Apache Tajo - Краткое руководство
Система распределенных хранилищ данных
Хранилище данных - это реляционная база данных, предназначенная для запросов и анализа, а не для обработки транзакций. Это предметно-ориентированный, интегрированный, изменяющийся во времени и энергонезависимый сбор данных. Эти данные помогают аналитикам принимать обоснованные решения в организации, но объемы реляционных данных увеличиваются день ото дня.
Чтобы решить эти проблемы, система распределенного хранилища данных обменивается данными между несколькими репозиториями данных для целей онлайн-аналитической обработки (OLAP). Каждое хранилище данных может принадлежать одной или нескольким организациям. Он выполняет балансировку нагрузки и масштабируемость. Метаданные реплицируются и распределяются централизованно.
Apache Tajo - это система распределенного хранилища данных, которая использует распределенную файловую систему Hadoop (HDFS) в качестве уровня хранения и имеет собственный механизм выполнения запросов вместо инфраструктуры MapReduce.
Обзор SQL в Hadoop
Hadoop - это платформа с открытым исходным кодом, которая позволяет хранить и обрабатывать большие данные в распределенной среде. Он очень быстрый и мощный. Однако Hadoop имеет ограниченные возможности запросов, поэтому его производительность можно повысить с помощью SQL на Hadoop. Это позволяет пользователям взаимодействовать с Hadoop с помощью простых команд SQL.
Некоторые из примеров SQL в приложениях Hadoop: Hive, Impala, Drill, Presto, Spark, HAWQ и Apache Tajo.
Что такое Apache Tajo
Apache Tajo - это среда для реляционной и распределенной обработки данных. Он разработан для малой задержки и масштабируемого специального анализа запросов.
Tajo поддерживает стандартный SQL и различные форматы данных. Большинство запросов Tajo можно выполнить без каких-либо изменений.
Тахо имеет fault-tolerance через механизм перезапуска для неудачных задач и расширяемый механизм перезаписи запросов.
Тахо выполняет необходимые ETL (Extract Transform and Load process)операции для суммирования больших наборов данных, хранящихся в HDFS. Это альтернатива Hive / Pig.
Последняя версия Tajo имеет улучшенные возможности подключения к программам Java и сторонним базам данных, таким как Oracle и PostGreSQL.
Особенности Apache Tajo
Apache Tajo имеет следующие особенности -
- Превосходная масштабируемость и оптимизированная производительность
- Низкая задержка
- Пользовательские функции
- Структура обработки хранения строк / столбцов.
- Совместимость с HiveQL и Hive MetaStore
- Простой поток данных и простота обслуживания.
Преимущества Apache Tajo
Apache Tajo предлагает следующие преимущества -
- Легко использовать
- Упрощенная архитектура
- Оптимизация запросов на основе затрат
- План выполнения векторизованного запроса
- Быстрая доставка
- Простой механизм ввода-вывода и поддерживает различные типы хранилищ.
- Отказоустойчивость
Примеры использования Apache Tajo
Ниже приведены некоторые варианты использования Apache Tajo:
Хранилище данных и анализ
Корейская компания SK Telecom обработала Tajo 1,7 терабайта данных и обнаружила, что она может выполнять запросы с большей скоростью, чем Hive или Impala.
Обнаружение данных
Корейский музыкальный потоковый сервис Melon использует Tajo для аналитической обработки. Tajo выполняет задания ETL (процесс извлечения-преобразования-загрузки) в 1,5–10 раз быстрее, чем Hive.
Анализ журнала
Корейская компания Bluehole Studio разработала TERA - фэнтезийную многопользовательскую онлайн-игру. Компания использует Tajo для анализа игрового журнала и поиска основных причин прерывания качества обслуживания.
Хранилище и форматы данных
Apache Tajo поддерживает следующие форматы данных -
- JSON
- Текстовый файл (CSV)
- Parquet
- Файл последовательности
- AVRO
- Буфер протокола
- Apache Orc
Tajo поддерживает следующие форматы хранения -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
На следующем рисунке изображена архитектура Apache Tajo.

В следующей таблице подробно описан каждый из компонентов.
| S.No. | Компонент и описание |
|---|---|
| 1 | Client Client отправляет операторы SQL в Tajo Master для получения результата. |
| 2 | Master Мастер - главный демон. Он отвечает за планирование запросов и является координатором для работников. |
| 3 | Catalog server Поддерживает описания таблиц и указателей. Он встроен в демон Master. Сервер каталога использует Apache Derby в качестве уровня хранения и подключается через клиент JDBC. |
| 4 | Worker Главный узел назначает задачу рабочим узлам. TajoWorker обрабатывает данные. По мере увеличения числа TajoWorkers производительность обработки также линейно увеличивается. |
| 5 | Query Master Мастер Tajo назначает запрос Мастеру запросов. Мастер запросов отвечает за управление распределенным планом выполнения. Он запускает TaskRunner и планирует задачи в TaskRunner. Основная роль мастера запросов - отслеживать выполняемые задачи и сообщать о них главному узлу. |
| 6 | Node Managers Управляет ресурсом рабочего узла. Он принимает решение о распределении запросов к узлу. |
| 7 | TaskRunner Действует как локальный механизм выполнения запросов. Он используется для запуска и мониторинга процесса запроса. TaskRunner обрабатывает одну задачу за раз. Он имеет следующие три основных атрибута -
|
| 8 | Query Executor Он используется для выполнения запроса. |
| 9 | Storage service Подключает базовое хранилище данных к Tajo. |
Рабочий процесс
Tajo использует распределенную файловую систему Hadoop (HDFS) в качестве уровня хранения и имеет собственный механизм выполнения запросов вместо платформы MapReduce. Кластер Tajo состоит из одного главного узла и нескольких рабочих узлов в узлах кластера.
Мастер в основном отвечает за планирование запросов и координатор для работников. Мастер делит запрос на небольшие задачи и назначает исполнителей. У каждого рабочего есть локальный механизм запросов, который выполняет направленный ациклический граф физических операторов.
Кроме того, Tajo может управлять распределенным потоком данных более гибко, чем MapReduce, и поддерживает методы индексирования.
Веб-интерфейс Tajo имеет следующие возможности:
- Возможность узнать, как планируются отправленные запросы
- Возможность узнать, как запросы распределяются по узлам
- Возможность проверить статус кластера и узлов
Чтобы установить Apache Tajo, в вашей системе должно быть следующее программное обеспечение:
- Hadoop версии 2.3 или выше
- Java версии 1.7 или выше
- Linux или Mac OS
Теперь давайте продолжим следующие шаги по установке Tajo.
