OrientDB - Guia Rápido
OrientDB é um sistema de gerenciamento de banco de dados NoSQL de código aberto. NoSQL Databasefornece um mecanismo para armazenar e recuperar dados NÃO-relacionais ou NÃO-relacionais que se referem a dados diferentes dos dados tabulares, como dados de documentos ou dados gráficos. Os bancos de dados NoSQL são cada vez mais usados em Big Data e aplicativos da web em tempo real. Os sistemas NoSQL às vezes também são chamados de "Não apenas SQL" para enfatizar que eles podem oferecer suporte a linguagens de consulta semelhantes a SQL.
OrientDB também pertence à família NoSQL. OrientDB é um banco de dados gráfico distribuído de segunda geração com a flexibilidade de documentos em um produto com um código-fonte aberto da licença Apache 2. Havia vários bancos de dados NoSQL no mercado antes do OrientDB, sendo um deles o MongoDB.
MongoDB vs OrientDB
MongoDB e OrientDB contêm muitos recursos comuns, mas os mecanismos são fundamentalmente diferentes. O MongoDB é um banco de dados de documentos puro e o OrientDB é um documento híbrido com mecanismo gráfico.
| Características | MongoDB | OrientDB |
|---|---|---|
| Relationships | Usa o RDBMS JOINS para criar relacionamento entre entidades. Ele tem alto custo de tempo de execução e não aumenta quando a escala do banco de dados aumenta. | Incorpora e conecta documentos como banco de dados relacional. Ele usa links diretos e super-rápidos tirados do mundo do banco de dados gráfico. |
| Fetch Plan | Operações JOIN caras. | Retorna facilmente o gráfico completo com documentos interconectados. |
| Transactions | Não suporta transações ACID, mas suporta operações atômicas. | Suporta transações ACID, bem como operações atômicas. |
| Query language | Possui linguagem própria baseada em JSON. | A linguagem de consulta é construída em SQL. |
| Indexes | Usa o algoritmo B-Tree para todos os índices. | Suporta três algoritmos de indexação diferentes para que o usuário possa obter o melhor desempenho. |
| Storage engine | Usa técnica de mapeamento de memória. | Usa o nome do mecanismo de armazenamento LOCAL e PLOCAL. |
OrientDB é o primeiro NoSQL DBMS de código aberto com vários modelos que reúne o poder dos gráficos e a flexibilidade dos documentos em um banco de dados operacional escalonável de alto desempenho.
O arquivo de instalação do OrientDB está disponível em duas edições -
Community Edition - A edição da comunidade OrientDB é lançada pela Apache sob a licença 0.2 como um código aberto
Enterprise Edition- A edição corporativa do OrientDB é lançada como um software proprietário, que se baseia na edição comunitária. Ele serve como uma extensão da edição da comunidade.
Este capítulo explica o procedimento de instalação da edição da comunidade OrientDB porque é um código aberto.
Pré-requisitos
As edições Community e Enterprise podem ser executadas em qualquer sistema operacional que implemente o Java Virtual Machine (JVM). OrientDB requer Java com versão 1.7 ou posterior.
Use as etapas a seguir para baixar e instalar o OrientDB em seu sistema.
Etapa 1 - Baixe o arquivo de configuração binária OrientDB
OrientDB vem com arquivo de configuração embutido para instalar o banco de dados em seu sistema. Ele fornece diferentes pacotes binários pré-compilados (pacotes com tar ou compactados) para diferentes sistemas operacionais. Você pode baixar arquivos OrientDB no link Baixar OrientDB .
A imagem a seguir mostra a página de download do OrientDB. Você pode baixar o arquivo compactado ou tarado clicando no ícone do sistema operacional adequado.
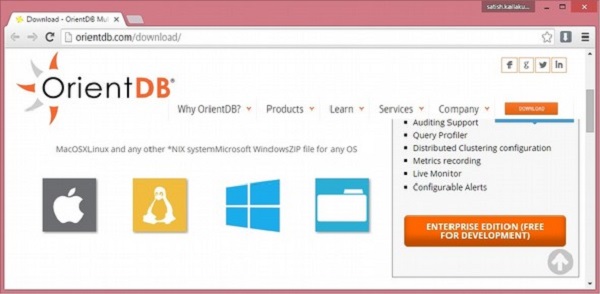
No download, você obterá o pacote binário em seu Downloads pasta.
Etapa 2 - Extrair e instalar o OrientDB
A seguir está o procedimento para extrair e instalar o OrientDB para diferentes sistemas operacionais.
Em Linux
Após o download, você obterá orientdb-community-2.1.9.tar.gz arquivo em seu Downloadspasta. Você pode usar o seguinte comando para extrair o arquivo tarred.
$ tar –zxvf orientdb-community-2.1.9.tar.gzVocê pode usar o seguinte comando para mover todos os arquivos da biblioteca OrientDB de orientdbcommunity-2.1.9 to /opt/orientdb/diretório. Aqui, estamos usando o comando de superusuário (sudo), portanto, você deve fornecer a senha de superusuário para executar o seguinte comando.
$ sudo mv orientdb-community-2.1.9 /opt/orientdbVocê pode usar os seguintes comandos para registrar o orientdb comando e o servidor Orient.
$ export ORIENTDB_HoME = /opt/orientdb $ export PATH = $PATH:$ORIENTDB_HOME/binNo Windows
Após o download, você obterá orientdb-community-2.1.9.zip arquivo em seu Downloadspasta. Extraia o arquivo zip usando o extrator zip.
Mova a pasta extraída para o C:\ diretório.
Crie duas variáveis de ambiente ORIENTDB_HOME e variáveis PATH com os seguintes valores fornecidos.
ORIENT_HOME = C:\orientdb-community-2.1.9
PATH = C:\orientdb-community-2.1.9\binEtapa 3 - Configurando o Servidor OrientDB como um serviço
Seguindo as etapas acima, você pode usar a versão Desktop do OrientDB. Você pode iniciar o servidor de banco de dados OrientDB como um serviço usando as etapas a seguir. O procedimento é diferente, dependendo do seu sistema operacional.
Em Linux
OrientDB fornece um arquivo de script chamado orientdb.shpara executar o banco de dados como um daemon. Você pode localizá-lo no diretório bin / do diretório de instalação do OrientDB que é $ ORIENTDB_HOME / bin / orientdb.sh.
Antes de executar o arquivo de script, você deve editar orientdb.sharquivo para definir duas variáveis. Um éORIENTDB_DIR que define o caminho para o diretório de instalação (/opt/orientdb) e o segundo é ORIENTDB_USER que define o nome de usuário para o qual você deseja executar o OrientDB como segue.
ORIENTDB_DIR = "/opt/orientdb"
ORIENTDB_USER = "<username you want to run OrientDB>"Use o seguinte comando para copiar orientdb.sh arquivo em /etc/init.d/diretório para inicializar e executar o script. Aqui, estamos usando o comando de superusuário (sudo), portanto, você deve fornecer a senha de superusuário para executar o seguinte comando.
$ sudo cp $ORIENTDB_HOME/bin/orientdb.sh /etc/init.d/orientdbUse o seguinte comando para copiar o arquivo console.sh do diretório de instalação do OrientDB que é $ORIENTDB_HOME/bin para o diretório bin do sistema que é /usr/bin para acessar o console do Orient DB.
$ sudo cp $ ORIENTDB_HOME/bin/console.sh /usr/bin/orientdbUse o seguinte comando para iniciar o servidor de banco de dados ORIENTDB como serviço. Aqui você tem que fornecer a senha do respectivo usuário mencionada no arquivo orientdb.sh para iniciar o servidor.
$ service orientdb startUse o seguinte comando para saber em qual PID o daemon do servidor OrientDB está sendo executado.
$ service orientdb statusUse o seguinte comando para parar o daemon do servidor OrientDB. Aqui você tem que fornecer a senha do respectivo usuário, que você mencionou no arquivo orientdb.sh para parar o servidor.
$ service orientdb stopNo Windows
OrientDB é um aplicativo de servidor, portanto, ele deve executar várias tarefas antes de iniciar o encerramento do processo da máquina virtual Java. Se você deseja desligar o servidor OrientDB manualmente, você deve executarshutdown.batArquivo. Mas as instâncias do servidor não param corretamente, quando o sistema é desligado repentinamente sem executar o script acima. Os programas que são controlados pelo sistema operacional com um conjunto de sinais especificados são chamadosservices no Windows.
Temos que usar Apache Common Daemonque permitem aos usuários do Windows agrupar aplicativos Java como serviço do Windows. A seguir está o procedimento para baixar e registrar o daemon comum do Apache.
Clique no link a seguir para Apache Common Daemons para Windows .
Clique em common-daemon-1.0.15-bin-windows baixar.
Descompacte o common-daemon-1.0.15-bin-windowsdiretório. Depois de extrair, você encontraráprunsrv.exe e prunmgr.exearquivos dentro do diretório. Naqueles -
prunsrv.exe file é um aplicativo de serviço para executar aplicativos como serviços.
prunmgr.exe arquivo é um aplicativo usado para monitorar e configurar serviços do Windows.
Vá para a pasta de instalação do OrientDB → crie um novo diretório e nomeie-o como serviço.
Copie o prunsrv.exe e prunmgr .exe cole-o no diretório de serviço.
Para configurar o OrientDB como serviço do Windows, é necessário executar um pequeno script que usa o prusrv.exe como serviço do Windows.
Antes de definir os serviços do Windows, você deve renomear prunsrv e prunmgr de acordo com o nome do serviço. Por exemplo, OrientDBGraph e OrientDBGraphw respectivamente. Aqui, OrientDBGraph é o nome do serviço.
Copie o seguinte script no arquivo denominado installService.bat e coloque-o em %ORIENTDB_HOME%\service\ diretório.
:: OrientDB Windows Service Installation
@echo off
rem Remove surrounding quotes from the first parameter
set str=%~1
rem Check JVM DLL location parameter
if "%str%" == "" goto missingJVM
set JVM_DLL=%str%
rem Remove surrounding quotes from the second parameter
set str=%~2
rem Check OrientDB Home location parameter
if "%str%" == "" goto missingOrientDBHome
set ORIENTDB_HOME=%str%
set CONFIG_FILE=%ORIENTDB_HOME%/config/orientdb-server-config.xml
set LOG_FILE = %ORIENTDB_HOME%/config/orientdb-server-log.properties
set LOG_CONSOLE_LEVEL = info
set LOG_FILE_LEVEL = fine
set WWW_PATH = %ORIENTDB_HOME%/www
set ORIENTDB_ENCODING = UTF8
set ORIENTDB_SETTINGS = -Dprofiler.enabled = true
-Dcache.level1.enabled = false Dcache.level2.strategy = 1
set JAVA_OPTS_SCRIPT = -XX:+HeapDumpOnOutOfMemoryError
rem Install service
OrientDBGraphX.X.X.exe //IS --DisplayName="OrientDB GraphEd X.X.X" ^
--Description = "OrientDB Graph Edition, aka GraphEd, contains OrientDB server
integrated with the latest release of the TinkerPop Open Source technology
stack supporting property graph data model." ^
--StartClass = com.orientechnologies.orient.server.OServerMain
-StopClass = com.orientechnologies.orient.server.OServerShutdownMain ^
--Classpath = "%ORIENTDB_HOME%\lib\*" --JvmOptions
"Dfile.Encoding = %ORIENTDB_ENCODING%; Djava.util.logging.config.file = "%LOG_FILE%";
Dorientdb.config.file = "%CONFIG_FILE%"; -Dorientdb.www.path = "%WWW_PATH%";
Dlog.console.level = %LOG_CONSOLE_LEVEL%; -Dlog.file.level = %LOG_FILE_LEVEL%;
Dorientdb.build.number = "@BUILD@"; -DORIENTDB_HOME = %ORIENTDB_HOME%" ^
--StartMode = jvm --StartPath = "%ORIENTDB_HOME%\bin" --StopMode = jvm
-StopPath = "%ORIENTDB_HOME%\bin" --Jvm = "%JVM_DLL%"
-LogPath = "%ORIENTDB_HOME%\log" --Startup = auto
EXIT /B
:missingJVM
echo Insert the JVM DLL location
goto printUsage
:missingOrientDBHome
echo Insert the OrientDB Home
goto printUsage
:printUsage
echo usage:
echo installService JVM_DLL_location OrientDB_Home
EXIT /BO script requer dois parâmetros -
A localização de jvm.dll, por exemplo, C: \ ProgramFiles \ java \ jdk1.8.0_66 \ jre \ bin \ server \ jvm.dll
A localização da instalação do OrientDB, por exemplo, C: \ orientdb-community-2.1.9
O serviço é instalado quando você executa o arquivo OrientDBGraph.exe (original prunsrv) e clica duas vezes nele.
Use o seguinte comando para instalar serviços no Windows.
> Cd %ORIENTDB_HOME%\service
> installService.bat "C:\Program Files\Java\jdk1.8.0_66\jre\bin\server
\jvm.dll" C:\orientdb-community-2.1.9Abra os serviços do Gerenciador de Tarefas, você encontrará a seguinte captura de tela com o nome do serviço registrado.
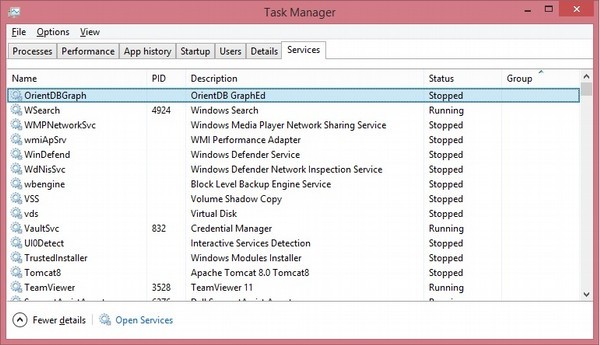
Etapa 4 - Verificando a instalação do OrientDB
Esta etapa verifica a instalação do servidor de banco de dados OrientDB usando as etapas a seguir.
- Execute o servidor.
- Execute o console.
- Administre o estúdio.
Isso é único de acordo com o sistema operacional.
Em Linux
Siga o procedimento fornecido para verificar a instalação do OrientDB no Linux.
Running the server - Você pode usar o seguinte comando para iniciar o servidor.
$ cd $ORIENTDB_HOME/bin $ ./server.shOu você pode usar o seguinte comando para iniciar o servidor OrientDB como daemon UNIX.
$ service orientdb startSe for instalado com sucesso, você receberá a seguinte saída.
.
.` `
, `:.
`,` ,:`
.,. :,,
.,, ,,,
. .,.::::: ```` ::::::::: :::::::::
,` .::,,,,::.,,,,,,`;; .: :::::::::: ::: :::
`,. ::,,,,,,,:.,,.` ` .: ::: ::: ::: :::
,,:,:,,,,,,,,::. ` ` `` .: ::: ::: ::: :::
,,:.,,,,,,,,,: `::, ,, ::,::` : :,::` :::: ::: ::: ::: :::
,:,,,,,,,,,,::,: ,, :. : :: : .: ::: ::: :::::::
:,,,,,,,,,,:,:: ,, : : : : .: ::: ::: :::::::::
` :,,,,,,,,,,:,::, ,, .:::::::: : : .: ::: ::: ::: :::
`,...,,:,,,,,,,,,: .:,. ,, ,, : : .: ::: ::: ::: :::
.,,,,::,,,,,,,: `: , ,, : ` : : .: ::: ::: ::: :::
...,::,,,,::.. `: .,, :, : : : .: ::::::::::: ::: :::
,::::,,,. `: ,, ::::: : : .: ::::::::: ::::::::::
,,:` `,,.
,,, .,`
,,. `, GRAPH DATABASE
`` `.
`` orientdb.com
`
2016-01-20 19:17:21:547 INFO OrientDB auto-config DISKCACHE = 1,
649MB (heap = 494MB os = 4, 192MB disk = 199, 595MB) [orientechnologies]
2016-01-20 19:17:21:816 INFO Loading configuration from:
/opt/orientdb/config/orientdb-server-config.xml... [OServerConfigurationLoaderXml]
2016-01-20 19:17:22:213 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is starting up... [OServer]
2016-01-20 19:17:22:220 INFO Databases directory: /opt/orientdb/databases [OServer]
2016-01-20 19:17:22:361 INFO Port 0.0.0.0:2424 busy,
trying the next available... [OServerNetworkListener]
2016-01-20 19:17:22:362 INFO Listening binary connections on 0.0.0.0:2425
(protocol v.32, socket = default) [OServerNetworkListener]
...
2016-01-20 19:17:22:614 INFO Installing Script interpreter. WARN:
authenticated clients can execute any kind of code into the server
by using the following allowed languages:
[sql] [OServerSideScriptInterpreter]
2016-01-20 19:17:22:615 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is active. [OServer]Running the console - Você pode usar o seguinte comando para executar o OrientDB no console.
$ orientdbSe for instalado com sucesso, você receberá a seguinte saída.
OrientDB console v.2.1.9-SNAPSHOT (build 2.1.x@r; 2016-01-07 10:51:24+0000) www.orientdb.com
Type 'help' to display all the supported commands.
Installing extensions for GREMLIN language v.2.6.0
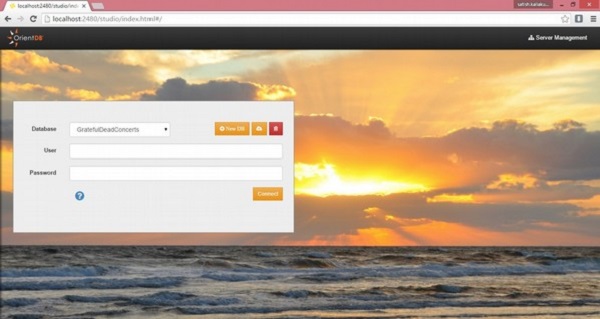
orientdb>Running the Studio - Depois de iniciar o servidor, você pode usar a seguinte URL (http://localhost:2480/) no seu navegador. Você obterá a seguinte captura de tela.
No Windows
Siga o procedimento fornecido para verificar a instalação do OrientDB no Windows.
Running the server - Você pode usar o seguinte comando para iniciar o servidor.
> cd %ORIENTDB_HOME%\bin
> ./server.batSe for instalado com sucesso, você receberá a seguinte saída.
.
.` `
, `:.
`,` ,:`
.,. :,,
.,, ,,,
. .,.::::: ```` ::::::::: :::::::::
,` .::,,,,::.,,,,,,`;; .: :::::::::: ::: :::
`,. ::,,,,,,,:.,,.` ` .: ::: ::: ::: :::
,,:,:,,,,,,,,::. ` ` `` .: ::: ::: ::: :::
,,:.,,,,,,,,,: `::, ,, ::,::` : :,::` :::: ::: ::: ::: :::
,:,,,,,,,,,,::,: ,, :. : :: : .: ::: ::: :::::::
:,,,,,,,,,,:,:: ,, : : : : .: ::: ::: :::::::::
` :,,,,,,,,,,:,::, ,, .:::::::: : : .: ::: ::: ::: :::
`,...,,:,,,,,,,,,: .:,. ,, ,, : : .: ::: ::: ::: :::
.,,,,::,,,,,,,: `: , ,, : ` : : .: ::: ::: ::: :::
...,::,,,,::.. `: .,, :, : : : .: ::::::::::: ::: :::
,::::,,,. `: ,, ::::: : : .: ::::::::: ::::::::::
,,:` `,,.
,,, .,`
,,. `, GRAPH DATABASE
`` `.
`` orientdb.com
`
2016-01-20 19:17:21:547 INFO OrientDB auto-config DISKCACHE = 1,649MB
(heap = 494MB os = 4, 192MB disk = 199, 595MB) [orientechnologies]
2016-01-20 19:17:21:816 INFO Loading configuration from:
/opt/orientdb/config/orientdb-server-config.xml...
[OServerConfigurationLoaderXml]
...
2016-01-20 19:17:22:615 INFO OrientDB Server v2.1.9-SNAPSHOT
(build 2.1.x@r; 2016-01-07 10:51:24+0000) is active. [OServer]Running the console - Você pode usar o seguinte comando para executar o OrientDB no console.
> %ORIENTDB_HOME%\bin\console.batSe for instalado com sucesso, você receberá a seguinte saída.
OrientDB console v.2.1.9-SNAPSHOT (build 2.1.x@r; 2016-01-07 10:51:24+0000) www.orientdb.com
Type 'help' to display all the supported commands.
Installing extensions for GREMLIN language v.2.6.0
orientdb\>Running the Studio - Depois de iniciar o servidor, você pode usar a seguinte URL (http://localhost:2480/) no seu navegador. Você obterá a seguinte captura de tela.
A principal característica do OrientDB é oferecer suporte a objetos de vários modelos, ou seja, ele suporta diferentes modelos como Documento, Gráfico, Chave / Valor e Objeto Real. Ele contém uma API separada para oferecer suporte a todos esses quatro modelos.
Modelo de Documento
A terminologia Document model pertence ao banco de dados NoSQL. Isso significa que os dados são armazenados nos Documentos e o grupo de Documentos são chamados deCollection. Tecnicamente, documento significa um conjunto de pares de chave / valor ou também conhecido como campos ou propriedades.
OrientDB usa conceitos como classes, clusters e link para armazenar, agrupar e analisar os documentos.
A tabela a seguir ilustra a comparação entre o modelo relacional, modelo de documento e modelo de documento OrientDB -
| Modelo Relacional | Modelo de Documento | Modelo de Documento OrientDB |
|---|---|---|
| Mesa | Coleção | Classe ou Cluster |
| Linha | Documento | Documento |
| Coluna | Par chave / valor | Campo de documento |
| Relação | Não disponível | Ligação |
Modelo de Gráfico
Uma estrutura de dados de gráfico é um modelo de dados que pode armazenar dados na forma de vértices (nós) interconectados por arestas (arcos). A ideia do banco de dados gráfico OrientDB veio do gráfico de propriedades. O vértice e a aresta são os principais artefatos do modelo Graph. Eles contêm as propriedades, que podem fazer com que pareçam semelhantes a documentos.
