MS SQL Server - Guia Rápido
Este capítulo apresenta o SQL Server, discute seu uso, vantagens, versões e componentes.
O que é SQL Server?
É um software, desenvolvido pela Microsoft, que é implementado a partir da especificação do RDBMS.
Também é um ORDBMS.
Depende da plataforma.
É um software baseado em GUI e comando.
Ele suporta a linguagem SQL (SEQUEL), que é um produto IBM, não procedural, banco de dados comum e linguagem que não diferencia maiúsculas de minúsculas.
Uso do SQL Server
- Para criar bancos de dados.
- Para manter bancos de dados.
- Para analisar os dados através do SQL Server Analysis Services (SSAS).
- Para gerar relatórios por meio do SQL Server Reporting Services (SSRS).
- Para realizar operações ETL por meio do SSIS (SQL Server Integration Services).
Versões do SQL Server
| Versão | Ano | Nome de código |
|---|---|---|
| 6,0 | 1995 | SQL95 |
| 6,5 | 1996 | Hidra |
| 7,0 | 1998 | Esfinge |
| 8.0 (2000) | 2000 | Shiloh |
| 9,0 (2005) | 2005 | Yukon |
| 10,0 (2008) | 2008 | Katmai |
| 10.5 (2008 R2) | 2010 | Kilimanjaro |
| 11,0 (2012) | 2012 | Denali |
| 12 (2014) | 2014 | Hekaton (inicialmente), SQL 14 (atual) |
Componentes do SQL Server
O SQL Server funciona na arquitetura cliente-servidor, portanto, oferece suporte a dois tipos de componentes - (a) Estação de trabalho e (b) Servidor.
Workstation componentssão instalados em todos os dispositivos / máquinas do operador do SQL Server. Essas são apenas interfaces para interagir com os componentes do servidor. Exemplo: SSMS, SSCM, Profiler, BIDS, SQLEM etc.
Server componentssão instalados em servidor centralizado. Esses são serviços. Exemplo: SQL Server, SQL Server Agent, SSIS, SSAS, SSRS, navegador SQL, pesquisa de texto completo do SQL Server etc.
Instância do SQL Server
- Uma instância é uma instalação do SQL Server.
- Uma instância é uma cópia exata do mesmo software.
- Se instalarmos 'n' vezes, então 'n' instâncias serão criadas.
- Existem dois tipos de instâncias no SQL Server a) Padrão b) Nomeada.
- Apenas uma instância padrão terá suporte em um servidor.
- Várias instâncias nomeadas terão suporte em um servidor.
- A instância padrão terá o nome do servidor como nome da instância.
- O nome do serviço de instância padrão é MSSQLSERVER.
- 16 instâncias serão suportadas na versão 2000.
- 50 instâncias serão suportadas em 2005 e versões posteriores.
Vantagens das Instâncias
- Para instalar versões diferentes em uma máquina.
- Para reduzir custos.
- Para manter os ambientes de produção, desenvolvimento e teste separadamente.
- Para reduzir problemas temporários de banco de dados.
- Para separar privilégios de segurança.
- Para manter o servidor em espera.
O SQL Server está disponível em várias edições. Este capítulo lista as várias edições com seus recursos.
Enterprise - Esta é a edição de ponta com um conjunto completo de recursos.
Standard - Tem menos recursos do que Enterprise, quando não há requisitos de recursos avançados.
Workgroup - Adequado para escritórios remotos de uma empresa maior.
Web - Isso é projetado para aplicativos da web.
Developer- É semelhante ao Enterprise, mas licenciado para apenas um usuário para desenvolvimento, teste e demonstração. Ele pode ser facilmente atualizado para o Enterprise sem reinstalação.
Express- Este é um banco de dados de nível de entrada gratuito. Ele pode utilizar apenas 1 CPU e 1 GB de memória, o tamanho máximo do banco de dados é de 10 GB.
Compact- Este é um banco de dados integrado gratuito para desenvolvimento de aplicativos móveis. O tamanho máximo do banco de dados é 4 GB.
Datacenter- A principal mudança no novo SQL Server 2008 R2 é o Datacenter Edition. A edição Datacenter não tem limitação de memória e oferece suporte para mais de 25 instâncias.
Business Intelligence - Business Intelligence Edition é uma nova introdução no SQL Server 2012. Esta edição inclui todos os recursos da edição Standard e suporte para recursos avançados de BI, como Power View e PowerPivot, mas carece de suporte para recursos de disponibilidade avançados, como AlwaysOn Availability Groups e outros operações online.
Enterprise Evaluation- O SQL Server Evaluation Edition é uma ótima maneira de obter uma instância totalmente funcional e gratuita do SQL Server para aprender e desenvolver soluções. Esta edição tem uma validade interna de 6 meses a partir do momento em que você a instala.
| 2005 | 2008 | 2008 R2 | 2012 | 2014 |
|---|---|---|---|---|
| Empreendimento | sim | sim | sim | sim |
| Padrão | sim | sim | sim | sim |
| Desenvolvedor | sim | sim | sim | sim |
| Grupo de Trabalho | sim | sim | Não | Não |
| Win Compact Edition - Móvel | sim | sim | sim | sim |
| Avaliação Empresarial | sim | sim | sim | sim |
| Expressar | sim | sim | sim | sim |
| Rede | sim | sim | sim | |
| Centro de dados | Não | Não | ||
| Business Intelligence | sim |
O SQL Server oferece suporte a dois tipos de instalação -
- Standalone
- Com base em cluster
Verificações
- Verifique o acesso RDP para o servidor.
- Verifique o bit do SO, IP, domínio do servidor.
- Verifique se sua conta está no grupo admin para executar o arquivo setup.exe.
- Localização do software.
Requisitos
- Qual versão, edição, SP e hotfix, se houver.
- Contas de serviço para mecanismo de banco de dados, agente, SSAS, SSIS, SSRS, se houver.
- Nome da instância nomeada, se houver.
- Localização para binários, sistema, bancos de dados do usuário.
- Modo de autenticação.
- Configuração de agrupamento.
- Lista de recursos.
Pré-requisitos para 2005
- Arquivos de suporte de instalação.
- .net framework 2.0.
- Cliente nativo do SQL Server.
Pré-requisitos para 2008 e 2008R2
- Arquivos de suporte de instalação.
- .net framework 3.5 SP1.
- Cliente nativo do SQL Server.
- Instalador do Windows 4.5 / versão posterior.
Pré-requisitos para 2012 e 2014
- Arquivos de suporte de instalação.
- .net framework 4.0.
- Cliente nativo do SQL Server.
- Instalador do Windows 4.5 / versão posterior.
- Windows PowerShell 2.0.
Etapas de instalação
Step 1 - Baixe a edição de avaliação de http://www.microsoft.com/download/en/details.aspx?id=29066
Depois de fazer o download do software, os seguintes arquivos estarão disponíveis com base na sua opção de download (32 ou 64 bits).
ENU \ x86 \ SQLFULL_x86_ENU_Core.box
ENU \ x86 \ SQLFULL_x86_ENU_Install.exe
ENU \ x86 \ SQLFULL_x86_ENU_Lang.box
OR
ENU \ x86 \ SQLFULL_x64_ENU_Core.box
ENU \ x86 \ SQLFULL_x64_ENU_Install.exe
ENU \ x86 \ SQLFULL_x64_ENU_Lang.box
Note - X86 (32 bits) e X64 (64 bits)
Step 2 - Dê um duplo clique em “SQLFULL_x86_ENU_Install.exe” ou “SQLFULL_x64_ENU_Install.exe”, irá extrair os arquivos necessários para instalação na pasta “SQLFULL_x86_ENU” ou “SQLFULL_x86_ENU” respectivamente.
Step 3 - Clique na pasta “SQLFULL_x86_ENU” ou “SQLFULL_x64_ENU_Install.exe” e clique duas vezes no aplicativo “SETUP”.
Para compreensão, aqui usamos o software SQLFULL_x64_ENU_Install.exe.
Step 4 - Assim que clicarmos no aplicativo 'setup', a seguinte tela será aberta.