Проверка установки Java
Надеюсь, вы уже установили Java версии 8 на свой компьютер. Теперь вам просто нужно продолжить, проверив его.
Для проверки используйте следующую команду -
$ java -versionЕсли Java успешно установлена на вашем компьютере, вы можете увидеть текущую версию установленной Java. Если Java не установлена, выполните следующие действия, чтобы установить Java 8 на ваш компьютер.
Скачать JDK
Загрузите последнюю версию JDK, перейдя по следующей ссылке, а затем загрузите последнюю версию.
https://www.oracle.com
Последняя версия JDK 8u 92 и файл “jdk-8u92-linux-x64.tar.gz”. Загрузите файл на свой компьютер. После этого извлеките файлы и переместите их в определенный каталог. Теперь установите альтернативы Java. Наконец, на вашем компьютере установлена Java.
Проверка установки Hadoop
Вы уже установили Hadoopв вашей системе. Теперь проверьте это, используя следующую команду -
$ hadoop versionЕсли с вашей настройкой все в порядке, вы можете увидеть версию Hadoop. Если Hadoop не установлен, загрузите и установите Hadoop, перейдя по следующей ссылке -https://www.apache.org
Установка Apache Tajo
Apache Tajo предоставляет два режима выполнения - локальный режим и полностью распределенный режим. После проверки установки Java и Hadoop выполните следующие действия, чтобы установить кластер Tajo на ваш компьютер. Экземпляр Tajo в локальном режиме требует очень простых настроек.
Загрузите последнюю версию Tajo, перейдя по следующей ссылке - https://www.apache.org/dyn/closer.cgi/tajo
Теперь вы можете скачать файл “tajo-0.11.3.tar.gz” с вашей машины.
Извлечь файл Tar
Извлеките tar-файл с помощью следующей команды -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Установить переменную среды
Добавьте следующие изменения в “conf/tajo-env.sh” файл
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Здесь вы должны указать путь Hadoop и Java к “tajo-env.sh”файл. После внесения изменений сохраните файл и выйдите из терминала.
Запустить сервер Tajo
Чтобы запустить сервер Tajo, выполните следующую команду -
$ bin/start-tajo.shВы получите ответ, подобный следующему -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Теперь введите команду «jps», чтобы увидеть запущенные демоны.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterЗапустите Tajo Shell (Tsql)
Чтобы запустить клиент оболочки Tajo, используйте следующую команду -
$ bin/tsqlВы получите следующий вывод -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Выйти из Tajo Shell
Выполните следующую команду, чтобы выйти из Tsql -
default> \q
bye!Здесь значение по умолчанию относится к каталогу в Tajo.
Веб-интерфейс
Введите следующий URL-адрес для запуска веб-интерфейса Tajo - http://localhost:26080/
Теперь вы увидите следующий экран, похожий на параметр ExecuteQuery.

Остановить Тахо
Чтобы остановить сервер Tajo, используйте следующую команду -
$ bin/stop-tajo.shВы получите следующий ответ -
localhost: stopping worker
stopping masterКонфигурация Tajo основана на системе конфигурации Hadoop. В этой главе подробно описаны настройки конфигурации Tajo.
Базовые настройки
Tajo использует следующие два файла конфигурации -
- catalog-site.xml - конфигурация для сервера каталога.
- tajo-site.xml - конфигурация для других модулей Tajo.
Конфигурация распределенного режима
Настройка распределенного режима выполняется в распределенной файловой системе Hadoop (HDFS). Давайте выполним шаги по настройке распределенного режима Tajo.
tajo-site.xml
Этот файл доступен @ /path/to/tajo/confкаталог и действует как конфигурация для других модулей Tajo. Чтобы получить доступ к Tajo в распределенном режиме, примените следующие изменения к“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Конфигурация главного узла
Tajo использует HDFS в качестве основного типа хранилища. Конфигурация следующая, ее следует добавить в“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Конфигурация каталога
Если вы хотите настроить службу каталога, скопируйте $path/to/Tajo/conf/catalogsite.xml.template к $path/to/Tajo/conf/catalog-site.xml и при необходимости добавьте любую из следующих конфигураций.
Например, если вы используете “Hive catalog store” чтобы получить доступ к Tajo, конфигурация должна быть такой:
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Если вам нужно хранить MySQL каталог, затем примените следующие изменения -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Точно так же вы можете зарегистрировать другие каталоги, поддерживаемые Tajo, в файле конфигурации.
Конфигурация рабочего
По умолчанию TajoWorker хранит временные данные в локальной файловой системе. Он определен в файле «tajo-site.xml» следующим образом:
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Чтобы увеличить производительность выполняемых задач каждого рабочего ресурса, выберите следующую конфигурацию -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Чтобы рабочий Tajo работал в выделенном режиме, выберите следующую конфигурацию -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>В этой главе мы подробно разберемся с командами Tajo Shell.
Чтобы выполнить команды оболочки Tajo, вам необходимо запустить сервер Tajo и оболочку Tajo, используя следующие команды:
Запустить сервер
$ bin/start-tajo.shЗапустить оболочку
$ bin/tsqlВышеупомянутые команды теперь готовы к выполнению.
Мета-команды
Давайте теперь обсудим Meta Commands. Мета-команды Tsql начинаются с обратной косой черты(‘\’).
Команда помощи
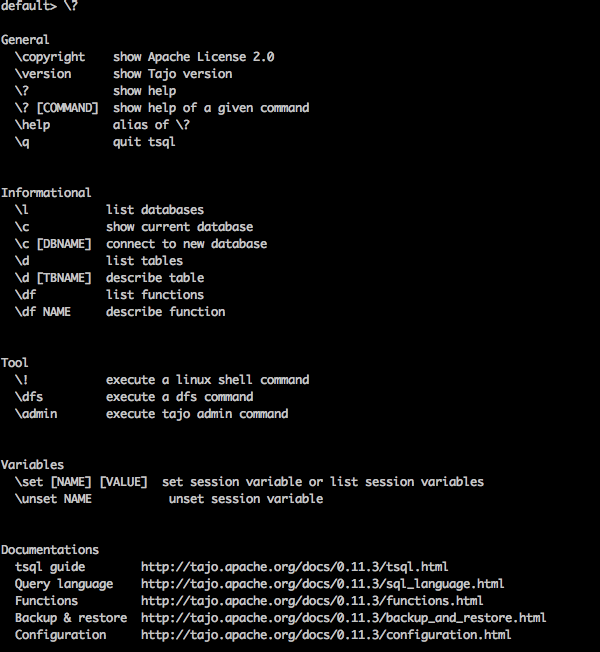
“\?” Команда используется для отображения опции справки.
