Кассандра - Краткое руководство
Apache Cassandra - это хорошо масштабируемая высокопроизводительная распределенная база данных, предназначенная для обработки больших объемов данных на многих стандартных серверах, обеспечивая высокую доступность без единой точки отказа. Это разновидность базы данных NoSQL. Давайте сначала поймем, что делает база данных NoSQL.
NoSQLDatabase
База данных NoSQL (иногда называемая Not Only SQL) - это база данных, которая предоставляет механизм для хранения и извлечения данных, отличный от табличных отношений, используемых в реляционных базах данных. Эти базы данных не содержат схемы, поддерживают легкую репликацию, имеют простой API, в конечном итоге согласованный, и могут обрабатывать огромные объемы данных.
Основная цель базы данных NoSQL - иметь
- простота конструкции,
- горизонтальное масштабирование и
- более тонкий контроль над доступностью.
Базы данных NoSql используют другие структуры данных по сравнению с реляционными базами данных. Это ускоряет некоторые операции в NoSQL. Пригодность данной базы данных NoSQL зависит от проблемы, которую она должна решить.
NoSQL против реляционной базы данных
В следующей таблице перечислены моменты, которые отличают реляционную базу данных от базы данных NoSQL.
| Реляционная база данных | База данных NoSql |
|---|---|
| Поддерживает мощный язык запросов. | Поддерживает очень простой язык запросов. |
| Имеет фиксированную схему. | Нет фиксированной схемы. |
| Следует ACID (атомарность, согласованность, изоляция и долговечность). | Это только «в конечном итоге». |
| Поддерживает транзакции. | Не поддерживает транзакции. |
Помимо Cassandra, у нас есть следующие довольно популярные базы данных NoSQL:
Apache HBase- HBase - это нереляционная распределенная база данных с открытым исходным кодом, созданная по образцу Google BigTable и написанная на Java. Он разработан как часть проекта Apache Hadoop и работает поверх HDFS, предоставляя возможности BigTable для Hadoop.
MongoDB - MongoDB - это кроссплатформенная система баз данных, ориентированная на документы, которая избегает использования традиционной табличной структуры реляционной базы данных в пользу JSON-подобных документов с динамическими схемами, что упрощает и ускоряет интеграцию данных в определенные типы приложений.
Что такое Apache Cassandra?
Apache Cassandra - это распределенная и децентрализованная / распределенная система хранения (база данных) с открытым исходным кодом, предназначенная для управления очень большими объемами структурированных данных, разбросанных по всему миру. Он обеспечивает высокодоступный сервис без единой точки отказа.
Ниже перечислены некоторые из примечательных моментов Apache Cassandra:
Он масштабируемый, отказоустойчивый и согласованный.
Это база данных, ориентированная на столбцы.
Его дизайн распространения основан на Dynamo от Amazon и его модели данных на Bigtable от Google.
Созданный в Facebook, он резко отличается от систем управления реляционными базами данных.
Cassandra реализует модель репликации в стиле Dynamo без единой точки отказа, но добавляет более мощную модель данных «семейства столбцов».
Cassandra используется некоторыми крупнейшими компаниями, такими как Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix и другими.
Особенности Кассандры
Кассандра стала настолько популярной из-за своих выдающихся технических характеристик. Ниже приведены некоторые особенности Cassandra:
Elastic scalability- Cassandra хорошо масштабируется; это позволяет добавить больше оборудования для обслуживания большего количества клиентов и большего количества данных в соответствии с требованиями.
Always on architecture - У Cassandra нет единой точки отказа, и она постоянно доступна для критически важных бизнес-приложений, которые не могут позволить себе отказ.
Fast linear-scale performance- Cassandra линейно масштабируется, т. Е. Увеличивает пропускную способность по мере увеличения количества узлов в кластере. Следовательно, он обеспечивает быстрое время отклика.
Flexible data storage- Cassandra поддерживает все возможные форматы данных, включая структурированные, полуструктурированные и неструктурированные. Он может динамически вносить изменения в ваши структуры данных в соответствии с вашими потребностями.
Easy data distribution - Cassandra обеспечивает гибкость для распределения данных там, где вам нужно, реплицируя данные в нескольких центрах обработки данных.
Transaction support - Cassandra поддерживает такие свойства, как атомарность, согласованность, изоляция и долговечность (ACID).
Fast writes- Cassandra была разработана для работы на дешевом стандартном оборудовании. Он выполняет невероятно быструю запись и может хранить сотни терабайт данных без ущерба для эффективности чтения.
История Кассандры
- Кассандра была разработана в Facebook для поиска во входящих.
- Он был открыт в Facebook в июле 2008 года.
- Кассандра была принята в Apache Incubator в марте 2009 года.
- Это был проект верхнего уровня Apache с февраля 2010 года.
Целью разработки Cassandra является обработка рабочих нагрузок с большими данными на нескольких узлах без единой точки отказа. У Cassandra есть одноранговая распределенная система между своими узлами, и данные распределяются между всеми узлами в кластере.
Все узлы в кластере играют одинаковую роль. Каждый узел независим и в то же время взаимосвязан с другими узлами.
Каждый узел в кластере может принимать запросы на чтение и запись независимо от того, где на самом деле находятся данные в кластере.
Когда узел выходит из строя, запросы на чтение / запись могут обслуживаться другими узлами в сети.
Репликация данных в Cassandra
В Cassandra один или несколько узлов в кластере действуют как реплики для данного фрагмента данных. Если обнаружено, что некоторые из узлов ответили устаревшим значением, Cassandra вернет клиенту самое последнее значение. После возврата самого последнего значения Cassandra выполняетread repair в фоновом режиме, чтобы обновить устаревшие значения.
На следующем рисунке схематично показано, как Cassandra использует репликацию данных между узлами в кластере, чтобы гарантировать отсутствие единой точки отказа.
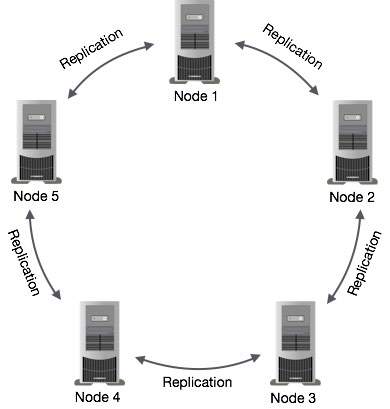
Note - Кассандра использует Gossip Protocol в фоновом режиме, чтобы узлы могли взаимодействовать друг с другом и обнаруживать любые неисправные узлы в кластере.
Компоненты Кассандры
Ключевые компоненты Cassandra следующие:
Node - Это место, где хранятся данные.
Data center - Это набор связанных узлов.
Cluster - Кластер - это компонент, содержащий один или несколько центров обработки данных.
Commit log- Журнал фиксации - это механизм восстановления после сбоя в Cassandra. Каждая операция записи записывается в журнал фиксации.
Mem-table- Mem-таблица - это резидентная структура данных в памяти. После журнала фиксации данные будут записаны в мем-таблицу. Иногда для семейства с одним столбцом может быть несколько таблиц памяти.
SSTable - Это дисковый файл, на который данные выгружаются из таблицы памяти, когда ее содержимое достигает порогового значения.
Bloom filter- Это не что иное, как быстрые, недетерминированные алгоритмы для проверки того, является ли элемент членом набора. Это особый вид тайника. Доступ к фильтрам Блума осуществляется после каждого запроса.
Язык запросов Cassandra
Пользователи могут получить доступ к Cassandra через его узлы, используя язык запросов Cassandra Query Language (CQL). CQL обрабатывает базу данных(Keyspace)как контейнер таблиц. Программисты используютcqlsh: подсказка для работы с CQL или драйверами отдельных языков приложения.
Клиенты обращаются к любому из узлов для выполнения операций чтения-записи. Этот узел (координатор) играет прокси между клиентом и узлами, содержащими данные.
Операции записи
Каждая операция записи узлов фиксируется commit logsнаписано в узлах. Позже данные будут захвачены и сохранены вmem-table. Когда мем-таблица заполнится, данные будут записаны в SStableфайл данных. Все записи автоматически разбиваются на разделы и реплицируются по всему кластеру. Cassandra периодически объединяет SSTables, удаляя ненужные данные.
Читать операции
Во время операций чтения Cassandra получает значения из таблицы mem и проверяет фильтр Блума, чтобы найти подходящую SSTable, которая содержит требуемые данные.
Модель данных Cassandra значительно отличается от того, что мы обычно видим в СУБД. В этой главе представлен обзор того, как Cassandra хранит свои данные.
Кластер
База данных Cassandra распределена по нескольким машинам, которые работают вместе. Самый внешний контейнер известен как кластер. Для обработки сбоев каждый узел содержит реплику, а в случае сбоя реплика берет на себя ответственность. Кассандра упорядочивает узлы в кластере в формате кольца и назначает им данные.
Keyspace
Keyspace - это внешний контейнер для данных в Cassandra. Основные атрибуты Keyspace в Cassandra:
Replication factor - Это количество машин в кластере, которые получат копии одних и тех же данных.
Replica placement strategy- Это не что иное, как стратегия размещения реплик на ринге. У нас есть такие стратегии, какsimple strategy (стратегия с учетом стойки), old network topology strategy (стратегия с учетом стойки) и network topology strategy (стратегия совместного использования центра обработки данных).
Column families- Keyspace - это контейнер для списка из одного или нескольких семейств столбцов. Семейство столбцов, в свою очередь, представляет собой контейнер для набора строк. Каждая строка содержит упорядоченные столбцы. Семейства столбцов представляют структуру ваших данных. Каждое пространство ключей имеет как минимум одно, а часто и несколько семейств столбцов.
Синтаксис создания пространства ключей следующий:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};На следующем рисунке показано схематическое изображение Keyspace.
