Параллелизм в Python - Краткое руководство
В этой главе мы поймем концепцию параллелизма в Python и узнаем о различных потоках и процессах.
Что такое параллелизм?
Проще говоря, параллелизм - это возникновение двух или более событий одновременно. Параллелизм - это естественное явление, потому что многие события происходят одновременно в любой момент времени.
С точки зрения программирования, параллелизм - это когда две задачи перекрываются при выполнении. Благодаря параллельному программированию производительность наших приложений и программных систем может быть улучшена, потому что мы можем одновременно обрабатывать запросы, а не ждать завершения предыдущего.
Исторический обзор параллелизма
Следующие пункты дадут нам краткий исторический обзор параллелизма.
Из концепции железных дорог
Параллелизм тесно связан с концепцией железных дорог. С железными дорогами возникла необходимость управлять несколькими поездами в одной и той же железнодорожной системе таким образом, чтобы каждый поезд мог безопасно добраться до места назначения.
Параллельные вычисления в академических кругах
Интерес к параллелизму в информатике начался с исследовательской работы, опубликованной Эдсгером В. Дейкстрой в 1965 году. В этой статье он определил и решил проблему взаимного исключения, свойства управления параллелизмом.
Примитивы параллелизма высокого уровня
В последнее время программисты получают улучшенные решения для параллелизма из-за введения высокоуровневых примитивов параллелизма.
Улучшенный параллелизм с языками программирования
Такие языки программирования, как Google Golang, Rust и Python, добились невероятных успехов в областях, которые помогают нам получать лучшие параллельные решения.
Что такое поток и многопоточность?
Threadэто наименьшая единица выполнения, которая может быть выполнена в операционной системе. Сама по себе программа не является программой, но выполняется внутри программы. Другими словами, потоки не независимы друг от друга. Каждый поток разделяет раздел кода, раздел данных и т. Д. С другими потоками. Их также называют облегченными процессами.
Поток состоит из следующих компонентов -
Программный счетчик, состоящий из адреса следующей исполняемой инструкции
Stack
Набор регистров
Уникальный идентификатор
Multithreadingс другой стороны, это способность ЦП управлять использованием операционной системы, выполняя несколько потоков одновременно. Основная идея многопоточности заключается в достижении параллелизма путем разделения процесса на несколько потоков. Понятие многопоточности можно понять с помощью следующего примера.
пример
Предположим, мы запускаем определенный процесс, в котором мы открываем MS Word для ввода в него содержимого. Один поток будет назначен для открытия MS Word, а другой поток потребуется для ввода в него содержимого. И теперь, если мы хотим отредактировать существующий, потребуется другой поток для выполнения задачи редактирования и так далее.
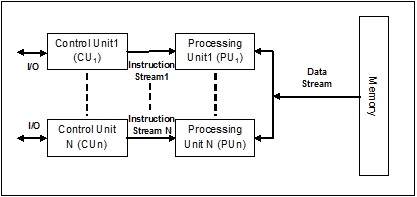
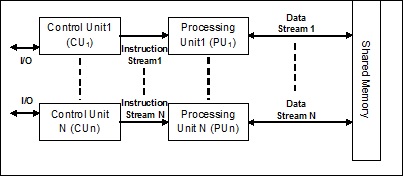
Что такое процесс и многопроцессорность?
Аprocessопределяется как объект, который представляет собой базовую единицу работы, которая должна быть реализована в системе. Проще говоря, мы пишем наши компьютерные программы в текстовом файле, и когда мы выполняем эту программу, она становится процессом, который выполняет все задачи, упомянутые в программе. В течение жизненного цикла процесса он проходит разные стадии - запуск, готовность, выполнение, ожидание и завершение.
На следующей диаграмме показаны различные этапы процесса -
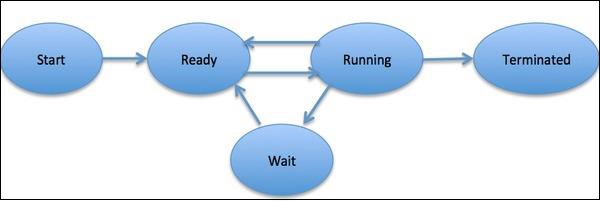
Процесс может иметь только один поток, называемый первичным потоком, или несколько потоков, имеющих собственный набор регистров, счетчик программ и стек. Следующая диаграмма покажет нам разницу -
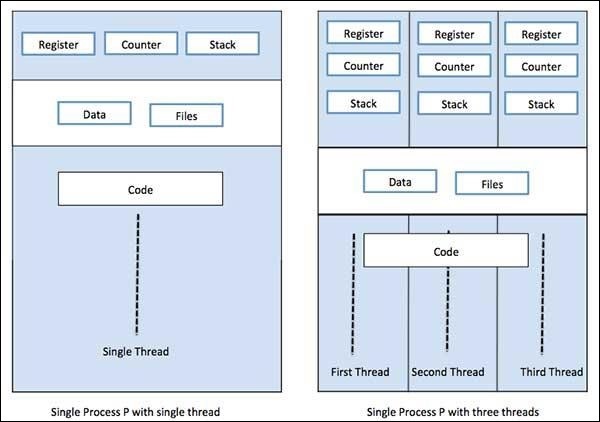
Multiprocessing,с другой стороны, это использование двух или более блоков ЦП в одной компьютерной системе. Наша основная цель - раскрыть весь потенциал нашего оборудования. Для этого нам нужно использовать все количество ядер ЦП, доступных в нашей компьютерной системе. Многопроцессорная обработка - лучший подход для этого.
Python - один из самых популярных языков программирования. Ниже приведены некоторые причины, по которым он подходит для одновременных приложений.
Синтаксический сахар
Синтаксический сахар - это синтаксис языка программирования, предназначенный для облегчения чтения или выражения. Это делает язык «более сладким» для человеческого использования: вещи могут быть выражены более четко, лаконично или в альтернативном стиле, основанном на предпочтениях. Python поставляется с методами Magic, которые можно определить для воздействия на объекты. Эти методы Magic используются в качестве синтаксического сахара и привязаны к более понятным ключевым словам.
Большое сообщество
Язык Python получил широкое распространение среди специалистов по обработке данных и математиков, работающих в области ИИ, машинного обучения, глубокого обучения и количественного анализа.
Полезные API для параллельного программирования
Python 2 и 3 имеют большое количество API, предназначенных для параллельного / параллельного программирования. Самые популярные из них:threading, concurrent.features, multiprocessing, asyncio, gevent and greenlets, и т.п.
Ограничения Python при реализации параллельных приложений
Python имеет ограничение для одновременных приложений. Это ограничение называетсяGIL (Global Interpreter Lock)присутствует в Python. GIL никогда не позволяет нам использовать несколько ядер ЦП, и поэтому мы можем сказать, что в Python нет настоящих потоков. Мы можем понять концепцию GIL следующим образом:
GIL (глобальная блокировка переводчика)
Это одна из самых противоречивых тем в мире Python. В CPython GIL - это мьютекс - блокировка взаимного исключения, которая делает вещи потокобезопасными. Другими словами, мы можем сказать, что GIL предотвращает параллельное выполнение кода Python несколькими потоками. Блокировка может удерживаться только одним потоком за раз, и если мы хотим выполнить поток, он должен сначала получить блокировку. Схема, показанная ниже, поможет вам понять работу GIL.
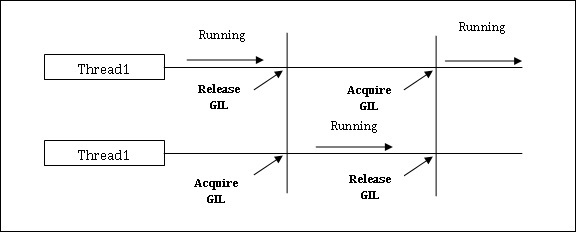
Однако в Python есть некоторые библиотеки и реализации, такие как Numpy, Jpython и IronPytbhon. Эти библиотеки работают без какого-либо взаимодействия с GIL.
И параллелизм, и параллелизм используются по отношению к многопоточным программам, но существует большая путаница в отношении сходства и различий между ними. В этой связи большой вопрос: параллелизм параллелизма или нет? Хотя оба термина кажутся очень похожими, но ответ на поставленный выше вопрос - НЕТ, параллелизм и параллелизм - это не одно и то же. Теперь, если они не совпадают, то в чем основная разница между ними?
Проще говоря, параллелизм имеет дело с управлением доступом к общему состоянию из разных потоков, а с другой стороны, параллелизм связан с использованием нескольких процессоров или их ядер для повышения производительности оборудования.
Параллелизм в деталях
Параллелизм - это когда две задачи перекрываются при выполнении. Это может быть ситуация, когда приложение выполняет более одной задачи одновременно. Мы можем понять это схематически; несколько задач выполняются одновременно, а именно:
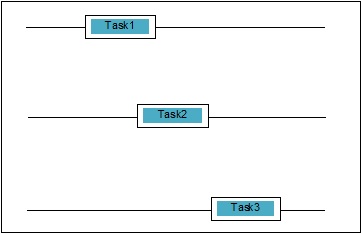
Уровни параллелизма
В этом разделе мы обсудим три важных уровня параллелизма с точки зрения программирования:
Параллелизм на низком уровне
На этом уровне параллелизма явно используются атомарные операции. Мы не можем использовать такой вид параллелизма для создания приложений, так как он очень подвержен ошибкам и труден для отладки. Даже Python не поддерживает такой параллелизм.
Параллелизм среднего уровня
В этом параллелизме не используются явные атомарные операции. Он использует явные блокировки. Python и другие языки программирования поддерживают такой параллелизм. Этим параллелизмом пользуются в основном прикладные программисты.
Параллелизм высокого уровня
В этом параллелизме не используются ни явные атомарные операции, ни явные блокировки. Python имеетconcurrent.futures модуль для поддержки такого вида параллелизма.
Свойства параллельных систем
Чтобы программа или параллельная система были правильными, она должна удовлетворять некоторым свойствам. Свойства, связанные с прекращением работы системы, следующие:
Свойство правильности
Свойство правильности означает, что программа или система должны предоставить желаемый правильный ответ. Для простоты можно сказать, что система должна правильно отображать начальное состояние программы в конечное состояние.
Свойство безопасности
Свойство безопасности означает, что программа или система должны оставаться в “good” или же “safe” заявлять и никогда ничего не делать “bad”.
Живучесть собственности
Это свойство означает, что программа или система должны “make progress” и он достигнет некоторого желаемого состояния.
Акторы параллельных систем
Это одно общее свойство параллельной системы, в которой может быть несколько процессов и потоков, которые запускаются одновременно для выполнения своих собственных задач. Эти процессы и потоки называются участниками параллельной системы.
Ресурсы параллельных систем
Актеры должны использовать такие ресурсы, как память, диск, принтер и т. Д., Для выполнения своих задач.
Определенный набор правил
Каждая параллельная система должна обладать набором правил для определения типа задач, которые должны выполняться участниками, и времени для каждой. Задачи могут заключаться в получении блокировок, разделении памяти, изменении состояния и т. Д.
Барьеры параллельных систем
Обмен данными
Важной проблемой при реализации параллельных систем является совместное использование данных между несколькими потоками или процессами. Фактически, программист должен гарантировать, что блокировки защищают совместно используемые данные, чтобы все обращения к ним были сериализованы, и только один поток или процесс мог получить доступ к совместно используемым данным одновременно. В случае, когда несколько потоков или процессов все пытаются получить доступ к одним и тем же общим данным, не все, но хотя бы один из них будут заблокированы и останутся простаивающими. Другими словами, мы можем сказать, что сможем использовать только один процесс или поток в то время, когда действует блокировка. Могут быть несколько простых решений для устранения вышеупомянутых барьеров -
Ограничение обмена данными
Самое простое решение - не делиться изменяемыми данными. В этом случае нам не нужно использовать явную блокировку, и барьер параллелизма из-за взаимных данных будет решен.
Поддержка структуры данных
Часто параллельным процессам требуется доступ к одним и тем же данным в одно и то же время. Другое решение, чем использование явных блокировок, - использовать структуру данных, поддерживающую одновременный доступ. Например, мы можем использоватьqueueмодуль, который обеспечивает потокобезопасные очереди. Мы также можем использоватьmultiprocessing.JoinableQueue классы для параллелизма на основе многопроцессорности.
Неизменяемая передача данных
Иногда структура данных, которую мы используем, например, очередь параллелизма, не подходит, тогда мы можем передать неизменяемые данные, не блокируя их.
Изменяемая передача данных
В продолжение вышеупомянутого решения предположим, что если требуется передавать только изменяемые данные, а не неизменяемые данные, тогда мы можем передавать изменяемые данные, которые доступны только для чтения.
Совместное использование ресурсов ввода-вывода
Другой важной проблемой при реализации параллельных систем является использование ресурсов ввода-вывода потоками или процессами. Проблема возникает, когда один поток или процесс использует ввод-вывод в течение такого длительного времени, а другой бездействует. Мы можем видеть такой барьер при работе с приложениями с большим объемом операций ввода-вывода. Это можно понять на примере запроса страниц из веб-браузера. Это тяжелое приложение. Здесь, если скорость, с которой запрашиваются данные, ниже, чем скорость, с которой они потребляются, тогда у нас есть барьер ввода-вывода в нашей параллельной системе.
Следующий скрипт Python предназначен для запроса веб-страницы и получения времени, затраченного нашей сетью на получение запрошенной страницы:
import urllib.request
import time
ts = time.time()
req = urllib.request.urlopen('http://www.tutorialspoint.com')
pageHtml = req.read()
te = time.time()
print("Page Fetching Time : {} Seconds".format (te-ts))После выполнения вышеуказанного сценария мы можем получить время загрузки страницы, как показано ниже.
Вывод
Page Fetching Time: 1.0991398811340332 SecondsМы видим, что время загрузки страницы превышает одну секунду. А что, если мы хотим получить тысячи различных веб-страниц, вы можете понять, сколько времени займет наша сеть.
Что такое параллелизм?
Параллелизм можно определить как искусство разделения задач на подзадачи, которые могут обрабатываться одновременно. Это противоположно параллелизму, как обсуждалось выше, при котором два или более события происходят одновременно. Мы можем понять это схематически; задача разбита на несколько подзадач, которые можно обрабатывать параллельно, а именно:
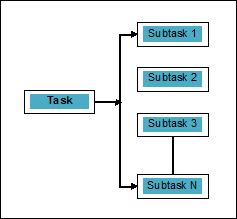
Чтобы получить больше информации о различии между параллелизмом и параллелизмом, рассмотрите следующие моменты:
Параллельно, но не параллельно
Приложение может быть параллельным, но не параллельным, это означает, что оно обрабатывает более одной задачи одновременно, но задачи не разбиваются на подзадачи.
Параллельно, но не одновременно
Приложение может быть параллельным, но не одновременно, это означает, что оно работает только над одной задачей за раз, а задачи, разбитые на подзадачи, могут обрабатываться параллельно.
Ни параллельно, ни одновременно
Приложение не может быть ни параллельным, ни параллельным. Это означает, что он работает только над одной задачей за раз, и задача никогда не разбивается на подзадачи.
И параллельные, и параллельные
Приложение может быть как параллельным, так и параллельным, что означает, что оно одновременно работает с несколькими задачами, а задача разбита на подзадачи для их параллельного выполнения.
Необходимость параллелизма
Мы можем добиться параллелизма, распределяя подзадачи между различными ядрами одного процессора или между несколькими компьютерами, подключенными к сети.
Рассмотрим следующие важные моменты, чтобы понять, почему необходимо добиться параллелизма:
Эффективное выполнение кода
С помощью параллелизма мы можем эффективно запускать наш код. Это сэкономит нам время, потому что один и тот же код по частям выполняется параллельно.
Быстрее, чем последовательные вычисления
Последовательные вычисления ограничены физическими и практическими факторами, из-за которых невозможно получить более быстрые результаты вычислений. С другой стороны, эта проблема решается с помощью параллельных вычислений и дает нам более быстрые результаты вычислений, чем последовательные вычисления.
