ArangoDB - Краткое руководство
Разработчики называют ArangoDB собственной многомодельной базой данных. Это не похоже на другие базы данных NoSQL. В этой базе данных данные могут храниться в виде документов, пар ключ / значение или графиков. А с помощью единого декларативного языка запросов можно получить доступ к любым или всем вашим данным. Более того, в одном запросе можно комбинировать разные модели. А благодаря многомодельному стилю можно создавать экономичные приложения, которые будут масштабироваться по горизонтали с любой или всеми из трех моделей данных.
Многоуровневые и собственные многомодельные базы данных
В этом разделе мы подчеркнем важное различие между собственными и многоуровневыми многомодельными базами данных.
Многие поставщики баз данных называют свой продукт «многомодельным», но добавление графического слоя в хранилище ключей / значений или в хранилище документов не квалифицируется как собственная мультимодель.
Используя ArangoDB, одно и то же ядро с одним и тем же языком запросов, можно объединить различные модели данных и функции в одном запросе, как мы уже заявляли в предыдущем разделе. В ArangoDB нет «переключения» между моделями данных, и нет сдвига данных от A к B для выполнения запросов. Это приводит к преимуществам в производительности для ArangoDB по сравнению с «многоуровневыми» подходами.
Потребность в мультимодальной базе данных
Интерпретация основной идеи [Фаулера] приводит нас к осознанию преимуществ использования множества подходящих моделей данных для различных частей уровня сохраняемости, который является частью более крупной программной архитектуры.
В соответствии с этим, можно, например, использовать реляционную базу данных для сохранения структурированных табличных данных; хранилище документов для неструктурированных объектно-подобных данных; хранилище ключей / значений для хеш-таблицы; и база данных графов для сильно связанных ссылочных данных.
Однако традиционная реализация этого подхода приведет к использованию нескольких баз данных в одном проекте. Это может привести к некоторым операционным трениям (более сложное развертывание, более частые обновления), а также к проблемам согласованности и дублирования данных.
Следующей задачей после объединения данных для трех моделей данных является разработка и реализация общего языка запросов, который может позволить администраторам данных выражать различные запросы, такие как запросы документов, поиск ключей / значений, графические запросы и произвольные комбинации. из этих.
По graphy queries, мы имеем в виду запросы, связанные с рассмотрением теории графов. В частности, они могут включать в себя особые возможности подключения, идущие от краев. Например,ShortestPath, GraphTraversal, и Neighbors.
Графы идеально подходят в качестве модели данных для отношений. Во многих реальных случаях, таких как социальные сети, система рекомендаций и т. Д., Очень естественной моделью данных является граф. Он фиксирует отношения и может содержать информацию о метках каждого ребра и каждой вершины. Кроме того, документы JSON идеально подходят для хранения данных о вершинах и ребрах этого типа.
ArangoDB ─ Возможности
В ArangoDB есть различные примечательные особенности. Мы выделим основные особенности ниже -
- Мультимодельная парадигма
- КИСЛОТНЫЕ Свойства
- HTTP API
ArangoDB поддерживает все популярные модели баз данных. Ниже приведены несколько моделей, поддерживаемых ArangoDB.
- Модель документа
- Модель ключ / значение
- Графическая модель
Одного языка запросов достаточно для извлечения данных из базы данных
Четыре свойства Atomicity, Consistency, Isolation, и Durability(ACID) описывают гарантии транзакций базы данных. ArangoDB поддерживает транзакции, совместимые с ACID.
ArangoDB позволяет клиентам, таким как браузеры, взаимодействовать с базой данных с помощью HTTP API, который ориентирован на ресурсы и расширяется с помощью JavaScript.
Ниже приведены преимущества использования ArangoDB:
Укрепление
Как собственная многомодельная база данных, ArangoDB устраняет необходимость в развертывании нескольких баз данных и, таким образом, уменьшает количество компонентов и их обслуживание. Следовательно, это снижает сложность технологического стека для приложения. Помимо объединения ваших общих технических потребностей, это упрощение приводит к снижению общей стоимости владения и повышению гибкости.
Упрощенное масштабирование производительности
По мере роста приложений со временем, ArangoDB может удовлетворить растущие потребности в производительности и хранении за счет независимого масштабирования с использованием различных моделей данных. Поскольку ArangoDB может масштабироваться как по вертикали, так и по горизонтали, поэтому в случае, если ваша производительность требует снижения (преднамеренного желаемого замедления), вашу внутреннюю систему можно легко уменьшить, чтобы сэкономить на оборудовании, а также на эксплуатационных расходах.
Сниженная операционная сложность
Постановление Polyglot Persistence - использовать лучшие инструменты для каждой работы, которую вы выполняете. Некоторым задачам нужна база данных документов, а другим может потребоваться база данных графов. В результате работы с одномодельными базами данных это может привести к множеству операционных проблем. Интеграция одномодельных баз данных сама по себе является сложной задачей. Но самая большая проблема - это создание большой связной структуры с согласованностью данных и отказоустойчивостью между отдельными, не связанными между собой системами баз данных. Это может оказаться почти невозможным.
Устойчивость полиглотов может быть обработана с помощью собственной многомодельной базы данных, поскольку она позволяет легко иметь данные полиглотов, но в то же время с согласованностью данных в отказоустойчивой системе. С ArangoDB мы можем использовать правильную модель данных для сложной работы.
Надежная согласованность данных
При использовании нескольких баз данных с одной моделью согласованность данных может стать проблемой. Эти базы данных не предназначены для взаимодействия друг с другом, поэтому необходимо реализовать некоторую форму функциональности транзакций, чтобы ваши данные были согласованы между различными моделями.
Поддерживая транзакции ACID, ArangoDB управляет различными моделями данных с помощью единой серверной части, обеспечивая высокую согласованность в одном экземпляре и атомарные операции при работе в кластерном режиме.
Отказоустойчивость
Создание отказоустойчивых систем со множеством несвязанных компонентов - сложная задача. Эта проблема усложняется при работе с кластерами. Для развертывания и обслуживания таких систем с использованием различных технологий и / или технологических стеков требуется опыт. Более того, интеграция нескольких подсистем, предназначенных для независимой работы, влечет за собой большие инженерные и эксплуатационные расходы.
В качестве консолидированного технологического стека многомодельная база данных представляет собой элегантное решение. Разработанный для создания современных модульных архитектур с различными моделями данных, ArangoDB также подходит для использования в кластерах.
Более низкая совокупная стоимость владения
Каждая технология баз данных требует постоянного обслуживания, исправлений ошибок и других изменений кода, которые предоставляются поставщиком. Внедрение многомодельной базы данных значительно снижает связанные с этим расходы на обслуживание, просто устраняя количество технологий баз данных при разработке приложения.
Сделки
Обеспечение транзакционных гарантий на нескольких машинах - настоящая проблема, и лишь немногие базы данных NoSQL дают такие гарантии. Будучи нативной мультимоделью, ArangoDB накладывает транзакции, чтобы гарантировать согласованность данных.
В этой главе мы обсудим основные концепции и терминологию для ArangoDB. Очень важно знать базовую терминологию, относящуюся к технической теме, с которой мы имеем дело.
