Краткое руководство по C ++
C ++ - это статически типизированный, скомпилированный, универсальный, чувствительный к регистру язык программирования произвольной формы, который поддерживает процедурное, объектно-ориентированное и универсальное программирование.
C ++ рассматривается как middle-level language, так как он сочетает в себе функции языка высокого и низкого уровня.
C ++ был разработан Бьярном Страуструпом, начиная с 1979 года в Bell Labs в Мюррей-Хилл, штат Нью-Джерси, как расширение языка C и первоначально назывался C с классами, но позже он был переименован в C ++ в 1983 году.
C ++ - это надмножество C, и что практически любая законная программа C является законной программой C ++.
Note - Говорят, что язык программирования использует статическую типизацию, когда проверка типа выполняется во время компиляции, а не во время выполнения.
Объектно-ориентированного программирования
C ++ полностью поддерживает объектно-ориентированное программирование, включая четыре столпа объектно-ориентированной разработки:
- Encapsulation
- Скрытие данных
- Inheritance
- Polymorphism
Стандартные библиотеки
Стандартный C ++ состоит из трех важных частей:
Основной язык, содержащий все строительные блоки, включая переменные, типы данных, литералы и т. Д.
Стандартная библиотека C ++ предоставляет богатый набор функций для работы с файлами, строками и т. Д.
Стандартная библиотека шаблонов (STL), предоставляющая богатый набор методов для управления структурами данных и т. Д.
Стандарт ANSI
Стандарт ANSI - это попытка обеспечить переносимость C ++; этот код, который вы пишете для компилятора Microsoft, будет компилироваться без ошибок с использованием компилятора на Mac, UNIX, Windows или Alpha.
Стандарт ANSI некоторое время оставался стабильным, и все основные производители компиляторов C ++ поддерживают стандарт ANSI.
Изучение C ++
Самое важное при изучении C ++ - сосредоточиться на концепциях.
Цель изучения языка программирования - стать лучшим программистом; то есть стать более эффективными при разработке и внедрении новых систем и обслуживании старых.
C ++ поддерживает множество стилей программирования. Вы можете писать в стиле Fortran, C, Smalltalk и т.д. на любом языке. Каждый стиль может эффективно достигать своих целей, сохраняя при этом эффективность работы и пространства.
Использование C ++
C ++ используется сотнями тысяч программистов практически во всех областях приложения.
C ++ широко используется для написания драйверов устройств и другого программного обеспечения, которое полагается на прямое управление оборудованием в условиях ограничений в реальном времени.
C ++ широко используется для обучения и исследований, поскольку он достаточно чист для успешного обучения базовым концепциям.
Любой, кто использовал Apple Macintosh или ПК под управлением Windows, косвенно использовал C ++, потому что основные пользовательские интерфейсы этих систем написаны на C ++.
Настройка локальной среды
Если вы все еще хотите настроить свою среду для C ++, на вашем компьютере должны быть два следующих программного обеспечения.
Текстовый редактор
Это будет использоваться для ввода вашей программы. Примеры нескольких редакторов включают Блокнот Windows, команду редактирования ОС, Brief, Epsilon, EMACS и vim или vi.
Название и версия текстового редактора могут различаться в разных операционных системах. Например, Блокнот будет использоваться в Windows, а vim или vi можно использовать в Windows, а также в Linux или UNIX.
Файлы, которые вы создаете с помощью своего редактора, называются исходными файлами, а для C ++ они обычно имеют расширение .cpp, .cp или .c.
Текстовый редактор должен быть на месте, чтобы начать программирование на C ++.
Компилятор C ++
Это настоящий компилятор C ++, который будет использоваться для компиляции вашего исходного кода в окончательную исполняемую программу.
Большинство компиляторов C ++ не заботятся о том, какое расширение вы дадите своему исходному коду, но если вы не укажете иное, многие будут использовать .cpp по умолчанию.
Наиболее часто используемый и бесплатный компилятор - это компилятор GNU C / C ++, в противном случае вы можете использовать компиляторы от HP или Solaris, если у вас есть соответствующие операционные системы.
Установка компилятора GNU C / C ++
Установка UNIX / Linux
Если вы используете Linux or UNIX затем проверьте, установлен ли GCC в вашей системе, введя следующую команду из командной строки -
$ g++ -vЕсли вы установили GCC, он должен напечатать сообщение, подобное следующему:
Using built-in specs.
Target: i386-redhat-linux
Configured with: ../configure --prefix=/usr .......
Thread model: posix
gcc version 4.1.2 20080704 (Red Hat 4.1.2-46)Если GCC не установлен, вам придется установить его самостоятельно, используя подробные инструкции, доступные на https://gcc.gnu.org/install/
Установка Mac OS X
Если вы используете Mac OS X, самый простой способ получить GCC - загрузить среду разработки Xcode с веб-сайта Apple и следовать простым инструкциям по установке.
Xcode в настоящее время доступен по адресу developer.apple.com/technologies/tools/ .
Установка Windows
Чтобы установить GCC в Windows, вам необходимо установить MinGW. Чтобы установить MinGW, перейдите на домашнюю страницу MinGW, www.mingw.org , и перейдите по ссылке на страницу загрузки MinGW. Загрузите последнюю версию программы установки MinGW, которая должна называться MinGW- <version> .exe.
При установке MinGW вы должны как минимум установить gcc-core, gcc-g ++, binutils и среду выполнения MinGW, но вы можете установить больше.
Добавьте подкаталог bin вашей установки MinGW в свой PATH переменная среды, чтобы вы могли указать эти инструменты в командной строке по их простым именам.
Когда установка будет завершена, вы сможете запускать gcc, g ++, ar, ranlib, dlltool и несколько других инструментов GNU из командной строки Windows.
Когда мы рассматриваем программу на C ++, ее можно определить как набор объектов, которые обмениваются данными посредством вызова методов друг друга. Давайте теперь кратко рассмотрим, что означают класс, объект, методы и мгновенные переменные.
Object- У объектов есть состояния и поведение. Пример: у собаки есть состояния - цвет, имя, порода, а также поведение - виляние, лай, еда. Объект - это экземпляр класса.
Class - Класс можно определить как шаблон / план, который описывает поведение / состояния, которые поддерживает объект его типа.
Methods- Метод - это в основном поведение. Класс может содержать множество методов. Именно в методах записывается логика, обрабатываются данные и выполняются все действия.
Instance Variables- Каждый объект имеет свой уникальный набор переменных экземпляра. Состояние объекта создается значениями, присвоенными этим переменным экземпляра.
Структура программы C ++
Давайте посмотрим на простой код, который будет печатать слова Hello World .
#include <iostream>
using namespace std;
// main() is where program execution begins.
int main() {
cout << "Hello World"; // prints Hello World
return 0;
}Давайте посмотрим на различные части вышеуказанной программы -
В языке C ++ определены несколько заголовков, которые содержат информацию, которая либо необходима, либо полезна для вашей программы. Для этой программы в шапке<iostream> нужно.
Линия using namespace std;сообщает компилятору использовать пространство имен std. Пространства имен - относительно недавнее дополнение к C ++.
Следующая строка '// main() is where program execution begins.'- однострочный комментарий, доступный в C ++. Однострочные комментарии начинаются с // и заканчиваются в конце строки.
Линия int main() - основная функция, с которой начинается выполнение программы.
Следующая строка cout << "Hello World"; вызывает отображение на экране сообщения «Hello World».
Следующая строка return 0; завершает функцию main () и заставляет ее вернуть значение 0 вызывающему процессу.
Компиляция и выполнение программы на C ++
Давайте посмотрим, как сохранить файл, скомпилировать и запустить программу. Пожалуйста, следуйте инструкциям ниже -
Откройте текстовый редактор и добавьте код, как указано выше.
Сохраните файл как: hello.cpp
Откройте командную строку и перейдите в каталог, в котором вы сохранили файл.
Введите g ++ hello.cpp и нажмите клавишу ВВОД, чтобы скомпилировать код. Если в вашем коде нет ошибок, командная строка переведет вас на следующую строку и сгенерирует исполняемый файл .out.
Теперь введите «a.out», чтобы запустить вашу программу.
Вы увидите напечатанное в окне «Hello World».
$ g++ hello.cpp
$ ./a.out
Hello WorldУбедитесь, что g ++ находится на вашем пути и что вы запускаете его в каталоге, содержащем файл hello.cpp.
Вы можете компилировать программы на C / C ++ с помощью makefile. Для получения дополнительной информации вы можете ознакомиться с нашим «Руководством по Makefile» .
Точки с запятой и блоки в C ++
В C ++ точка с запятой является терминатором оператора. То есть каждый отдельный оператор должен заканчиваться точкой с запятой. Это указывает на конец одного логического объекта.
Например, следующие три разных утверждения -
x = y;
y = y + 1;
add(x, y);Блок - это набор логически связанных операторов, заключенных в открывающие и закрывающие фигурные скобки. Например -
{
cout << "Hello World"; // prints Hello World
return 0;
}C ++ не распознает конец строки как терминатор. По этой причине не имеет значения, где вы помещаете утверждение в строку. Например -
x = y;
y = y + 1;
add(x, y);такой же как
x = y; y = y + 1; add(x, y);Идентификаторы C ++
Идентификатор C ++ - это имя, используемое для идентификации переменной, функции, класса, модуля или любого другого определяемого пользователем элемента. Идентификатор начинается с буквы от A до Z, от a до z или символа подчеркивания (_), за которым следуют ноль или более букв, подчеркиваний и цифр (от 0 до 9).
C ++ не допускает символов пунктуации, таких как @, $ и%, в идентификаторах. C ++ - это язык программирования с учетом регистра. Таким образом,Manpower и manpower - это два разных идентификатора в C ++.
Вот несколько примеров приемлемых идентификаторов -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValКлючевые слова C ++
В следующем списке показаны зарезервированные слова в C ++. Эти зарезервированные слова нельзя использовать в качестве имен констант, переменных или любых других идентификаторов.
| как м | еще | новый | это |
| авто | перечислить | оператор | бросить |
| bool | явный | частный | правда |
| сломать | экспорт | защищенный | пытаться |
| дело | внешний | общественный | typedef |
| поймать | ложный | регистр | типичный |
| char | плавать | reinterpret_cast | typename |
| класс | за | возвращение | союз |
| const | друг | короткая | беззнаковый |
| const_cast | идти к | подписанный | с помощью |
| Продолжить | если | размер | виртуальный |
| по умолчанию | в линию | статический | пустота |
| удалять | int | static_cast | летучий |
| делать | долго | структура | wchar_t |
| двойной | изменчивый | переключатель | в то время как |
| dynamic_cast | пространство имен | шаблон |
Триграфы
Некоторые символы имеют альтернативное представление, называемое триграфической последовательностью. Триграф - это трехсимвольная последовательность, представляющая один символ, и последовательность всегда начинается с двух вопросительных знаков.
Триграфы раскрываются везде, где они появляются, в том числе в строковых литералах и символьных литералах, в комментариях и в директивах препроцессора.
Ниже приведены наиболее часто используемые последовательности триграфов -
| Триграф | Замена |
|---|---|
| знак равно | # |
| ?? / | \ |
| ?? ' | ^ |
| ?? ( | [ |
| ??) | ] |
| ??! | | |
| ?? < | { |
| ??> | } |
| ?? - | ~ |
Все компиляторы не поддерживают триграфы, и их не рекомендуется использовать из-за их запутанного характера.
Пробелы в C ++
Строка, содержащая только пробелы, возможно с комментарием, называется пустой строкой, и компилятор C ++ полностью игнорирует ее.
Пробел - это термин, используемый в C ++ для описания пробелов, табуляции, символов новой строки и комментариев. Пробел отделяет одну часть оператора от другой и позволяет компилятору определить, где заканчивается один элемент в операторе, например int, и начинается следующий элемент.
Положение 1
int age;В приведенном выше утверждении должен быть хотя бы один пробел (обычно пробел) между int и age, чтобы компилятор мог их различать.
Положение 2
fruit = apples + oranges; // Get the total fruitВ приведенном выше утверждении 2 не требуется никаких пробелов между фруктами и = или между = и яблоками, хотя вы можете включить некоторые из них, если хотите для удобства чтения.
Комментарии к программе - это пояснительные утверждения, которые вы можете включать в код C ++. Эти комментарии помогут любому, кто читает исходный код. Все языки программирования допускают ту или иную форму комментариев.
C ++ поддерживает однострочные и многострочные комментарии. Все символы, доступные внутри любого комментария, игнорируются компилятором C ++.
Комментарии C ++ начинаются с / * и заканчиваются * /. Например -
/* This is a comment */
/* C++ comments can also
* span multiple lines
*/Комментарий также может начинаться с символа // и доходить до конца строки. Например -
#include <iostream>
using namespace std;
main() {
cout << "Hello World"; // prints Hello World
return 0;
}Когда приведенный выше код скомпилирован, он проигнорирует // prints Hello World и окончательный исполняемый файл даст следующий результат -
Hello WorldВ комментариях / * и * / символы // не имеют особого значения. Внутри комментария // / * и * / не имеют особого значения. Таким образом, вы можете «вкладывать» один вид комментария в другой. Например -
/* Comment out printing of Hello World:
cout << "Hello World"; // prints Hello World
*/При написании программы на любом языке вам необходимо использовать различные переменные для хранения различной информации. Переменные - это не что иное, как зарезервированные ячейки памяти для хранения значений. Это означает, что когда вы создаете переменную, вы резервируете некоторое место в памяти.
Вы можете хранить информацию о различных типах данных, таких как символ, широкий символ, целое число, с плавающей запятой, с двойной плавающей запятой, логическое значение и т. Д. На основе типа данных переменной операционная система выделяет память и решает, что можно сохранить зарезервированная память.
Примитивные встроенные типы
C ++ предлагает программисту богатый набор как встроенных, так и определяемых пользователем типов данных. В следующей таблице перечислены семь основных типов данных C ++.
| Тип | Ключевое слово |
|---|---|
| Булево | bool |
| символ | char |
| Целое число | int |
| Плавающая запятая | плавать |
| Двойная плавающая точка | двойной |
| Бесполезный | пустота |
| Широкий характер | wchar_t |
Некоторые из основных типов могут быть изменены с использованием одного или нескольких из этих модификаторов типов:
- signed
- unsigned
- short
- long
В следующей таблице показан тип переменной, сколько памяти требуется для хранения значения в памяти, а также какое максимальное и минимальное значение может быть сохранено в таких типах переменных.
| Тип | Типичная битовая ширина | Типичный диапазон |
|---|---|---|
| char | 1 байт | От -127 до 127 или от 0 до 255 |
| беззнаковый символ | 1 байт | От 0 до 255 |
| подписанный символ | 1 байт | От -127 до 127 |
| int | 4 байта | От -2147483648 до 2147483647 |
| беззнаковое целое | 4 байта | 0 на 4294967295 |
| подписанный int | 4 байта | От -2147483648 до 2147483647 |
| короткий int | 2 байта | От -32768 до 32767 |
| беззнаковый короткий int | 2 байта | От 0 до 65 535 |
| подписанный короткий int | 2 байта | От -32768 до 32767 |
| длинный интервал | 8 байтов | От -2 147 483 648 до 2 147 483 647 |
| подписанный длинный int | 8 байтов | то же, что и long int |
| беззнаковый длинный int | 8 байтов | От 0 до 4 294 967 295 |
| длинный длинный int | 8 байтов | - (2 ^ 63) до (2 ^ 63) -1 |
| беззнаковый длинный длинный int | 8 байтов | От 0 до 18 446 744 073 709 551 615 |
| плавать | 4 байта | |
| двойной | 8 байтов | |
| длинный двойной | 12 байтов | |
| wchar_t | 2 или 4 байта | 1 широкий символ |
Размер переменных может отличаться от размера, указанного в приведенной выше таблице, в зависимости от компилятора и компьютера, который вы используете.
Ниже приведен пример, который позволит получить правильный размер различных типов данных на вашем компьютере.
#include <iostream>
using namespace std;
int main() {
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
return 0;
}В этом примере используется endl, который вставляет символ новой строки после каждой строки, а оператор << используется для передачи нескольких значений на экран. Мы также используемsizeof() оператор, чтобы получить размер различных типов данных.
Когда приведенный выше код компилируется и выполняется, он дает следующий результат, который может варьироваться от машины к машине:
Size of char : 1
Size of int : 4
Size of short int : 2
Size of long int : 4
Size of float : 4
Size of double : 8
Size of wchar_t : 4Объявления typedef
Вы можете создать новое имя для существующего типа, используя typedef. Ниже приведен простой синтаксис для определения нового типа с помощью typedef:
typedef type newname;Например, следующее говорит компилятору, что ноги - это другое имя для int:
typedef int feet;Теперь следующее объявление совершенно законно и создает целочисленную переменную с именем distance -
feet distance;Нумерованные типы
Перечислимый тип объявляет необязательное имя типа и набор из нуля или более идентификаторов, которые могут использоваться в качестве значений типа. Каждый перечислитель - это константа, тип которой - перечисление.
Создание перечисления требует использования ключевого слова enum. Общая форма перечислимого типа -
enum enum-name { list of names } var-list;Здесь enum-name - это имя типа перечисления. Список имен разделен запятыми.
Например, следующий код определяет перечисление цветов, называемых цветами, и переменную c типа color. Наконец, c присваивается значение «синий».
enum color { red, green, blue } c;
c = blue;По умолчанию значение первого имени равно 0, второе имя имеет значение 1, третье - значение 2 и так далее. Но вы можете дать имя, конкретное значение, добавив инициализатор. Например, в следующем перечисленииgreen будет иметь значение 5.
enum color { red, green = 5, blue };Вот, blue будет иметь значение 6, потому что каждое имя будет на единицу больше, чем предшествующее ему.
Переменная предоставляет нам именованное хранилище, которым могут управлять наши программы. Каждая переменная в C ++ имеет определенный тип, который определяет размер и структуру памяти переменной; диапазон значений, которые могут быть сохранены в этой памяти; и набор операций, которые можно применить к переменной.
Имя переменной может состоять из букв, цифр и символа подчеркивания. Он должен начинаться с буквы или символа подчеркивания. Прописные и строчные буквы различны, потому что C ++ чувствителен к регистру -
В C ++ есть следующие основные типы переменных, как описано в предыдущей главе:
| Старший Нет | Тип и описание |
|---|---|
| 1 | bool Сохраняет либо значение true, либо false. |
| 2 | char Обычно один октет (один байт). Это целочисленный тип. |
| 3 | int Самый естественный размер целого числа для машины. |
| 4 | float Значение с плавающей запятой одинарной точности. |
| 5 | double Значение с плавающей запятой двойной точности. |
| 6 | void Представляет отсутствие типа. |
| 7 | wchar_t Широкий символьный тип. |
C ++ также позволяет определять различные другие типы переменных, которые мы рассмотрим в следующих главах, например Enumeration, Pointer, Array, Reference, Data structures, и Classes.
В следующем разделе будет рассказано, как определять, объявлять и использовать различные типы переменных.
Определение переменной в C ++
Определение переменной сообщает компилятору, где и сколько памяти создать для переменной. Определение переменной указывает тип данных и содержит список из одной или нескольких переменных этого типа следующим образом:
type variable_list;Вот, type должен быть допустимым типом данных C ++, включая char, w_char, int, float, double, bool или любой пользовательский объект и т. д., и variable_listможет состоять из одного или нескольких имен идентификаторов, разделенных запятыми. Здесь показаны некоторые действительные декларации -
int i, j, k;
char c, ch;
float f, salary;
double d;Линия int i, j, k;оба объявляют и определяют переменные i, j и k; который инструктирует компилятор создать переменные с именами i, j и k типа int.
Переменные можно инициализировать (присвоить начальное значение) в их объявлении. Инициализатор состоит из знака равенства, за которым следует постоянное выражение:
type variable_name = value;Вот несколько примеров -
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Для определения без инициализатора: переменные со статической продолжительностью хранения неявно инициализируются NULL (все байты имеют значение 0); начальное значение всех остальных переменных не определено.
Объявление переменной в C ++
Объявление переменной обеспечивает компилятору гарантию того, что существует одна переменная с данным типом и именем, так что компилятор приступит к дальнейшей компиляции, не требуя полной информации о переменной. Объявление переменной имеет значение только во время компиляции, компилятору требуется фактическое определение переменной во время связывания программы.
Объявление переменной полезно, когда вы используете несколько файлов и определяете переменную в одном из файлов, который будет доступен во время связывания программы. Вы будете использоватьexternключевое слово для объявления переменной в любом месте. Хотя вы можете объявить переменную несколько раз в своей программе на C ++, но она может быть определена только один раз в файле, функции или блоке кода.
