Python Web Scraping - Lidando com Texto
No capítulo anterior, vimos como lidar com vídeos e imagens que obtemos como parte do conteúdo de web scraping. Neste capítulo, vamos lidar com a análise de texto usando a biblioteca Python e aprenderemos sobre isso em detalhes.
Introdução
Você pode realizar a análise de texto usando a biblioteca Python chamada Natural Language Tool Kit (NLTK). Antes de prosseguirmos nos conceitos de NLTK, vamos entender a relação entre análise de texto e web scraping.
A análise das palavras do texto pode nos levar a saber quais palavras são importantes, quais palavras são incomuns, como as palavras são agrupadas. Essa análise facilita a tarefa de web scraping.
Primeiros passos com NLTK
O Kit de ferramentas de linguagem natural (NLTK) é uma coleção de bibliotecas Python projetadas especialmente para identificar e marcar classes gramaticais encontradas no texto de linguagem natural como o inglês.
Instalando NLTK
Você pode usar o seguinte comando para instalar o NLTK em Python -
pip install nltkSe você estiver usando o Anaconda, então um pacote conda para NLTK pode ser construído usando o seguinte comando -
conda install -c anaconda nltkBaixando dados do NLTK
Depois de instalar o NLTK, temos que baixar os repositórios de texto predefinidos. Mas antes de baixar os repositórios predefinidos de texto, precisamos importar NLTK com a ajuda deimport comando da seguinte forma -
mport nltkAgora, com a ajuda do seguinte comando, os dados NLTK podem ser baixados -
nltk.download()A instalação de todos os pacotes disponíveis do NLTK levará algum tempo, mas é sempre recomendável instalar todos os pacotes.
Instalando outros pacotes necessários
Também precisamos de alguns outros pacotes Python, como gensim e pattern para fazer análise de texto, bem como construir aplicativos de processamento de linguagem natural usando NLTK.
gensim- Uma biblioteca de modelagem semântica robusta que é útil para muitos aplicativos. Ele pode ser instalado pelo seguinte comando -
pip install gensimpattern - Costumava fazer gensimpacote funcionar corretamente. Ele pode ser instalado pelo seguinte comando -
pip install patternTokenização
O processo de quebrar o texto fornecido em unidades menores chamadas tokens é chamado de tokenização. Esses tokens podem ser palavras, números ou sinais de pontuação. Também é chamadoword segmentation.
Exemplo

O módulo NLTK fornece pacotes diferentes para tokenização. Podemos usar esses pacotes de acordo com nossa exigência. Alguns dos pacotes são descritos aqui -
sent_tokenize package- Este pacote irá dividir o texto de entrada em frases. Você pode usar o seguinte comando para importar este pacote -
from nltk.tokenize import sent_tokenizeword_tokenize package- Este pacote irá dividir o texto de entrada em palavras. Você pode usar o seguinte comando para importar este pacote -
from nltk.tokenize import word_tokenizeWordPunctTokenizer package- Este pacote irá dividir o texto de entrada, bem como os sinais de pontuação em palavras. Você pode usar o seguinte comando para importar este pacote -
from nltk.tokenize import WordPuncttokenizerStemming
Em qualquer idioma, existem diferentes formas de palavras. Um idioma inclui muitas variações devido a razões gramaticais. Por exemplo, considere as palavrasdemocracy, democratic, e democratization. Para projetos de aprendizado de máquina e de web scraping, é importante que as máquinas entendam que essas palavras diferentes têm a mesma forma básica. Portanto, podemos dizer que pode ser útil extrair as formas básicas das palavras durante a análise do texto.
Isso pode ser conseguido por radicais, que pode ser definido como o processo heurístico de extrair as formas básicas das palavras cortando as pontas das palavras.
O módulo NLTK fornece pacotes diferentes para lematização. Podemos usar esses pacotes de acordo com nossa exigência. Alguns desses pacotes são descritos aqui -
PorterStemmer package- O algoritmo de Porter é usado por este pacote de derivação do Python para extrair o formulário básico. Você pode usar o seguinte comando para importar este pacote -
from nltk.stem.porter import PorterStemmerPor exemplo, depois de dar a palavra ‘writing’ como entrada para este lematizador, a saída seria a palavra ‘write’ após a retirada.
LancasterStemmer package- O algoritmo de Lancaster é usado por este pacote de derivação do Python para extrair o formulário básico. Você pode usar o seguinte comando para importar este pacote -
from nltk.stem.lancaster import LancasterStemmerPor exemplo, depois de dar a palavra ‘writing’ como entrada para este lematizador, a saída seria a palavra ‘writ’ após a retirada.
SnowballStemmer package- O algoritmo do Snowball é usado por este pacote de lematização do Python para extrair o formulário básico. Você pode usar o seguinte comando para importar este pacote -
from nltk.stem.snowball import SnowballStemmerPor exemplo, depois de fornecer a palavra 'escrita' como entrada para este lematizador, a saída seria a palavra 'escrever' após a lematização.
Lemmatização
Outra maneira de extrair a forma básica das palavras é por lematização, normalmente com o objetivo de remover terminações flexionais usando vocabulário e análise morfológica. A forma básica de qualquer palavra após a lematização é chamada de lema.
O módulo NLTK fornece os seguintes pacotes para lematização -
WordNetLemmatizer package- Ele irá extrair a forma básica da palavra dependendo se é usada como substantivo ou verbo. Você pode usar o seguinte comando para importar este pacote -
from nltk.stem import WordNetLemmatizerChunking
Chunking, que significa dividir os dados em pequenos pedaços, é um dos processos importantes no processamento da linguagem natural para identificar as classes gramaticais e frases curtas como frases nominais. Chunking é fazer a rotulagem de tokens. Podemos obter a estrutura da frase com a ajuda do processo de chunking.
