Engenharia de Software - Guia Rápido
Vamos primeiro entender o que a engenharia de software representa. O termo é composto de duas palavras, software e engenharia.
Software é mais do que apenas um código de programa. Um programa é um código executável que serve a algum propósito computacional. Software é considerado uma coleção de código de programação executável, bibliotecas associadas e documentações. Software, quando feito para um requisito específico é chamadosoftware product.
Engineering por outro lado, trata-se de desenvolver produtos, usando princípios e métodos científicos bem definidos.
Software engineeringé um ramo da engenharia associado ao desenvolvimento de produtos de software usando princípios, métodos e procedimentos científicos bem definidos. O resultado da engenharia de software é um produto de software eficiente e confiável.
Definições
IEEE define engenharia de software como:
(1) A aplicação de uma abordagem sistemática, disciplinada e quantificável para o desenvolvimento, operação e manutenção de software; isto é, a aplicação da engenharia ao software.
(2) O estudo das abordagens conforme a declaração acima.
Fritz Bauer, um cientista da computação alemão, define a engenharia de software como:
Engenharia de software é o estabelecimento e o uso de princípios sólidos de engenharia para obter software econômico que seja confiável e funcione de maneira eficiente em máquinas reais.
Evolução de Software
O processo de desenvolvimento de um produto de software usando princípios e métodos de engenharia de software é conhecido como software evolution. Isso inclui o desenvolvimento inicial do software e sua manutenção e atualizações, até que o produto de software desejado seja desenvolvido, que satisfaça os requisitos esperados.

A evolução começa a partir do processo de coleta de requisitos. Depois disso, os desenvolvedores criam um protótipo do software pretendido e o mostram aos usuários para obter seu feedback no estágio inicial de desenvolvimento do produto de software. Os usuários sugerem mudanças, nas quais várias atualizações e manutenções consecutivas também mudam. Este processo muda para o software original, até que o software desejado seja realizado.
Mesmo depois de o usuário ter o software desejado em mãos, o avanço da tecnologia e as mudanças nos requisitos forçam o produto de software a mudar de acordo. Recriar o software do zero e ir um a um com os requisitos não é viável. A única solução viável e econômica é atualizar o software existente para que corresponda aos requisitos mais recentes.
Leis de evolução de software
Lehman deu leis para a evolução do software. Ele dividiu o software em três categorias diferentes:
- S-type (static-type) - Este é um software que funciona estritamente de acordo com as especificações e soluções definidas . A solução e o método para alcançá-la são imediatamente compreendidos antes da codificação. O software tipo s está menos sujeito a alterações, portanto, este é o mais simples de todos. Por exemplo, programa de calculadora para computação matemática.
- P-type (practical-type) - Este é um software com uma coleção de procedimentos. Isso é definido exatamente pelo que os procedimentos podem fazer. Neste software, as especificações podem ser descritas, mas a solução não é óbvia instantaneamente. Por exemplo, software de jogos.
- E-type (embedded-type) - Este software funciona de acordo com o requisito do ambiente do mundo real . Este software tem um alto grau de evolução visto que existem várias mudanças nas leis, impostos etc. em situações do mundo real. Por exemplo, software de comércio online.
Evolução do software E-Type
Lehman deu oito leis para a evolução do software E-Type -
- Continuing change - Um sistema de software do tipo E deve continuar a se adaptar às mudanças do mundo real, caso contrário, ele se torna progressivamente menos útil.
- Increasing complexity - À medida que um sistema de software do tipo E evolui, sua complexidade tende a aumentar, a menos que seja feito um trabalho para mantê-lo ou reduzi-lo.
- Conservation of familiarity - A familiaridade com o software ou o conhecimento sobre como ele foi desenvolvido, por que foi desenvolvido daquela maneira particular etc. deve ser mantida a qualquer custo, para implementar as mudanças no sistema.
- Continuing growth- Para que um sistema do tipo E tenha como objetivo resolver algum problema empresarial, seu tamanho de implementação das mudanças cresce de acordo com as mudanças no estilo de vida da empresa.
- Reducing quality - Um sistema de software do tipo E diminui em qualidade, a menos que seja rigorosamente mantido e adaptado a um ambiente operacional em constante mudança.
- Feedback systems- Os sistemas de software do tipo E constituem sistemas de feedback de vários níveis e loops e devem ser tratados como tal para serem modificados ou melhorados com sucesso.
- Self-regulation - Os processos de evolução do sistema tipo E são autorregulados com a distribuição de medidas de produto e processo próximas do normal.
- Organizational stability - A taxa média de atividade global efetiva em um sistema do tipo E em evolução é invariável durante a vida útil do produto.
Paradigmas de software
Paradigmas de software referem-se aos métodos e etapas que são realizadas durante o projeto do software. Muitos métodos são propostos e estão em funcionamento hoje, mas precisamos ver onde esses paradigmas se encontram na engenharia de software. Eles podem ser combinados em várias categorias, embora cada um deles esteja contido um no outro:

O paradigma de programação é um subconjunto do paradigma de design de software que é ainda um subconjunto do paradigma de desenvolvimento de software.
Paradigma de Desenvolvimento de Software
Este Paradigma é conhecido como paradigmas de engenharia de software, onde são aplicados todos os conceitos de engenharia pertinentes ao desenvolvimento de software. Inclui várias pesquisas e coleta de requisitos que ajudam a construir o produto de software. Isso consiste de -
- Recolha de requisitos
- Design de software
- Programming
Paradigma de Design de Software
Este paradigma é parte do Desenvolvimento de Software e inclui -
- Design
- Maintenance
- Programming
Paradigma de Programação
Este paradigma está intimamente relacionado ao aspecto de programação do desenvolvimento de software. Isso inclui -
- Coding
- Testing
- Integration
Necessidade de Engenharia de Software
A necessidade da engenharia de software surge devido à maior taxa de mudança nos requisitos do usuário e no ambiente no qual o software está trabalhando.
- Large software - É mais fácil construir uma parede do que uma casa ou prédio, da mesma forma, como o tamanho do software se torna grande, a engenharia tem que dar um passo para dar a ele um processo científico.
- Scalability- Se o processo de software não fosse baseado em conceitos científicos e de engenharia, seria mais fácil recriar um novo software do que dimensionar um existente.
- Cost- À medida que a indústria de hardware mostrou suas habilidades e a enorme fabricação baixou o preço do hardware de computador e eletrônico. Mas o custo do software permanece alto se o processo adequado não for adaptado.
- Dynamic Nature- A natureza sempre crescente e adaptável do software depende enormemente do ambiente em que o usuário trabalha. Se a natureza do software está sempre mudando, novos aprimoramentos precisam ser feitos no existente. É aqui que a engenharia de software desempenha um bom papel.
- Quality Management- Um melhor processo de desenvolvimento de software fornece um produto de software melhor e de qualidade.
Características de um bom software
Um produto de software pode ser julgado pelo que oferece e quão bem pode ser usado. Este software deve atender aos seguintes motivos:
- Operational
- Transitional
- Maintenance
Espera-se que um software bem projetado e elaborado tenha as seguintes características:
Operacional
Isso nos diz quão bem o software funciona nas operações. Pode ser medido em:
- Budget
- Usability
- Efficiency
- Correctness
- Functionality
- Dependability
- Security
- Safety
Transitório
Este aspecto é importante quando o software é movido de uma plataforma para outra:
- Portability
- Interoperability
- Reusability
- Adaptability
Manutenção
Este aspecto descreve como um software tem os recursos para se manter no ambiente em constante mudança:
- Modularity
- Maintainability
- Flexibility
- Scalability
Resumindo, a engenharia de software é um ramo da ciência da computação, que usa conceitos de engenharia bem definidos necessários para produzir produtos de software eficientes, duráveis, escaláveis, dentro do orçamento e dentro do prazo.
O Ciclo de Vida de Desenvolvimento de Software, para abreviar SDLC, é uma sequência bem definida e estruturada de estágios em engenharia de software para desenvolver o produto de software pretendido.
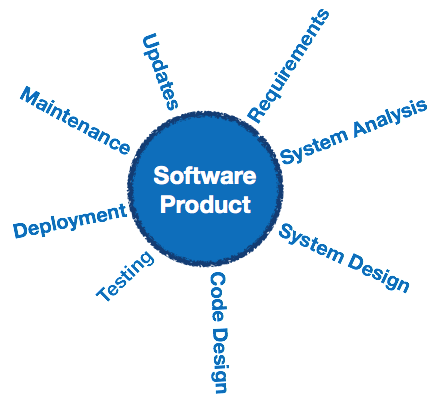
Atividades SDLC
SDLC fornece uma série de etapas a serem seguidas para projetar e desenvolver um produto de software com eficiência. A estrutura SDLC inclui as seguintes etapas:
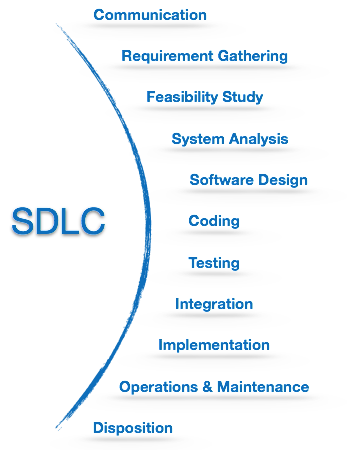
Comunicação
Esta é a primeira etapa em que o usuário inicia a solicitação de um produto de software desejado. Ele contata o provedor de serviços e tenta negociar os termos. Ele submete o seu pedido por escrito à organização prestadora de serviços.
Recolha de requisitos
A partir dessa etapa, a equipe de desenvolvimento de software trabalha para dar continuidade ao projeto. A equipe mantém discussões com várias partes interessadas do domínio do problema e tenta trazer o máximo de informações possível sobre seus requisitos. Os requisitos são contemplados e segregados em requisitos de usuário, requisitos de sistema e requisitos funcionais. Os requisitos são coletados usando uma série de práticas conforme fornecidas -
- estudar o sistema e software existente ou obsoleto,
- conduzindo entrevistas de usuários e desenvolvedores,
- referindo-se ao banco de dados ou
- coleta de respostas dos questionários.
Estudo de viabilidade
Após a coleta de requisitos, a equipe apresenta um plano preliminar do processo de software. Nesta etapa a equipe analisa se um software pode ser feito para atender todos os requisitos do usuário e se existe alguma possibilidade de o software não ser mais útil. Verifica-se, se o projeto é viável financeira, prática e tecnologicamente para a organização. Existem muitos algoritmos disponíveis, que ajudam os desenvolvedores a concluir a viabilidade de um projeto de software.
Análise de sistema
Nesta etapa, os desenvolvedores decidem um roteiro de seu plano e tentam trazer o melhor modelo de software adequado para o projeto. A análise do sistema inclui a compreensão das limitações do produto de software, problemas relacionados ao sistema de aprendizagem ou mudanças a serem feitas em sistemas existentes de antemão, identificando e abordando o impacto do projeto na organização e pessoal, etc. recursos em conformidade.
Design de software
O próximo passo é trazer todo o conhecimento dos requisitos e análises para a mesa e projetar o produto de software. As entradas dos usuários e as informações coletadas na fase de coleta de requisitos são as entradas desta etapa. A saída desta etapa vem na forma de dois designs; design lógico e design físico. Os engenheiros produzem metadados e dicionários de dados, diagramas lógicos, diagramas de fluxo de dados e, em alguns casos, pseudocódigos.
Codificação
Esta etapa também é conhecida como fase de programação. A implementação do design de software começa em termos de escrever o código do programa na linguagem de programação adequada e desenvolver programas executáveis sem erros de forma eficiente.
Testando
Uma estimativa diz que 50% de todo o processo de desenvolvimento de software deve ser testado. Erros podem arruinar o software do nível crítico até sua própria remoção. O teste de software é feito durante a codificação pelos desenvolvedores e o teste completo é conduzido por especialistas em testes em vários níveis de código, como teste de módulo, teste de programa, teste de produto, teste interno e teste do produto no final do usuário. A descoberta precoce de erros e sua solução é a chave para um software confiável.
Integração
O software pode precisar ser integrado às bibliotecas, bancos de dados e outro (s) programa (s). Este estágio do SDLC está envolvido na integração do software com entidades do mundo externo.
Implementação
Isso significa instalar o software nas máquinas dos usuários. Às vezes, o software precisa de configurações pós-instalação no final do usuário. O software é testado quanto à portabilidade e adaptabilidade e os problemas relacionados à integração são resolvidos durante a implementação.
Operação e manutenção
Esta fase confirma o funcionamento do software em termos de mais eficiência e menos erros. Se necessário, os usuários são treinados ou auxiliados com a documentação sobre como operar o software e como mantê-lo operacional. O software é mantido em tempo hábil, atualizando o código de acordo com as mudanças que ocorrem no ambiente ou tecnologia final do usuário. Esta fase pode enfrentar desafios de bugs ocultos e problemas não identificados do mundo real.
Disposição
Conforme o tempo passa, o software pode declinar no desempenho. Ele pode ficar completamente obsoleto ou precisar de uma atualização intensa. Portanto, surge uma necessidade premente de eliminar uma parte importante do sistema. Esta fase inclui o arquivamento de dados e componentes de software necessários, encerrando o sistema, planejando a atividade de disposição e encerrando o sistema no momento apropriado de final de sistema.
Paradigma de Desenvolvimento de Software
O paradigma de desenvolvimento de software ajuda o desenvolvedor a selecionar uma estratégia para desenvolver o software. Um paradigma de desenvolvimento de software possui seu próprio conjunto de ferramentas, métodos e procedimentos, que são expressos claramente e definem o ciclo de vida de desenvolvimento de software. Alguns paradigmas de desenvolvimento de software ou modelos de processo são definidos da seguinte forma:
Modelo de Cachoeira
O modelo em cascata é o modelo mais simples de paradigma de desenvolvimento de software. Ele diz que todas as fases do SDLC funcionarão uma após a outra de maneira linear. Ou seja, quando a primeira fase for concluída, apenas a segunda fase terá início e assim por diante.

Este modelo parte do pressuposto de que tudo se desenrola e decorre perfeitamente conforme planeado na fase anterior e não há necessidade de pensar nas questões do passado que podem surgir na fase seguinte. Este modelo não funcionará perfeitamente se houver alguns problemas deixados na etapa anterior. A natureza sequencial do modelo não nos permite voltar e desfazer ou refazer nossas ações.
Este modelo é mais adequado quando os desenvolvedores já projetaram e desenvolveram software semelhante no passado e estão cientes de todos os seus domínios.
Modelo Iterativo
Este modelo conduz o processo de desenvolvimento de software em iterações. Ele projeta o processo de desenvolvimento de maneira cíclica repetindo cada etapa após cada ciclo do processo SDLC.

O software é inicialmente desenvolvido em uma escala muito pequena e todas as etapas são seguidas e levadas em consideração. Então, em cada iteração seguinte, mais recursos e módulos são projetados, codificados, testados e adicionados ao software. Cada ciclo produz um software completo em si mesmo e com mais recursos e capacidades do que o anterior.
Após cada iteração, a equipe de gerenciamento pode trabalhar no gerenciamento de riscos e se preparar para a próxima iteração. Como um ciclo inclui uma pequena parte de todo o processo de software, é mais fácil gerenciar o processo de desenvolvimento, mas consome mais recursos.
Modelo Espiral
O modelo espiral é uma combinação de ambos, o modelo iterativo e um do modelo SDLC. Pode ser visto como se você escolhesse um modelo SDLC e o combinasse com o processo cíclico (modelo iterativo).

