VSAM - Guia Rápido
O Virtual Storage Access Method (VSAM) é um método de acesso de alto desempenho e organização de conjunto de dados, que organiza e mantém os dados por meio de uma estrutura de catálogo. Ele utiliza o conceito de armazenamento virtual e pode proteger conjuntos de dados em vários níveis, fornecendo senhas. VSAM pode ser usado em programas COBOL como arquivos sequenciais físicos. VSAM são os conjuntos de dados lógicos para armazenar registros. Os arquivos podem ser lidos sequencialmente e aleatoriamente no VSAM. É uma maneira aprimorada de armazenar dados que supera algumas das limitações dos sistemas de arquivos convencionais, como arquivos sequenciais.
Características do VSAM
A seguir estão as características do VSAM -
VSAM protege os dados contra acesso não autorizado usando senhas.
VSAM fornece acesso rápido a conjuntos de dados.
VSAM tem opções para otimizar o desempenho.
O VSAM permite o compartilhamento de conjuntos de dados em ambientes online e em lote.
VSAM são mais estruturados e organizados no armazenamento de dados.
O espaço livre é reutilizado automaticamente em arquivos VSAM.
Limitações do VSAM
A única limitação do VSAM é que ele não pode ser armazenado no volume TAPE. Ele sempre é armazenado no espaço DASD. São necessários vários cilindros para armazenar os dados, o que não é econômico.
VSAM consiste nos seguintes componentes -
- Grupo VSAM
- Área de Controle
- Intervalo de controle
Grupo VSAM
VSAM são conjuntos de dados lógicos para armazenar registros e são conhecidos como clusters. Um cluster é uma associação de índice, conjunto de sequência e partes de dados do conjunto de dados. O espaço ocupado por um cluster VSAM é dividido em áreas contíguas chamadas de Intervalos de Controle. Discutiremos sobre os intervalos de controle posteriormente neste módulo.
Existem dois componentes principais em um cluster VSAM -
Index Componentcontém a parte do índice. Os registros do índice estão presentes no componente Índice. Usando o componente de índice, o VSAM pode recuperar registros do componente de dados.
Data Componentcontém a parte de dados. Os registros de dados reais estão presentes no componente de dados.
Intervalo de controle
Intervalos de controle (CI) em VSAM são equivalentes a blocos para conjuntos de dados não VSAM. Em métodos não VSAM, a unidade de dados é definida pelo bloco. VSAM trabalha com área de dados lógicos que é conhecida como Intervalos de Controle.
Intervalos de controle são a menor unidade de transferência entre um disco e o sistema operacional. Sempre que um registro é recuperado diretamente do armazenamento, todo o CI que contém o registro é lido no buffer de entrada-saída VSAM. O registro desejado é então transferido para a área de trabalho do buffer VSAM.
O intervalo de controle consiste em -
- Registros Lógicos
- Campos de informação de controle
- Espaço livre
Quando um conjunto de dados VSAM é carregado, intervalos de controle são criados. O tamanho do intervalo de controle padrão é de 4 K bytes e pode estender até 32 K bytes.
Análise do intervalo de controle
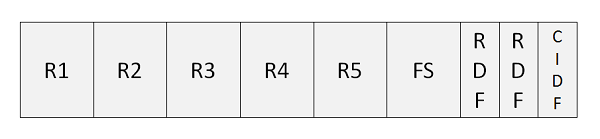
A seguir está a descrição dos termos usados no programa acima -
R1..R5 - Registros que são armazenados no intervalo de controle.
FS - FS é o espaço livre, que pode ser usado para expandir ainda mais o conjunto de dados.
RDF- RDF é conhecido como campos de definição de registro. RDF tem 3 bytes de comprimento. Descreve o comprimento dos registros e informa quantos registros adjacentes têm o mesmo comprimento.
CIDF- CIDF é conhecido como campos de definição de intervalo de controle. O CIDF tem 4 bytes e contém informações sobre o intervalo de controle.
Área de Controle
Uma Área de Controle (CA) é formada pela reunião de dois ou mais Intervalos de Controle. Um conjunto de dados VSAM é composto por uma ou mais áreas de controle. O tamanho do VSAM é sempre um múltiplo de sua área de controle. Os arquivos VSAM são estendidos em unidades de áreas de controle.
A seguir está o exemplo de Área de Controle -

O cluster VSAM é definido em JCL. JCL usaIDCAMSutilitário para criar um cluster. IDCAMS é um utilitário, desenvolvido pela IBM, para serviços de métodos de acesso. É usado principalmente para definir conjuntos de dados VSAM.
Definindo um Cluster
A sintaxe a seguir mostra os principais parâmetros agrupados em Define Cluster, Data e Index.
.DEFINE CLUSTER (NAME(vsam-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
[INDEXED / NONINDEXED / NUMBERED / LINEAR] -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[KEYS(length offset)] -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE] ) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index)) -
CATALOG(catalog-name[/password]))Os parâmetros no nível CLUSTER se aplicam a todo o cluster. Os parâmetros no nível DATA ou INDEX se aplicam apenas aos dados ou ao componente de índice.