пример
Попробуйте следующий пример, где переменная была объявлена вверху, но была определена внутри основной функции:
#include <iostream>
using namespace std;
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
// Variable definition:
int a, b;
int c;
float f;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c << endl ;
f = 70.0/3.0;
cout << f << endl ;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
30
23.3333Та же концепция применяется к объявлению функции, где вы указываете имя функции во время ее объявления, а ее фактическое определение может быть дано где угодно. Например -
// function declaration
int func();
int main() {
// function call
int i = func();
}
// function definition
int func() {
return 0;
}L-значения и R-значения
В C ++ есть два вида выражений:
lvalue- Выражение, относящееся к области памяти, называется выражением «lvalue». Lvalue может отображаться как левая или правая часть присваивания.
rvalue- Термин rvalue относится к значению данных, которое хранится по некоторому адресу в памяти. Rvalue - это выражение, которому не может быть присвоено значение, что означает, что rvalue может появляться справа, но не слева от присваивания.
Переменные - это lvalue, поэтому они могут появляться в левой части присваивания. Числовые литералы являются r-значениями, поэтому не могут быть присвоены и не могут отображаться с левой стороны. Ниже приводится действительное заявление -
int g = 20;Но следующее утверждение не является допустимым и приведет к ошибке времени компиляции:
10 = 20;Область видимости - это область программы, и, в общем, есть три места, где можно объявлять переменные:
Внутри функции или блока, который называется локальными переменными,
В определении параметров функции, которая называется формальными параметрами.
Вне всех функций, которые называются глобальными переменными.
Мы узнаем, что такое функция и ее параметр, в следующих главах. Здесь давайте объясним, что такое локальные и глобальные переменные.
Локальные переменные
Переменные, объявленные внутри функции или блока, являются локальными переменными. Они могут использоваться только операторами, которые находятся внутри этой функции или блока кода. Локальные переменные не известны функциям вне их собственных. Ниже приведен пример с использованием локальных переменных -
#include <iostream>
using namespace std;
int main () {
// Local variable declaration:
int a, b;
int c;
// actual initialization
a = 10;
b = 20;
c = a + b;
cout << c;
return 0;
}Глобальные переменные
Глобальные переменные определяются вне всех функций, обычно поверх программы. Глобальные переменные будут сохранять свое значение на протяжении всего времени существования вашей программы.
Доступ к глобальной переменной может получить любая функция. То есть глобальная переменная доступна для использования во всей программе после ее объявления. Ниже приведен пример использования глобальных и локальных переменных -
#include <iostream>
using namespace std;
// Global variable declaration:
int g;
int main () {
// Local variable declaration:
int a, b;
// actual initialization
a = 10;
b = 20;
g = a + b;
cout << g;
return 0;
}Программа может иметь одно и то же имя для локальных и глобальных переменных, но значение локальной переменной внутри функции будет иметь приоритет. Например -
#include <iostream>
using namespace std;
// Global variable declaration:
int g = 20;
int main () {
// Local variable declaration:
int g = 10;
cout << g;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
10Инициализация локальных и глобальных переменных
Когда локальная переменная определена, она не инициализируется системой, вы должны инициализировать ее самостоятельно. Глобальные переменные инициализируются системой автоматически, когда вы определяете их следующим образом:
| Тип данных | Инициализатор |
|---|---|
| int | 0 |
| char | '\ 0' |
| плавать | 0 |
| двойной | 0 |
| указатель | НОЛЬ |
Хорошая практика программирования - правильно инициализировать переменные, иначе программа может дать неожиданный результат.
Константы относятся к фиксированным значениям, которые программа не может изменять, и они называются literals.
Константы могут относиться к любому из основных типов данных и делиться на целые числа, числа с плавающей запятой, символы, строки и логические значения.
Опять же, константы обрабатываются так же, как обычные переменные, за исключением того, что их значения не могут быть изменены после их определения.
Целочисленные литералы
Целочисленный литерал может быть десятичной, восьмеричной или шестнадцатеричной константой. Префикс определяет основание или основание системы счисления: 0x или 0X для шестнадцатеричного числа, 0 для восьмеричного и ничего для десятичного.
Целочисленный литерал также может иметь суффикс, который представляет собой комбинацию U и L для unsigned и long соответственно. Суффикс может быть в верхнем или нижнем регистре и может быть в любом порядке.
Вот несколько примеров целочисленных литералов -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixНиже приведены другие примеры различных типов целочисленных литералов.
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned longЛитералы с плавающей точкой
Литерал с плавающей запятой состоит из целой части, десятичной точки, дробной части и экспоненты. Вы можете представлять литералы с плавающей запятой в десятичной или экспоненциальной форме.
При представлении с использованием десятичной формы вы должны включать десятичную точку, показатель степени или и то, и другое, а при представлении с использованием экспоненциальной формы вы должны включать целую часть, дробную часть или и то, и другое. Знаковая экспонента вводится буквами e или E.
Вот несколько примеров литералов с плавающей запятой -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fractionЛогические литералы
Есть два логических литерала, и они являются частью стандартных ключевых слов C ++ -
Ценность true представляющий истину.
Ценность false представляющий ложь.
Не следует считать, что значение true равно 1, а значение false - 0.
Символьные литералы
Символьные литералы заключаются в одинарные кавычки. Если литерал начинается с L (только в верхнем регистре), это литерал с широкими символами (например, L'x ') и должен храниться вwchar_tтип переменной. В противном случае это узкий символьный литерал (например, 'x') и может быть сохранен в простой переменнойchar тип.
Символьный литерал может быть простым символом (например, 'x'), escape-последовательностью (например, '\ t') или универсальным символом (например, '\ u02C0').
В C ++ есть определенные символы, которым предшествует обратная косая черта, они будут иметь особое значение и используются для обозначения новой строки (\ n) или табуляции (\ t). Здесь у вас есть список некоторых таких кодов escape-последовательностей -
| Последовательность выхода | Имея в виду |
|---|---|
| \\ | \ персонаж |
| \ ' | ' персонаж |
| \ " | " персонаж |
| \? | ? персонаж |
| \ а | Оповещение или звонок |
| \ b | Backspace |
| \ f | Подача формы |
| \ п | Новая линия |
| \р | Возврат каретки |
| \ т | Горизонтальная вкладка |
| \ v | Вертикальная табуляция |
| \ ооо | Восьмеричное число от одной до трех цифр |
| \ ххх. . . | Шестнадцатеричное число из одной или нескольких цифр |
Ниже приведен пример, показывающий несколько символов escape-последовательности.
#include <iostream>
using namespace std;
int main() {
cout << "Hello\tWorld\n\n";
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Hello WorldСтроковые литералы
Строковые литералы заключаются в двойные кавычки. Строка содержит символы, похожие на символьные литералы: простые символы, escape-последовательности и универсальные символы.
Вы можете разбить длинную строку на несколько строк, используя строковые литералы, и разделить их пробелами.
Вот несколько примеров строковых литералов. Все три формы - идентичные струны.
"hello, dear"
"hello, \
dear"
"hello, " "d" "ear"Определение констант
В C ++ есть два простых способа определения констант:
С помощью #define препроцессор.
С помощью const ключевое слово.
Препроцессор #define
Ниже приведена форма использования препроцессора #define для определения константы.
#define identifier valueСледующий пример подробно объясняет это -
#include <iostream>
using namespace std;
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
50Ключевое слово const
Вы можете использовать const префикс для объявления констант определенного типа следующим образом:
const type variable = value;Следующий пример подробно объясняет это -
#include <iostream>
using namespace std;
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
cout << area;
cout << NEWLINE;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
50Обратите внимание, что определение констант ЗАГЛАВНЫМИ буквами является хорошей практикой программирования.
C ++ позволяет char, int, и doubleтипы данных, чтобы им предшествовали модификаторы. Модификатор используется для изменения значения базового типа, чтобы он более точно соответствовал потребностям различных ситуаций.
Модификаторы типа данных перечислены здесь -
- signed
- unsigned
- long
- short
Модификаторы signed, unsigned, long, и shortможет применяться к целочисленным базовым типам. К тому же,signed и unsigned может применяться к char, и long может применяться к двойному.
Модификаторы signed и unsigned также может использоваться как префикс к long или же shortмодификаторы. Например,unsigned long int.
C ++ допускает сокращенную запись для объявления unsigned, short, или же longцелые числа. Вы можете просто использовать словоunsigned, short, или же long, без int. Это автоматически подразумеваетint. Например, следующие два оператора объявляют целочисленные переменные без знака.
unsigned x;
unsigned int y;Чтобы понять разницу между способом интерпретации целочисленных модификаторов со знаком и без знака в C ++, вы должны запустить следующую короткую программу:
#include <iostream>
using namespace std;
/* This program shows the difference between
* signed and unsigned integers.
*/
int main() {
short int i; // a signed short integer
short unsigned int j; // an unsigned short integer
j = 50000;
i = j;
cout << i << " " << j;
return 0;
}Когда эта программа запускается, следующий вывод -
-15536 50000Приведенный выше результат объясняется тем, что битовая комбинация, представляющая 50 000 как короткое целое число без знака, интерпретируется как -15 536 коротким.
Квалификаторы типов в C ++
Квалификаторы типа предоставляют дополнительную информацию о переменных, которым они предшествуют.
| Старший Нет | Классификатор и значение |
|---|---|
| 1 | const Объекты типа const не может быть изменен вашей программой во время выполнения. |
| 2 | volatile Модификатор volatile сообщает компилятору, что значение переменной может быть изменено способами, явно не указанными программой. |
| 3 | restrict Указатель, квалифицированный restrictизначально является единственным средством, с помощью которого можно получить доступ к объекту, на который он указывает. Только C99 добавляет новый квалификатор типа под названием restrict. |
Класс хранения определяет объем (видимость) и время жизни переменных и / или функций в программе C ++. Эти спецификаторы предшествуют типу, который они изменяют. Существуют следующие классы хранения, которые можно использовать в программе на C ++.
- auto
- register
- static
- extern
- mutable
Класс автоматического хранения
В auto класс хранения - это класс хранения по умолчанию для всех локальных переменных.
{
int mount;
auto int month;
}В приведенном выше примере определены две переменные с одним и тем же классом хранения, auto может использоваться только внутри функций, то есть локальных переменных.
Класс хранения регистра
В registerкласс хранения используется для определения локальных переменных, которые должны храниться в регистре вместо ОЗУ. Это означает, что переменная имеет максимальный размер, равный размеру регистра (обычно одно слово), и к ней не может применяться унарный оператор '&' (поскольку у нее нет места в памяти).
{
register int miles;
}Регистр следует использовать только для переменных, требующих быстрого доступа, таких как счетчики. Также следует отметить, что определение «регистра» не означает, что переменная будет храниться в регистре. Это означает, что он МОЖЕТ быть сохранен в регистре в зависимости от аппаратных и реализационных ограничений.
Статический класс хранения
В staticкласс хранилища инструктирует компилятор поддерживать локальную переменную в существовании в течение всего времени жизни программы вместо того, чтобы создавать и уничтожать ее каждый раз, когда она входит в область видимости и выходит за ее пределы. Следовательно, создание статических локальных переменных позволяет им сохранять свои значения между вызовами функций.
Модификатор static также может применяться к глобальным переменным. Когда это будет сделано, это приведет к тому, что область действия этой переменной будет ограничена файлом, в котором она объявлена.
В C ++, когда static используется для члена данных класса, это приводит к тому, что только одна копия этого члена используется всеми объектами его класса.
#include <iostream>
// Function declaration
void func(void);
static int count = 10; /* Global variable */
main() {
while(count--) {
func();
}
return 0;
}
// Function definition
void func( void ) {
static int i = 5; // local static variable
i++;
std::cout << "i is " << i ;
std::cout << " and count is " << count << std::endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
i is 6 and count is 9
i is 7 and count is 8
i is 8 and count is 7
i is 9 and count is 6
i is 10 and count is 5
i is 11 and count is 4
i is 12 and count is 3
i is 13 and count is 2
i is 14 and count is 1
i is 15 and count is 0Класс внешнего хранилища
В externкласс хранилища используется для указания ссылки на глобальную переменную, которая видна ВСЕМ программным файлам. Когда вы используете extern, переменная не может быть инициализирована, поскольку все, что она делает, это указывает имя переменной на место хранения, которое было ранее определено.
Когда у вас есть несколько файлов и вы определяете глобальную переменную или функцию, которая также будет использоваться в других файлах, тогда extern будет использоваться в другом файле для указания ссылки на определенную переменную или функцию. Просто для понимания extern используется для объявления глобальной переменной или функции в другом файле.
Модификатор extern чаще всего используется, когда два или более файла используют одни и те же глобальные переменные или функции, как описано ниже.
Первый файл: main.cpp
#include <iostream>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}Второй файл: support.cpp
#include <iostream>
extern int count;
void write_extern(void) {
std::cout << "Count is " << count << std::endl;
}Здесь ключевое слово extern используется для объявления счетчика в другом файле. Теперь скомпилируйте эти два файла следующим образом -
$g++ main.cpp support.cpp -o writeЭто произведет write исполняемая программа, попробуйте выполнить write и проверьте результат следующим образом -
$./write
5Изменяемый класс хранения
В mutableспецификатор применяется только к объектам класса, которые обсуждаются позже в этом руководстве. Он позволяет члену объекта переопределять константную функцию-член. Таким образом, изменяемый член может быть изменен константной функцией-членом.
Оператор - это символ, который сообщает компилятору о необходимости выполнения определенных математических или логических операций. C ++ богат встроенными операторами и предоставляет следующие типы операторов:
- Арифметические операторы
- Операторы отношения
- Логические операторы
- Побитовые операторы
- Операторы присваивания
- Разные операторы
В этой главе будут последовательно рассмотрены арифметические, реляционные, логические, побитовые, присваивающие и другие операторы.
Арифметические операторы
Язык С ++ поддерживает следующие арифметические операторы:
Предположим, что переменная A содержит 10, а переменная B содержит 20, тогда -
Показать примеры
| Оператор | Описание | пример |
|---|---|---|
| + | Добавляет два операнда | A + B даст 30 |
| - | Вычитает второй операнд из первого | A - B даст -10 |
| * | Умножает оба операнда | A * B даст 200 |
| / | Делит числитель на де-числитель | Б / А даст 2 |
| % | Оператор модуля и остаток после целочисленного деления | B% A даст 0 |
| ++ | Оператор увеличения, увеличивает целочисленное значение на единицу | A ++ даст 11 |
| - | Оператор декремента , уменьшает целое значение на единицу | A - даст 9 |
Операторы отношения
В языке C ++ поддерживаются следующие операторы отношения
Предположим, что переменная A содержит 10, а переменная B содержит 20, тогда -
Показать примеры
| Оператор | Описание | пример |
|---|---|---|
| == | Проверяет, равны ли значения двух операндов или нет, если да, то условие становится истинным. | (A == B) неверно. |
| знак равно | Проверяет, равны ли значения двух операндов или нет, если значения не равны, условие становится истинным. | (A! = B) верно. |
| > | Проверяет, больше ли значение левого операнда, чем значение правого операнда, если да, то условие становится истинным. | (A> B) неверно. |
| < | Проверяет, меньше ли значение левого операнда, чем значение правого операнда, если да, то условие становится истинным. | (A <B) верно. |
| > = | Проверяет, больше ли значение левого операнда или равно значению правого операнда, если да, то условие становится истинным. | (A> = B) неверно. |
| <= | Проверяет, меньше ли значение левого операнда или равно значению правого операнда, если да, то условие становится истинным. | (A <= B) верно. |
Логические операторы
В языке C ++ поддерживаются следующие логические операторы.
Предположим, что переменная A содержит 1, а переменная B содержит 0, тогда -
Показать примеры
| Оператор | Описание | пример |
|---|---|---|
| && | Вызывается логическим оператором И. Если оба операнда не равны нулю, тогда условие становится истинным. | (A && B) ложно. |
| || | Вызывается логическим оператором ИЛИ. Если какой-либо из двух операндов не равен нулю, условие становится истинным. | (A || B) верно. |
| ! | Вызывается оператором логического НЕ. Используется для изменения логического состояния операнда на обратное. Если условие истинно, то оператор логического НЕ сделает ложным. | ! (A && B) верно. |
Побитовые операторы
Побитовый оператор работает с битами и выполняет побитовую операцию. Таблицы истинности для &, | и ^ следующие:
| п | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Допустим, если A = 60; и B = 13; теперь в двоичном формате они будут такими -
А = 0011 1100
В = 0000 1101
-----------------
A&B = 0000 1100
А | В = 0011 1101
A ^ B = 0011 0001
~ А = 1100 0011
Побитовые операторы, поддерживаемые языком C ++, перечислены в следующей таблице. Предположим, что переменная A содержит 60, а переменная B содержит 13, тогда -
Показать примеры
| Оператор | Описание | пример |
|---|---|---|
| & | Двоичный оператор И копирует бит в результат, если он существует в обоих операндах. | (A и B) даст 12, что составляет 0000 1100 |
| | | Оператор двоичного ИЛИ копирует бит, если он существует в любом из операндов. | (A | B) даст 61, что составляет 0011 1101 |
| ^ | Двоичный оператор XOR копирует бит, если он установлен в одном операнде, но не в обоих. | (A ^ B) даст 49, что составляет 0011 0001 |
| ~ | Оператор дополнения двоичных единиц является унарным и имеет эффект «переворачивания» битов. | (~ A) даст -61, что составляет 1100 0011 в форме дополнения до 2 из-за двоичного числа со знаком. |
| << | Оператор двоичного сдвига влево. Значение левого операнда сдвигается влево на количество битов, указанное правым операндом. | << 2 даст 240, что составляет 1111 0000 |
| >> | Оператор двоичного сдвига вправо. Значение левого операнда перемещается вправо на количество битов, указанное правым операндом. | A >> 2 даст 15, что равно 0000 1111 |
Операторы присваивания
Язык С ++ поддерживает следующие операторы присваивания:
Показать примеры
| Оператор | Описание | пример |
|---|---|---|
| знак равно | Простой оператор присваивания, присваивает значения из правых операндов левому операнду. | C = A + B присвоит значение A + B в C |
| + = | Добавить оператор присваивания И, он добавляет правый операнд к левому операнду и присваивает результат левому операнду. | C + = A эквивалентно C = C + A |
| знак равно | Оператор вычитания И присваивания. Он вычитает правый операнд из левого операнда и присваивает результат левому операнду. | C - = A эквивалентно C = C - A |
| знак равно | Оператор умножения И присваивания, он умножает правый операнд на левый операнд и присваивает результат левому операнду. | C * = A эквивалентно C = C * A |
| знак равно | Оператор деления И присваивания. Он делит левый операнд на правый операнд и присваивает результат левому операнду. | C / = A эквивалентно C = C / A |
| знак равно | Оператор модуля И присваивания. Он принимает модуль с использованием двух операндов и присваивает результат левому операнду. | C% = A эквивалентно C = C% A |
| << = | Оператор сдвига влево И присваивания. | C << = 2 совпадает с C = C << 2 |
| >> = | Оператор сдвига вправо И присваивания. | C >> = 2 совпадает с C = C >> 2 |
| знак равно | Побитовый оператор присваивания И. | C & = 2 совпадает с C = C & 2 |
| ^ = | Побитовое исключающее ИЛИ и оператор присваивания. | C ^ = 2 совпадает с C = C ^ 2 |
| | = | Побитовое включающее ИЛИ и оператор присваивания. | C | = 2 совпадает с C = C | 2 |
Разные операторы
В следующей таблице перечислены некоторые другие операторы, поддерживаемые C ++.
| Старший Нет | Оператор и описание |
|---|---|
| 1 | sizeof Оператор sizeof возвращает размер переменной. Например, sizeof (a), где a - целое число, вернет 4. |
| 2 | Condition ? X : Y Условный оператор (?) . Если условие истинно, то возвращается значение X, иначе возвращается значение Y. |
| 3 | , Оператор запятая вызывает выполнение последовательности операций. Значение всего выражения запятой является значением последнего выражения списка, разделенного запятыми. |
| 4 | . (dot) and -> (arrow) Операторы-члены используются для ссылки на отдельные члены классов, структур и объединений. |
| 5 | Cast Операторы приведения преобразуют один тип данных в другой. Например, int (2.2000) вернет 2. |
| 6 | & Оператор указателя & возвращает адрес переменной. Например, & a; даст фактический адрес переменной. |
| 7 | * Оператор-указатель * - это указатель на переменную. Например * var; будет указатель на переменную var. |
Приоритет операторов в C ++
Приоритет оператора определяет группировку терминов в выражении. Это влияет на то, как оценивается выражение. Некоторые операторы имеют более высокий приоритет, чем другие; например, оператор умножения имеет более высокий приоритет, чем оператор сложения -
Например, x = 7 + 3 * 2; здесь x присваивается 13, а не 20, потому что оператор * имеет более высокий приоритет, чем +, поэтому он сначала умножается на 3 * 2, а затем складывается в 7.
