Regressão logística em Python - Guia rápido
A regressão logística é um método estatístico de classificação de objetos. Este capítulo dará uma introdução à regressão logística com a ajuda de alguns exemplos.
Classificação
Para entender a regressão logística, você deve saber o que significa classificação. Vamos considerar os exemplos a seguir para entender isso melhor -
- O médico classifica o tumor como maligno ou benigno.
- Uma transação bancária pode ser fraudulenta ou genuína.
Por muitos anos, os humanos vêm realizando essas tarefas - embora sejam propensos a erros. A questão é: podemos treinar máquinas para fazer essas tarefas para nós com uma precisão melhor?
Um exemplo de máquina que faz a classificação é o e-mail Clientem sua máquina que classifica cada e-mail recebido como “spam” ou “não spam” e faz isso com uma precisão bastante grande. A técnica estatística de regressão logística foi aplicada com sucesso no cliente de email. Neste caso, treinamos nossa máquina para resolver um problema de classificação.
A regressão logística é apenas uma parte do aprendizado de máquina usado para resolver esse tipo de problema de classificação binária. Existem várias outras técnicas de aprendizado de máquina que já foram desenvolvidas e estão em prática para resolver outros tipos de problemas.
Se você notou, em todos os exemplos acima, o resultado da predicação tem apenas dois valores - Sim ou Não. Chamamos isso de classes - de modo a dizer que dizemos que nosso classificador classifica os objetos em duas classes. Em termos técnicos, podemos dizer que o resultado ou variável-alvo é dicotômica por natureza.
Existem outros problemas de classificação em que a saída pode ser classificada em mais de duas classes. Por exemplo, com uma cesta cheia de frutas, você deve separar frutas de diferentes tipos. Agora, a cesta pode conter laranjas, maçãs, mangas e assim por diante. Então, quando você separa as frutas, você as separa em mais de duas classes. Este é um problema de classificação multivariada.
Considere que um banco o aborda para desenvolver um aplicativo de aprendizado de máquina que os ajudará a identificar os clientes em potencial que abririam um depósito a prazo (também chamado de depósito fixo por alguns bancos) com eles. O banco realiza regularmente pesquisas por meio de ligações telefônicas ou formulários da web para coletar informações sobre os potenciais clientes. A pesquisa é de natureza geral e é conduzida para um público muito grande, do qual muitos podem não estar interessados em negociar com o próprio banco. Do resto, apenas alguns podem estar interessados em abrir um depósito a prazo. Outros podem estar interessados em outras facilidades oferecidas pelo banco. Portanto, a pesquisa não é necessariamente conduzida para identificar os clientes que estão abrindo TDs. Sua tarefa é identificar todos os clientes com alta probabilidade de abrir o TD a partir dos enormes dados de pesquisa que o banco vai compartilhar com você.
Felizmente, um desses tipos de dados está disponível publicamente para aqueles que desejam desenvolver modelos de aprendizado de máquina. Estes dados foram preparados por alguns alunos da UC Irvine com financiamento externo. O banco de dados está disponível como parte doUCI Machine Learning Repositorye é amplamente utilizado por estudantes, educadores e pesquisadores em todo o mundo. Os dados podem ser baixados aqui .
Nos próximos capítulos, vamos agora realizar o desenvolvimento do aplicativo usando os mesmos dados.
Neste capítulo, vamos entender o processo envolvido na configuração de um projeto para realizar regressão logística em Python, em detalhes.
Instalando Jupyter
Estaremos usando o Jupyter - uma das plataformas mais utilizadas para aprendizado de máquina. Se você não tiver o Jupyter instalado em sua máquina, baixe-o aqui . Para instalação, você pode seguir as instruções em seu site para instalar a plataforma. Como o site sugere, você pode preferir usarAnaconda Distributionque vem junto com o Python e muitos pacotes Python comumente usados para computação científica e ciência de dados. Isso aliviará a necessidade de instalar esses pacotes individualmente.
Após a instalação bem-sucedida do Jupyter, inicie um novo projeto, sua tela neste estágio se pareceria com a seguinte pronta para aceitar seu código.