Query
default> \?Result
Выше \?Команда перечисляет все основные параметры использования в Tajo. Вы получите следующий вывод -
База данных списка
Чтобы вывести список всех баз данных в Tajo, используйте следующую команду -
Query
default> \lResult
Вы получите следующий вывод -
information_schema
defaultВ настоящее время мы не создали ни одной базы данных, поэтому показаны две встроенные базы данных Tajo.
Текущая база данных
\c опция используется для отображения текущего имени базы данных.
Query
default> \cResult
Теперь вы подключены к базе данных «default» как пользователь «имя пользователя».
Список встроенных функций
Чтобы вывести список всех встроенных функций, введите следующий запрос:
Query
default> \dfResult
Вы получите следующий вывод -

Опишите функцию
\df function name - Этот запрос возвращает полное описание данной функции.
Query
default> \df sqrtResult
Вы получите следующий вывод -

Выйти из терминала
Чтобы выйти из терминала, введите следующий запрос -
Query
default> \qResult
Вы получите следующий вывод -
bye!Команды администратора
Оболочка Tajo обеспечивает \admin возможность перечислить все функции администратора.
Query
default> \adminResult
Вы получите следующий вывод -

Информация о кластере
Чтобы отобразить информацию о кластере в Tajo, используйте следующий запрос
Query
default> \admin -clusterResult
Вы получите следующий вывод -

Показать мастера
Следующий запрос отображает текущую основную информацию.
Query
default> \admin -showmastersResult
localhostТочно так же вы можете попробовать другие команды администратора.
Переменные сеанса
Клиент Tajo подключается к Мастеру через уникальный идентификатор сеанса. Сеанс активен, пока клиент не отключится или не истечет срок его действия.
Следующая команда используется для вывода списка всех переменных сеанса.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'В \set key val установит переменную сеанса с именем key со значением val. Например,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Здесь вы можете назначить ключ и значение в \setкоманда. Если вам нужно отменить изменения, используйте\unset команда.
Чтобы выполнить запрос в оболочке Tajo, откройте свой терминал и перейдите в установленный каталог Tajo, а затем введите следующую команду -
$ bin/tsqlТеперь вы увидите ответ, как показано в следующей программе -
default>Теперь вы можете выполнять свои запросы. В противном случае вы можете запускать свои запросы через приложение веб-консоли по следующему URL-адресу -http://localhost:26080/
Примитивные типы данных
Apache Tajo поддерживает следующий список примитивных типов данных -
| S.No. | Тип данных и описание |
|---|---|
| 1 | integer Используется для хранения целочисленных значений с памятью 4 байта. |
| 2 | tinyint Крошечное целочисленное значение - 1 байт |
| 3 | smallint Используется для хранения небольшого целочисленного значения 2 байта. |
| 4 | bigint Целочисленное значение большого диапазона имеет хранилище 8 байтов. |
| 5 | boolean Возвращает истину / ложь. |
| 6 | real Используется для хранения реальной стоимости. Размер 4 байта. |
| 7 | float Значение точности с плавающей запятой, занимающее 4 или 8 байтов. |
| 8 | double Значение точности двойной точки хранится в 8 байтах. |
| 9 | char[(n)] Значение символа. |
| 10 | varchar[(n)] Данные переменной длины не в Юникоде. |
| 11 | number Десятичные значения. |
| 12 | binary Двоичные значения. |
| 13 | date Календарная дата (год, месяц, день). Example - ДАТА '2016-08-22' |
| 14 | time Время дня (час, минута, секунда, миллисекунда) без часового пояса. Значения этого типа анализируются и отображаются в часовом поясе сеанса. |
| 15 | timezone Время дня (час, минута, секунда, миллисекунда) с часовым поясом. Значения этого типа отображаются с использованием часового пояса из значения. Example - ВРЕМЯ '01: 02: 03.456 Asia / kolkata ' |
| 16 | timestamp Мгновенный по времени, который включает дату и время дня без часового пояса. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Текст в Юникоде переменной длины. |
Следующие операторы используются в Tajo для выполнения желаемых операций.
| S.No. | Оператор и описание |
|---|---|
| 1 | Арифметические операторы Presto поддерживает арифметические операторы, такие как +, -, *, /,%. |
| 2 | Операторы отношения <,>, <=,> =, =, <> |
| 3 | Логические операторы И, ИЛИ, НЕ |
| 4 | Строковые операторы "||" Оператор выполняет конкатенацию строк. |
| 5 | Операторы диапазона Оператор диапазона используется для проверки значения в определенном диапазоне. Tajo поддерживает операторы BETWEEN, IS NULL, IS NOT NULL. |
На данный момент вы знали о выполнении простых базовых запросов в Tajo. В следующих нескольких главах мы обсудим следующие функции SQL:
- Математические функции
- Строковые функции
- Функции DateTime
- Функции JSON
Математические функции оперируют математическими формулами. В следующей таблице подробно описан список функций.
| S.No. | Описание функции |
|---|---|
| 1 | абс (х) Возвращает абсолютное значение x. |
| 2 | cbrt (x) Возвращает кубический корень из x. |
| 3 | ceil (x) Возвращает значение x, округленное до ближайшего целого числа. |
| 4 | этаж (x) Возвращает x, округленное в меньшую сторону до ближайшего целого числа. |
| 5 | Пи() Возвращает значение пи. Результат будет возвращен как двойное значение. |
| 6 | радианы (х) преобразует угол x в градусы радианы. |
| 7 | градусы (х) Возвращает значение степени для x. |
| 8 | pow (x, p) Возвращает степень значения p в значение x. |
| 9 | div (х, у) Возвращает результат деления для заданных двух целочисленных значений x, y. |
| 10 | ехр (х) Возвращает число Эйлера. e в степени числа. |
| 11 | sqrt (х) Возвращает квадратный корень из x. |
| 12 | знак (х) Возвращает сигнум-функцию x, то есть -
|
| 13 | мод (п, м) Возвращает модуль (остаток) от деления n на m. |
| 14 | круглый (х) Возвращает округленное значение x. |
| 15 | cos (x) Возвращает значение косинуса (x). |
| 16 | asin (х) Возвращает значение обратного синуса (x). |
| 17 | acos (x) Возвращает значение обратного косинуса (x). |
| 18 | атан (х) Возвращает значение арктангенса (x). |
| 19 | atan2 (у, х) Возвращает значение арктангенса (y / x). |
Функции типов данных
В следующей таблице перечислены функции типов данных, доступные в Apache Tajo.