Меньше времени выполнения
Параллельная обработка сокращает время выполнения программного кода.
Если мы говорим о реальном примере параллелизма, графическая карта нашего компьютера является примером, который подчеркивает истинную мощь параллельной обработки, поскольку она имеет сотни отдельных процессорных ядер, которые работают независимо и могут выполнять выполнение одновременно. По этой причине мы также можем запускать высококачественные приложения и игры.
Понимание процессоров для реализации
Мы знаем о параллелизме, параллелизме и различии между ними, но как насчет системы, в которой это должно быть реализовано. Очень важно иметь представление о системе, которую мы собираемся внедрить, потому что это дает нам возможность принимать обоснованные решения при разработке программного обеспечения. У нас есть следующие два типа процессоров -
Одноядерные процессоры
Одноядерные процессоры могут выполнять один поток в любой момент времени. Эти процессоры используютcontext switchingчтобы сохранить всю необходимую информацию для потока в определенное время, а затем восстановить информацию позже. Механизм переключения контекста помогает нам добиться прогресса в нескольких потоках в течение заданной секунды, и похоже, что система работает над несколькими вещами.
Одноядерные процессоры обладают множеством преимуществ. Эти процессоры требуют меньше энергии, и нет сложного протокола связи между несколькими ядрами. С другой стороны, скорость одноядерных процессоров ограничена и не подходит для больших приложений.
Многоядерные процессоры
Многоядерные процессоры имеют несколько независимых процессоров, также называемых cores.
Таким процессорам не нужен механизм переключения контекста, поскольку каждое ядро содержит все необходимое для выполнения последовательности хранимых инструкций.
Цикл Fetch-Decode-Execute
Ядра многоядерных процессоров следуют циклу выполнения. Этот цикл называетсяFetch-Decode-Executeцикл. Это включает в себя следующие шаги -
Получить
Это первый шаг цикла, который включает выборку инструкций из памяти программы.
Декодировать
Недавно полученные инструкции будут преобразованы в серию сигналов, которые будут запускать другие части процессора.
Выполнить
Это последний шаг, на котором будут выполняться извлеченные и декодированные инструкции. Результат выполнения будет сохранен в регистре ЦП.
Одним из преимуществ здесь является то, что выполнение в многоядерных процессорах происходит быстрее, чем в одноядерных процессорах. Он подходит для более крупных приложений. С другой стороны, сложный протокол связи между несколькими ядрами является проблемой. Для нескольких ядер требуется больше энергии, чем для одноядерных процессоров.
Существуют различные стили архитектуры системы и памяти, которые необходимо учитывать при разработке программы или параллельной системы. Это очень необходимо, потому что один стиль системы и памяти может подходить для одной задачи, но может быть подвержен ошибкам при выполнении другой задачи.
Архитектура компьютерных систем, поддерживающая параллелизм
Майкл Флинн в 1972 году дал таксономию для категоризации различных стилей архитектуры компьютерных систем. Эта таксономия определяет четыре разных стиля следующим образом:
- Одиночный поток инструкций, одиночный поток данных (SISD)
- Единый поток инструкций, множественный поток данных (SIMD)
- Множественный поток инструкций, единый поток данных (MISD)
- Множественный поток инструкций, множественный поток данных (MIMD).
Одиночный поток инструкций, одиночный поток данных (SISD)
Как следует из названия, такие системы будут иметь один последовательный входящий поток данных и один единый блок обработки для выполнения потока данных. Они похожи на однопроцессорные системы с архитектурой параллельных вычислений. Ниже приводится архитектура SISD -
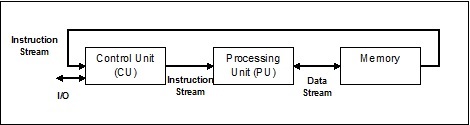
Преимущества SISD
Преимущества архитектуры SISD следующие:
- Требуется меньше энергии.
- Нет проблем со сложным протоколом связи между несколькими ядрами.
Недостатки SISD
Недостатки архитектуры SISD следующие:
- Скорость архитектуры SISD ограничена, как и у одноядерных процессоров.
- Он не подходит для больших приложений.
Единый поток инструкций, множественный поток данных (SIMD)
Как следует из названия, такие системы будут иметь несколько потоков входящих данных и количество процессоров, которые могут действовать по одной инструкции в любой момент времени. Они похожи на многопроцессорные системы с архитектурой параллельных вычислений. Ниже приводится архитектура SIMD -
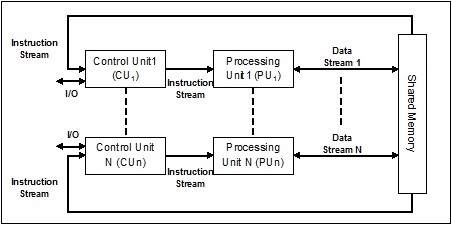
Лучший пример для SIMD - видеокарты. Эти карты имеют сотни отдельных процессоров. Если говорить о вычислительной разнице между SISD и SIMD, то для добавляемых массивов[5, 15, 20] и [15, 25, 10],Архитектура SISD должна будет выполнять три разные операции добавления. С другой стороны, с архитектурой SIMD мы можем добавить их за одну операцию добавления.
Преимущества SIMD
Преимущества архитектуры SIMD следующие:
Одна и та же операция с несколькими элементами может быть выполнена с использованием только одной инструкции.
Увеличить пропускную способность системы можно за счет увеличения количества ядер процессора.
Скорость обработки выше, чем у архитектуры SISD.
Недостатки SIMD
Недостатки SIMD-архитектуры следующие:
- Между номерами ядер процессора существует сложная связь.
- Стоимость выше, чем у архитектуры SISD.
Поток нескольких инструкций и одиночных данных (MISD)
Системы с потоком MISD имеют несколько блоков обработки, выполняющих разные операции, выполняя разные инструкции с одним и тем же набором данных. Ниже приводится архитектура MISD -
Представителей архитектуры MISD пока нет в продаже.
Поток с множественными инструкциями и множественными данными (MIMD)
В системе, использующей архитектуру MIMD, каждый процессор в многопроцессорной системе может выполнять разные наборы инструкций независимо от другого набора данных параллельно. Это противоположно архитектуре SIMD, в которой одна операция выполняется над несколькими наборами данных. Ниже приводится архитектура MIMD -
Обычный мультипроцессор использует архитектуру MIMD. Эти архитектуры в основном используются в ряде областей приложений, таких как автоматизированное проектирование / автоматизированное производство, моделирование, моделирование, переключатели связи и т. Д.
Архитектуры памяти, поддерживающие параллелизм
При работе с такими понятиями, как параллелизм и параллелизм, всегда необходимо ускорить работу программ. Одним из решений, найденных разработчиками компьютеров, является создание нескольких компьютеров с общей памятью, т. Е. Компьютеров с единым физическим адресным пространством, к которому имеют доступ все ядра процессора. В этом сценарии может быть несколько разных стилей архитектуры, но следующие три важных архитектурных стиля:
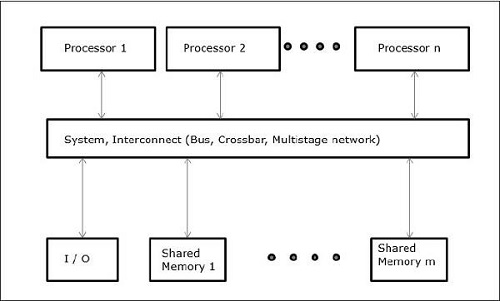
UMA (унифицированный доступ к памяти)
В этой модели все процессоры равномерно распределяют физическую память. Все процессоры имеют одинаковое время доступа ко всем словам памяти. Каждый процессор может иметь частную кэш-память. Периферийные устройства подчиняются набору правил.
Когда все процессоры имеют равный доступ ко всем периферийным устройствам, система называется symmetric multiprocessor. Когда только один или несколько процессоров могут получить доступ к периферийным устройствам, система называетсяasymmetric multiprocessor.
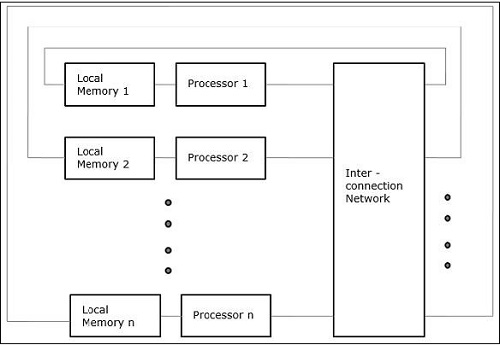
Неравномерный доступ к памяти (NUMA)
В многопроцессорной модели NUMA время доступа зависит от местоположения слова памяти. Здесь общая память физически распределяется между всеми процессорами и называется локальной памятью. Совокупность всех локальных запоминающих устройств образует глобальное адресное пространство, доступное для всех процессоров.
Архитектура только кэш-памяти (COMA)
Модель COMA - это специализированная версия модели NUMA. Здесь вся распределенная основная память преобразуется в кэш-память.
В общем, как мы знаем, нить представляет собой очень тонкую скрученную нить, обычно из хлопковой или шелковой ткани и используемую для шитья одежды и тому подобного. Тот же термин поток также используется в мире компьютерного программирования. Как же связать нить, используемую для шитья одежды, и нить, используемую для компьютерного программирования? Роли, выполняемые двумя потоками, здесь схожи. В одежде нить скрепляет ткань, а с другой стороны - в компьютерном программировании - нить удерживает компьютерную программу и позволяет программе выполнять последовательные действия или множество действий одновременно.
Threadэто наименьшая единица выполнения в операционной системе. Сама по себе это не программа, а выполняется внутри программы. Другими словами, потоки не являются независимыми друг от друга и совместно используют раздел кода, раздел данных и т. Д. С другими потоками. Эти потоки также известны как облегченные процессы.
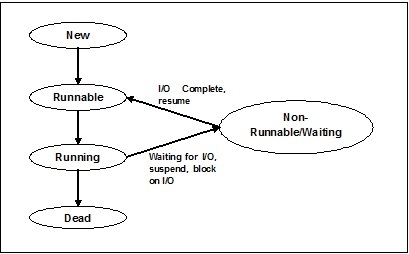
Состояния потока
Чтобы глубже понять функциональность потоков, нам нужно узнать о жизненном цикле потоков или различных состояниях потоков. Обычно поток может существовать в пяти различных состояниях. Различные состояния показаны ниже -
Новый поток
Новый поток начинает свой жизненный цикл в новом состоянии. Однако на данном этапе он еще не запущен, и ему не выделены какие-либо ресурсы. Можно сказать, что это просто экземпляр объекта.
Работоспособен
Когда только что созданный поток запускается, он становится работоспособным, т.е. ожидает запуска. В этом состоянии у него есть все ресурсы, но планировщик задач еще не запланировал его запуск.
Бег
В этом состоянии поток выполняет прогресс и выполняет задачу, которая была выбрана планировщиком задач для запуска. Теперь поток может перейти либо в мертвое состояние, либо в состояние неработоспособности / ожидания.
Не работает / ожидает
В этом состоянии поток приостановлен, потому что он либо ожидает ответа на некоторый запрос ввода-вывода, либо ожидает завершения выполнения другого потока.
мертв
Выполняемый поток переходит в состояние завершения, когда он завершает свою задачу или иным образом завершается.
На следующей диаграмме показан полный жизненный цикл потока -
Типы резьбы
В этом разделе мы увидим различные типы ниток. Типы описаны ниже -
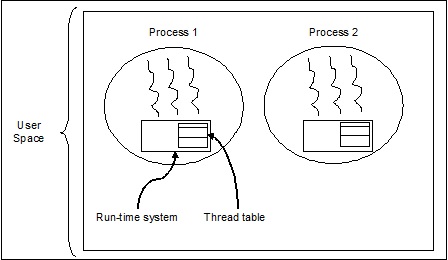
Потоки уровня пользователя
Это потоки, управляемые пользователем.
В этом случае ядро управления потоками не знает о существовании потоков. Библиотека потоков содержит код для создания и уничтожения потоков, для передачи сообщений и данных между потоками, для планирования выполнения потоков и для сохранения и восстановления контекстов потоков. Приложение запускается с одного потока.
Примеры потоков пользовательского уровня:
- Потоки Java
- Потоки POSIX
Преимущества потоков пользовательского уровня
Ниже приведены различные преимущества потоков пользовательского уровня.
- Для переключения потоков не требуются привилегии режима ядра.
- Поток пользовательского уровня может работать в любой операционной системе.
- Планирование может зависеть от приложения в потоке пользовательского уровня.
- Потоки пользовательского уровня быстро создаются и управляются.
Недостатки потоков пользовательского уровня
Ниже приведены различные недостатки потоков пользовательского уровня.
- В типичной операционной системе большинство системных вызовов блокируются.
- Многопоточное приложение не может использовать преимущества многопроцессорности.
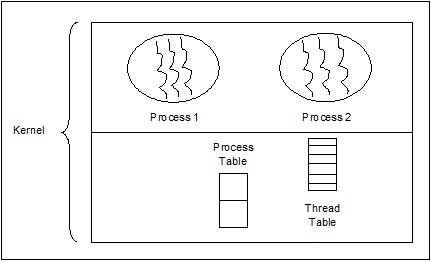
Потоки уровня ядра
Управляемые потоки операционной системы воздействуют на ядро, которое является ядром операционной системы.
В этом случае ядро выполняет управление потоками. В области приложения нет кода управления потоками. Потоки ядра поддерживаются непосредственно операционной системой. Любое приложение можно запрограммировать на многопоточность. Все потоки в приложении поддерживаются в рамках одного процесса.
Ядро хранит контекстную информацию для процесса в целом и для отдельных потоков внутри процесса. Планирование ядром выполняется на основе потоков. Ядро выполняет создание, планирование и управление потоками в пространстве ядра. Потоки ядра обычно создаются и управляются медленнее, чем потоки пользователя. Примеры потоков уровня ядра: Windows, Solaris.
Преимущества потоков уровня ядра
Ниже приведены различные преимущества потоков уровня ядра.
Ядро может одновременно планировать несколько потоков одного и того же процесса для нескольких процессов.
Если один поток в процессе заблокирован, ядро может запланировать другой поток того же процесса.
Сами процедуры ядра могут быть многопоточными.
Недостатки потоков уровня ядра
Потоки ядра обычно создаются и управляются медленнее, чем потоки пользователя.
Передача управления от одного потока к другому в рамках одного процесса требует переключения режима на ядро.
Блок управления потоком - TCB
Блок управления потоком (TCB) может быть определен как структура данных в ядре операционной системы, которая в основном содержит информацию о потоке. Информация о потоке, хранящаяся в TCB, выделяет важную информацию о каждом процессе.
Рассмотрим следующие моменты, связанные с потоками, содержащимися в TCB:
Thread identification - Это уникальный идентификатор потока (tid), назначаемый каждому новому потоку.
Thread state - Он содержит информацию, относящуюся к состоянию (Выполняется, Выполняется, Не работает, Не работает) потока.
Program Counter (PC) - Указывает на текущую программную инструкцию потока.
Register set - Он содержит значения регистров потока, назначенные им для вычислений.
Stack Pointer- Указывает на стек потока в процессе. Он содержит локальные переменные в области видимости потока.
Pointer to PCB - Он содержит указатель на процесс, создавший этот поток.

Связь между процессом и потоком
В многопоточности процесс и поток - это два очень тесно связанных термина, имеющих одну и ту же цель - сделать компьютер способным выполнять более одной задачи одновременно. Процесс может содержать один или несколько потоков, но, наоборот, поток не может содержать процесс. Однако они оба остаются двумя основными единицами исполнения. Программа, выполняя серию инструкций, запускает как процесс, так и поток.
