Spark SQL - Guia rápido
As indústrias estão usando o Hadoop extensivamente para analisar seus conjuntos de dados. A razão é que a estrutura do Hadoop é baseada em um modelo de programação simples (MapReduce) e permite uma solução de computação que é escalável, flexível, tolerante a falhas e econômica. Aqui, a principal preocupação é manter a velocidade no processamento de grandes conjuntos de dados em termos de tempo de espera entre as consultas e tempo de espera para executar o programa.
Spark foi apresentado pela Apache Software Foundation para acelerar o processo de software de computação computacional Hadoop.
Contra uma crença comum, Spark is not a modified version of Hadoope não é, realmente, dependente do Hadoop porque ele tem seu próprio gerenciamento de cluster. Hadoop é apenas uma das maneiras de implementar o Spark.
O Spark usa o Hadoop de duas maneiras - uma é storage e o segundo é processing. Como o Spark tem sua própria computação de gerenciamento de cluster, ele usa o Hadoop apenas para fins de armazenamento.
Apache Spark
Apache Spark é uma tecnologia de computação em cluster ultrarrápida, projetada para computação rápida. É baseado no Hadoop MapReduce e estende o modelo MapReduce para usá-lo com eficiência para mais tipos de cálculos, o que inclui consultas interativas e processamento de fluxo. A principal característica do Spark é o seuin-memory cluster computing que aumenta a velocidade de processamento de um aplicativo.
O Spark foi projetado para cobrir uma ampla gama de cargas de trabalho, como aplicativos em lote, algoritmos iterativos, consultas interativas e streaming. Além de suportar toda essa carga de trabalho em um respectivo sistema, ele reduz a carga de gerenciamento de manter ferramentas separadas.
Evolução do Apache Spark
Spark é um dos subprojetos do Hadoop desenvolvido em 2009 no AMPLab da UC Berkeley por Matei Zaharia. Foi Open Sourced em 2010 sob uma licença BSD. Ele foi doado à Fundação de software Apache em 2013, e agora o Apache Spark se tornou um projeto Apache de nível superior a partir de fevereiro de 2014.
Recursos do Apache Spark
O Apache Spark tem os seguintes recursos.
Speed- O Spark ajuda a executar um aplicativo no cluster Hadoop, até 100 vezes mais rápido na memória e 10 vezes mais rápido quando executado no disco. Isso é possível reduzindo o número de operações de leitura / gravação no disco. Ele armazena os dados de processamento intermediários na memória.
Supports multiple languages- O Spark oferece APIs integradas em Java, Scala ou Python. Portanto, você pode escrever aplicativos em diferentes idiomas. O Spark traz 80 operadores de alto nível para consultas interativas.
Advanced Analytics- Spark não suporta apenas 'Mapear' e 'reduzir'. Ele também oferece suporte a consultas SQL, dados de streaming, aprendizado de máquina (ML) e algoritmos de gráfico.
Spark construído em Hadoop
O diagrama a seguir mostra três maneiras de como o Spark pode ser construído com componentes do Hadoop.
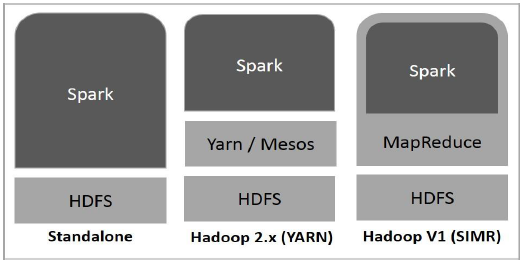
Existem três maneiras de implantação do Spark, conforme explicado abaixo.
Standalone- A implantação autônoma do Spark significa que o Spark ocupa o lugar acima do HDFS (Hadoop Distributed File System) e o espaço é alocado para o HDFS, explicitamente. Aqui, o Spark e o MapReduce serão executados lado a lado para cobrir todos os jobs do Spark no cluster.
Hadoop Yarn- A implantação do Hadoop Yarn significa, simplesmente, que o Spark roda no Yarn sem qualquer pré-instalação ou acesso root necessário. Isso ajuda a integrar o Spark ao ecossistema Hadoop ou pilha Hadoop. Ele permite que outros componentes sejam executados no topo da pilha.