Discutiremos cada parâmetro em detalhes na tabela a seguir -
| Sr. Não | Parâmetros com Descrição |
|---|---|
| 1 | DEFINE CLUSTER O comando Definir Cluster é usado para definir um cluster e especificar atributos de parâmetro para o cluster e seus componentes. |
| 2 | NAME NAME especifica o nome do arquivo VSAM para o qual estamos definindo o cluster. |
| 3 | BLOCKS Blocos especifica o número de blocos atribuídos ao cluster. |
| 4 | VOLUMES Volumes especifica um ou mais volumes que conterão o cluster ou componente. |
| 5 | INDEXED / NONINDEXED / NUMBERED / LINEAR Este parâmetro pode assumir três valores INDEXED, NONINDEXED ou NUMBERED dependendo do tipo de conjunto de dados que estamos criando. Para arquivos sequenciados por chave (KSDS), a opção INDEXED é usada. Para arquivos de seqüência de entrada (ESDS), a opção NONINDEXED é usada. Para arquivos de registro relativo (RRDS), a opção NUMBERED é necessária. Para arquivos Linear (LDS), a opção LINEAR é necessária. O valor padrão deste parâmetro é INDEXED. Discutiremos mais sobre KSDS, ESDS, RRDS e LDS nos próximos módulos. |
| 6 | RECSZ O parâmetro Tamanho do registro tem dois valores que são o tamanho médio e máximo do registro. A Média especifica o comprimento médio dos registros lógicos no arquivo e o Máximo denota o comprimento dos registros. |
| 7 | FREESPACE Espaço livre especifica a porcentagem de espaço livre a ser reservado para os intervalos de controle (CI) e áreas de controle (CA) do componente de dados. O valor padrão deste parâmetro é a porcentagem zero. |
| 8 | CISZ CISZ é conhecido como tamanho do intervalo de controle. Ele especifica o tamanho dos intervalos de controle. |
| 9 | KEYS O parâmetro de chaves é definido apenas em arquivos sequenciados por chave (KSDS). Ele especifica o comprimento e deslocamento da chave primária da primeira coluna. A faixa de valor deste parâmetro é de 1 a 255 bytes. |
| 10 | READPW O valor no parâmetro READPW especifica a senha do nível de leitura. |
| 11 | FOR/TO O valor deste parâmetro especifica a quantidade de tempo em termos de data e dias para reter o arquivo. O valor padrão para este parâmetro é zero dias. |
| 12 | UPDATEPW O valor no parâmetro UPDATEPW especifica a senha do nível de atualização. |
| 13 | REUSE / NOREUSE O parâmetro REUSE permite que os clusters sejam definidos, os quais podem ser redefinidos para o status vazio sem excluí-los e redefini-los. |
| 14 | DATA - NAME A parte DATA do cluster contém o nome do conjunto de dados que contém os dados reais do arquivo. |
| 15 | INDEX-NAME A parte INDEX do cluster contém a chave primária e o ponteiro de memória para o registro correspondente na parte de dados. É definido quando um cluster Key Sequenced é usado. |
| 16 | CATALOG O parâmetro Catálogo denota o catálogo sob o qual o arquivo será definido. Discutiremos sobre o catálogo separadamente nos próximos módulos. |
Exemplo
A seguir está um exemplo básico para mostrar como definir um cluster em JCL -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
KEYS(5 0) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o arquivo VSAM MY.VSAM.KSDSFILE.
Excluindo um Cluster
Para excluir um arquivo VSAM, o cluster VSAM precisa ser excluído usando o utilitário IDCAMS. O comando DELETE remove a entrada do cluster VSAM do catálogo e, opcionalmente, remove o arquivo, liberando assim o espaço ocupado pelo objeto. Se o conjunto de dados VSAM não tiver expirado, ele não será excluído. Para excluir esses tipos de conjuntos de dados, use a opção PURGE.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]A sintaxe acima mostra os parâmetros que podemos usar com a instrução Delete. Discutiremos cada um deles em detalhes na tabela a seguir -
| Sr. Não | Parâmetros com Descrição |
|---|---|
| 1 | ERASE / NOERASE A opção ERASE é especificada para substituir o atributo ERASE especificado para o objeto no catálogo. A opção NOERASE é usada por padrão. |
| 2 | FORCE / NOFORCE A opção FORCE é especificada para excluir SPACE e USERCATALOG mesmo se eles não estiverem vazios. A opção NOFORCE é usada por padrão. |
| 3 | PURGE / NOPURGE A opção PURGE é usada para excluir o conjunto de dados VSAM se o conjunto de dados não tiver expirado. A opção NOPURGE é usada por padrão. |
| 4 | SCRATCH / NOSCRATCH A opção SCRATCH é especificada para remover a entrada associada para o objeto do Índice de Volume. É usado principalmente para conjuntos de dados não vsam, como GDGs. A opção NOSCRATCH é usada por padrão. |
Exemplo
A seguir está um exemplo básico para mostrar como excluir um cluster em JCL -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
PURGE
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e excluirá o arquivo VSAM MY.VSAM.KSDSFILE.