| S.No. | Описание функции |
|---|---|
| 1 | to_bin (x) Возвращает двоичное представление целого числа. |
| 2 | to_char (число, текст) Преобразует целое число в строку. |
| 3 | to_hex (x) Преобразует значение x в шестнадцатеричное. |
В следующей таблице перечислены строковые функции в Tajo.
| S.No. | Описание функции |
|---|---|
| 1 | concat (строка1, ..., строкаN) Объедините данные строки. |
| 2 | длина (строка) Возвращает длину заданной строки. |
| 3 | нижний (строка) Возвращает строчный формат строки. |
| 4 | верхний (строка) Возвращает формат заданной строки в верхнем регистре. |
| 5 | ascii (текст строки) Возвращает ASCII-код первого символа текста. |
| 6 | bit_length (текст строки) Возвращает количество бит в строке. |
| 7 | char_length (текст строки) Возвращает количество символов в строке. |
| 8 | octet_length (текст строки) Возвращает количество байтов в строке. |
| 9 | дайджест (вводимый текст, текст метода) Рассчитывает Digestхеш строки. Здесь второй метод arg относится к методу хеширования. |
| 10 | initcap (текстовая строка) Преобразует первую букву каждого слова в верхний регистр. |
| 11 | md5 (текстовая строка) Рассчитывает MD5 хеш строки. |
| 12 | left (текст строки, размер int) Возвращает первые n символов в строке. |
| 13 | справа (текст строки, размер int) Возвращает последние n символов в строке. |
| 14 | найти (исходный текст, целевой текст, начальный_индекс) Возвращает расположение указанной подстроки. |
| 15 | strposb (исходный текст, целевой текст) Возвращает двоичное расположение указанной подстроки. |
| 16 | substr (исходный текст, начальный индекс, длина) Возвращает подстроку указанной длины. |
| 17 | обрезать (текст строки [, текст символов]) Удаляет символы (по умолчанию пробел) из начала / конца / обоих концов строки. |
| 18 | split_part (текст строки, текст разделителя, поле int) Разбивает строку по разделителю и возвращает заданное поле (считая от единицы). |
| 19 | regexp_replace (текст строки, текст шаблона, текст замены) Заменяет подстроки, соответствующие заданному шаблону регулярного выражения. |
| 20 | обратный (строка) Для строки выполнена обратная операция. |
Apache Tajo поддерживает следующие функции DateTime.
| S.No. | Описание функции |
|---|---|
| 1 | add_days (дата, дата или отметка времени, int день Возвращает дату, добавленную к заданному значению дня. |
| 2 | add_months (дата, дата или временная метка, int месяц) Возвращает дату, добавленную к заданному значению месяца. |
| 3 | текущая дата() Возвращает сегодняшнюю дату. |
| 4 | Текущее время() Возвращает сегодняшнее время. |
| 5 | извлечение (век от даты / времени) Извлекает век из данного параметра. |
| 6 | извлечение (день с даты / отметки времени) Извлекает день из данного параметра. |
| 7 | извлечение (декада от даты / времени) Извлекает декаду из данного параметра. |
| 8 | извлечение (день, дата / время) Извлекает день недели из данного параметра. |
| 9 | извлечь (doy от даты / времени) Извлекает день года из данного параметра. |
| 10 | выберите выдержку (час от отметки времени) Извлекает час из данного параметра. |
| 11 | выберите экстракт (isodow from timestamp) Извлекает день недели из данного параметра. Это идентично Dow, за исключением воскресенья. Это соответствует нумерации дней недели ISO 8601. |
| 12 | выберите экстракт (год от даты) Извлекает год по ISO из указанной даты. Год по ISO может отличаться от года по григорианскому календарю. |
| 13 | извлечение (микросекунды от времени) Извлекает микросекунды из данного параметра. Поле секунд, включая дробные части, умноженное на 1 000 000; |
| 14 | извлечение (тысячелетие из метки времени) Из данного параметра извлекает тысячелетие. Одно тысячелетие соответствует 1000 годам. Таким образом, третье тысячелетие началось 1 января 2001 года. |
| 15 | извлечение (миллисекунды от времени) Извлекает миллисекунды из данного параметра. |
| 16 | извлечение (минута с отметки времени) Извлекает минуту из данного параметра. |
| 17 | извлечение (четверть от отметки времени) Извлекает квартал года (1–4) из данного параметра. |
| 18 | date_part (текст поля, исходная дата или временная метка или время) Извлекает поле даты из текста. |
| 19 | в настоящее время() Возвращает текущую отметку времени. |
| 20 | to_char (отметка времени, формат текста) Преобразует метку времени в текст. |
| 21 год | to_date (текст SRC, формат текста) Преобразует текст в дату. |
| 22 | to_timestamp (текст SRC, формат текста) Преобразует текст в метку времени. |
Функции JSON перечислены в следующей таблице -
| S.No. | Описание функции |
|---|---|
| 1 | json_extract_path_text (js в тексте, json_path текст) Извлекает строку JSON из строки JSON на основе указанного пути json. |
| 2 | json_array_get (текст json_array, индекс int4) Возвращает элемент по указанному индексу в массив JSON. |
| 3 | json_array_contains (текст массива json_, значение любое) Определите, существует ли данное значение в массиве JSON. |
| 4 | json_array_length (текст луча json_ar) Возвращает длину массива json. |
В этом разделе объясняются команды Tajo DDL. Tajo имеет встроенную базу данных под названиемdefault.
Создать инструкцию базы данных
Create Database- это инструкция, используемая для создания базы данных в Tajo. Синтаксис этого оператора следующий:
CREATE DATABASE [IF NOT EXISTS] <database_name>Запрос
default> default> create database if not exists test;Результат
Вышеупомянутый запрос даст следующий результат.
OKБаза данных - это пространство имен в Tajo. База данных может содержать несколько таблиц с уникальным именем.
Показать текущую базу данных
Чтобы проверить текущее имя базы данных, введите следующую команду -
Запрос
default> \cРезультат
Вышеупомянутый запрос даст следующий результат.
You are now connected to database "default" as user “user1".
default>Подключиться к базе данных
На данный момент вы создали базу данных с именем «test». Следующий синтаксис используется для подключения «тестовой» базы данных.
\c <database name>Query
default> \c testResult
The above query will generate the following result.
You are now connected to database "test" as user “user1”.
test>You can now see the prompt changes from default database to test database.