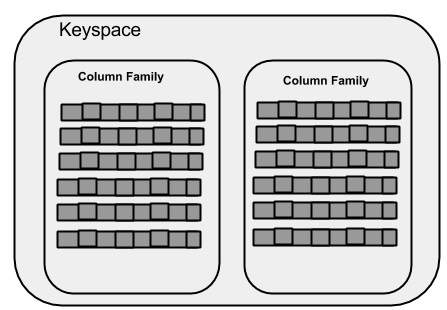
Семейство столбцов
Семейство столбцов - это контейнер для упорядоченного набора строк. Каждая строка, в свою очередь, представляет собой упорядоченный набор столбцов. В следующей таблице перечислены моменты, которые отличают семейство столбцов от таблицы реляционных баз данных.
| Реляционная таблица | Кассандра колонна Семья |
|---|---|
| Схема в реляционной модели фиксирована. После того как мы определим определенные столбцы для таблицы, при вставке данных в каждую строку все столбцы должны быть заполнены как минимум нулевым значением. | В Cassandra, хотя семейства столбцов определены, столбцы - нет. Вы можете в любое время добавить любой столбец в любое семейство столбцов. |
| В реляционных таблицах определяются только столбцы, и пользователь заполняет таблицу значениями. | В Cassandra таблица содержит столбцы или может быть определена как семейство супер столбцов. |
Семейство столбцов Cassandra имеет следующие атрибуты:
keys_cached - Он представляет собой количество кэшированных мест для каждой SSTable.
rows_cached - Он представляет количество строк, все содержимое которых будет кэшировано в памяти.
preload_row_cache - Он указывает, хотите ли вы предварительно заполнить кеш строк.
Note − В отличие от реляционных таблиц, в которых схема семейства столбцов не фиксирована, Cassandra не заставляет отдельные строки содержать все столбцы.
На следующем рисунке показан пример семейства столбцов Cassandra.
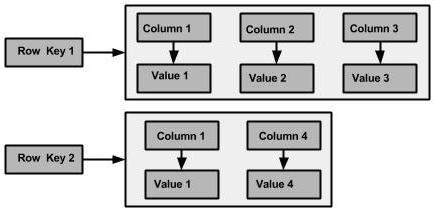
Столбец
Столбец - это основная структура данных Cassandra с тремя значениями, а именно: ключ или имя столбца, значение и отметка времени. Ниже приводится структура столбца.

Суперколонка
Супер-столбец - это специальный столбец, поэтому он также является парой ключ-значение. Но суперколонка хранит карту подколонок.
Обычно семейства столбцов хранятся на диске в отдельных файлах. Поэтому для оптимизации производительности важно хранить столбцы, которые вы, вероятно, запрашиваете вместе, в одном семействе столбцов, и здесь может быть полезен суперколбец. Ниже представлена структура супершолбца.

Модели данных Cassandra и СУБД
В следующей таблице перечислены моменты, которые отличают модель данных Cassandra от модели данных СУБД.
| СУБД | Кассандра |
|---|---|
| РСУБД работает со структурированными данными. | Кассандра работает с неструктурированными данными. |
| Имеет фиксированную схему. | У Кассандры гибкая схема. |
| В СУБД таблица - это массив массивов. (СТРОКА x КОЛОННА) | В Cassandra таблица - это список «вложенных пар ключ-значение». (СТРОКА x клавиша COLUMN x значение COLUMN) |
| База данных - это самый внешний контейнер, содержащий данные, соответствующие приложению. | Keyspace - это самый внешний контейнер, содержащий данные, соответствующие приложению. |
| Таблицы - это сущности базы данных. | Таблицы или семейства столбцов являются сущностью пространства ключей. |
| Строка - это отдельная запись в СУБД. | Строка - это единица репликации в Кассандре. |
| Столбец представляет атрибуты отношения. | Колонна - это единица хранения в Кассандре. |
| РСУБД поддерживает концепции внешних ключей, объединений. | Отношения представлены с помощью коллекций. |
Доступ к Cassandra можно получить с помощью cqlsh, а также драйверов на разных языках. В этой главе объясняется, как настроить среды cqlsh и java для работы с Cassandra.
Подготовка к установке
Перед установкой Cassandra в среде Linux нам необходимо настроить Linux с помощью ssh(Безопасная оболочка). Следуйте инструкциям ниже, чтобы настроить среду Linux.
Создать пользователя
Вначале рекомендуется создать отдельного пользователя для Hadoop, чтобы изолировать файловую систему Hadoop от файловой системы Unix. Следуйте инструкциям ниже, чтобы создать пользователя.
Откройте корень с помощью команды “su”.
Создайте пользователя из учетной записи root с помощью команды “useradd username”.
Теперь вы можете открыть существующую учетную запись пользователя с помощью команды “su username”.
Откройте терминал Linux и введите следующие команды, чтобы создать пользователя.
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdНастройка SSH и генерация ключей
Настройка SSH требуется для выполнения различных операций в кластере, таких как запуск, остановка и операции распределенной оболочки демона. Для аутентификации разных пользователей Hadoop необходимо предоставить пару открытого / закрытого ключей для пользователя Hadoop и поделиться ею с разными пользователями.
Следующие команды используются для генерации пары ключ-значение с использованием SSH:
- скопируйте форму открытых ключей id_rsa.pub в authorized_keys,
- и предоставить собственнику,
- права на чтение и запись в файл authorized_keys соответственно.
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys- Проверить ssh:
ssh localhostУстановка Java
Java - это главное условие для Cassandra. Прежде всего, вы должны проверить наличие Java в вашей системе, используя следующую команду -
$ java -versionЕсли все работает нормально, вы получите следующий результат.
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Если в вашей системе нет Java, следуйте инструкциям ниже для установки Java.
Шаг 1
Загрузите java (JDK <последняя версия> - X64.tar.gz) по следующей ссылке:
Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
Шаг 2
Обычно вы найдете загруженный файл java в папке Downloads. Проверьте это и извлекитеjdk-7u71-linux-x64.gz файл, используя следующие команды.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzШаг 3
Чтобы сделать Java доступной для всех пользователей, вы должны переместить ее в папку «/ usr / local /». Откройте root и введите следующие команды.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitШаг 4
Для настройки PATH и JAVA_HOME переменных, добавьте следующие команды в ~/.bashrc файл.
export JAVA_HOME = /usr/local/jdk1.7.0_71
export PATH = $PATH:$JAVA_HOME/binТеперь примените все изменения к текущей работающей системе.
$ source ~/.bashrcШаг 5
Используйте следующие команды для настройки альтернатив Java.
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarТеперь используйте java -version команду из терминала, как описано выше.
Установка пути
Задайте путь пути Cassandra в «/.bashrc», как показано ниже.
[hadoop@linux ~]$ gedit ~/.bashrc
export CASSANDRA_HOME = ~/cassandra
export PATH = $PATH:$CASSANDRA_HOME/binСкачать Кассандру
Apache Cassandra доступен по ссылке для скачивания Cassandra с помощью следующей команды.
$ wget http://supergsego.com/apache/cassandra/2.1.2/apache-cassandra-2.1.2-bin.tar.gzРазархивируйте Cassandra с помощью команды zxvf как показано ниже.
$ tar zxvf apache-cassandra-2.1.2-bin.tar.gz.Создайте новый каталог с именем cassandra и переместите в него содержимое загруженного файла, как показано ниже.
$ mkdir Cassandra $ mv apache-cassandra-2.1.2/* cassandra.Настроить Кассандру
Открыть cassandra.yaml: файл, который будет доступен в bin справочник Кассандры.
$ gedit cassandra.yamlNote - Если вы установили Cassandra из пакета deb или rpm, файлы конфигурации будут расположены в /etc/cassandra справочник Кассандры.
Приведенная выше команда открывает cassandra.yamlфайл. Проверьте следующие конфигурации. По умолчанию эти значения будут установлены в указанные каталоги.
data_file_directories “/var/lib/cassandra/data”
commitlog_directory “/var/lib/cassandra/commitlog”
save_caches_directory “/var/lib/cassandra/saved_caches”
Убедитесь, что эти каталоги существуют и могут быть записаны, как показано ниже.
Создать каталоги
Как суперпользователь создайте два каталога /var/lib/cassandra и /var./log/cassandra в который Кассандра записывает свои данные.
[root@linux cassandra]# mkdir /var/lib/cassandra
[root@linux cassandra]# mkdir /var/log/cassandraПредоставить разрешения папкам
Предоставьте разрешения на чтение и запись для вновь созданных папок, как показано ниже.
[root@linux /]# chmod 777 /var/lib/cassandra
[root@linux /]# chmod 777 /var/log/cassandraЗапустить Кассандру
Чтобы запустить Cassandra, откройте окно терминала, перейдите в домашний каталог Cassandra / home, где вы распаковали Cassandra, и выполните следующую команду, чтобы запустить сервер Cassandra.
$ cd $CASSANDRA_HOME $./bin/cassandra -fИспользование опции –f указывает Cassandra оставаться на переднем плане, а не работать как фоновый процесс. Если все пойдет хорошо, вы увидите, что сервер Cassandra запускается.
Среда программирования
Чтобы настроить Cassandra программно, загрузите следующие файлы jar -
- slf4j-api-1.7.5.jar
- cassandra-driver-core-2.0.2.jar
- guava-16.0.1.jar
- metrics-core-3.0.2.jar
- netty-3.9.0.Final.jar
Поместите их в отдельную папку. Например, мы загружаем эти банки в папку с именем“Cassandra_jars”.
Задайте путь к классам для этой папки в “.bashrc”файл, как показано ниже.
[hadoop@linux ~]$ gedit ~/.bashrc //Set the following class path in the .bashrc file. export CLASSPATH = $CLASSPATH:/home/hadoop/Cassandra_jars/*Eclipse Environment
Откройте Eclipse и создайте новый проект под названием Cassandra _Examples.
Щелкните правой кнопкой мыши проект, выберите Build Path→Configure Build Path как показано ниже.
Откроется окно свойств. На вкладке "Библиотеки" выберитеAdd External JARs. Перейдите в каталог, в котором вы сохранили файлы jar. Выберите все пять файлов jar и нажмите OK, как показано ниже.