ESDS é conhecido como Entry Sequenced Data Set. Um conjunto de dados sequencial de entrada se comporta como uma organização de arquivo sequencial com mais alguns recursos incluídos. Podemos acessar os registros diretamente e, para fins de segurança, também podemos usar senhas. Devemos codificarNONINDEXEDdentro do comando DEFINE CLUSTER para conjuntos de dados ESDS. A seguir estão os principais recursos do ESDS -
Os registros no cluster ESDS são armazenados na ordem em que foram inseridos no conjunto de dados.
Os registros são referenciados por endereço físico conhecido como Relative Byte Address (RBA). Suponha que se em um conjunto de dados ESDS, temos 80 registros de bytes, o RBA do primeiro registro será 0, o RBA do segundo registro será 80, para o terceiro registro será 160 e assim por diante.
Os registros podem ser acessados sequencialmente por RBA, que é conhecido como addressed access.
Os registros são mantidos na ordem em que foram inseridos. Novos registros são inseridos no final.
A exclusão de registros não é possível no conjunto de dados ESDS. Mas eles podem ser marcados como inativos.
Os registros no conjunto de dados ESDS podem ter comprimento fixo ou comprimento variável.
ESDS não é indexado. As chaves não estão presentes no conjunto de dados ESDS, portanto, pode conter registros duplicados.
O ESDS pode ser usado em programas COBOL como qualquer outro arquivo. Vamos especificar o nome do arquivo em JCL e podemos usar o arquivo ESDS para processamento dentro do programa. No programa COBOL, especifique a organização do arquivo comoSequential e modo de acesso como Sequential com conjunto de dados ESDS.
Definindo cluster ESDS
A sintaxe a seguir mostra quais parâmetros podemos usar ao criar o cluster ESDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
DEFINE CLUSTER (NAME(esds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NONINDEXED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(esds-file-name.data))Exemplo
O exemplo a seguir mostra como criar um cluster ESDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.ESDSFILE) -
NONINDEXED -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.ESDSFILE.DATA))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o arquivo VSAM MY.VSAM.ESDSFILE.
Excluindo Cluster ESDS
O cluster ESDS é excluído usando o utilitário IDCAMS. O comando DELETE remove a entrada do cluster VSAM do catálogo e, opcionalmente, remove o arquivo, liberando assim o espaço ocupado pelo objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]A sintaxe acima mostra quais parâmetros podemos usar ao excluir o cluster ESDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
Exemplo
O exemplo a seguir mostra como excluir um cluster ESDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.ESDSFILE CLUSTER
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e excluirá MY.VSAM.ESDSFILE VSAM Cluster.
KSDS é conhecido como Key Sequenced Data Set. Um conjunto de dados sequenciados por chave (KSDS) é mais complexo do que ESDS e RRDS, mas é mais útil e versátil. Devemos codificarINDEXEDdentro do comando DEFINE CLUSTER para conjuntos de dados KSDS. O cluster KSDS consiste nos dois componentes a seguir -
Index- O componente de índice do cluster KSDS contém a lista de valores-chave para os registros no cluster com ponteiros para os registros correspondentes no componente de dados. O componente de índice se refere ao endereço físico de um registro KSDS. Isso relaciona a chave de cada registro à localização relativa do registro no conjunto de dados. Quando um registro é adicionado ou excluído, este índice é atualizado de acordo.
Data- O componente de dados do cluster KSDS contém os dados reais. Cada registro no componente de dados de um cluster KSDS contém um campo-chave com o mesmo número de caracteres e ocorre na mesma posição relativa em cada registro.
A seguir estão os principais recursos do KSDS -
Os registros no conjunto de dados KSDS são sempre mantidos classificados por campo-chave. Os registros são armazenados em ordem crescente, ordenando a seqüência por chave.
Os registros podem ser acessados sequencialmente e o acesso direto também é possível.
Os registros são identificados por meio de uma chave. A chave de cada registro é um campo em uma posição predefinida dentro do registro. Cada chave deve ser exclusiva no conjunto de dados KSDS. Portanto, a duplicação de registros não é possível.
Quando novos registros são inseridos, a ordem lógica dos registros depende da seqüência de agrupamento do campo-chave.
Os registros no conjunto de dados KSDS podem ter comprimento fixo ou comprimento variável.
KSDS pode ser usado em COBOLprogramas como qualquer outro arquivo. Vamos especificar o nome do arquivo em JCL e podemos usar o arquivo KSDS para processamento dentro do programa. No programa COBOL, especifique a organização do arquivo comoIndexed e você pode usar qualquer modo de acesso (Sequential, Random or Dynamic) com conjunto de dados KSDS.