Drop Database
To drop a database, use the following syntax −
DROP DATABASE <database-name>Query
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Result
The above query will generate the following result.
OKA table is a logical view of one data source. It consists of a logical schema, partitions, URL, and various properties. A Tajo table can be a directory in HDFS, a single file, one HBase table, or a RDBMS table.
Tajo supports the following two types of tables −
- external table
- internal table
External Table
External table needs the location property when the table is created. For example, if your data is already there as Text/JSON files or HBase table, you can register it as Tajo external table.
The following query is an example of external table creation.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Here,
External keyword − This is used to create an external table. This helps to create a table in the specified location.
Sample refers to the table name.
Location − It is a directory for HDFS,Amazon S3, HBase or local file system. To assign a location property for directories, use the below URI examples −
HDFS − hdfs://localhost:port/path/to/table
Amazon S3 − s3://bucket-name/table
local file system − file:///path/to/table
Openstack Swift − swift://bucket-name/table
Table Properties
An external table has the following properties −
TimeZone − Users can specify a time zone for reading or writing a table.
Compression format − Used to make data size compact. For example, the text/json file uses compression.codec property.
Internal Table
A Internal table is also called an Managed Table. It is created in a pre-defined physical location called the Tablespace.
Syntax
create table table1(col1 int,col2 text);By default, Tajo uses “tajo.warehouse.directory” located in “conf/tajo-site.xml” . To assign new location for the table, you can use Tablespace configuration.
Tablespace
Tablespace is used to define locations in the storage system. It is supported for only internal tables. You can access the tablespaces by their names. Each tablespace can use a different storage type. If you don’t specify tablespaces then, Tajo uses the default tablespace in the root directory.
Tablespace Configuration
You have “conf/tajo-site.xml.template” in Tajo. Copy the file and rename it to “storagesite.json”. This file will act as a configuration for Tablespaces. Tajo data formats uses the following configuration −
HDFS Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Text File Configuration
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Tablespace Creation
Tajo’s internal table records can be accessed from another table only. You can configure it with tablespace.
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Here,
IF NOT EXISTS − This avoids an error if the same table has not been created already.
TABLESPACE − This clause is used to assign the tablespace name.
Storage type − Tajo data supports formats like text,JSON,HBase,Parquet,Sequencefile and ORC.
AS select statement − Select records from another table.
Configure Tablespace
Start your Hadoop services and open the file “conf/storage-site.json”, then add the following changes −
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Here, Tajo will refer to the data from HDFS location and space1 is the tablespace name. If you do not start Hadoop services, you can’t register tablespace.
Query
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;The above query creates a table named “table1” and “space1” refers to the tablespace name.
Data formats
Tajo supports data formats. Let’s go through each of the formats one by one in detail.
Text
A character-separated values’ plain text file represents a tabular data set consisting of rows and columns. Each row is a plain text line.
Creating Table
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Here, “customers.csv” file refers to a comma separated value file located in the Tajo installation directory.
To create internal table using text format, use the following query −
default> create table customer(id int,name text,address text,age int) using text;In the above query, you have not assigned any tablespace so it will take Tajo’s default tablespace.
Properties
A text file format has the following properties −
text.delimiter − This is a delimiter character. Default is ‘|’.
compression.codec − This is a compression format. By default, it is disabled. you can change the settings using specified algorithm.
timezone − The table used for reading or writing.
text.error-tolerance.max-num − The maximum number of tolerance levels.
text.skip.headerlines − The number of header lines per skipped.
text.serde − This is serialization property.
JSON
Apache Tajo supports JSON format for querying data. Tajo treats a JSON object as SQL record. One object equals one row in a Tajo table. Let’s consider “array.json” as follows −
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}After you create this file, switch to the Tajo shell and type the following query to create a table using the JSON format.
Query
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Always remember that the file data must match with the table schema. Otherwise, you can omit the column names and use * which doesn’t require columns list.
To create an internal table, use the following query −
default> create table sample (num1 int,num2 text,num3 float) using json;Parquet
Parquet is a columnar storage format. Tajo uses Parquet format for easy, fast and efficient access.
Table creation
The following query is an example for table creation −
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Parquet file format has the following properties −
parquet.block.size − size of a row group being buffered in memory.
parquet.page.size − The page size is for compression.
parquet.compression − The compression algorithm used to compress pages.
parquet.enable.dictionary − The boolean value is to enable/disable dictionary encoding.
RCFile
RCFile is the Record Columnar File. It consists of binary key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile has the following properties −
rcfile.serde − custom deserializer class.
compression.codec − compression algorithm.
rcfile.null − NULL character.
SequenceFile
SequenceFile is a basic file format in Hadoop which consists of key/value pairs.
Table creation
The following query is an example for table creation −
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;This sequence file has Hive compatibility. This can be written in Hive as,
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimized Row Columnar) is a columnar storage format from Hive.
Table creation
The following query is an example for table creation −
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;The ORC format has the following properties −
orc.max.merge.distance − ORC file is read, it merges when the distance is lower.
orc.stripe.size − This is the size of each stripe.
orc.buffer.size − The default is 256KB.
orc.rowindex.stride − This is the ORC index stride in number of rows.
In the previous chapter, you have understood how to create tables in Tajo. This chapter explains about the SQL statement in Tajo.
Create Table Statement
Before moving to create a table, create a text file “students.csv” in Tajo installation directory path as follows −
students.csv
| Id | Name | Address | Age | Marks |
|---|---|---|---|---|
| 1 | Adam | 23 New Street | 21 | 90 |
| 2 | Amit | 12 Old Street | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Express Avenue | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 North Street | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
After the file has been created, move to the terminal and start the Tajo server and shell one by one.
Create Database
Create a new database using the following command −
Query
default> create database sampledb;
OKConnect to the database “sampledb” which is now created.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Then, create a table in “sampledb” as follows −
Query
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Result
The above query will generate the following result.
OKHere, the external table is created. Now, you just have to enter the file location. If you have to assign the table from hdfs then use hdfs instead of file.
Next, the “students.csv” file contains comma separated values. The text.delimiter field is assigned with ‘,’.
You have now created “mytable” successfully in “sampledb”.
Show Table
To show tables in Tajo, use the following query.
Query
sampledb> \d
mytable
sampledb> \d mytableResult
The above query will generate the following result.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4List table
To fetch all the records in the table, type the following query −
Query
sampledb> select * from mytable;Result
The above query will generate the following result.

Insert Table Statement
Tajo uses the following syntax to insert records in table.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo’s insert statement is similar to the INSERT INTO SELECT statement of SQL.