Терминология для ArangoDB приведена ниже -
- Document
- Collection
- Идентификатор коллекции
- Название коллекции
- Database
- Имя базы данных
- Организация базы данных
С точки зрения модели данных, ArangoDB можно рассматривать как документно-ориентированную базу данных, поскольку понятие документа является математической идеей последней. Документно-ориентированные базы данных - одна из основных категорий баз данных NoSQL.
Иерархия выглядит так: документы сгруппированы в коллекции, а коллекции существуют внутри баз данных.
Должно быть очевидно, что идентификатор и имя - это два атрибута для коллекции и базы данных.
Обычно два документа (вершины), хранящиеся в коллекциях документов, связаны документом (краем), хранящимся в коллекции краев. Это модель данных графика ArangoDB. Он следует математической концепции ориентированного помеченного графа, за исключением того, что у ребер есть не только метки, но и полноценные документы.
Ознакомившись с основными терминами этой базы данных, мы начинаем понимать модель данных графа ArangoDB. В этой модели существует два типа коллекций: коллекции документов и периферийные коллекции. Коллекции Edge хранят документы и также включают два специальных атрибута: первый - это_from атрибут, а второй - _toатрибут. Эти атрибуты используются для создания ребер (отношений) между документами, необходимых для базы данных графов. Коллекции документов также называются наборами вершин в контексте графов (см. Любую книгу по теории графов).
Давайте теперь посмотрим, насколько важны базы данных. Они важны, потому что коллекции существуют внутри баз данных. В одном экземпляре ArangoDB может быть одна или несколько баз данных. Для мультитенантных установок обычно используются разные базы данных, поскольку различные наборы данных внутри них (коллекции, документы и т. Д.) Изолированы друг от друга. База данных по умолчанию_systemособенный, потому что его нельзя удалить. Пользователи управляются в этой базе данных, и их учетные данные действительны для всех баз данных экземпляра сервера.
В этой главе мы обсудим системные требования для ArangoDB.
Системные требования для ArangoDB следующие:
- VPS-сервер с установкой Ubuntu
- Оперативная память: 1 ГБ; Процессор: 2,2 ГГц
Для всех команд в этом руководстве мы использовали экземпляр Ubuntu 16.04 (xenial) с оперативной памятью 1 ГБ с одним процессором, имеющим вычислительную мощность 2,2 ГГц. И все команды arangosh в этом руководстве были протестированы для ArangoDB версии 3.1.27.
Как установить ArangoDB?
В этом разделе мы увидим, как установить ArangoDB. ArangoDB поставляется предварительно созданным для многих операционных систем и дистрибутивов. Для получения дополнительных сведений см. Документацию по ArangoDB. Как уже упоминалось, для этого урока мы будем использовать Ubuntu 16.04x64.
Первый шаг - загрузить открытый ключ для своих репозиториев -
# wget https://www.arangodb.com/repositories/arangodb31/
xUbuntu_16.04/Release.keyВывод
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key
Resolving https://www.arangodb.com/
(www.arangodb.com)... 104.25.1 64.21, 104.25.165.21,
2400:cb00:2048:1::6819:a415, ...
Connecting to https://www.arangodb.com/
(www.arangodb.com)|104.25. 164.21|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3924 (3.8K) [application/pgpkeys]
Saving to: ‘Release.key’
Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s
2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]Важно то, что вы должны увидеть Release.key сохраняется в конце вывода.
Давайте установим сохраненный ключ, используя следующую строку кода -
# sudo apt-key add Release.keyВывод
OKВыполните следующие команды, чтобы добавить репозиторий apt и обновить индекс:
# sudo apt-add-repository 'deb
https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /'
# sudo apt-get updateВ качестве последнего шага мы можем установить ArangoDB -
# sudo apt-get install arangodb3Вывод
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
grub-pc-bin
Use 'sudo apt autoremove' to remove it.
The following NEW packages will be installed:
arangodb3
0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded.
Need to get 55.6 MB of archives.
After this operation, 343 MB of additional disk space will be used.Нажмите Enter. Теперь начнется процесс установки ArangoDB -
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04
arangodb3 3.1.27 [55.6 MB]
Fetched 55.6 MB in 59s (942 kB/s)
Preconfiguring packages ...
Selecting previously unselected package arangodb3.
(Reading database ... 54209 files and directories currently installed.)
Preparing to unpack .../arangodb3_3.1.27_amd64.deb ...
Unpacking arangodb3 (3.1.27) ...
Processing triggers for systemd (229-4ubuntu19) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up arangodb3 (3.1.27) ...
Database files are up-to-date.Когда установка ArangoDB подходит к завершению, появляется следующий экран -
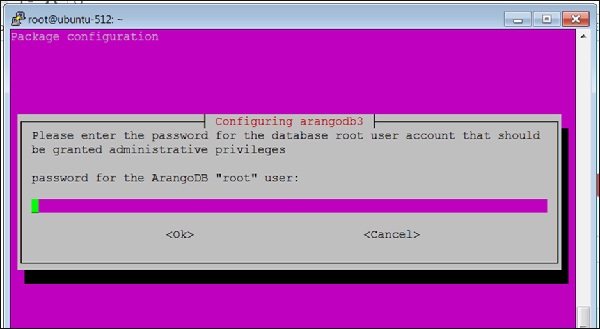
Здесь вам будет предложено ввести пароль для ArangoDB. rootпользователь. Запишите это внимательно.
Выберите yes вариант, когда появится следующее диалоговое окно -
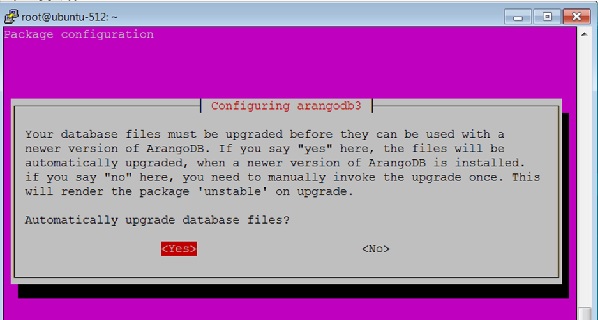
Когда вы нажимаете Yesкак и в приведенном выше диалоговом окне, появляется следующее диалоговое окно. НажмитеYes Вот.
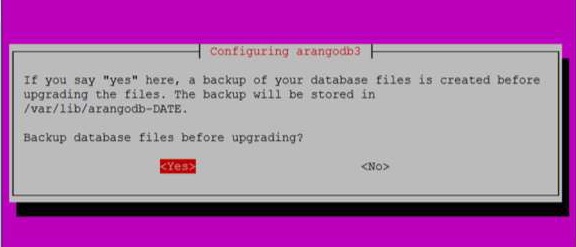
Вы также можете проверить статус ArangoDB с помощью следующей команды -
# sudo systemctl status arangodb3Вывод
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)Теперь ArangoDB готов к использованию.
Чтобы вызвать терминал arangosh, введите в терминале следующую команду -
# arangoshВывод
Please specify a password:Поставлять root пароль, созданный при установке -
_
__ _ _ __ __ _ _ __ __ _ ___ | |
/ | '__/ _ | ’ \ / ` |/ _ / | ’
| (| | | | (| | | | | (| | () _ \ | | |
_,|| _,|| ||_, |_/|/| ||
|__/arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server],
database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system> exit
Чтобы выйти из ArangoDB, введите следующую команду -
127.0.0.1:8529@_system> exitВывод
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego!
