PySpark - Guia rápido
Neste capítulo, vamos nos familiarizar com o que é o Apache Spark e como o PySpark foi desenvolvido.
Spark - Visão geral
Apache Spark é uma estrutura de processamento em tempo real extremamente rápida. Ele faz cálculos na memória para analisar dados em tempo real. Ele entrou em cena comoApache Hadoop MapReduceestava realizando processamento em lote apenas e não tinha um recurso de processamento em tempo real. Portanto, o Apache Spark foi introduzido porque pode realizar processamento de stream em tempo real e também pode cuidar do processamento em lote.
Além do processamento em tempo real e em lote, o Apache Spark também oferece suporte a consultas interativas e algoritmos iterativos. Apache Spark possui seu próprio gerenciador de cluster, onde pode hospedar seu aplicativo. Ele aproveita o Apache Hadoop para armazenamento e processamento. UsaHDFS (Sistema de arquivos distribuídos Hadoop) para armazenamento e pode executar aplicativos Spark em YARN também.
PySpark - Visão geral
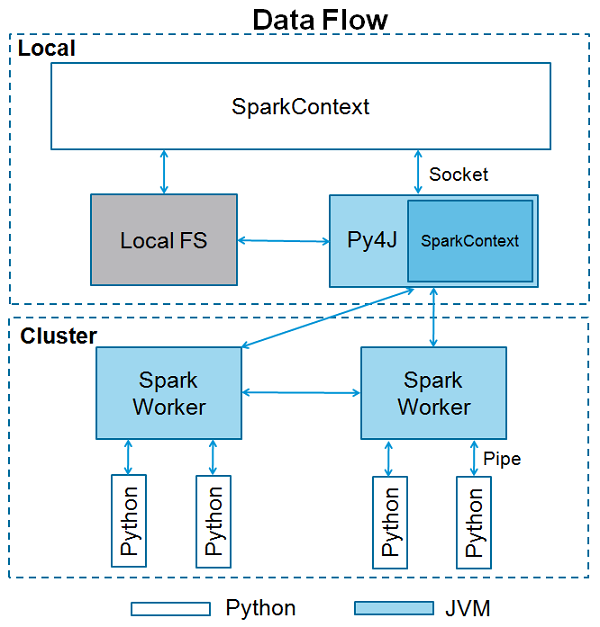
Apache Spark é escrito em Scala programming language. Para oferecer suporte a Python com Spark, a comunidade Apache Spark lançou uma ferramenta, PySpark. Usando o PySpark, você pode trabalhar comRDDsna linguagem de programação Python também. É por causa de uma biblioteca chamadaPy4j que eles são capazes de alcançar isso.
Ofertas PySpark PySpark Shellque vincula a API Python ao núcleo do Spark e inicializa o contexto do Spark. A maioria dos cientistas de dados e especialistas em análise hoje usa Python por causa de seu rico conjunto de bibliotecas. Integrar Python com Spark é uma bênção para eles.
Neste capítulo, entenderemos a configuração do ambiente do PySpark.
Note - Isso considerando que você tem Java e Scala instalados em seu computador.
Vamos agora baixar e configurar o PySpark com as seguintes etapas.
Step 1- Vá para a página oficial de download do Apache Spark e baixe a versão mais recente do Apache Spark disponível lá. Neste tutorial, estamos usandospark-2.1.0-bin-hadoop2.7.
Step 2- Agora, extraia o arquivo Spark tar baixado. Por padrão, ele será baixado no diretório Downloads.
# tar -xvf Downloads/spark-2.1.0-bin-hadoop2.7.tgzIrá criar um diretório spark-2.1.0-bin-hadoop2.7. Antes de iniciar o PySpark, você precisa definir os seguintes ambientes para definir o caminho do Spark e oPy4j path.
export SPARK_HOME = /home/hadoop/spark-2.1.0-bin-hadoop2.7
export PATH = $PATH:/home/hadoop/spark-2.1.0-bin-hadoop2.7/bin
export PYTHONPATH = $SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH
export PATH = $SPARK_HOME/python:$PATHOu, para definir os ambientes acima globalmente, coloque-os no .bashrc file. Em seguida, execute o seguinte comando para que os ambientes funcionem.