Step 5 - Clique em Instalação que está no lado esquerdo da tela acima.

Step 6- Clique na primeira opção do lado direito visto na tela acima. A tela a seguir será aberta.

Step 7 - Clique em OK e a tela a seguir será exibida.
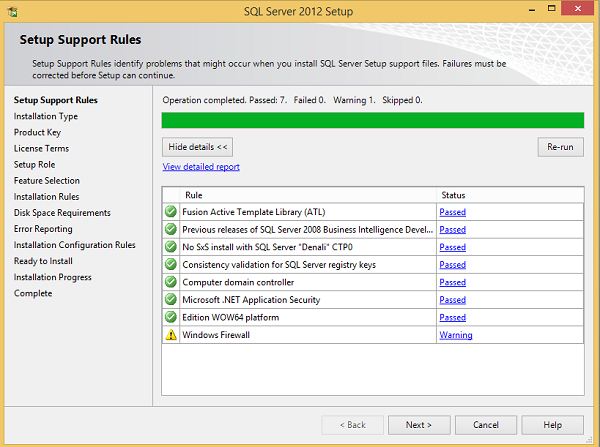
Step 8 - Clique em Avançar para obter a tela a seguir.

Step 9 - Certifique-se de verificar a seleção da chave do produto e clique em Avançar.

Step 10 - Marque a caixa de seleção para aceitar a opção de licença e clique em Avançar.

Step 11 - Selecione a opção de instalação de recursos do SQL Server e clique em Avançar.

Step 12 - Selecione a caixa de seleção Database engine services e clique em Next.
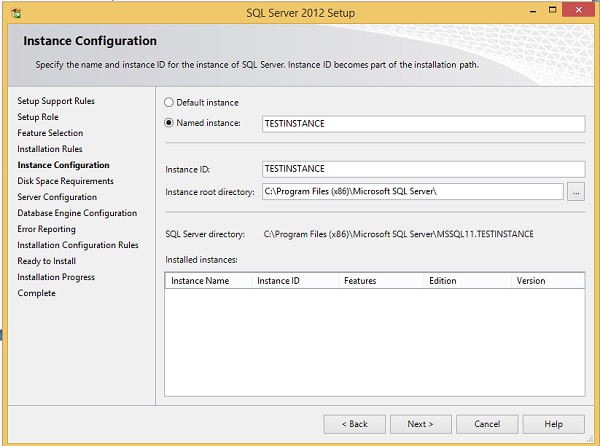
Step 13 - Insira a instância nomeada (aqui eu usei TestInstance) e clique em Avançar.

Step 14 - Clique em Avançar na tela acima e a tela a seguir será exibida.

Step 15 - Selecione nomes de contas de serviço e tipos de inicialização para os serviços listados acima e clique em Agrupamento.

Step 16 - Certifique-se de que a seleção de intercalação correta esteja marcada e clique em Avançar.

Step 17 - Certifique-se de que a seleção do modo de autenticação e os administradores estejam marcados e clique em Diretórios de dados.
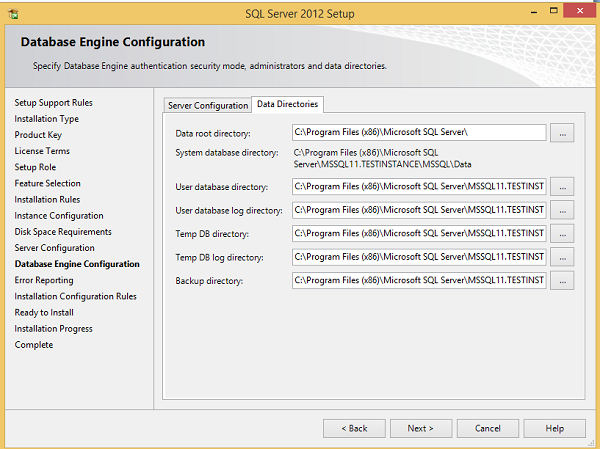
Step 18- Certifique-se de selecionar os locais de diretório acima e clique em Avançar. A tela a seguir é exibida.

Step 19 - Clique em Avançar na tela acima.

Step 20 - Clique em Avançar na tela acima para obter a tela a seguir.