Εις το επανιδείν!
להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até
Breve! !خداحافظВ этой главе мы обсудим, как Arangosh работает в качестве командной строки для ArangoDB. Мы начнем с изучения того, как добавить пользователя базы данных.
Note - Помните, что цифровая клавиатура может не работать на Арангоше.
Предположим, что пользователь - «harry», а пароль - «hpwdb».
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");Вывод
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}В этой главе мы узнаем, как включить / отключить аутентификацию и как привязать ArangoDB к общедоступному сетевому интерфейсу.
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"Он предложит вам ввести пароль, сохраненный ранее -
Please specify a password:Используйте пароль, который вы создали для root, при конфигурации.
Вы также можете использовать curl, чтобы проверить, действительно ли вы получаете ответы сервера HTTP 401 (неавторизованный) для запросов, требующих аутентификации -
# curl --dump - http://127.0.0.1:8529/_api/versionВывод
HTTP/1.1 401 Unauthorized
X-Content-Type-Options: nosniff
Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB"
Server: ArangoDB
Connection: Keep-Alive
Content-Type: text/plain; charset = utf-8
Content-Length: 0Чтобы не вводить пароль каждый раз в процессе обучения, мы отключим аутентификацию. Для этого откройте файл конфигурации -
# vim /etc/arangodb3/arangod.confВам следует изменить цветовую схему, если код не отображается должным образом.
:colorscheme desertУстановите для аутентификации значение false, как показано на скриншоте ниже.
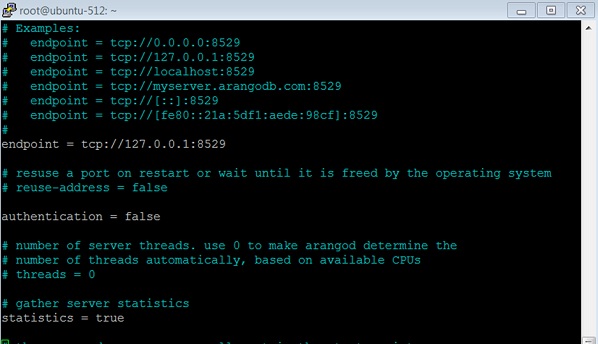
Перезапустите службу -
# service arangodb3 restartСделав аутентификацию ложной, вы сможете войти в систему (либо с root, либо с созданным пользователем, например Harry в этом случае) без ввода пароля в please specify a password.
Давайте проверим api версия при выключенной аутентификации -
# curl --dump - http://127.0.0.1:8529/_api/versionВывод
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}В этой главе мы рассмотрим два примера сценария. Эти примеры легче понять и помогут нам понять, как работает функциональность ArangoDB.
Для демонстрации API-интерфейсов ArangoDB поставляется с предварительно загруженным набором легко понятных графиков. Есть два метода создания экземпляров этих графиков в вашей ArangoDB:
- Добавить вкладку Пример в окне создания графика в веб-интерфейсе,
- или загрузите модуль @arangodb/graph-examples/example-graph в Арангоше.
Для начала загрузим график с помощью веб-интерфейса. Для этого запустите веб-интерфейс и нажмите кнопкуgraphs таб.
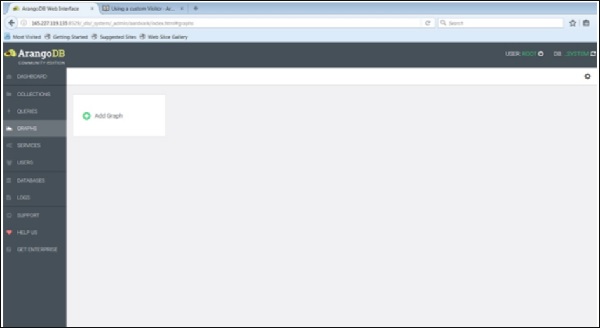
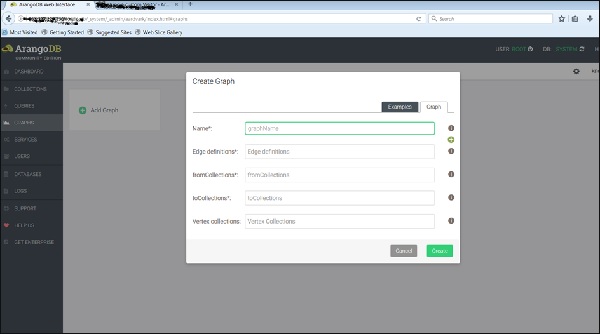
В Create Graphпоявится диалоговое окно. Мастер содержит две вкладки -Examples и Graph. ВGraphвкладка открыта по умолчанию; Предположим, мы хотим создать новый граф, он запросит имя и другие определения для графа.
Теперь загрузим уже созданный график. Для этого выберемExamples таб.
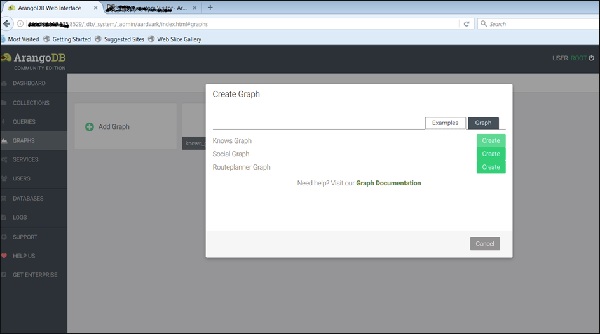
Мы можем видеть три примера графиков. ВыберитеKnows_Graph и нажмите зеленую кнопку Создать.
Создав их, вы можете просмотреть их в веб-интерфейсе, который использовался для создания изображений ниже.
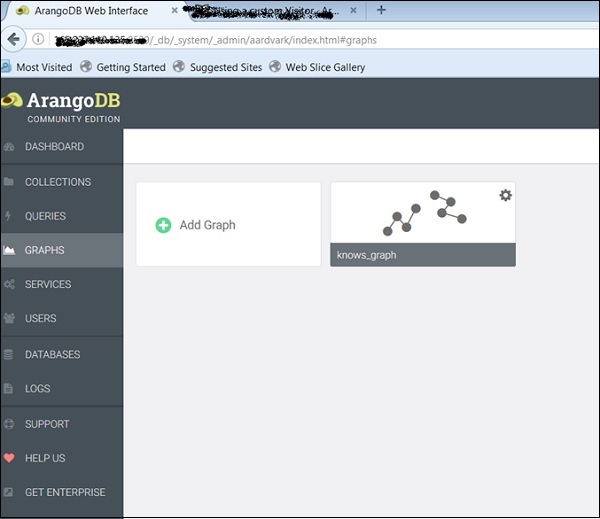
Knows_Graph
Давайте теперь посмотрим, как Knows_Graphработает. Выберите Knows_Graph, и он получит данные графика.