# source .bashrcAgora que temos todos os ambientes configurados, vamos ao diretório Spark e invoque o shell PySpark executando o seguinte comando -
# ./bin/pysparkIsso iniciará seu shell PySpark.
Python 2.7.12 (default, Nov 19 2016, 06:48:10)
[GCC 5.4.0 20160609] on linux2
Type "help", "copyright", "credits" or "license" for more information.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Python version 2.7.12 (default, Nov 19 2016 06:48:10)
SparkSession available as 'spark'.
<<<SparkContext é o ponto de entrada para qualquer funcionalidade de faísca. Quando executamos qualquer aplicativo Spark, um programa de driver é iniciado, que tem a função principal e seu SparkContext é iniciado aqui. O programa driver então executa as operações dentro dos executores nos nós de trabalho.
SparkContext usa Py4J para lançar um JVM e cria um JavaSparkContext. Por padrão, o PySpark tem SparkContext disponível como‘sc’, portanto, criar um novo SparkContext não funcionará.
O bloco de código a seguir contém os detalhes de uma classe PySpark e os parâmetros que um SparkContext pode usar.
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)Parâmetros
A seguir estão os parâmetros de um SparkContext.
Master - É a URL do cluster ao qual ele se conecta.
appName - Nome do seu trabalho.
sparkHome - Diretório de instalação do Spark.
pyFiles - Os arquivos .zip ou .py a serem enviados ao cluster e adicionados ao PYTHONPATH.
Environment - Variáveis de ambiente dos nós de trabalho.
batchSize- O número de objetos Python representados como um único objeto Java. Defina 1 para desativar o lote, 0 para escolher automaticamente o tamanho do lote com base nos tamanhos dos objetos ou -1 para usar um tamanho de lote ilimitado.
Serializer - serializador RDD.
Conf - Um objeto de L {SparkConf} para definir todas as propriedades do Spark.
Gateway - Use um gateway e JVM existentes, caso contrário, inicialize uma nova JVM.
JSC - A instância JavaSparkContext.
profiler_cls - Uma classe de Profiler customizado usada para fazer perfis (o padrão é pyspark.profiler.BasicProfiler).
Entre os parâmetros acima, master e appnamesão usados principalmente. As primeiras duas linhas de qualquer programa PySpark têm a aparência mostrada abaixo -
from pyspark import SparkContext
sc = SparkContext("local", "First App")Exemplo de SparkContext - PySpark Shell
Agora que você sabe o suficiente sobre SparkContext, vamos executar um exemplo simples no shell PySpark. Neste exemplo, estaremos contando o número de linhas com o caractere 'a' ou 'b' noREADME.mdArquivo. Então, digamos que se houver 5 linhas em um arquivo e 3 linhas tiverem o caractere 'a', a saída será →Line with a: 3. O mesmo será feito para o caractere 'b'.
Note- Não estamos criando nenhum objeto SparkContext no exemplo a seguir porque, por padrão, o Spark cria automaticamente o objeto SparkContext denominado sc, quando o shell PySpark é iniciado. Caso você tente criar outro objeto SparkContext, obterá o seguinte erro -"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30Exemplo de SparkContext - programa Python
Vamos executar o mesmo exemplo usando um programa Python. Crie um arquivo Python chamadofirstapp.py e digite o código a seguir nesse arquivo.
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------Em seguida, executaremos o seguinte comando no terminal para executar este arquivo Python. Obteremos a mesma saída acima.
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30Agora que instalamos e configuramos o PySpark em nosso sistema, podemos programar em Python no Apache Spark. Porém, antes de fazer isso, vamos entender um conceito fundamental no Spark - RDD.
