Caffe2 - Краткое руководство
Последние пару лет глубокое обучение стало большой тенденцией в машинном обучении. Он успешно применяется для решения ранее неразрешимых проблем в Vision, Speech Recognition and Natural Language Processing(НЛП). Есть еще много областей, в которых глубокое обучение применяется и показало свою полезность.
Caffe (Convolutional Architecture for Fast Feature Embedding) фреймворк глубокого обучения, разработанный в Berkeley Vision and Learning Center (BVLC). Проект Caffe был создан Янцин Цзя во время его докторской диссертации. в Калифорнийском университете в Беркли. Caffe предоставляет простой способ экспериментировать с глубоким обучением. Он написан на C ++ и предоставляет привязки дляPython а также Matlab.
Он поддерживает множество различных типов архитектур глубокого обучения, таких как CNN (Сверточная нейронная сеть), LSTM(Долговременная память) и FC (Полностью подключена). Он поддерживает графический процессор и, таким образом, идеально подходит для производственных сред с глубокими нейронными сетями. Он также поддерживает библиотеки ядра на базе ЦП, такие какNVIDIA, Библиотека CUDA Deep Neural Network (cuDNN) и библиотека Intel Math Kernel (Intel MKL).
В апреле 2017 года американская компания по предоставлению социальных сетей Facebook анонсировала Caffe2, который теперь включает RNN (Recurrent Neural Networks), а в марте 2018 года Caffe2 был объединен с PyTorch. Создатели Caffe2 и члены сообщества создали модели для решения различных задач. Эти модели доступны общественности в виде предварительно обученных моделей. Caffe2 помогает создателям использовать эти модели и создавать собственную сеть для прогнозирования набора данных.
Прежде чем мы углубимся в подробности Caffe2, давайте поймем разницу между machine learning а также deep learning. Это необходимо для понимания того, как модели создаются и используются в Caffe2.
Машинное обучение против глубокого обучения
В любом алгоритме машинного обучения, будь то традиционный или глубокий, выбор функций в наборе данных играет чрезвычайно важную роль в достижении желаемой точности прогнозов. В традиционных методах машинного обученияfeature selectionделается в основном с помощью человеческого осмотра, суждения и глубоких знаний в предметной области. Иногда вы можете обратиться за помощью к нескольким проверенным алгоритмам для выбора функций.
Традиционный процесс машинного обучения изображен на рисунке ниже -

В глубоком обучении выбор функций происходит автоматически и является частью самого алгоритма глубокого обучения. Это показано на рисунке ниже -

В алгоритмах глубокого обучения feature engineeringвыполняется автоматически. Как правило, разработка функций занимает много времени и требует хороших знаний в данной области. Чтобы реализовать автоматическое извлечение признаков, алгоритмы глубокого обучения обычно запрашивают огромный объем данных, поэтому, если у вас есть только тысячи и десятки тысяч точек данных, метод глубокого обучения может не дать вам удовлетворительных результатов.
При больших объемах данных алгоритмы глубокого обучения дают лучшие результаты по сравнению с традиционными алгоритмами машинного обучения с дополнительным преимуществом в виде меньшего количества функций или их отсутствия.
Теперь, когда вы получили некоторое представление о глубоком обучении, давайте рассмотрим, что такое Caffe.
Обучение CNN
Давайте изучим процесс обучения CNN классификации изображений. Процесс состоит из следующих шагов -
Data Preparation- На этом этапе мы обрезаем изображения по центру и изменяем их размер, чтобы все изображения для обучения и тестирования были одинакового размера. Обычно это делается путем запуска небольшого скрипта Python для данных изображения.
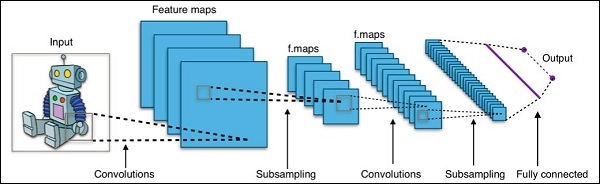
Model Definition- На этом этапе мы определяем архитектуру CNN. Конфигурация хранится в.pb (protobuf)файл. Типичная архитектура CNN показана на рисунке ниже.
Solver Definition- Определяем файл конфигурации решателя. Решатель выполняет оптимизацию модели.
Model Training- Для обучения модели используем встроенную утилиту Caffe. Обучение может занять много времени и ресурсов ЦП. После завершения обучения Caffe сохраняет модель в файле, который впоследствии можно использовать для тестовых данных и окончательного развертывания для прогнозов.
