostrada abaixo -
Uma visualização de medidor informa como sua métrica considerada nos dados cai no intervalo predefinido.
A visualização de uma meta informa sobre sua meta e como sua métrica em seus dados progride em direção à meta.
Trabalhando com Medidor
Para começar a usar o Gauge, vá para visualização e selecione a aba Visualizar na IU do Kibana.
Clique em Medir e selecione o índice que deseja usar.
Vamos trabalhar no índice medicalvisits-26.01.2019 .
Selecione o período de fevereiro de 2017
Agora você pode selecionar a agregação de métrica e intervalo.
Selecionamos a agregação métrica como Contagem.
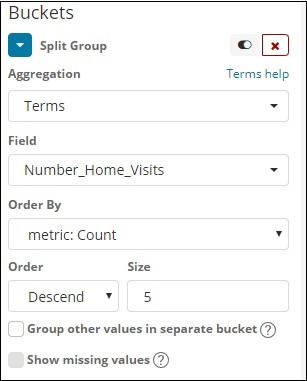
A agregação de bucket que selecionamos Termos e o campo selecionado é Number_Home_Visits.
Na guia de opções de dados, as opções selecionadas são mostradas abaixo -

O tipo de medidor pode ser na forma de círculo ou arco. Selecionamos como arco e descansamos todos os outros como valores padrão.
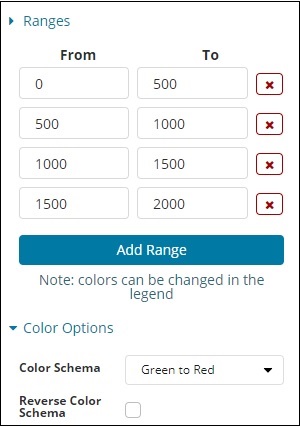
O intervalo predefinido que adicionamos é mostrado aqui -
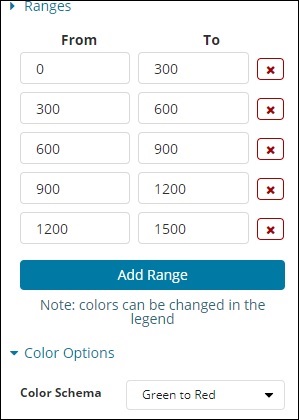
A cor selecionada é Verde para Vermelho.
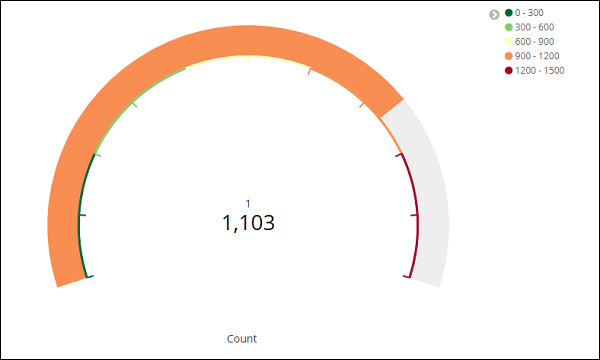
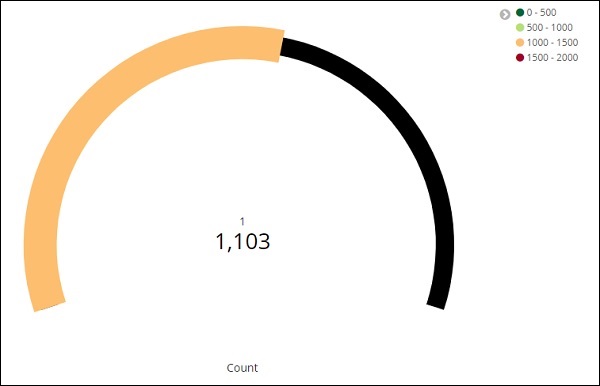
Agora, clique no botão Analisar para ver a visualização na forma de medidor conforme mostrado abaixo -
Trabalhando com Meta
Vá para a guia Visualizar e selecione Meta conforme mostrado abaixo -
Selecione Objetivo e selecione o índice.
Use medicalvisits-26.01.2019 como o índice.
Selecione a agregação de métrica e agregação de intervalo.
Agregação métrica

Selecionamos Contagem como a agregação métrica.
Agregação de balde
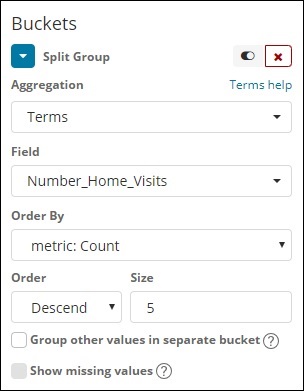
Selecionamos Termos como a agregação do intervalo e o campo é Number_Home_Visits.
As opções selecionadas são as seguintes -
O intervalo selecionado é o seguinte -
Clique em Analisar e você verá a meta exibida da seguinte forma -
O Canvas é outro recurso poderoso do Kibana. Usando a visualização de tela, você pode representar seus dados em diferentes combinações de cores, formas, texto, configuração de várias páginas, etc.
Precisamos de dados para mostrar na tela. Agora, vamos carregar alguns dados de amostra já disponíveis no Kibana.
Carregando dados de amostra para criação de tela
Para obter os dados de amostra, vá para a página inicial do Kibana e clique em Adicionar dados de amostra conforme mostrado abaixo -

