Sqoop - Introdução
O sistema tradicional de gerenciamento de aplicativos, ou seja, a interação de aplicativos com banco de dados relacional utilizando RDBMS, é uma das fontes geradoras de Big Data. Tal Big Data, gerado por RDBMS, é armazenado no RelationalDatabase Servers na estrutura do banco de dados relacional.
Quando armazenamentos de Big Data e analisadores como MapReduce, Hive, HBase, Cassandra, Pig, etc. do ecossistema Hadoop entraram em cena, eles precisaram de uma ferramenta para interagir com os servidores de banco de dados relacional para importar e exportar o Big Data que residia neles. Aqui, o Sqoop ocupa um lugar no ecossistema Hadoop para fornecer interação viável entre o servidor de banco de dados relacional e o HDFS do Hadoop.
Sqoop - “SQL para Hadoop e Hadoop para SQL”
Sqoop é uma ferramenta projetada para transferir dados entre o Hadoop e os servidores de banco de dados relacional. Ele é usado para importar dados de bancos de dados relacionais como MySQL, Oracle para Hadoop HDFS e exportar do sistema de arquivos Hadoop para bancos de dados relacionais. É fornecido pela Apache Software Foundation.
Como funciona o Sqoop?
A imagem a seguir descreve o fluxo de trabalho do Sqoop.
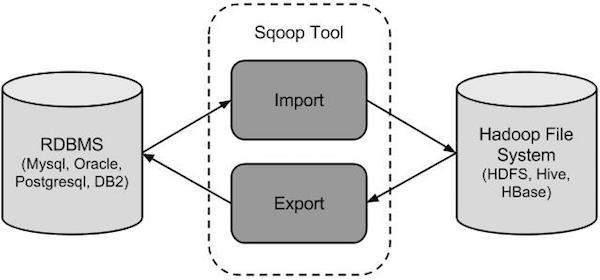
Importação Sqoop
A ferramenta de importação importa tabelas individuais de RDBMS para HDFS. Cada linha em uma tabela é tratada como um registro no HDFS. Todos os registros são armazenados como dados de texto em arquivos de texto ou como dados binários em arquivos Avro e Sequence.
Exportação Sqoop
A ferramenta de exportação exporta um conjunto de arquivos do HDFS de volta para um RDBMS. Os arquivos fornecidos como entrada para o Sqoop contêm registros, que são chamados de linhas na tabela. Eles são lidos e analisados em um conjunto de registros e delimitados com um delimitador especificado pelo usuário.