Что нового в Caffe2
В Caffe2 вы найдете множество готовых к использованию предварительно обученных моделей, а также довольно часто используете вклад сообщества в виде новых моделей и алгоритмов. Создаваемые вами модели можно легко масштабировать, используя возможности графического процессора в облаке, а также можно использовать массовые мобильные устройства с помощью кроссплатформенных библиотек.
Улучшения, сделанные в Caffe2 по сравнению с Caffe, можно резюмировать следующим образом:
- Мобильное развертывание
- Поддержка нового оборудования
- Поддержка масштабного распределенного обучения
- Квантованное вычисление
- Стресс-тест на Facebook
Демонстрация предварительно обученной модели
На сайте Berkeley Vision and Learning Center (BVLC) представлены демонстрации их предварительно обученных сетей. Одна такая сеть для классификации изображений доступна по указанной здесь ссылке.https://caffe2.ai/docs/learn-more#null__caffe-neural-network-for-image-classification и изображен на скриншоте ниже.
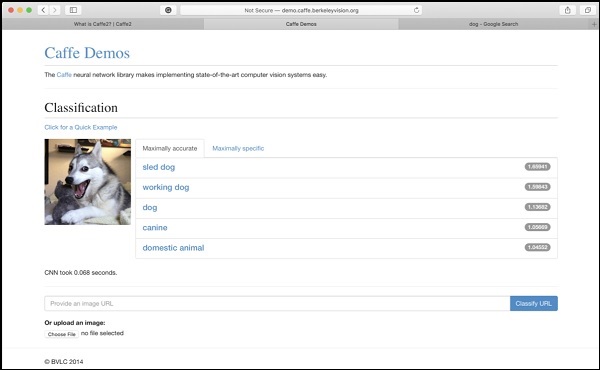
На скриншоте изображение собаки классифицировано и помечено с учетом точности прогноза. Также сказано, что потребовалось всего0.068 secondsклассифицировать изображение. Вы можете попробовать изображение по вашему выбору, указав URL-адрес изображения или загрузив само изображение в параметрах, указанных в нижней части экрана.
Теперь, когда вы получили достаточно информации о возможностях Caffe2, пришло время поэкспериментировать с Caffe2 самостоятельно. Чтобы использовать предварительно обученные модели или разрабатывать модели в собственном коде Python, вы должны сначала установить Caffe2 на свой компьютер.
На странице установки сайта Caffe2, доступной по ссылке https://caffe2.ai/docs/getting-started.html вы увидите следующее, чтобы выбрать свою платформу и тип установки.

Как вы можете видеть на скриншоте выше, Caffe2 поддерживает несколько популярных платформ, в том числе и мобильные.
Теперь мы поймем шаги для MacOS installation на котором тестируются все проекты в этом руководстве.
Установка MacOS
Установка может быть четырех типов, как указано ниже -
- Предварительно созданные двоичные файлы
- Сборка из исходного кода
- Образы Docker
- Cloud
В зависимости от ваших предпочтений выберите любой из вышеперечисленных в качестве типа установки. Приведенные здесь инструкции относятся к месту установки Caffe2 дляpre-built binaries. Он использует Anaconda дляJupyter environment. Выполните следующую команду в командной строке консоли
pip install torch_nightly -f
https://download.pytorch.org/whl/nightly/cpu/torch_nightly.htmlВ дополнение к вышесказанному вам понадобится несколько сторонних библиотек, которые устанавливаются с помощью следующих команд:
conda install -c anaconda setuptools
conda install -c conda-forge graphviz
conda install -c conda-forge hypothesis
conda install -c conda-forge ipython
conda install -c conda-forge jupyter
conda install -c conda-forge matplotlib
conda install -c anaconda notebook
conda install -c anaconda pydot
conda install -c conda-forge python-nvd3
conda install -c anaconda pyyaml
conda install -c anaconda requests
conda install -c anaconda scikit-image
conda install -c anaconda scipyДля некоторых руководств на веб-сайте Caffe2 также требуется установка zeromq, который устанавливается с помощью следующей команды -
conda install -c anaconda zeromqУстановка Windows / Linux
Выполните следующую команду в командной строке консоли -
conda install -c pytorch pytorch-nightly-cpuКак вы, должно быть, заметили, для использования вышеуказанной установки вам понадобится Anaconda. Вам нужно будет установить дополнительные пакеты, как указано вMacOS installation.