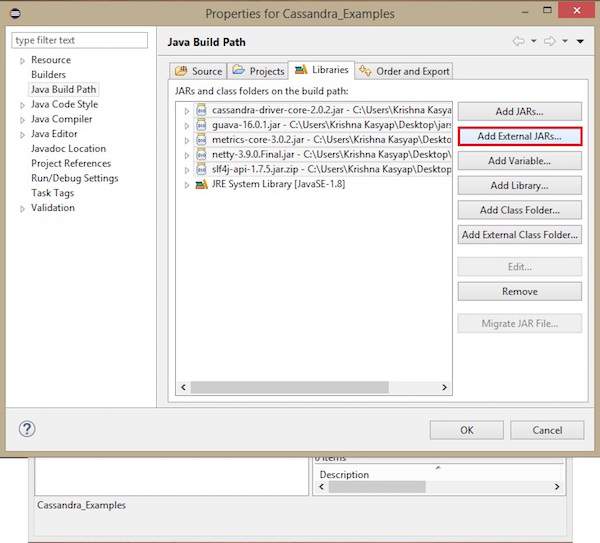
В Ссылочных библиотеках вы можете увидеть все необходимые банки, добавленные, как показано ниже -
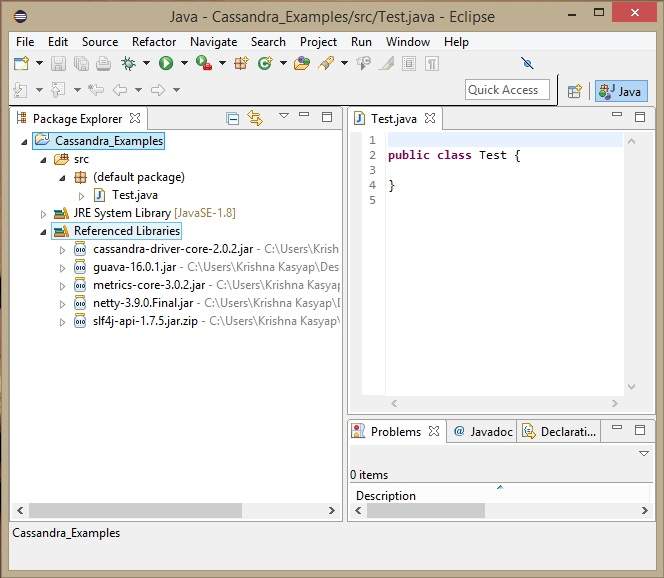
Зависимости Maven
Ниже приведен файл pom.xml для создания проекта Cassandra с использованием maven.
<project xmlns = "http://maven.apache.org/POM/4.0.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>2.0.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
<dependency>
<groupId>com.codahale.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty</artifactId>
<version>3.9.0.Final</version>
</dependency>
</dependencies>
</project>В этой главе рассматриваются все важные классы в Cassandra.
Кластер
Этот класс является основной точкой входа драйвера. Это принадлежитcom.datastax.driver.core пакет.
Методы
| С. Нет. | Методы и описание |
|---|---|
| 1 | Session connect() Он создает новый сеанс в текущем кластере и инициализирует его. |
| 2 | void close() Он используется для закрытия экземпляра кластера. |
| 3 | static Cluster.Builder builder() Он используется для создания нового экземпляра Cluster.Builder. |
Cluster.Builder
Этот класс используется для создания экземпляра Cluster.Builder класс.
Методы
| С. Нет | Методы и описание |
|---|---|
| 1 | Cluster.Builder addContactPoint(String address) Этот метод добавляет точку контакта в кластер. |
| 2 | Cluster build() Этот метод создает кластер с указанными точками контакта. |
Сессия
Этот интерфейс содержит подключения к кластеру Cassandra. Используя этот интерфейс, вы можете выполнитьCQLзапросы. Это принадлежитcom.datastax.driver.core пакет.
Методы
| С. Нет. | Методы и описание |
|---|---|
| 1 | void close() Этот метод используется для закрытия текущего экземпляра сеанса. |
| 2 | ResultSet execute(Statement statement) Этот метод используется для выполнения запроса. Требуется объект оператора. |
| 3 | ResultSet execute(String query) Этот метод используется для выполнения запроса. Для этого требуется запрос в виде объекта String. |
| 4 | PreparedStatement prepare(RegularStatement statement) Этот метод подготавливает предоставленный запрос. Запрос должен быть оформлен в форме Заявления. |
| 5 | PreparedStatement prepare(String query) Этот метод подготавливает предоставленный запрос. Запрос должен быть предоставлен в виде строки. |
В этой главе представлена оболочка языка запросов Cassandra и объясняется, как использовать ее команды.
По умолчанию Cassandra предоставляет командную оболочку языка запросов Cassandra. (cqlsh)что позволяет пользователям общаться с ним. Используя эту оболочку, вы можете выполнитьCassandra Query Language (CQL).
Используя cqlsh, вы можете
- определить схему,
- вставить данные и
- выполнить запрос.
Запуск cqlsh
Запустите cqlsh с помощью команды cqlshкак показано ниже. В качестве вывода он выдает приглашение Cassandra cqlsh.
[hadoop@linux bin]$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]
Use HELP for help.
cqlsh>Cqlsh- Как обсуждалось выше, эта команда используется для запуска приглашения cqlsh. Кроме того, он поддерживает еще несколько опций. В следующей таблице описаны все вариантыcqlsh и их использование.
| Параметры | Применение |
|---|---|
| cqlsh --help | Показывает разделы справки о параметрах cqlsh команды. |
| cqlsh --version | Предоставляет версию cqlsh, которую вы используете. |
| cqlsh - цвет | Указывает оболочке использовать цветной вывод. |
| cqlsh --debug | Показывает дополнительную отладочную информацию. |
| cqlsh --execute cql_statement |
Указывает оболочке принять и выполнить команду CQL. |
| cqlsh --file = “file name” | Если вы используете эту опцию, Cassandra выполнит команду в данном файле и завершит работу. |
| cqlsh --no-color | Указывает Кассандре не использовать цветной вывод. |
| cqlsh -u “user name” | Используя эту опцию, вы можете аутентифицировать пользователя. Имя пользователя по умолчанию: cassandra. |
| cqlsh-p “pass word” | Используя эту опцию, вы можете аутентифицировать пользователя с помощью пароля. Пароль по умолчанию: cassandra. |
Команды Cqlsh
В Cqlsh есть несколько команд, которые позволяют пользователям взаимодействовать с ним. Команды перечислены ниже.
Документированные команды оболочки
Ниже приведены документированные команды оболочки Cqlsh. Это команды, используемые для выполнения таких задач, как отображение разделов справки, выход из cqlsh, описание и т. Д.
HELP - Отображает разделы справки для всех команд cqlsh.
CAPTURE - Захватывает вывод команды и добавляет его в файл.
CONSISTENCY - Показывает текущий уровень согласованности или устанавливает новый уровень согласованности.
COPY - Копирует данные в и из Кассандры.
DESCRIBE - Описывает текущий кластер Кассандры и его объекты.
EXPAND - Расширяет вывод запроса по вертикали.
EXIT - Используя эту команду, вы можете завершить cqlsh.
PAGING - Включает или отключает поиск по страницам.
SHOW - Отображает детали текущего сеанса cqlsh, такие как версия Cassandra, хост или предположения о типе данных.
SOURCE - Выполняет файл, содержащий операторы CQL.
TRACING - Включает или отключает отслеживание запросов.
Команды определения данных CQL
CREATE KEYSPACE - Создает KeySpace в Cassandra.
USE - Подключается к созданному KeySpace.
ALTER KEYSPACE - Изменяет свойства KeySpace.
DROP KEYSPACE - Удаляет KeySpace
CREATE TABLE - Создает таблицу в KeySpace.
ALTER TABLE - Изменяет свойства столбца таблицы.
DROP TABLE - Удаляет стол.
TRUNCATE - Удаляет все данные из таблицы.
CREATE INDEX - Определяет новый индекс для одного столбца таблицы.
DROP INDEX - Удаляет именованный индекс.
Команды управления данными CQL
INSERT - Добавляет столбцы для строки в таблице.
UPDATE - Обновляет столбец в строке.
DELETE - Удаляет данные из таблицы.
BATCH - Выполняет сразу несколько операторов DML.
Пункты CQL
SELECT - Это предложение считывает данные из таблицы
WHERE - Предложение where используется вместе с select для чтения определенных данных.
ORDERBY - Предложение orderby используется вместе с select для чтения определенных данных в определенном порядке.
Cassandra предоставляет документированные команды оболочки в дополнение к командам CQL. Ниже приведены документированные команды оболочки Cassandra.
Помогите
Команда HELP отображает синопсис и краткое описание всех команд cqlsh. Ниже приводится использование команды справки.
cqlsh> help
Documented shell commands:
===========================
CAPTURE COPY DESCRIBE EXPAND PAGING SOURCE
CONSISTENCY DESC EXIT HELP SHOW TRACING.
CQL help topics:
================
ALTER CREATE_TABLE_OPTIONS SELECT
ALTER_ADD CREATE_TABLE_TYPES SELECT_COLUMNFAMILY
ALTER_ALTER CREATE_USER SELECT_EXPR
ALTER_DROP DELETE SELECT_LIMIT
ALTER_RENAME DELETE_COLUMNS SELECT_TABLEЗахватить
Эта команда фиксирует вывод команды и добавляет его в файл. Например, взгляните на следующий код, который записывает вывод в файл с именемOutputfile.
cqlsh> CAPTURE '/home/hadoop/CassandraProgs/Outputfile'Когда мы вводим любую команду в терминале, вывод будет захвачен указанным файлом. Ниже приводится используемая команда и снимок выходного файла.
cqlsh:tutorialspoint> select * from emp;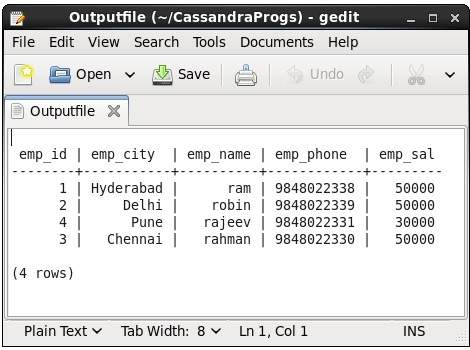
Вы можете отключить захват с помощью следующей команды.
cqlsh:tutorialspoint> capture off;Последовательность
Эта команда показывает текущий уровень согласованности или устанавливает новый уровень согласованности.
cqlsh:tutorialspoint> CONSISTENCY
Current consistency level is 1.Копировать
Эта команда копирует данные в и из Cassandra в файл. Ниже приведен пример копирования таблицы с именемemp в файл myfile.
cqlsh:tutorialspoint> COPY emp (emp_id, emp_city, emp_name, emp_phone,emp_sal) TO ‘myfile’;
4 rows exported in 0.034 seconds.Если вы откроете и проверите указанный файл, вы сможете найти скопированные данные, как показано ниже.