RDD significa Resilient Distributed Dataset, esses são os elementos que são executados e operam em vários nós para fazer processamento paralelo em um cluster. Os RDDs são elementos imutáveis, o que significa que, depois de criar um RDD, você não pode alterá-lo. Os RDDs também são tolerantes a falhas, portanto, em caso de qualquer falha, eles se recuperam automaticamente. Você pode aplicar várias operações nesses RDDs para realizar uma determinada tarefa.
Para aplicar operações nestes RDDs, existem duas maneiras -
- Transformação e
- Action
Vamos entender essas duas maneiras em detalhes.
Transformation- Estas são as operações aplicadas em um RDD para criar um novo RDD. Filter, groupBy e map são exemplos de transformações.
Action - Essas são as operações aplicadas no RDD, que instruem o Spark a realizar cálculos e enviar o resultado de volta ao driver.
Para aplicar qualquer operação no PySpark, precisamos criar um PySpark RDDprimeiro. O bloco de código a seguir contém os detalhes de uma classe PySpark RDD -
class pyspark.RDD (
jrdd,
ctx,
jrdd_deserializer = AutoBatchedSerializer(PickleSerializer())
)Vamos ver como executar algumas operações básicas usando o PySpark. O código a seguir em um arquivo Python cria palavras RDD, que armazenam um conjunto de palavras mencionadas.
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)Agora vamos executar algumas operações em palavras.
contagem()
Número de elementos no RDD é retornado.
----------------------------------------count.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
counts = words.count()
print "Number of elements in RDD -> %i" % (counts)
----------------------------------------count.py---------------------------------------Command - O comando para count () é -
$SPARK_HOME/bin/spark-submit count.pyOutput - A saída para o comando acima é -
Number of elements in RDD → 8coletar ()
Todos os elementos do RDD são retornados.
----------------------------------------collect.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Collect app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
coll = words.collect()
print "Elements in RDD -> %s" % (coll)
----------------------------------------collect.py---------------------------------------Command - O comando para collect () é -
$SPARK_HOME/bin/spark-submit collect.pyOutput - A saída para o comando acima é -
Elements in RDD -> [
'scala',
'java',
'hadoop',
'spark',
'akka',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]foreach (f)
Retorna apenas os elementos que atendem à condição da função dentro de foreach. No exemplo a seguir, chamamos uma função de impressão em foreach, que imprime todos os elementos no RDD.
----------------------------------------foreach.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "ForEach app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
def f(x): print(x)
fore = words.foreach(f)
----------------------------------------foreach.py---------------------------------------Command - O comando para foreach (f) é -
$SPARK_HOME/bin/spark-submit foreach.pyOutput - A saída para o comando acima é -
scala
java
hadoop
spark
akka
spark vs hadoop
pyspark
pyspark and sparkfiltro (f)
Um novo RDD é retornado contendo os elementos, o que satisfaz a função dentro do filtro. No exemplo a seguir, filtramos as strings que contêm '' spark ".
----------------------------------------filter.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Filter app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_filter = words.filter(lambda x: 'spark' in x)
filtered = words_filter.collect()
print "Fitered RDD -> %s" % (filtered)
----------------------------------------filter.py----------------------------------------Command - O comando para filtro (f) é -
$SPARK_HOME/bin/spark-submit filter.pyOutput - A saída para o comando acima é -
Fitered RDD -> [
'spark',
'spark vs hadoop',
'pyspark',
'pyspark and spark'
]map (f, preservesPartitioning = False)
Um novo RDD é retornado aplicando uma função a cada elemento no RDD. No exemplo a seguir, formamos um par de valores-chave e mapeamos cada string com o valor 1.
----------------------------------------map.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Map app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words_map = words.map(lambda x: (x, 1))
mapping = words_map.collect()
print "Key value pair -> %s" % (mapping)
----------------------------------------map.py---------------------------------------Command - O comando para map (f, preservesPartitioning = False) é -
$SPARK_HOME/bin/spark-submit map.pyOutput - A saída do comando acima é -
Key value pair -> [
('scala', 1),
('java', 1),
('hadoop', 1),
('spark', 1),
('akka', 1),
('spark vs hadoop', 1),
('pyspark', 1),
('pyspark and spark', 1)
]reduzir (f)
Depois de realizar a operação binária comutativa e associativa especificada, o elemento no RDD é retornado. No exemplo a seguir, estamos importando pacote de adição do operador e aplicando-o em 'num' para realizar uma operação de adição simples.
