MongoDB - Краткое руководство
MongoDB - это кроссплатформенная документно-ориентированная база данных, которая обеспечивает высокую производительность, доступность и простую масштабируемость. MongoDB работает над концепцией коллекции и документа.
База данных
База данных - это физический контейнер для коллекций. Каждая база данных получает свой собственный набор файлов в файловой системе. Один сервер MongoDB обычно имеет несколько баз данных.
Коллекция
Коллекция - это группа документов MongoDB. Это эквивалент таблицы СУБД. Коллекция существует в одной базе данных. Коллекции не применяют схему. Документы в коллекции могут иметь разные поля. Как правило, все документы в коллекции имеют схожие или связанные цели.
Документ
Документ - это набор пар ключ-значение. Документы имеют динамическую схему. Динамическая схема означает, что документы в одной коллекции не обязательно должны иметь одинаковый набор полей или структуру, а общие поля в документах коллекции могут содержать разные типы данных.
В следующей таблице показана связь терминологии СУБД с MongoDB.
| СУБД | MongoDB |
|---|---|
| База данных | База данных |
| Стол | Коллекция |
| Кортеж / строка | Документ |
| столбец | Поле |
| Присоединение к таблице | Встроенные документы |
| Основной ключ | Первичный ключ (ключ по умолчанию _id, предоставляемый самим mongodb) |
| Сервер базы данных и клиент | |
| Mysqld / Oracle | монгод |
| mysql / sqlplus | монго |
Образец документа
В следующем примере показана структура документа сайта блога, которая представляет собой просто пару значений ключа, разделенных запятыми.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}_idпредставляет собой шестнадцатеричное число из 12 байтов, обеспечивающее уникальность каждого документа. Вы можете указать _id при вставке документа. Если вы не предоставите, MongoDB предоставляет уникальный идентификатор для каждого документа. Эти 12 байтов: первые 4 байта для текущей метки времени, следующие 3 байта для идентификатора машины, следующие 2 байта для идентификатора процесса сервера MongoDB и оставшиеся 3 байта представляют собой простое инкрементное ЗНАЧЕНИЕ.
Любая реляционная база данных имеет типичный дизайн схемы, который показывает количество таблиц и отношения между этими таблицами. В MongoDB нет концепции отношений.
Преимущества MongoDB перед СУБД
Schema less- MongoDB - это база данных документов, в одной коллекции которой хранятся разные документы. Количество полей, содержание и размер документа могут отличаться от одного документа к другому.
Структура единого объекта понятна.
Никаких сложных стыков.
Возможность глубокого запроса. MongoDB поддерживает динамические запросы к документам, используя язык запросов на основе документов, который почти такой же мощный, как SQL.
Tuning.
Ease of scale-out - MongoDB легко масштабируется.
Преобразование / отображение объектов приложения в объекты базы данных не требуется.
Использует внутреннюю память для хранения (оконного) рабочего набора, что обеспечивает более быстрый доступ к данным.
Зачем использовать MongoDB?
Document Oriented Storage - Данные хранятся в виде документов в стиле JSON.
Индексировать любой атрибут
Репликация и высокая доступность
Auto-sharding
Богатые запросы
Быстрые обновления на месте
Профессиональная поддержка MongoDB
Где использовать MongoDB?
- Большие данные
- Управление контентом и доставка
- Мобильная и социальная инфраструктура
- Управление данными пользователей
- Центр данных
Давайте теперь посмотрим, как установить MongoDB в Windows.
Установить MongoDB в Windows
Чтобы установить MongoDB в Windows, сначала загрузите последнюю версию MongoDB из https://www.mongodb.org/downloads. Убедитесь, что вы получили правильную версию MongoDB в зависимости от вашей версии Windows. Чтобы получить версию Windows, откройте командную строку и выполните следующую команду.
C:\>wmic os get osarchitecture
OSArchitecture
64-bit
C:\>32-разрядные версии MongoDB поддерживают только базы данных размером менее 2 ГБ и подходят только для целей тестирования и оценки.
Теперь извлеките загруженный файл на диск c: \ или в любое другое место. Убедитесь, что имя извлеченной папки - mongodb-win32-i386- [версия] или mongodb-win32-x86_64- [версия]. Здесь [версия] - это версия загрузки MongoDB.
Затем откройте командную строку и выполните следующую команду.
C:\>move mongodb-win64-* mongodb
1 dir(s) moved.
C:\>Если вы извлекли MongoDB в другом месте, перейдите по этому пути с помощью команды cd FOLDER/DIR и теперь запустите указанный выше процесс.
MongoDB требует папки данных для хранения файлов. Расположение по умолчанию для каталога данных MongoDB - c: \ data \ db. Итак, вам нужно создать эту папку с помощью командной строки. Выполните следующую последовательность команд.
C:\>md data
C:\md data\dbЕсли вам нужно установить MongoDB в другом месте, вам нужно указать альтернативный путь для \data\db задав путь dbpath в mongod.exe. Для того же введите следующие команды.
В командной строке перейдите в каталог bin, находящийся в папке установки MongoDB. Предположим, моя установочная папкаD:\set up\mongodb
C:\Users\XYZ>d:
D:\>cd "set up"
D:\set up>cd mongodb
D:\set up\mongodb>cd bin
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"Это покажет waiting for connections сообщение на выходе консоли, которое указывает, что процесс mongod.exe выполняется успешно.
Теперь, чтобы запустить MongoDB, вам нужно открыть другую командную строку и ввести следующую команду.
D:\set up\mongodb\bin>mongo.exe
MongoDB shell version: 2.4.6
connecting to: test
>db.test.save( { a: 1 } )
>db.test.find()
{ "_id" : ObjectId(5879b0f65a56a454), "a" : 1 }
>Это покажет, что MongoDB установлена и работает успешно. В следующий раз, когда вы запустите MongoDB, вам нужно будет вводить только команды.
D:\set up\mongodb\bin>mongod.exe --dbpath "d:\set up\mongodb\data"
D:\set up\mongodb\bin>mongo.exeУстановите MongoDB в Ubuntu
Выполните следующую команду, чтобы импортировать открытый ключ GPG MongoDB -
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10Создайте файл /etc/apt/sources.list.d/mongodb.list, используя следующую команду.
echo 'deb http://downloads-distro.mongodb.org/repo/ubuntu-upstart dist 10gen'
| sudo tee /etc/apt/sources.list.d/mongodb.listТеперь выполните следующую команду, чтобы обновить репозиторий -
sudo apt-get updateЗатем установите MongoDB, используя следующую команду -
apt-get install mongodb-10gen = 2.2.3В указанной выше установке в настоящее время выпущена версия MongoDB 2.2.3. Всегда устанавливайте последнюю версию. Теперь MongoDB успешно установлен.
Запустить MongoDB
sudo service mongodb startОстановить MongoDB
sudo service mongodb stopПерезапустите MongoDB
sudo service mongodb restartЧтобы использовать MongoDB, выполните следующую команду.
mongoЭто подключит вас к запущенному экземпляру MongoDB.
Справка MongoDB
Чтобы получить список команд, введите db.help()в клиенте MongoDB. Это даст вам список команд, как показано на следующем снимке экрана.

Статистика MongoDB
Чтобы получить статистику о сервере MongoDB, введите команду db.stats()в клиенте MongoDB. Это покажет имя базы данных, номер коллекции и документов в базе данных. Вывод команды показан на следующем снимке экрана.

Данные в MongoDB имеют гибкую схему. Документы в одной коллекции. Им не обязательно иметь одинаковый набор полей или структуру, а общие поля в документах коллекции могут содержать разные типы данных.
Некоторые соображения при разработке схемы в MongoDB
Создайте схему в соответствии с требованиями пользователя.
Объединяйте объекты в один документ, если будете использовать их вместе. В противном случае разделите их (но убедитесь, что соединения не нужны).
Дублируйте данные (но с ограничениями), потому что дисковое пространство дешево по сравнению со временем вычислений.
Присоединяется при записи, а не при чтении.
Оптимизируйте схему для наиболее частых случаев использования.
Выполните сложную агрегацию в схеме.
пример
Предположим, клиенту нужен дизайн базы данных для своего блога / веб-сайта и он видит различия между РСУБД и схемой MongoDB. Веб-сайт имеет следующие требования.
- Каждый пост имеет уникальный заголовок, описание и URL.
- У каждого сообщения может быть один или несколько тегов.
- У каждого поста есть имя его издателя и общее количество лайков.
- У каждого поста есть комментарии, оставленные пользователями, а также их имя, сообщение, время данных и лайки.
- К каждому посту может быть ноль или более комментариев.
В схеме РСУБД дизайн для вышеуказанных требований будет иметь минимум три таблицы.

В схеме MongoDB дизайн будет иметь один пост коллекции и следующую структуру:
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}Таким образом, при отображении данных в РСУБД необходимо объединить три таблицы, а в MongoDB данные будут отображаться только из одной коллекции.
В этой главе мы увидим, как создать базу данных в MongoDB.
Команда использования
MongoDB use DATABASE_NAMEиспользуется для создания базы данных. Команда создаст новую базу данных, если она не существует, в противном случае она вернет существующую базу данных.
Синтаксис
Базовый синтаксис use DATABASE заявление выглядит следующим образом -
use DATABASE_NAMEпример
Если вы хотите использовать базу данных с именем <mydb>, тогда use DATABASE заявление будет следующим -
>use mydb
switched to db mydbЧтобы проверить текущую выбранную базу данных, используйте команду db
>db
mydbЕсли вы хотите проверить список своих баз данных, используйте команду show dbs.
>show dbs
local 0.78125GB
test 0.23012GBСозданная вами база данных (mydb) отсутствует в списке. Для отображения базы данных необходимо вставить в нее хотя бы один документ.
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GBВ MongoDB база данных по умолчанию - test. Если вы не создавали никакой базы данных, то коллекции будут храниться в тестовой базе данных.
В этой главе мы увидим, как удалить базу данных с помощью команды MongoDB.
Метод dropDatabase ()
MongoDB db.dropDatabase() команда используется для удаления существующей базы данных.
Синтаксис
Базовый синтаксис dropDatabase() команда выглядит следующим образом -
db.dropDatabase()Это удалит выбранную базу данных. Если вы не выбрали ни одной базы данных, будет удалена «тестовая» база данных по умолчанию.