Step 21 - Certifique-se de verificar a seleção acima corretamente e clique em Instalar.
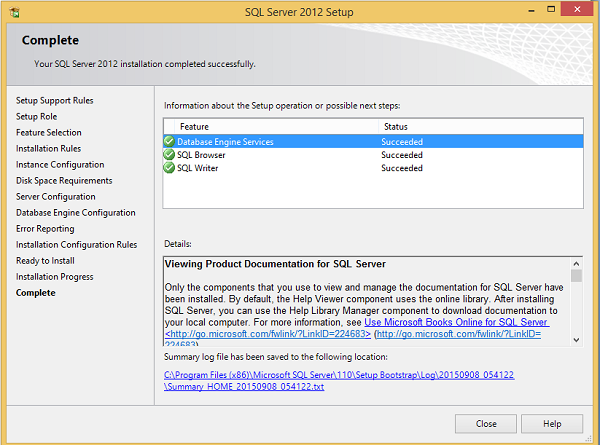
A instalação foi bem-sucedida conforme mostrado na tela acima. Clique em Fechar para terminar.
Classificamos a arquitetura do SQL Server nas seguintes partes para fácil compreensão -
- Arquitetura geral
- Arquitetura de memória
- Arquitetura de arquivo de dados
- Arquitetura do arquivo de log
Arquitetura Geral
Client - Onde a solicitação foi iniciada.
Query - Consulta SQL que é uma linguagem de alto nível.
Logical Units - Palavras-chave, expressões e operadores, etc.
N/W Packets - Código relacionado à rede.
Protocols - No SQL Server temos 4 protocolos.
Memória compartilhada (para conexões locais e solução de problemas).
Pipes nomeados (para conexões que estão em conectividade LAN).
TCP / IP (para conexões que estão em conectividade WAN).
VIA-Virtual Interface Adapter (requer hardware especial para configuração do fornecedor e também obsoleto da versão SQL 2012).
Server - Onde o SQL Services foi instalado e os bancos de dados residem.
Relational Engine- É aqui que a execução real será feita. Ele contém analisador de consulta, otimizador de consulta e executor de consulta.
Query Parser (Command Parser) and Compiler (Translator) - Isso verificará a sintaxe da consulta e converterá a consulta em linguagem de máquina.
Query Optimizer - Ele irá preparar o plano de execução como saída, tendo como entrada a consulta, estatísticas e árvore Algebrizer.
Execution Plan - É como um roteiro, que contém a ordem de todas as etapas a serem realizadas como parte da execução da consulta.
Query Executor - É aqui que a consulta será executada passo a passo com o auxílio do plano de execução e também o mecanismo de armazenamento será contatado.
Storage Engine - É responsável pelo armazenamento e recuperação de dados no sistema de armazenamento (disco, SAN, etc.,), manipulação de dados, bloqueio e gerenciamento de transações.
SQL OS- Situa-se entre a máquina host (sistema operacional Windows) e o SQL Server. Todas as atividades realizadas no mecanismo de banco de dados são atendidas pelo sistema operacional SQL. O SQL OS fornece vários serviços de sistema operacional, como gerenciamento de memória, lida com buffer pool, buffer de log e detecção de deadlock usando a estrutura de bloqueio e bloqueio.
Checkpoint Process- Checkpoint é um processo interno que grava todas as páginas sujas (páginas modificadas) do cache de buffer para o disco físico. Além disso, ele também grava os registros de log do buffer de log para o arquivo físico. A gravação de páginas sujas do cache de buffer em um arquivo de dados também é conhecida como Hardening of dirty pages.
É um processo dedicado e executado automaticamente pelo SQL Server em intervalos específicos. O SQL Server executa o processo de checkpoint para cada banco de dados individualmente. O Checkpoint ajuda a reduzir o tempo de recuperação do SQL Server no caso de desligamento inesperado ou falha / falha do sistema.
Pontos de verificação no SQL Server
No SQL Server 2012, existem quatro tipos de checkpoints -
Automatic - Este é o ponto de verificação mais comum executado como um processo em segundo plano para garantir que o banco de dados do SQL Server possa ser recuperado no limite de tempo definido pelo intervalo de recuperação - opção de configuração do servidor.
Indirect- Isso é novo no SQL Server 2012. Ele também é executado em segundo plano, mas para atender a um tempo de recuperação de destino especificado pelo usuário para o banco de dados específico onde a opção foi configurada. Depois que o Target_Recovery_Time para um determinado banco de dados tiver sido selecionado, isso substituirá o intervalo de recuperação especificado para o servidor e evitará o ponto de verificação automático em tal banco de dados.
Manual- Este é executado como qualquer outra instrução T-SQL, assim que você emitir o comando de ponto de verificação, ele será executado até sua conclusão. O ponto de verificação manual é executado apenas para seu banco de dados atual. Você também pode especificar o Checkpoint_Duration que é opcional - esta duração especifica o tempo em que você deseja que o seu checkpoint seja concluído.
Internal- Como usuário, você não pode controlar o ponto de verificação interno. Emitido em operações específicas, como
O desligamento inicia uma operação de ponto de verificação em todos os bancos de dados, exceto quando o desligamento não é limpo (desligamento com nowait).
Se o modelo de recuperação for alterado de Full \ Bulk-logging para Simples.
Ao fazer backup do banco de dados.
Se seu banco de dados estiver em um modelo de recuperação simples, o processo de checkpoint é executado automaticamente quando o log fica 70% cheio ou com base na opção do servidor - intervalo de recuperação.
Alterar o comando do banco de dados para adicionar ou remover um arquivo de dados \ log também inicia um ponto de verificação.
O ponto de verificação também ocorre quando o modelo de recuperação do banco de dados é registrado em massa e uma operação com registro mínimo é executada.
Criação de instantâneos de banco de dados.
Lazy Writer Process- O gravador lento enviará páginas sujas para o disco por um motivo totalmente diferente, porque ele precisa liberar memória no buffer pool. Isso acontece quando o servidor SQL fica sob pressão de memória. Pelo que eu sei, isso é controlado por um processo interno e não há configuração para isso.
O servidor SQL monitora constantemente o uso de memória para avaliar a contenção (ou disponibilidade) de recursos; sua função é garantir que haja uma certa quantidade de espaço livre disponível o tempo todo. Como parte desse processo, quando ele percebe qualquer contenção de recurso, ele aciona o Lazy Writer para liberar algumas páginas na memória gravando páginas sujas no disco. Ele emprega o algoritmo Least Recent Used (LRU) para decidir quais páginas devem ser transferidas para o disco.
Se Lazy Writer estiver sempre ativo, isso pode indicar gargalo de memória.
Arquitetura de Memória
A seguir estão alguns dos principais recursos da arquitetura de memória.
Um dos principais objetivos de design de todo software de banco de dados é minimizar a E / S de disco, porque as leituras e gravações de disco estão entre as operações que consomem mais recursos.
A memória no Windows pode ser chamada com Espaço de Endereço Virtual, compartilhado pelo modo Kernel (modo OS) e modo Usuário (Aplicativo como SQL Server).
O "espaço de endereço do usuário" do SQL Server é dividido em duas regiões: MemToLeave e Buffer Pool.
O tamanho de MemToLeave (MTL) e Buffer Pool (BPool) é determinado pelo SQL Server durante a inicialização.
Buffer managementé um componente chave para alcançar alta eficiência de E / S. O componente de gerenciamento de buffer consiste em dois mecanismos: o gerenciador de buffer para acessar e atualizar as páginas do banco de dados e o pool de buffer para reduzir a E / S do arquivo de banco de dados.
O buffer pool é dividido em várias seções. Os mais importantes são o cache de buffer (também conhecido como cache de dados) e o cache de procedimento.Buffer cachemantém as páginas de dados na memória para que os dados acessados com frequência possam ser recuperados do cache. A alternativa seria ler as páginas de dados do disco. Ler páginas de dados do cache otimiza o desempenho, minimizando o número de operações de E / S necessárias que são inerentemente mais lentas do que recuperar dados da memória.
Procedure cachemantém o procedimento armazenado e os planos de execução de consulta para minimizar o número de vezes que os planos de consulta devem ser gerados. Você pode descobrir informações sobre o tamanho e a atividade no cache de procedimento usando a instrução DBCC PROCCACHE.
Outras partes do pool de buffer incluem -
System level data structures - Contém dados de nível de instância do SQL Server sobre bancos de dados e bloqueios.
Log cache - Reservado para ler e gravar páginas de log de transações.
Connection context- Cada conexão com a instância possui uma pequena área de memória para registrar o estado atual da conexão. Essas informações incluem procedimento armazenado e parâmetros de função definidos pelo usuário, posições do cursor e muito mais.
Stack space - O Windows aloca espaço de pilha para cada thread iniciado pelo SQL Server.
Arquitetura de arquivo de dados
A arquitetura do arquivo de dados tem os seguintes componentes -
Grupos de arquivos
Os arquivos de banco de dados podem ser agrupados em grupos de arquivos para fins de alocação e administração. Nenhum arquivo pode ser membro de mais de um grupo de arquivos. Os arquivos de log nunca fazem parte de um grupo de arquivos. O espaço de log é gerenciado separadamente do espaço de dados.
Existem dois tipos de grupos de arquivos no SQL Server, Primário e Definido pelo usuário. O grupo de arquivos primário contém o arquivo de dados primário e quaisquer outros arquivos não atribuídos especificamente a outro grupo de arquivos. Todas as páginas das tabelas do sistema são alocadas no grupo de arquivos principal. Os grupos de arquivos definidos pelo usuário são quaisquer grupos de arquivos especificados usando a palavra-chave do grupo de arquivos em criar banco de dados ou alterar a instrução do banco de dados.
Um grupo de arquivos em cada banco de dados opera como o grupo de arquivos padrão. Quando o SQL Server aloca uma página para uma tabela ou índice para o qual nenhum grupo de arquivos foi especificado quando foram criados, as páginas são alocadas do grupo de arquivos padrão. Para mudar o grupo de arquivos padrão de um grupo para outro, ele deve ter a função db fixa db_owner.
Por padrão, o grupo de arquivos principal é o grupo de arquivos padrão. O usuário deve ter a função de banco de dados fixa db_owner para fazer backup de arquivos e grupos de arquivos individualmente.
arquivos
Os bancos de dados têm três tipos de arquivos - arquivo de dados primário, arquivo de dados secundário e arquivo de log. O arquivo de dados primário é o ponto de partida do banco de dados e aponta para os outros arquivos no banco de dados.
Cada banco de dados possui um arquivo de dados primário. Podemos dar qualquer extensão para o arquivo de dados principal, mas a extensão recomendada é.mdf. O arquivo de dados secundário é um arquivo diferente do arquivo de dados primário nesse banco de dados. Alguns bancos de dados podem ter vários arquivos de dados secundários. Alguns bancos de dados podem não ter um único arquivo de dados secundário. A extensão recomendada para o arquivo de dados secundários é.ndf.
Os arquivos de log contêm todas as informações de log usadas para recuperar o banco de dados. O banco de dados deve ter pelo menos um arquivo de log. Podemos ter vários arquivos de log para um banco de dados. A extensão recomendada para o arquivo de log é.ldf.
A localização de todos os arquivos em um banco de dados é registrada no banco de dados mestre e no arquivo principal do banco de dados. Na maioria das vezes, o mecanismo de banco de dados usa o local do arquivo do banco de dados mestre.
Os arquivos têm dois nomes - lógico e físico. O nome lógico é usado para se referir ao arquivo em todas as instruções T-SQL. O nome físico é OS_file_name, ele deve seguir as regras do SO. Os arquivos de dados e log podem ser colocados em sistemas de arquivos FAT ou NTFS, mas não podem ser colocados em sistemas de arquivos compactados. Pode haver até 32.767 arquivos em um banco de dados.
Extensões
As extensões são unidades básicas nas quais o espaço é alocado para tabelas e índices. Uma extensão é de 8 páginas contíguas ou 64 KB. O SQL Server tem dois tipos de extensão - Uniforme e Mista. As extensões uniformes são compostas por um único objeto. Extensões mistas são compartilhadas por até oito objetos.
Páginas
É a unidade fundamental de armazenamento de dados no MS SQL Server. O tamanho da página é de 8 KB. O início de cada página é um cabeçalho de 96 bytes usado para armazenar informações do sistema, como tipo de página, quantidade de espaço livre na página e id do objeto que possui a página. Existem 9 tipos de páginas de dados no SQL Server.
Data - Linhas de dados com todos os dados, exceto texto, ntext e dados de imagem.
Index - Entradas de índice.
Text\Image - Dados de texto, imagem e ntext.
GAM - Informações sobre extensões alocadas.
SGAM - Informações sobre extensões alocadas no nível do sistema.
Page Free Space (PFS) - Informações sobre o espaço livre disponível nas páginas.
Index Allocation Map (IAM) - Informações sobre extensões usadas por uma tabela ou índice.
Bulk Changed Map (BCM) - Informações sobre extensões modificadas por operações em massa desde a última instrução de log de backup.
Differential Changed Map (DCM) - Informações sobre extensões que foram alteradas desde a última instrução de backup do banco de dados.
Arquitetura do arquivo de log
O log de transações do SQL Server opera logicamente como se o log de transações fosse uma string de registros de log. Cada registro de log é identificado por Log Sequence Number (LSN). Cada registro de log contém o ID da transação à qual pertence.
Os registros de log para modificações de dados registram a operação lógica realizada ou gravam as imagens anteriores e posteriores dos dados modificados. A imagem anterior é uma cópia dos dados antes de a operação ser executada; a pós-imagem é uma cópia dos dados após a operação ter sido realizada.
As etapas para recuperar uma operação dependem do tipo de registro de log -
- Operação lógica registrada.
- Para avançar a operação lógica, a operação é executada novamente.
- Para reverter a operação lógica, a operação lógica reversa é executada.
- Antes e depois da imagem registrada.
- Para avançar a operação, a pós-imagem é aplicada.
- Para reverter a operação, a imagem anterior é aplicada.
Diferentes tipos de operações são registrados no log de transações. Essas operações incluem -
O início e o final de cada transação.
Cada modificação de dados (inserir, atualizar ou excluir). Isso inclui alterações por procedimentos armazenados do sistema ou instruções de linguagem de definição de dados (DDL) em qualquer tabela, incluindo tabelas do sistema.
Cada extensão e alocação ou desalocação de página.
Criação ou eliminação de uma tabela ou índice.
As operações de reversão também são registradas. Cada transação reserva espaço no log de transações para garantir que exista espaço de log suficiente para suportar uma reversão causada por uma instrução de reversão explícita ou se um erro for encontrado. Este espaço reservado é liberado quando a transação é concluída.
A seção do arquivo de log do primeiro registro de log que deve estar presente para uma reversão bem-sucedida de todo o banco de dados para o último registro de log é chamada de parte ativa do log ou log ativo. Esta é a seção do log necessária para uma recuperação completa do banco de dados. Nenhuma parte do log ativo pode ser truncada. O LSN desse primeiro registro de log é conhecido como o LSN de recuperação mínima (LSN mínimo).
O SQL Server Database Engine divide cada arquivo de log físico internamente em vários arquivos de log virtuais. Os arquivos de log virtuais não têm tamanho fixo e não há um número fixo de arquivos de log virtuais para um arquivo de log físico.
O Mecanismo de Banco de Dados escolhe o tamanho dos arquivos de log virtuais dinamicamente enquanto cria ou estende os arquivos de log. O Mecanismo de Banco de Dados tenta manter um pequeno número de arquivos virtuais. O tamanho ou o número de arquivos de log virtuais não podem ser configurados ou definidos pelos administradores. A única vez que os arquivos de log virtuais afetam o desempenho do sistema é se os arquivos de log físicos são definidos por valores de tamanho pequeno e growth_increment.
O valor de tamanho é o tamanho inicial do arquivo de log e o valor de growth_increment é a quantidade de espaço adicionado ao arquivo sempre que um novo espaço é necessário. Se os arquivos de log atingirem um tamanho grande devido a muitos pequenos incrementos, eles terão muitos arquivos de log virtuais. Isso pode retardar a inicialização do banco de dados e também registrar operações de backup e restauração.
Recomendamos que você atribua aos arquivos de log um valor de tamanho próximo ao tamanho final necessário e também tenha um valor growth_increment relativamente grande. O SQL Server usa um log write-ahead (WAL), que garante que nenhuma modificação de dados seja gravada no disco antes que o registro de log associado seja gravado no disco. Isso mantém as propriedades ACID para uma transação.
SQL Server Management Studio é um componente de estação de trabalho \ ferramenta cliente que será instalado se selecionarmos o componente de estação de trabalho nas etapas de instalação. Isso permite que você se conecte e gerencie seu SQL Server a partir de uma interface gráfica, em vez de usar a linha de comando.
Para se conectar a uma instância remota de um SQL Server, você precisará deste ou de um software semelhante. É usado por administradores, desenvolvedores, testadores, etc.
Os métodos a seguir são usados para abrir o SQL Server Management Studio.
Primeiro Método
Iniciar → Todos os programas → MS SQL Server 2012 → SQL Server Management Studio
Segundo método
Vá para Executar e digite SQLWB (para a versão 2005) SSMS (para as versões 2008 e posteriores). Em seguida, clique em Enter.
O SQL Server Management Studio será aberto conforme mostrado no instantâneo a seguir em qualquer um dos métodos acima.