Estrutura do arquivo KSDS
Para pesquisar um determinado registro, fornecemos um valor-chave exclusivo. O valor da chave é pesquisado no componente de índice. Assim que a chave é encontrada, o endereço de memória correspondente que se refere ao componente de dados é recuperado. Do endereço da memória, podemos buscar os dados reais que estão armazenados no componente de dados. O exemplo a seguir mostra a estrutura básica do índice e do arquivo de dados -
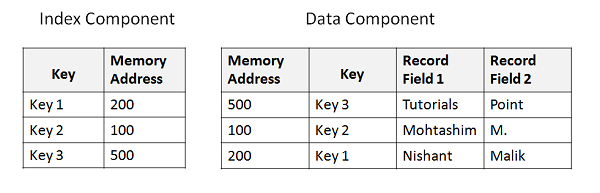
Definindo o cluster KSDS
A sintaxe a seguir mostra quais parâmetros podemos usar ao criar o cluster KSDS.
A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
DEFINE CLUSTER (NAME(ksds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
INDEXED -
KEYS(length offset) -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(ksds-file-name.data)) -
INDEX -
(NAME(ksds-file-name.index))Exemplo
O exemplo a seguir mostra como criar um cluster KSDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.KSDSFILE) -
INDEXED -
KEYS(6 1) -
RECSZ(80 80) -
TRACKS(1,1) -
CISZ(4096) -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.KSDSFILE.DATA)) -
INDEX (NAME(MY.VSAM.KSDSFILE.INDEX)) -
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o arquivo VSAM MY.VSAM.KSDSFILE.
Excluindo Cluster KSDS
O cluster KSDS é excluído usando o utilitário IDCAMS. O comando DELETE remove a entrada do cluster VSAM do catálogo e, opcionalmente, remove o arquivo, liberando assim o espaço ocupado pelo objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]A sintaxe acima mostra quais parâmetros podemos usar ao excluir o cluster KSDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
Exemplo
O exemplo a seguir mostra como excluir um cluster KSDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.KSDSFILE CLUSTER
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e excluirá MY.VSAM.KSDSFILE VSAM Cluster.
RRDS é conhecido como Conjunto de dados de registro relativo. O cluster RRDS é semelhante a um cluster ESDS. A única diferença é que os registros RRDS são acessados porRelative Record Number (RRN), devemos codificar NUMBEREDdentro do comando DEFINE CLUSTER. A seguir estão os principais recursos do RRDS -
Um conjunto de dados de registro Relativo tem registros que são identificados pelo Relative Record Number (RRN), que é o número de sequência relativo ao primeiro registro.
O RRDS permite o acesso a registros por número, como registro 1, registro 2 e assim por diante. Isso fornece acesso aleatório e assume que o programa aplicativo tem uma maneira de obter os números de registro desejados.
Os registros em um conjunto de dados RRDS podem ser acessados sequencialmente, em ordem de número de registro relativo ou diretamente, fornecendo o número de registro relativo do registro desejado.
Os registros em um conjunto de dados RRDS são armazenados em slots de comprimento fixo. Cada registro é referenciado pelo número de seu slot, o número pode variar de 1 ao número máximo de registros no conjunto de dados.
Os registros em um RRDS podem ser gravados inserindo um novo registro em um slot vazio.
Os registros podem ser excluídos de um cluster RRDS, deixando um slot vazio.
Aplicativos que usam registros de comprimento fixo ou um número de registro com significado contextual que podem usar conjuntos de dados RRDS.
RRDS pode ser usado em COBOLprogramas como qualquer outro arquivo. Vamos especificar o nome do arquivo em JCL e podemos usar o arquivo KSDS para processamento dentro do programa. No programa COBOL, especifique a organização do arquivo comoRELATIVE e você pode usar qualquer modo de acesso (Sequential, Random or Dynamic) com conjunto de dados RRDS.
Estrutura do arquivo RRDS
O espaço é dividido em slots de comprimento fixo na estrutura de arquivos RRDS. Um slot pode estar completamente vazio ou cheio. Assim, novos registros podem ser adicionados aos slots vazios e os registros existentes podem ser excluídos dos slots que estão preenchidos. Podemos acessar qualquer registro diretamente fornecendo o Número do Registro Relativo. O exemplo a seguir mostra a estrutura básica do arquivo de dados -
Componente de Dados
| Número de registro relativo | Campo de registro 1 | Campo de registro 2 |
|---|---|---|
| 1 | Tutorial | Ponto |
| 2 | Mohtashim | M. |
| 3 | Nishant | Malik |
Definindo o cluster RRDS
A sintaxe a seguir mostra quais parâmetros podemos usar ao criar o cluster RRDS.
A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
DEFINE CLUSTER (NAME(rrds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
NUMBERED -
RECSZ(average maximum) -
[FREESPACE(CI-Percentage,CA-Percentage)] -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(rrds-file-name.data))Exemplo
O exemplo a seguir mostra como criar um cluster RRDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.RRDSFILE) -
NUMBERED -
RECSZ(80 80) -
TRACKS(1,1) -
REUSE -
FREESPACE(3 3) ) -
DATA (NAME(MY.VSAM.RRDSFILE.DATA))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o arquivo VSAM MY.VSAM.RRDSFILE.