A tabela a seguir mostra uma comparação entre o modelo de gráfico, o modelo de dados relacionais e o modelo de gráfico OrientDB.
| Modelo Relacional | Modelo de Gráfico | Modelo de gráfico OrientDB |
|---|---|---|
| Mesa | Classe Vertex e Edge | Classe que estende "V" (para vértices) e "E" (para bordas) |
| Linha | Vértice | Vértice |
| Coluna | Propriedade de vértice e borda | Propriedade de vértice e borda |
| Relação | Beira | Beira |
O Modelo Chave / Valor
O modelo Chave / Valor significa que os dados podem ser armazenados na forma de par chave / valor, onde os valores podem ser de tipos simples e complexos. Ele pode suportar documentos e elementos gráficos como valores.
A tabela a seguir ilustra a comparação entre o modelo relacional, modelo de chave / valor e modelo de chave / valor OrientDB.
| Modelo Relacional | Modelo de chave / valor | Modelo de chave / valor OrientDB |
|---|---|---|
| Mesa | Balde | Classe ou Cluster |
| Linha | Par chave / valor | Documento |
| Coluna | Não disponível | Campo do documento ou propriedade Vértice / Borda |
| Relação | Não disponível | Ligação |
O modelo de objeto
Este modelo foi herdado pela programação orientada a objetos e suporta Inheritance entre tipos (subtipos estendem os supertipos), Polymorphism quando você se refere a uma classe base e Direct binding de / para Objetos usados em linguagens de programação.
A tabela a seguir ilustra a comparação entre o modelo relacional, o modelo de objeto e o modelo de objeto OrientDB.
| Modelo Relacional | Modelo de Objeto | Modelo de Objeto OrientDB |
|---|---|---|
| Mesa | Classe | Classe ou Cluster |
| Linha | Objeto | Documento ou vértice |
| Coluna | Propriedade do objeto | Campo do documento ou propriedade Vértice / Borda |
| Relação | Pointer | Ligação |
Antes de prosseguir em detalhes, é melhor conhecer a terminologia básica associada ao OrientDB. A seguir estão algumas das terminologias importantes.
Registro
A menor unidade que você pode carregar e armazenar no banco de dados. Os registros podem ser armazenados em quatro tipos.
- Document
- Bytes de registro
- Vertex
- Edge
ID de registro
Quando OrientDB gera um registro, o servidor de banco de dados atribui automaticamente um identificador de unidade ao registro, chamado RecordID (RID). O RID se parece com # <cluster>: <position>. <cluster> significa número de identificação do cluster e <position> significa posição absoluta do registro no cluster.
Documentos
O Documento é o tipo de registro mais flexível disponível no OrientDB. Os documentos são digitados suavemente e são definidos por classes de esquema com restrição definida, mas você também pode inserir o documento sem qualquer esquema, ou seja, ele também suporta o modo sem esquema.
Os documentos podem ser facilmente exportados e importados no formato JSON. Por exemplo, dê uma olhada no seguinte documento de amostra JSON. Ele define os detalhes do documento.
{
"id" : "1201",
"name" : "Jay",
"job" : "Developer",
"creations" : [
{
"name" : "Amiga",
"company" : "Commodore Inc."
},
{
"name" : "Amiga 500",
"company" : "Commodore Inc."
}
]
}RecordBytes
O tipo de registro é igual ao tipo BLOB no RDBMS. OrientDB pode carregar e armazenar o tipo de registro de documento junto com dados binários.
Vértice
O banco de dados OrientDB não é apenas um banco de dados de documentos, mas também um banco de dados Graph. Os novos conceitos como Vertex e Edge são usados para armazenar os dados na forma de gráfico. Em bancos de dados gráficos, a unidade de dados mais básica é o nó, que no OrientDB é chamado de vértice. O Vertex armazena informações para o banco de dados.
Beira
Há um tipo de registro separado denominado Edge que conecta um vértice a outro. As arestas são bidirecionais e só podem conectar dois vértices. Existem dois tipos de arestas no OrientDB, uma é regular e outra leve.
Classe
A classe é um tipo de modelo de dados e o conceito extraído do paradigma de programação orientada a objetos. Com base no modelo de banco de dados de documentos tradicional, os dados são armazenados na forma de coleção, enquanto no modelo de banco de dados Relacional os dados são armazenados em tabelas. O OrientDB segue a API do Documento juntamente com o paradigma OPPS. Como conceito, a classe em OrientDB tem o relacionamento mais próximo com a tabela em bancos de dados relacionais, mas (ao contrário das tabelas) as classes podem ser sem esquema, com esquema completo ou mistas. As classes podem herdar de outras classes, criando árvores de classes. Cada classe tem seu próprio cluster ou clusters (criados por padrão, se nenhum estiver definido).
Grupo
Cluster é um conceito importante usado para armazenar registros, documentos ou vértices. Em palavras simples, Cluster é um local onde um grupo de registros é armazenado. Por padrão, o OrientDB criará um cluster por classe. Todos os registros de uma classe são armazenados no mesmo cluster com o mesmo nome da classe. Você pode criar até 32.767 (2 ^ 15-1) clusters em um banco de dados.
A classe CREATE é um comando usado para criar um cluster com um nome específico. Depois que o cluster é criado, você pode usar o cluster para salvar registros, especificando o nome durante a criação de qualquer modelo de dados.
Relacionamentos
OrientDB oferece suporte a dois tipos de relacionamentos: referenciado e incorporado. Referenced relationships significa que ele armazena link direto para os objetos de destino dos relacionamentos. Embedded relationshipssignifica que ele armazena o relacionamento dentro do registro que o incorpora. Esse relacionamento é mais forte do que o relacionamento de referência.
Base de dados
O banco de dados é uma interface para acessar o armazenamento real. A TI entende conceitos de alto nível, como consultas, esquemas, metadados, índices e assim por diante. OrientDB também fornece vários tipos de banco de dados. Para obter mais informações sobre esses tipos, consulte Tipos de banco de dados.
OrientDB suporta vários tipos de dados nativamente. A seguir está a tabela completa sobre o mesmo.
| Sr. Não. | Tipo | Descrição |
|---|---|---|
| 1 | boleano | Lida apenas com os valores True ou False. Java types: java.lang.Boolean Min: 0 Max: 1 |
| 2 | Inteiro | Inteiros assinados de 32 bits. Java types: java.lang.Interger Min: -2.147.483.648 Max: +2.147.483.647 |
| 3 | Baixo | Inteiros pequenos com sinal de 16 bits. Java types: java.lang.short Min: -32.768 Max: 32.767 |
| 4 | Grandes | Grandes inteiros assinados de 64 bits. Java types: java.lang.Long Min: -2 63 Max: +2 63 -1 |
| 5 | Flutuador | Números decimais. Java types: java.lang.Float : 2 -149 Max: (2-2 -23 ) * 2, 127 |
| 6 | em dobro | Números decimais com alta precisão. Java types: Java.lang.Double. Min: 2 -1074 Max: (2-2 -52 ) * 2 1023 |
| 7 | Data hora | Qualquer data com precisão de até milissegundos. Java types: java.util.Date |
| 8 | Corda | Qualquer string como sequência alfanumérica de caracteres. Java types: java.lang.String |
| 9 | Binário | Pode conter qualquer valor como matriz de bytes. Java types: byte [] Min: 0 Max: 2.147.483.647 |
| 10 | embutido | O registro está contido dentro do proprietário. O registro contido não tem RecordId. Java types: ORecord |
| 11 | Lista incorporada | Os registros ficam dentro do proprietário. Os registros contidos não têm RecordIds e são acessíveis apenas navegando pelo registro do proprietário. Java types: Listar <objetos> Min: 0 Max: 41.000.000 itens |
| 12 | Conjunto incorporado | Os registros ficam dentro do proprietário. Os registros contidos não têm RecordId e são acessíveis apenas navegando pelo registro do proprietário. Java types: definir <objetos> Min: 0 Max: 41.000.000 itens |
| 13 | Mapa embutido | Os registros estão contidos dentro do proprietário como valores das entradas, enquanto as chaves podem ser apenas strings. Os registros contidos não têm RecordId e são acessíveis apenas navegando no Registro do proprietário. Java types: Map <String, ORecord> Min: 0 Max: 41.000.000 itens |
| 14 | Ligação | Link para outro registro. É um relacionamento um para um comum Java Types: ORID, <? estende ORecord> Min: 1 Max: 32767: 2 ^ 63-1 |
| 15 | Lista de links | Links para outros registros. É um relacionamento um-para-muitos comum, em que apenas os RecordIds são armazenados. Java types: Lista <? Estende ORecord> Min: 0 Max: 41.000.000 itens |
| 16 | Conjunto de links | Links para outros registros. É um relacionamento comum de um para muitos. Java types: Definir <? estende ORecord> Min: 0 Max: 41.000.000 itens |
| 17 | Mapa de link | Links para outros registros como valor das entradas, enquanto as chaves podem ser apenas strings. É um relacionamento comum de um para muitos. Apenas os RecordIds são armazenados. Java types: Map <String,? extends Record> Min: 0 Max: 41.000.000 itens |
| 18 | Byte | Byte único. Útil para armazenar pequenos inteiros assinados de 8 bits. Java types: java.lang.Byte Min: -128 Max: +127 |
| 19 | Transiente | Qualquer valor não armazenado no banco de dados. |
| 20 | Encontro | Qualquer data como ano, mês e dia. Java Types: java.util.Date |
| 21 | personalizadas | Usado para armazenar um tipo personalizado fornecendo os métodos Marshall e Unmarshall. Java types: OSerializableStream Min: 0 Max: x |
| 22 | Decimal | Números decimais sem arredondamento. Java types: java.math.BigDecimal |
| 23 | LinkBag | Lista de RecordIds como RidBag específico. Java types: ORidBag |
| 24 | Qualquer | Tipo não determinado, usado para especificar coleções de tipo misto e nulo. |
Nos capítulos seguintes, é discutido como usar esses tipos de dados no OrientDB.
O OrientDB Console é um aplicativo Java feito para funcionar em bancos de dados OrientDB e instâncias de servidor. Existem vários modos de console que o OrientDB suporta.
Modo Interativo
Este é o modo padrão. Basta iniciar o console executando o seguinte scriptbin/console.sh (ou bin/console.batem sistemas MS Windows). Certifique-se de ter permissão de execução nele.
OrientDB console v.1.6.6 www.orientechnologies.com
Type 'help' to display all the commands supported.
orientdb>Uma vez feito isso, o console está pronto para aceitar comandos.
Modo de lote
Para executar comandos em lote, execute o seguinte bin/console.sh (ou bin/console.bat em sistemas MS Windows) script passando todos os comandos separados por ponto e vírgula ";".
orientdb> console.bat "connect remote:localhost/demo;select * from profile"Ou chame o script do console passando o nome do arquivo em formato de texto contendo a lista de comandos a serem executados. Os comandos devem ser separados por ponto e vírgula ";".
Exemplo
Command.txt contém a lista de comandos que você deseja executar por meio do console OrientDB. O comando a seguir aceita o lote de comandos do arquivo command.txt.
orientdb> console.bat commands.txtNo modo batch, você pode ignorar os erros para permitir que o script continue a execução definindo a variável "ignoreErrors" como true.
orientdb> set ignoreErrors trueHabilitar Eco
Ao executar comandos do console no pipeline, você precisará exibi-los. Habilite o "eco" de comandos definindo-o como propriedade no início. A seguir está a sintaxe para habilitar a propriedade echo no console OrientDB.
orientdb> set echo trueO SQL Reference do banco de dados OrientDB fornece vários comandos para criar, alterar e eliminar bancos de dados.
A instrução a seguir é uma sintaxe básica do comando Create Database.
CREATE DATABASE <database-url> [<user> <password> <storage-type> [<db-type>]]A seguir estão os detalhes sobre as opções na sintaxe acima.
<database-url>- Define a URL do banco de dados. O URL contém duas partes, uma é <mode> e a segunda é <path>.
<mode> - Define o modo, ou seja, modo local ou modo remoto.
<path> - Define o caminho para o banco de dados.
<user> - Define o usuário que você deseja conectar ao banco de dados.
<password> - Define a senha para conexão com o banco de dados.
<storage-type>- Define os tipos de armazenamento. Você pode escolher entre PLOCAL e MEMÓRIA.
Exemplo
Você pode usar o seguinte comando para criar um banco de dados local denominado demo.
Orientdb> CREATE DATABASE PLOCAL:/opt/orientdb/databses/demoSe o banco de dados for criado com êxito, você obterá a seguinte saída.
Database created successfully.
Current database is: plocal: /opt/orientdb/databases/demo
orientdb {db = demo}>O banco de dados é um dos modelos de dados importantes com diferentes atributos que você pode modificar de acordo com seus requisitos.
A instrução a seguir é a sintaxe básica do comando Alter Database.
ALTER DATABASE <attribute-name> <attribute-value>Onde <attribute-name> define o atributo que você deseja modificar e <attributevalue> define o valor que você deseja definir para esse atributo.
A tabela a seguir define a lista de atributos suportados para alterar um banco de dados.
| Sr. Não. | Nome do Atributo | Descrição |
|---|---|---|
| 1 | STATUS | Define o status do banco de dados entre diferentes atributos. |
| 2 | IMPORTANDO | Define o status de importação. |
| 3 | DEFAULTCLUSTERID | Define o cluster padrão usando ID. Por padrão, é 2. |
| 4 | FORMATO DE DATA | Define o formato de data específico como padrão. Por padrão, é "aaaa-MM-dd". |
| 5 | DATETIMEFORMAT | Define o formato de data e hora específico como padrão. Por padrão, é "aaaa-MM-dd HH: mm: ss". |
| 6 | FUSO HORÁRIO | Define o fuso horário específico. Por padrão, é o fuso horário padrão da Java Virtual Machine (JVM). |
| 7 | LOCALECONTRY | Define o país da localidade padrão. Por padrão, é o país de localidade padrão da JVM. Por exemplo: "GB". |
| 8 | LOCALELANGUAGE | Define o idioma local padrão. Por padrão, é o idioma local padrão da JVM. Por exemplo: "en". |
| 9 | CHARSET | Define o tipo de conjunto de caracteres. Por padrão, é o conjunto de caracteres padrão da JVM. Por exemplo: "utf8". |
| 10 | CLUSTERSELECTION | Define a estratégia padrão usada para selecionar o cluster. Essas estratégias são criadas junto com a criação da classe. As estratégias com suporte são default, roundrobin e balanced. |
| 11 | MINIMUMCLUSTERS | Define o número mínimo de clusters a serem criados automaticamente quando uma nova classe é criada. Por padrão, é 1. |
| 12 | PERSONALIZADAS | Define a propriedade personalizada. |
| 13 | VALIDAÇÃO | Desabilita ou habilita as validações para todo o banco de dados. |
Exemplo
A partir da versão do OrientDB-2.2, o novo analisador SQL é adicionado, o que não permite a sintaxe regular em alguns casos. Portanto, temos que desabilitar o novo analisador SQL (StrictSQL) em alguns casos. Você pode usar o seguinte comando do banco de dados Alter para desativar o analisador StrictSQL.
orientdb> ALTER DATABASE custom strictSQL = falseSe o comando for executado com sucesso, você obterá a seguinte saída.
Database updated successfullyComo RDBMS, OrientDB também suporta as operações de backup e restauração. Durante a execução da operação de backup, todos os arquivos do banco de dados atual serão colocados em um formato zip compactado usando o algoritmo ZIP. Este recurso (Backup) pode ser aproveitado automaticamente ativando o plugin do servidor de Backup Automático.
Fazer backup de um banco de dados ou exportar um banco de dados é o mesmo, porém, com base no procedimento que temos que saber quando usar o backup e quando usar a exportação.
Ao fazer o backup, ele criará uma cópia consistente de um banco de dados, todas as outras operações de gravação são bloqueadas e aguardam a conclusão do processo de backup. Nesta operação, ele criará um arquivo de backup somente leitura.
Se você precisar da operação simultânea de leitura e gravação durante o backup, terá que escolher exportar um banco de dados em vez de fazer o backup de um banco de dados. A exportação não bloqueia o banco de dados e permite gravações simultâneas durante o processo de exportação.
A instrução a seguir é a sintaxe básica do backup do banco de dados.
./backup.sh <dburl> <user> <password> <destination> [<type>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<dburl> - O URL do banco de dados onde o banco de dados está localizado no local ou no local remoto.
<user> - Especifica o nome de usuário para executar o backup.
<password> - Fornece a senha para o usuário específico.
<destination> - Local do arquivo de destino informando onde armazenar o arquivo zip de backup.
<type>- Tipo de backup opcional. Ele tem uma das duas opções.
Padrão - bloqueia o banco de dados durante o backup.
LVM - usa o instantâneo de cópia na gravação do LVM em segundo plano.
Exemplo
Faça um backup do banco de dados demo que está localizado no sistema de arquivos local / opt / orientdb / databases / demo em um arquivo chamado sample-demo.zip e localizado no diretório atual.
Você pode usar o seguinte comando para fazer um backup da demonstração do banco de dados.
$ backup.sh plocal: opt/orientdb/database/demo admin admin ./backup-demo.zipUsando o console
O mesmo pode ser feito usando o console do OrientDB. Antes de fazer o backup de um banco de dados específico, você deve primeiro se conectar ao banco de dados. Você pode usar o seguinte comando para se conectar ao banco de dados denominado demo.
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin adminDepois de conectar, você pode usar o seguinte comando para fazer backup do banco de dados em um arquivo chamado 'backup-demo.zip' no diretório atual.
orientdb {db=demo}> BACKUP DATABASE ./backup-demo.zipSe este comando for executado com sucesso, você receberá algumas notificações de sucesso junto com a seguinte mensagem.
Backup executed in 0.30 secondsAssim como o RDBMS, o OrientDB também oferece suporte à operação de restauração. Apenas no modo de console, você pode executar esta operação com sucesso.
A instrução a seguir é a sintaxe básica para a operação de restauração.
orientdb> RESTORE DATABSE <url of the backup zip file>Exemplo
Você deve realizar esta operação apenas no modo de console. Portanto, primeiro você deve iniciar o console do OrientDB usando o seguinte comando OrientDB.
$ orientdbEm seguida, conecte-se ao respectivo banco de dados para restaurar o backup. Você pode usar o seguinte comando para se conectar ao banco de dados denominado demo.
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin adminApós a conexão bem-sucedida, você pode usar o seguinte comando para restaurar o backup do arquivo 'backup-demo.zip'. Antes de executar, certifique-se de que o arquivo backup-demo.zip seja colocado no diretório atual.
Orientdb {db = demo}> RESTORE DATABASE backup-demo.zipSe este comando for executado com sucesso, você receberá algumas notificações de sucesso junto com a seguinte mensagem.
Database restored in 0.26 secondsEste capítulo explica como se conectar a um banco de dados específico a partir da linha de comando OrientDB. Ele abre um banco de dados.
A instrução a seguir é a sintaxe básica do comando Connect.
CONNECT <database-url> <user> <password>A seguir estão os detalhes sobre as opções na sintaxe acima.
<database-url>- Define a URL do banco de dados. URL contém duas partes, uma é <mode> e a segunda é <path>.
<mode> - Define o modo, ou seja, modo local ou modo remoto.
<path> - Define o caminho para o banco de dados.
<user> - Define o usuário que você deseja conectar ao banco de dados.
<password> - Define a senha para conexão com o banco de dados.
Exemplo
Já criamos um banco de dados chamado 'demo' nos capítulos anteriores. Neste exemplo, vamos conectar a ele usando o usuário admin.
Você pode usar o seguinte comando para se conectar ao banco de dados de demonstração.
orientdb> CONNECT PLOCAL:/opt/orientdb/databases/demo admin adminSe for conectado com sucesso, você obterá a seguinte saída -
Connecting to database [plocal:/opt/orientdb/databases/demo] with user 'admin'…OK
Orientdb {db = demo}>Este capítulo explica como se desconectar de um banco de dados específico a partir da linha de comando do OrientDB. Ele fecha o banco de dados aberto no momento.
A instrução a seguir é a sintaxe básica do comando Disconnect.
DISCONNECTNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e ele só fechará o banco de dados em execução no momento.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Vamos nos desconectar do banco de dados de demonstração.
Você pode usar o seguinte comando para desconectar o banco de dados.
orientdb {db = demo}> DISCONNECTSe for desconectado com sucesso, você obterá a seguinte saída -
Disconnecting to database [plocal:/opt/orientdb/databases/demo] with user 'admin'…OK
orientdb>Este capítulo explica como obter informações de um banco de dados específico a partir da linha de comando do OrientDB.
A instrução a seguir é a sintaxe básica do comando Info.
infoNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e ele recuperará as informações apenas do banco de dados em execução no momento.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Iremos recuperar as informações básicas do banco de dados de demonstração.
Você pode usar o seguinte comando para desconectar o banco de dados.
orientdb {db = demo}> infoSe for desconectado com sucesso, você obterá a seguinte saída.
Current database: demo (url = plocal:/opt/orientdb/databases/demo)
DATABASE PROPERTIES
--------------------------------+---------------------------------------------+
NAME | VALUE |
--------------------------------+---------------------------------------------+
Name | null |
Version | 14 |
Conflict Strategy | version |
Date format | yyyy-MM-dd |
Datetime format | yyyy-MM-dd HH:mm:ss |
Timezone | Asia/Kolkata |
Locale Country | IN |
Locale Language | en |
Charset | UTF-8 |
Schema RID | #0:1 |
Index Manager RID | #0:2 |
Dictionary RID | null |
--------------------------------+---------------------------------------------+
DATABASE CUSTOM PROPERTIES:
+-------------------------------+--------------------------------------------+
| NAME | VALUE |
+-------------------------------+--------------------------------------------+
| strictSql | true |
+-------------------------------+--------------------------------------------+
CLUSTERS (collections)
---------------------------------+-------+-------------------+----------------+
NAME | ID | CONFLICT STRATEGY | RECORDS |
---------------------------------+-------+-------------------+----------------+Este capítulo explica como obter a lista de todos os bancos de dados em uma instância da linha de comando OrientDB.
A instrução a seguir é a sintaxe básica do comando info.
LIST DATABASESNote - Você pode usar este comando somente após se conectar a um servidor local ou remoto.