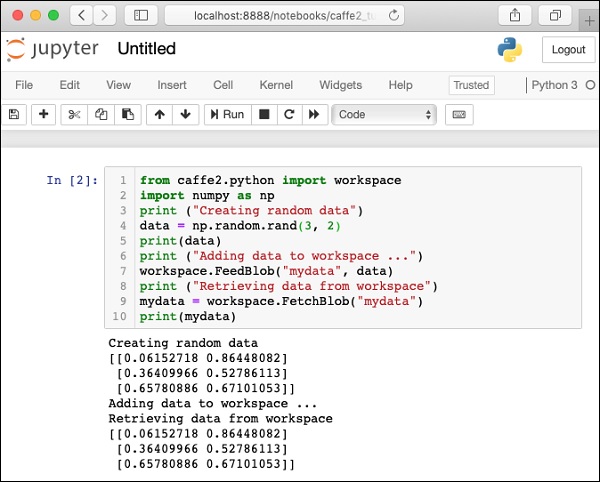
Тестовая установка
Для проверки вашей установки ниже приведен небольшой скрипт Python, который вы можете вырезать и вставить в свой проект Juypter и выполнить.
from caffe2.python import workspace
import numpy as np
print ("Creating random data")
data = np.random.rand(3, 2)
print(data)
print ("Adding data to workspace ...")
workspace.FeedBlob("mydata", data)
print ("Retrieving data from workspace")
mydata = workspace.FetchBlob("mydata")
print(mydata)Когда вы выполните приведенный выше код, вы должны увидеть следующий результат -
Creating random data
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]
Adding data to workspace ...
Retrieving data from workspace
[[0.06152718 0.86448082]
[0.36409966 0.52786113]
[0.65780886 0.67101053]]Снимок экрана с тестовой страницей установки показан здесь для вашего быстрого ознакомления -
Теперь, когда вы установили Caffe2 на свой компьютер, приступайте к установке обучающих приложений.
Учебник по установке
Загрузите исходный код учебников, используя следующую команду на вашей консоли -
git clone --recursive https://github.com/caffe2/tutorials caffe2_tutorialsПосле завершения загрузки вы найдете несколько проектов Python в папке caffe2_tutorialsпапку в каталоге установки. Скриншот этой папки предоставлен для быстрого ознакомления.
/Users/yourusername/caffe2_tutorials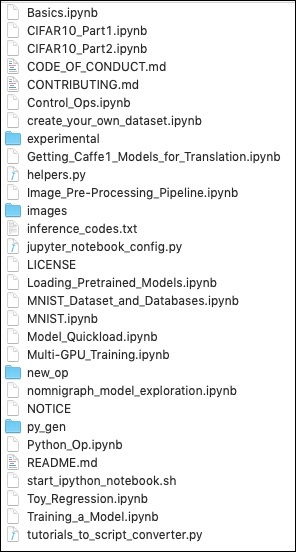
Вы можете открыть некоторые из этих руководств, чтобы узнать, что Caffe2 codeпохоже. Следующие два проекта, описанные в этом руководстве, в значительной степени основаны на примерах, показанных выше.
Пришло время заняться написанием кода на Python самостоятельно. Давайте разберемся, как пользоваться предварительно обученной моделью из Caffe2. Позже вы научитесь создавать свою собственную тривиальную нейронную сеть для обучения на собственном наборе данных.
Прежде чем вы научитесь использовать предварительно обученную модель в своем приложении Python, позвольте нам сначала убедиться, что модели установлены на вашем компьютере и доступны через код Python.
При установке Caffe2 предварительно обученные модели копируются в папку установки. На машине с установленной Anaconda эти модели доступны в следующей папке.
anaconda3/lib/python3.7/site-packages/caffe2/python/modelsПроверьте наличие этих моделей в папке установки на вашем компьютере. Вы можете попробовать загрузить эти модели из установочной папки с помощью следующего короткого скрипта Python -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Когда скрипт запустится успешно, вы увидите следующий вывод -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbЭто подтверждает, что squeezenet модуль установлен на вашем компьютере и доступен для вашего кода.
Теперь вы готовы написать свой собственный код Python для классификации изображений с помощью Caffe2. squeezenet предварительно обученный модуль.
В этом уроке вы научитесь использовать предварительно обученную модель для обнаружения объектов на заданном изображении. Вы будете использоватьsqueezenet предварительно обученный модуль, который с большой точностью обнаруживает и классифицирует объекты на заданном изображении.
Открыть новый Juypter notebook и следуйте инструкциям по разработке этого приложения для классификации изображений.