----------------------------------------reduce.py---------------------------------------
from pyspark import SparkContext
from operator import add
sc = SparkContext("local", "Reduce app")
nums = sc.parallelize([1, 2, 3, 4, 5])
adding = nums.reduce(add)
print "Adding all the elements -> %i" % (adding)
----------------------------------------reduce.py---------------------------------------Command - O comando para reduzir (f) é -
$SPARK_HOME/bin/spark-submit reduce.pyOutput - A saída do comando acima é -
Adding all the elements -> 15juntar (outro, numPartitions = None)
Ele retorna RDD com um par de elementos com as chaves correspondentes e todos os valores dessa chave específica. No exemplo a seguir, há dois pares de elementos em dois RDDs diferentes. Depois de juntar esses dois RDDs, obtemos um RDD com elementos com chaves correspondentes e seus valores.
----------------------------------------join.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Join app")
x = sc.parallelize([("spark", 1), ("hadoop", 4)])
y = sc.parallelize([("spark", 2), ("hadoop", 5)])
joined = x.join(y)
final = joined.collect()
print "Join RDD -> %s" % (final)
----------------------------------------join.py---------------------------------------Command - O comando para juntar (outro, numPartitions = None) é -
$SPARK_HOME/bin/spark-submit join.pyOutput - A saída para o comando acima é -
Join RDD -> [
('spark', (1, 2)),
('hadoop', (4, 5))
]cache ()
Persista este RDD com o nível de armazenamento padrão (MEMORY_ONLY). Você também pode verificar se o RDD está armazenado em cache ou não.
----------------------------------------cache.py---------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Cache app")
words = sc.parallelize (
["scala",
"java",
"hadoop",
"spark",
"akka",
"spark vs hadoop",
"pyspark",
"pyspark and spark"]
)
words.cache()
caching = words.persist().is_cached
print "Words got chached > %s" % (caching)
----------------------------------------cache.py---------------------------------------Command - O comando para cache () é -
$SPARK_HOME/bin/spark-submit cache.pyOutput - A saída para o programa acima é -
Words got cached -> TrueEssas foram algumas das operações mais importantes realizadas no PySpark RDD.
Para processamento paralelo, o Apache Spark usa variáveis compartilhadas. Uma cópia da variável compartilhada vai em cada nó do cluster quando o driver envia uma tarefa ao executor no cluster, para que ele possa ser usado para executar tarefas.
Existem dois tipos de variáveis compartilhadas com suporte pelo Apache Spark -
- Broadcast
- Accumulator
Vamos entendê-los em detalhes.
Broadcast
Variáveis de broadcast são usadas para salvar a cópia dos dados em todos os nós. Esta variável é armazenada em cache em todas as máquinas e não enviada em máquinas com tarefas. O bloco de código a seguir contém os detalhes de uma classe Broadcast para PySpark.
class pyspark.Broadcast (
sc = None,
value = None,
pickle_registry = None,
path = None
)O exemplo a seguir mostra como usar uma variável Broadcast. Uma variável de transmissão possui um atributo chamado valor, que armazena os dados e é usado para retornar um valor transmitido.
----------------------------------------broadcast.py--------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Broadcast app")
words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"])
data = words_new.value
print "Stored data -> %s" % (data)
elem = words_new.value[2]
print "Printing a particular element in RDD -> %s" % (elem)
----------------------------------------broadcast.py--------------------------------------Command - O comando para uma variável de transmissão é o seguinte -
$SPARK_HOME/bin/spark-submit broadcast.pyOutput - A saída para o seguinte comando é fornecida abaixo.