Este modelo considera o risco, que muitas vezes passa despercebido pela maioria dos outros modelos. O modelo começa com a determinação de objetivos e restrições do software no início de uma iteração. A próxima fase é a prototipagem do software. Isso inclui a análise de risco. Em seguida, um modelo SDLC padrão é usado para construir o software. Na quarta fase do plano de próxima iteração é preparado.
V - modelo
A principal desvantagem do modelo em cascata é que passamos para o próximo estágio apenas quando o anterior estiver concluído e não havia chance de voltar se algo fosse encontrado errado nos estágios posteriores. O V-Model fornece meios de testar o software em cada estágio de maneira reversa.

Em cada etapa, planos e casos de teste são criados para verificar e validar o produto de acordo com a exigência daquela etapa. Por exemplo, no estágio de coleta de requisitos, a equipe de teste prepara todos os casos de teste em correspondência com os requisitos. Posteriormente, quando o produto for desenvolvido e estiver pronto para teste, os casos de teste dessa etapa verificam o software em relação à sua validade em relação aos requisitos dessa etapa.
Isso faz com que a verificação e a validação ocorram em paralelo. Este modelo também é conhecido como modelo de verificação e validação.
Modelo big bang
Este modelo é o modelo mais simples em sua forma. Requer pouco planejamento, muita programação e muitos fundos. Este modelo é conceituado em torno do big bang do universo. Como dizem os cientistas, após o big bang, muitas galáxias, planetas e estrelas evoluíram apenas como um evento. Da mesma forma, se juntarmos muita programação e fundos, você poderá obter o melhor produto de software.

Para este modelo, é necessária uma quantidade muito pequena de planejamento. Não segue nenhum processo, ou às vezes o cliente não tem certeza sobre os requisitos e necessidades futuras. Portanto, os requisitos de entrada são arbitrários.
Este modelo não é adequado para grandes projetos de software, mas é bom para aprender e experimentar.
Para uma leitura aprofundada sobre SDLC e seus vários modelos, clique aqui.
O padrão de trabalho de uma empresa de TI envolvida no desenvolvimento de software pode ser visto dividido em duas partes:
- Criação de Software
- Gerenciamento de Projetos de Software
Um projeto é uma tarefa bem definida, que é uma coleção de várias operações feitas para atingir um objetivo (por exemplo, desenvolvimento e entrega de software). Um projeto pode ser caracterizado como:
- Cada projeto pode ter um objetivo único e distinto.
- O projeto não é uma atividade de rotina ou operações do dia-a-dia.
- O projeto vem com uma hora de início e uma hora de término.
- O projeto termina quando seu objetivo é alcançado, portanto, é uma fase temporária na vida de uma organização.
- O projeto precisa de recursos adequados em termos de tempo, mão de obra, finanças, material e banco de conhecimento.
Projeto de Software
Um Projeto de Software é o procedimento completo de desenvolvimento de software, desde a coleta de requisitos até o teste e manutenção, realizado de acordo com as metodologias de execução, em um período de tempo especificado para atingir o produto de software pretendido.
Necessidade de gerenciamento de projeto de software
O software é considerado um produto intangível. O desenvolvimento de software é um tipo de fluxo totalmente novo no mundo dos negócios e há muito pouca experiência na construção de produtos de software. A maioria dos produtos de software é feita sob medida para atender aos requisitos do cliente. O mais importante é que a tecnologia subjacente muda e avança com tanta frequência e rapidez que a experiência de um produto pode não ser aplicada ao outro. Todas essas restrições de negócios e ambientais trazem riscos no desenvolvimento de software, portanto, é essencial gerenciar projetos de software com eficiência.

A imagem acima mostra restrições triplas para projetos de software. É parte essencial da organização de software entregar produtos de qualidade, mantendo o custo dentro do orçamento do cliente e entregar o projeto conforme o programado. Existem vários fatores, internos e externos, que podem impactar este triângulo de restrição triplo. Qualquer um dos três fatores pode afetar severamente os outros dois.
Portanto, o gerenciamento de projetos de software é essencial para incorporar os requisitos do usuário junto com as restrições de orçamento e tempo.
Gerente de Projeto de Software
Um gerente de projeto de software é uma pessoa que assume a responsabilidade de executar o projeto de software. O gerente de projeto de software está totalmente ciente de todas as fases do SDLC pelas quais o software passaria. O gerente de projeto nunca pode se envolver diretamente na produção do produto final, mas ele controla e gerencia as atividades envolvidas na produção.
Um gerente de projeto monitora de perto o processo de desenvolvimento, prepara e executa vários planos, organiza os recursos necessários e adequados, mantém a comunicação entre todos os membros da equipe para tratar de questões de custo, orçamento, recursos, tempo, qualidade e satisfação do cliente.
Vamos ver algumas responsabilidades que um gerente de projeto tem -
Gerenciando pessoas
- Atuar como líder do projeto
- Lesão com partes interessadas
- Gestão de recursos humanos
- Configurando hierarquia de relatórios, etc.
Gerenciando Projeto
- Definição e configuração do escopo do projeto
- Gerenciando atividades de gerenciamento de projetos
- Monitorando o progresso e desempenho
- Análise de risco em todas as fases
- Tome as medidas necessárias para evitar ou resolver os problemas
- Atuar como porta-voz do projeto
Atividades de gerenciamento de software
O gerenciamento de projetos de software compreende uma série de atividades, que incluem planejamento do projeto, decisão do escopo do produto de software, estimativa de custo em vários termos, agendamento de tarefas e eventos e gerenciamento de recursos. As atividades de gerenciamento de projetos podem incluir:
- Project Planning
- Scope Management
- Project Estimation
Planejamento de Projeto
O planejamento do projeto de software é uma tarefa executada antes do início da produção do software. Está lá para a produção de software, mas não envolve nenhuma atividade concreta que tenha qualquer conexão de direção com a produção de software; em vez disso, é um conjunto de vários processos, o que facilita a produção de software. O planejamento do projeto pode incluir o seguinte:
Gerenciamento do escopo
Ele define o escopo do projeto; isso inclui todas as atividades, processos que precisam ser executados para fazer um produto de software a ser entregue. O gerenciamento do escopo é essencial porque cria limites do projeto, definindo claramente o que seria feito no projeto e o que não seria feito. Isso faz com que o projeto contenha tarefas limitadas e quantificáveis, que podem ser facilmente documentadas e, por sua vez, evita o estouro de custos e tempo.
Durante o gerenciamento do escopo do projeto, é necessário -
- Defina o escopo
- Decidir sua verificação e controle
- Divida o projeto em várias partes menores para facilitar o gerenciamento.
- Verifique o escopo
- Controle o escopo incorporando mudanças no escopo
Estimativa de Projeto
Para uma gestão eficaz, uma estimativa precisa de várias medidas é uma obrigação. Com a estimativa correta, os gerentes podem gerenciar e controlar o projeto com mais eficiência e eficácia.
A estimativa do projeto pode envolver o seguinte:
- Software size estimation
O tamanho do software pode ser estimado em termos de KLOC (Kilo Line of Code) ou calculando o número de pontos de função no software. As linhas de código dependem das práticas de codificação e os pontos de função variam de acordo com o usuário ou requisito de software.
- Effort estimation
Os gerentes estimam os esforços em termos de requisitos de pessoal e horas de trabalho necessárias para produzir o software. Para estimativa de esforço, o tamanho do software deve ser conhecido. Isso pode ser derivado da experiência dos gerentes, dados históricos da organização ou tamanho do software podem ser convertidos em esforços usando algumas fórmulas padrão.
- Time estimation
Uma vez que o tamanho e os esforços são estimados, o tempo necessário para produzir o software pode ser estimado. Os esforços necessários são separados em subcategorias de acordo com as especificações dos requisitos e a interdependência de vários componentes do software. As tarefas de software são divididas em tarefas, atividades ou eventos menores por Work Breakthrough Structure (WBS). As tarefas são agendadas no dia-a-dia ou em meses do calendário.
A soma de tempo necessária para concluir todas as tarefas em horas ou dias é o tempo total investido para concluir o projeto.
- Cost estimation
Isso pode ser considerado o mais difícil de todos, porque depende de mais elementos do que qualquer um dos anteriores. Para estimar o custo do projeto, é necessário considerar -
- Tamanho do software
- Qualidade de software
- Hardware
- Software ou ferramentas adicionais, licenças etc.
- Pessoal qualificado com habilidades específicas para tarefas
- Viagem envolvida
- Communication
- Treinamento e suporte
Técnicas de estimativa de projeto
Discutimos vários parâmetros que envolvem estimativa de projeto, como tamanho, esforço, tempo e custo.
O gerente de projeto pode estimar os fatores listados usando duas técnicas amplamente reconhecidas -
Técnica de Decomposição
Esta técnica assume o software como um produto de várias composições.
Existem dois modelos principais -
- Line of Code A estimativa é feita em nome do número de linhas de códigos no produto de software.
- Function Points A estimativa é feita em nome do número de pontos de função no produto de software.
Técnica de Estimativa Empírica
Esta técnica usa fórmulas derivadas empiricamente para fazer estimativas. Essas fórmulas são baseadas em LOC ou FPs.
- Putnam Model
Este modelo é feito por Lawrence H. Putnam, que é baseado na distribuição de frequência de Norden (curva de Rayleigh). O modelo de Putnam mapeia o tempo e os esforços necessários com o tamanho do software.
- COCOMO
COCOMO significa COnstructive COst MOdel, desenvolvido por Barry W. Boehm. Ele divide o produto de software em três categorias de software: orgânico, semi-separado e incorporado.
Agendamento de Projeto
A programação do projeto em um projeto se refere ao roteiro de todas as atividades a serem realizadas com a ordem especificada e dentro do intervalo de tempo alocado para cada atividade. Os gerentes de projeto tendem a definir várias tarefas e marcos do projeto e organizá-los mantendo vários fatores em mente. Eles procuram tarefas que estão no caminho crítico do cronograma, que são necessárias para serem concluídas de maneira específica (por causa da interdependência das tarefas) e estritamente dentro do tempo alocado. A organização das tarefas fora do caminho crítico tem menos probabilidade de impactar em todo o cronograma do projeto.
Para agendar um projeto, é necessário -
- Divida as tarefas do projeto em formas menores e gerenciáveis
- Descubra várias tarefas e correlacione-as
- Estimar o prazo necessário para cada tarefa
- Divida o tempo em unidades de trabalho
- Atribua um número adequado de unidades de trabalho para cada tarefa
- Calcule o tempo total necessário para o projeto do início ao fim
Gestão de recursos
Todos os elementos usados para desenvolver um produto de software podem ser considerados como recursos para esse projeto. Isso pode incluir recursos humanos, ferramentas produtivas e bibliotecas de software.
Os recursos estão disponíveis em quantidade limitada e permanecem na organização como um conjunto de ativos. A escassez de recursos dificulta o desenvolvimento do projeto e pode atrasar o cronograma. A alocação de recursos extras aumenta o custo de desenvolvimento no final. Portanto, é necessário estimar e alocar recursos adequados para o projeto.
A gestão de recursos inclui -
- Definir o projeto de organização adequado, criando uma equipe de projeto e atribuindo responsabilidades a cada membro da equipe
- Determinar os recursos necessários em um determinado estágio e sua disponibilidade
- Gerencie recursos gerando solicitações de recursos quando forem necessários e desalocando-os quando não forem mais necessários.
Gestão de Riscos do Projeto
A gestão de riscos envolve todas as atividades relativas à identificação, análise e provisão para riscos previsíveis e não previsíveis no projeto. O risco pode incluir o seguinte:
- Equipe experiente deixando o projeto e nova equipe entrando.
- Mudança na gestão organizacional.
- Alteração do requisito ou interpretação incorreta do requisito.
- Subestimação do tempo e recursos necessários.
- Mudanças tecnológicas, mudanças ambientais, competição empresarial.
Processo de Gestão de Risco
Existem as seguintes atividades envolvidas no processo de gestão de risco:
- Identification - Anote todos os riscos possíveis que podem ocorrer no projeto.
- Categorize - Categorize os riscos conhecidos em alta, média e baixa intensidade de risco de acordo com seu possível impacto no projeto.
- Manage - Analise a probabilidade de ocorrência de riscos nas várias fases. Faça um plano para evitar ou enfrentar riscos. Tente minimizar seus efeitos colaterais.
- Monitor - Monitore de perto os riscos potenciais e seus primeiros sintomas. Monitore também os efeitos das medidas tomadas para mitigá-los ou evitá-los.
Execução e monitoramento do projeto
Nesta fase, as tarefas descritas nos planos do projeto são executadas de acordo com seus cronogramas.
A execução precisa de monitoramento para verificar se tudo está indo de acordo com o planejado. Monitorar é observar para verificar a probabilidade de risco e tomar medidas para lidar com o risco ou relatar o status de várias tarefas.
Essas medidas incluem -
- Activity Monitoring - Todas as atividades programadas em alguma tarefa podem ser monitoradas no dia a dia. Quando todas as atividades em uma tarefa são concluídas, ela é considerada concluída.
- Status Reports - Os relatórios contêm o status das atividades e tarefas concluídas em um determinado período, geralmente uma semana. O status pode ser marcado como concluído, pendente ou em andamento, etc.
- Milestones Checklist - Cada projeto é dividido em várias fases, onde as principais tarefas são realizadas (marcos) com base nas fases do SDLC. Esta lista de verificação de marcos é preparada uma vez a cada poucas semanas e relata o status dos marcos.
Gerenciamento de comunicação do projeto
A comunicação eficaz desempenha um papel vital no sucesso de um projeto. Ele preenche as lacunas entre o cliente e a organização, entre os membros da equipe, bem como outras partes interessadas no projeto, como fornecedores de hardware.
A comunicação pode ser oral ou escrita. O processo de gerenciamento de comunicação pode ter as seguintes etapas:
- Planning - Esta etapa inclui a identificação de todas as partes interessadas no projeto e o modo de comunicação entre eles. Ele também considera se quaisquer recursos de comunicação adicionais são necessários.
- Sharing - Depois de determinar vários aspectos do planejamento, o gerente se concentra em compartilhar as informações corretas com a pessoa certa no momento certo. Isso mantém todos os envolvidos no projeto atualizados com o andamento do projeto e seu status.
- Feedback - Os gerentes de projeto usam várias medidas e mecanismos de feedback e criam relatórios de status e desempenho. Esse mecanismo garante que a entrada de várias partes interessadas chegue ao gerente de projeto como feedback.
- Closure - Ao final de cada grande evento, final de uma fase do SDLC ou do próprio projeto, é formalmente anunciado o encerramento administrativo para atualização de todas as partes interessadas por meio de envio de e-mail, distribuição de cópia impressa de documento ou outro meio de comunicação eficaz.
Após o fechamento, a equipe passa para a próxima fase ou projeto.
Gerenciamento de configurações
O gerenciamento de configuração é um processo de rastreamento e controle das mudanças no software em termos de requisitos, design, funções e desenvolvimento do produto.
O IEEE o define como “o processo de identificar e definir os itens no sistema, controlando a mudança desses itens ao longo de seu ciclo de vida, registrando e relatando o status dos itens e solicitações de mudança e verificando a integridade e exatidão dos itens”.
Geralmente, uma vez que o SRS é finalizado, há menos chance de exigência de mudanças do usuário. Se ocorrerem, as mudanças são tratadas apenas com a aprovação prévia da alta administração, pois existe a possibilidade de estouro de custos e prazos.
Linha de base
Uma fase do SDLC é assumida se tiver uma linha de base, ou seja, a linha de base é uma medida que define a integridade de uma fase. Uma fase é definida como linha de base quando todas as atividades pertencentes a ela são concluídas e bem documentadas. Se não fosse a fase final, sua saída seria usada na próxima fase imediata.
O gerenciamento da configuração é uma disciplina da administração da organização, que cuida da ocorrência de qualquer mudança (processo, requisito, tecnológica, estratégica etc.) após uma fase ser definida. CM verifica todas as alterações feitas no software.
Controle de Mudança
O controle de alterações é função do gerenciamento de configuração, que garante que todas as alterações feitas no sistema de software sejam consistentes e feitas de acordo com as regras e regulamentos organizacionais.
Uma mudança na configuração do produto passa pelas seguintes etapas -
Identification- Uma solicitação de mudança chega de uma fonte interna ou externa. Quando a solicitação de mudança é identificada formalmente, ela é devidamente documentada.
Validation - A validade da solicitação de mudança é verificada e seu procedimento de tratamento é confirmado.
Analysis- O impacto da solicitação de mudança é analisado em termos de cronograma, custo e esforços necessários. O impacto geral da mudança prospectiva no sistema é analisado.
Control- Se a mudança em perspectiva impactar muitas entidades no sistema ou for inevitável, é obrigatório obter a aprovação de altas autoridades antes que a mudança seja incorporada ao sistema. É decidido se a mudança vale a pena incorporar ou não. Caso contrário, a solicitação de mudança é recusada formalmente.
Execution - Se a fase anterior determinar a execução da solicitação de mudança, esta fase executa as ações apropriadas para executar a mudança e faz uma revisão completa, se necessário.
Close request- A mudança é verificada para implementação correta e fusão com o resto do sistema. Essa alteração recém-incorporada ao software é documentada de maneira adequada e a solicitação é formalmente encerrada.
Ferramentas de gerenciamento de projetos
O risco e a incerteza aumentam de forma multifacetada no que diz respeito à dimensão do projeto, mesmo quando o projeto é desenvolvido de acordo com metodologias definidas.
Existem ferramentas disponíveis que auxiliam no gerenciamento eficaz de projetos. Alguns são descritos -
Gráfico de Gantt
Os gráficos de Gantt foram desenvolvidos por Henry Gantt (1917). Representa o cronograma do projeto em relação aos períodos de tempo. É um gráfico de barras horizontais com barras que representam as atividades e o tempo programado para as atividades do projeto.