Импорт библиотек
Сначала мы импортируем необходимые пакеты, используя приведенный ниже код -
from caffe2.proto import caffe2_pb2
from caffe2.python import core, workspace, models
import numpy as np
import skimage.io
import skimage.transform
from matplotlib import pyplot
import os
import urllib.request as urllib2
import operatorДалее мы настроили несколько variables -
INPUT_IMAGE_SIZE = 227
mean = 128Очевидно, что изображения, используемые для обучения, будут разных размеров. Все эти изображения необходимо преобразовать в фиксированный размер для точного обучения. Точно так же тестовые изображения и изображение, которое вы хотите прогнозировать в производственной среде, также должны быть преобразованы в размер, такой же, как тот, который использовался во время обучения. Таким образом, мы создаем переменную выше, названнуюINPUT_IMAGE_SIZE имеющий ценность 227. Следовательно, мы конвертируем все наши изображения в размер227x227 перед использованием в нашем классификаторе.
Мы также объявляем переменную с именем mean имеющий ценность 128, который позже используется для улучшения результатов классификации.
Далее мы разработаем две функции для обработки изображения.
Обработка изображения
Обработка изображения состоит из двух этапов. Первый - изменить размер изображения, а второй - обрезать его по центру. Для этих двух шагов мы напишем две функции для изменения размера и обрезки.
Изменение размера изображения
Сначала мы напишем функцию для изменения размера изображения. Как было сказано ранее, мы изменим размер изображения на227x227. Итак, давайте определим функциюresize следующим образом -
def resize(img, input_height, input_width):Соотношение сторон изображения получается делением ширины на высоту.
original_aspect = img.shape[1]/float(img.shape[0])Если соотношение сторон больше 1, это означает, что изображение широкое, то есть в альбомном режиме. Теперь мы настраиваем высоту изображения и возвращаем изображение с измененным размером, используя следующий код -
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Если соотношение сторон less than 1, это указывает portrait mode. Теперь мы настраиваем ширину, используя следующий код -
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Если соотношение сторон равно 1, мы не делаем никаких корректировок по высоте / ширине.
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Полный код функции приведен ниже для вашего быстрого ознакомления -
def resize(img, input_height, input_width):
original_aspect = img.shape[1]/float(img.shape[0])
if(original_aspect>1):
new_height = int(original_aspect * input_height)
return skimage.transform.resize(img, (input_width,
new_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect<1):
new_width = int(input_width/original_aspect)
return skimage.transform.resize(img, (new_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)
if(original_aspect == 1):
return skimage.transform.resize(img, (input_width,
input_height), mode='constant', anti_aliasing=True, anti_aliasing_sigma=None)Теперь напишем функцию обрезки изображения вокруг его центра.
Обрезка изображения
Мы объявляем crop_image функционируют следующим образом -
def crop_image(img,cropx,cropy):Мы извлекаем размеры изображения, используя следующее утверждение -
y,x,c = img.shapeМы создаем новую отправную точку для изображения, используя следующие две строки кода:
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)Наконец, мы возвращаем обрезанное изображение, создавая объект изображения с новыми размерами -
return img[starty:starty+cropy,startx:startx+cropx]Полный код функции приведен ниже для вашего быстрого ознакомления -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]Теперь мы напишем код для тестирования этих функций.
Обработка изображения
Сначала скопируйте файл изображения в images вложенная папка в каталоге вашего проекта. tree.jpgфайл копируется в проект. Следующий код Python загружает изображение и отображает его на консоли:
img = skimage.img_as_float(skimage.io.imread("images/tree.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')Результат выглядит следующим образом -
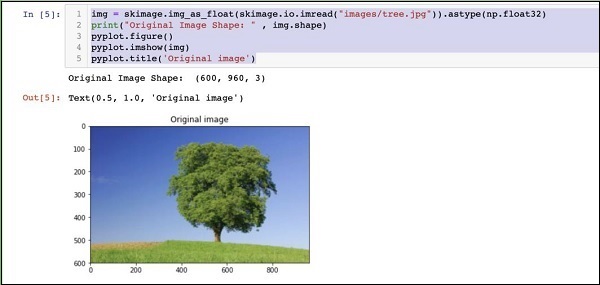
Обратите внимание, что размер исходного изображения 600 x 960. Нам нужно изменить его размер в соответствии с нашей спецификацией227 x 227. Вызов нашего ранее определенногоresizeфункция выполняет эту работу.
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')Результат приведен ниже -
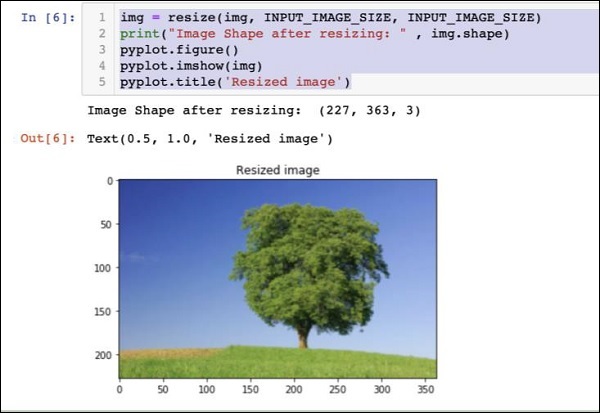
Обратите внимание, что теперь размер изображения 227 x 363. Нам нужно обрезать это до227 x 227для окончательной подачи нашего алгоритма. Для этого мы вызываем ранее определенную функцию кадрирования.