Stored data -> [
'scala',
'java',
'hadoop',
'spark',
'akka'
]
Printing a particular element in RDD -> hadoopAcumulador
Variáveis acumuladoras são utilizadas para agregar as informações por meio de operações associativas e comutativas. Por exemplo, você pode usar um acumulador para uma operação de soma ou contadores (em MapReduce). O bloco de código a seguir contém os detalhes de uma classe de acumulador para PySpark.
class pyspark.Accumulator(aid, value, accum_param)O exemplo a seguir mostra como usar uma variável de acumulador. Uma variável de acumulador tem um atributo chamado valor que é semelhante ao que uma variável de transmissão tem. Ele armazena os dados e é usado para retornar o valor do acumulador, mas pode ser usado apenas em um programa de driver.
Neste exemplo, uma variável de acumulador é usada por vários trabalhadores e retorna um valor acumulado.
----------------------------------------accumulator.py------------------------------------
from pyspark import SparkContext
sc = SparkContext("local", "Accumulator app")
num = sc.accumulator(10)
def f(x):
global num
num+=x
rdd = sc.parallelize([20,30,40,50])
rdd.foreach(f)
final = num.value
print "Accumulated value is -> %i" % (final)
----------------------------------------accumulator.py------------------------------------Command - O comando para uma variável de acumulador é o seguinte -
$SPARK_HOME/bin/spark-submit accumulator.pyOutput - A saída para o comando acima é fornecida abaixo.
Accumulated value is -> 150Para executar um aplicativo Spark no local / cluster, você precisa definir algumas configurações e parâmetros, é nisso que o SparkConf ajuda. Ele fornece configurações para executar um aplicativo Spark. O bloco de código a seguir contém os detalhes de uma classe SparkConf para PySpark.
class pyspark.SparkConf (
loadDefaults = True,
_jvm = None,
_jconf = None
)Inicialmente, criaremos um objeto SparkConf com SparkConf (), que carregará os valores de spark.*Propriedades do sistema Java também. Agora você pode definir diferentes parâmetros usando o objeto SparkConf e seus parâmetros terão prioridade sobre as propriedades do sistema.
Em uma classe SparkConf, existem métodos setter, que oferecem suporte ao encadeamento. Por exemplo, você pode escreverconf.setAppName(“PySpark App”).setMaster(“local”). Depois de passar um objeto SparkConf para o Apache Spark, ele não pode ser modificado por nenhum usuário.
A seguir estão alguns dos atributos mais comumente usados do SparkConf -
set(key, value) - Para definir uma propriedade de configuração.
setMaster(value) - Para definir o URL mestre.
setAppName(value) - Para definir um nome de aplicativo.
get(key, defaultValue=None) - Para obter um valor de configuração de uma chave.
setSparkHome(value) - Para definir o caminho de instalação do Spark em nós de trabalho.
Vamos considerar o seguinte exemplo de uso do SparkConf em um programa PySpark. Neste exemplo, estamos definindo o nome do aplicativo spark comoPySpark App e definir o URL mestre de um aplicativo Spark para → spark://master:7077.
O bloco de código a seguir contém as linhas, quando são adicionadas ao arquivo Python, ele define as configurações básicas para executar um aplicativo PySpark.
---------------------------------------------------------------------------------------
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("PySpark App").setMaster("spark://master:7077")
sc = SparkContext(conf=conf)
---------------------------------------------------------------------------------------No Apache Spark, você pode fazer upload de seus arquivos usando sc.addFile (sc é o SparkContext padrão) e obtenha o caminho em um trabalhador usando SparkFiles.get. Assim, SparkFiles resolve os caminhos para arquivos adicionados por meio deSparkContext.addFile().
SparkFiles contém os seguintes métodos de classe -
- get(filename)
- getrootdirectory()
Vamos entendê-los em detalhes.
obter (nome do arquivo)
Ele especifica o caminho do arquivo adicionado por meio de SparkContext.addFile ().
getrootdirectory ()
Ele especifica o caminho para o diretório raiz, que contém o arquivo adicionado por meio de SparkContext.addFile ().