Gráfico PERT
O gráfico PERT (técnica de avaliação e revisão do programa) é uma ferramenta que descreve o projeto como um diagrama de rede. É capaz de representar graficamente os principais eventos do projeto de forma paralela e consecutiva. Os eventos, que ocorrem um após o outro, mostram dependência do evento posterior em relação ao anterior.

Os eventos são mostrados como nós numerados. Eles são conectados por setas rotuladas que representam a sequência de tarefas no projeto.
Histograma de recursos
Esta é uma ferramenta gráfica que contém barras ou gráficos que representam o número de recursos (geralmente equipe qualificada) necessários ao longo do tempo para um evento (ou fase) do projeto. O Histograma de recursos é uma ferramenta eficaz para planejamento e coordenação de equipe.


Análise do Caminho Crítico
Esta ferramenta é útil para reconhecer tarefas interdependentes no projeto. Também ajuda a descobrir o caminho mais curto ou o caminho crítico para concluir o projeto com sucesso. Como o diagrama PERT, cada evento é atribuído a um período de tempo específico. Esta ferramenta mostra a dependência do evento presumindo que um evento pode prosseguir para o próximo apenas se o anterior for concluído.
Os eventos são organizados de acordo com o horário de início mais próximo possível. O caminho entre o nó inicial e o nó final é um caminho crítico que não pode ser reduzido ainda mais e todos os eventos precisam ser executados na mesma ordem.
Os requisitos de software são a descrição dos recursos e funcionalidades do sistema de destino. Os requisitos transmitem as expectativas dos usuários do produto de software. Os requisitos podem ser óbvios ou ocultos, conhecidos ou desconhecidos, esperados ou inesperados do ponto de vista do cliente.
Engenharia de Requisitos
O processo de reunir os requisitos de software do cliente, analisá-los e documentá-los é conhecido como engenharia de requisitos.
O objetivo da engenharia de requisitos é desenvolver e manter um documento sofisticado e descritivo de 'Especificação de Requisitos do Sistema'.
Processo de Engenharia de Requisitos
É um processo de quatro etapas, que inclui -
- Estudo de viabilidade
- Recolha de requisitos
- Especificação de Requisitos de Software
- Validação de Requisitos de Software
Vamos ver o processo brevemente -
Estudo de viabilidade
Quando o cliente aborda a organização para desenvolver o produto desejado, ele tem uma ideia aproximada sobre quais funções o software deve executar e quais recursos são esperados do software.
A partir dessas informações, o analista faz um estudo detalhado sobre se o sistema desejado e sua funcionalidade são viáveis de desenvolver.
Este estudo de viabilidade é voltado para o objetivo da organização. Este estudo analisa se o produto de software pode ser materializado na prática em termos de implementação, contribuição do projeto para a organização, restrições de custos e de acordo com os valores e objetivos da organização. Explora aspectos técnicos do projeto e do produto, como usabilidade, facilidade de manutenção, produtividade e capacidade de integração.
A saída desta fase deve ser um relatório de estudo de viabilidade que deve conter comentários e recomendações adequados para a gerência sobre se o projeto deve ou não ser realizado.
Recolha de requisitos
Se o relatório de viabilidade for positivo para a realização do projeto, a próxima fase começa com a coleta de requisitos do usuário. Analistas e engenheiros se comunicam com o cliente e os usuários finais para saber suas idéias sobre o que o software deve fornecer e quais recursos eles desejam que o software inclua.
Especificação de Requisitos de Software
SRS é um documento criado pelo analista de sistema depois que os requisitos são coletados de várias partes interessadas.
SRS define como o software pretendido irá interagir com o hardware, interfaces externas, velocidade de operação, tempo de resposta do sistema, portabilidade do software em várias plataformas, capacidade de manutenção, velocidade de recuperação após travamento, Segurança, Qualidade, Limitações, etc.
Os requisitos recebidos do cliente são escritos em linguagem natural. É responsabilidade do analista de sistema documentar os requisitos em linguagem técnica para que possam ser compreendidos e úteis pela equipe de desenvolvimento de software.
O SRS deve apresentar os seguintes recursos:
- Os requisitos do usuário são expressos em linguagem natural.
- Os requisitos técnicos são expressos em linguagem estruturada, que é usada dentro da organização.
- A descrição do projeto deve ser escrita em pseudo código.
- Formato de formulários e impressões de tela da GUI.
- Notações condicionais e matemáticas para DFDs etc.
Validação de Requisitos de Software
Após o desenvolvimento das especificações de requisitos, os requisitos mencionados neste documento são validados. O usuário pode solicitar uma solução ilegal e impraticável ou os especialistas podem interpretar os requisitos incorretamente. Isso resulta em um grande aumento no custo, se não for cortado pela raiz. Os requisitos podem ser verificados em relação às seguintes condições -
- Se eles podem ser implementados de forma prática
- Se eles são válidos e de acordo com a funcionalidade e domínio do software
- Se houver alguma ambigüidade
- Se eles estão completos
- Se eles podem ser demonstrados
Processo de Elicitação de Requisito
O processo de elicitação de requisitos pode ser descrito usando o diagrama a seguir:

- Requirements gathering - Os desenvolvedores discutem com o cliente e usuários finais e conhecem suas expectativas em relação ao software.
- Organizing Requirements - Os desenvolvedores priorizam e organizam os requisitos em ordem de importância, urgência e conveniência.
Negotiation & discussion - Se os requisitos forem ambíguos ou houver alguns conflitos nos requisitos de várias partes interessadas, se forem, isso será negociado e discutido com as partes interessadas. Os requisitos podem ser priorizados e razoavelmente comprometidos.
Os requisitos vêm de várias partes interessadas. Para remover a ambigüidade e os conflitos, eles são discutidos para maior clareza e correção. Requisitos irrealistas são comprometidos razoavelmente.
- Documentation - Todos os requisitos formais e informais, funcionais e não funcionais são documentados e disponibilizados para o processamento da próxima fase.
Técnicas de Elicitação de Requisitos
Elicitação de requisitos é o processo para descobrir os requisitos de um sistema de software pretendido, comunicando-se com o cliente, usuários finais, usuários do sistema e outros que tenham interesse no desenvolvimento do sistema de software.
Existem várias maneiras de descobrir os requisitos
Entrevistas
As entrevistas são um meio forte para coletar os requisitos. A organização pode realizar vários tipos de entrevistas, como:
- Entrevistas estruturadas (fechadas), onde todas as informações a serem coletadas são decididas com antecedência, elas seguem o padrão e o assunto de discussão com firmeza.
- Entrevistas não estruturadas (abertas), em que as informações a recolher não são decididas com antecedência, são mais flexíveis e menos tendenciosas.
- Entrevistas orais
- Entrevistas escritas
- Entrevistas individuais realizadas entre duas pessoas do outro lado da mesa.
- Entrevistas em grupo que são realizadas entre grupos de participantes. Eles ajudam a descobrir qualquer requisito ausente, pois várias pessoas estão envolvidas.
pesquisas
A organização pode conduzir pesquisas entre várias partes interessadas, perguntando sobre suas expectativas e requisitos do sistema que está por vir.
Questionnaires
A document with pre-defined set of objective questions and respective options is handed over to all stakeholders to answer, which are collected and compiled.
A shortcoming of this technique is, if an option for some issue is not mentioned in the questionnaire, the issue might be left unattended.
Task analysis
Team of engineers and developers may analyze the operation for which the new system is required. If the client already has some software to perform certain operation, it is studied and requirements of proposed system are collected.
Análise de Domínio
Todo software se enquadra em alguma categoria de domínio. Os especialistas no domínio podem ser de grande ajuda na análise de requisitos gerais e específicos.
Debate
Um debate informal é realizado entre várias partes interessadas e todas as suas entradas são registradas para posterior análise de requisitos.
Prototipagem
Prototipar é construir uma interface de usuário sem adicionar funcionalidade de detalhes para o usuário interpretar os recursos do produto de software pretendido. Ajuda a dar uma ideia melhor dos requisitos. Se não houver software instalado na extremidade do cliente para referência do desenvolvedor e o cliente não estiver ciente de seus próprios requisitos, o desenvolvedor cria um protótipo com base nos requisitos mencionados inicialmente. O protótipo é mostrado ao cliente e o feedback é anotado. O feedback do cliente serve como uma entrada para a coleta de requisitos.
Observação
Equipe de especialistas visita a organização ou local de trabalho do cliente. Eles observam o funcionamento real dos sistemas instalados existentes. Eles observam o fluxo de trabalho no final do cliente e como os problemas de execução são tratados. A própria equipe tira algumas conclusões que ajudam a formar os requisitos esperados do software.
Características de Requisitos de Software
A coleta de requisitos de software é a base de todo o projeto de desenvolvimento de software. Portanto, devem ser claros, corretos e bem definidos.
As especificações completas de requisitos de software devem ser:
- Clear
- Correct
- Consistent
- Coherent
- Comprehensible
- Modifiable
- Verifiable
- Prioritized
- Unambiguous
- Traceable
- Fonte confiável
Requisitos de software
Devemos tentar entender que tipo de requisitos podem surgir na fase de elicitação de requisitos e que tipos de requisitos são esperados do sistema de software.
Em termos gerais, os requisitos de software devem ser categorizados em duas categorias:
Requisitos funcionais
Requisitos, que estão relacionados ao aspecto funcional do software, se enquadram nesta categoria.
Eles definem funções e funcionalidades dentro e a partir do sistema de software.
Exemplos -
- Opção de pesquisa dada ao usuário para pesquisar a partir de várias faturas.
- O usuário deve ser capaz de enviar qualquer relatório para a gerência.
- Os usuários podem ser divididos em grupos e os grupos podem receber direitos separados.
- Deve cumprir as regras de negócios e funções administrativas.
- O software é desenvolvido mantendo a compatibilidade com versões anteriores intacta.
Requisitos não Funcionais
Os requisitos, que não estão relacionados ao aspecto funcional do software, se enquadram nesta categoria. Eles são características implícitas ou esperadas do software, que os usuários fazem suposições.
Os requisitos não funcionais incluem -
- Security
- Logging
- Storage
- Configuration
- Performance
- Cost
- Interoperability
- Flexibility
- Recuperação de desastre
- Accessibility
Os requisitos são categorizados logicamente como
- Must Have : O software não pode ser dito operacional sem eles.
- Should have : Aprimorando a funcionalidade do software.
- Could have : O software ainda pode funcionar adequadamente com esses requisitos.
- Wish list : Esses requisitos não correspondem a nenhum objetivo do software.
Durante o desenvolvimento de software, 'Deve ter' deve ser implementado, 'Deve ter' é uma questão de debate com as partes interessadas e negação, enquanto 'poderia ter' e 'lista de desejos' podem ser mantidos para atualizações de software.
Requisitos de interface do usuário
A IU é uma parte importante de qualquer software ou hardware ou sistema híbrido. Um software é amplamente aceito se for -
- fácil de operar
- resposta rápida
- lidar eficazmente com erros operacionais
- fornecendo interface de usuário simples, mas consistente
A aceitação do usuário depende principalmente de como o usuário pode usar o software. A IU é a única maneira dos usuários perceberem o sistema. Um sistema de software com bom desempenho também deve ser equipado com uma interface de usuário atraente, clara, consistente e responsiva. Caso contrário, as funcionalidades do sistema de software não podem ser utilizadas de forma conveniente. Um sistema é considerado bom se fornecer meios para usá-lo com eficiência. Os requisitos de interface do usuário são brevemente mencionados abaixo -
- Apresentação de conteúdo
- Navegação Fácil
- Interface simples
- Responsive
- Elementos de IU consistentes
- Mecanismo de retorno
- Configurações padrão
- Layout proposital
- Uso estratégico de cor e textura.
- Forneça informações de ajuda
- Abordagem centrada no usuário
- Configurações de visualização baseadas em grupo.
Analista de Sistema de Software
O analista de sistemas em uma organização de TI é uma pessoa que analisa os requisitos do sistema proposto e garante que os requisitos sejam concebidos e documentados de forma adequada e correta. A função de um analista começa durante a fase de análise de software do SDLC. É responsabilidade do analista garantir que o software desenvolvido atenda aos requisitos do cliente.
Os analistas de sistema têm as seguintes responsabilidades:
- Analisar e compreender os requisitos do software pretendido
- Compreender como o projeto contribuirá nos objetivos da organização
- Identifique as fontes de requisitos
- Validação de requisito
- Desenvolver e implementar plano de gerenciamento de requisitos
- Documentação de requisitos de negócios, técnicos, de processo e de produto
- Coordenação com clientes para priorizar os requisitos e remover a ambigüidade
- Finalizando os critérios de aceitação com o cliente e outras partes interessadas
Métricas e medidas de software
Medidas de software podem ser entendidas como um processo de quantificar e simbolizar vários atributos e aspectos do software.
Software Metrics fornece medidas para vários aspectos do processo de software e do produto de software.
Medidas de software são requisitos fundamentais da engenharia de software. Eles não apenas ajudam a controlar o processo de desenvolvimento de software, mas também ajudam a manter a qualidade do produto final excelente.
De acordo com Tom DeMarco, um (Engenheiro de Software), “Você não pode controlar o que não pode medir.” Com suas palavras, é muito claro o quão importante são as medidas de software.
Vamos ver algumas métricas de software:
Size Metrics - LOC (linhas de código), principalmente calculado em milhares de linhas de código-fonte entregues, denotado como KLOC.
A contagem de pontos de função é a medida da funcionalidade fornecida pelo software. A contagem de pontos de função define o tamanho do aspecto funcional do software.
- Complexity Metrics - A complexidade ciclomática de McCabe quantifica o limite superior do número de caminhos independentes em um programa, que é percebido como complexidade do programa ou de seus módulos. É representado em termos de conceitos de teoria de grafos usando o gráfico de fluxo de controle.
Quality Metrics - Defeitos, seus tipos e causas, consequência, intensidade de gravidade e suas implicações definem a qualidade do produto.
O número de defeitos encontrados no processo de desenvolvimento e o número de defeitos relatados pelo cliente após a instalação ou entrega do produto no cliente definem a qualidade do produto.
- Process Metrics - Em várias fases do SDLC, os métodos e ferramentas usados, os padrões da empresa e o desempenho de desenvolvimento são métricas de processo de software.
- Resource Metrics - Esforço, tempo e vários recursos usados representam métricas para medição de recursos.
O projeto de software é um processo para transformar os requisitos do usuário em alguma forma adequada, o que ajuda o programador na codificação e implementação do software.
Para avaliar os requisitos do usuário, um documento SRS (Software Requirement Specification) é criado, enquanto para codificação e implementação, são necessários requisitos mais específicos e detalhados em termos de software. A saída desse processo pode ser usada diretamente na implementação em linguagens de programação.
O projeto de software é a primeira etapa no SDLC (Ciclo de Vida do Projeto de Software), que move a concentração do domínio do problema para o domínio da solução. Tenta especificar como cumprir os requisitos mencionados na SRS.
Níveis de Design de Software
O design de software produz três níveis de resultados:
- Architectural Design - O projeto arquitetônico é a versão abstrata mais elevada do sistema. Ele identifica o software como um sistema com muitos componentes interagindo entre si. Nesse nível, os designers têm a ideia do domínio da solução proposta.
- High-level Design- O projeto de alto nível quebra o conceito de projeto arquitetônico de 'entidade única-componente múltiplo' em uma visão menos abstrata de subsistemas e módulos e descreve sua interação uns com os outros. O design de alto nível concentra-se em como o sistema, juntamente com todos os seus componentes, podem ser implementados em formas de módulos. Ele reconhece a estrutura modular de cada subsistema e sua relação e interação entre si.
- Detailed Design- O projeto detalhado lida com a parte de implementação do que é visto como um sistema e seus subsistemas nos dois projetos anteriores. É mais detalhado em relação aos módulos e suas implementações. Ele define a estrutura lógica de cada módulo e suas interfaces para se comunicar com outros módulos.
Modularização
Modularização é uma técnica para dividir um sistema de software em vários módulos discretos e independentes, que devem ser capazes de realizar tarefas de forma independente. Esses módulos podem funcionar como construções básicas para todo o software. Os projetistas tendem a projetar módulos de forma que possam ser executados e / ou compilados separadamente e independentemente.
O design modular segue involuntariamente as regras da estratégia de solução de problemas de "dividir para conquistar", porque há muitos outros benefícios associados ao design modular de um software.
Vantagem da modularização:
- Componentes menores são mais fáceis de manter
- O programa pode ser dividido com base em aspectos funcionais
- O nível de abstração desejado pode ser incluído no programa
- Componentes com alta coesão podem ser reutilizados novamente
- A execução simultânea pode ser possível
- Desejado do aspecto de segurança
Simultaneidade
No passado, todos os softwares devem ser executados sequencialmente. Por execução sequencial, queremos dizer que a instrução codificada será executada uma após a outra, implicando que apenas uma parte do programa seja ativada em um determinado momento. Digamos que um software tenha vários módulos, então apenas um de todos os módulos pode ser encontrado ativo em qualquer momento de execução.
No projeto de software, a simultaneidade é implementada dividindo o software em várias unidades independentes de execução, como módulos, e executando-os em paralelo. Em outras palavras, a simultaneidade fornece capacidade para o software executar mais de uma parte do código em paralelo entre si.
É necessário que os programadores e designers reconheçam esses módulos, que podem ser executados em paralelo.
Exemplo
O recurso de verificação ortográfica no processador de texto é um módulo de software que funciona junto com o próprio processador de texto.
Acoplamento e Coesão
Quando um programa de software é modularizado, suas tarefas são divididas em vários módulos com base em algumas características. Como sabemos, os módulos são um conjunto de instruções reunidas para realizar algumas tarefas. No entanto, eles são considerados como uma entidade única, mas podem referir-se um ao outro para trabalharem juntos. Existem medidas pelas quais a qualidade de um design de módulos e sua interação entre eles pode ser medida. Essas medidas são chamadas de acoplamento e coesão.
Coesão
Coesão é uma medida que define o grau de intra-confiança dentro dos elementos de um módulo. Quanto maior a coesão, melhor é o desenho do programa.
Existem sete tipos de coesão, a saber -
- Co-incidental cohesion -É uma coesão não planejada e aleatória, que pode ser o resultado da divisão do programa em módulos menores por causa da modularização. Por não ser planejado, pode confundir os programadores e geralmente não é aceito.
- Logical cohesion - Quando elementos categorizados logicamente são colocados juntos em um módulo, isso é chamado de coesão lógica.
- emporal Cohesion - Quando os elementos do módulo são organizados de forma que sejam processados em um momento semelhante, isso é chamado de coesão temporal.
- Procedural cohesion - Quando os elementos do módulo são agrupados, os quais são executados sequencialmente para realizar uma tarefa, é chamado de coesão procedural.
- Communicational cohesion - Quando os elementos do módulo são agrupados, os quais são executados sequencialmente e funcionam sobre os mesmos dados (informações), é chamado de coesão comunicacional.
- Sequential cohesion - Quando os elementos do módulo são agrupados porque a saída de um elemento serve como entrada para outro e assim por diante, isso é chamado de coesão sequencial.
- Functional cohesion - É considerado o mais alto grau de coesão e é altamente esperado. Os elementos do módulo na coesão funcional são agrupados porque todos contribuem para uma única função bem definida. Também pode ser reutilizado.
Acoplamento
O acoplamento é uma medida que define o nível de inter-confiança entre os módulos de um programa. Diz em que nível os módulos interferem e interagem uns com os outros. Quanto mais baixo for o acoplamento, melhor será o programa.
Existem cinco níveis de acoplamento, a saber -
- Content coupling - Quando um módulo pode acessar ou modificar diretamente ou referir-se ao conteúdo de outro módulo, isso é chamado de acoplamento de nível de conteúdo.
- Common coupling- Quando vários módulos têm acesso de leitura e gravação a alguns dados globais, isso é chamado de acoplamento comum ou global.
- Control coupling- Dois módulos são chamados de controle acoplado se um deles decide a função do outro módulo ou altera seu fluxo de execução.
- Stamp coupling- Quando vários módulos compartilham uma estrutura de dados comum e trabalham em diferentes partes dela, isso é chamado de acoplamento de selo.
- Data coupling- O acoplamento de dados é quando dois módulos interagem entre si por meio da passagem de dados (como parâmetro). Se um módulo passa a estrutura de dados como parâmetro, o módulo receptor deve usar todos os seus componentes.
Idealmente, nenhum acoplamento é considerado o melhor.
Verificação de Design
A saída do processo de design de software é a documentação de design, pseudocódigos, diagramas lógicos detalhados, diagramas de processo e descrição detalhada de todos os requisitos funcionais ou não funcionais.
A próxima fase, que é a implementação do software, depende de todas as saídas mencionadas acima.
É então necessário verificar a saída antes de prosseguir para a próxima fase. Quanto mais cedo qualquer erro for detectado, melhor será ou pode não ser detectado até o teste do produto. Se as saídas da fase de projeto estiverem na forma de notação formal, então suas ferramentas associadas para verificação devem ser usadas, caso contrário, uma revisão completa do projeto pode ser usada para verificação e validação.
Por meio da abordagem de verificação estruturada, os revisores podem detectar defeitos que podem ser causados pela negligência de algumas condições. Uma boa revisão de projeto é importante para um bom projeto de software, precisão e qualidade.
A análise e o design de software incluem todas as atividades que ajudam na transformação da especificação de requisitos em implementação. As especificações de requisitos especificam todas as expectativas funcionais e não funcionais do software. Essas especificações de requisitos vêm na forma de documentos legíveis e compreensíveis por humanos, para os quais um computador não tem nada a ver.
A análise e design de software é o estágio intermediário, o que ajuda os requisitos legíveis por humanos a serem transformados em código real.
Vamos ver algumas ferramentas de análise e design usadas por designers de software:
Diagrama de fluxo de dados
O diagrama de fluxo de dados é uma representação gráfica do fluxo de dados em um sistema de informação. É capaz de representar o fluxo de dados de entrada, fluxo de dados de saída e dados armazenados. O DFD não menciona nada sobre como os dados fluem pelo sistema.
Há uma diferença importante entre DFD e fluxograma. O fluxograma descreve o fluxo de controle nos módulos do programa. Os DFDs representam o fluxo de dados no sistema em vários níveis. DFD não contém nenhum controle ou elementos de ramificação.
Tipos de DFD
Os diagramas de fluxo de dados são lógicos ou físicos.
- Logical DFD - Este tipo de DFD concentra-se no processo do sistema e no fluxo de dados no sistema. Por exemplo, em um sistema de software Banking, como os dados são movidos entre diferentes entidades.
- Physical DFD- Este tipo de DFD mostra como o fluxo de dados é realmente implementado no sistema. É mais específico e próximo da implementação.
Componentes DFD
DFD pode representar origem, destino, armazenamento e fluxo de dados usando o seguinte conjunto de componentes -

- Entities- Entidades são fonte e destino dos dados de informação. As entidades são representadas por retângulos com seus respectivos nomes.
- Process - As atividades e ações executadas nos dados são representadas por retângulos circulares ou arredondados.
- Data Storage - Existem duas variantes de armazenamento de dados - pode ser representado como um retângulo com ausência de ambos os lados menores ou como um retângulo de lados abertos com apenas um lado faltando.
- Data Flow- O movimento dos dados é mostrado por setas pontiagudas. A movimentação de dados é mostrada da base da seta como sua origem até a ponta da seta como destino.
Níveis de DFD
- Level 0- O DFD de nível de abstração mais alto é conhecido como DFD de nível 0, que representa todo o sistema de informações como um diagrama que esconde todos os detalhes subjacentes. Os DFDs de nível 0 também são conhecidos como DFDs de nível de contexto.
- Level 1- O nível 0 DFD é dividido em mais específico, nível 1 DFD. Nível 1 DFD descreve módulos básicos no sistema e fluxo de dados entre vários módulos. O DFD de nível 1 também menciona processos básicos e fontes de informação.
Level 2 - Neste nível, o DFD mostra como os dados fluem dentro dos módulos mencionados no Nível 1.
Os DFDs de nível superior podem ser transformados em DFDs de nível inferior mais específicos com um nível de compreensão mais profundo, a menos que o nível desejado de especificação seja alcançado.


Gráficos de Estrutura
O gráfico de estrutura é um gráfico derivado do Diagrama de fluxo de dados. Ele representa o sistema em mais detalhes do que o DFD. Ele divide todo o sistema em módulos funcionais mais baixos, descreve as funções e subfunções de cada módulo do sistema com mais detalhes do que o DFD.
O gráfico de estrutura representa a estrutura hierárquica dos módulos. Em cada camada, uma tarefa específica é executada.
Aqui estão os símbolos usados na construção de gráficos de estrutura -
- Module- Representa processo ou sub-rotina ou tarefa. Um módulo de controle se ramifica para mais de um submódulo. Módulos de biblioteca são reutilizáveis e invocáveis a partir de qualquer módulo.

- Condition- É representado por um pequeno diamante na base do módulo. Ele descreve que o módulo de controle pode selecionar qualquer uma das sub-rotinas com base em alguma condição.

- Jump - Uma seta é mostrada apontando para dentro do módulo para representar que o controle irá saltar no meio do submódulo.

- Loop- Uma seta curva representa o loop no módulo. Todos os submódulos cobertos pelo loop repetem a execução do módulo.

- Data flow - Uma seta direcionada com um círculo vazio no final representa o fluxo de dados.

- Control flow - Uma seta direcionada com um círculo preenchido no final representa o fluxo de controle.

Diagrama HIPO
O diagrama HIPO (Hierarchical Input Process Output) é uma combinação de dois métodos organizados para analisar o sistema e fornecer os meios de documentação. O modelo HIPO foi desenvolvido pela IBM no ano de 1970.
O diagrama HIPO representa a hierarquia dos módulos no sistema de software. O analista usa o diagrama HIPO para obter uma visão de alto nível das funções do sistema. Ele decompõe funções em subfunções de maneira hierárquica. Ele descreve as funções desempenhadas pelo sistema.
Os diagramas HIPO são bons para fins de documentação. Sua representação gráfica torna mais fácil para designers e gerentes obter uma ideia pictórica da estrutura do sistema.

Em contraste com o diagrama IPO (Input Process Output), que descreve o fluxo de controle e dados em um módulo, o HIPO não fornece nenhuma informação sobre fluxo de dados ou fluxo de controle.

Exemplo
Ambas as partes do diagrama HIPO, apresentação hierárquica e gráfico IPO são usados para o design da estrutura do programa de software, bem como a documentação do mesmo.
Inglês Estruturado
A maioria dos programadores não tem conhecimento do panorama geral do software, por isso confia apenas no que seus gerentes lhes dizem para fazer. É responsabilidade do gerenciamento de software superior fornecer informações precisas aos programadores para desenvolver um código preciso, mas rápido.
Outras formas de métodos, que usam gráficos ou diagramas, podem às vezes ser interpretados de maneira diferente por pessoas diferentes.
Conseqüentemente, analistas e designers do software apresentam ferramentas como o inglês estruturado. Não é nada além da descrição do que é necessário para codificar e como codificá-lo. O inglês estruturado ajuda o programador a escrever código sem erros.
Outras formas de métodos, que usam gráficos ou diagramas, podem às vezes ser interpretados de maneira diferente por pessoas diferentes. Aqui, o inglês estruturado e o pseudo-código tentam atenuar essa lacuna de compreensão.
O inglês estruturado é o que usa palavras simples em inglês no paradigma de programação estruturada. Não é o código final, mas um tipo de descrição do que é necessário para codificar e como codificá-lo. A seguir estão alguns tokens de programação estruturada.
IF-THEN-ELSE,
DO-WHILE-UNTILAnalyst usa a mesma variável e nome de dados, que são armazenados no Dicionário de Dados, tornando muito mais simples escrever e entender o código.
Exemplo
Tomamos o mesmo exemplo de autenticação do cliente no ambiente de compras online. Este procedimento para autenticar o cliente pode ser escrito em inglês estruturado como:
Enter Customer_Name
SEEK Customer_Name in Customer_Name_DB file
IF Customer_Name found THEN
Call procedure USER_PASSWORD_AUTHENTICATE()
ELSE
PRINT error message
Call procedure NEW_CUSTOMER_REQUEST()
ENDIFThe code written in Structured English is more like day-to-day spoken English. It can not be implemented directly as a code of software. Structured English is independent of programming language.
Pseudo-Code
Pseudo code is written more close to programming language. It may be considered as augmented programming language, full of comments and descriptions.
Pseudo code avoids variable declaration but they are written using some actual programming language’s constructs, like C, Fortran, Pascal etc.
Pseudo code contains more programming details than Structured English. It provides a method to perform the task, as if a computer is executing the code.
Example
Program to print Fibonacci up to n numbers.
void function Fibonacci
Get value of n;
Set value of a to 1;
Set value of b to 1;
Initialize I to 0
for (i=0; i< n; i++)
{
if a greater than b
{
Increase b by a;
Print b;
}
else if b greater than a
{
increase a by b;
print a;
}
}Decision Tables
A Decision table represents conditions and the respective actions to be taken to address them, in a structured tabular format.
It is a powerful tool to debug and prevent errors. It helps group similar information into a single table and then by combining tables it delivers easy and convenient decision-making.
Creating Decision Table
To create the decision table, the developer must follow basic four steps:
- Identify all possible conditions to be addressed
- Determine actions for all identified conditions
- Create Maximum possible rules
- Define action for each rule
Decision Tables should be verified by end-users and can lately be simplified by eliminating duplicate rules and actions.
Example
Let us take a simple example of day-to-day problem with our Internet connectivity. We begin by identifying all problems that can arise while starting the internet and their respective possible solutions.
We list all possible problems under column conditions and the prospective actions under column Actions.
| Conditions/Actions | Rules | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Conditions | Shows Connected | N | N | N | N | Y | Y | Y | Y |
| Ping is Working | N | N | Y | Y | N | N | Y | Y | |
| Opens Website | Y | N | Y | N | Y | N | Y | N | |
| Actions | Check network cable | X | |||||||
| Check internet router | X | X | X | X | |||||
| Restart Web Browser | X | ||||||||
| Contact Service provider | X | X | X | X | X | X | |||
| Do no action | |||||||||
Entity-Relationship Model
Entity-Relationship model is a type of database model based on the notion of real world entities and relationship among them. We can map real world scenario onto ER database model. ER Model creates a set of entities with their attributes, a set of constraints and relation among them.
ER Model is best used for the conceptual design of database. ER Model can be represented as follows :