Query
Let’s create a table to overwrite table data of an existing table.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Где пункт
Предложение Where используется для фильтрации записей из таблицы.
Запрос
sampledb> select * from mytable where id > 5;Результат
Вышеупомянутый запрос даст следующий результат.
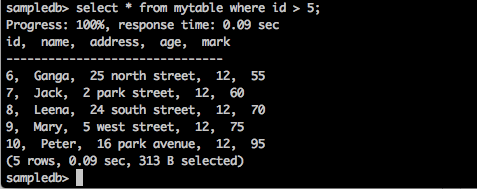
Запрос возвращает записи тех студентов, у которых id больше 5.
Запрос
sampledb> select * from mytable where name = ‘Peter’;Результат
Вышеупомянутый запрос даст следующий результат.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Результат фильтрует только записи Питера.
Особая оговорка
Столбец таблицы может содержать повторяющиеся значения. Ключевое слово DISTINCT может использоваться для возврата только различных (разных) значений.
Синтаксис
SELECT DISTINCT column1,column2 FROM table_name;Запрос
sampledb> select distinct age from mytable;Результат
Вышеупомянутый запрос даст следующий результат.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Запрос возвращает различный возраст студентов из mytable.
Группировать по пунктам
Предложение GROUP BY используется совместно с оператором SELECT для организации идентичных данных в группы.
Синтаксис
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Запрос
select age,sum(mark) as sumofmarks from mytable group by age;Результат
Вышеупомянутый запрос даст следующий результат.
age, sumofmarks
-------------------------------
13, 145
12, 610Здесь в столбце mytable есть два типа возраста - 12 и 13. Теперь запрос группирует записи по возрасту и выдает сумму оценок для соответствующего возраста учащихся.
Имея пункт
Предложение HAVING позволяет указать условия, которые фильтруют результаты группы, которые появляются в окончательных результатах. Предложение WHERE помещает условия в выбранные столбцы, тогда как предложение HAVING ставит условия в группы, созданные предложением GROUP BY.
Синтаксис
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Запрос
sampledb> select age from mytable group by age having sum(mark) > 200;Результат
Вышеупомянутый запрос даст следующий результат.
age
-------------------------------
12Запрос группирует записи по возрасту и возвращает возраст, когда сумма результата условия (отметка)> 200.
Заказ по пункту
Предложение ORDER BY используется для сортировки данных в порядке возрастания или убывания на основе одного или нескольких столбцов. По умолчанию база данных Tajo сортирует результаты запросов в порядке возрастания.
Синтаксис
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Запрос
sampledb> select * from mytable where mark > 60 order by name desc;Результат
Вышеупомянутый запрос даст следующий результат.

Запрос возвращает имена тех студентов в порядке убывания, чьи оценки выше 60.
Создать оператор индекса
Оператор CREATE INDEX используется для создания индексов в таблицах. Индекс используется для быстрого поиска данных. Текущая версия поддерживает индекс только для простых текстовых форматов, хранящихся в HDFS.
Синтаксис
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Запрос
create index student_index on mytable(id);Результат
Вышеупомянутый запрос даст следующий результат.
id
———————————————Чтобы просмотреть назначенный индекс для столбца, введите следующий запрос.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Здесь метод TWO_LEVEL_BIN_TREE используется по умолчанию в Tajo.
Оператор Drop Table
Оператор Drop Table используется для удаления таблицы из базы данных.
Синтаксис
drop table table name;Запрос
sampledb> drop table mytable;Чтобы проверить, была ли таблица удалена из таблицы, введите следующий запрос.
sampledb> \d mytable;Результат
Вышеупомянутый запрос даст следующий результат.
ERROR: relation 'mytable' does not existВы также можете проверить запрос, используя команду «\ d», чтобы вывести список доступных таблиц Tajo.
В этой главе подробно описываются агрегатные и оконные функции.
Функции агрегирования
Агрегатные функции производят единый результат из набора входных значений. В следующей таблице подробно описан список агрегатных функций.
| S.No. | Описание функции |
|---|---|
| 1 | СРЕДНЕЕ (эксп.) Усредняет столбец всех записей в источнике данных. |
| 2 | КОРР (выражение1; выражение2) Возвращает коэффициент корреляции между набором пар чисел. |
| 3 | COUNT () Возвращает количество строк. |
| 4 | МАКС (выражение) Возвращает наибольшее значение выбранного столбца. |
| 5 | MIN (выражение) Возвращает наименьшее значение выбранного столбца. |
| 6 | СУММ (выражение) Возвращает сумму данного столбца. |
| 7 | LAST_VALUE (выражение) Возвращает последнее значение данного столбца. |
Функция окна
Оконные функции выполняются для набора строк и возвращают одно значение для каждой строки из запроса. Термин «окно» имеет значение набора строк для функции.
Функция Window в запросе определяет окно с помощью предложения OVER ().
В OVER() статья имеет следующие возможности -
- Определяет оконные перегородки для формирования групп строк. (Пункт PARTITION BY)
- Упорядочивает строки внутри раздела. (Предложение ORDER BY)
В следующей таблице подробно описаны функции окна.
| Функция | Тип возврата | Описание |
|---|---|---|
| ранг() | int | Возвращает ранг текущей строки с пробелами. |
| row_num () | int | Возвращает текущую строку в своем разделе, начиная с 1. |
| lead (значение [, целое смещение [, по умолчанию любое]]) | То же, что и тип ввода | Возвращает значение, вычисленное в строке, которая смещена на строки после текущей строки в разделе. Если такой строки нет, будет возвращено значение по умолчанию. |
| lag (значение [, целое смещение [, по умолчанию любое]]) | То же, что и тип ввода | Возвращает значение, вычисленное в строке, которая является смещенной строкой перед текущей строкой в разделе. |
| first_value (значение) | То же, что и тип ввода | Возвращает первое значение входных строк. |
| last_value (значение) | То же, что и тип ввода | Возвращает последнее значение входных строк. |
В этой главе рассказывается о следующих важных запросах.
- Predicates
- Explain
- Join
Давайте продолжим и выполним запросы.
Предикаты
Предикат - это выражение, которое используется для оценки истинных / ложных значений и НЕИЗВЕСТНО. Предикаты используются в условии поиска предложений WHERE и HAVING и других конструкций, где требуется логическое значение.