пример
Сначала проверьте список доступных баз данных с помощью команды, show dbs.
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
>Если вы хотите удалить новую базу данных <mydb>, тогда dropDatabase() команда будет следующей -
>use mydb
switched to db mydb
>db.dropDatabase()
>{ "dropped" : "mydb", "ok" : 1 }
>Теперь проверьте список баз данных.
>show dbs
local 0.78125GB
test 0.23012GB
>В этой главе мы увидим, как создать коллекцию с помощью MongoDB.
Метод createCollection ()
MongoDB db.createCollection(name, options) используется для создания коллекции.
Синтаксис
Базовый синтаксис createCollection() команда выглядит следующим образом -
db.createCollection(name, options)В команде name - название создаваемой коллекции. Options является документом и используется для указания конфигурации коллекции.
| Параметр | Тип | Описание |
|---|---|---|
| имя | Строка | Название создаваемой коллекции |
| Параметры | Документ | (Необязательно) Укажите параметры, касающиеся размера памяти и индексации |
Параметр Options является необязательным, поэтому вам нужно указать только название коллекции. Ниже приведен список опций, которые вы можете использовать -
| Поле | Тип | Описание |
|---|---|---|
| закрытый | Булево | (Необязательно) Если true, включает ограниченную коллекцию. Ограниченная коллекция - это коллекция фиксированного размера, которая автоматически перезаписывает свои самые старые записи при достижении максимального размера.If you specify true, you need to specify size parameter also. |
| autoIndexId | Булево | (Необязательно) Если true, автоматически создать индекс для поля _id. Значение по умолчанию - false. |
| размер | количество | (Необязательно) Задает максимальный размер в байтах для закрытой коллекции. If capped is true, then you need to specify this field also. |
| Максимум | количество | (Необязательно) Задает максимальное количество документов, разрешенное в закрытой коллекции. |
При вставке документа MongoDB сначала проверяет поле размера ограниченной коллекции, а затем проверяет поле max.
Примеры
Базовый синтаксис createCollection() метод без параметров выглядит следующим образом -
>use test
switched to db test
>db.createCollection("mycollection")
{ "ok" : 1 }
>Проверить созданную коллекцию можно с помощью команды show collections.
>show collections
mycollection
system.indexesВ следующем примере показан синтаксис createCollection() метод с несколькими важными опциями -
>db.createCollection("mycol", { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
{ "ok" : 1 }
>В MongoDB вам не нужно создавать коллекцию. MongoDB создает коллекцию автоматически, когда вы вставляете какой-либо документ.
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>В этой главе мы увидим, как удалить коллекцию с помощью MongoDB.
Метод drop ()
MongoDB's db.collection.drop() используется для удаления коллекции из базы данных.
Синтаксис
Базовый синтаксис drop() команда выглядит следующим образом -
db.COLLECTION_NAME.drop()пример
Сначала проверьте доступные коллекции в своей базе данных mydb.
>use mydb
switched to db mydb
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>Теперь опустите коллекцию с названием mycollection.
>db.mycollection.drop()
true
>Снова проверьте список коллекций в базе данных.
>show collections
mycol
system.indexes
tutorialspoint
>drop () вернет true, если выбранная коллекция будет успешно удалена, иначе вернет false.
MongoDB поддерживает множество типов данных. Некоторые из них -
String- Это наиболее часто используемый тип данных для хранения данных. Строка в MongoDB должна быть действительной в кодировке UTF-8.
Integer- Этот тип используется для хранения числового значения. Целое число может быть 32-битным или 64-битным в зависимости от вашего сервера.
Boolean - Этот тип используется для хранения логического (истина / ложь) значения.
Double - Этот тип используется для хранения значений с плавающей запятой.
Min/ Max keys - Этот тип используется для сравнения значения с самым низким и самым высоким элементами BSON.
Arrays - Этот тип используется для хранения массивов или списка или нескольких значений в одном ключе.
Timestamp- ctimestamp. Это может быть удобно для записи, когда документ был изменен или добавлен.
Object - Этот тип данных используется для встроенных документов.
Null - Этот тип используется для хранения нулевого значения.
Symbol- Этот тип данных используется идентично строке; однако обычно он зарезервирован для языков, использующих определенный тип символа.
Date - Этот тип данных используется для хранения текущей даты или времени в формате времени UNIX. Вы можете указать собственное время даты, создав объект Date и пропустив в него день, месяц, год.
Object ID - Этот тип данных используется для хранения идентификатора документа.
Binary data - Этот тип данных используется для хранения двоичных данных.
Code - Этот тип данных используется для хранения кода JavaScript в документе.
Regular expression - Этот тип данных используется для хранения регулярного выражения.
В этой главе мы узнаем, как вставить документ в коллекцию MongoDB.
Метод insert ()
Чтобы вставить данные в коллекцию MongoDB, вам необходимо использовать MongoDB insert() или же save() метод.
Синтаксис
Базовый синтаксис insert() команда выглядит следующим образом -
>db.COLLECTION_NAME.insert(document)пример
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})Вот mycolэто имя нашей коллекции, созданной в предыдущей главе. Если коллекция не существует в базе данных, MongoDB создаст эту коллекцию, а затем вставит в нее документ.
Во вставленном документе, если мы не указываем параметр _id, MongoDB назначает уникальный ObjectId для этого документа.
_id - это 12-байтовое шестнадцатеричное число, уникальное для каждого документа в коллекции. 12 байтов делятся следующим образом -
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id,
3 bytes incrementer)Чтобы вставить несколько документов в один запрос, вы можете передать массив документов в команде insert ().
пример
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: "NoSQL database doesn't have tables",
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])Чтобы вставить документ, вы можете использовать db.post.save(document)также. Если вы не укажете_id в документе тогда save() метод будет работать так же, как insert()метод. Если вы укажете _id, он заменит все данные документа, содержащего _id, как указано в методе save ().
В этой главе мы узнаем, как запрашивать документ из коллекции MongoDB.
Метод find ()
Чтобы запросить данные из коллекции MongoDB, вам необходимо использовать MongoDB find() метод.
Синтаксис
Базовый синтаксис find() метод выглядит следующим образом -
>db.COLLECTION_NAME.find()find() метод отобразит все документы в неструктурированном виде.
Метод pretty ()
Чтобы отобразить результаты в форматированном виде, вы можете использовать pretty() метод.
Синтаксис
>db.mycol.find().pretty()пример
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Помимо метода find () существует findOne() метод, который возвращает только один документ.
РСУБД, эквивалентные предложениям в MongoDB
Чтобы запросить документ на основе некоторого условия, вы можете использовать следующие операции.
| Операция | Синтаксис | пример | Эквивалент РСУБД |
|---|---|---|---|
| Равенство | {<ключ>: <значение>} | db.mycol.find ({"автор": "точка обучения"}). pretty () | где by = 'точка обучения' |
| Меньше, чем | {<ключ>: {$ lt: <значение>}} | db.mycol.find ({"любит": {$ lt: 50}}). pretty () | где лайков <50 |
| Меньше, чем равно | {<ключ>: {$ lte: <значение>}} | db.mycol.find ({"любит": {$ lte: 50}}). pretty () | где лайков <= 50 |
| Лучше чем | {<ключ>: {$ gt: <значение>}} | db.mycol.find ({"любит": {$ gt: 50}}). pretty () | где лайков> 50 |
| Больше, чем равно | {<ключ>: {$ gte: <значение>}} | db.mycol.find ({"любит": {$ gte: 50}}). pretty () | где лайков> = 50 |
| Не равно | {<ключ>: {$ ne: <значение>}} | db.mycol.find ({"любит": {$ ne: 50}}). pretty () | где лайки! = 50 |
И в MongoDB
Синтаксис
в find() метод, если вы передаете несколько ключей, разделяя их символом ',' MongoDB рассматривает его как ANDсостояние. Ниже приводится базовый синтаксисAND -
>db.mycol.find(
{
$and: [
{key1: value1}, {key2:value2}
]
}
).pretty()пример
В следующем примере будут показаны все учебные пособия, написанные «точкой обучения» и названные «Обзор MongoDB».
>db.mycol.find({$and:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty() {
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}Для приведенного выше примера эквивалент предложения where будет ' where by = 'tutorials point' AND title = 'MongoDB Overview' '. Вы можете передать любое количество пар ключ-значение в предложении find.
ИЛИ в MongoDB
Синтаксис
Чтобы запрашивать документы на основе условия ИЛИ, вам необходимо использовать $orключевое слово. Ниже приводится базовый синтаксисOR -
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()пример
В следующем примере будут показаны все учебные пособия, написанные «точкой обучения» или название которых - «Обзор MongoDB».
>db.mycol.find({$or:[{"by":"tutorials point"},{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>Использование И и ИЛИ вместе
пример
В следующем примере будут показаны документы, которые имеют больше 10 лайков и заголовок либо «Обзор MongoDB», либо «Точка обучения». Эквивалентный SQL-запрос where'where likes>10 AND (by = 'tutorials point' OR title = 'MongoDB Overview')'
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>MongoDB's update() и save()методы используются для обновления документа в коллекцию. Метод update () обновляет значения в существующем документе, а метод save () заменяет существующий документ документом, переданным в методе save ().
Метод обновления MongoDB ()
Метод update () обновляет значения в существующем документе.
Синтаксис
Базовый синтаксис update() метод выглядит следующим образом -
>db.COLLECTION_NAME.update(SELECTION_CRITERIA, UPDATED_DATA)пример
Учтите, что коллекция mycol содержит следующие данные.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}В следующем примере будет установлено новое название «Новое руководство по MongoDB» для документов с названием «Обзор MongoDB».
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>По умолчанию MongoDB обновляет только один документ. Чтобы обновить несколько документов, вам необходимо установить для параметра multi значение true.
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})Метод MongoDB Save ()
В save() заменяет существующий документ новым документом, переданным в методе save ().
Синтаксис
Базовый синтаксис MongoDB save() метод показан ниже -
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})пример
В следующем примере документ заменяется на _id '5983548781331adf45ec5'.
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"
}
)
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>В этой главе мы узнаем, как удалить документ с помощью MongoDB.