Excluindo o cluster RRDS
O cluster RRDS é excluído usando o utilitário IDCAMS. O comando DELETE remove a entrada do cluster VSAM do catálogo e, opcionalmente, remove o arquivo, liberando assim o espaço ocupado pelo objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]A sintaxe acima mostra quais parâmetros podemos usar ao excluir o cluster RRDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
Exemplo
O exemplo a seguir mostra como excluir um cluster RRDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.RRDSFILE CLUSTER
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e excluirá MY.VSAM.RRDSFILE VSAM Cluster.
LDS é conhecido como Conjunto de Dados Linear. Conjunto de dados linear é a única forma de conjunto de dados de fluxo de bytes que é usado em arquivos de sistema operacional tradicionais. Conjuntos de dados lineares raramente são usados. A seguir estão os principais recursos do LDS -
Os conjuntos de dados lineares não contêm RDFs e CIDFs, pois não possuem nenhuma informação de controle embutida em seu CI.
Dados que podem ser acessados como strings endereçáveis por byte no armazenamento virtual em conjuntos de dados Linear.
Os conjuntos de dados lineares têm um tamanho de intervalo de controle de 4KBytes.
LDS é um tipo de arquivo não vsam com alguns recursos VSAM, como o uso de IDCAMS e informações específicas do VSAM no catálogo.
O DB2 é atualmente o maior usuário de Conjuntos de dados lineares.
IDCAMS é usado para definir um LDS, mas é acessado usando uma macro Data-In-Virtual (DIV).
O conjunto de dados linear não possui conceitos de registros. Todos os bytes LDS são bytes de dados.
Definindo o cluster SUD
A sintaxe a seguir mostra quais parâmetros podemos usar ao criar um cluster LDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
DEFINE CLUSTER (NAME(lds-file-name) -
BLOCKS(number) -
VOLUMES(volume-serial) -
LINEAR -
CISZ(number) -
[READPW(password)] -
[FOR(days)|TO(date)] -
[UPDATEPW(password)] -
[REUSE / NOREUSE]) -
DATA -
(NAME(lds-file-name.data))Exemplo
O exemplo a seguir mostra como criar um cluster LDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE CLUSTER (NAME(MY.VSAM.LDSFILE) -
LINEAR -
TRACKS(1,1) -
CISZ(4096) ) -
DATA (NAME(MY.VSAM.LDSFILE.DATA))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o arquivo MY.VSAM.LDSFILE VSAM.
Excluindo Cluster SUD
O cluster LDS é excluído usando o utilitário IDCAMS. O comando DELETE remove a entrada do cluster VSAM do catálogo e, opcionalmente, remove o arquivo, liberando assim o espaço ocupado pelo objeto.
DELETE data-set-name CLUSTER
[ERASE / NOERASE]
[FORCE / NOFORCE]
[PURGE / NOPURGE]
[SCRATCH / NOSCRATCH]A sintaxe acima mostra quais parâmetros podemos usar ao excluir o cluster LDS. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
Exemplo
O exemplo a seguir mostra como excluir um cluster LDS em JCL usando o utilitário IDCAMS -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEPNAME EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DELETE MY.VSAM.LDSFILE CLUSTER
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e excluirá MY.VSAM.LDSFILE VSAM Cluster.
Os comandos VSAM são usados para executar certas operações em conjuntos de dados VSAM. A seguir estão os comandos VSAM mais úteis -
- Alter
- Repro
- Listcat
- Examine
- Verify
Alterar
O comando ALTER é usado para modificar os atributos do arquivo VSAM. Podemos alterar os atributos do arquivo VSAM que mencionamos na definição do cluster VSAM. A seguir está a sintaxe para alterar os atributos -
ALTER file-cluster-name [password]
[ADDVOLUMES(volume-serial)]
[BUFFERSPACE(size)]
[EMPTY / NOEMPTY]
[ERASE / NOERASE]
[FREESPACE(CI-percentage CA-percentage)]
[KEYS(length offset)]
[NEWNAME(new-name)]
[RECORDSIZE(average maximum)]
[REMOVEVOLUMES(volume-serial)]
[SCRATCH / NOSCRATCH]
[TO(date) / FOR(days)]
[UPGRADE / NOUPGRADE]
[CATALOG(catalog-name [password]]A sintaxe acima mostra quais parâmetros podemos alterar em um cluster VSAM existente. A descrição do parâmetro permanece a mesma mencionada no módulo VSAM - Cluster.
Exemplo
O exemplo a seguir mostra como usar o comando ALTER para aumentar o espaço livre, para adicionar mais volumes e para alterar chaves -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
ALTER MY.VSAM.KSDSFILE
[ADDVOLUMES(2)]
[FREESPACE(6 6)]
[KEYS(10 2)]
/*Se você for executar o JCL acima no servidor Mainframes. Deve executar com MAXCC = 0 e irá alterar o Espaço Livre, Volumes e Chaves.
Repro
O comando REPRO é usado para carregar dados no conjunto de dados VSAM. Ele também é usado para copiar dados de um conjunto de dados VSAM para outro. Podemos usar este comando para copiar dados do arquivo sequencial para o arquivo VSAM. O utilitário IDCAMS usa o comando REPRO para carregar os conjuntos de dados.