----------------------------------------sparkfile.py------------------------------------
from pyspark import SparkContext
from pyspark import SparkFiles
finddistance = "/home/hadoop/examples_pyspark/finddistance.R"
finddistancename = "finddistance.R"
sc = SparkContext("local", "SparkFile App")
sc.addFile(finddistance)
print "Absolute Path -> %s" % SparkFiles.get(finddistancename)
----------------------------------------sparkfile.py------------------------------------Command - O comando é o seguinte -
$SPARK_HOME/bin/spark-submit sparkfiles.pyOutput - A saída para o comando acima é -
Absolute Path ->
/tmp/spark-f1170149-af01-4620-9805-f61c85fecee4/userFiles-641dfd0f-240b-4264-a650-4e06e7a57839/finddistance.RStorageLevel decide como o RDD deve ser armazenado. No Apache Spark, o StorageLevel decide se o RDD deve ser armazenado na memória ou no disco, ou ambos. Ele também decide se serializar RDD e se deve replicar partições RDD.
O seguinte bloco de código tem a definição de classe de um StorageLevel -
class pyspark.StorageLevel(useDisk, useMemory, useOffHeap, deserialized, replication = 1)Agora, para decidir o armazenamento de RDD, existem diferentes níveis de armazenamento, que são fornecidos a seguir -
DISK_ONLY = StorageLevel (True, False, False, False, 1)
DISK_ONLY_2 = StorageLevel (True, False, False, False, 2)
MEMORY_AND_DISK = StorageLevel (True, True, False, False, 1)
MEMORY_AND_DISK_2 = StorageLevel (True, True, False, False, 2)
MEMORY_AND_DISK_SER = StorageLevel (True, True, False, False, 1)
MEMORY_AND_DISK_SER_2 = StorageLevel (True, True, False, False, 2)
MEMORY_ONLY = StorageLevel (False, True, False, False, 1)
MEMORY_ONLY_2 = StorageLevel (False, True, False, False, 2)
MEMORY_ONLY_SER = StorageLevel (False, True, False, False, 1)
MEMORY_ONLY_SER_2 = StorageLevel (False, True, False, False, 2)
OFF_HEAP = StorageLevel (True, True, True, False, 1)
Vamos considerar o seguinte exemplo de StorageLevel, onde usamos o nível de armazenamento MEMORY_AND_DISK_2, o que significa que as partições RDD terão replicação de 2.
------------------------------------storagelevel.py-------------------------------------
from pyspark import SparkContext
import pyspark
sc = SparkContext (
"local",
"storagelevel app"
)
rdd1 = sc.parallelize([1,2])
rdd1.persist( pyspark.StorageLevel.MEMORY_AND_DISK_2 )
rdd1.getStorageLevel()
print(rdd1.getStorageLevel())
------------------------------------storagelevel.py-------------------------------------Command - O comando é o seguinte -
$SPARK_HOME/bin/spark-submit storagelevel.pyOutput - A saída para o comando acima é fornecida abaixo -
Disk Memory Serialized 2x ReplicatedApache Spark oferece uma API de aprendizado de máquina chamada MLlib. O PySpark também possui essa API de aprendizado de máquina em Python. Ele suporta diferentes tipos de algoritmos, que são mencionados abaixo -
mllib.classification - o spark.mllibO pacote suporta vários métodos para classificação binária, classificação multiclasse e análise de regressão. Alguns dos algoritmos mais populares de classificação sãoRandom Forest, Naive Bayes, Decision Treeetc.
mllib.clustering - O agrupamento é um problema de aprendizagem não supervisionado, em que você pretende agrupar subconjuntos de entidades entre si com base em alguma noção de similaridade.
mllib.fpm- A correspondência de padrão frequente é a mineração de itens frequentes, conjuntos de itens, subsequências ou outras subestruturas que geralmente estão entre as primeiras etapas para analisar um conjunto de dados em grande escala. Este tem sido um tópico ativo de pesquisa em mineração de dados há anos.
mllib.linalg - Utilitários MLlib para álgebra linear.
mllib.recommendation- A filtragem colaborativa é comumente usada para sistemas de recomendação. Essas técnicas visam preencher as entradas ausentes de uma matriz de associação de itens do usuário.
spark.mllib- Suporta atualmente a filtragem colaborativa baseada em modelo, na qual usuários e produtos são descritos por um pequeno conjunto de fatores latentes que podem ser usados para prever entradas ausentes. spark.mllib usa o algoritmo Alternating Least Squares (ALS) para aprender esses fatores latentes.
mllib.regression- A regressão linear pertence à família dos algoritmos de regressão. O objetivo da regressão é encontrar relacionamentos e dependências entre variáveis. A interface para trabalhar com modelos de regressão linear e resumos de modelo é semelhante ao caso de regressão logística.