Knows_Graph состоит из одной коллекции вершин persons соединены через один край knows. Он будет содержать пять человек Алису, Боба, Чарли, Дэйва и Еву в качестве вершин. У нас будут следующие направленные отношения
Alice knows Bob
Bob knows Charlie
Bob knows Dave
Eve knows Alice
Eve knows Bob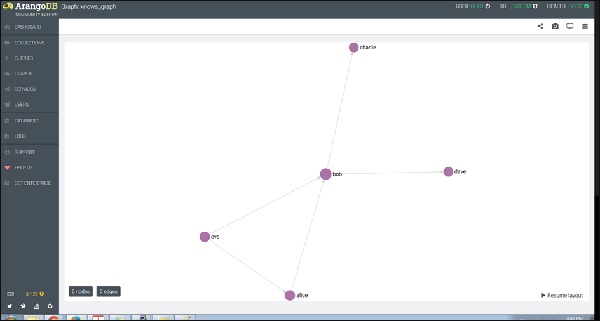
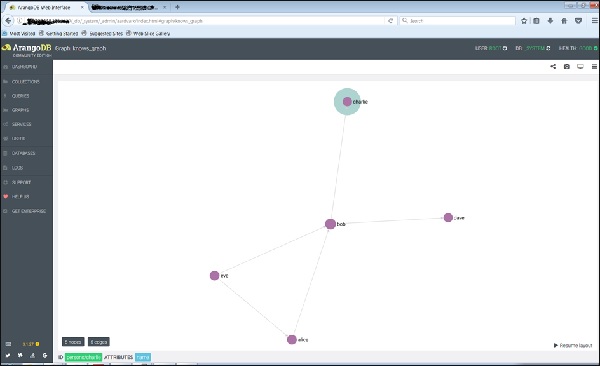
Если вы щелкните узел (вершину), скажем «bob», он покажет имя атрибута ID (people / bob).
И при щелчке любого края он покажет атрибуты ID (знает / 4590).
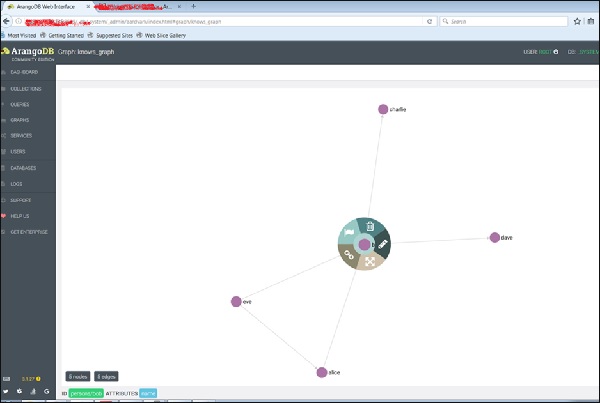
Вот как мы его создаем, осматриваем его вершины и ребра.
Давайте добавим еще один график, на этот раз с использованием Арангоша. Для этого нам нужно включить другую конечную точку в файл конфигурации ArangoDB.
Как добавить несколько конечных точек
Откройте файл конфигурации -
# vim /etc/arangodb3/arangod.confДобавьте еще одну конечную точку, как показано на скриншоте терминала ниже.
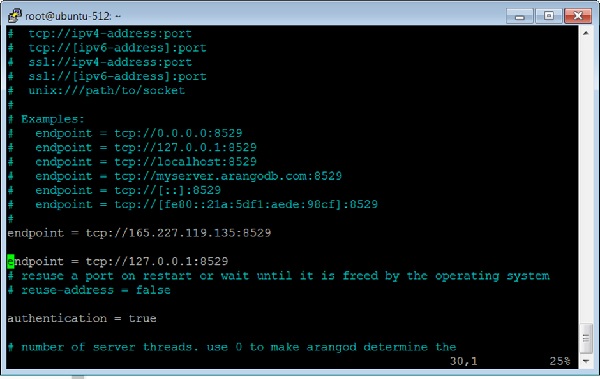
Перезагрузите ArangoDB -
# service arangodb3 restartЗапускаем Арангош -
# arangosh
Please specify a password:
_
__ _ _ __ __ _ _ __ __ _ ___ ___| |__
/ _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \
| (_| | | | (_| | | | | (_| | (_) \__ \ | | |
\__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_|
|___/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27
[server], database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system>Социальный_граф
Давайте теперь разберемся, что такое Social_Graph и как он работает. График показывает набор людей и их отношения -
В этом примере женщины и мужчины являются вершинами в двух наборах вершин - женской и мужской. Ребра - это их соединения в коллекции ребер отношения. Мы описали, как создать этот граф с помощью Арангоша. Читатель может обойти его и изучить его атрибуты, как мы это сделали с Knows_Graph.
В этой главе мы сосредоточимся на следующих темах -
- Взаимодействие с базой данных
- Модель данных
- Получение данных
ArangoDB поддерживает модель данных на основе документов, а также модель данных на основе графов. Давайте сначала опишем модель данных на основе документа.
Документы ArangoDB очень похожи на формат JSON. В документе содержится ноль или более атрибутов, и к каждому атрибуту прилагается значение. Значение имеет либо атомарный тип, например число, логическое значение или значение null, буквальную строку, либо составной тип данных, например встроенный документ / объект или массив. Массивы или подобъекты могут состоять из этих типов данных, что означает, что один документ может представлять нетривиальные структуры данных.
Далее по иерархии документы организованы в коллекции, которые могут не содержать документов (теоретически) или содержать более одного документа. Можно сравнивать документы со строками, а коллекции с таблицами (здесь таблицы и строки относятся к таковым систем управления реляционными базами данных - RDBMS).
Но в РСУБД определение столбцов является необходимым условием для хранения записей в таблице, вызывая эти схемы определений. Однако в качестве новой функции ArangoDB не имеет схемы - нет никакой априорной причины указывать, какие атрибуты будет иметь документ.
И, в отличие от СУБД, каждый документ может быть структурирован совершенно иначе, чем другой документ. Эти документы можно сохранить вместе в одной коллекции. На практике у документов в коллекции могут быть общие характеристики, однако система баз данных, то есть сама ArangoDB, не привязывает вас к определенной структуре данных.
Теперь попробуем разобраться в [graph data model], для которого требуются два типа коллекций: первая - это коллекции документов (известные как коллекции вершин на теоретико-групповом языке), вторая - это коллекции ребер. Между этими двумя типами есть небольшая разница. Коллекции Edge также хранят документы, но они характеризуются двумя уникальными атрибутами:_from и _toдля создания отношений между документами. На практике документ (край чтения) связывает два документа (вершины чтения), оба хранятся в своих коллекциях. Эта архитектура основана на теоретико-графической концепции помеченного ориентированного графа, за исключением ребер, которые могут иметь не только метки, но и сами по себе могут быть полным документом, подобным JSON.
Для вычисления свежих данных, удаления документов или для управления ими используются запросы, которые выбирают или фильтруют документы в соответствии с заданными критериями. Будучи простыми как «пример запроса» или сложными как «соединения», запросы кодируются на AQL - языке запросов ArangoDB.
В этой главе мы обсудим различные методы базы данных в ArangoDB.