Exemplo
Neste exemplo, vamos implementar o chunking de Noun-Phrase usando o módulo NLTK Python. O chunking NP é uma categoria de chunking que encontrará os chunks do sintagma nominal na frase.
Etapas para implementar a fragmentação de frases nominais
Precisamos seguir as etapas fornecidas abaixo para a implementação de chunking substantivo-frase -
Etapa 1 - definição da gramática do bloco
Na primeira etapa, definiremos a gramática para chunking. Consistiria nas regras que devemos seguir.
Etapa 2 - criação do analisador de bloco
Agora, vamos criar um analisador de pedaços. Ele analisaria a gramática e forneceria a saída.
Etapa 3 - O resultado
Nesta última etapa, a saída seria produzida em formato de árvore.
Primeiro, precisamos importar o pacote NLTK da seguinte maneira -
import nltkEm seguida, precisamos definir a frase. Aqui DT: o determinante, VBP: o verbo, JJ: o adjetivo, IN: a preposição e NN: o substantivo.
sentence = [("a", "DT"),("clever","JJ"),("fox","NN"),("was","VBP"),("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]A seguir, estamos fornecendo a gramática na forma de expressão regular.
grammar = "NP:{<DT>?<JJ>*<NN>}"Agora, a próxima linha de código definirá um analisador para analisar a gramática.
parser_chunking = nltk.RegexpParser(grammar)Agora, o analisador analisará a frase.
parser_chunking.parse(sentence)A seguir, estamos dando nossa saída na variável.
Output = parser_chunking.parse(sentence)Com a ajuda do código a seguir, podemos desenhar nossa saída na forma de uma árvore, conforme mostrado abaixo.
output.draw()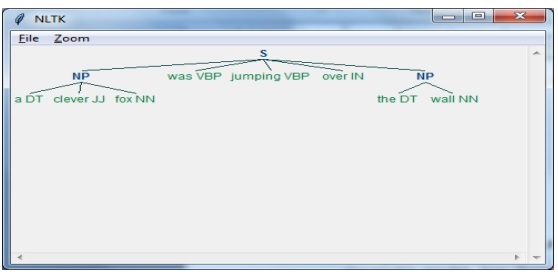
Modelo Bag of Word (BoW) Extraindo e convertendo o texto em formato numérico
Bag of Word (BoW), um modelo útil no processamento de linguagem natural, é basicamente usado para extrair os recursos do texto. Depois de extrair os recursos do texto, eles podem ser usados na modelagem em algoritmos de aprendizado de máquina, pois os dados brutos não podem ser usados em aplicativos de ML.
Trabalho do modelo BoW
Inicialmente, o modelo extrai um vocabulário de todas as palavras do documento. Posteriormente, usando uma matriz de termos de documento, ele construiria um modelo. Dessa forma, o modelo BoW representa o documento como um pacote de palavras apenas e a ordem ou estrutura é descartada.
Exemplo
Suponha que temos as seguintes duas sentenças -
Sentence1 - Este é um exemplo do modelo Saco de Palavras.
Sentence2 - Podemos extrair recursos usando o modelo Bag of Words.
Agora, considerando essas duas frases, temos as seguintes 14 palavras distintas -
- This
- is
- an
- example
- bag
- of
- words
- model
- we
- can
- extract
- features
- by
- using
Construindo um modelo de saco de palavras em NLTK
Vejamos o seguinte script Python que construirá um modelo BoW em NLTK.
Primeiro, importe o seguinte pacote -
from sklearn.feature_extraction.text import CountVectorizerEm seguida, defina o conjunto de frases -
Sentences=['This is an example of Bag of Words model.', ' We can extract
features by using Bag of Words model.']
vector_count = CountVectorizer()
features_text = vector_count.fit_transform(Sentences).todense()
print(vector_count.vocabulary_)Resultado
Isso mostra que temos 14 palavras distintas nas duas frases acima -
{
'this': 10, 'is': 7, 'an': 0, 'example': 4, 'of': 9,
'bag': 1, 'words': 13, 'model': 8, 'we': 12, 'can': 3,
'extract': 5, 'features': 6, 'by': 2, 'using':11
}Modelagem de Tópico: Identificando Padrões em Dados de Texto
Geralmente, os documentos são agrupados em tópicos e a modelagem de tópicos é uma técnica para identificar os padrões em um texto que correspondem a um tópico específico. Em outras palavras, a modelagem de tópicos é usada para descobrir temas abstratos ou estruturas ocultas em um determinado conjunto de documentos.
Você pode usar a modelagem de tópicos nos seguintes cenários -
Classificação de Texto
A classificação pode ser melhorada pela modelagem de tópicos porque agrupa palavras semelhantes em vez de usar cada palavra separadamente como um recurso.
Sistemas de Recomendação
Podemos construir sistemas de recomendação usando medidas de similaridade.
Algoritmos de modelagem de tópicos
Podemos implementar a modelagem de tópicos usando os seguintes algoritmos -
Latent Dirichlet Allocation(LDA) - É um dos algoritmos mais populares que usa os modelos gráficos probabilísticos para implementar a modelagem de tópicos.
Latent Semantic Analysis(LDA) or Latent Semantic Indexing(LSI) - É baseado na Álgebra Linear e usa o conceito de SVD (Singular Value Decomposition) na matriz de termos do documento.
Non-Negative Matrix Factorization (NMF) - Também é baseado em Álgebra Linear como LDA.
Os algoritmos mencionados acima teriam os seguintes elementos -
- Número de tópicos: Parâmetro
- Matriz Documento-Word: Entrada
- WTM (Word Topic Matrix) e TDM (Topic Document Matrix): Saída