Предикат IN
Определяет, соответствует ли значение проверяемого выражения любому значению в подзапросе или списке. Подзапрос - это обычный оператор SELECT, который имеет набор результатов из одного столбца и одной или нескольких строк. Этот столбец или все выражения в списке должны иметь тот же тип данных, что и проверяемое выражение.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Вышеупомянутый запрос даст следующий результат.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueЗапрос возвращает записи из mytable для студентов id 2,3 и 4.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Вышеупомянутый запрос даст следующий результат.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueВышеупомянутый запрос возвращает записи из mytable где студентов нет в 2,3 и 4.
Как предикат
Предикат LIKE сравнивает строку, указанную в первом выражении, для вычисления строкового значения, на которое ссылаются как на значение для проверки, с шаблоном, который определен во втором выражении для вычисления строкового значения.
Шаблон может содержать любую комбинацию подстановочных знаков, например -
Символ подчеркивания (_), который можно использовать вместо любого отдельного символа в проверяемом значении.
Знак процента (%), который заменяет любую строку из нуля или более символов в проверяемом значении.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Вышеупомянутый запрос даст следующий результат.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Запрос возвращает записи из моей таблицы тех студентов, имена которых начинаются с буквы «А».
Query
select * from mytable where name like ‘_a%';Result
Вышеупомянутый запрос даст следующий результат.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Запрос возвращает записи из mytable тех студентов, чьи имена начинаются с буквы «а» в качестве второго символа.
Использование значения NULL в условиях поиска
Давайте теперь поймем, как использовать значение NULL в условиях поиска.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Вышеупомянутый запрос даст следующий результат.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Здесь результат истинный, поэтому он возвращает все имена из таблицы.
Query
Давайте теперь проверим запрос с условием NULL.
default> select name from mytable where name is null;Result
Вышеупомянутый запрос даст следующий результат.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Объясните
Explainиспользуется для получения плана выполнения запроса. Он показывает логический и глобальный план выполнения оператора.
Запрос логического плана
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Вышеупомянутый запрос даст следующий результат.

Результат запроса показывает формат логического плана для данной таблицы. Логический план возвращает следующие три результата -
- Список целей
- Схема
- В схеме
Запрос глобального плана
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Вышеупомянутый запрос даст следующий результат.

Здесь Глобальный план показывает идентификатор блока выполнения, порядок выполнения и его информацию.
Присоединяется
Соединения SQL используются для объединения строк из двух или более таблиц. Ниже приведены различные типы соединений SQL.
- Внутреннее соединение
- {LEFT | ВПРАВО | ПОЛНОЕ} ВНЕШНЕЕ СОЕДИНЕНИЕ
- Перекрестное соединение
- Самостоятельное присоединение
- Естественное соединение
Рассмотрим следующие две таблицы для выполнения операций объединения.
Таблица1 - Заказчики
| Я бы | имя | Адрес | Возраст |
|---|---|---|---|
| 1 | Клиент 1 | 23 Old Street | 21 год |
| 2 | Клиент 2 | 12 Нью-Стрит | 23 |
| 3 | Клиент 3 | 10 Express Avenue | 22 |
| 4 | Клиент 4 | 15 Express Avenue | 22 |
| 5 | Клиент 5 | 20 Garden Street | 33 |
| 6 | Клиент 6 | 21 Северная улица | 25 |
Таблица2 - customer_order
| Я бы | Номер заказа | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Давайте теперь продолжим и выполним операции объединения SQL для двух вышеуказанных таблиц.
Внутреннее соединение
Внутреннее соединение выбирает все строки из обеих таблиц, если есть совпадения между столбцами в обеих таблицах.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Вышеупомянутый запрос даст следующий результат.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Запрос соответствует пяти строкам из обеих таблиц. Следовательно, он возвращает возраст совпавших строк из первой таблицы.
Левое внешнее соединение
Левое внешнее соединение сохраняет все строки «левой» таблицы, независимо от того, есть ли строка в «правой» таблице или нет.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Вышеупомянутый запрос даст следующий результат.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Здесь левое внешнее соединение возвращает строки столбцов имен из таблицы клиентов (слева) и очищает строки, соответствующие столбцам из таблицы customer_order (справа).
Правое внешнее соединение
Правое внешнее соединение сохраняет все строки «правой» таблицы, независимо от того, есть ли строка, совпадающая с «левой» таблицей.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Вышеупомянутый запрос даст следующий результат.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Здесь правое внешнее объединение возвращает строки empid из таблицы customer_order (справа) и строки столбца имен из таблицы клиентов.
Полное внешнее соединение
Полное внешнее объединение сохраняет все строки как из левой, так и из правой таблицы.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Вышеупомянутый запрос даст следующий результат.

Запрос возвращает все совпадающие и несовпадающие строки как из таблицы customers, так и из таблицы customer_order.
Крестовое соединение
Это возвращает декартово произведение наборов записей из двух или более объединенных таблиц.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Вышеупомянутый запрос даст следующий результат.
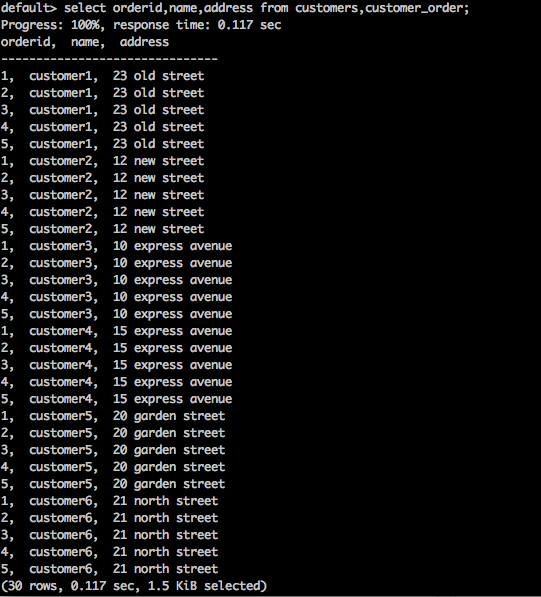
Вышеупомянутый запрос возвращает декартово произведение таблицы.
Естественное соединение
Естественное соединение не использует никаких операторов сравнения. Он не объединяет, как декартово произведение. Мы можем выполнить естественное соединение, только если между двумя отношениями существует хотя бы один общий атрибут.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Вышеупомянутый запрос даст следующий результат.

Здесь есть один общий идентификатор столбца, который существует между двумя таблицами. Используя этот общий столбец,Natural Join присоединяется к обеим таблицам.