REPRO INFILE(in-ddname)
OUTFILE(out-ddname)Na sintaxe acima, o in-ddname é o nome DD para o Conjunto de dados de entrada que está tendo registros. O out-ddname é o nome DD para o conjunto de dados de saída, onde os registros dos conjuntos de dados de entrada serão copiados.
Exemplo
O exemplo a seguir mostra como copiar registros de um conjunto de dados para outro conjunto de dados VSAM -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//IN DD DSN = MY.VSAM.KSDSFILE,DISP = SHR
//OUT DD DSN = MY.VSAM1.KSDSFILE,DISP = SHR
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
REPRO INFILE(IN)
OUTFILE(OUT)
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve executar com MAXCC = 0 e copiará todos os registros do arquivo MY.VSAM.KSDSFILE para o arquivo MY.VSAM1.KSDSFILE VSAM.
Listcat
O comando LISTCAT é usado para obter os detalhes do catálogo de um conjunto de dados VSAM. O comando Listcat fornece as seguintes informações sobre conjuntos de dados VSAM -
- Informação SMS
- Informação RLS
- Informação de Volume
- Informação da esfera
- Informação de Alocação
- Atributos do conjunto de dados
LISTCAT ENTRY(vsam-file-name) ALLNa sintaxe acima, vsam-file-name é o nome do conjunto de dados VSAM para o qual precisamos de todas as informações. A palavra-chave ALL é especificada para obter todos os detalhes do catálogo.
Exemplo
O exemplo a seguir mostra como buscar todos os detalhes usando o comando Listcat para um conjunto de dados VSAM -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
LISTCAT ENTRY(MY.VSAM.KSDSFILE)
ALL
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e mostrará todos os detalhes do catálogo sobre o conjunto de dados MY.VSAM.KSDSFILE.
Examinar
O comando Examine é usado para verificar a integridade estrutural de um cluster de conjunto de dados sequenciado por chave. Ele verifica o índice e os componentes de dados e, se algum problema for encontrado, as mensagens de erro serão enviadas para o spool. Você pode verificar qualquer uma das mensagens IDCxxxxx.
EXAMINE NAME(vsam-ksds-name) -
INDEXTEST DATATEST -
ERRORLIMIT(50)Na sintaxe acima, vsam-ksds-name é o nome do conjunto de dados VSAM para o qual precisamos examinar o índice e a parte de dados do cluster VSAM.
Exemplo
O exemplo a seguir mostra como verificar se o índice e a parte dos dados do conjunto de dados KSDS estão sincronizados ou não -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
EXAMINE NAME(MY.VSAM.KSDSFILE) -
INDEXTEST DATATEST -
ERRORLIMIT(50)
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e mostrará todos os problemas com o conjunto de dados VSAM em uma das mensagens IDCxxxxx no spool.
Verificar
O comando Verify é usado para verificar e corrigir arquivos VSAM que não foram fechados corretamente após um erro. O comando adiciona registros de fim de dados corretos ao arquivo.
VERIFY DS(vsam-file-name)Na sintaxe acima, vsam-file-name é o nome do conjunto de dados VSAM para o qual precisamos verificar os erros.
Exemplo
O exemplo a seguir mostra como verificar e corrigir erros no conjunto de dados VSAM -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
VERIFY DS(MY.VSAM.KSDSFILE)
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e corrigirá os erros no conjunto de dados VSAM.
O índice alternativo é o índice adicional criado para conjuntos de dados KSDS / ESDS, além de seu índice primário. Um índice alternativo fornece acesso aos registros usando mais de uma chave. A chave do índice alternativo pode ser uma chave não exclusiva, pode ter duplicatas.
Criação de Índice Alternativo
As etapas a seguir são usadas para criar um índice alternativo -
- Definir Índice Alternativo
- Definir caminho
- Índice de construção
Definir Índice Alternativo
Índice alternativo é definido usando DEFINE AIX comando.