Метод remove ()
MongoDB's remove()используется для удаления документа из коллекции. Метод remove () принимает два параметра. Один - это критерии удаления, а второй - флаг justOne.
deletion criteria - (Необязательно) критерии удаления по документам будут удалены.
justOne - (Необязательно) если установлено значение true или 1, удалить только один документ.
Синтаксис
Базовый синтаксис remove() метод выглядит следующим образом -
>db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)пример
Учтите, что коллекция mycol содержит следующие данные.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}В следующем примере будут удалены все документы с заголовком «Обзор MongoDB».
>db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>Удалить только один
Если имеется несколько записей и вы хотите удалить только первую запись, установите justOne параметр в remove() метод.
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)Удалить все документы
Если вы не укажете критерии удаления, MongoDB удалит все документы из коллекции. This is equivalent of SQL's truncate command.
>db.mycol.remove({})
>db.mycol.find()
>В MongoDB проекция означает выбор только необходимых данных, а не выбор всех данных документа. Если в документе 5 полей и вам нужно показать только 3, выберите из них только 3 поля.
Метод find ()
MongoDB's find()Метод, описанный в документе запроса MongoDB, принимает второй необязательный параметр, который представляет собой список полей, которые вы хотите получить. В MongoDB при выполненииfind()метод, то он отображает все поля документа. Чтобы ограничить это, вам необходимо установить список полей со значением 1 или 0. 1 используется для отображения поля, а 0 используется для скрытия полей.
Синтаксис
Базовый синтаксис find() метод с проекцией выглядит следующим образом -
>db.COLLECTION_NAME.find({},{KEY:1})пример
Учтите, что коллекция mycol имеет следующие данные -
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}В следующем примере будет отображаться заголовок документа при запросе документа.
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>пожалуйста, обратите внимание _id поле всегда отображается при выполнении find() метод, если вам не нужно это поле, вам нужно установить его как 0.
В этой главе мы узнаем, как ограничить количество записей с помощью MongoDB.
Метод Limit ()
Чтобы ограничить записи в MongoDB, вам необходимо использовать limit()метод. Метод принимает один аргумент числового типа, который представляет собой количество документов, которые вы хотите отобразить.
Синтаксис
Базовый синтаксис limit() метод выглядит следующим образом -
>db.COLLECTION_NAME.find().limit(NUMBER)пример
Рассмотрим коллекцию myycol, имеющую следующие данные.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}В следующем примере при запросе документа будут отображаться только два документа.
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>Если вы не укажете числовой аргумент в limit() , то он отобразит все документы из коллекции.
Метод MongoDB Skip ()
Помимо метода limit (), есть еще один метод skip() который также принимает аргумент числового типа и используется для пропуска количества документов.
Синтаксис
Базовый синтаксис skip() метод выглядит следующим образом -
>db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)пример
В следующем примере будет отображаться только второй документ.
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>Обратите внимание, значение по умолчанию в skip() метод 0.
В этой главе мы узнаем, как сортировать записи в MongoDB.
Метод sort ()
Чтобы отсортировать документы в MongoDB, вам необходимо использовать sort()метод. Метод принимает документ, содержащий список полей вместе с порядком их сортировки. Для указания порядка сортировки используются 1 и -1. 1 используется в порядке возрастания, а -1 - в порядке убывания.
Синтаксис
Базовый синтаксис sort() метод выглядит следующим образом -
>db.COLLECTION_NAME.find().sort({KEY:1})пример
Рассмотрим коллекцию myycol, имеющую следующие данные.
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}В следующем примере будут отображаться документы, отсортированные по заголовку в порядке убывания.
>db.mycol.find({},{"title":1,_id:0}).sort({"title":-1})
{"title":"Tutorials Point Overview"}
{"title":"NoSQL Overview"}
{"title":"MongoDB Overview"}
>Обратите внимание: если вы не укажете предпочтение сортировки, то sort() метод отобразит документы в порядке возрастания.
Индексы поддерживают эффективное разрешение запросов. Без индексов MongoDB должен сканировать каждый документ коллекции, чтобы выбрать те документы, которые соответствуют запросу запроса. Это сканирование крайне неэффективно и требует от MongoDB обработки большого объема данных.
Индексы - это специальные структуры данных, которые хранят небольшую часть набора данных в удобной для просмотра форме. В индексе хранится значение определенного поля или набора полей, упорядоченных по значению поля, как указано в индексе.
Метод sureIndex ()
Чтобы создать индекс, вам необходимо использовать метод sureIndex () MongoDB.
Синтаксис
Базовый синтаксис ensureIndex() метод выглядит следующим образом ().
>db.COLLECTION_NAME.ensureIndex({KEY:1})Здесь ключ - это имя поля, для которого вы хотите создать индекс, а 1 - для возрастания. Чтобы создать индекс в порядке убывания, вам нужно использовать -1.
пример
>db.mycol.ensureIndex({"title":1})
>В ensureIndex() вы можете передать несколько полей, чтобы создать индекс для нескольких полей.
>db.mycol.ensureIndex({"title":1,"description":-1})
>ensureIndex()Метод также принимает список опций (которые не являются обязательными). Ниже приводится список -
| Параметр | Тип | Описание |
|---|---|---|
| задний план | Булево | Создает индекс в фоновом режиме, чтобы создание индекса не блокировало другие действия базы данных. Укажите true для построения в фоновом режиме. Значение по умолчанию -false. |
| уникальный | Булево | Создает уникальный индекс, чтобы коллекция не принимала вставку документов, в которых индексный ключ или ключи совпадают с существующим значением в индексе. Укажите true, чтобы создать уникальный индекс. Значение по умолчанию -false. |
| имя | строка | Имя индекса. Если не указано иное, MongoDB генерирует имя индекса, объединяя имена проиндексированных полей и порядок сортировки. |
| dropDups | Булево | Создает уникальный индекс для поля, которое может иметь дубликаты. MongoDB индексирует только первое вхождение ключа и удаляет все документы из коллекции, которые содержат последующие вхождения этого ключа. Укажите true, чтобы создать уникальный индекс. Значение по умолчанию -false. |
| редкий | Булево | Если true, индекс ссылается только на документы с указанным полем. Эти индексы занимают меньше места, но в некоторых ситуациях (особенно при сортировке) ведут себя иначе. Значение по умолчанию -false. |
| expireAfterSeconds | целое число | Задает значение в секундах в качестве TTL, чтобы контролировать, как долго MongoDB хранит документы в этой коллекции. |
| v | индексная версия | Номер версии индекса. Версия индекса по умолчанию зависит от версии MongoDB, запущенной при создании индекса. |
| веса | документ | Вес представляет собой число от 1 до 99 999 и обозначает значимость поля по сравнению с другими проиндексированными полями с точки зрения оценки. |
| язык по умолчанию | строка | Для текстового индекса - язык, определяющий список стоп-слов и правила для стеммера и токенизатора. Значение по умолчанию -english. |
| language_override | строка | Для текстового индекса укажите имя поля в документе, которое содержит язык, который будет заменять язык по умолчанию. Значение по умолчанию - язык. |
Операции агрегирования обрабатывают записи данных и возвращают вычисленные результаты. Операции агрегирования группируют значения из нескольких документов вместе и могут выполнять различные операции с сгруппированными данными для возврата одного результата. В SQL count (*) и с group by эквивалентно агрегации mongodb.
Метод aggregate ()
Для агрегации в MongoDB вы должны использовать aggregate() метод.
Синтаксис
Базовый синтаксис aggregate() метод выглядит следующим образом -
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)пример
В коллекции у вас есть следующие данные -
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},Теперь из приведенной выше коллекции, если вы хотите отобразить список, в котором указано, сколько руководств написано каждым пользователем, вы будете использовать следующие aggregate() метод -
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>Эквивалентный запрос sql для вышеуказанного варианта использования будет select by_user, count(*) from mycol group by by_user.
В приведенном выше примере мы сгруппировали документы по полю by_userи при каждом появлении by_user предыдущее значение суммы увеличивается. Ниже приведен список доступных выражений агрегирования.
| Выражение | Описание | пример |
|---|---|---|
| $ сумма | Суммирует определенное значение из всех документов в коллекции. | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$сумма: "$ любит"}}}]) |
| в среднем | Вычисляет среднее значение всех заданных значений для всех документов в коллекции. | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$avg : "$нравится"}}}]) |
| $ мин | Получает минимум соответствующих значений из всех документов в коллекции. | db.mycol.aggregate ([{$ group: {_id: "$by_user", num_tutorial : {$min: "$ like"}}}]) |
| $ макс | Получает максимум соответствующих значений из всех документов в коллекции. | db.mycol.aggregate ([{$group : {_id : "$by_user ", num_tutorial: {$max : "$нравится"}}}]) |
| $ push | Вставляет значение в массив в результирующий документ. | db.mycol.aggregate ([{$ group: {_id: "$by_user", url : {$push: "$ url"}}}]) |
| $ addToSet | Вставляет значение в массив в итоговом документе, но не создает дубликатов. | db.mycol.aggregate ([{$group : {_id : "$by_user ", url: {$addToSet : "$url "}}}]) |
| $ первый | Получает первый документ из исходных документов в соответствии с группировкой. Обычно это имеет смысл только вместе с некоторым ранее примененным этапом «$ sort». | db.mycol.aggregate ([{$group : {_id : "$by_user ", first_url: {$first : "$url "}}}]) |
| $ последний | Получает последний документ из исходных документов в соответствии с группировкой. Обычно это имеет смысл только вместе с некоторым ранее примененным этапом «$ sort». | db.mycol.aggregate ([{$group : {_id : "$by_user ", last_url: {$last : "$url "}}}]) |
Концепция трубопровода
В команде UNIX конвейер оболочки означает возможность выполнить операцию над некоторым вводом и использовать вывод как ввод для следующей команды и так далее. MongoDB также поддерживает ту же концепцию в структуре агрегирования. Существует набор возможных этапов, и каждый из них берется как набор документов в качестве входных и создает результирующий набор документов (или окончательный результирующий документ JSON в конце конвейера). Затем это, в свою очередь, можно использовать на следующем этапе и так далее.
Ниже приведены возможные этапы в структуре агрегирования.
$project - Используется для выбора определенных полей из коллекции.
$match - Это операция фильтрации, и, таким образом, это может уменьшить количество документов, которые вводятся на следующем этапе.