Clique em Carregar um conjunto de dados e um painel Kibana. Irá levá-lo para a tela conforme mostrado abaixo -
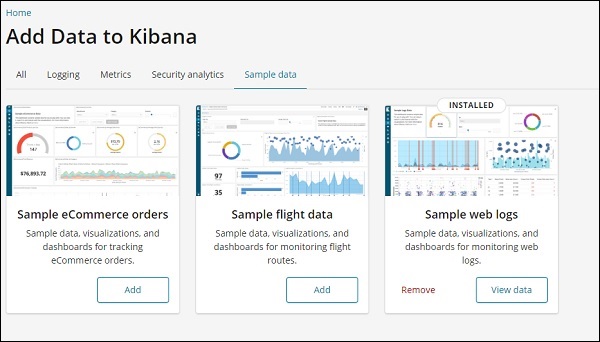
Clique no botão Adicionar para pedidos de comércio eletrônico de amostra. Levará algum tempo para carregar os dados de amostra. Depois de fazer isso, você receberá uma mensagem de alerta mostrando "Dados de comércio eletrônico de amostra carregados".
Primeiros passos com visualização de tela
Agora vá para Visualização do Canvas como mostrado abaixo -
Clique na tela e ela exibirá a tela conforme mostrado abaixo -
Adicionamos dados de amostra de comércio eletrônico e tráfego da web. Podemos criar um novo workpad ou usar o existente.
Aqui, selecionaremos o existente. Selecione o nome do workpad de rastreamento de receita de comércio eletrônico e ele exibirá a tela conforme mostrado abaixo -
Clonando um Workpad Existente na Tela
Vamos clonar o workpad para que possamos fazer alterações nele. Para clonar um workpad existente, clique no nome do workpad mostrado no canto inferior esquerdo -
Clique no nome e selecione a opção de clonagem conforme mostrado abaixo -
Clique no botão clone para criar uma cópia do workpad de Rastreamento de receita de comércio eletrônico. Você pode encontrá-lo conforme mostrado abaixo -
Nesta seção, vamos entender como usar o workpad. Se você vir o workpad acima, há 2 páginas para ele. Portanto, na tela podemos representar os dados em várias páginas.
A tela da página 2 é mostrada abaixo -

Selecione a Página 1 e clique no Total de vendas exibido no lado esquerdo, conforme mostrado abaixo -
No lado direito, você obterá os dados relacionados a ele -
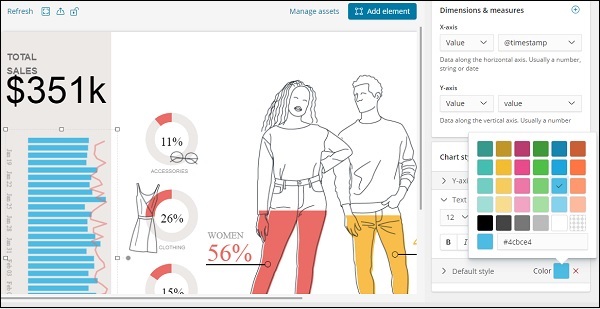
No momento, o estilo padrão usado é a cor verde. Podemos mudar a cor aqui e verificar a exibição da mesma.
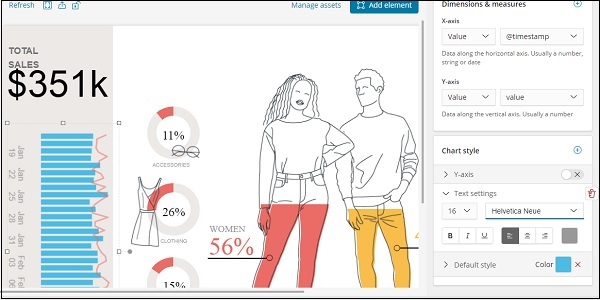
Também alteramos a fonte e o tamanho das configurações de texto, conforme mostrado abaixo -
Adicionando nova página ao workpad dentro da tela
Para adicionar uma nova página ao workpad, faça como mostrado abaixo -
Uma vez que a página é criada conforme mostrado abaixo -
Clique em Adicionar elemento e ele exibirá todas as visualizações possíveis conforme mostrado abaixo -
Nós adicionamos dois elementos: tabela de dados e gráfico de área, conforme mostrado abaixo
Você pode adicionar mais elementos de dados à mesma página ou adicionar mais páginas também.
Em nossos capítulos anteriores, vimos como criar a visualização na forma de barra vertical, barra horizontal, gráfico de pizza, etc. Neste capítulo, vamos aprender como combiná-los na forma de Dashboard. Um painel é uma coleção de suas visualizações criadas, para que você possa dar uma olhada em tudo de uma vez.
Introdução ao Dashboard
Para criar o Dashboard no Kibana, clique na opção Dashboard disponível conforme mostrado abaixo -

Agora, clique no botão Criar novo painel como mostrado acima. Isso nos levará à tela conforme mostrado abaixo -

Observe que não temos nenhum painel criado até o momento. Existem opções na parte superior onde podemos Salvar, Cancelar, Adicionar, Opções, Compartilhar, Atualizar automaticamente e também alterar o tempo para obter os dados em nosso painel. Vamos criar um novo painel, clicando no botão Adicionar mostrado acima.
Adicionar visualização ao painel
Quando clicamos no botão Adicionar (canto superior esquerdo), ele nos mostra a visualização que criamos conforme mostrado abaixo -

Selecione a visualização que deseja adicionar ao seu painel. Vamos selecionar as três primeiras visualizações, conforme mostrado abaixo -
É assim que é visto na tela juntos -

Assim, como usuário, você pode obter os detalhes gerais sobre os dados que carregamos - por país, com os campos nome do país, nome da região, área e população.
Portanto, agora sabemos todas as regiões disponíveis, a população máxima do país em ordem decrescente, a área máxima etc.
Esta é apenas uma amostra de visualização de dados que carregamos, mas no mundo real torna-se muito fácil rastrear os detalhes do seu negócio, por exemplo, você tem um site que recebe milhões de acessos mensalmente ou diariamente, você deseja acompanhar as vendas feito todos os dias, horas, minutos, segundos e se você tiver sua pilha ELK no lugar, Kibana pode mostrar sua visualização de vendas bem na frente de seus olhos a cada hora, minuto, segundo como você deseja ver. Ele exibe os dados em tempo real conforme estão acontecendo no mundo real.
Kibana, em geral, desempenha um papel muito importante na extração de detalhes precisos sobre sua transação de negócios dia, hora ou minuto, para que a empresa saiba como o progresso está acontecendo.
Salvar painel
Você pode salvar seu painel usando o botão Salvar na parte superior.