Exemplo
Antes de recuperar a lista de bancos de dados, temos que nos conectar ao servidor localhost através do servidor remoto. É necessário lembrar que o nome de usuário e a senha para se conectar à instância localhost são guest e guest respectivamente, configurados noorintdb/config/orientdb-server-config.xml Arquivo.
Você pode usar o seguinte comando para se conectar à instância do servidor de banco de dados localhost.
orientdb> connect remote:localhost guestEle vai pedir a senha. De acordo com a senha do arquivo de configuração para convidado também é convidado. Se for conectado com sucesso, você obterá a seguinte saída.
Connecting to remote Server instance [remote:localhost] with user 'guest'...OK
orientdb {server = remote:localhost/}>Depois de se conectar ao servidor de banco de dados localhost, você pode usar o seguinte comando para listar os bancos de dados.
orientdb {server = remote:localhost/}> list databasesSe for executado com sucesso, você obterá a seguinte saída -
Found 6 databases:
* demo (plocal)
* s2 (plocal)
* s1 (plocal)
* GratefulDeadConcerts (plocal)
* s3 (plocal)
* sample (plocal)
orientdb {server = remote:localhost/}>Sempre que você quiser tornar o estado do banco de dados estático, significa um estado em que o banco de dados não respondeu a nenhuma das operações de leitura e gravação. Simplificando, o banco de dados está em estado de congelamento.
Neste capítulo, você pode aprender como congelar o banco de dados a partir da linha de comando OrientDB.
A instrução a seguir é a sintaxe básica do comando freeze database.
FREEZE DATABASENote - Você pode usar este comando somente após conectar-se a um banco de dados específico, seja no banco de dados remoto ou local.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Vamos congelar esse banco de dados da CLI.
Você pode usar o seguinte comando para congelar o banco de dados.
Orientdb {db = demo}> FREEZE DATABASESe for executado com sucesso, você obterá a seguinte saída.
Database 'demo' was frozen successfullyNeste capítulo, você pode aprender como liberar o banco de dados do estado de congelamento por meio da linha de comando do OrientDB.
A instrução a seguir é a sintaxe básica do comando do banco de dados Release.
RELEASE DATABASENote - Você pode usar este comando somente após conectar-se a um banco de dados específico, que está em estado de congelamento.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Vamos liberar o banco de dados que foi congelado no capítulo anterior.
Você pode usar o seguinte comando para liberar o banco de dados.
Orientdb {db = demo}> RELEASE DATABASESe for executado com sucesso, você obterá a seguinte saída.
Database 'demo' was release successfullyNeste capítulo, você pode aprender como exibir a configuração de um banco de dados específico por meio da linha de comando do OrientDB. Este comando é aplicável para bancos de dados locais e remotos.
As informações de configuração contêm o cache padrão habilitado ou não, o tamanho desse cache, o valor do fator de carga, memória máxima para mapa, tamanho da página do nó, tamanho mínimo e máximo do pool, etc.
A instrução a seguir é a sintaxe básica do comando config database.
CONFIGNote - Você pode usar este comando somente após conectar-se a um banco de dados específico.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior.
Você pode usar o seguinte comando para exibir a configuração do banco de dados de demonstração.
Orientdb {db = demo}> CONFIGSe for executado com sucesso, você obterá a seguinte saída.
LOCAL SERVER CONFIGURATION:
+---------------------------------------+-------------------------+
| NAME | VALUE |
+---------------------------------------+-------------------------+
| environment.dumpCfgAtStartup | false |
| environment.concurrent | true |
| environment.allowJVMShutdown | true |
| script.pool.maxSize | 20 |
| memory.useUnsafe | true |
| memory.directMemory.safeMode | true |
| memory.directMemory.trackMode | false |
|……………………………….. | |
| storage.lowestFreeListBound | 16 |
| network.binary.debug | false |
| network.http.maxLength | 1000000 |
| network.http.charset | utf-8 |
| network.http.jsonResponseError | true |
| network.http.json | false |
| tx.log.fileType | classic |
| tx.log.synch | false |
| tx.autoRetry | 1 |
| client.channel.minPool | 1 |
| storage.keepOpen | true |
| cache.local.enabled | true |
+---------------------------------------+-------------------------+
orientdb {db = demo}>Na lista de parâmetros de configuração acima, se você quiser alterar qualquer um dos valores do parâmetro, poderá fazê-lo facilmente a partir da linha de comando usando config set e get command.
Conjunto de configuração
Você pode atualizar o valor da variável de configuração usando o CONFIG SET comando.
A instrução a seguir é a sintaxe básica do comando config set.
CONFIG SET <config-variable> <config-value>Note - Você pode usar este comando somente após conectar-se a um banco de dados específico.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Modificaremos o valor da variável 'tx.autoRetry' para 5.
Você pode usar o seguinte comando para definir a configuração do banco de dados de demonstração.
orientdb {db = demo}> CONFIG SET tx.autoRetry 5Se for executado com sucesso, você obterá a seguinte saída.
Local configuration value changed correctlyConfig Get
Você pode exibir o valor da variável de configuração usando o CONFIG GET comando.
A instrução a seguir é a sintaxe básica do comando config get.
CONFIG GET <config-variable>Note - Você pode usar este comando somente após conectar-se a um banco de dados específico.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Tentaremos recuperar o valor da variável 'tx.autoRetry'.
Você pode usar o seguinte comando para exibir a configuração do banco de dados de demonstração.
orientdb {db = demo}> CONFIG GET tx.autoRetrySe for executado com sucesso, você obterá a seguinte saída.
Local configuration: tx.autoRetry = 5Como o RDBMS, o OrientDB também fornece recursos como Exportar e Importar o banco de dados. OrientDB usa o formato JSON para exportar os dados. Por padrão, o comando de exportação usa o algoritmo GZIP para compactar os arquivos.
Ao exportar um banco de dados, ele não está bloqueando o banco de dados, o que significa que você pode executar operações simultâneas de leitura e gravação nele. Também significa que você pode criar uma cópia exata desses dados por causa de operações simultâneas de leitura e gravação.
Neste capítulo, você pode aprender como exportar o banco de dados a partir da linha de comando OrientDB.
A instrução a seguir é a sintaxe básica do comando Export database.
EXPORT DATABASE <output file>Note - Você pode usar este comando somente após conectar-se a um banco de dados específico.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Você pode usar o seguinte comando para exportar o banco de dados para um arquivo denominado 'export-demo'.
orientdb {db = demo}> EXPORT DATABASE ./export-demo.exportSe for executado com sucesso, ele criará um arquivo chamado 'export-demo.zip' ou 'exportdemo.gz' com base no sistema operacional e você obterá a seguinte saída.
Exporting current database to: DATABASE /home/linuxtp/Desktop/demo.export in
GZipped JSON format ...
Started export of database 'demo' to /home/linuxtp/Desktop/demo.export.gz...
Exporting database info...OK
Exporting clusters...OK (12 clusters)
Exporting schema...OK (11 classes)
Exporting records...
- Cluster 'internal' (id = 0)...OK (records = 3/3)
- Cluster 'index' (id = 1)...OK (records = 0/0)
- Cluster 'manindex' (id = 2)...OK (records = 0/0)
- Cluster 'default' (id = 3)...OK (records = 0/0)
- Cluster 'orole' (id = 4)...OK (records = 3/3)
- Cluster 'ouser' (id = 5)...OK (records = 3/3)
- Cluster 'ofunction' (id = 6)...OK (records = 0/0)
- Cluster 'oschedule' (id = 7)...OK (records = 0/0)
- Cluster 'orids' (id = 8)...OK (records = 0/0)
- Cluster 'v' (id = 9)...OK (records = 0/0)
- Cluster 'e' (id = 10)...OK (records = 0/0)
- Cluster '_studio' (id = 11)...OK (records = 1/1)
Done. Exported 10 of total 10 records
Exporting index info...
- Index dictionary...OK
- Index OUser.name...OK
- Index ORole.name...OK
OK (3 indexes)
Exporting manual indexes content...
- Exporting index dictionary ...OK (entries = 0)
OK (1 manual indexes)
Database export completed in 377msSempre que desejar importar o banco de dados, deve-se utilizar o arquivo exportado no formato JSON, gerado pelo comando export.
Neste capítulo, você pode aprender como importar o banco de dados da linha de comando OrientDB.
A instrução a seguir é a sintaxe básica do comando Import database.
IMPORT DATABASE <input file>Note - Você pode usar este comando somente após conectar-se a um banco de dados específico.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Você pode usar o seguinte comando para importar o banco de dados para um arquivo chamado 'export-demo.gz'.
orientdb {db = demo}> IMPORT DATABASE ./export-demo.export.gzSe for executado com sucesso, você obterá a seguinte saída junto com a notificação de sucesso.
Database import completed in 11612msSemelhante ao RDBMS, o OrientDB também fornece conceitos de transação como Commit e Rollback. Commit refere-se ao fechamento da transação salvando todas as alterações no banco de dados. Rollback refere-se à recuperação do estado do banco de dados até o ponto em que você abriu a transação.
A instrução a seguir é a sintaxe básica do comando Commit do banco de dados.
COMMITNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e após o início da transação.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Veremos a operação de confirmar transação e armazenar um registro usando transações.
Primeiro, inicie a transação usando o seguinte BEGIN comando.
orientdb {db = demo}> BEGINEm seguida, insira um registro em uma tabela de funcionários com os valores id = 12 e name = satish.P usando o seguinte comando.
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')Você pode usar o seguinte comando para confirmar a transação.
orientdb> commitSe esta transação for confirmada com sucesso, você obterá a seguinte saída.
Transaction 2 has been committed in 4msNeste capítulo, você aprenderá como reverter a transação não confirmada por meio da interface de linha de comando OrientDB.
A instrução a seguir é a sintaxe básica do comando Rollback do banco de dados.
ROLLBACKNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e após o início da transação.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Veremos a operação de transação de rollback e armazenaremos um registro usando transações.
Primeiro, inicie a transação usando o seguinte BEGIN comando.
orientdb {db = demo}> BEGINEm seguida, insira um registro em uma tabela de funcionários com os valores id = 12 e name = satish.P usando o seguinte comando.
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')Você pode usar o seguinte comando para recuperar os registros da tabela Funcionário.
orientdb> SELECT FROM employee WHERE name LIKE '%.P'Se este comando for executado com sucesso, você obterá a seguinte saída.
---+-------+--------------------
# | ID | name
---+-------+--------------------
0 | 12 | satish.P
---+-------+--------------------
1 item(s) found. Query executed in 0.076 sec(s).Agora você pode usar o seguinte comando para reverter esta transação.
orientdb> ROLLBACKVerifique a consulta selecionada novamente para recuperar o mesmo registro da tabela de funcionários.
orientdb> SELECT FROM employee WHERE name LIKE '%.P'Se o rollback for executado com sucesso, você obterá 0 registros encontrados na saída.
0 item(s) found. Query executed in 0.037 sec(s).De acordo com a terminologia técnica Optimizationsignifica "Alcance o melhor desempenho possível no menor tempo possível." Com referência ao banco de dados, a otimização envolve maximizar a velocidade e eficiência com que os dados são recuperados.
OrientDB oferece suporte a bordas leves, o que significa uma relação direta entre as entidades de dados. Em termos simples, é uma relação campo a campo. OrientDB fornece diferentes maneiras de otimizar o banco de dados. Suporta a conversão de arestas regulares em arestas leves.
A instrução a seguir é a sintaxe básica do comando Optimize database.
OPTMIZE DATABASE [-lwedges] [-noverbose]Onde lwedges converte bordas regulares em bordas leves e noverbose desativa a saída.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos no capítulo anterior. Você pode usar o seguinte comando de otimização do banco de dados.
OPTIMIZE DATABASE -lwedgesSe for executado com sucesso, você receberá algumas notificações de sucesso junto com a mensagem de conclusão.
Database Optimization completed in 35msSemelhante ao RDBMS, o OrientDB fornece o recurso de descartar um banco de dados. Drop database refere-se à remoção completa de um banco de dados.
A declaração a seguir é a sintaxe básica do comando Drop database.
DROP DATABASE [<database-name> <server-username> <server-user-password>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<database-name> - Nome do banco de dados que você deseja eliminar.
<server-username> - Nome de usuário do banco de dados que tem o privilégio de eliminar um banco de dados.
<server-user-password> - Senha do usuário específico.
Exemplo
Existem duas maneiras de eliminar um banco de dados, uma é eliminar um banco de dados aberto no momento e a segunda é eliminar um banco de dados específico fornecendo o nome específico.
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos em um capítulo anterior. Você pode usar o seguinte comando para eliminar um banco de dadosdemo.
orientdb {db = demo}> DROP DATABASESe este comando for executado com sucesso, você obterá a seguinte saída.
Database 'demo' deleted successfullyOR
Você pode usar outro comando para eliminar um banco de dados da seguinte maneira.
orientdb> DROP DATABASE PLOCAL:/opt/orientdb/databases/demo admin adminSe este comando for executado com sucesso, você obterá a seguinte saída.
Database 'demo' deleted successfullyOrientDB é um banco de dados NoSQL que pode armazenar os documentos e dados orientados a gráficos. O banco de dados NoSQL não contém nenhuma tabela, então como você pode inserir dados como um registro. Aqui você pode ver os dados da tabela na forma de classe, propriedade, vértice e classes de significado de aresta são como tabelas e propriedades são como arquivos nas tabelas.
Podemos definir todas essas entidades usando schemano OrientDB. Os dados de propriedade podem ser inseridos em uma classe. O comando Insert cria um novo registro no esquema do banco de dados. Os registros podem ser sem esquema ou seguir algumas regras especificadas.
A instrução a seguir é a sintaxe básica do comando Inserir registro.
INSERT INTO [class:]<class>|cluster:<cluster>|index:<index>
[(<field>[,]*) VALUES (<expression>[,]*)[,]*]|
[SET <field> = <expression>|<sub-command>[,]*]|
[CONTENT {<JSON>}]
[RETURN <expression>]
[FROM <query>]A seguir estão os detalhes sobre as opções na sintaxe acima.
SET - Define cada campo junto com o valor.
CONTENT- Define dados JSON para definir valores de campo. Isso é opcional.
RETURN- Define a expressão a retornar ao invés do número de registros inseridos. Os casos de uso mais comuns são -
@rid - Retorna o ID do registro do novo registro.
@this - Retorna o novo registro inteiro.
FROM - Onde você deseja inserir o registro ou um conjunto de resultados.
Exemplo
Vamos considerar uma tabela de clientes com os seguintes campos e tipos.
| Sr. Não. | Nome do Campo | Tipo |
|---|---|---|
| 1 | Eu iria | Inteiro |
| 2 | Nome | Corda |
| 3 | Era | Inteiro |
Você pode criar o Esquema (tabela) executando os seguintes comandos.
CREATE DATABASE PLOCAL:/opt/orientdb/databases/sales
CREATE CLASS Customer
CREATE PROPERTY Customer.id integer
CREATE PROPERTY Customer.name String
CREATE PROPERTY Customer.age integerDepois de executar todos os comandos, você obterá o nome da tabela Customer com os campos id, name e age. Você pode verificar a tabela executando a consulta de seleção na tabela Cliente.
OrientDB fornece diferentes maneiras de inserir um registro. Considere a seguinte tabela de clientes contendo os registros de amostra.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
O seguinte comando é inserir o primeiro registro na tabela Customer.
INSERT INTO Customer (id, name, age) VALUES (01,'satish', 25)Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Inserted record 'Customer#11:0{id:1,name:satish,age:25} v1' in 0.069000 sec(s).O seguinte comando é inserir o segundo registro na tabela Customer.
INSERT INTO Customer SET id = 02, name = 'krishna', age = 26Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Inserted record 'Customer#11:1{id:2,age:26,name:krishna} v1' in 0.005000 sec(s).O seguinte comando é inserir o terceiro registro na tabela Cliente.
INSERT INTO Customer CONTENT {"id": "03", "name": "kiran", "age": "29"}Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Inserted record 'Customer#11:2{id:3,name:kiran,age:29} v1' in 0.004000 sec(s).O seguinte comando é inserir os próximos dois registros na tabela Customer.
INSERT INTO Customer (id, name, age) VALUES (04,'javeed', 21), (05,'raja', 29)Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Inserted record '[Customer#11:3{id:4,name:javeed,age:21} v1,
Customer#11:4{id:5,name:raja,age:29} v1]' in 0.007000 sec(s).Você pode verificar se todos esses registros estão inseridos ou não executando o seguinte comando.
SELECT FROM CustomerSe o comando acima for executado com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
2 |#11:2|Customer|3 |kiran |29
3 |#11:3|Customer|4 |javeed |21
4 |#11:4|Customer|5 |raja |29
----+-----+--------+----+-------+----Semelhante ao RDBMS, o OrientDB suporta diferentes tipos de consultas SQL para recuperar os registros do banco de dados. Ao recuperar os registros, temos diferentes variações ou opções de consultas junto com a instrução select.
A instrução a seguir é a sintaxe básica do comando SELECT.
SELECT [ <Projections> ] [ FROM <Target> [ LET <Assignment>* ] ]
[ WHERE <Condition>* ]
[ GROUP BY <Field>* ]
[ ORDER BY <Fields>* [ ASC|DESC ] * ]
[ UNWIND <Field>* ]
[ SKIP <SkipRecords> ]
[ LIMIT <MaxRecords> ]
[ FETCHPLAN <FetchPlan> ]
[ TIMEOUT <Timeout> [ <STRATEGY> ] ]
[ LOCK default|record ]
[ PARALLEL ]
[ NOCACHE ]A seguir estão os detalhes sobre as opções na sintaxe acima.
<Projections> - indica os dados que você deseja extrair da consulta como um conjunto de registros de resultados.
FROM- Indica o objeto a ser consultado. Pode ser uma classe, cluster, ID de registro único, conjunto de IDs de registro. Você pode especificar todos esses objetos como destino.
WHERE - Especifica a condição para filtrar o conjunto de resultados.
LET - Indica as variáveis de contexto que são utilizadas nas projeções, condições ou subconsultas.
GROUP BY - Indica o campo para agrupar os registros.
ORDER BY - Indica o campo para organizar um registro em ordem.
UNWIND - Designa o campo no qual será desfeita a coleção de registros.
SKIP - Define o número de registros que você deseja ignorar desde o início do conjunto de resultados.
LIMIT - indica o número máximo de registros no conjunto de resultados.
FETCHPLAN - Especifica a estratégia que define como você deseja buscar resultados.
TIMEOUT - Define o tempo máximo em milissegundos para a consulta.
LOCK- Define a estratégia de bloqueio. DEFAULT e RECORD são as estratégias de bloqueio disponíveis.
PARALLEL - Executa a consulta em 'x' threads simultâneos.
NOCACHE - Define se você deseja usar o cache ou não.
Exemplo
Vamos considerar a seguinte tabela de clientes criada no capítulo anterior.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
Tente consultas de seleção diferentes para recuperar os registros de dados da tabela do cliente.
Method 1 - Você pode usar a seguinte consulta para selecionar todos os registros da tabela Cliente.
orientdb {db = demo}> SELECT FROM CustomerSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
2 |#11:2|Customer|3 |kiran |29
3 |#11:3|Customer|4 |javeed |21
4 |#11:4|Customer|5 |raja |29
----+-----+--------+----+-------+----Method 2 - Selecione todos os registros cujo nome comece com a letra 'k'.
orientdb {db = demo}> SELECT FROM Customer WHERE name LIKE 'k%'OU você pode usar a seguinte consulta para o exemplo acima.
orientdb {db = demo}> SELECT FROM Customer WHERE name.left(1) = 'k'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:1|Customer|2 |krishna|26
1 |#11:2|Customer|3 |kiran |29
----+-----+--------+----+-------+----Method 3 - Selecione id, registros de nome da tabela de clientes com nomes em letras maiúsculas.
orientdb {db = demo}> SELECT id, name.toUpperCase() FROM CustomerSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+--------+----+-------
# |@CLASS |id |name
----+--------+----+-------
0 |null |1 |SATISH
1 |null |2 |KRISHNA
2 |null |3 |KIRAN
3 |null |4 |JAVEED
4 |null |5 |RAJA
----+--------+----+-------Method 4 - Selecione todos os registros da tabela Cliente em que a idade esteja na faixa de 25 a 29 anos.
orientdb {db = demo}> SELECT FROM Customer WHERE age in [25,29]Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:2|Customer|3 |kiran |29
2 |#11:4|Customer|5 |raja |29
----+-----+--------+----+-------+----Method 5 - Selecione todos os registros da tabela Cliente onde qualquer campo contém a palavra 'sh'.
orientdb {db = demo}> SELECT FROM Customer WHERE ANY() LIKE '%sh%'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
----+-----+--------+----+-------+----Method 6 - Selecione todos os registros da tabela Cliente, ordenados por idade em ordem decrescente.
orientdb {db = demo}> SELECT FROM Customer ORDER BY age DESCSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:2|Customer|3 |kiran |29
1 |#11:4|Customer|5 |raja |29
2 |#11:1|Customer|2 |krishna|26
3 |#11:0|Customer|1 |satish |25
4 |#11:3|Customer|4 |javeed |21
----+-----+--------+----+-------+----Load Recordé usado para carregar um determinado registro do esquema. Carregar registro carregará o registro com a ajuda de ID de registro. É representado com@rid símbolo no conjunto de resultados.
A instrução a seguir é a sintaxe básica do comando LOAD Record.
LOAD RECORD <record-id>Onde <record-id> define a id do registro que você deseja carregar.
Se você não souber o ID do Registro de um determinado registro, poderá executar qualquer consulta na tabela. No conjunto de resultados, você encontrará a ID do registro (@rid) do respectivo registro.
Exemplo
Vamos considerar a mesma tabela Cliente que usamos nos capítulos anteriores.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
Tente a seguinte consulta para recuperar o registro com ID de registro @rid: #11:0.
orientdb {db = demo}> LOAD RECORD #11:0Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
+---------------------------------------------------------------------------+
| Document - @class: Customer @rid: #11:0 @version: 1 |
+---------------------------------------------------------------------------+
| Name | Value |
+---------------------------------------------------------------------------+
| id | 1 |
| name | satish |
| age | 25 |
+---------------------------------------------------------------------------+Reload Recordtambém funciona de forma semelhante ao comando Carregar registro e também é usado para carregar um registro específico do esquema. Carregar registro carregará o registro com a ajuda de ID de registro. É representado com@ridsímbolo no conjunto de resultados. A principal diferença é que Reload record ignora o cache, o que é útil quando transações externas simultâneas são aplicadas para alterar o registro. Ele dará a atualização mais recente.