Spark in MapReduce (SIMR)- Spark em MapReduce é usado para iniciar trabalho de faísca, além de implantação autônoma. Com o SIMR, o usuário pode iniciar o Spark e usar seu shell sem qualquer acesso administrativo.
Componentes do Spark
A ilustração a seguir descreve os diferentes componentes do Spark.
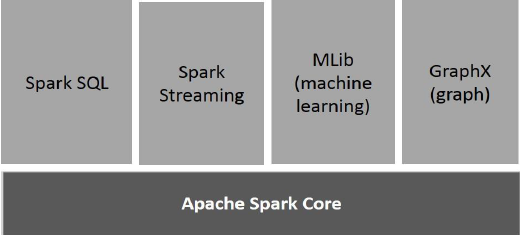
Apache Spark Core
Spark Core é o mecanismo de execução geral subjacente para a plataforma Spark sobre a qual todas as outras funcionalidades são construídas. Ele fornece computação In-Memory e conjuntos de dados de referência em sistemas de armazenamento externo.
Spark SQL
Spark SQL é um componente no topo do Spark Core que apresenta uma nova abstração de dados chamada SchemaRDD, que fornece suporte para dados estruturados e semiestruturados.
Spark Streaming
O Spark Streaming aproveita a capacidade de agendamento rápido do Spark Core para realizar análises de streaming. Ele ingere dados em minilotes e realiza transformações RDD (Resilient Distributed Datasets) nesses minilotes de dados.
MLlib (Biblioteca de aprendizado de máquina)
MLlib é uma estrutura de aprendizado de máquina distribuída acima do Spark por causa da arquitetura do Spark baseada em memória distribuída. É, de acordo com benchmarks, feito pelos desenvolvedores MLlib contra as implementações Alternating Least Squares (ALS). Spark MLlib é nove vezes mais rápido que a versão baseada em disco Hadoop doApache Mahout (antes de Mahout ganhar uma interface Spark).
GraphX
GraphX é uma estrutura de processamento de gráficos distribuída sobre o Spark. Ele fornece uma API para expressar computação de gráfico que pode modelar os gráficos definidos pelo usuário usando a API de abstração Pregel. Ele também fornece um tempo de execução otimizado para essa abstração.
Conjuntos de dados distribuídos resilientes
Resilient Distributed Datasets (RDD) é uma estrutura de dados fundamental do Spark. É uma coleção imutável de objetos distribuídos. Cada conjunto de dados em RDD é dividido em partições lógicas, que podem ser calculadas em diferentes nós do cluster. Os RDDs podem conter qualquer tipo de objetos Python, Java ou Scala, incluindo classes definidas pelo usuário.
Formalmente, um RDD é uma coleção de registros particionada somente leitura. Os RDDs podem ser criados por meio de operações determinísticas em dados no armazenamento estável ou em outros RDDs. RDD é uma coleção de elementos tolerantes a falhas que podem ser operados em paralelo.
Existem duas maneiras de criar RDDs - parallelizing uma coleção existente em seu programa de driver, ou referencing a dataset em um sistema de armazenamento externo, como um sistema de arquivos compartilhado, HDFS, HBase ou qualquer fonte de dados que ofereça um formato de entrada Hadoop.
O Spark usa o conceito de RDD para obter operações MapReduce mais rápidas e eficientes. Vamos primeiro discutir como as operações MapReduce ocorrem e por que não são tão eficientes.
O compartilhamento de dados é lento no MapReduce
MapReduce é amplamente adotado para processar e gerar grandes conjuntos de dados com um algoritmo paralelo distribuído em um cluster. Ele permite aos usuários escrever cálculos paralelos, usando um conjunto de operadores de alto nível, sem ter que se preocupar com a distribuição do trabalho e tolerância a falhas.
Infelizmente, na maioria das estruturas atuais, a única maneira de reutilizar dados entre cálculos (Ex: entre duas tarefas MapReduce) é gravá-los em um sistema de armazenamento externo estável (Ex: HDFS). Embora essa estrutura forneça várias abstrações para acessar os recursos computacionais de um cluster, os usuários ainda querem mais.