Há um título e uma descrição onde você pode inserir o nome do painel e uma breve descrição que informa o que o painel faz. Agora, clique em Confirmar Salvar para salvar o painel.
Alteração do intervalo de tempo para o painel
No momento você pode ver que os dados mostrados são dos últimos 15 minutos. Observe que este é um dado estático sem nenhum campo de hora, portanto, os dados exibidos não serão alterados. Quando você tiver os dados conectados ao sistema de tempo real alterando a hora, também mostrará os dados refletidos.
Por padrão, você verá Últimos 15 minutos conforme mostrado abaixo -
Clique em Últimos 15 minutos e será exibido o intervalo de tempo que você pode selecionar de acordo com sua escolha.
Observe que existem as opções Rápida, Relativa, Absoluta e Recente. A captura de tela a seguir mostra os detalhes da opção Rápida -
Agora, clique em Relativo para ver a opção disponível -
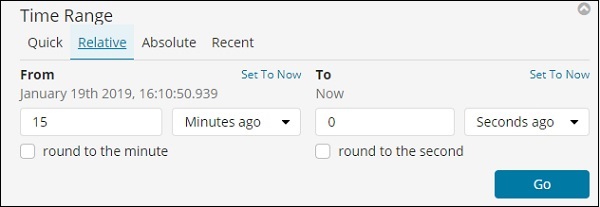
Aqui você pode especificar a data De e Até em minutos, horas, segundos, meses, anos atrás.
A opção Absoluto tem os seguintes detalhes -
Você pode ver a opção de calendário e pode selecionar um intervalo de datas.
A opção recente devolverá a opção Últimos 15 minutos e também outra opção que você selecionou recentemente. A escolha do intervalo de tempo atualizará os dados dentro desse intervalo de tempo.
Usando pesquisa e filtro no painel
Também podemos usar a pesquisa e o filtro no painel. Na pesquisa, suponha que se desejamos obter os detalhes de uma determinada região, podemos adicionar uma pesquisa conforme mostrado abaixo -

Na pesquisa acima, utilizamos o campo Região e queremos exibir os detalhes da região: OCEANIA.
Obtemos os seguintes resultados -
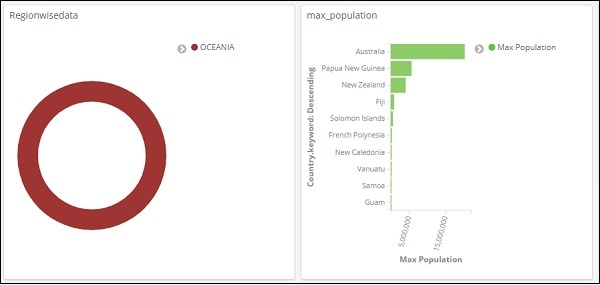
Olhando para os dados acima, podemos dizer que na região da OCEANIA, a Austrália tem a população e a área máximas.
Da mesma forma, podemos adicionar um filtro conforme mostrado abaixo -
Em seguida, clique no botão Adicionar um filtro e ele exibirá os detalhes do campo disponível em seu índice, conforme mostrado abaixo -
Escolha o campo que deseja filtrar. Usarei o campo Região para obter os detalhes da região da ASIA conforme mostrado abaixo -
Salve o filtro e você verá o filtro da seguinte maneira -
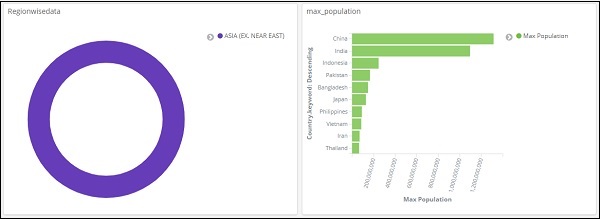
Os dados agora serão mostrados de acordo com o filtro adicionado -
Você também pode adicionar mais filtros conforme mostrado abaixo -
Você pode desativar o filtro clicando na caixa de seleção desativar, conforme mostrado abaixo.

Você pode ativar o filtro clicando na mesma caixa de seleção para ativá-lo. Observe que existe um botão delete para deletar o filtro. Botão Editar para editar o filtro ou alterar as opções do filtro.
Para a visualização exibida, você notará três pontos como mostrado abaixo -
Clique nele e ele exibirá as opções mostradas abaixo -
Inspecionar e tela inteira
Clique em Inspecionar e dá os detalhes da região em formato tabular conforme mostrado abaixo -
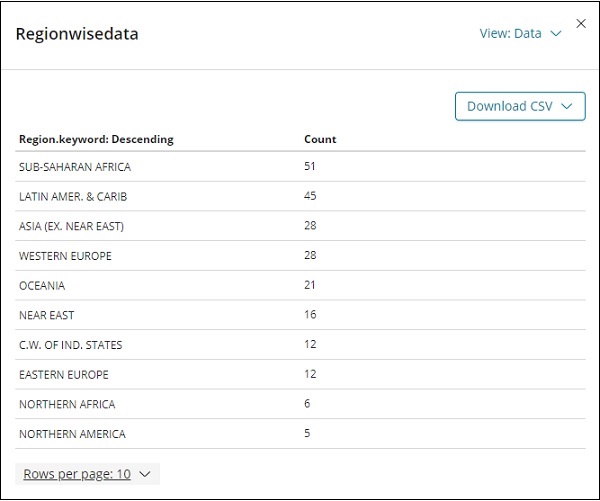
Existe a opção de baixar a visualização em formato CSV caso deseje visualizá-la em planilha excel.
A próxima opção tela cheia obterá a visualização em modo de tela cheia conforme mostrado abaixo -