Здесь операторы с наивысшим приоритетом отображаются вверху таблицы, а операторы с самым низким - внизу. Внутри выражения в первую очередь будут оцениваться операторы с более высоким приоритетом.
Показать примеры
| Категория | Оператор | Ассоциативность |
|---|---|---|
| Постфикс | () [] ->. ++ - - | Слева направо |
| Унарный | + -! ~ ++ - - (тип) * и размер | Справа налево |
| Мультипликативный | * /% | Слева направо |
| Добавка | + - | Слева направо |
| сдвиг | << >> | Слева направо |
| Реляционный | <<=>> = | Слева направо |
| Равенство | ==! = | Слева направо |
| Побитовое И | & | Слева направо |
| Побитовое исключающее ИЛИ | ^ | Слева направо |
| Побитовое ИЛИ | | | Слева направо |
| Логическое И | && | Слева направо |
| Логическое ИЛИ | || | Слева направо |
| Условный | ?: | Справа налево |
| Назначение | = + = - = * = / =% = >> = << = & = ^ = | = | Справа налево |
| Запятая | , | Слева направо |
Возможна ситуация, когда вам нужно выполнить блок кода несколько раз. Как правило, операторы выполняются последовательно: сначала выполняется первый оператор функции, затем второй и т. Д.
Языки программирования предоставляют различные структуры управления, которые позволяют использовать более сложные пути выполнения.
Оператор цикла позволяет нам выполнять оператор или группу операторов несколько раз, и ниже приводится общий от оператора цикла в большинстве языков программирования:
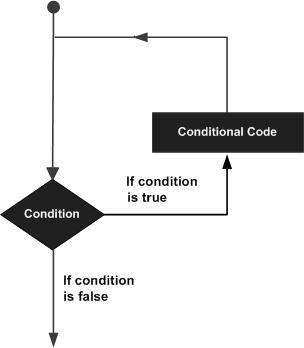
Язык программирования C ++ предоставляет следующие типы циклов для обработки требований цикла.
| Старший Нет | Тип и описание петли |
|---|---|
| 1 | пока цикл Повторяет утверждение или группу утверждений, пока выполняется заданное условие. Он проверяет условие перед выполнением тела цикла. |
| 2 | для цикла Выполнить последовательность операторов несколько раз и сократить код, управляющий переменной цикла. |
| 3 | делать ... пока цикл Подобен оператору while, за исключением того, что он проверяет условие в конце тела цикла. |
| 4 | вложенные циклы Вы можете использовать один или несколько циклов внутри любого другого цикла while, for или do.. while. |
Заявления контроля цикла
Операторы управления циклом изменяют выполнение обычной последовательности. Когда выполнение покидает область действия, все автоматические объекты, созданные в этой области, уничтожаются.
C ++ поддерживает следующие управляющие операторы.
| Старший Нет | Положение и описание управления |
|---|---|
| 1 | заявление о прерывании Прекращает loop или же switch оператор и передает выполнение оператору сразу после цикла или переключателя. |
| 2 | продолжить заявление Заставляет цикл пропускать оставшуюся часть своего тела и немедленно повторно проверять свое состояние перед повторением. |
| 3 | инструкция goto Передает управление помеченному оператору. Хотя не рекомендуется использовать оператор goto в вашей программе. |
Бесконечный цикл
Цикл становится бесконечным, если условие никогда не становится ложным. Вforloop традиционно используется для этой цели. Поскольку ни одно из трех выражений, образующих цикл for, не требуется, вы можете создать бесконечный цикл, оставив условное выражение пустым.
#include <iostream>
using namespace std;
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}Когда условное выражение отсутствует, оно считается истинным. У вас может быть выражение инициализации и приращения, но программисты на C ++ чаще используют конструкцию for (;;) для обозначения бесконечного цикла.
NOTE - Вы можете прервать бесконечный цикл, нажав клавиши Ctrl + C.
Структуры принятия решений требуют, чтобы программист указал одно или несколько условий, которые должны быть оценены или проверены программой, вместе с оператором или операторами, которые должны быть выполнены, если условие определено как истинное, и, необязательно, другие операторы, которые должны выполняться, если условие определяется как ложь.
Ниже приводится общая форма типичной структуры принятия решений, встречающейся в большинстве языков программирования.
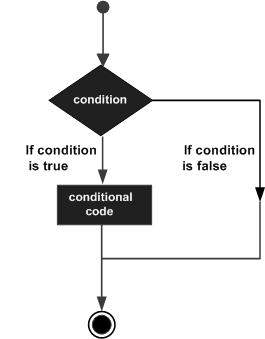
Язык программирования C ++ предоставляет следующие типы операторов принятия решений.
| Старший Нет | Заявление и описание |
|---|---|
| 1 | если заявление Оператор if состоит из логического выражения, за которым следует одно или несколько операторов. |
| 2 | если ... еще заявление За оператором if может следовать необязательный оператор else, который выполняется, когда логическое выражение ложно. |
| 3 | оператор переключения Оператор switch позволяет проверять переменную на равенство со списком значений. |
| 4 | вложенные операторы if Вы можете использовать один оператор if или else if внутри другого оператора if или else if. |
| 5 | вложенные операторы переключения Вы можете использовать один оператор switch внутри другого оператора switch. |
? : Оператор
Мы рассмотрели условный оператор «? : » В предыдущей главе, которую можно использовать для заменыif...elseзаявления. Он имеет следующий общий вид -
Exp1 ? Exp2 : Exp3;Exp1, Exp2 и Exp3 - это выражения. Обратите внимание на использование и размещение двоеточия.
Значение '?' выражение определяется следующим образом: вычисляется Exp1. Если это правда, то вычисляется Exp2 и становится значением всего '?' выражение. Если Exp1 ложно, то вычисляется Exp3, и его значение становится значением выражения.
Функция - это группа операторов, которые вместе выполняют задачу. Каждая программа на C ++ имеет хотя бы одну функцию, а именноmain(), и все самые тривиальные программы могут определять дополнительные функции.
Вы можете разделить свой код на отдельные функции. Как разделить код между различными функциями - решать вам, но логически разделение обычно таково, что каждая функция выполняет определенную задачу.
Функция declarationсообщает компилятору имя функции, тип возвращаемого значения и параметры. Функцияdefinition предоставляет фактическое тело функции.
Стандартная библиотека C ++ предоставляет множество встроенных функций, которые может вызывать ваша программа. Например, функцияstrcat() для объединения двух строк функция memcpy() для копирования одной ячейки памяти в другую и многих других функций.
Функция известна под разными именами, такими как метод, подпрограмма, процедура и т. Д.
Определение функции
Общая форма определения функции C ++ выглядит следующим образом:
return_type function_name( parameter list ) {
body of the function
}Определение функции C ++ состоит из заголовка функции и тела функции. Вот все части функции -
Return Type- Функция может возвращать значение. Вreturn_type- тип данных значения, возвращаемого функцией. Некоторые функции выполняют желаемые операции без возврата значения. В этом случае return_type - это ключевое словоvoid.
Function Name- Это настоящее имя функции. Имя функции и список параметров вместе составляют сигнатуру функции.
Parameters- Параметр похож на заполнитель. Когда функция вызывается, вы передаете значение параметру. Это значение называется фактическим параметром или аргументом. Список параметров относится к типу, порядку и количеству параметров функции. Параметры не обязательны; то есть функция может не содержать параметров.
Function Body - Тело функции содержит набор операторов, которые определяют, что функция делает.
пример
Ниже приведен исходный код функции с именем max(). Эта функция принимает два параметра num1 и num2 и возвращает самый большой из них -
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Объявления функций
Функция declarationсообщает компилятору об имени функции и о том, как ее вызвать. Фактическое тело функции можно определить отдельно.
Объявление функции состоит из следующих частей -
return_type function_name( parameter list );Для указанной выше функции max () следующее объявление функции:
int max(int num1, int num2);Имена параметров не важны в объявлении функции, требуется только их тип, поэтому следующее также является допустимым объявлением:
int max(int, int);Объявление функции требуется, когда вы определяете функцию в одном исходном файле и вызываете эту функцию в другом файле. В таком случае вы должны объявить функцию в верхней части файла, вызывающего функцию.
Вызов функции
При создании функции C ++ вы даете определение того, что функция должна делать. Чтобы использовать функцию, вам нужно будет вызвать или вызвать эту функцию.
Когда программа вызывает функцию, управление программой передается вызываемой функции. Вызываемая функция выполняет определенную задачу, и когда она выполняет оператор return или когда достигается закрывающая скобка, завершающая функцию, она возвращает управление программой обратно в основную программу.
Чтобы вызвать функцию, вам просто нужно передать необходимые параметры вместе с именем функции, и если функция возвращает значение, вы можете сохранить возвращаемое значение. Например -
#include <iostream>
using namespace std;
// function declaration
int max(int num1, int num2);
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int ret;
// calling a function to get max value.
ret = max(a, b);
cout << "Max value is : " << ret << endl;
return 0;
}
// function returning the max between two numbers
int max(int num1, int num2) {
// local variable declaration
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}Я сохранил функцию max () вместе с функцией main () и скомпилировал исходный код. При запуске финального исполняемого файла он даст следующий результат:
Max value is : 200Аргументы функции
Если функция должна использовать аргументы, она должна объявить переменные, которые принимают значения аргументов. Эти переменные называютсяformal parameters функции.
Формальные параметры ведут себя как другие локальные переменные внутри функции и создаются при входе в функцию и уничтожаются при выходе.
При вызове функции аргументы могут быть переданы в функцию двумя способами:
| Старший Нет | Тип звонка и описание |
|---|---|
| 1 | Звонок по значению Этот метод копирует фактическое значение аргумента в формальный параметр функции. В этом случае изменения, внесенные в параметр внутри функции, не влияют на аргумент. |
| 2 | Звонок по указателю Этот метод копирует адрес аргумента в формальный параметр. Внутри функции адрес используется для доступа к фактическому аргументу, используемому в вызове. Это означает, что изменения, внесенные в параметр, влияют на аргумент. |
| 3 | Звоните по ссылке Этот метод копирует ссылку на аргумент в формальный параметр. Внутри функции ссылка используется для доступа к фактическому аргументу, используемому в вызове. Это означает, что изменения, внесенные в параметр, влияют на аргумент. |
По умолчанию C ++ использует call by valueпередавать аргументы. В общем, это означает, что код внутри функции не может изменять аргументы, используемые для вызова функции, и вышеупомянутый пример при вызове функции max () использовал тот же метод.
Значения по умолчанию для параметров
Когда вы определяете функцию, вы можете указать значение по умолчанию для каждого из последних параметров. Это значение будет использоваться, если соответствующий аргумент останется пустым при вызове функции.
Это делается с помощью оператора присваивания и присвоения значений аргументам в определении функции. Если значение этого параметра не передается при вызове функции, используется значение по умолчанию, но если значение указано, это значение по умолчанию игнорируется и вместо него используется переданное значение. Рассмотрим следующий пример -
#include <iostream>
using namespace std;
int sum(int a, int b = 20) {
int result;
result = a + b;
return (result);
}
int main () {
// local variable declaration:
int a = 100;
int b = 200;
int result;
// calling a function to add the values.
result = sum(a, b);
cout << "Total value is :" << result << endl;
// calling a function again as follows.
result = sum(a);
cout << "Total value is :" << result << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total value is :300
Total value is :120Обычно, когда мы работаем с Numbers, мы используем примитивные типы данных, такие как int, short, long, float и double и т. Д. Числовые типы данных, их возможные значения и диапазоны номеров были объяснены при обсуждении типов данных C ++.
Определение чисел в C ++
Вы уже определили числа в различных примерах, приведенных в предыдущих главах. Вот еще один сводный пример для определения различных типов чисел в C ++ -
#include <iostream>
using namespace std;
int main () {
// number definition:
short s;
int i;
long l;
float f;
double d;
// number assignments;
s = 10;
i = 1000;
l = 1000000;
f = 230.47;
d = 30949.374;
// number printing;
cout << "short s :" << s << endl;
cout << "int i :" << i << endl;
cout << "long l :" << l << endl;
cout << "float f :" << f << endl;
cout << "double d :" << d << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
short s :10
int i :1000
long l :1000000
float f :230.47
double d :30949.4Математические операции в C ++
В дополнение к различным функциям, которые вы можете создавать, C ++ также включает некоторые полезные функции, которые вы можете использовать. Эти функции доступны в стандартных библиотеках C и C ++ и называютсяbuilt-inфункции. Это функции, которые можно включить в вашу программу, а затем использовать.
C ++ имеет богатый набор математических операций, которые можно выполнять с различными числами. В следующей таблице перечислены некоторые полезные встроенные математические функции, доступные в C ++.
Чтобы использовать эти функции, вам необходимо включить файл математического заголовка <cmath>.
| Старший Нет | Функция и цель |
|---|---|
| 1 | double cos(double); Эта функция принимает угол (как двойной) и возвращает косинус. |
| 2 | double sin(double); Эта функция принимает угол (как двойной) и возвращает синус. |
| 3 | double tan(double); Эта функция принимает угол (как двойной) и возвращает тангенс. |
| 4 | double log(double); Эта функция принимает число и возвращает натуральный логарифм этого числа. |
| 5 | double pow(double, double); Первое - это число, которое вы хотите поднять, а второе - это степень, которую вы хотите поднять. |
| 6 | double hypot(double, double); Если вы передадите этой функции длину двух сторон прямоугольного треугольника, она вернет вам длину гипотенузы. |
| 7 | double sqrt(double); Вы передаете этой функции число, и она дает вам квадратный корень. |
| 8 | int abs(int); Эта функция возвращает абсолютное значение переданного ей целого числа. |
| 9 | double fabs(double); Эта функция возвращает абсолютное значение любого переданного ей десятичного числа. |
| 10 | double floor(double); Находит целое число, которое меньше или равно переданному ему аргументу. |
Ниже приведен простой пример, показывающий несколько математических операций.
#include <iostream>
#include <cmath>
using namespace std;
int main () {
// number definition:
short s = 10;
int i = -1000;
long l = 100000;
float f = 230.47;
double d = 200.374;
// mathematical operations;
cout << "sin(d) :" << sin(d) << endl;
cout << "abs(i) :" << abs(i) << endl;
cout << "floor(d) :" << floor(d) << endl;
cout << "sqrt(f) :" << sqrt(f) << endl;
cout << "pow( d, 2) :" << pow(d, 2) << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
sign(d) :-0.634939
abs(i) :1000
floor(d) :200
sqrt(f) :15.1812
pow( d, 2 ) :40149.7Случайные числа в C ++
Есть много случаев, когда вы захотите сгенерировать случайное число. На самом деле вам нужно знать две функции о генерации случайных чисел. Первый - этоrand(), эта функция вернет только псевдослучайное число. Чтобы исправить это, сначала вызовитеsrand() функция.
Ниже приводится простой пример генерации нескольких случайных чисел. В этом примере используетсяtime() функция, чтобы получить количество секунд в вашем системном времени, для случайного заполнения функции rand () -
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
int main () {
int i,j;
// set the seed
srand( (unsigned)time( NULL ) );
/* generate 10 random numbers. */
for( i = 0; i < 10; i++ ) {
// generate actual random number
j = rand();
cout <<" Random Number : " << j << endl;
}
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Random Number : 1748144778
Random Number : 630873888
Random Number : 2134540646
Random Number : 219404170
Random Number : 902129458
Random Number : 920445370
Random Number : 1319072661
Random Number : 257938873
Random Number : 1256201101
Random Number : 580322989C ++ предоставляет структуру данных, the array, в котором хранится последовательная коллекция фиксированного размера элементов одного типа. Массив используется для хранения набора данных, но часто бывает более полезно думать о массиве как о коллекции переменных одного типа.
Вместо объявления отдельных переменных, таких как число0, число1, ... и число99, вы объявляете одну переменную массива, например числа, и используете числа [0], числа [1] и ..., числа [99] для представления отдельные переменные. Доступ к определенному элементу в массиве осуществляется по индексу.
Все массивы состоят из непрерывных ячеек памяти. Самый низкий адрес соответствует первому элементу, а самый высокий адрес - последнему элементу.
Объявление массивов
Чтобы объявить массив в C ++, программист указывает тип элементов и количество элементов, необходимых для массива, следующим образом:
type arrayName [ arraySize ];Это называется одномерным массивом. ВarraySize должен быть целочисленной константой больше нуля и typeможет быть любым допустимым типом данных C ++. Например, чтобы объявить массив из 10 элементов под названием balance типа double, используйте этот оператор:
double balance[10];Инициализация массивов
Вы можете инициализировать элементы массива С ++ либо один за другим, либо с помощью одного оператора следующим образом:
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};Количество значений в скобках {} не может быть больше количества элементов, объявленных нами для массива в квадратных скобках []. Ниже приведен пример назначения одного элемента массива:
Если вы не укажете размер массива, будет создан массив, достаточно большой, чтобы вместить инициализацию. Поэтому если написать -
double balance[] = {1000.0, 2.0, 3.4, 17.0, 50.0};Вы создадите точно такой же массив, как и в предыдущем примере.
balance[4] = 50.0;Выше оператор присваивает номер элемента 5 - й в массиве значение 50,0. Массив с 4- м индексом будет 5- м , т.е. последним элементом, потому что все массивы имеют 0 в качестве индекса своего первого элемента, который также называется базовым индексом. Ниже приведено графическое изображение того же массива, который мы обсуждали выше.

Доступ к элементам массива
Доступ к элементу осуществляется путем индексации имени массива. Это делается путем помещения индекса элемента в квадратные скобки после имени массива. Например -
double salary = balance[9];Приведенный выше оператор возьмет 10- й элемент из массива и присвоит значение переменной зарплаты. Ниже приведен пример, в котором будут использоваться все три вышеупомянутых концепции, а именно. объявление, присвоение и доступ к массивам -
#include <iostream>
using namespace std;
#include <iomanip>
using std::setw;
int main () {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
cout << "Element" << setw( 13 ) << "Value" << endl;
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
cout << setw( 7 )<< j << setw( 13 ) << n[ j ] << endl;
}
return 0;
}Эта программа использует setw()функция для форматирования вывода. Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Массивы в C ++
Массивы важны для C ++ и требуют более подробной информации. Существует несколько важных концепций, которые должны быть понятны программисту на C ++:
| Старший Нет | Концепция и описание |
|---|---|
| 1 | Многомерные массивы C ++ поддерживает многомерные массивы. Простейшей формой многомерного массива является двумерный массив. |
| 2 | Указатель на массив Вы можете сгенерировать указатель на первый элемент массива, просто указав имя массива без индекса. |
| 3 | Передача массивов в функции Вы можете передать функции указатель на массив, указав имя массива без индекса. |
| 4 | Возврат массива из функций C ++ позволяет функции возвращать массив. |
C ++ предоставляет следующие два типа строковых представлений:
- Строка символов в стиле C.
- Тип строкового класса, представленный в Стандартном C ++.
Строка символов в стиле C
Строка символов в стиле C возникла в языке C и продолжает поддерживаться в C ++. Эта строка на самом деле представляет собой одномерный массив символов, который заканчиваетсяnullсимвол '\ 0'. Таким образом, строка с завершающим нулем содержит символы, которые составляют строку, за которой следуетnull.
Следующее объявление и инициализация создают строку, состоящую из слова «Hello». Чтобы сохранить нулевой символ в конце массива, размер массива символов, содержащего строку, на единицу больше, чем количество символов в слове «Hello».