Um login é uma credencial simples para acessar o SQL Server. Por exemplo, você fornece seu nome de usuário e senha ao fazer logon no Windows ou mesmo em sua conta de e-mail. Este nome de usuário e senha constroem as credenciais. Portanto, as credenciais são simplesmente um nome de usuário e uma senha.
O SQL Server permite quatro tipos de logins -
- Um login baseado em credenciais do Windows.
- Um logon específico para SQL Server.
- Um login mapeado para um certificado.
- Um login mapeado para chave assimétrica.
Neste tutorial, estamos interessados em logins baseados em credenciais do Windows e logins específicos para SQL Server.
Logins baseados em credenciais do Windows permitem que você faça logon no SQL Server usando um nome de usuário e senha do Windows. Se precisar criar suas próprias credenciais (nome de usuário e senha), você pode criar um login específico para o SQL Server.
Para criar, alterar ou remover um login do SQL Server, você pode adotar uma das duas abordagens -
- Usando o SQL Server Management Studio.
- Usando instruções T-SQL.
Os seguintes métodos são usados para criar o Login -
Primeiro método - usando o SQL Server Management Studio
Step 1 - Depois de se conectar à instância do SQL Server, expanda a pasta de logins, conforme mostrado no instantâneo a seguir.

Step 2 - Clique com o botão direito em Logins, clique em Newlogin e a tela a seguir será aberta.