Entity - An entity in ER Model is a real world being, which has some properties called attributes. Every attribute is defined by its corresponding set of values, called domain.
For example, Consider a school database. Here, a student is an entity. Student has various attributes like name, id, age and class etc.
Relationship - The logical association among entities is called relationship. Relationships are mapped with entities in various ways. Mapping cardinalities define the number of associations between two entities.
Mapping cardinalities:
- one to one
- one to many
- many to one
- many to many
Data Dictionary
Data dictionary is the centralized collection of information about data. It stores meaning and origin of data, its relationship with other data, data format for usage etc. Data dictionary has rigorous definitions of all names in order to facilitate user and software designers.
Data dictionary is often referenced as meta-data (data about data) repository. It is created along with DFD (Data Flow Diagram) model of software program and is expected to be updated whenever DFD is changed or updated.
Requirement of Data Dictionary
The data is referenced via data dictionary while designing and implementing software. Data dictionary removes any chances of ambiguity. It helps keeping work of programmers and designers synchronized while using same object reference everywhere in the program.
Data dictionary provides a way of documentation for the complete database system in one place. Validation of DFD is carried out using data dictionary.
Contents
Data dictionary should contain information about the following
- Data Flow
- Data Structure
- Data Elements
- Data Stores
- Data Processing
Data Flow is described by means of DFDs as studied earlier and represented in algebraic form as described.
| = | Composed of |
|---|---|
| {} | Repetition |
| () | Optional |
| + | And |
| [ / ] | Or |
Example
Address = House No + (Street / Area) + City + State
Course ID = Course Number + Course Name + Course Level + Course Grades
Data Elements
Data elements consist of Name and descriptions of Data and Control Items, Internal or External data stores etc. with the following details:
- Primary Name
- Secondary Name (Alias)
- Use-case (How and where to use)
- Content Description (Notation etc. )
- Supplementary Information (preset values, constraints etc.)
Data Store
It stores the information from where the data enters into the system and exists out of the system. The Data Store may include -
- Files
- Internal to software.
- External to software but on the same machine.
- External to software and system, located on different machine.
- Tables
- Naming convention
- Indexing property
Data Processing
There are two types of Data Processing:
- Logical: As user sees it
- Physical: As software sees it
Software design is a process to conceptualize the software requirements into software implementation. Software design takes the user requirements as challenges and tries to find optimum solution. While the software is being conceptualized, a plan is chalked out to find the best possible design for implementing the intended solution.
There are multiple variants of software design. Let us study them briefly:
Structured Design
Structured design is a conceptualization of problem into several well-organized elements of solution. It is basically concerned with the solution design. Benefit of structured design is, it gives better understanding of how the problem is being solved. Structured design also makes it simpler for designer to concentrate on the problem more accurately.
Structured design is mostly based on ‘divide and conquer’ strategy where a problem is broken into several small problems and each small problem is individually solved until the whole problem is solved.
The small pieces of problem are solved by means of solution modules. Structured design emphasis that these modules be well organized in order to achieve precise solution.
These modules are arranged in hierarchy. They communicate with each other. A good structured design always follows some rules for communication among multiple modules, namely -
Cohesion - grouping of all functionally related elements.
Coupling - communication between different modules.
A good structured design has high cohesion and low coupling arrangements.
Function Oriented Design
In function-oriented design, the system is comprised of many smaller sub-systems known as functions. These functions are capable of performing significant task in the system. The system is considered as top view of all functions.
Function oriented design inherits some properties of structured design where divide and conquer methodology is used.
This design mechanism divides the whole system into smaller functions, which provides means of abstraction by concealing the information and their operation.. These functional modules can share information among themselves by means of information passing and using information available globally.
Another characteristic of functions is that when a program calls a function, the function changes the state of the program, which sometimes is not acceptable by other modules. Function oriented design works well where the system state does not matter and program/functions work on input rather than on a state.
Design Process
- The whole system is seen as how data flows in the system by means of data flow diagram.
- DFD depicts how functions changes data and state of entire system.
- The entire system is logically broken down into smaller units known as functions on the basis of their operation in the system.
- Each function is then described at large.
Object Oriented Design
Object oriented design works around the entities and their characteristics instead of functions involved in the software system. This design strategies focuses on entities and its characteristics. The whole concept of software solution revolves around the engaged entities.
Let us see the important concepts of Object Oriented Design:
- Objects - All entities involved in the solution design are known as objects. For example, person, banks, company and customers are treated as objects. Every entity has some attributes associated to it and has some methods to perform on the attributes.
Classes - A class is a generalized description of an object. An object is an instance of a class. Class defines all the attributes, which an object can have and methods, which defines the functionality of the object.
In the solution design, attributes are stored as variables and functionalities are defined by means of methods or procedures.
- Encapsulation - In OOD, the attributes (data variables) and methods (operation on the data) are bundled together is called encapsulation. Encapsulation not only bundles important information of an object together, but also restricts access of the data and methods from the outside world. This is called information hiding.
- Inheritance - OOD allows similar classes to stack up in hierarchical manner where the lower or sub-classes can import, implement and re-use allowed variables and methods from their immediate super classes. This property of OOD is known as inheritance. This makes it easier to define specific class and to create generalized classes from specific ones.
- Polymorphism - OOD languages provide a mechanism where methods performing similar tasks but vary in arguments, can be assigned same name. This is called polymorphism, which allows a single interface performing tasks for different types. Depending upon how the function is invoked, respective portion of the code gets executed.
Design Process
Software design process can be perceived as series of well-defined steps. Though it varies according to design approach (function oriented or object oriented, yet It may have the following steps involved:
- A solution design is created from requirement or previous used system and/or system sequence diagram.
- Objects are identified and grouped into classes on behalf of similarity in attribute characteristics.
- Class hierarchy and relation among them is defined.
- Application framework is defined.
Software Design Approaches
Here are two generic approaches for software designing:
Top Down Design
We know that a system is composed of more than one sub-systems and it contains a number of components. Further, these sub-systems and components may have their on set of sub-system and components and creates hierarchical structure in the system.
Top-down design takes the whole software system as one entity and then decomposes it to achieve more than one sub-system or component based on some characteristics. Each sub-system or component is then treated as a system and decomposed further. This process keeps on running until the lowest level of system in the top-down hierarchy is achieved.
Top-down design starts with a generalized model of system and keeps on defining the more specific part of it. When all components are composed the whole system comes into existence.
Top-down design is more suitable when the software solution needs to be designed from scratch and specific details are unknown.
Bottom-up Design
The bottom up design model starts with most specific and basic components. It proceeds with composing higher level of components by using basic or lower level components. It keeps creating higher level components until the desired system is not evolved as one single component. With each higher level, the amount of abstraction is increased.
Bottom-up strategy is more suitable when a system needs to be created from some existing system, where the basic primitives can be used in the newer system.
Both, top-down and bottom-up approaches are not practical individually. Instead, a good combination of both is used.
User interface is the front-end application view to which user interacts in order to use the software. User can manipulate and control the software as well as hardware by means of user interface. Today, user interface is found at almost every place where digital technology exists, right from computers, mobile phones, cars, music players, airplanes, ships etc.
User interface is part of software and is designed such a way that it is expected to provide the user insight of the software. UI provides fundamental platform for human-computer interaction.
UI can be graphical, text-based, audio-video based, depending upon the underlying hardware and software combination. UI can be hardware or software or a combination of both.
The software becomes more popular if its user interface is:
- Attractive
- Simple to use
- Responsive in short time
- Clear to understand
- Consistent on all interfacing screens
UI is broadly divided into two categories:
- Command Line Interface
- Graphical User Interface
Command Line Interface (CLI)
CLI has been a great tool of interaction with computers until the video display monitors came into existence. CLI is first choice of many technical users and programmers. CLI is minimum interface a software can provide to its users.
CLI provides a command prompt, the place where the user types the command and feeds to the system. The user needs to remember the syntax of command and its use. Earlier CLI were not programmed to handle the user errors effectively.
A command is a text-based reference to set of instructions, which are expected to be executed by the system. There are methods like macros, scripts that make it easy for the user to operate.
CLI uses less amount of computer resource as compared to GUI.
CLI Elements

A text-based command line interface can have the following elements:
Command Prompt - It is text-based notifier that is mostly shows the context in which the user is working. It is generated by the software system.
Cursor - It is a small horizontal line or a vertical bar of the height of line, to represent position of character while typing. Cursor is mostly found in blinking state. It moves as the user writes or deletes something.
Command - A command is an executable instruction. It may have one or more parameters. Output on command execution is shown inline on the screen. When output is produced, command prompt is displayed on the next line.
Graphical User Interface
Graphical User Interface provides the user graphical means to interact with the system. GUI can be combination of both hardware and software. Using GUI, user interprets the software.
Typically, GUI is more resource consuming than that of CLI. With advancing technology, the programmers and designers create complex GUI designs that work with more efficiency, accuracy and speed.
GUI Elements
GUI provides a set of components to interact with software or hardware.
Every graphical component provides a way to work with the system. A GUI system has following elements such as:

Window - An area where contents of application are displayed. Contents in a window can be displayed in the form of icons or lists, if the window represents file structure. It is easier for a user to navigate in the file system in an exploring window. Windows can be minimized, resized or maximized to the size of screen. They can be moved anywhere on the screen. A window may contain another window of the same application, called child window.
Tabs - If an application allows executing multiple instances of itself, they appear on the screen as separate windows. Tabbed Document Interface has come up to open multiple documents in the same window. This interface also helps in viewing preference panel in application. All modern web-browsers use this feature.
Menu - Menu is an array of standard commands, grouped together and placed at a visible place (usually top) inside the application window. The menu can be programmed to appear or hide on mouse clicks.
Icon - An icon is small picture representing an associated application. When these icons are clicked or double clicked, the application window is opened. Icon displays application and programs installed on a system in the form of small pictures.
Cursor - Interacting devices such as mouse, touch pad, digital pen are represented in GUI as cursors. On screen cursor follows the instructions from hardware in almost real-time. Cursors are also named pointers in GUI systems. They are used to select menus, windows and other application features.
Application specific GUI components
A GUI of an application contains one or more of the listed GUI elements:
Application Window - Most application windows uses the constructs supplied by operating systems but many use their own customer created windows to contain the contents of application.
Dialogue Box - It is a child window that contains message for the user and request for some action to be taken. For Example: Application generate a dialogue to get confirmation from user to delete a file.
Text-Box - Provides an area for user to type and enter text-based data.
Buttons - They imitate real life buttons and are used to submit inputs to the software.

Radio-button - Displays available options for selection. Only one can be selected among all offered.
Check-box - Functions similar to list-box. When an option is selected, the box is marked as checked. Multiple options represented by check boxes can be selected.
List-box - Provides list of available items for selection. More than one item can be selected.

Other impressive GUI components are:
- Sliders
- Combo-box
- Data-grid
- Drop-down list
User Interface Design Activities
There are a number of activities performed for designing user interface. The process of GUI design and implementation is alike SDLC. Any model can be used for GUI implementation among Waterfall, Iterative or Spiral Model.
A model used for GUI design and development should fulfill these GUI specific steps.