Agora, mude o nome do projeto de Untitled1 to “Logistic Regression” clicando no nome do título e editando-o.
Primeiro, importaremos vários pacotes Python de que precisaremos em nosso código.
Importando pacotes Python
Para isso, digite ou recorte e cole o seguinte código no editor de código -
In [1]: # import statements
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_splitSeu Notebook deve ser semelhante ao seguinte nesta fase -
Execute o código clicando no Runbotão. Se nenhum erro for gerado, você instalou o Jupyter com sucesso e agora está pronto para o resto do desenvolvimento.
As três primeiras instruções import importam os pacotes pandas, numpy e matplotlib.pyplot em nosso projeto. As próximas três instruções importam os módulos especificados do sklearn.
Nossa próxima tarefa é baixar os dados necessários para nosso projeto. Aprenderemos isso no próximo capítulo.
As etapas envolvidas na obtenção de dados para realizar a regressão logística em Python são discutidas em detalhes neste capítulo.
Baixando conjunto de dados
Se você ainda não baixou o conjunto de dados UCI mencionado anteriormente, baixe-o agora aqui . Clique na pasta de dados. Você verá a seguinte tela -

Baixe o arquivo bank.zip clicando no link fornecido. O arquivo zip contém os seguintes arquivos -

Usaremos o arquivo bank.csv para o desenvolvimento do nosso modelo. O arquivo bank-names.txt contém a descrição do banco de dados de que você precisará posteriormente. O bank-full.csv contém um conjunto de dados muito maior que você pode usar para desenvolvimentos mais avançados.
Aqui, incluímos o arquivo bank.csv no zip de origem para download. Este arquivo contém os campos delimitados por vírgulas. Também fizemos algumas modificações no arquivo. É recomendável que você use o arquivo incluído no zip do código-fonte do projeto para seu aprendizado.
Carregando dados
Para carregar os dados do arquivo csv que você copiou agora, digite a seguinte instrução e execute o código.
In [2]: df = pd.read_csv('bank.csv', header=0)Você também poderá examinar os dados carregados executando a seguinte instrução de código -
IN [3]: df.head()Assim que o comando for executado, você verá a seguinte saída -
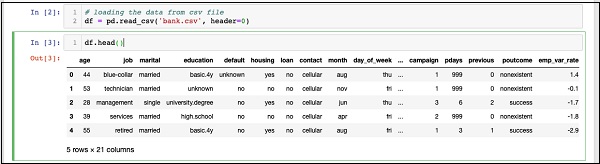
Basicamente, ele imprimiu as primeiras cinco linhas dos dados carregados. Examine as 21 colunas presentes. Estaremos usando apenas algumas colunas para o desenvolvimento do nosso modelo.
Em seguida, precisamos limpar os dados. Os dados podem conter algumas linhas comNaN. Para eliminar essas linhas, use o seguinte comando -
IN [4]: df = df.dropna()Felizmente, o bank.csv não contém nenhuma linha com NaN, portanto, essa etapa não é realmente necessária em nosso caso. No entanto, em geral, é difícil descobrir essas linhas em um banco de dados enorme. Portanto, é sempre mais seguro executar a instrução acima para limpar os dados.
Note - Você pode examinar facilmente o tamanho dos dados em qualquer ponto do tempo usando a seguinte declaração -
IN [5]: print (df.shape)
(41188, 21)O número de linhas e colunas seria impresso na saída, conforme mostrado na segunda linha acima.
A próxima coisa a fazer é examinar a adequação de cada coluna para o modelo que estamos tentando construir.
Sempre que uma organização realiza uma pesquisa, ela tenta coletar o máximo de informações possível do cliente, com a ideia de que essas informações seriam úteis para a organização de uma forma ou de outra, em um momento posterior. Para resolver o problema atual, temos que coletar as informações que são diretamente relevantes para o nosso problema.
Exibindo todos os campos
Agora, vamos ver como selecionar os campos de dados úteis para nós. Execute a seguinte instrução no editor de código.