$group - Это фактическое агрегирование, как описано выше.
$sort - Сортировка документов.
$skip - При этом можно перейти вперед в списке документов для заданного количества документов.
$limit - Это ограничивает количество документов для просмотра заданным числом, начиная с текущих позиций.
$unwind- Используется для раскрутки документа, использующего массивы. При использовании массива данные предварительно объединяются, и эта операция будет отменена, чтобы снова получить отдельные документы. Таким образом, на этом этапе мы увеличим количество документов для следующего этапа.
Репликация - это процесс синхронизации данных на нескольких серверах. Репликация обеспечивает избыточность и увеличивает доступность данных за счет нескольких копий данных на разных серверах баз данных. Репликация защищает базу данных от потери одного сервера. Репликация также позволяет восстанавливаться после сбоя оборудования и прерывания обслуживания. Имея дополнительные копии данных, вы можете выделить одну для аварийного восстановления, создания отчетов или резервного копирования.
Почему репликация?
- Чтобы ваши данные были в безопасности
- Высокая (24 * 7) доступность данных
- Аварийное восстановление
- Отсутствие простоев на обслуживание (например, резервное копирование, восстановление индексов, сжатие)
- Масштабирование чтения (дополнительные копии для чтения)
- Набор реплик прозрачен для приложения
Как работает репликация в MongoDB
MongoDB обеспечивает репликацию с помощью набора реплик. Набор реплик - это группаmongodэкземпляры, содержащие один и тот же набор данных. В реплике один узел является основным узлом, на который выполняются все операции записи. Все другие экземпляры, такие как вторичные, применяют операции из первичного, чтобы у них был тот же набор данных. Набор реплик может иметь только один основной узел.
Набор реплик - это группа из двух или более узлов (обычно требуется минимум 3 узла).
В наборе реплик один узел является первичным, а остальные - вторичными.
Все данные реплицируются с первичного на вторичный узел.
Во время автоматического переключения при отказе или обслуживания выбирается основной и выбирается новый основной узел.
После восстановления отказавшего узла он снова присоединяется к набору реплик и работает как вторичный узел.
Показана типичная схема репликации MongoDB, на которой клиентское приложение всегда взаимодействует с первичным узлом, а первичный узел затем реплицирует данные на вторичные узлы.

Функции набора реплик
- Кластер из N узлов
- Любой узел может быть первичным
- Все операции записи переходят к основному
- Автоматическое переключение при отказе
- Автоматическое восстановление
- Консенсусные выборы первичных
Настройка набора реплик
В этом руководстве мы преобразуем автономный экземпляр MongoDB в набор реплик. Чтобы преобразовать в набор реплик, выполните следующие действия:
Завершение работы уже запущенного сервера MongoDB.
Запустите сервер MongoDB, указав параметр - replSet. Ниже приведен основной синтаксис --replSet -
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"пример
mongod --port 27017 --dbpath "D:\set up\mongodb\data" --replSet rs0Он запустит экземпляр mongod с именем rs0 на порту 27017.
Теперь запустите командную строку и подключитесь к этому экземпляру mongod.
В клиенте Mongo введите команду rs.initiate() для создания нового набора реплик.
Чтобы проверить конфигурацию набора реплик, введите команду rs.conf(). Чтобы проверить статус набора реплик, выполните командуrs.status().
Добавить участников в набор реплик
Чтобы добавить участников в набор реплик, запустите экземпляры mongod на нескольких машинах. Теперь запустите клиент mongo и введите командуrs.add().
Синтаксис
Базовый синтаксис rs.add() команда выглядит следующим образом -
>rs.add(HOST_NAME:PORT)пример
Предположим, что имя вашего экземпляра mongod - mongod1.net и он работает на порту 27017. Чтобы добавить этот экземпляр в набор реплик, введите командуrs.add() в клиенте Mongo.
>rs.add("mongod1.net:27017")
>Вы можете добавить экземпляр mongod в набор реплик, только когда вы подключены к первичному узлу. Чтобы проверить, подключены ли вы к основному или нет, введите командуdb.isMaster() в клиенте монго.
Шардинг - это процесс хранения записей данных на нескольких машинах, и это подход MongoDB к удовлетворению требований роста объемов данных. По мере увеличения размера данных одной машины может оказаться недостаточно для хранения данных и обеспечения приемлемой пропускной способности чтения и записи. Шардинг решает проблему горизонтального масштабирования. С сегментированием вы добавляете больше машин для поддержки роста объемов данных и требований операций чтения и записи.
Почему шардинг?
- При репликации все записи идут на главный узел
- Запросы, чувствительные к задержке, по-прежнему передаются мастеру
- Набор одиночных реплик имеет ограничение в 12 узлов
- Память не может быть достаточно большой, когда активный набор данных большой
- Локальный диск недостаточно велик
- Вертикальное масштабирование слишком дорого
Шардинг в MongoDB
На следующей диаграмме показано сегментирование в MongoDB с использованием сегментированного кластера.

На следующей диаграмме есть три основных компонента:
Shards- Осколки используются для хранения данных. Они обеспечивают высокую доступность и согласованность данных. В производственной среде каждый сегмент представляет собой отдельный набор реплик.
Config Servers- Серверы конфигурации хранят метаданные кластера. Эти данные содержат сопоставление набора данных кластера с шардами. Маршрутизатор запросов использует эти метаданные для нацеливания операций на определенные сегменты. В производственной среде сегментированные кластеры имеют ровно 3 сервера конфигурации.
Query Routers- Маршрутизаторы запросов - это в основном экземпляры mongo, интерфейс с клиентскими приложениями и прямые операции с соответствующим шардом. Маршрутизатор запросов обрабатывает и направляет операции на шарды, а затем возвращает результаты клиентам. Разделенный кластер может содержать более одного маршрутизатора запросов для разделения нагрузки клиентских запросов. Клиент отправляет запросы одному маршрутизатору запросов. Обычно сегментированный кластер имеет много маршрутизаторов запросов.
В этой главе мы увидим, как создать резервную копию в MongoDB.
Дамп данных MongoDB
Чтобы создать резервную копию базы данных в MongoDB, вы должны использовать mongodumpкоманда. Эта команда сбросит все данные вашего сервера в каталог дампа. Доступно множество опций, с помощью которых вы можете ограничить объем данных или создать резервную копию вашего удаленного сервера.
Синтаксис
Базовый синтаксис mongodump команда выглядит следующим образом -
>mongodumpпример
Запустите свой сервер mongod. Предполагая, что ваш сервер mongod работает на локальном хосте и порту 27017, откройте командную строку, перейдите в каталог bin вашего экземпляра mongodb и введите командуmongodump
Учтите, что коллекция mycol содержит следующие данные.
>mongodumpКоманда подключится к серверу, работающему на 127.0.0.1 и порт 27017 и обратно все данные сервера в каталог /bin/dump/. Ниже приводится вывод команды -

Ниже приводится список доступных опций, которые можно использовать с mongodump команда.
| Синтаксис | Описание | пример |
|---|---|---|
| mongodump --host HOST_NAME --port PORT_NUMBER | Эта команда создаст резервную копию всех баз данных указанного экземпляра mongod. | mongodump --host tutorialspoint.com --port 27017 |
| mongodump --dbpath DB_PATH --out BACKUP_DIRECTORY | Эта команда создаст резервную копию только указанной базы данных по указанному пути. | mongodump --dbpath / data / db / --out / data / backup / |
| mongodump --collection КОЛЛЕКЦИЯ --db DB_NAME | Эта команда создаст резервную копию только указанной коллекции указанной базы данных. | mongodump --collection mycol --db test |
Восстановить данные
Чтобы восстановить данные из резервной копии MongoDB's mongorestoreиспользуется команда. Эта команда восстанавливает все данные из каталога резервных копий.
Синтаксис
Базовый синтаксис mongorestore команда -
>mongorestoreНиже приводится вывод команды -

Когда вы готовите развертывание MongoDB, вы должны попытаться понять, как ваше приложение будет оставаться в рабочем состоянии. Хорошая идея - разработать последовательный, повторяемый подход к управлению средой развертывания, чтобы свести к минимуму любые неожиданности, когда вы начнете работать.
Лучший подход включает создание прототипа вашей установки, проведение нагрузочного тестирования, мониторинг ключевых показателей и использование этой информации для масштабирования вашей установки. Ключевой частью этого подхода является проактивный мониторинг всей вашей системы - это поможет вам понять, как ваша производственная система будет работать до развертывания, и определить, где вам нужно будет добавить емкость. Например, понимание потенциальных всплесков использования памяти может помочь потушить пожар блокировки записи до того, как он начнется.
Для мониторинга вашего развертывания MongoDB предоставляет некоторые из следующих команд:
монгостат
Эта команда проверяет состояние всех запущенных экземпляров mongod и возвращает счетчики операций с базой данных. Эти счетчики включают вставки, запросы, обновления, удаления и курсоры. Команда также показывает, когда вы сталкиваетесь с ошибками страницы, и демонстрирует ваш процент блокировки. Это означает, что у вас не хватает памяти, ограничена емкость записи или есть проблемы с производительностью.
Чтобы запустить команду, запустите свой экземпляр mongod. В другой командной строке перейдите кbin каталог вашей установки mongodb и введите mongostat.
D:\set up\mongodb\bin>mongostatНиже приводится вывод команды -

монготоп
Эта команда отслеживает и сообщает об активности чтения и записи экземпляра MongoDB на основе коллекции. По умолчанию,mongotopвозвращает информацию каждую секунду, которую вы можете соответствующим образом изменить. Вы должны убедиться, что это действие чтения и записи соответствует намерению вашего приложения, и вы не запускаете слишком много операций записи в базу данных одновременно, не слишком часто читаете с диска или не превышаете размер рабочего набора.
Чтобы запустить команду, запустите свой экземпляр mongod. В другой командной строке перейдите кbin каталог вашей установки mongodb и введите mongotop.