Для начала давайте получим свойства базы данных -
- Name
- ID
- Path
Сначала мы вызываем Арангош. Как только будет вызван Арангош, мы перечислим базы данных, которые мы создали до сих пор -
Мы будем использовать следующую строку кода для вызова Арангоша -
127.0.0.1:8529@_system> db._databases()Вывод
[
"_system",
"song_collection"
]Мы видим две базы данных, одну _system создается по умолчанию, а второй song_collection что мы создали.
Давайте теперь перейдем к базе данных song_collection со следующей строкой кода -
127.0.0.1:8529@_system> db._useDatabase("song_collection")Вывод
true
127.0.0.1:8529@song_collection>Мы исследуем свойства нашей базы данных song_collection.
Чтобы найти имя
Мы будем использовать следующую строку кода, чтобы найти имя.
127.0.0.1:8529@song_collection> db._name()Вывод
song_collectionЧтобы найти идентификатор -
Мы будем использовать следующую строку кода, чтобы найти идентификатор.
song_collectionВывод
4838Чтобы найти путь -
Мы будем использовать следующую строку кода, чтобы найти путь.
127.0.0.1:8529@song_collection> db._path()Вывод
/var/lib/arangodb3/databases/database-4838Давайте теперь проверим, находимся ли мы в системной базе данных или нет, используя следующую строку кода -
127.0.0.1:8529@song_collection&t; db._isSystem()Вывод
falseЭто означает, что нас нет в системной базе данных (поскольку мы создали и перешли в song_collection). Следующий снимок экрана поможет вам понять это.
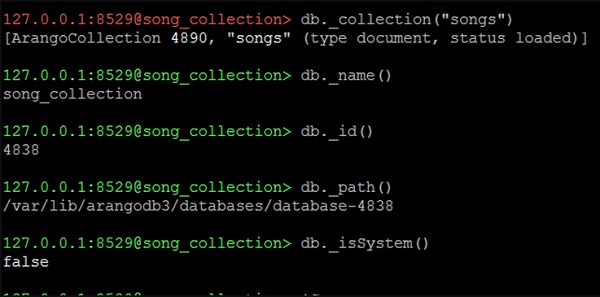
Чтобы получить конкретный сборник, скажите песни -
Мы будем использовать следующую строку кода, чтобы получить конкретную коллекцию.
127.0.0.1:8529@song_collection> db._collection("songs")Вывод
[ArangoCollection 4890, "songs" (type document, status loaded)]Строка кода возвращает единственную коллекцию.
Давайте перейдем к основам операций с базой данных в наших последующих главах.
В этой главе мы изучим различные операции с Арангошем.
Ниже приведены возможные операции с Арангошем -
- Создание коллекции документов
- Создание документов
- Чтение документов
- Обновление документов
Начнем с создания новой базы данных. Мы будем использовать следующую строку кода для создания новой базы данных -
127.0.0.1:8529@_system> db._createDatabase("song_collection")
trueСледующая строка кода поможет вам перейти на новую базу данных -
127.0.0.1:8529@_system> db._useDatabase("song_collection")
trueПодсказка сменится на "@@ song_collection"
127.0.0.1:8529@song_collection>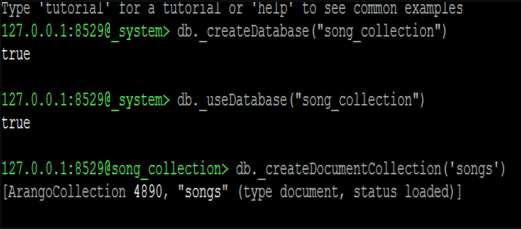
Отсюда мы будем изучать операции CRUD. Давайте создадим коллекцию в новой базе данных -
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')Вывод
[ArangoCollection 4890, "songs" (type document, status loaded)]
127.0.0.1:8529@song_collection>Давайте добавим несколько документов (объектов JSON) в нашу коллекцию «песен».
Добавляем первый документ следующим образом -
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})Вывод
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}Добавим в базу другие документы. Это поможет нам изучить процесс запроса данных. Вы можете скопировать эти коды и вставить их в Арангош, чтобы имитировать процесс -
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}Как читать документы
В _keyили дескриптор документа можно использовать для извлечения документа. Используйте дескриптор документа, если нет необходимости перемещаться по самой коллекции. Если у вас есть коллекция, функция документа проста в использовании -
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}Как обновить документы
Доступны два варианта обновления сохраненных данных - replace и update.
Функция обновления исправляет документ, объединяя его с заданными атрибутами. С другой стороны, функция замены заменит предыдущий документ новым. Замена все равно произойдет, даже если предоставлены совершенно другие атрибуты. Сначала мы увидим неразрушающее обновление, обновив атрибут Production` в песне -
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});Вывод
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}Давайте теперь прочитаем обновленные атрибуты песни -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Вывод
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}Большой документ можно легко обновить с помощью update функция, особенно когда атрибутов очень мало.
Напротив, replace функция отменяет ваши данные при использовании ее с тем же документом.
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});Давайте теперь проверим песню, которую мы только что обновили, с помощью следующей строки кода -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Вывод
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}Теперь вы можете заметить, что в документе больше нет исходных данных.
Как удалить документы
Функция удаления используется в сочетании с дескриптором документа для удаления документа из коллекции -
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');Давайте теперь проверим атрибуты песни, которые мы только что удалили, используя следующую строку кода -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');В качестве вывода мы получим ошибку исключения, подобную следующей:
JavaScript exception in file
'/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7:
ArangoError 1202: document not found
! throw error;
! ^
stacktrace: ArangoError: document not found
at Object.exports.checkRequestResult
(/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21)
at ArangoCollection.document
(/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12)
at <shell command>:1:10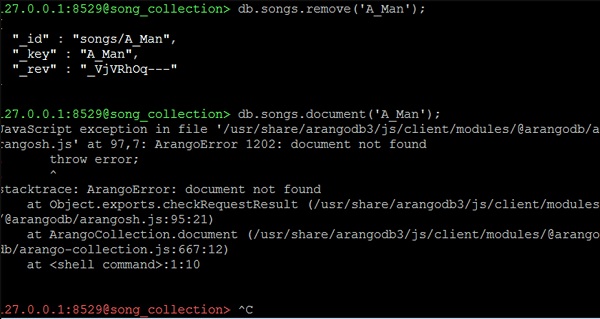
В нашей предыдущей главе мы узнали, как выполнять различные операции с документами с помощью Arangosh, командной строки. Теперь мы узнаем, как выполнять те же операции с помощью веб-интерфейса. Для начала введите следующий адрес - http: // your_server_ip: 8529 / _db / song_collection / _admin / aardvark / index.html # login в адресной строке вашего браузера. Вы будете перенаправлены на следующую страницу входа.
Теперь введите имя пользователя и пароль.
В случае успеха появится следующий экран. Нам нужно сделать выбор, над чем будет работать база данных,_systemбаза данных по умолчанию. Выберемsong_collection база данных и нажмите на зеленую вкладку -
Создание коллекции
В этом разделе мы узнаем, как создать коллекцию. Откройте вкладку Коллекции на панели навигации вверху.
Видна наша коллекция песен, добавленная в командную строку. Щелчок по нему покажет записи. Теперь мы добавимartists’сбор с помощью веб-интерфейса. Коллекцияsongsкоторый мы создали с Арангошем, уже есть. В поле Имя напишитеartists в New Collectionдиалоговое окно, которое появляется. Расширенные параметры можно игнорировать, и тип коллекции по умолчанию, то есть Document, подойдет.