Ambos Iterative e Interactiveos aplicativos exigem compartilhamento de dados mais rápido em trabalhos paralelos. O compartilhamento de dados é lento no MapReduce devido areplication, serialization, e disk IO. Com relação ao sistema de armazenamento, a maioria dos aplicativos Hadoop passam mais de 90% do tempo executando operações de leitura e gravação HDFS.
Operações iterativas no MapReduce
Reutilize resultados intermediários em vários cálculos em aplicativos de vários estágios. A ilustração a seguir explica como a estrutura atual funciona, ao fazer as operações iterativas no MapReduce. Isso incorre em sobrecargas substanciais devido à replicação de dados, E / S de disco e serialização, o que torna o sistema lento.
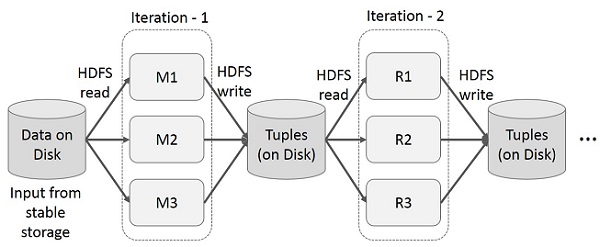
Operações interativas no MapReduce
O usuário executa consultas ad-hoc no mesmo subconjunto de dados. Cada consulta fará a E / S do disco no armazenamento estável, que pode dominar o tempo de execução do aplicativo.
A ilustração a seguir explica como a estrutura atual funciona ao fazer as consultas interativas no MapReduce.
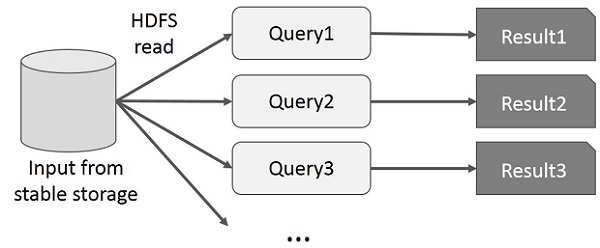
Compartilhamento de dados usando Spark RDD
O compartilhamento de dados é lento no MapReduce devido a replication, serialization, e disk IO. A maioria dos aplicativos Hadoop, eles passam mais de 90% do tempo fazendo operações de leitura e gravação HDFS.
Reconhecendo esse problema, os pesquisadores desenvolveram uma estrutura especializada chamada Apache Spark. A ideia principal da faísca éResiliente Distribuído Datasets (RDD); ele suporta computação de processamento na memória. Isso significa que ele armazena o estado da memória como um objeto entre os trabalhos e o objeto pode ser compartilhado entre esses trabalhos. O compartilhamento de dados na memória é 10 a 100 vezes mais rápido do que a rede e o disco.
Vamos agora tentar descobrir como as operações iterativas e interativas ocorrem no Spark RDD.
Operações iterativas no Spark RDD
A ilustração a seguir mostra as operações iterativas no Spark RDD. Ele armazenará resultados intermediários em uma memória distribuída em vez de armazenamento estável (disco) e tornará o sistema mais rápido.
Note - Se a memória distribuída (RAM) for suficiente para armazenar resultados intermediários (Estado do JOB), ele armazenará esses resultados no disco
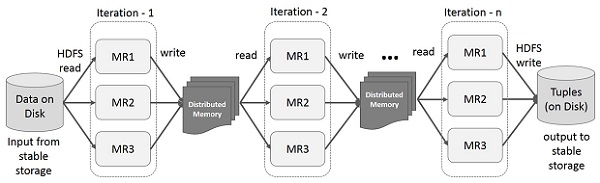
Operações interativas no Spark RDD
Esta ilustração mostra operações interativas no Spark RDD. Se consultas diferentes forem executadas no mesmo conjunto de dados repetidamente, esses dados específicos podem ser mantidos na memória para melhores tempos de execução.

Por padrão, cada RDD transformado pode ser recalculado cada vez que você executa uma ação nele. No entanto, você também podepersistum RDD na memória, caso em que o Spark manterá os elementos no cluster para um acesso muito mais rápido na próxima vez que você o consultar. Também há suporte para RDDs persistentes no disco ou replicados em vários nós.
Spark é o subprojeto do Hadoop. Portanto, é melhor instalar o Spark em um sistema baseado em Linux. As etapas a seguir mostram como instalar o Apache Spark.
