Zookeeper - Рабочий процесс
После запуска ансамбль ZooKeeper будет ждать подключения клиентов. Клиенты подключатся к одному из узлов ансамбля ZooKeeper. Это может быть ведущий или ведомый узел. Как только клиент подключен, узел назначает идентификатор сеанса конкретному клиенту и отправляет подтверждение клиенту. Если клиент не получает подтверждения, он просто пытается подключить другой узел в ансамбле ZooKeeper. После подключения к узлу клиент будет регулярно посылать контрольные сигналы узлу, чтобы убедиться, что соединение не потеряно.
If a client wants to read a particular znode, он отправляет read requestк узлу с путем znode, и узел возвращает запрошенный znode, получая его из своей собственной базы данных. По этой причине в ансамбле ZooKeeper чтение выполняется быстро.
If a client wants to store data in the ZooKeeper ensemble, он отправляет на сервер путь znode и данные. Подключенный сервер перешлет запрос лидеру, а затем лидер повторно отправит запрос записи всем фолловерам. Если только большинство узлов ответят успешно, то запрос на запись будет успешным, и успешный код возврата будет отправлен клиенту. В противном случае запрос на запись не будет выполнен. Строгое большинство узлов называетсяQuorum.
Узлы в ансамбле ZooKeeper
Давайте проанализируем эффект наличия разного количества узлов в ансамбле ZooKeeper.
Если мы имеем a single node, то ансамбль ZooKeeper откажет, когда этот узел откажет. Это способствует возникновению «единой точки отказа» и не рекомендуется в производственной среде.
Если мы имеем two nodes и один узел выходит из строя, у нас тоже нет большинства, поскольку один из двух не является большинством.
Если мы имеем three nodesи один узел выходит из строя, у нас большинство, так что это минимальное требование. Для ансамбля ZooKeeper обязательно наличие как минимум трех узлов в действующей производственной среде.
Если мы имеем four nodesи два узла выходят из строя, он снова выходит из строя, и это похоже на наличие трех узлов. Дополнительный узел не служит никакой цели, поэтому лучше добавлять узлы в нечетных числах, например, 3, 5, 7.
Мы знаем, что процесс записи дороже, чем процесс чтения в ансамбле ZooKeeper, так как все узлы должны записывать одни и те же данные в свою базу данных. Поэтому для сбалансированной среды лучше иметь меньшее количество узлов (3, 5 или 7), чем большое количество узлов.
На следующей схеме изображен ZooKeeper WorkFlow, а в следующей таблице поясняются его различные компоненты.
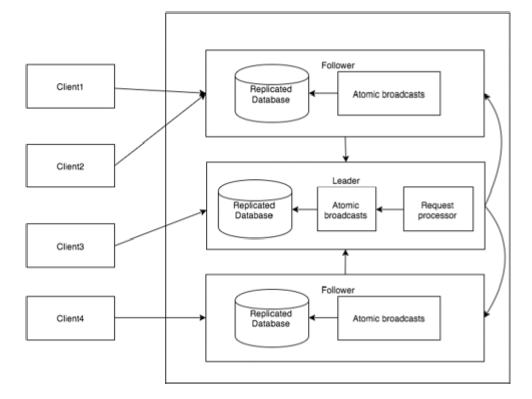
| Составная часть | Описание |
|---|---|
| Написать | Процесс записи обрабатывается ведущим узлом. Лидер пересылает запрос на запись всем znodes и ожидает ответов от znodes. Если половина znodes отвечает, то процесс записи завершен. |
| Читать | Чтение выполняется внутри конкретного подключенного znode, поэтому нет необходимости взаимодействовать с кластером. |
| Реплицированная база данных | Он используется для хранения данных в zookeeper. Каждый znode имеет свою собственную базу данных, и каждый znode имеет одни и те же данные в любое время с помощью согласованности. |
| Лидер | Лидер - это Znode, который отвечает за обработку запросов на запись. |
| Последователь | Последователи получают запросы на запись от клиентов и пересылают их ведущему узлу. |
| Обработчик запросов | Присутствует только в ведущем узле. Он управляет запросами на запись от ведомого узла. |
| Атомные трансляции | Отвечает за трансляцию изменений от ведущего узла к ведомым узлам. |