DEFINE AIX -
(NAME(alternate-index-name) -
RELATE(vsam-file-name) -
CISZ(number) -
FREESPACE(CI-Percentage,CA-Percentage) -
KEYS(length offset) -
NONUNIQUEKEY / UNIQUEKEY -
UPGRADE / NOUPGRADE -
RECORDSIZE(average maximum)) -
DATA -
(NAME(vsam-file-name.data)) -
INDEX -
(NAME(vsam-file-name.index))A sintaxe acima mostra os parâmetros que são usados durante a definição do Índice Alternativo. Já discutimos alguns parâmetros no Módulo Define Cluster e alguns dos novos parâmetros são usados na definição do Índice Alternativo, que discutiremos aqui -
| Sr. Não | Parâmetros com Descrição |
|---|---|
| 1 | DEFINE AIX O comando Definir AIX é usado para definir o Índice Alternativo e especificar atributos de parâmetro para seus componentes. |
| 2 | NAME NAME especifica o nome do Índice Alternativo. |
| 3 | RELATE RELATE especifica o nome do cluster VSAM para o qual o índice alternativo é criado. |
| 4 | NONUNIQUEKEY / UNIQUEKEY UNIQUEKEY especifica que o índice alternativo é exclusivo e NONUNIQUEKEY especifica que podem existir duplicatas. |
| 5 | UPGRADE / NOUPGRADE UPGRADE especifica que o índice alternativo deve ser modificado se o cluster base for modificado e NOUPGRADE especifica que os índices alternativos devem ser deixados sozinhos se o cluster base for modificado. |
Exemplo
A seguir está um exemplo básico para mostrar como definir um índice alternativo em JCL -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE AIX (NAME(MY.VSAM.KSDSAIX) -
RELATE(MY.VSAM.KSDSFILE) -
CISZ(4096) -
FREESPACE(20,20) -
KEYS(20,7) -
NONUNIQUEKEY -
UPGRADE -
RECORDSIZE(80,80)) -
DATA(NAME(MY.VSAM.KSDSAIX.DATA)) -
INDEX(NAME(MY.VSAM.KSDSAIX.INDEX))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará MY.VSAM.KSDSAIX Índice alternativo.
Definir caminho
Definir caminho é usado para relacionar o índice alternativo ao cluster base. Ao definir o caminho, especificamos o nome do caminho e o índice alternativo ao qual esse caminho está relacionado.
DEFINE PATH -
NAME(alternate-index-path-name) -
PATHENTRY(alternate-index-name))A sintaxe acima possui dois parâmetros. NAME é usado para especificar o nome do caminho do índice alternativo e PATHENTRY é usado para especificar o nome do índice alternativo.
Exemplo
A seguir está um exemplo básico para definir o caminho em JCL -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
DEFINE PATH -
NAME(MY.VSAM.KSDSAIX.PATH) -
PATHENTRY(MY.VSAM.KSDSAIX))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará um caminho entre o Índice Alternativo para o cluster base.
Índice de construção
O comando BLDINDEX é usado para construir o índice alternativo. BLDINDEX lê todos os registros no conjunto de dados indexados VSAM (ou cluster base) e extrai os dados necessários para construir o índice alternativo.
BLDINDEX -
INDATASET(vsam-cluster-name) -
OUTDATASET(alternate-index-name))A sintaxe acima possui dois parâmetros. INDATASET é usado para especificar o nome do cluster VSAM e OUTDATASET é usado para especificar o nome do índice alternativo.
Exemplo
A seguir está um exemplo básico para construir índice em JCL -
//SAMPLE JOB(TESTJCL,XXXXXX),CLASS = A,MSGCLASS = C
//STEP1 EXEC PGM = IDCAMS
//SYSPRINT DD SYSOUT = *
//SYSIN DD *
BLDINDEX -
INDATASET(MY.VSAM.KSDSFILE) -
OUTDATASET(MY.VSAM.KSDSAIX))
/*Se você for executar o JCL acima no servidor Mainframes. Ele deve ser executado com MAXCC = 0 e criará o índice.
Catálogo mantém a unidade e o volume onde o conjunto de dados reside. Catálogo é usado para recuperação de conjuntos de dados. Conjuntos de dados não VSAM criam uma entrada de catálogo por meio do parâmetro de disposição em JCL. Os conjuntos de dados VSAM mantêm seu próprio catálogo na forma de cluster KSDS. Na imagem a seguir você pode ver o tipo de catálogos VSAM -
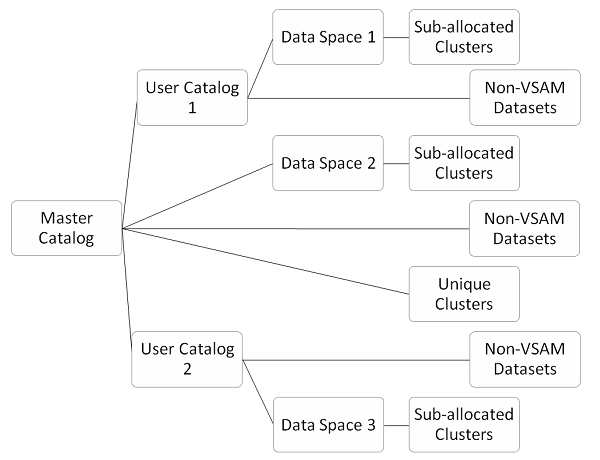
Catálogo Mestre
O catálogo principal é em si um arquivo que monitora e gerencia as operações do VSAM. Ele é apenas um catálogo mestre em qualquer sistema que contém entradas sobre conjuntos de dados do sistema e conjuntos de dados VSAM. Conjuntos de dados VSAM e não VSAM podem ter entrada no catálogo principal, mas isso não é uma boa prática. O catálogo mestre é criado durante o processo de geração do sistema e reside no volume do sistema. O catálogo principal possui todos os recursos VSAM no sistema operacional. Todos os arquivos usados no VSAM são controlados pelo catálogo principal. O catálogo principal é responsável pelas seguintes operações -
- Autorização de senha para arquivos
- Aumentando a Segurança
- Acesso VSAM para arquivos
- Gerenciamento de espaço de arquivo
- Localização do arquivo
- Espaço livre disponível em arquivo
Quando qualquer um dos atributos de arquivo acima são alterados, eles são atualizados automaticamente no catálogo principal. O catálogo mestre é definido usando programas IDCAMS.