Etapa 1: Verificar a instalação do Java
A instalação do Java é uma das coisas obrigatórias na instalação do Spark. Tente o seguinte comando para verificar a versão JAVA.
$java -versionSe o Java já estiver instalado em seu sistema, você verá a seguinte resposta -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Caso você não tenha o Java instalado em seu sistema, instale o Java antes de prosseguir para a próxima etapa.
Etapa 2: Verificando a instalação do Scala
Você deve usar a linguagem Scala para implementar o Spark. Portanto, vamos verificar a instalação do Scala usando o seguinte comando.
$scala -versionSe o Scala já estiver instalado em seu sistema, você verá a seguinte resposta -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLCaso você não tenha o Scala instalado em seu sistema, prossiga para a próxima etapa para a instalação do Scala.
Passo 3: Baixando Scala
Baixe a versão mais recente do Scala visitando o seguinte link: Baixe o Scala . Para este tutorial, estamos usando a versão scala-2.11.6. Após o download, você encontrará o arquivo Scala tar na pasta de download.
Passo 4: Instalando o Scala
Siga as etapas abaixo fornecidas para instalar o Scala.
Extraia o arquivo Scala tar
Digite o seguinte comando para extrair o arquivo tar Scala.
$ tar xvf scala-2.11.6.tgzMover arquivos de software Scala
Use os seguintes comandos para mover os arquivos do software Scala para o respectivo diretório (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitDefinir PATH para Scala
Use o seguinte comando para definir PATH para Scala.
$ export PATH = $PATH:/usr/local/scala/binVerificando a instalação do Scala
Após a instalação, é melhor verificar. Use o seguinte comando para verificar a instalação do Scala.
$scala -versionSe o Scala já estiver instalado em seu sistema, você verá a seguinte resposta -
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLEtapa 5: Baixar Apache Spark
Baixe a versão mais recente do Spark visitando o seguinte link Baixar Spark . Para este tutorial, estamos usandospark-1.3.1-bin-hadoop2.6versão. Depois de baixá-lo, você encontrará o arquivo Spark tar na pasta de download.
Etapa 6: Instalando o Spark
Siga as etapas abaixo para instalar o Spark.
Extraindo piche de faísca
O seguinte comando para extrair o arquivo spark tar.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzMovendo arquivos de software Spark
Os seguintes comandos para mover os arquivos do software Spark para o respectivo diretório (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitConfigurando o ambiente para Spark
Adicione a seguinte linha a ~/.bashrcArquivo. Isso significa adicionar o local onde o arquivo do software spark está localizado na variável PATH.
export PATH = $PATH:/usr/local/spark/binUse o seguinte comando para obter o arquivo ~ / .bashrc.
$ source ~/.bashrcEtapa 7: Verificando a instalação do Spark
Escreva o seguinte comando para abrir o shell do Spark.
$spark-shellSe o Spark for instalado com sucesso, você encontrará a seguinte saída.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>O Spark apresenta um módulo de programação para processamento de dados estruturados chamado Spark SQL. Ele fornece uma abstração de programação chamada DataFrame e pode atuar como mecanismo de consulta SQL distribuído.
Recursos do Spark SQL
A seguir estão os recursos do Spark SQL -
Integrated- Misture perfeitamente consultas SQL com programas Spark. Spark SQL permite consultar dados estruturados como um conjunto de dados distribuído (RDD) no Spark, com APIs integradas em Python, Scala e Java. Essa integração estreita facilita a execução de consultas SQL junto com algoritmos analíticos complexos.
Unified Data Access- Carregue e consulte dados de uma variedade de fontes. Os Schema-RDDs fornecem uma interface única para trabalhar com eficiência com dados estruturados, incluindo tabelas Apache Hive, arquivos em parquet e arquivos JSON.
Hive Compatibility- Execute consultas do Hive não modificadas em depósitos existentes. O Spark SQL reutiliza o front-end e o MetaStore do Hive, oferecendo compatibilidade total com os dados, consultas e UDFs existentes do Hive. Basta instalá-lo junto com o Hive.
Standard Connectivity- Conecte-se por meio de JDBC ou ODBC. Spark SQL inclui um modo de servidor com conectividade JDBC e ODBC padrão da indústria.