D:\set up\mongodb\bin>mongotopНиже приводится вывод команды -
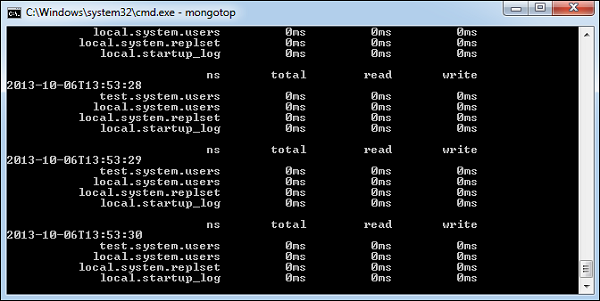
Изменить mongotop Чтобы информация возвращалась реже, укажите конкретное число после команды mongotop.
D:\set up\mongodb\bin>mongotop 30В приведенном выше примере значения будут возвращаться каждые 30 секунд.
Помимо инструментов MongoDB, 10gen предоставляет бесплатную размещенную службу мониторинга MongoDB Management Service (MMS), которая предоставляет панель управления и дает вам представление о показателях всего вашего кластера.
В этой главе мы узнаем, как настроить драйвер JDBC MongoDB.
Установка
Прежде чем вы начнете использовать MongoDB в своих программах Java, вам необходимо убедиться, что на вашем компьютере установлены драйвер MongoDB JDBC и Java. Вы можете проверить руководство по Java для установки Java на свой компьютер. Теперь давайте проверим, как настроить JDBC-драйвер MongoDB.
Вам необходимо скачать jar по пути Download mongo.jar . Обязательно скачайте последнюю версию.
Вам необходимо включить mongo.jar в свой путь к классам.
Подключиться к базе данных
Для подключения базы данных необходимо указать имя базы данных, если база данных не существует, MongoDB создает ее автоматически.
Ниже приведен фрагмент кода для подключения к базе данных.
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ConnectToDB {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Credentials ::"+ credential);
}
}Теперь давайте скомпилируем и запустим вышеуказанную программу, чтобы создать нашу базу данных myDb, как показано ниже.
$javac ConnectToDB.java
$java ConnectToDBПри выполнении вышеуказанная программа дает следующий результат.
Connected to the database successfully
Credentials ::MongoCredential{
mechanism = null,
userName = 'sampleUser',
source = 'myDb',
password = <hidden>,
mechanismProperties = {}
}Создать коллекцию
Чтобы создать коллекцию, createCollection() метод com.mongodb.client.MongoDatabase класс используется.
Ниже приведен фрагмент кода для создания коллекции -
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class CreatingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
//Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
//Creating a collection
database.createCollection("sampleCollection");
System.out.println("Collection created successfully");
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection created successfullyПолучение / выбор коллекции
Чтобы получить / выбрать коллекцию из базы данных, getCollection() метод com.mongodb.client.MongoDatabase класс используется.
Ниже приведена программа для получения / выбора коллекции -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class selectingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collection created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("myCollection");
System.out.println("Collection myCollection selected successfully");
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection created successfully
Collection myCollection selected successfullyВставить документ
Чтобы вставить документ в MongoDB, insert() метод com.mongodb.client.MongoCollection класс используется.
Ниже приведен фрагмент кода для вставки документа -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class InsertingDocument {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
Document document = new Document("title", "MongoDB")
.append("id", 1)
.append("description", "database")
.append("likes", 100)
.append("url", "http://www.tutorialspoint.com/mongodb/")
.append("by", "tutorials point");
collection.insertOne(document);
System.out.println("Document inserted successfully");
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection sampleCollection selected successfully
Document inserted successfullyПолучить все документы
Чтобы выбрать все документы из коллекции, find() метод com.mongodb.client.MongoCollectionкласс используется. Этот метод возвращает курсор, поэтому вам нужно перебрать этот курсор.
Ниже приводится программа для выбора всех документов -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class RetrievingAllDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}При компиляции вышеуказанная программа дает следующий результат -
Document{{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 100,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}
Document{{
_id = 7452239959673a32646baab8,
title = RethinkDB,
id = 2,
description = database,
likes = 200,
url = http://www.tutorialspoint.com/rethinkdb/, by = tutorials point
}}Обновить документ
Чтобы обновить документ из коллекции, updateOne() метод com.mongodb.client.MongoCollection класс используется.
Ниже приводится программа для выбора первого документа -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import com.mongodb.client.model.Updates;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class UpdatingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection myCollection selected successfully");
collection.updateOne(Filters.eq("id", 1), Updates.set("likes", 150));
System.out.println("Document update successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println(it.next());
i++;
}
}
}При компиляции вышеуказанная программа дает следующий результат -
Document update successfully...
Document {{
_id = 5967745223993a32646baab8,
title = MongoDB,
id = 1,
description = database,
likes = 150,
url = http://www.tutorialspoint.com/mongodb/, by = tutorials point
}}Удалить документ
Чтобы удалить документ из коллекции, вам необходимо использовать deleteOne() метод com.mongodb.client.MongoCollection класс.
Ниже приводится программа для удаления документа -
import com.mongodb.client.FindIterable;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import com.mongodb.client.model.Filters;
import java.util.Iterator;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DeletingDocuments {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Retrieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
System.out.println("Collection sampleCollection selected successfully");
// Deleting the documents
collection.deleteOne(Filters.eq("id", 1));
System.out.println("Document deleted successfully...");
// Retrieving the documents after updation
// Getting the iterable object
FindIterable<Document> iterDoc = collection.find();
int i = 1;
// Getting the iterator
Iterator it = iterDoc.iterator();
while (it.hasNext()) {
System.out.println("Inserted Document: "+i);
System.out.println(it.next());
i++;
}
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection sampleCollection selected successfully
Document deleted successfully...Удаление коллекции
Чтобы удалить коллекцию из базы данных, вам необходимо использовать drop() метод com.mongodb.client.MongoCollection класс.
Ниже приводится программа для удаления коллекции -
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
// Creating a collection
System.out.println("Collections created successfully");
// Retieving a collection
MongoCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping a Collection
collection.drop();
System.out.println("Collection dropped successfully");
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection sampleCollection selected successfully
Collection dropped successfullyСписок всех коллекций
Чтобы перечислить все коллекции в базе данных, вам необходимо использовать listCollectionNames() метод com.mongodb.client.MongoDatabase класс.
Ниже приведена программа для перечисления всех коллекций базы данных.
import com.mongodb.client.MongoDatabase;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class ListOfCollection {
public static void main( String args[] ) {
// Creating a Mongo client
MongoClient mongo = new MongoClient( "localhost" , 27017 );
// Creating Credentials
MongoCredential credential;
credential = MongoCredential.createCredential("sampleUser", "myDb",
"password".toCharArray());
System.out.println("Connected to the database successfully");
// Accessing the database
MongoDatabase database = mongo.getDatabase("myDb");
System.out.println("Collection created successfully");
for (String name : database.listCollectionNames()) {
System.out.println(name);
}
}
}При компиляции вышеуказанная программа дает следующий результат -
Connected to the database successfully
Collection created successfully
myCollection
myCollection1
myCollection5Остальные методы MongoDB save(), limit(), skip(), sort() и т. д. работают так же, как описано в следующем руководстве.
Чтобы использовать MongoDB с PHP, вам необходимо использовать драйвер MongoDB PHP. Загрузите драйвер по ссылке Загрузить драйвер PHP . Обязательно скачайте последнюю версию. Теперь распакуйте архив и поместите php_mongo.dll в каталог расширений PHP (по умолчанию "ext") и добавьте следующую строку в свой файл php.ini -
extension = php_mongo.dllУстановите соединение и выберите базу данных
Чтобы установить соединение, вам необходимо указать имя базы данных, если база данных не существует, MongoDB создает ее автоматически.
Ниже приведен фрагмент кода для подключения к базе данных.
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selectedСоздать коллекцию
Ниже приведен фрагмент кода для создания коллекции -
<?php
// connect to mongodb
$m = new MongoClient(); echo "Connection to database successfully"; // select a database $db = $m->mydb; echo "Database mydb selected"; $collection = $db->createCollection("mycol");
echo "Collection created succsessfully";
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selected
Collection created succsessfullyВставить документ
Чтобы вставить документ в MongoDB, insert() используется метод.
Ниже приведен фрагмент кода для вставки документа -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$document = array( "title" => "MongoDB", "description" => "database", "likes" => 100, "url" => "http://www.tutorialspoint.com/mongodb/", "by" => "tutorials point" ); $collection->insert($document);
echo "Document inserted successfully";
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document inserted successfullyНайти все документы
Для выбора всех документов из коллекции используется метод find ().
Ниже приведен фрагмент кода для выбора всех документов -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
$cursor = $collection->find();
// iterate cursor to display title of documents
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selected
Collection selected succsessfully {
"title": "MongoDB"
}Обновить документ
Чтобы обновить документ, вам нужно использовать метод update ().
В следующем примере мы обновим заголовок вставленного документа на MongoDB Tutorial. Ниже приведен фрагмент кода для обновления документа.
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now update the document
$collection->update(array("title"=>"MongoDB"), array('$set'=>array("title"=>"MongoDB Tutorial")));
echo "Document updated successfully";
// now display the updated document
$cursor = $collection->find();
// iterate cursor to display title of documents
echo "Updated document";
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Document updated successfully
Updated document {
"title": "MongoDB Tutorial"
}Удалить документ
Чтобы удалить документ, вам нужно использовать метод remove ().
В следующем примере мы удалим документы с заголовком MongoDB Tutorial. Ниже приведен фрагмент кода для удаления документа -
<?php
// connect to mongodb
$m = new MongoClient();
echo "Connection to database successfully";
// select a database
$db = $m->mydb;
echo "Database mydb selected";
$collection = $db->mycol;
echo "Collection selected succsessfully";
// now remove the document
$collection->remove(array("title"=>"MongoDB Tutorial"),false); echo "Documents deleted successfully"; // now display the available documents $cursor = $collection->find(); // iterate cursor to display title of documents echo "Updated document"; foreach ($cursor as $document) { echo $document["title"] . "\n";
}
?>Когда программа будет выполнена, она выдаст следующий результат -
Connection to database successfully
Database mydb selected
Collection selected succsessfully
Documents deleted successfullyВ приведенном выше примере второй параметр имеет логический тип и используется для justOne поле remove() метод.
Остальные методы MongoDB findOne(), save(), limit(), skip(), sort() и т.д. работает так же, как описано выше.
Отношения в MongoDB представляют, как различные документы логически связаны друг с другом. Отношения можно смоделировать с помощьюEmbedded и Referencedподходы. Такие отношения могут быть 1: 1, 1: N, N: 1 или N: N.