В следующей таблице показано сравнение между процессом и потоком -
| Процесс | Нить |
|---|---|
| Процесс тяжелый или ресурсоемкий. | Поток является легковесным и требует меньше ресурсов, чем процесс. |
| Переключение процессов требует взаимодействия с операционной системой. | Переключение потоков не требует взаимодействия с операционной системой. |
| В нескольких средах обработки каждый процесс выполняет один и тот же код, но имеет свою собственную память и файловые ресурсы. | Все потоки могут использовать один и тот же набор открытых файлов, дочерних процессов. |
| Если один процесс заблокирован, то никакой другой процесс не может выполняться, пока не будет разблокирован первый процесс. | Пока один поток заблокирован и ожидает, второй поток в той же задаче может работать. |
| Несколько процессов без использования потоков используют больше ресурсов. | Многопоточные процессы используют меньше ресурсов. |
| В нескольких процессах каждый процесс работает независимо от других. | Один поток может читать, записывать или изменять данные другого потока. |
| Если в родительском процессе произойдут какие-либо изменения, это не повлияет на дочерние процессы. | Если в основном потоке произойдут какие-либо изменения, это может повлиять на поведение других потоков этого процесса. |
| Для взаимодействия с родственными процессами процессы должны использовать межпроцессное взаимодействие. | Потоки могут напрямую связываться с другими потоками этого процесса. |
Концепция многопоточности
Как мы обсуждали ранее, многопоточность - это способность ЦП управлять использованием операционной системы путем одновременного выполнения нескольких потоков. Основная идея многопоточности заключается в достижении параллелизма путем разделения процесса на несколько потоков. Проще говоря, мы можем сказать, что многопоточность - это способ достижения многозадачности с помощью концепции потоков.
Понятие многопоточности можно понять с помощью следующего примера.
пример
Предположим, мы запускаем процесс. Процесс может заключаться в открытии слова MS для написания чего-либо. В таком процессе один поток будет назначен для открытия слова MS, а другой поток потребуется для записи. Теперь предположим, что если мы хотим что-то отредактировать, тогда потребуется другой поток для выполнения задачи редактирования и так далее.
Следующая диаграмма помогает нам понять, как в памяти существует несколько потоков.
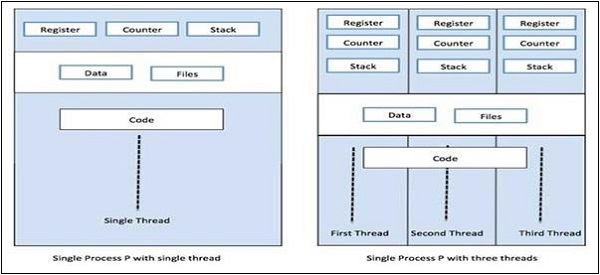
На приведенной выше диаграмме мы можем видеть, что в одном процессе может существовать более одного потока, где каждый поток содержит свой собственный набор регистров и локальные переменные. Помимо этого, все потоки в процессе имеют общие глобальные переменные.
Плюсы многопоточности
Давайте теперь посмотрим на несколько преимуществ многопоточности. Преимущества заключаются в следующем -
Speed of communication - Многопоточность повышает скорость вычислений, поскольку каждое ядро или процессор одновременно обрабатывает отдельные потоки.
Program remains responsive - Это позволяет программе оставаться отзывчивой, потому что один поток ожидает ввода, а другой одновременно запускает графический интерфейс.
Access to global variables - В многопоточности все потоки конкретного процесса могут обращаться к глобальным переменным, и если есть какие-либо изменения в глобальной переменной, они также видны другим потокам.
Utilization of resources - Запуск нескольких потоков в каждой программе позволяет лучше использовать ЦП и время простоя ЦП становится меньше.
Sharing of data - Нет необходимости в дополнительном пространстве для каждого потока, потому что потоки в программе могут совместно использовать одни и те же данные.
Минусы многопоточности
Давайте теперь посмотрим на несколько недостатков многопоточности. Недостатки следующие -
Not suitable for single processor system - Многопоточность затрудняет достижение производительности с точки зрения скорости вычислений в однопроцессорной системе по сравнению с производительностью в многопроцессорной системе.
Issue of security - Поскольку мы знаем, что все потоки в программе используют одни и те же данные, поэтому всегда существует проблема безопасности, потому что любой неизвестный поток может изменить данные.
Increase in complexity - Многопоточность может увеличить сложность программы и затруднить отладку.
Lead to deadlock state - Многопоточность может привести к потенциальному риску выхода программы из состояния тупика.
Synchronization required- Синхронизация требуется, чтобы избежать взаимного исключения. Это приводит к большей загрузке памяти и ЦП.
В этой главе мы узнаем, как реализовать потоки в Python.
Модуль Python для реализации потоков
Потоки Python иногда называют облегченными процессами, потому что потоки занимают гораздо меньше памяти, чем процессы. Потоки позволяют выполнять сразу несколько задач. В Python у нас есть следующие два модуля, которые реализуют потоки в программе:
<_thread>module
<threading>module
Основное различие между этими двумя модулями заключается в том, что <_thread> модуль обрабатывает поток как функцию, тогда как <threading>Модуль рассматривает каждый поток как объект и реализует его объектно-ориентированным способом. Более того,<_thread>модуль эффективен в потоках низкого уровня и имеет меньше возможностей, чем <threading> модуль.
<_thread> модуль
В более ранней версии Python у нас был <thread>модуль, но он долгое время считался "устаревшим". Пользователям рекомендуется использовать<threading>модуль вместо этого. Следовательно, в Python 3 модуль «поток» больше не доступен. Он был переименован в "<_thread>"для обратной несовместимости в Python3.
Чтобы сгенерировать новый поток с помощью <_thread> модуль, нам нужно вызвать start_new_threadметод этого. Работу этого метода можно понять с помощью следующего синтаксиса -
_thread.start_new_thread ( function, args[, kwargs] )Здесь -
args это набор аргументов
kwargs необязательный словарь аргументов ключевых слов
Если мы хотим вызвать функцию без передачи аргумента, нам нужно использовать пустой кортеж аргументов в args.
Вызов этого метода немедленно возвращается, дочерний поток запускается и вызывает функцию с переданным списком аргументов, если таковой имеется. Поток завершается, когда функция возвращается.
пример
Ниже приведен пример создания нового потока с использованием <_thread>модуль. Здесь мы используем метод start_new_thread ().
import _thread
import time
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: unable to start thread")
while 1:
passВывод
Следующий вывод поможет нам понять генерацию новых потоков с помощью <_thread> модуль.
Thread-1: Mon Apr 23 10:03:33 2018
Thread-2: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:35 2018
Thread-1: Mon Apr 23 10:03:37 2018
Thread-2: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:39 2018
Thread-1: Mon Apr 23 10:03:41 2018
Thread-2: Mon Apr 23 10:03:43 2018
Thread-2: Mon Apr 23 10:03:47 2018
Thread-2: Mon Apr 23 10:03:51 2018модуль <threading>
В <threading>модуль реализуется объектно-ориентированным образом и рассматривает каждый поток как объект. Следовательно, он обеспечивает гораздо более мощную поддержку высокого уровня для потоков, чем модуль <_thread>. Этот модуль входит в состав Python 2.4.
Дополнительные методы в модуле <threading>
В <threading> модуль включает в себя все методы <_thread>модуль, но он также предоставляет дополнительные методы. Дополнительные методы заключаются в следующем -
threading.activeCount() - Этот метод возвращает количество активных объектов потока.
threading.currentThread() - Этот метод возвращает количество объектов потока в элементе управления потоком вызывающего объекта.
threading.enumerate() - Этот метод возвращает список всех активных в данный момент объектов потока.
run() - Метод run () - это точка входа для потока.
start() - Метод start () запускает поток, вызывая метод run.
join([time]) - join () ожидает завершения потоков.
isAlive() - Метод isAlive () проверяет, выполняется ли все еще поток.
getName() - Метод getName () возвращает имя потока.
setName() - Метод setName () устанавливает имя потока.
Для реализации потоковой передачи <threading> модуль имеет Thread класс, который предоставляет следующие методы -
Как создавать потоки с помощью модуля <threading>?
В этом разделе мы узнаем, как создавать потоки с помощью <threading>модуль. Выполните следующие действия, чтобы создать новый поток с помощью модуля <threading> -
Step 1 - На этом этапе нам нужно определить новый подкласс класса Thread класс.
Step 2 - Затем для добавления дополнительных аргументов нам нужно переопределить __init__(self [,args]) метод.
Step 3 - На этом этапе нам нужно переопределить метод run (self [, args]), чтобы реализовать то, что поток должен делать при запуске.
Теперь, после создания нового Thread подкласса, мы можем создать его экземпляр, а затем запустить новый поток, вызвав start(), который, в свою очередь, вызывает run() метод.
пример
Рассмотрим этот пример, чтобы узнать, как создать новый поток с помощью <threading> модуль.
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("Starting " + self.name)
print_time(self.name, self.counter, 5)
print ("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("Exiting Main Thread")
Starting Thread-1
Starting Thread-2Вывод
Теперь рассмотрим следующий вывод -
Thread-1: Mon Apr 23 10:52:09 2018
Thread-1: Mon Apr 23 10:52:10 2018
Thread-2: Mon Apr 23 10:52:10 2018
Thread-1: Mon Apr 23 10:52:11 2018
Thread-1: Mon Apr 23 10:52:12 2018
Thread-2: Mon Apr 23 10:52:12 2018
Thread-1: Mon Apr 23 10:52:13 2018
Exiting Thread-1
Thread-2: Mon Apr 23 10:52:14 2018
Thread-2: Mon Apr 23 10:52:16 2018
Thread-2: Mon Apr 23 10:52:18 2018
Exiting Thread-2
Exiting Main ThreadПрограмма Python для различных состояний потока
Существует пять состояний потока: новый, работоспособный, запущенный, ожидающий и мертвый. Среди этих пяти из этих пяти мы в основном сосредоточимся на трех состояниях - беге, ожидании и смерти. Поток получает свои ресурсы в состоянии выполнения, ожидает ресурсов в состоянии ожидания; окончательное освобождение ресурса, если выполнение и получение находится в мертвом состоянии.
Следующая программа Python с помощью методов start (), sleep () и join () покажет, как поток вошел в состояние выполнения, ожидания и мертвого состояния соответственно.
Step 1 - Импортировать необходимые модули, <поток> и <время>
import threading
import timeStep 2 - Определите функцию, которая будет вызываться при создании потока.
def thread_states():
print("Thread entered in running state")Step 3 - Мы используем метод sleep () модуля time, чтобы заставить наш поток ждать, скажем, 2 секунды.
time.sleep(2)Step 4 - Теперь мы создаем поток с именем T1, который принимает аргумент функции, определенной выше.
T1 = threading.Thread(target=thread_states)Step 5- Теперь с помощью функции start () мы можем запустить наш поток. Он выдаст сообщение, которое мы установили при определении функции.
T1.start()
Thread entered in running stateStep 6 - Теперь, наконец, мы можем убить поток с помощью метода join () после того, как он завершит свое выполнение.
T1.join()Запуск потока в Python
В python мы можем запустить новый поток разными способами, но самый простой из них - определить его как одну функцию. После определения функции мы можем передать это как цель для новогоthreading.Threadобъект и так далее. Выполните следующий код Python, чтобы понять, как работает функция:
import threading
import time
import random
def Thread_execution(i):
print("Execution of Thread {} started\n".format(i))
sleepTime = random.randint(1,4)
time.sleep(sleepTime)
print("Execution of Thread {} finished".format(i))
for i in range(4):
thread = threading.Thread(target=Thread_execution, args=(i,))
thread.start()
print("Active Threads:" , threading.enumerate())Вывод
Execution of Thread 0 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>]
Execution of Thread 1 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>]
Execution of Thread 2 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>]
Execution of Thread 3 started
Active Threads:
[<_MainThread(MainThread, started 6040)>,
<HistorySavingThread(IPythonHistorySavingThread, started 5968)>,
<Thread(Thread-3576, started 3932)>,
<Thread(Thread-3577, started 3080)>,
<Thread(Thread-3578, started 2268)>,
<Thread(Thread-3579, started 4520)>]
Execution of Thread 0 finished
Execution of Thread 1 finished
Execution of Thread 2 finished
Execution of Thread 3 finishedДемонические потоки в Python
Перед реализацией потоков демонов в Python нам нужно узнать о потоках демонов и их использовании. С точки зрения вычислений, демон - это фоновый процесс, который обрабатывает запросы различных служб, таких как отправка данных, передача файлов и т. Д. Он будет бездействующим, если он больше не потребуется. Эту же задачу можно выполнить и с помощью потоков, не являющихся демонами. Однако в этом случае основной поток должен вручную отслеживать потоки, не являющиеся демонами. С другой стороны, если мы используем потоки демона, тогда основной поток может полностью забыть об этом, и он будет убит при выходе из основного потока. Еще один важный момент, связанный с потоками демонов, заключается в том, что мы можем использовать их только для несущественных задач, которые не повлияют на нас, если они не завершатся или будут убиты между ними. Ниже приведена реализация потоков демона в python.
import threading
import time
def nondaemonThread():
print("starting my thread")
time.sleep(8)
print("ending my thread")
def daemonThread():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonThread = threading.Thread(target = nondaemonThread)
daemonThread = threading.Thread(target = daemonThread)
daemonThread.setDaemon(True)
daemonThread.start()
nondaemonThread.start()В приведенном выше коде есть две функции, а именно >nondaemonThread() и >daemonThread(). Первая функция печатает свое состояние и засыпает через 8 секунд, в то время как функция deamonThread () печатает Hello через каждые 2 секунды до бесконечности. Мы можем понять разницу между потоками nondaemon и daemon с помощью следующего вывода:
Hello
starting my thread
Hello
Hello
Hello
Hello
ending my thread
Hello
Hello
Hello
Hello
HelloСинхронизация потоков может быть определена как метод, с помощью которого мы можем быть уверены, что два или более параллельных потока не обращаются одновременно к сегменту программы, известному как критическая секция. С другой стороны, как мы знаем, критическая секция - это часть программы, в которой осуществляется доступ к общему ресурсу. Следовательно, мы можем сказать, что синхронизация - это процесс обеспечения того, чтобы два или более потоков не взаимодействовали друг с другом, одновременно обращаясь к ресурсам. На диаграмме ниже показано, что четыре потока одновременно пытаются получить доступ к критическому разделу программы.
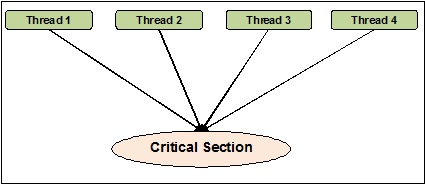
Чтобы было понятнее, предположим, что два или более потока одновременно пытаются добавить объект в список. Это действие не может привести к успешному завершению, потому что оно либо отбрасывает один или все объекты, либо полностью искажает состояние списка. Здесь роль синхронизации заключается в том, что только один поток одновременно может получить доступ к списку.
Проблемы с синхронизацией потоков
Мы можем столкнуться с проблемами при реализации параллельного программирования или применении синхронизирующих примитивов. В этом разделе мы обсудим два основных вопроса. Проблемы -
- Deadlock
- Состояние гонки
Состояние гонки
Это одна из основных проблем параллельного программирования. Одновременный доступ к общим ресурсам может привести к состоянию гонки. Состояние гонки может быть определено как возникновение условия, когда два или более потоков могут получить доступ к совместно используемым данным, а затем пытаются одновременно изменить их значение. Из-за этого значения переменных могут быть непредсказуемыми и варьироваться в зависимости от таймингов переключения контекста процессов.