Você pode usar o mesmo botão para sair do modo de tela inteira.
Painel de Compartilhamento
Podemos compartilhar o painel usando o botão de compartilhamento. Ao clicar no botão de compartilhamento, você terá a seguinte exibição -
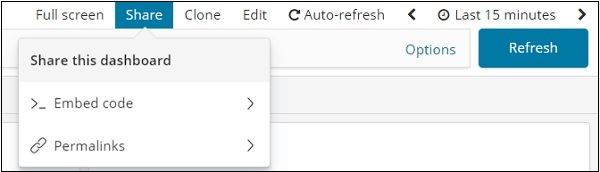
Você também pode usar o código incorporado para mostrar o painel em seu site ou usar permalinks, que serão um link para compartilhar com outras pessoas.
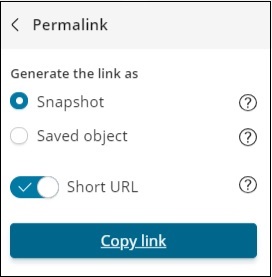
O url será o seguinte -
http://localhost:5601/goto/519c1a088d5d0f8703937d754923b84bTimelion, também chamado de linha do tempo, é outra ferramenta de visualização usada principalmente para análise de dados com base no tempo. Para trabalhar com a linha do tempo, precisamos usar uma linguagem de expressão simples que nos ajudará a nos conectar ao índice e também realizar cálculos nos dados para obter os resultados que precisamos.
Onde podemos usar o Timelion?
Timelion é usado quando você deseja comparar dados relacionados ao tempo. Por exemplo, você tem um site e recebe suas visualizações diariamente. Você deseja analisar os dados em que deseja comparar os dados da semana atual com a semana anterior, ou seja, segunda a segunda, terça a terça e assim por diante, como as visualizações são diferentes e também o tráfego.
Introdução ao Timelion
Para começar a trabalhar com Timelion, clique em Timelion conforme mostrado abaixo -

Timelion por padrão mostra a linha do tempo de todos os índices, conforme mostrado abaixo -
Timelion trabalha com sintaxe de expressão.
Note - es (*) => significa todos os índices.
Para obter os detalhes da função disponível para ser usada com o Timelion, basta clicar na área de texto conforme mostrado abaixo -

Fornece a lista de funções a serem usadas com a sintaxe da expressão.
Depois de iniciar com o Timelion, ele exibe uma mensagem de boas-vindas conforme mostrado abaixo. A seção destacada, ou seja, pular para a referência da função, fornece os detalhes de todas as funções disponíveis para serem usadas com o timelion.
Mensagem de boas-vindas do Timelion
A mensagem de boas-vindas do Timelion é mostrada abaixo -
Clique no botão seguinte e ele o guiará por sua funcionalidade e uso básicos. Agora, ao clicar em Avançar, você pode ver os seguintes detalhes -
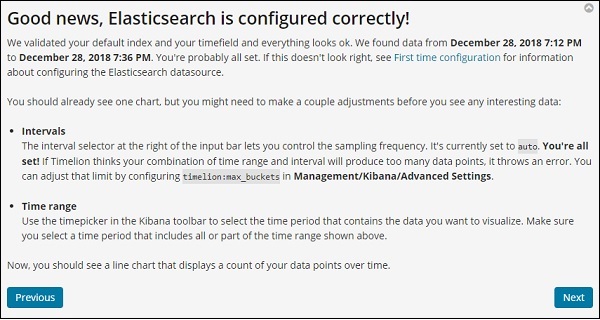