GUI Requirement Gathering - The designers may like to have list of all functional and non-functional requirements of GUI. This can be taken from user and their existing software solution.
User Analysis - The designer studies who is going to use the software GUI. The target audience matters as the design details change according to the knowledge and competency level of the user. If user is technical savvy, advanced and complex GUI can be incorporated. For a novice user, more information is included on how-to of software.
Task Analysis - Designers have to analyze what task is to be done by the software solution. Here in GUI, it does not matter how it will be done. Tasks can be represented in hierarchical manner taking one major task and dividing it further into smaller sub-tasks. Tasks provide goals for GUI presentation. Flow of information among sub-tasks determines the flow of GUI contents in the software.
GUI Design & implementation - Designers after having information about requirements, tasks and user environment, design the GUI and implements into code and embed the GUI with working or dummy software in the background. It is then self-tested by the developers.
Testing - GUI testing can be done in various ways. Organization can have in-house inspection, direct involvement of users and release of beta version are few of them. Testing may include usability, compatibility, user acceptance etc.
Ferramentas de implementação de GUI
Existem várias ferramentas disponíveis com as quais os designers podem criar GUI inteira com um clique do mouse. Algumas ferramentas podem ser incorporadas ao ambiente de software (IDE).
As ferramentas de implementação de GUI fornecem uma matriz poderosa de controles de GUI. Para personalização do software, os designers podem alterar o código de acordo.
Existem diferentes segmentos de ferramentas GUI de acordo com seus diferentes usos e plataformas.
Exemplo
GUI móvel, GUI do computador, GUI da tela de toque, etc. Aqui está uma lista de algumas ferramentas que são úteis para construir uma GUI:
- FLUID
- AppInventor (Android)
- LucidChart
- Wavemaker
- Estúdio visual
Regras de ouro da interface do usuário
As regras a seguir são mencionadas como as regras de ouro para o design de GUI, descritas por Shneiderman e Plaisant em seu livro (Designing the User Interface).
Strive for consistency- Sequências consistentes de ações devem ser exigidas em situações semelhantes. Terminologia idêntica deve ser usada em prompts, menus e telas de ajuda. Comandos consistentes devem ser empregados em todo o processo.
Enable frequent users to use short-cuts- O desejo do usuário de reduzir o número de interações aumenta com a frequência de uso. Abreviações, teclas de função, comandos ocultos e recursos de macro são muito úteis para um usuário experiente.
Offer informative feedback- Para cada ação do operador, deve haver algum feedback do sistema. Para ações frequentes e menores, a resposta deve ser modesta, enquanto para ações não frequentes e grandes, a resposta deve ser mais substancial.
Design dialog to yield closure- As sequências de ações devem ser organizadas em grupos com início, meio e fim. O feedback informativo na conclusão de um grupo de ações dá aos operadores a satisfação da realização, uma sensação de alívio, o sinal para retirar planos e opções de contingência de suas mentes, e isso indica que o caminho a seguir está claro para se preparar para o próximo grupo de ações.
Offer simple error handling- Tanto quanto possível, projete o sistema de forma que o usuário não cometa erros graves. Se um erro for cometido, o sistema deve ser capaz de detectá-lo e oferecer mecanismos simples e compreensíveis para lidar com o erro.
Permit easy reversal of actions- Esse recurso alivia a ansiedade, pois o usuário sabe que erros podem ser desfeitos. A reversão fácil de ações incentiva a exploração de opções desconhecidas. As unidades de reversibilidade podem ser uma única ação, uma entrada de dados ou um grupo completo de ações.
Support internal locus of control- Operadores experientes desejam fortemente ter a sensação de que estão no comando do sistema e que o sistema responde às suas ações. Projete o sistema para tornar os usuários os iniciadores das ações, e não os respondentes.
Reduce short-term memory load - A limitação do processamento de informações humanas na memória de curto prazo exige que as exibições sejam mantidas simples, exibições de várias páginas sejam consolidadas, a frequência do movimento da janela seja reduzida e o tempo de treinamento suficiente seja alocado para códigos, mnemônicos e sequências de ações.
O termo complexidade significa estado de eventos ou coisas, que têm vários links interconectados e estruturas altamente complicadas. Na programação de software, à medida que o design do software é realizado, o número de elementos e suas interconexões gradualmente torna-se enorme, o que se torna muito difícil de entender imediatamente.
A complexidade do projeto de software é difícil de avaliar sem o uso de métricas e medidas de complexidade. Vejamos três medidas importantes de complexidade de software.
Medidas de complexidade de Halstead
Em 1977, o Sr. Maurice Howard Halstead introduziu métricas para medir a complexidade do software. As métricas da Halstead dependem da implementação real do programa e de suas medidas, que são calculadas diretamente dos operadores e operandos do código-fonte, de maneira estática. Ele permite avaliar o tempo de teste, vocabulário, tamanho, dificuldade, erros e esforços para o código-fonte C / C ++ / Java.
De acordo com Halstead, “Um programa de computador é uma implementação de um algoritmo considerado uma coleção de tokens que podem ser classificados como operadores ou operandos”. As métricas Halstead consideram um programa como uma sequência de operadores e seus operandos associados.
Ele define vários indicadores para verificar a complexidade do módulo.
| Parâmetro | Significado |
|---|---|
| n1 | Número de operadores únicos |
| n2 | Número de operandos únicos |
| N1 | Número de ocorrência total de operadores |
| N2 | Número de ocorrência total de operandos |
Quando selecionamos o arquivo de origem para visualizar seus detalhes de complexidade no Metric Viewer, o seguinte resultado é visto no Metric Report:
| Métrica | Significado | Representação Matemática |
|---|---|---|
| n | Vocabulário | n1 + n2 |
| N | Tamanho | N1 + N2 |
| V | Volume | Comprimento * Log2 Vocabulário |
| D | Dificuldade | (n1 / 2) * (N1 / n2) |
| E | Esforços | Dificuldade * Volume |
| B | Erros | Volume / 3000 |
| T | Tempo de teste | Tempo = Esforços / S, onde S = 18 segundos. |
Medidas de complexidade ciclomática
Cada programa inclui instruções a serem executadas para realizar alguma tarefa e outras instruções de tomada de decisão que decidem quais instruções precisam ser executadas. Essas construções de tomada de decisão mudam o fluxo do programa.
Se compararmos dois programas do mesmo tamanho, aquele com mais instruções de tomada de decisão será mais complexo, pois o controle do programa salta com frequência.
McCabe, em 1976, propôs Medida de Complexidade Ciclomática para quantificar a complexidade de um determinado software. É um modelo orientado por gráfico que se baseia em construções de programa de tomada de decisão, como instruções if-else, do-while, repeat-until, switch-case e goto.
Processo para fazer o gráfico de controle de fluxo:
- Quebre o programa em blocos menores, delimitados por construções de tomada de decisão.
- Crie nós que representam cada um desses nós.
- Conecte os nós da seguinte forma:
Se o controle pode ramificar do bloco i para o bloco j
Desenhe um arco
Do nó de saída para o nó de entrada
Desenhe um arco.
Para calcular a complexidade ciclomática de um módulo de programa, usamos a fórmula -
V(G) = e – n + 2
Where
e is total number of edges
n is total number of nodes
A complexidade ciclomática do módulo acima é
e = 10
n = 8
Cyclomatic Complexity = 10 - 8 + 2
= 4De acordo com P. Jorgensen, a Complexidade Ciclomática de um módulo não deve exceder 10.
Ponto de Função
É amplamente utilizado para medir o tamanho do software. O ponto de função concentra-se na funcionalidade fornecida pelo sistema. Os recursos e a funcionalidade do sistema são usados para medir a complexidade do software.
O ponto de função conta com cinco parâmetros, nomeados como Entrada Externa, Saída Externa, Arquivos Internos Lógicos, Arquivos de Interface Externa e Consulta Externa. Para considerar a complexidade do software, cada parâmetro é categorizado como simples, médio ou complexo.
Vamos ver os parâmetros do ponto de função:
Entrada externa
Cada entrada única para o sistema, de fora, é considerada uma entrada externa. A exclusividade da entrada é medida, já que duas entradas não devem ter os mesmos formatos. Essas entradas podem ser dados ou parâmetros de controle.
Simple - se a contagem de entrada for baixa e afetar menos arquivos internos
Complex - se a contagem de entrada for alta e afetar mais arquivos internos
Average - entre o simples e o complexo.
Saída Externa
Todos os tipos de saída fornecidos pelo sistema são contados nesta categoria. A saída é considerada única se seu formato de saída e / ou processamento forem únicos.
Simple - se a contagem de saída for baixa
Complex - se a contagem de saída for alta
Average - entre o simples e o complexo.
Arquivos internos lógicos
Todo sistema de software mantém arquivos internos para manter suas informações funcionais e funcionar adequadamente. Esses arquivos contêm dados lógicos do sistema. Esses dados lógicos podem conter dados funcionais e dados de controle.
Simple - se o número de tipos de registro for baixo
Complex - se o número de tipos de registro for alto
Average - entre o simples e o complexo.
Arquivos de interface externa
O sistema de software pode precisar compartilhar seus arquivos com algum software externo ou pode precisar passar o arquivo para processamento ou como parâmetro para alguma função. Todos esses arquivos são contados como arquivos de interface externa.
Simple - se o número de tipos de registro no arquivo compartilhado for baixo
Complex - se o número de tipos de registro no arquivo compartilhado for alto
Average - entre o simples e o complexo.
Inquérito externo
Uma consulta é uma combinação de entrada e saída, em que o usuário envia alguns dados para consultar como entrada e o sistema responde ao usuário com a saída da consulta processada. A complexidade de uma consulta é mais do que uma entrada externa e uma saída externa. A consulta é considerada única se sua entrada e saída forem únicas em termos de formato e dados.
Simple - se a consulta precisa de baixo processamento e produz uma pequena quantidade de dados de saída
Complex - se a consulta precisa de um alto processo e produz uma grande quantidade de dados de saída
Average - entre o simples e o complexo.
Cada um desses parâmetros no sistema é ponderado de acordo com sua classe e complexidade. A tabela abaixo menciona a ponderação atribuída a cada parâmetro:
| Parâmetro | Simples | Média | Complexo |
|---|---|---|---|
| Entradas | 3 | 4 | 6 |
| Saídas | 4 | 5 | 7 |
| Inquérito | 3 | 4 | 6 |
| arquivos | 7 | 10 | 15 |
| Interfaces | 5 | 7 | 10 |
A tabela acima produz pontos de função brutos. Esses pontos de função são ajustados de acordo com a complexidade do ambiente. O sistema é descrito usando quatorze características diferentes:
- Comunicações de dados
- Processo de distribuição
- Objetivos de desempenho
- Carga de configuração de operação
- Taxa de transação
- Entrada de dados online,
- Eficiência do usuário final
- Atualização online
- Lógica de processamento complexa
- Re-usability
- Facilidade de instalação
- Facilidade operacional
- Vários sites
- Desejo de facilitar mudanças
Esses fatores de características são então avaliados de 0 a 5, conforme mencionado abaixo:
- Sem influência
- Incidental
- Moderate
- Average
- Significant
- Essential
Todas as classificações são então somadas como N. O valor de N varia de 0 a 70 (14 tipos de características x 5 tipos de classificações). É usado para calcular os Fatores de Ajuste de Complexidade (CAF), usando as seguintes fórmulas:
CAF = 0.65 + 0.01NEntão,
Delivered Function Points (FP)= CAF x Raw FPEste PF pode então ser usado em várias métricas, como:
Cost = $ / FP
Quality = Erros / FP
Productivity = FP / pessoa-mês
Neste capítulo, estudaremos sobre métodos de programação, documentação e desafios na implementação de software.
Programação Estruturada
No processo de codificação, as linhas de código vão se multiplicando, assim, o tamanho do software aumenta. Gradualmente, torna-se quase impossível lembrar o fluxo do programa. Se alguém esquecer como o software e seus programas, arquivos e procedimentos subjacentes são construídos, torna-se muito difícil compartilhar, depurar e modificar o programa. A solução para isso é a programação estruturada. Ele encoraja o desenvolvedor a usar sub-rotinas e loops em vez de usar saltos simples no código, trazendo clareza no código e melhorando sua eficiência. A programação estruturada também ajuda o programador a reduzir o tempo de codificação e organizar o código corretamente.
A programação estruturada indica como o programa deve ser codificado. A programação estruturada usa três conceitos principais:
Top-down analysis- Um software é sempre feito para realizar algum trabalho racional. Esse trabalho racional é conhecido como problema na linguagem do software. Portanto, é muito importante que entendamos como resolver o problema. Na análise de cima para baixo, o problema é dividido em pequenos pedaços, onde cada um tem algum significado. Cada problema é resolvido individualmente e as etapas são claramente definidas sobre como resolver o problema.
Modular Programming- Durante a programação, o código é dividido em grupos menores de instruções. Esses grupos são conhecidos como módulos, subprogramas ou sub-rotinas. Programação modular baseada no entendimento da análise top-down. Isso desencoraja saltos usando instruções 'goto' no programa, o que geralmente torna o fluxo do programa não rastreável. Saltos são proibidos e o formato modular é encorajado na programação estruturada.
Structured Coding - Em referência à análise de cima para baixo, a codificação estruturada subdivide os módulos em outras unidades menores de código na ordem de sua execução. A programação estruturada usa estrutura de controle, que controla o fluxo do programa, enquanto a codificação estruturada usa estrutura de controle para organizar suas instruções em padrões definíveis.
Programação Funcional
A programação funcional é um estilo de linguagem de programação, que usa os conceitos de funções matemáticas. Uma função em matemática deve sempre produzir o mesmo resultado ao receber o mesmo argumento. Nas linguagens procedurais, o fluxo do programa passa por procedimentos, ou seja, o controle do programa é transferido para o procedimento chamado. Enquanto o fluxo de controle está sendo transferido de um procedimento para outro, o programa muda de estado.
Na programação procedural, é possível que um procedimento produza resultados diferentes quando é chamado com o mesmo argumento, pois o próprio programa pode estar em um estado diferente ao chamá-lo. Esta é uma propriedade e também uma desvantagem da programação procedural, na qual a sequência ou o tempo de execução do procedimento torna-se importante.
A programação funcional fornece meios de computação como funções matemáticas, que produzem resultados independentemente do estado do programa. Isso torna possível prever o comportamento do programa.
A programação funcional usa os seguintes conceitos:
First class and High-order functions - Essas funções têm capacidade de aceitar outra função como argumento ou retornam outras funções como resultados.
Pure functions - Essas funções não incluem atualizações destrutivas, ou seja, não afetam nenhuma E / S ou memória e, se não estiverem em uso, podem ser facilmente removidas sem prejudicar o restante do programa.
Recursion- A recursão é uma técnica de programação em que uma função chama a si mesma e repete o código do programa nela, a menos que alguma condição predefinida corresponda. A recursão é a maneira de criar loops na programação funcional.
Strict evaluation- É um método de avaliação da expressão passada para uma função como um argumento. A programação funcional tem dois tipos de métodos de avaliação, estritos (ansiosos) ou não estritos (preguiçosos). A avaliação estrita sempre avalia a expressão antes de chamar a função. A avaliação não estrita não avalia a expressão a menos que seja necessária.
λ-calculus- A maioria das linguagens de programação funcional usa λ-cálculo como seus sistemas de tipo. As expressões λ são executadas avaliando-as à medida que ocorrem.
Common Lisp, Scala, Haskell, Erlang e F # são alguns exemplos de linguagens de programação funcionais.
Estilo de programação
O estilo de programação é um conjunto de regras de codificação seguidas por todos os programadores para escrever o código. Quando vários programadores trabalham no mesmo projeto de software, eles freqüentemente precisam trabalhar com o código do programa escrito por algum outro desenvolvedor. Isso se torna tedioso ou às vezes impossível, se todos os desenvolvedores não seguirem algum estilo de programação padrão para codificar o programa.
Um estilo de programação apropriado inclui o uso de nomes de funções e variáveis relevantes para a tarefa pretendida, usando recuo bem colocado, código de comentários para a conveniência do leitor e apresentação geral do código. Isso torna o código do programa legível e compreensível por todos, o que, por sua vez, torna a depuração e a solução de erros mais fáceis. Além disso, o estilo de codificação adequado ajuda a facilitar a documentação e atualização.
Diretrizes de codificação
A prática do estilo de codificação varia com as organizações, sistemas operacionais e linguagem de codificação em si.
Os seguintes elementos de codificação podem ser definidos sob as diretrizes de codificação de uma organização:
Naming conventions - Esta seção define como nomear funções, variáveis, constantes e variáveis globais.
Indenting - Este é o espaço deixado no início da linha, geralmente de 2 a 8 espaços em branco ou tabulação única.
Whitespace - Geralmente é omitido no final da linha.
Operators- Define as regras de escrita de operadores matemáticos, de atribuição e lógicos. Por exemplo, o operador de atribuição '=' deve ter espaço antes e depois dele, como em “x = 2”.
Control Structures - As regras para escrever if-then-else, case-switch, while-until e para instruções de fluxo de controle somente e de maneira aninhada.
Line length and wrapping- Define quantos caracteres devem existir em uma linha, principalmente uma linha com 80 caracteres. Quebra automática define como uma linha deve ser quebrada, se for muito longa.
Functions - Isso define como as funções devem ser declaradas e chamadas, com e sem parâmetros.
Variables - Isso menciona como as variáveis de diferentes tipos de dados são declaradas e definidas.
Comments- Este é um dos componentes de codificação importantes, pois os comentários incluídos no código descrevem o que o código realmente faz e todas as outras descrições associadas. Esta seção também ajuda a criar documentações de ajuda para outros desenvolvedores.
Documentação de software
A documentação do software é uma parte importante do processo de software. Um documento bem escrito fornece uma ótima ferramenta e meio de repositório de informações necessárias para saber sobre o processo de software. A documentação do software também fornece informações sobre como usar o produto.
Uma documentação bem mantida deve envolver os seguintes documentos:
Requirement documentation - Esta documentação funciona como uma ferramenta fundamental para o designer de software, desenvolvedor e equipe de teste para realizar suas respectivas tarefas. Este documento contém todas as descrições funcionais, não funcionais e comportamentais do software pretendido.
A fonte deste documento pode ser dados previamente armazenados sobre o software, software já em execução no cliente final, entrevista do cliente, questionários e pesquisas. Geralmente, ele é armazenado na forma de planilha ou documento de processamento de texto com a equipe de gerenciamento de software de ponta.
Esta documentação serve de base para o software a ser desenvolvido e é utilizada principalmente nas fases de verificação e validação. A maioria dos casos de teste é construída diretamente da documentação de requisitos.
Software Design documentation - Estas documentações contêm todas as informações necessárias para construir o software. Contém:(a) Arquitetura de software de alto nível, (b) Detalhes de design de software, (c) Diagramas de fluxo de dados, (d) Projeto de banco de dados
Esses documentos funcionam como repositório para desenvolvedores implementarem o software. Embora esses documentos não forneçam detalhes sobre como codificar o programa, eles fornecem todas as informações necessárias para a codificação e implementação.
Technical documentation- Essas documentações são mantidas pelos desenvolvedores e programadores reais. Esses documentos, como um todo, representam informações sobre o código. Ao escrever o código, os programadores também mencionam o objetivo do código, quem o escreveu, onde será necessário, o que faz e como faz, que outros recursos o código usa, etc.
A documentação técnica aumenta o entendimento entre vários programadores que trabalham no mesmo código. Ele aprimora a capacidade de reutilização do código. Isso torna a depuração fácil e rastreável.
Existem várias ferramentas automatizadas disponíveis e algumas vêm com a própria linguagem de programação. Por exemplo, java vem com a ferramenta JavaDoc para gerar documentação técnica de código.
User documentation- Esta documentação é diferente de todas as explicadas acima. Todas as documentações anteriores são mantidas para fornecer informações sobre o software e seu processo de desenvolvimento. Mas a documentação do usuário explica como o produto de software deve funcionar e como deve ser usado para obter os resultados desejados.
Essas documentações podem incluir procedimentos de instalação de software, guias de procedimentos, guias do usuário, método de desinstalação e referências especiais para obter mais informações como atualização de licença, etc.
Desafios de implementação de software
Existem alguns desafios enfrentados pela equipe de desenvolvimento durante a implementação do software. Alguns deles são mencionados abaixo:
Code-reuse- As interfaces de programação das linguagens atuais são muito sofisticadas e estão equipadas com enormes funções de biblioteca. Ainda assim, para reduzir o custo do produto final, a gerência da organização prefere reutilizar o código, que foi criado anteriormente para algum outro software. Existem enormes problemas enfrentados pelos programadores para verificações de compatibilidade e decidir quanto código reutilizar.
Version Management- Cada vez que um novo software é lançado para o cliente, os desenvolvedores precisam manter a versão e a documentação relacionada à configuração. Esta documentação precisa ser altamente precisa e estar disponível no prazo.
Target-Host- O programa de software, que está sendo desenvolvido na organização, precisa ser projetado para máquinas host no final do cliente. Mas às vezes, é impossível projetar um software que funcione nas máquinas de destino.
O Teste de Software é a avaliação do software em relação aos requisitos coletados dos usuários e especificações do sistema. O teste é conduzido no nível de fase do ciclo de vida de desenvolvimento de software ou no nível de módulo no código do programa. O teste de software inclui Validação e Verificação.
Validação de Software
A validação é o processo de examinar se o software satisfaz ou não os requisitos do usuário. É realizado no final do SDLC. Se o software atender aos requisitos para os quais foi feito, ele é validado.
- A validação garante que o produto em desenvolvimento esteja de acordo com os requisitos do usuário.
- A validação responde à pergunta - "Estamos desenvolvendo o produto que atende a tudo que o usuário precisa deste software?".
- A validação enfatiza os requisitos do usuário.
Verificação de Software
Verificação é o processo de confirmar se o software está atendendo aos requisitos de negócios e é desenvolvido de acordo com as especificações e metodologias adequadas.
- A verificação garante que o produto sendo desenvolvido está de acordo com as especificações do projeto.
- A verificação responde à pergunta - "Estamos desenvolvendo este produto seguindo firmemente todas as especificações de design?"
- As verificações se concentram no projeto e nas especificações do sistema.
Alvos do teste são -
Errors- Esses são erros reais de codificação cometidos por desenvolvedores. Além disso, há uma diferença na saída do software e a saída desejada, é considerada um erro.
Fault- Quando existe um erro, ocorre uma falha. Uma falha, também conhecida como bug, é o resultado de um erro que pode causar a falha do sistema.
Failure - a falha é a incapacidade do sistema de realizar a tarefa desejada. A falha ocorre quando existe falha no sistema.
Teste manual versus teste automatizado
O teste pode ser feito manualmente ou usando uma ferramenta de teste automatizada:
Manual- Este teste é executado sem a ajuda de ferramentas de teste automatizadas. O testador de software prepara casos de teste para diferentes seções e níveis do código, executa os testes e relata o resultado ao gerente.
O teste manual consome tempo e recursos. O testador precisa confirmar se os casos de teste corretos são usados ou não. A maior parte dos testes envolve testes manuais.
AutomatedEste teste é um procedimento de teste feito com a ajuda de ferramentas de teste automatizadas. As limitações do teste manual podem ser superadas usando ferramentas de teste automatizadas.
Um teste precisa verificar se uma página da web pode ser aberta no Internet Explorer. Isso pode ser feito facilmente com testes manuais. Mas, para verificar se o servidor web pode suportar a carga de 1 milhão de usuários, é quase impossível testar manualmente.
Existem ferramentas de software e hardware que ajudam o testador na realização de testes de carga, testes de estresse e testes de regressão.
Abordagens de teste
Os testes podem ser realizados com base em duas abordagens -
- Teste de funcionalidade
- Teste de implementação
Quando a funcionalidade está sendo testada sem levar em consideração a implementação real, isso é conhecido como teste de caixa preta. O outro lado é conhecido como teste de caixa branca, em que não apenas a funcionalidade é testada, mas a maneira como ela é implementada também é analisada.
Testes exaustivos são o método mais desejado para um teste perfeito. Todos os valores possíveis na faixa dos valores de entrada e saída são testados. Não é possível testar todos os valores no cenário do mundo real se a faixa de valores for grande.
Teste de caixa preta
É realizado para testar a funcionalidade do programa. Também é chamado de teste 'comportamental'. O testador, neste caso, possui um conjunto de valores de entrada e respectivos resultados desejados. Ao fornecer a entrada, se a saída corresponder aos resultados desejados, o programa é testado 'ok' e, de outra forma, problemático.