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')Ниже приведен вывод кода -
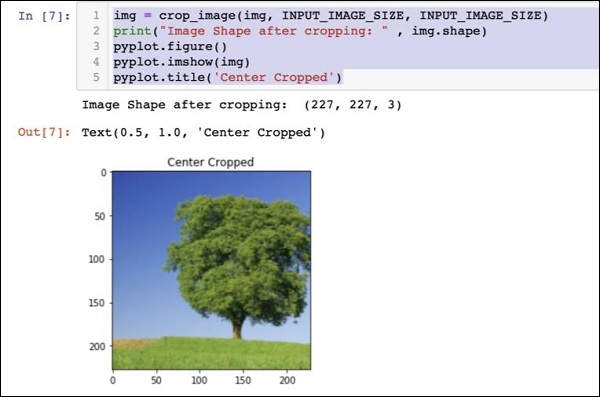
На данный момент изображение имеет размер 227 x 227и готов к дальнейшей обработке. Теперь мы меняем местами оси изображения, чтобы выделить три цвета в три разные зоны.
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)Ниже приведен результат -
CHW Image Shape: (3, 227, 227)Обратите внимание, что последняя ось теперь стала первым измерением в массиве. Теперь мы построим три канала, используя следующий код -
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))Результат указан ниже -

Наконец, мы делаем некоторую дополнительную обработку изображения, такую как преобразование Red Green Blue к Blue Green Red (RGB to BGR), удалив среднее значение для лучших результатов и добавив ось размера партии, используя следующие три строки кода:
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)На данный момент ваше изображение находится в NCHW formatи готов к использованию в нашей сети. Затем мы загрузим файлы наших предварительно обученных моделей и загрузим в них приведенное выше изображение для прогнозирования.
Прогнозирование объектов в обработанном изображении
Сначала мы настраиваем пути для init а также predict сети, определенные в предварительно обученных моделях Caffe.
Установка путей к файлам модели
Помните из нашего предыдущего обсуждения, все предварительно обученные модели устанавливаются в modelsпапка. Мы настроили путь к этой папке следующим образом -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")Мы проложили путь к init_net protobuf файл squeezenet модель следующим образом -
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')Таким же образом мы настраиваем путь к predict_net protobuf следующим образом -
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')Мы печатаем два пути для диагностики -
print(INIT_NET)
print(PREDICT_NET)Приведенный выше код вместе с выводом приведен здесь для вашего быстрого ознакомления -
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)Вывод упомянут ниже -
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/init_net.pb
/anaconda3/lib/python3.7/site-packages/caffe2/python/models/squeezenet/predict_net.pbДалее мы создадим предсказатель.
Создание предиктора
Мы читаем файлы модели, используя следующие два оператора:
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()Предиктор создается путем передачи указателей на два файла в качестве параметров в Predictor функция.
p = workspace.Predictor(init_net, predict_net)В pобъект - это предсказатель, который используется для предсказания объектов в любом данном изображении. Обратите внимание, что каждое входное изображение должно быть в формате NCHW, как то, что мы сделали ранее с нашимtree.jpg файл.
Предсказание объектов
Предсказать объекты на данном изображении тривиально - достаточно выполнить единственную строку команды. Мы называемrun метод на predictor объект для обнаружения объекта на данном изображении.
results = p.run({'data': img})Результаты прогнозов теперь доступны в results объект, который мы конвертируем в массив для удобства чтения.
results = np.asarray(results)Распечатайте размеры массива для вашего понимания, используя следующий оператор -
print("results shape: ", results.shape)Результат показан ниже -
results shape: (1, 1, 1000, 1, 1)Теперь удалим ненужную ось -
preds = np.squeeze(results)Теперь можно получить верхнее предикатное значение, взяв max ценность в preds массив.
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)Результат выглядит следующим образом -
Prediction: 984
Confidence: 0.89235985Как видите, модель предсказала объект со значением индекса 984 с участием 89%уверенность. Индекс 984 не имеет большого смысла для понимания того, какой объект обнаружен. Нам нужно получить строковое имя для объекта, используя его значение индекса. Типы объектов, которые распознает модель, и соответствующие им значения индекса доступны в репозитории github.