In [6]: print(list(df.columns))Você verá a seguinte saída -
['age', 'job', 'marital', 'education', 'default', 'housing', 'loan',
'contact', 'month', 'day_of_week', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'emp_var_rate', 'cons_price_idx', 'cons_conf_idx',
'euribor3m', 'nr_employed', 'y']A saída mostra os nomes de todas as colunas do banco de dados. A última coluna “y” é um valor booleano que indica se este cliente tem um depósito a prazo no banco. Os valores deste campo são “y” ou “n”. Você pode ler a descrição e o propósito de cada coluna no arquivo banks-name.txt que foi baixado como parte dos dados.
Eliminando campos indesejados
Examinando os nomes das colunas, você saberá que alguns dos campos não têm importância para o problema em questão. Por exemplo, campos comomonth, day_of_week, campanha, etc. não são úteis para nós. Eliminaremos esses campos de nosso banco de dados. Para eliminar uma coluna, usamos o comando drop conforme mostrado abaixo -
In [8]: #drop columns which are not needed.
df.drop(df.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]],
axis = 1, inplace = True)O comando diz que solte a coluna número 0, 3, 7, 8 e assim por diante. Para garantir que o índice seja selecionado corretamente, use a seguinte declaração -
In [7]: df.columns[9]
Out[7]: 'day_of_week'Isso imprime o nome da coluna para o índice fornecido.
Depois de eliminar as colunas que não são obrigatórias, examine os dados com a instrução head. A saída da tela é mostrada aqui -
In [9]: df.head()
Out[9]:
job marital default housing loan poutcome y
0 blue-collar married unknown yes no nonexistent 0
1 technician married no no no nonexistent 0
2 management single no yes no success 1
3 services married no no no nonexistent 0
4 retired married no yes no success 1Agora, temos apenas os campos que consideramos importantes para nossa análise e previsão de dados. A importância deData Scientistentra em cena nesta etapa. O cientista de dados deve selecionar as colunas apropriadas para a construção do modelo.
Por exemplo, o tipo de jobembora à primeira vista possa não convencer a todos para a inclusão no banco de dados, será um campo muito útil. Nem todos os tipos de clientes abrirão o TD. As pessoas de renda mais baixa podem não abrir os TDs, enquanto as pessoas de renda mais alta geralmente estacionam seu dinheiro excedente em TDs. Portanto, o tipo de trabalho torna-se significativamente relevante neste cenário. Da mesma forma, selecione cuidadosamente as colunas que você acha que serão relevantes para sua análise.
No próximo capítulo, prepararemos nossos dados para construir o modelo.
Para criar o classificador, devemos preparar os dados em um formato que é solicitado pelo módulo de construção do classificador. Preparamos os dados fazendoOne Hot Encoding.
Dados de codificação
Discutiremos em breve o que queremos dizer com codificação de dados. Primeiro, vamos executar o código. Execute o seguinte comando na janela de código.
In [10]: # creating one hot encoding of the categorical columns.
data = pd.get_dummies(df, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])Como diz o comentário, a instrução acima criará a única codificação quente dos dados. Vamos ver o que isso criou? Examine os dados criados chamados“data” imprimindo os registros de cabeça no banco de dados.
In [11]: data.head()Você verá a seguinte saída -
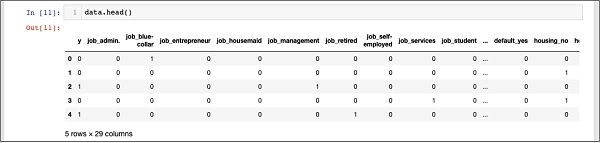
Para entender os dados acima, listaremos os nomes das colunas executando o data.columns comando como mostrado abaixo -
In [12]: data.columns
Out[12]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'job_unknown', 'marital_divorced', 'marital_married', 'marital_single',
'marital_unknown', 'default_no', 'default_unknown', 'default_yes',
'housing_no', 'housing_unknown', 'housing_yes', 'loan_no',
'loan_unknown', 'loan_yes', 'poutcome_failure', 'poutcome_nonexistent',
'poutcome_success'], dtype='object')Agora, vamos explicar como uma codificação quente é feita pelo get_dummiescomando. A primeira coluna no banco de dados recém-gerado é o campo “y” que indica se este cliente se inscreveu em um TD ou não. Agora, vejamos as colunas que estão codificadas. A primeira coluna codificada é“job”. No banco de dados, você descobrirá que a coluna “emprego” tem muitos valores possíveis, como “admin”, “operário”, “empresário” e assim por diante. Para cada valor possível, temos uma nova coluna criada no banco de dados, com o nome da coluna anexado como um prefixo.