Nesse método de teste, o design e a estrutura do código não são conhecidos pelo testador, e os engenheiros de teste e os usuários finais conduzem esse teste no software.
Técnicas de teste de caixa preta:
Equivalence class- A entrada é dividida em classes semelhantes. Se um elemento de uma classe passar no teste, presume-se que toda a classe foi aprovada.
Boundary values- A entrada é dividida em valores finais superiores e inferiores. Se esses valores passarem no teste, presume-se que todos os valores intermediários também podem passar.
Cause-effect graphing- Em ambos os métodos anteriores, apenas um valor de entrada por vez é testado. Causa (entrada) - O efeito (saída) é uma técnica de teste em que combinações de valores de entrada são testadas de forma sistemática.
Pair-wise Testing- O comportamento do software depende de vários parâmetros. No teste de pares, os vários parâmetros são testados em pares para seus diferentes valores.
State-based testing- O sistema muda de estado no fornecimento de entrada. Esses sistemas são testados com base em seus estados e entrada.
Teste de caixa branca
É conduzido para testar o programa e sua implementação, a fim de melhorar a eficiência ou estrutura do código. Também é conhecido como teste 'Estrutural'.

Neste método de teste, o design e a estrutura do código são conhecidos pelo testador. Os programadores do código conduzem este teste no código.
A seguir estão algumas técnicas de teste de caixa branca:
Control-flow testing- O objetivo do teste de fluxo de controle para configurar casos de teste que cobrem todas as instruções e condições de ramificação. As condições de ramificação são testadas para serem verdadeiras e falsas, para que todas as declarações possam ser cobertas.
Data-flow testing- Esta ênfase técnica de teste para cobrir todas as variáveis de dados incluídas no programa. Testa onde as variáveis foram declaradas e definidas e onde foram usadas ou alteradas.
Níveis de Teste
O teste em si pode ser definido em vários níveis de SDLC. O processo de teste é executado em paralelo ao desenvolvimento de software. Antes de saltar para a próxima etapa, uma etapa é testada, validada e verificada.
O teste separadamente é feito apenas para garantir que não haja erros ocultos ou problemas deixados no software. O software é testado em vários níveis -
Teste de Unidade
Durante a codificação, o programador executa alguns testes nessa unidade de programa para saber se ela está livre de erros. O teste é realizado sob a abordagem de teste de caixa branca. O teste de unidade ajuda os desenvolvedores a decidir se as unidades individuais do programa estão funcionando de acordo com os requisitos e sem erros.
Teste de integração
Mesmo que as unidades de software funcionem bem individualmente, é necessário descobrir se as unidades, se integradas juntas, também funcionariam sem erros. Por exemplo, passagem de argumento e atualização de dados etc.
Teste de Sistema
O software é compilado como produto e depois testado como um todo. Isso pode ser feito usando um ou mais dos seguintes testes:
Functionality testing - Testa todas as funcionalidades do software em relação ao requisito.
Performance testing- Este teste prova a eficiência do software. Ele testa a eficácia e o tempo médio gasto pelo software para realizar a tarefa desejada. O teste de desempenho é feito por meio de teste de carga e teste de estresse, onde o software é colocado sob alta carga de usuário e dados em várias condições ambientais.
Security & Portability - Esses testes são feitos quando o software se destina a funcionar em várias plataformas e é acessado por várias pessoas.
Teste de aceitação
Quando o software está pronto para ser entregue ao cliente, ele passa pela última fase de testes, onde é testado quanto à interação e resposta do usuário. Isso é importante porque, mesmo que o software atenda a todos os requisitos do usuário e o usuário não goste da forma como aparece ou funciona, ele pode ser rejeitado.
Alpha testing- A própria equipe de desenvolvedores realiza o teste alfa usando o sistema como se estivesse sendo usado no ambiente de trabalho. Eles tentam descobrir como o usuário reagiria a alguma ação no software e como o sistema deveria responder às entradas.
Beta testing- Depois que o software é testado internamente, ele é entregue aos usuários para usá-lo em seu ambiente de produção apenas para fins de teste. Este ainda não é o produto entregue. Os desenvolvedores esperam que os usuários, neste estágio, tragam problemas de minuto, que foram omitidos para comparecer.
Teste de Regressão
Sempre que um produto de software é atualizado com um novo código, recurso ou funcionalidade, ele é testado exaustivamente para detectar se há algum impacto negativo do código adicionado. Isso é conhecido como teste de regressão.
Documentação de teste
Os documentos de teste são preparados em diferentes estágios -
Antes do Teste
O teste começa com a geração de casos de teste. Os seguintes documentos são necessários para referência -
SRS document - Documento de requisitos funcionais
Test Policy document - Descreve até que ponto o teste deve ser realizado antes de liberar o produto.
Test Strategy document - Isso menciona aspectos detalhados da equipe de teste, matriz de responsabilidade e direitos / responsabilidades do gerente e engenheiro de teste.
Traceability Matrix document- Este é um documento SDLC, que está relacionado ao processo de coleta de requisitos. Conforme surgem novos requisitos, eles são adicionados a esta matriz. Essas matrizes ajudam os testadores a saber a origem do requisito. Eles podem ser rastreados para frente e para trás.
Enquanto está sendo testado
Os seguintes documentos podem ser exigidos enquanto o teste é iniciado e está sendo feito:
Test Case document- Este documento contém uma lista de testes que devem ser realizados. Inclui plano de teste de unidade, plano de teste de integração, plano de teste de sistema e plano de teste de aceitação.
Test description - Este documento é uma descrição detalhada de todos os casos de teste e procedimentos para executá-los.
Test case report - Este documento contém o relatório do caso de teste como resultado do teste.
Test logs - Este documento contém logs de teste para cada relatório de caso de teste.
Após o teste
Os seguintes documentos podem ser gerados após o teste:
Test summary- Este resumo de teste é uma análise coletiva de todos os relatórios e registros de teste. Ele resume e conclui se o software está pronto para ser iniciado. O software é lançado sob o sistema de controle de versão se estiver pronto para iniciar.
Teste vs. Controle de Qualidade, Garantia de Qualidade e Auditoria
Precisamos entender que o teste de software é diferente de garantia de qualidade de software, controle de qualidade de software e auditoria de software.
Software quality assurance- São meios de monitoramento do processo de desenvolvimento de software, pelos quais se garante que todas as medidas sejam tomadas de acordo com os padrões da organização. Esse monitoramento é feito para garantir que os métodos de desenvolvimento de software adequados foram seguidos.
Software quality control- Este é um sistema para manter a qualidade do produto de software. Pode incluir aspectos funcionais e não funcionais do produto de software, que aumentam a boa vontade da organização. Este sistema garante que o cliente está recebendo um produto de qualidade para sua necessidade e o produto certificado como 'apto para uso'.
Software audit- Esta é uma revisão do procedimento usado pela organização para desenvolver o software. Uma equipe de auditores, independente da equipe de desenvolvimento, examina o processo de software, procedimento, requisitos e outros aspectos do SDLC. O objetivo da auditoria de software é verificar se o software e seu processo de desenvolvimento estão em conformidade com os padrões, regras e regulamentos.
A manutenção de software é amplamente aceita como parte do SDLC hoje em dia. Significa todas as modificações e atualizações feitas após a entrega do produto de software. Existem várias razões pelas quais as modificações são necessárias, algumas delas são brevemente mencionadas abaixo:
Market Conditions - As políticas, que mudam com o tempo, como tributação e restrições recentemente introduzidas, como manter a contabilidade, podem gerar a necessidade de modificação.
Client Requirements - Com o tempo, o cliente pode solicitar novos recursos ou funções no software.
Host Modifications - Se algum hardware e / ou plataforma (como sistema operacional) do host de destino for alterado, alterações de software serão necessárias para manter a adaptabilidade.
Organization Changes - Se houver qualquer mudança no nível de negócios na extremidade do cliente, como redução da força da organização, aquisição de outra empresa, organização se aventurando em novos negócios, pode haver necessidade de modificação no software original.
Tipos de manutenção
Durante a vida útil do software, o tipo de manutenção pode variar de acordo com sua natureza. Pode ser apenas uma tarefa de manutenção de rotina como algum bug descoberto por algum usuário ou pode ser um grande evento em si mesmo com base no tamanho ou natureza da manutenção. A seguir estão alguns tipos de manutenção com base em suas características:
Corrective Maintenance - Inclui modificações e atualizações feitas para corrigir ou corrigir problemas, que são descobertos pelo usuário ou concluídos por relatórios de erro do usuário.
Adaptive Maintenance - Isso inclui modificações e atualizações aplicadas para manter o produto de software atualizado e ajustado para o mundo em constante mudança da tecnologia e do ambiente de negócios.
Perfective Maintenance- Isso inclui modificações e atualizações feitas para manter o software utilizável por um longo período de tempo. Inclui novos recursos, novos requisitos do usuário para refinar o software e melhorar sua confiabilidade e desempenho.
Preventive Maintenance- Isso inclui modificações e atualizações para evitar problemas futuros do software. Tem como objetivo atender problemas, que não são significativos neste momento, mas podem causar sérios problemas no futuro.
Custo de Manutenção
Os relatórios sugerem que o custo de manutenção é alto. Um estudo sobre a estimativa de manutenção de software descobriu que o custo de manutenção chega a 67% do custo de todo o ciclo do processo de software.
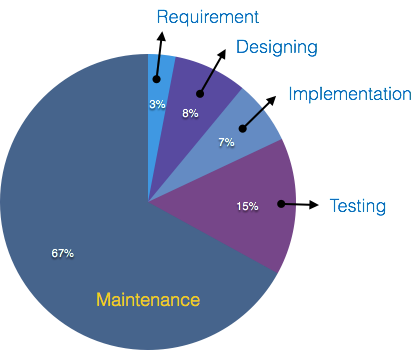
Em média, o custo de manutenção do software é superior a 50% de todas as fases do SDLC. Existem vários fatores que fazem com que o custo de manutenção seja alto, tais como:
Fatores do mundo real que afetam o custo de manutenção
- A idade padrão de qualquer software é considerada de 10 a 15 anos.
- Softwares mais antigos, que deveriam funcionar em máquinas lentas com menos memória e capacidade de armazenamento, não podem se manter desafiadores contra os novos softwares aprimorados em hardware moderno.
- Conforme a tecnologia avança, torna-se caro manter o software antigo.
- A maioria dos engenheiros de manutenção são novatos e usam o método de tentativa e erro para corrigir o problema.
- Freqüentemente, as alterações feitas podem facilmente prejudicar a estrutura original do software, dificultando quaisquer alterações subsequentes.
- Frequentemente, as alterações não são documentadas, o que pode causar mais conflitos no futuro.
Fatores finais do software que afetam o custo de manutenção
- Estrutura do Programa de Software
- Linguagem de programação
- Dependência do ambiente externo
- Confiabilidade e disponibilidade da equipe
Atividades de manutenção
O IEEE fornece uma estrutura para atividades de processo de manutenção sequencial. Ele pode ser usado de maneira iterativa e pode ser estendido para que itens e processos personalizados possam ser incluídos.