Scalability- Use o mesmo mecanismo para consultas interativas e longas. O Spark SQL aproveita as vantagens do modelo RDD para oferecer suporte à tolerância a falhas de consulta intermediária, permitindo que ele seja dimensionado para trabalhos grandes também. Não se preocupe em usar um mecanismo diferente para dados históricos.
Arquitetura do Spark SQL
A ilustração a seguir explica a arquitetura do Spark SQL -
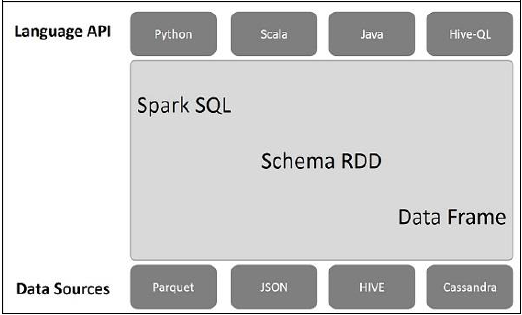
Essa arquitetura contém três camadas: API de linguagem, Esquema RDD e Fontes de dados.
Language API- O Spark é compatível com diferentes idiomas e Spark SQL. Também é suportado por essas linguagens - API (python, scala, java, HiveQL).
Schema RDD- Spark Core é projetado com estrutura de dados especial chamada RDD. Geralmente, o Spark SQL funciona em esquemas, tabelas e registros. Portanto, podemos usar o Schema RDD como tabela temporária. Podemos chamar esse Esquema RDD de Quadro de Dados.
Data Sources- Normalmente, a fonte de dados para spark-core é um arquivo de texto, arquivo Avro, etc. No entanto, as fontes de dados para Spark SQL são diferentes. Esses são o arquivo Parquet, o documento JSON, as tabelas HIVE e o banco de dados Cassandra.
Discutiremos mais sobre isso nos capítulos subsequentes.
Um DataFrame é uma coleção distribuída de dados, que é organizada em colunas nomeadas. Conceitualmente, é equivalente a tabelas relacionais com boas técnicas de otimização.
Um DataFrame pode ser construído a partir de uma matriz de fontes diferentes, como tabelas Hive, arquivos de dados estruturados, bancos de dados externos ou RDDs existentes. Esta API foi projetada para aplicativos modernos de Big Data e ciência de dados, inspirando-se emDataFrame in R Programming e Pandas in Python.
Recursos do DataFrame
Aqui está um conjunto de alguns recursos característicos do DataFrame -
Capacidade de processar os dados no tamanho de Kilobytes a Petabytes em um cluster de nó único para cluster grande.
Suporta diferentes formatos de dados (Avro, csv, elastic search e Cassandra) e sistemas de armazenamento (HDFS, tabelas HIVE, mysql, etc).
Otimização de última geração e geração de código por meio do otimizador Spark SQL Catalyst (estrutura de transformação de árvore).
Pode ser facilmente integrado com todas as ferramentas e estruturas de Big Data via Spark-Core.
Fornece API para programação Python, Java, Scala e R.
SQLContext
SQLContext é uma classe e é usado para inicializar as funcionalidades do Spark SQL. O objeto de classe SparkContext (sc) é necessário para inicializar o objeto de classe SQLContext.
O seguinte comando é usado para inicializar o SparkContext por meio do spark-shell.
$ spark-shellPor padrão, o objeto SparkContext é inicializado com o nome sc quando a faísca começa.
Use o seguinte comando para criar SQLContext.
scala> val sqlcontext = new org.apache.spark.sql.SQLContext(sc)Exemplo
Vamos considerar um exemplo de registros de funcionários em um arquivo JSON chamado employee.json. Use os comandos a seguir para criar um DataFrame (df) e ler um documento JSON chamadoemployee.json com o seguinte conteúdo.
employee.json - Coloque este arquivo no diretório onde o atual scala> o ponteiro está localizado.