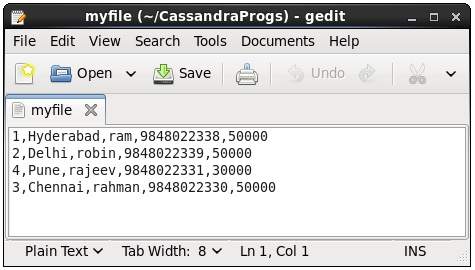
Опишите
Эта команда описывает текущий кластер Cassandra и его объекты. Ниже описаны варианты этой команды.
Describe cluster - Эта команда предоставляет информацию о кластере.
cqlsh:tutorialspoint> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
Range ownership:
-658380912249644557 [127.0.0.1]
-2833890865268921414 [127.0.0.1]
-6792159006375935836 [127.0.0.1]Describe Keyspaces- Эта команда выводит список всех пространств ключей в кластере. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> describe keyspaces;
system_traces system tp tutorialspointDescribe tables- Эта команда выводит список всех таблиц в пространстве ключей. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> describe tables;
empDescribe table- Эта команда предоставляет описание таблицы. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> describe table emp;
CREATE TABLE tutorialspoint.emp (
emp_id int PRIMARY KEY,
emp_city text,
emp_name text,
emp_phone varint,
emp_sal varint
) WITH bloom_filter_fp_chance = 0.01
AND caching = '{"keys":"ALL", "rows_per_partition":"NONE"}'
AND comment = ''
AND compaction = {'min_threshold': '4', 'class':
'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy',
'max_threshold': '32'}
AND compression = {'sstable_compression':
'org.apache.cassandra.io.compress.LZ4Compressor'}
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';
CREATE INDEX emp_emp_sal_idx ON tutorialspoint.emp (emp_sal);Опишите тип
Эта команда используется для описания пользовательского типа данных. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Описать типы
Эта команда выводит список всех типов данных, определенных пользователем. Ниже приводится использование этой команды. Предположим, есть два типа данных, определяемых пользователем:card и card_details.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardРазвернуть
Эта команда используется для расширения вывода. Перед использованием этой команды вы должны включить команду расширения. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> expand on;
cqlsh:tutorialspoint> select * from emp;
@ Row 1
-----------+------------
emp_id | 1
emp_city | Hyderabad
emp_name | ram
emp_phone | 9848022338
emp_sal | 50000
@ Row 2
-----------+------------
emp_id | 2
emp_city | Delhi
emp_name | robin
emp_phone | 9848022339
emp_sal | 50000
@ Row 3
-----------+------------
emp_id | 4
emp_city | Pune
emp_name | rajeev
emp_phone | 9848022331
emp_sal | 30000
@ Row 4
-----------+------------
emp_id | 3
emp_city | Chennai
emp_name | rahman
emp_phone | 9848022330
emp_sal | 50000
(4 rows)Note - Вы можете отключить параметр раскрытия с помощью следующей команды.
cqlsh:tutorialspoint> expand off;
Disabled Expanded output.Выход
Эта команда используется для завершения оболочки cql.
Показать
Эта команда отображает детали текущего сеанса cqlsh, такие как версия Cassandra, хост или предположения о типе данных. Ниже приводится использование этой команды.
cqlsh:tutorialspoint> show host;
Connected to Test Cluster at 127.0.0.1:9042.
cqlsh:tutorialspoint> show version;
[cqlsh 5.0.1 | Cassandra 2.1.2 | CQL spec 3.2.0 | Native protocol v3]Источник
Используя эту команду, вы можете выполнять команды в файле. Предположим, что наш входной файл выглядит следующим образом -
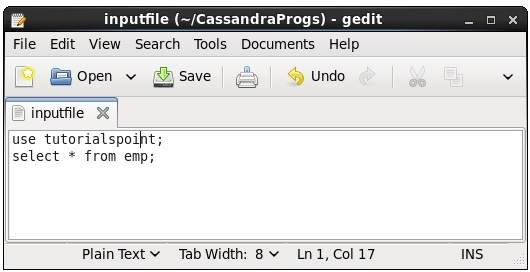
Затем вы можете выполнить файл, содержащий команды, как показано ниже.
cqlsh:tutorialspoint> source '/home/hadoop/CassandraProgs/inputfile';
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Pune | rajeev | 9848022331 | 30000
4 | Chennai | rahman | 9848022330 | 50000
(4 rows)Создание пространства ключей с помощью Cqlsh
Пространство ключей в Cassandra - это пространство имен, которое определяет репликацию данных на узлах. Кластер содержит одно пространство ключей на узел. Ниже приведен синтаксис для создания пространства ключей с помощью оператораCREATE KEYSPACE.
Синтаксис
CREATE KEYSPACE <identifier> WITH <properties>т.е.
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};
CREATE KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’}
AND durable_writes = ‘Boolean value’;Оператор CREATE KEYSPACE имеет два свойства: replication и durable_writes.
Репликация
Опция репликации - указать Replica Placement strategyи количество требуемых реплик. В следующей таблице перечислены все стратегии размещения реплик.
| Название стратегии | Описание |
|---|---|
| Simple Strategy' | Задает простой коэффициент репликации для кластера. |
| Network Topology Strategy | Используя эту опцию, вы можете установить коэффициент репликации для каждого дата-центра независимо. |
| Old Network Topology Strategy | Это устаревшая стратегия репликации. |
Используя эту опцию, вы можете указать Кассандре, следует ли использовать commitlogдля обновлений текущего KeySpace. Этот параметр не является обязательным и по умолчанию установлен в значение true.
пример
Ниже приведен пример создания KeySpace.
Здесь мы создаем KeySpace с именем TutorialsPoint.
Мы используем первую стратегию размещения реплик, т. Е. Simple Strategy.
И мы выбираем коэффициент репликации, чтобы 1 replica.
cqlsh.> CREATE KEYSPACE tutorialspoint
WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};Проверка
Проверить, создана ли таблица или нет, можно с помощью команды Describe. Если вы используете эту команду над пространствами ключей, она отобразит все созданные пространства ключей, как показано ниже.
cqlsh> DESCRIBE keyspaces;
tutorialspoint system system_tracesЗдесь вы можете наблюдать за недавно созданным KeySpace tutorialspoint.
Durable_writes
По умолчанию для свойств Durable_writes таблицы установлено значение true,однако может быть установлено значение false. Вы не можете установить для этого свойства значениеsimplex strategy.
пример
Ниже приведен пример, демонстрирующий использование свойства длительной записи.
cqlsh> CREATE KEYSPACE test
... WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
... AND DURABLE_WRITES = false;Проверка
Вы можете проверить, установлено ли для свойства длительное_писание тестового пространства ключей значение false, запросив системное пространство ключей. Этот запрос дает вам все KeySpaces вместе с их свойствами.
cqlsh> SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1" : "3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor" : "2"}
(4 rows)Здесь вы можете заметить, что для свойства Durable_writes тестового KeySpace было установлено значение false.
Использование пространства ключей
Вы можете использовать созданное KeySpace с помощью ключевого слова USE. Его синтаксис следующий -
Syntax:USE <identifier>пример
В следующем примере мы используем KeySpace tutorialspoint.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>Создание пространства ключей с использованием Java API
Вы можете создать пространство ключей, используя execute() метод Sessionкласс. Следуйте инструкциям ниже, чтобы создать пространство ключей с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера в одной строке кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр Session объект с помощью connect() метод Cluster класс, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его в существующее, передав имя пространства ключей в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Шаг 3: Выполнить запрос
Вы можете выполнить CQL запросы с использованием execute() метод Sessionкласс. Передайте запрос либо в строковом формате, либо какStatement объект класса в execute()метод. Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В этом примере мы создаем KeySpace с именем tp. Мы используем первую стратегию размещения реплик, т. Е. Простую стратегию, и выбираем коэффициент репликации для 1 реплики.
Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1}; ";
session.execute(query);Шаг 4: используйте KeySpace
Вы можете использовать созданное KeySpace с помощью метода execute (), как показано ниже.
execute(“ USE tp ” );Ниже приведена полная программа для создания и использования пространства ключей в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_KeySpace {
public static void main(String args[]){
//Query
String query = "CREATE KEYSPACE tp WITH replication "
+ "= {'class':'SimpleStrategy', 'replication_factor':1};";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
//using the KeySpace
session.execute("USE tp");
System.out.println("Keyspace created");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Create_KeySpace.java
$java Create_KeySpaceВ нормальных условиях он выдаст следующий результат -
Keyspace createdИзменение KeySpace
ALTER KEYSPACE можно использовать для изменения таких свойств, как количество реплик и длительность записи KeySpace. Ниже приводится синтаксис этой команды.
Синтаксис
ALTER KEYSPACE <identifier> WITH <properties>т.е.
ALTER KEYSPACE “KeySpace Name”
WITH replication = {'class': ‘Strategy name’, 'replication_factor' : ‘No.Of replicas’};Свойства ALTER KEYSPACEтакие же, как CREATE KEYSPACE. У него два свойства:replication и durable_writes.
Репликация
Параметр репликации определяет стратегию размещения реплик и количество требуемых реплик.