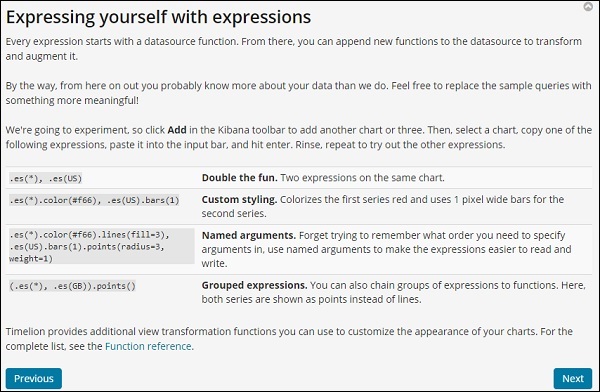
Referência da Função Timelion
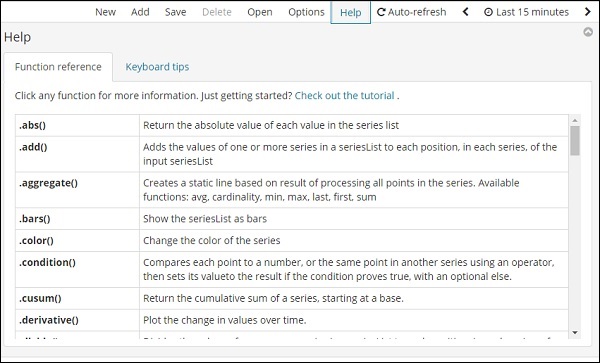
Clique no botão Ajuda para obter os detalhes da referência de função disponível para Timelion -
Configuração de Timelion
As configurações do timelion são feitas em Kibana Management → Advanced Settings.
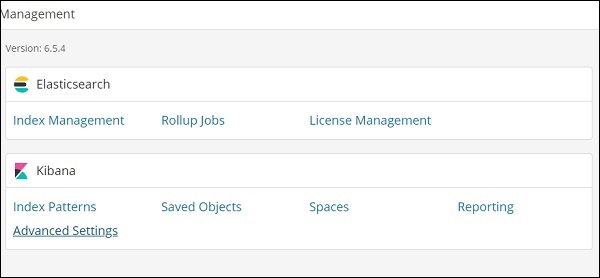
Clique em Configurações avançadas e selecione Timelion da categoria
Assim que o Timelion for selecionado, ele exibirá todos os campos necessários para a configuração do timelion.
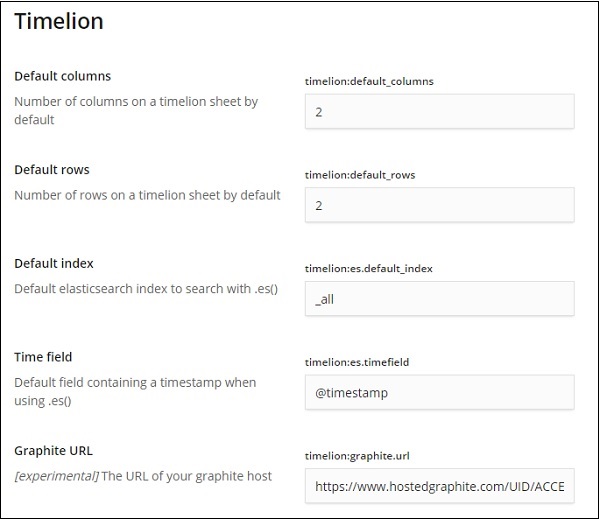
Nos campos a seguir, você pode alterar o índice padrão e o campo de tempo a ser usado no índice -
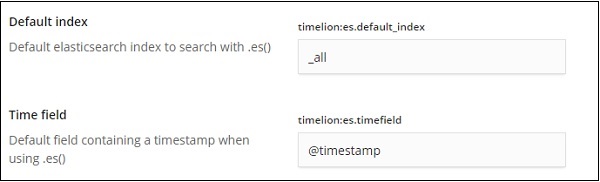
O padrão é _all e timefield é @timestamp. Deixaríamos como está e mudaríamos o índice e o campo de tempo no próprio timelion.
Usando Timelion para visualizar dados
Vamos usar o índice: medicalvisits-26.01.2019 . A seguir estão os dados exibidos a partir do cronograma de 1º de janeiro de 2017 a 31 de dezembro de 2017 -
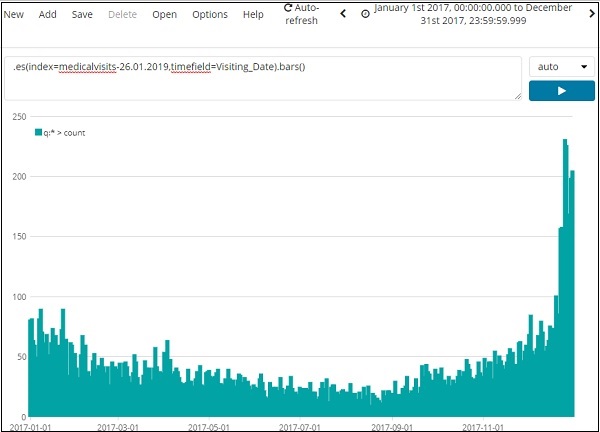
A expressão usada para a visualização acima é a seguinte -
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).bars()Usamos o índice medicalvisits-26.01.2019 e o campo de tempo nesse índice é Visiting_Date e usamos a função de barras.
A seguir, analisamos 2 cidades para o mês de janeiro de 2017, dia sábio.
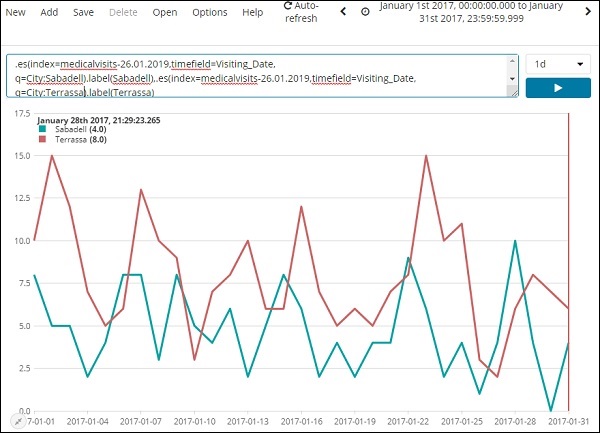
A expressão usada é -
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,
q=City:Sabadell).label(Sabadell),.es(index=medicalvisits-26.01.2019,
timefield=Visiting_Date, q=City:Terrassa).label(Terrassa)A comparação da linha do tempo para 2 dias é mostrada aqui -