Step 3 - Preencha as colunas Nome de login, Senha e Confirmar senha conforme mostrado na tela acima e clique em OK.
O login será criado conforme mostrado na imagem a seguir.

Segundo método - usando o script T-SQL
Create login yourloginname with password='yourpassword'Para criar o nome de login com TestLogin e senha 'P @ ssword', execute a consulta a seguir.
Create login TestLogin with password='P@ssword'Banco de dados é uma coleção de objetos, como tabela, visão, procedimento armazenado, função, gatilho, etc.
No MS SQL Server, dois tipos de bancos de dados estão disponíveis.
- Bancos de dados do sistema
- Banco de dados do usuário
Bancos de dados do sistema
Os bancos de dados do sistema são criados automaticamente quando instalamos o MS SQL Server. A seguir está uma lista de bancos de dados do sistema -
- Master
- Model
- MSDB
- Tempdb
- Recurso (introduzido na versão 2005)
- Distribuição (é apenas para recurso de replicação)
Banco de dados do usuário
Os bancos de dados do usuário são criados por usuários (administradores, desenvolvedores e testadores que têm acesso para criar bancos de dados).
Os métodos a seguir são usados para criar o banco de dados do usuário.
Método 1 - Usando T-SQL Script ou Restaurar Banco de Dados
A seguir está a sintaxe básica para a criação de banco de dados no MS SQL Server.
Create database <yourdatabasename>OU
Restore Database <Your database name> from disk = '<Backup file location + file name>Exemplo
Para criar um banco de dados chamado 'Testdb', execute a seguinte consulta.
Create database TestdbOU
Restore database Testdb from disk = 'D:\Backup\Testdb_full_backup.bak'Note - D: \ backup é a localização do arquivo de backup e Testdb_full_backup.bak é o nome do arquivo de backup
Método 2 - Usando o SQL Server Management Studio
Conecte-se à instância do SQL Server e clique com o botão direito na pasta de bancos de dados. Clique no novo banco de dados e a tela a seguir aparecerá.

Insira o campo do nome do banco de dados com o nome do seu banco de dados (exemplo: para criar um banco de dados com o nome 'Testdb') e clique em OK. O banco de dados Testdb será criado conforme mostrado no instantâneo a seguir.
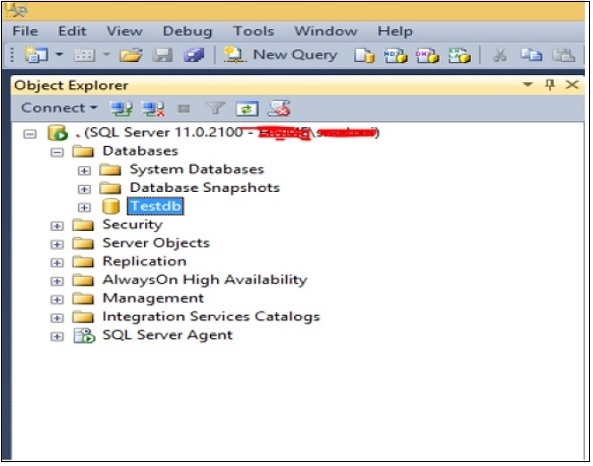
Selecione seu banco de dados com base em sua ação antes de prosseguir com qualquer um dos métodos a seguir.
Método 1 - Usando o SQL Server Management Studio
Exemplo
Para executar uma consulta para selecionar o histórico de backup no banco de dados chamado 'msdb', selecione o banco de dados msdb conforme mostrado no instantâneo a seguir.
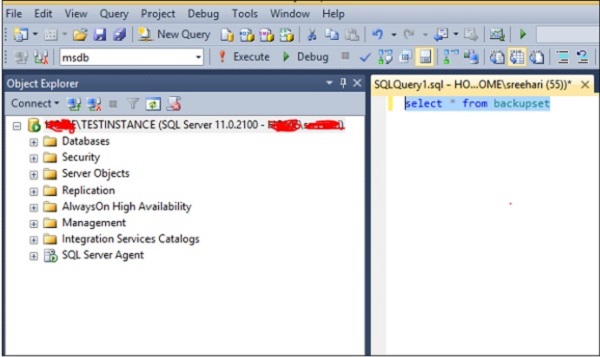
Método 2 - Usando T-SQL Script
Use <your database name>Exemplo
Para executar sua consulta para selecionar o histórico de backup no banco de dados chamado 'msdb', selecione o banco de dados msdb executando a seguinte consulta.
Exec use msdbA consulta abrirá o banco de dados msdb. Você pode executar a seguinte consulta para selecionar o histórico de backup.
Select * from backupsetPara remover seu banco de dados do MS SQL Server, use o comando drop database. Os dois métodos a seguir podem ser usados para esse fim.
Método 1 - Usando T-SQL Script
A seguir está a sintaxe básica para remover o banco de dados do MS SQL Server.
Drop database <your database name>Exemplo
Para remover o nome do banco de dados 'Testdb', execute a seguinte consulta.
Drop database TestdbMétodo 2 - Usando MS SQL Server Management Studio
Conecte-se ao SQL Server e clique com o botão direito do mouse no banco de dados que deseja remover. Clique no comando delete e a tela a seguir aparecerá.

Clique em OK para remover o banco de dados (neste exemplo, o nome é Testdb conforme mostrado na tela acima) do MS SQL Server.
Backupé uma cópia de dados / banco de dados, etc. Fazer backup do banco de dados MS SQL Server é essencial para proteger os dados. Os backups do MS SQL Server são principalmente de três tipos - completo ou banco de dados, diferencial ou incremental e log ou log transacional.
O backup do banco de dados pode ser feito usando um dos dois métodos a seguir.
Método 1 - Usando T-SQL
Tipo Completo
Backup database <Your database name> to disk = '<Backup file location + file name>'Tipo Diferencial
Backup database <Your database name> to
disk = '<Backup file location + file name>' with differentialTipo de Log
Backup log <Your database name> to disk = '<Backup file location + file name>'Exemplo
O seguinte comando é usado para o banco de dados de backup completo chamado 'TestDB' para o local 'D: \' com o nome do arquivo de backup 'TestDB_Full.bak'
Backup database TestDB to disk = 'D:\TestDB_Full.bak'O seguinte comando é usado para o banco de dados de backup diferencial chamado 'TestDB' para o local 'D: \' com o nome do arquivo de backup 'TestDB_diff.bak'
Backup database TestDB to disk = 'D:\TestDB_diff.bak' with differentialO seguinte comando é usado para o banco de dados de backup de log chamado 'TestDB' para o local 'D: \' com o nome do arquivo de backup 'TestDB_log.trn'
Backup log TestDB to disk = 'D:\TestDB_log.trn'Método 2 - Usando SSMS (SQL SERVER Management Studio)
Step 1 - Conecte-se à instância do banco de dados chamada 'TESTINSTANCE' e expanda a pasta de bancos de dados conforme mostrado no instantâneo a seguir.

Step 2- Clique com o botão direito no banco de dados 'TestDB' e selecione as tarefas. Clique em Backup e a tela a seguir aparecerá.

Step 3- Selecione o tipo de backup (Full \ diff \ log) e certifique-se de verificar o caminho de destino, onde o arquivo de backup será criado. Selecione as opções no canto superior esquerdo para ver a tela a seguir.

Step 4 - Clique em OK para criar o backup completo do banco de dados 'TestDB', conforme mostrado no instantâneo a seguir.


