SAP HANA - вычислительный механизм в памяти
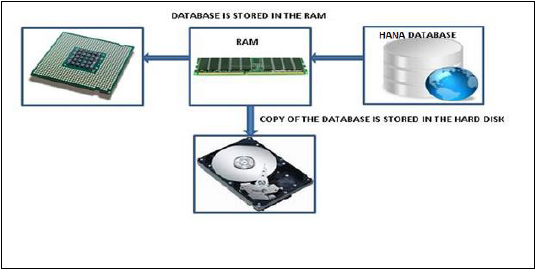
База данных в оперативной памяти означает, что все данные из исходной системы хранятся в оперативной памяти. В обычной системе баз данных все данные хранятся на жестком диске. База данных SAP HANA In-Memory не тратит время на загрузку данных с жесткого диска в оперативную память. Он обеспечивает более быстрый доступ к данным многоядерным процессорам для обработки и анализа информации.
Особенности базы данных в памяти
Основные особенности базы данных SAP HANA в памяти:
SAP HANA - это гибридная база данных в памяти.
Он сочетает в себе базовую технологию на основе строк, столбцов и объектно-ориентированную основу.
Он использует параллельную обработку с многоядерной архитектурой ЦП.
Обычная база данных считывает данные из памяти за 5 миллисекунд. База данных SAP HANA In-Memory считывает данные за 5 наносекунд.
Это означает, что чтение из памяти в базе данных HANA в 1 миллион раз быстрее, чем чтение из памяти обычного жесткого диска.
Аналитики хотят видеть текущие данные немедленно в режиме реального времени и не хотят ждать, пока данные будут загружены в систему SAP BW. Обработка SAP HANA In-Memory позволяет загружать данные в реальном времени с использованием различных методов предоставления данных.
Преимущества базы данных в памяти
База данных HANA использует преимущества обработки в оперативной памяти для обеспечения максимальной скорости извлечения данных, что привлекает компании, которые борются с крупномасштабными онлайн-транзакциями или своевременным прогнозированием и планированием.
Дисковые хранилища по-прежнему являются корпоративным стандартом, а цена на оперативную память неуклонно снижается, поэтому архитектуры с интенсивным использованием памяти в конечном итоге заменят медленные механически вращающиеся диски и снизят стоимость хранения данных.
Хранение в памяти на основе столбцов обеспечивает сжатие данных до 11 раз, тем самым уменьшая пространство для хранения огромных данных.
Эти преимущества скорости, предлагаемые системой хранения RAM, дополнительно увеличиваются за счет использования многоядерных процессоров, нескольких процессоров на узел и нескольких узлов на сервере в распределенной среде.