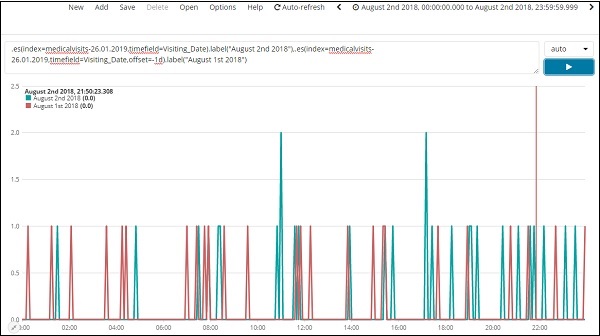
Expressão
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date).label("August 2nd 2018"),
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,offset=-1d).label("August 1st 2018")Aqui, usamos o deslocamento e atribuímos uma diferença de 1 dia. Selecionamos a data atual como 2 de agosto de 2018. Portanto, ele fornece a diferença de dados para 2 de agosto de 2018 e 1 de agosto de 2018.
A lista dos dados das 5 principais cidades para o mês de janeiro de 2017 é mostrada abaixo. A expressão que usamos aqui é dada abaixo -
.es(index=medicalvisits-26.01.2019,timefield=Visiting_Date,split=City.keyword:5)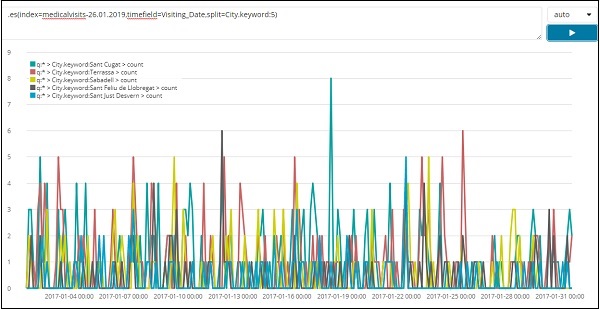
Usamos split e atribuímos o nome do campo como city e, como precisamos das cinco principais cidades do índice, fornecemos como split = City.keyword: 5
Ele fornece a contagem de cada cidade e lista seus nomes conforme mostrado no gráfico traçado.
Podemos usar Dev Tools para fazer upload de dados no Elasticsearch, sem usar o Logstash. Podemos postar, colocar, deletar, pesquisar os dados que queremos no Kibana usando Dev Tools.
Para criar um novo índice no Kibana, podemos usar o seguinte comando nas ferramentas de desenvolvimento -
Criar Índice USING PUT
O comando para criar o índice é mostrado aqui -
PUT /usersdata?prettyDepois de executar isso, um índice vazio userdata é criado.
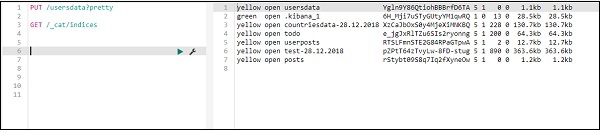
Concluímos a criação do índice. Agora adicionarei os dados no índice -
Adicionar dados ao índice usando PUT
Você pode adicionar dados a um índice da seguinte maneira -