Essas atividades vão de mãos dadas com cada uma das seguintes fases:
Identification & Tracing- Envolve atividades relativas à identificação de requisitos de modificação ou manutenção. Ele é gerado pelo usuário ou o próprio sistema pode reportar via logs ou mensagens de erro. Aqui, o tipo de manutenção também é classificado.
Analysis- A modificação é analisada por seu impacto no sistema, incluindo implicações de segurança e proteção. Se o impacto provável for severo, procura-se uma solução alternativa. Um conjunto de modificações necessárias é então materializado em especificações de requisitos. O custo de modificação / manutenção é analisado e a estimativa é concluída.
Design- Novos módulos, que precisam ser substituídos ou modificados, são projetados de acordo com as especificações de requisitos definidas no estágio anterior. Os casos de teste são criados para validação e verificação.
Implementation - Os novos módulos são codificados com a ajuda de design estruturado criado na etapa de design. Espera-se que cada programador faça testes de unidade em paralelo.
System Testing- O teste de integração é feito entre os módulos recém-criados. O teste de integração também é realizado entre os novos módulos e o sistema. Por fim, o sistema é testado como um todo, seguindo procedimentos de teste regressivos.
Acceptance Testing- Depois de testar o sistema internamente, ele é testado para aceitação com a ajuda dos usuários. Se estiver neste estado, o usuário reclamará de alguns problemas que serão tratados ou anotados para tratar na próxima iteração.
Delivery- Após o teste de aceitação, o sistema é implantado em toda a organização por meio de um pequeno pacote de atualização ou nova instalação do sistema. O teste final ocorre no cliente após a entrega do software.
Instalações de treinamento são fornecidas, se necessário, além da cópia impressa do manual do usuário.
Maintenance management- O gerenciamento da configuração é uma parte essencial da manutenção do sistema. É auxiliado por ferramentas de controle de versão para controlar versões, semi-versão ou gerenciamento de patch.
Reengenharia de software
Quando precisamos atualizar o software para mantê-lo no mercado atual, sem afetar sua funcionalidade, isso é chamado de reengenharia de software. É um processo completo em que o design do software é alterado e os programas reescritos.
O software legado não consegue ficar em sintonia com a tecnologia mais recente disponível no mercado. À medida que o hardware se torna obsoleto, a atualização do software se torna uma dor de cabeça. Mesmo que o software envelheça com o tempo, sua funcionalidade não envelhece.
Por exemplo, inicialmente o Unix foi desenvolvido em linguagem assembly. Quando a linguagem C surgiu, o Unix foi reprojetado em C, porque trabalhar em linguagem assembly era difícil.
Fora isso, às vezes os programadores percebem que poucas partes do software precisam de mais manutenção do que outras e também precisam de reengenharia.

Processo de Reengenharia
- Decideo que reengenharia. É um software completo ou parte dele?
- Perform Engenharia reversa, a fim de obter especificações de softwares existentes.
- Restructure Programse necessário. Por exemplo, transformar programas orientados a funções em programas orientados a objetos.
- Re-structure data como requerido.
- Apply Forward engineering conceitos para obter software reprojetado.
Existem alguns termos importantes usados na reengenharia de software
Engenharia reversa
É um processo para atingir a especificação do sistema por meio de uma análise completa e da compreensão do sistema existente. Este processo pode ser visto como um modelo SDLC reverso, ou seja, tentamos obter um nível de abstração mais alto analisando os níveis de abstração mais baixos.
Um sistema existente é projeto previamente implementado, sobre o qual nada sabemos. Os designers, então, fazem engenharia reversa olhando para o código e tentam obter o design. Com o design em mãos, procuram concluir as especificações. Portanto, indo ao contrário do código para a especificação do sistema.

Reestruturação do Programa
É um processo para reestruturar e reconstruir o software existente. É tudo sobre como reorganizar o código-fonte, seja na mesma linguagem de programação ou de uma linguagem de programação para outra diferente. A reestruturação pode ter a reestruturação do código-fonte e a reestruturação dos dados, ou ambas.
A reestruturação não afeta a funcionalidade do software, mas aumenta a confiabilidade e a facilidade de manutenção. Os componentes do programa, que causam erros com muita frequência, podem ser alterados ou atualizados com reestruturação.
A confiabilidade do software em uma plataforma de hardware obsoleta pode ser removida por meio de reestruturação.
Engenharia Avançada
A engenharia avançada é um processo de obtenção do software desejado a partir das especificações em mãos, que foram derrubadas por meio da engenharia reversa. Ele assume que já houve alguma engenharia de software feita no passado.
A engenharia direta é igual ao processo de engenharia de software, com apenas uma diferença - ela é realizada sempre após a engenharia reversa.

Reutilização de componentes
Um componente é uma parte do código do programa de software, que executa uma tarefa independente no sistema. Pode ser um pequeno módulo ou o próprio subsistema.
Exemplo
Os procedimentos de login usados na web podem ser considerados como componentes, o sistema de impressão no software pode ser visto como um componente do software.
Os componentes possuem alta coesão de funcionalidade e menor taxa de acoplamento, ou seja, funcionam de forma independente e podem realizar tarefas sem depender de outros módulos.
Na OOP, os objetos projetados são muito específicos para sua preocupação e têm menos chances de serem usados em algum outro software.
Na programação modular, os módulos são codificados para executar tarefas específicas que podem ser usadas em vários outros programas de software.
Há toda uma nova vertical, que se baseia na reutilização de componentes de software, e é conhecida como Component Based Software Engineering (CBSE).

A reutilização pode ser feita em vários níveis
Application level - Onde um aplicativo inteiro é usado como subsistema de um novo software.
Component level - Onde o subsistema de um aplicativo é usado.
Modules level - Onde os módulos funcionais são reutilizados.
Os componentes de software fornecem interfaces que podem ser usadas para estabelecer comunicação entre diferentes componentes.
Processo de Reutilização
Dois tipos de método podem ser adotados: mantendo os mesmos requisitos e ajustando os componentes, ou mantendo os mesmos componentes e modificando os requisitos.

Requirement Specification - Os requisitos funcionais e não funcionais são especificados, aos quais um produto de software deve cumprir, com a ajuda do sistema existente, entrada do usuário ou ambos.
Design- Esta também é uma etapa do processo SDLC padrão, onde os requisitos são definidos em termos de linguagem de software. A arquitetura básica do sistema como um todo e seus subsistemas são criados.
Specify Components - Ao estudar o design do software, os designers separam todo o sistema em componentes ou subsistemas menores. Um projeto de software completo se transforma em uma coleção de um enorme conjunto de componentes trabalhando juntos.
Search Suitable Components - O repositório de componentes de software é indicado pelos designers para pesquisar o componente correspondente, com base na funcionalidade e nos requisitos de software pretendidos.
Incorporate Components - Todos os componentes combinados são embalados juntos para moldá-los como um software completo.
CASE significa Ccomputador Aided Software Eengenharia. Significa, desenvolvimento e manutenção de projetos de software com o auxílio de diversas ferramentas de software automatizadas.
Ferramentas CASE
As ferramentas CASE são conjuntos de programas de aplicativos de software, usados para automatizar as atividades do SDLC. As ferramentas CASE são usadas por gerentes de projetos de software, analistas e engenheiros para desenvolver sistemas de software.
Existem várias ferramentas CASE disponíveis para simplificar os vários estágios do ciclo de vida de desenvolvimento de software, como ferramentas de análise, ferramentas de design, ferramentas de gerenciamento de projeto, ferramentas de gerenciamento de banco de dados, ferramentas de documentação, entre outros.
O uso de ferramentas CASE acelera o desenvolvimento do projeto para produzir o resultado desejado e ajuda a descobrir falhas antes de seguir em frente com o próximo estágio de desenvolvimento de software.
Componentes de ferramentas CASE
As ferramentas CASE podem ser amplamente divididas nas seguintes partes com base em seu uso em um estágio SDLC específico:
Central Repository- As ferramentas CASE requerem um repositório central, que pode servir como fonte de informação comum, integrada e consistente. O repositório central é um local central de armazenamento onde especificações de produtos, documentos de requisitos, relatórios e diagramas relacionados e outras informações úteis relacionadas ao gerenciamento são armazenadas. O repositório central também serve como dicionário de dados.

Upper Case Tools - As ferramentas Upper CASE são utilizadas nas etapas de planejamento, análise e projeto do SDLC.
Lower Case Tools - Ferramentas de baixo CASE são usadas na implementação, teste e manutenção.
Integrated Case Tools - Ferramentas CASE integradas são úteis em todas as etapas do SDLC, desde a coleta de requisitos até o teste e a documentação.
As ferramentas CASE podem ser agrupadas se tiverem funcionalidade, atividades de processo e capacidade de integração com outras ferramentas semelhantes.
Escopo das ferramentas de caso
O escopo das ferramentas CASE abrange todo o SDLC.
Tipos de ferramentas de caso
Agora, examinamos rapidamente várias ferramentas CASE
Ferramentas de diagrama
Essas ferramentas são usadas para representar componentes do sistema, dados e fluxo de controle entre vários componentes de software e estrutura do sistema em um formato gráfico. Por exemplo, a ferramenta Flow Chart Maker para criar fluxogramas de última geração.
Ferramentas de modelagem de processos
A modelagem de processo é um método para criar o modelo de processo de software, que é usado para desenvolver o software. As ferramentas de modelagem de processos ajudam os gerentes a escolher um modelo de processo ou modificá-lo de acordo com os requisitos do produto de software. Por exemplo, EPF Composer
Ferramentas de gerenciamento de projetos
Essas ferramentas são usadas para planejamento de projetos, estimativa de custos e esforços, agendamento de projetos e planejamento de recursos. Os gerentes devem cumprir rigorosamente a execução do projeto com todas as etapas mencionadas no gerenciamento de projetos de software. As ferramentas de gerenciamento de projetos ajudam a armazenar e compartilhar informações do projeto em tempo real em toda a organização. Por exemplo, Creative Pro Office, Trac Project, Basecamp.
Ferramentas de Documentação
A documentação em um projeto de software começa antes do processo de software, passa por todas as fases do SDLC e após a conclusão do projeto.
As ferramentas de documentação geram documentos para usuários técnicos e usuários finais. Os usuários técnicos são, em sua maioria, profissionais internos da equipe de desenvolvimento que consultam o manual do sistema, manual de referência, manual de treinamento, manuais de instalação, etc. Os documentos do usuário final descrevem o funcionamento e instruções do sistema, como o manual do usuário. Por exemplo, Doxygen, DrExplain, Adobe RoboHelp para documentação.
Ferramentas de Análise
Essas ferramentas ajudam a reunir requisitos, verificar automaticamente qualquer inconsistência, imprecisão nos diagramas, redundâncias de dados ou omissões errôneas. Por exemplo, Accept 360, Accompa, CaseComplete para análise de requisitos, Visible Analyst para análise total.
Ferramentas de Design
Essas ferramentas ajudam os designers de software a projetar a estrutura de blocos do software, que pode ser dividida em módulos menores usando técnicas de refinamento. Essas ferramentas fornecem detalhes de cada módulo e interconexões entre os módulos. Por exemplo, Design de software animado
Ferramentas de gerenciamento de configuração
Uma instância de software é lançada em uma versão. Ferramentas de gerenciamento de configuração lidam com -
- Gerenciamento de versão e revisão
- Gerenciamento de configuração de linha de base
- Gerenciamento de controle de mudanças
As ferramentas CASE ajudam nisso por meio do rastreamento automático, gerenciamento de versão e gerenciamento de lançamento. Por exemplo, Fossil, Git, Accu REV.
Ferramentas de controle de mudança
Essas ferramentas são consideradas parte das ferramentas de gerenciamento de configuração. Eles lidam com as alterações feitas no software depois que sua linha de base foi corrigida ou quando o software foi lançado pela primeira vez. As ferramentas CASE automatizam o controle de alterações, gerenciamento de arquivos, gerenciamento de código e muito mais. Também ajuda a reforçar a política de mudança da organização.
Ferramentas de Programação
Essas ferramentas consistem em ambientes de programação como IDE (Integrated Development Environment), biblioteca de módulos embutidos e ferramentas de simulação. Essas ferramentas fornecem ajuda abrangente na construção de produtos de software e incluem recursos para simulação e teste. Por exemplo, Cscope para pesquisar código em C, Eclipse.
Ferramentas de prototipagem
O protótipo de software é uma versão simulada do produto de software pretendido. Prototype fornece a aparência inicial do produto e simula poucos aspectos do produto real.
Ferramentas CASE de prototipagem essencialmente vêm com bibliotecas gráficas. Eles podem criar interfaces de usuário e design independentes de hardware. Essas ferramentas nos ajudam a construir protótipos rápidos com base nas informações existentes. Além disso, eles fornecem simulação de protótipo de software. Por exemplo, o compositor de protótipos Serena, Mockup Builder.
Ferramentas de desenvolvimento web
Essas ferramentas auxiliam no design de páginas da web com todos os elementos associados, como formulários, texto, script, gráfico e assim por diante. As ferramentas da Web também fornecem uma visualização ao vivo do que está sendo desenvolvido e como ficará após a conclusão. Por exemplo, Fontello, Adobe Edge Inspect, Foundation 3, Brackets.
Ferramentas de garantia de qualidade
A garantia de qualidade em uma organização de software está monitorando o processo de engenharia e os métodos adotados para desenvolver o produto de software a fim de garantir a conformidade de qualidade de acordo com os padrões da organização. As ferramentas de QA consistem em ferramentas de configuração e controle de alterações e ferramentas de teste de software. Por exemplo, SoapTest, AppsWatch, JMeter.
Ferramentas de Manutenção
A manutenção do software inclui modificações no produto de software após sua entrega. Técnicas de registro automático e relatório de erros, geração automática de tíquetes de erro e análise de causa raiz são algumas ferramentas CASE que ajudam a organização de software na fase de manutenção do SDLC. Por exemplo, Bugzilla para rastreamento de defeitos, HP Quality Center.