A instrução a seguir é a sintaxe básica do comando RELOAD Record.
RELOAD RECORD <record-id>Onde <record-id> define a id do registro que você deseja recarregar.
Se você não souber o ID do Registro de um determinado registro, poderá executar qualquer consulta na tabela. No conjunto de resultados, você encontrará a ID do registro (@rid) do respectivo registro.
Exemplo
Vamos considerar a mesma tabela de clientes que usamos no capítulo anterior.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
Tente a seguinte consulta para recuperar o registro com ID de registro @rid: #11:0.
orientdb {db = demo}> LOAD RECORD #11:0Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
+---------------------------------------------------------------------------+
| Document - @class: Customer @rid: #11:0 @version: 1 |
+---------------------------------------------------------------------------+
| Name | Value |
+---------------------------------------------------------------------------+
| id | 1 |
| name | satish |
| age | 25 |
+---------------------------------------------------------------------------+Export Recordé o comando usado para exportar o registro carregado para o formato solicitado e compatível. Se você estiver executando qualquer sintaxe errada, ele fornecerá a lista de formatos suportados. OrientDB é uma família de banco de dados de documentos, portanto JSON é o formato padrão com suporte.
A instrução a seguir é a sintaxe básica do comando Exportar Registro.
EXPORT RECORD <format>Onde <Format> define o formato que você deseja obter o registro.
Note - O comando Export exportará o registro carregado com base no ID do Registro.
Exemplo
Vamos considerar a mesma tabela de clientes que usamos no capítulo anterior.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
Tente a seguinte consulta para recuperar o registro com ID de registro @rid: #11:0.
orientdb {db = demo}> LOAD RECORD #11:0Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
+---------------------------------------------------------------------------+
| Document - @class: Customer @rid: #11:0 @version: 1 |
+---------------------------------------------------------------------------+
| Name | Value |
+---------------------------------------------------------------------------+
| id | 1 |
| name | satish |
| age | 25 |
+---------------------------------------------------------------------------+Use a seguinte consulta para exportar o registro carregado (# 11: 0) para o formato JSON.
orientdb {db = demo}> EXPORT RECORD jsonSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
{
"@type": "d",
"@rid": "#11:0",
"@version": 1,
"@class": "Customer",
"id": 1,
"name": "satish",
"age": 25
}Update Recordcomando é usado para modificar o valor de um determinado registro. SET é o comando básico para atualizar um valor de campo específico.
A instrução a seguir é a sintaxe básica do comando Atualizar.
UPDATE <class>|cluster:<cluster>|<recordID>
[SET|INCREMENT|ADD|REMOVE|PUT <field-name> = <field-value>[,]*] |[CONTENT| MERGE <JSON>]
[UPSERT]
[RETURN <returning> [<returning-expression>]]
[WHERE <conditions>]
[LOCK default|record]
[LIMIT <max-records>] [TIMEOUT <timeout>]A seguir estão os detalhes sobre as opções na sintaxe acima.
SET - Define o campo a ser atualizado.
INCREMENT - Incrementa o valor do campo especificado pelo valor fornecido.
ADD - Adiciona o novo item nos campos da coleção.
REMOVE - Remove um item do campo de coleção.
PUT - Coloca uma entrada no campo do mapa.
CONTENT - Substitui o conteúdo do registro pelo conteúdo do documento JSON.
MERGE - Mescla o conteúdo do registro com um documento JSON.
LOCK- Especifica como bloquear os registros entre o carregamento e a atualização. Temos duas opções para especificarDefault e Record.
UPSERT- Atualiza um registro se existir ou insere um novo registro se não existir. Ele ajuda a executar uma única consulta em vez de executar duas consultas.
RETURN - Especifica uma expressão a ser retornada em vez do número de registros.
LIMIT - Define o número máximo de registros a serem atualizados.
TIMEOUT - Define o tempo que você deseja permitir que a atualização seja executada antes que ela expire.
Exemplo
Vamos considerar a mesma tabela de clientes que usamos no capítulo anterior.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 29 |
Tente a seguinte consulta para atualizar a idade de um cliente 'Raja'.
Orientdb {db = demo}> UPDATE Customer SET age = 28 WHERE name = 'Raja'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Updated 1 record(s) in 0.008000 sec(s).Para verificar o registro da tabela de clientes você pode usar a seguinte consulta.
orientdb {db = demo}> SELECT FROM CustomerSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
2 |#11:2|Customer|3 |kiran |29
3 |#11:3|Customer|4 |javeed |21
4 |#11:4|Customer|5 |raja |28
----+-----+--------+----+-------+----Truncate Record comando é usado para excluir os valores de um determinado registro.
A instrução a seguir é a sintaxe básica do comando Truncate.
TRUNCATE RECORD <rid>*Onde <rid>* indica o ID do registro a ser truncado. Você pode usar vários Rids separados por vírgula para truncar vários registros. Ele retorna o número de registros truncados.
Exemplo
Vamos considerar a mesma tabela de clientes que usamos no capítulo anterior.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
| 5 | Rajá | 28 |
Tente a seguinte consulta para truncar o registro com a ID de registro 11: 4.
Orientdb {db = demo}> TRUNCATE RECORD #11:4Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Truncated 1 record(s) in 0.008000 sec(s).Para verificar o registro da tabela de clientes você pode usar a seguinte consulta.
Orientdb {db = demo}> SELECT FROM CustomerSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
2 |#11:2|Customer|3 |kiran |29
3 |#11:3|Customer|4 |javeed |21
----+-----+--------+----+-------+----Delete Record comando é usado para excluir um ou mais registros completamente do banco de dados.
A instrução a seguir é a sintaxe básica do comando Delete.
DELETE FROM <Class>|cluster:<cluster>|index:<index>
[LOCK <default|record>]
[RETURN <returning>]
[WHERE <Condition>*]
[LIMIT <MaxRecords>]
[TIMEOUT <timeout>]A seguir estão os detalhes sobre as opções na sintaxe acima.
LOCK- Especifica como bloquear os registros entre o carregamento e a atualização. Temos duas opções para especificarDefault e Record.
RETURN - Especifica uma expressão a ser retornada em vez do número de registros.
LIMIT - Define o número máximo de registros a serem atualizados.
TIMEOUT - Define o tempo que você deseja permitir que a atualização seja executada antes que ela expire.
Note - Não use DELETE para remover vértices ou arestas porque isso afeta a integridade do gráfico.
Exemplo
Vamos considerar a tabela Cliente.
| Sr. Não. | Nome | Era |
|---|---|---|
| 1 | Satish | 25 |
| 2 | Krishna | 26 |
| 3 | Kiran | 29 |
| 4 | Javeed | 21 |
Tente a seguinte consulta para excluir o registro com id = 4.
orientdb {db = demo}> DELETE FROM Customer WHERE id = 4Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Delete 1 record(s) in 0.008000 sec(s).Para verificar o registro da tabela de clientes você pode usar a seguinte consulta.
Orientdb {db = demo}> SELECT FROM CustomerSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+-----+--------+----+-------+----
# |@RID |@CLASS |id |name |age
----+-----+--------+----+-------+----
0 |#11:0|Customer|1 |satish |25
1 |#11:1|Customer|2 |krishna|26
2 |#11:2|Customer|3 |kiran |29
----+-----+--------+----+-------+----O OrientDB oferece suporte ao recurso de vários modelos e oferece diferentes maneiras de abordar e compreender os conceitos básicos de um banco de dados. No entanto, podemos acessar facilmente esses modelos da perspectiva da API do banco de dados de documentos. Como o RDBMS, o OrientDB também usa o Registro como um elemento de armazenamento, mas usa o tipo de documento. Os documentos são armazenados na forma de pares chave / valor. Estamos armazenando campos e propriedades como pares chave / valor que pertencem a uma classe de conceitos.
Classé um tipo de modelo de dados e o conceito é extraído do paradigma de programação orientada a objetos. Com base no modelo tradicional de banco de dados de documentos, os dados são armazenados na forma de coleção, enquanto no modelo de banco de dados relacional os dados são armazenados em tabelas. O OrientDB segue a API do Documento juntamente com o paradigma OPPS. Como conceito, a classe no OrientDB tem o relacionamento mais próximo com a tabela nos bancos de dados relacionais, mas (ao contrário das tabelas) as classes podem ser sem esquema, com esquema completo ou mistas. As classes podem herdar de outras classes, criando árvores de classes. Cada classe tem seu próprio cluster ou clusters (criados por padrão, se nenhum estiver definido).
A instrução a seguir é a sintaxe básica do comando Create Class.
CREATE CLASS <class>
[EXTENDS <super-class>]
[CLUSTER <cluster-id>*]
[CLUSTERS <total-cluster-number>]
[ABSTRACT]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define o nome da classe que você deseja criar.
<super-class> - Define a superclasse que você deseja estender com esta classe.
<total-cluster-number>- Define o número total de clusters usados nesta classe. O padrão é 1.
ABSTARCT- Define que a classe é abstrata. Isso é opcional.
Exemplo
Conforme discutido, classe é um conceito relacionado à mesa. Portanto aqui iremos criar uma conta de mesa. No entanto, ao criar a classe, não podemos definir campos, ou seja, propriedades baseadas no paradigma OOPS.
O comando a seguir é para criar uma classe chamada Conta.
orientdb> CREATE CLASS AccountSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Class created successfullyVocê pode usar o seguinte comando para criar uma classe Car que se estende à classe Vehicle.
orientdb> CREATE CLASS Car EXTENDS VehicleSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Class created successfullyVocê pode usar o seguinte comando para criar uma classe Person como abstrata.
orientdb> CREATE CLASS Person ABSTRACTSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Class created successfullyNote- Sem ter propriedades, a classe é inútil e incapaz de construir objetos reais. Nos próximos capítulos, você pode aprender como criar propriedades para uma classe específica.
Classe e propriedade em OrientDB são usadas para construir um esquema com os respectivos atributos, como nome de classe, superclasse, cluster, número de clusters, Resumo, etc. Se você deseja modificar ou atualizar qualquer atributo de classes existentes no esquema, então você tem que usar Alter Class comando.
A instrução a seguir é a sintaxe básica do comando Alter Class.
ALTER CLASS <class> <attribute-name> <attribute-value>A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define o nome da classe.
<attribute-name> - Define o atributo que você deseja alterar.
<attribute-value> - Define o valor que você deseja definir para o atributo.
A tabela a seguir define a lista de atributos que oferecem suporte ao comando Alterar Class.
| Atributo | Tipo | Descrição |
|---|---|---|
| NOME | Corda | Muda o nome da classe. |
| NOME CURTO | Corda | Define um nome abreviado (ou seja, um alias) para a classe. Use NULL para remover uma atribuição de nome curto. |
| SUPERCLASS | Corda | Define uma superclasse para a classe. Para adicionar uma nova classe, você pode usar a sintaxe + <class>, para removê-la use - <class>. |
| OVERSIZE | Número decimal | Define o fator de tamanho grande. |
| ADDCLUSTER | Corda | Adiciona um cluster à classe. Se o cluster não existir, ele cria um cluster físico. Adicionar clusters a uma classe também é útil para armazenar registros em servidores distribuídos. |
| REMOVECLUSTER | Corda | Remove um cluster de uma classe. Ele não exclui o cluster, apenas o remove da classe. |
| MODO ESTRITO | - | Habilita ou desabilita o modo estrito. No modo estrito, você trabalha no modo de esquema completo e não pode adicionar novas propriedades a um registro se elas fizerem parte da definição do esquema da classe. |
| CLUSTERSELECTION | - | Define a estratégia de seleção na escolha de qual cluster usar para novos registros. |
| PERSONALIZADAS | - | Define propriedades personalizadas. Os nomes e valores das propriedades devem seguir a sintaxe <propertyname> = <value> sem espaços entre o nome e o valor. |
| ABSTRATO | boleano | Converte a classe em uma classe abstrata ou o oposto. |
Exemplo
Vamos tentar alguns exemplos que irão atualizar ou modificar os atributos da classe existente.
A consulta a seguir é usada para definir uma superclasse 'Pessoa' para uma classe existente 'Funcionário'.
orientdb> ALTER CLASS Employee SUPERCLASS PersonSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Class altered successfullyA consulta a seguir é usada para adicionar uma superclasse 'Pessoa' para uma classe existente 'Funcionário'.
orientdb> ALTER CLASS Employee SUPERCLASS +PersonSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Class altered successfullyTruncate classapagará todos os registros de clusters definidos como parte da classe. No OrientDB, cada classe possui um cluster associado com o mesmo nome. Se você também deseja remover todos os registros da hierarquia de classes, é necessário usar a palavra-chave POLYMORPHIC.
A instrução a seguir é a sintaxe básica do comando Truncate Class.
TRUNCATE CLASS <class> [ POLYMORPHIC ] [ UNSAFE ]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define a classe que você deseja truncar.
POLYMORPHIC - Define se o comando também trunca a hierarquia.
UNSAFE - Define que o comando força o truncamento no vértice ou classe de aresta.
Exemplo
A seguinte consulta para truncar uma classe Profile.
orientdb> TRUNCATE CLASS ProfileSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Class truncated successfullyo Drop Classcomando remove uma classe do esquema. É importante prestar atenção e manter um esquema consistente. Por exemplo, evite remover classes que são superclasses de outras pessoas. O cluster associado não será excluído.
A instrução a seguir é a sintaxe básica do comando Drop Class.
DROP CLASS <class>Abandone uma classe com o nome da classe.
Exemplo
Tente a seguinte consulta para Eliminar um funcionário da classe.
Orientdb> DROP CLASS EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Class dropped successfullyClusteré um conceito importante no OrientDB que é usado para armazenar registros, documentos ou vértices. Em palavras simples, cluster é um local onde um grupo de registros é armazenado. Por padrão, o OrientDB criará um cluster por classe. Todos os registros de uma classe são armazenados no mesmo cluster, que tem o mesmo nome da classe. Você pode criar até 32.767 (2 ^ 15-1) clusters em um banco de dados.
A classe CREATE é um comando usado para criar um cluster com um nome específico. Depois que o cluster é criado, você pode usar o cluster para salvar registros, especificando o nome durante a criação de qualquer modelo de dados. Se você deseja adicionar um novo cluster a uma classe, use o comando Alter Class e o comando ADDCLUSTER.
A instrução a seguir é a sintaxe básica do comando Create Cluster.
CREATE CLUSTER <cluster> [ID <cluster-id>]Onde <cluster> define o nome do cluster que você deseja criar e <cluster-id> define o ID numérico que você deseja usar para o cluster.
A tabela a seguir fornece a lista de estratégias de seleção de cluster.
| Sr. Não. | Estratégia e Descrição |
|---|---|
| 1 | Default Seleciona o cluster usando o padrão de propriedade de classe ClusterId. |
| 2 | Round-robin Seleciona o próximo cluster em ordem circular. Ele está reiniciando depois de concluído. |
| 3 | Balanced Seleciona o menor cluster. Permite que a classe tenha todos os clusters subjacentes balanceados em tamanho. Ao adicionar um novo cluster a uma classe existente, ele preenche o novo cluster primeiro. |
Exemplo
Tomemos um exemplo para criar um cluster denominado vendas.
orientdb> CREATE CLUSTER salesSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Cluster created correctly with id #12Alter Clustercomando é atualizar os atributos em um cluster existente. Neste capítulo, você pode aprender como adicionar ou modificar os atributos de um cluster.
A instrução a seguir é a sintaxe básica do comando Alter Cluster.
ALTER CLUSTER <cluster> <attribute-name> <attribute-value>A seguir estão os detalhes sobre as opções na sintaxe acima.
<cluster> - Define o nome do cluster.
<attribute-name> - Define o atributo que você deseja alterar.
<attribute-value> - Define o valor que você deseja definir para este atributo.
O formato tabular a seguir fornece a lista de atributos suportados que você pode usar junto com o comando Alter cluster.
| Nome | Tipo | Descrição |
|---|---|---|
| NOME | Corda | Altera o nome do cluster. |
| STATUS | Corda | Altera o status do cluster. Os valores permitidos são ONLINE e OFFLINE. Por padrão, os clusters estão online. |
| COMPRESSÃO | Corda | Define o tipo de compactação a ser usado. Os valores permitidos são NOTHING, SNAPPY, GZIP e quaisquer outros tipos de compactação registrados na classe OCompressionFactory. |
| USE_WAL | boleano | Define se ele usa o Journal quando OrientDB opera no cluster |
| RECORD_GROW_FACTO R | Inteiro | Define o fator de crescimento para economizar mais espaço na criação do registro. Você pode achar isso útil ao atualizar o registro com informações adicionais. |
| RECORD_OVERFLOW_GR OW_FACTOR | Inteiro | Define o fator de crescimento nas atualizações. Quando atinge o limite de tamanho, usa esta configuração para obter mais espaço, (fator> 1). |
| ESTRATÉGIA DE CONFLITO | Corda | Define a estratégia que usa para lidar com conflitos no caso de OrientDB MVCC encontrar uma atualização ou uma operação de exclusão que executa em um registro antigo. |
A tabela a seguir fornece a lista de estratégias de conflito.
| Sr. Não. | Estratégia e Descrição |
|---|---|
| 1 | Version Lança uma exceção quando as versões são diferentes. Esta é a configuração padrão. |
| 2 | Content Caso as versões sejam diferentes, ele verifica se há alterações no conteúdo, caso contrário, usa a versão mais alta para evitar o lançamento de uma exceção. |
| 3 | Automerge Mescla as alterações. |
Exemplo
Tente as consultas de exemplo a seguir para aprender o comando Alter cluster.
Execute o seguinte comando para alterar o nome de um cluster de Employee para Employee2.
orientdb {db = demo}> ALTER CLUSTER Employee NAME Employee2Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Cluster updated successfullyExecute o seguinte comando para alterar o nome de um cluster de Employee2 para Employee usando a ID do cluster.
orientdb {db = demo}> ALTER CLUSTER 12 NAME EmployeeSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Cluster updated successfullyExecute o seguinte comando para alterar a estratégia de conflito de cluster para automerge.
orientdb {db = demo}> ALTER CLUSTER V CONFICTSTRATEGY automergeSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Cluster updated successfullyo Truncate Cluster comando exclui todos os registros de um cluster.
A instrução a seguir é a sintaxe básica do comando Truncate Cluster.
TRUNCATE CLUSTER <cluster-name>Onde <cluster-name> é o nome do cluster.
Exemplo
Experimente a seguinte consulta para truncar o cluster denominado vendas.
Orientdb {db = demo}> TRUNCATE CLUSTER ProfileSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Cluster truncated successfully.o Drop Clustercomando remove o cluster e todo o seu conteúdo relacionado. Esta operação é permanente e reversível.
A instrução a seguir é a sintaxe básica do comando Drop Cluster.
DROP CLUSTER <cluster-name>|<cluster-id>Onde <cluster-name> define o nome do cluster que você deseja remover e <cluster-id> define o ID do cluster que você deseja remover.
Exemplo
Tente o seguinte comando para remover o cluster de vendas.
orientdb> DROP CLUSTER SalesSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Cluster dropped successfullyPropertyno OrientDB funciona como um campo de classe e coluna na tabela do banco de dados. Criar propriedade é um comando usado para criar uma propriedade para uma classe específica. O nome da classe que você usou no comando deve existir.
A instrução a seguir é a sintaxe básica do comando Create Property.
CREATE PROPERTY <class-name>.<property-name> <property-type> [<linked-type>][ <linked-class>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class-name> - Define a classe na qual você deseja criar a propriedade.
<property-name> - Define o nome lógico da propriedade.
<property-type> - Define o tipo de propriedade que você deseja criar.
<linked-type> - Define o tipo de contêiner, usado no tipo de propriedade do contêiner.
<linked-class> - Define a classe do contêiner, usada no tipo de propriedade do contêiner.
A tabela a seguir fornece o tipo de dados da propriedade para que OrientDB saiba o tipo de dados a armazenar.
| BOLEANO | INTEIRO | BAIXO | GRANDES |
| FLUTUADOR | ENCONTRO | CORDA | EMBUTIDO |
| LIGAÇÃO | BYTE | BINÁRIO | EM DOBRO |
Além desses, existem vários outros tipos de propriedades que funcionam como contêineres.
| EMBEDDEDLIST | EMBEDDEDSET | EMBEDDEDMAP |
| LINKLIST | LINKSET | LINKMAP |
Exemplo
Tente o exemplo a seguir para criar um nome de propriedade na classe Employee, do tipo String.
orientdb> CREATE PROPERTY Employee.name STRINGSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Property created successfully with id = 1Alter Propertyé um comando usado para modificar ou atualizar a propriedade de uma classe particular. Alterar a propriedade significa modificar os campos de uma tabela. Neste capítulo, você pode aprender como atualizar a propriedade.
A instrução a seguir é a sintaxe básica do comando Alter Property.
ALTER PROPERTY <class>.<property> <attribute-name> <attribute-value>A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define a classe à qual pertence a propriedade.
<property> - Define a propriedade que você deseja atualizar.
<attribute-name> - Define o atributo de uma propriedade que você deseja atualizar.
<attribute-value> - Define o valor que você deseja definir no atributo.