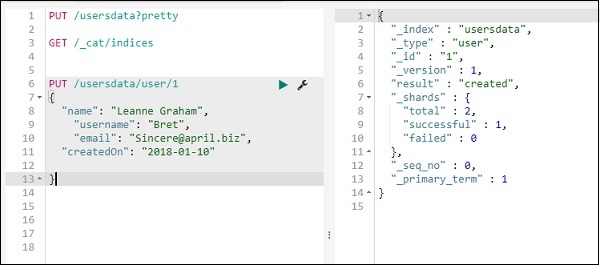
Vamos adicionar mais um registro no índice de dados do usuário -
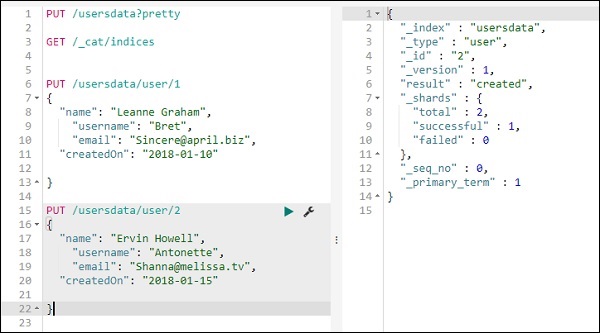
Portanto, temos 2 registros no índice de dados do usuário.
Obter dados do índice usando GET
Podemos obter os detalhes do registro 1 da seguinte forma -

Você pode obter todos os registros da seguinte forma -
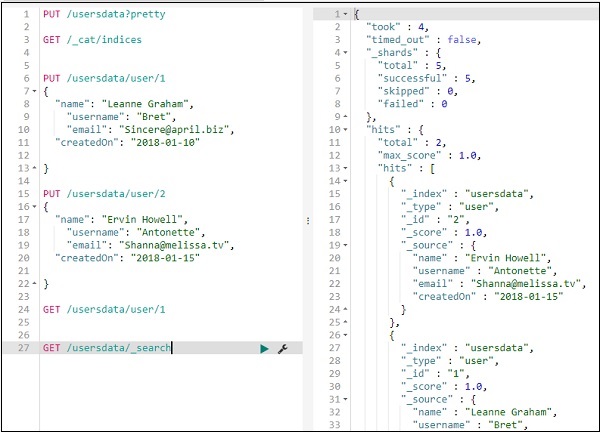
Assim, podemos obter todos os registros dos dados do usuário, conforme mostrado acima.
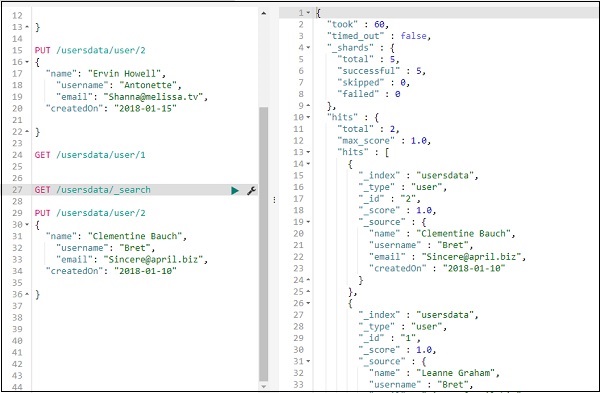
Atualize os dados no índice usando PUT
Para atualizar o registro, você pode fazer o seguinte -
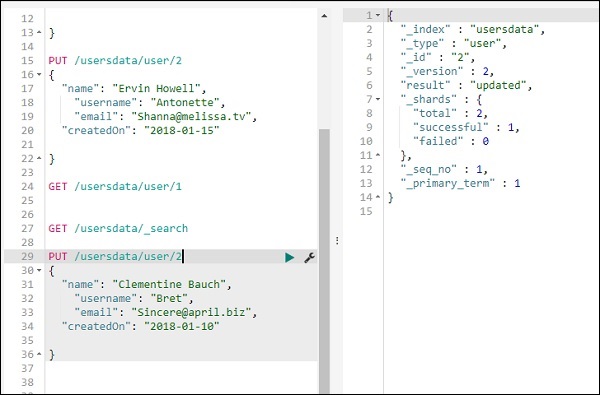
Mudamos o nome de “Ervin Howell” para “Clementine Bauch”. Agora podemos obter todos os registros do índice e ver o registro atualizado da seguinte forma -
Exclua os dados do índice usando DELETE
Você pode excluir o registro conforme mostrado aqui -
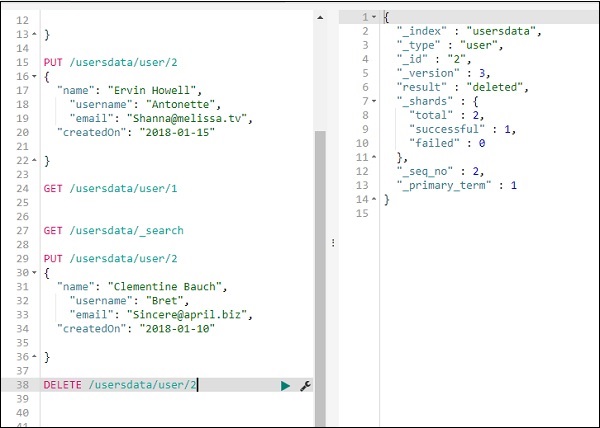
Agora, se você ver o total de registros, teremos apenas um registro -
Podemos excluir o índice criado da seguinte maneira -