пример
Рассмотрим этот пример, чтобы понять концепцию состояния гонки -
Step 1 - На этом этапе нам нужно импортировать модуль потоковой передачи -
import threadingStep 2 - Теперь определите глобальную переменную, скажем x, вместе со значением 0 -
x = 0Step 3 - Теперь нам нужно определить increment_global() функция, которая будет делать приращение на 1 в этой глобальной функции x -
def increment_global():
global x
x += 1Step 4 - На этом этапе мы определим taskofThread()функция, которая будет вызывать функцию increment_global () указанное количество раз; для нашего примера это 50000 раз -
def taskofThread():
for _ in range(50000):
increment_global()Step 5- Теперь определите функцию main (), в которой создаются потоки t1 и t2. Оба будут запущены с помощью функции start () и дождаться завершения своей работы с помощью функции join ().
def main():
global x
x = 0
t1 = threading.Thread(target= taskofThread)
t2 = threading.Thread(target= taskofThread)
t1.start()
t2.start()
t1.join()
t2.join()Step 6- Теперь нам нужно указать диапазон количества итераций, которые мы хотим вызвать функцию main (). Здесь мы звоним 5 раз.
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))В выходных данных, показанных ниже, мы можем увидеть эффект состояния гонки, поскольку значение x после каждой итерации ожидается 100000. Тем не менее, есть много вариаций в значении. Это связано с одновременным доступом потоков к общей глобальной переменной x.
Вывод
x = 100000 after Iteration 0
x = 54034 after Iteration 1
x = 80230 after Iteration 2
x = 93602 after Iteration 3
x = 93289 after Iteration 4Работа с состоянием гонки с помощью блокировок
Поскольку мы видели эффект состояния гонки в приведенной выше программе, нам нужен инструмент синхронизации, который может обрабатывать состояние гонки между несколькими потоками. В Python<threading>Модуль предоставляет класс Lock для обработки состояния гонки. ДалееLockclass предоставляет различные методы, с помощью которых мы можем обрабатывать состояние гонки между несколькими потоками. Методы описаны ниже -
получить () метод
Этот метод используется для получения, т. Е. Блокировки блокировки. Блокировка может быть блокирующей или неблокирующей в зависимости от следующего истинного или ложного значения:
With value set to True - Если метод Acquire () вызывается с True, которое является аргументом по умолчанию, то выполнение потока блокируется до тех пор, пока блокировка не будет разблокирована.
With value set to False - Если метод Acqua () вызывается с False, что не является аргументом по умолчанию, то выполнение потока не блокируется, пока не будет установлено значение true, то есть пока оно не будет заблокировано.
release () метод
Этот метод используется для снятия блокировки. Ниже приведены несколько важных задач, связанных с этим методом.
Если замок заблокирован, то release()метод разблокировал бы его. Его задача - разрешить выполнение ровно одного потока, если более одного потока заблокированы и ожидают разблокировки блокировки.
Это поднимет ThreadError если замок уже разблокирован.
Теперь мы можем переписать указанную выше программу с классом блокировки и его методами, чтобы избежать состояния гонки. Нам нужно определить метод taskofThread () с аргументом блокировки, а затем нужно использовать методы Acquire () и Release () для блокировки и неблокирования блокировок, чтобы избежать состояния гонки.
пример
Ниже приведен пример программы Python, чтобы понять концепцию блокировок для работы с состоянием гонки.
import threading
x = 0
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target = taskofThread, args = (lock,))
t2 = threading.Thread(target = taskofThread, args = (lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))Следующий вывод показывает, что эффект состояния гонки не учитывается; поскольку значение x после каждой & каждой итерации теперь равно 100000, что соответствует ожиданиям этой программы.
Вывод
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4Тупики - проблема обедающих философов
Тупик - это неприятная проблема, с которой можно столкнуться при проектировании параллельных систем. Мы можем проиллюстрировать эту проблему с помощью проблемы обеденного философа следующим образом:
Эдсгер Дейкстра первоначально представил проблему обеденного философа, одну из известных иллюстраций одной из самых больших проблем параллельной системы, называемой тупиком.
В этой задаче пять известных философов сидят за круглым столом и поедают еду из своих мисок. Пять философов могут использовать пять вилок для еды. Однако философы решают использовать две вилки одновременно, чтобы съесть свою пищу.
Итак, для философов есть два основных условия. Во-первых, каждый из философов может находиться либо в состоянии еды, либо в состоянии мышления, а во-вторых, они сначала должны получить обе вилки, то есть левую и правую. Проблема возникает, когда каждому из пяти философов удается одновременно выбрать левую вилку. Теперь все они ждут, пока освободится нужная вилка, но они никогда не откажутся от вилки, пока не съедят свою еду, и нужная вилка никогда не будет доступна. Следовательно, за обеденным столом возникнет тупиковая ситуация.
Тупик в параллельной системе
Теперь, если мы видим, такая же проблема может возникнуть и в наших параллельных системах. Вилками в приведенном выше примере будут системные ресурсы, и каждый философ может представить процесс, который конкурирует за ресурсы.
Решение с программой Python
Решение этой проблемы можно найти, разделив философов на два типа: greedy philosophers и generous philosophers. В основном жадный философ будет пытаться взять левую вилку и ждать, пока она там не окажется. Затем он будет ждать, пока там окажется нужная вилка, возьмет ее, съест, а затем положит. С другой стороны, великодушный философ попытается подобрать левую вилку, и если ее там нет, он подождет и попробует снова через некоторое время. Если они получат левую вилку, они попытаются получить правую. Если они получат и правильную вилку, они съедят и отпустят обе вилки. Однако, если они не получат правую вилку, они освободят левую вилку.
пример
Следующая программа Python поможет нам найти решение проблемы обеденного философа -
import threading
import random
import time
class DiningPhilosopher(threading.Thread):
running = True
def __init__(self, xname, Leftfork, Rightfork):
threading.Thread.__init__(self)
self.name = xname
self.Leftfork = Leftfork
self.Rightfork = Rightfork
def run(self):
while(self.running):
time.sleep( random.uniform(3,13))
print ('%s is hungry.' % self.name)
self.dine()
def dine(self):
fork1, fork2 = self.Leftfork, self.Rightfork
while self.running:
fork1.acquire(True)
locked = fork2.acquire(False)
if locked: break
fork1.release()
print ('%s swaps forks' % self.name)
fork1, fork2 = fork2, fork1
else:
return
self.dining()
fork2.release()
fork1.release()
def dining(self):
print ('%s starts eating '% self.name)
time.sleep(random.uniform(1,10))
print ('%s finishes eating and now thinking.' % self.name)
def Dining_Philosophers():
forks = [threading.Lock() for n in range(5)]
philosopherNames = ('1st','2nd','3rd','4th', '5th')
philosophers= [DiningPhilosopher(philosopherNames[i], forks[i%5], forks[(i+1)%5]) \
for i in range(5)]
random.seed()
DiningPhilosopher.running = True
for p in philosophers: p.start()
time.sleep(30)
DiningPhilosopher.running = False
print (" It is finishing.")
Dining_Philosophers()В приведенной выше программе используется концепция жадных и щедрых философов. Программа также использовалаacquire() и release() методы Lock класс <threading>модуль. Мы можем увидеть решение в следующем выводе -
Вывод
4th is hungry.
4th starts eating
1st is hungry.
1st starts eating
2nd is hungry.
5th is hungry.
3rd is hungry.
1st finishes eating and now thinking.3rd swaps forks
2nd starts eating
4th finishes eating and now thinking.
3rd swaps forks5th starts eating
5th finishes eating and now thinking.
4th is hungry.
4th starts eating
2nd finishes eating and now thinking.
3rd swaps forks
1st is hungry.
1st starts eating
4th finishes eating and now thinking.
3rd starts eating
5th is hungry.
5th swaps forks
1st finishes eating and now thinking.
5th starts eating
2nd is hungry.
2nd swaps forks
4th is hungry.
5th finishes eating and now thinking.
3rd finishes eating and now thinking.
2nd starts eating 4th starts eating
It is finishing.В реальной жизни, если группа людей работает над общей задачей, между ними должна быть связь для правильного выполнения задачи. Та же аналогия применима и к потокам. В программировании, чтобы сократить идеальное время процессора, мы создаем несколько потоков и назначаем разные подзадачи каждому потоку. Следовательно, должно быть средство связи, и они должны взаимодействовать друг с другом, чтобы завершить работу синхронно.
Рассмотрим следующие важные моменты, связанные с взаимодействием потоков:
No performance gain - Если мы не можем обеспечить надлежащую связь между потоками и процессами, тогда выигрыш в производительности от параллелизма и параллелизма бесполезен.
Accomplish task properly - Без надлежащего механизма взаимодействия между потоками поставленная задача не может быть выполнена должным образом.
More efficient than inter-process communication - Обмен данными между потоками более эффективен и прост в использовании, чем обмен данными между процессами, поскольку все потоки в рамках процесса используют одно и то же адресное пространство и им не нужно использовать общую память.
Структуры данных Python для потоковой связи
Многопоточный код сталкивается с проблемой передачи информации из одного потока в другой. Стандартные примитивы связи не решают эту проблему. Следовательно, нам нужно реализовать наш собственный составной объект, чтобы разделять объекты между потоками, чтобы сделать коммуникацию потокобезопасной. Ниже приведены несколько структур данных, которые обеспечивают потокобезопасную связь после внесения в них некоторых изменений.
Наборы
Для использования структуры данных набора в потокобезопасном режиме нам необходимо расширить класс набора для реализации нашего собственного механизма блокировки.
пример
Вот пример расширения класса Python -
class extend_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(extend_class, self).__init__(*args, **kwargs)
def add(self, elem):
self._lock.acquire()
try:
super(extend_class, self).add(elem)
finally:
self._lock.release()
def delete(self, elem):
self._lock.acquire()
try:
super(extend_class, self).delete(elem)
finally:
self._lock.release()В приведенном выше примере объект класса с именем extend_class был определен, который в дальнейшем унаследован от Python set class. В конструкторе этого класса создается объект блокировки. Теперь есть две функции -add() и delete(). Эти функции определены и являются потокобезопасными. Они оба полагаются наsuper функциональность класса с одним ключевым исключением.
Декоратор
Это еще один ключевой метод поточно-ориентированного взаимодействия - использование декораторов.
пример
Рассмотрим пример Python, показывающий, как использовать декораторы & mminus;
def lock_decorator(method):
def new_deco_method(self, *args, **kwargs):
with self._lock:
return method(self, *args, **kwargs)
return new_deco_method
class Decorator_class(set):
def __init__(self, *args, **kwargs):
self._lock = Lock()
super(Decorator_class, self).__init__(*args, **kwargs)
@lock_decorator
def add(self, *args, **kwargs):
return super(Decorator_class, self).add(elem)
@lock_decorator
def delete(self, *args, **kwargs):
return super(Decorator_class, self).delete(elem)В приведенном выше примере был определен метод декоратора с именем lock_decorator, который в дальнейшем наследуется от класса методов Python. Затем в конструкторе этого класса создается объект блокировки. Теперь есть две функции - add () и delete (). Эти функции определены и являются потокобезопасными. Оба они полагаются на функциональность суперкласса, за одним ключевым исключением.
Списки
Структура данных списка является поточно-ориентированной, быстрой и простой для временного хранения в памяти. В Cpython GIL защищает от одновременного доступа к ним. Как мы узнали, списки потокобезопасны, но как насчет данных, которые в них хранятся? Собственно, данные списка не защищены. Например,L.append(x)не гарантирует возврата ожидаемого результата, если другой поток пытается сделать то же самое. Это потому, что, хотяappend() является атомарной операцией и потокобезопасной, но другой поток пытается изменить данные списка параллельно, поэтому мы можем видеть побочные эффекты условий гонки на выходе.
Чтобы решить эту проблему и безопасно изменить данные, мы должны реализовать надлежащий механизм блокировки, который дополнительно гарантирует, что несколько потоков не могут потенциально работать в условиях гонки. Чтобы реализовать правильный механизм блокировки, мы можем расширить класс, как мы это делали в предыдущих примерах.
Некоторые другие атомарные операции со списками следующие:
L.append(x)
L1.extend(L2)
x = L[i]
x = L.pop()
L1[i:j] = L2
L.sort()
x = y
x.field = y
D[x] = y
D1.update(D2)
D.keys()Здесь -
- L, L1, L2 все списки
- D, D1, D2 диктуют
- x, y - объекты
- я, j целые
Очереди
Если данные списка не защищены, нам, возможно, придется столкнуться с последствиями. Мы можем получить или удалить неправильный элемент данных условий гонки. Поэтому рекомендуется использовать структуру данных очереди. Реальным примером очереди может быть однополосная дорога с односторонним движением, когда автомобиль входит первым, а выезжает первым. Более реальные примеры можно увидеть в очередях у билетных касс и на автобусных остановках.
Очереди по умолчанию представляют собой поточно-ориентированную структуру данных, и нам не нужно беспокоиться о реализации сложного механизма блокировки. Python предоставляет нам
Типы очередей
В этом разделе мы узнаем о разных типах очередей. Python предоставляет три варианта использования очередей из<queue> модуль -
- Обычные очереди (FIFO, первым пришел - первым ушел)
- LIFO, последний пришел - первым ушел
- Priority
Мы узнаем о различных очередях в следующих разделах.
Обычные очереди (FIFO, первым пришел - первым ушел)
Это наиболее часто используемые реализации очереди, предлагаемые Python. В этом механизме очередей тот, кто придет первым, первым получит услугу. FIFO также называют обычными очередями. Очереди FIFO могут быть представлены следующим образом -

Реализация очереди FIFO в Python
В Python очередь FIFO может быть реализована как с одним потоком, так и с многопоточностью.
Очередь FIFO с одним потоком
Для реализации очереди FIFO с одним потоком Queueclass реализует базовый контейнер "первым пришел - первым ушел". Элементы будут добавлены к одному «концу» последовательности с помощьюput(), и удален с другого конца с помощью get().
пример
Ниже приведена программа Python для реализации очереди FIFO с одним потоком.
import queue
q = queue.Queue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end = " ")Вывод
item-0 item-1 item-2 item-3 item-4 item-5 item-6 item-7Выходные данные показывают, что вышеуказанная программа использует один поток, чтобы продемонстрировать, что элементы удаляются из очереди в том же порядке, в котором они вставляются.
Очередь FIFO с несколькими потоками
Для реализации FIFO с несколькими потоками нам необходимо определить функцию myqueue (), которая расширяется из модуля очереди. Работа методов get () и put () такая же, как описано выше при реализации очереди FIFO с одним потоком. Затем, чтобы сделать его многопоточным, нам нужно объявить и создать экземпляры потоков. Эти потоки будут использовать очередь в режиме FIFO.
пример
Ниже приведена программа Python для реализации очереди FIFO с несколькими потоками.
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.Queue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Вывод
<Thread(Thread-3654, started 5044)> removed 0 from the queue
<Thread(Thread-3655, started 3144)> removed 1 from the queue
<Thread(Thread-3656, started 6996)> removed 2 from the queue
<Thread(Thread-3657, started 2672)> removed 3 from the queue
<Thread(Thread-3654, started 5044)> removed 4 from the queueLIFO, очередь "последний в первом ушел"
Эта очередь использует полностью противоположную аналогию, чем очереди FIFO (First in First Out). В этом механизме очередей тот, кто идет последним, получит услугу первым. Это похоже на реализацию структуры данных стека. Очереди LIFO оказались полезными при реализации поиска в глубину, как алгоритмы искусственного интеллекта.
Реализация очереди LIFO в Python
В python очередь LIFO может быть реализована как с однопоточным, так и с многопоточным режимом.
Очередь LIFO с одним потоком
Для реализации очереди LIFO с одним потоком Queue class будет реализовывать базовый контейнер «последним пришел - первым ушел», используя структуру Queue.LifoQueue. Теперь по звонкуput(), элементы добавляются в головку контейнера и удаляются из головки также при использовании get().
пример
Ниже приведена программа Python для реализации очереди LIFO с одним потоком.
import queue
q = queue.LifoQueue()
for i in range(8):
q.put("item-" + str(i))
while not q.empty():
print (q.get(), end=" ")
Output:
item-7 item-6 item-5 item-4 item-3 item-2 item-1 item-0Выходные данные показывают, что указанная выше программа использует один поток, чтобы проиллюстрировать, что элементы удаляются из очереди в порядке, обратном их вставке.