Portanto, temos colunas chamadas “job_admin”, “job_blue-collar” e assim por diante. Para cada campo codificado em nosso banco de dados original, você encontrará uma lista de colunas adicionadas no banco de dados criado com todos os valores possíveis que a coluna assume no banco de dados original. Examine cuidadosamente a lista de colunas para entender como os dados são mapeados para um novo banco de dados.
Compreendendo o mapeamento de dados
Para entender os dados gerados, vamos imprimir todos os dados usando o comando data. A saída parcial após a execução do comando é mostrada abaixo.
In [13]: data
A tela acima mostra as primeiras doze linhas. Se você rolar mais para baixo, verá que o mapeamento é feito para todas as linhas.
Uma saída de tela parcial mais abaixo no banco de dados é mostrada aqui para sua referência rápida.
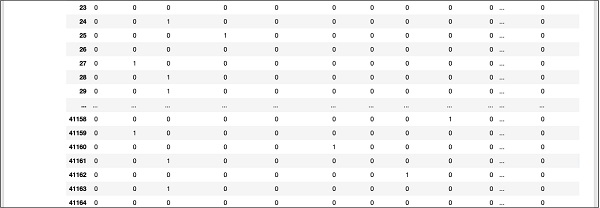
Para entender os dados mapeados, vamos examinar a primeira linha.

Diz que este cliente não se inscreveu no TD, conforme indicado pelo valor no campo “y”. Também indica que esse cliente é um cliente “operário”. Rolando para baixo horizontalmente, ele dirá que ele tem uma “habitação” e não fez nenhum “empréstimo”.
Depois dessa codificação a quente, precisamos de mais processamento de dados antes de começar a construir nosso modelo.
Abandonando o “desconhecido”
Se examinarmos as colunas no banco de dados mapeado, você encontrará a presença de algumas colunas terminando com “desconhecido”. Por exemplo, examine a coluna no índice 12 com o seguinte comando mostrado na captura de tela -
In [14]: data.columns[12]
Out[14]: 'job_unknown'Isso indica que o trabalho para o cliente especificado é desconhecido. Obviamente, não há sentido em incluir essas colunas em nossa análise e construção de modelo. Portanto, todas as colunas com o valor “desconhecido” devem ser descartadas. Isso é feito com o seguinte comando -
In [15]: data.drop(data.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)Certifique-se de especificar os números de coluna corretos. Em caso de dúvida, você pode examinar o nome da coluna a qualquer momento, especificando seu índice no comando de colunas, conforme descrito anteriormente.
Depois de eliminar as colunas indesejadas, você pode examinar a lista final de colunas conforme mostrado na saída abaixo -
In [16]: data.columns
Out[16]: Index(['y', 'job_admin.', 'job_blue-collar', 'job_entrepreneur',
'job_housemaid', 'job_management', 'job_retired', 'job_self-employed',
'job_services', 'job_student', 'job_technician', 'job_unemployed',
'marital_divorced', 'marital_married', 'marital_single', 'default_no',
'default_yes', 'housing_no', 'housing_yes', 'loan_no', 'loan_yes',
'poutcome_failure', 'poutcome_nonexistent', 'poutcome_success'],
dtype='object')Neste ponto, nossos dados estão prontos para a construção do modelo.
Temos cerca de quarenta e um mil registros ímpares. Se usarmos todos os dados para construção do modelo, não ficaremos com nenhum dado para teste. Geralmente, dividimos todo o conjunto de dados em duas partes, digamos 70/30 de porcentagem. Usamos 70% dos dados para a construção do modelo e o restante para testar a precisão na previsão do nosso modelo criado. Você pode usar uma taxa de divisão diferente de acordo com sua necessidade.
Criando Matriz de Recursos
Antes de dividir os dados, separamos os dados em duas matrizes X e Y. A matriz X contém todos os recursos (colunas de dados) que desejamos analisar e a matriz Y é uma matriz unidimensional de valores booleanos que é a saída de a previsão. Para entender isso, vamos executar alguns códigos.