Нажатие на кнопку «Сохранить», наконец, создаст коллекцию, и теперь две коллекции будут видны на этой странице.
Наполнение новой коллекции документами
Вам будет представлена пустая коллекция при нажатии на artists коллекция -
Чтобы добавить документ, вам нужно щелкнуть значок +, расположенный в правом верхнем углу. Когда вам будет предложено ввести_key, войти Affable_Balding как ключ.
Теперь появится форма для добавления и редактирования атрибутов документа. Есть два способа добавления атрибутов:Graphical и Tree. Графический способ интуитивно понятен, но медленный, поэтому мы перейдем кCode view, используя раскрывающееся меню Tree, чтобы выбрать его -
Чтобы упростить процесс, мы создали образец данных в формате JSON, который вы можете скопировать, а затем вставить в область редактора запросов -
{"artist": "Johnny Mercer", "title": "Affable Balding Me", "composer": "Robert Emmett Dolan", "Year": 1950}
(Примечание: следует использовать только одну пару фигурных скобок; см. Снимок экрана ниже)
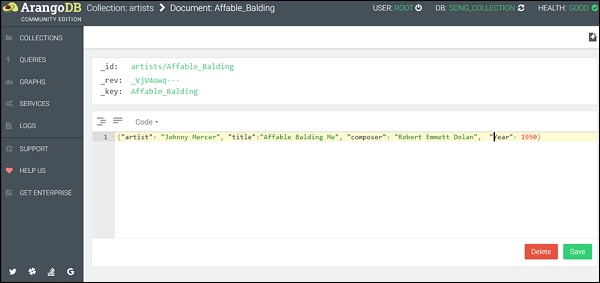
Вы можете заметить, что мы процитировали ключи, а также значения в режиме просмотра кода. Теперь нажмитеSave. После успешного завершения на странице на мгновение появляется зеленая вспышка.
Как читать документы
Чтобы читать документы, вернитесь на страницу Коллекции.
Когда щелкают по artist коллекция появляется новая запись.
Как обновить документы
Редактировать записи в документе просто; вам просто нужно щелкнуть строку, которую вы хотите отредактировать, в обзоре документа. Здесь снова будет представлен тот же редактор запросов, что и при создании новых документов.
Удаление документов
Вы можете удалить документы, нажав значок «-». В конце каждой строки документа есть этот знак. Вам будет предложено подтвердить, чтобы избежать небезопасного удаления.
Более того, для конкретной коллекции другие операции, такие как фильтрация документов, управление индексами и импорт данных, также существуют на Collections Overview страница.
В нашей следующей главе мы обсудим важную функцию веб-интерфейса, то есть редактор запросов AQL.
В этой главе мы обсудим, как запрашивать данные с помощью AQL. Мы уже обсуждали в наших предыдущих главах, что ArangoDB разработал свой собственный язык запросов и что он называется AQL.
Давайте теперь начнем взаимодействовать с AQL. Как показано на изображении ниже, в веб-интерфейсе нажмите кнопкуAQL Editorвкладка находится в верхней части панели навигации. Появится пустой редактор запросов.
При необходимости вы можете переключиться в редактор из представления результатов и наоборот, щелкнув вкладку «Запрос» или «Результат» в верхнем правом углу, как показано на изображении ниже -
Помимо прочего, в редакторе есть подсветка синтаксиса, функция отмены / повтора и сохранение запросов. Более подробную информацию можно найти в официальной документации. Мы выделим несколько основных и часто используемых функций редактора запросов AQL.
Основы AQL
В AQL запрос представляет конечный результат, который должен быть достигнут, но не процесс, посредством которого должен быть достигнут конечный результат. Эта функция обычно известна как декларативное свойство языка. Более того, AQL может запрашивать, а также изменять данные, и, таким образом, сложные запросы могут быть созданы путем объединения обоих процессов.
Обратите внимание, что AQL полностью соответствует требованиям ACID. Чтение или изменение запросов либо завершатся полностью, либо не завершатся вовсе. Даже чтение данных документа завершится последовательной единицей данных.
Добавляем два новых songsв уже созданный сборник песен. Вместо того, чтобы печатать, вы можете скопировать следующий запрос и вставить его в редактор AQL -
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songsНажмите кнопку «Выполнить» в левом нижнем углу.
Он запишет два новых документа в songs коллекция.
Этот запрос описывает, как цикл FOR работает в AQL; он перебирает список закодированных документов JSON, выполняя закодированные операции с каждым из документов в коллекции. Различные операции могут включать создание новых структур, фильтрацию, выбор документов, изменение или вставку документов в базу данных (см. Мгновенный пример). По сути, AQL может эффективно выполнять операции CRUD.
Чтобы найти все песни в нашей базе данных, давайте еще раз выполним следующий запрос, эквивалентный SELECT * FROM songs базы данных типа SQL (поскольку редактор запоминает последний запрос, нажмите *New* кнопка очистки редактора) -
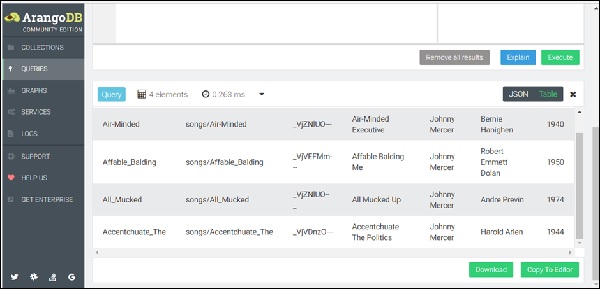
FOR song IN songs
RETURN songВ наборе результатов отобразится список песен, сохраненных в songs коллекция, как показано на скриншоте ниже.
Операции вроде FILTER, SORT и LIMIT можно добавить в For loop тело, чтобы сузить и упорядочить результат.
FOR song IN songs
FILTER song.Year > 1940
RETURN songВышеупомянутый запрос предоставит песни, созданные после 1940 года, на вкладке «Результат» (см. Изображение ниже).
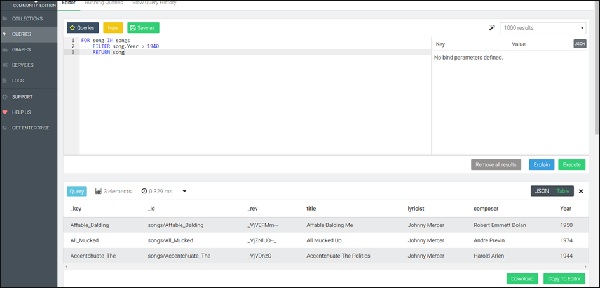
В этом примере используется ключ документа, но любой другой атрибут также может использоваться как эквивалент для фильтрации. Поскольку ключ документа гарантированно уникален, этому фильтру будет соответствовать не более одного документа. Для других атрибутов это может быть не так. Чтобы вернуть подмножество активных пользователей (определяемое атрибутом, называемым статусом), отсортированное по имени в порядке возрастания, мы используем следующий синтаксис:
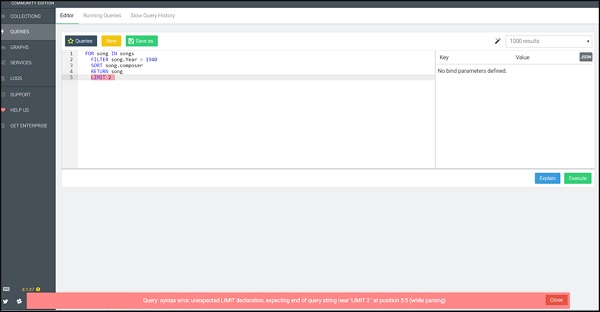
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
RETURN song
LIMIT 2Мы сознательно включили этот пример. Здесь мы видим сообщение об ошибке синтаксиса запроса, выделенное красным цветом с помощью AQL. Этот синтаксис выделяет ошибки и помогает при отладке запросов, как показано на снимке экрана ниже.