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};Если вы следуете правилу инициализации массива, вы можете написать приведенный выше оператор следующим образом:
char greeting[] = "Hello";Ниже приведено представление памяти указанной выше строки в C / C ++ -

На самом деле вы не помещаете нулевой символ в конец строковой константы. Компилятор C ++ автоматически помещает '\ 0' в конец строки при инициализации массива. Попробуем вывести указанную выше строку -
#include <iostream>
using namespace std;
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
cout << "Greeting message: ";
cout << greeting << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Greeting message: HelloC ++ поддерживает широкий спектр функций, которые управляют строками с завершающим нулем -
| Старший Нет | Функция и цель |
|---|---|
| 1 | strcpy(s1, s2); Копирует строку s2 в строку s1. |
| 2 | strcat(s1, s2); Объединяет строку s2 в конец строки s1. |
| 3 | strlen(s1); Возвращает длину строки s1. |
| 4 | strcmp(s1, s2); Возвращает 0, если s1 и s2 совпадают; меньше 0, если s1 <s2; больше 0, если s1> s2. |
| 5 | strchr(s1, ch); Возвращает указатель на первое вхождение символа ch в строке s1. |
| 6 | strstr(s1, s2); Возвращает указатель на первое вхождение строки s2 в строку s1. |
В следующем примере используются некоторые из вышеупомянутых функций -
#include <iostream>
#include <cstring>
using namespace std;
int main () {
char str1[10] = "Hello";
char str2[10] = "World";
char str3[10];
int len ;
// copy str1 into str3
strcpy( str3, str1);
cout << "strcpy( str3, str1) : " << str3 << endl;
// concatenates str1 and str2
strcat( str1, str2);
cout << "strcat( str1, str2): " << str1 << endl;
// total lenghth of str1 after concatenation
len = strlen(str1);
cout << "strlen(str1) : " << len << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
strcpy( str3, str1) : Hello
strcat( str1, str2): HelloWorld
strlen(str1) : 10Класс String в C ++
Стандартная библиотека C ++ предоставляет stringТип класса, который поддерживает все операции, упомянутые выше, дополнительно гораздо больше функциональности. Давайте проверим следующий пример -
#include <iostream>
#include <string>
using namespace std;
int main () {
string str1 = "Hello";
string str2 = "World";
string str3;
int len ;
// copy str1 into str3
str3 = str1;
cout << "str3 : " << str3 << endl;
// concatenates str1 and str2
str3 = str1 + str2;
cout << "str1 + str2 : " << str3 << endl;
// total length of str3 after concatenation
len = str3.size();
cout << "str3.size() : " << len << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
str3 : Hello
str1 + str2 : HelloWorld
str3.size() : 10Указатели C ++ легко и весело изучать. Некоторые задачи C ++ легче выполнять с помощью указателей, а другие задачи C ++, такие как распределение динамической памяти, не могут выполняться без них.
Как вы знаете, каждая переменная является ячейкой памяти, и каждая ячейка памяти имеет свой адрес, доступ к которому можно получить с помощью оператора амперсанда (&), который обозначает адрес в памяти. Рассмотрим следующее, которое напечатает адрес определенных переменных:
#include <iostream>
using namespace std;
int main () {
int var1;
char var2[10];
cout << "Address of var1 variable: ";
cout << &var1 << endl;
cout << "Address of var2 variable: ";
cout << &var2 << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Address of var1 variable: 0xbfebd5c0
Address of var2 variable: 0xbfebd5b6Что такое указатели?
А pointer- переменная, значение которой является адресом другой переменной. Как и любую переменную или константу, вы должны объявить указатель, прежде чем вы сможете с ним работать. Общая форма объявления переменной-указателя -
type *var-name;Вот, type- базовый тип указателя; это должен быть допустимый тип C ++ иvar-nameэто имя переменной-указателя. Звездочка, которую вы использовали для объявления указателя, - это та же звездочка, которую вы используете для умножения. Однако в этом заявлении звездочка используется для обозначения переменной как указателя. Ниже приведено действительное объявление указателя -
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterФактический тип данных значения всех указателей, будь то целое число, число с плавающей запятой, символьный или иначе, является одинаковым, длинным шестнадцатеричным числом, представляющим адрес памяти. Единственное различие между указателями разных типов данных - это тип данных переменной или константы, на которые указывает указатель.
Использование указателей в C ++
Есть несколько важных операций, которые мы будем делать с указателями очень часто. (a) Мы определяем переменную-указатель. (b) Назначьте адрес переменной указателю. (c)Наконец, получите доступ к значению по адресу, доступному в переменной-указателе. Это делается с помощью унарного оператора *, который возвращает значение переменной, расположенной по адресу, указанному ее операндом. В следующем примере используются эти операции -
#include <iostream>
using namespace std;
int main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
cout << "Value of var variable: ";
cout << var << endl;
// print the address stored in ip pointer variable
cout << "Address stored in ip variable: ";
cout << ip << endl;
// access the value at the address available in pointer
cout << "Value of *ip variable: ";
cout << *ip << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Value of var variable: 20
Address stored in ip variable: 0xbfc601ac
Value of *ip variable: 20Указатели в C ++
У указателей много, но простых концепций, и они очень важны для программирования на C ++. Существует несколько важных концепций указателей, которые должны быть понятны программисту на C ++:
| Старший Нет | Концепция и описание |
|---|---|
| 1 | Нулевые указатели C ++ поддерживает нулевой указатель, который представляет собой константу со значением нуля, определенную в нескольких стандартных библиотеках. |
| 2 | Указатель арифметики Есть четыре арифметических оператора, которые можно использовать с указателями: ++, -, +, - |
| 3 | Указатели против массивов Между указателями и массивами существует тесная связь. |
| 4 | Массив указателей Вы можете определить массивы для хранения нескольких указателей. |
| 5 | Указатель на указатель C ++ позволяет вам иметь указатель на указатель и так далее. |
| 6 | Передача указателей на функции Передача аргумента по ссылке или по адресу позволяет изменять переданный аргумент в вызывающей функции вызываемой функцией. |
| 7 | Указатель возврата из функций C ++ позволяет функции возвращать указатель на локальную переменную, статическую переменную и динамически выделяемую память. |
Ссылочная переменная - это псевдоним, то есть другое имя уже существующей переменной. После инициализации ссылки с помощью переменной для ссылки на переменную может использоваться имя переменной или имя ссылки.
Ссылки против указателей
Ссылки часто путают с указателями, но между ссылками и указателями есть три основных различия:
У вас не может быть ссылок NULL. Вы всегда должны иметь возможность предположить, что ссылка связана с законным хранилищем.
После инициализации ссылки на объект ее нельзя изменить для ссылки на другой объект. Указатели можно указывать на другой объект в любое время.
Ссылка должна быть инициализирована при ее создании. Указатели можно инициализировать в любое время.
Создание ссылок в C ++
Думайте об имени переменной как о метке, прикрепленной к местоположению переменной в памяти. Затем вы можете рассматривать ссылку как вторую метку, прикрепленную к этой ячейке памяти. Следовательно, вы можете получить доступ к содержимому переменной либо по исходному имени переменной, либо по ссылке. Например, предположим, что у нас есть следующий пример -
int i = 17;Мы можем объявить ссылочные переменные для i следующим образом.
int& r = i;Прочтите & в этих объявлениях как reference. Таким образом, прочтите первое объявление как «r - это целочисленная ссылка, инициализированная значением i», а второе - как «s - двойная ссылка, инициализированная значением d.». В следующем примере используются ссылки на int и double -
#include <iostream>
using namespace std;
int main () {
// declare simple variables
int i;
double d;
// declare reference variables
int& r = i;
double& s = d;
i = 5;
cout << "Value of i : " << i << endl;
cout << "Value of i reference : " << r << endl;
d = 11.7;
cout << "Value of d : " << d << endl;
cout << "Value of d reference : " << s << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Value of i : 5
Value of i reference : 5
Value of d : 11.7
Value of d reference : 11.7Ссылки обычно используются для списков аргументов функций и возвращаемых значений функций. Итак, ниже приведены две важные темы, связанные со ссылками на C ++, которые должны быть понятны программисту на C ++:
| Старший Нет | Концепция и описание |
|---|---|
| 1 | Ссылки как параметры C ++ более безопасно поддерживает передачу ссылок в качестве параметра функции, чем параметры. |
| 2 | Ссылка как возвращаемое значение Вы можете вернуть ссылку из функции C ++, как и любой другой тип данных. |
Стандартная библиотека C ++ не предоставляет правильный тип даты. C ++ наследует структуры и функции для управления датой и временем от C. Чтобы получить доступ к функциям и структурам, связанным с датой и временем, вам необходимо включить файл заголовка <ctime> в вашу программу на C ++.
Есть четыре типа, связанных со временем: clock_t, time_t, size_t, и tm. Типы - clock_t, size_t и time_t могут представлять системное время и дату как своего рода целое число.
Тип структуры tm содержит дату и время в виде структуры C, имеющей следующие элементы:
struct tm {
int tm_sec; // seconds of minutes from 0 to 61
int tm_min; // minutes of hour from 0 to 59
int tm_hour; // hours of day from 0 to 24
int tm_mday; // day of month from 1 to 31
int tm_mon; // month of year from 0 to 11
int tm_year; // year since 1900
int tm_wday; // days since sunday
int tm_yday; // days since January 1st
int tm_isdst; // hours of daylight savings time
}Ниже приведены важные функции, которые мы используем при работе с датой и временем в C или C ++. Все эти функции являются частью стандартной библиотеки C и C ++, и вы можете проверить их детали, используя ссылку на стандартную библиотеку C ++, приведенную ниже.
| Старший Нет | Функция и цель |
|---|---|
| 1 | time_t time(time_t *time); Это возвращает текущее календарное время системы в секундах, прошедшее с 1 января 1970 года. Если в системе нет времени, возвращается .1. |
| 2 | char *ctime(const time_t *time); Это возвращает указатель на строку вида день месяц год часы: минуты: секунды год \ n \ 0 . |
| 3 | struct tm *localtime(const time_t *time); Это возвращает указатель на tm структура, представляющая местное время. |
| 4 | clock_t clock(void); Это возвращает значение, которое приблизительно соответствует количеству времени, в течение которого выполнялась вызывающая программа. Если время недоступно, возвращается .1. |
| 5 | char * asctime ( const struct tm * time ); Это возвращает указатель на строку, содержащую информацию, хранящуюся в структуре, на которую указывает время, преобразованное в форму: день месяц дата часы: минуты: секунды год \ n \ 0 |
| 6 | struct tm *gmtime(const time_t *time); Это возвращает указатель на время в виде структуры tm. Время представлено в формате всемирного координированного времени (UTC), которое по сути является средним временем по Гринвичу (GMT). |
| 7 | time_t mktime(struct tm *time); Это возвращает календарный эквивалент времени, найденного в структуре, на которую указывает time. |
| 8 | double difftime ( time_t time2, time_t time1 ); Эта функция вычисляет разницу в секундах между time1 и time2. |
| 9 | size_t strftime(); Эта функция может использоваться для форматирования даты и времени в определенном формате. |
Текущая дата и время
Предположим, вы хотите получить текущую системную дату и время либо как местное время, либо как всемирное координированное время (UTC). Ниже приведен пример достижения того же -
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
// convert now to string form
char* dt = ctime(&now);
cout << "The local date and time is: " << dt << endl;
// convert now to tm struct for UTC
tm *gmtm = gmtime(&now);
dt = asctime(gmtm);
cout << "The UTC date and time is:"<< dt << endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
The local date and time is: Sat Jan 8 20:07:41 2011
The UTC date and time is:Sun Jan 9 03:07:41 2011Форматирование времени с помощью struct tm
В tmструктура очень важна при работе с датой и временем в C или C ++. Эта структура содержит дату и время в виде структуры C, как упоминалось выше. Большинство функций, связанных со временем, используют структуру tm. Ниже приведен пример, в котором используются различные функции, связанные с датой и временем, и структура tm.
Используя структуру в этой главе, я предполагаю, что у вас есть базовые представления о структуре C и о том, как получить доступ к элементам структуры с помощью оператора стрелка ->.
#include <iostream>
#include <ctime>
using namespace std;
int main() {
// current date/time based on current system
time_t now = time(0);
cout << "Number of sec since January 1,1970 is:: " << now << endl;
tm *ltm = localtime(&now);
// print various components of tm structure.
cout << "Year:" << 1900 + ltm->tm_year<<endl;
cout << "Month: "<< 1 + ltm->tm_mon<< endl;
cout << "Day: "<< ltm->tm_mday << endl;
cout << "Time: "<< 5+ltm->tm_hour << ":";
cout << 30+ltm->tm_min << ":";
cout << ltm->tm_sec << endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Number of sec since January 1,1970 is:: 1588485717
Year:2020
Month: 5
Day: 3
Time: 11:31:57Стандартные библиотеки C ++ предоставляют обширный набор возможностей ввода / вывода, который мы увидим в следующих главах. В этой главе будут обсуждаться самые основные и наиболее распространенные операции ввода-вывода, необходимые для программирования на C ++.
Ввод-вывод C ++ происходит в потоках, которые представляют собой последовательности байтов. Если байты поступают от устройства, такого как клавиатура, дисковый накопитель, сетевое соединение и т. Д., В основную память, это называетсяinput operation и если байты перетекают из основной памяти в устройство, такое как экран дисплея, принтер, дисковод, сетевое соединение и т. д., это называется output operation.
Заголовочные файлы библиотеки ввода-вывода
Для программ на C ++ важны следующие файлы заголовков:
| Старший Нет | Заголовочный файл, функция и описание |
|---|---|
| 1 | <iostream> Этот файл определяет cin, cout, cerr и clog объекты, которые соответствуют стандартному входному потоку, стандартному выходному потоку, небуферизованному стандартному потоку ошибок и буферизованному стандартному потоку ошибок, соответственно. |
| 2 | <iomanip> В этом файле объявляются службы, полезные для выполнения форматированного ввода-вывода с помощью так называемых параметризованных манипуляторов потока, таких как setw и setprecision. |
| 3 | <fstream> Этот файл объявляет службы для управляемой пользователем обработки файлов. Мы обсудим это подробно в главе, посвященной файлам и потокам. |
Стандартный выходной поток (cout)
Предопределенный объект cout это пример ostreamкласс. Говорят, что объект cout «подключен» к стандартному устройству вывода, которым обычно является экран дисплея. Вcout используется вместе с оператором вставки потока, который записывается как <<, что на два знака меньше чем, как показано в следующем примере.
#include <iostream>
using namespace std;
int main() {
char str[] = "Hello C++";
cout << "Value of str is : " << str << endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Value of str is : Hello C++Компилятор C ++ также определяет тип данных переменной для вывода и выбирает соответствующий оператор вставки потока для отображения значения. Оператор << перегружен для вывода элементов данных встроенных типов integer, float, double, strings и указателей.
Оператор вставки << может использоваться более одного раза в одном операторе, как показано выше и endl используется для добавления новой строки в конец строки.
Стандартный входной поток (cin)
Предопределенный объект cin это пример istreamкласс. Считается, что объект cin прикреплен к стандартному устройству ввода, которым обычно является клавиатура. Вcin используется вместе с оператором извлечения потока, который записывается как >>, что на два знака больше чем, как показано в следующем примере.
#include <iostream>
using namespace std;
int main() {
char name[50];
cout << "Please enter your name: ";
cin >> name;
cout << "Your name is: " << name << endl;
}Когда приведенный выше код скомпилирован и запущен, вам будет предложено ввести имя. Вы вводите значение, а затем нажимаете ввод, чтобы увидеть следующий результат -
Please enter your name: cplusplus
Your name is: cplusplusКомпилятор C ++ также определяет тип данных введенного значения и выбирает соответствующий оператор извлечения потока для извлечения значения и сохранения его в заданных переменных.
Оператор извлечения потока >> может использоваться более одного раза в одном операторе. Чтобы запросить более одного элемента данных, вы можете использовать следующее:
cin >> name >> age;Это будет эквивалентно следующим двум утверждениям -
cin >> name;
cin >> age;Стандартный поток ошибок (cerr)
Предопределенный объект cerr это пример ostreamкласс. Говорят, что объект cerr прикреплен к стандартному устройству ошибок, которое также является экраном дисплея, но объектcerr не буферизуется, и каждая вставка потока в cerr вызывает немедленное появление его вывода.
В cerr также используется вместе с оператором вставки потока, как показано в следующем примере.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
cerr << "Error message : " << str << endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Error message : Unable to read....Стандартный поток журнала (засорение)
Предопределенный объект clog это пример ostreamкласс. Считается, что объект засорения прикреплен к стандартному устройству ошибок, которое также является экраном дисплея, но объектclogбуферизируется. Это означает, что каждая вставка для засорения может привести к тому, что его вывод будет удерживаться в буфере, пока буфер не будет заполнен или пока буфер не будет очищен.
В clog также используется вместе с оператором вставки потока, как показано в следующем примере.
#include <iostream>
using namespace std;
int main() {
char str[] = "Unable to read....";
clog << "Error message : " << str << endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Error message : Unable to read....Вы не сможете увидеть никакой разницы в cout, cerr и clog с этими небольшими примерами, но при написании и выполнении больших программ разница становится очевидной. Поэтому рекомендуется отображать сообщения об ошибках с помощью потока cerr, а при отображении других сообщений журнала следует использовать clog.
Массивы C / C ++ позволяют определять переменные, которые объединяют несколько элементов данных одного типа, но structure - это еще один определяемый пользователем тип данных, который позволяет комбинировать элементы данных разных типов.
Структуры используются для представления записи, предположим, вы хотите отслеживать свои книги в библиотеке. Возможно, вы захотите отслеживать следующие атрибуты каждой книги -
- Title
- Author
- Subject
- Идентификатор книги
Определение структуры
Чтобы определить структуру, вы должны использовать оператор struct. Оператор struct определяет новый тип данных с более чем одним членом для вашей программы. Формат оператора структуры следующий -
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];В structure tagявляется необязательным, и каждое определение члена является обычным определением переменной, например int i; или float f; или любое другое допустимое определение переменной. В конце определения структуры, перед последней точкой с запятой, вы можете указать одну или несколько структурных переменных, но это необязательно. Вот как бы вы объявили структуру книги -
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;Доступ к членам структуры
Для доступа к любому члену структуры мы используем member access operator (.). Оператор доступа к члену кодируется как точка между именем переменной структуры и элементом структуры, к которому мы хотим получить доступ. Вы бы использовалиstructключевое слово для определения переменных структурного типа. Ниже приведен пример, объясняющий использование структуры -
#include <iostream>
#include <cstring>
using namespace std;
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
cout << "Book 1 title : " << Book1.title <<endl;
cout << "Book 1 author : " << Book1.author <<endl;
cout << "Book 1 subject : " << Book1.subject <<endl;
cout << "Book 1 id : " << Book1.book_id <<endl;
// Print Book2 info
cout << "Book 2 title : " << Book2.title <<endl;
cout << "Book 2 author : " << Book2.author <<endl;
cout << "Book 2 subject : " << Book2.subject <<endl;
cout << "Book 2 id : " << Book2.book_id <<endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Book 1 title : Learn C++ Programming
Book 1 author : Chand Miyan
Book 1 subject : C++ Programming
Book 1 id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Yakit Singha
Book 2 subject : Telecom
Book 2 id : 6495700Структуры как аргументы функций
Вы можете передать структуру в качестве аргумента функции так же, как и любую другую переменную или указатель. Вы можете получить доступ к структурным переменным так же, как в приведенном выше примере:
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info
printBook( Book1 );
// Print Book2 info
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
cout << "Book title : " << book.title <<endl;
cout << "Book author : " << book.author <<endl;
cout << "Book subject : " << book.subject <<endl;
cout << "Book id : " << book.book_id <<endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700Указатели на структуры
Вы можете определять указатели на структуры очень похоже, как вы определяете указатели на любую другую переменную, следующим образом:
struct Books *struct_pointer;Теперь вы можете сохранить адрес структурной переменной в указанной выше переменной-указателе. Чтобы найти адрес структурной переменной, поместите оператор & перед именем структуры следующим образом:
struct_pointer = &Book1;Чтобы получить доступ к членам структуры с помощью указателя на эту структуру, вы должны использовать оператор -> следующим образом:
struct_pointer->title;Давайте перепишем приведенный выше пример, используя указатель на структуру, надеюсь, вам будет легко понять концепцию -
#include <iostream>
#include <cstring>
using namespace std;
void printBook( struct Books *book );
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main() {
struct Books Book1; // Declare Book1 of type Book
struct Books Book2; // Declare Book2 of type Book
// Book 1 specification
strcpy( Book1.title, "Learn C++ Programming");
strcpy( Book1.author, "Chand Miyan");
strcpy( Book1.subject, "C++ Programming");
Book1.book_id = 6495407;
// Book 2 specification
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Yakit Singha");
strcpy( Book2.subject, "Telecom");
Book2.book_id = 6495700;
// Print Book1 info, passing address of structure
printBook( &Book1 );
// Print Book1 info, passing address of structure
printBook( &Book2 );
return 0;
}
// This function accept pointer to structure as parameter.
void printBook( struct Books *book ) {
cout << "Book title : " << book->title <<endl;
cout << "Book author : " << book->author <<endl;
cout << "Book subject : " << book->subject <<endl;
cout << "Book id : " << book->book_id <<endl;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Book title : Learn C++ Programming
Book author : Chand Miyan
Book subject : C++ Programming
Book id : 6495407
Book title : Telecom Billing
Book author : Yakit Singha
Book subject : Telecom
Book id : 6495700Ключевое слово typedef
Существует более простой способ определения структур или создание «псевдонимов» типов. Например -
typedef struct {
char title[50];
char author[50];
char subject[100];
int book_id;
} Books;Теперь вы можете использовать Книги напрямую для определения переменных типа Книги без использования ключевого слова struct. Ниже приведен пример -
Books Book1, Book2;Вы можете использовать typedef ключевое слово для неструктур, а также следующее -
typedef long int *pint32;
pint32 x, y, z;x, y и z - все указатели на длинные целые числа.