Em primeiro lugar, execute a seguinte instrução Python para criar a matriz X -
In [17]: X = data.iloc[:,1:]Para examinar o conteúdo de X usar headpara imprimir alguns registros iniciais. A tela a seguir mostra o conteúdo do array X.
In [18]: X.head ()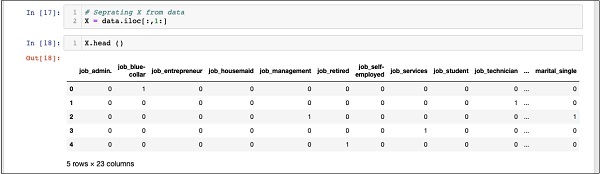
A matriz possui várias linhas e 23 colunas.
A seguir, criaremos uma matriz de saída contendo “y”Valores.
Criando Matriz de Saída
Para criar uma matriz para a coluna de valor previsto, use a seguinte instrução Python -
In [19]: Y = data.iloc[:,0]Examine seu conteúdo chamando head. A saída da tela abaixo mostra o resultado -
In [20]: Y.head()
Out[20]: 0 0
1 0
2 1
3 0
4 1
Name: y, dtype: int64Agora, divida os dados usando o seguinte comando -
In [21]: X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)Isso criará os quatro arrays chamados X_train, Y_train, X_test, and Y_test. Como antes, você pode examinar o conteúdo dessas matrizes usando o comando head. Usaremos os arrays X_train e Y_train para treinar nosso modelo e os arrays X_test e Y_test para teste e validação.
Agora, estamos prontos para construir nosso classificador. Veremos isso no próximo capítulo.
Não é necessário construir o classificador do zero. Construir classificadores é complexo e requer conhecimento de várias áreas, como estatística, teorias de probabilidade, técnicas de otimização e assim por diante. Existem várias bibliotecas pré-construídas disponíveis no mercado que possuem uma implementação totalmente testada e muito eficiente desses classificadores. Usaremos um desses modelos pré-construídos dosklearn.
O classificador sklearn
A criação do classificador de regressão logística a partir do kit de ferramentas sklearn é trivial e é feita em uma única instrução de programa, conforme mostrado aqui -
In [22]: classifier = LogisticRegression(solver='lbfgs',random_state=0)Depois que o classificador for criado, você alimentará seus dados de treinamento no classificador para que ele possa ajustar seus parâmetros internos e estar pronto para as previsões sobre seus dados futuros. Para ajustar o classificador, executamos a seguinte instrução -
In [23]: classifier.fit(X_train, Y_train)O classificador agora está pronto para teste. O código a seguir é a saída da execução das duas instruções acima -
Out[23]: LogisticRegression(C = 1.0, class_weight = None, dual = False,
fit_intercept=True, intercept_scaling=1, max_iter=100,
multi_class='warn', n_jobs=None, penalty='l2', random_state=0,
solver='lbfgs', tol=0.0001, verbose=0, warm_start=False))Agora, estamos prontos para testar o classificador criado. Trataremos disso no próximo capítulo.
Precisamos testar o classificador criado acima antes de colocá-lo em uso em produção. Se o teste revelar que o modelo não atende à precisão desejada, teremos que voltar ao processo acima, selecionar outro conjunto de recursos (campos de dados), construir o modelo novamente e testá-lo. Essa será uma etapa iterativa até que o classificador atenda ao requisito de precisão desejada. Então, vamos testar nosso classificador.