Самостоятельное присоединение
SQL SELF JOIN используется для присоединения таблицы к самой себе, как если бы таблица была двумя таблицами, временно переименовывая по крайней мере одну таблицу в операторе SQL.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Вышеупомянутый запрос даст следующий результат.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Запрос присоединяет к себе таблицу клиентов.
Tajo поддерживает различные форматы хранения. Чтобы зарегистрировать конфигурацию плагина хранилища, вы должны добавить изменения в конфигурационный файл storage-site.json.
storage-site.json
Структура определяется следующим образом -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Каждый экземпляр хранилища идентифицируется URI.
Обработчик хранилища PostgreSQL
Tajo поддерживает обработчик хранилища PostgreSQL. Он позволяет запросам пользователей обращаться к объектам базы данных в PostgreSQL. Это обработчик хранилища по умолчанию в Tajo, поэтому вы можете легко его настроить.
конфигурация
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Вот, “database1” относится к postgreSQL база данных, которая сопоставлена с базой данных “sampledb” в Тахо.
Apache Tajo поддерживает интеграцию HBase. Это позволяет нам получить доступ к таблицам HBase в Tajo. HBase - это распределенная база данных, ориентированная на столбцы, построенная на основе файловой системы Hadoop. Это часть экосистемы Hadoop, которая обеспечивает произвольный доступ для чтения / записи в реальном времени к данным в файловой системе Hadoop. Следующие шаги необходимы для настройки интеграции HBase.
Установить переменную среды
Добавьте следующие изменения в файл «conf / tajo-env.sh».
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseПосле того, как вы указали путь HBase, Tajo установит для файла библиотеки HBase путь к классам.
Создать внешнюю таблицу
Создайте внешнюю таблицу, используя следующий синтаксис -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;Для доступа к таблицам HBase необходимо настроить расположение табличного пространства.
Вот,
Table- Установить имя исходной таблицы hbase. Если вы хотите создать внешнюю таблицу, она должна существовать в HBase.
Columns- Ключ относится к ключу строки HBase. Количество столбцов записи должно быть равно количеству столбцов таблицы Tajo.
hbase.zookeeper.quorum - Установить адрес кворума zookeeper.
hbase.zookeeper.property.clientPort - Установите порт клиента zookeeper.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Здесь поле Путь к местоположению устанавливает идентификатор порта клиента zookeeper. Если вы не установите порт, Tajo будет ссылаться на свойство файла hbase-site.xml.
Создать таблицу в HBase
Вы можете запустить интерактивную оболочку HBase с помощью команды «hbase shell», как показано в следующем запросе.
Query
/bin/hbase shellResult
Вышеупомянутый запрос даст следующий результат.
hbase(main):001:0>Шаги по запросу HBase
Чтобы запросить HBase, вы должны выполнить следующие шаги -
Step 1 - Подключите следующие команды к оболочке HBase, чтобы создать «учебную» таблицу.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Теперь введите следующую команду в оболочке hbase, чтобы загрузить данные в таблицу.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Теперь вернитесь в оболочку Tajo и выполните следующую команду, чтобы просмотреть метаданные таблицы -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Чтобы получить результаты из таблицы, используйте следующий запрос -
Query
default> select * from studentsResult
Вышеупомянутый запрос даст следующий результат -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo поддерживает HiveCatalogStore для интеграции с Apache Hive. Эта интеграция позволяет Tajo получать доступ к таблицам в Apache Hive.
Установить переменную среды
Добавьте следующие изменения в файл «conf / tajo-env.sh».
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveПосле того, как вы включили путь Hive, Tajo установит файл библиотеки Hive в путь к классам.
Конфигурация каталога
Добавьте следующие изменения в файл «conf / catalog-site.xml».
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>После настройки HiveCatalogStore вы можете получить доступ к таблице Hive в Tajo.
Swift - это распределенное и согласованное хранилище объектов / BLOB-объектов. Swift предлагает программное обеспечение для облачного хранилища, чтобы вы могли хранить и извлекать большой объем данных с помощью простого API. Tajo поддерживает интеграцию со Swift.
Ниже приведены предварительные условия для быстрой интеграции.
- Swift
- Hadoop
Core-site.xml
Добавьте следующие изменения в файл hadoop «core-site.xml»:
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Это будет использоваться Hadoop для доступа к объектам Swift. После внесения всех изменений перейдите в каталог Tajo, чтобы установить переменную среды Swift.
conf / tajo-env.h
Откройте файл конфигурации Tajo и добавьте переменную среды следующим образом:
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarТеперь Tajo сможет запрашивать данные с помощью Swift.
Создать таблицу
Давайте создадим внешнюю таблицу для доступа к объектам Swift в Tajo следующим образом:
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';После создания таблицы вы можете запускать SQL-запросы.
Apache Tajo предоставляет интерфейс JDBC для подключения и выполнения запросов. Мы можем использовать тот же интерфейс JDBC для подключения Tajo из нашего Java-приложения. Давайте теперь поймем, как подключить Tajo и выполнить команды в нашем примере Java-приложения с использованием интерфейса JDBC из этого раздела.
Загрузить драйвер JDBC
Загрузите драйвер JDBC, перейдя по следующей ссылке - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Теперь файл «tajo-jdbc-0.11.3.jar» загружен на ваш компьютер.
Установить путь к классу
Чтобы использовать драйвер JDBC в вашей программе, установите путь к классу следующим образом:
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHПодключиться к Тахо
Apache Tajo предоставляет драйвер JDBC в виде одного файла jar, и он доступен @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
Строка подключения для подключения Apache Tajo имеет следующий формат -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseВот,
host - Имя хоста TajoMaster.
port- Номер порта, который прослушивает сервер. Номер порта по умолчанию - 26002.
database- Имя базы данных. Имя базы данных по умолчанию - default.
Приложение Java
Давайте теперь разберемся с Java-приложением.
Кодирование
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Приложение можно скомпилировать и запустить с помощью следующих команд.
Компиляция
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaИсполнение
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleРезультат
Приведенные выше команды сгенерируют следующий результат -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo поддерживает настраиваемые / определяемые пользователем функции (UDF). Пользовательские функции могут быть созданы на Python.
Пользовательские функции - это простые функции Python с декоратором. “@output_type(<tajo sql datatype>)” следующим образом -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;Скрипты python с UDF можно зарегистрировать, добавив приведенную ниже конфигурацию в “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>После регистрации сценариев перезапустите кластер, и UDF будут доступны прямо в запросе SQL следующим образом:
select sum_py(10, 10) as pyfn;Apache Tajo также поддерживает определенные пользователем агрегатные функции, но не поддерживает определенные пользователем оконные функции.