Теперь мы увидим, как получить имя для нашего объекта, имеющего значение индекса 984.
Стрингирующий результат
Мы создаем объект URL для репозитория github следующим образом:
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac0
71eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"Читаем содержимое URL -
response = urllib2.urlopen(codes)Ответ будет содержать список всех кодов и их описания. Ниже показано несколько строк ответа, чтобы вы поняли, что он содержит -
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',Теперь мы перебираем весь массив, чтобы найти желаемый код 984, используя for цикл следующим образом -
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")Когда вы запустите код, вы увидите следующий вывод -
Model predicts rapeseed with 0.89235985 confidenceТеперь вы можете попробовать модель на другом изображении.
Предсказание другого изображения
Чтобы предсказать другое изображение, просто скопируйте файл изображения в imagesпапка в каталоге вашего проекта. Это каталог, в котором былиtree.jpgфайл сохраняется. Измените имя файла изображения в коде. Требуется только одно изменение, как показано ниже
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)Исходное изображение и результат прогноза показаны ниже -

Вывод упомянут ниже -
Model predicts pretzel with 0.99999976 confidenceКак видите, предварительно обученная модель способна обнаруживать объекты на заданном изображении с большой точностью.
Полный исходный код
Полный источник приведенного выше кода, который использует предварительно обученную модель для обнаружения объектов на данном изображении, упомянут здесь для вашего быстрого ознакомления -
def crop_image(img,cropx,cropy):
y,x,c = img.shape
startx = x//2-(cropx//2)
starty = y//2-(cropy//2)
return img[starty:starty+cropy,startx:startx+cropx]
img = skimage.img_as_float(skimage.io.imread("images/pretzel.jpg")).astype(np.float32)
print("Original Image Shape: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Original image')
img = resize(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after resizing: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Resized image')
img = crop_image(img, INPUT_IMAGE_SIZE, INPUT_IMAGE_SIZE)
print("Image Shape after cropping: " , img.shape)
pyplot.figure()
pyplot.imshow(img)
pyplot.title('Center Cropped')
img = img.swapaxes(1, 2).swapaxes(0, 1)
print("CHW Image Shape: " , img.shape)
pyplot.figure()
for i in range(3):
pyplot.subplot(1, 3, i+1)
pyplot.imshow(img[i])
pyplot.axis('off')
pyplot.title('RGB channel %d' % (i+1))
# convert RGB --> BGR
img = img[(2, 1, 0), :, :]
# remove mean
img = img * 255 - mean
# add batch size axis
img = img[np.newaxis, :, :, :].astype(np.float32)
CAFFE_MODELS = os.path.expanduser("/anaconda3/lib/python3.7/site-packages/caffe2/python/models")
INIT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'init_net.pb')
PREDICT_NET = os.path.join(CAFFE_MODELS, 'squeezenet', 'predict_net.pb')
print(INIT_NET)
print(PREDICT_NET)
with open(INIT_NET, "rb") as f:
init_net = f.read()
with open(PREDICT_NET, "rb") as f:
predict_net = f.read()
p = workspace.Predictor(init_net, predict_net)
results = p.run({'data': img})
results = np.asarray(results)
print("results shape: ", results.shape)
preds = np.squeeze(results)
curr_pred, curr_conf = max(enumerate(preds), key=operator.itemgetter(1))
print("Prediction: ", curr_pred)
print("Confidence: ", curr_conf)
codes = "https://gist.githubusercontent.com/aaronmarkham/cd3a6b6ac071eca6f7b4a6e40e6038aa/raw/9edb4038a37da6b5a44c3b5bc52e448ff09bfe5b/alexnet_codes"
response = urllib2.urlopen(codes)
for line in response:
mystring = line.decode('ascii')
code, result = mystring.partition(":")[::2]
code = code.strip()
result = result.replace("'", "")
if (code == str(curr_pred)):
name = result.split(",")[0][1:]
print("Model predicts", name, "with", curr_conf, "confidence")К этому времени вы знаете, как использовать предварительно обученную модель для прогнозирования вашего набора данных.
Что дальше - узнать, как определить свой neural network (NN) архитектуры в Caffe2и обучите их на своем наборе данных. Теперь мы узнаем, как создать простую однослойную NN.
В этом уроке вы научитесь определять single layer neural network (NN)в Caffe2 и запустите его на случайно сгенерированном наборе данных. Мы напишем код для графического изображения сетевой архитектуры, печати ввода, вывода, весов и значений смещения. Чтобы понять этот урок, вы должны знатьneural network architectures, его terms а также mathematics используется в них.