A tabela a seguir define a lista de atributos para alterar a propriedade.
| Atributo | Tipo | Descrição |
|---|---|---|
| LINKEDCLASS | Corda | Define o nome da classe vinculada. Use NULL para remover um valor existente. |
| LINKEDTYPE | Corda | Define o tipo de link. Use NULL para remover um valor existente. |
| MIN | Inteiro | Define o valor mínimo como uma restrição. Use NULL para remover uma restrição existente. |
| OBRIGATÓRIO | boleano | Define se a propriedade requer um valor. |
| MAX | Inteiro | Define o valor máximo como uma restrição. Use NULL para remover uma restrição existente. |
| NOME | Corda | Define o nome da propriedade. |
| NÃO NULO | boleano | Define se a propriedade pode ter um valor NULL. |
| REGEX | Corda | Define uma Expressão regular como restrição. Use NULL para remover uma restrição existente. |
| TIPO | Corda | Define um tipo de propriedade. |
| COLLATE | Corda | Conjuntos de agrupamento para uma das estratégias de comparação definidas. Por padrão, é definido como sensível a maiúsculas e minúsculas (cs). Você também pode definir como não diferencia maiúsculas de minúsculas (ci). |
| SOMENTE LEITURA | boleano | Define se o valor da propriedade é imutável. Ou seja, se for possível alterá-lo após a primeira atribuição. Use com DEFAULT para ter valores imutáveis na criação. |
| PERSONALIZADAS | Corda | Define propriedades personalizadas. A sintaxe para propriedades customizadas é <custom-name> = <custom-value>, como stereotype = icon. |
| PADRÃO | Define o valor ou função padrão. |
Note - se você estiver alterando NAME ou TYPE, este comando levará algum tempo para ser atualizado dependendo da quantidade de dados.
Exemplo
Tente algumas consultas fornecidas abaixo para entender a propriedade Alter.
Execute a seguinte consulta para alterar o nome da propriedade de 'idade' para 'nascido' na classe Cliente.
orinetdb {db = demo}> ALTER PROPERTY Customer.age NAME bornSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Property altered successfullyExecute a seguinte consulta para tornar 'nome' a propriedade obrigatória da classe 'Cliente'.
orientdb {db = demo}> ALTER PROPERTY Customer.name MANDATORY TRUESe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Property altered successfullyo Drop propertycomando remove a propriedade do esquema. Não remove os valores das propriedades do registro, apenas altera o esquema.
A declaração a seguir é a sintaxe básica do comando Drop Property.
DROP PROPERTY <class>.<property> [FORCE]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define a classe onde existe a propriedade.
<property> - Define a propriedade que você deseja remover.
[Force] - Caso um ou mais índices sejam definidos na propriedade.
Exemplo
Tente o seguinte comando para remover a propriedade 'age' da classe 'Cliente'.
orientdb> DROP PROPERTY Customer.ageSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Property dropped successfullyO banco de dados OrientDB não é apenas um banco de dados de documentos, mas também um banco de dados Graph. Novos conceitos como Vertex e Edge são usados para armazenar os dados na forma de gráfico. Ele aplica polimorfismo em vértices. A classe base para Vertex é V.
Neste capítulo, você pode aprender como criar vértices para armazenar dados gráficos.
A declaração a seguir é a sintaxe básica do comando Create Vertex.
CREATE VERTEX [<class>] [CLUSTER <cluster>] [SET <field> = <expression>[,]*]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define a classe à qual pertence o vértice.
<cluster> - Define o cluster no qual armazena o vértice.
<field> - Define o campo que você deseja definir.
<expression> - Define o expresso a configurar para o campo.
Exemplo
Tente o seguinte exemplo para entender como criar vértices.
Execute a seguinte consulta para criar um vértice sem 'nome' e na classe base V.
orientdb> CREATE VERTEXSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Created vertex 'V#9:0 v1' in 0.118000 sec(s)Execute a consulta a seguir para criar uma nova classe de vértice chamada v1 e, em seguida, crie o vértice nessa classe.
orientdb> CREATE CLASS V1 EXTENDS V
orientdb> CREATE VERTEX V1Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Created vertex 'V1#14:0 v1' in 0.004000 sec(s)Execute a consulta a seguir para criar um novo vértice da classe chamada v1, definindo suas propriedades como marca = 'Maruti' e nome = 'Swift'.
orientdb> CREATE VERTEX V1 SET brand = 'maruti', name = 'swift'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Created vertex 'V1#14:1{brand:maruti,name:swift} v1' in 0.004000 sec(s)O comando Mover vértice no OrientDB é mover um ou mais vértices da localização atual para uma classe ou cluster diferente. Se você estiver aplicando o comando de movimento em um vértice específico, ele atualizará todas as arestas que estão conectadas a este vértice. Se você estiver especificando um cluster para mover o vértice, ele moverá os vértices para o proprietário do servidor do cluster de destino.
A declaração a seguir é a sintaxe básica do comando Move Vertex.
MOVE VERTEX <source> TO <destination>
[SET [<field>=<value>]* [,]]
[MERGE <JSON>]
[BATCH <batch-size>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<source>- Define o vértice que você deseja mover. Ele aceita o ID de registro de um determinado vértice ou matriz de IDs de registro para vértices.
<destination>- Define para onde você deseja mover o vértice. Ele oferece suporte a uma classe ou a um cluster como destino.
SET - Define os valores para os campos.
MERGE - Define os valores para campos por meio de JSON.
BATCH - Define o tamanho do lote.
Note- Este comando atualiza todas as arestas conectadas, mas não os links. Ao usar Graph API, é recomendado usar borda conectada a vértices.
Exemplo
Experimente os exemplos a seguir para aprender como mover vértices.
Execute a seguinte consulta para mover um único vértice com ID de registro # 11: 2 de sua posição atual para Funcionário de classe.
orientdb> MOVE VERTEX #11:2 TO CLASS:EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída -
Move vertex command executed with result '[{old:#11:2, new:#13:0}]' in 0.022000 sec(s)Execute a seguinte consulta para mover o conjunto de vértices da classe 'Cliente' para a classe 'Funcionário'.
orientdb> MOVE VERTEX (SELECT FROM Customer) TO CLASS:EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Move vertex command executed with result '[{old:#11:0,
new:#13:1},{old:#11:1, new:#13:2},{old:#11:2, new:#13:3}]' in 0.011000 sec(s)Delete Vertexcomando é usado para remover vértices do banco de dados. Durante a exclusão, ele verifica e mantém a consistência com as arestas e remove todas as referências cruzadas (com as arestas) para o vértice excluído.
A declaração a seguir é a sintaxe básica do comando Delete Vertex.
DELETE VERTEX <vertex> [WHERE <conditions>]
[LIMIT <MaxRecords>>] [BATCH <batch-size>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<vertex> - Define o vértice que você deseja remover, usando sua classe, ID de registro ou por meio de uma subconsulta.
WHERE - Condição de filtros para determinar quais registros o comando remove.
LIMIT - Define o número máximo de registros a serem removidos.
BATCH - Define quantos registros o comando remove por vez, permitindo que você divida grandes transações em blocos menores para economizar no uso de memória.
Exemplo
Tente o seguinte comando para aprender como excluir um único vértice ou vários vértices.
Execute o seguinte comando para remover o vértice '# 14: 1'.
orientdb> DELETE VERTEX #14:1Se o comando acima for executado com sucesso, você obterá a seguinte saída.
Delete record(s) '1' in 0.005000 sec(s)Execute o seguinte comando para remover todos os vértices da classe 'Cliente' marcados com a propriedade 'isSpam'.
orientdb> DELETE VERTEX Customer WHERE isSpam = TRUESe o comando acima for executado com sucesso, você obterá a seguinte saída.
Delete record(s) '3' in 0.005000 sec(s)No OrientDB, o conceito Edgefunciona como uma relação entre vértices com a ajuda de algumas propriedades. Arestas e vértices são os principais componentes de um banco de dados de gráficos. Ele aplica polimorfismo em Edges. A classe base para um Edge é E. Durante a implementação de bordas, se os vértices de origem ou destino estiverem ausentes ou não existirem, a transação será revertida.
A instrução a seguir é a sintaxe básica do comando Create Edge.
CREATE EDGE <class> [CLUSTER <cluster>] FROM <rid>|(<query>)|[<rid>]* TO <rid>|(<query>)|[<rid>]*
[SET <field> = <expression>[,]*]|CONTENT {<JSON>}
[RETRY <retry> [WAIT <pauseBetweenRetriesInMs]] [BATCH <batch-size>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<class> - Define o nome da classe para a borda.
<cluster> - Define o cluster no qual você deseja armazenar a borda.
JSON - Fornece conteúdo JSON para definir como registro.
RETRY - Define o número de tentativas para tentar em caso de conflito.
WAIT - Define o tempo de atraso entre as novas tentativas em milissegundos.
BATCH - Define se divide o comando em blocos menores e o tamanho dos lotes.
Exemplo
Execute a seguinte consulta para criar uma aresta E entre dois vértices # 9: 0 e # 14: 0.
orientdb> CREATE EDGE FROM #11:4 TO #13:2Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Created edge '[e[#10:0][#9:0->#14:0]]' in 0.012000 sec(s)Execute a seguinte consulta para criar um novo tipo de borda e uma borda de novo tipo.
orientdb> CREATE CLASS E1 EXTENDS E
orientdb> CREATE EDGE E1 FROM #10:3 TO #11:4Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Created edge '[e[#10:1][#10:3->#11:4]]' in 0.011000 sec(s)Update edgecomando é usado para atualizar os registros de borda no banco de dados atual. Isso é equivalente ao comando de atualização real, além de verificar e manter a consistência do gráfico com vértices, no caso de você atualizar oout e in propriedades.
A instrução a seguir é a sintaxe básica do comando Update Edge.
UPDATE EDGE <edge>
[SET|INCREMENT|ADD|REMOVE|PUT <field-name> = <field-value> [,]*]|[CONTENT|MERGE <JSON>]
[RETURN <returning> [<returning-expression>]]
[WHERE <conditions>]
[LOCK default|record]
[LIMIT <max-records>] [TIMEOUT <timeout>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<edge>- Define a aresta que você deseja atualizar. Você pode escolher entreClass que atualiza as bordas por classe, Cluster que atualiza bordas por cluster, usando o prefixo CLUSTER, ou Record ID aquela atualização de bordas por ID de registro.
SET - Atualiza o campo para os valores fornecidos.
INCREMENT - Incrementa o campo fornecido pelo valor.
ADD - Define um item para adicionar a uma coleção de campos.
REMOVE - Define um item a ser removido de uma coleção de campos.
PUT - Define uma entrada para colocar nos campos do mapa.
RETURN - Define a expressão que você deseja retornar após executar a atualização.
WHERE - Define a condição do filtro.
LOCK - Define como o registro bloqueia entre o carregamento e as atualizações.
LIMIT - Define o número máximo de registros.
Exemplo
Vamos considerar um exemplo de atualização da borda chamada 'endereço' na classe de pessoa, obtendo dados da tabela de endereço com Id de área = 001 e o nome de pessoa = Krishna.
orientdb> UPDATE EDGE address SET out = (SELECT FROM Address WHERE areaID = 001)
WHERE name = 'krishna'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Updated edge '[address[#10:3][#11:3->#14:2]]' in 0.012000 sec(s)Delete edgecomando é usado para remover o banco de dados. Isso é equivalente ao comando delete, com a adição de verificar e manter a consistência com vértices, removendo todas as referências cruzadas para a aresta das propriedades de vértice 'de entrada' e 'de saída'.
A instrução a seguir é a sintaxe básica do comando Delete Edge.
DELETE EDGE
( <rid>
|
[<rid> (, <rid>)*]
|
( [ FROM (<rid> | <select_statement> ) ] [ TO ( <rid> | <select_statement> ) ] )
|
[<class>]
(
[WHERE <conditions>]
[LIMIT <MaxRecords>]
[BATCH <batch-size>]
))A seguir estão os detalhes sobre as opções na sintaxe acima.
FROM - Define o vértice do ponto inicial da aresta a ser excluída.
To - Define o vértice do ponto final da aresta a ser excluída.
WHERE - Define as condições de filtragem.
LIMIT - Define o número máximo de arestas a serem excluídas.
BATCH - Define o tamanho do bloco para a operação.
Exemplo
Experimente os exemplos a seguir para aprender como excluir arestas.
Execute a seguinte consulta para excluir a aresta entre dois vértices (# 11: 2, # 11: 10). Mas pode haver uma chance de haver uma ou mais arestas entre dois vértices. Para que possamos usar a propriedade date para a funcionalidade adequada. Esta consulta irá deletar as arestas que são criadas em '2015-01-15' e depois.
orientdb {db = demo}> DELETE EDGE FROM #11:2 TO #11:10 WHERE date >= "2012-01-15"Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Delete record(s) '2' in 0.00200 sec(s)Execute a seguinte consulta para deletar arestas começando do vértice '# 11: 5' até o vértice '# 11: 10' e que estão relacionadas a 'classe = Cliente'.
orientdb {db = demo}> DELETE EDGE FROM #11:5 TO #11:10 WHERE @class = 'Customer'Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Delete record(s) '2' in 0.00200 sec(s)Este capítulo explica a referência completa de diferentes tipos de funções no OrientDB. A tabela a seguir define a lista de funções, que são categorizadas por sua funcionalidade.
Funções de gráfico
| Sr. Não. | Nome e descrição da função |
|---|---|
| 1 | Out(): Obtém os vértices de saída adjacentes a partir do registro atual como Vertex. Syntax - out ([<label-1>] [, <label-n>] *) |
| 2 | In(): Obtém os vértices adjacentes de entrada a partir do registro atual como Vertex. Syntax - em ([<label-1>] [, <label-n>] *) |
| 3 | Both(): Obtém os vértices de saída e de entrada adjacentes a partir do registro atual como Vertex. Syntax - ambos ([<label1>] [, <label-n>] *) |
| 4 | outE(): Obtém as bordas de saída adjacentes a partir do registro atual como Vertex. Syntax - outE ([<label1>] [, <label-n>] *) |
| 5 | inE(): Obtém as bordas de entrada adjacentes a partir do registro atual como Vertex. Syntax - inE ([<label1>] [, <label-n>] *) |
| 6 | bothE(): Obtém as bordas de saída e de entrada adjacentes a partir do registro atual como Vertex. Syntax - bothE ([<label1>] [, <label-n>] *) |
| 7 | outV(): Obtém os vértices de saída a partir do registro atual como Edge. Syntax - outV () |
| 8 | inV(): Obtenha os vértices de entrada do registro atual como Edge. Syntax - inV () |
| 9 | traversedElement(): Retorna o (s) elemento (s) percorrido (s) em comandos Traverse. Syntax - traversedElement (<index> [, <items>]) |
| 10 | traversedVertex(): Retorne o (s) vértice (s) atravessado (s) em comandos Traverse. Syntax - traversedVertex (<index> [, <items>]) |
| 11 | traversedEdge(): Retorna a (s) aresta (s) atravessada (s) em comandos Traverse. Syntax - traversedEdge (<index> [, <items>]) |
| 12 | shortestPath(): Retorna o caminho mais curto entre dois vértices. A direção pode ser OUT (padrão), IN ou AMBOS. Synatx - shortestPath (<sourceVertex>, <destinationVertex> [, <direction> [, <edgeClassName>]]) |
| 13 | dijkstra(): Retorna o caminho mais barato entre dois vértices usando o algoritmo Dijkstra. Syntax - dijkstra (<sourceVertex>, <destinationVertex>, <weightEdgeFieldName> [, <direction>]) |
Experimente algumas funções de gráfico junto com as seguintes consultas.
Execute a seguinte consulta para obter todos os vértices de saída de todos os vértices do veículo.
orientdb {db = demo}>SELECT out() from VehicleSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+----------+---------
# | @class | out
---+----------+---------
0 | Vehicle | #11:2
1 | Vehicle | #13:1
2 | Vehicle | #13:4
---+----------+---------Execute a consulta a seguir para obter os vértices de entrada e saída do vértice 11: 3.
orientdb {db = demo}>SELECT both() FROM #11:3Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+----------+--------+-------
# | @class | out | in
---+----------+--------+-------
0 | Vehicle | #13:2 | #10:2
---+----------+-------+-------Funções Matemáticas
| Sr. Não. | Nome e descrição da função |
|---|---|
| 1 | eval(): Avalia a expressão entre aspas (ou aspas duplas). Syntax - eval ('<expressão>') |
| 2 | min(): Retorna o valor mínimo. Se chamado com mais de um parâmetro, ele retorna o valor mínimo do argumento entre todos os argumentos. Syntax - min (<campo> [, <campo-n>] *) |
| 3 | max(): Retorna o valor máximo. Se chamado com mais de um parâmetro, retorna o valor máximo entre todos os argumentos. Syntax - max (<campo> [, <campo-n>] *) |
| 4 | sum() Retorna a soma de todos os valores retornados. Syntax - soma (<campo>) |
| 5 | abs(): Retorna o valor absoluto. Funciona com Integer, Long, Short, Double, Float, BigInteger, BigDecimal, null. Syntax - abs (<campo>) |
| 6 | avg(): Retorna o valor médio. Syntax - média (<campo>) |
| 7 | count(): Conta o registro que corresponde à condição da consulta. Se * não for usado como um campo, o registro será contado apenas se o conteúdo não for nulo. Syntax - contagem (<campo>) |
| 8 | mode(): Retorna o valor que ocorre com a maior frequência. Os nulos são ignorados no cálculo. Syntax - modo (<campo>) |
| 9 | median(): Retorna o valor do meio ou um valor interpolado que representa o valor do meio depois que os valores são classificados. Os nulos são ignorados no cálculo. Syntax - mediana (<campo>) |
| 10 | percentile(): Retorna o enésimo percentil. Nulo é ignorado no cálculo. Syntax - percentil (<campo> [, <quantil-n>] *) |
| 11 | variance() Retorna a variância média: a média da diferença quadrática da média.
Syntax - variância (<campo>) |
| 12 | stddev() Retorna o desvio padrão: a medida de quão dispersos são os valores. Os nulos são ignorados no cálculo. Syntax - stddev (<campo>) |
Experimente algumas funções matemáticas usando as seguintes consultas.
Execute a seguinte consulta para obter a soma dos salários de todos os funcionários.
orientdb {db = demo}>SELECT SUM(salary) FROM EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+----------+---------
# | @CLASS | sum
---+----------+---------
0 | null | 150000
---+----------+---------Execute a seguinte consulta para obter o salário médio de todos os funcionários.
orientdb {db = demo}>SELECT avg(salary) FROM EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+----------+---------
# | @CLASS | avg
---+----------+---------
0 | null | 25
---+----------+---------Funções de coleções
| Sr. Não. | Nome e descrição da função |
|---|---|
| 1 | set(): Adiciona um valor a um conjunto. Se o valor for uma coleção, ele será mesclado com o conjunto, caso contrário, <valor> será adicionado. Syntax - definir (<campo>) |
| 2 | map(): Adiciona um valor a um mapa na primeira vez que o mapa é criado. Se <valor> for um mapa, ele será mesclado com o mapa, caso contrário, o par <chave> e <valor> será adicionado ao mapa como uma nova entrada. Syntax - mapa (<key>, <value>) |
| 3 | ist(): Adiciona um valor para listar na primeira vez que a lista é criada. Se <valor> for uma coleção, ele será mesclado com a lista; caso contrário, <valor> será adicionado à lista. Syntax - lista (<campo>) |
| 4 | difference(): Funciona como agregado ou embutido. Se apenas um argumento for passado, ele agrega, caso contrário, executa e retorna a DIFERENÇA entre as coleções recebidas como parâmetros. Syntax - diferença (<campo> [, <campo-n>] *) |
| 5 | first(): Recupera apenas o primeiro item de campos de vários valores (matrizes, coleções e mapas). Para tipos que não sejam de vários valores, apenas retorna o valor. Syntax - primeiro (<campo>) |
| 6 | intersect(): Funciona como agregado ou embutido. Se apenas um argumento for passado, agrega, caso contrário, executa e retorna a INTERAÇÃO das coleções recebidas como parâmetros. Syntax - interseção (<campo> [, <campo-n>] *) |
| 7 | distinct(): Recupera apenas entradas de dados exclusivas, dependendo do campo que você especificou como argumento. A principal diferença em relação ao SQL DISTINCT padrão é que com OrientDB, uma função com parênteses e apenas um campo pode ser especificado. Syntax - distinto (<campo>) |
| 8 | expand(): Esta função tem dois significados-
Syntax - expandir (<campo>) |
| 9 | unionall(): Funciona como agregado ou embutido. Se apenas um argumento for passado, ele agrega; caso contrário, executa e retorna uma UNION de todas as coleções recebidas como parâmetros. Também funciona sem valores de coleção. Syntax - unionall (<field> [, <field-n>] *) |
| 10 | flatten(): Extrai a coleção no campo e a usa como resultado. Ele está obsoleto, use expand () em seu lugar. Syntax - achatar (<campo>) |
| 11 | last(): Recupera apenas o último item de campos de vários valores (matrizes, coleções e mapas). Para tipos que não sejam de vários valores, apenas retorna o valor. Syntax - último (<campo>) |
| 12 | symmetricDifference(): Funciona como agregado ou embutido. Se apenas um argumento for passado, agrega, caso contrário, executa e retorna a DIFERENÇA SIMÉTRICA entre as coleções recebidas como parâmetros. Syntax - symmetricDifference (<field> [, <field-n>] *) |
Experimente algumas funções de coleção usando as seguintes consultas.
Execute a seguinte consulta para obter um conjunto de professores, dando aula para a 9ª.
orientdb {db = demo}>SELECT ID, set(teacher.id) AS teacherID from classess where class_id = 9Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+----------+--------+--------------------------
# | @CLASS | id | TeacherID
---+----------+--------+--------------------------
0 | null | 9 | 1201, 1202, 1205, 1208
---+----------+-------+---------------------------Funções diversas
| Sr. Não. | Nome e descrição da função |
|---|---|
| 1 | date(): Retorna uma data formatando uma string. <date-as-string> é a data no formato de string e <formato> é o formato de data de acordo com essas regras. Syntax - data (<date-as-string> [<format>] [, <timezone>]) |
| 2 | sysdate(): Retorna a data e hora atuais. Syntax - sysdate ([<formato>] [, <timezone>]) |
| 3 | format(): Formata um valor usando as convenções String.format (). Syntax - formato (<formato> [, <arg1>] (, <arg-n>] *. Md) |
| 4 | distance(): Retorna a distância entre dois pontos no globo usando o algoritmo Haversine. As coordenadas devem ser graus. Syntax - distância (<x-field>, <y-field>, <x-value>, <y-value>) |
| 5 | ifnull(): Retorna o campo / valor passado (ou parâmetro opcional return_value_if_not_null). Se o campo / valor não for nulo, ele retornará return_value_if_null. Syntax - ifnull (<campo | valor>, <return_value_if_null> [, <return_value_if_not_null>] (, <campo & .md # 124; valor>] *) |
| 6 | coalesce(): Retorna o primeiro campo / valor não parâmetro nulo. Se nenhum campo / valor não for nulo, retorna nulo. Syntax - coalescer (<campo | valor> [, <campo-n | valor-n>] *) |
| 7 | uuid(): Gera um UUID como um valor de 128 bits usando a variante Leach-Salz. Syntax - uuid () |
| 8 | if(): Avalia uma condição (primeiros parâmetros) e retorna o segundo parâmetro se a condição for verdadeira, o terceiro caso contrário. Syntax - if (<expression>, <result-if-true>, <result-if-false>) |
Experimente algumas funções Misc usando as seguintes consultas.