Restoringé o processo de copiar dados de um backup e aplicar transações registradas aos dados. Restaurar é o que você faz com backups. Pegue o arquivo de backup e transforme-o em um banco de dados.
A opção Restaurar banco de dados pode ser feita usando um dos dois métodos a seguir.
Método 1 - T-SQL
Sintaxe
Restore database <Your database name> from disk = '<Backup file location + file name>'Exemplo
O seguinte comando é usado para restaurar o banco de dados chamado 'TestDB' com o nome do arquivo de backup 'TestDB_Full.bak' que está disponível no local 'D: \' se você estiver sobrescrevendo o banco de dados existente.
Restore database TestDB from disk = ' D:\TestDB_Full.bak' with replaceSe você estiver criando um novo banco de dados com este comando de restauração e não houver um caminho de dados e arquivos de log semelhantes no servidor de destino, use a opção mover como o comando a seguir.
Certifique-se de que o caminho D: \ Data exista conforme usado no comando a seguir para dados e arquivos de log.
RESTORE DATABASE TestDB FROM DISK = 'D:\ TestDB_Full.bak' WITH MOVE 'TestDB' TO
'D:\Data\TestDB.mdf', MOVE 'TestDB_Log' TO 'D:\Data\TestDB_Log.ldf'Método 2 - SSMS (SQL SERVER Management Studio)
Step 1- Conecte-se à instância do banco de dados chamada 'TESTINSTANCE' e clique com o botão direito na pasta de bancos de dados. Clique em Restaurar banco de dados, conforme mostrado no instantâneo a seguir.

Step 2 - Selecione o botão de rádio do dispositivo e clique na elipse para selecionar o arquivo de backup conforme mostrado no instantâneo a seguir.
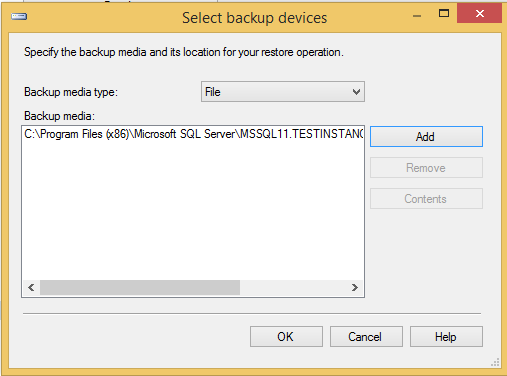
Step 3 - Clique em OK e a tela a seguir será exibida.

Step 4 - Selecione a opção Arquivos que está no canto superior esquerdo, conforme mostrado no instantâneo a seguir.

Step 5 - Selecione Opções que está no canto superior esquerdo e clique em OK para restaurar o banco de dados 'TestDB' conforme mostrado no instantâneo a seguir.

O usuário se refere a uma conta no banco de dados do MS SQL Server que é usada para acessar o banco de dados.
Os usuários podem ser criados usando um dos dois métodos a seguir.
Método 1 - Usando T-SQL
Sintaxe
Create user <username> for login <loginname>Exemplo
Para criar o nome de usuário 'TestUser' com mapeamento para o nome de login 'TestLogin' no banco de dados TestDB, execute a seguinte consulta.
create user TestUser for login TestLoginOnde 'TestLogin' é o nome de login que foi criado como parte da criação do login
Método 2 - Usando SSMS (SQL Server Management Studio)
Note - Primeiro temos que criar um Login com qualquer nome antes de criar uma conta de usuário.
Vamos usar o nome de login chamado 'TestLogin'.
Step 1- Conecte o SQL Server e expanda a pasta de bancos de dados. Em seguida, expanda o banco de dados chamado 'TestDB', onde vamos criar a conta do usuário e expandir a pasta de segurança. Clique com o botão direito nos usuários e clique no novo usuário para ver a tela a seguir.

Step 2 - Digite 'TestUser' no campo de nome do usuário e clique na elipse para selecionar o nome de Login chamado 'TestLogin' conforme mostrado no instantâneo a seguir.

Step 3- Clique em OK para exibir o nome de login. Clique novamente em OK para criar o usuário 'TestUser' conforme mostrado no instantâneo a seguir.

Permissionsconsulte as regras que regem os níveis de acesso que os principais têm aos protegíveis. Você pode conceder, revogar e negar permissões no MS SQL Server.
Para atribuir permissões, um dos dois métodos a seguir pode ser usado.
Método 1 - Usando T-SQL
Sintaxe
Use <database name>
Grant <permission name> on <object name> to <username\principle>Exemplo
Para atribuir permissão de seleção a um usuário chamado 'TestUser' no objeto chamado 'TestTable' no banco de dados 'TestDB', execute a seguinte consulta.
USE TestDB
GO
Grant select on TestTable to TestUserMétodo 2 - Usando SSMS (SQL Server Management Studio)
Step 1 - Conecte-se à instância e expanda as pastas conforme mostrado no instantâneo a seguir.

Step 2- Clique com o botão direito em TestUser e clique em Propriedades. A tela a seguir é exibida.
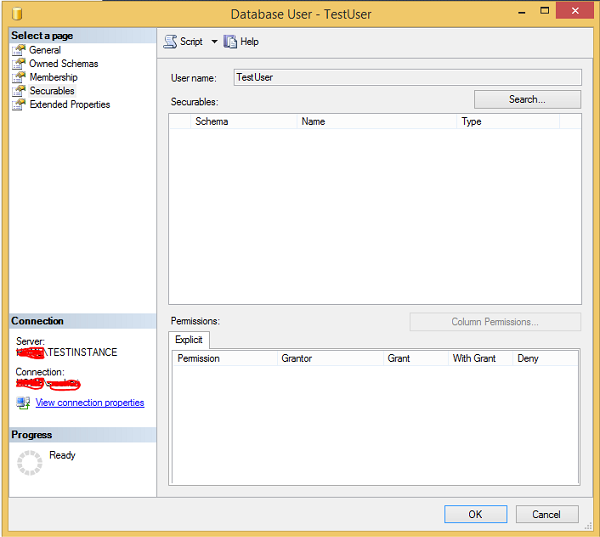
Step 3Clique em Pesquisar e selecione opções específicas. Clique em Tipos de objeto, selecione as tabelas e clique em navegar. Selecione 'TestTable' e clique em OK. A tela a seguir é exibida.

Step 4 Marque a caixa de seleção para a coluna Conceder em Selecionar permissão e clique em OK conforme mostrado no instantâneo acima.

Step 5Selecione a permissão em 'TestTable' do banco de dados TestDB concedida a 'TestUser'. Clique OK.
Monitoramento refere-se à verificação do status do banco de dados, configurações que podem ser o nome do proprietário, nomes de arquivo, tamanhos de arquivo, agendamentos de backup, etc.
Os bancos de dados do SQL Server podem ser monitorados principalmente por meio do SQL Server Management Studio ou T-SQL e também podem ser monitorados por meio de vários métodos, como criação de trabalhos de agente e configuração de correio de banco de dados, ferramentas de terceiros, etc.
O status do banco de dados pode ser verificado se está online ou em qualquer outro estado, conforme mostrado no instantâneo a seguir.

Conforme a tela acima, todos os bancos de dados estão com o status 'Online'. Se qualquer banco de dados estiver em qualquer outro estado, esse estado será mostrado conforme mostrado no instantâneo a seguir.

O MS SQL Server fornece os dois serviços a seguir, que são obrigatórios para a criação e manutenção de bancos de dados. Outros serviços complementares disponíveis para diferentes fins também são listados.
- servidor SQL
- Agente SQL Server
Outros serviços
- SQL Server Browser
- Pesquisa de texto completo do SQL Server
- SQL Server Integration Services
- SQL Server Reporting Services
- SQL Server Analysis Services
Os serviços acima podem ser aproveitados usando o método a seguir.
Iniciar serviços
Para iniciar qualquer um dos serviços, qualquer um dos dois métodos a seguir pode ser usado.
Método 1 - Services.msc
Step 1- Vá para Executar, digite services.msc e clique em OK. A tela a seguir é exibida.

Step 2- Para iniciar o serviço, clique com o botão direito no serviço e clique no botão Iniciar. Os serviços serão iniciados conforme mostrado no instantâneo a seguir.