Previsão de dados de teste
Para testar o classificador, usamos os dados de teste gerados no estágio anterior. Nós chamamos opredict método no objeto criado e passe o X matriz dos dados de teste, conforme mostrado no seguinte comando -
In [24]: predicted_y = classifier.predict(X_test)Isso gera uma única matriz dimensional para todo o conjunto de dados de treinamento, dando a previsão para cada linha na matriz X. Você pode examinar esta matriz usando o seguinte comando -
In [25]: predicted_yO seguinte é o resultado da execução dos dois comandos acima -
Out[25]: array([0, 0, 0, ..., 0, 0, 0])A saída indica que o primeiro e os três últimos clientes não são os candidatos potenciais para o Term Deposit. Você pode examinar toda a gama para classificar os clientes potenciais. Para fazer isso, use o seguinte snippet de código Python -
In [26]: for x in range(len(predicted_y)):
if (predicted_y[x] == 1):
print(x, end="\t")O resultado da execução do código acima é mostrado abaixo -

A saída mostra os índices de todas as linhas que são prováveis candidatos à assinatura do TD. Agora você pode fornecer essa saída para a equipe de marketing do banco, que coletará os detalhes de contato de cada cliente na linha selecionada e continuará com seu trabalho.
Antes de colocar este modelo em produção, precisamos verificar a precisão da previsão.
Verificando a precisão
Para testar a precisão do modelo, use o método de pontuação no classificador conforme mostrado abaixo -
In [27]: print('Accuracy: {:.2f}'.format(classifier.score(X_test, Y_test)))A saída da tela de execução deste comando é mostrada abaixo -
Accuracy: 0.90Isso mostra que a precisão do nosso modelo é de 90%, o que é considerado muito bom na maioria das aplicações. Portanto, nenhum ajuste adicional é necessário. Agora, nosso cliente está pronto para executar a próxima campanha, obter a lista de clientes em potencial e persegui-los para a abertura do TD com uma provável alta taxa de sucesso.
Como você viu no exemplo acima, aplicar regressão logística para aprendizado de máquina não é uma tarefa difícil. No entanto, ele vem com suas próprias limitações. A regressão logística não será capaz de lidar com um grande número de características categóricas. No exemplo que discutimos até agora, reduzimos muito o número de recursos.
No entanto, se esses recursos fossem importantes em nossa previsão, teríamos sido forçados a incluí-los, mas então a regressão logística não nos forneceria uma boa precisão. A regressão logística também é vulnerável ao sobreajuste. Não pode ser aplicado a um problema não linear. Ele terá um desempenho insatisfatório com variáveis independentes que não estão correlacionadas com o alvo e estão correlacionadas entre si. Assim, você terá que avaliar cuidadosamente a adequação da regressão logística ao problema que está tentando resolver.
Existem muitas áreas de aprendizado de máquina em que outras técnicas são desenvolvidas. Para citar alguns, temos algoritmos como k-vizinhos mais próximos (kNN), regressão linear, máquinas de vetores de suporte (SVM), árvores de decisão, Naive Bayes e assim por diante. Antes de finalizar em um modelo específico, você terá que avaliar a aplicabilidade dessas várias técnicas ao problema que estamos tentando resolver.
A regressão logística é uma técnica estatística de classificação binária. Neste tutorial, você aprendeu como treinar a máquina para usar a regressão logística. Na criação de modelos de aprendizado de máquina, o requisito mais importante é a disponibilidade dos dados. Sem dados adequados e relevantes, você não pode simplesmente fazer a máquina aprender.
Depois de ter os dados, sua próxima tarefa principal é limpar os dados, eliminar as linhas e campos indesejados e selecionar os campos apropriados para o desenvolvimento do seu modelo. Depois de fazer isso, você precisa mapear os dados em um formato exigido pelo classificador para seu treinamento. Assim, a preparação de dados é uma tarefa importante em qualquer aplicativo de aprendizado de máquina. Quando estiver pronto com os dados, você pode selecionar um tipo específico de classificador.
Neste tutorial, você aprendeu como usar um classificador de regressão logística fornecido no sklearnbiblioteca. Para treinar o classificador, usamos cerca de 70% dos dados para treinar o modelo. Usamos o restante dos dados para teste. Testamos a precisão do modelo. Se isso não estiver dentro dos limites aceitáveis, voltamos a selecionar o novo conjunto de recursos.
Mais uma vez, siga todo o processo de preparação dos dados, treine o modelo e teste-o, até ficar satisfeito com sua precisão. Antes de iniciar qualquer projeto de aprendizado de máquina, você deve aprender e ter contato com uma ampla variedade de técnicas que foram desenvolvidas até agora e que foram aplicadas com sucesso na indústria.