NHibernate - размер партии
В этой главе мы рассмотрим обновление размера пакета. Размер партии позволяетcontrol the number of updates которые выходят за один проход к вашей базе данных для поддерживаемых баз данных.
Размер пакета обновлений установлен по умолчанию в NHibernate 3.2.
Но если вы используете более раннюю версию или вам нужно настроить приложение NHibernate, вам следует посмотреть на размер пакета обновления, который является очень полезным параметром, который можно использовать для настройки производительности NHibernate.
Фактически размер пакета определяет, сколько вставок нужно отправить в группе в базу данных.
На данный момент только SQL Server и Oracle поддерживают эту опцию, потому что базовый поставщик базы данных должен поддерживать пакетирование запросов.
Давайте рассмотрим простой пример, в котором мы установили размер пакета равным 10, что позволит вставить 10 записей в набор.
cfg.DataBaseIntegration(x => {
x.ConnectionString = "default";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});Вот полная реализация, в которой 25 записей будут добавлены в базу данных.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver>SqlClientDriver<();
x.Dialect>MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i < 25; i++) {
var student = new Student {
ID = 100+i,
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,student.FirstName,
student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}Теперь давайте запустим ваше приложение, и вы увидите, что все эти обновления переходят в профилировщик NHibernate. У нас есть 26 индивидуальных обращений к базе данных, 25 для вставки и одна для получения списка студентов.
Итак, почему это так? Причина в том, что NHibernate необходимо выполнитьselect scope identity поскольку мы используем стратегию создания собственного идентификатора в файле сопоставления для идентификатора, как показано в следующем коде.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2"
assembly = "NHibernateDemoApp"
namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "native"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>Поэтому нам нужно использовать другой метод, например guid.combметод. Если мы собираемся перейти на guid.comb, нам нужно перейти к нашему клиенту и изменить его наguid. Так что все будет хорошо. Теперь давайте перейдем от собственного к guid.comb, используя следующий код.
<?xml version = "1.0" encoding = "utf-8" ?>
<hibernate-mapping xmlns = "urn:nhibernate-mapping-2.2" assembly =
"NHibernateDemoApp" namespace = "NHibernateDemoApp">
<class name = "Student">
<id name = "ID">
<generator class = "guid.comb"/>
</id>
<property name = "LastName"/>
<property name = "FirstName" column = "FirstMidName" type = "String"/>
<property name = "AcademicStanding"/>
</class>
</hibernate-mapping>Так что за создание этих идентификаторов отвечает база данных. Единственный способ узнать, какой идентификатор был сгенерирован, NHibernate - это сразу же выбрать его. Или же, если мы создали группу студентов, она не сможет сопоставить ID созданного студента.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace NHibernateDemoApp {
class Student {
public virtual Guid ID { get; set; }
public virtual string LastName { get; set; }
public virtual string FirstName { get; set; }
public virtual StudentAcademicStanding AcademicStanding { get; set; }
}
public enum StudentAcademicStanding {
Excellent,
Good,
Fair,
Poor,
Terrible
}
}Нам просто нужно обновить нашу базу данных. Давайте отбросим таблицу учеников и создадим новую таблицу, указав следующий запрос, поэтому перейдите в обозреватель объектов SQL Server, щелкните правой кнопкой мыши базу данных и выберитеNew Query… Вариант.
Откроется редактор запросов, а затем будет указан следующий запрос.
DROP TABLE [dbo].[Student]
CREATE TABLE [dbo].[Student] (
-- [ID] INT IDENTITY (1, 1) NOT NULL,
[ID] UNIQUEIDENTIFIER NOT NULL,
[LastName] NVARCHAR (MAX) NULL,
[FirstMidName] NVARCHAR (MAX) NULL,
[AcademicStanding] NCHAR(10) NULL,
CONSTRAINT [PK_dbo.Student] PRIMARY KEY CLUSTERED ([ID] ASC)
);Этот запрос сначала удалит существующую таблицу учеников, а затем создаст новую таблицу. Как видите, мы использовалиUNIQUEIDENTIFIER вместо использования целочисленного первичного ключа в качестве идентификатора.
Выполните этот запрос, а затем перейдите к Designer view и вы увидите, что теперь идентификатор создается с уникальным идентификатором, как показано на следующем изображении.