Очередь LIFO с несколькими потоками
Реализация аналогична тому, как мы реализовали очереди FIFO с несколькими потоками. Единственная разница в том, что нам нужно использоватьQueue класс, который будет реализовывать базовый контейнер «последним пришел - первым ушел», используя структуру Queue.LifoQueue.
пример
Ниже приведена программа Python для реализации очереди LIFO с несколькими потоками.
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(2)
q = queue.LifoQueue()
for i in range(5):
q.put(i)
threads = []
for i in range(4):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Вывод
<Thread(Thread-3882, started 4928)> removed 4 from the queue
<Thread(Thread-3883, started 4364)> removed 3 from the queue
<Thread(Thread-3884, started 6908)> removed 2 from the queue
<Thread(Thread-3885, started 3584)> removed 1 from the queue
<Thread(Thread-3882, started 4928)> removed 0 from the queueПриоритетная очередь
В очередях FIFO и LIFO порядок элементов связан с порядком вставки. Однако во многих случаях приоритет важнее, чем порядок вставки. Давайте рассмотрим пример из реального мира. Допустим, охрана в аэропорту проверяет людей разных категорий. Люди из VVIP, персонал авиакомпании, таможенный офицер, категории могут проверяться по приоритету, а не по прибытию, как это происходит с простыми людьми.
Еще один важный аспект, который необходимо учитывать для очереди с приоритетами, - это разработка планировщика задач. Один из распространенных способов состоит в том, чтобы обслуживать большую часть задач агента на основе приоритета в очереди. Эта структура данных может использоваться для выбора элементов из очереди на основе их значения приоритета.
Реализация очереди приоритетов в Python
В python приоритетная очередь может быть реализована как с однопоточным, так и с многопоточным режимом.
Очередь приоритета с одним потоком
Для реализации приоритетной очереди с одним потоком Queue класс будет реализовывать задачу в приоритетном контейнере, используя структуру Queue.PriorityQueue. Теперь по звонкуput(), элементы добавляются со значением, где наименьшее значение будет иметь наивысший приоритет и, следовательно, извлекаются первыми с помощью get().
пример
Рассмотрим следующую программу Python для реализации очереди Priority с одним потоком -
import queue as Q
p_queue = Q.PriorityQueue()
p_queue.put((2, 'Urgent'))
p_queue.put((1, 'Most Urgent'))
p_queue.put((10, 'Nothing important'))
prio_queue.put((5, 'Important'))
while not p_queue.empty():
item = p_queue.get()
print('%s - %s' % item)Вывод
1 – Most Urgent
2 - Urgent
5 - Important
10 – Nothing importantВ приведенных выше выходных данных мы видим, что очередь хранила элементы на основе приоритета - меньшее значение имеет высокий приоритет.
Приоритетная очередь с несколькими потоками
Реализация аналогична реализации очередей FIFO и LIFO с несколькими потоками. Единственная разница в том, что нам нужно использоватьQueue класс для инициализации приоритета с помощью структуры Queue.PriorityQueue. Другое отличие заключается в способе создания очереди. В приведенном ниже примере он будет создан с двумя идентичными наборами данных.
пример
Следующая программа Python помогает в реализации очереди приоритетов с несколькими потоками:
import threading
import queue
import random
import time
def myqueue(queue):
while not queue.empty():
item = queue.get()
if item is None:
break
print("{} removed {} from the queue".format(threading.current_thread(), item))
queue.task_done()
time.sleep(1)
q = queue.PriorityQueue()
for i in range(5):
q.put(i,1)
for i in range(5):
q.put(i,1)
threads = []
for i in range(2):
thread = threading.Thread(target=myqueue, args=(q,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()Вывод
<Thread(Thread-4939, started 2420)> removed 0 from the queue
<Thread(Thread-4940, started 3284)> removed 0 from the queue
<Thread(Thread-4939, started 2420)> removed 1 from the queue
<Thread(Thread-4940, started 3284)> removed 1 from the queue
<Thread(Thread-4939, started 2420)> removed 2 from the queue
<Thread(Thread-4940, started 3284)> removed 2 from the queue
<Thread(Thread-4939, started 2420)> removed 3 from the queue
<Thread(Thread-4940, started 3284)> removed 3 from the queue
<Thread(Thread-4939, started 2420)> removed 4 from the queue
<Thread(Thread-4940, started 3284)> removed 4 from the queueВ этой главе мы узнаем о тестировании потоковых приложений. Мы также узнаем о важности тестирования.
Зачем тестировать?
Прежде чем мы углубимся в обсуждение важности тестирования, нам нужно знать, что такое тестирование. В общих чертах, тестирование - это метод определения того, насколько хорошо что-то работает. С другой стороны, если мы говорим о компьютерных программах или программном обеспечении, то тестирование - это метод доступа к функциям программного обеспечения.
В этом разделе мы обсудим важность тестирования программного обеспечения. При разработке программного обеспечения перед выпуском программного обеспечения для клиента необходимо выполнить двойную проверку. Поэтому очень важно протестировать программу опытной командой тестировщиков. Рассмотрите следующие моменты, чтобы понять важность тестирования программного обеспечения:
Повышение качества программного обеспечения
Конечно, ни одна компания не хочет поставлять некачественное программное обеспечение, и ни один клиент не хочет покупать некачественное программное обеспечение. Тестирование улучшает качество программного обеспечения за счет обнаружения и исправления в нем ошибок.
Удовлетворенность клиентов
Самая важная часть любого бизнеса - это удовлетворение потребностей клиентов. Предоставляя бесплатное и качественное программное обеспечение, компании могут удовлетворить потребности клиентов.
Уменьшите влияние новых функций
Предположим, мы создали программную систему из 10000 строк, и нам нужно добавить новую функцию, тогда команда разработчиков будет беспокоиться о влиянии этой новой функции на все программное обеспечение. Здесь также тестирование играет жизненно важную роль, потому что, если команда тестирования подготовила хороший набор тестов, это может спасти нас от любых потенциальных катастрофических сбоев.
Пользовательский опыт
Еще одна наиболее важная часть любого бизнеса - это опыт пользователей этого продукта. Только тестирование может гарантировать, что конечный пользователь сочтет использование продукта простым и легким.
Сокращение расходов
Тестирование может снизить общую стоимость программного обеспечения за счет обнаружения и исправления ошибок на этапе тестирования его разработки, а не исправления после доставки. Если после поставки программного обеспечения обнаружится серьезная ошибка, это увеличит его материальную стоимость, например, с точки зрения затрат и нематериальных затрат, например, с точки зрения неудовлетворенности клиентов, отрицательной репутации компании и т. Д.
Что тестировать?
Всегда рекомендуется иметь соответствующие знания о том, что нужно тестировать. В этом разделе мы сначала поймем, что является основным мотивом тестировщика при тестировании любого программного обеспечения. Следует избегать покрытия кода, т. Е. Того, сколько строк кода попадает в наш набор тестов во время тестирования. Это потому, что во время тестирования сосредоточение внимания только на количестве строк кода не добавляет реальной ценности нашей системе. Могут остаться некоторые ошибки, которые появятся позже, на более позднем этапе, даже после развертывания.
Учтите следующие важные моменты, связанные с тем, что тестировать:
Нам нужно сосредоточиться на тестировании функциональности кода, а не на его покрытии.
Нам нужно сначала протестировать наиболее важные части кода, а затем перейти к менее важным частям кода. Это точно сэкономит время.
У тестера должно быть множество различных тестов, которые могут подтолкнуть программное обеспечение к его пределам.
Подходы к тестированию параллельных программ
Благодаря способности использовать истинные возможности многоядерной архитектуры, параллельные программные системы заменяют последовательные системы. В последнее время параллельные системные программы используются во всем: от мобильных телефонов до стиральных машин, от автомобилей до самолетов и т.д. уже ошибка, тогда мы получим несколько ошибок.
Методы тестирования параллельных программных продуктов в значительной степени сосредоточены на выборе чередования, которое выявляет потенциально опасные шаблоны, такие как условия гонки, взаимоблокировки и нарушение атомарности. Ниже приведены два подхода к тестированию параллельных программ.
Систематическое исследование
Этот подход направлен на как можно более широкое исследование пространства перемежений. Такие подходы могут использовать технику грубой силы, а другие используют технику редукции частичного порядка или эвристическую технику для исследования пространства перемежений.
На основе собственности
Подходы, основанные на свойствах, основаны на наблюдении, что сбои параллелизма более вероятны при чередовании, которое раскрывает определенные свойства, такие как подозрительный шаблон доступа к памяти. Различные подходы, основанные на свойствах, нацелены на разные ошибки, такие как состояния гонки, взаимоблокировки и нарушение атомарности, что дополнительно зависит от тех или иных конкретных свойств.
Стратегии тестирования
Стратегия тестирования также известна как тестовый подход. Стратегия определяет, как будет проводиться тестирование. Подход к тестированию имеет две техники -
Проактивный
Подход, при котором процесс разработки теста запускается как можно раньше, чтобы найти и исправить дефекты до создания сборки.
Реактивный
Подход, при котором тестирование не начинается до завершения процесса разработки.
Прежде чем применять любую стратегию тестирования или подход к программе на Python, мы должны иметь базовое представление о типах ошибок, которые может иметь программа. Ошибки следующие -
Синтаксические ошибки
Во время разработки программы может быть много мелких ошибок. Ошибки в основном связаны с опечатками. Например, отсутствие двоеточия или неправильное написание ключевого слова и т. Д. Такие ошибки возникают из-за ошибки в синтаксисе программы, а не в логике. Следовательно, эти ошибки называются синтаксическими ошибками.
Семантические ошибки
Семантические ошибки также называют логическими ошибками. Если в программе есть логическая или семантическая ошибка, то оператор будет компилироваться и работать правильно, но не даст желаемого результата, потому что логика неверна.
Модульное тестирование
Это одна из наиболее часто используемых стратегий тестирования программ на Python. Эта стратегия используется для тестирования модулей или компонентов кода. Под модулями или компонентами мы подразумеваем классы или функции кода. Модульное тестирование упрощает тестирование больших программных систем путем тестирования «маленьких» модулей. С помощью вышеупомянутой концепции модульное тестирование можно определить как метод, при котором отдельные единицы исходного кода тестируются, чтобы определить, возвращают ли они желаемый результат.
В наших последующих разделах мы узнаем о различных модулях Python для модульного тестирования.
модуль unittest
Самый первый модуль для модульного тестирования - это модуль unittest. Он основан на JUnit и по умолчанию включен в Python3.6. Он поддерживает автоматизацию тестирования, совместное использование кода настройки и выключения для тестов, объединение тестов в коллекции и независимость тестов от структуры отчетности.
Ниже приведены несколько важных концепций, поддерживаемых модулем unittest.
Текстовое приспособление
Он используется для настройки теста, чтобы его можно было запустить до начала теста и разорвать после его завершения. Это может включать создание временной базы данных, каталогов и т.д., необходимых перед запуском теста.
Прецедент
Тестовый пример проверяет, исходит ли требуемый ответ от определенного набора входных данных или нет. Модуль unittest включает базовый класс TestCase, который можно использовать для создания новых тестовых случаев. По умолчанию он включает два метода -
setUp()- метод крюка для установки испытательного приспособления перед его испытанием. Это вызывается перед вызовом реализованных методов тестирования.
tearDown( - метод перехвата для деконструкции фикстуры класса после выполнения всех тестов в классе.
Тестирование
Это набор тестовых наборов, тестовых примеров или того и другого.
Тестовый бегун
Он контролирует выполнение тестовых случаев или костюмов и предоставляет результат пользователю. Он может использовать графический интерфейс или простой текстовый интерфейс для предоставления результата.
Example
Следующая программа Python использует модуль unittest для тестирования модуля с именем Fibonacci. Программа помогает в вычислении ряда Фибоначчи числа. В этом примере мы создали класс с именем Fibo_test для определения тестовых случаев с использованием различных методов. Эти методы унаследованы от unittest.TestCase. По умолчанию мы используем два метода - setUp () и tearDown (). Мы также определяем метод testfibocal. Название теста должно начинаться с буквы test. В последнем блоке unittest.main () предоставляет интерфейс командной строки для тестового сценария.
import unittest
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return a
class Fibo_Test(unittest.TestCase):
def setUp(self):
print("This is run before our tests would be executed")
def tearDown(self):
print("This is run after the completion of execution of our tests")
def testfibocal(self):
self.assertEqual(fib(0), 0)
self.assertEqual(fib(1), 1)
self.assertEqual(fib(5), 5)
self.assertEqual(fib(10), 55)
self.assertEqual(fib(20), 6765)
if __name__ == "__main__":
unittest.main()При запуске из командной строки приведенный выше сценарий производит вывод, который выглядит следующим образом:
Вывод
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
.
----------------------------------------------------------------------
Ran 1 test in 0.006s
OKТеперь, чтобы было понятнее, мы изменяем наш код, который помог в определении модуля Фибоначчи.
Рассмотрим следующий блок кода в качестве примера -
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aВ блок кода внесены несколько изменений, как показано ниже -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aТеперь, после запуска скрипта с измененным кодом, мы получим следующий вывод:
This runs before our tests would be executed.
This runs after the completion of execution of our tests.
F
======================================================================
FAIL: testCalculation (__main__.Fibo_Test)
----------------------------------------------------------------------
Traceback (most recent call last):
File "unitg.py", line 15, in testCalculation
self.assertEqual(fib(0), 0)
AssertionError: 1 != 0
----------------------------------------------------------------------
Ran 1 test in 0.007s
FAILED (failures = 1)Приведенный выше вывод показывает, что модуль не смог выдать желаемый результат.
Модуль доктеста
Модуль docktest также помогает в модульном тестировании. Он также поставляется с предварительно упакованным питоном. Его проще использовать, чем модуль unittest. Модуль unittest больше подходит для сложных тестов. Для использования модуля doctest нам необходимо его импортировать. Строка документации соответствующей функции должна иметь интерактивный сеанс Python вместе с их выходными данными.
Если в нашем коде все в порядке, то модуль docktest не будет выводить данные; в противном случае он предоставит результат.
пример
В следующем примере Python используется модуль docktest для тестирования модуля с именем Fibonacci, который помогает в вычислении ряда Фибоначчи числа.
import doctest
def fibonacci(n):
"""
Calculates the Fibonacci number
>>> fibonacci(0)
0
>>> fibonacci(1)
1
>>> fibonacci(10)
55
>>> fibonacci(20)
6765
>>>
"""
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
doctest.testmod()Мы видим, что в строке документации соответствующей функции с именем fib был интерактивный сеанс Python вместе с выходными данными. Если наш код в порядке, то модуль doctest не будет выводить данные. Но чтобы увидеть, как это работает, мы можем запустить его с параметром –v.
(base) D:\ProgramData>python dock_test.py -v
Trying:
fibonacci(0)
Expecting:
0
ok
Trying:
fibonacci(1)
Expecting:
1
ok
Trying:
fibonacci(10)
Expecting:
55
ok
Trying:
fibonacci(20)
Expecting:
6765
ok
1 items had no tests:
__main__
1 items passed all tests:
4 tests in __main__.fibonacci
4 tests in 2 items.
4 passed and 0 failed.
Test passed.Теперь мы изменим код, который помог в определении модуля Фибоначчи.
Рассмотрим следующий блок кода в качестве примера -
def fibonacci(n):
a, b = 0, 1
for i in range(n):
a, b = b, a + b
return aСледующий блок кода помогает с изменениями -
def fibonacci(n):
a, b = 1, 1
for i in range(n):
a, b = b, a + b
return aПосле запуска сценария даже без опции –v с измененным кодом мы получим результат, как показано ниже.
Вывод
(base) D:\ProgramData>python dock_test.py
**********************************************************************
File "unitg.py", line 6, in __main__.fibonacci
Failed example:
fibonacci(0)
Expected:
0
Got:
1
**********************************************************************
File "unitg.py", line 10, in __main__.fibonacci
Failed example:
fibonacci(10)
Expected:
55
Got:
89
**********************************************************************
File "unitg.py", line 12, in __main__.fibonacci
Failed example:
fibonacci(20)
Expected:
6765
Got:
10946
**********************************************************************
1 items had failures:
3 of 4 in __main__.fibonacci
***Test Failed*** 3 failures.Как видно из вышеприведенного вывода, три теста не прошли.
В этой главе мы узнаем, как отлаживать потоковые приложения. Мы также узнаем о важности отладки.