Основная цель программирования на C ++ - добавить объектно-ориентированный подход к языку программирования C, а классы являются центральной особенностью C ++, которая поддерживает объектно-ориентированное программирование и часто называется определяемыми пользователем типами.
Класс используется для определения формы объекта и объединяет представление данных и методы для управления этими данными в один аккуратный пакет. Данные и функции внутри класса называются членами класса.
Определения классов C ++
Когда вы определяете класс, вы определяете схему для типа данных. Это фактически не определяет какие-либо данные, но определяет, что означает имя класса, то есть из чего будет состоять объект класса и какие операции могут быть выполнены с таким объектом.
Определение класса начинается с ключевого слова classза которым следует имя класса; и тело класса, заключенное в фигурные скобки. После определения класса должна стоять точка с запятой или список объявлений. Например, мы определили тип данных Box с помощью ключевого словаclass следующим образом -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Ключевое слово publicопределяет атрибуты доступа членов следующего за ним класса. Доступ к общедоступному члену можно получить извне класса в любом месте в пределах объекта класса. Вы также можете указать членов класса какprivate или же protected которые мы обсудим в подразделе.
Определить объекты C ++
Класс предоставляет чертежи для объектов, поэтому в основном объект создается из класса. Мы объявляем объекты класса с таким же типом объявления, как мы объявляем переменные базовых типов. Следующие утверждения объявляют два объекта класса Box -
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxОба объекта Box1 и Box2 будут иметь свою собственную копию членов данных.
Доступ к элементам данных
Доступ к открытым элементам данных объектов класса можно получить с помощью оператора прямого доступа к членам (.). Давайте попробуем следующий пример, чтобы прояснить ситуацию -
#include <iostream>
using namespace std;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Volume of Box1 : 210
Volume of Box2 : 1560Важно отметить, что к закрытым и защищенным членам нельзя получить доступ напрямую с помощью оператора прямого доступа к члену (.). Мы узнаем, как можно получить доступ к закрытым и защищенным членам.
Классы и объекты в деталях
Пока что у вас есть очень общее представление о классах и объектах C ++. Есть и другие интересные концепции, связанные с классами и объектами C ++, которые мы обсудим в различных подразделах, перечисленных ниже:
| Старший Нет | Концепция и описание |
|---|---|
| 1 | Функции-члены класса Функция-член класса - это функция, которая имеет свое определение или свой прототип в определении класса, как и любая другая переменная. |
| 2 | Модификаторы доступа к классам Член класса может быть публичным, частным или защищенным. По умолчанию участники считаются частными. |
| 3 | Конструктор и деструктор Конструктор класса - это специальная функция в классе, которая вызывается при создании нового объекта класса. Деструктор - это также специальная функция, которая вызывается при удалении созданного объекта. |
| 4 | Копировать конструктор Конструктор копирования - это конструктор, который создает объект, инициализируя его объектом того же класса, который был создан ранее. |
| 5 | Функции друзей А friend функции разрешен полный доступ к закрытым и защищенным членам класса. |
| 6 | Встроенные функции С помощью встроенной функции компилятор пытается развернуть код в теле функции вместо вызова функции. |
| 7 | этот указатель У каждого объекта есть специальный указатель this который указывает на сам объект. |
| 8 | Указатель на классы C ++ Указатель на класс выполняется точно так же, как указатель на структуру. Фактически класс - это просто структура с функциями в ней. |
| 9 | Статические члены класса И члены данных, и члены функций класса могут быть объявлены как статические. |
Одна из наиболее важных концепций объектно-ориентированного программирования - это наследование. Наследование позволяет нам определять класс в терминах другого класса, что упрощает создание и поддержку приложения. Это также дает возможность повторно использовать функциональность кода и быстрое время реализации.
При создании класса вместо написания полностью новых элементов данных и функций-членов программист может указать, что новый класс должен наследовать члены существующего класса. Этот существующий класс называетсяbase класс, а новый класс называется derived класс.
Идея наследования реализует is aотношения. Например, млекопитающее - это животное, собака - это млекопитающее, следовательно, собака - это тоже животное, и так далее.
Базовые и производные классы
Класс может быть производным от нескольких классов, что означает, что он может наследовать данные и функции от нескольких базовых классов. Чтобы определить производный класс, мы используем список производных классов, чтобы указать базовый класс (классы). Список производных классов называет один или несколько базовых классов и имеет форму -
class derived-class: access-specifier base-classГде спецификатор доступа является одним из public, protected, или же private, а базовый класс - это имя ранее определенного класса. Если спецификатор доступа не используется, по умолчанию он является частным.
Рассмотрим базовый класс Shape и его производный класс Rectangle следующим образом -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total area: 35Контроль доступа и наследование
Производный класс может получить доступ ко всем не закрытым членам своего базового класса. Таким образом, члены базового класса, которые не должны быть доступны для функций-членов производных классов, должны быть объявлены частными в базовом классе.
Мы можем суммировать различные типы доступа в зависимости от того, кто может получить к ним доступ следующим образом:
| Доступ | общественный | защищенный | частный |
|---|---|---|---|
| Тот же класс | да | да | да |
| Производные классы | да | да | нет |
| Вне занятий | да | нет | нет |
Производный класс наследует все методы базового класса со следующими исключениями:
- Конструкторы, деструкторы и конструкторы копирования базового класса.
- Перегруженные операторы базового класса.
- Дружественные функции базового класса.
Тип наследования
При наследовании класса от базового класса базовый класс может быть унаследован через public, protected или же privateнаследство. Тип наследования определяется спецификатором доступа, как описано выше.
Мы почти не используем protected или же private наследство, но publicобычно используется наследование. При использовании другого типа наследования применяются следующие правила:
Public Inheritance - При выводе класса из public базовый класс, public члены базового класса становятся public члены производного класса и protected члены базового класса становятся protectedчлены производного класса. Базовый классprivate члены никогда не доступны напрямую из производного класса, но могут быть доступны через вызовы public и protected члены базового класса.
Protected Inheritance - При выводе из protected базовый класс, public и protected члены базового класса становятся protected члены производного класса.
Private Inheritance - При выводе из private базовый класс, public и protected члены базового класса становятся private члены производного класса.
Множественное наследование
Класс C ++ может наследовать члены более чем одного класса, и вот расширенный синтаксис:
class derived-class: access baseA, access baseB....Где доступ является одним из public, protected, или же privateи будет дан для каждого базового класса, и они будут разделены запятой, как показано выше. Давайте попробуем следующий пример -
#include <iostream>
using namespace std;
// Base class Shape
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost {
public:
int getCost(int area) {
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost {
public:
int getArea() {
return (width * height);
}
};
int main(void) {
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total area: 35
Total paint cost: $2450C ++ позволяет указать более одного определения для function имя или operator в той же области, которая называется function overloading и operator overloading соответственно.
Перегруженное объявление - это объявление, которое объявлено с тем же именем, что и ранее объявленное объявление в той же области, за исключением того, что оба объявления имеют разные аргументы и, очевидно, разные определения (реализации).
Когда вы вызываете перегруженный function или же operator, компилятор определяет наиболее подходящее определение для использования, сравнивая типы аргументов, которые вы использовали для вызова функции или оператора, с типами параметров, указанными в определениях. Процесс выбора наиболее подходящей перегруженной функции или оператора называетсяoverload resolution.
Перегрузка функций в C ++
У вас может быть несколько определений для одного и того же имени функции в одной и той же области. Определение функции должно отличаться друг от друга типами и / или количеством аргументов в списке аргументов. Вы не можете перегрузить объявления функций, которые различаются только типом возвращаемого значения.
Ниже приведен пример той же функции print() используется для печати разных типов данных -
#include <iostream>
using namespace std;
class printData {
public:
void print(int i) {
cout << "Printing int: " << i << endl;
}
void print(double f) {
cout << "Printing float: " << f << endl;
}
void print(char* c) {
cout << "Printing character: " << c << endl;
}
};
int main(void) {
printData pd;
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello C++");
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Printing int: 5
Printing float: 500.263
Printing character: Hello C++Перегрузка операторов в C ++
Вы можете переопределить или перегрузить большинство встроенных операторов, доступных в C ++. Таким образом, программист может использовать операторы и с пользовательскими типами.
Перегруженные операторы - это функции со специальными именами: ключевое слово «оператор», за которым следует символ определяемого оператора. Как и любая другая функция, перегруженный оператор имеет возвращаемый тип и список параметров.
Box operator+(const Box&);объявляет оператор сложения, который можно использовать для addдва объекта Box и возвращает окончательный объект Box. Большинство перегруженных операторов можно определить как обычные функции, не являющиеся членами, или как функции-члены класса. В случае, если мы определяем вышеуказанную функцию как функцию, не являющуюся членом класса, нам нужно будет передать два аргумента для каждого операнда следующим образом:
Box operator+(const Box&, const Box&);Ниже приведен пример, показывающий концепцию перегрузки оператора с использованием функции-члена. Здесь в качестве аргумента передается объект, свойства которого будут доступны с помощью этого объекта, объект, который вызовет этот оператор, может быть доступен с помощьюthis оператор, как описано ниже -
#include <iostream>
using namespace std;
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
// Overload + operator to add two Box objects.
Box operator+(const Box& b) {
Box box;
box.length = this->length + b.length;
box.breadth = this->breadth + b.breadth;
box.height = this->height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
int main() {
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Box Box3; // Declare Box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.setLength(6.0);
Box1.setBreadth(7.0);
Box1.setHeight(5.0);
// box 2 specification
Box2.setLength(12.0);
Box2.setBreadth(13.0);
Box2.setHeight(10.0);
// volume of box 1
volume = Box1.getVolume();
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.getVolume();
cout << "Volume of Box2 : " << volume <<endl;
// Add two object as follows:
Box3 = Box1 + Box2;
// volume of box 3
volume = Box3.getVolume();
cout << "Volume of Box3 : " << volume <<endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Перегружаемые / неперегружаемые операторы
Ниже приведен список операторов, которые могут быть перегружены -
| + | - | * | / | % | ^ |
| & | | | ~ | ! | , | знак равно |
| < | > | <= | > = | ++ | - |
| << | >> | == | знак равно | && | || |
| + = | знак равно | знак равно | знак равно | ^ = | знак равно |
| | = | знак равно | << = | >> = | [] | () |
| -> | -> * | новый | новый [] | удалять | удалять [] |
Ниже приведен список операторов, которые нельзя перегружать -
| :: | . * | . | ?: |
Примеры перегрузки оператора
Вот различные примеры перегрузки операторов, которые помогут вам понять концепцию.
| Старший Нет | Операторы и пример |
|---|---|
| 1 | Перегрузка унарных операторов |
| 2 | Перегрузка бинарных операторов |
| 3 | Перегрузка операторов отношения |
| 4 | Перегрузка операторов ввода / вывода |
| 5 | ++ и - Перегрузка операторов |
| 6 | Перегрузка операторов присваивания |
| 7 | Вызов функции () Перегрузка оператора |
| 8 | Подписка [] Перегрузка оператора |
| 9 | Оператор доступа к членам класса -> Перегрузка |
Слово polymorphismозначает наличие множества форм. Обычно полиморфизм возникает, когда есть иерархия классов, и они связаны наследованием.
Полиморфизм C ++ означает, что вызов функции-члена приведет к выполнению другой функции в зависимости от типа объекта, который вызывает функцию.
Рассмотрим следующий пример, в котором базовый класс был получен двумя другими классами:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0){
width = a;
height = b;
}
int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape {
public:
Rectangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape {
public:
Triangle( int a = 0, int b = 0):Shape(a, b) { }
int area () {
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main() {
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Parent class area :
Parent class area :Причина неверного вывода заключается в том, что вызов функции area () устанавливается компилятором один раз в качестве версии, определенной в базовом классе. Это называетсяstatic resolution вызова функции, или static linkage- вызов функции фиксируется до выполнения программы. Это также иногда называютearly binding потому что функция area () устанавливается во время компиляции программы.
Но теперь давайте внесем небольшие изменения в нашу программу и перед объявлением area () в классе Shape с ключевым словом virtual чтобы это выглядело так -
class Shape {
protected:
int width, height;
public:
Shape( int a = 0, int b = 0) {
width = a;
height = b;
}
virtual int area() {
cout << "Parent class area :" <<endl;
return 0;
}
};После этой небольшой модификации, когда предыдущий пример кода компилируется и выполняется, он дает следующий результат:
Rectangle class area
Triangle class areaНа этот раз компилятор смотрит на содержимое указателя, а не на его тип. Следовательно, поскольку адреса объектов классов tri и rec хранятся в форме *, вызывается соответствующая функция area ().
Как видите, каждый из дочерних классов имеет отдельную реализацию для функции area (). Вот какpolymorphismобычно используется. У вас есть разные классы с функцией с одинаковым именем и даже с одинаковыми параметрами, но с разными реализациями.
Виртуальная функция
А virtual function - это функция базового класса, объявленная с использованием ключевого слова virtual. Определение в базовом классе виртуальной функции с другой версией в производном классе сигнализирует компилятору, что нам не нужна статическая связь для этой функции.
Что мы действительно хотим, так это выбор функции, которая будет вызываться в любой заданной точке программы, в зависимости от типа объекта, для которого она вызывается. Такая операция называетсяdynamic linkage, или же late binding.
Чистые виртуальные функции
Возможно, вы захотите включить виртуальную функцию в базовый класс, чтобы ее можно было переопределить в производном классе в соответствии с объектами этого класса, но при этом нет значимого определения, которое вы могли бы дать для функции в базовом классе. .
Мы можем изменить виртуальную функцию area () в базовом классе на следующую:
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};= 0 сообщает компилятору, что функция не имеет тела и будет вызвана виртуальная функция выше. pure virtual function.
Абстракция данных относится к предоставлению только важной информации внешнему миру и сокрытию их фоновых деталей, т. Е. Для представления необходимой информации в программе без представления деталей.
Абстракция данных - это метод программирования (и проектирования), основанный на разделении интерфейса и реализации.
Давайте возьмем один реальный пример телевизора, который вы можете включать и выключать, изменять канал, регулировать громкость и добавлять внешние компоненты, такие как динамики, видеомагнитофоны и DVD-плееры, НО вы не знаете его внутренних деталей, что То есть вы не знаете, как он принимает сигналы по воздуху или по кабелю, как он их транслирует и, наконец, отображает их на экране.
Таким образом, мы можем сказать, что телевизор четко отделяет свою внутреннюю реализацию от внешнего интерфейса, и вы можете играть с его интерфейсами, такими как кнопка питания, переключатель каналов и регулятор громкости, не зная его внутренних устройств.
В C ++ классы обеспечивают высокий уровень data abstraction. Они предоставляют внешнему миру достаточно общедоступных методов, чтобы играть с функциональностью объекта и манипулировать данными объекта, т. Е. Состоянием, не зная на самом деле, как класс был реализован внутри.
Например, ваша программа может вызывать sort()функция, не зная, какой алгоритм фактически использует функция для сортировки заданных значений. Фактически, базовая реализация функции сортировки может меняться между выпусками библиотеки, и до тех пор, пока интерфейс остается неизменным, ваш вызов функции по-прежнему будет работать.
В C ++ мы используем classesдля определения наших собственных абстрактных типов данных (ADT). Вы можете использоватьcout объект класса ostream для потоковой передачи данных на стандартный вывод, например:
#include <iostream>
using namespace std;
int main() {
cout << "Hello C++" <<endl;
return 0;
}Здесь не нужно понимать, как coutотображает текст на экране пользователя. Вам нужно знать только общедоступный интерфейс, а базовая реализация cout может быть изменена бесплатно.
Ярлыки доступа обеспечивают абстракцию
В C ++ мы используем метки доступа для определения абстрактного интерфейса класса. Класс может содержать ноль или более меток доступа -
Члены, определенные с помощью общедоступной метки, доступны для всех частей программы. Представление типа с абстракцией данных определяется его общедоступными членами.
Члены, определенные с помощью частной метки, недоступны для кода, использующего класс. Частные разделы скрывают реализацию от кода, который использует этот тип.
Нет никаких ограничений на то, как часто может появляться метка доступа. Каждая метка доступа определяет уровень доступа для последующих определений членов. Указанный уровень доступа остается в силе до тех пор, пока не встретится следующая метка доступа или не появится закрывающая правая фигурная скобка тела класса.
Преимущества абстракции данных
Абстракция данных дает два важных преимущества:
Внутренние элементы класса защищены от непреднамеренных ошибок на уровне пользователя, которые могут повредить состояние объекта.
Реализация класса может со временем развиваться в ответ на изменение требований или отчетов об ошибках, не требуя изменения кода пользовательского уровня.
Определяя элементы данных только в закрытом разделе класса, автор класса может вносить изменения в данные. Если реализация изменяется, нужно исследовать только код класса, чтобы увидеть, какое влияние может иметь это изменение. Если данные являются общедоступными, то любая функция, которая напрямую обращается к элементам данных старого представления, может быть нарушена.
Пример абстракции данных
Любая программа на C ++, в которой вы реализуете класс с общедоступными и закрытыми членами, является примером абстракции данных. Рассмотрим следующий пример -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total 60Вышеупомянутый класс складывает числа и возвращает сумму. Публичные члены -addNum и getTotalявляются интерфейсами с внешним миром, и пользователь должен знать их, чтобы использовать класс. Частный членtotal это то, о чем пользователю не нужно знать, но необходимо для правильной работы класса.
Разработка стратегии
Абстракция разделяет код на интерфейс и реализацию. Таким образом, при разработке компонента вы должны сохранять интерфейс независимым от реализации, чтобы при изменении базовой реализации интерфейс оставался неизменным.
В этом случае какие бы программы ни использовали эти интерфейсы, они не пострадали бы, и им просто нужно было бы перекомпилировать с последней реализацией.
Все программы на C ++ состоят из следующих двух основных элементов:
Program statements (code) - Это часть программы, которая выполняет действия, и они называются функциями.
Program data - Данные - это информация о программе, на которую влияют функции программы.
Инкапсуляция - это концепция объектно-ориентированного программирования, которая связывает вместе данные и функции, которые манипулируют данными, и защищает как от внешнего вмешательства, так и от неправильного использования. Инкапсуляция данных привела к важной концепции ООП:data hiding.
Data encapsulation это механизм объединения данных, а функции, которые их используют, и data abstraction - это механизм, показывающий только интерфейсы и скрывающий детали реализации от пользователя.
C ++ поддерживает свойства инкапсуляции и сокрытия данных посредством создания определяемых пользователем типов, называемых classes. Мы уже выяснили, что класс может содержатьprivate, protected и publicчлены. По умолчанию все элементы, определенные в классе, являются частными. Например -
class Box {
public:
double getVolume(void) {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Переменные длина, ширина и высота: private. Это означает, что к ним могут получить доступ только другие члены класса Box, а не какая-либо другая часть вашей программы. Это односторонняя инкапсуляция.
Чтобы сделать части класса public (т. е. доступными для других частей вашей программы), вы должны объявить их после publicключевое слово. Все переменные или функции, определенные после спецификатора public, доступны для всех других функций в вашей программе.
Сделав один класс другом другого, вы обнаружите детали реализации и уменьшите инкапсуляцию. В идеале как можно больше деталей каждого класса скрывать от всех других классов.
Пример инкапсуляции данных
Любая программа C ++, в которой вы реализуете класс с общедоступными и частными членами, является примером инкапсуляции и абстракции данных. Рассмотрим следующий пример -
#include <iostream>
using namespace std;
class Adder {
public:
// constructor
Adder(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
};
int main() {
Adder a;
a.addNum(10);
a.addNum(20);
a.addNum(30);
cout << "Total " << a.getTotal() <<endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total 60Вышеупомянутый класс складывает числа и возвращает сумму. Общественные членыaddNum и getTotal являются интерфейсами с внешним миром, и пользователь должен знать их, чтобы использовать класс. Частный членtotal это то, что скрыто от внешнего мира, но необходимо для правильной работы класса.