Сетевая архитектура
Давайте предположим, что мы хотим построить однослойную NN, как показано на рисунке ниже -

Математически эта сеть представлена следующим кодом Python -
Y = X * W^T + bкуда X, W, b являются тензорами и Yэто выход. Мы заполним все три тензора случайными данными, запустим сеть и исследуемYвыход. Для определения сети и тензоров Caffe2 предоставляет несколькоOperator функции.
Операторы Caffe2
В Caffe2, Operatorэто основная единица вычисления. Кафе2Operator представлен следующим образом.
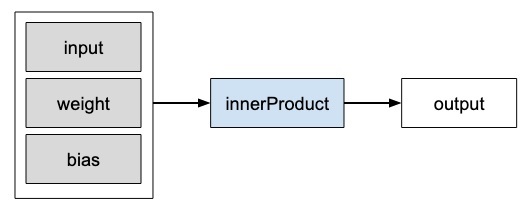
Caffe2 предоставляет исчерпывающий список операторов. Для сети, которую мы проектируем в настоящее время, мы будем использовать оператор FC, который вычисляет результат передачи входного вектора.X в полносвязную сеть с двумерной весовой матрицей W и одномерный вектор смещения b. Другими словами, он вычисляет следующее математическое уравнение
Y = X * W^T + bкуда X имеет размеры (M x k), W имеет размеры (n x k) а также b является (1 x n). ВыходY будет иметь размер (M x n), где M размер партии.
Для векторов X а также W, мы будем использовать GaussianFillоператор для создания случайных данных. Для создания значений смещенияb, мы будем использовать ConstantFill оператор.
Теперь приступим к определению нашей сети.
Создание сети
Прежде всего, импортируйте необходимые пакеты -
from caffe2.python import core, workspaceЗатем определите сеть, вызвав core.Net следующим образом -
net = core.Net("SingleLayerFC")Имя сети указывается как SingleLayerFC. На этом этапе создается сетевой объект с именем net. Пока он не содержит слоев.
Создание тензоров
Теперь мы создадим три вектора, необходимые для нашей сети. Сначала мы создадим тензор X, вызвавGaussianFill оператор следующим образом -
X = net.GaussianFill([], ["X"], mean=0.0, std=1.0, shape=[2, 3], run_once=0)В X вектор имеет размеры 2 x 3 со средним значением данных 0,0 и стандартным отклонением 1.0.
Точно так же мы создаем W тензор следующим образом -
W = net.GaussianFill([], ["W"], mean=0.0, std=1.0, shape=[5, 3], run_once=0)В W вектор имеет размер 5 x 3.
Наконец, мы создаем предвзятость b матрица размера 5.
b = net.ConstantFill([], ["b"], shape=[5,], value=1.0, run_once=0)Теперь наступает самая важная часть кода - определение самой сети.
Определение сети
Мы определяем сеть в следующем заявлении Python -
Y = X.FC([W, b], ["Y"])Мы называем FC оператор входных данных X. Вес указан вWи предвзятость в b. На выходеY. В качестве альтернативы вы можете создать сеть, используя следующую инструкцию Python, которая является более подробной.
Y = net.FC([X, W, b], ["Y"])На этом этапе сеть просто создана. Пока мы не запустим сеть хотя бы один раз, она не будет содержать никаких данных. Перед запуском сети рассмотрим ее архитектуру.
Архитектура сети печати
Caffe2 определяет сетевую архитектуру в файле JSON, который можно проверить, вызвав метод Proto на созданном net объект.
print (net.Proto())Это дает следующий результат -
name: "SingleLayerFC"
op {
output: "X"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 2
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "W"
name: ""
type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
arg {
name: "run_once"
i: 0
}
}
op {
output: "b"
name: ""
type: "ConstantFill"
arg {
name: "shape"
ints: 5
}
arg {
name: "value"
f: 1.0
}
arg {
name: "run_once"
i: 0
}
}
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Как вы можете видеть в приведенном выше листинге, он сначала определяет операторы X, W а также b. Разберем определениеWНапример. ТипW указывается как GausianFill. Вmean определяется как float 0.0, стандартное отклонение определяется как float 1.0, а shape является 5 x 3.
op {
output: "W"
name: "" type: "GaussianFill"
arg {
name: "mean"
f: 0.0
}
arg {
name: "std"
f: 1.0
}
arg {
name: "shape"
ints: 5
ints: 3
}
...
}Изучите определения X а также bдля вашего собственного понимания. Наконец, давайте посмотрим на определение нашей однослойной сети, которое воспроизводится здесь.
op {
input: "X"
input: "W"
input: "b"
output: "Y"
name: ""
type: "FC"
}Здесь тип сети FC (Полностью подключен) с X, W, b в качестве входов и Yэто выход. Это определение сети слишком подробное, и для больших сетей будет утомительно изучать его содержимое. К счастью, Caffe2 предоставляет графическое представление созданных сетей.
