PySpark - SparkContext
SparkContext - это точка входа в любую функциональность Spark. Когда мы запускаем любое приложение Spark, запускается программа драйвера, которая выполняет функцию main, и здесь запускается ваш SparkContext. Затем программа драйвера выполняет операции внутри исполнителей на рабочих узлах.
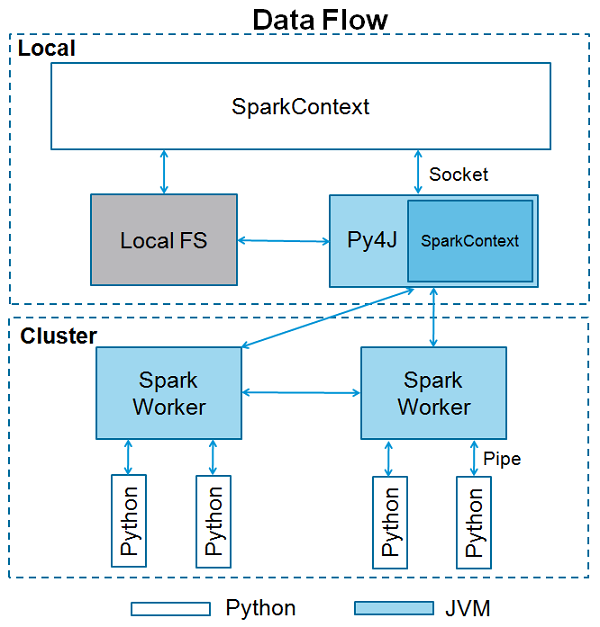
SparkContext использует Py4J для запуска JVM и создает JavaSparkContext. По умолчанию в PySpark SparkContext доступен как‘sc’, поэтому создание нового SparkContext не сработает.
Следующий блок кода содержит подробную информацию о классе PySpark и параметрах, которые может принимать SparkContext.
class pyspark.SparkContext (
master = None,
appName = None,
sparkHome = None,
pyFiles = None,
environment = None,
batchSize = 0,
serializer = PickleSerializer(),
conf = None,
gateway = None,
jsc = None,
profiler_cls = <class 'pyspark.profiler.BasicProfiler'>
)Параметры
Ниже приведены параметры SparkContext.
Master - Это URL-адрес кластера, к которому он подключается.
appName - Название вашей работы.
sparkHome - Каталог установки Spark.
pyFiles - Файлы .zip или .py для отправки в кластер и добавления в PYTHONPATH.
Environment - Переменные среды рабочих узлов.
batchSize- Количество объектов Python, представленных как один объект Java. Установите 1 для отключения пакетной обработки, 0 для автоматического выбора размера пакета на основе размеров объекта или -1 для использования неограниченного размера пакета.
Serializer - Сериализатор RDD.
Conf - Объект L {SparkConf} для установки всех свойств Spark.
Gateway - Используйте существующий шлюз и JVM, в противном случае инициализируйте новую JVM.
JSC - Экземпляр JavaSparkContext.
profiler_cls - Класс настраиваемого профилировщика, используемый для профилирования (по умолчанию - pyspark.profiler.BasicProfiler).
Среди вышеперечисленных параметров master и appnameв основном используются. Первые две строки любой программы PySpark выглядят так, как показано ниже -
from pyspark import SparkContext
sc = SparkContext("local", "First App")Пример SparkContext - оболочка PySpark
Теперь, когда вы достаточно знаете о SparkContext, давайте запустим простой пример в оболочке PySpark. В этом примере мы будем подсчитывать количество строк с символом 'a' или 'b' вREADME.mdфайл. Итак, допустим, если в файле 5 строк и 3 строки имеют символ 'a', то вывод будет →Line with a: 3. То же самое будет сделано для символа «b».
Note- Мы не создаем никаких объектов SparkContext в следующем примере, потому что по умолчанию Spark автоматически создает объект SparkContext с именем sc при запуске оболочки PySpark. Если вы попытаетесь создать другой объект SparkContext, вы получите следующую ошибку:"ValueError: Cannot run multiple SparkContexts at once".

<<< logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
<<< logData = sc.textFile(logFile).cache()
<<< numAs = logData.filter(lambda s: 'a' in s).count()
<<< numBs = logData.filter(lambda s: 'b' in s).count()
<<< print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
Lines with a: 62, lines with b: 30Пример SparkContext - программа Python
Давайте запустим тот же пример, используя программу Python. Создайте файл Python с именемfirstapp.py и введите в этот файл следующий код.
----------------------------------------firstapp.py---------------------------------------
from pyspark import SparkContext
logFile = "file:///home/hadoop/spark-2.1.0-bin-hadoop2.7/README.md"
sc = SparkContext("local", "first app")
logData = sc.textFile(logFile).cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print "Lines with a: %i, lines with b: %i" % (numAs, numBs)
----------------------------------------firstapp.py---------------------------------------Затем мы выполним следующую команду в терминале, чтобы запустить этот файл Python. Мы получим тот же результат, что и выше.
$SPARK_HOME/bin/spark-submit firstapp.py
Output: Lines with a: 62, lines with b: 30