Рассмотрим случай хранения адресов для пользователей. Таким образом, у одного пользователя может быть несколько адресов, что соответствует соотношению 1: N.
Ниже приводится образец структуры документа user документ -
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"name": "Tom Hanks",
"contact": "987654321",
"dob": "01-01-1991"
}Ниже приводится образец структуры документа address документ -
{
"_id":ObjectId("52ffc4a5d85242602e000000"),
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
}Моделирование встроенных отношений
При встроенном подходе мы встроим адресный документ в пользовательский документ.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}
]
}При таком подходе все связанные данные хранятся в едином документе, что упрощает извлечение и обслуживание. Весь документ можно получить одним запросом, например:
>db.users.findOne({"name":"Tom Benzamin"},{"address":1})Обратите внимание, что в приведенном выше запросе db и users - база данных и коллекция соответственно.
Недостатком является то, что если встроенный документ продолжает слишком сильно увеличиваться в размере, это может повлиять на производительность чтения / записи.
Моделирование ссылочных отношений
Это подход к построению нормализованных отношений. При таком подходе и пользовательский, и адресный документы будут поддерживаться отдельно, но пользовательский документ будет содержать поле, которое будет ссылаться на адресный документ.id поле.
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}Как показано выше, пользовательский документ содержит поле массива address_idsкоторый содержит ObjectIds соответствующих адресов. Используя эти ObjectIds, мы можем запрашивать адресные документы и получать оттуда данные адреса. При таком подходе нам понадобятся два запроса: первый для полученияaddress_ids поля из user документ и второй, чтобы получить эти адреса из address коллекция.
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})Как было показано в последней главе отношений MongoDB, для реализации нормализованной структуры базы данных в MongoDB мы используем концепцию Referenced Relationships также упоминается как Manual Referencesв котором мы вручную сохраняем идентификатор указанного документа внутри другого документа. Однако в случаях, когда документ содержит ссылки из разных коллекций, мы можем использоватьMongoDB DBRefs.
DBRefs и ссылки на руководства
В качестве примера сценария, в котором мы будем использовать DBRefs вместо ручных ссылок, рассмотрим базу данных, в которой мы храним разные типы адресов (домашний, офис, почтовые и т. Д.) В разных коллекциях (address_home, address_office, address_mailing и т. Д.). Теперь, когдаuserДокумент коллекции ссылается на адрес, он также должен указать, какую коллекцию следует искать в зависимости от типа адреса. В таких сценариях, когда документ ссылается на документы из многих коллекций, мы должны использовать DBRefs.
Использование DBRefs
В DBRefs есть три поля -
$ref - В этом поле указывается коллекция указанного документа.
$id - В этом поле указывается поле _id указанного документа.
$db - Это необязательное поле, оно содержит имя базы данных, в которой находится указанный документ.
Рассмотрим образец пользовательского документа с полем DBRef address как показано во фрагменте кода -
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home", "$id": ObjectId("534009e4d852427820000002"),
"$db": "tutorialspoint"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}В address Поле DBRef здесь указывает, что указанный адресный документ находится в address_home сбор под tutorialspoint база данных и имеет идентификатор 534009e4d852427820000002.
Следующий код динамически просматривает коллекцию, указанную $ref параметр (address_home в нашем случае) для документа с идентификатором, указанным в $id параметр в DBRef.
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})Приведенный выше код возвращает следующий адресный документ, представленный в address_home коллекция -
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}В этой главе мы узнаем о покрытых запросах.
Что такое закрытый запрос?
Согласно официальной документации MongoDB, покрытый запрос - это запрос, в котором:
- Все поля в запросе являются частью индекса.
- Все поля, возвращаемые в запросе, находятся в одном индексе.
Поскольку все поля, присутствующие в запросе, являются частью индекса, MongoDB соответствует условиям запроса и возвращает результат, используя тот же индекс, не просматривая документы. Поскольку индексы находятся в ОЗУ, выборка данных из индексов происходит намного быстрее по сравнению с получением данных путем сканирования документов.
Использование покрытых запросов
Чтобы проверить покрытые запросы, рассмотрите следующий документ в users коллекция -
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}Сначала мы создадим составной индекс для users сбор на полях gender и user_name используя следующий запрос -
>db.users.ensureIndex({gender:1,user_name:1})Теперь этот индекс будет охватывать следующий запрос -
>db.users.find({gender:"M"},{user_name:1,_id:0})Это означает, что для вышеуказанного запроса MongoDB не будет искать документы базы данных. Вместо этого он будет получать необходимые данные из индексированных данных, что очень быстро.
Поскольку наш индекс не включает _idполе, мы явно исключили его из набора результатов нашего запроса, так как MongoDB по умолчанию возвращает поле _id в каждом запросе. Таким образом, следующий запрос не был бы включен в индекс, созданный выше:
>db.users.find({gender:"M"},{user_name:1})Наконец, помните, что индекс не может покрыть запрос, если -
- Любое из проиндексированных полей представляет собой массив
- Любое из проиндексированных полей является вложенным документом
Анализ запросов - очень важный аспект измерения эффективности базы данных и дизайна индексации. Узнаем о часто используемых$explain и $hint запросы.
Использование $ объяснять
В $explainОператор предоставляет информацию о запросе, индексах, используемых в запросе, и другую статистику. Это очень полезно при анализе того, насколько хорошо ваши индексы оптимизированы.
В предыдущей главе мы уже создали индекс для users сбор на полях gender и user_name используя следующий запрос -
>db.users.ensureIndex({gender:1,user_name:1})Теперь мы будем использовать $explain по следующему запросу -
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()Вышеупомянутый запрос объяснения () возвращает следующий проанализированный результат -
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1 }, { "$maxElement" : 1
}
]
]
}
}Теперь мы посмотрим на поля в этом наборе результатов -
Истинная ценность indexOnly указывает, что в этом запросе использовалась индексация.
В cursorполе определяет тип используемого курсора. Тип BTreeCursor указывает, что индекс использовался, а также дает имя используемого индекса. BasicCursor указывает, что полное сканирование было выполнено без использования индексов.
n указывает количество возвращенных совпадающих документов.
nscannedObjects указывает общее количество отсканированных документов.
nscanned указывает общее количество отсканированных документов или записей указателя.
Использование $ hint
В $hintОператор заставляет оптимизатор запросов использовать указанный индекс для выполнения запроса. Это особенно полезно, если вы хотите проверить производительность запроса с разными индексами. Например, следующий запрос указывает индекс для полейgender и user_name для использования в этом запросе -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})Чтобы проанализировать вышеуказанный запрос с помощью $ объяснение -
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()Данные модели для атомарных операций
Рекомендуемый подход к поддержанию атомарности - хранить всю связанную информацию, которая часто обновляется вместе в одном документе с использованием embedded documents. Это обеспечит атомарность всех обновлений для одного документа.
Рассмотрим следующий документ о продуктах -
{
"_id":1,
"product_name": "Samsung S3",
"category": "mobiles",
"product_total": 5,
"product_available": 3,
"product_bought_by": [
{
"customer": "john",
"date": "7-Jan-2014"
},
{
"customer": "mark",
"date": "8-Jan-2014"
}
]
}В этом документе мы встроили информацию о клиенте, который покупает продукт, в product_bought_byполе. Теперь, когда новый клиент покупает продукт, мы сначала проверяем, доступен ли он, используяproduct_availableполе. Если возможно, мы уменьшим значение поля product_available, а также вставим встроенный документ нового клиента в поле product_bought_by. Мы будем использоватьfindAndModify для этой функции, потому что она ищет и обновляет документ одновременно.
>db.products.findAndModify({
query:{_id:2,product_available:{$gt:0}},
update:{
$inc:{product_available:-1}, $push:{product_bought_by:{customer:"rob",date:"9-Jan-2014"}}
}
})Наш подход встроенного документа и использования запроса findAndModify гарантирует, что информация о покупке продукта обновляется только в том случае, если продукт доступен. И вся эта транзакция, находящаяся в одном запросе, является атомарной.
В отличие от этого, рассмотрим сценарий, в котором мы могли сохранить доступность продукта и информацию о том, кто купил продукт, отдельно. В этом случае мы сначала проверим, доступен ли товар, с помощью первого запроса. Затем во втором запросе мы обновим информацию о покупке. Однако возможно, что между выполнением этих двух запросов какой-либо другой пользователь приобрел продукт, и он больше не доступен. Не зная об этом, наш второй запрос обновит информацию о покупке на основе результата нашего первого запроса. Это сделает базу данных несовместимой, потому что мы продали товар, которого нет в наличии.
Рассмотрим следующий документ users коллекция -
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}Приведенный выше документ содержит address sub-document и tags array.
Индексирование полей массива
Предположим, мы хотим искать пользовательские документы на основе пользовательских тегов. Для этого мы создадим индекс по массиву тегов в коллекции.
Создание индекса в массиве, в свою очередь, создает отдельные записи индекса для каждого из его полей. Таким образом, в нашем случае, когда мы создаем индекс для массива тегов, для его значений будут созданы отдельные индексы: музыка, крикет и блоги.
Чтобы создать индекс по массиву тегов, используйте следующий код -
>db.users.ensureIndex({"tags":1})После создания индекса мы можем искать в поле тегов коллекции следующим образом:
>db.users.find({tags:"cricket"})Чтобы убедиться, что используется правильная индексация, используйте следующие explain команда -
>db.users.find({tags:"cricket"}).explain()Приведенная выше команда привела к появлению "cursor": "BtreeCursor tags_1", что подтверждает, что используется правильная индексация.
Индексирование полей субдокумента
Предположим, мы хотим искать документы на основе полей города, штата и пин-кода. Поскольку все эти поля являются частью адресного поля вложенного документа, мы создадим индекс для всех полей вложенного документа.
Для создания индекса по всем трем полям вложенного документа используйте следующий код -
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})Как только индекс создан, мы можем искать любое из полей субдокумента, используя этот индекс, следующим образом:
>db.users.find({"address.city":"Los Angeles"})Помните, что выражение запроса должно следовать порядку указанного индекса. Таким образом, созданный выше индекс будет поддерживать следующие запросы:
>db.users.find({"address.city":"Los Angeles","address.state":"California"})Он также будет поддерживать следующий запрос -
>db.users.find({"address.city":"LosAngeles","address.state":"California",
"address.pincode":"123"})В этой главе мы узнаем об ограничениях индексирования и других его компонентах.