Графическое представление сети
Чтобы получить графическое представление сети, запустите следующий фрагмент кода, который по сути представляет собой только две строки кода Python.
from caffe2.python import net_drawer
from IPython import display
graph = net_drawer.GetPydotGraph(net, rankdir="LR")
display.Image(graph.create_png(), width=800)Когда вы запустите код, вы увидите следующий вывод -
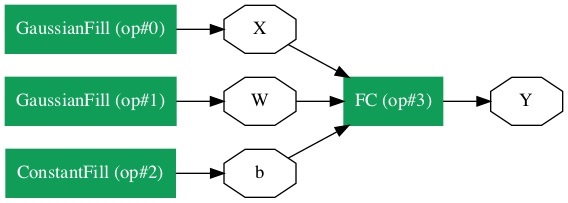
Для больших сетей графическое представление становится чрезвычайно полезным при визуализации и отладке ошибок определения сети.
Наконец, пришло время запустить сеть.
Запуск сети
Вы запускаете сеть, вызывая RunNetOnce метод на workspace объект -
workspace.RunNetOnce(net)После того, как сеть будет запущена один раз, все наши данные, которые генерируются случайным образом, будут созданы, введены в сеть и будут созданы выходные данные. Тензоры, которые создаются после запуска сети, называютсяblobsв Caffe2. Рабочее пространство состоит изblobsвы создаете и храните в памяти. Это очень похоже на Matlab.
После запуска сети вы можете проверить blobs что рабочая область содержит, используя следующие print команда
print("Blobs in the workspace: {}".format(workspace.Blobs()))Вы увидите следующий вывод -
Blobs in the workspace: ['W', 'X', 'Y', 'b']Обратите внимание, что рабочая область состоит из трех входных BLOB-объектов - X, W а также b. Он также содержит выходной BLOB-объект с именемY. Давайте теперь исследуем содержимое этих блобов.
for name in workspace.Blobs():
print("{}:\n{}".format(name, workspace.FetchBlob(name)))Вы увидите следующий вывод -
W:
[[ 1.0426593 0.15479846 0.25635982]
[-2.2461145 1.4581774 0.16827184]
[-0.12009818 0.30771437 0.00791338]
[ 1.2274994 -0.903331 -0.68799865]
[ 0.30834186 -0.53060573 0.88776857]]
X:
[[ 1.6588869e+00 1.5279824e+00 1.1889904e+00]
[ 6.7048723e-01 -9.7490678e-04 2.5114202e-01]]
Y:
[[ 3.2709925 -0.297907 1.2803618 0.837985 1.7562964]
[ 1.7633215 -0.4651525 0.9211631 1.6511179 1.4302125]]
b:
[1. 1. 1. 1. 1.]Обратите внимание, что данные на вашем компьютере или, фактически, при каждом запуске сети будут разными, поскольку все входные данные создаются случайным образом. Вы успешно определили сеть и запустили ее на своем компьютере.
На предыдущем уроке вы научились создавать простую сеть, научились ее выполнять и исследовать ее выходные данные. Процесс создания сложных сетей аналогичен процессу, описанному выше. Caffe2 предоставляет огромный набор операторов для создания сложных архитектур. Предлагаем вам изучить документацию Caffe2 для получения списка операторов. Изучив назначение различных операторов, вы сможете создавать сложные сети и обучать их. Для обучения сети Caffe2 предоставляет несколькоpredefined computation units- это операторы. Вам нужно будет выбрать подходящих операторов для обучения вашей сети тому типу проблемы, которую вы пытаетесь решить.
После того, как сеть обучена до вашего удовлетворения, вы можете сохранить ее в файле модели, аналогичном предварительно обученным файлам модели, которые вы использовали ранее. Эти обученные модели могут быть добавлены в репозиторий Caffe2 для использования другими пользователями. Или вы можете просто использовать обученную модель для собственного частного производственного использования.
Резюме
Caffe2, фреймворк для глубокого обучения, позволяет экспериментировать с несколькими видами нейронных сетей для прогнозирования ваших данных. Сайт Caffe2 предоставляет множество предварительно обученных моделей. Вы научились использовать одну из предварительно обученных моделей для классификации объектов на данном изображении. Вы также научились определять архитектуру нейронной сети по своему выбору. Такие пользовательские сети можно обучить с помощью множества предопределенных операторов в Caffe. Обученная модель сохраняется в файле, который можно использовать в производственной среде.