Método 2 - SQL Server Configuration Manager
Step 1 - Abra o gerenciador de configuração usando o seguinte processo.
Iniciar → Todos os programas → MS SQL Server 2012 → Ferramentas de configuração → Gerenciador de configuração do SQL Server.

Step 2- Selecione o nome do serviço, clique com o botão direito e clique na opção iniciar. Os serviços serão iniciados conforme mostrado no instantâneo a seguir.

Parar serviços
Para interromper qualquer um dos serviços, qualquer um dos três métodos a seguir pode ser usado.
Método 1 - Services.msc
Step 1- Vá para Executar, digite services.msc e clique em OK. A tela a seguir é exibida.

Step 2- Para parar os serviços, clique com o botão direito no serviço e clique em Parar. O serviço selecionado será interrompido conforme mostrado no instantâneo a seguir.

Método 2 - SQL Server Configuration Manager
Step 1 - Abra o gerenciador de configuração usando o seguinte processo.
Iniciar → Todos os programas → MS SQL Server 2012 → Ferramentas de configuração → Gerenciador de configuração do SQL Server.

Step 2- Selecione o nome do serviço, clique com o botão direito e clique na opção Parar. O serviço selecionado será interrompido conforme mostrado no instantâneo a seguir.

Método 3 - SSMS (SQL Server Management Studio)
Step 1 - Conecte-se à instância conforme mostrado no instantâneo a seguir.

Step 2- Clique com o botão direito no nome da instância e clique na opção Parar. A tela a seguir é exibida.

Step 3 - Clique no botão Sim e a tela a seguir será aberta.

Step 4- Clique na opção Sim na tela acima para interromper o serviço do agente do SQL Server. Os serviços serão interrompidos conforme mostrado na imagem a seguir.

Nota
Não podemos usar o método SQL Server Management Studio para iniciar os Serviços, pois não é possível se conectar devido ao estado de serviços já interrompidos.
Não podemos excluir a interrupção do serviço do agente do SQL Service ao interromper o serviço do SQL Server, pois o serviço do SQL Server Agent é um serviço dependente.
Alta disponibilidade (HA) é a solução \ processo \ tecnologia para tornar o aplicativo \ banco de dados disponível 24 horas por dia, 7 dias por semana, seja em interrupções planejadas ou não.
Principalmente, existem cinco opções no MS SQL Server para conseguir \ configurar a solução de alta disponibilidade para os bancos de dados.
Replicação
Os dados de origem serão copiados para o destino por meio de agentes de replicação (trabalhos). Tecnologia de nível de objeto.
Terminologia
- O editor é o servidor de origem.
- O distribuidor é opcional e armazena dados replicados para o assinante.
- O assinante é o servidor de destino.
Envio de toras
Os dados de origem serão copiados para o destino por meio de tarefas de backup do log de transações. Tecnologia de nível de banco de dados.
Terminologia
- O servidor primário é o servidor de origem.
- O servidor secundário é o servidor de destino.
- O servidor de monitoramento é opcional e será monitorado pelo status de envio de log.
Espelhamento
Os dados primários serão copiados para o secundário por meio de transações de rede com a ajuda do ponto de extremidade de espelhamento e número da porta. Tecnologia de nível de banco de dados.
Terminologia
- O servidor principal é o servidor de origem.
- O servidor espelho é o servidor de destino.
- O servidor Witness é opcional e usado para fazer failover automático.
Clustering
Os dados serão armazenados em local compartilhado que é usado por servidores primários e secundários com base na disponibilidade do servidor. Tecnologia de nível de instância. A configuração do Windows Clustering é necessária com armazenamento compartilhado.
Terminologia
- O nó ativo é onde o SQL Services está sendo executado.
- O nó passivo é onde o SQL Services não está sendo executado.
Grupos de disponibilidade AlwaysON
Os dados primários serão copiados para o secundário por meio de transações de rede. Grupo de tecnologia de nível de banco de dados. A configuração do Windows Clustering é necessária sem armazenamento compartilhado.
Terminologia
- A réplica primária é o servidor de origem.
- A réplica secundária é o servidor de destino.
A seguir estão as etapas para configurar a tecnologia HA (espelhamento e envio de log), exceto clustering, grupos de disponibilidade AlwaysON e replicação.
Step 1 - Faça um backup completo e um T-log do banco de dados de origem.
Exemplo
Para configurar o envio de espelhamento \ log para o banco de dados 'TestDB' em 'TESTINSTANCE' como primário e 'DEVINSTANCE' como SQL Servers secundários, escreva a seguinte consulta para fazer backups completos e T-log no servidor de origem (TESTINSTANCE).
Conecte-se ao SQL Server 'TESTINSTANCE' e abra uma nova consulta e escreva o código a seguir e execute conforme mostrado na captura de tela a seguir.
Backup database TestDB to disk = 'D:\testdb_full.bak'
GO
Backup log TestDB to disk = 'D:\testdb_log.trn'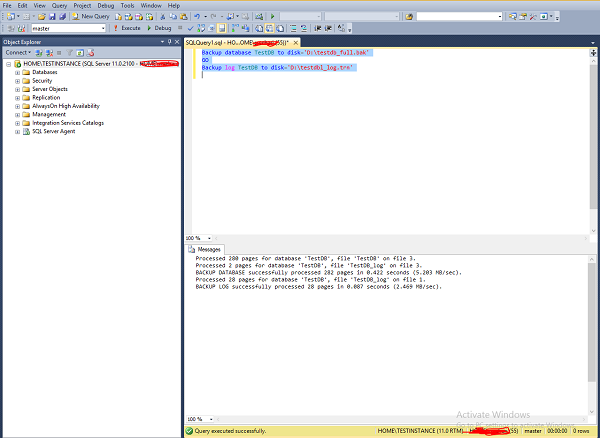
Step 2 - Copie os arquivos de backup para o servidor de destino.
Neste caso, temos apenas um servidor físico e duas instâncias de SQL Servers instaladas, portanto, não há necessidade de copiar, mas se duas instâncias de SQL Server estiverem em um servidor físico diferente, precisamos copiar os dois arquivos a seguir para qualquer local do servidor secundário onde a instância 'DEVINSTANCE' está instalada.

Step 3 - Restaure o banco de dados com arquivos de backup no servidor de destino com a opção 'norecovery'.
Exemplo
Conecte-se ao SQL Server 'DEVINSTANCE' e abra Nova Consulta. Escreva o seguinte código para restaurar o banco de dados com o nome 'TestDB', que é o mesmo nome do banco de dados primário ('TestDB') para espelhamento de banco de dados. No entanto, podemos fornecer um nome diferente para a configuração de envio de log. Nesse caso, vamos usar o nome do banco de dados 'TestDB'. Use a opção 'norecovery' para duas restaurações (arquivos de backup completo e t-log).
Restore database TestDB from disk = 'D:\TestDB_full.bak'
with move 'TestDB' to 'D:\DATA\TestDB_DR.mdf',
move 'TestDB_log' to 'D:\DATA\TestDB_log_DR.ldf',
norecovery
GO
Restore database TestDB from disk = 'D:\TestDB_log.trn' with norecovery
Atualize a pasta de bancos de dados no servidor 'DEVINSTANCE' para ver o banco de dados restaurado 'TestDB' com o status de restauração, conforme mostrado no instantâneo a seguir.
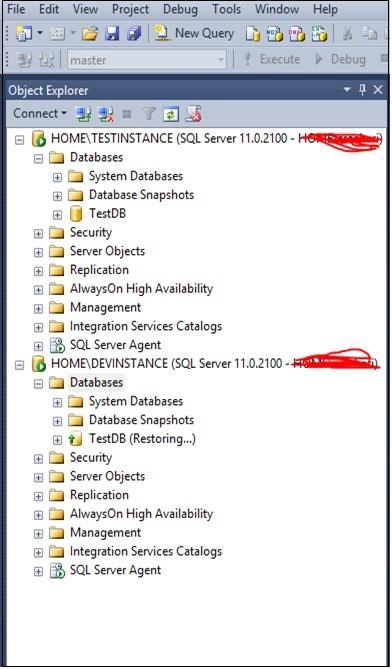
Step 4 - Configure o HA (Log shipping, Mirroring) de acordo com sua necessidade, conforme mostrado no instantâneo a seguir.
Exemplo
Clique com o botão direito no banco de dados 'TestDB' do SQL Server 'TESTINSTANCE' que é primário e clique em Propriedades. A tela a seguir aparecerá.