Durable_writes
Используя эту опцию, вы можете указать Cassandra, следует ли использовать журнал фиксации для обновлений в текущем KeySpace. Этот параметр не является обязательным и по умолчанию установлен в значение true.
пример
Ниже приведен пример изменения KeySpace.
Здесь мы меняем KeySpace с именем TutorialsPoint.
Мы меняем коэффициент репликации с 1 на 3.
cqlsh.> ALTER KEYSPACE tutorialspoint
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 3};Изменение Durable_writes
Вы также можете изменить свойство Durable_writes для KeySpace. Ниже приведено свойство Durable_writes объектаtest KeySpace.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | False | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)ALTER KEYSPACE test
WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}
AND DURABLE_WRITES = true;Еще раз, если вы проверите свойства KeySpaces, он выдаст следующий результат.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | strategy_class | strategy_options
----------------+----------------+------------------------------------------------------+----------------------------
test | True | org.apache.cassandra.locator.NetworkTopologyStrategy | {"datacenter1":"3"}
tutorialspoint | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"4"}
system | True | org.apache.cassandra.locator.LocalStrategy | { }
system_traces | True | org.apache.cassandra.locator.SimpleStrategy | {"replication_factor":"2"}
(4 rows)Изменение пространства ключей с помощью Java API
Вы можете изменить пространство ключей, используя execute() метод Sessionкласс. Следуйте инструкциям ниже, чтобы изменить пространство ключей с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр Session объект с помощью connect() метод Clusterкласс, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его в существующее, передав имя пространства ключей в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос либо в строковом формате, либо какStatementобъект класса в метод execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В этом примере
Мы изменяем пространство ключей с именем tp. Мы меняем вариант репликации с простой стратегии на стратегию топологии сети.
Мы меняем durable_writes ложь
Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}" +" AND DURABLE_WRITES = false;";
session.execute(query);Ниже приведена полная программа для создания и использования пространства ключей в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Alter_KeySpace {
public static void main(String args[]){
//Query
String query = "ALTER KEYSPACE tp WITH replication " + "= {'class':'NetworkTopologyStrategy', 'datacenter1':3}"
+ "AND DURABLE_WRITES = false;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace altered");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Alter_KeySpace.java
$java Alter_KeySpaceВ нормальных условиях он производит следующий вывод -
Keyspace AlteredУдаление ключевого пространства
Вы можете удалить KeySpace с помощью команды DROP KEYSPACE. Ниже приведен синтаксис удаления KeySpace.
Синтаксис
DROP KEYSPACE <identifier>т.е.
DROP KEYSPACE “KeySpace name”пример
Следующий код удаляет пространство ключей tutorialspoint.
cqlsh> DROP KEYSPACE tutorialspoint;Проверка
Проверьте пространства ключей с помощью команды Describe и проверьте, сброшена ли таблица, как показано ниже.
cqlsh> DESCRIBE keyspaces;
system system_tracesПоскольку мы удалили учебную точку по пространству ключей, вы не найдете ее в списке пространств ключей.
Удаление пространства ключей с помощью Java API
Вы можете создать пространство ключей, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы удалить пространство ключей с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его в существующее, передав имя пространства ключей в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено в cqlsh.
В следующем примере мы удаляем пространство ключей с именем tp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
String query = "DROP KEYSPACE tp; ";
session.execute(query);Ниже приведена полная программа для создания и использования пространства ключей в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_KeySpace {
public static void main(String args[]){
//Query
String query = "Drop KEYSPACE tp";
//creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect();
//Executing the query
session.execute(query);
System.out.println("Keyspace deleted");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Delete_KeySpace.java
$java Delete_KeySpaceВ нормальных условиях он должен выдавать следующий результат -
Keyspace deletedСоздание таблицы
Вы можете создать таблицу с помощью команды CREATE TABLE. Ниже приведен синтаксис для создания таблицы.
Синтаксис
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)Определение столбца
Вы можете определить столбец, как показано ниже.
column name1 data type,
column name2 data type,
example:
age int,
name textОсновной ключ
Первичный ключ - это столбец, который используется для однозначной идентификации строки. Следовательно, определение первичного ключа обязательно при создании таблицы. Первичный ключ состоит из одного или нескольких столбцов таблицы. Вы можете определить первичный ключ таблицы, как показано ниже.
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)or
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type,
PRIMARY KEY (column1)
)пример
Ниже приведен пример создания таблицы в Cassandra с использованием cqlsh. Вот и мы -
Использование keypace tutorialspoint
Создание таблицы с именем emp
Он будет содержать такие данные, как имя сотрудника, идентификатор, город, зарплата и номер телефона. Идентификатор сотрудника - это первичный ключ.
cqlsh> USE tutorialspoint;
cqlsh:tutorialspoint>; CREATE TABLE emp(
emp_id int PRIMARY KEY,
emp_name text,
emp_city text,
emp_sal varint,
emp_phone varint
);Проверка
Оператор select предоставит вам схему. Проверьте таблицу с помощью оператора select, как показано ниже.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)Здесь вы можете увидеть таблицу, созданную с данными столбцами. Поскольку мы удалили учебную точку по пространству ключей, вы не найдете ее в списке пространств ключей.
Создание таблицы с использованием Java API
Вы можете создать таблицу, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы создать таблицу с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя connect() метод Cluster класс, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его в существующее, передав имя пространства ключей в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Здесь мы используем пространство ключей с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“ tp” );Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено в cqlsh.
В следующем примере мы создаем таблицу с именем emp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
session.execute(query);Ниже приведена полная программа для создания и использования пространства ключей в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Table {
public static void main(String args[]){
//Query
String query = "CREATE TABLE emp(emp_id int PRIMARY KEY, "
+ "emp_name text, "
+ "emp_city text, "
+ "emp_sal varint, "
+ "emp_phone varint );";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table created");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Create_Table.java
$java Create_TableВ нормальных условиях он должен выдавать следующий результат -
Table createdИзменение таблицы
Вы можете изменить таблицу с помощью команды ALTER TABLE. Ниже приведен синтаксис для создания таблицы.
Синтаксис
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>Используя команду ALTER, вы можете выполнить следующие операции -
Добавить столбец
Отбросить столбец
Добавление столбца
Используя команду ALTER, вы можете добавить столбец в таблицу. При добавлении столбцов вы должны позаботиться о том, чтобы имя столбца не конфликтовало с существующими именами столбцов и чтобы таблица не была определена с опцией компактного хранения. Ниже приведен синтаксис для добавления столбца в таблицу.
ALTER TABLE table name
ADD new column datatype;Example
Ниже приведен пример добавления столбца в существующую таблицу. Здесь мы добавляем столбец с именемemp_email типа текстовых данных в таблицу с именем emp.
cqlsh:tutorialspoint> ALTER TABLE emp
... ADD emp_email text;Verification
Используйте оператор SELECT, чтобы проверить, добавлен ли столбец. Здесь вы можете увидеть недавно добавленный столбец emp_email.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_email | emp_name | emp_phone | emp_sal
--------+----------+-----------+----------+-----------+---------Удаление столбца
Используя команду ALTER, вы можете удалить столбец из таблицы. Перед удалением столбца из таблицы убедитесь, что для таблицы не задана опция компактного хранения. Ниже приведен синтаксис для удаления столбца из таблицы с помощью команды ALTER.
ALTER table name
DROP column name;Example
Ниже приведен пример удаления столбца из таблицы. Здесь мы удаляем столбец с именемemp_email.
cqlsh:tutorialspoint> ALTER TABLE emp DROP emp_email;Verification
Убедитесь, что столбец удален, используя select заявление, как показано ниже.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+----------+----------+-----------+---------
(0 rows)поскольку emp_email столбец удален, вы больше не можете его найти.
Изменение таблицы с помощью Java API
Вы можете создать таблицу, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы изменить таблицу с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Здесь мы используем KeySpace с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы добавляем столбец в таблицу с именем emp. Для этого вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
//Query
String query1 = "ALTER TABLE emp ADD emp_email text";
session.execute(query);Ниже приведена полная программа для добавления столбца в существующую таблицу.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Add_column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp ADD emp_email text";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Column added");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Add_Column.java
$java Add_ColumnВ нормальных условиях он должен выдавать следующий результат -
Column addedУдаление столбца
Ниже приведена полная программа для удаления столбца из существующей таблицы.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Column {
public static void main(String args[]){
//Query
String query = "ALTER TABLE emp DROP emp_email;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//executing the query
session.execute(query);
System.out.println("Column deleted");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Delete_Column.java
$java Delete_ColumnВ нормальных условиях он должен выдавать следующий результат -
Column deletedПадение стола
Вы можете отбросить таблицу с помощью команды Drop Table. Его синтаксис следующий -
Синтаксис
DROP TABLE <tablename>пример
Следующий код удаляет существующую таблицу из KeySpace.
cqlsh:tutorialspoint> DROP TABLE emp;Проверка
Используйте команду Describe, чтобы проверить, удалена ли таблица. Поскольку таблица emp была удалена, вы не найдете ее в списке семейств столбцов.
cqlsh:tutorialspoint> DESCRIBE COLUMNFAMILIES;
employeeУдаление таблицы с помощью Java API
Вы можете удалить таблицу с помощью метода execute () класса Session. Следуйте инструкциям ниже, чтобы удалить таблицу с помощью Java API.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже -
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“Your keyspace name”);Здесь мы используем пространство ключей с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы удаляем таблицу с именем emp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
// Query
String query = "DROP TABLE emp1;”;
session.execute(query);Ниже приведена полная программа для удаления таблицы в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Table {
public static void main(String args[]){
//Query
String query = "DROP TABLE emp1;";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table dropped");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Drop_Table.java
$java Drop_TableВ нормальных условиях он должен выдавать следующий результат -
Table droppedУсечение таблицы
Вы можете усечь таблицу с помощью команды TRUNCATE. При усечении таблицы все строки таблицы удаляются безвозвратно. Ниже приводится синтаксис этой команды.