Catálogo de usuários
O catálogo do usuário tem a mesma estrutura e conceitos do catálogo principal. Ele está presente no próximo nível de hierarquia após o catálogo mestre. O catálogo do usuário não é obrigatório no sistema, mas é usado para aprimorar a segurança do sistema VSAM. O catálogo principal aponta para arquivos VSAM, mas se o catálogo do usuário estiver presente, o catálogo principal aponta para o catálogo do usuário. Os catálogos do usuário podem ser numerosos de acordo com os requisitos do sistema. Na estrutura VSAM, se o catálogo principal for removido, ele não afetará o catálogo do usuário. O catálogo do usuário contém entradas sobre conjuntos de dados específicos do aplicativo. As informações do catálogo do usuário são armazenadas no catálogo mestre.
Espaço de Dados
O espaço de dados é uma área do dispositivo de armazenamento de acesso direto alocada exclusivamente para uso do VSAM. O espaço de dados deve ser criado antes de criar clusters VSAM. A área ocupada pelo espaço de dados é registrada no Volume Table of Contents (VTOC), de forma que o espaço não estará disponível para alocação para qualquer outro uso, seja VSAM ou não VSAM. O VTOC tem entrada de área ocupada por espaço. VSAM cria um espaço de dados para conter as entradas do catálogo do usuário. O VSAM assume o controle desse espaço e monitora e mantém esse espaço conforme necessário para os arquivos VSAM.
Clusters Únicos
Clusters exclusivos consistem em um espaço de dados separado que é utilizado completamente pelo cluster criado dentro dele. Clusters exclusivos são criados a partir do espaço não alocado no armazenamento de acesso direto.
Clusters Subalocados
Um arquivo VSAM subalocado compartilha o espaço VSAM com outros arquivos subalocados. Ele especifica que o arquivo deve ser subalocado no espaço VSAM existente. A subalocação é usada para facilitar o gerenciamento e o controle de espaços VSAM.
Conjuntos de dados não VSAM
Conjuntos de dados não VSAM residem em fita e armazenamento de acesso direto. Conjuntos de dados não VSAM podem ter entradas no catálogo principal e nos catálogos do usuário. A principal função de catalogar conjuntos de dados não VSAM é reter informações seriais da unidade e do volume.
Ao trabalhar com conjuntos de dados VSAM, você pode encontrar abends. A seguir estão os códigos de status de arquivo comuns com suas descrições que o ajudarão a resolver os problemas -
| Código | Descrição |
|---|---|
| 00 | Operação concluída com sucesso |
| 02 | Chave duplicada de índice alternativo não exclusivo encontrada |
| 04 | Registro de comprimento fixo inválido |
| 05 | Durante a execução de OPEN, o arquivo e o arquivo não estão presentes |
| 10 | Fim do arquivo encontrado |
| 14 | Tentativa de LER um registro relativo fora do limite do arquivo |
| 20 | Chave inválida para VSAM KSDS ou RRDS |
| 21 | Erro de sequência ao executar WRITE ou alterar a chave em REWRITE |
| 22 | Chave primária duplicada encontrada |
| 23 | Registro não encontrado ou arquivo não encontrado |
| 24 | Chave fora do limite do arquivo |
| 30 | Erro de E / S permanente |
| 34 | Registro fora do limite do arquivo |
| 35 | Durante a execução de OPEN, o arquivo e o arquivo não estão presentes |
| 37 | ABRIR arquivo com modo errado |
| 38 | Tentou ABRIR um arquivo bloqueado |
| 39 | OPEN falhou devido a atributos de arquivo conflitantes |
| 41 | Tentei ABRIR um arquivo que já está aberto |
| 42 | Tentei FECHAR um arquivo que não está ABERTO |
| 43 | Tentei REescrever sem LER um registro primeiro |
| 44 | Tentei REESCRITAR um registro de duração diferente |
| 46 | Tentei READ além do fim do arquivo |
| 47 | Tentei READ de um arquivo que não foi aberto IO ou INPUT |
| 48 | Tentei ESCREVER para um arquivo que não foi aberto IO ou OUTPUT |
| 49 | Tentei EXCLUIR ou RECORDAR em um arquivo que não foi aberto IO |
| 91 | Falha na senha ou autorização |
| 92 | Erro Lógico |
| 93 | Recursos não disponíveis |
| 94 | Registro sequencial indisponível ou erro OPEN simultâneo |
| 95 | Informações do arquivo inválidas ou incompletas |
| 96 | Nenhuma declaração DD para o arquivo |
| 97 | ABERTO com sucesso e integridade do arquivo verificada |
| 98 | Arquivo está bloqueado - OPEN falhou |
| 99 | Registro bloqueado - falha no acesso ao registro |