Что такое отладка?
В компьютерном программировании отладка - это процесс поиска и удаления ошибок, ошибок и отклонений в компьютерной программе. Этот процесс начинается, как только код написан, и продолжается в последовательных этапах, когда код объединяется с другими модулями программирования для формирования программного продукта. Отладка - это часть процесса тестирования программного обеспечения и неотъемлемая часть всего жизненного цикла разработки программного обеспечения.
Отладчик Python
Отладчик Python или pdbявляется частью стандартной библиотеки Python. Это хороший резервный инструмент для отслеживания труднодоступных ошибок и позволяет нам быстро и надежно исправить неисправный код. Следующие две самые важные задачиpdp отладчик -
- Это позволяет нам проверять значения переменных во время выполнения.
- Мы можем пошагово выполнять код и также устанавливать точки останова.
Мы можем работать с pdb двумя способами:
- Через командную строку; это также называется посмертной отладкой.
- Интерактивно запустив pdb.
Работа с pdb
Для работы с отладчиком Python нам нужно использовать следующий код в том месте, где мы хотим взломать отладчик:
import pdb;
pdb.set_trace()Рассмотрим следующие команды для работы с pdb через командную строку.
- h(help)
- d(down)
- u(up)
- b(break)
- cl(clear)
- l(list))
- n(next))
- c(continue)
- s(step)
- r(return))
- b(break)
Ниже приводится демонстрация команды h (help) отладчика Python.
import pdb
pdb.set_trace()
--Call--
>d:\programdata\lib\site-packages\ipython\core\displayhook.py(247)__call__()
-> def __call__(self, result = None):
(Pdb) h
Documented commands (type help <topic>):
========================================
EOF c d h list q rv undisplay
a cl debug help ll quit s unt
alias clear disable ignore longlist r source until
args commands display interact n restart step up
b condition down j next return tbreak w
break cont enable jump p retval u whatis
bt continue exit l pp run unalias where
Miscellaneous help topics:
==========================
exec pdbпример
Во время работы с отладчиком Python мы можем установить точку останова в любом месте скрипта, используя следующие строки:
import pdb;
pdb.set_trace()После установки точки останова мы можем запустить сценарий в обычном режиме. Скрипт будет выполняться до определенного момента; до тех пор, пока не будет установлена линия. Рассмотрим следующий пример, в котором мы запустим сценарий, используя вышеупомянутые строки в различных местах сценария:
import pdb;
a = "aaa"
pdb.set_trace()
b = "bbb"
c = "ccc"
final = a + b + c
print (final)Когда приведенный выше сценарий запущен, он будет выполнять программу до a = «aaa», мы можем проверить это в следующем выводе.
Вывод
--Return--
> <ipython-input-7-8a7d1b5cc854>(3)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
*** NameError: name 'b' is not defined
(Pdb) p c
*** NameError: name 'c' is not definedПосле использования команды 'p (print)' в pdb этот скрипт печатает только 'aaa'. За этим следует ошибка, потому что мы установили точку останова до a = "aaa".
Точно так же мы можем запустить скрипт, изменив точки останова и увидеть разницу в выводе -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
pdb.set_trace()
final = a + b + c
print (final)Вывод
--Return--
> <ipython-input-9-a59ef5caf723>(5)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
*** NameError: name 'final' is not defined
(Pdb) exitВ следующем скрипте мы устанавливаем точку останова в последней строке программы -
import pdb
a = "aaa"
b = "bbb"
c = "ccc"
final = a + b + c
pdb.set_trace()
print (final)Результат выглядит следующим образом -
--Return--
> <ipython-input-11-8019b029997d>(6)<module>()->None
-> pdb.set_trace()
(Pdb) p a
'aaa'
(Pdb) p b
'bbb'
(Pdb) p c
'ccc'
(Pdb) p final
'aaabbbccc'
(Pdb)В этой главе мы узнаем, как тестирование производительности и профилирование помогают в решении проблем с производительностью.
Предположим, мы написали код, и он тоже дает желаемый результат, но что, если мы хотим запустить этот код немного быстрее, потому что потребности изменились. В этом случае нам нужно выяснить, какие части нашего кода замедляют работу всей программы. В этом случае могут быть полезны сравнительный анализ и профилирование.
Что такое сравнительный анализ?
Бенчмаркинг направлен на оценку чего-либо по сравнению со стандартом. Однако здесь возникает вопрос: что это за бенчмаркинг и зачем он нам нужен в случае программирования. Бенчмаркинг кода означает, насколько быстро выполняется код и где находится узкое место. Одна из основных причин тестирования производительности заключается в том, что он оптимизирует код.
Как работает бенчмаркинг?
Если мы говорим о работе эталонного тестирования, нам нужно начать с эталонного тестирования всей программы как одного текущего состояния, затем мы можем объединить микро-тесты, а затем разложить программу на более мелкие программы. Чтобы найти узкие места в нашей программе и оптимизировать ее. Другими словами, мы можем понять это как разбиение большой и сложной проблемы на серии более мелких и немного более простых задач для их оптимизации.
Модуль Python для тестирования производительности
В Python у нас есть модуль по умолчанию для тестирования производительности, который называется timeit. С помощьюtimeit модуль, мы можем измерить производительность небольшого фрагмента кода Python в нашей основной программе.
пример
В следующем скрипте Python мы импортируем timeit модуль, который дополнительно измеряет время, необходимое для выполнения двух функций: functionA и functionB -
import timeit
import time
def functionA():
print("Function A starts the execution:")
print("Function A completes the execution:")
def functionB():
print("Function B starts the execution")
print("Function B completes the execution")
start_time = timeit.default_timer()
functionA()
print(timeit.default_timer() - start_time)
start_time = timeit.default_timer()
functionB()
print(timeit.default_timer() - start_time)После выполнения вышеуказанного скрипта мы получим время выполнения обеих функций, как показано ниже.
Вывод
Function A starts the execution:
Function A completes the execution:
0.0014599495514175942
Function B starts the execution
Function B completes the execution
0.0017024724827479076Написание собственного таймера с помощью функции декоратора
В Python мы можем создать собственный таймер, который будет действовать так же, как и timeitмодуль. Это можно сделать с помощьюdecoratorфункция. Ниже приведен пример настраиваемого таймера -
import random
import time
def timer_func(func):
def function_timer(*args, **kwargs):
start = time.time()
value = func(*args, **kwargs)
end = time.time()
runtime = end - start
msg = "{func} took {time} seconds to complete its execution."
print(msg.format(func = func.__name__,time = runtime))
return value
return function_timer
@timer_func
def Myfunction():
for x in range(5):
sleep_time = random.choice(range(1,3))
time.sleep(sleep_time)
if __name__ == '__main__':
Myfunction()Вышеупомянутый скрипт python помогает импортировать случайные модули времени. Мы создали функцию-декоратор timer_func (). Внутри него есть функция function_timer (). Теперь вложенная функция захватит время перед вызовом переданной функции. Затем он ожидает возврата функции и получает время окончания. Таким образом, мы наконец можем заставить скрипт Python печатать время выполнения. Сценарий сгенерирует вывод, как показано ниже.
Вывод
Myfunction took 8.000457763671875 seconds to complete its execution.Что такое профилирование?
Иногда программист хочет измерить некоторые атрибуты, такие как использование памяти, временная сложность или использование определенных инструкций о программах, чтобы измерить реальные возможности этой программы. Такой вид измерения программы называется профилированием. Профилирование использует динамический программный анализ для выполнения таких измерений.
В следующих разделах мы узнаем о различных модулях Python для профилирования.
cProfile - встроенный модуль
cProfile- это встроенный модуль Python для профилирования. Модуль представляет собой C-расширение с разумными накладными расходами, что делает его пригодным для профилирования долго выполняющихся программ. После его запуска он регистрирует все функции и время выполнения. Это очень мощно, но иногда немного сложно интерпретировать и действовать. В следующем примере мы используем cProfile в приведенном ниже коде -
пример
def increment_global():
global x
x += 1
def taskofThread(lock):
for _ in range(50000):
lock.acquire()
increment_global()
lock.release()
def main():
global x
x = 0
lock = threading.Lock()
t1 = threading.Thread(target=taskofThread, args=(lock,))
t2 = threading.Thread(target= taskofThread, args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
if __name__ == "__main__":
for i in range(5):
main()
print("x = {1} after Iteration {0}".format(i,x))Приведенный выше код сохраняется в thread_increment.pyфайл. Теперь выполните код с помощью cProfile в командной строке следующим образом:
(base) D:\ProgramData>python -m cProfile thread_increment.py
x = 100000 after Iteration 0
x = 100000 after Iteration 1
x = 100000 after Iteration 2
x = 100000 after Iteration 3
x = 100000 after Iteration 4
3577 function calls (3522 primitive calls) in 1.688 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:103(release)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:143(__init__)
5 0.000 0.000 0.000 0.000 <frozen importlib._bootstrap>:147(__enter__)
… … … …Из приведенного выше вывода ясно, что cProfile распечатывает все 3577 вызванных функций с указанием времени, затраченного на каждую, и количества их вызовов. Ниже приведены столбцы, которые мы получили на выходе -
ncalls - Это количество сделанных звонков.
tottime - Это общее время, потраченное на данную функцию.
percall - Это отношение общего времени к ncalls.
cumtime- Это совокупное время, потраченное на эту и все подфункции. Это верно даже для рекурсивных функций.
percall - Это частное от суммарного времени деления на примитивные звонки.
filename:lineno(function) - Он в основном предоставляет соответствующие данные для каждой функции.
Предположим, нам нужно было создать большое количество потоков для наших многопоточных задач. Это было бы наиболее затратно в вычислительном отношении, поскольку из-за слишком большого количества потоков может возникнуть много проблем с производительностью. Основная проблема может заключаться в ограничении пропускной способности. Мы можем решить эту проблему, создав пул потоков. Пул потоков может быть определен как группа предварительно созданных и бездействующих потоков, готовых к выполнению работы. Создание пула потоков предпочтительнее создания экземпляров новых потоков для каждой задачи, когда нам нужно выполнить большое количество задач. Пул потоков может управлять одновременным выполнением большого количества потоков следующим образом:
Если поток в пуле потоков завершает свое выполнение, этот поток можно использовать повторно.
Если поток завершен, будет создан другой поток, который заменит этот поток.
Модуль Python - Concurrent.futures
Стандартная библиотека Python включает concurrent.futuresмодуль. Этот модуль был добавлен в Python 3.2 для предоставления разработчикам высокоуровневого интерфейса для запуска асинхронных задач. Это уровень абстракции над модулями потоковой обработки и многопроцессорности Python для предоставления интерфейса для выполнения задач с использованием пула потоков или процессов.
В наших последующих разделах мы узнаем о различных классах модуля concurrent.futures.
Класс исполнителя
Executorэто абстрактный класс concurrent.futuresМодуль Python. Его нельзя использовать напрямую, и нам нужно использовать один из следующих конкретных подклассов -
- ThreadPoolExecutor
- ProcessPoolExecutor
ThreadPoolExecutor - конкретный подкласс
Это один из конкретных подклассов класса Executor. Подкласс использует многопоточность, и мы получаем пул потоков для отправки задач. Этот пул назначает задачи доступным потокам и планирует их запуск.
Как создать ThreadPoolExecutor?
С помощью concurrent.futures модуль и его конкретный подкласс Executor, мы можем легко создать пул потоков. Для этого нам нужно построитьThreadPoolExecutorс количеством потоков, которые мы хотим в пуле. По умолчанию это число 5. Затем мы можем отправить задачу в пул потоков. Когда мыsubmit() задача, мы возвращаем Future. У объекта Future есть метод, называемыйdone(), который сообщает, решилось ли будущее. Таким образом, для этого конкретного будущего объекта установлено значение. Когда задача завершается, исполнитель пула потоков устанавливает значение для будущего объекта.
пример
from concurrent.futures import ThreadPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ThreadPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Вывод
False
True
CompletedВ приведенном выше примере ThreadPoolExecutorбыл построен с 5 потоками. Затем исполнителю пула потоков передается задача, которая будет ждать 2 секунды перед отправкой сообщения. Как видно из выходных данных, задача не выполняется до 2 секунд, поэтому первый вызовdone()вернет False. Через 2 секунды задача выполнена, и мы получаем результат будущего, вызываяresult() метод на нем.
Создание экземпляра ThreadPoolExecutor - диспетчера контекста
Другой способ создать экземпляр ThreadPoolExecutorс помощью диспетчера контекста. Он работает аналогично методу, использованному в приведенном выше примере. Основное преимущество использования диспетчера контекста в том, что он синтаксически хорошо выглядит. Создание экземпляра может быть выполнено с помощью следующего кода -
with ThreadPoolExecutor(max_workers = 5) as executorпример
Следующий пример заимствован из документации Python. В этом примере, прежде всего,concurrent.futuresмодуль должен быть импортирован. Затем функция с именемload_url()создается, который загрузит запрошенный URL. Затем функция создаетThreadPoolExecutorс 5 потоками в пуле. ВThreadPoolExecutorбыл использован как менеджер контекста. Мы можем получить результат будущего, позвонивresult() метод на нем.
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
with concurrent.futures.ThreadPoolExecutor(max_workers = 5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))Вывод
Ниже будет вывод вышеуказанного скрипта Python -
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229313 bytes
'http://www.cnn.com/' page is 168933 bytes
'http://www.bbc.co.uk/' page is 283893 bytes
'http://europe.wsj.com/' page is 938109 bytesИспользование функции Executor.map ()
Питон map()Функция широко используется в ряде задач. Одна из таких задач - применить определенную функцию к каждому элементу в итерациях. Точно так же мы можем сопоставить все элементы итератора с функцией и отправить их как независимые задания на outThreadPoolExecutor. Рассмотрим следующий пример скрипта Python, чтобы понять, как работает функция.
пример
В этом примере ниже функция карты используется для применения square() для каждого значения в массиве значений.
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ThreadPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Вывод
Вышеупомянутый скрипт Python генерирует следующий вывод -
4
9
16
25Пул процессов можно создать и использовать так же, как мы создали и использовали пул потоков. Пул процессов можно определить как группу предварительно созданных и бездействующих процессов, которые готовы к работе. Создание пула процессов предпочтительнее, чем создание экземпляров новых процессов для каждой задачи, когда нам нужно выполнить большое количество задач.
Модуль Python - Concurrent.futures
В стандартной библиотеке Python есть модуль, называемый concurrent.futures. Этот модуль был добавлен в Python 3.2 для предоставления разработчикам высокоуровневого интерфейса для запуска асинхронных задач. Это уровень абстракции над модулями потоковой обработки и многопроцессорности Python для предоставления интерфейса для выполнения задач с использованием пула потоков или процессов.
В наших последующих разделах мы рассмотрим различные подклассы модуля concurrent.futures.
Класс исполнителя
Executor это абстрактный класс concurrent.futuresМодуль Python. Его нельзя использовать напрямую, и нам нужно использовать один из следующих конкретных подклассов -
- ThreadPoolExecutor
- ProcessPoolExecutor
ProcessPoolExecutor - конкретный подкласс
Это один из конкретных подклассов класса Executor. Он использует многопроцессорную обработку, и мы получаем пул процессов для отправки задач. Этот пул назначает задачи доступным процессам и планирует их запуск.
Как создать ProcessPoolExecutor?
С помощью concurrent.futures модуль и его конкретный подкласс Executor, мы можем легко создать пул процессов. Для этого нам нужно построитьProcessPoolExecutorс количеством процессов, которые мы хотим в пуле. По умолчанию это число 5. После этого выполняется отправка задачи в пул процессов.