Разработка стратегии
Большинство из нас научились делать членов класса закрытыми по умолчанию, если нам действительно не нужно их раскрывать. Это просто хорошоencapsulation.
Чаще всего это применяется к элементам данных, но в равной степени применяется ко всем членам, включая виртуальные функции.
Интерфейс описывает поведение или возможности класса C ++ без привязки к конкретной реализации этого класса.
Интерфейсы C ++ реализованы с использованием abstract classes и эти абстрактные классы не следует путать с абстракцией данных, которая представляет собой концепцию хранения деталей реализации отдельно от связанных данных.
Класс делается абстрактным, объявляя по крайней мере одну из его функций как pure virtualфункция. Чистая виртуальная функция указывается путем помещения "= 0" в ее объявление следующим образом:
class Box {
public:
// pure virtual function
virtual double getVolume() = 0;
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Цель abstract class(часто называемый ABC) заключается в предоставлении соответствующего базового класса, от которого могут наследовать другие классы. Абстрактные классы не могут использоваться для создания экземпляров объектов и служат только в качествеinterface. Попытка создать экземпляр объекта абстрактного класса вызывает ошибку компиляции.
Таким образом, если необходимо создать подкласс ABC, он должен реализовать каждую из виртуальных функций, что означает, что он поддерживает интерфейс, объявленный ABC. Неспособность переопределить чистую виртуальную функцию в производном классе, а затем попытаться создать экземпляры объектов этого класса, является ошибкой компиляции.
Классы, которые можно использовать для создания экземпляров объектов, называются concrete classes.
Пример абстрактного класса
Рассмотрим следующий пример, в котором родительский класс предоставляет интерфейс базовому классу для реализации функции с именем getArea() -
#include <iostream>
using namespace std;
// Base class
class Shape {
public:
// pure virtual function providing interface framework.
virtual int getArea() = 0;
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
};
// Derived classes
class Rectangle: public Shape {
public:
int getArea() {
return (width * height);
}
};
class Triangle: public Shape {
public:
int getArea() {
return (width * height)/2;
}
};
int main(void) {
Rectangle Rect;
Triangle Tri;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total Rectangle area: " << Rect.getArea() << endl;
Tri.setWidth(5);
Tri.setHeight(7);
// Print the area of the object.
cout << "Total Triangle area: " << Tri.getArea() << endl;
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Total Rectangle area: 35
Total Triangle area: 17Вы можете увидеть, как абстрактный класс определил интерфейс в терминах getArea (), а два других класса реализовали ту же функцию, но с другим алгоритмом для вычисления области, специфичной для формы.
Разработка стратегии
Объектно-ориентированная система может использовать абстрактный базовый класс для предоставления общего и стандартизованного интерфейса, подходящего для всех внешних приложений. Затем посредством наследования от этого абстрактного базового класса формируются производные классы, которые работают аналогично.
Возможности (т. Е. Общедоступные функции), предлагаемые внешними приложениями, предоставляются как чистые виртуальные функции в абстрактном базовом классе. Реализации этих чисто виртуальных функций предоставляются в производных классах, которые соответствуют конкретным типам приложения.
Эта архитектура также позволяет легко добавлять новые приложения в систему даже после того, как система была определена.
До сих пор мы использовали iostream стандартная библиотека, которая предоставляет cin и cout методы для чтения из стандартного ввода и записи в стандартный вывод соответственно.
Этот учебник научит вас читать и писать из файла. Для этого требуется другая стандартная библиотека C ++ под названиемfstream, который определяет три новых типа данных -
| Старший Нет | Тип данных и описание |
|---|---|
| 1 | ofstream Этот тип данных представляет поток выходного файла и используется для создания файлов и записи информации в файлы. |
| 2 | ifstream Этот тип данных представляет поток входного файла и используется для чтения информации из файлов. |
| 3 | fstream Этот тип данных представляет файловый поток в целом и имеет возможности как ofstream, так и ifstream, что означает, что он может создавать файлы, записывать информацию в файлы и читать информацию из файлов. |
Чтобы выполнить обработку файлов в C ++, файлы заголовков <iostream> и <fstream> должны быть включены в ваш исходный файл C ++.
Открытие файла
Файл должен быть открыт, прежде чем вы сможете читать из него или писать в него. Илиofstream или же fstreamобъект может использоваться для открытия файла для записи. И объект ifstream используется для открытия файла только для чтения.
Ниже приведен стандартный синтаксис функции open (), которая является членом объектов fstream, ifstream и ofstream.
void open(const char *filename, ios::openmode mode);Здесь первый аргумент указывает имя и расположение файла, который нужно открыть, а второй аргумент open() функция-член определяет режим, в котором должен быть открыт файл.
| Старший Нет | Флаг и описание режима |
|---|---|
| 1 | ios::app Режим добавления. Весь вывод в этот файл будет добавлен в конец. |
| 2 | ios::ate Откройте файл для вывода и переместите элемент управления чтением / записью в конец файла. |
| 3 | ios::in Откройте файл для чтения. |
| 4 | ios::out Откройте файл для записи. |
| 5 | ios::trunc Если файл уже существует, его содержимое будет обрезано перед открытием файла. |
Вы можете объединить два или более этих значения, ORсоединяя их вместе. Например, если вы хотите открыть файл в режиме записи и хотите усечь его, если он уже существует, синтаксис будет следующим:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );Аналогичным образом вы можете открыть файл для чтения и записи следующим образом:
fstream afile;
afile.open("file.dat", ios::out | ios::in );Закрытие файла
Когда программа C ++ завершает свою работу, она автоматически очищает все потоки, освобождает всю выделенную память и закрывает все открытые файлы. Но всегда рекомендуется закрывать все открытые файлы перед завершением программы.
Ниже приведен стандартный синтаксис функции close (), которая является членом объектов fstream, ifstream и ofstream.
void close();Запись в файл
При программировании на C ++ вы записываете информацию в файл из своей программы с помощью оператора вставки потока (<<) точно так же, как вы используете этот оператор для вывода информации на экран. Единственная разница в том, что вы используетеofstream или же fstream объект вместо cout объект.
Чтение из файла
Вы считываете информацию из файла в свою программу, используя оператор извлечения потока (>>), точно так же, как вы используете этот оператор для ввода информации с клавиатуры. Единственная разница в том, что вы используетеifstream или же fstream объект вместо cin объект.
Пример чтения и записи
Ниже приводится программа на C ++, которая открывает файл в режиме чтения и записи. После записи информации, введенной пользователем, в файл с именем afile.dat, программа считывает информацию из файла и выводит ее на экран -
#include <fstream>
#include <iostream>
using namespace std;
int main () {
char data[100];
// open a file in write mode.
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// write inputted data into the file.
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// again write inputted data into the file.
outfile << data << endl;
// close the opened file.
outfile.close();
// open a file in read mode.
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// write the data at the screen.
cout << data << endl;
// again read the data from the file and display it.
infile >> data;
cout << data << endl;
// close the opened file.
infile.close();
return 0;
}Когда приведенный выше код компилируется и выполняется, он производит следующий пример ввода и вывода:
$./a.out
Writing to the file
Enter your name: Zara
Enter your age: 9
Reading from the file
Zara
9В приведенных выше примерах используются дополнительные функции из объекта cin, такие как функция getline () для чтения строки извне и функция ignore () для игнорирования лишних символов, оставленных предыдущим оператором чтения.
Указатели положения файла
И то и другое istream и ostreamпредоставить функции-члены для изменения положения указателя позиции файла. Эти функции-членыseekg ("seek get") для istream и seekp ("seek put") вместо ostream.
Обычно аргумент seekg и seekp - длинное целое число. Второй аргумент может быть указан для указания направления поиска. Направление поиска может бытьios::beg (по умолчанию) для позиционирования относительно начала потока, ios::cur для позиционирования относительно текущей позиции в потоке или ios::end для позиционирования относительно конца потока.
Указатель позиции файла - это целочисленное значение, которое указывает местоположение в файле в виде количества байтов от его начального местоположения. Вот некоторые примеры размещения указателя позиции файла "get":
// position to the nth byte of fileObject (assumes ios::beg)
fileObject.seekg( n );
// position n bytes forward in fileObject
fileObject.seekg( n, ios::cur );
// position n bytes back from end of fileObject
fileObject.seekg( n, ios::end );
// position at end of fileObject
fileObject.seekg( 0, ios::end );Исключением является проблема, возникающая во время выполнения программы. Исключение C ++ - это реакция на исключительное обстоятельство, которое возникает во время работы программы, например при попытке деления на ноль.
Исключения позволяют передавать управление от одной части программы к другой. Обработка исключений C ++ построена на трех ключевых словах:try, catch, и throw.
throw- Программа выдает исключение при обнаружении проблемы. Это делается с помощьюthrow ключевое слово.
catch- Программа перехватывает исключение с помощью обработчика исключений в том месте программы, где вы хотите обработать проблему. Вcatch ключевое слово указывает на перехват исключения.
try - А tryblock определяет блок кода, для которого будут активированы определенные исключения. За ним следует один или несколько блоков catch.
Предполагая, что блок вызовет исключение, метод перехватывает исключение, используя комбинацию try и catchключевые слова. Блок try / catch помещается вокруг кода, который может вызвать исключение. Код в блоке try / catch называется защищенным кодом, а синтаксис для использования try / catch выглядит следующим образом:
try {
// protected code
} catch( ExceptionName e1 ) {
// catch block
} catch( ExceptionName e2 ) {
// catch block
} catch( ExceptionName eN ) {
// catch block
}Вы можете перечислить несколько catch операторы для перехвата различных типов исключений в случае, если ваш try block вызывает более одного исключения в разных ситуациях.
Выбрасывание исключений
Исключения могут быть выброшены в любом месте блока кода, используя throwзаявление. Операнд оператора throw определяет тип исключения и может быть любым выражением, а тип результата выражения определяет тип создаваемого исключения.
Ниже приведен пример выброса исключения при выполнении условия деления на ноль.
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}Выявление исключений
В catch блок после tryблок перехватывает любое исключение. Вы можете указать, какой тип исключения вы хотите перехватить, и это определяется объявлением исключения, которое появляется в круглых скобках после ключевого слова catch.
try {
// protected code
} catch( ExceptionName e ) {
// code to handle ExceptionName exception
}Приведенный выше код поймает исключение ExceptionNameтип. Если вы хотите указать, что блок catch должен обрабатывать любой тип исключения, которое генерируется в блоке try, вы должны поставить многоточие, ..., между круглыми скобками, заключая объявление исключения следующим образом:
try {
// protected code
} catch(...) {
// code to handle any exception
}Ниже приведен пример, в котором генерируется исключение деления на ноль, и мы перехватываем его в блоке catch.
#include <iostream>
using namespace std;
double division(int a, int b) {
if( b == 0 ) {
throw "Division by zero condition!";
}
return (a/b);
}
int main () {
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
} catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}Поскольку мы вызываем исключение типа const char*, поэтому при перехвате этого исключения мы должны использовать const char * в блоке catch. Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Division by zero condition!Стандартные исключения C ++
C ++ предоставляет список стандартных исключений, определенных в <exception>которые мы можем использовать в наших программах. Они расположены в иерархии родительско-дочерних классов, показанной ниже -
Вот небольшое описание каждого исключения, упомянутого в приведенной выше иерархии -
| Старший Нет | Исключение и описание |
|---|---|
| 1 | std::exception Исключение и родительский класс для всех стандартных исключений C ++. |
| 2 | std::bad_alloc Это может быть брошено new. |
| 3 | std::bad_cast Это может быть брошено dynamic_cast. |
| 4 | std::bad_exception Это полезное устройство для обработки неожиданных исключений в программе на C ++. |
| 5 | std::bad_typeid Это может быть брошено typeid. |
| 6 | std::logic_error Исключение, которое теоретически можно обнаружить, прочитав код. |
| 7 | std::domain_error Это исключение, возникающее при использовании математически неверного домена. |
| 8 | std::invalid_argument Это выбрано из-за недопустимых аргументов. |
| 9 | std::length_error Это выдается, когда создается слишком большой std :: string. |
| 10 | std::out_of_range Это может быть вызвано методом 'at', например std :: vector и std :: bitset <> :: operator [] (). |
| 11 | std::runtime_error Исключение, которое теоретически невозможно обнаружить путем чтения кода. |
| 12 | std::overflow_error Это выбрасывается, если происходит математическое переполнение. |
| 13 | std::range_error Это происходит, когда вы пытаетесь сохранить значение, выходящее за пределы допустимого диапазона. |
| 14 | std::underflow_error Это выбрасывается, если происходит математическое недополнение. |
Определить новые исключения
Вы можете определить свои собственные исключения, наследовав и переопределив exceptionфункциональность класса. Ниже приведен пример, который показывает, как вы можете использовать класс std :: exception для реализации вашего собственного исключения стандартным способом.
#include <iostream>
#include <exception>
using namespace std;
struct MyException : public exception {
const char * what () const throw () {
return "C++ Exception";
}
};
int main() {
try {
throw MyException();
} catch(MyException& e) {
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
} catch(std::exception& e) {
//Other errors
}
}Это даст следующий результат -
MyException caught
C++ ExceptionВот, what()- это общедоступный метод, предоставляемый классом исключений, и он был переопределен всеми дочерними классами исключений. Это возвращает причину исключения.
Хорошее понимание того, как на самом деле работает динамическая память в C ++, необходимо для того, чтобы стать хорошим программистом на C ++. Память в вашей программе на C ++ разделена на две части:
The stack - Все переменные, объявленные внутри функции, будут занимать память из стека.
The heap - Это неиспользуемая память программы, которая может использоваться для динамического распределения памяти при запуске программы.
Часто вы не знаете заранее, сколько памяти вам понадобится для хранения определенной информации в определенной переменной, и размер требуемой памяти можно определить во время выполнения.
Вы можете выделить память во время выполнения в куче для переменной данного типа, используя специальный оператор в C ++, который возвращает адрес выделенного пространства. Этот оператор называетсяnew оператор.
Если вам больше не нужна динамически выделяемая память, вы можете использовать delete оператор, который освобождает память, ранее выделенную оператором new.
операторы new и delete
Существует следующий общий синтаксис для использования new Оператор для динамического выделения памяти для любого типа данных.
new data-type;Вот, data-typeможет быть любым встроенным типом данных, включая массив, или любыми определяемыми пользователем типами данных, включая класс или структуру. Начнем со встроенных типов данных. Например, мы можем определить указатель на тип double, а затем запросить выделение памяти во время выполнения. Мы можем сделать это с помощьюnew оператор со следующими операторами -
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variableВозможно, память не была выделена успешно, если свободное хранилище было израсходовано. Поэтому рекомендуется проверить, возвращает ли новый оператор указатель NULL, и предпринять соответствующие действия, как показано ниже:
double* pvalue = NULL;
if( !(pvalue = new double )) {
cout << "Error: out of memory." <<endl;
exit(1);
}В malloc()функция из C, все еще существует в C ++, но рекомендуется избегать использования функции malloc (). Основное преимущество new перед malloc () заключается в том, что new не просто выделяет память, он создает объекты, что является основной целью C ++.
В любой момент, когда вы чувствуете, что переменная, которая была динамически распределена, больше не требуется, вы можете освободить память, которую она занимает в бесплатном хранилище, с помощью оператора delete следующим образом:
delete pvalue; // Release memory pointed to by pvalueДавайте представим вышеупомянутые концепции и сформируем следующий пример, чтобы показать, как работают «новое» и «удаление»:
#include <iostream>
using namespace std;
int main () {
double* pvalue = NULL; // Pointer initialized with null
pvalue = new double; // Request memory for the variable
*pvalue = 29494.99; // Store value at allocated address
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // free up the memory.
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Value of pvalue : 29495Распределение динамической памяти для массивов
Предположим, вы хотите выделить память для массива символов, т. Е. Строки из 20 символов. Используя тот же синтаксис, который мы использовали выше, мы можем динамически выделять память, как показано ниже.
char* pvalue = NULL; // Pointer initialized with null
pvalue = new char[20]; // Request memory for the variableЧтобы удалить массив, который мы только что создали, оператор будет выглядеть так:
delete [] pvalue; // Delete array pointed to by pvalueСледуя аналогичному универсальному синтаксису оператора new, вы можете выделить для многомерного массива следующим образом:
double** pvalue = NULL; // Pointer initialized with null
pvalue = new double [3][4]; // Allocate memory for a 3x4 arrayОднако синтаксис для освобождения памяти для многомерного массива по-прежнему останется таким же, как указано выше -
delete [] pvalue; // Delete array pointed to by pvalueРаспределение динамической памяти для объектов
Объекты ничем не отличаются от простых типов данных. Например, рассмотрим следующий код, в котором мы собираемся использовать массив объектов, чтобы прояснить концепцию:
#include <iostream>
using namespace std;
class Box {
public:
Box() {
cout << "Constructor called!" <<endl;
}
~Box() {
cout << "Destructor called!" <<endl;
}
};
int main() {
Box* myBoxArray = new Box[4];
delete [] myBoxArray; // Delete array
return 0;
}Если бы вы выделяли массив из четырех объектов Box, простой конструктор вызывался бы четыре раза, и аналогично при удалении этих объектов деструктор также будет вызываться такое же количество раз.
Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Constructor called!
Constructor called!
Constructor called!
Constructor called!
Destructor called!
Destructor called!
Destructor called!
Destructor called!Рассмотрим ситуацию, когда у нас есть два человека с одним и тем же именем, Зара, в одном классе. Всякий раз, когда нам нужно определенно дифференцировать их, мы должны использовать некоторую дополнительную информацию вместе с их именем, например, либо район, если они живут в другом районе, либо имя их матери или отца и т.
Такая же ситуация может возникнуть в ваших приложениях на C ++. Например, вы можете писать код, в котором есть функция xyz (), и есть еще одна доступная библиотека, которая также имеет такую же функцию xyz (). Теперь компилятор не имеет возможности узнать, на какую версию функции xyz () вы ссылаетесь в своем коде.
А namespaceразработан для преодоления этой трудности и используется в качестве дополнительной информации для различения похожих функций, классов, переменных и т. д. с одинаковыми именами, доступных в разных библиотеках. Используя пространство имен, вы можете определить контекст, в котором определены имена. По сути, пространство имен определяет область видимости.
Определение пространства имен
Определение пространства имен начинается с ключевого слова namespace за которым следует имя пространства имен следующим образом -
namespace namespace_name {
// code declarations
}Чтобы вызвать версию функции или переменной с включенным пространством имен, добавьте (: :) к имени пространства имен следующим образом:
name::code; // code could be variable or function.Давайте посмотрим, как пространство имен охватывает объекты, включая переменную и функции -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
int main () {
// Calls function from first name space.
first_space::func();
// Calls function from second name space.
second_space::func();
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Inside first_space
Inside second_spaceДиректива using
Вы также можете избежать добавления пространств имен с помощью using namespaceдиректива. Эта директива сообщает компилятору, что последующий код использует имена в указанном пространстве имен. Таким образом, пространство имен подразумевается для следующего кода -
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main () {
// This calls function from first name space.
func();
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Inside first_spaceДиректива using также может использоваться для ссылки на конкретный элемент в пространстве имен. Например, если единственная часть пространства имен std, которую вы собираетесь использовать, - это cout, вы можете ссылаться на нее следующим образом:
using std::cout;Последующий код может ссылаться на cout без добавления пространства имен, но другие элементы в std пространство имен по-прежнему должно быть явным:
#include <iostream>
using std::cout;
int main () {
cout << "std::endl is used with std!" << std::endl;
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
std::endl is used with std!Имена введены в usingДиректива подчиняется нормальным правилам области видимости. Имя видно с точкиusingдиректива до конца области, в которой находится директива. Сущности с тем же именем, определенные во внешней области видимости, скрыты.
Несмежные пространства имен
Пространство имен может быть определено в нескольких частях, поэтому пространство имен состоит из суммы его отдельно определенных частей. Отдельные части пространства имен могут быть распределены по нескольким файлам.