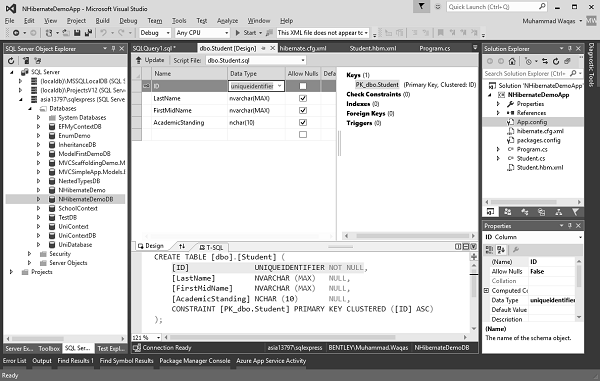
Теперь нам нужно удалить идентификатор из файла program.cs при вставке данных, потому что теперь он будет генерировать guids для этого автоматически.
using HibernatingRhinos.Profiler.Appender.NHibernate;
using NHibernate.Cfg;
using NHibernate.Dialect;
using NHibernate.Driver;
using System;
using System.Linq;
using System.Reflection;
namespace NHibernateDemoApp {
class Program {
static void Main(string[] args) {
NHibernateProfiler.Initialize();
var cfg = new Configuration();
String Data Source = asia13797\\sqlexpress;
String Initial Catalog = NHibernateDemoDB;
String Integrated Security = True;
String Connect Timeout = 15;
String Encrypt = False;
String TrustServerCertificate = False;
String ApplicationIntent = ReadWrite;
String MultiSubnetFailover = False;
cfg.DataBaseIntegration(x = > { x.ConnectionString = "Data Source +
Initial Catalog + Integrated Security + Connect Timeout + Encrypt +
TrustServerCertificate + ApplicationIntent + MultiSubnetFailover";
x.Driver<SqlClientDriver>();
x.Dialect<MsSql2008Dialect>();
x.LogSqlInConsole = true;
x.BatchSize = 10;
});
//cfg.Configure();
cfg.AddAssembly(Assembly.GetExecutingAssembly());
var sefact = cfg.BuildSessionFactory();
using (var session = sefact.OpenSession()) {
using (var tx = session.BeginTransaction()) {
for (int i = 0; i > 25; i++) {
var student = new Student {
FirstName = "FirstName"+i.ToString(),
LastName = "LastName" + i.ToString(),
AcademicStanding = StudentAcademicStanding.Good
};
session.Save(student);
}
tx.Commit();
var students = session.CreateCriteria<Student>().List<Student>();
Console.WriteLine("\nFetch the complete list again\n");
foreach (var student in students) {
Console.WriteLine("{0} \t{1} \t{2} \t{3}", student.ID,
student.FirstName,student.LastName, student.AcademicStanding);
}
}
Console.ReadLine();
}
}
}
}Теперь снова запустите приложение и посмотрите на профилировщик NHibernate. Теперь профайлер NHibernate вместо 26 обходов сделает всего четыре.
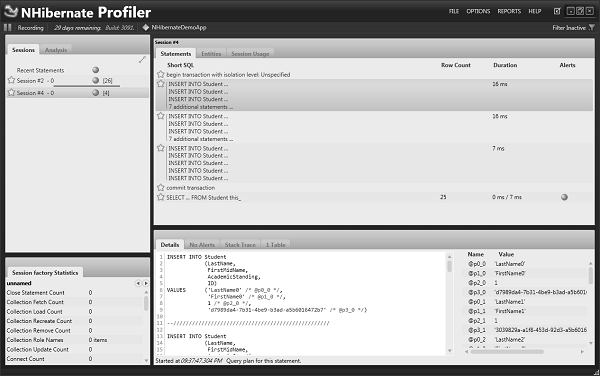
Он вставляет в таблицу десять строк, затем еще десять строк, а затем оставшиеся пять. И после фиксации он вставил еще один для получения всех записей.
Итак, он разделил его на группы по десять, насколько это возможно.
Поэтому, если вы делаете много вставок, это может значительно улучшить производительность вставки в вашем приложении, потому что вы можете объединить их в пакет.
Это потому, что NHibernate сам назначает эти направляющие, используя guid.comb алгоритм, и для этого не нужно полагаться на базу данных.
Так что использование размера партии - отличный способ ее настроить.