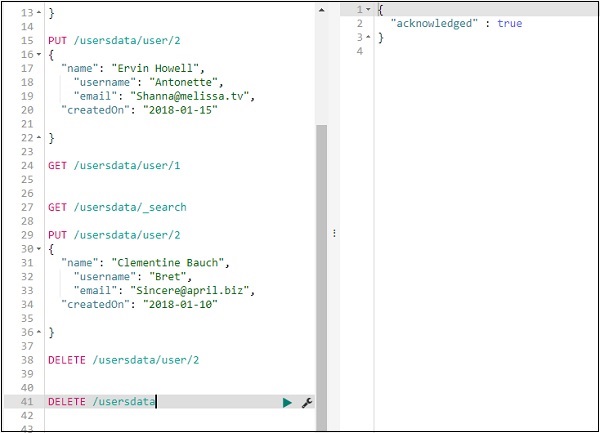
Agora, se você verificar os índices disponíveis, não teremos o índice de dados do usuário nele, pois o índice foi excluído.
O Kibana Monitoring fornece detalhes sobre o desempenho da pilha ELK. Podemos obter os detalhes da memória usada, tempo de resposta etc.
Detalhes de monitoramento
Para obter detalhes de monitoramento em Kibana, clique na guia de monitoramento conforme mostrado abaixo -
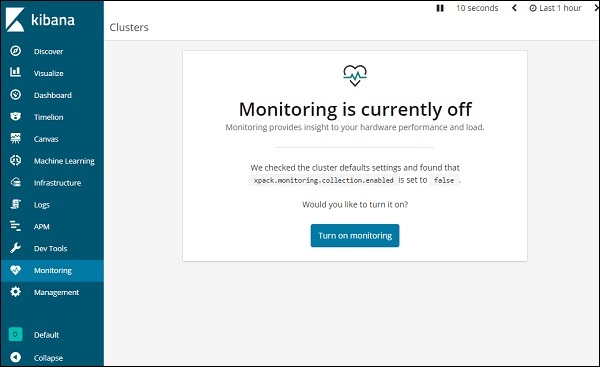
Como estamos usando o monitoramento pela primeira vez, precisamos mantê-lo ATIVADO. Para isso, clique no botãoTurn on monitoringcomo mostrado acima. Aqui estão os detalhes exibidos para Elasticsearch -
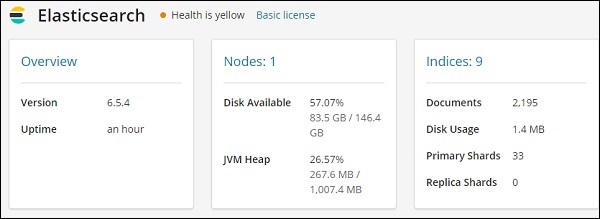
Ele fornece a versão do elasticsearch, disco disponível, índices adicionados ao elasticsearch, uso do disco, etc.
Os detalhes de monitoramento para Kibana são mostrados aqui -
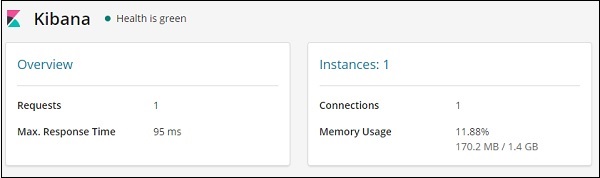
Ele fornece as Solicitações e o tempo máximo de resposta para a solicitação e também as instâncias em execução e o uso de memória.
Os relatórios podem ser facilmente criados usando o botão Compartilhar disponível na IU do Kibana.
Os relatórios em Kibana estão disponíveis nos dois formulários a seguir -
- Permalinks
- Relatório CSV
Reportar como links permanentes
Ao executar a visualização, você pode compartilhar o mesmo da seguinte forma -
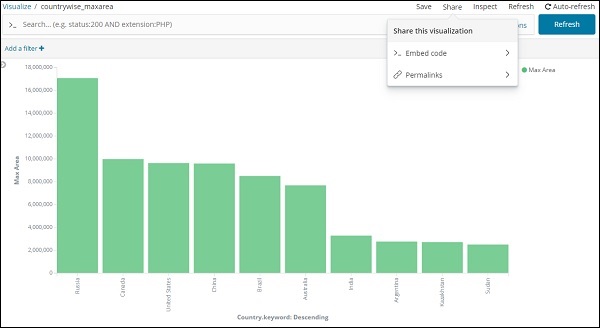
Use o botão de compartilhamento para compartilhar a visualização com outras pessoas como Código de incorporação ou Permalinks.
No caso de código de incorporação, você obtém as seguintes opções -
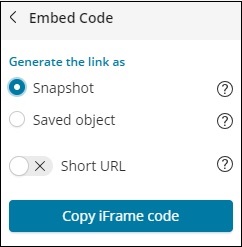
Você pode gerar o código iframe como url curto ou url longo para instantâneo ou objeto salvo. O instantâneo não fornecerá os dados recentes e o usuário poderá ver os dados salvos quando o link foi compartilhado. Quaisquer alterações feitas posteriormente não serão refletidas.
No caso de objeto salvo, você obterá as alterações recentes feitas nessa visualização.
Código IFrame instantâneo para url longo -
<iframe src="http://localhost:5601/app/kibana#/visualize/edit/87af
cb60-165f-11e9-aaf1-3524d1f04792?embed=true&_g=()&_a=(filters:!(),linked:!f,query:(language:lucene,query:''),
uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),schema:metric,type:max),(enabled:!t,id:'2',p
arams:(field:Country.keyword,missingBucket:!f,missingBucketLabel:Missing,order:desc,orderBy:'1',otherBucket:!
f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),params:(addLegend:!t,addTimeMarker:!f,addToo
ltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,truncate:100),position:bottom,scale:(type:linear),
show:!t,style:(),title:(),type:category)),grid:(categoryLines:!f,style:(color:%23eee)),legendPosition:right,
seriesParams:!((data:(id:'1',label:'Max+Area'),drawLi
nesBetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(),
type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1,
position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max+Area'),type:value))),title:
'countrywise_maxarea+',type:histogram))" height="600" width="800"></iframe>Código Iframe de instantâneo para url curto -
<iframe src="http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4?embed=true" height="600" width="800"><iframe>Como instantâneo e url de foto.
Com URL curto -
http://localhost:5601/goto/f0a6c852daedcb6b4fa74cce8c2ff6c4Com o URL curto desativado, o link tem a seguinte aparência -
http://localhost:5601/app/kibana#/visualize/edit/87afcb60-165f-11e9-aaf1-3524d1f04792?_g=()&_a=(filters:!(
),linked:!f,query:(language:lucene,query:''),uiState:(),vis:(aggs:!((enabled:!t,id:'1',params:(field:Area),
schema:metric,type:max),(enabled:!t,id:'2',params:(field:Country.keyword,missingBucket:!f,missingBucketLabel:
Missing,order:desc,orderBy:'1',otherBucket:!f,otherBucketLabel:Other,size:10),schema:segment,type:terms)),
params:(addLegend:!t,addTimeMarker:!f,addTooltip:!t,categoryAxes:!((id:CategoryAxis-1,labels:(show:!t,trun
cate:100),position:bottom,scale:(type:linear),show:!t,style:(),title:(),type:category)),grid:(categoryLine
s:!f,style:(color:%23eee)),legendPosition:right,seriesParams:!((data:(id:'1',label:'Max%20Area'),drawLines
BetweenPoints:!t,mode:stacked,show:true,showCircles:!t,type:histogram,valueAxis:ValueAxis-1)),times:!(),
type:histogram,valueAxes:!((id:ValueAxis-1,labels:(filter:!f,rotate:0,show:!t,truncate:100),name:LeftAxis-1,
position:left,scale:(mode:normal,type:linear),show:!t,style:(),title:(text:'Max%20Area'),type:value))),title:'countrywise_maxarea%20',type:histogram))Ao clicar no link acima no navegador, você obterá a mesma visualização mostrada acima. Os links acima são hospedados localmente, portanto, não funcionarão quando usados fora do ambiente local.
Relatório CSV
Você pode obter o Relatório CSV em Kibana, onde há dados, que estão principalmente na guia Descobrir.
Vá para a guia Descobrir e pegue qualquer índice para o qual deseja os dados. Aqui pegamos o índice: countriesdata-26.12.2018 . Aqui estão os dados exibidos a partir do índice -

Você pode criar dados tabulares a partir dos dados acima, conforme mostrado abaixo -

Selecionamos os campos em Campos disponíveis e os dados vistos anteriormente são convertidos em formato tabular.
Você pode obter os dados acima no relatório CSV conforme mostrado abaixo -

O botão de compartilhamento tem a opção de relatório CSV e permalinks. Você pode clicar em Relatório CSV e fazer o download do mesmo.
Observe que, para obter os relatórios CSV, você precisa salvar seus dados.

Confirme Salvar e clique no botão Compartilhar e em Relatórios CSV. Você obterá a seguinte exibição -
Clique em Gerar CSV para obter seu relatório. Uma vez feito isso, ele o instruirá a ir para a guia de gerenciamento.
Vá para a guia Gerenciamento → Relatórios

Ele exibe o nome do relatório, criado em, status e ações. Você pode clicar no botão de download conforme destacado acima e obter seu relatório csv.
O arquivo CSV que acabamos de baixar é mostrado aqui -