Lucene - Classes de Indexação
O processo de indexação é uma das principais funcionalidades fornecidas pela Lucene. O diagrama a seguir ilustra o processo de indexação e o uso de classes.IndexWriter é o componente mais importante e central do processo de indexação.
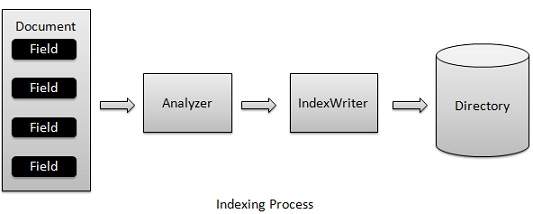
Nós adicionamos Document(s) contendo Field(s) para IndexWriter que analisa o Document(s) usando o Analyzer e então cria / abre / edita índices conforme necessário e os armazena / atualiza em um Directory. IndexWriter é usado para atualizar ou criar índices. Não é usado para ler índices.
Classes de indexação
A seguir está uma lista de classes comumente usadas durante o processo de indexação.
| S.No. | Classe e descrição |
|---|---|
| 1 | IndexWriter
Esta classe atua como um componente principal que cria / atualiza índices durante o processo de indexação. |
| 2 | Diretório
Esta classe representa o local de armazenamento dos índices. |
| 3 | Analisador
Esta classe é responsável por analisar um documento e obter os tokens / palavras do texto a ser indexado. Sem a análise feita, IndexWriter não pode criar índice. |
| 4 | Documento
Esta classe representa um documento virtual com Fields onde o Field é um objeto que pode conter o conteúdo do documento físico, seus metadados e assim por diante. O Analyzer pode compreender apenas um documento. |
| 5 | Campo
Esta é a unidade mais baixa ou o ponto de partida do processo de indexação. Ele representa o relacionamento do par de valores-chave em que uma chave é usada para identificar o valor a ser indexado. Vamos supor que um campo usado para representar o conteúdo de um documento terá a chave como "conteúdo" e o valor pode conter parte ou todo o texto ou conteúdo numérico do documento. O Lucene pode indexar apenas texto ou conteúdo numérico apenas. |