Step 5 - Selecione a opção chamada 'Espelhamento' ou 'Envio de Log de Transação' que estão na caixa de cor vermelha conforme mostrado na tela acima de acordo com sua necessidade e siga as etapas do assistente guiadas pelo próprio sistema para concluir a configuração.
Report é um componente exibível.
Uso
O relatório é utilizado basicamente para dois fins - Operações Internas da Empresa e Operações Externas da Empresa.
Reporting Services
Este é um serviço que permite criar e publicar vários tipos de relatórios.
A seguir estão os três requisitos necessários para desenvolver qualquer relatório.
- Processo de negócio
- Layout
- Query\Procedure\View
O BIDS (Business Intelligence Studio até 2008 R2) e o SSDT (SQL Server Data Tools de 2012) são ambientes para desenvolvimento de relatórios.
A seguir estão as etapas para abrir o ambiente BIDS \ SSDT para desenvolver relatórios.
Step 1- Abra BIDS \ SSDT com base na versão do grupo de programas Microsoft SQL Server. A tela a seguir aparecerá. Neste caso, o SSDT foi aberto.
Step 2- Vá para o arquivo no canto superior esquerdo da imagem acima. Clique em Novo e selecione o projeto. A tela a seguir será aberta.

Step 3 - Na tela acima, selecione serviços de relatório em inteligência de negócios no canto superior esquerdo, conforme mostrado na captura de tela a seguir.

Step 4 - Na tela acima, selecione o assistente de projeto do servidor de relatório (ele o guiará passo a passo pelos assistentes) ou o projeto do servidor de relatório (ele será usado para selecionar configurações personalizadas) com base em seus requisitos para desenvolver o relatório.
O plano de execução será gerado pelo otimizador de consulta com a ajuda de estatísticas e árvore Algebrizer \ processador. É o resultado do otimizador de consulta e informa como fazer \ executar seu trabalho \ requisito.
Existem dois planos de execução diferentes - Estimado e Real.
Estimated execution plan indica a visualização do otimizador.
Actual execution plan indica o que executou a consulta e como foi feita.
Os planos de execução são armazenados na memória chamada cache do plano, portanto, podem ser reutilizados. Cada plano é armazenado uma vez, a menos que o otimizador decida o paralelismo para a execução da consulta.
Existem três formatos diferentes de planos de execução disponíveis no SQL Server - planos gráficos, planos de texto e planos XML.
SHOWPLAN é a permissão necessária para o usuário que deseja ver o plano de execução.
Exemplo 1
A seguir está o procedimento para visualizar o plano de execução estimado.
Step 1- Conecte-se à instância do SQL Server. Nesse caso, 'TESTINSTANCE' é o nome da instância, conforme mostrado no instantâneo a seguir.

Step 2- Clique na opção Nova Consulta na tela acima e escreva a seguinte consulta. Antes de escrever a consulta, selecione o nome do banco de dados. Nesse caso, 'TestDB' é o nome do banco de dados.
Select * from StudentTable
Step 3 - Clique no símbolo destacado na caixa de cor vermelha na tela acima para exibir o plano de execução estimado conforme mostrado na captura de tela a seguir.

Step 4- Posicione o mouse na varredura da mesa, que é o segundo símbolo acima da caixa de cor vermelha na tela acima para exibir o plano de execução estimado em detalhes. A seguinte captura de tela é exibida.

Exemplo 2
A seguir está o procedimento para visualizar o plano de execução real.
Step 1Conecte-se à instância do SQL Server. Nesse caso, 'TESTINSTANCE' é o nome da instância.

Step 2- Clique na opção Nova Consulta exibida na tela acima e escreva a seguinte consulta. Antes de escrever a consulta, selecione o nome do banco de dados. Nesse caso, 'TestDB' é o nome do banco de dados.
Select * from StudentTable
Step 3 - Clique no símbolo destacado em uma caixa de cor vermelha na tela acima e execute a consulta para exibir o plano de execução real junto com o resultado da consulta, conforme mostrado na captura de tela a seguir.

Step 4- Posicione o mouse na varredura da mesa, que é o segundo símbolo acima da caixa de cor vermelha na tela para exibir o plano de execução real em detalhes. A seguinte captura de tela é exibida.

Step 5 - Clique em Resultados que está no canto superior esquerdo da tela acima para obter a tela a seguir.

Este serviço é usado para realizar ETL (Extração, Transformar e Carregar dados) e operações administrativas. O BIDS (Business Intelligence Studio até 2008 R2) e o SSDT (SQL Server Data Tools de 2012) são os ambientes para desenvolver pacotes.
Arquitetura Básica SSIS
Solução (coleção de projetos) ---> Projeto (coleção de pacotes) ---> Pacote (coleção de tarefas para operações ETL e admin)
Em Pacote, os seguintes componentes estão disponíveis -
- Fluxo de controle (recipientes e tarefas)
- Fluxo de dados (fonte, transformações, destinos)
- Manipulador de eventos (envio de mensagens, e-mails)
- Package Explorer (uma visão única para todos no pacote)
- Parâmetros (interação do usuário)
A seguir estão as etapas para abrir BIDS \ SSDT.
Step 1- Abra BIDS \ SSDT com base na versão do grupo de programas Microsoft SQL Server. A tela a seguir é exibida.
Step 2- A tela acima mostra que o SSDT foi aberto. Vá para o arquivo no canto superior esquerdo da imagem acima e clique em Novo. Selecione o projeto e a tela a seguir será aberta.

Step 3 - Selecione Integration Services em Business Intelligence no canto superior esquerdo da tela acima para obter a tela a seguir.

Step 4 - Na tela acima, selecione Projeto do Integration Services ou Assistente de Importação do Projeto do Integration Services com base em sua necessidade de desenvolver \ criar o pacote.
Este serviço é usado para analisar grandes quantidades de dados e aplicar às decisões de negócios. Também é usado para criar modelos de negócios bidimensionais ou multidimensionais.
Na versão SQL Server 2000, é denominado MSAS (Microsoft Analysis Services).
Do SQL Server 2005, é denominado SSAS (SQL Server Analysis Services).
Modos
Existem dois modos - Modo Nativo (Modo SQL Server) e Modo de Ponto de Compartilhamento.
Modelos
Existem dois modelos - Modelo Tabular (para Análise de Equipe e Pessoal) e Modelo Multidimensional (para Análise Corporativa).
Os BIDS (Business Intelligence Studio até 2008 R2) e SSDT (SQL Server Data Tools de 2012) são ambientes para trabalhar com SSAS.
Step 1- Abra BIDS \ SSDT com base na versão do grupo de programas Microsoft SQL Server. A tela a seguir aparecerá.

Step 2- A tela acima mostra que o SSDT foi aberto. Vá para o arquivo no canto superior esquerdo da imagem acima e clique em Novo. Selecione o projeto e a tela a seguir será aberta.

Step 3- Selecione Analysis Services na tela acima em Business Intelligence como visto no canto superior esquerdo. A tela a seguir é exibida.
Step 4 - Na tela acima, selecione qualquer uma das cinco opções listadas com base em sua necessidade de trabalhar com serviços de análise.