Синтаксис
TRUNCATE <tablename>пример
Предположим, есть таблица с именем student со следующими данными.
| s_id | s_name | s_branch | s_aggregate |
|---|---|---|---|
| 1 | баран | ЭТО | 70 |
| 2 | рахман | EEE | 75 |
| 3 | Роббин | Мех | 72 |
Когда вы выполняете оператор select, чтобы получить таблицу student, это даст вам следующий результат.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
1 | 70 | IT | ram
2 | 75 | EEE | rahman
3 | 72 | MECH | robbin
(3 rows)Теперь обрежьте таблицу с помощью команды TRUNCATE.
cqlsh:tp> TRUNCATE student;Проверка
Убедитесь, что таблица усечена, выполнив selectзаявление. Ниже приведены выходные данные оператора select для таблицы учеников после усечения.
cqlsh:tp> select * from student;
s_id | s_aggregate | s_branch | s_name
------+-------------+----------+--------
(0 rows)Усечение таблицы с использованием Java API
Вы можете усечь таблицу, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы обрезать таблицу.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2: Создание объекта сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );
Session session = cluster.connect(“ tp” );Здесь мы используем пространство ключей с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы усекаем таблицу с именем emp. Вы должны сохранить запрос в строковой переменной и передать его вexecute() метод, как показано ниже.
//Query
String query = "TRUNCATE emp;;”;
session.execute(query);Ниже приведена полная программа для усечения таблицы в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Truncate_Table {
public static void main(String args[]){
//Query
String query = "Truncate student;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Table truncated");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Truncate_Table.java
$java Truncate_TableВ нормальных условиях он должен выдавать следующий результат -
Table truncatedСоздание индекса с использованием Cqlsh
Вы можете создать индекс в Cassandra, используя команду CREATE INDEX. Его синтаксис следующий -
CREATE INDEX <identifier> ON <tablename>Ниже приведен пример создания индекса для столбца. Здесь мы создаем индекс столбца emp_name в таблице с именем emp.
cqlsh:tutorialspoint> CREATE INDEX name ON emp1 (emp_name);Создание индекса с использованием Java API
Вы можете создать индекс для столбца таблицы, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы создать индекс для столбца в таблице.
Шаг 1. Создайте кластерный объект.
Прежде всего, создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session с помощью метода connect () из Cluster класс, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Здесь мы используем KeySpace под названием tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“ tp” );Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы создаем индекс для столбца emp_name в таблице с именем emp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
session.execute(query);Ниже приведена полная программа для создания индекса столбца в таблице в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Index {
public static void main(String args[]){
//Query
String query = "CREATE INDEX name ON emp1 (emp_name);";
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index created");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Create_Index.java
$java Create_IndexВ нормальных условиях он должен выдавать следующий результат -
Index createdУдаление индекса
Вы можете удалить индекс с помощью команды DROP INDEX. Его синтаксис следующий -
DROP INDEX <identifier>Ниже приведен пример удаления индекса столбца в таблице. Здесь мы отбрасываем индекс имени столбца в таблице emp.
cqlsh:tp> drop index name;Удаление индекса с помощью Java API
Вы можете удалить индекс таблицы, используя метод execute () класса Session. Следуйте инструкциям ниже, чтобы удалить индекс из таблицы.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builder object. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Здесь мы используем KeySpace с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“ tp” );Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос либо в строковом формате, либо какStatementобъект класса в метод execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы удаляем индекс «имя» empстол. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
//Query
String query = "DROP INDEX user_name;";
session.execute(query);Ниже приведена полная программа для удаления индекса в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Drop_Index {
public static void main(String args[]){
//Query
String query = "DROP INDEX user_name;";
//Creating cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();.
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Index dropped");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Drop_index.java
$java Drop_indexВ нормальных условиях он должен выдавать следующий результат -
Index droppedИспользование пакетных операторов
С помощью BATCH,вы можете выполнять несколько операторов модификации (вставка, обновление, удаление) одновременно. Его синтаксис следующий -
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCHпример
Предположим, что в Cassandra есть таблица с именем emp, имеющая следующие данные:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | Дели | 9848022339 | 50000 |
| 3 | рахман | Ченнаи | 9848022330 | 45000 |
В этом примере мы выполним следующие операции -
- Вставьте новую строку со следующими деталями (4, rajeev, pune, 9848022331, 30000).
- Обновите зарплату сотрудника с идентификатором строки 3 до 50000.
- Удалить город сотрудника с идентификатором строки 2.
Чтобы выполнить вышеуказанные операции за один раз, используйте следующую команду BATCH -
cqlsh:tutorialspoint> BEGIN BATCH
... INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
... UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
... DELETE emp_city FROM emp WHERE emp_id = 2;
... APPLY BATCH;Проверка
После внесения изменений проверьте таблицу с помощью оператора SELECT. Он должен выдать следующий результат -
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Здесь вы можете увидеть таблицу с измененными данными.
Пакетные заявления с использованием Java API
Операторы пакетной обработки могут быть записаны программно в таблицу с помощью метода execute () класса Session. Следуйте приведенным ниже инструкциям, чтобы выполнить несколько операторов с помощью пакетного оператора с помощью Java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. Используйте следующий код для создания объекта кластера -
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ”);Здесь мы используем KeySpace с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В этом примере мы выполним следующие операции -
- Вставьте новую строку со следующими деталями (4, rajeev, pune, 9848022331, 30000).
- Обновите зарплату сотрудника с идентификатором строки 3 до 50000.
- Удалите город сотрудника с идентификатором строки 2.
Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
String query1 = ” BEGIN BATCH INSERT INTO emp (emp_id, emp_city, emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);
UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;
DELETE emp_city FROM emp WHERE emp_id = 2;
APPLY BATCH;”;Ниже приведена полная программа для одновременного выполнения нескольких операторов в таблице в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Batch {
public static void main(String args[]){
//query
String query =" BEGIN BATCH INSERT INTO emp (emp_id, emp_city,
emp_name, emp_phone, emp_sal) values( 4,'Pune','rajeev',9848022331, 30000);"
+ "UPDATE emp SET emp_sal = 50000 WHERE emp_id =3;"
+ "DELETE emp_city FROM emp WHERE emp_id = 2;"
+ "APPLY BATCH;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Changes done");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Batch.java
$java BatchВ нормальных условиях он должен выдавать следующий результат -
Changes doneСоздание данных в таблице
Вы можете вставить данные в столбцы строки таблицы с помощью команды INSERT. Ниже приведен синтаксис для создания данных в таблице.
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>пример
Предположим, есть таблица с именем emp со столбцами (emp_id, emp_name, emp_city, emp_phone, emp_sal), и вы должны вставить следующие данные в emp стол.
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | Хайдарабад | 9848022339 | 40000 |
| 3 | рахман | Ченнаи | 9848022330 | 45000 |
Используйте приведенные ниже команды, чтобы заполнить таблицу необходимыми данными.
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);
cqlsh:tutorialspoint> INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal) VALUES(3,'rahman', 'Chennai', 9848022330, 45000);Проверка
После вставки данных используйте оператор SELECT, чтобы проверить, были ли данные вставлены или нет. Если вы проверите таблицу emp с помощью оператора SELECT, вы получите следующий результат.
cqlsh:tutorialspoint> SELECT * FROM emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Hyderabad | robin | 9848022339 | 40000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Здесь вы можете увидеть, что таблица заполнена данными, которые мы вставили.
Создание данных с использованием Java API
Вы можете создавать данные в таблице, используя метод execute () класса Session. Следуйте инструкциям, приведенным ниже, чтобы создать данные в таблице с помощью java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. В следующем коде показано, как создать объект кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ” );Здесь мы используем KeySpace под названием tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“ tp” );Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос либо в строковом формате, либо какStatementобъект класса в метод execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы вставляем данные в таблицу с именем emp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже.
String query1 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);” ;
String query2 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);” ;
String query3 = “INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)
VALUES(3,'rahman', 'Chennai', 9848022330, 45000);” ;
session.execute(query1);
session.execute(query2);
session.execute(query3);Ниже приведена полная программа для вставки данных в таблицу в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Create_Data {
public static void main(String args[]){
//queries
String query1 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(1,'ram', 'Hyderabad', 9848022338, 50000);" ;
String query2 = "INSERT INTO emp (emp_id, emp_name, emp_city,
emp_phone, emp_sal)"
+ " VALUES(2,'robin', 'Hyderabad', 9848022339, 40000);" ;
String query3 = "INSERT INTO emp (emp_id, emp_name, emp_city, emp_phone, emp_sal)"
+ " VALUES(3,'rahman', 'Chennai', 9848022330, 45000);" ;
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query1);
session.execute(query2);
session.execute(query3);
System.out.println("Data created");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Create_Data.java
$java Create_DataВ нормальных условиях он должен выдавать следующий результат -
Data createdОбновление данных в таблице
UPDATEэто команда, используемая для обновления данных в таблице. Следующие ключевые слова используются при обновлении данных в таблице -
Where - Это предложение используется для выбора строки для обновления.
Set - Установите значение с помощью этого ключевого слова.
Must - Включает все столбцы, составляющие первичный ключ.
При обновлении строк, если данная строка недоступна, UPDATE создает новую строку. Ниже приведен синтаксис команды UPDATE -
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>пример
Предположим, есть таблица с именем emp. В этой таблице хранятся данные о сотрудниках определенной компании, и в ней есть следующие данные:
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | Хайдарабад | 9848022339 | 40000 |
| 3 | рахман | Ченнаи | 9848022330 | 45000 |
Давайте теперь обновим emp_city робина до Дели и его зарплату до 50000. Ниже приведен запрос для выполнения необходимых обновлений.
cqlsh:tutorialspoint> UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id=2;Проверка
Используйте оператор SELECT, чтобы проверить, были ли данные обновлены или нет. Если вы проверите таблицу emp с помощью оператора SELECT, она выдаст следующий результат.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 45000
(3 rows)Здесь вы можете увидеть, что данные таблицы обновились.