Давайте теперь запустим правильный запрос (обратите внимание на исправление) -
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
LIMIT 2
RETURN song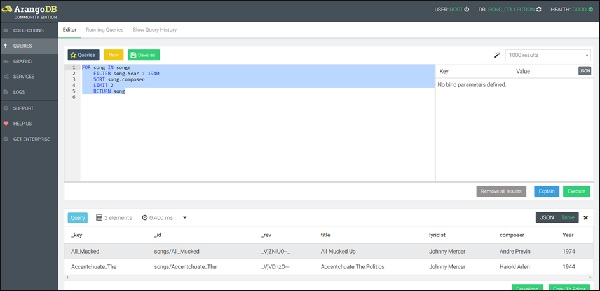
Сложный запрос в AQL
AQL снабжен множеством функций для всех поддерживаемых типов данных. Назначение переменной в запросе позволяет создавать очень сложные вложенные конструкции. Таким образом, операции с интенсивным использованием данных перемещаются ближе к данным на сервере, чем к клиенту (например, браузеру). Чтобы понять это, давайте сначала добавим произвольную продолжительность (длину) к песням.
Начнем с первой функции, то есть с функции обновления -
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs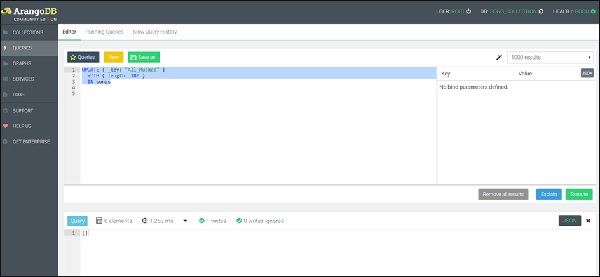
Мы видим, что один документ был написан, как показано на скриншоте выше.
Давайте теперь обновим и другие документы (песни).
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songsТеперь мы можем проверить, что все наши песни имеют новый атрибут length -
FOR song IN songs
RETURN songВывод
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]Чтобы проиллюстрировать использование других ключевых слов AQL, таких как LET, FILTER, SORT и т. Д., Теперь мы форматируем продолжительность песни в mm:ss формат.
Запрос
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}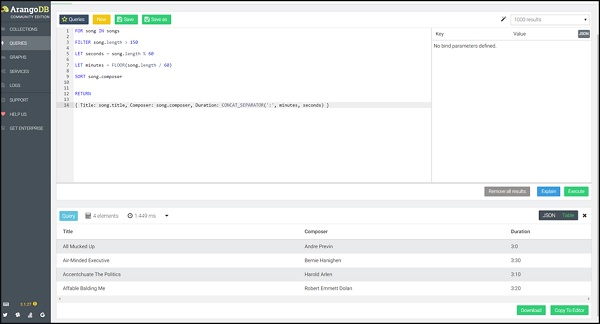
На этот раз мы вернем название песни вместе с продолжительностью. ВReturn Функция позволяет вам создать новый объект JSON, который будет возвращаться для каждого входного документа.
Теперь мы поговорим о функции «Объединения» в базе данных AQL.
Начнем с создания коллекции composer_dob. Далее мы создадим четыре документа с гипотетической датой рождения композиторов, выполнив следующий запрос в поле запроса -
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob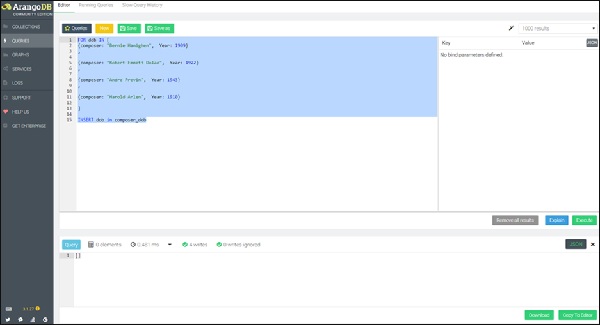
Чтобы подчеркнуть сходство с SQL, мы представляем вложенный запрос цикла FOR в AQL, ведущий к операции REPLACE, итерации сначала во внутреннем цикле, по всем dob композиторов, а затем по всем связанным песням, создавая новый документ, содержащий атрибут song_with_composer_key вместо song атрибут.
Вот вопрос -
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs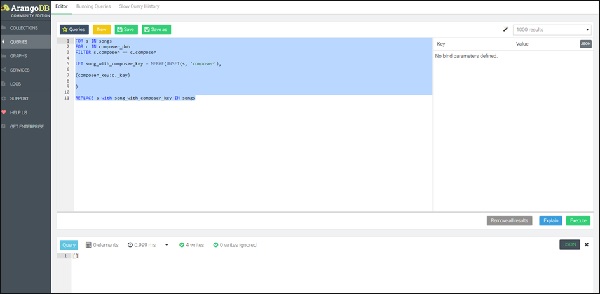
Давайте теперь запустим запрос FOR song IN songs RETURN song еще раз, чтобы увидеть, как изменилась коллекция песен.
Вывод
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]Вышеупомянутый запрос завершает процесс миграции данных, добавляя composer_key к каждой песне.
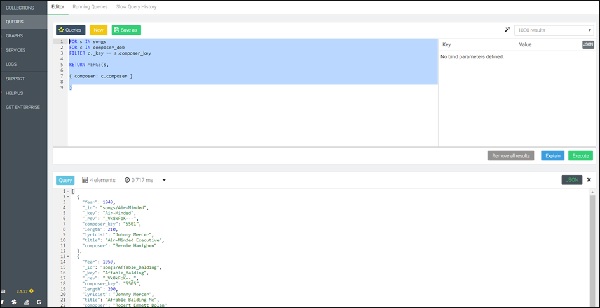
Теперь следующий запрос снова является вложенным запросом цикла FOR, но на этот раз он ведет к операции Join, добавляя имя связанного композитора (выбор с помощью composer_key) к каждой песне -
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)Вывод
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
В этой главе мы рассмотрим несколько примеров запросов AQL на Actors and MoviesБаза данных. Эти запросы основаны на графиках.
Проблема
Учитывая коллекцию актеров и коллекцию фильмов, а также коллекцию ребер actIn (со свойством года) для соединения вершины, как показано ниже -
[Actor] <- act in -> [Movie]
Как мы получаем -
- Все актеры, которые играли в "movie1" ИЛИ "movie2"?