Дополнительные накладные расходы
Каждый индекс занимает некоторое пространство, а также вызывает накладные расходы при каждой вставке, обновлении и удалении. Поэтому, если вы редко используете свою коллекцию для операций чтения, имеет смысл не использовать индексы.
Использование RAM
Поскольку индексы хранятся в ОЗУ, вы должны убедиться, что общий размер индекса не превышает лимит ОЗУ. Если общий размер увеличивает размер ОЗУ, он начнет удалять некоторые индексы, что приведет к потере производительности.
Ограничения запросов
Индексирование нельзя использовать в запросах, которые используют -
- Регулярные выражения или операторы отрицания, такие как $nin, $нет и т. д.
- Арифметические операторы, такие как $ mod и т. Д.
- предложение $ where
Следовательно, всегда рекомендуется проверять использование индекса для ваших запросов.
Пределы ключа индекса
Начиная с версии 2.6, MongoDB не будет создавать индекс, если значение существующего поля индекса превышает ограничение ключа индекса.
Вставка документов, превышающих предел ключа индекса
MongoDB не будет вставлять какой-либо документ в проиндексированную коллекцию, если значение индексированного поля этого документа превышает ограничение ключа индекса. То же самое и с утилитами mongorestore и mongoimport.
Максимальные диапазоны
- В коллекции не может быть более 64 индексов.
- Длина имени индекса не может превышать 125 символов.
- Составной индекс может иметь максимум 31 индексируемое поле.
Мы использовали идентификатор объекта MongoDB во всех предыдущих главах. В этой главе мы поймем структуру ObjectId.
An ObjectId это 12-байтовый тип BSON, имеющий следующую структуру:
- Первые 4 байта, представляющие секунды с эпохи unix
- Следующие 3 байта - это идентификатор машины.
- Следующие 2 байта состоят из process id
- Последние 3 байта - случайное значение счетчика
MongoDB использует ObjectIds как значение по умолчанию для _idполе каждого документа, которое создается при создании любого документа. Сложная комбинация ObjectId делает все поля _id уникальными.
Создание нового ObjectId
Чтобы создать новый ObjectId, используйте следующий код -
>newObjectId = ObjectId()Приведенный выше оператор вернул следующий уникально сгенерированный идентификатор -
ObjectId("5349b4ddd2781d08c09890f3")Вместо того, чтобы MongoDB генерировал ObjectId, вы также можете предоставить 12-байтовый идентификатор -
>myObjectId = ObjectId("5349b4ddd2781d08c09890f4")Создание отметки времени документа
Поскольку _id ObjectId по умолчанию хранит 4-байтовую метку времени, в большинстве случаев вам не нужно сохранять время создания какого-либо документа. Вы можете получить время создания документа с помощью метода getTimestamp -
>ObjectId("5349b4ddd2781d08c09890f4").getTimestamp()Это вернет время создания этого документа в формате даты ISO -
ISODate("2014-04-12T21:49:17Z")Преобразование ObjectId в строку
В некоторых случаях может потребоваться значение ObjectId в строковом формате. Чтобы преобразовать ObjectId в строку, используйте следующий код -
>newObjectId.strПриведенный выше код вернет строковый формат Guid -
5349b4ddd2781d08c09890f3Согласно документации MongoDB, Map-reduceпредставляет собой парадигму обработки данных для сжатия больших объемов данных в полезные агрегированные результаты. MongoDB используетmapReduceкоманда для операций уменьшения карты. MapReduce обычно используется для обработки больших наборов данных.
Команда MapReduce
Ниже приведен синтаксис основной команды mapReduce:
>db.collection.mapReduce(
function() {emit(key,value);}, //map function
function(key,values) {return reduceFunction}, { //reduce function
out: collection,
query: document,
sort: document,
limit: number
}
)Функция map-reduce сначала запрашивает коллекцию, затем сопоставляет результирующие документы, создавая пары ключ-значение, которые затем сокращаются на основе ключей, имеющих несколько значений.
В приведенном выше синтаксисе -
map это функция javascript, которая сопоставляет значение с ключом и выдает пару ключ-значение
reduce это функция javascript, которая уменьшает или группирует все документы, имеющие одинаковый ключ
out указывает расположение результата запроса сокращения карты
query указывает дополнительные критерии выбора для выбора документов
sort указывает необязательные критерии сортировки
limit указывает необязательное максимальное количество возвращаемых документов
Использование MapReduce
Рассмотрим следующую структуру документа, в которой хранятся сообщения пользователей. В документе хранится user_name пользователя и статус сообщения.
{
"post_text": "tutorialspoint is an awesome website for tutorials",
"user_name": "mark",
"status":"active"
}Теперь мы будем использовать функцию mapReduce на нашем posts коллекция, чтобы выбрать все активные сообщения, сгруппировать их на основе user_name, а затем подсчитать количество сообщений каждым пользователем, используя следующий код -
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
)Вышеупомянутый запрос mapReduce выводит следующий результат -
{
"result" : "post_total",
"timeMillis" : 9,
"counts" : {
"input" : 4,
"emit" : 4,
"reduce" : 2,
"output" : 2
},
"ok" : 1,
}Результат показывает, что всего 4 документа соответствовали запросу (статус: «активный»), функция сопоставления создала 4 документа с парами ключ-значение и, наконец, функция сокращения сгруппировала сопоставленные документы с одинаковыми ключами в 2.
Чтобы увидеть результат этого запроса mapReduce, используйте оператор поиска -
>db.posts.mapReduce(
function() { emit(this.user_id,1); },
function(key, values) {return Array.sum(values)}, {
query:{status:"active"},
out:"post_total"
}
).find()Вышеупомянутый запрос дает следующий результат, который указывает, что оба пользователя tom и mark иметь два сообщения в активных состояниях -
{ "_id" : "tom", "value" : 2 }
{ "_id" : "mark", "value" : 2 }Аналогичным образом запросы MapReduce можно использовать для создания больших сложных запросов агрегирования. Использование пользовательских функций Javascript позволяет использовать MapReduce, который является очень гибким и мощным.
Начиная с версии 2.4, MongoDB начала поддерживать текстовые индексы для поиска внутри строкового содержимого. ВText Search использует методы выделения корня для поиска заданных слов в строковых полях, отбрасывая остановочные слова, такие как a, an, the, и т.д. В настоящее время MongoDB поддерживает около 15 языков.
Включение текстового поиска
Первоначально текстовый поиск был экспериментальной функцией, но, начиная с версии 2.6, конфигурация включена по умолчанию. Но если вы используете предыдущую версию MongoDB, вам необходимо включить текстовый поиск с помощью следующего кода:
>db.adminCommand({setParameter:true,textSearchEnabled:true})Создание текстового указателя
Рассмотрим следующий документ под posts коллекция, содержащая текст сообщения и его теги -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Мы создадим текстовый индекс в поле post_text, чтобы мы могли искать внутри текста наших сообщений -
>db.posts.ensureIndex({post_text:"text"})Использование текстового индекса
Теперь, когда мы создали текстовый индекс для поля post_text, мы будем искать все сообщения, содержащие слово tutorialspoint в их тексте.
>db.posts.find({$text:{$search:"tutorialspoint"}})Приведенная выше команда вернула следующие документы результатов, содержащие слово tutorialspoint в их тексте поста -
{
"_id" : ObjectId("53493d14d852429c10000002"),
"post_text" : "enjoy the mongodb articles on tutorialspoint",
"tags" : [ "mongodb", "tutorialspoint" ]
}
{
"_id" : ObjectId("53493d1fd852429c10000003"),
"post_text" : "writing tutorials on mongodb",
"tags" : [ "mongodb", "tutorial" ]
}Если вы используете старые версии MongoDB, вы должны использовать следующую команду -
>db.posts.runCommand("text",{search:" tutorialspoint "})Использование текстового поиска значительно повышает эффективность поиска по сравнению с обычным поиском.
Удаление текстового указателя
Чтобы удалить существующий текстовый индекс, сначала найдите имя индекса, используя следующий запрос -
>db.posts.getIndexes()Получив имя вашего индекса из вышеуказанного запроса, выполните следующую команду. Вот,post_text_text это имя индекса.
>db.posts.dropIndex("post_text_text")Регулярные выражения часто используются во всех языках для поиска шаблона или слова в любой строке. MongoDB также предоставляет функциональность регулярного выражения для сопоставления строкового шаблона с использованием$regexоператор. MongoDB использует PCRE (Perl-совместимое регулярное выражение) в качестве языка регулярных выражений.
В отличие от текстового поиска, нам не нужно выполнять какие-либо настройки или команды для использования регулярных выражений.
Рассмотрим следующую структуру документа в разделе posts коллекция, содержащая текст сообщения и его теги -
{
"post_text": "enjoy the mongodb articles on tutorialspoint",
"tags": [
"mongodb",
"tutorialspoint"
]
}Использование выражения регулярного выражения
Следующий запрос регулярного выражения ищет все сообщения, содержащие строку tutorialspoint в нем -
>db.posts.find({post_text:{$regex:"tutorialspoint"}})Тот же запрос также можно записать как -
>db.posts.find({post_text:/tutorialspoint/})Использование выражения регулярного выражения с нечувствительностью к регистру
Чтобы сделать поиск нечувствительным к регистру, мы используем $options параметр со значением $i. Следующая команда будет искать строки со словомtutorialspoint, независимо от мелкого или прописного случая -
>db.posts.find({post_text:{$regex:"tutorialspoint",$options:"$i"}})Одним из результатов этого запроса является следующий документ, содержащий слово tutorialspoint в разных случаях -
{
"_id" : ObjectId("53493d37d852429c10000004"),
"post_text" : "hey! this is my post on TutorialsPoint",
"tags" : [ "tutorialspoint" ]
}Использование регулярного выражения для элементов массива
Мы также можем использовать концепцию регулярного выражения в поле массива. Это особенно важно, когда мы реализуем функции тегов. Итак, если вы хотите найти все сообщения с тегами, начинающимися со слова «учебник» (либо учебник, либо учебные пособия, либо учебная точка, либо учебникphp), вы можете использовать следующий код -
>db.posts.find({tags:{$regex:"tutorial"}})Оптимизация запросов с регулярными выражениями
Если поля документа indexed, запрос будет использовать индексированные значения для соответствия регулярному выражению. Это делает поиск очень быстрым по сравнению с регулярным выражением, просматривающим всю коллекцию.