Итак, если для одной части пространства имен требуется имя, определенное в другом файле, это имя все равно должно быть объявлено. Написание следующего определения пространства имен либо определяет новое пространство имен, либо добавляет новые элементы к существующему -
namespace namespace_name {
// code declarations
}Вложенные пространства имен
Пространства имен могут быть вложенными, где вы можете определить одно пространство имен внутри другого пространства имен следующим образом:
namespace namespace_name1 {
// code declarations
namespace namespace_name2 {
// code declarations
}
}Вы можете получить доступ к членам вложенного пространства имен, используя следующие операторы разрешения:
// to access members of namespace_name2
using namespace namespace_name1::namespace_name2;
// to access members of namespace:name1
using namespace namespace_name1;В приведенных выше операторах, если вы используете namespace_name1, тогда он сделает элементы namespace_name2 доступными в области следующим образом:
#include <iostream>
using namespace std;
// first name space
namespace first_space {
void func() {
cout << "Inside first_space" << endl;
}
// second name space
namespace second_space {
void func() {
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main () {
// This calls function from second name space.
func();
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Inside second_spaceШаблоны являются основой общего программирования, которое включает в себя написание кода способом, независимым от какого-либо конкретного типа.
Шаблон - это план или формула для создания универсального класса или функции. Контейнеры библиотеки, такие как итераторы и алгоритмы, являются примерами общего программирования и были разработаны с использованием концепции шаблона.
У каждого контейнера есть одно определение, например vector, но мы можем определить много разных типов векторов, например, vector <int> или же vector <string>.
Вы можете использовать шаблоны для определения функций, а также классов, давайте посмотрим, как они работают -
Шаблон функции
Общая форма определения функции шаблона показана здесь -
template <class type> ret-type func-name(parameter list) {
// body of function
}Здесь тип - это имя-заполнитель для типа данных, используемого функцией. Это имя можно использовать в определении функции.
Ниже приведен пример шаблона функции, который возвращает максимум два значения:
#include <iostream>
#include <string>
using namespace std;
template <typename T>
inline T const& Max (T const& a, T const& b) {
return a < b ? b:a;
}
int main () {
int i = 39;
int j = 20;
cout << "Max(i, j): " << Max(i, j) << endl;
double f1 = 13.5;
double f2 = 20.7;
cout << "Max(f1, f2): " << Max(f1, f2) << endl;
string s1 = "Hello";
string s2 = "World";
cout << "Max(s1, s2): " << Max(s1, s2) << endl;
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Max(i, j): 39
Max(f1, f2): 20.7
Max(s1, s2): WorldШаблон класса
Так же, как мы можем определять шаблоны функций, мы можем определять шаблоны классов. Общая форма объявления универсального класса показана здесь -
template <class type> class class-name {
.
.
.
}Вот, type- это имя типа заполнителя, которое будет указано при создании экземпляра класса. Вы можете определить более одного универсального типа данных, используя список, разделенный запятыми.
Ниже приведен пример определения класса Stack <> и реализации общих методов для выталкивания и выталкивания элементов из стека.
#include <iostream>
#include <vector>
#include <cstdlib>
#include <string>
#include <stdexcept>
using namespace std;
template <class T>
class Stack {
private:
vector<T> elems; // elements
public:
void push(T const&); // push element
void pop(); // pop element
T top() const; // return top element
bool empty() const { // return true if empty.
return elems.empty();
}
};
template <class T>
void Stack<T>::push (T const& elem) {
// append copy of passed element
elems.push_back(elem);
}
template <class T>
void Stack<T>::pop () {
if (elems.empty()) {
throw out_of_range("Stack<>::pop(): empty stack");
}
// remove last element
elems.pop_back();
}
template <class T>
T Stack<T>::top () const {
if (elems.empty()) {
throw out_of_range("Stack<>::top(): empty stack");
}
// return copy of last element
return elems.back();
}
int main() {
try {
Stack<int> intStack; // stack of ints
Stack<string> stringStack; // stack of strings
// manipulate int stack
intStack.push(7);
cout << intStack.top() <<endl;
// manipulate string stack
stringStack.push("hello");
cout << stringStack.top() << std::endl;
stringStack.pop();
stringStack.pop();
} catch (exception const& ex) {
cerr << "Exception: " << ex.what() <<endl;
return -1;
}
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
7
hello
Exception: Stack<>::pop(): empty stackПрепроцессоры - это директивы, которые дают инструкции компилятору для предварительной обработки информации перед фактическим началом компиляции.
Все директивы препроцессора начинаются с символа #, и только символы пробела могут появляться перед директивой препроцессора в строке. Директивы препроцессора не являются операторами C ++, поэтому они не заканчиваются точкой с запятой (;).
Вы уже видели #includeдиректива во всех примерах. Этот макрос используется для включения файла заголовка в исходный файл.
Существует ряд директив препроцессора, поддерживаемых C ++, таких как #include, #define, #if, #else, #line и т. Д. Давайте посмотрим на важные директивы -
Препроцессор #define
Директива препроцессора #define создает символические константы. Символьная константа называетсяmacro и общая форма директивы -
#define macro-name replacement-textКогда эта строка появляется в файле, все последующие вхождения макроса в этом файле будут заменены замещающим текстом перед компиляцией программы. Например -
#include <iostream>
using namespace std;
#define PI 3.14159
int main () {
cout << "Value of PI :" << PI << endl;
return 0;
}Теперь давайте сделаем предварительную обработку этого кода, чтобы увидеть результат, предполагая, что у нас есть файл исходного кода. Итак, давайте скомпилируем его с опцией -E и перенаправим результат на test.p. Теперь, если вы проверите test.p, он будет содержать много информации, и внизу вы найдете значение, замененное следующим образом:
$gcc -E test.cpp > test.p
...
int main () {
cout << "Value of PI :" << 3.14159 << endl;
return 0;
}Функциональные макросы
Вы можете использовать #define для определения макроса, который будет принимать следующие аргументы:
#include <iostream>
using namespace std;
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
cout <<"The minimum is " << MIN(i, j) << endl;
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
The minimum is 30Условная компиляция
Есть несколько директив, которые можно использовать для компиляции отдельных частей исходного кода вашей программы. Этот процесс называется условной компиляцией.
Конструкция условного препроцессора очень похожа на структуру выбора if. Рассмотрим следующий код препроцессора -
#ifndef NULL
#define NULL 0
#endifВы можете скомпилировать программу для отладки. Вы также можете включить или выключить отладку с помощью одного макроса следующим образом:
#ifdef DEBUG
cerr <<"Variable x = " << x << endl;
#endifЭто вызывает cerrоператор, который будет скомпилирован в программе, если символическая константа DEBUG была определена до директивы #ifdef DEBUG. Вы можете использовать статус #if 0, чтобы закомментировать часть программы следующим образом:
#if 0
code prevented from compiling
#endifДавайте попробуем следующий пример -
#include <iostream>
using namespace std;
#define DEBUG
#define MIN(a,b) (((a)<(b)) ? a : b)
int main () {
int i, j;
i = 100;
j = 30;
#ifdef DEBUG
cerr <<"Trace: Inside main function" << endl;
#endif
#if 0
/* This is commented part */
cout << MKSTR(HELLO C++) << endl;
#endif
cout <<"The minimum is " << MIN(i, j) << endl;
#ifdef DEBUG
cerr <<"Trace: Coming out of main function" << endl;
#endif
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
The minimum is 30
Trace: Inside main function
Trace: Coming out of main functionОператоры # и ##
Операторы препроцессора # и ## доступны в C ++ и ANSI / ISO C. Оператор # приводит к преобразованию токена замещающего текста в строку, заключенную в кавычки.
Рассмотрим следующее определение макроса -
#include <iostream>
using namespace std;
#define MKSTR( x ) #x
int main () {
cout << MKSTR(HELLO C++) << endl;
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
HELLO C++Посмотрим, как это работало. Легко понять, что препроцессор C ++ меняет положение -
cout << MKSTR(HELLO C++) << endl;Вышеупомянутая строка будет преобразована в следующую строку -
cout << "HELLO C++" << endl;Оператор ## используется для объединения двух токенов. Вот пример -
#define CONCAT( x, y ) x ## yКогда в программе появляется CONCAT, его аргументы объединяются и используются для замены макроса. Например, CONCAT (HELLO, C ++) заменяется в программе на «HELLO C ++» следующим образом.
#include <iostream>
using namespace std;
#define concat(a, b) a ## b
int main() {
int xy = 100;
cout << concat(x, y);
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
100Посмотрим, как это работало. Несложно понять, что препроцессор C ++ преобразует:
cout << concat(x, y);Вышеупомянутая строка будет преобразована в следующую строку -
cout << xy;Предопределенные макросы C ++
C ++ предоставляет ряд предопределенных макросов, упомянутых ниже -
| Старший Нет | Макрос и описание |
|---|---|
| 1 | __LINE__ Он содержит текущий номер строки программы, когда она компилируется. |
| 2 | __FILE__ Он содержит имя текущего файла программы, когда она компилируется. |
| 3 | __DATE__ Он содержит строку вида месяц / день / год, которая является датой преобразования исходного файла в объектный код. |
| 4 | __TIME__ Он содержит строку вида час: минута: секунда - время, в которое была скомпилирована программа. |
Давайте посмотрим пример для всех вышеуказанных макросов -
#include <iostream>
using namespace std;
int main () {
cout << "Value of __LINE__ : " << __LINE__ << endl;
cout << "Value of __FILE__ : " << __FILE__ << endl;
cout << "Value of __DATE__ : " << __DATE__ << endl;
cout << "Value of __TIME__ : " << __TIME__ << endl;
return 0;
}Если мы скомпилируем и запустим приведенный выше код, это даст следующий результат:
Value of __LINE__ : 6
Value of __FILE__ : test.cpp
Value of __DATE__ : Feb 28 2011
Value of __TIME__ : 18:52:48Сигналы - это прерывания, доставляемые процессу операционной системой, которые могут преждевременно завершить программу. Вы можете генерировать прерывания, нажав Ctrl + C в системе UNIX, LINUX, Mac OS X или Windows.
Есть сигналы, которые программа не может уловить, но есть следующий список сигналов, которые вы можете уловить в своей программе и предпринять соответствующие действия на основе сигнала. Эти сигналы определены в заголовочном файле C ++ <csignal>.
| Старший Нет | Сигнал и описание |
|---|---|
| 1 | SIGABRT Аномальное завершение программы, например, вызов abort. |
| 2 | SIGFPE Ошибочная арифметическая операция, например деление на ноль или операция, приводящая к переполнению. |
| 3 | SIGILL Обнаружение незаконной инструкции. |
| 4 | SIGINT Получение интерактивного сигнала внимания. |
| 5 | SIGSEGV Недействительный доступ к хранилищу. |
| 6 | SIGTERM Запрос на завершение, отправленный программе. |
Функция signal ()
Библиотека обработки сигналов C ++ предоставляет функцию signalловить неожиданные события. Ниже приведен синтаксис функции signal () -
void (*signal (int sig, void (*func)(int)))(int);Для простоты эта функция получает два аргумента: первый аргумент как целое число, представляющий номер сигнала, и второй аргумент как указатель на функцию обработки сигнала.
Давайте напишем простую программу на C ++, в которой мы будем ловить сигнал SIGINT с помощью функции signal (). Какой бы сигнал вы ни хотели уловить в своей программе, вы должны зарегистрировать этот сигнал, используяsignalфункцию и свяжите ее с обработчиком сигнала. Рассмотрим следующий пример -
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(1) {
cout << "Going to sleep...." << endl;
sleep(1);
}
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
Going to sleep....
Going to sleep....
Going to sleep....Теперь нажмите Ctrl + c, чтобы прервать программу, и вы увидите, что ваша программа поймает сигнал и выйдет, напечатав следующее:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.Функция raise ()
Вы можете генерировать сигналы по функциям raise(), который принимает в качестве аргумента целочисленный номер сигнала и имеет следующий синтаксис.
int raise (signal sig);Вот, sig- это номер сигнала для отправки любого из сигналов: SIGINT, SIGABRT, SIGFPE, SIGILL, SIGSEGV, SIGTERM, SIGHUP. Ниже приведен пример, в котором мы поднимаем сигнал внутренне с помощью функции raise () следующим образом:
#include <iostream>
#include <csignal>
using namespace std;
void signalHandler( int signum ) {
cout << "Interrupt signal (" << signum << ") received.\n";
// cleanup and close up stuff here
// terminate program
exit(signum);
}
int main () {
int i = 0;
// register signal SIGINT and signal handler
signal(SIGINT, signalHandler);
while(++i) {
cout << "Going to sleep...." << endl;
if( i == 3 ) {
raise( SIGINT);
}
sleep(1);
}
return 0;
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат и выйдет автоматически:
Going to sleep....
Going to sleep....
Going to sleep....
Interrupt signal (2) received.Многопоточность - это специализированная форма многозадачности, а многозадачность - это функция, которая позволяет вашему компьютеру одновременно запускать две или более программы. В общем, существует два типа многозадачности: основанная на процессе и основанная на потоках.
Многозадачность, основанная на процессах, обеспечивает одновременное выполнение программ. Многозадачность на основе потоков связана с одновременным выполнением частей одной и той же программы.
Многопоточная программа состоит из двух или более частей, которые могут выполняться одновременно. Каждая часть такой программы называется потоком, и каждый поток определяет отдельный путь выполнения.
C ++ не содержит встроенной поддержки многопоточных приложений. Вместо этого он полностью полагается на операционную систему, чтобы обеспечить эту функцию.
В этом руководстве предполагается, что вы работаете в ОС Linux, и мы собираемся написать многопоточную программу на C ++ с использованием POSIX. POSIX Threads или Pthreads предоставляет API, который доступен во многих Unix-подобных системах POSIX, таких как FreeBSD, NetBSD, GNU / Linux, Mac OS X и Solaris.
Создание потоков
Следующая процедура используется для создания потока POSIX -
#include <pthread.h>
pthread_create (thread, attr, start_routine, arg)Вот, pthread_createсоздает новый поток и делает его исполняемым. Эту процедуру можно вызывать любое количество раз из любого места в вашем коде. Вот описание параметров -
| Старший Нет | Параметр и описание |
|---|---|
| 1 | thread Непрозрачный уникальный идентификатор нового потока, возвращаемый подпрограммой. |
| 2 | attr Непрозрачный объект атрибута, который может использоваться для установки атрибутов потока. Вы можете указать объект атрибутов потока или NULL для значений по умолчанию. |
| 3 | start_routine Подпрограмма C ++, которую поток будет выполнять после создания. |
| 4 | arg Единственный аргумент, который можно передать start_routine. Он должен передаваться по ссылке как приведение указателя типа void. Если аргумент не передается, можно использовать NULL. |
Максимальное количество потоков, которое может быть создано процессом, зависит от реализации. После создания потоки являются одноранговыми и могут создавать другие потоки. Между потоками нет подразумеваемой иерархии или зависимости.
Завершение потоков
Существует следующая процедура, которую мы используем для завершения потока POSIX:
#include <pthread.h>
pthread_exit (status)Вот pthread_exitиспользуется для явного выхода из потока. Обычно процедура pthread_exit () вызывается после того, как поток завершил свою работу и больше не требуется для существования.
Если main () завершается раньше, чем потоки, которые он создал, и завершается с помощью pthread_exit (), другие потоки продолжат выполнение. В противном случае они будут автоматически завершены после завершения main ().
Example
Этот простой пример кода создает 5 потоков с помощью процедуры pthread_create (). Каждая нить печатает «Hello World!» сообщение, а затем завершается вызовом pthread_exit ().
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
void *PrintHello(void *threadid) {
long tid;
tid = (long)threadid;
cout << "Hello World! Thread ID, " << tid << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)i);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Скомпилируйте следующую программу с использованием библиотеки -lpthread следующим образом:
$gcc test.cpp -lpthreadТеперь запустите вашу программу, которая даст следующий результат -
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Hello World! Thread ID, 0
Hello World! Thread ID, 1
Hello World! Thread ID, 2
Hello World! Thread ID, 3
Hello World! Thread ID, 4Передача аргументов в потоки
В этом примере показано, как передать несколько аргументов через структуру. Вы можете передать любой тип данных в обратном вызове потока, потому что он указывает на void, как описано в следующем примере:
#include <iostream>
#include <cstdlib>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
struct thread_data {
int thread_id;
char *message;
};
void *PrintHello(void *threadarg) {
struct thread_data *my_data;
my_data = (struct thread_data *) threadarg;
cout << "Thread ID : " << my_data->thread_id ;
cout << " Message : " << my_data->message << endl;
pthread_exit(NULL);
}
int main () {
pthread_t threads[NUM_THREADS];
struct thread_data td[NUM_THREADS];
int rc;
int i;
for( i = 0; i < NUM_THREADS; i++ ) {
cout <<"main() : creating thread, " << i << endl;
td[i].thread_id = i;
td[i].message = "This is message";
rc = pthread_create(&threads[i], NULL, PrintHello, (void *)&td[i]);
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
pthread_exit(NULL);
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Thread ID : 3 Message : This is message
Thread ID : 2 Message : This is message
Thread ID : 0 Message : This is message
Thread ID : 1 Message : This is message
Thread ID : 4 Message : This is messageПрисоединение и отсоединение потоков
Есть следующие две процедуры, которые мы можем использовать для соединения или отсоединения потоков:
pthread_join (threadid, status)
pthread_detach (threadid)Подпрограмма pthread_join () блокирует вызывающий поток до тех пор, пока не завершится указанный поток 'threadid'. Когда поток создается, один из его атрибутов определяет, может ли он присоединиться или отсоединиться. Можно присоединить только те потоки, которые созданы как присоединяемые. Если поток создается как отсоединенный, он никогда не может быть присоединен.
В этом примере показано, как дождаться завершения потока с помощью процедуры соединения Pthread.
#include <iostream>
#include <cstdlib>
#include <pthread.h>
#include <unistd.h>
using namespace std;
#define NUM_THREADS 5
void *wait(void *t) {
int i;
long tid;
tid = (long)t;
sleep(1);
cout << "Sleeping in thread " << endl;
cout << "Thread with id : " << tid << " ...exiting " << endl;
pthread_exit(NULL);
}
int main () {
int rc;
int i;
pthread_t threads[NUM_THREADS];
pthread_attr_t attr;
void *status;
// Initialize and set thread joinable
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
for( i = 0; i < NUM_THREADS; i++ ) {
cout << "main() : creating thread, " << i << endl;
rc = pthread_create(&threads[i], &attr, wait, (void *)i );
if (rc) {
cout << "Error:unable to create thread," << rc << endl;
exit(-1);
}
}
// free attribute and wait for the other threads
pthread_attr_destroy(&attr);
for( i = 0; i < NUM_THREADS; i++ ) {
rc = pthread_join(threads[i], &status);
if (rc) {
cout << "Error:unable to join," << rc << endl;
exit(-1);
}
cout << "Main: completed thread id :" << i ;
cout << " exiting with status :" << status << endl;
}
cout << "Main: program exiting." << endl;
pthread_exit(NULL);
}Когда приведенный выше код компилируется и выполняется, он дает следующий результат:
main() : creating thread, 0
main() : creating thread, 1
main() : creating thread, 2
main() : creating thread, 3
main() : creating thread, 4
Sleeping in thread
Thread with id : 0 .... exiting
Sleeping in thread
Thread with id : 1 .... exiting
Sleeping in thread
Thread with id : 2 .... exiting
Sleeping in thread
Thread with id : 3 .... exiting
Sleeping in thread
Thread with id : 4 .... exiting
Main: completed thread id :0 exiting with status :0
Main: completed thread id :1 exiting with status :0
Main: completed thread id :2 exiting with status :0
Main: completed thread id :3 exiting with status :0
Main: completed thread id :4 exiting with status :0
Main: program exiting.Что такое CGI?
Общий интерфейс шлюза или CGI - это набор стандартов, которые определяют, как происходит обмен информацией между веб-сервером и настраиваемым сценарием.
Спецификации CGI в настоящее время поддерживаются NCSA, и NCSA определяет CGI следующим образом:
Общий интерфейс шлюза, или CGI, является стандартом для программ внешнего шлюза для взаимодействия с информационными серверами, такими как серверы HTTP.
Текущая версия - CGI / 1.1, а CGI / 1.2 находится в стадии разработки.
Просмотр веб-страниц
Чтобы понять концепцию CGI, давайте посмотрим, что происходит, когда мы щелкаем гиперссылку для просмотра определенной веб-страницы или URL-адреса.
Ваш браузер связывается с веб-сервером HTTP и запрашивает URL, т.е. имя файла.
Веб-сервер проанализирует URL-адрес и будет искать имя файла. Если он находит запрошенный файл, веб-сервер отправляет этот файл обратно в браузер, в противном случае отправляет сообщение об ошибке, указывающее, что вы запросили неправильный файл.
Веб-браузер принимает ответ от веб-сервера и отображает полученный файл или сообщение об ошибке на основе полученного ответа.