{
{"id" : "1201", "name" : "satish", "age" : "25"}
{"id" : "1202", "name" : "krishna", "age" : "28"}
{"id" : "1203", "name" : "amith", "age" : "39"}
{"id" : "1204", "name" : "javed", "age" : "23"}
{"id" : "1205", "name" : "prudvi", "age" : "23"}
}Operações de DataFrame
DataFrame fornece uma linguagem específica de domínio para manipulação de dados estruturados. Aqui, incluímos alguns exemplos básicos de processamento de dados estruturados usando DataFrames.
Siga as etapas fornecidas abaixo para realizar operações DataFrame -
Leia o documento JSON
Primeiro, temos que ler o documento JSON. Com base nisso, gere um DataFrame denominado (dfs).
Use o seguinte comando para ler o documento JSON denominado employee.json. Os dados são mostrados como uma tabela com os campos - id, nome e idade.
scala> val dfs = sqlContext.read.json("employee.json")Output - Os nomes dos campos são retirados automaticamente de employee.json.
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, name: string]Mostrar os dados
Se você quiser ver os dados no DataFrame, use o seguinte comando.
scala> dfs.show()Output - Você pode ver os dados do funcionário em um formato tabular.
<console>:22, took 0.052610 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
| 23 | 1204 | javed |
| 23 | 1205 | prudvi |
+----+------+--------+Use o método printSchema
Se você quiser ver a Estrutura (Esquema) do DataFrame, use o seguinte comando.
scala> dfs.printSchema()Output
root
|-- age: string (nullable = true)
|-- id: string (nullable = true)
|-- name: string (nullable = true)Use Select Method
Use o seguinte comando para buscar name-coluna entre três colunas do DataFrame.
scala> dfs.select("name").show()Output - Você pode ver os valores do name coluna.
<console>:22, took 0.044023 s
+--------+
| name |
+--------+
| satish |
| krishna|
| amith |
| javed |
| prudvi |
+--------+Usar filtro de idade
Use o seguinte comando para localizar os funcionários com idade superior a 23 (idade> 23).
scala> dfs.filter(dfs("age") > 23).show()Output
<console>:22, took 0.078670 s
+----+------+--------+
|age | id | name |
+----+------+--------+
| 25 | 1201 | satish |
| 28 | 1202 | krishna|
| 39 | 1203 | amith |
+----+------+--------+Use o método groupBy
Use o seguinte comando para contar o número de funcionários que têm a mesma idade.
scala> dfs.groupBy("age").count().show()Output - dois funcionários têm 23 anos.
<console>:22, took 5.196091 s
+----+-----+
|age |count|
+----+-----+
| 23 | 2 |
| 25 | 1 |
| 28 | 1 |
| 39 | 1 |
+----+-----+Execução de consultas SQL programaticamente
Um SQLContext permite que os aplicativos executem consultas SQL programaticamente enquanto executam funções SQL e retorna o resultado como um DataFrame.
Geralmente, em segundo plano, SparkSQL oferece suporte a dois métodos diferentes para converter RDDs existentes em DataFrames -
| Sr. Não | Métodos e Descrição |
|---|---|
| 1 | Inferindo o esquema usando reflexão Este método usa reflexão para gerar o esquema de um RDD que contém tipos específicos de objetos. |
| 2 | Especificando programaticamente o esquema O segundo método para criar DataFrame é por meio de uma interface programática que permite construir um esquema e aplicá-lo a um RDD existente. |
Uma interface DataFrame permite que diferentes DataSources funcionem no Spark SQL. É uma mesa temporária e pode ser operada como um RDD normal. Registrar um DataFrame como uma tabela permite que você execute consultas SQL sobre seus dados.
Neste capítulo, descreveremos os métodos gerais para carregar e salvar dados usando diferentes fontes de dados Spark. Depois disso, discutiremos em detalhes as opções específicas que estão disponíveis para as fontes de dados integradas.
Existem diferentes tipos de fontes de dados disponíveis no SparkSQL, alguns dos quais estão listados abaixo -
| Sr. Não | Fontes de dados |
|---|---|
| 1 | Conjuntos de dados JSON O Spark SQL pode capturar automaticamente o esquema de um conjunto de dados JSON e carregá-lo como um DataFrame. |
| 2 | Hive Tables O Hive vem junto com a biblioteca Spark como HiveContext, que herda de SQLContext. |
| 3 | Arquivos Parquet Parquet é um formato colunar, suportado por muitos sistemas de processamento de dados. |