пример
Теперь мы рассмотрим тот же пример, который мы использовали при создании пула потоков, с той лишь разницей, что теперь мы будем использовать ProcessPoolExecutor вместо ThreadPoolExecutor .
from concurrent.futures import ProcessPoolExecutor
from time import sleep
def task(message):
sleep(2)
return message
def main():
executor = ProcessPoolExecutor(5)
future = executor.submit(task, ("Completed"))
print(future.done())
sleep(2)
print(future.done())
print(future.result())
if __name__ == '__main__':
main()Вывод
False
False
CompletedВ приведенном выше примере процессPoolExecutorбыл построен с 5 потоками. Затем задача, которая будет ждать 2 секунды перед отправкой сообщения, отправляется исполнителю пула процессов. Как видно из выходных данных, задача не выполняется до 2 секунд, поэтому первый вызовdone()вернет False. Через 2 секунды задача выполнена, и мы получаем результат будущего, вызываяresult() метод на нем.
Создание экземпляра ProcessPoolExecutor - диспетчера контекста
Другой способ создать экземпляр ProcessPoolExecutor - использовать диспетчер контекста. Он работает аналогично методу, использованному в приведенном выше примере. Основное преимущество использования диспетчера контекста в том, что он синтаксически хорошо выглядит. Создание экземпляра может быть выполнено с помощью следующего кода -
with ProcessPoolExecutor(max_workers = 5) as executorпример
Для лучшего понимания мы берем тот же пример, который использовался при создании пула потоков. В этом примере нам нужно начать с импортаconcurrent.futuresмодуль. Затем функция с именемload_url()создается, который загрузит запрошенный URL. ВProcessPoolExecutorзатем создается 5 потоков в пуле. ПроцессPoolExecutorбыл использован как менеджер контекста. Мы можем получить результат будущего, позвонивresult() метод на нем.
import concurrent.futures
from concurrent.futures import ProcessPoolExecutor
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://some-made-up-domain.com/']
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout = timeout) as conn:
return conn.read()
def main():
with concurrent.futures.ProcessPoolExecutor(max_workers=5) as executor:
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
if __name__ == '__main__':
main()Вывод
Вышеупомянутый скрипт Python сгенерирует следующий вывод -
'http://some-made-up-domain.com/' generated an exception: <urlopen error [Errno 11004] getaddrinfo failed>
'http://www.foxnews.com/' page is 229476 bytes
'http://www.cnn.com/' page is 165323 bytes
'http://www.bbc.co.uk/' page is 284981 bytes
'http://europe.wsj.com/' page is 967575 bytesИспользование функции Executor.map ()
Питон map()Функция широко используется для выполнения ряда задач. Одна из таких задач - применить определенную функцию к каждому элементу в итерациях. Точно так же мы можем сопоставить все элементы итератора с функцией и отправить их как независимые задания вProcessPoolExecutor. Чтобы понять это, рассмотрим следующий пример скрипта Python.
пример
Мы рассмотрим тот же пример, который мы использовали при создании пула потоков с использованием Executor.map()функция. В приведенном ниже примере функция карты используется для примененияsquare() для каждого значения в массиве значений.
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import as_completed
values = [2,3,4,5]
def square(n):
return n * n
def main():
with ProcessPoolExecutor(max_workers = 3) as executor:
results = executor.map(square, values)
for result in results:
print(result)
if __name__ == '__main__':
main()Вывод
Приведенный выше сценарий Python сгенерирует следующий вывод
4
9
16
25Когда использовать ProcessPoolExecutor и ThreadPoolExecutor?
Теперь, когда мы изучили оба класса Executor - ThreadPoolExecutor и ProcessPoolExecutor, нам нужно знать, когда использовать какой исполнитель. Нам нужно выбрать ProcessPoolExecutor в случае рабочих нагрузок, связанных с процессором, и ThreadPoolExecutor в случае рабочих нагрузок, связанных с вводом-выводом.
Если мы используем ProcessPoolExecutor, то нам не нужно беспокоиться о GIL, потому что он использует многопроцессорность. Более того, время выполнения будет меньше по сравнению сThreadPoolExecution. Чтобы понять это, рассмотрим следующий пример сценария Python.
пример
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Вывод
Start: 8000000 Time taken: 1.5509998798370361
Start: 7000000 Time taken: 1.3259999752044678
Total time taken: 2.0840001106262207
Example- Python script with ThreadPoolExecutor:
import time
import concurrent.futures
value = [8000000, 7000000]
def counting(n):
start = time.time()
while n > 0:
n -= 1
return time.time() - start
def main():
start = time.time()
with concurrent.futures.ThreadPoolExecutor() as executor:
for number, time_taken in zip(value, executor.map(counting, value)):
print('Start: {} Time taken: {}'.format(number, time_taken))
print('Total time taken: {}'.format(time.time() - start))
if __name__ == '__main__':
main()Вывод
Start: 8000000 Time taken: 3.8420000076293945
Start: 7000000 Time taken: 3.6010000705718994
Total time taken: 3.8480000495910645Из результатов обеих программ выше мы можем увидеть разницу во времени выполнения при использовании ProcessPoolExecutor и ThreadPoolExecutor.
В этой главе мы больше сосредоточимся на сравнении многопроцессорности и многопоточности.
Многопроцессорность
Это использование двух или более процессоров в одной компьютерной системе. Это лучший способ раскрыть весь потенциал нашего оборудования за счет использования всего количества ядер ЦП, доступных в нашей компьютерной системе.
Многопоточность
Это способность ЦП управлять использованием операционной системы путем одновременного выполнения нескольких потоков. Основная идея многопоточности заключается в достижении параллелизма путем разделения процесса на несколько потоков.
В следующей таблице показаны некоторые важные различия между ними -
| Многопроцессорность | Мультипрограммирование |
|---|---|
| Под многопроцессорностью понимается одновременная обработка нескольких процессов несколькими процессорами. | Мультипрограммирование сохраняет несколько программ в основной памяти одновременно и выполняет их одновременно с использованием одного процессора. |
| Он использует несколько процессоров. | Он использует один процессор. |
| Это разрешает параллельную обработку. | Происходит переключение контекста. |
| Меньше времени на обработку заданий. | Больше времени на обработку заданий. |
| Это способствует более эффективному использованию устройств компьютерной системы. | Менее эффективен, чем многопроцессорность. |
| Обычно дороже. | Такие системы дешевле. |
Устранение влияния глобальной блокировки интерпретатора (GIL)
При работе с параллельными приложениями в Python присутствует ограничение, называемое GIL (Global Interpreter Lock). GIL никогда не позволяет нам использовать несколько ядер ЦП, и поэтому мы можем сказать, что в Python нет настоящих потоков. GIL - это мьютекс - блокировка взаимного исключения, которая делает вещи потокобезопасными. Другими словами, мы можем сказать, что GIL предотвращает параллельное выполнение кода Python несколькими потоками. Блокировка может удерживаться только одним потоком за раз, и если мы хотим выполнить поток, он должен сначала получить блокировку.
Используя многопроцессорность, мы можем эффективно обойти ограничение, вызванное GIL -
Используя многопроцессорность, мы используем возможности нескольких процессов и, следовательно, используем несколько экземпляров GIL.
Благодаря этому нет ограничений на одновременное выполнение байт-кода одного потока в наших программах.
Запуск процессов в Python
Следующие три метода можно использовать для запуска процесса в Python в модуле многопроцессорности:
- Fork
- Spawn
- Forkserver
Создание процесса с помощью Fork
Команда Fork - это стандартная команда в UNIX. Он используется для создания новых процессов, называемых дочерними процессами. Этот дочерний процесс выполняется одновременно с процессом, называемым родительским процессом. Эти дочерние процессы также идентичны своим родительским процессам и наследуют все ресурсы, доступные родительскому процессу. Следующие системные вызовы используются при создании процесса с помощью Fork -
fork()- Это системный вызов, обычно реализованный в ядре. Он используется для создания копии процесса. P>
getpid() - Этот системный вызов возвращает идентификатор процесса (PID) вызывающего процесса.
пример
Следующий пример скрипта Python поможет вам понять, как создать новый дочерний процесс и получить PID дочерних и родительских процессов:
import os
def child():
n = os.fork()
if n > 0:
print("PID of Parent process is : ", os.getpid())
else:
print("PID of Child process is : ", os.getpid())
child()Вывод
PID of Parent process is : 25989
PID of Child process is : 25990Создание процесса с помощью Spawn
Спаун означает начать что-то новое. Следовательно, порождение процесса означает создание нового процесса родительским процессом. Родительский процесс продолжает выполнение в асинхронном режиме или ждет, пока дочерний процесс завершит свое выполнение. Выполните следующие шаги для создания процесса -
Импорт многопроцессорного модуля.
Создание объектного процесса.
Запуск активности процесса вызовом start() метод.
Дождитесь, пока процесс завершит свою работу и выйдите, позвонив join() метод.
пример
Следующий пример скрипта Python помогает создать три процесса.
import multiprocessing
def spawn_process(i):
print ('This is process: %s' %i)
return
if __name__ == '__main__':
Process_jobs = []
for i in range(3):
p = multiprocessing.Process(target = spawn_process, args = (i,))
Process_jobs.append(p)
p.start()
p.join()Вывод
This is process: 0
This is process: 1
This is process: 2Создание процесса с помощью Forkserver
Механизм Forkserver доступен только на тех выбранных платформах UNIX, которые поддерживают передачу файловых дескрипторов через Unix Pipes. Рассмотрим следующие моменты, чтобы понять работу механизма Forkserver:
Сервер создается при использовании механизма Forkserver для запуска нового процесса.
Затем сервер получает команду и обрабатывает все запросы на создание новых процессов.
Для создания нового процесса наша программа на Python отправит запрос на Forkserver, и он создаст для нас процесс.
Наконец, мы можем использовать этот новый созданный процесс в наших программах.
Демонические процессы в Python
Python multiprocessingmodule позволяет нам иметь процессы демона через его демоническую опцию. Процессы-демоны или процессы, работающие в фоновом режиме, следуют концепции, аналогичной принципам потоков-демонов. Чтобы выполнить процесс в фоновом режиме, нам нужно установить флаг демона в значение true. Процесс-демон будет продолжать работать, пока выполняется основной процесс, и завершится после завершения его выполнения или когда основная программа будет убита.
пример
Здесь мы используем тот же пример, что и в потоках демона. Единственное отличие - смена модуля сmultithreading к multiprocessingи установив демонический флаг в значение true. Тем не менее, будет изменение вывода, как показано ниже -
import multiprocessing
import time
def nondaemonProcess():
print("starting my Process")
time.sleep(8)
print("ending my Process")
def daemonProcess():
while True:
print("Hello")
time.sleep(2)
if __name__ == '__main__':
nondaemonProcess = multiprocessing.Process(target = nondaemonProcess)
daemonProcess = multiprocessing.Process(target = daemonProcess)
daemonProcess.daemon = True
nondaemonProcess.daemon = False
daemonProcess.start()
nondaemonProcess.start()Вывод
starting my Process
ending my ProcessВывод отличается от вывода, сгенерированного потоками демона, потому что процесс не в режиме демона имеет вывод. Следовательно, демонический процесс завершается автоматически после завершения основных программ, чтобы избежать сохранения запущенных процессов.
Завершение процессов в Python
Мы можем немедленно убить или завершить процесс, используя terminate()метод. Мы будем использовать этот метод для завершения дочернего процесса, который был создан с помощью функции, непосредственно перед завершением его выполнения.
пример
import multiprocessing
import time
def Child_process():
print ('Starting function')
time.sleep(5)
print ('Finished function')
P = multiprocessing.Process(target = Child_process)
P.start()
print("My Process has terminated, terminating main thread")
print("Terminating Child Process")
P.terminate()
print("Child Process successfully terminated")Вывод
My Process has terminated, terminating main thread
Terminating Child Process
Child Process successfully terminatedВывод показывает, что программа завершается до выполнения дочернего процесса, который был создан с помощью функции Child_process (). Это означает, что дочерний процесс был успешно завершен.
Определение текущего процесса в Python
Каждый процесс в операционной системе имеет идентификатор процесса, известный как PID. В Python мы можем узнать PID текущего процесса с помощью следующей команды -
import multiprocessing
print(multiprocessing.current_process().pid)пример
Следующий пример скрипта Python помогает узнать PID основного процесса, а также PID дочернего процесса -
import multiprocessing
import time
def Child_process():
print("PID of Child Process is: {}".format(multiprocessing.current_process().pid))
print("PID of Main process is: {}".format(multiprocessing.current_process().pid))
P = multiprocessing.Process(target=Child_process)
P.start()
P.join()Вывод
PID of Main process is: 9401
PID of Child Process is: 9402Использование процесса в подклассе
Мы можем создавать потоки, подклассифицировав threading.Threadкласс. Кроме того, мы также можем создавать процессы путем подклассаmultiprocessing.Processкласс. Для использования процесса в подклассе нам необходимо учитывать следующие моменты:
Нам нужно определить новый подкласс класса Process класс.
Нам нужно переопределить _init_(self [,args] ) класс.
Нам нужно переопределить run(self [,args] ) метод реализации того, что Process
Нам нужно запустить процесс, вызвавstart() метод.
пример
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print ('called run method in process: %s' %self.name)
return
if __name__ == '__main__':
jobs = []
for i in range(5):
P = MyProcess()
jobs.append(P)
P.start()
P.join()Вывод
called run method in process: MyProcess-1
called run method in process: MyProcess-2
called run method in process: MyProcess-3
called run method in process: MyProcess-4
called run method in process: MyProcess-5Модуль многопроцессорной обработки Python - класс пула
Если говорить о простой параллели processingзадач в наших приложениях Python, затем модуль многопроцессорности предоставляет нам класс Pool. Следующие методыPool class может использоваться для увеличения количества дочерних процессов в нашей основной программе
apply () метод
Этот метод похож на.submit()метод .ThreadPoolExecutor.Блокирует, пока не будет готов результат.
apply_async () метод
Когда нам нужно параллельное выполнение наших задач, нам нужно использоватьapply_async()для отправки задач в пул. Это асинхронная операция, которая не блокирует основной поток, пока не будут выполнены все дочерние процессы.
map () метод
Как и apply()метод, он также блокируется, пока результат не будет готов. Это эквивалент встроенногоmap() функция, которая разделяет итерируемые данные на несколько частей и отправляет их в пул процессов как отдельные задачи.
map_async () метод
Это вариант map() метод как apply_async() к apply()метод. Он возвращает объект результата. Когда результат становится готовым, к нему применяется вызываемый объект. Вызываемый должен быть завершен немедленно; в противном случае поток, обрабатывающий результаты, будет заблокирован.
пример
Следующий пример поможет вам реализовать пул процессов для параллельного выполнения. Простой расчет квадрата числа был выполнен с применениемsquare() функционировать через multiprocessing.Poolметод. потомpool.map() был использован для отправки 5, потому что ввод - это список целых чисел от 0 до 4. Результат будет сохранен в p_outputs и это напечатано.
def square(n):
result = n*n
return result
if __name__ == '__main__':
inputs = list(range(5))
p = multiprocessing.Pool(processes = 4)
p_outputs = pool.map(function_square, inputs)
p.close()
p.join()
print ('Pool :', p_outputs)Вывод
Pool : [0, 1, 4, 9, 16]Взаимосвязь процессов означает обмен данными между процессами. Для разработки параллельного приложения необходим обмен данными между процессами. На следующей диаграмме показаны различные механизмы связи для синхронизации между несколькими подпроцессами.

Различные механизмы коммуникации
В этом разделе мы узнаем о различных механизмах связи. Механизмы описаны ниже -
Очереди
Очереди можно использовать в многопроцессорных программах. Класс Queuemultiprocessing модуль похож на Queue.Queueкласс. Следовательно, можно использовать тот же API.Multiprocessing.Queue предоставляет нам безопасный для потоков и процессов FIFO (first-in first-out) механизм связи между процессами.
