Apache MXNet - Пакеты Python
В этой главе мы узнаем о пакетах Python, доступных в Apache MXNet.
Важные пакеты MXNet Python
MXNet имеет следующие важные пакеты Python, которые мы будем обсуждать один за другим:
Автоград (автоматическое дифференцирование)
NDArray
KVStore
Gluon
Visualization
Сначала давайте начнем с Autograd Пакет Python для Apache MXNet.
Автоград
Autograd означает automatic differentiationиспользуется для обратного распространения градиентов от метрики потерь к каждому из параметров. Наряду с обратным распространением в нем используется подход динамического программирования для эффективного вычисления градиентов. Это также называется автоматическим дифференцированием в обратном режиме. Этот метод очень эффективен в ситуациях «разветвления», когда многие параметры влияют на одну метрику потерь.
Что такое градиенты?
Градиенты - это основа процесса обучения нейронной сети. Они в основном говорят нам, как изменить параметры сети, чтобы улучшить ее производительность.
Как мы знаем, нейронные сети (NN) состоят из таких операторов, как суммы, произведение, свертки и т. Д. Эти операторы для своих вычислений используют такие параметры, как веса в ядрах свертки. Мы должны найти оптимальные значения для этих параметров, и градиенты укажут нам путь и также приведут к решению.
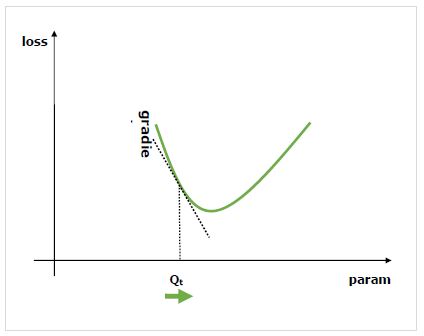
Нас интересует влияние изменения параметра на производительность сети, и градиенты говорят нам, насколько данная переменная увеличивается или уменьшается, когда мы меняем переменную, от которой она зависит. Производительность обычно определяется с помощью показателя потерь, который мы стараемся минимизировать. Например, для регрессии мы можем попытаться минимизироватьL2 потери между нашими прогнозами и точным значением, тогда как для классификации мы могли бы минимизировать cross-entropy loss.
После того, как мы вычислим градиент каждого параметра со ссылкой на потери, мы можем использовать оптимизатор, такой как стохастический градиентный спуск.
Как рассчитать градиенты?
У нас есть следующие варианты для расчета градиентов -
Symbolic Differentiation- Самый первый вариант - это символьное дифференцирование, которое вычисляет формулы для каждого градиента. Недостатком этого метода является то, что он быстро приводит к невероятно длинным формулам, поскольку сеть становится глубже, а операторы - сложнее.
Finite Differencing- Другой вариант - использовать конечную разность, при которой проверяются небольшие различия по каждому параметру и проверяется, как реагирует метрика потерь. Недостатком этого метода является то, что он требует больших вычислительных ресурсов и может иметь низкую точность вычислений.
Automatic differentiation- Решение недостатков вышеупомянутых методов заключается в использовании автоматического дифференцирования для обратного распространения градиентов от метрики потерь обратно к каждому из параметров. Распространение позволяет нам использовать метод динамического программирования для эффективного вычисления градиентов. Этот метод также называется автоматическим дифференцированием в обратном режиме.
Автоматическое дифференцирование (автоград)
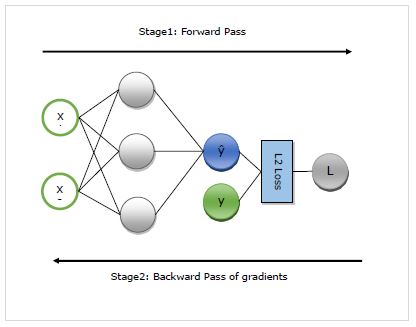
Здесь мы подробно разберемся с работой автограда. Он в основном работает в следующих двух этапах -
Stage 1 - Этот этап называется ‘Forward Pass’обучения. Как следует из названия, на этом этапе создается запись об операторе, используемого сетью для прогнозирования и расчета метрики потерь.
Stage 2 - Этот этап называется ‘Backward Pass’обучения. Как следует из названия, на этом этапе он работает в обратном направлении через эту запись. Возвращаясь назад, он оценивает частные производные каждого оператора, вплоть до сетевого параметра.
Преимущества автограда
Ниже приведены преимущества использования автоматической дифференциации (автограда).
Flexible- Гибкость, которую он дает нам при определении нашей сети, является одним из огромных преимуществ использования autograd. Мы можем изменять операции на каждой итерации. Они называются динамическими графами, которые намного сложнее реализовать в средах, требующих статического графа. Autograd даже в таких случаях по-прежнему сможет правильно распространять градиенты в обратном направлении.
Automatic- Autograd работает автоматически, то есть он берет на себя всю сложность процедуры обратного распространения ошибки. Нам просто нужно указать, какие градиенты мы хотим вычислить.
Efficient - Autogard очень эффективно рассчитывает градиенты.
Can use native Python control flow operators- Мы можем использовать собственные операторы потока управления Python, такие как условие if и цикл while. Autograd по-прежнему сможет эффективно и правильно распространять градиенты в обратном направлении.
Использование autograd в MXNet Gluon
Здесь на примере мы увидим, как можно использовать autograd в MXNet Gluon.
Пример реализации
В следующем примере мы реализуем двухуровневую регрессионную модель. После реализации мы будем использовать autograd для автоматического расчета градиента потерь со ссылкой на каждый из весовых параметров -
Сначала импортируйте autogrard и другие необходимые пакеты следующим образом:
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2LossТеперь нам нужно определить сеть следующим образом -
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()Теперь нам нужно определить потерю следующим образом -
loss_function = L2Loss()Затем нам нужно создать фиктивные данные следующим образом:
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])Теперь мы готовы к нашему первому прямому проходу через сеть. Мы хотим, чтобы autograd записывал вычислительный граф, чтобы мы могли вычислять градиенты. Для этого нам нужно запустить сетевой код в рамкахautograd.record контекст следующим образом -
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)Теперь мы готовы к обратному проходу, который мы начинаем с вызова обратного метода для интересующего нас количества. Интересующим качеством в нашем примере является потеря, потому что мы пытаемся вычислить градиент потерь со ссылкой на параметры -
loss.backward()Теперь у нас есть градиенты для каждого параметра сети, которые будут использоваться оптимизатором для обновления значения параметра для повышения производительности. Давайте проверим градиенты 1-го слоя следующим образом -
N_net[0].weight.grad()Output
Результат выглядит следующим образом:
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
<NDArray 3x2 @cpu(0)>Полный пример реализации
Ниже приведен полный пример реализации.
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()