Если регулярное выражение prefix expression, все совпадения должны начинаться с определенных строковых символов. Например, если выражение регулярного выражения^tut, то запрос должен искать только те строки, которые начинаются с tut.
RockMongo - это инструмент администрирования MongoDB, с помощью которого вы можете управлять своим сервером, базами данных, коллекциями, документами, индексами и многим другим. Он обеспечивает очень удобный способ чтения, записи и создания документов. Он похож на инструмент PHPMyAdmin для PHP и MySQL.
Скачивание RockMongo
Вы можете скачать последнюю версию RockMongo отсюда: https://github.com/iwind/rockmongo
Установка RockMongo
После загрузки вы можете разархивировать пакет в корневой папке сервера и переименовать извлеченную папку в rockmongo. Откройте любой веб-браузер и получите доступ кindex.phpстраница из папки rockmongo. Введите admin / admin как имя пользователя / пароль соответственно.
Работа с RockMongo
Теперь мы рассмотрим некоторые основные операции, которые вы можете выполнять с RockMongo.
Создание новой базы данных
Чтобы создать новую базу данных, нажмите Databasesтаб. НажмитеCreate New Database. На следующем экране укажите имя новой базы данных и нажмитеCreate. Вы увидите добавление новой базы данных на левой панели.
Создание новой коллекции
Чтобы создать новую коллекцию в базе данных, щелкните эту базу данных на левой панели. Нажми наNew Collectionссылка сверху. Укажите требуемое название коллекции. Не беспокойтесь о других полях Is Capped, Size и Max. Нажмите наCreate. Будет создана новая коллекция, и вы сможете увидеть ее на левой панели.
Создание нового документа
Чтобы создать новый документ, щелкните коллекцию, в которую вы хотите добавить документы. При нажатии на коллекцию вы сможете увидеть все документы в этой коллекции, перечисленные там. Чтобы создать новый документ, нажмите наInsertссылка вверху. Вы можете ввести данные документа в формате JSON или в формате массива и нажатьSave.
Экспорт / импорт данных
Чтобы импортировать / экспортировать данные любой коллекции, щелкните эту коллекцию, а затем нажмите Export/Importссылка на верхней панели. Следуйте следующим инструкциям, чтобы экспортировать данные в формате zip, а затем импортировать тот же файл zip для обратного импорта данных.
GridFS- это спецификация MongoDB для хранения и извлечения больших файлов, таких как изображения, аудиофайлы, видеофайлы и т. д. Это своего рода файловая система для хранения файлов, но ее данные хранятся в коллекциях MongoDB. GridFS может хранить файлы, даже превышающие ограничение на размер документа, равное 16 МБ.
GridFS делит файл на фрагменты и сохраняет каждый фрагмент данных в отдельном документе, каждый размером не более 255 КБ.
GridFS по умолчанию использует две коллекции fs.files и fs.chunksдля хранения метаданных файла и фрагментов. Каждый фрагмент идентифицируется своим уникальным полем _id ObjectId. Файлы fs.files служат родительским документом. Вfiles_id поле в документе fs.chunks связывает чанк с его родителем.
Ниже приведен образец документа коллекции fs.files -
{
"filename": "test.txt",
"chunkSize": NumberInt(261120),
"uploadDate": ISODate("2014-04-13T11:32:33.557Z"),
"md5": "7b762939321e146569b07f72c62cca4f",
"length": NumberInt(646)
}В документе указывается имя файла, размер блока, дата загрузки и длина.
Ниже приведен образец документа fs.chunks -
{
"files_id": ObjectId("534a75d19f54bfec8a2fe44b"),
"n": NumberInt(0),
"data": "Mongo Binary Data"
}Добавление файлов в GridFS
Теперь мы будем хранить mp3-файл с помощью GridFS, используя putкоманда. Для этого воспользуемсяmongofiles.exe Утилита находится в папке bin установочной папки MongoDB.
Откройте командную строку, перейдите к mongofiles.exe в папке bin установочной папки MongoDB и введите следующий код -
>mongofiles.exe -d gridfs put song.mp3Вот, gridfs- это имя базы данных, в которой будет храниться файл. Если база данных отсутствует, MongoDB автоматически создаст новый документ на лету. Song.mp3 - это имя загруженного файла. Чтобы увидеть документ файла в базе данных, вы можете использовать поисковый запрос -
>db.fs.files.find()Приведенная выше команда вернула следующий документ -
{
_id: ObjectId('534a811bf8b4aa4d33fdf94d'),
filename: "song.mp3",
chunkSize: 261120,
uploadDate: new Date(1397391643474), md5: "e4f53379c909f7bed2e9d631e15c1c41",
length: 10401959
}Мы также можем увидеть все фрагменты, присутствующие в коллекции fs.chunks, связанные с сохраненным файлом, с помощью следующего кода, используя идентификатор документа, возвращенный в предыдущем запросе:
>db.fs.chunks.find({files_id:ObjectId('534a811bf8b4aa4d33fdf94d')})В моем случае запрос вернул 40 документов, что означает, что весь mp3-документ был разделен на 40 блоков данных.
Capped collectionsпредставляют собой кольцевые коллекции фиксированного размера, которые следуют порядку вставки для поддержки высокой производительности операций создания, чтения и удаления. Циркулярно это означает, что когда фиксированный размер, выделенный для коллекции, исчерпан, он начнет удаление самого старого документа в коллекции без предоставления каких-либо явных команд.
Ограниченные коллекции ограничивают обновления документов, если обновление приводит к увеличению размера документа. Поскольку ограниченные коллекции хранят документы в порядке дискового хранилища, это гарантирует, что размер документа не увеличивает размер, выделенный на диске. Коллекции с ограничениями лучше всего подходят для хранения информации журнала, данных кэша или любых других данных большого объема.
Создание закрытой коллекции
Чтобы создать ограниченную коллекцию, мы используем обычную команду createCollection, но с capped вариант как true и указание максимального размера коллекции в байтах.
>db.createCollection("cappedLogCollection",{capped:true,size:10000})Помимо размера коллекции, мы также можем ограничить количество документов в коллекции, используя max параметр -
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})Если вы хотите проверить, ограничена ли коллекция или нет, используйте следующие isCapped команда -
>db.cappedLogCollection.isCapped()Если есть существующая коллекция, которую вы планируете преобразовать в ограниченную, вы можете сделать это с помощью следующего кода -
>db.runCommand({"convertToCapped":"posts",size:10000})Этот код преобразует нашу существующую коллекцию posts в закрытую коллекцию.
Запрос закрытой коллекции
По умолчанию поисковый запрос в ограниченной коллекции отображает результаты в порядке вставки. Но если вы хотите, чтобы документы извлекались в обратном порядке, используйтеsort команда, как показано в следующем коде -
>db.cappedLogCollection.find().sort({$natural:-1})Есть еще несколько важных моментов относительно ограниченных коллекций, которые стоит знать:
Мы не можем удалять документы из закрытой коллекции.
В закрытой коллекции нет индексов по умолчанию, даже в поле _id.
При вставке нового документа MongoDB не нужно искать место на диске для размещения нового документа. Он может вслепую вставить новый документ в хвост коллекции. Это делает операции вставки в закрытые коллекции очень быстрыми.
Точно так же при чтении документов MongoDB возвращает документы в том же порядке, что и на диске. Это делает операцию чтения очень быстрой.
MongoDB не имеет готовой функции автоматического увеличения, как базы данных SQL. По умолчанию он использует 12-байтовый ObjectId для_idполе в качестве первичного ключа для однозначной идентификации документов. Однако могут быть сценарии, в которых мы можем захотеть, чтобы поле _id имело какое-то автоматически увеличивающееся значение, отличное от ObjectId.
Поскольку это не функция по умолчанию в MongoDB, мы программно реализуем эту функцию, используя counters коллекция, как это предлагается в документации MongoDB.
Использование коллекции счетчиков
Рассмотрим следующие productsдокумент. Мы хотим, чтобы поле _id былоauto-incremented integer sequence начиная с 1,2,3,4 до н.
{
"_id":1,
"product_name": "Apple iPhone",
"category": "mobiles"
}Для этого создайте counters коллекция, которая будет отслеживать последнее значение последовательности для всех полей последовательности.
>db.createCollection("counters")Теперь мы вставим следующий документ в коллекцию счетчиков с productid как его ключ -
{
"_id":"productid",
"sequence_value": 0
}Поле sequence_value отслеживает последнее значение последовательности.
Используйте следующий код, чтобы вставить этот документ последовательности в коллекцию счетчиков -
>db.counters.insert({_id:"productid",sequence_value:0})Создание функции Javascript
Теперь мы создадим функцию getNextSequenceValueкоторый примет имя последовательности в качестве входных данных, увеличит порядковый номер на 1 и вернет обновленный порядковый номер. В нашем случае имя последовательностиproductid.
>function getNextSequenceValue(sequenceName){
var sequenceDocument = db.counters.findAndModify({
query:{_id: sequenceName },
update: {$inc:{sequence_value:1}},
new:true
});
return sequenceDocument.sequence_value;
}Использование функции Javascript
Теперь мы будем использовать функцию getNextSequenceValue при создании нового документа и назначении возвращаемого значения последовательности в качестве поля _id документа.
Вставьте два образца документа, используя следующий код -
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Apple iPhone",
"category":"mobiles"
})
>db.products.insert({
"_id":getNextSequenceValue("productid"),
"product_name":"Samsung S3",
"category":"mobiles"
})Как видите, мы использовали функцию getNextSequenceValue, чтобы установить значение для поля _id.
Чтобы проверить функциональность, позвольте нам получить документы с помощью команды find -
>db.products.find()Вышеупомянутый запрос вернул следующие документы с автоматически увеличивающимся полем _id:
{ "_id" : 1, "product_name" : "Apple iPhone", "category" : "mobiles"}
{ "_id" : 2, "product_name" : "Samsung S3", "category" : "mobiles" }