Execute a consulta a seguir para aprender como executar a expressão if.
orientdb {db = demo}> SELECT if(eval("name = 'satish'"), "My name is satish",
"My name is not satish") FROM EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+--------+-----------------------
# |@CLASS | IF
----+--------+-----------------------
0 |null |My name is satish
1 |null |My name is not satish
2 |null |My name is not satish
3 |null |My name is not satish
4 |null |My name is not satish
----+--------+------------------------Execute a seguinte consulta para obter a data do sistema.
orientdb {db = demo}> SELECT SYSDATE() FROM EmployeeSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+--------+-----------------------
# |@CLASS | SYSDATE
----+--------+-----------------------
0 |null |2016-02-10 12:05:06
1 |null |2016-02-10 12:05:06
2 |null |2016-02-10 12:05:06
3 |null |2016-02-10 12:05:06
4 |null |2016-02-10 12:05:06
----+--------+------------------------Usando esta função completamente, você pode facilmente manipular os dados OrientDB.
Sequencesé um conceito usado no mecanismo de incremento automático e é introduzido no OrientDB v2.2. Na terminologia de banco de dados, sequência é uma estrutura que gerencia o campo do contador. Simplificando, as sequências são usadas principalmente quando você precisa de um número que sempre aumenta. Ele suporta dois tipos -
ORDERED - Cada vez que o ponteiro chama o método .next que retorna um novo valor.
CACHED- A sequência armazenará em cache 'N' itens em cada nó. Para chamar cada item que usamos.next(), que é preferencial quando o cache contém mais de um item.
Criar sequência
A sequência geralmente é usada para incrementar automaticamente o valor de id de uma pessoa. Como outros conceitos SQL do OrientDB, ele também realiza operações semelhantes como Sequence em RDBMS.
A instrução a seguir é a sintaxe básica para criar sequências.
CREATE SEQUENCE <sequence> TYPE <CACHED|ORDERED> [START <start>]
[INCREMENT <increment>] [CACHE <cache>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<Sequence> - Nome local para sequência.
TYPE - Define o tipo de sequência ORDERED ou CACHED.
START - Define o valor inicial.
INCREMENT - Define o incremento para cada chamada de método .next.
CACHE - Define o número de valores para pré-armazenar em cache, caso você tenha usado para armazenar em cache o tipo de sequência.
Vamos criar uma sequência chamada 'seqid' que começa com o número 1201. Experimente as seguintes consultas para implementar este exemplo com sequência.
CREATE SEQUENCE seqid START 1201Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Sequence created successfullyTente a seguinte consulta para usar a sequência 'seqid' para inserir o valor de id da tabela Conta.
INSERT INTO Account SET id = sequence('seqid').next()Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Insert 1 record(s) in 0.001000 sec(s)Alterar sequência
Alterar sequência é um comando usado para alterar as propriedades de uma sequência. Ele irá modificar todas as opções de sequência, exceto o tipo de sequência.
A instrução a seguir é a sintaxe básica para alterar a sequência.
ALTER SEQUENCE <sequence> [START <start-point>]
[INCREMENT <increment>] [CACHE <cache>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<Sequence> - Define a sequência que você deseja alterar.
START - Define o valor inicial.
INCREMENT - Define o incremento para cada chamada de método .next.
CACHE - Define o número de valor para pré-armazenar em cache no evento que você usou para armazenar em cache o tipo de sequência.
Tente a seguinte consulta para alterar o valor inicial de '1201 para 1000' de uma sequência chamada seqid.
ALTER SEQUENCE seqid START 1000Se a consulta acima for executada com sucesso, você obterá a seguinte saída.
Altered sequence successfullySequência de queda
A sequência de descarte é um comando usado para descartar uma sequência.
A instrução a seguir é a sintaxe básica para eliminar uma sequência.
DROP SEQUENCE <sequence>Onde <Sequence> define a sequência que você deseja descartar.
Tente a seguinte consulta para eliminar uma sequência chamada 'seqid'.
DROP SEQUENCE seqidSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Sequence dropped successfullyIndex é um ponteiro que aponta para uma localização de dados no banco de dados. Indexingé um conceito usado para localizar rapidamente os dados sem ter que pesquisar todos os registros em um banco de dados. OrientDB suporta quatro algoritmos de índice e vários tipos dentro de cada um.
Os quatro tipos de índice são -
Índice SB-Tree
Ele fornece uma boa combinação de recursos disponíveis em outros tipos de índice. Melhor usar isso para utilidade geral. É durável, transacional e oferece suporte a consultas de intervalo. É o tipo de índice padrão. Os diferentes tipos de plug-ins que suportam este algoritmo são -
UNIQUE- Esses índices não permitem chaves duplicadas. Para índices compostos, refere-se à exclusividade das chaves compostas.
NOTUNIQUE - Esses índices permitem chaves duplicadas.
FULLTEXT- Esses índices são baseados em qualquer palavra do texto. Você pode usá-los em consultas por meio doCONTAINSTEXT operador.
DICTIONARY - Esses índices são semelhantes aos que usam UNIQUE, mas no caso de chaves duplicadas, eles substituem o registro existente pelo novo registro.
Índice Hash
Ele tem um desempenho mais rápido e é muito leve no uso do disco. É durável, transacional, mas não oferece suporte a consultas de intervalo. Funciona como o HASHMAP, o que o torna mais rápido em pesquisas pontuais e consome menos recursos do que outros tipos de índice. Os diferentes tipos de plug-ins que suportam este algoritmo são -
UNIQUE_HASH_INDEX- Esses índices não permitem chaves duplicadas. Para índices compostos, refere-se à exclusividade das chaves compostas.
NOTUNIQUE_HASH_INDEX - Esses índices permitem chaves duplicadas.
FULLTEXT_HASH_INDEX- Esses índices são baseados em qualquer palavra do texto. Você pode usá-los em consultas por meio do operador CONTAINSTEXT.
DICTIONARY_HASH_INDEX - Esses índices são semelhantes aos que usam UNIQUE_HASH_INDEX, mas em casos de chaves duplicadas, eles substituem o registro existente pelo novo registro.
Lucene Índice de Texto Completo
Ele fornece bons índices de texto completo, mas não pode ser usado para indexar outros tipos. É durável, transacional e oferece suporte a consultas de intervalo.
Lucene Spatial Index
Ele fornece bons índices espaciais, mas não pode ser usado para indexar outros tipos. É durável, transacional e oferece suporte a consultas de intervalo.
Criação de índices
Criar índice é um comando para criar um índice em um esquema específico.
A instrução a seguir é a sintaxe básica para criar um índice.
CREATE INDEX <name> [ON <class-name> (prop-names)] <type> [<key-type>]
[METADATA {<metadata>}]A seguir estão os detalhes sobre as opções na sintaxe acima.
<name>- Define o nome lógico do índice. Você também pode usar a notação <class.property> para criar um índice automático vinculado a uma propriedade de esquema. <class> usa a classe do esquema e <property> usa a propriedade criada na classe.
<class-name>- Fornece o nome da classe que você está criando o índice automático para indexar. Esta classe deve existir no banco de dados.
<prop-names>- Fornece a lista de propriedades que você deseja que o índice automático indexe. Essas propriedades já devem existir no esquema.
<type> - Fornece o algoritmo e o tipo de índice que você deseja criar.
<key-type> - Fornece o tipo de chave opcional com índices automáticos.
<metadata> - Fornece a representação JSON.
Exemplo
Experimente a seguinte consulta para criar um índice automático vinculado à propriedade 'ID' do usuário sales_user.
orientdb> CREATE INDEX indexforID ON sales_user (id) UNIQUESe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Creating index...
Index created successfully with 4 entries in 0.021000 sec(s)Consultando índices
Você pode usar a consulta selecionada para obter os registros no índice.
Tente a seguinte consulta para recuperar as chaves do índice denominado 'indexforId'.
SELECT FROM INDEX:indexforIdSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
----+------+----+-----
# |@CLASS|key |rid
----+------+----+-----
0 |null |1 |#11:7
1 |null |2 |#11:6
2 |null |3 |#11:5
3 |null |4 |#11:8
----+------+----+-----Índices de queda
Se você deseja eliminar um índice específico, pode usar este comando. Esta operação não remove os registros vinculados.
A instrução a seguir é a sintaxe básica para eliminar um índice.
DROP INDEX <name>Onde <name> fornece o nome do índice que você deseja eliminar.
Tente a seguinte consulta para eliminar um índice denominado 'ID' do usuário sales_user.
DROP INDEX sales_users.IdSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
Index dropped successfullyComo o RDBMS, o OrientDB oferece suporte às propriedades ACID de transações. UMAtransactioncompreende uma unidade de trabalho executada em um sistema de gerenciamento de banco de dados. Existem dois motivos principais para manter as transações em um ambiente de banco de dados.
Para permitir a recuperação simultânea de falhas e manter um banco de dados consistente mesmo em caso de falhas do sistema.
Para fornecer isolamento entre programas que acessam um banco de dados simultaneamente.
Por padrão, a transação do banco de dados deve seguir as propriedades ACID, como as propriedades Atomic, Consistent, Isolated e Durable. Mas o OrientDB é um banco de dados compatível com ACID, o que significa que ele não contradiz ou nega o conceito ACID, mas muda sua percepção ao lidar com o banco de dados NoSQL. Dê uma olhada em como as propriedades ACID funcionam junto com o banco de dados NoSQL.
Atomic - Quando você faz algo para alterar o banco de dados, a alteração deve funcionar ou falhar como um todo.
Consistent - O banco de dados deve permanecer consistente.
Isolated - Se outras execuções de transação estiverem sendo executadas ao mesmo tempo, o usuário não poderá ver os registros em execução simultânea.
Durable - Se o sistema travar (hardware ou software), o próprio banco de dados deve ser capaz de fazer um backup.
A transação do banco de dados pode ser realizada usando os comandos Commit e Rollback.
Comprometer
Confirmar significa fechar a transação salvando todas as alterações no banco de dados. Rollback significa recuperar o estado do banco de dados até o ponto em que você abriu a transação.
A instrução a seguir é a sintaxe básica do comando de banco de dados COMMIT.
COMMITNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e após o início da transação.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos em um capítulo anterior deste tutorial. Veremos a operação de confirmar transação e armazenar um registro usando transações.
Você precisa primeiro iniciar a transação usando o seguinte comando BEGIN.
orientdb {db = demo}> BEGINInsira um registro em uma tabela de funcionários com os valores id = 12 e name = satish.P usando o seguinte comando.
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')Você pode usar o seguinte comando para confirmar a transação.
orientdb> commitSe esta transação for confirmada com sucesso, você obterá a seguinte saída.
Transaction 2 has been committed in 4msRollback
Rollback significa recuperar o estado do banco de dados até o ponto em que você abriu a transação.
A instrução a seguir é a sintaxe básica do comando do banco de dados ROLLBACK.
ROLLBACKNote - Você pode usar este comando somente após conectar-se a um banco de dados específico e após o início da transação.
Exemplo
Neste exemplo, usaremos o mesmo banco de dados chamado 'demo' que criamos em um capítulo anterior do tutorial. Veremos a operação de transação de rollback e armazenaremos um registro usando transações.
Você deve primeiro iniciar a transação usando o seguinte comando BEGIN.
orientdb {db = demo}> BEGINInsira um registro em uma tabela de funcionários com os valores id = 12 e name = satish.P usando o seguinte comando.
orientdb> INSERT INTO employee (id, name) VALUES (12, 'satish.P')Você pode usar o seguinte comando para recuperar os registros do funcionário da mesa.
orientdb> SELECT FROM employee WHERE name LIKE '%.P'Se este comando for executado com sucesso, você obterá a seguinte saída.
---+-------+--------------------
# | ID | name
---+-------+--------------------
0 | 12 | satish.P
---+-------+--------------------
1 item(s) found. Query executed in 0.076 sec(s).Você pode usar o seguinte comando para reverter esta transação.
orientdb> ROLLBACKVerifique a consulta selecionada novamente para recuperar o mesmo registro da tabela Funcionário.
orientdb> SELECT FROM employee WHERE name LIKE '%.P'Se a reversão for executada com sucesso, você obterá 0 registros encontrados na saída.
0 item(s) found. Query executed in 0.037 sec(s).OrientDB Hooksnada mais são do que gatilhos na terminologia do banco de dados que permitem eventos internos antes e depois de cada operação CRUD nos aplicativos do usuário. Você pode usar ganchos para escrever regras de validação personalizadas, para impor a segurança ou para organizar eventos externos, como a replicação em um DBMS relacional.
OrientDB suporta dois tipos de ganchos -
Dynamic Hook - Gatilhos, que podem ser construídos em nível de classe e / ou nível de documento.
Java (Native) Hook - Triggers, que podem ser construídos usando classes Java.
Ganchos Dinâmicos
Os ganchos dinâmicos são mais flexíveis do que os ganchos Java, porque podem ser alterados no tempo de execução e podem ser executados por documento, se necessário, mas são mais lentos do que os ganchos Java.
Para executar ganchos em seus documentos, primeiro permita que suas classes estendam OTriggeredclasse base. Posteriormente, defina uma propriedade customizada para o evento de interesse. A seguir estão os eventos disponíveis.
onBeforeCreate - Chamado before criando um novo documento.
onAfterCreate - Chamado after criando um novo documento.
onBeforeRead - Chamado before lendo um documento.
onAfterRead - Chamado after lendo um documento.
onBeforeUpdate - Chamado before atualizar um documento.
onAfterUpdate - Chamado after atualizar um documento.
onBeforeDelete - Chamado before deletar um documento.
onAfterDelete - Chamado after deletar um documento.
Os ganchos dinâmicos podem chamar -
Funções, escritas em SQL, Javascript ou qualquer linguagem suportada por OrientDB e JVM.
Métodos estáticos Java.
Ganchos de nível de classe
Ganchos de nível de classe são definidos para todos os documentos relacionados a uma classe. A seguir está um exemplo para configurar um gancho que atua em nível de classe contra documentos de fatura.
CREATE CLASS Invoice EXTENDS OTriggered
ALTER CLASS Invoice CUSTOM onAfterCreate = invoiceCreatedVamos criar a função invoiceCreated em Javascript que imprime no console do servidor o número da fatura criada.
CREATE FUNCTION invoiceCreated "print('\\nInvoice created: ' + doc.field ('number'));"
LANGUAGE JavascriptAgora tente o gancho criando um novo Invoice documento.
INSERT INTO Invoice CONTENT {number: 100, notes: 'This is a test}Se este comando for executado com sucesso, você obterá a seguinte saída.
Invoice created: 100Gancho de nível de documento
Você pode definir uma ação especial apenas contra um ou mais documentos. Para fazer isso, permita que sua classe estendaOTriggered classe.
Por exemplo, vamos executar um gatilho, como função Javascript, contra uma classe de Perfil existente, para todos os documentos com conta de propriedade = 'Premium'. O gatilho será chamado para evitar a exclusão de documentos.
ALTER CLASS Profile SUPERCLASS OTriggered UPDATE Profile
SET onBeforeDelete = 'preventDeletion' WHERE account = 'Premium'Vamos criar o preventDeletion() Função Javascript.
CREATE FUNCTION preventDeletion "throw new java.lang.RuntimeException('Cannot
delete Premium profile ' + doc)" LANGUAGE JavascriptE, em seguida, teste o gancho tentando excluir uma conta 'Premium'.
DELETE FROM #12:1
java.lang.RuntimeException: Cannot delete Premium profile
profile#12:1{onBeforeDelete:preventDeletion,account:Premium,name:Jill} v-1
(<Unknown source>#2) in <Unknown source> at line number 2JAVA Hooks
Um caso de uso comum para OrientDB Hooks (gatilhos) é gerenciar datas de criação e atualização para qualquer uma ou todas as classes. Por exemplo, você pode definir umCreatedDate sempre que um registro é criado e definir um UpdatedDate sempre que um registro for atualizado, e faça isso de uma forma em que você implemente a lógica uma vez na camada de banco de dados e nunca precise se preocupar com isso novamente na camada de aplicativo.
Antes de criar, você terá que baixar orientdb-core.jarvisite o seguinte link para baixar o núcleo do OrientDB . E depois copie esse arquivo jar para a pasta onde deseja armazenar o arquivo de origem Java.
Criar arquivo de gancho
Crie um arquivo Java chamado HookTest.java, que testará o mecanismo do Hook usando a linguagem Java.
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
import com.orientechnologies.orient.core.hook.ODocumentHookAbstract;
import com.orientechnologies.orient.core.hook.ORecordHook;
import com.orientechnologies.orient.core.hook.ORecordHookAbstract;
import com.orientechnologies.orient.core.db.ODatabaseLifecycleListener;
import com.orientechnologies.orient.core.db.ODatabase;
import com.orientechnologies.orient.core.record.ORecord;
import com.orientechnologies.orient.core.record.impl.ODocument;
public class HookTest extends ODocumentHookAbstract implements ORecordHook {
public HookTest() {
}
@Override
public DISTRIBUTED_EXECUTION_MODE getDistributedExecutionMode() {
return DISTRIBUTED_EXECUTION_MODE.BOTH;
}
public RESULT onRecordBeforeCreate( ODocument iDocument ) {
System.out.println("Ran create hook");
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
public RESULT onRecordBeforeUpdate( ODocument iDocument ) {
System.out.println("Ran update hook");
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}O código de exemplo acima imprime o comentário apropriado sempre que você cria ou atualiza um registro dessa classe.
Vamos adicionar mais um arquivo de gancho setCreatedUpdatedDates.java como segue -
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.locks.ReentrantLock;
import com.orientechnologies.orient.core.hook.ODocumentHookAbstract;
import com.orientechnologies.orient.core.hook.ORecordHook;
import com.orientechnologies.orient.core.hook.ORecordHookAbstract;
import com.orientechnologies.orient.core.db.ODatabaseLifecycleListener;
import com.orientechnologies.orient.core.db.ODatabase;
import com.orientechnologies.orient.core.record.ORecord;
import com.orientechnologies.orient.core.record.impl.ODocument;
public class setCreatedUpdatedDates extends ODocumentHookAbstract implements ORecordHook {
public setCreatedUpdatedDates() {
}
@Override
public DISTRIBUTED_EXECUTION_MODE getDistributedExecutionMode() {
return DISTRIBUTED_EXECUTION_MODE.BOTH;
}
public RESULT onRecordBeforeCreate( ODocument iDocument ) {
if ((iDocument.getClassName().charAt(0) == 't') || (iDocument.getClassName().charAt(0)=='r')) {
iDocument.field("CreatedDate", System.currentTimeMillis() / 1000l);
iDocument.field("UpdatedDate", System.currentTimeMillis() / 1000l);
return ORecordHook.RESULT.RECORD_CHANGED;
} else {
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}
public RESULT onRecordBeforeUpdate( ODocument iDocument ) {
if ((iDocument.getClassName().charAt(0) == 't') || (iDocument.getClassName().charAt(0)=='r')) {
iDocument.field("UpdatedDate", System.currentTimeMillis() / 1000l);
return ORecordHook.RESULT.RECORD_CHANGED;
} else {
return ORecordHook.RESULT.RECORD_NOT_CHANGED;
}
}
}O que o código acima faz é procurar qualquer classe que comece com as letras 'r'ou't'e define CreatedDate e UpdatedDate quando o registro é criado e define apenas UpdatedDate toda vez que o registro é atualizado.
Compilar Java Hooks
Compile o código Java usando o seguinte comando. Note: Mantenha o arquivo jar baixado e esses arquivos Java na mesma pasta.
$ jar cf hooks-1.0-SNAPSHOT.jar *.javaMova o código compilado para onde o servidor OrientDB possa encontrá-lo
Você precisa copiar o arquivo .jar concluído para o diretório onde o servidor OrientDB os procurará. Isso significa que './lib'pasta sob o diretório raiz do servidor OrientDB terá a seguinte aparência -
$ cp hooks-1.0-SNAPSHOT.jar "$ORIENTDB_HOME/lib"Habilitar gancho de teste no arquivo de configuração do servidor OrientDB
Editar $ORIENTDB_HOME/config/orientdb-server-config.xml e adicione a seção a seguir próximo ao final do arquivo.
<hooks>
<hook class = "HookTest" position = "REGULAR"/>
</hooks>
...
</orient-server>Reinicie o servidor OrientDB
Depois de reiniciar o OrientDB Server, o gancho definido em orientdb-server-config.xmlagora está ativo. Inicie um console OrientDB, conecte-o ao seu banco de dados e execute o seguinte comando -
INSERT INTO V SET ID = 1;Se este comando for executado com sucesso, você obterá a seguinte saída.
Ran create hookAgora execute o seguinte comando -
UPDATE V SET ID = 2 WHERE ID = 1;Se este comando for executado com sucesso, você obterá a seguinte saída.
Ran update hookHabilitar Real Hook no arquivo de configuração do servidor OrientDB
Editar $ORIENTDB_HOME/config/orientdb-server-config.xml e altere a seção de ganchos da seguinte forma -
<hooks>
<hook class="setCreatedUpdatedDates" position="REGULAR"/>
</hooks>
...
</orient-server>Reinicie o servidor OrientDB
Crie uma nova classe que comece com a letra 'r'ou't'-
CREATE CLASS tTest EXTENDS V;Agora insira um registro -
INSERT INTO tTest SET ID = 1
SELECT FROM tTestSe este comando for executado com sucesso, você obterá a seguinte saída.