- Все актеры, которые играли как в "movie1", так и "movie2"?
- Все общие фильмы между «актер1» и «актер2»?
- Все актеры, сыгравшие в 3 и более фильмах?
- Все фильмы, в которых снялось ровно 6 актеров?
- Количество актеров по фильму?
- Количество фильмов по актеру?
- Сколько фильмов снял актер с 2005 по 2010 год?
Решение
В процессе решения и получения ответов на вышеуказанные запросы мы будем использовать Arangosh для создания набора данных и выполнения запросов по нему. Все запросы AQL являются строками, и их можно просто скопировать в свой любимый драйвер вместо Arangosh.
Давайте начнем с создания тестового набора данных в Арангоше. Сначала скачайте этот файл -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingВывод
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]Вы можете видеть в выводе выше, что мы загрузили файл JavaScript. dataset.js.Этот файл содержит команды Арангоша для создания набора данных в базе данных. Вместо того, чтобы копировать и вставлять команды одну за другой, мы будем использовать--javascript.executeопция Арангоша для выполнения нескольких команд в неинтерактивном режиме. Считайте это командой спасателя!
Теперь выполните следующую команду в оболочке -
$ arangosh --javascript.execute dataset.js
При появлении запроса введите пароль, как показано на скриншоте выше. Теперь мы сохранили данные, поэтому мы создадим AQL-запросы, чтобы ответить на конкретные вопросы, поднятые в начале этой главы.
Первый вопрос
Давайте возьмем первый вопрос: All actors who acted in "movie1" OR "movie2". Предположим, мы хотим найти имена всех актеров, которые действовали в "TheMatrix" ИЛИ "TheDevilsAdvocate" -
Мы начнем с одного фильма за раз, чтобы узнать имена актеров -
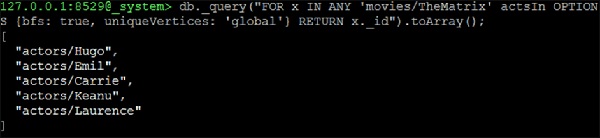
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();Вывод
Мы получим следующий вывод -
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
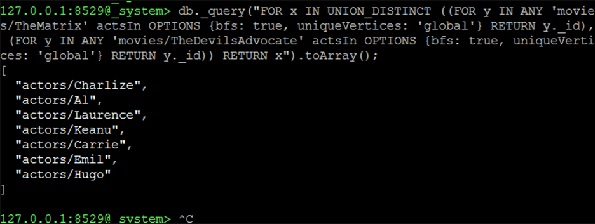
Теперь мы продолжаем формировать UNION_DISTINCT из двух запросов NEIGHBORS, которые будут решением -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Вывод
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
Второй вопрос
Давайте теперь рассмотрим второй вопрос: All actors who acted in both "movie1" AND "movie2". Это почти идентично поставленному выше вопросу. Но на этот раз нас интересует не СОЮЗ, а ПЕРЕСЕЧЕНИЕ -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Вывод
Мы получим следующий вывод -
[
"actors/Keanu"
]
Третий вопрос
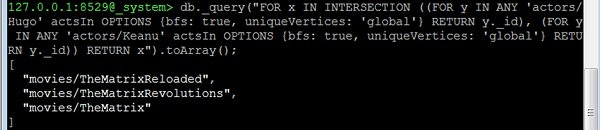
Давайте теперь рассмотрим третий вопрос: All common movies between "actor1" and "actor2". На самом деле это идентично вопросу об общих актерах в movie1 и movie2. Нам просто нужно изменить стартовые вершины. В качестве примера давайте найдем все фильмы, в которых снимаются Хьюго Уивинг («Хьюго») и Киану Ривз:
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();Вывод
Мы получим следующий вывод -
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
Четвертый вопрос
Давайте теперь рассмотрим четвертый вопрос. All actors who acted in 3 or more movies. Это другой вопрос; мы не можем использовать функцию соседей здесь. Вместо этого мы будем использовать edge-index и оператор COLLECT AQL для группировки. Основная идея - сгруппировать все ребра по ихstartVertex(который в этом наборе данных всегда является актером). Затем мы удаляем всех актеров с менее чем 3 фильмами из результата, поскольку здесь мы включили количество фильмов, в которых снимался актер -
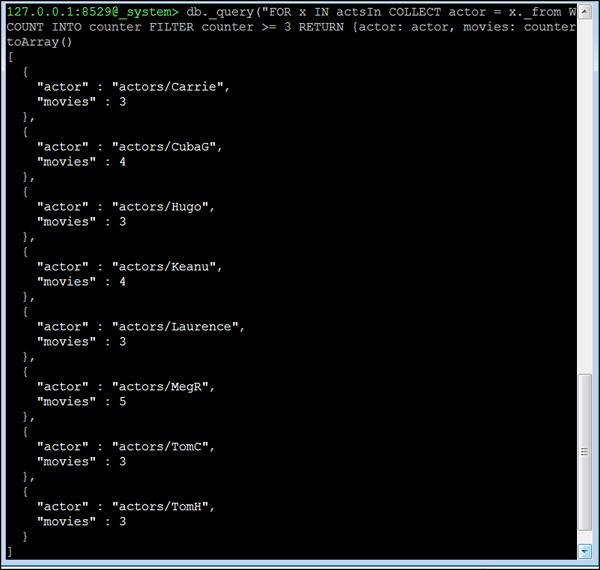
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()Вывод
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
По оставшимся вопросам мы обсудим формирование запроса и предоставим только запросы. Читателю следует самостоятельно запустить запрос на терминале Арангоша.
Пятый вопрос
Давайте теперь рассмотрим пятый вопрос: All movies where exactly 6 actors acted in. Та же идея, что и в предыдущем запросе, но с фильтром равенства. Однако теперь нам нужен фильм вместо актера, поэтому мы возвращаем_to attribute -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()Количество актеров по фильму?
Мы помним в нашем наборе данных _to по краю соответствует фильму, поэтому считаем, как часто _toпоявляется. Это количество актеров. Запрос почти идентичен предыдущим, ноwithout the FILTER after COLLECT -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()Шестой вопрос
Давайте теперь рассмотрим шестой вопрос: The number of movies by an actor.
То, как мы нашли решения для наших вышеуказанных запросов, поможет вам найти решение и для этого запроса.
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()В этой главе мы опишем различные возможности развертывания ArangoDB.
Развертывание: одиночный экземпляр
Мы уже узнали, как развернуть единственный экземпляр Linux (Ubuntu) в одной из наших предыдущих глав. Давайте теперь посмотрим, как выполнить развертывание с помощью Docker.
Развертывание: Docker
Для развертывания с помощью Docker мы установим Docker на нашу машину. Дополнительные сведения о Docker см. В нашем руководстве по Docker .
После установки Docker вы можете использовать следующую команду -
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d
arangodb/arangodbОн создаст и запустит экземпляр Docker для ArangoDB с идентифицирующим именем. agdbfoo как фоновый процесс Docker.
Также терминал распечатает идентификатор процесса.
По умолчанию порт 8529 зарезервирован для ArangoDB для прослушивания запросов. Также этот порт автоматически доступен для всех контейнеров приложений Docker, которые вы могли связать.