Обновление данных с помощью Java API
Вы можете обновить данные в таблице, используя метод execute () класса Session. Следуйте приведенным ниже инструкциям, чтобы обновить данные в таблице с помощью Java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint("127.0.0.1");Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. Используйте следующий код для создания объекта кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name”);Здесь мы используем KeySpace с именем tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы обновляем таблицу emp. Вы должны сохранить запрос в строковой переменной и передать его методу execute (), как показано ниже:
String query = “ UPDATE emp SET emp_city='Delhi',emp_sal=50000
WHERE emp_id = 2;” ;Ниже приведена полная программа для обновления данных в таблице с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Update_Data {
public static void main(String args[]){
//query
String query = " UPDATE emp SET emp_city='Delhi',emp_sal=50000"
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data updated");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Update_Data.java
$java Update_DataВ нормальных условиях он должен выдавать следующий результат -
Data updatedЧтение данных с помощью предложения Select
Предложение SELECT используется для чтения данных из таблицы в Cassandra. Используя это предложение, вы можете прочитать всю таблицу, отдельный столбец или определенную ячейку. Ниже приведен синтаксис предложения SELECT.
SELECT FROM <tablename>пример
Предположим, что в пространстве ключей есть таблица с именем emp со следующими деталями -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | ноль | 9848022339 | 50000 |
| 3 | рахман | Ченнаи | 9848022330 | 50000 |
| 4 | Раджив | Пуна | 9848022331 | 30000 |
В следующем примере показано, как прочитать всю таблицу с помощью предложения SELECT. Здесь мы читаем таблицу под названиемemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Чтение обязательных столбцов
В следующем примере показано, как читать определенный столбец в таблице.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Где пункт
Используя предложение WHERE, вы можете наложить ограничение на требуемые столбцы. Его синтаксис следующий -
SELECT FROM <table name> WHERE <condition>;Note - Предложение WHERE можно использовать только для столбцов, которые являются частью первичного ключа или имеют вторичный индекс.
В следующем примере мы читаем сведения о сотруднике, чья зарплата составляет 50000. Прежде всего, установите вторичный индекс в столбец emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Чтение данных с использованием Java API
Вы можете читать данные из таблицы, используя метод execute () класса Session. Следуйте приведенным ниже инструкциям, чтобы выполнить несколько операторов с помощью пакетного оператора с помощью Java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. Используйте следующий код для создания объекта кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“Your keyspace name”);Здесь мы используем KeySpace под названием tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В этом примере мы получаем данные из empстол. Сохраните запрос в строке и передайте его методу execute () класса сеанса, как показано ниже.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Выполните запрос, используя метод execute () класса Session.
Шаг 4. Получите объект ResultSet
Запросы на выбор вернут результат в виде ResultSet объект, поэтому сохраните результат в объекте RESULTSET класс, как показано ниже.
ResultSet result = session.execute( );Ниже приведена полная программа для чтения данных из таблицы.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Read_Data.java
$java Read_DataВ нормальных условиях он должен выдавать следующий результат -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Чтение данных с помощью предложения Select
Предложение SELECT используется для чтения данных из таблицы в Cassandra. Используя это предложение, вы можете прочитать всю таблицу, отдельный столбец или определенную ячейку. Ниже приведен синтаксис предложения SELECT.
SELECT FROM <tablename>пример
Предположим, что в пространстве ключей есть таблица с именем emp со следующими деталями -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | ноль | 9848022339 | 50000 |
| 3 | рахман | Ченнаи | 9848022330 | 50000 |
| 4 | Раджив | Пуна | 9848022331 | 30000 |
В следующем примере показано, как прочитать всю таблицу с помощью предложения SELECT. Здесь мы читаем таблицу под названиемemp.
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000
4 | Pune | rajeev | 9848022331 | 30000
(4 rows)Чтение обязательных столбцов
В следующем примере показано, как читать определенный столбец в таблице.
cqlsh:tutorialspoint> SELECT emp_name, emp_sal from emp;
emp_name | emp_sal
----------+---------
ram | 50000
robin | 50000
rajeev | 30000
rahman | 50000
(4 rows)Где пункт
Используя предложение WHERE, вы можете наложить ограничение на требуемые столбцы. Его синтаксис следующий -
SELECT FROM <table name> WHERE <condition>;Note - Предложение WHERE можно использовать только для столбцов, которые являются частью первичного ключа или имеют вторичный индекс.
В следующем примере мы читаем сведения о сотруднике, чья зарплата составляет 50000. Прежде всего, установите вторичный индекс в столбец emp_sal.
cqlsh:tutorialspoint> CREATE INDEX ON emp(emp_sal);
cqlsh:tutorialspoint> SELECT * FROM emp WHERE emp_sal=50000;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | null | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | 50000Чтение данных с использованием Java API
Вы можете читать данные из таблицы, используя метод execute () класса Session. Следуйте приведенным ниже инструкциям, чтобы выполнить несколько операторов с помощью пакетного оператора с помощью Java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. Используйте следующий код для создания объекта кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect( );Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“Your keyspace name”);Здесь мы используем KeySpace под названием tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В этом примере мы получаем данные из empстол. Сохраните запрос в строке и передайте его методу execute () класса сеанса, как показано ниже.
String query = ”SELECT 8 FROM emp”;
session.execute(query);Выполните запрос, используя метод execute () класса Session.
Шаг 4. Получите объект ResultSet
Запросы на выбор вернут результат в виде ResultSet объект, поэтому сохраните результат в объекте RESULTSET класс, как показано ниже.
ResultSet result = session.execute( );Ниже приведена полная программа для чтения данных из таблицы.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Session;
public class Read_Data {
public static void main(String args[])throws Exception{
//queries
String query = "SELECT * FROM emp";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tutorialspoint");
//Getting the ResultSet
ResultSet result = session.execute(query);
System.out.println(result.all());
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Read_Data.java
$java Read_DataВ нормальных условиях он должен выдавать следующий результат -
[Row[1, Hyderabad, ram, 9848022338, 50000], Row[2, Delhi, robin,
9848022339, 50000], Row[4, Pune, rajeev, 9848022331, 30000], Row[3,
Chennai, rahman, 9848022330, 50000]]Удаление данных из таблицы
Удалить данные из таблицы можно с помощью команды DELETE. Его синтаксис следующий -
DELETE FROM <identifier> WHERE <condition>;пример
Предположим, в Кассандре есть стол под названием emp имея следующие данные -
| emp_id | emp_name | emp_city | emp_phone | emp_sal |
|---|---|---|---|---|
| 1 | баран | Хайдарабад | 9848022338 | 50000 |
| 2 | Робин | Хайдарабад | 9848022339 | 40000 |
| 3 | рахман | Ченнаи | 9848022330 | 45000 |
Следующий оператор удаляет столбец emp_sal последней строки -
cqlsh:tutorialspoint> DELETE emp_sal FROM emp WHERE emp_id=3;Проверка
Используйте оператор SELECT, чтобы проверить, были ли данные удалены или нет. Если вы проверите таблицу emp с помощью SELECT, она выдаст следующий вывод:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
3 | Chennai | rahman | 9848022330 | null
(3 rows)Поскольку мы удалили зарплату Рахмана, вы увидите нулевое значение вместо зарплаты.
Удаление всей строки
Следующая команда удаляет всю строку из таблицы.
cqlsh:tutorialspoint> DELETE FROM emp WHERE emp_id=3;Проверка
Используйте оператор SELECT, чтобы проверить, были ли данные удалены или нет. Если вы проверите таблицу emp с помощью SELECT, она выдаст следующий вывод:
cqlsh:tutorialspoint> select * from emp;
emp_id | emp_city | emp_name | emp_phone | emp_sal
--------+-----------+----------+------------+---------
1 | Hyderabad | ram | 9848022338 | 50000
2 | Delhi | robin | 9848022339 | 50000
(2 rows)Поскольку мы удалили последнюю строку, в таблице остались только две строки.
Удаление данных с помощью Java API
Вы можете удалить данные в таблице с помощью метода execute () класса Session. Следуйте инструкциям ниже, чтобы удалить данные из таблицы с помощью java API.
Шаг 1. Создайте кластерный объект.
Создайте экземпляр Cluster.builder класс com.datastax.driver.core пакет, как показано ниже.
//Creating Cluster.Builder object
Cluster.Builder builder1 = Cluster.builder();Добавьте точку контакта (IP-адрес узла), используя addContactPoint() метод Cluster.Builderобъект. Этот метод возвращаетCluster.Builder.
//Adding contact point to the Cluster.Builder object
Cluster.Builder builder2 = build.addContactPoint( "127.0.0.1" );Используя новый объект построителя, создайте объект кластера. Для этого у вас есть метод под названиемbuild() в Cluster.Builderкласс. Используйте следующий код для создания объекта кластера.
//Building a cluster
Cluster cluster = builder.build();Вы можете построить объект кластера, используя одну строку кода, как показано ниже.
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();Шаг 2. Создайте объект сеанса
Создайте экземпляр объекта Session, используя метод connect () класса Cluster, как показано ниже.
Session session = cluster.connect();Этот метод создает новый сеанс и инициализирует его. Если у вас уже есть пространство ключей, вы можете установить его на существующее, передав имя KeySpace в строковом формате этому методу, как показано ниже.
Session session = cluster.connect(“ Your keyspace name ”);Здесь мы используем KeySpace под названием tp. Поэтому создайте объект сеанса, как показано ниже.
Session session = cluster.connect(“tp”);Шаг 3: Выполнить запрос
Вы можете выполнять запросы CQL, используя метод execute () класса Session. Передайте запрос в строковом формате или в виде объекта класса Statement методу execute (). Все, что вы передадите этому методу в строковом формате, будет выполнено наcqlsh.
В следующем примере мы удаляем данные из таблицы с именем emp. Вы должны сохранить запрос в строковой переменной и передать его в execute() метод, как показано ниже.