----+-----+------+----+-----------+-----------
# |@RID |@CLASS|ID |CreatedDate|UpdatedDate
----+-----+------+----+-----------+-----------
0 |#19:0|tTest |1 |1427597275 |1427597275
----+-----+------+----+-----------+-----------Mesmo que você não tenha especificado valores para definir para CreatedDate e UpdatedDate, O OrientDB configurou esses campos automaticamente para você.
Em seguida, você precisa atualizar o registro usando o seguinte comando -
UPDATE tTest SET ID = 2 WHERE ID = 1;
SELECT FROM tTest;Se este comando for executado com sucesso, você obterá a seguinte saída.
----+-----+------+----+-----------+-----------
# |@RID |@CLASS|ID |CreatedDate|UpdatedDate
----+-----+------+----+-----------+-----------
0 |#19:0|tTest |2 |1427597275 |1427597306
----+-----+------+----+-----------+-----------Você pode ver que o OrientDB mudou o UpdatedDate mas deixou o CreatedDate permanece inalterado.
Os Ganchos Java do OrientDB podem ser uma ferramenta extremamente valiosa para ajudar a automatizar o trabalho que você teria que fazer no código do aplicativo. Como muitos DBAs nem sempre são especialistas em Java, esperamos que as informações contidas neste tutorial dêem a você uma vantagem e façam você se sentir confortável com a tecnologia, capacitando-o para criar triggers de banco de dados com êxito conforme a necessidade.
Cachingé um conceito que criará uma cópia da estrutura da tabela do banco de dados, proporcionando um ambiente confortável para os aplicativos do usuário. OrientDB tem vários mecanismos de cache em diferentes níveis.
A ilustração a seguir dá uma ideia sobre o que é cache.

Na ilustração acima DB1, DB2, DB3 são as três diferentes instâncias de banco de dados usadas em um aplicativo.
Level-1 cache é um Local cacheque armazena todas as entidades conhecidas por uma sessão específica. Se você tiver três transações nesta sessão, ela conterá todas as entidades usadas por todas as três transações. Este cache é limpo quando você fecha a sessão ou quando executa o método "limpar". Ele reduz a carga das operações de E / S entre o aplicativo e o banco de dados e, por sua vez, aumenta o desempenho.
Level-2 cache é um Real cacheque funciona usando um provedor de terceiros. Você pode ter controle total sobre o conteúdo do cache, ou seja, você poderá especificar quais entradas devem ser removidas, quais devem ser armazenadas por mais tempo e assim por diante. É um cache compartilhado completo entre vários threads.
Storage model nada mais é do que um dispositivo de armazenamento que é disco, memória ou servidor remoto.
Como funciona o cache no OrientDB?
O armazenamento em cache do OrientDB fornece diferentes metodologias em diferentes ambientes. O cache é usado principalmente para transações de banco de dados mais rápidas, reduzindo o tempo de processamento de uma transação e aumentando o desempenho. Os diagramas de fluxo a seguir mostram como o armazenamento em cache funciona no modo local e no modo cliente-servidor.
Modo local (banco de dados incorporado)
O diagrama de fluxo a seguir mostra como o registro está entre o armazenamento e o aplicativo usado no modo local, ou seja, quando o servidor de banco de dados está em seu host local.
Quando o aplicativo cliente pede um registro, o OrientDB verifica o seguinte -
Se uma transação foi iniciada, ele procura dentro da transação os registros alterados e os retorna, se encontrados.
Se o cache local estiver habilitado e contiver o registro solicitado, ele o retornará.
Se neste ponto o registro não estiver no cache, então pede para o Storage (disco, memória).
Modo Cliente Servidor (Banco de Dados Remoto)
O diagrama de fluxo a seguir mostra como o registro está entre o armazenamento e o aplicativo usado no modo cliente-servidor, ou seja, quando o servidor de banco de dados está em um local remoto.
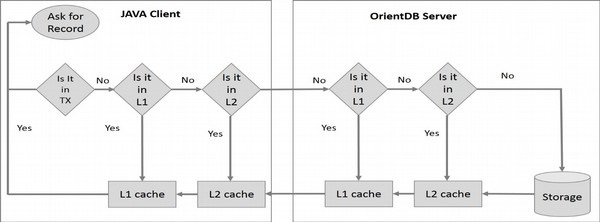
Quando o aplicativo cliente pede um registro, o OrientDB verifica o seguinte -
Se uma transação foi iniciada, ele procura dentro da transação os registros alterados e os retorna, se encontrados.
Se o cache local estiver habilitado e contiver o registro solicitado, ele o retornará.
Nesse ponto, se o registro não estiver no cache, ele será solicitado ao Servidor por meio de uma chamada TCP / IP.
No servidor, se o cache local estiver habilitado e contiver o registro solicitado, ele o retorna.
Neste ponto, ainda o registro não está em cache no servidor, então pede para o Storage (disco, memória).
O OrientDB usa a estrutura Java Logging incluída na Java Virtual Machine. O formato de registro padrão do OrientDB é gerenciado porOLogFormatter classe.
A instrução a seguir é a sintaxe básica do comando de registro.
<date> <level> <message> [<requester>]A seguir estão os detalhes sobre as opções na sintaxe acima.
<date> - É a data do registro no seguinte formato: aaaa-MM-dd HH: mm: ss: SSS.
<level> - É o nível de registro como saída de 5 caracteres.
<message> - É o texto do log, pode ser de qualquer tamanho.
[<class>] - É a classe Java que é registrada (opcional).
Os níveis suportados são aqueles contidos na classe JRE java.util.logging.Level. Eles são -
- SEVERE (valor mais alto)
- WARNING
- INFO
- CONFIG
- FINE
- FINER
- FINEST (valor mais baixo)
Por padrão, dois registradores são instalados -
Console, como a saída do shell / prompt de comando que inicia o aplicativo / servidor. Pode ser alterado definindo a variável 'log.console.level'.
File, como a saída para os arquivos de log. Pode ser alterado definindo o 'log.file.level'.
Configurar registro
As estratégias e políticas de registro podem ser configuradas usando um arquivo seguindo o Java.
syntax - Configuração do Java Logging.
Exemplo
Copie o seguinte conteúdo de orientdb-server-log.properties arquivo e colocá-lo no $ORIENTDB_HOME/config Arquivo.
# Specify the handlers to create in the root logger
# (all loggers are children of the root logger)
# The following creates two handlers
handlers = java.util.logging.ConsoleHandler, java.util.logging.FileHandler
# Set the default logging level for the root logger
.level = ALL
# Set the default logging level for new ConsoleHandler instances
java.util.logging.ConsoleHandler.level = INFO
# Set the default formatter for new ConsoleHandler instances
java.util.logging.ConsoleHandler.formatter =
com.orientechnologies.common.log.OLogFormatter
# Set the default logging level for new FileHandler instances
java.util.logging.FileHandler.level = INFO
# Naming style for the output file
java.util.logging.FileHandler.pattern =../log/orient-server.log
# Set the default formatter for new FileHandler instances
java.util.logging.FileHandler.formatter = com.orientechnologies.common.log.OLogFormatter
# Limiting size of output file in bytes:
java.util.logging.FileHandler.limit = 10000000
# Number of output files to cycle through, by appending an
# integer to the base file name:
java.util.logging.FileHandler.count = 10Para informar à JVM onde o arquivo de propriedades é colocado, você precisa definir o "java.util.logging.config.file"propriedade do sistema para ele. Por exemplo, use o seguinte comando -
$ java -Djava.util.logging.config.file=mylog.properties ...Defina o nível de registro
Para alterar o nível de registro sem modificar a configuração de registro, basta definir o "log.console.level"e"log.file.level"variáveis do sistema para os níveis solicitados.
Registro na inicialização
A seguir estão os procedimentos para definir o log no nível de inicialização de maneiras diferentes.
Na configuração do servidor
Abra o arquivo orientdb-server-config.xml e adicione ou atualize essas linhas no final do arquivo dentro da seção <properties> -
<entry value = "fine" name = "log.console.level" />
<entry value = "fine" name = "log.file.level" />No script Server.sh (ou .bat)
Defina a propriedade do sistema "log.console.level"e"log.file.level"para os níveis que você deseja usando o parâmetro -D de java.
$ java -Dlog.console.level = FINE ...Registro em tempo de execução
A seguir estão os procedimentos para definir o log no nível de inicialização de maneiras diferentes.
Usando código Java
A variável do sistema pode ser definida na inicialização usando a API System.setProperty (). O fragmento de código a seguir é a sintaxe para definir o nível de registro usando o código Java.
public void main(String[] args){
System.setProperty("log.console.level", "FINE");
...
}No servidor remoto
Execute um HTTP POST no URL: /server/log.<type>/ <level>, onde -
- <tipo> pode ser "console" ou "arquivo"
- <level> é um dos níveis suportados
Exemplo
O exemplo a seguir usa cURLpara executar um comando HTTP POST no servidor OrientDB. Foram usados o usuário "root" e a senha do servidor, substitua por sua própria senha.
Habilite o melhor nível de rastreamento para o console -
curl -u root:root -X POST http://localhost:2480/server/log.console/FINESTHabilite o melhor nível de rastreamento para o arquivo -
curl -u root:root -X POST http://localhost:2480/server/log.file/FINESTNeste capítulo, você pode obter algumas dicas gerais sobre como otimizar seu aplicativo que usa OrientDB. Existem três maneiras de aumentar o desempenho para diferentes tipos de banco de dados.
Document Database Performance Tuning - Ele usa uma técnica que ajuda a evitar a criação de documentos para cada novo documento.
Object Database Performance Tuning - Ele usa as técnicas genéricas para melhorar o desempenho.
Distributed Configuration Tuning - Utiliza diferentes metodologias para melhorar o desempenho na configuração distribuída.
Você pode obter um ajuste de desempenho genérico alterando as configurações de memória, JVM e conexão remota.
Configurações de memória
Existem diferentes estratégias na configuração da memória para melhorar o desempenho.
Configurações de servidor e incorporadas
Essas configurações são válidas para o componente do servidor e a JVM onde o aplicativo Java é executado usando OrientDB no modo incorporado, usando diretamente plocal.
O mais importante no ajuste é garantir que as configurações de memória estejam corretas. O que pode fazer uma diferença real é o equilíbrio certo entre o heap e a memória virtual usada pelo mapeamento de memória, especialmente em grandes conjuntos de dados (GBs, TBs e mais) onde as estruturas de cache de memória contam menos do que o IO bruto.
Por exemplo, se você pode atribuir no máximo 8 GB ao processo Java, geralmente é melhor atribuir um heap pequeno e um buffer de cache de disco grande (memória off-heap).
Tente o seguinte comando para aumentar a memória heap.
java -Xmx800m -Dstorage.diskCache.bufferSize=7200 ...o storage.diskCache.bufferSize configuração (com o antigo armazenamento "local" era file.mmap.maxMemory) está em MB e informa a quantidade de memória a ser usada para o componente Disk Cache. Por padrão, é de 4 GB.
NOTE - Se a soma do heap máximo e do buffer do cache de disco for muito alta, isso pode fazer com que o sistema operacional troque com grande lentidão.
Configurações JVM
As configurações de JVM são codificadas em arquivos em lote server.sh (e server.bat). Você pode alterá-los para ajustar a JVM de acordo com seu uso e configurações de hw / sw. Adicione a seguinte linha no arquivo server.bat.
-server -XX:+PerfDisableSharedMemEsta configuração desativará a gravação de informações de depuração sobre a JVM. Caso você precise criar o perfil da JVM, apenas remova esta configuração.
Conexões Remotas
Existem muitas maneiras de melhorar o desempenho ao acessar o banco de dados usando uma conexão remota.
Estratégia de busca
Ao trabalhar com um banco de dados remoto, você deve prestar atenção à estratégia de busca usada. Por padrão, o cliente OrientDB carrega apenas o registro contido no conjunto de resultados. Por exemplo, se uma consulta retornar 100 elementos, mas se você cruzar esses elementos do cliente, o cliente OrientDB carrega lentamente os elementos com mais uma chamada de rede para o servidor para cada registro perdido.
Pool de conexão de rede
Cada cliente, por padrão, usa apenas uma conexão de rede para se comunicar com o servidor. Vários threads no mesmo cliente compartilham o mesmo pool de conexão de rede.
Quando você tem vários threads, pode haver um gargalo, pois muito tempo é gasto esperando por uma conexão de rede gratuita. É por isso que é importante configurar o pool de conexão de rede.
A configuração é muito simples, apenas 2 parâmetros -
minPool- É o tamanho inicial do pool de conexão. O valor padrão é configurado como parâmetros globais "client.channel.minPool".
maxPool- É o tamanho máximo que o pool de conexão pode atingir. O valor padrão é configurado como parâmetros globais "client.channel.maxPool".
Se todas as conexões do pool estiverem ocupadas, o encadeamento do cliente aguardará a primeira conexão livre.
Exemplo de comando de configuração usando propriedades do banco de dados.
database = new ODatabaseDocumentTx("remote:localhost/demo");
database.setProperty("minPool", 2);
database.setProperty("maxPool", 5);
database.open("admin", "admin");Ajuste de configuração distribuída
Existem muitas maneiras de melhorar o desempenho na configuração distribuída.
Use transações
Mesmo quando você atualiza gráficos, você deve sempre trabalhar em transações. OrientDB permite que você trabalhe fora deles. Casos comuns são consultas somente leitura ou operações massivas e não simultâneas podem ser restauradas em caso de falha. Quando você executa em configuração distribuída, o uso de transações ajuda a reduzir a latência. Isso ocorre porque a operação distribuída acontece apenas no momento da confirmação. Distribuir uma grande operação é muito mais eficiente do que transferir pequenas operações múltiplas, devido à latência.
Replicação vs Sharding
A configuração distribuída do OrientDB está definida para replicação completa. Ter vários nós com a mesma cópia do banco de dados é importante para leituras de escala. Na verdade, cada servidor é independente na execução de leituras e consultas. Se você tiver 10 nós de servidor, a taxa de transferência de leitura é 10x.
Com gravações, é o oposto: ter vários nós com replicação completa retarda as operações, se a replicação for síncrona. Nesse caso, fragmentar o banco de dados em vários nós permite aumentar as gravações, porque apenas um subconjunto de nós está envolvido na gravação. Além disso, você poderia ter um banco de dados maior que um nó de servidor HD.
Amplie as gravações
Se você tiver uma rede lenta e uma replicação síncrona (padrão), poderá pagar o custo da latência. Na verdade, quando o OrientDB é executado de forma síncrona, ele espera pelo menos pelowriteQuorum. Isso significa que se o writeQuorum for 3 e você tiver 5 nós, o nó do servidor coordenador (onde a operação distribuída é iniciada) deve aguardar a resposta de pelo menos 3 nós para fornecer a resposta ao cliente.
Para manter a consistência, o writeQuorum deve ser definido como a maioria. Se você tiver 5 nós, a maioria é 3. Com 4 nós, ainda é 3. Definir o writeQuorum para 3 em vez de 4 ou 5 permite reduzir o custo de latência e ainda manter a consistência.
Replicação Assíncrona
Para acelerar as coisas, você pode configurar a replicação assíncrona para remover o gargalo de latência. Nesse caso, o nó do servidor coordenador executa a operação localmente e dá a resposta ao cliente. Toda a replicação ficará em segundo plano. Caso o quorum não seja alcançado, as alterações serão revertidas de forma transparente.
Amplie as leituras
Se você já definiu o writeQuorum para a maioria dos nós, pode deixar o readQuorumpara 1 (o padrão). Isso acelera todas as leituras.
Durante a atualização, você deve considerar o número da versão e o formato. Existem três tipos de formatos - MAJOR, MINOR, PATCH.
MAJOR versão implica alterações de API incompatíveis.
MINOR versão envolve funcionalidade de maneira compatível com versões anteriores.
PTCH versão envolve correções de bugs compatíveis com versões anteriores.
Para sincronizar entre as versões secundária e principal, pode ser necessário exportar e importar os bancos de dados. Às vezes, você precisa migrar o banco de dados de LOCAL para PLOCAL e precisa migrar o gráfico para RidBag.
Migrar de LOCAL Storage Engine para PLOCAL
A partir da versão 1.5.x, o OrientDB vem com um novo mecanismo de armazenamento: PLOCAL (Paginated LOCAL). É persistente como o LOCAL, mas armazena informações de uma maneira diferente. Os pontos a seguir mostram a comparação entre PLOCAL e LOCAL -
Em PLOCAL, os registros são armazenados em arquivos de cluster, enquanto com LOCAL foi dividido entre cluster e segmentos de dados.
PLOCAL é mais durável que LOCAL por causa do modo anexar na gravação.
PLOCAL tem bloqueios de contenção menores nas gravações, o que significa mais simultaneidade.
PLOCAL não usa técnicas de mapeamento de memória (MMap), então o comportamento é mais "previsível".
Para migrar seu armazenamento LOCAL para o novo PLOCAL, você precisa exportar e reimportar o banco de dados usando PLOCAL como mecanismo de armazenamento. A seguir está o procedimento.
Step 1 - Abra um novo shell (Linux / Mac) ou um Prompt de Comando (Windows).
Step 2- Exporte o banco de dados usando o console. Siga o comando fornecido para exportar a demonstração do banco de dados parademo.json.gzip Arquivo.
$ bin/console.sh (or bin/console.bat under Windows)
orientdb> CONNECT DATABASE local:/temp/demo admin admin
orientdb> EXPORT DATABASE /temp/demo.json.gzip
orientdb> DISCONNECTStep 3 - Em um sistema de arquivos local, crie um novo banco de dados usando o mecanismo "plocal" -
orientdb> CREATE DATABASE plocal:/temp/newdb admin admin plocal graphStep 4 - Importe o banco de dados antigo para o novo.
orientdb> IMPORT DATABASE /temp/demo.json.gzip -preserveClusterIDs=true
orientdb> QUITSe você acessar o banco de dados na mesma JVM, lembre-se de alterar a URL de "local:" para "plocal:"
Migrar gráfico para RidBag
A partir do OrientDB 1.7, o RidBag é uma coleção padrão que gerencia relações de adjacência em grafos. Embora os bancos de dados mais antigos gerenciados por uma árvore MVRB sejam totalmente compatíveis, você pode atualizar seu banco de dados para o formato mais recente.
Você pode atualizar seu gráfico via console ou usando o ORidBagMigration classe.
Conectar ao banco de dados CONNECT plocal:databases/<graphdb-name>
Execute o comando gráfico de atualização
Como o RDBMS, o OrientDB também fornece segurança com base em conceitos, usuários e funções bem conhecidos. Cada banco de dados possui seus próprios usuários e cada usuário possui uma ou mais funções. Funções são a combinação de modos de trabalho e conjunto de permissões.
Comercial
Por padrão, o OrientDB mantém três usuários diferentes para todos os bancos de dados no servidor -
Admin - Este usuário tem acesso a todas as funções do banco de dados, sem limitação.
Reader- Este usuário é um usuário somente leitura. O leitor pode consultar qualquer registro no banco de dados, mas não pode modificá-lo ou excluí-lo. Ele não tem acesso a informações internas, como os usuários e as próprias funções.
Writer - Este usuário é igual ao usuário leitor, mas também pode criar, atualizar e excluir registros.
Trabalho com usuários
Quando você está conectado a um banco de dados, você pode consultar os usuários atuais no banco de dados usando SELECT consultas no OUser classe.
orientdb> SELECT RID, name, status FROM OUserSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
---+--------+--------+--------
# | @CLASS | name | status
---+--------+--------+--------
0 | null | admin | ACTIVE
1 | null | reader | ACTIVE
2 | null | writer | ACTIVE
---+--------+--------+--------
3 item(s) found. Query executed in 0.005 sec(s).Criação de um novo usuário
Para criar um novo usuário, use o comando INSERT. Lembre-se, ao fazer isso, você deve definir o status como ACTIVE e atribuir a ele uma função válida.
orientdb> INSERT INTO OUser SET
name = 'jay',
password = 'JaY',
status = 'ACTIVE',
roles = (SELECT FROM ORole WHERE name = 'reader')Atualizando usuários
Você pode alterar o nome do usuário com a instrução UPDATE.
orientdb> UPDATE OUser SET name = 'jay' WHERE name = 'reader'Da mesma forma, você também pode alterar a senha do usuário.
orientdb> UPDATE OUser SET password = 'hello' WHERE name = 'reader'OrientDB salva a senha em formato hash. O gatilhoOUserTrigger criptografa a senha de forma transparente antes de salvar o registro.
Desativando usuários
Para desabilitar um usuário, use UPDATE para mudar seu status de ACTIVE para SUSPENDED. Por exemplo, se você deseja desabilitar todos os usuários, exceto o administrador, use o seguinte comando -
orientdb> UPDATE OUser SET status = 'SUSPENDED' WHERE name <> 'admin'Funções
Uma função determina quais operações um usuário pode executar em um recurso. Principalmente, essa decisão depende do modo de trabalho e das regras. As próprias regras funcionam de maneira diferente, dependendo do modo de trabalho.
Trabalho com funções
Quando você está conectado a um banco de dados, pode consultar as funções atuais no banco de dados usando SELECT consultas no ORole classe.
orientdb> SELECT RID, mode, name, rules FROM ORoleSe a consulta acima for executada com sucesso, você obterá a seguinte saída.
--+------+----+--------+-------------------------------------------------------
# |@CLASS|mode| name | rules
--+------+----+--------+-------------------------------------------------------
0 | null | 1 | admin | {database.bypassRestricted = 15}
1 | null | 0 | reader | {database.cluster.internal = 2, database.cluster.orole = 0...
2 | null | 0 | writer | {database.cluster.internal = 2, database.cluster.orole = 0...
--+------+----+--------+-------------------------------------------------------
3 item(s) found. Query executed in 0.002 sec(s).Criação de novas funções
Para criar uma nova função, use a instrução INSERT.
orientdb> INSERT INTO ORole SET name = 'developer', mode = 0Trabalhando com Modos
Onde as regras determinam o que os usuários pertencentes a certas funções podem fazer nos bancos de dados, os modos de trabalho determinam como o OrientDB interpreta essas regras. Existem dois tipos de modos de trabalho, designados por 1 e 0.