Однако можно настроить HTTP-сервер таким образом, чтобы всякий раз, когда запрашивается файл в определенном каталоге, этот файл не отправляется обратно; вместо этого он выполняется как программа, и вывод, произведенный программой, отправляется обратно в ваш браузер для отображения.
Общий интерфейс шлюза (CGI) - это стандартный протокол, позволяющий приложениям (называемым программами CGI или сценариями CGI) взаимодействовать с веб-серверами и клиентами. Эти программы CGI могут быть написаны на Python, PERL, Shell, C или C ++ и т. Д.
Схема архитектуры CGI
Следующая простая программа показывает простую архитектуру CGI -
Конфигурация веб-сервера
Прежде чем приступить к программированию CGI, убедитесь, что ваш веб-сервер поддерживает CGI и настроен для обработки программ CGI. Все программы CGI, выполняемые сервером HTTP, хранятся в предварительно настроенном каталоге. Этот каталог называется каталогом CGI и по соглашению называется / var / www / cgi-bin. По соглашению файлы CGI будут иметь расширение как.cgi, хотя они являются исполняемыми файлами C ++.
По умолчанию веб-сервер Apache настроен на запуск программ CGI в / var / www / cgi-bin. Если вы хотите указать любой другой каталог для запуска ваших сценариев CGI, вы можете изменить следующий раздел в файле httpd.conf -
<Directory "/var/www/cgi-bin">
AllowOverride None
Options ExecCGI
Order allow,deny
Allow from all
</Directory>
<Directory "/var/www/cgi-bin">
Options All
</Directory>Здесь я предполагаю, что у вас есть и успешно работает веб-сервер, и вы можете запускать любую другую программу CGI, такую как Perl или Shell и т. Д.
Первая программа CGI
Рассмотрим следующий контент программы C ++ -
#include <iostream>
using namespace std;
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Hello World - First CGI Program</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<h2>Hello World! This is my first CGI program</h2>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Скомпилируйте приведенный выше код и назовите исполняемый файл cplusplus.cgi. Этот файл хранится в каталоге / var / www / cgi-bin и имеет следующее содержимое. Перед запуском вашей программы CGI убедитесь, что у вас есть режим изменения файла, используяchmod 755 cplusplus.cgi Команда UNIX для создания исполняемого файла.
Моя первая программа CGI
Вышеупомянутая программа на C ++ представляет собой простую программу, которая записывает свой вывод в файл STDOUT, т.е. Доступна одна важная и дополнительная функция - печать первой строки.Content-type:text/html\r\n\r\n. Эта строка отправляется обратно в браузер и указывает тип контента, который будет отображаться на экране браузера. Теперь вы, должно быть, поняли основную концепцию CGI и можете писать множество сложных программ CGI, используя Python. Программа C ++ CGI может взаимодействовать с любой другой внешней системой, такой как СУБД, для обмена информацией.
Заголовок HTTP
Линия Content-type:text/html\r\n\r\nявляется частью HTTP-заголовка, который отправляется браузеру для понимания содержимого. Весь HTTP-заголовок будет в следующей форме -
HTTP Field Name: Field Content
For Example
Content-type: text/html\r\n\r\nЕсть несколько других важных заголовков HTTP, которые вы будете часто использовать в программировании CGI.
| Старший Нет | Заголовок и описание |
|---|---|
| 1 | Content-type: Строка MIME, определяющая формат возвращаемого файла. Пример: Content-type: text / html. |
| 2 | Expires: Date Дата, когда информация становится недействительной. Это должно использоваться браузером, чтобы решить, когда страницу необходимо обновить. Допустимая строка даты должна быть в формате 01 января 1998 12:00:00 GMT. |
| 3 | Location: URL URL-адрес, который должен быть возвращен вместо запрашиваемого URL-адреса. Вы можете использовать это поле для перенаправления запроса в любой файл. |
| 4 | Last-modified: Date Дата последней модификации ресурса. |
| 5 | Content-length: N Длина возвращаемых данных в байтах. Браузер использует это значение, чтобы сообщить приблизительное время загрузки файла. |
| 6 | Set-Cookie: String Установите cookie, передаваемый через строку . |
Переменные среды CGI
Вся программа CGI будет иметь доступ к следующим переменным среды. Эти переменные играют важную роль при написании любой программы CGI.
| Старший Нет | Имя и описание переменной |
|---|---|
| 1 | CONTENT_TYPE Тип данных содержимого, используемый, когда клиент отправляет прикрепленный контент на сервер. Например, загрузка файла и т. Д. |
| 2 | CONTENT_LENGTH Длина информации запроса, доступная только для запросов POST. |
| 3 | HTTP_COOKIE Возвращает установленные файлы cookie в виде пары ключ-значение. |
| 4 | HTTP_USER_AGENT Поле заголовка запроса User-Agent содержит информацию о пользовательском агенте, создавшем запрос. Это имя веб-браузера. |
| 5 | PATH_INFO Путь к сценарию CGI. |
| 6 | QUERY_STRING Информация в кодировке URL, отправляемая с запросом метода GET. |
| 7 | REMOTE_ADDR IP-адрес удаленного хоста, отправляющего запрос. Это может быть полезно для ведения журнала или для аутентификации. |
| 8 | REMOTE_HOST Полное имя хоста, выполняющего запрос. Если эта информация недоступна, то REMOTE_ADDR можно использовать для получения IR-адреса. |
| 9 | REQUEST_METHOD Метод, использованный для отправки запроса. Наиболее распространены методы GET и POST. |
| 10 | SCRIPT_FILENAME Полный путь к сценарию CGI. |
| 11 | SCRIPT_NAME Имя сценария CGI. |
| 12 | SERVER_NAME Имя хоста или IP-адрес сервера. |
| 13 | SERVER_SOFTWARE Название и версия программного обеспечения, на котором работает сервер. |
Вот небольшая программа CGI для вывода всех переменных CGI.
#include <iostream>
#include <stdlib.h>
using namespace std;
const string ENV[ 24 ] = {
"COMSPEC", "DOCUMENT_ROOT", "GATEWAY_INTERFACE",
"HTTP_ACCEPT", "HTTP_ACCEPT_ENCODING",
"HTTP_ACCEPT_LANGUAGE", "HTTP_CONNECTION",
"HTTP_HOST", "HTTP_USER_AGENT", "PATH",
"QUERY_STRING", "REMOTE_ADDR", "REMOTE_PORT",
"REQUEST_METHOD", "REQUEST_URI", "SCRIPT_FILENAME",
"SCRIPT_NAME", "SERVER_ADDR", "SERVER_ADMIN",
"SERVER_NAME","SERVER_PORT","SERVER_PROTOCOL",
"SERVER_SIGNATURE","SERVER_SOFTWARE" };
int main () {
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>CGI Environment Variables</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
for ( int i = 0; i < 24; i++ ) {
cout << "<tr><td>" << ENV[ i ] << "</td><td>";
// attempt to retrieve value of environment variable
char *value = getenv( ENV[ i ].c_str() );
if ( value != 0 ) {
cout << value;
} else {
cout << "Environment variable does not exist.";
}
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Библиотека C ++ CGI
Для реальных примеров вам потребуется проделать множество операций с помощью вашей программы CGI. Существует библиотека CGI, написанная для программы на C ++, которую вы можете скачать с ftp://ftp.gnu.org/gnu/cgicc/ и выполнить шаги по установке библиотеки -
$tar xzf cgicc-X.X.X.tar.gz
$cd cgicc-X.X.X/ $./configure --prefix=/usr
$make $make installВы можете проверить соответствующую документацию, доступную в разделе «Документация по C ++ CGI Lib .
Методы GET и POST
Вы, должно быть, сталкивались со многими ситуациями, когда вам нужно было передать некоторую информацию из вашего браузера на веб-сервер и, в конечном итоге, в вашу программу CGI. Чаще всего браузер использует два метода для передачи этой информации на веб-сервер. Это методы GET и POST.
Передача информации с использованием метода GET
Метод GET отправляет закодированную информацию о пользователе, добавленную к запросу страницы. Страница и закодированная информация разделяются знаком? характер следующим образом -
http://www.test.com/cgi-bin/cpp.cgi?key1=value1&key2=value2Метод GET - это метод по умолчанию для передачи информации из браузера на веб-сервер, который создает длинную строку, которая появляется в поле Location: вашего браузера. Никогда не используйте метод GET, если у вас есть пароль или другая конфиденциальная информация для передачи на сервер. Метод GET имеет ограничение по размеру, и вы можете передать до 1024 символов в строке запроса.
При использовании метода GET информация передается с использованием HTTP-заголовка QUERY_STRING и будет доступна в вашей программе CGI через переменную среды QUERY_STRING.
Вы можете передать информацию, просто объединив пары ключ и значение вместе с любым URL-адресом, или вы можете использовать теги HTML <FORM> для передачи информации с помощью метода GET.
Пример простого URL: метод получения
Вот простой URL-адрес, который передаст два значения программе hello_get.py с помощью метода GET.
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIНиже представлена программа для создания cpp_get.cgiПрограмма CGI для обработки ввода данных веб-браузером. Мы собираемся использовать библиотеку C ++ CGI, которая упрощает доступ к передаваемой информации -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Using GET and POST Methods</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("first_name");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "First name: " << **fi << endl;
} else {
cout << "No text entered for first name" << endl;
}
cout << "<br/>\n";
fi = formData.getElement("last_name");
if( !fi->isEmpty() &&fi != (*formData).end()) {
cout << "Last name: " << **fi << endl;
} else {
cout << "No text entered for last name" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Теперь скомпилируйте указанную выше программу следующим образом -
$g++ -o cpp_get.cgi cpp_get.cpp -lcgiccСоздайте cpp_get.cgi и поместите его в свой каталог CGI и попробуйте получить доступ, используя следующую ссылку -
/cgi-bin/cpp_get.cgi?first_name=ZARA&last_name=ALIЭто приведет к следующему результату -
First name: ZARA
Last name: ALIПростой пример FORM: метод GET
Вот простой пример, который передает два значения с помощью HTML FORM и кнопки отправки. Мы собираемся использовать тот же CGI-скрипт cpp_get.cgi для обработки этого ввода.
<form action = "/cgi-bin/cpp_get.cgi" method = "get">
First Name: <input type = "text" name = "first_name"> <br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Вот фактический результат вышеуказанной формы. Вы вводите имя и фамилию, а затем нажимаете кнопку отправки, чтобы увидеть результат.
Передача информации с помощью метода POST
Обычно более надежным методом передачи информации программе CGI является метод POST. Это упаковывает информацию точно так же, как методы GET, но вместо того, чтобы отправлять ее в виде текстовой строки после символа? в URL-адресе он отправляет его как отдельное сообщение. Это сообщение поступает в сценарий CGI в виде стандартного ввода.
Та же программа cpp_get.cgi также обрабатывает метод POST. Давайте возьмем тот же пример, что и выше, который передает два значения с помощью HTML FORM и кнопки отправки, но на этот раз с помощью метода POST следующим образом:
<form action = "/cgi-bin/cpp_get.cgi" method = "post">
First Name: <input type = "text" name = "first_name"><br />
Last Name: <input type = "text" name = "last_name" />
<input type = "submit" value = "Submit" />
</form>Вот фактический результат вышеуказанной формы. Вы вводите имя и фамилию, а затем нажимаете кнопку отправки, чтобы увидеть результат.
Передача данных флажка в программу CGI
Флажки используются, когда требуется выбрать более одного параметра.
Вот пример HTML-кода для формы с двумя флажками -
<form action = "/cgi-bin/cpp_checkbox.cgi" method = "POST" target = "_blank">
<input type = "checkbox" name = "maths" value = "on" /> Maths
<input type = "checkbox" name = "physics" value = "on" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Результатом этого кода является следующая форма -
Ниже представлена программа на C ++, которая сгенерирует скрипт cpp_checkbox.cgi для обработки ввода, вводимого веб-браузером с помощью кнопки флажка.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
bool maths_flag, physics_flag;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Checkbox Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
maths_flag = formData.queryCheckbox("maths");
if( maths_flag ) {
cout << "Maths Flag: ON " << endl;
} else {
cout << "Maths Flag: OFF " << endl;
}
cout << "<br/>\n";
physics_flag = formData.queryCheckbox("physics");
if( physics_flag ) {
cout << "Physics Flag: ON " << endl;
} else {
cout << "Physics Flag: OFF " << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Передача данных радиокнопки в программу CGI
Радиокнопки используются, когда требуется выбрать только один вариант.
Вот пример HTML-кода для формы с двумя переключателями -
<form action = "/cgi-bin/cpp_radiobutton.cgi" method = "post" target = "_blank">
<input type = "radio" name = "subject" value = "maths" checked = "checked"/> Maths
<input type = "radio" name = "subject" value = "physics" /> Physics
<input type = "submit" value = "Select Subject" />
</form>Результатом этого кода является следующая форма -
Ниже представлена программа на C ++, которая сгенерирует сценарий cpp_radiobutton.cgi для обработки ввода данных веб-браузером с помощью переключателей.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Radio Button Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("subject");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Radio box selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Передача данных текстовой области в программу CGI
Элемент TEXTAREA используется, когда многострочный текст должен быть передан программе CGI.
Вот пример HTML-кода для формы с полем ТЕКСТАРА -
<form action = "/cgi-bin/cpp_textarea.cgi" method = "post" target = "_blank">
<textarea name = "textcontent" cols = "40" rows = "4">
Type your text here...
</textarea>
<input type = "submit" value = "Submit" />
</form>Результатом этого кода является следующая форма -
Ниже представлена программа на C ++, которая сгенерирует скрипт cpp_textarea.cgi для обработки ввода данных веб-браузером через текстовую область.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Text Area Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("textcontent");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Text Content: " << **fi << endl;
} else {
cout << "No text entered" << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Передача данных раскрывающегося списка в программу CGI
Выпадающий список используется, когда у нас много доступных вариантов, но будут выбраны только один или два.
Вот пример HTML-кода для формы с одним раскрывающимся списком -
<form action = "/cgi-bin/cpp_dropdown.cgi" method = "post" target = "_blank">
<select name = "dropdown">
<option value = "Maths" selected>Maths</option>
<option value = "Physics">Physics</option>
</select>
<input type = "submit" value = "Submit"/>
</form>Результатом этого кода является следующая форма -
Ниже приведена программа на C ++, которая сгенерирует скрипт cpp_dropdown.cgi для обработки ввода, вводимого веб-браузером через раскрывающийся список.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc formData;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Drop Down Box Data to CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
form_iterator fi = formData.getElement("dropdown");
if( !fi->isEmpty() && fi != (*formData).end()) {
cout << "Value Selected: " << **fi << endl;
}
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Использование файлов cookie в CGI
Протокол HTTP - это протокол без сохранения состояния. Но для коммерческого веб-сайта требуется поддерживать информацию о сеансе между разными страницами. Например, регистрация одного пользователя заканчивается после заполнения множества страниц. Но как сохранить информацию о сеансе пользователя на всех веб-страницах.
Во многих ситуациях использование файлов cookie является наиболее эффективным методом запоминания и отслеживания предпочтений, покупок, комиссионных и другой информации, необходимой для лучшего взаимодействия с посетителями или статистики сайта.
Как это устроено
Ваш сервер отправляет некоторые данные в браузер посетителя в виде файла cookie. Браузер может принять файл cookie. Если это так, он сохраняется в виде простой текстовой записи на жестком диске посетителя. Теперь, когда посетитель переходит на другую страницу вашего сайта, cookie доступен для поиска. После получения ваш сервер знает / запоминает, что было сохранено.
Файлы cookie представляют собой запись данных в виде простого текста из 5 полей переменной длины:
Expires- Показывает дату истечения срока действия cookie. Если это поле пусто, срок действия cookie истечет, когда посетитель закроет браузер.
Domain - Это показывает доменное имя вашего сайта.
Path- Показывает путь к каталогу или веб-странице, в которой установлен файл cookie. Это может быть пустое поле, если вы хотите получить cookie из любого каталога или страницы.
Secure- Если это поле содержит слово «безопасный», то cookie может быть получен только с помощью безопасного сервера. Если это поле пустое, такое ограничение отсутствует.
Name = Value - Файлы cookie устанавливаются и извлекаются в виде пар ключ-значение.
Настройка файлов cookie
Отправить файлы cookie в браузер очень просто. Эти файлы cookie будут отправлены вместе с заголовком HTTP перед заполнением типа содержимого. Предполагая, что вы хотите установить UserID и Password как файлы cookie. Таким образом, настройка файлов cookie будет осуществляться следующим образом
#include <iostream>
using namespace std;
int main () {
cout << "Set-Cookie:UserID = XYZ;\r\n";
cout << "Set-Cookie:Password = XYZ123;\r\n";
cout << "Set-Cookie:Domain = www.tutorialspoint.com;\r\n";
cout << "Set-Cookie:Path = /perl;\n";
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "Setting cookies" << endl;
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Из этого примера вы, должно быть, поняли, как устанавливать файлы cookie. Мы используемSet-Cookie Заголовок HTTP для установки файлов cookie.
Здесь необязательно устанавливать атрибуты файлов cookie, такие как Expires, Domain и Path. Примечательно, что файлы cookie устанавливаются перед отправкой волшебной строки"Content-type:text/html\r\n\r\n.
Скомпилируйте указанную выше программу для создания setcookies.cgi и попробуйте установить файлы cookie, используя следующую ссылку. На вашем компьютере будут установлены четыре файла cookie -
/cgi-bin/setcookies.cgi
Получение файлов cookie
Получить все установленные файлы cookie легко. Файлы cookie хранятся в переменной среды CGI HTTP_COOKIE и будут иметь следующую форму.
key1 = value1; key2 = value2; key3 = value3....Вот пример того, как получить файлы cookie.
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
const_cookie_iterator cci;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>Cookies in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
cout << "<table border = \"0\" cellspacing = \"2\">";
// get environment variables
const CgiEnvironment& env = cgi.getEnvironment();
for( cci = env.getCookieList().begin();
cci != env.getCookieList().end();
++cci ) {
cout << "<tr><td>" << cci->getName() << "</td><td>";
cout << cci->getValue();
cout << "</td></tr>\n";
}
cout << "</table><\n";
cout << "<br/>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Теперь скомпилируйте указанную выше программу для создания getcookies.cgi и попытайтесь получить список всех файлов cookie, доступных на вашем компьютере -
/cgi-bin/getcookies.cgi
Это создаст список всех четырех файлов cookie, установленных в предыдущем разделе, и всех других файлов cookie, установленных на вашем компьютере -
UserID XYZ
Password XYZ123
Domain www.tutorialspoint.com
Path /perlПример загрузки файла
Чтобы загрузить файл, HTML-форма должна иметь атрибут enctype, установленный на multipart/form-data. Тег ввода с типом файла создаст кнопку «Обзор».
<html>
<body>
<form enctype = "multipart/form-data" action = "/cgi-bin/cpp_uploadfile.cgi"
method = "post">
<p>File: <input type = "file" name = "userfile" /></p>
<p><input type = "submit" value = "Upload" /></p>
</form>
</body>
</html>Результатом этого кода является следующая форма -
Note- Приведенный выше пример был отключен намеренно, чтобы люди не загружали файлы на наш сервер. Но вы можете попробовать приведенный выше код на своем сервере.
Вот сценарий cpp_uploadfile.cpp для обработки загрузки файла -
#include <iostream>
#include <vector>
#include <string>
#include <stdio.h>
#include <stdlib.h>
#include <cgicc/CgiDefs.h>
#include <cgicc/Cgicc.h>
#include <cgicc/HTTPHTMLHeader.h>
#include <cgicc/HTMLClasses.h>
using namespace std;
using namespace cgicc;
int main () {
Cgicc cgi;
cout << "Content-type:text/html\r\n\r\n";
cout << "<html>\n";
cout << "<head>\n";
cout << "<title>File Upload in CGI</title>\n";
cout << "</head>\n";
cout << "<body>\n";
// get list of files to be uploaded
const_file_iterator file = cgi.getFile("userfile");
if(file != cgi.getFiles().end()) {
// send data type at cout.
cout << HTTPContentHeader(file->getDataType());
// write content at cout.
file->writeToStream(cout);
}
cout << "<File uploaded successfully>\n";
cout << "</body>\n";
cout << "</html>\n";
return 0;
}Приведенный выше пример предназначен для записи содержимого на cout stream, но вы можете открыть свой файловый поток и сохранить содержимое загруженного файла в файл в нужном месте.
Надеюсь, вам понравился этот урок. Если да, пришлите нам свой отзыв.