Компилятор - Генерация промежуточного кода
Исходный код можно напрямую транслировать в его целевой машинный код, тогда зачем вообще нам нужно переводить исходный код в промежуточный код, который затем транслируется в его целевой код? Давайте посмотрим, почему нам нужен промежуточный код.
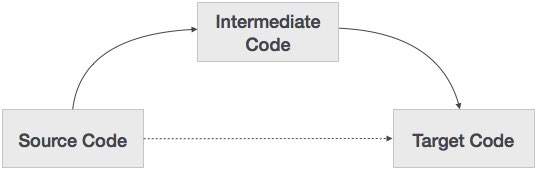
Если компилятор переводит исходный язык на свой целевой машинный язык, не имея возможности генерировать промежуточный код, то для каждой новой машины требуется полный собственный компилятор.
Промежуточный код устраняет необходимость в новом полном компиляторе для каждой уникальной машины, сохраняя часть анализа одинаковой для всех компиляторов.
Вторая часть компилятора, синтез, изменяется в зависимости от целевой машины.
Становится проще применять модификации исходного кода для повышения производительности кода, применяя методы оптимизации кода к промежуточному коду.
Промежуточное представление
Промежуточные коды могут быть представлены различными способами, и у них есть свои преимущества.
High Level IR- Представление промежуточного кода высокого уровня очень близко к самому исходному языку. Их можно легко сгенерировать из исходного кода, и мы можем легко применить модификации кода для повышения производительности. Но для оптимизации целевой машины это менее предпочтительно.
Low Level IR - Он близок к целевой машине, что делает его подходящим для распределения регистров и памяти, выбора набора команд и т. Д. Это хорошо для машинно-зависимых оптимизаций.
Промежуточный код может быть либо специфичным для языка (например, байтовый код для Java), либо независимым от языка (трехадресный код).
Трехадресный код
Генератор промежуточного кода получает входные данные от предшествующей ему фазы, семантического анализатора, в виде аннотированного синтаксического дерева. Это синтаксическое дерево затем может быть преобразовано в линейное представление, например, в постфиксную нотацию. Промежуточный код обычно является машинно-независимым кодом. Следовательно, генератор кода предполагает наличие неограниченного количества хранилищ памяти (регистров) для генерации кода.
Например:
a = b + c * d;Генератор промежуточного кода попытается разделить это выражение на подвыражения, а затем сгенерировать соответствующий код.
r1 = c * d;
r2 = b + r1;
a = r2r используется в качестве регистров в целевой программе.
Трехадресный код имеет не более трех адресов для вычисления выражения. Трехадресный код может быть представлен в двух формах: четверной и тройной.
Четверки
Каждая инструкция в четырехкратном представлении разделена на четыре поля: оператор, arg1, arg2 и результат. Приведенный выше пример представлен ниже в четверном формате:
| Op | аргумент 1 | аргумент 2 | результат |
| * | c | d | r1 |
| + | б | r1 | r2 |
| + | r2 | r1 | r3 |
| знак равно | r3 | а |
Тройки
Каждая инструкция в тройном представлении имеет три поля: op, arg1 и arg2. Результаты соответствующих подвыражений обозначаются позицией выражения. Тройки представляют собой сходство с DAG и синтаксическим деревом. Они эквивалентны DAG при представлении выражений.
| Op | аргумент 1 | аргумент 2 |
| * | c | d |
| + | б | (0) |
| + | (1) | (0) |
| знак равно | (2) |
Триплы сталкиваются с проблемой неподвижности кода при оптимизации, поскольку результаты являются позиционными, и изменение порядка или позиции выражения может вызвать проблемы.
Косвенные тройки
Это представление является улучшением представления троек. Он использует указатели вместо позиции для хранения результатов. Это позволяет оптимизаторам свободно перемещать подвыражение для создания оптимизированного кода.
Декларации
Перед использованием переменная или процедура должны быть объявлены. Объявление включает в себя выделение места в памяти и запись типа и имени в таблице символов. Программа может быть написана и разработана с учетом структуры целевой машины, но не всегда может быть возможно точно преобразовать исходный код на целевой язык.
Принимая всю программу как набор процедур и подпроцедур, становится возможным объявить все имена локальными для процедуры. Распределение памяти выполняется последовательно, и имена выделяются в памяти в той последовательности, в которой они объявлены в программе. Мы используем переменную смещения и устанавливаем ее в ноль {offset = 0}, что обозначает базовый адрес.
Исходный язык программирования и архитектура целевой машины могут различаться по способу хранения имен, поэтому используется относительная адресация. В то время как первое имя выделяется памятью, начиная с ячейки памяти 0 {offset = 0}, следующее имя, объявленное позже, должно располагаться в памяти рядом с первым.
Example:
Мы возьмем пример языка программирования C, в котором целочисленной переменной назначается 2 байта памяти, а переменной с плавающей запятой назначается 4 байта памяти.
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}Чтобы ввести эту деталь в таблицу символов, можно использовать процедуру ввода . Этот метод может иметь следующую структуру:
enter(name, type, offset)Эта процедура должна создать запись в таблице символов для имени переменной , для которой задан тип и относительное смещение адреса в области данных.