Allow All But (Rules)- Por padrão, é o modo de superusuário. Especifique exceções a isso usando as regras. Se o OrientDB não encontrar regras para um recurso solicitado, ele permite que o usuário execute a operação. Use este modo principalmente para usuários avançados e administradores. A função admin padrão usa este modo por padrão e não tem regras de exceção. É escrito como 1 no banco de dados.
Deny All But (Rules)- Por padrão, este modo não permite nada. Especifique exceções a isso usando as regras. Se o OrientDB encontrar regras para um recurso solicitado, ele permitirá que o usuário execute a operação. Use este modo como padrão para todos os usuários clássicos. As funções padrão, leitor e escritor, usam este modo. Ele é escrito como 0 no banco de dados.
OrientDB fornece uma IU da web para realizar operações de banco de dados por meio de GUI. Este capítulo explica as diferentes opções disponíveis no OrientDB.
Página inicial do Studio
Studio é uma interface da web para a administração do OrientDB que vem em conjunto com a distribuição do OrientDB.
Primeiro, você precisa iniciar o servidor OrientDB usando o seguinte comando.
$ server.shSe você executa OrientDB em sua máquina, a interface da web pode ser acessada através do URL -
http://localhost:2480Se o comando for executado com sucesso, o seguinte será o resultado na tela.
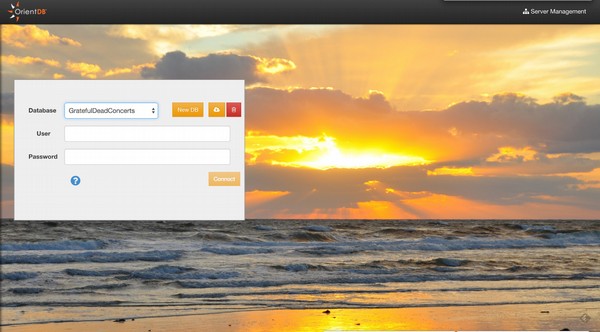
Conecte-se a um banco de dados existente
Para fazer o login, selecione um banco de dados da lista de bancos de dados e use qualquer usuário do banco de dados. Por padrão (nome de usuário / senha)reader/reader pode ler registros do banco de dados, writer/writer pode ler, criar, atualizar e excluir registros, enquanto admin/admin tem todos os direitos.
Elimine um banco de dados existente
Selecione um banco de dados na lista de bancos de dados e clique no ícone da lixeira. O Studio abrirá um pop-up de confirmação onde você deve inserir o usuário do servidor e a senha do servidor.
Em seguida, clique no botão "Eliminar banco de dados". Você pode encontrar as credenciais do servidor no$ORIENTDB_HOME/config/orientdb-server-config.xml Arquivo.
<users>
<user name = "root" password = "pwd" resources = "*" />
</users>Crie um novo banco de dados
Para criar um novo banco de dados, clique no botão "Novo banco de dados" na página inicial.
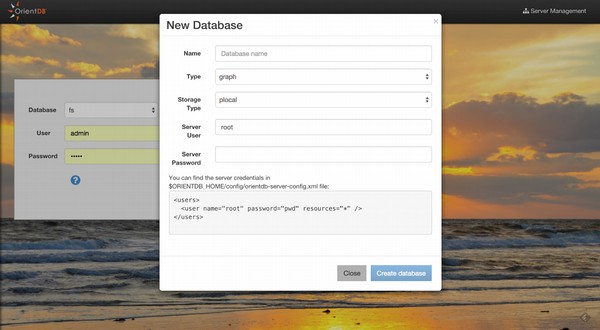
As seguintes informações são necessárias para criar um novo banco de dados -
- Nome do banco de dados
- Tipo de banco de dados (documento / gráfico)
- Tipo de armazenamento (plocal / memória)
- Usuário do servidor
- Senha do servidor
Você pode encontrar as credenciais do servidor no $ORIENTDB_HOME/config/orientdbserver-config.xml Arquivo.
<users>
<user name = "root" password = "pwd" resources = "*" />
</users>Depois de criado, o Studio fará o login automaticamente no novo banco de dados.
Execute uma consulta
O Studio oferece suporte ao reconhecimento automático do idioma que você está usando entre os compatíveis: SQL e Gremlin. Ao escrever, use o recurso autocompletar pressionandoCtrl + Space.
Os seguintes atalhos estão disponíveis no editor de consultas -
Ctrl + Return - Para executar a consulta ou simplesmente clicar no Run botão.
Ctrl/Cmd + Z - Para desfazer alterações.
Ctrl/Cmd + Shift + Z - Para refazer as alterações.
Ctrl/Cmd + F - Para pesquisar no editor.
Ctrl/Cmd + / - Para alternar um comentário.
A captura de tela a seguir mostra como executar uma consulta.
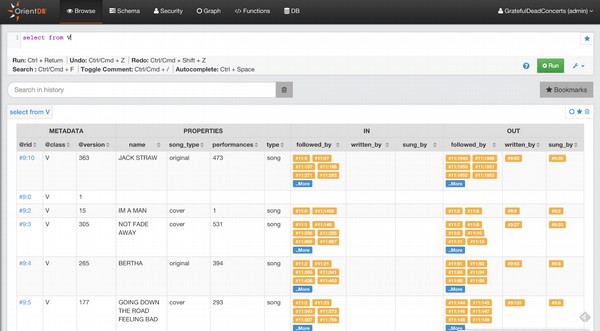
Ao clicar em qualquer @rid valor no conjunto de resultados, você irá para o modo de edição de documento se o registro for um Documento, caso contrário, você irá para a edição de vértice.
Você pode marcar suas consultas clicando no ícone de estrela no conjunto de resultados ou no editor. Para navegar nas consultas marcadas, clique noBookmarksbotão. O Studio abrirá a lista de favoritos à esquerda, onde você pode editar / excluir ou executar novamente as consultas.
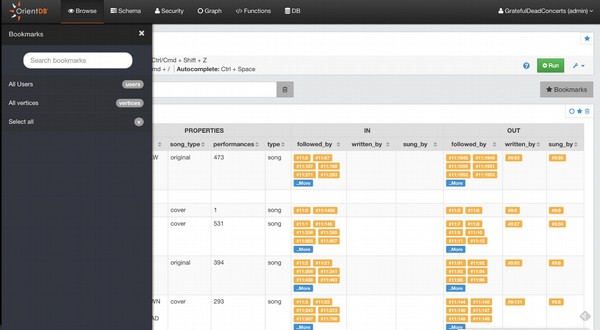
O Studio salva as consultas executadas no Armazenamento Local do navegador. Nas configurações de consulta, você pode configurar quantas consultas o Studio manterá no histórico. Você também pode pesquisar uma consulta executada anteriormente, excluir todas as consultas do histórico ou excluir uma única consulta.
Editar vértice
Para editar o vértice do gráfico, vá para a seção Gráfico. Em seguida, execute a seguinte consulta.
Select From CustomerAo executar a consulta com sucesso, veja a captura de tela de saída. Selecione o vértice específico na tela do gráfico para editar.

Selecione o símbolo de edição no vértice específico. Você verá a seguinte tela que contém as opções para editar o vértice.
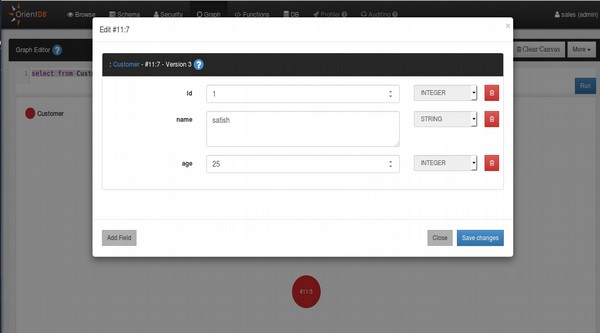
Schema Manager
OrientDB pode funcionar no modo sem esquema, no modo esquema ou em uma combinação de ambos. Aqui, discutiremos o modo de esquema. Clique na seção Esquema na parte superior da IU da web. Você obterá a seguinte captura de tela.
Criar uma nova classe
Para criar uma nova classe, basta clicar no New Classbotão. A captura de tela a seguir aparecerá. Você terá que fornecer as seguintes informações, conforme mostrado na captura de tela, para criar a nova classe.
Ver todos os índices
Quando você quiser ter uma visão geral de todos os índices criados em seu banco de dados, basta clicar no botão todos os índices na UI do Schema. Isso fornecerá um acesso rápido a algumas informações sobre os índices (nome, tipo, propriedades, etc.) e você pode descartá-los ou reconstruí-los a partir daqui.
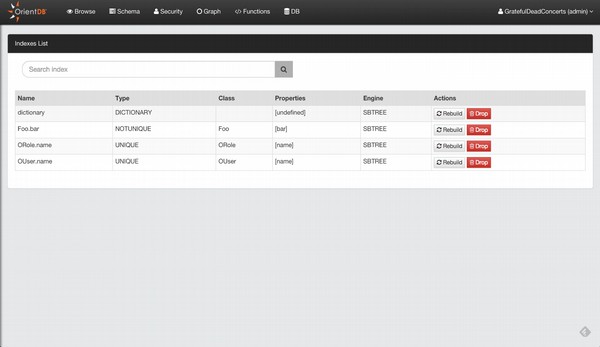
Editar aula
Clique em qualquer classe na seção de esquema, você obterá a seguinte captura de tela.
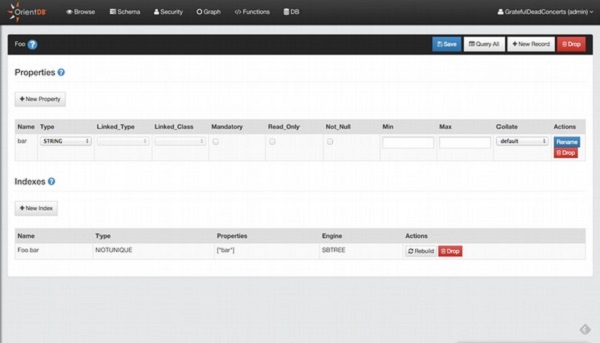
Ao editar uma classe, você pode adicionar uma propriedade ou adicionar um novo índice.
Adicionar uma propriedade
Clique no botão Nova Propriedade para adicionar uma propriedade. Você obterá a seguinte captura de tela.
Você deve fornecer os seguintes detalhes, conforme mostrado na captura de tela, para adicionar a propriedade.
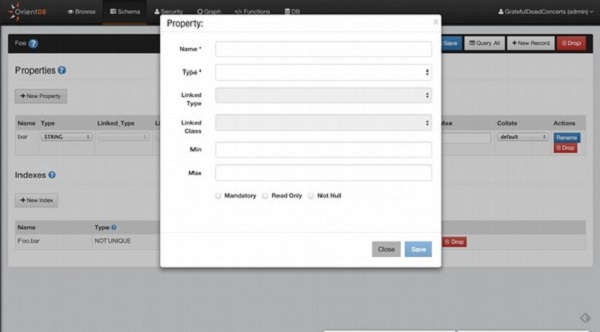
Adicionar um Índice
Clique no botão Novo índice. Você obterá a seguinte captura de tela. Você deve fornecer os seguintes detalhes, conforme mostrado na captura de tela, para adicionar um índice.
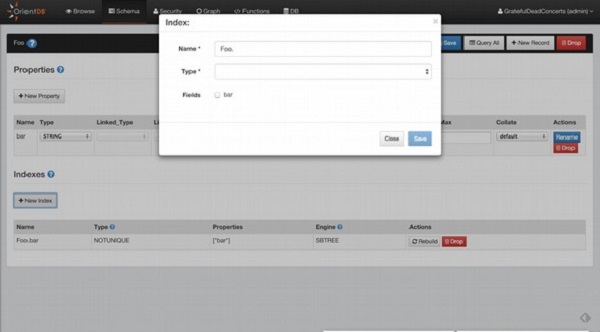
Editor de Gráfico
Clique na seção do gráfico. Você pode não apenas visualizar seus dados em um estilo de gráfico, mas também interagir com o gráfico e modificá-lo.
Para preencher a área do gráfico, digite uma consulta no editor de consulta ou use a funcionalidade Enviar para gráfico na IU de navegação.

Adicionar vértices
Para adicionar um novo vértice no seu banco de dados gráfico e na área da tela do gráfico, você deve pressionar o botão Add Vertex. Esta operação é feita em duas etapas.
Na primeira etapa, você deve escolher a classe para o novo vértice e clicar em Avançar.
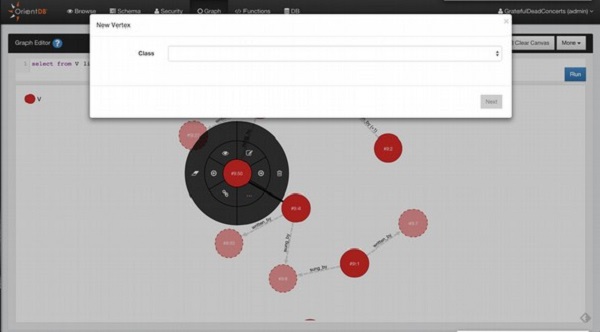
Na segunda etapa, você deve inserir os valores dos campos do novo vértice. Você também pode adicionar campos personalizados, pois o OrientDB oferece suporte ao modo sem esquema. Para tornar o novo vértice persistente, clique em 'Salvar alterações' e o vértice será salvo no banco de dados e adicionado à área da tela.

Excluir vértices
Abra o menu circular clicando no vértice que deseja excluir. Abra o submenu passando o mouse até a entrada do menu mais (...) e clique no ícone da lixeira.
Remover vértices da tela
Abra o menu circular, abra o submenu passando o mouse até a entrada do menu mais (...) e clique no ícone de borracha.
Inspecionar vértices
Se você quiser dar uma olhada rápida na propriedade Vertex, clique no ícone do olho.
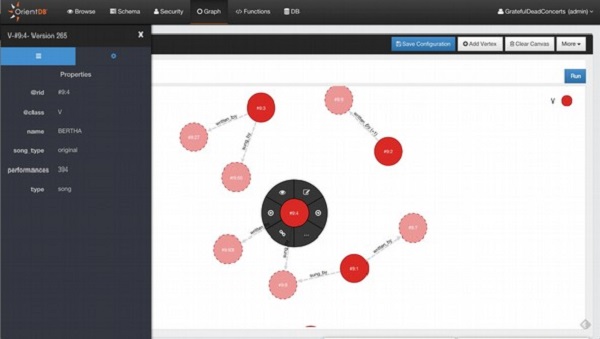
Segurança
O Studio 2.0 inclui o novo Gerenciamento de Segurança, onde você pode gerenciar usuários e funções de forma gráfica.
Comercial
Você pode realizar as seguintes ações para gerenciar os usuários do banco de dados -
- Usuários de busca
- Adicionar usuários
- Excluir usuários
- Editar usuário: as funções podem ser editadas em linha; para nome, status e senha, clique no botão Edit botão
Adicionar usuários
Para adicionar um novo usuário, clique no Add User , preencha as informações para o novo usuário (nome, senha, status, funções) e salve para adicionar o novo usuário ao banco de dados.
Funções
Você pode realizar as seguintes ações para gerenciar as funções de banco de dados -
- Função de pesquisa
- Adicionar papel
- Excluir função
- Editar papel
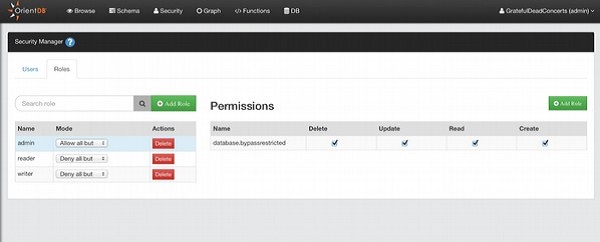
Adicionar papel
Para adicionar um novo usuário, clique no Add Role botão, preencha as informações para a nova função (nome, função pai, modo) e salve para adicionar a nova função ao banco de dados.
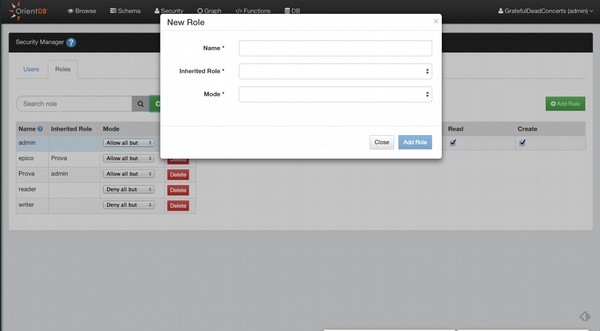
Adicionar regra a uma função
Para adicionar uma nova regra de segurança para a função selecionada, clique no Add Rulebotão. Isso irá perguntar a você a string do recurso que você deseja proteger. Em seguida, você pode configurar as permissões CRUD no recurso recém-criado.
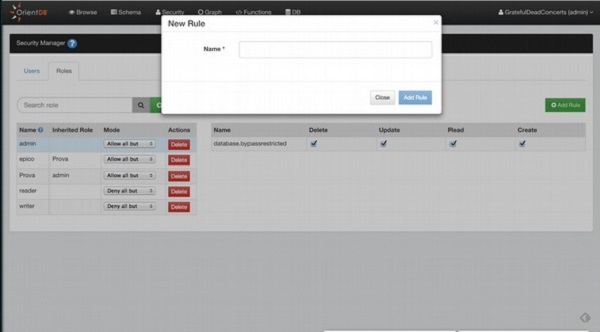
Semelhante ao RDBMS, o OrientDB suporta JDBC. Para isso, primeiro precisamos configurar o ambiente para programação JDBC. A seguir está o procedimento para criar uma conexão entre seu aplicativo e o banco de dados.
Primeiro, precisamos baixar o driver JDBC. Visite o seguinte linkhttps://code.google.com/archive/p/orient/downloads para baixar OrientDB-JDBC.
A seguir estão as cinco etapas básicas para obter a conectividade OrientDB-jdbc.
- Carregar driver JDBC
- Criar conexão
- Criar declaração
- Executar declaração
- Fechar conexão
Exemplo
Tente o exemplo a seguir para entender a conectividade OrientDB-JDBC. Vamos considerar que temos uma tabela de funcionários que contém os seguintes campos e seus tipos.
| Sr. Não. | Nome do Campo | Tipo |
|---|---|---|
| 1 | Eu iria | Inteiro |
| 2 | Nome | Corda |
| 3 | Salário | Inteiro |
| 4 | Data de afiliação | Encontro |
Você pode criar um esquema (tabela) executando os seguintes comandos.
CREATE DATABASE PLOCAL:/opt/orientdb/databases/testdb
CREATE CLASS Employee
CREATE PROPERTY Customer.id integer
CREATE PROPERTY Customer.name String
CREATE PROPERTY Customer.salary integer
CREATE PROPERTY Customer.join_date dateDepois de executar todos os comandos, você obterá a tabela Employee com os seguintes campos, nome do funcionário com id, idade e campos join_date.
Salve o seguinte código em OrientJdbcDemo.java Arquivo.
import com.orientechnologies.common.log.OLogManager;
import com.orientechnologies.orient.core.db.document.ODatabaseDocumentTx;
import org.junit.After;
import org.junit.Before;
import org.junit.BeforeClass;
import java.io.File;
import java.sql.DriverManager;
import java.util.Properties;
import static com.orientechnologies.orient.jdbc.OrientDbCreationHelper.createSchemaDB;
import static com.orientechnologies.orient.jdbc.OrientDbCreationHelper.loadDB;
import static java.lang.Class.forName;
public abstract class OrientJdbcDemo {
protected OrientJdbcConnection conn;
public static void main(String ar[]){
//load Driver
forName(OrientJdbcDriver.class.getName());
String dbUrl = "memory:testdb";
ODatabaseDocumentTx db = new ODatabaseDocumentTx(dbUrl);
String username = "admin";
String password = "admin";
createSchemaDB(db);
loadDB(db, 20);
dbtx.create();
//Create Connection
Properties info = new Properties();
info.put("user", username);
info.put("password", password);
conn = (OrientJdbcConnection) DriverManager.getConnection("jdbc:orient:" + dbUrl, info);
//create and execute statement
Statement stmt = conn.createStatement();
int updated = stmt.executeUpdate("INSERT into emplyoee
(intKey, text, salary, date) values ('001','satish','25000','"
+ date.toString() + "')");
int updated = stmt.executeUpdate("INSERT into emplyoee
(intKey, text, salary, date) values ('002','krishna','25000','"
+ date.toString() + "')");
System.out.println("Records successfully inserted");
//Close Connection
if (conn != null && !conn.isClosed())
conn.close();
}
}O seguinte comando é usado para compilar o programa acima.
$ javac –classpath:.:orientdb-jdbc-1.0-SNAPSHOT.jar OrientJdbcDemo.java $ java –classpath:.:orientdb-jdbc-1.0-SNAPSHOT.jar OrientJdbcDemoSe o comando acima for executado com sucesso, você obterá a seguinte saída.
Records Successfully InsertedO driver OrientDB para Python usa o protocolo binário. PyOrient é o nome do projeto do hub git que ajuda a conectar o OrientDB ao Python. Funciona com OrientDB versão 1.7 e posterior.
O seguinte comando é usado para instalar o PyOrient.
pip install pyorientVocê pode usar o arquivo de script chamado demo.py para fazer as seguintes tarefas -
Criar uma instância do cliente significa criar uma conexão.
Criar banco de dados chamado DB_Demo.
Abra o banco de dados denominado DB_Demo.
Crie a classe my_class.
Crie o id e o nome das propriedades.
Inserir registro em minha classe.
//create connection
client = pyorient.OrientDB("localhost", 2424)
session_id = client.connect( "admin", "admin" )
//create a databse
client.db_create( db_name, pyorient.DB_TYPE_GRAPH, pyorient.STORAGE_TYPE_MEMORY )
//open databse
client.db_open( DB_Demo, "admin", "admin" )
//create class
cluster_id = client.command( "create class my_class extends V" )
//create property
cluster_id = client.command( "create property my_class.id Integer" )
cluster_id = client.command( "create property my_class.name String" )
//insert record
client.command("insert into my_class ( 'id','’name' ) values( 1201, 'satish')")Execute o script acima usando o seguinte comando.
$ python demo.py