Existem outros algoritmos, classes e funções também como parte do pacote mllib. A partir de agora, vamos entender uma demonstração sobrepyspark.mllib.
O exemplo a seguir é de filtragem colaborativa usando algoritmo ALS para construir o modelo de recomendação e avaliá-lo nos dados de treinamento.
Dataset used - test.data
1,1,5.0
1,2,1.0
1,3,5.0
1,4,1.0
2,1,5.0
2,2,1.0
2,3,5.0
2,4,1.0
3,1,1.0
3,2,5.0
3,3,1.0
3,4,5.0
4,1,1.0
4,2,5.0
4,3,1.0
4,4,5.0--------------------------------------recommend.py----------------------------------------
from __future__ import print_function
from pyspark import SparkContext
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Rating
if __name__ == "__main__":
sc = SparkContext(appName="Pspark mllib Example")
data = sc.textFile("test.data")
ratings = data.map(lambda l: l.split(','))\
.map(lambda l: Rating(int(l[0]), int(l[1]), float(l[2])))
# Build the recommendation model using Alternating Least Squares
rank = 10
numIterations = 10
model = ALS.train(ratings, rank, numIterations)
# Evaluate the model on training data
testdata = ratings.map(lambda p: (p[0], p[1]))
predictions = model.predictAll(testdata).map(lambda r: ((r[0], r[1]), r[2]))
ratesAndPreds = ratings.map(lambda r: ((r[0], r[1]), r[2])).join(predictions)
MSE = ratesAndPreds.map(lambda r: (r[1][0] - r[1][1])**2).mean()
print("Mean Squared Error = " + str(MSE))
# Save and load model
model.save(sc, "target/tmp/myCollaborativeFilter")
sameModel = MatrixFactorizationModel.load(sc, "target/tmp/myCollaborativeFilter")
--------------------------------------recommend.py----------------------------------------Command - O comando será o seguinte -
$SPARK_HOME/bin/spark-submit recommend.pyOutput - A saída do comando acima será -
Mean Squared Error = 1.20536041839e-05A serialização é usada para ajuste de desempenho no Apache Spark. Todos os dados enviados pela rede, gravados no disco ou persistentes na memória devem ser serializados. A serialização desempenha um papel importante em operações caras.
O PySpark oferece suporte a serializadores personalizados para ajuste de desempenho. Os dois serializadores a seguir são compatíveis com PySpark -
MarshalSerializer
Serializa objetos usando Marshal Serializer do Python. Este serializador é mais rápido do que PickleSerializer, mas suporta menos tipos de dados.
class pyspark.MarshalSerializerPickleSerializer
Serializa objetos usando o Pickle Serializer do Python. Este serializador suporta quase qualquer objeto Python, mas pode não ser tão rápido quanto serializadores mais especializados.
class pyspark.PickleSerializerVejamos um exemplo de serialização do PySpark. Aqui, serializamos os dados usando MarshalSerializer.
--------------------------------------serializing.py-------------------------------------
from pyspark.context import SparkContext
from pyspark.serializers import MarshalSerializer
sc = SparkContext("local", "serialization app", serializer = MarshalSerializer())
print(sc.parallelize(list(range(1000))).map(lambda x: 2 * x).take(10))
sc.stop()
--------------------------------------serializing.py-------------------------------------Command - O comando é o seguinte -
$SPARK_HOME/bin/spark-submit serializing.pyOutput - A saída do comando acima é -
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]