String query1 = ”DELETE FROM emp WHERE emp_id=3; ”;
session.execute(query);Ниже приведена полная программа для удаления данных из таблицы в Cassandra с использованием Java API.
import com.datastax.driver.core.Cluster;
import com.datastax.driver.core.Session;
public class Delete_Data {
public static void main(String args[]){
//query
String query = "DELETE FROM emp WHERE emp_id=3;";
//Creating Cluster object
Cluster cluster = Cluster.builder().addContactPoint("127.0.0.1").build();
//Creating Session object
Session session = cluster.connect("tp");
//Executing the query
session.execute(query);
System.out.println("Data deleted");
}
}Сохраните указанную выше программу с именем класса, за которым следует .java, перейдите к месту, где она сохранена. Скомпилируйте и выполните программу, как показано ниже.
$javac Delete_Data.java
$java Delete_DataВ нормальных условиях он должен выдавать следующий результат -
Data deletedCQL предоставляет богатый набор встроенных типов данных, включая типы коллекций. Наряду с этими типами данных пользователи также могут создавать свои собственные типы данных. В следующей таблице представлен список встроенных типов данных, доступных в CQL.
| Тип данных | Константы | Описание |
|---|---|---|
| ascii | струны | Представляет строку символов ASCII |
| Bigint | Bigint | Представляет 64-битный подписанный длинный |
| blob | капли | Представляет произвольные байты |
| Булево | булевы | Представляет истину или ложь |
| counter | целые числа | Представляет столбец счетчика |
| десятичный | целые числа, числа с плавающей запятой | Представляет десятичную дробь переменной точности |
| двойной | целые числа | Представляет 64-битную с плавающей запятой IEEE-754 |
| плавать | целые числа, числа с плавающей запятой | Представляет 32-битное число с плавающей запятой IEEE-754 |
| инет | струны | Представляет IP-адрес, IPv4 или IPv6 |
| int | целые числа | Представляет 32-разрядное целое число со знаком |
| текст | струны | Представляет строку в кодировке UTF8 |
| timestamp | целые числа, строки | Представляет отметку времени |
| timeuuid | uuids | Представляет UUID типа 1 |
| uuid | uuids | Представляет тип 1 или тип 4 |
| UUID | ||
| варчар | струны | Представляет строку в кодировке uTF8 |
| варинт | целые числа | Представляет целое число произвольной точности |
Типы коллекций
Cassandra Query Language также предоставляет коллекцию типов данных. В следующей таблице представлен список коллекций, доступных в CQL.
| Коллекция | Описание |
|---|---|
| список | Список - это набор из одного или нескольких упорядоченных элементов. |
| карта | Карта - это набор пар ключ-значение. |
| набор | Набор - это набор из одного или нескольких элементов. |
Типы данных, определяемые пользователем
Cqlsh предоставляет пользователям возможность создавать свои собственные типы данных. Ниже приведены команды, используемые при работе с пользовательскими типами данных.
CREATE TYPE - Создает определяемый пользователем тип данных.
ALTER TYPE - Изменяет определенный пользователем тип данных.
DROP TYPE - Отбрасывает определенный пользователем тип данных.
DESCRIBE TYPE - Описывает определяемый пользователем тип данных.
DESCRIBE TYPES - Описывает определяемые пользователем типы данных.
CQL предоставляет возможность использования типов данных Collection. Используя эти типы коллекций, вы можете хранить несколько значений в одной переменной. В этой главе объясняется, как использовать Коллекции в Кассандре.
Список
Список используется в тех случаях, когда
- порядок элементов должен быть сохранен, и
- значение должно сохраняться несколько раз.
Вы можете получить значения типа данных списка, используя индекс элементов в списке.
Создание таблицы со списком
Ниже приведен пример создания таблицы-образца с двумя столбцами: имя и адрес электронной почты. Для хранения нескольких писем мы используем список.
cqlsh:tutorialspoint> CREATE TABLE data(name text PRIMARY KEY, email list<text>);Вставка данных в список
При вставке данных в элементы списка введите все значения, разделенные запятой, в квадратных скобках [], как показано ниже.
cqlsh:tutorialspoint> INSERT INTO data(name, email) VALUES ('ramu',
['[email protected]','[email protected]'])Обновление списка
Ниже приведен пример обновления типа данных списка в таблице с именем data. Здесь мы добавляем еще один адрес электронной почты в список.
cqlsh:tutorialspoint> UPDATE data
... SET email = email +['[email protected]']
... where name = 'ramu';Проверка
Если вы проверите таблицу с помощью оператора SELECT, вы получите следующий результат:
cqlsh:tutorialspoint> SELECT * FROM data;
name | email
------+--------------------------------------------------------------
ramu | ['[email protected]', '[email protected]', '[email protected]']
(1 rows)НАБОР
Набор - это тип данных, который используется для хранения группы элементов. Элементы набора будут возвращены в отсортированном порядке.
Создание таблицы с помощью Set
В следующем примере создается образец таблицы с двумя столбцами: имя и телефон. Для хранения нескольких телефонных номеров мы используем set.
cqlsh:tutorialspoint> CREATE TABLE data2 (name text PRIMARY KEY, phone set<varint>);Вставка данных в набор
При вставке данных в элементы набора введите все значения, разделенные запятой, в фигурных скобках {}, как показано ниже.
cqlsh:tutorialspoint> INSERT INTO data2(name, phone)VALUES ('rahman', {9848022338,9848022339});Обновление набора
В следующем коде показано, как обновить набор в таблице с именем data2. Здесь мы добавляем в набор еще один номер телефона.
cqlsh:tutorialspoint> UPDATE data2
... SET phone = phone + {9848022330}
... where name = 'rahman';Проверка
Если вы проверите таблицу с помощью оператора SELECT, вы получите следующий результат:
cqlsh:tutorialspoint> SELECT * FROM data2;
name | phone
--------+--------------------------------------
rahman | {9848022330, 9848022338, 9848022339}
(1 rows)КАРТА
Карта - это тип данных, который используется для хранения пары элементов "ключ-значение".
Создание таблицы с картой
В следующем примере показано, как создать образец таблицы с двумя столбцами, именем и адресом. Для хранения нескольких значений адресов мы используем map.
cqlsh:tutorialspoint> CREATE TABLE data3 (name text PRIMARY KEY, address
map<timestamp, text>);Вставка данных на карту
При вставке данных в элементы на карте введите все key : value пары, разделенные запятой в фигурных скобках {}, как показано ниже.
cqlsh:tutorialspoint> INSERT INTO data3 (name, address)
VALUES ('robin', {'home' : 'hyderabad' , 'office' : 'Delhi' } );Обновление набора
В следующем коде показано, как обновить тип данных карты в таблице с именем data3. Здесь мы меняем значение ключевого офиса, то есть мы меняем адрес офиса человека по имени robin.
cqlsh:tutorialspoint> UPDATE data3
... SET address = address+{'office':'mumbai'}
... WHERE name = 'robin';Проверка
Если вы проверите таблицу с помощью оператора SELECT, вы получите следующий результат:
cqlsh:tutorialspoint> select * from data3;
name | address
-------+-------------------------------------------
robin | {'home': 'hyderabad', 'office': 'mumbai'}
(1 rows)CQL предоставляет возможность создания и использования пользовательских типов данных. Вы можете создать тип данных для обработки нескольких полей. В этой главе объясняется, как создавать, изменять и удалять пользовательский тип данных.
Создание определяемого пользователем типа данных
Команда CREATE TYPEиспользуется для создания определяемого пользователем типа данных. Его синтаксис следующий -
CREATE TYPE <keyspace name>. <data typename>
( variable1, variable2).пример
Ниже приводится пример создания пользовательского типа данных. В этом примере мы создаемcard_details тип данных, содержащий следующие сведения.
| Поле | Имя поля | Тип данных |
|---|---|---|
| кредитная карта нет | число | int |
| пин-код кредитной карты | штырь | int |
| Имя на кредитной карте | имя | текст |
| cvv | cvv | int |
| Контактные данные держателя карты | Телефон | набор |
cqlsh:tutorialspoint> CREATE TYPE card_details (
... num int,
... pin int,
... name text,
... cvv int,
... phone set<int>
... );Note - Имя, используемое для пользовательского типа данных, не должно совпадать с зарезервированными именами типов.
Проверка
Использовать DESCRIBE команда, чтобы проверить, был ли создан созданный тип или нет.
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>
);Изменение определяемого пользователем типа данных
ALTER TYPE- команда используется для изменения существующего типа данных. Используя ALTER, вы можете добавить новое поле или переименовать существующее.
Добавление поля к типу
Используйте следующий синтаксис, чтобы добавить новое поле к существующему пользовательскому типу данных.
ALTER TYPE typename
ADD field_name field_type;Следующий код добавляет новое поле в Card_detailsтип данных. Здесь мы добавляем новое поле под названием электронная почта.
cqlsh:tutorialspoint> ALTER TYPE card_details ADD email text;Проверка
Использовать DESCRIBE команда, чтобы проверить, добавлено ли новое поле или нет.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
);Переименование поля в типе
Используйте следующий синтаксис для переименования существующего пользовательского типа данных.
ALTER TYPE typename
RENAME existing_name TO new_name;Следующий код изменяет имя поля в типе. Здесь мы переименовываем поле email в mail.
cqlsh:tutorialspoint> ALTER TYPE card_details RENAME email TO mail;Проверка
Использовать DESCRIBE команда, чтобы проверить, изменилось ли имя типа или нет.
cqlsh:tutorialspoint> describe type card_details;
CREATE TYPE tutorialspoint.card_details (
num int,
pin int,
name text,
cvv int,
phone set<int>,
mail text
);Удаление пользовательского типа данных
DROP TYPEэто команда, используемая для удаления определенного пользователем типа данных. Ниже приведен пример удаления определенного пользователем типа данных.
пример
Перед удалением проверьте список всех пользовательских типов данных, используя DESCRIBE_TYPES как показано ниже.
cqlsh:tutorialspoint> DESCRIBE TYPES;
card_details cardИз двух типов удалите тип с именем card как показано ниже.
cqlsh:tutorialspoint> drop type card;Использовать DESCRIBE команда, чтобы проверить, сброшен ли тип данных или нет.
cqlsh:tutorialspoint> describe types;
card_details