пример
Ниже приведен простой пример, взятый из официальных документов python по многопроцессорности, чтобы понять концепцию многопроцессорного класса Queue.
from multiprocessing import Process, Queue
import queue
import random
def f(q):
q.put([42, None, 'hello'])
def main():
q = Queue()
p = Process(target = f, args = (q,))
p.start()
print (q.get())
if __name__ == '__main__':
main()Вывод
[42, None, 'hello']Трубы
Это структура данных, которая используется для связи между процессами в многопроцессорных программах. Функция Pipe () возвращает пару объектов подключения, соединенных конвейером, который по умолчанию является дуплексным (двусторонним). Это работает следующим образом -
Он возвращает пару объектов соединения, которые представляют два конца трубы.
У каждого объекта есть два метода - send() и recv(), чтобы общаться между процессами.
пример
Ниже приведен простой пример, взятый из официальных документов Python по многопроцессорности, чтобы понять концепцию Pipe() функция многопроцессорности.
from multiprocessing import Process, Pipe
def f(conn):
conn.send([42, None, 'hello'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target = f, args = (child_conn,))
p.start()
print (parent_conn.recv())
p.join()Вывод
[42, None, 'hello']Управляющий делами
Менеджер - это класс многопроцессорных модулей, которые обеспечивают способ координации общей информации между всеми пользователями. Объект-менеджер управляет серверным процессом, который управляет общими объектами и позволяет другим процессам манипулировать ими. Другими словами, менеджеры предоставляют способ создания данных, которые могут использоваться разными процессами. Ниже приведены различные свойства объекта менеджера -
Главное свойство менеджера - управлять серверным процессом, который управляет разделяемыми объектами.
Еще одно важное свойство - обновлять все общие объекты, когда какой-либо процесс изменяет их.
пример
Ниже приведен пример, в котором объект-менеджер используется для создания записи списка в серверном процессе и последующего добавления новой записи в этот список.
import multiprocessing
def print_records(records):
for record in records:
print("Name: {0}\nScore: {1}\n".format(record[0], record[1]))
def insert_record(record, records):
records.append(record)
print("A New record is added\n")
if __name__ == '__main__':
with multiprocessing.Manager() as manager:
records = manager.list([('Computers', 1), ('Histoty', 5), ('Hindi',9)])
new_record = ('English', 3)
p1 = multiprocessing.Process(target = insert_record, args = (new_record, records))
p2 = multiprocessing.Process(target = print_records, args = (records,))
p1.start()
p1.join()
p2.start()
p2.join()Вывод
A New record is added
Name: Computers
Score: 1
Name: Histoty
Score: 5
Name: Hindi
Score: 9
Name: English
Score: 3Концепция пространств имен в Manager
Класс Manager поставляется с концепцией пространств имен, которая представляет собой быстрый способ совместного использования нескольких атрибутов в нескольких процессах. Пространства имен не содержат никаких общедоступных методов, которые можно вызвать, но у них есть атрибуты с возможностью записи.
пример
Следующий пример сценария Python помогает нам использовать пространства имен для обмена данными между основным процессом и дочерним процессом:
import multiprocessing
def Mng_NaSp(using_ns):
using_ns.x +=5
using_ns.y *= 10
if __name__ == '__main__':
manager = multiprocessing.Manager()
using_ns = manager.Namespace()
using_ns.x = 1
using_ns.y = 1
print ('before', using_ns)
p = multiprocessing.Process(target = Mng_NaSp, args = (using_ns,))
p.start()
p.join()
print ('after', using_ns)Вывод
before Namespace(x = 1, y = 1)
after Namespace(x = 6, y = 10)Ctypes-массив и значение
Модуль многопроцессорности предоставляет объекты Array и Value для хранения данных на карте общей памяти. Array представляет собой массив ctypes, выделенный из общей памяти и Value это объект ctypes, выделенный из общей памяти.
Чтобы быть с, импортируйте Process, Value, Array из многопроцессорности.
пример
Следующий скрипт Python - это пример, взятый из документации Python, для использования массива Ctypes и значения для обмена некоторыми данными между процессами.
def f(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
if __name__ == '__main__':
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target = f, args = (num, arr))
p.start()
p.join()
print (num.value)
print (arr[:])Вывод
3.1415927
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]Взаимодействие с последовательными процессами (CSP)
CSP используется для иллюстрации взаимодействия систем с другими системами с параллельными моделями. CSP - это структура для написания параллельной программы или программы через передачу сообщений, и, следовательно, она эффективна для описания параллелизма.
Библиотека Python - PyCSP
Для реализации основных примитивов, имеющихся в CSP, в Python есть библиотека PyCSP. Это делает реализацию очень короткой и удобочитаемой, так что ее можно очень легко понять. Ниже приведена основная сеть процессов PyCSP -
В вышеупомянутой сети процессов PyCSP есть два процесса - Process1 и Process 2. Эти процессы взаимодействуют, передавая сообщения через два канала - канал 1 и канал 2.
Установка PyCSP
С помощью следующей команды мы можем установить библиотеку Python PyCSP -
pip install PyCSPпример
Следующий сценарий Python - это простой пример запуска двух процессов параллельно друг другу. Это делается с помощью библиотеки Python PyCSP -
from pycsp.parallel import *
import time
@process
def P1():
time.sleep(1)
print('P1 exiting')
@process
def P2():
time.sleep(1)
print('P2 exiting')
def main():
Parallel(P1(), P2())
print('Terminating')
if __name__ == '__main__':
main()В приведенном выше скрипте две функции, а именно P1 и P2 были созданы, а затем украшены @process для преобразования их в процессы.
Вывод
P2 exiting
P1 exiting
TerminatingПрограммирование, управляемое событиями, фокусируется на событиях. В конце концов, ход программы зависит от событий. До сих пор мы имели дело либо с последовательной, либо с параллельной моделью выполнения, но модель, имеющая концепцию программирования, управляемого событиями, называется асинхронной. Программирование, управляемое событиями, зависит от цикла событий, который всегда ожидает новых входящих событий. Работа событийного программирования зависит от событий. Как только событие зацикливается, события решают, что выполнять и в каком порядке. Следующая блок-схема поможет вам понять, как это работает -
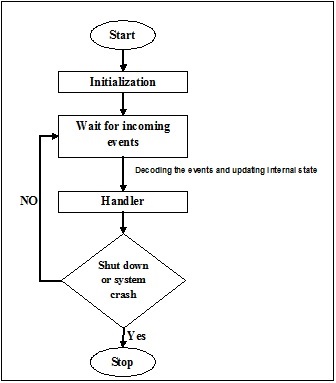
Модуль Python - Asyncio
Модуль Asyncio был добавлен в Python 3.4 и предоставляет инфраструктуру для написания однопоточного параллельного кода с использованием совместных подпрограмм. Ниже приведены различные концепции, используемые модулем Asyncio.
Цикл событий
Цикл событий - это функция для обработки всех событий в вычислительном коде. Он действует непрерывно во время выполнения всей программы и отслеживает поступление и выполнение событий. Модуль Asyncio допускает один цикл событий для каждого процесса. Ниже приведены некоторые методы, предоставляемые модулем Asyncio для управления циклом событий.
loop = get_event_loop() - Этот метод предоставит цикл событий для текущего контекста.
loop.call_later(time_delay,callback,argument) - Этот метод организует обратный вызов, который должен быть вызван через заданные секунды time_delay.
loop.call_soon(callback,argument)- Этот метод организует обратный вызов, который должен быть вызван как можно скорее. Обратный вызов вызывается после возврата call_soon () и когда управление возвращается в цикл событий.
loop.time() - Этот метод используется для возврата текущего времени в соответствии с внутренними часами цикла событий.
asyncio.set_event_loop() - Этот метод устанавливает цикл событий для текущего контекста в цикл.
asyncio.new_event_loop() - Этот метод создаст и вернет новый объект цикла событий.
loop.run_forever() - Этот метод будет работать до тех пор, пока не будет вызван метод stop ().
пример
Следующий пример цикла событий помогает при печати hello worldс помощью метода get_event_loop (). Этот пример взят из официальных документов Python.
import asyncio
def hello_world(loop):
print('Hello World')
loop.stop()
loop = asyncio.get_event_loop()
loop.call_soon(hello_world, loop)
loop.run_forever()
loop.close()Вывод
Hello WorldФьючерсы
Это совместимо с классом concurrent.futures.Future, который представляет вычисление, которое не было выполнено. Существуют следующие различия между asyncio.futures.Future и concurrent.futures.Future -
Методы result () и exception () не принимают аргумент тайм-аута и вызывают исключение, когда будущее еще не сделано.
Обратные вызовы, зарегистрированные с помощью add_done_callback (), всегда вызываются через call_soon () цикла событий.
Класс asyncio.futures.Future несовместим с функциями wait () и as_completed () в пакете concurrent.futures.
пример
Ниже приведен пример, который поможет вам понять, как использовать класс asyncio.futures.future.
import asyncio
async def Myoperation(future):
await asyncio.sleep(2)
future.set_result('Future Completed')
loop = asyncio.get_event_loop()
future = asyncio.Future()
asyncio.ensure_future(Myoperation(future))
try:
loop.run_until_complete(future)
print(future.result())
finally:
loop.close()Вывод
Future CompletedСопрограммы
Концепция сопрограмм в Asyncio аналогична концепции стандартного объекта Thread в модуле потоковой передачи. Это обобщение концепции подпрограммы. Сопрограмма может быть приостановлена во время выполнения, чтобы она ожидала внешней обработки и возвращалась из точки, в которой она остановилась, когда внешняя обработка была выполнена. Следующие два способа помогают нам в реализации сопрограмм:
функция async def ()
Это метод реализации сопрограмм в модуле Asyncio. Ниже приведен сценарий Python для того же -
import asyncio
async def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Вывод
First Coroutine@ asyncio.coroutine декоратор
Другой метод реализации сопрограмм - использование генераторов с декоратором @ asyncio.coroutine. Ниже приведен сценарий Python для того же -
import asyncio
@asyncio.coroutine
def Myoperation():
print("First Coroutine")
loop = asyncio.get_event_loop()
try:
loop.run_until_complete(Myoperation())
finally:
loop.close()Вывод
First CoroutineЗадания
Этот подкласс модуля Asyncio отвечает за параллельное выполнение сопрограмм в цикле событий. Следующий сценарий Python - это пример параллельной обработки некоторых задач.
import asyncio
import time
async def Task_ex(n):
time.sleep(1)
print("Processing {}".format(n))
async def Generator_task():
for i in range(10):
asyncio.ensure_future(Task_ex(i))
int("Tasks Completed")
asyncio.sleep(2)
loop = asyncio.get_event_loop()
loop.run_until_complete(Generator_task())
loop.close()Вывод
Tasks Completed
Processing 0
Processing 1
Processing 2
Processing 3
Processing 4
Processing 5
Processing 6
Processing 7
Processing 8
Processing 9Транспорт
Модуль Asyncio предоставляет транспортные классы для реализации различных типов связи. Эти классы не являются потокобезопасными и всегда связаны с экземпляром протокола после установления канала связи.
Ниже приведены различные типы транспорта, унаследованные от BaseTransport.
ReadTransport - Это интерфейс для транспорта только для чтения.
WriteTransport - Это интерфейс для транспорта только для записи.
DatagramTransport - Это интерфейс для отправки данных.
BaseSubprocessTransport - Аналогично классу BaseTransport.
Ниже приведены пять различных методов класса BaseTransport, которые впоследствии переходят через четыре типа транспорта:
close() - Он закрывает транспорт.
is_closing() - Этот метод вернет истину, если транспорт закрывается или уже закрыт.
get_extra_info(name, default = none) - Это даст нам дополнительную информацию о транспорте.
get_protocol() - Этот метод вернет текущий протокол.
Протоколы
Модуль Asyncio предоставляет базовые классы, которые вы можете подклассифицировать для реализации ваших сетевых протоколов. Эти классы используются вместе с транспортами; протокол анализирует входящие данные и запрашивает запись исходящих данных, в то время как транспорт отвечает за фактический ввод-вывод и буферизацию. Ниже приведены три класса протокола -
Protocol - Это базовый класс для реализации протоколов потоковой передачи для использования с транспортом TCP и SSL.
DatagramProtocol - Это базовый класс для реализации протоколов дейтаграмм для использования с транспортом UDP.
SubprocessProtocol - Это базовый класс для реализации протоколов, взаимодействующих с дочерними процессами через набор однонаправленных каналов.
Реактивное программирование - это парадигма программирования, которая имеет дело с потоками данных и распространением изменений. Это означает, что когда поток данных испускается одним компонентом, изменение будет распространено на другие компоненты библиотекой реактивного программирования. Распространение изменения будет продолжаться до тех пор, пока оно не достигнет последнего получателя. Разница между программированием, управляемым событиями, и реактивным программированием заключается в том, что программирование, управляемое событиями, вращается вокруг событий, а реактивное программирование - вокруг данных.
ReactiveX или RX для реактивного программирования
ReactiveX или Raective Extension - самая известная реализация реактивного программирования. Работа ReactiveX зависит от следующих двух классов:
Наблюдаемый класс
Этот класс является источником потока данных или событий, и он упаковывает входящие данные, чтобы данные можно было передавать из одного потока в другой. Он не выдаст данные, пока на него не подпишется какой-нибудь наблюдатель.
Класс наблюдателя
Этот класс потребляет поток данных, излучаемый observable. Может быть несколько наблюдателей с наблюдаемым, и каждый наблюдатель будет получать каждый элемент данных, который испускается. Наблюдатель может получать три типа событий, подписавшись на наблюдаемое -
on_next() event - Это означает, что в потоке данных есть элемент.
on_completed() event - Это означает конец эмиссии и больше никаких предметов не будет.
on_error() event - Также подразумевается конец эмиссии, но в случае, когда ошибка выдается observable.
RxPY - модуль Python для реактивного программирования
RxPY - это модуль Python, который можно использовать для реактивного программирования. Нам нужно убедиться, что модуль установлен. Для установки модуля RxPY можно использовать следующую команду -
pip install RxPYпример
Ниже приведен сценарий Python, который использует RxPY модуль и его классы Observable и Observe forреактивное программирование. В основном есть два класса -
get_strings() - для получения строк от наблюдателя.
PrintObserver()- для печати строк от наблюдателя. Он использует все три события класса наблюдателя. Он также использует класс subscribe ().
from rx import Observable, Observer
def get_strings(observer):
observer.on_next("Ram")
observer.on_next("Mohan")
observer.on_next("Shyam")
observer.on_completed()
class PrintObserver(Observer):
def on_next(self, value):
print("Received {0}".format(value))
def on_completed(self):
print("Finished")
def on_error(self, error):
print("Error: {0}".format(error))
source = Observable.create(get_strings)
source.subscribe(PrintObserver())Вывод
Received Ram
Received Mohan
Received Shyam
FinishedPyFunctional библиотека для реактивного программирования
PyFunctional- еще одна библиотека Python, которую можно использовать для реактивного программирования. Это позволяет нам создавать функциональные программы с использованием языка программирования Python. Это полезно, потому что позволяет нам создавать конвейеры данных с помощью связанных функциональных операторов.
Разница между RxPY и PyFunctional
Обе библиотеки используются для реактивного программирования и обрабатывают поток аналогичным образом, но основное различие между ними зависит от обработки данных. RxPY обрабатывает данные и события в системе, пока PyFunctional ориентирована на преобразование данных с использованием парадигм функционального программирования.
Установка PyFunctional модуля
Нам необходимо установить этот модуль перед его использованием. Его можно установить с помощью команды pip следующим образом:
pip install pyfunctionalпример
В следующем примере используется the PyFunctional модуль и его seqкласс, который действует как объект потока, с которым мы можем выполнять итерацию и манипулировать. В этой программе он отображает последовательность, используя функцию lamda, которая удваивает каждое значение, затем фильтрует значение, где x больше 4, и, наконец, сокращает последовательность до суммы всех оставшихся значений.
from functional import seq
result = seq(1,2,3).map(lambda x: x*2).filter(lambda x: x > 4).reduce(lambda x, y: x + y)
print ("Result: {}".format(result))Вывод
Result: 6